
Enhancing Geomagnetic Navigation with PPO-LSTM: Robust Navigation Utilizing Observed Geomagnetic Field Data

Abstract
1. Introduction
1.1. Background and Motivation
1.2. Literature Review
1.3. Research Significance
1.4. Article Contributions
- We propose a DRL-based bionic geomagnetic navigation framework that does not rely on traditional mapping algorithms. This framework infers optimal actions by sensing the geomagnetic field along the carrier, mimicking the navigation methods of migratory animals that travel long distances without pre-constructed maps.
- We integrate the POMDP to address the challenges of limited geomagnetic observations. The PPO-LSTM algorithm enables the agent to optimize navigation decisions by considering historical observations, ensuring robust performance despite the inherent uncertainty in local geomagnetic sensing.
- We design a dense reward function that provides continuous feedback, ensuring the agent receives informative signals throughout the navigation process. This design combines potential-based and intrinsically motivated rewards to encourage agents to explore actively, resulting in more efficient navigation.
- We construct a long-distance navigation simulation environment and utilize real geomagnetic data from the IGRF-14 geomagnetic model for comprehensive experimental validation. Extensive comparative studies demonstrate our approach’s superior performance over existing heuristic search-based navigation methods, while the effectiveness of our POMDP-based improvements in handling partial observability is thoroughly validated through empirical results.
1.5. Article Organization
2. Fundamentals for Geomagnetic Navigation
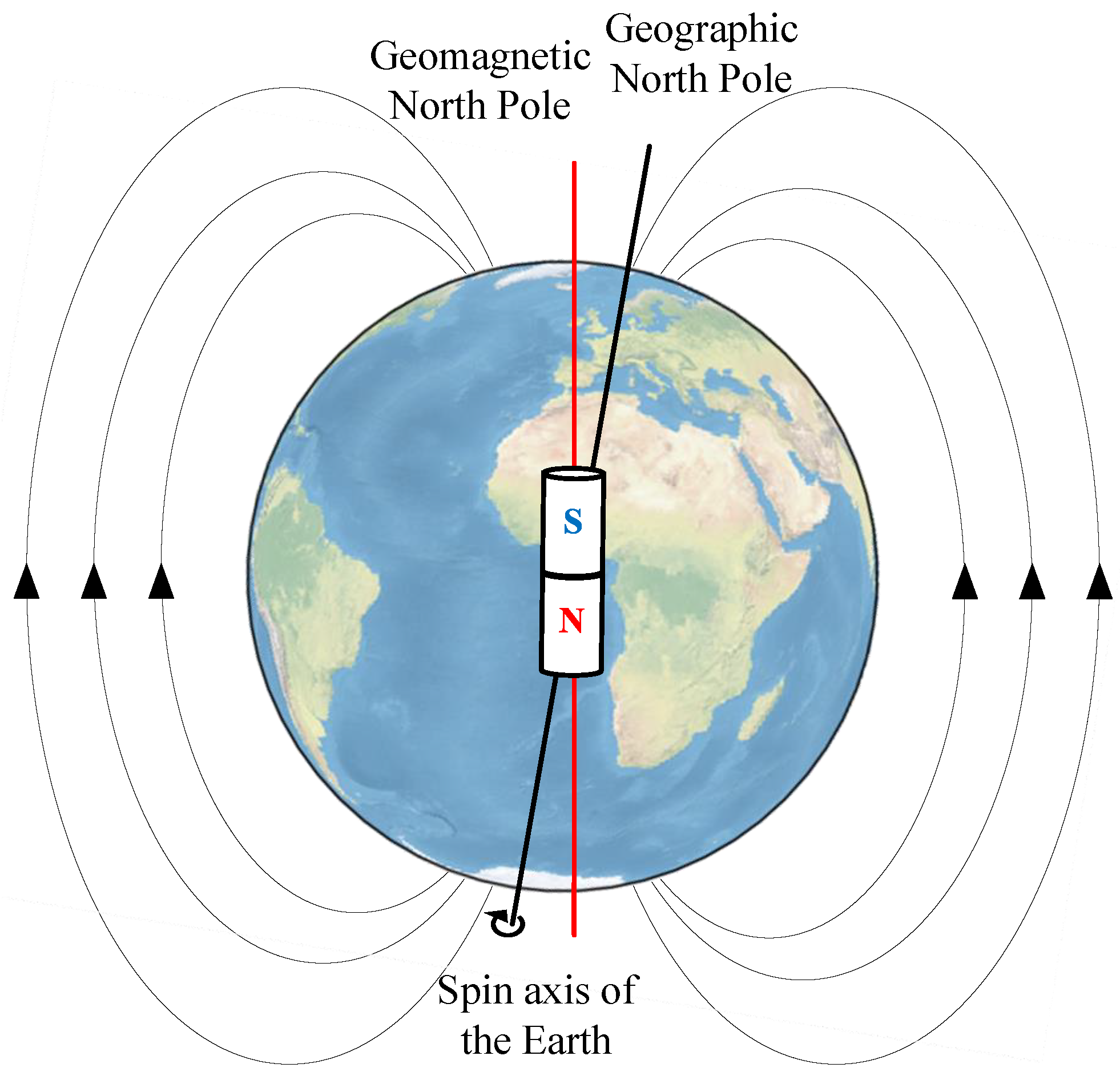
2.1. Mathematical Description of the Geomagnetic Field
- Total Field Intensity (F): The overall strength of the magnetic field, calculated as the magnitude of :
- Horizontal Intensity (H): The magnitude of the field’s projection onto the horizontal (north–east) plane:
- Declination (D): The angle between the horizontal component and true north, computed as follows:The function considers the signs of both X and Y to determine the correct quadrant, providing D as an angle in the range , which resolves the directional ambiguity inherent in traditional methods, like arctan or arccos.
- Inclination (I): The angle between the total field vector and the horizontal plane, derived as follows:Here, is the magnitude of the horizontal component, ensuring a non-negative denominator. The sign of Z determines whether the field tilts downward () or upward (), with I ranging from to .
2.2. Bionic Geomagnetic Navigation System Model
2.3. Partial Observability and Decision Modeling
3. PPO Algorithm Based on POMDP
3.1. PPO Framework
- Unlike value-based methods such as a DQN, which struggle with continuous action spaces [21,22], PPO directly optimizes policies, making it particularly effective for high-dimensional control tasks. Its actor–critic architecture allows for the efficient mapping of sensory inputs to actions. In bionic geomagnetic navigation, where agents adjust their trajectories based on variations in the magnetic field, PPO facilitates smooth and adaptive control, outperforming approaches that rely on discrete actions.
- PPO learns a stochastic policy by sampling actions from a probability distribution instead of selecting them deterministically [32], enhancing exploration and helping prevent premature convergence to suboptimal strategies. Given the uncertainties of environmental variability in geomagnetic navigation, a stochastic policy enhances adaptability and generalization across various scenarios. The policy gradient updates of PPO ensure efficient exploration without introducing excessive randomness.
- As an on-policy algorithm, PPO updates its policy based on recent interactions rather than relying on stored experiences. Although on-policy learning is generally less sample-efficient than off-policy methods such as soft actor–critic (SAC), it offers more reliable performance. For geomagnetic navigation, where real-time policy refinement is essential, the PPO’s clipped surrogate objective prevents drastic updates, thereby enhancing training stability and making it suitable for real-world applications.
3.2. State, Action and Reward
3.2.1. State Space
3.2.2. Observation Function and Observation Space
3.2.3. Action Space
3.2.4. Transition Function
3.2.5. Reward Function
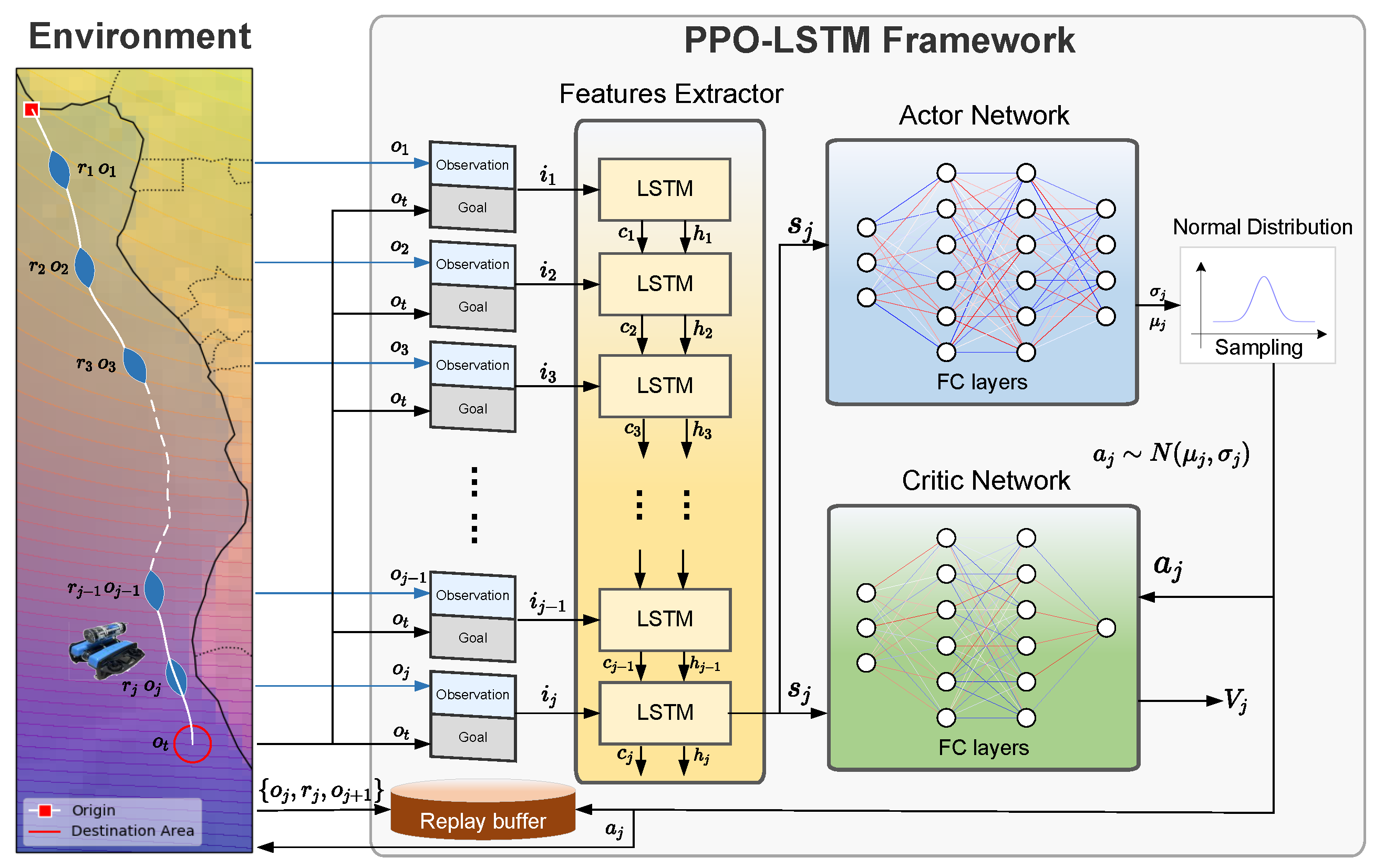
3.3. The PPO-LSTM Algorithm
| Algorithm 1: PPO-LSTM for Bionic Geomagnetic Navigation |
 |
4. Algorithm Implementation and Result
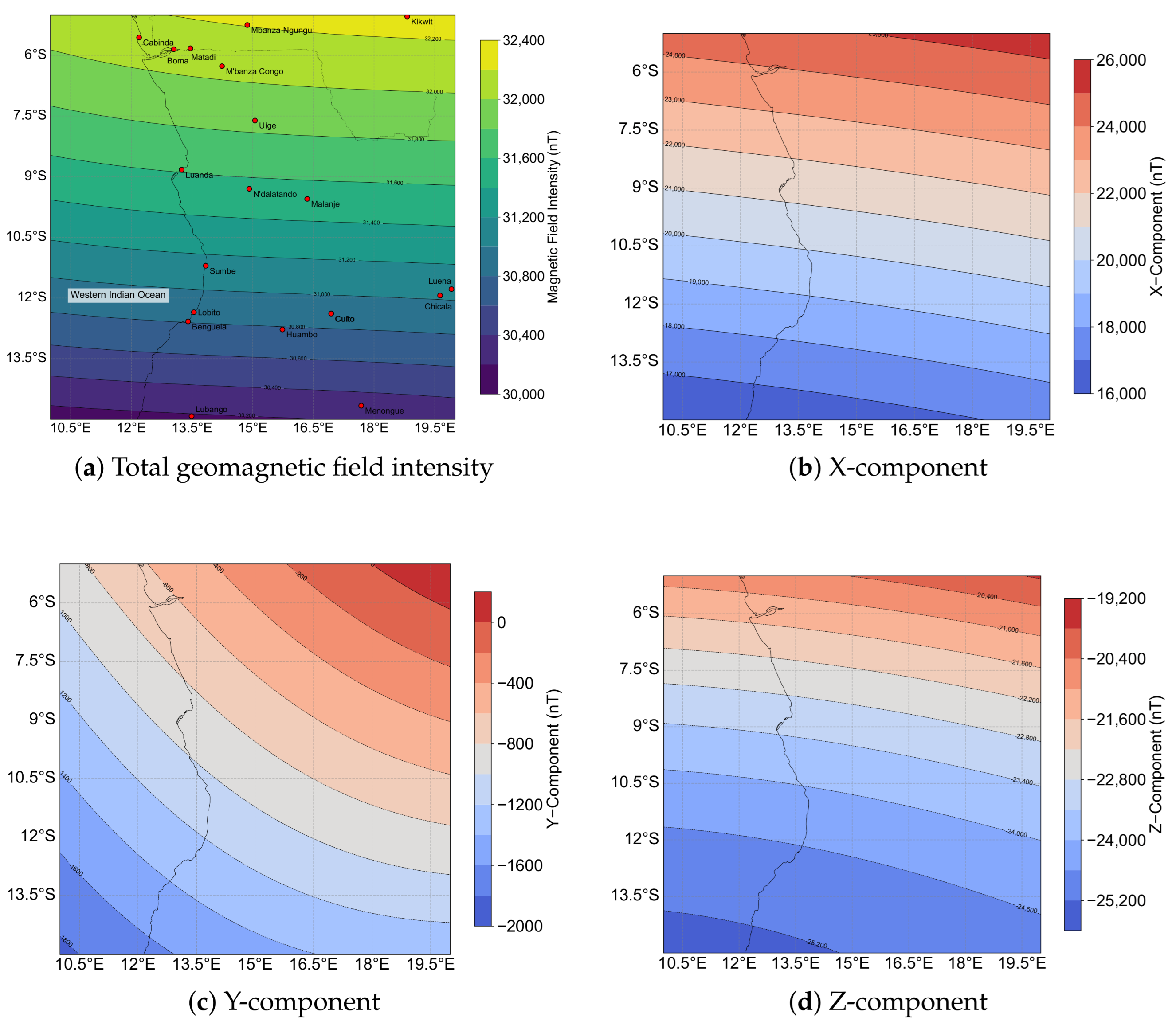
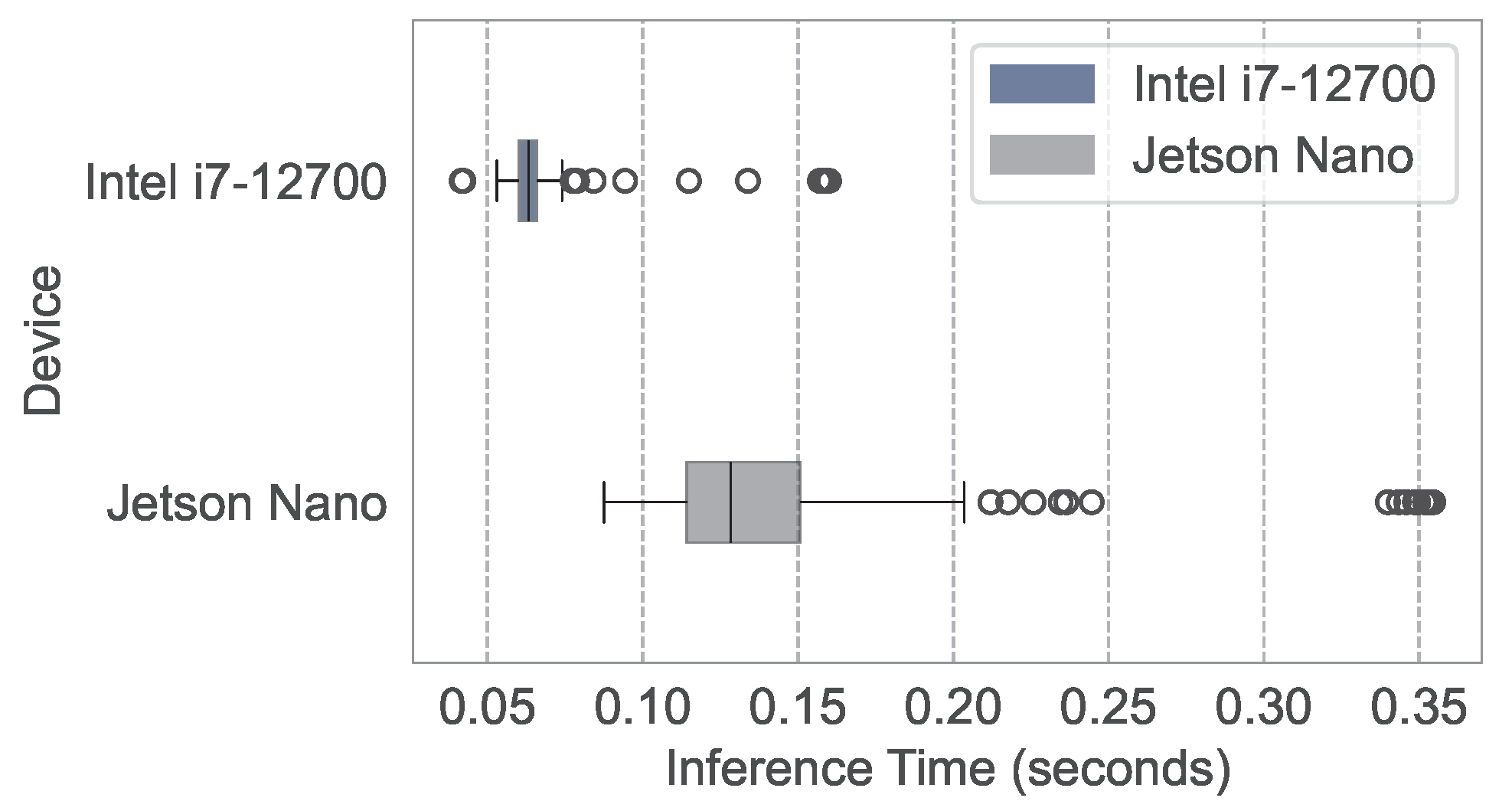
4.1. Experimental Setup
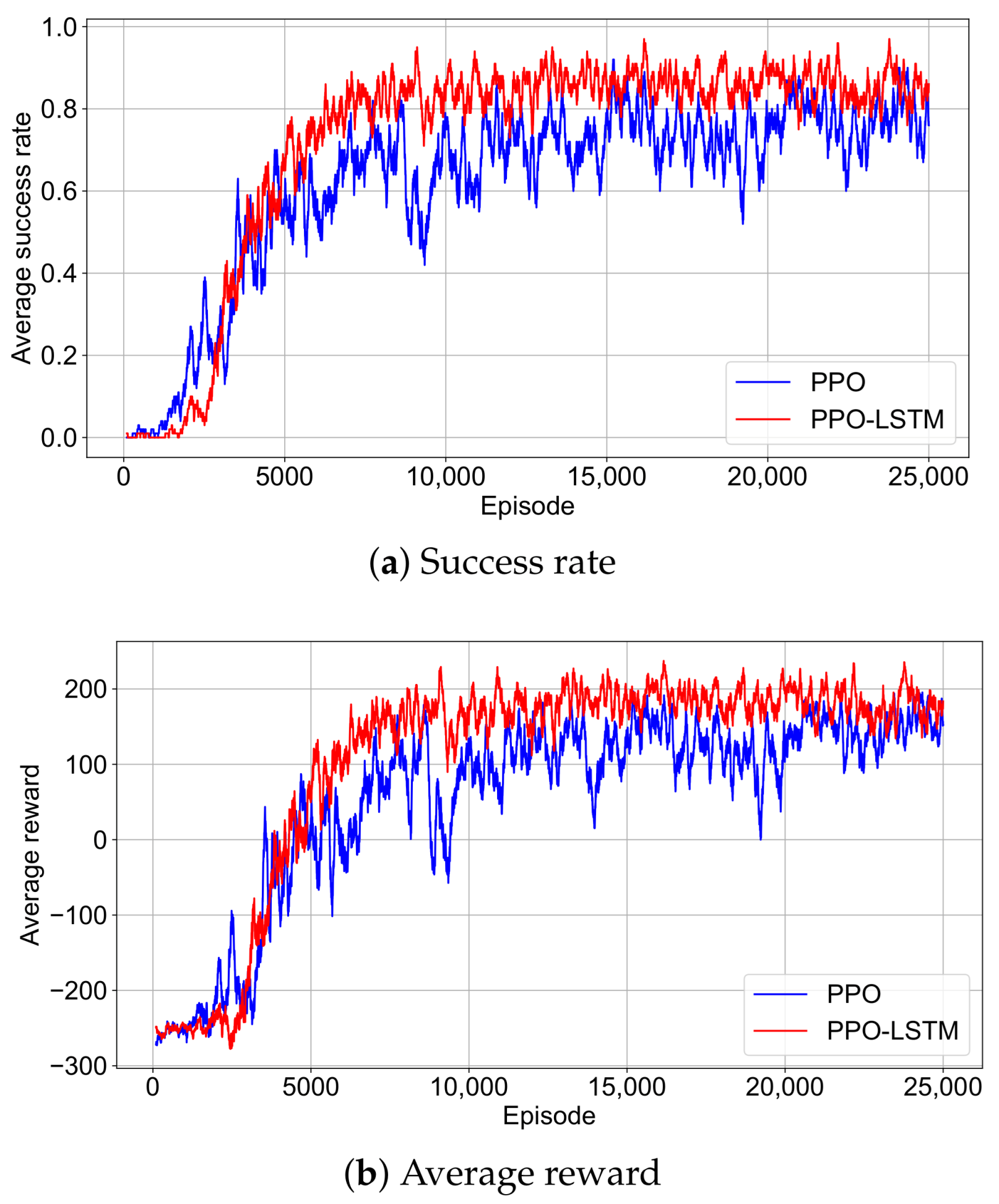
4.2. Success Rate and Reward Convergence
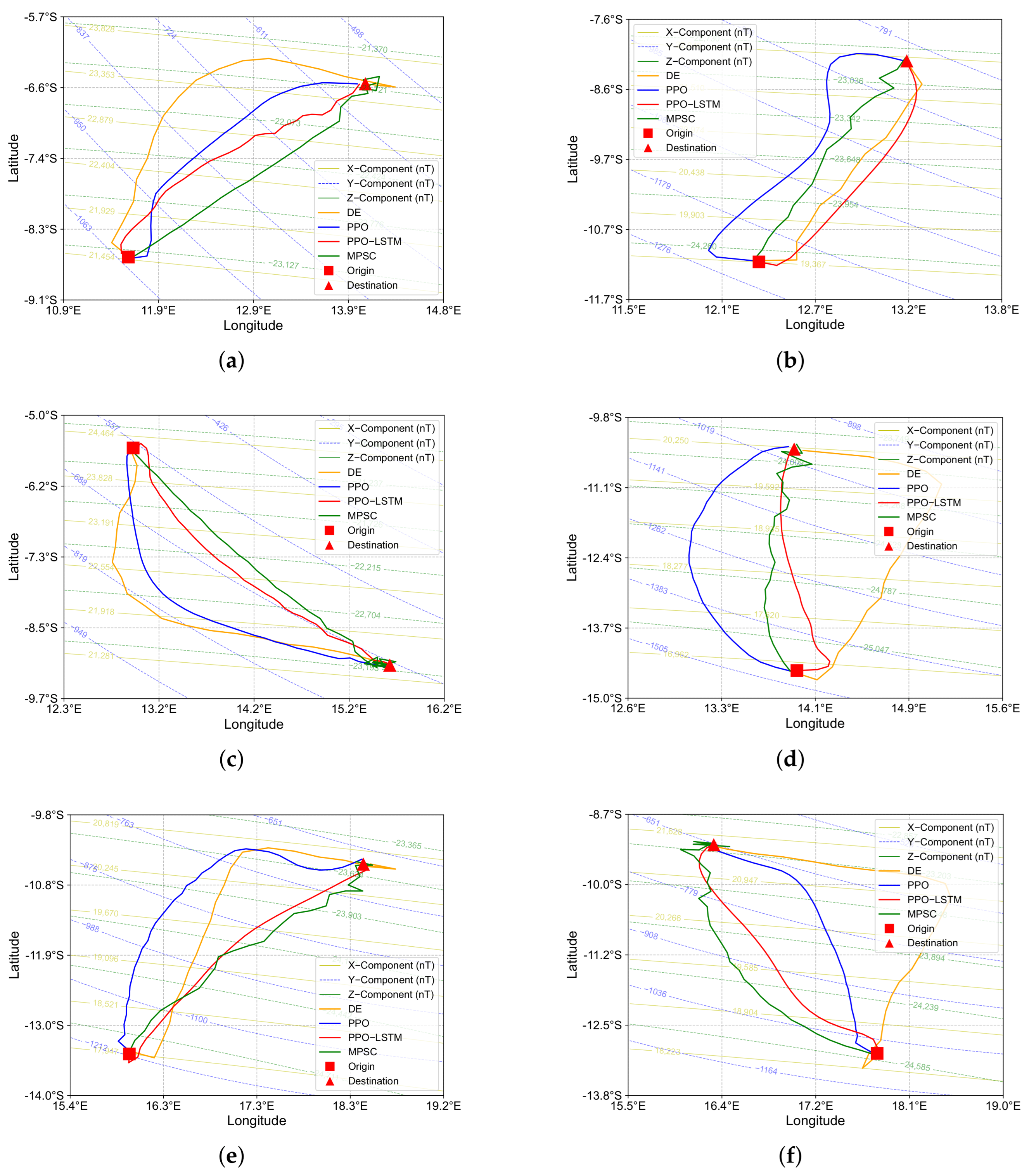
4.3. Imitation in Long-Range Navigation Missions Between Cities
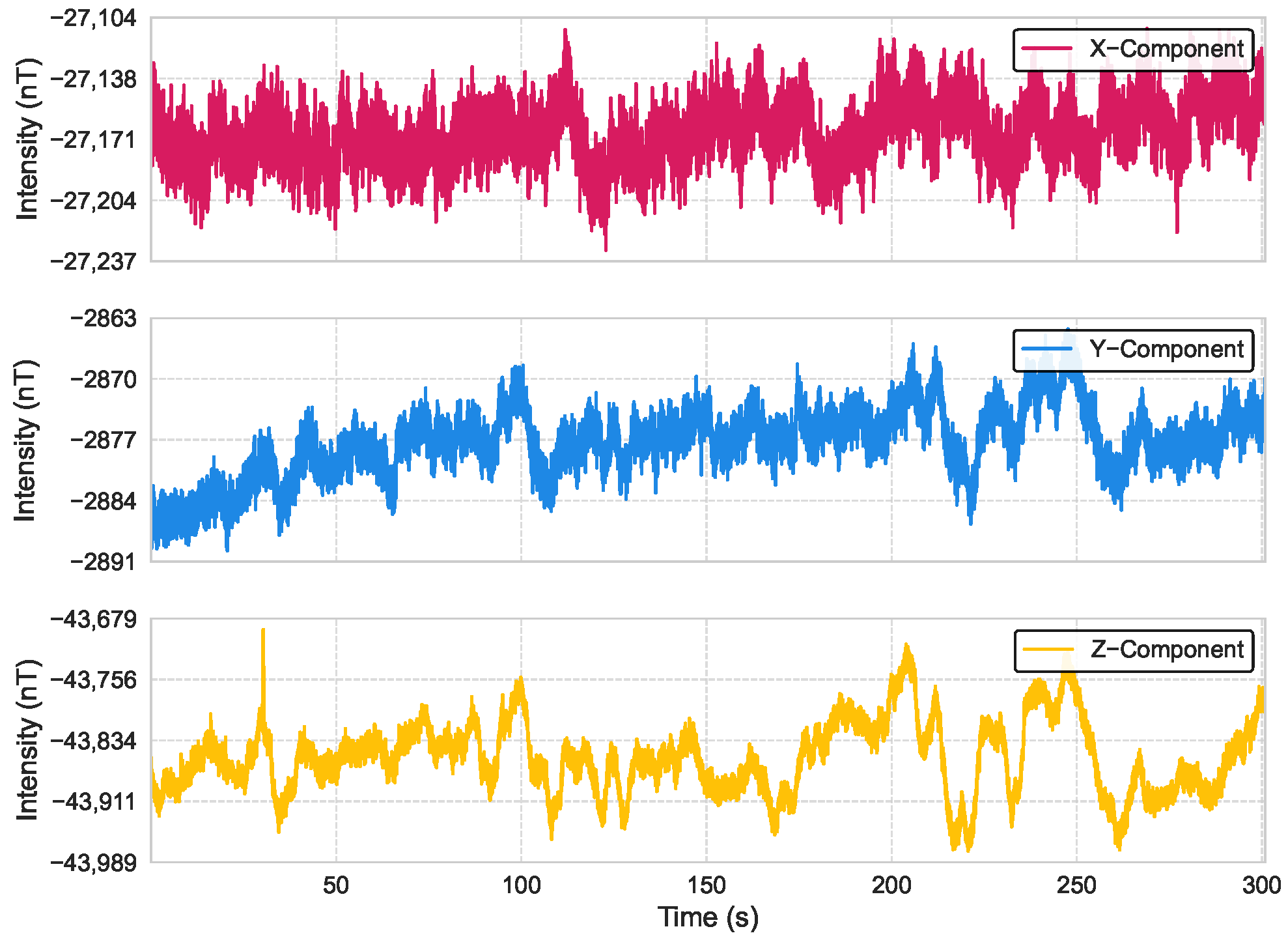
4.4. Navigation Trajectory with Sensor Noise
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Glaβmeier, K.H.; Soffel, H.; Negendank, J.F.; Lühr, H.; Korte, M.; Mandea, M. The recent geomagnetic field and its variations. In Geomagnetic Field Variations; Advances in Geophysical and Environmental Mechanics and Mathematics; Springer: Berlin/Heidelberg, Germany, 2009; pp. 25–63. [Google Scholar]
- Xu, Y.; Guan, G.; Song, Q.; Jiang, C.; Wang, L. Heuristic and random search algorithm in optimization of route planning for robot’s geomagnetic navigation. Comput. Commun. 2020, 154, 12–17. [Google Scholar] [CrossRef]
- Estima, J.; Jesus, I.; Fonte, C.C.; Cardoso, A. Remotely geolocating static events observed by citizens using data collected by mobile devices. Int. J. Appl. Earth Obs. 2024, 135, 104287. [Google Scholar] [CrossRef]
- Abdelkareem, M.; El-Din, G.M.K.; Osman, I. An integrated approach for mapping mineral resources in the Eastern Desert of Egypt. Int. J. Appl. Earth Obs. 2018, 73, 682–696. [Google Scholar] [CrossRef]
- Wang, H.; Xu, X.; Zhang, T. Multipath parallel ICCP underwater terrain matching algorithm based on multibeam bathymetric data. IEEE Access 2018, 6, 48708–48715. [Google Scholar] [CrossRef]
- Zhao, J.; Wang, S.; Wang, A. Study on underwater navigation system based on geomagnetic match technique. In Proceedings of the 2009 9th International Conference on Electronic Measurement & Instruments, Beijing, China, 16–19 August 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 3–255. [Google Scholar]
- Wang, B.; Zhu, Y.; Deng, Z.; Fu, M. The gravity matching area selection criteria for underwater gravity-aided navigation application based on the comprehensive characteristic parameter. IEEE/ASME Trans. Mechatron. 2016, 21, 2935–2943. [Google Scholar] [CrossRef]
- Wiltschko, W.; Wiltschko, R. Magnetoreception in birds: Two receptors for two different tasks. J. Ornithol. 2007, 148, 61–76. [Google Scholar] [CrossRef]
- Lohmann, K.J.; Lohmann, C.M. Orientation and open-sea navigation in sea turtles. J. Exp. Biol. 1996, 199, 73–81. [Google Scholar] [CrossRef]
- Putman, N.F. Inherited magnetic maps in salmon and the role of geomagnetic change. Integr. Comp. Biol. 2015, 55, 396–405. [Google Scholar] [CrossRef]
- Boles, L.C.; Lohmann, K.J. True navigation and magnetic maps in spiny lobsters. Nature 2003, 421, 60–63. [Google Scholar] [CrossRef]
- Geva-Sagiv, M.; Las, L.; Yovel, Y.; Ulanovsky, N. Spatial cognition in bats and rats: From sensory acquisition to multiscale maps and navigation. Nat. Rev. Neurosci. 2015, 16, 94–108. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, T.; Shin, H.S.; Wang, J.; Zhang, C. Geomagnetic gradient-assisted evolutionary algorithm for long-range underwater navigation. IEEE Trans. Instrum. Meas. 2020, 70, 1–12. [Google Scholar] [CrossRef]
- Liu, M.; Liu, K.; Yang, P.; Lei, X.; Li, H. Bio-inspired navigation based on geomagnetic. In Proceedings of the 2013 IEEE International Conference on Robotics and Biomimetics (ROBIO), Shenzhen, China, 12–14 December 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 2339–2344. [Google Scholar]
- Liu, M.; Li, H.; Liu, K. Geomagnetic navigation of AUV without a priori magnetic map. In Proceedings of the OCEANS 2014-TAIPEI, Taipei, Taiwan, 7–10 April 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 1–5. [Google Scholar]
- Zhou, Y.; Niu, Y.; Liu, M. Bionic geomagnetic navigation method for AUV based on differential evolution algorithm. In Proceedings of the OCEANS 2022, Hampton Roads, VA, USA, 17–20 October 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–5. [Google Scholar]
- Jun, Z.; Qiong, W.; Cheng, C. Geomagnetic gradient bionic navigation based on the parallel approaching method. Proc. Inst. Mech. Eng. Part J. Aerosp. Eng. 2019, 233, 3131–3140. [Google Scholar] [CrossRef]
- Zhao, Z.; Hu, T.; Cui, W.; Huangfu, J.; Li, C.; Ran, L. Long-distance geomagnetic navigation: Imitations of animal migration based on a new assumption. IEEE Trans. Geosci. Remote Sens. 2014, 52, 6715–6723. [Google Scholar] [CrossRef]
- Liu, J.; Wang, Y.; Sun, G.; Pang, T. Multisurrogate-assisted ant colony optimization for expensive optimization problems with continuous and categorical variables. IEEE Trans. Cybern. 2021, 52, 11348–11361. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Wang, C.; Niu, Y.; Liu, M.; Shi, T.; Li, J.; You, L. Geomagnetic navigation for AUV based on deep reinforcement learning algorithm. In Proceedings of the 2019 IEEE International Conference on Robotics and Biomimetics (ROBIO), Dali, China, 6–8 December 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 2571–2575. [Google Scholar]
- Wang, C.; Liu, M.; Niu, Y.; He, Y.; You, L.; Shi, T. Geomagnetic navigation with adaptive search space for AUV based on deep double-Q-network. In Proceedings of the Global Oceans 2020: Singapore–US Gulf Coast, Virtual, 5–14 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- Avanzato, R.; Beritelli, F.; Raftopoulos, R.; Schembra, G. A deep reinforcement learning-based UAV-smallcell system for mobile terminals Geolocalization in disaster scenarios. Comput. Commun. 2025, 234, 108088. [Google Scholar] [CrossRef]
- Zhu, Y.; Mottaghi, R.; Kolve, E.; Lim, J.J.; Gupta, A.; Fei-Fei, L.; Farhadi, A. Target-driven visual navigation in indoor scenes using deep reinforcement learning. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May 2017–3 June 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 3357–3364. [Google Scholar]
- Sabaka, T.J.; Olsen, N.; Langel, R.A. A comprehensive model of the quiet-time, near-Earth magnetic field: Phase 3. Geophys. J. Int. 2002, 151, 32–68. [Google Scholar] [CrossRef]
- Mandea, M.; Macmillan, S.; Bondar, T.; Golovkov, V.; Langlais, B.; Lowes, F.J.; Olsen, N.; Quinn, J.; Sabaka, T. International geomagnetic reference field—2000. Phys. Earth Planet. Inter. 2000, 120, 39–42. [Google Scholar] [CrossRef]
- Finlay, C.C.; Maus, S.; Beggan, C.; Bondar, T.; Chambodut, A.; Chernova, T.; Chulliat, A.; Golovkov, V.; Hamilton, B.; Hamoudi, M.; et al. International geomagnetic reference field: The eleventh generation. Geophys. J. Int. 2010, 183, 1216–1230. [Google Scholar]
- Alken, P.; Thébault, E.; Beggan, C.D.; Amit, H.; Aubert, J.; Baerenzung, J.; Bondar, T.; Brown, W.; Califf, S.; Chambodut, A.; et al. International geomagnetic reference field: The thirteenth generation. Earth Planets Space 2021, 73, 1–25. [Google Scholar] [CrossRef]
- Tyrén, C. Magnetic anomalies as a reference for ground-speed and map-matching navigation. J. Navig. 1982, 35, 242–254. [Google Scholar] [CrossRef]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar] [CrossRef]
- Bick, D. Towards delivering a coherent self-contained explanation of proximal policy optimization. Ph.D. Thesis, University of Groningen, Groningen, The Netherlands, 2021. [Google Scholar]
- Bai, W.; Zhang, X.; Zhang, S.; Yang, S.; Li, Y.; Huang, T. Long-distance geomagnetic navigation in GNSS-denied environments with deep reinforcement learning. arXiv 2024, arXiv:2410.15837. [Google Scholar] [CrossRef]
- Gledhill, J. Aeronomic effects of the South Atlantic anomaly. Rev. Geophys. 1976, 14, 173–187. [Google Scholar] [CrossRef]
- Brockman, G.; Cheung, V.; Pettersson, L.; Schneider, J.; Schulman, J.; Tang, J.; Zaremba, W. OpenAI Gym. arXiv 2016, arXiv:1606.01540. [Google Scholar] [CrossRef]
- National Centers for Environmental Information (NCEI). International Geomagnetic Reference Field (IGRF-14). Data Set; 2024. Available online: https://www.ncei.noaa.gov/products/international-geomagnetic-reference-field (accessed on 15 May 2025).
- Storn, R.; Price, K. Differential evolution—A simple and efficient heuristic for global optimization over continuous spaces. J. Glob. Optim. 1997, 11, 341–359. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Value |
|---|---|
| Normalize observations | True |
| Number of parallel environments | 1 |
| Total training time steps | 1,000,000 |
| Batch size for updates | 512 |
| Steps per environment per update | 2048 |
| Discount factor () | 0.995 |
| Learning rate | 0.00010881173007479382 |
| Entropy coefficient | 3.651742693016306 × 10 |
| Clip range | 0.2 |
| Number of epochs per update | 20 |
| GAE lambda () | 0.95 |
| Maximum gradient norm | 0.8 |
| Value function coefficient | 0.46198070763807675 |
| Initial log standard deviation | −2 |
| Orthogonal initialization | False |
| Activation function | ReLU |
| Network Architecture | |
| Feature extractor type | LSTM |
| Feature extractor hidden layers | 1 |
| Feature extractor hidden layer size | 64 |
| Policy network type | MLP |
| Policy network hidden layers | 2 |
| Policy network hidden layer sizes | [64, 64] |
| Critic network type | MLP |
| Critic network hidden layers | 2 |
| Critic network hidden layer sizes | [64, 64] |
| Algorithm | Without Noise | With Noise | ||
|---|---|---|---|---|
| SR (%) | SPL (%) | SR (%) | SPL (%) | |
| PPO | 94.7 | 74.41856 | 76.3 | 57.92835 |
| PPO-LSTM | 95.7 | 84.89380 | 79.3 | 65.88631 |
| Task | Algorithm | Smoothness | Heading Deviation | ||
|---|---|---|---|---|---|
| MSE | MAE | MSE | MAE | ||
| Task 1 | PPO-LSTM | 0.2408 | 0.3558 | 0.1049 | 0.2562 |
| PPO | 0.0481 | 0.1247 | 0.1927 | 0.3769 | |
| MPSC | 5.3887 | 1.0685 | 0.1624 | 0.2558 | |
| DE | 0.8259 | 0.4696 | 0.7740 | 0.6569 | |
| Task 2 | PPO-LSTM | 0.0042 | 0.0298 | 0.0360 | 0.1737 |
| PPO | 0.0250 | 0.0932 | 0.3091 | 0.3651 | |
| MPSC | 0.8102 | 0.5781 | 0.0560 | 0.1599 | |
| DE | 0.4436 | 0.4626 | 0.1554 | 0.2413 | |
| Task 3 | PPO-LSTM | 0.0788 | 0.1952 | 0.0676 | 0.2119 |
| PPO | 0.0733 | 0.1405 | 0.2668 | 0.4380 | |
| MPSC | 9.4671 | 1.7805 | 0.5978 | 0.4016 | |
| DE | 0.1252 | 0.2812 | 0.3787 | 0.4660 | |
| Task 4 | PPO-LSTM | 0.0080 | 0.0465 | 0.0436 | 0.1509 |
| PPO | 0.0134 | 0.0957 | 0.2462 | 0.4671 | |
| MPSC | 1.7252 | 0.7933 | 0.1417 | 0.2821 | |
| DE | 0.1994 | 0.3035 | 0.5704 | 0.5906 | |
| Task 5 | PPO-LSTM | 0.0366 | 0.0768 | 0.0431 | 0.1768 |
| PPO | 0.2327 | 0.3202 | 0.4567 | 0.6101 | |
| MPSC | 3.1330 | 1.1738 | 0.1903 | 0.3451 | |
| DE | 4.5133 | 1.0672 | 1.0579 | 0.7055 | |
| Task 6 | PPO-LSTM | 0.0063 | 0.0418 | 0.0987 | 0.2699 |
| PPO | 0.0634 | 0.1254 | 0.1131 | 0.3209 | |
| MPSC | 3.4181 | 1.1068 | 0.5582 | 0.5171 | |
| DE | 0.7108 | 0.3656 | 0.7149 | 0.6387 | |
| Ave. | PPO-LSTM | 0.0625 | 0.1243 | 0.0657 | 0.2066 |
| PPO | 0.0760 | 0.1499 | 0.2641 | 0.4297 | |
| MPSC | 3.9904 | 1.0835 | 0.2844 | 0.3269 | |
| DE | 1.1364 | 0.4916 | 0.6086 | 0.5498 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Bai, W.; Liu, J.; Yang, S.; Shang, T.; Liu, H. Enhancing Geomagnetic Navigation with PPO-LSTM: Robust Navigation Utilizing Observed Geomagnetic Field Data. Sensors 2025, 25, 3699. https://doi.org/10.3390/s25123699
Zhang X, Bai W, Liu J, Yang S, Shang T, Liu H. Enhancing Geomagnetic Navigation with PPO-LSTM: Robust Navigation Utilizing Observed Geomagnetic Field Data. Sensors. 2025; 25(12):3699. https://doi.org/10.3390/s25123699
Chicago/Turabian StyleZhang, Xiaohui, Wenqi Bai, Jun Liu, Songnan Yang, Ting Shang, and Haolin Liu. 2025. "Enhancing Geomagnetic Navigation with PPO-LSTM: Robust Navigation Utilizing Observed Geomagnetic Field Data" Sensors 25, no. 12: 3699. https://doi.org/10.3390/s25123699
APA StyleZhang, X., Bai, W., Liu, J., Yang, S., Shang, T., & Liu, H. (2025). Enhancing Geomagnetic Navigation with PPO-LSTM: Robust Navigation Utilizing Observed Geomagnetic Field Data. Sensors, 25(12), 3699. https://doi.org/10.3390/s25123699