4.3. Evaluation Metrics
To conduct a systematic comparison, we employed five widely used metrics to evaluate the performance of all semantic segmentation models: mIoU, precision, recall, F1 score, accuracy, and kappa. These metrics provide a comprehensive assessment of the models’ capabilities in accurately segmenting landslide regions.
mIoU is a metric used to evaluate the performance of image segmentation models, measuring the degree of overlap between the predicted segmentation and the ground truth labels.
Precision is used to determine the correctness of landslide area detection.
Recall is used to define how many actual landslide areas are identified in the image.
Accuracy is the percentage of correctly predicted data out of all data.
The balance between precision and recall is calculated using the F1 score.
The kappa coefficient is used to measure the consistency between landslide and non-landslide areas.
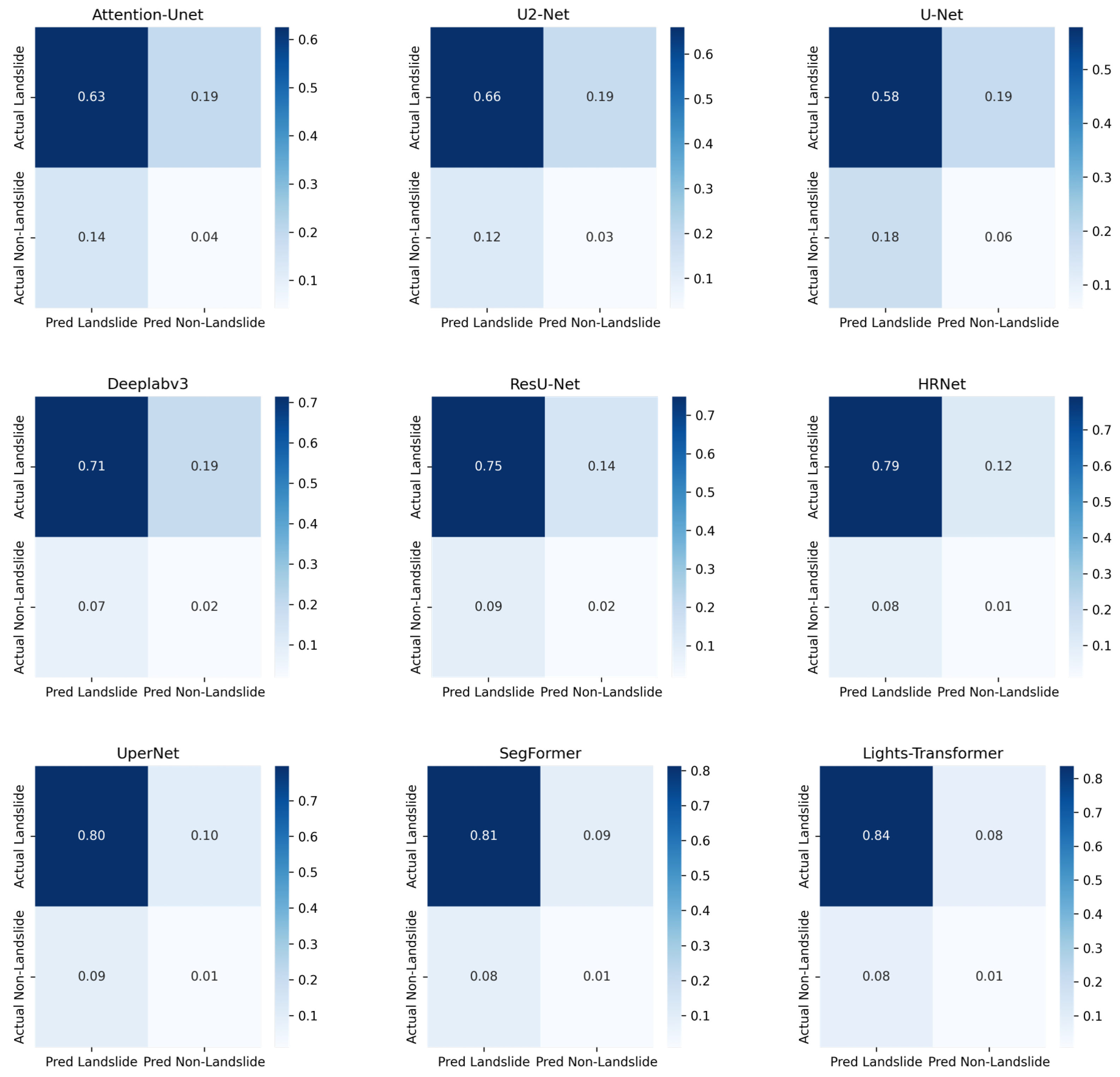
where TP (True Positive), FP (False Positive), TN (True Negative), and FN (False Negative) can be calculated using the confusion matrix (see
Table 4), and N represents the number of samples. The overall performance is evaluated using the average IoU, precision, recall, accuracy, and F1 score for both the landslide and background classes. For all metrics in the above formulas, the higher, the better.
4.4. Comparison of Landslide Detection Accuracy
In this study, the effectiveness of the Lights-Transformer model was compared with models from other application domains. During the experiments, our model was trained and tested alongside other well-known models under the same conditions to objectively assess the performance of Lights-Transformer. The same dataset was used for processing.
Table 5 shows the performance evaluation metrics of these models tested on the research set.
As shown in the
Table 5, the proposed Lights-Transformer model demonstrates significant advantages in landslide detection tasks. The experimental results indicate that Lights-Transformer outperforms across key performance metrics, including mean Intersection over Union (mIoU, 85.11%), accuracy (97.44%), F1 score (91.49%), kappa coefficient (82.98%), precision (91.46%), and recall (91.52%). These results clearly demonstrate the exceptional overall segmentation accuracy and category differentiation capabilities of Lights-Transformer.
As a core metric for evaluating segmentation models, mIoU reflects the model’s ability to distinguish between different categories. Lights-Transformer achieves an mIoU of 85.11%, significantly surpassing the second-best model, SegFormer (83.13%), with an improvement of 1.98 percentage points. This advantage highlights the superior boundary refinement and single-pixel classification accuracy of Lights-Transformer. Furthermore, compared to other mainstream models such as HRNet, UperNet, and Deeplabv3, Lights-Transformer exhibits a more pronounced improvement in mIoU, underscoring the Transformer model’s ability to capture global contextual information and handle complex features. In contrast, traditional convolutional networks such as U-Net and Attention-UNet show significantly inferior performance, while ResU-Net achieved an mIoU of 77.50%, which is at an upper–medium level.
Accuracy measures the correctness of the model in overall pixel classification. Lights-Transformer achieves the highest accuracy of 97.44%, demonstrating its ability to accurately classify landslide regions and background areas, ensuring high reliability. In comparison, while SegFormer achieves an accuracy of 97.09%, Lights-Transformer improves by 0.35 percentage points, showcasing stronger global modeling capabilities and classification robustness. Moreover, compared to traditional models such as U-Net (92.95%) and Deeplabv3 (95.76%), Lights-Transformer’s advantage in accuracy is even more evident, further highlighting its superior performance.
The F1 score, which combines precision and recall, is an important metric for evaluating segmentation models. In this study, Lights-Transformer achieves an F1 score of 91.49%, significantly higher than SegFormer (90.17%) with an improvement of 1.32 percentage points, demonstrating its precise capture of landslide regions while effectively reducing false positives. Additionally, Lights-Transformer improves by approximately 2 percentage points compared to HRNet (88.93%) and UperNet (89.26%). Traditional models such as U-Net (76.02%) and Attention-UNet (78.81%) show significantly lower F1 scores, particularly struggling with complex landslide boundary recognition.
The kappa coefficient measures the agreement between classification results and ground truth, accounting for random classification effects. Lights-Transformer achieves the best kappa coefficient of 82.98%, indicating higher consistency in classifying landslide and background regions. By comparison, the second-best model, SegFormer, achieves a kappa coefficient of 80.34%, while traditional models such as U-Net (52.03%) and Attention-UNet (57.66%) show significantly lower consistency, further highlighting the advantages of Transformer models.
Lights-Transformer also excels in precision and recall, achieving 91.46% and 91.52%, respectively, which are the highest among all models. High precision indicates Lights-Transformer’s significant advantage in reducing false positives, while high recall demonstrates its strong capability in comprehensive landslide region identification. Although HRNet approaches Lights-Transformer in precision (90.82%), it shows a noticeable gap in recall (87.24%). Compared to traditional models such as U-Net and Attention-UNet, Lights-Transformer’s leading position in these metrics is even more prominent.
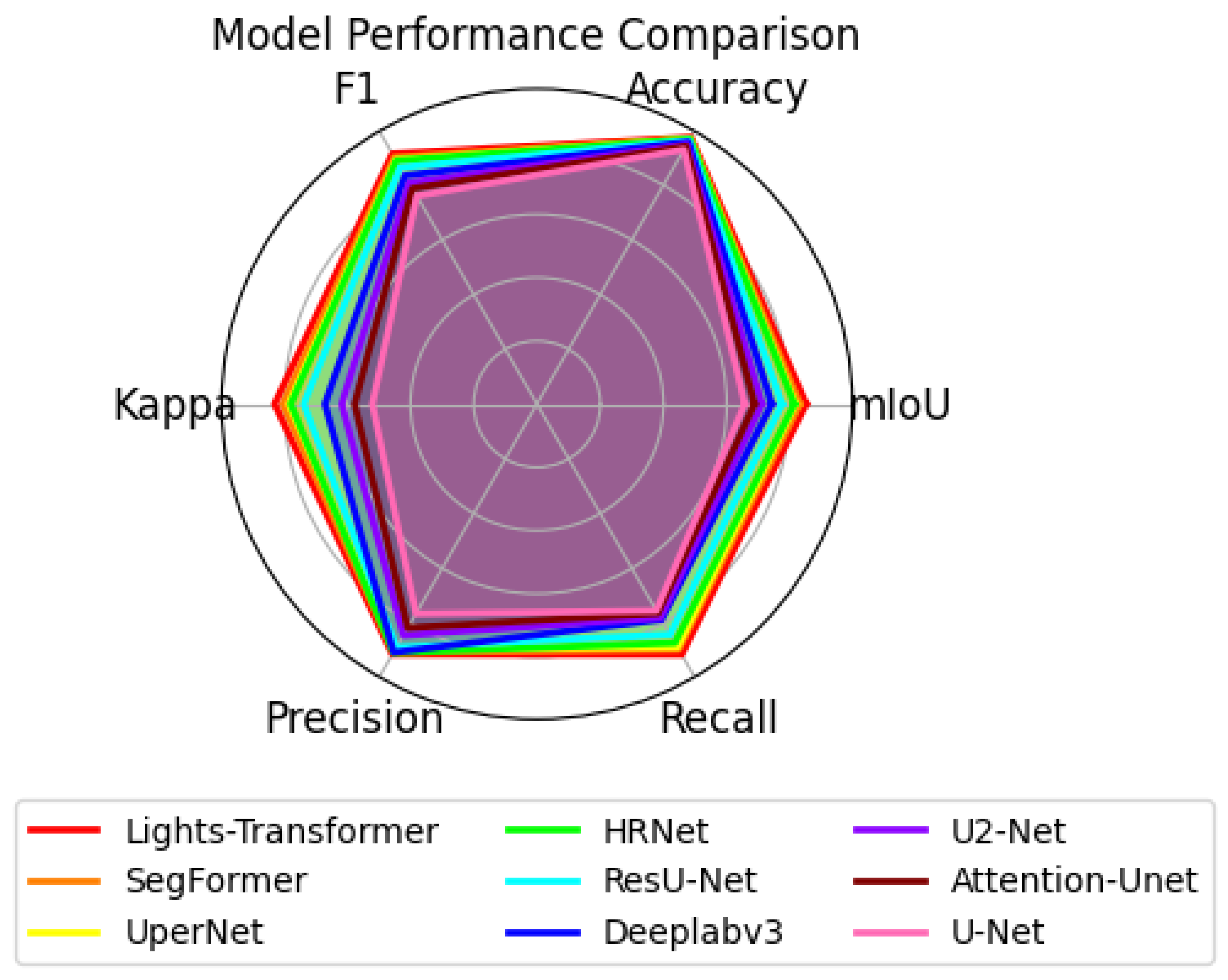
To provide a more intuitive comparison of the overall performance of different models in the landslide detection task,
Figure 5 presents a comparison of Lights-Transformer with other mainstream models across several important evaluation metrics. The chart clearly shows that Lights-Transformer leads in all evaluation metrics, particularly in F1 score, accuracy, and mIoU, where it significantly outperforms other methods.
In conclusion, Lights-Transformer demonstrates outstanding all-around performance in landslide detection tasks.
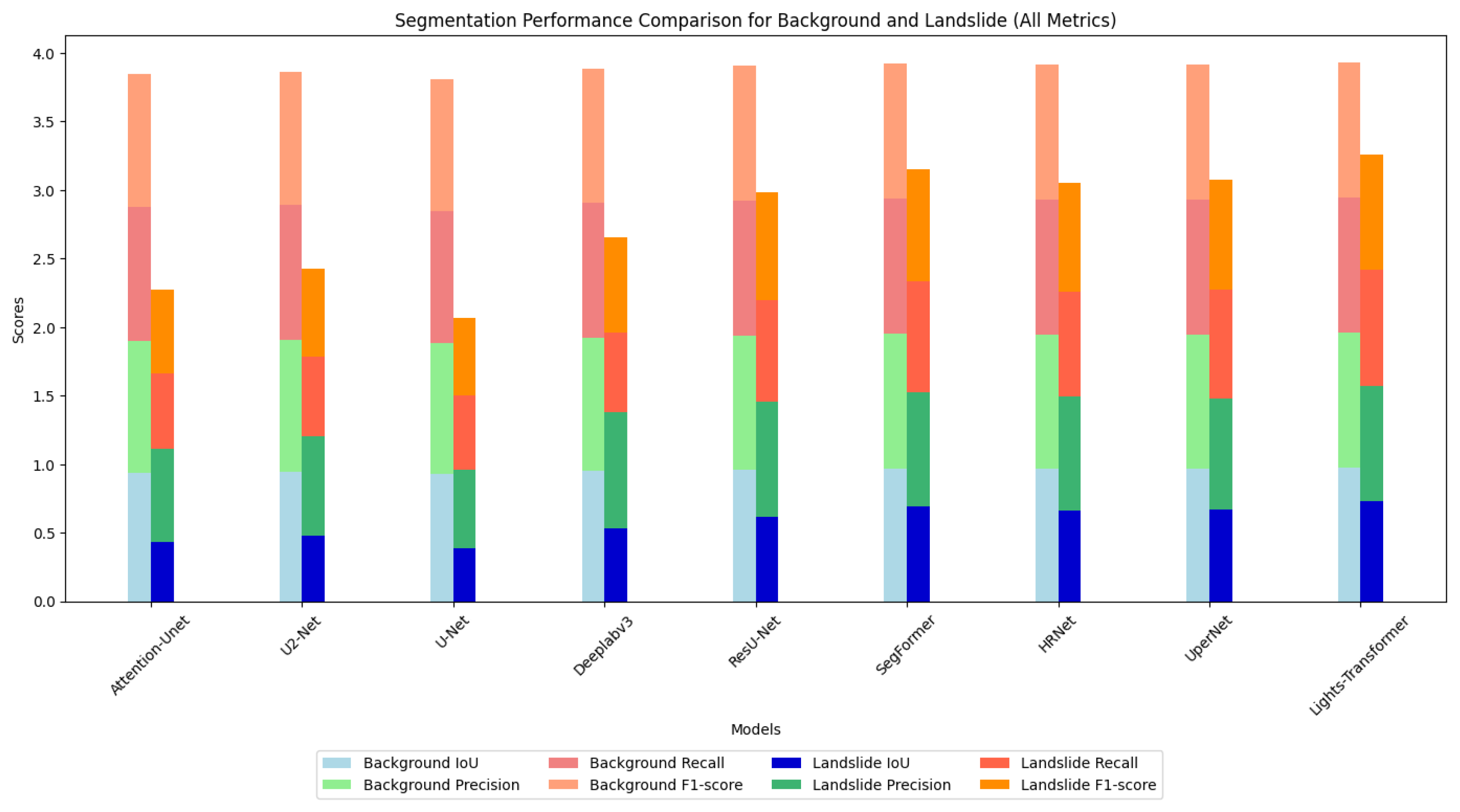
In the landslide detection task, analyzing the segmentation performance for landslide areas and background regions provides a more comprehensive evaluation of the model’s practical performance. Furthermore,
Figure 6 presents a detailed comparison of the segmentation performance across various models for both background and landslide regions using bar charts. According to the results, the Lights-Transformer outperforms other models in both background and landslide regions, demonstrating a particularly significant advantage in segmentation accuracy for landslide areas. This figure vividly illustrates the exceptional capability of the Lights-Transformer in fine-grained segmentation tasks, especially in identifying complex boundaries and segmenting small targets.
Based on the IoU, precision, recall, and F1 score metrics in
Table 6, the proposed Lights-Transformer model demonstrates significant advantages in both categories, particularly excelling in the segmentation of landslide areas. The segmentation quality of background regions is crucial for the overall task, since they occupy the majority of the image. Lights-Transformer achieves an IoU of 97.25% for background regions, which is the highest among all models. Its precision (98.62%) and recall (98.60%) are near perfect, and the F1 score reaches an impressive 98.61%. These results indicate that Lights-Transformer can accurately and comprehensively identify background regions. In comparison, other models perform similarly on background regions but fail to surpass Lights-Transformer. SegFormer achieves a background IoU of 96.88%, which is second only to Lights-Transformer with slightly lower precision (98.29%) and recall (98.54%). HRNet and UperNet record background IoUs of 96.61% and 96.59%, respectively, showing a notable performance gap compared to Lights-Transformer. ResU-Net achieved a background IoU of 96.20% and a precision of 97.85%, demonstrating superior performance among CNN architectures yet still falling short of the Lights-Transformer.
The segmentation performance of landslide regions is a key indicator of model effectiveness in landslide detection tasks. Compared to background regions, landslide segmentation is more challenging due to the complex boundaries and relatively small area. In this aspect, Lights-Transformer also excels, achieving an IoU of 72.96%, the highest among all models, significantly surpassing the second-best model, SegFormer (69.39%) with an improvement of 3.57 percentage points. This highlights its capability in capturing complex boundaries and segmenting small targets. The precision (84.30%) and recall (84.44%) of Lights-Transformer are also the highest, indicating that it not only predicts landslide regions accurately but also provides comprehensive coverage of the actual landslide areas. Its F1 score (84.37%) is substantially higher than other models, especially traditional ones like U-Net (55.86%) and Attention-Unet (60.78%) with performance improvements exceeding 20%. SegFormer achieves a landslide IoU of 69.39%, precision of 83.15%, recall of 80.74%, and F1 score of 81.93%, ranking just behind Lights-Transformer but slightly inferior in detail capture. HRNet and UperNet record landslide IoUs of 66.08% and 67.03%, respectively, with moderate precision and recall, but their F1 scores are about 4 percentage points lower than Lights-Transformer. ResU-Net achieved a landslide IoU of 61.50%, a precision of 84.50%, a recall of 73.50%, and an F1 score of 78.68%, demonstrating considerable competitiveness among CNN models but still slightly inferior to Transformer architectures in small-target and complex-boundary recognition.
In the segmentation of background regions, Lights-Transformer achieves the highest IoU (97.25%) and the best F1 score (98.61%), demonstrating exceptional reliability and accuracy. For landslide region segmentation, Lights-Transformer also leads with an IoU of 72.96% and an F1 score of 84.37%, showcasing outstanding small-target recognition and complex boundary-capturing capabilities. These results fully validate the comprehensive advantages of Lights-Transformer in landslide detection segmentation tasks, particularly in the detailed segmentation of landslide areas and accurate classification of global backgrounds. Compared to other Transformer-based models such as SegFormer, Lights-Transformer achieves further optimization in global modeling and boundary recognition capabilities. Its advantages over traditional convolutional network models are even more pronounced.
4.6. Model Inference Analysis
To comprehensively evaluate the efficiency of different models in practical applications, we measured the average inference time (including forward propagation and result output) for processing a single 1024 × 1024 pixel image on the GDCLD test set. The comparison of inference times between Lights-Transformer and other mainstream models is summarized in
Table 7.
Lights-Transformer demonstrates outstanding performance in terms of inference time, requiring only 103 ms, indicating high inference efficiency and making it suitable for applications with strict real-time requirements. Despite having a moderate model complexity of 183 G and 61 M parameters, it achieves a well-balanced trade-off between inference speed and computational cost.
In comparison, SegFormer exhibits a slightly longer inference time of 126 ms. However, with its higher model complexity (341 G) and 64 M parameters, it delivers enhanced capability in handling more complex tasks. Its architecture is evidently optimized for fine-grained and detailed feature extraction, which, although at the cost of speed, makes SegFormer advantageous in scenarios requiring high-precision feature analysis.
UperNet has the longest inference time among all models, reaching 193 ms, reflecting its substantial computational demand. With 93 M parameters and an extremely high model complexity of 2052 G, UperNet is suited for computationally intensive tasks and may outperform other models in terms of accuracy when deployed on high-performance computing platforms.
HRNet, with an inference time of 123 ms, strikes a balance between performance and computational load. It contains 70 M parameters and a complexity of 646 G. This balance makes HRNet a strong candidate for applications requiring relatively high precision without incurring excessive computational costs.
U-Net stands out with the shortest inference time of just 74 ms, making it particularly attractive for applications requiring rapid responses. Its low model complexity (497 G) and small parameter count (13 M) ensure minimal computational demand and memory usage, making it ideal for deployment in resource-constrained environments.
U2-Net, with an inference time of 97 ms, 44 M parameters, and a complexity of 603 G, offers a good compromise between inference efficiency and computational requirements. Although its inference time is slightly longer than U-Net, its relatively low complexity and parameter count make it well suited for tasks with limited computational resources but increased model demands.
Deeplabv3 achieves a relatively short inference time of 76 ms, making it suitable for fast-response applications. With a model complexity of 651 G and 39 M parameters, it exhibits a favorable balance between computational efficiency and memory consumption.
Attention-UNet, with an inference time of 120 ms, features a relatively low parameter count (35 M) and a model complexity of 1065 G. Although its inference time is longer, it shows efficient memory and computational usage, making it especially suitable for deployment in resource-constrained environments.
ResU-Net’s inference time was 115 milliseconds, with a model complexity of 385 G and a parameter count of 54 M, achieving a relatively balanced performance between inference efficiency and computational cost, making it a viable complementary choice as a lightweight model.
In summary, Lights-Transformer emerges as an ideal choice for scenarios requiring real-time performance with limited computational resources, owing to its fast inference time and moderate computational cost. In contrast, UperNet and SegFormer trade inference efficiency for greater capability in handling complex tasks, enabled by their higher model complexity and parameter count, making them well suited for deployment on high-performance computing platforms. For resource-constrained environments, U-Net and Attention-UNet offer a favorable compromise between inference speed and computational efficiency, delivering reasonable performance with low memory and computational overhead.
To comprehensively evaluate the practicality of each model in landslide detection tasks, we not only focused on segmentation accuracy metrics (such as mIoU and F1 score) but also compared the inference time of each model under the same hardware environment to further analyze their deployment potential in real-world scenarios. As shown in the table above, models such as UperNet and SegFormer demonstrated outstanding accuracy, but due to their complex structures, they exhibited inference times exceeding 120 ms, rendering them unsuitable for scenarios requiring high response speeds. In contrast, lightweight architectures such as U-Net and U2-Net achieved shorter inference times (less than 90 ms), but their segmentation accuracy was insufficient in complex terrain.
While ensuring leading accuracy (mIoU = 85.11%, F1 = 91.49%), Lights-Transformer maintains an inference time of 103 ms, achieving a favorable balance between speed and accuracy. This result indicates that Lights-Transformer possesses good “quasi-real-time” processing capabilities, offering support for practical applications such as post-disaster rapid response and emergency early warning in landslide scenarios.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}