
Continuous Assessment of Mental Workload During Complex Human–Machine Interaction: Inferring Cognitive State from Signals External to the Operator †

 , and
, and
Abstract
1. Introduction
2. Materials and Methods
2.1. Population
2.2. Simulator
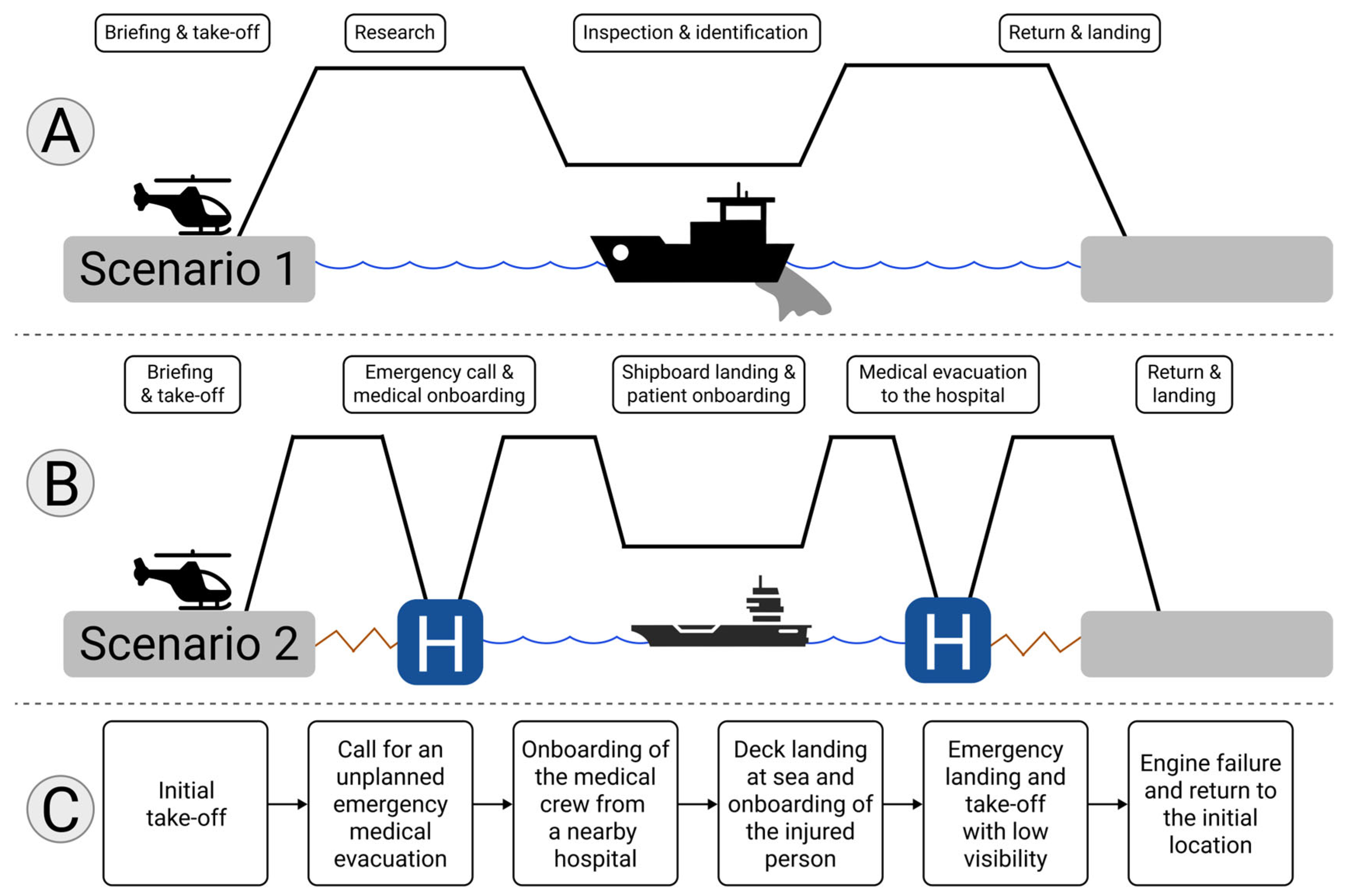
2.3. Flight Scenarios
2.4. Features
2.5. Machine-Learning Model
3. Results
3.1. Model Performance
3.2. Operational Features Outperform Physiological Parameters
3.3. Impact of the Ground Truth on Model Performance
4. Discussion
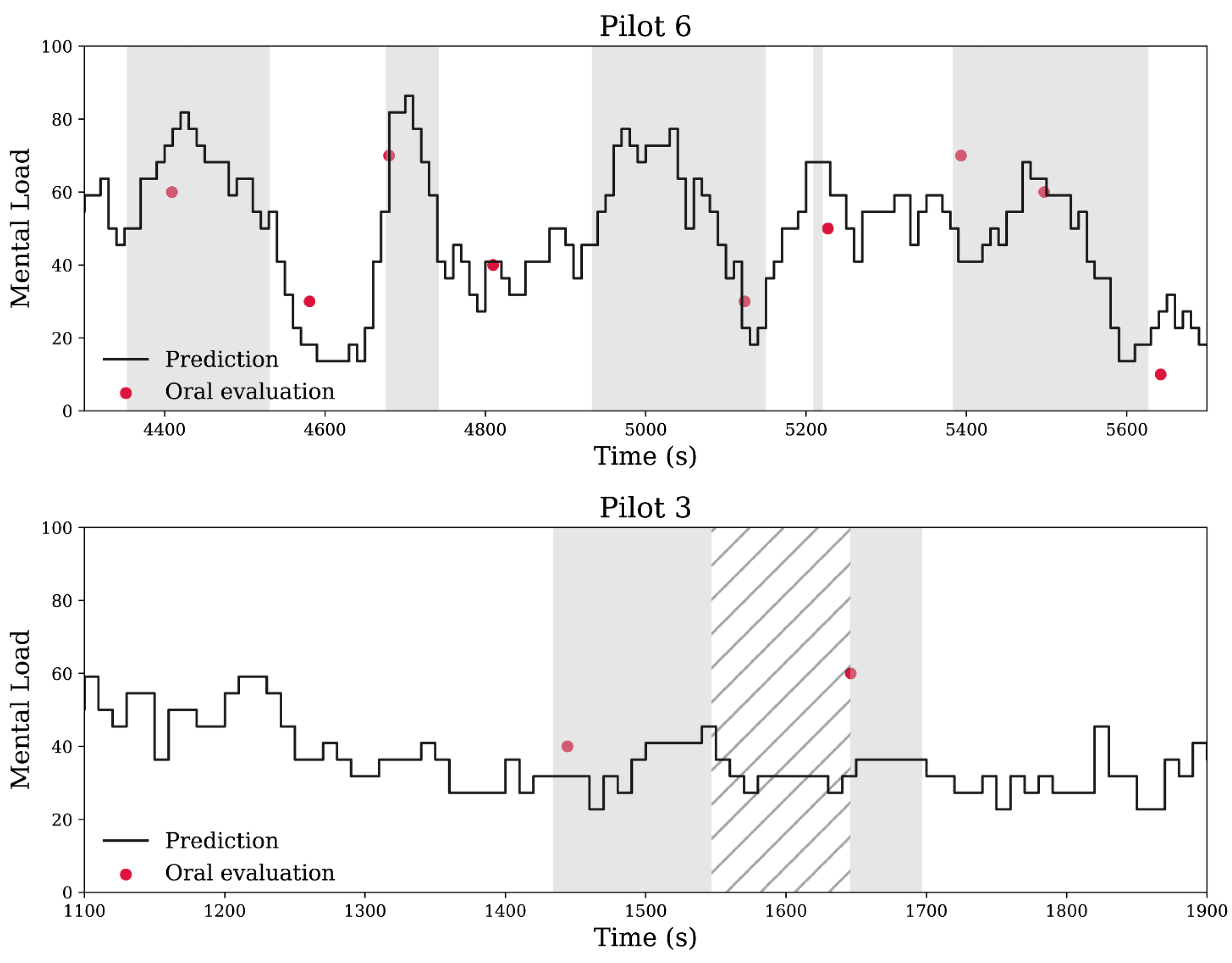
4.1. Self-Reports vs. NASA-TLX Questionnaires for MWL Evaluation
4.2. Best Set of Signals for MWL Estimation
5. Limitations and Perspectives
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zimmerman, M.E. Task Load BT—Encyclopedia of Clinical Neuropsychology; Kreutzer, J.S., DeLuca, J., Caplan, B., Eds.; Springer: New York, NY, USA, 2011; pp. 2469–2470. [Google Scholar]
- Longo, L.; Wickens, C.D.; Hancock, G.; Hancock, P.A. Human Mental Workload: A Survey and a Novel Inclusive Definition. Front. Psychol. 2022, 13, 883321. [Google Scholar] [CrossRef] [PubMed]
- Neerincx, M.A. Cognitive task load analysis: Allocating tasks and designing support. In Handbook of Cognitive Task Design; Routledge: Oxfordshire, UK, 2003; Volume 2003, pp. 283–305. [Google Scholar]
- Charles, R.L.; Nixon, J. Measuring mental workload using physiological measures: A systematic review. Appl. Ergon. 2019, 74, 221–232. [Google Scholar] [CrossRef] [PubMed]
- Kramer, A.F. Physiological metrics of mental workload: A review of recent progress. In Multiple-Task Performance; CRC Press: Boca Raton, FL, USA, 2020; pp. 279–328. [Google Scholar]
- Leplat, J. Eléments Pour une Histoire de la Notion de Charge Mentale. Charge Mentale: Notion Floue et vrai Problème Toulouse; Octarès: Toulouse, France, 2002. [Google Scholar]
- Cain, B. A Review of the Mental Workload Literature. 2007. Available online: https://apps.dtic.mil/sti/pdfs/ADA474193.pdf (accessed on 12 March 2025).
- Chanquoy, L.; Tricot, A.; Sweller, J. La Charge Cognitive: Théorie et Applications; Armand Colin: London, UK, 2007. [Google Scholar]
- Young, M.S.; Brookhuis, K.A.; Wickens, C.D.; Hancock, P.A. State of science: Mental workload in ergonomics. Ergonomics 2015, 58, 1–17. [Google Scholar] [CrossRef] [PubMed]
- Falzon, P.; Sauvagnac, C. Charge de travail et stress. In Ergonomie; Presses Universitaires de France: Paris, France, 2004; pp. 175–190. [Google Scholar]
- De Waard, D.; Brookhuis, K.A. The Measurement of Drivers’ Mental Workload; University of Groningen: Groningen, The Netherlands, 1996. [Google Scholar]
- Majumdar, A.; Mak, K.; Lettington, C.; Nalder, P. A causal factors analysis of helicopter accidents in New Zealand 1996–2005 and the United Kingdom 1986–2005. Aeronaut. J. 2009, 113, 647–660. [Google Scholar] [CrossRef]
- Burian, B.K.; Pruchnicki, S.; Rogers, J.; Christopher, B.; Williams, K.; Silverman, E.; Drechsler, G.; Mead, A.; Hackworth, C.; Runnels, B. Single-Pilot Workload Management in Entry-Level Jets; National Aeronautics and Space Administration Ames Research Center: Moffett Field, CA, USA, 2013. [Google Scholar]
- Gray, R.; Gaska, J.; Winterbottom, M. Relationship between sustained, orientated, divided, and selective attention and simulated aviation performance: Training & pressure effects. J. Appl. Res. Mem. Cogn. 2016, 5, 34–42. [Google Scholar]
- Castor, M.; Hanson, E.; Svensson, E.; Nählinder, S.; Le Blaye, P.; MacLeod, I.; Wright, N.; Ågren, L.; Berggren, P.; Juppet, V.; et al. GARTEUR Handbook of Mental Workload Measurement; Springer: New York, NY, USA, 2003. [Google Scholar]
- Cooper, G.E.; Harper, R.P. The Use of Pilot Rating in the Evaluation of Aircraft Handling Qualities; National Aeronautics and Space Administration: Washington, DC, USA, 1969. [Google Scholar]
- Reid, G.B.; Nygren, T.E. The subjective workload assessment technique: A scaling procedure for measuring mental workload. In Advances in Psychology; Elsevier: Amsterdam, The Netherlands, 1988; pp. 185–218. [Google Scholar]
- Hart, S.G.; Staveland, L.E. Development of NASA-TLX (Task Load Index): Results of empirical and theoretical research. Adv. Psychol. 1988, 52, 139–183. [Google Scholar]
- Paas, F.G.W.C.; van Merriënboer, J.J.G.; Adam, J.J. Measurement of Cognitive Load in Instructional Research. Percept. Mot. Ski. 1994, 79, 419–430. [Google Scholar] [CrossRef]
- Rubio, S.; Diaz, E.; Martin, J.; Puente, J.M. Evaluation of subjective mental workload: A comparison of SWAT, NASA-TLX, and workload profile methods. Appl. Psychol. 2004, 53, 61–86. [Google Scholar] [CrossRef]
- Pauzié, A.; Pachiaudi, G. Traffic and Transport Psychology: Theory and Application. Chapter 18. Subjective Evaluation of the Mental Workload in The Driving Context; University of Derby: Derby, UK, 1997. [Google Scholar]
- Muckler, F.A.; Seven, S.A. Selecting performance measures: “Objective” versus “subjective” measurement. Hum. Factors J. Hum. Factors Ergon. Soc. 1992, 34, 441–455. [Google Scholar] [CrossRef]
- Luzzani, G.; Buraioli, I.; Demarchi, D.; Guglieri, G. A review of physiological measures for mental workload assessment in aviation: A state-of-the-art review of mental workload physiological assessment methods in human-machine interaction analysis. Aeronaut. J. 2024, 128, 928–949. [Google Scholar] [CrossRef]
- Masi, G.; Amprimo, G.; Ferraris, C.; Priano, L. Stress and Workload Assessment in Aviation—A Narrative Review. Sensors 2023, 23, 3556. [Google Scholar] [CrossRef]
- Rainieri, G.; Fraboni, F.; Russo, G.; Tul, M.; Pingitore, A.; Tessari, A.; Pietrantoni, L. Visual Scanning Techniques and Mental Workload of Helicopter Pilots During Simulated Flight. Aerosp. Med. Hum. Perform. 2021, 92, 11–19. [Google Scholar] [CrossRef] [PubMed]
- Scarpari, J.R.S.; Ribeiro, M.W.; Deolindo, C.S.; Aratanha, M.A.A.; de Andrade, D.; Forster, C.H.Q.; Figueira, J.M.P.; Corrêa, F.L.S.; Lacerda, S.S.; Machado, B.S.; et al. Quantitative assessment of pilot-endured workloads during helicopter flying emergencies: An analysis of physiological parameters during an autorotation. Sci. Rep. 2021, 11, 17734. [Google Scholar] [CrossRef] [PubMed]
- Besson, P.; Bourdin, C.; Bringoux, L.; Dousset, E.; Maiano, C.; Marqueste, T.; Mestre, D.R.; Gaetan, S.; Baudry, J.-P.; Vercher, J.-L. Effectiveness of physiological and psychological features to estimate helicopter pilots’ workload: A bayesian network approach. IEEE Trans. Intell. Transp. Syst. 2013, 14, 1872–1881. [Google Scholar] [CrossRef]
- Harrivel, A.R.; Stephens, C.L.; Milletich, R.J.; Heinich, C.M.; Last, M.C.; Napoli, N.J.; Abraham, N.; Prinzel, L.J.; Motter, M.A.; Pope, A.T. Prediction of cognitive states during flight simulation using multimodal psychophysiological sensing. In Proceedings of the AIAA Information Systems-AIAA Infotech@ Aerospace, Grapevine, TX, USA, 9–13 January 2017; p. 1135. [Google Scholar]
- Bargiotas, I.; Nicolaï, A.; Vidal, P.P.; Labourdette, C.; Vayatis, N.; Buffat, S. The complementary role of activity context in the mental workload evaluation of helicopter pilots: A multi-tasking learning approach. In International Symposium on Human Mental Workload: Models and Applications; Springer: New York, NY, USA, 2018; pp. 222–238. [Google Scholar]
- Lew, R. Assessing Cognitive Workload from Multiple Physiological Measures Using Wavelets and Machine Learning; University of Idaho: Moscow, Russia, 2014. [Google Scholar]
- Solovey, E.T.; Zec, M.; Garcia Perez, E.A.; Reimer, B.; Mehler, B. Classifying driver workload using physiological and driving performance data: Two field studies. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Toronto, ON, Canada, 26 April–1 May 2014; pp. 4057–4066. [Google Scholar]
- Moustafa, K.; Luz, S.; Longo, L. Assessment of mental workload: A comparison of machine learning methods and subjective assessment techniques. In International Symposium on Human Mental Workload: Models and Applications; Springer: New York, NY, USA, 2017; pp. 30–50. [Google Scholar]
- Ding, Y.; Cao, Y.; Duffy, V.G.; Wang, Y.; Zhang, X. Measurement and identification of mental workload during simulated computer tasks with multimodal methods and machine learning. Ergonomics 2020, 63, 896–908. [Google Scholar] [CrossRef]
- Barua, S.; Ahmed, M.U.; Begum, S. Towards intelligent data analytics: A case study in driver cognitive load classification. Brain Sci. 2020, 10, 526. [Google Scholar] [CrossRef] [PubMed]
- Mozos, O.M.; Sandulescu, V.; Andrews, S.; Ellis, D.; Bellotto, N.; Dobrescu, R.; Ferrandez, J.M. Stress detection using wearable physiological and sociometric sensors. Int. J. Neural Syst. 2016, 27, 1650041. [Google Scholar] [CrossRef]
- Jeong, M.; Ko, B.C. Driver’s facial expression recognition in real-time for safe driving. Sensors 2018, 18, 4270. [Google Scholar] [CrossRef]
- Ji, Q.; Zhu, Z.; Lan, P. Real-time nonintrusive monitoring and prediction of driver fatigue. IEEE Trans. Veh. Technol. 2004, 53, 1052–1068. [Google Scholar] [CrossRef]
- Liang, Y.; Lee, J.D. A hybrid Bayesian Network approach to detect driver cognitive distraction. Transp. Res. Part C Emerg. Technol. 2014, 38, 146–155. [Google Scholar] [CrossRef]
- Yan, S.; Tran, C.C.; Wei, Y.; Habiyaremye, J.L. Driver’s mental workload prediction model based on physiological indices. Int. J. Occup. Saf. Ergon. 2017, 25, 476–484. [Google Scholar] [CrossRef] [PubMed]
- Johnson, M.K.; Blanco, J.A.; Gentili, R.J.; Jaquess, K.J.; Oh, H.; Hatfield, B.D. Probe-independent EEG assessment of mental workload in pilots. In Proceedings of the 2015 7th International IEEE/EMBS Conference on Neural Engineering (NER), Montpellier, France, 22–24 April 2015; pp. 581–584. [Google Scholar]
- Nicolai, A.; Audiffren, J. Model-Space Regularization and Fully Interpretable Algorithms for Postural Control Quantification. In Proceedings of the 2018 IEEE 42nd Annual Computer Software and Applications Conference (COMPSAC), Tokyo, Japan, 23–27 July 2018; pp. 177–182. [Google Scholar]
- Hidalgo-Muñoz, A.R.; Mouratille, D.; Causse, M.; Matton, N.; Rouillard, Y. Cognitive Workload and Personality Style in PilotsHeart Rate Study. In Proceedings of the DDI 2018, 6th International Conference on Driver Distraction and Inattention, Gothenburg, Sweden, 15–17 October 2018. [Google Scholar]
- Houck, J.A.; Telban, R.J.; Cardullo, F.M. Motion Cueing Algorithm Development: Human-Centered Linear and Nonlinear Approaches; NTRS: Chicago, IL, USA, 2005. [Google Scholar]
- Stanton, N.A. Hierarchical task analysis: Developments, applications, and extensions. Appl. Ergon. 2006, 37, 55–79. [Google Scholar] [CrossRef] [PubMed]
- Hart, S.G. NASA-task load index (NASA-TLX); 20 years later. Proc. Hum. Factors Ergon. Soc. Annu. Meet. 2006, 50, 904–908. [Google Scholar] [CrossRef]
- Zhang, H.; Zhu, Y.; Maniyeri, J.; Guan, C. Detection of Variations in Cognitive Workload Using Multi-Modality Physiological Sensors and a Large Margin Unbiased Regression Machine. In Proceedings of the 2014 36th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Chicago, IL, USA, 26–30 August 2014; pp. 2985–2988. [Google Scholar]
- Van Roon, A.M.; Mulder, L.J.; Althaus, M.; Mulder, G. Introducing a baroreflex model for studying cardiovascular effects of mental workload. Psychophysiology 2004, 41, 961–981. [Google Scholar] [CrossRef] [PubMed]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Grier, R.A. How high is high? A meta-analysis of NASA-TLX global workload scores. Proc. Hum. Factors Ergon. Soc. Annu. Meet. 2015, 59, 1727–1731. [Google Scholar] [CrossRef]
- Singh, G.; Chanel, C.P.C.; Roy, R.N. Mental Workload estimation based on physiological features for Pilot-UAV teaming applications. Front. Hum. Neurosci. 2021, 15, 692878. [Google Scholar] [CrossRef]
- Liu, C.; Wanyan, X.; Xiao, X.; Zhao, J.; Duan, Y. Pilots’ mental workload prediction based on timeline analysis. Technol. Health Care 2020, 28, 207–216. [Google Scholar] [CrossRef]
- Miller, S. Workload Measures; National Advanced Driving Simulator: Iowa City, IA, USA, 2001. [Google Scholar]
- Vidal, P.P.; Lacquaniti, F. Perceptual-motor styles. Exp. Brain Res. 2021, 239, 1359–1380. [Google Scholar] [CrossRef]
- Ruben, M.A.; van Osch, M.; Blanch-Hartigan, D. Healthcare providers’ accuracy in assessing patients’ pain: A systematic review. Patient Educ. Couns. 2015, 98, 1197–1206. [Google Scholar] [CrossRef]
- Ikehara, C.S.; Crosby, M.E. Assessing cognitive load with physiological sensors. In Proceedings of the 38th Annual Hawaii International Conference on system Sciences, Big Island, HI, USA, 3–6 January 2005; p. 295a. [Google Scholar]
- Marquart, G.; Cabrall, C.; de Winter, J. Review of eye-related measures of drivers’ mental workload. Procedia Manuf. 2015, 3, 2854–2861. [Google Scholar] [CrossRef]
- Dubois, E. Optimisation de la Formation des Pilotes par L’éducation du Comportement Oculaire; ISAE: Toulouse, France, 2017. [Google Scholar]
- Kramer, A.F.; Tham, M.; Konrad, C.; Wickens, C.; Lintern, G.; Marsh, R.; Fox, J.; Merwin, D. Instrument scan and pilot expertise. Proc. Hum. Factors Ergon. Soc. 1994, 1, 36–40. [Google Scholar]
- Kasarskis, P.; Stehwien, J.; Hickox, J.; Aretz, A.; Wickens, C. Comparison of expert and novice scan behaviors during VFR flight. In Proceedings of the 11th International Symposium on Aviation Psychology, Columbus, OH, USA, 5–8 March 2001. [Google Scholar]
- Bellenkes, A.H.; Wickens, C.D.; Kramer, A. Visual scanning and pilot expertise: The role of attentional flexibility and mental model development. Aviat. Space Environ. Med. 1997, 68, 569–579. [Google Scholar]
- Maggi, P.; Di Nocera, F. Sensitivity of the spatial distribution of fixations to variations in the type of task demand and its relation to visual entropy. Front. Hum. Neurosci. 2021, 15, 642535. [Google Scholar] [CrossRef]
- de Haart, M.; Geurts, A.C.; Huidekoper, S.C.; Fasotti, L.; van Limbeek, J. Recovery of standing balance in postacute stroke patients: A rehabilitation cohort study. Arch. Phys. Med. Rehabil. 2004, 85, 886–895. [Google Scholar] [CrossRef] [PubMed]
- Nickel, P.; Nachreiner, F. Sensitivity and diagnosticity of the 0.1-hz component of heart rate variability as an indicator of mental workload. Hum. Factors J. Hum. Factors Ergon. Soc. 2003, 45, 575–590. [Google Scholar] [CrossRef]
- Gabaude, C.; Baracat, B.; Jallais, C.; Bonniaud, M.; Fort, A. Cognitive load measurement while driving. In Human Factors: A View from an Integrative Perspective; Human Factors and Ergonomics Society: Washington, DC, USA, 2012. [Google Scholar]
- Li, W.; Li, R.; Xie, X.; Chang, Y. Evaluating mental workload during multitasking in simulated flight. Brain Behav. 2022, 12, e2489. [Google Scholar] [CrossRef] [PubMed]
- Heine, T.; Lenis, G.; Reichensperger, P.; Beran, T.; Doessel, O.; Deml, B. Electrocardiographic features for the measurement of drivers’ mental workload. Appl. Ergon. 2017, 61, 31–43. [Google Scholar] [CrossRef]
- Hidalgo-Muñoz, A.R.; Béquet, A.J.; Astier-Juvenon, M.; Pépin, G.; Fort, A.; Jallais, C.; Tattegrain, H.; Gabaude, C. Respiration and Heart Rate Modulation Due to Competing Cognitive Tasks While Driving. Front. Hum. Neurosci. 2019, 12, 525. [Google Scholar] [CrossRef]
- Roscoe, A.H. Assessing pilot workload. Why measure heart rate, HRV and respiration? Biol. Psychol. 1992, 34, 259–287. [Google Scholar] [CrossRef]
- Lorenzini, M.; Lagomarsino, M.; Fortini, L.; Gholami, S.; Ajoudani, A. Ergonomic human-Robot Collaboration in Industry: A review. Front. Robot. AI 2023, 9, 813907. [Google Scholar] [CrossRef] [PubMed]
- Bonan, I.; Marquer, A.; Eskiizmirliler, S.; Yelnik, A.; Vidal, P.-P. Sensory reweighting in controls and stroke patients. Clin. Neurophysiol. 2013, 124, 713–722. [Google Scholar] [CrossRef] [PubMed]
- Mantilla, J.; Wang, D.; Bargiotas, I.; Wang, J.; Cao, J.; Oudre, L.; Vidal, P.-P. Motor style at rest and during locomotion in humans. J. Neurophysiol. 2020, 123, 2269–2284. [Google Scholar] [CrossRef] [PubMed]
- Delp, S.L.; Anderson, F.C.; Arnold, A.S.; Loan, P.; Habib, A.; John, C.T.; Guendelman, E.; Thelen, D.G. OpenSim: Open-source software to create and analyze dynamic simulations of movement. IEEE Trans. Biomed. Eng. 2007, 54, 1940–1950. [Google Scholar] [CrossRef]
- Damsgaard, M.; Rasmussen, J.; Christensen, S.T.; Surma, E.; de Zee, M. Analysis of musculoskeletal systems in the AnyBody Modeling System. Simul. Model. Pract Theory 2006, 14, 1100–1111. [Google Scholar] [CrossRef]
- Chao, E.Y.; Armiger, R.S.; Yoshida, H.; Lim, J.; Haraguchi, N. Virtual interactive musculoskeletal system (VIMS) in orthopaedic research, education and clinical patient care. J. Orthop. Surg. Res. 2007, 2, 2. [Google Scholar] [CrossRef]
- Naegelin, M.; Weibel, R.P.; Kerr, J.I.; Schinazi, V.R.; La Marca, R.; von Wangenheim, F.; Hoelscher, C.; Ferrario, A. An interpretable machine learning approach to multimodal stress detection in a simulated office environment. J. Biomed. Inform. 2023, 139, 104299. [Google Scholar] [CrossRef]
- Zhang, J.; Li, J.; Wang, R. Instantaneous mental workload assessment using time–frequency analysis and semi-supervised learning. Cogn. Neurodynamics 2020, 14, 619–642. [Google Scholar] [CrossRef]
- Tao, D.; Tan, H.; Wang, H.; Zhang, X.; Qu, X.; Zhang, T. A systematic review of physiological measures of mental workload. Int. J. Environ. Res. Public Health 2019, 16, 2716. [Google Scholar] [CrossRef]
- Salvucci, D.D.; Goldberg, J.H. Identifying fixations and saccades in eye-tracking protocols. In Proceedings of the 2000 Symposium on Eye Tracking Research & Applications, Palm Beach Gardens, FL, USA, 6–8 November 2000; pp. 71–78. [Google Scholar]
- Schubert, P.; Kirchner, M. Ellipse area calculations and their applicability in posturography. Gait Posture 2014, 39, 518–522. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
| Signal | Sampling Frequency (Hz) | Features | Unit | |
|---|---|---|---|---|
| Physiology | ECG | Mean HR | bpm | |
| HR standard deviation | bpm | |||
| Mean IBI | ms | |||
| IBI standard deviation | ms | |||
| Plethysmography | Mean BR | bpm | ||
| BR standard deviation | bpm | |||
| Oculometry | Mean fixation duration | s | ||
| Mean saccade duration | s | |||
| Mean saccade amplitude | deg | |||
| Gaze (eyes + head) | 95% prediction ellipse | pixels2 | ||
| Time spent in each AoI | s | |||
| Machine | Helicopter position | Altitude standard deviation | ft | |
| Altitude mean-crossings | ||||
| Yaw orientation standard deviation | deg | |||
| Yaw orientation mean-crossings | ||||
| Mean pitch orientation | deg | |||
| Pitch orientation standard deviation | deg | |||
| Pitch orientation mean-crossings | ||||
| Mean roll orientation | deg | |||
| Roll orientation standard deviation | deg | |||
| Roll orientation mean-crossings | ||||
| Automatic pilot | Not applicable | Time spent in each horizontal sub-mode | s | |
| Time spent in each vertical sub-mode | s | |||
| Human–machine interface | Flight instruments: thrust lever, anti-torque pedals, cyclic pitch, cyclic roll | Mean displacement | % | |
| Displacement standard deviation | % | |||
| Displacement mean-crossings | ||||
| Mean force | daN | |||
| Force standard deviation | daN | |||
| Force zero-crossings | ||||
| Radio communication | Not applicable | Proportion of time spent in communication | % |
| N° Pilot | ]) | ) |
|---|---|---|
| 3 | ||
| 4 | ||
| 5 | ||
| 6 | ||
| 7 | ||
| 8 | ||
| 9 |
| Features | Percentage of Use |
|---|---|
| Standard deviation of the displacement: pedals, cyclic in the pitch and roll planes | 100, 100, 100 |
| Standard deviation of the position of the helicopter: yaw, pitch and roll planes | 100, 100, 100 |
| Standard deviation of the force applied: pedals, cyclic in the pitch plane | 100, 100 |
| Movement frequency of the pedals | 100 |
| Proportion of time looking out of the cockpit | 100 |
| Standard deviation of the displacement and of the force applied on the collective lever | 98.7, 97.6 |
| Proportion of time spent with a horizontal or vertical autopilot | 98.5, 97.5 |
| Standard deviation of helicopter altitude | 95.7 |
| Mean heart rate | 93.3 |
| Dataset | ) | ) | ) |
|---|---|---|---|
| All | |||
| Physiological data | |||
| Machine data | |||
| Interface data |
| NASA-TLX Subsets | ) |
|---|---|
| RTLX (unweighted mean) | |
| Mental demand | |
| Temporal demand | |
| Frustration | |
| Effort | |
| Theoretical RTLX (unweighted mean) | |
| Theoretical mental demand | |
| Theoretical temporal demand | |
| Theoretical effort |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Roques, A.; Keriven Serpollet, D.; Nicolaï, A.; Buffat, S.; James, Y.; Vayatis, N.; Bargiotas, I.; Vidal, P.-P. Continuous Assessment of Mental Workload During Complex Human–Machine Interaction: Inferring Cognitive State from Signals External to the Operator. Sensors 2025, 25, 3624. https://doi.org/10.3390/s25123624
Roques A, Keriven Serpollet D, Nicolaï A, Buffat S, James Y, Vayatis N, Bargiotas I, Vidal P-P. Continuous Assessment of Mental Workload During Complex Human–Machine Interaction: Inferring Cognitive State from Signals External to the Operator. Sensors. 2025; 25(12):3624. https://doi.org/10.3390/s25123624
Chicago/Turabian StyleRoques, Axel, Dimitri Keriven Serpollet, Alice Nicolaï, Stéphane Buffat, Yannick James, Nicolas Vayatis, Ioannis Bargiotas, and Pierre-Paul Vidal. 2025. "Continuous Assessment of Mental Workload During Complex Human–Machine Interaction: Inferring Cognitive State from Signals External to the Operator" Sensors 25, no. 12: 3624. https://doi.org/10.3390/s25123624
APA StyleRoques, A., Keriven Serpollet, D., Nicolaï, A., Buffat, S., James, Y., Vayatis, N., Bargiotas, I., & Vidal, P.-P. (2025). Continuous Assessment of Mental Workload During Complex Human–Machine Interaction: Inferring Cognitive State from Signals External to the Operator. Sensors, 25(12), 3624. https://doi.org/10.3390/s25123624