
TDA-L: Reducing Latency and Memory Consumption of Test-Time Adaptation for Real-Time Intelligent Sensing



Abstract
1. Introduction
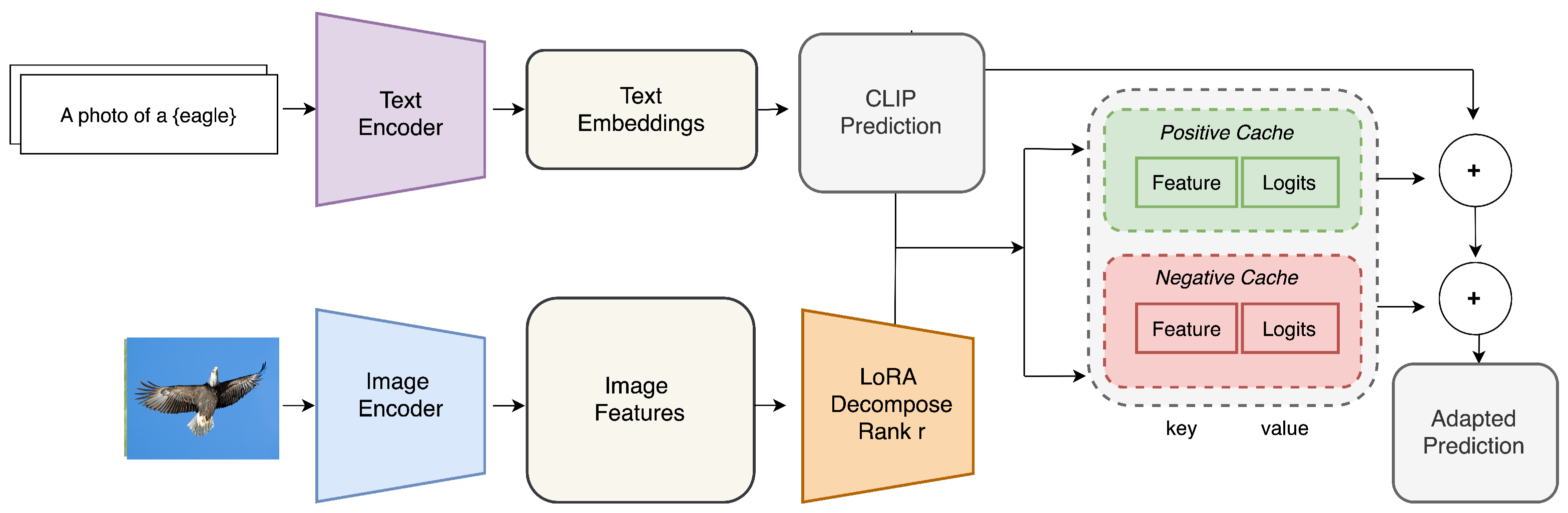
- We introduce TDA-L, a test-time adaptation framework that integrates LoRA-based feature adaptation with a dynamic KV cache, operating in a training-free setting.
- We curate a custom dataset by combining 10% of multiple datasets (described in Section 4.1) and learn generalized LoRA matrices offline for diverse domain adaptation. By using a small fraction of samples, we avoid our model memorizing and overfitting them while supporting efficient training of the LoRA module.
- We demonstrate that TDA-L preserves accuracy while significantly reducing both latency and memory usage, especially with low-rank configurations.
- We conduct a thorough comparison of TDA-L with state-of-the-art approaches to TTA [9,10,19]—across seven benchmarks, showcasing its robustness under distribution shifts and computational efficiency in terms of latency, memory usage, and throughput, validating the real-world viability of our method on a commodity machine that mimics a cost-effective edge server much less expensive than a cloud server with high-end GPUs and massive resources.
2. Related Work
2.1. Vision–Language Models and Test-Time Adaptation
2.2. Key–Value Caching for Efficient Test-Time Adaptation
- Static KV Caching: Methods such as Tip-Adapter [27] use a fixed cache of precomputed embeddings from a few-shot labeled dataset. While effective, these approaches cannot adapt to shifting data distributions.
- Dynamic KV Caching: The Training-Free Dynamic Adapter (TDA) [10] introduces dynamic KV caching, where test-time predictions are stored and progressively updated. This enables continuous adaptation without backpropagation. In particular, TDA maintains two dynamic caches for effective TTA: (1) a positive cache that stores high-confidence pseudo-labels to improve classification and (2) a negative cache that mitigates noisy predictions by storing ambiguous or uncertain test samples.
2.3. Parameter-Efficient Adaptation with LoRA
2.4. Test-Time Adaptation in Resource-Constrained Environments
- TDA-L does not perform gradient-based fine-tuning and backpropagation that are resource-demanding, different from other TTA methods such as Tent and Tip-Adapter.
- TDA-L supports dynamic KV caching, which is more effective than the static alternative, similar to TDA. Unlike TDA, it applies LoRA to support efficient adaptation to test-time distributions using lightweight, low-rank matrices.
3. Method
3.1. TDA Background
3.1.1. Positive Key–Value Cache
3.1.2. Negative Key–Value Cache
3.1.3. Cache Management
- Its predicted class has previously had no sample in the cache (lines 1–2 in Algorithm 1).
- The total number of the samples currently in that class is less than K (lines 3–4).
- The class already has K samples; however, the new sample’s loss is smaller than the highest loss of the cached samples in that class (lines 5–6).
| Algorithm 1: Cache Management for Test-Time Adaptation |
 |
3.2. TDA-L: TDA with Low-Rank Adaptation
3.2.1. Low-Rank Adaptation (LoRA)
3.2.2. Offline Learning of the LoRA Matrices
| Algorithm 2: Algorithm for Fine-Tuning LoRA |
 |
3.2.3. Test Time Adaptation During Inference
3.2.4. Efficient Design of TDA-L to Reduce Latency and Resource Consumption
- TDA caches triples in Algorithm 1, where the feature vector and the probability vector are the full soft-max vector with float32 precision. However, TDA-L only stores without storing . This reduces the memory usage and lookup time of the caches.
- To look up the negative cache, TDA requires a masking operation that filters out uncertain cache entries. To do it, TDA concatenates the cached vectors and thresholds them to build a class-specific mask at every lookup by doing a cache-wide multiplication. In contrast, TDA-L builds a compact one-hot vector from integer labels with no additional multiplications.
4. Evaluation
4.1. Datasets
- ImageNet [12]: A large-scale dataset with over 1.2 million labeled images spanning 1000 categories. It is commonly used for training and evaluating image classification models and serves as a standard benchmark in computer vision.
- ImageNet-A [13]: A subset of ImageNet with real-world, unmodified, difficult samples misclassified by ResNet (Residual Neural Network) models. It contains images specifically chosen to challenge the robustness of models trained on ImageNet.
- ImageNet-S [15]: A dataset designed to test robustness under distributional shifts, especially in terms of style variations. It consists of the same categories as ImageNet but includes significant style differences in images (e.g., black-and-white and sketches).
- ImageNet-R [14]: A dataset that includes altered ImageNet data. In particular, they are altered with various types of real-world transformations, such as rotations or occlusions. The objective of this dataset is to challenge models to recognize objects under more complex, real-world conditions.
- ImageNet-V2 [16]: A re-evaluated and re-labeled version of ImageNet, addressing discrepancies in the dataset’s original annotations. It contains images drawn from the same categories; however, they have updated labels and different distributions.
- Caltech101 [17]: A dataset containing 9,146 images from 101 object categories, including animals, vehicles, and other objects. Unlike ImageNet, Caltech101 images are low resolution and not normalized. It is widely used to evaluate fine-grained recognition tasks and object classification in more constrained environments.
- UCF101 [18]: A popular human action recognition dataset of 13,320 videos collected from YouTube. UCF101 has 101 categories, extending UCF50 with 50 action classes. It provides a large diversity in terms of actions and large variations in camera rotation, object appearance and pose, object scale, viewpoint, etc.
4.2. Experiment Setup
4.3. Accuracy and Latency
4.4. Memory Usage, Throughput, and GPU Utilization
5. Discussion
- More Efficient Cache Management: Exploring more efficient cache management techniques, such as adaptive pruning or memory-efficient storage, could help mitigate the memory constraints of the cache. This could also include strategies for dynamically adapting the cache size without sacrificing performance.
- A Case Study: It will be interesting to evaluate TDA-L in a realistic case study. For example, our system can be extended to classify objects and speak the results to a user who could be visually impaired with low latency. Further optimizing our approach for augmented/virtual reality applications can be an interesting direction as well.
- Continual Learning of LoRA Matrices: In this paper, the LoRA matrices are trained offline and remain fixed at test time. Robustness could be further enhanced if they are continually updated in real time, especially in case of significant unforeseen domain shifts. A new challenge, however, is the cost of continual updates (deriving gradients and performing backpropagation) at test time, which could disturb ongoing real-time inferences. A thorough investigation to address this challenge is reserved for future work.
- Other Vision Language Models: CLIP (Contrastive Language–Image Pre-training) [1] takes an innovative approach that directly learns from raw text about images, using web-scale public images and textual annotations, which provide a wide variety of natural language supervision. As a result, it is effective in zero-shot classification and semantic search. Other advanced VLMs support more sophisticated tasks [20,33,34,35]; however, they are more complex and computationally intensive, imposing challenges for real-time/low-latency inference. On the other hand, there are quantized CLIP models [36,37,38] that are more efficient but subject to lower accuracy/robustness. Generally speaking, it is challenging to support robust performance even in the presence of domain shifts while supporting real-time inference at the same time. A rigorous exploration of this issue is reserved for future studies.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Software Installation, Datasets, and Execution
Appendix A.1. Requirements
Appendix A.1.1. Installation
- git clone git@github.com:Real-Time-Lab/TDA-L.git
- cd TDA-L
- conda create -n tdal python=3.8.20
- conda activate tdal
- # The results are produced with PyTorch 2.4.1 and CUDA 12.1
- conda install pytorch==2.4.1 torchvision==0.15.1 torchaudio==2.0.1 cudatoolkit=12.1 -c pytorch
- pip install -r requirements.txt
Appendix A.1.2. Datasets
Appendix A.2. Running TDA-L
Appendix A.2.1. Configuration
- Positive Cache Configuration: A user may tune parameters such as shot_capacity, alpha, and beta to strengthen the influence of reliable predictions.
- Negative Cache Configuration: In addition to shot_capacity, alpha, and beta, this cache supports entropy_threshold and mask_threshold settings.
Appendix A.2.2. Execution
- 1.
- LoRA Dataset Creation
- bash ./scripts/run_create_lora_data.sh
- 2.
- LoRA Fine-Tuning
- bash ./scripts/run_train_lora.sh
- Note: You may need to modify this script to experiment with different ranks or training durations.
- 3.
- Benchmarking
- ResNet50 Backbone:
- bash ./scripts/run_benchmark_rn50.sh
- ViT-B/16 Backbone:
- bash ./scripts/run_benchmark_vit.sh
References
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J. Learning Transferable Visual Models From Natural Language Supervision. Int. Conf. Mach. Learn. 2021, 8748–8763. [Google Scholar]
- Li, J.; Li, D.; Xiong, C.; Hoi, S.C. BLIP: Bootstrapped Language-Image Pre-training for Unified Vision-Language Understanding and Generation. Proc. IEEE Conf. Comput. Vis. Pattern Recognit. 2022, 12888–12900. [Google Scholar]
- Hossain, R.; Samad, M.D. A Hybrid Clustering Pipeline for Mining Baseline Local Patterns in 3D Point Cloud. In Proceedings of the 2021 6th International Conference for Convergence in Technology (I2CT), Maharashtra, India, 2–4 April 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Kamath, S.; Singh, D.; LeCun, Y.; Synnaeve, G.; Misra, I.; Carion, N. MDETR: Modulated Detection for End-to-End Multi-Modal Understanding. Proc. IEEE Int. Conf. Comput. Vis. 2021, 1780–1790. [Google Scholar]
- Ahmed, S.; Al Arafat, A.; Rizve, M.N.; Hossain, R.; Guo, Z.; Rakin, A.S. SSDA: Secure Source-Free Domain Adaptation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 19180–19190. [Google Scholar]
- Wang, D.; Shelhamer, E.; Liu, S.; Olshausen, B.; Darrell, T. Tent: Fully Test-Time Adaptation by Entropy Minimization. Proc. Int. Conf. Learn. Represent. 2021. [Google Scholar] [CrossRef]
- Shu, M.; Nie, W.; Huang, D.A.; Yu, Z.; Goldstein, T.; Anandkumar, A.; Xiao, C. Test-Time Prompt Tuning for Zero-Shot Generalization in Vision-Language Models. arXiv 2022, arXiv:cs.CV/2209.07511. [Google Scholar]
- Feng, C.M.; He, Y.; Zou, J.; Khan, S.; Xiong, H.; Li, Z.; Zuo, W.; Goh, R.S.M.; Liu, Y. Diffusion-Enhanced Test-time Adaptation with Text and Image Augmentation. Int. J. Comput. Vis. 2025, 1–16. [Google Scholar] [CrossRef]
- Zhou, K.; Yang, J.; Loy, C.C.; Liu, Z. Learning to Prompt for Vision-Language Models. In Proceedings of the International Conference on Learning Representations (ICLR), Virtual Event, 25–29 April 2022. [Google Scholar]
- Karmanov, A.; Guan, D.; Lu, S.; El Saddik, A.; Xing, E. Efficient Test-Time Adaptation of Vision-Language Models. arXiv 2024, arXiv:2403.18293. [Google Scholar]
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, L.; Chen, W. LoRA: Low-rank adaptation of large language models. arXiv 2021, arXiv:2106.09685. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Hendrycks, D.; Zhao, K.; Basart, S.; Chen, P.; Sharma, Y.; Song, D. Natural adversarial examples. Nat. Mach. Intell. 2021, 3, 741–746. [Google Scholar]
- L., R.R.; Zhao, Y.; Werling, N.; Li, X.; Chen, C.H. ImageNet-R: A Dataset of Fine-Grained Visual Categories for Robustness Evaluation. arXiv 2021, arXiv:2103.01457. [Google Scholar]
- Oh, S.; Park, S.; Lee, J. Robustness of deep learning-based classifiers under various image corruptions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Recht, B.; Rebecca, R.; Ludwig, S.; Vaishaal, S. Do ImageNet Classifiers Generalize to ImageNet? Int. Conf. Mach. Learn. 2019, 5389–5400. [Google Scholar]
- Fei-Fei, L.; Fergus, R.; Perona, P. Learning generative visual models from few training examples: An incremental bayesian approach tested on 101 object categories. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Washington, DC, USA, 27 June–2 July 2004. [Google Scholar]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A dataset of 101 human actions classes from videos in the wild. arXiv 2012, arXiv:1212.0402. [Google Scholar]
- Zhang, R.; Zhang, W.; Fang, R.; Gao, P.; Li, K.; Dai, J.; Qiao, Y.; Li, H. Tip-adapter: Training-free adaption of clip for few-shot classification. arXiv 2021, arXiv:2111.03930. [Google Scholar]
- Lu, J.; Batra, D.; Parikh, D.; Lee, S. ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks. arXiv 2019, arXiv:1908.02265. [Google Scholar]
- Murshed, R.U.; Dhruba, S.K.; Bhuian, M.T.I.; Akter, M.R. Automated Level Crossing System: A Computer Vision Based Approach with Raspberry Pi Microcontroller. In Proceedings of the 2022 12th International Conference on Electrical and Computer Engineering (ICECE), Dhaka, Bangladesh, 21–23 December 2022; pp. 180–183. [Google Scholar]
- Nado, Z.; Mosbach, M.; Farnia, F.; Krishnan, S.; Izmailov, P.; Wilson, A.G. Evaluating test-time adaptation for covariate shift. In Proceedings of the International Conference on Machine Learning, Virtual Event, 13–18 July 2020; pp. 8037–8048. [Google Scholar]
- Li, Y.; Grandvalet, Y.; Davoine, F. Revisiting Batch Normalization for Practical Domain Adaptation. In Proceedings of the ICLR Workshop, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Schneider, S.; Rusak, E.; Tran, N.; Schölkopf, B.; Bethge, M.; Brendel, W. Improving Robustness Against Common Corruptions by Covariate Shift Adaptation. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Online, 6–12 December 2020. [Google Scholar]
- Bartler, A.; Bühler, A.; Wiewel, F.; Döbler, M.; Yang, B. MT3: Meta Test-Time Training for Self-Supervised Test-Time Adaption. In Proceedings of the 25th International Conference on Artificial Intelligence and Statistics, Valencia, Spain, 28–30 March 2022; pp. 3080–3090. [Google Scholar]
- Choi, M.; Choi, J.; Baik, S.; Kim, T.H.; Lee, K.M. Test-Time Adaptation for Video Frame Interpolation via Meta-Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 9615–9628. [Google Scholar] [CrossRef] [PubMed]
- Zhang, R.; Zhang, W.; Fang, R.; Gao, P.; Li, K.; Dai, J.; Qiao, Y.; Li, H. Tip-Adapter: Training-free Adaption of CLIP for Few-shot Classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Santoro, A.; Bartunov, S.; Botvinick, M.; Wierstra, D.; Lillicrap, T.P. One-shot Learning with Memory-Augmented Neural Networks. In Proceedings of the 33rd International Conference on Machine Learning (ICML), New York, NY, USA, 19–24 June 2016; pp. 1842–1850. [Google Scholar]
- Liu, H.; Zhang, P.; Liao, H.; Luo, J.; Xu, Q. Leveraging Key-Value Memory to Mitigate Feature Forgetting in Online Continual Learning. arXiv 2021, arXiv:2110.09430. [Google Scholar]
- Samad, M.D.; Hossain, R.; Iftekharuddin, K.M. Dynamic Perturbation of Weights for Improved Data Reconstruction in Unsupervised Learning. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 1–7. [Google Scholar] [CrossRef]
- Lin, Z.; Courbariaux, M.; Memisevic, R.; Bengio, Y. Fixed Point Quantization of Deep Convolutional Networks. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016. [Google Scholar]
- Hossain, R. A Deep Neural Network for Detecting Spotted Lanternflies Using Energy Efficient Wide Area Networks. Master’s Thesis, State University of New York at Binghamton, Binghamton, NY, USA, 2024. [Google Scholar]
- Li, Z.; Wu, X.; Du, H.; Liu, F.; Nghiem, H.; Shi, G. A Survey of State of the Art Large Vision Language Models: Alignment, Benchmark, Evaluations and Challenges. arXiv 2025, arXiv:cs.CV/2501.02189. [Google Scholar]
- Zhang, Z.; Boykov, Y. Collision Cross-entropy for Soft Class Labels and Deep Clustering. arXiv 2023, arXiv:2303.07321. [Google Scholar]
- Gao, P.; Geng, S.; Zhang, R.; Ma, T.; Fang, R.; Zhang, Y.; Li, H.; Qiao, Y. CLIP-Adapter: Better Vision-Language Models with Feature Adapters. arXiv 2021, arXiv:2110.04544. [Google Scholar] [CrossRef]
- Han, S.; Joohee, K. CLIP-VQDiffusion: Langauge Free Training of Text To Image generation using CLIP and vector quantized diffusion model. arXiv 2024, arXiv:2403.14944. [Google Scholar]
- Team, O.A. Post-Training Quantization of OpenAI CLIP model with NNCF. 2023. Available online: https://docs.openvino.ai/2023.3/notebooks/228-clip-zero-shot-quantize-with-output.html (accessed on 1 May 2025).
- Cullan, M. Quantizing CLIP with ONNX Pt. 1: Smaller, Faster, Feasible? 2021. Available online: https://heartbeat.comet.ml/quantizing-clip-with-onnx-pt-1-smaller-faster-feasible-919966d44dbb (accessed on 7 December 2021).

{kind=link}
| Dataset | CLIP | Tip-A. | CoOp | TDA | TDA-L (16) | TDA-L (8) | TDA-L (4) | TDA-L (2) | TDA-L (1) |
|---|---|---|---|---|---|---|---|---|---|
| ImageNet | 59.81% | 62.03% | 63.33% | 61.32% | 61.32% | 60.32% | 60.31% | 60.33% | 60.33% |
| ImageNet-A | 23.06% | 23.13% | 23.06% | 30.85% | 30.04% | 30.04% | 30.02% | 30.28% | 30.28% |
| ImageNet-R | 60.72% | 60.35% | 56.60% | 62.30% | 62.19% | 62.19% | 62.18% | 62.04% | 62.04% |
| ImageNet-S | 21.48% | 21.74% | 20.67% | 24.45% | 23.10% | 23.01% | 23.00% | 23.17% | 23.17% |
| ImageNet-V2 | 52.91% | 53.97% | 55.40% | 55.32% | 55.32% | 54.77% | 54.75% | 54.58% | 54.58% |
| Caltech-101 | 87.26% | 87.53% | 86.53% | 89.45% | 88.02% | 87.87% | 87.87% | 87.87% | 87.87% |
| UCF-101 | 59.48% | 59.55% | 59.05% | 64.02% | 62.33% | 61.27% | 61.27% | 61.27% | 61.27% |
| Average | 52.10% | 52.61% | 52.09% | 55.38% | 54.62% | 54.21% | 54.20% | 54.22% | 54.22% |
| Dataset | TDA | TDA-L (16) | TDA-L (8) | TDA-L (4) | TDA-L (2) | TDA-L (1) |
|---|---|---|---|---|---|---|
| ImageNet | 18.45 ms | 16.27 ms | 15.71 ms | 15.43 ms | 15.42 ms | 15.38 ms |
| ImageNet-A | 63.88 ms | 60.36 ms | 58.68 ms | 60.24 ms | 58.62 ms | 58.61 ms |
| ImageNet-R | 64.05 ms | 59.42 ms | 58.52 ms | 56.14 ms | 56.14 ms | 56.14 ms |
| ImageNet-S | 68.23 ms | 67.79 ms | 67.23 ms | 64.78 ms | 64.71 ms | 64.75 ms |
| ImageNet-V2 | 63.08 ms | 55.34 ms | 53.27 ms | 54.77 ms | 53.79 ms | 52.97 ms |
| Caltech-101 | 6.02 ms | 5.98 ms | 6.00 ms | 5.92 ms | 5.90 ms | 5.90 ms |
| UCF-101 | 6.00 ms | 5.94 ms | 5.94 ms | 5.86 ms | 5.90 ms | 5.90 ms |
| Average | 41.39 ms | 38.73 ms | 37.91 ms | 37.59 ms | 37.21 ms | 37.09 ms |
| Method | Duration (Minute) | Avg. Memory Usage (MB) | Avg. GPU Utilization (%) | Throughput (Images/s) |
|---|---|---|---|---|
| TDA [10] | 5 | 3107.71 | 30.80 | 50.55 |
| TDA-L (rank 16) | 5 | 2535.17 | 26.63 | 59.23 |
| TDA-L (rank 8) | 5 | 2512 | 24.18 | 60 |
| TDA-L (rank 4) | 5 | 2495.17 | 23.22 | 61.50 |
| TDA-L (rank 2) | 5 | 2489.12 | 23.19 | 61.62 |
| TDA-L (rank 1) | 5 | 2476.37 | 23.20 | 61.63 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hossain, R.; Islam Bhuian, M.T.; Kang, K.-D. TDA-L: Reducing Latency and Memory Consumption of Test-Time Adaptation for Real-Time Intelligent Sensing. Sensors 2025, 25, 3574. https://doi.org/10.3390/s25123574
Hossain R, Islam Bhuian MT, Kang K-D. TDA-L: Reducing Latency and Memory Consumption of Test-Time Adaptation for Real-Time Intelligent Sensing. Sensors. 2025; 25(12):3574. https://doi.org/10.3390/s25123574
Chicago/Turabian StyleHossain, Rahim, Md Tawheedul Islam Bhuian, and Kyoung-Don Kang. 2025. "TDA-L: Reducing Latency and Memory Consumption of Test-Time Adaptation for Real-Time Intelligent Sensing" Sensors 25, no. 12: 3574. https://doi.org/10.3390/s25123574
APA StyleHossain, R., Islam Bhuian, M. T., & Kang, K.-D. (2025). TDA-L: Reducing Latency and Memory Consumption of Test-Time Adaptation for Real-Time Intelligent Sensing. Sensors, 25(12), 3574. https://doi.org/10.3390/s25123574