
Privacy-Conducive Data Ecosystem Architecture: By-Design Vulnerability Assessment Using Privacy Risk Expansion Factor and Privacy Exposure Index


 , ,
, , 
Abstract
1. Introduction
2. Materials and Related Work
2.1. Background and Definitions
2.2. Related Work
3. Methodology
3.1. Framework Objectives
3.2. Privacy Risk Expansion Factor (PREF)
- Governance and Access Metrics capture how the storage architecture controls and restricts access to data, as well as the geopolitical implications of its location:
- (a)
- (Access Control Scope): This represents the extent and granularity of access control mechanisms applied to the i-th data copy. Potential values are [1–2], where a lower value means strictly limited access with fine-grained roles and strong policies with automated auditing, and a higher value indicates broad or poorly enforced access rights (see Appendix A).
- (b)
- (Geopolitical Location Risk): This reflects the privacy and regulatory risk associated with the physical or legal location of the i-th data copy. Potential values are [1–2], where low values represent the introduction of minimal risk relative to expected geopolitical and legal constraints, while higher values indicate increased potential for extraterritorial access, weak regulatory oversight, or misalignment with the required data localization standards (see Appendix B).
- Retention and Disposal Metrics evaluate the policies and technical mechanisms for governing data lifespan and erasure:
- (a)
- (Retention and Lifecycle Policy Compliance): This captures whether a data copy is governed by a defined and automatically enforced retention policy. Potential values are [0–1], where higher values indicate weak, absent or manual policies leading to prolonged exposure (see Appendix C).
- (b)
- (Data Erasure Resistance): This represents how difficult it is to fully remove or delete the i-th data copy. Potential values are [0–1], where low values mean an easily erasable copy without the ability to recover data after deletion, and higher values indicate high persistence and/or potential to retrieve the data after deletion (see Appendix D).
- Secondary Exposure Metrics consider indirect or auxiliary sources of privacy leakage outside the primary data store:
- (a)
- (Log Accessibility Risk): This indicates the exposure of logs of the i-th copy. Potential values are [0–1], where low values reflect no exposed logs, and high values represent logs that are accessible, poorly secured, or maintain traces of deleted data (see Appendix E).
- n is the number of distinct data copies in the layer (e.g., database nodes, backups, distributed replicas).
- m is the total number of data layers in the ecosystem architecture.
- is the privacy risk expansion factor calculated for the Lth layer in the architecture, as defined in the layer-level calculation (see Equation (1)).
3.3. Ecosystem Vulnerability Score
- represents the vulnerability score of the data storage layer;
- represents the ecosystem vulnerability score accounting for all data layers included;
- n represents the number of fields in the dataset;
- m represents the number of data storage layers in the ecosystem.
3.4. Privacy Exposure Index (PEI)
- represents the privacy risk expansion factor for a single data layer;
- represents the vulnerability score for the same data layer.
- represents the privacy risk expansion factor for the data layer;
- represents the vulnerability score of the same data layer;
- m represents the number of data storage layers in the ecosystem.
3.5. Interpretation of VS, PREF, and PEI
4. Use Cases and Validation
4.1. Video-On-Demand (VOD) Ecosystem
4.2. VOD—Multi-Layered Ecosystem Architecture Design
4.2.1. MLE Ecosystem Vulnerability Score
4.2.2. MLE Privacy Risk Expansion Factor (PREF)
4.2.3. MLE Privacy Exposure Index (PEI)
4.3. VOD—Privacy-Aware Ecosystem Architecture Design
4.3.1. PAE Ecosystem Vulnerability Score
4.3.2. PAE Privacy Risk Expansion Factor (PREF)
4.3.3. PAE Privacy Exposure Index (PEI)
4.4. VOD—HTAP Ecosystem Architecture Design
4.4.1. HTAP Ecosystem Vulnerability Score
4.4.2. HTAP Privacy Risk Expansion Factor (PREF)
4.4.3. HTAP Privacy Exposure Index (PEI)
4.5. VOD Use Case Evaluation and Discussion
4.6. IoT Room Cooling Ecosystem
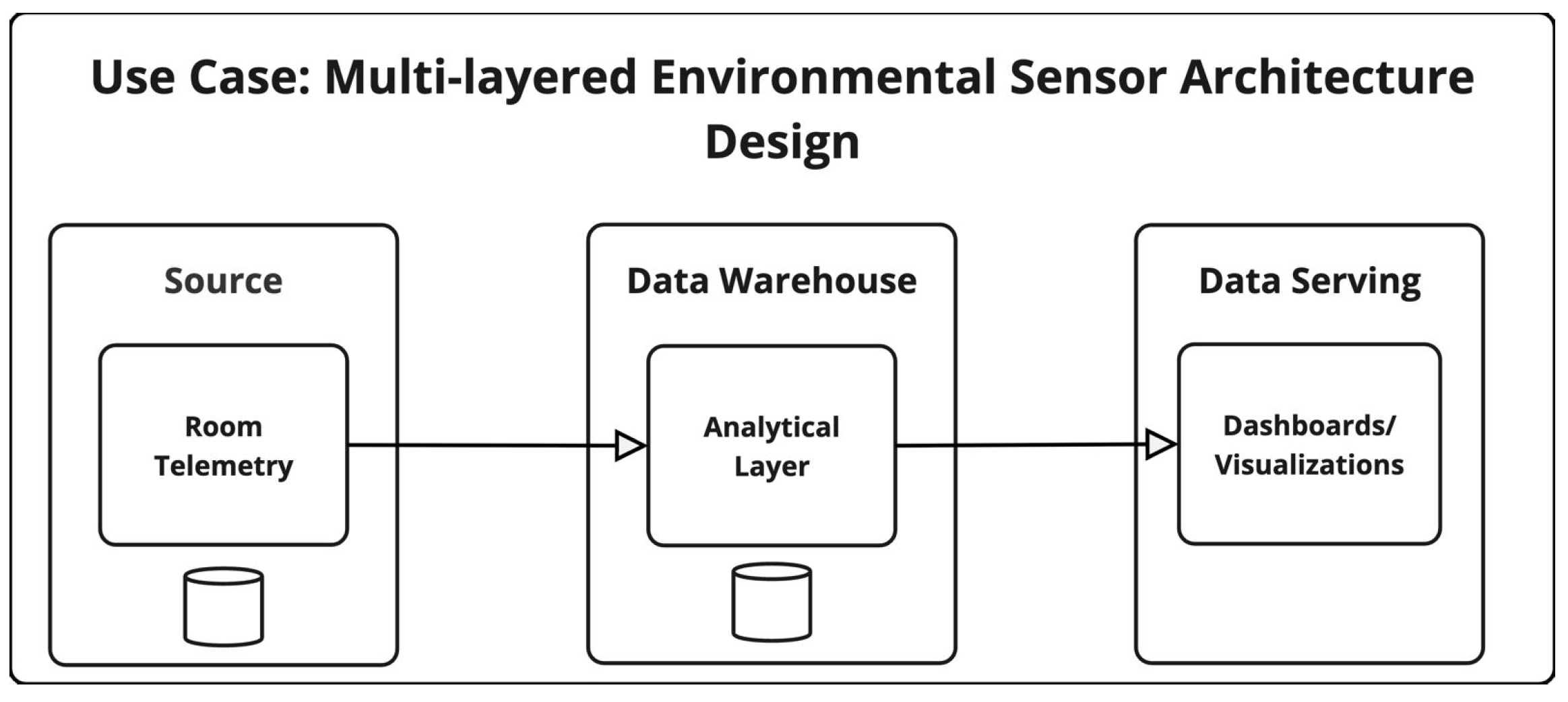
4.7. IoT—Multi-Layered Environmental Sensor Ecosystem Architecture Design
4.7.1. MLES Ecosystem Vulnerability Score
4.7.2. MLES Privacy Risk Expansion Factor (PREF)
4.7.3. MLES Privacy Exposure Index (PEI)
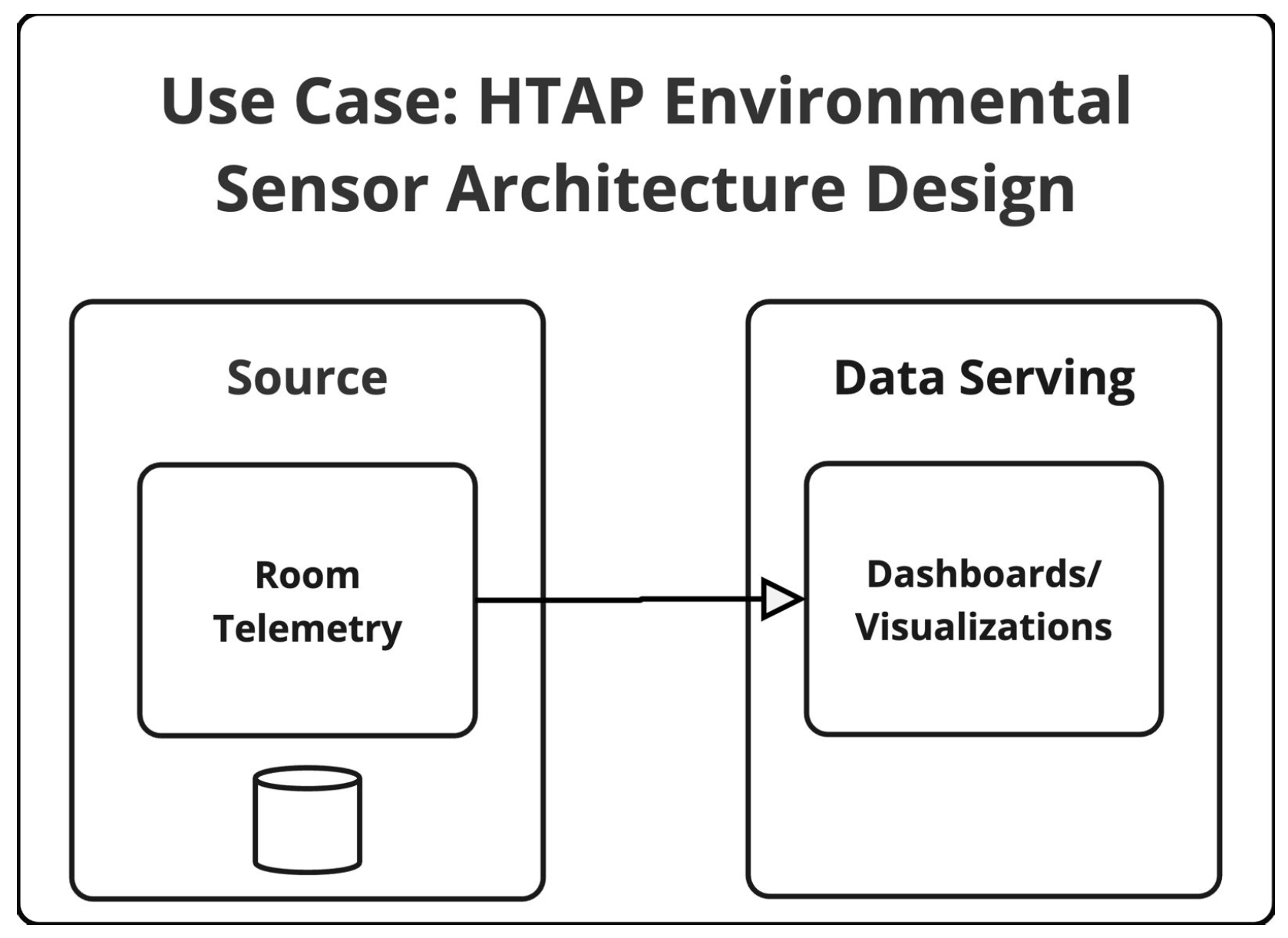
4.8. IoT—HTAP Environmental Sensor Ecosystem Architecture Design
4.8.1. HTAPS Ecosystem Vulnerability Score
4.8.2. HTAPS Privacy Risk Expansion Factor (PREF)
4.8.3. HTAPS Privacy Exposure Index (PEI)
4.9. IoT Use Case Evaluation and Discussion
5. Results
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial intelligence |
| CCPA | California Consumer Privacy Act |
| CVSS | Common vulnerability scoring system |
| ENCD | Encoded data metric |
| ENCR | Encrypted data metric |
| EXPL | Exploitability data metric |
| GDPR | General Data Protection Regulation |
| HPI | Personal information data metric |
| HSI | Sensitive/secret information data metric |
| HNS | Nested sensitive information data metric |
| HUS | Unstructured sensitive/secret information data metric |
| HTAP | Hybrid transactional/analytical processing |
| IoT | Internet of Things |
| LLM | Large language model |
| MASK | Masked data metric |
| PbD | Privacy by design |
| PEI | Privacy exposure index |
| PET | Privacy-enhancing technologies |
| PII | Personal identifiable information |
| PREF | Privacy risk expansion factor |
| SMPC | Secure multi-party computation |
| TEE | Trusted execution environment |
| VS | Vulnerability score |
Appendix A. Access Control Scope Score

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Value | Access Control Level | Examples |
|---|---|---|
| 1.0 | Strong Access Control | Role-based access control (RBAC) with automated enforcement, attribute-based access control (ABAC), database-level row/column restrictions, just-in-time (JIT) access with expiry and audit trails |
| 1.5 | Moderate or Weak Access Control | Single access role for multiple users, stale or unrevoked access rights, lack of context-aware or fine-grained policies |
| 2.0 | Minimal or No Access Control | Shared or hardcoded credentials, no access logging or monitoring, anonymous or unrestricted access |
Appendix B. Geopolitical Location Risk Score
| Value | Geopolitical Risk Level | Example |
|---|---|---|
| 1.0 | Low Risk | Data hosted in jurisdictions with strong privacy robust enforcement, and strong alignment with the data owner’s legal and operational base. (on premises, private, or public cloud: legally under full control of the data owner’s organization) |
| 2.0 | High Risk | Data located in or accessible from jurisdictions with extraterritorial surveillance laws, weak privacy enforcement, or conflicting legal systems. Providers in non-adequate countries without contractual/legal protections. |
Appendix C. Retention and Life Cycle Policy Compliance Score
| Value | Policy Enforcement Level | Example |
|---|---|---|
| 0.0 | Strictly enforced or Not Applicable | Automated deletion based on policy; retention schedules enforced by system; temporary or read-only data copies not subject to policy due to non-persistence; Not Applicable |
| 0.5 | Partially enforced policy | Retention policy defined but dependent on manual enforcement; risk of human error or delays in deletion |
| 1.0 | Unclear or missing policy | No defined retention schedule; data retained indefinitely or deleted without auditability |
Appendix D. Data Erasure Resistance Score
| Value | Erasure Resistance Level | Example |
|---|---|---|
| 0.0 | Low erasure resistance | Data copies can be fully deleted; no residual data remains; complete erasure confirmed |
| 0.5 | Moderate erasure resistance | Erasure possible but incomplete; copy may be recoverable through shadow copies or incomplete deletion of replica |
| 1.0 | High erasure resistance | Copies are immutable or persistent by design; includes backups, unmodifiable snapshots, or retention-locked archives |
Appendix E. Log Accessibility Risk Score
| Value | Risk Category | Example |
|---|---|---|
| 0.0 | Low Risk | Logs encrypted at rest and in transit, access-controlled platforms, log redaction of sensitive data, short retention with auto-deletion |
| 0.5 | Medium Risk | Partial encryption (e.g., only at rest), basic access control with limited auditing, inconsistent redaction, moderate retention periods, occasional inclusion of metadata like IPs or user IDs |
| 1.0 | High Risk | Logs in plain text, broad or unmonitored access, over-retention or missing expiration policy, debug/trace logs exposing internals, soft deletion allowing sensitive data recovery |
Appendix F. Encryption Algorithms Score
| Value | Algorithm |
|---|---|
| 1.00 | AES |
| 1.10 | ECC |
| 1.20 | 3DES |
| 1.30 | |
| 1.40 | |
| 1.50 | RSA 1024 |
| 1.60 | |
| 1.70 | |
| 1.80 | SHA-1 |
| 1.90 | MD5 |
| 2.00 | No Encryption |
Appendix G. Exploitability Score
| Value | Contents | Examples |
|---|---|---|
| 1.00 | Data with no direct or indirect link to specific persons, groups of persons, families, or neighborhoods | Environmental data (temperature) |
| 1.10 | ||
| 1.20 | Data with a weak potential link to persons | Land GPS coordinates that might be private property |
| 1.30 | ||
| 1.40 | Data with a strong potential link to persons | Anonymous information about houses that might be used to locate them (price or neighborhood) |
| 1.50 | Non-exploitable personal information (that might still have potential economic value), i.e., anonymized medical data | Height, hair color, eye color, blood test results, or preferences (food, beverages, or deserts) |
| 1.60 | ||
| 1.70 | Anonymized medical data with demographic/personal information | Cancer screening results or AIDS patient data |
| 1.80 | Low-exploitable personal information (that is easy to change or cannot be used to locate the person in real life) | Email (but no password!) or mobile number |
| 1.90 | Non-anonymized medical data | |
| 2.00 | Highly-exploitable and secret personal information, identity information, or national security-related information | Complete name, social security number, home address, home phone number, home building properties (e.g., intercom code), intimate personal photos, personal messages, sexual preferences, passwords, religious views, or political affiliation |
References
- Voigt, P.; Von dem Bussche, A. The EU General Data Protection Regulation (GDPR): A Practical Guide, 1st ed.; Springer International Publishing: Cham, Switzerland, 2017; Volume 10, pp. 10–5555. [Google Scholar]
- Bonta, R. California Consumer Privacy Act (CCPA). State of California Department of Justice. 2022. Available online: https://oag.ca.gov/privacy/ccpa (accessed on 4 May 2025).
- Zaeem, R.N.; Barber, K.S. The effect of the GDPR on privacy policies: Recent progress and future promise. ACM Trans. Manag. Inf. Syst. (TMIS) 2020, 12, 1–20. [Google Scholar] [CrossRef]
- Delinschi, D.; Erdei, R.; Pasca, E.; Matei, O. Data quality assessment methodology. In Proceedings of the International Conference on Soft Computing Models in Industrial and Environmental Applications, Salamanca, Spain, 9–11 October 2024; Springer: Cham, Switzerland, 2024; pp. 199–209. [Google Scholar]
- Gupta, S.; Kumar, A.; Gupta, P. Security Landscape of a Strong Ecosystem to Protect Sensitive Information in E-Governance. Int. Res. J. Eng. Technol. (IRJET) 2023, 10, 362–369. [Google Scholar]
- Zahid, R.; Altaf, A.; Ahmad, T.; Iqbal, F.; Vera, Y.A.M.; Flores, M.A.L.; Ashraf, I. Secure data management life cycle for government big-data ecosystem: Design and development perspective. Systems 2023, 11, 380. [Google Scholar] [CrossRef]
- Raja, V.; Chopra, B. Exploring challenges and solutions in cloud computing: A review of data security and privacy concerns. J. Artif. Intell. Gen. Sci. (JAIGS) 2024, 4, 121–144. [Google Scholar]
- Celeste, E.; Fabbrini, F. Competing jurisdictions: Data privacy across the borders. In Data Privacy and Trust in Cloud Computing; Palgrave Macmillan: London, UK, 2020; pp. 43–58. [Google Scholar]
- Terzi, D.S.; Terzi, R.; Sagiroglu, S. A survey on security and privacy issues in big data. In Proceedings of the 2015 10th International Conference for Internet Technology and Secured Transactions (ICITST), London, UK, 14–16 December 2015; pp. 202–207. [Google Scholar] [CrossRef]
- Samaraweera, G.D.; Chang, J.M. Security and Privacy Implications on Database Systems in Big Data Era: A Survey. IEEE Trans. Knowl. Data Eng. 2021, 33, 239–258. [Google Scholar] [CrossRef]
- Schäfer, F.; Gebauer, H.; Gröger, C.; Gassmann, O.; Wortmann, F. Data-driven business and data privacy: Challenges and measures for product-based companies. Bus. Horiz. 2023, 66, 493–504. [Google Scholar] [CrossRef]
- Carvalho, T.; Moniz, N.; Faria, P.; Antunes, L. Towards a data privacy-predictive performance trade-off. Expert Syst. Appl. 2023, 223, 119785. [Google Scholar] [CrossRef]
- Erdei, R.; Delinschi, D.; Matei, O. Security centric scalable architecture for distributed learning and knowledge preservation. In Proceedings of the International Workshop on Soft Computing Models in Industrial and Environmental Applications, Salamanca, Spain, 5–7 September 2022; Springer: Cham, Switzerland, 2022; pp. 655–665. [Google Scholar]
- Erdem, M.; Özdemir, A. Sustainability and risk assessment of data center locations under a fuzzy environment. J. Clean. Prod. 2024, 450, 141982. [Google Scholar] [CrossRef]
- von Scherenberg, F.; Hellmeier, M.; Otto, B. Data sovereignty in information systems. Electron. Mark. 2024, 34, 15. [Google Scholar] [CrossRef]
- Singh, K.; Singh, A. Data Governance Best Practices in Cloud Migration Projects. Int. J. Res. Radic. Multidiscip. Fields 2024, 3, 821–836. [Google Scholar]
- Cavoukian, A. Privacy by Design: The 7 Foundational Principles; Information and Privacy Commissioner of Ontario: Toronto, ON, Canada, 2009; Volume 5, p. 12. [Google Scholar]
- Danezis, G.; Domingo-Ferrer, J.; Hansen, M.; Hoepman, J.H.; Metayer, D.L.; Tirtea, R.; Schiffner, S. Privacy and data protection by design-from policy to engineering. arXiv 2015, arXiv:1501.03726. [Google Scholar]
- Makridis, C.A. Do data breaches damage reputation? Evidence from 45 companies between 2002 and 2018. J. Cybersecur. 2021, 7, tyab021. [Google Scholar] [CrossRef]
- Mayer, P.; Zou, Y.; Lowens, B.M.; Dyer, H.A.; Le, K.; Schaub, F.; Aviv, A.J. Awareness, Intention, (In)Action: Individuals’ Reactions to Data Breaches. ACM Trans.-Comput.-Hum. Interact. 2023, 30, 1–53. [Google Scholar] [CrossRef]
- Johnson, M.; Kang, M.J.; Lawson, T. Stock price reaction to data breaches. J. Financ. Issues 2017, 16, 1–13. [Google Scholar] [CrossRef]
- Wolff, J.; Atallah, N. Early GDPR penalties: Analysis of implementation and fines through May 2020. J. Inf. Policy 2021, 11, 63–103. [Google Scholar] [CrossRef]
- Gürses, S.; Troncoso, C.; Diaz, C. Engineering privacy by design. Comput. Priv. Data Prot. 2011, 14, 25. [Google Scholar]
- Spiekermann, S.; Cranor, L.F. Engineering privacy. IEEE Trans. Softw. Eng. 2008, 35, 67–82. [Google Scholar] [CrossRef]
- Park, H.A. The DtMin Protocol: Implementing Data Minimization Principles in Medical Information Sharing. Electronics 2025, 14, 1501. [Google Scholar] [CrossRef]
- Bu, F.; Wang, N.; Jiang, Q.; Tian, X. Research on Privacy-by-Design Behavioural Decision-Making of Information Engineers Considering Perceived Work Risk. Systems 2024, 12, 250. [Google Scholar] [CrossRef]
- Ali, T.; Al-Khalidi, M.; Al-Zaidi, R. Information security risk assessment methods in cloud computing: Comprehensive review. J. Comput. Inf. Syst. 2024, 1–28. [Google Scholar] [CrossRef]
- Luehr, P.; Reilly, B. Data minimisation: A crucial pillar of cyber security. Cyber Secur.-Peer-Rev. J. 2025, 8, 243–254. [Google Scholar] [CrossRef]
- Hoepman, J.H. Privacy design strategies. In Proceedings of the IFIP International Information Security Conference, Marrakech, Morocco, 2–4 June 2014; Springer: Cham, Switzerland, 2014; pp. 446–459. [Google Scholar]
- Das, B.C.; Amini, M.H.; Wu, Y. Security and privacy challenges of large language models: A survey. ACM Comput. Surv. 2025, 57, 1–39. [Google Scholar] [CrossRef]
- Finck, M.; Biega, A. Reviving purpose limitation and data minimisation in personalisation, profiling and decision-making systems. Technol. Regul. 2021, 2021, 44–61. [Google Scholar] [CrossRef]
- Zarsky, T.Z. Incompatible: The GDPR in the age of big data. Seton Hall Law Rev. 2016, 47, 995. [Google Scholar]
- Dwork, C.; Roth, A. The algorithmic foundations of differential privacy. Found. Trends® Theor. Comput. Sci. 2014, 9, 211–407. [Google Scholar] [CrossRef]
- Acar, A.; Aksu, H.; Uluagac, A.S.; Conti, M. A survey on homomorphic encryption schemes: Theory and implementation. ACM Comput. Surv. (Csur) 2018, 51, 1–35. [Google Scholar] [CrossRef]
- Sahinbas, K.; Catak, F.O. Secure multi-party computation-based privacy-preserving data analysis in healthcare IoT systems. In Interpretable Cognitive Internet of Things for Healthcare; Springer International Publishing: Cham, Switzerland, 2023; pp. 57–72. [Google Scholar]
- Geppert, T.; Deml, S.; Sturzenegger, D.; Ebert, N. Trusted execution environments: Applications and organizational challenges. Front. Comput. Sci. 2022, 4, 930741. [Google Scholar] [CrossRef]
- Li, T.; Sahu, A.K.; Talwalkar, A.; Smith, V. Federated learning: Challenges, methods, and future directions. IEEE Signal Process. Mag. 2020, 37, 50–60. [Google Scholar] [CrossRef]
- Sion, L.; Dewitte, P.; Van Landuyt, D.; Wuyts, K.; Emanuilov, I.; Valcke, P.; Joosen, W. An architectural view for data protection by design. In Proceedings of the 2019 IEEE International Conference on Software Architecture (ICSA), Hamburg, Germany, 25–29 March 2019; IEEE: New York, NY, USA, 2019; pp. 11–20. [Google Scholar]
- Morali, A.; Zambon, E.; Etalle, S.; Overbeek, P. It confidentiality risk assessment for an architecture-based approach. In Proceedings of the 2008 3rd IEEE/IFIP International Workshop on Business-Driven IT Management, Salvador, Brazil, 7 April 2008; IEEE: New York, NY, USA, 2008; pp. 31–40. [Google Scholar]
- Antignac, T.; Le Métayer, D. Privacy architectures: Reasoning about data minimisation and integrity. In Proceedings of the International Workshop on Security and Trust Management, Wroclaw, Poland, 10–11 September 2014; Springer: Cham, Switzerland, 2014; pp. 17–32. [Google Scholar]
- Wagner, I.; Boiten, E. Privacy risk assessment: From art to science, by metrics. In Proceedings of the Data Privacy Management, Cryptocurrencies and Blockchain Technology: ESORICS 2018 International Workshops, DPM 2018 and CBT 2018, Barcelona, Spain, 6–7 September 2018; Proceedings 13. Springer: Cham, Switzerland, 2018; pp. 225–241. [Google Scholar]
- Senarath, A.; Grobler, M.; Arachchilage, N.A.G. A model for system developers to measure the privacy risk of data. arXiv 2018, arXiv:1809.10884. [Google Scholar]
- De, S.J.; Le Métayer, D. Privacy risk analysis to enable informed privacy settings. In Proceedings of the 2018 IEEE European Symposium on Security and Privacy Workshops (EuroS&PW), London, UK, 23–27 April 2018; IEEE: New York, NY, USA, 2018; pp. 95–102. [Google Scholar]
- Abu Bakar, A.; Mahinderjit Singh, M.; Mohd Shariff, A.R. A privacy preservation quality of service (Qos) model for data exposure in android smartphone usage. Sensors 2021, 21, 1667. [Google Scholar] [CrossRef]
- Cao, Y.; Yoshikawa, M.; Xiao, Y.; Xiong, L. Quantifying differential privacy in continuous data release under temporal correlations. IEEE Trans. Knowl. Data Eng. 2018, 31, 1281–1295. [Google Scholar] [CrossRef] [PubMed]
- Giomi, M.; Boenisch, F.; Wehmeyer, C.; Tasnádi, B. A unified framework for quantifying privacy risk in synthetic data. arXiv 2022, arXiv:2211.10459. [Google Scholar] [CrossRef]
- Ali-Eldin, A.; Zuiderwijk-van Eijk, A.; Janssen, M. Opening more data: A new privacy risk scoring model for open data. In Proceedings of the 7th International Symposium on Business Modeling and Software Design, BMSD 2017, Barcelona, Spain, 3–5 July 2017; pp. 146–154. [Google Scholar]
- Matei, O.; Erdei, R.; Delinschi, D.; Andreica, L. Data based message validation as a security cornerstone in loose coupling software architecture. In Proceedings of the Computational Intelligence in Security for Information Systems Conference, Bilbao, Spain, 22–24 September 2021; Springer: Cham, Switzerland, 2021; pp. 214–223. [Google Scholar]
- Erdei, R.; Delinschi, D.; Pașca, E.; Matei, O. Orchestrator architecture and communication methodology for flexible event driven message based communication. In Proceedings of the Computational Intelligence in Security for Information Systems Conference, Salamanca, Spain, 5–7 September 2022; Springer: Cham, Switzerland, 2022; pp. 127–137. [Google Scholar]
- Sun, P.; Shen, S.; Wan, Y.; Wu, Z.; Fang, Z.; Gao, X.Z. A survey of iot privacy security: Architecture, technology, challenges, and trends. IEEE Internet Things J. 2024, 11, 34567–34591. [Google Scholar] [CrossRef]
- Khan, N.e.; Rudman, R.J. IoT medical device risks: Data security, privacy, confidentiality and compliance with HIPAA and COBIT 2019. S. Afr. J. Bus. Manag. 2025, 56, 4796. [Google Scholar] [CrossRef]
- Alwarafy, A.; Al-Thelaya, K.A.; Abdallah, M.; Schneider, J.; Hamdi, M. A survey on security and privacy issues in edge-computing-assisted internet of things. IEEE Internet Things J. 2020, 8, 4004–4022. [Google Scholar] [CrossRef]
- Chakraborty, N.; Sharma, A.; Dutta, J.; Kumar, H.D. Privacy-Preserving Data Quality Assessment for Time-Series IoT Sensors. In Proceedings of the 2024 IEEE International Conference on Internet of Things and Intelligence Systems (IoTaIS), Bali, Indonesia, 28–30 November 2024; IEEE: New York, NY, USA, 2024; pp. 51–57. [Google Scholar]
- Buitrago, M.; Borne, I.; Buisson, J. Model-Based Assessment of Conformance to Acknowledged Security-Related Software Architecture Good Practices. In Proceedings of the 12th International Conference on Model-Based Software and Systems Engineering, Rome, Italy, 21–23 February 2024; SCITEPRESS-Science and Technology Publications: Porto, Portugal, 2024; pp. 117–124. [Google Scholar]
- Manadhata, P.K.; Wing, J.M. An attack surface metric. IEEE Trans. Softw. Eng. 2010, 37, 371–386. [Google Scholar] [CrossRef]
- Maclean, D. The NIST risk management framework: Problems and recommendations. Cyber Secur.-Peer-Rev. J. 2017, 1, 207–217. [Google Scholar] [CrossRef]
- Erdei, R.; Pasca, E.; Delinschi, D.; Avram, A.; Chereja, I.; Matei, O. Privacy assessment methodology for machine learning models and data sources. In Proceedings of the International Conference on Soft Computing Models in Industrial and Environmental Applications, Salamanca, Spain, 9–11 October 2024; Springer: Cham, Switzerland, 2024; pp. 210–220. [Google Scholar]
- Chereja, I.; Erdei, R.; Pasca, E.; Delinschi, D.; Avram, A.; Matei, O. A Privacy Assessment Framework for Data Tiers in Multilayered Ecosystem Architectures. Mathematics 2025, 13, 1116. [Google Scholar] [CrossRef]
- Mell, P.; Scarfone, K.; Romanosky, S. Common vulnerability scoring system. IEEE Secur. Priv. 2006, 4, 85–89. [Google Scholar] [CrossRef]
- Mell, P.; Scarfone, K.; Romanosky, S. A Complete Guide to the Common Vulnerability Scoring System Version 2.0. FIRST—Forum of Incident Response and Security Teams, 2007; Volume 1, p. 23. Available online: https://tsapps.nist.gov/publication/get_pdf.cfm?pub_id=51198 (accessed on 4 May 2025).
- Sargiotis, D. Data security and privacy: Protecting sensitive information. In Data Governance: A Guide; Springer: Cham, Switzerland, 2024; pp. 217–245. [Google Scholar]
- Coche, E.; Kolk, A.; Ocelík, V. Unravelling cross-country regulatory intricacies of data governance: The relevance of legal insights for digitalization and international business. J. Int. Bus. Policy 2024, 7, 112–127. [Google Scholar] [CrossRef]
- Pimenta Rodrigues, G.A.; Marques Serrano, A.L.; Lopes Espiñeira Lemos, A.N.; Canedo, E.D.; Mendonça, F.L.L.d.; de Oliveira Albuquerque, R.; Sandoval Orozco, A.L.; García Villalba, L.J. Understanding data breach from a global perspective: Incident visualization and data protection law review. Data 2024, 9, 27. [Google Scholar] [CrossRef]
- Pestana, G.; Sofou, S. Data governance to counter hybrid threats against critical infrastructures. Smart Cities 2024, 7, 1857–1877. [Google Scholar] [CrossRef]
- Nambiar, A.; Mundra, D. An overview of data warehouse and data lake in modern enterprise data management. Big Data Cogn. Comput. 2022, 6, 132. [Google Scholar] [CrossRef]
- Chereja, I.; Hahn, S.M.L.; Matei, O.; Avram, A. Operationalizing analytics with NewSQL. In Proceedings of the Software Engineering and Algorithms: Proceedings of 10th Computer Science On-line Conference 2021, Online, 1 April 2021; Springer: Cham, Switzerland, 2021; Volume 1, pp. 249–263. [Google Scholar]
- Chereja, I.; Hahn, S.M.L.; Matei, O.; Avram, A. Multidimensional analysis of NewSQL database systems. In Proceedings of the Computer Science On-line Conference, Online, 1 April 2021; Springer: Cham, Switzerland, 2021. [Google Scholar]
- Hahn, S.M.L.; Chereja, I.; Matei, O. Analysis of transformation tools applicable on NewSQL databases. In Proceedings of the Software Engineering and Algorithms: Proceedings of 10th Computer Science On-line Conference 2021, Online, 1 April 2021; Springer: Cham, Switzerland, 2021; Volume 1, pp. 180–195. [Google Scholar]
- Chereja, I.; Hahn, S.M.L.; Matei, O. Benchmarking NewSQL Cloud-Native or Cloud-Hosted Databases. In Proceedings of the Software Engineering Application in Informatics: Proceedings of 5th Computational Methods in Systems and Software 2021, Online, 1 October 2021; Springer: Cham, Switzerland, 2021; Volume 1, pp. 296–310. [Google Scholar]
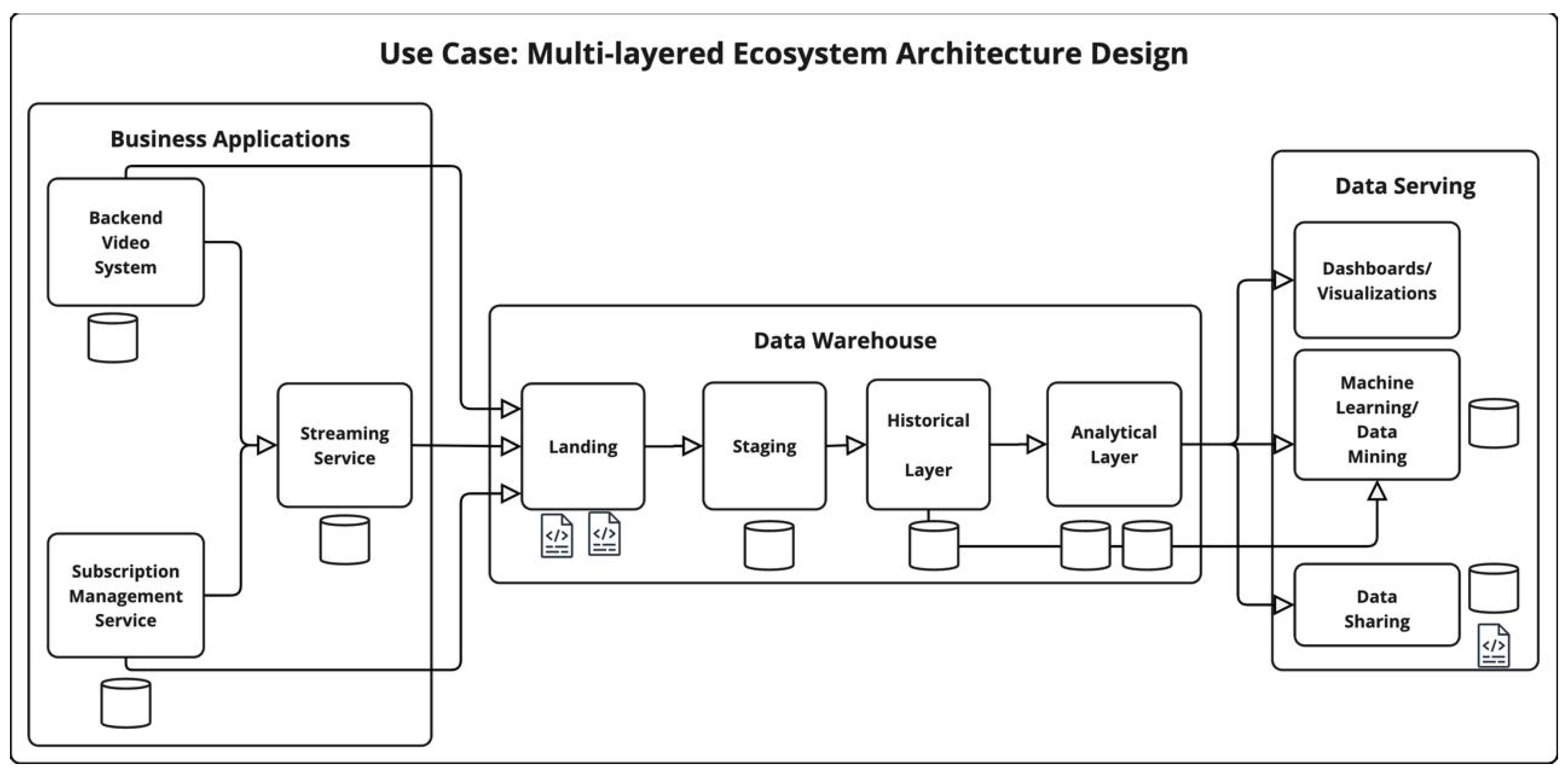
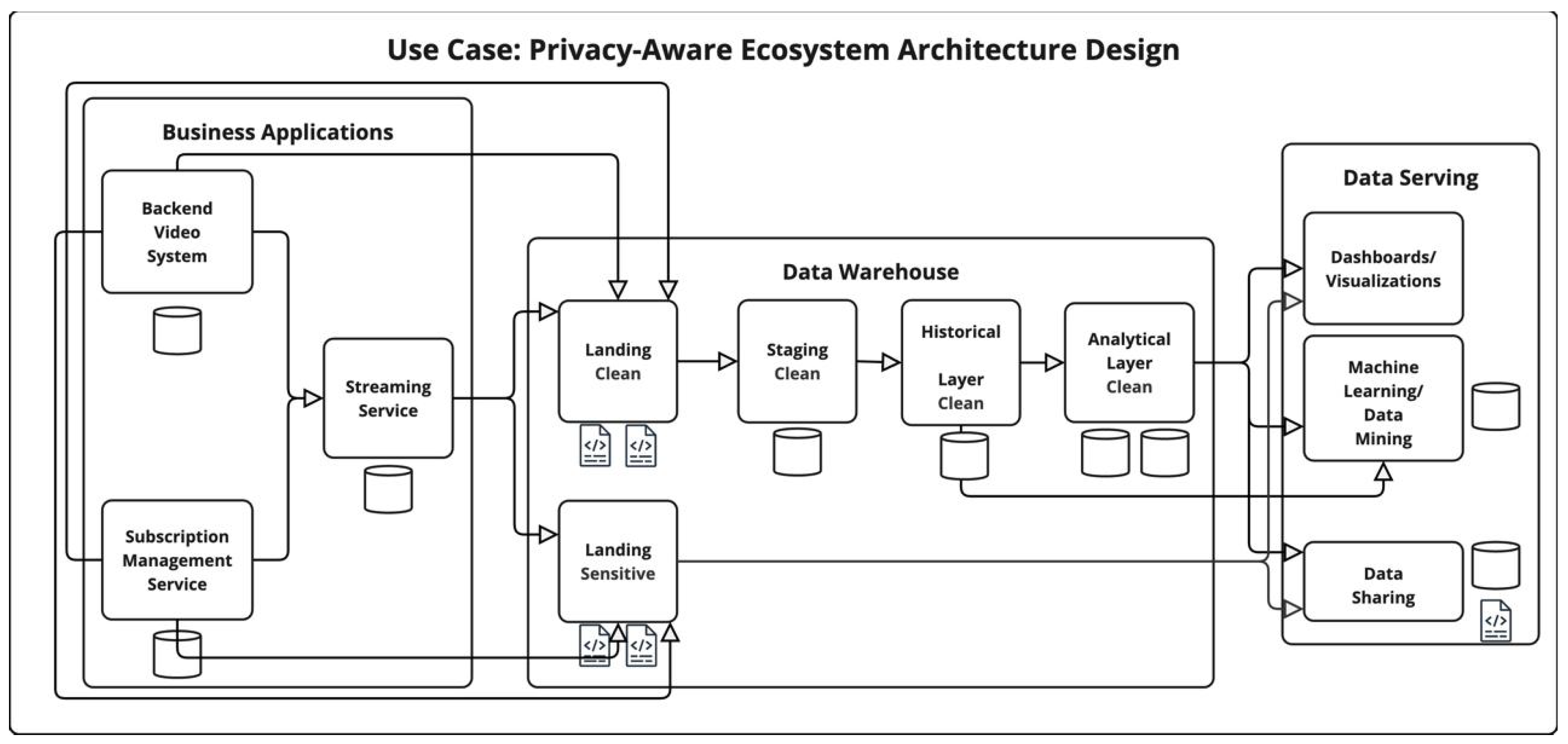
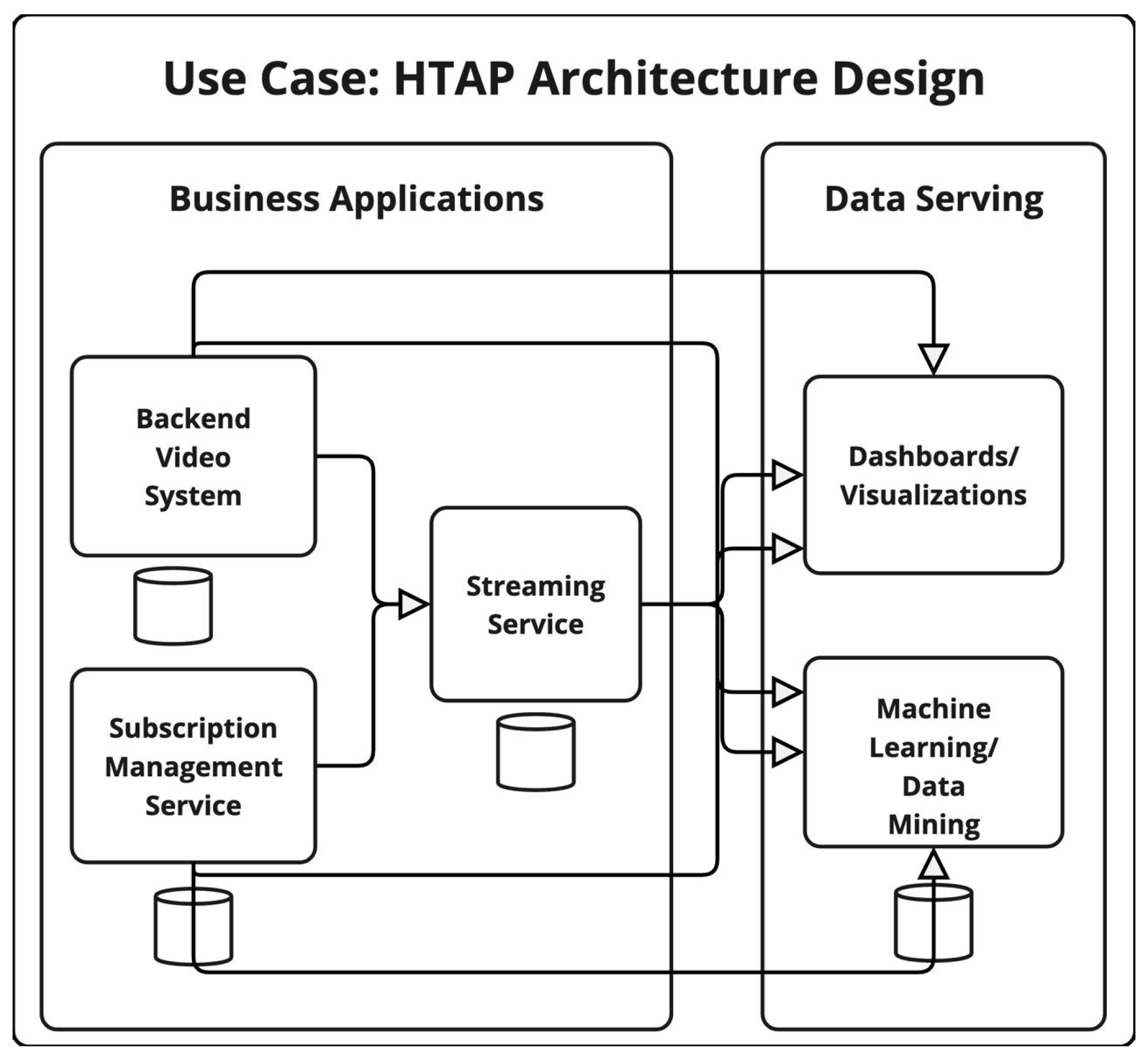
| Data Layer | Vulnerability Score |
|---|---|
| Streaming Service | 212.4 |
| Subscription Management Service | 164.0 |
| Backend Streaming Hosting Service | 159.5 |
| Landing | 559.7 |
| Staging | 535.9 |
| Historical | 524.7 |
| Analytical | 285.2 |
| Sharing | 206.5 |
| Ecosystem | 2647.9 |
| Copy Type | G | A | R | D | L | PREF |
|---|---|---|---|---|---|---|
| Main Copy | 1.00 | 1.00 | 0.00 | 1.00 | 1.00 | 3.00 |
| Secondary Copy | 1.00 | 1.00 | 0.00 | 1.00 | 1.00 | 3.00 |
| Disaster Recovery Copy | 2.00 | 1.00 | 0.00 | 0.50 | 1.00 | 5.00 |
| Daily Backup | 1.00 | 1.50 | 0.00 | 0.00 | 0.00 | 1.50 |
| Total PREF | 12.50 |
| Copy Type | G | A | R | D | L | PREF |
|---|---|---|---|---|---|---|
| Main Copy | 1.00 | 1.00 | 0.00 | 1.00 | 1.00 | 3.00 |
| Secondary Copy | 1.00 | 1.00 | 0.00 | 1.00 | 1.00 | 3.00 |
| Disaster Recovery Copy | 1.00 | 1.00 | 0.00 | 1.00 | 1.00 | 3.00 |
| Daily Backup | 1.00 | 1.50 | 0.00 | 0.00 | 0.00 | 1.50 |
| Total PREF | 10.50 |
| Copy Type | G | A | R | D | L | PREF |
|---|---|---|---|---|---|---|
| Main Copy | 1.00 | 1.00 | 0.00 | 1.00 | 1.00 | 3.00 |
| Secondary Copy | 1.00 | 1.00 | 0.00 | 1.00 | 1.00 | 3.00 |
| Disaster Recovery Copy | 1.00 | 1.00 | 0.00 | 0.50 | 1.00 | 2.50 |
| Daily Backup | 1.00 | 1.50 | 0.00 | 0.00 | 0.00 | 1.50 |
| Total PREF | 10.00 |
| Copy Type | G | A | R | D | L | PREF |
|---|---|---|---|---|---|---|
| Main Copy | 1.00 | 1.00 | 0.00 | 1.00 | 0.00 | 2.00 |
| Secondary Copy | 1.00 | 1.00 | 0.00 | 0.50 | 0.00 | 1.50 |
| Weekly Backup | 1.00 | 1.50 | 0.50 | 0.00 | 0.00 | 2.25 |
| Total PREF | 5.75 |
| Copy Type | G | A | R | D | L | PREF |
|---|---|---|---|---|---|---|
| Main Copy | 1.00 | 1.00 | 0.00 | 1.00 | 0.00 | 2.00 |
| Secondary Copy | 1.00 | 1.00 | 0.00 | 0.00 | 0.00 | 1.00 |
| Weekly Backup | 1.00 | 1.50 | 0.00 | 0.00 | 0.00 | 1.50 |
| Total PREF | 4.50 |
| Copy Type | G | A | R | D | L | PREF |
|---|---|---|---|---|---|---|
| Main Copy | 1.00 | 1.00 | 0.00 | 1.00 | 0.00 | 2.00 |
| Secondary Copy | 1.00 | 1.00 | 0.00 | 1.00 | 0.00 | 2.00 |
| Weekly Backup | 1.00 | 1.50 | 0.00 | 0.00 | 0.00 | 1.50 |
| Total PREF | 5.50 |
| Copy Type | G | A | R | D | L | PREF |
|---|---|---|---|---|---|---|
| Main Copy | 1.00 | 1.00 | 0.00 | 1.00 | 0.00 | 2.00 |
| Secondary Copy | 1.00 | 1.00 | 0.00 | 0.00 | 0.00 | 1.00 |
| Weekly Backup | 1.00 | 1.50 | 0.00 | 0.00 | 0.00 | 1.50 |
| Total PREF | 4.50 |
| Copy Type | G | A | R | D | L | PREF |
|---|---|---|---|---|---|---|
| Main Copy | 1.00 | 1.00 | 0.00 | 1.00 | 0.00 | 2.00 |
| Secondary Copy | 1.00 | 1.00 | 0.00 | 0.00 | 0.00 | 1.00 |
| Manual Backup | 1.00 | 1.50 | 0.50 | 0.00 | 0.00 | 2.25 |
| Total PREF | 5.25 |
| Data Layer | PREF Score |
|---|---|
| Streaming Service | 12.5 |
| Subscription Management Service | 10.5 |
| Backend Streaming Hosting Service | 10.0 |
| Landing | 5.75 |
| Staging | 4.5 |
| Historical | 5.5 |
| Analytical | 4.5 |
| Sharing | 5.25 |
| Ecosystem | 58.5 |
| Data Layer | VS | PREF | PEI |
|---|---|---|---|
| Streaming Service | 212.4 | 12.5 | 2655.0 |
| Subscription Management Service | 164.0 | 10.5 | 1722.0 |
| Backend Streaming Hosting Service | 159.5 | 10.0 | 1595.0 |
| Landing | 559.7 | 5.75 | 3218.275 |
| Staging | 535.9 | 4.5 | 2411.55 |
| Historical | 524.7 | 5.5 | 2885.85 |
| Analytical | 285.2 | 4.5 | 1283.4 |
| Sharing | 206.5 | 5.25 | 1084.125 |
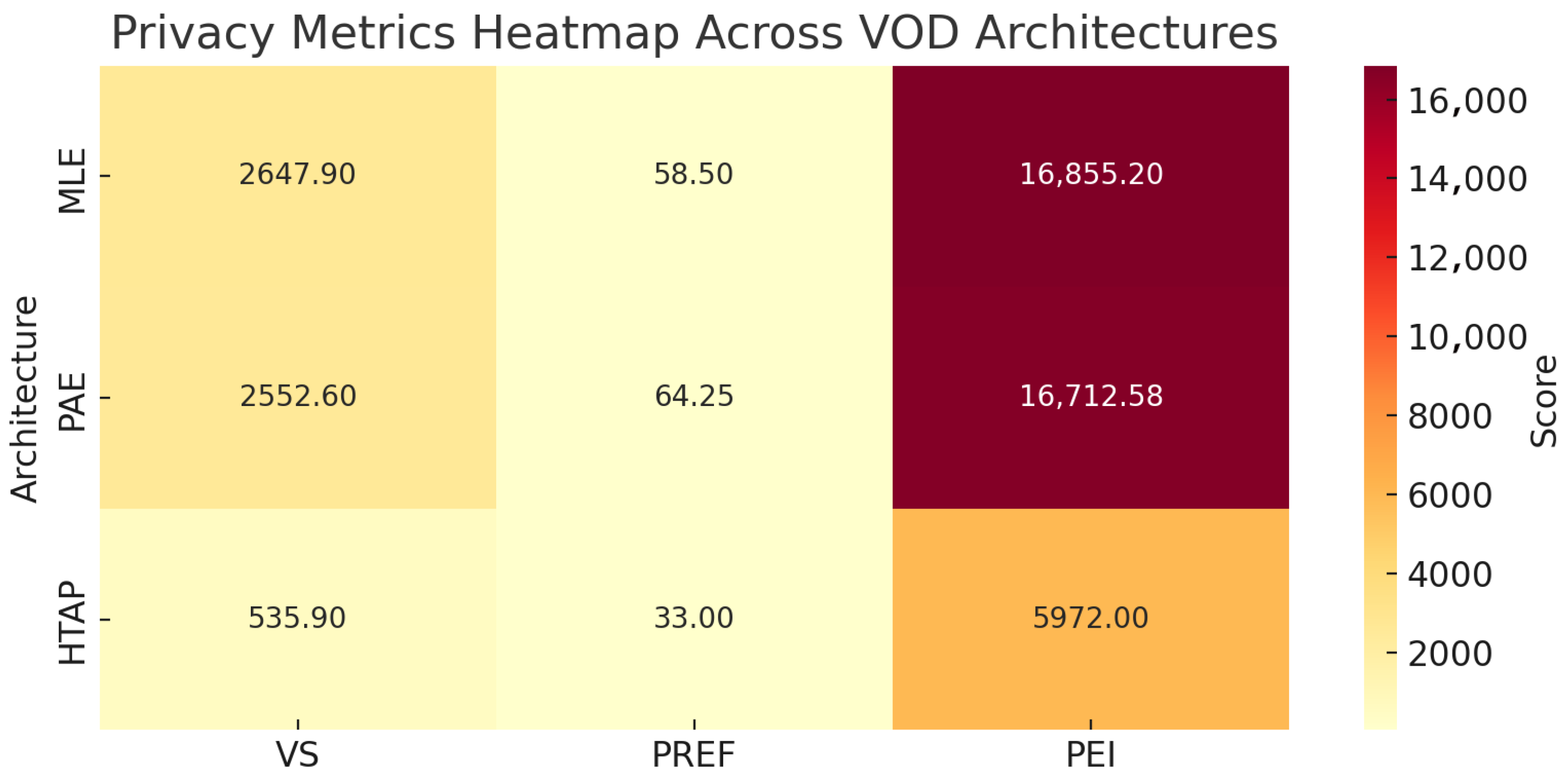
| Ecosystem | 2647.9 | 58.5 | 16,855.2 |
| Data Layer | Vulnerability Score |
|---|---|
| Streaming Service | 212.4 |
| Subscription Management Service | 164.0 |
| Backend Streaming Hosting Service | 159.5 |
| Landing Sensitive | 559.7 |
| Landing Clean | 368.5 |
| Staging Clean | 350.3 |
| Historical Clean | 350.3 |
| Analytical Clean | 181.4 |
| Sharing | 206.5 |
| Ecosystem | 2552.6 |
| Data Layer | PREF |
|---|---|
| Streaming Service | 12.5 |
| Subscription Management Service | 10.5 |
| Backend Streaming Hosting Service | 10.0 |
| Landing Sensitive | 5.75 |
| Landing Clean | 5.75 |
| Staging Clean | 4.5 |
| Historical Clean | 5.5 |
| Analytical Clean | 4.5 |
| Sharing | 5.25 |
| Ecosystem | 64.25 |
| Data Layer | VS | PREF | PEI |
|---|---|---|---|
| Streaming Service | 212.4 | 12.5 | 2655.0 |
| Subscription Management Service | 164.0 | 10.5 | 1722.0 |
| Backend Streaming Hosting Service | 159.5 | 10.0 | 1595.0 |
| Landing Sensitive | 559.7 | 5.75 | 3218.275 |
| Landing Clean | 368.5 | 5.75 | 2118.875 |
| Staging Clean | 350.3 | 4.5 | 1576.35 |
| Historical Clean | 350.3 | 5.5 | 1926.65 |
| Analytical Clean | 181.4 | 4.5 | 816.3 |
| Sharing | 206.5 | 5.25 | 1084.125 |
| Ecosystem | 2552.6 | 64.25 | 16,712.575 |
| Data Layer | Vulnerability Score |
|---|---|
| Streaming Service | 212.4 |
| Subscription Management Service | 164.0 |
| Backend Streaming Hosting Service | 159.5 |
| Ecosystem | 535.9 |
| Data Layer | PREF |
|---|---|
| Streaming Service | 12.5 |
| Subscription Management Service | 10.5 |
| Backend Streaming Hosting Service | 10.0 |
| Ecosystem | 33.0 |
| Data Layer | VS | PREF | PEI |
|---|---|---|---|
| Streaming Service | 212.4 | 12.5 | 2655.0 |
| Subscription Management Service | 164.0 | 10.5 | 1722.0 |
| Backend Streaming Hosting Service | 159.5 | 10.0 | 1595.0 |
| Ecosystem | 535.9 | 33.0 | 5972.0 |
| Architecture | Design Trade-Offs | Privacy Risk Summary |
|---|---|---|
| MLE | High duplication, persistent storage across layers | High PREF and highest PEI, especially in the landing and historical layers |
| PAE | Layer separation, minimized duplication, clean/sensitive data split | Highest PREF, lower PEI, improved downstream privacy posture |
| HTAP | Minimal redundancy, centralized processing, real-time access | Lowest PREF, lowest PEI centralized in single processing tier |
| Data Layer | Vulnerability Score |
|---|---|
| Room Telemetry | 81.5 |
| Analytical Layer | 81.5 |
| Ecosystem | 163.0 |
| Data Layer | PREF |
|---|---|
| Room Telemetry | 7.0 |
| Analytical Layer | 9.0 |
| Ecosystem | 16.0 |
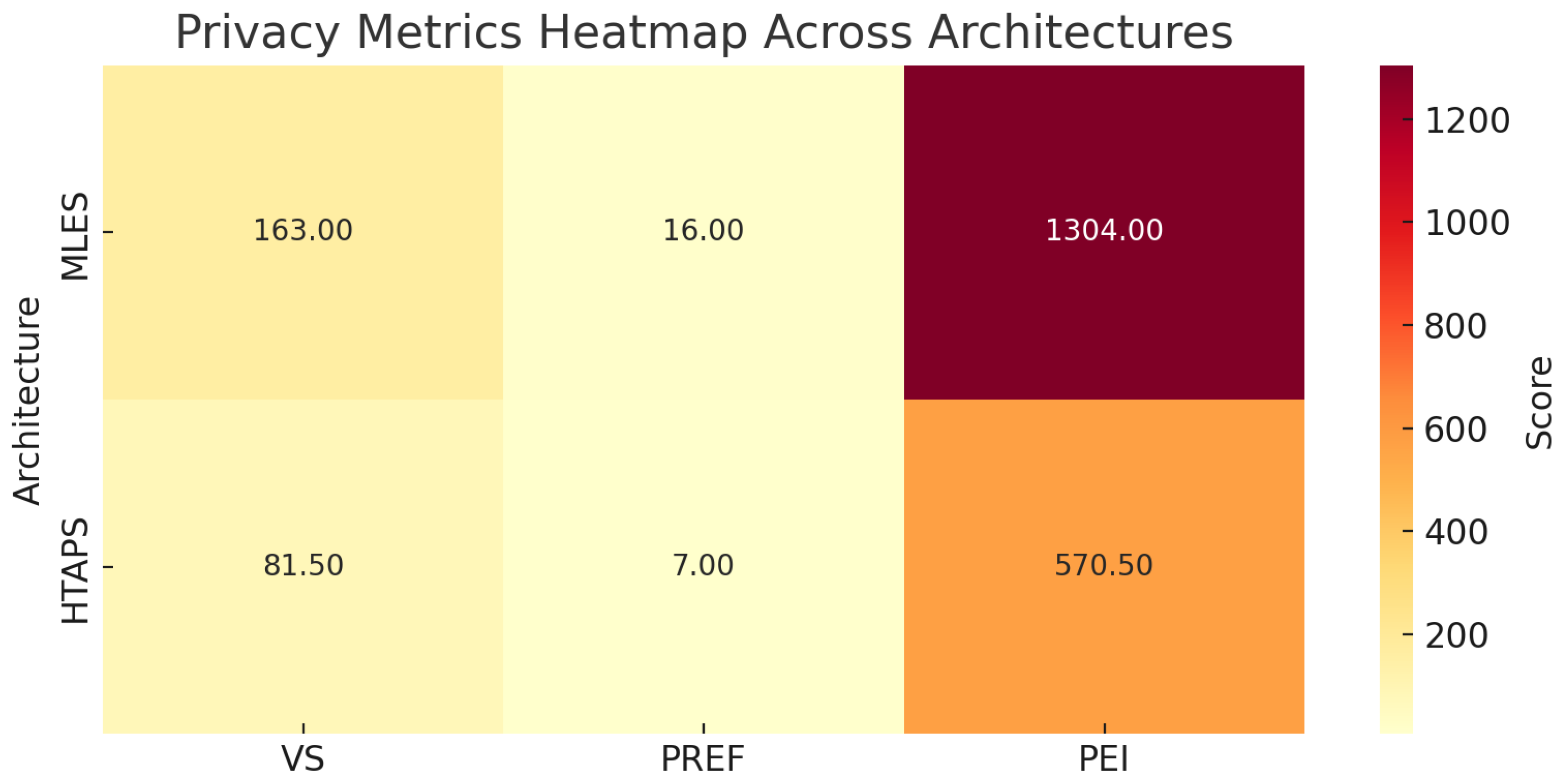
| Data Layer | VS | PREF | PEI |
|---|---|---|---|
| Room Telemetry | 81.5 | 7.0 | 570.5 |
| Analytical Layer | 81.5 | 9.0 | 733.5 |
| Ecosystem | 163 | 16.0 | 1304.0 |
| Data Layer | Vulnerability Score |
|---|---|
| Room Telemetry | 81.5 |
| Ecosystem | 81.5 |
| Data Layer | PREF |
|---|---|
| Room Telemetry | 7.0 |
| Ecosystem | 7.0 |
| Data Layer | VS | PREF | PEI |
|---|---|---|---|
| Room Telemetry | 81.5 | 7.0 | 570.5 |
| Ecosystem | 81.5 | 7.0 | 570.5 |
| Architecture | Design Trade-Offs | Privacy Risk Summary |
|---|---|---|
| MLES | Multi-stage data handling, separate analytical layer, multiple replicas and backups | Increased exposure from duplication and retention layers; higher PREF and PEI due to redundancy across tiers |
| HTAP | Single-stage HTAP system, unified transactional and analytical processing | Minimal replication and movement; lower PREF and PEI; reduced vulnerability surface |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chereja, I.; Erdei, R.; Delinschi, D.; Pasca, E.; Avram, A.; Matei, O. Privacy-Conducive Data Ecosystem Architecture: By-Design Vulnerability Assessment Using Privacy Risk Expansion Factor and Privacy Exposure Index. Sensors 2025, 25, 3554. https://doi.org/10.3390/s25113554
Chereja I, Erdei R, Delinschi D, Pasca E, Avram A, Matei O. Privacy-Conducive Data Ecosystem Architecture: By-Design Vulnerability Assessment Using Privacy Risk Expansion Factor and Privacy Exposure Index. Sensors. 2025; 25(11):3554. https://doi.org/10.3390/s25113554
Chicago/Turabian StyleChereja, Ionela, Rudolf Erdei, Daniela Delinschi, Emil Pasca, Anca Avram, and Oliviu Matei. 2025. "Privacy-Conducive Data Ecosystem Architecture: By-Design Vulnerability Assessment Using Privacy Risk Expansion Factor and Privacy Exposure Index" Sensors 25, no. 11: 3554. https://doi.org/10.3390/s25113554
APA StyleChereja, I., Erdei, R., Delinschi, D., Pasca, E., Avram, A., & Matei, O. (2025). Privacy-Conducive Data Ecosystem Architecture: By-Design Vulnerability Assessment Using Privacy Risk Expansion Factor and Privacy Exposure Index. Sensors, 25(11), 3554. https://doi.org/10.3390/s25113554