1. Introduction
In recent years, with the rapid urbanization and a significant increase in the number of motor vehicles, traffic congestion has become a major challenge, limiting urban development and the improvement of residents’ quality of life. Intelligent transportation systems (ITSs), a key technology [
1] for addressing this issue, place traffic flow prediction at their core, aiming to achieve both accuracy and efficiency. Accurate traffic flow prediction can help alleviate road congestion, optimize urban traffic network management, and enhance overall traffic efficiency [
2]. The primary challenge in traffic flow prediction, however, lies in effectively integrating time-series features with the complex spatial structure of road networks. Over the past few decades, traffic flow prediction has become a pivotal research focus within the realm of intelligent transportation systems, garnering extensive scholarly attention [
3].
Traffic flow forecasting plays a vital role in enabling intelligent decision-making within modern transportation systems. As urban traffic becomes increasingly dynamic and complex, accurate forecasting provides the foundation for proactive traffic management, including congestion mitigation, adaptive signal control, and route planning. Moreover, with the integration of smart city infrastructure and real-time sensing technologies, the demand for reliable and fine-grained traffic prediction models has grown rapidly. Traffic forecasting not only supports the operational efficiency of transportation agencies but also enhances road safety and environmental sustainability by reducing travel delays, fuel consumption, and emissions. Therefore, developing robust and generalizable models for traffic flow prediction is of both theoretical and practical importance, especially under conditions of uncertainty and sudden disruptions.
Traffic flow prediction seeks to forecast future traffic conditions based on historical traffic data. Early efforts in traffic flow prediction mainly relied on traditional time-series analysis models, such as the Autoregressive Integrated Moving Average (ARIMA) [
4] model and the Vector Autoregression (VAR) [
5] model. However, these models have limitations in handling nonlinear relationships and leveraging the spatial correlations of urban traffic networks, making them less effective for complex traffic flow predictions. To address the challenges posed by nonlinearity, researchers have turned to various machine learning methods, including Bayesian Networks [
6], support vector regression (SVR) [
7], and K-Nearest Neighbors (KNNs) [
8]. While these approaches have been instrumental in uncovering the nonlinear characteristics of traffic flow, they often require labor-intensive manual feature selection and construction, which can be both costly and susceptible to subjective bias.
With the rapid advancement of deep learning technologies, traffic flow prediction research has increasingly shifted towards neural network architectures. Significant advancements have been made in traffic flow forecasting, owing to its unparalleled capacity for automatic feature extraction from raw data [
9]. Recurrent neural networks (RNNs) [
10] and their variants, such as Long Short-Term Memory (LSTM) [
11,
12] and gated recurrent units (GRUs) [
13], have demonstrated significant advantages in capturing the temporal dynamics of traffic flow. Notably, Ma et al. [
14] pioneered the use of LSTM networks for traffic speed prediction, while Tian et al. [
15] employed stacked bidirectional and unidirectional LSTMs to model bidirectional temporal dependencies. However, RNN-based methods primarily focus on the temporal variability of the data, often neglecting the spatial correlations inherent in traffic systems. To address this limitation, Convolutional Neural Networks (CNNs) were introduced to capture spatial dependencies in traffic data structured on Euclidean grids [
16]. For example, Zhang et al. [
17] proposed ST-ResNet, a CNN-based model for urban pedestrian flow prediction. Additionally, CNN-based architectures such as temporal convolutional networks (TCNs) [
18,
19] and Graph WaveNet [
20] have been utilized to overcome the sequential limitations of RNNs and enhance the modeling of temporal dependencies. However, these models still fall short in capturing the spatial irregularities of real-world traffic networks, which are fundamentally non-Euclidean in nature [
21,
22].
To better model the complex and irregular topologies of traffic systems, graph neural networks (GNNs) have gained increasing attention for their ability to process non-Euclidean structured data and capture intricate spatial dependencies. GNN-based approaches have become a core technology in traffic forecasting research [
23,
24], as they naturally align with the spatial structure of road networks. Among them, STGCN [
25] marked a significant milestone by pioneering the use of graph convolution to model spatio-temporal dependencies. Subsequent models built upon this foundation: DCRNN [
26] combined RNNs with diffusion graph convolution; GMAN [
27] introduced multi-attention mechanisms.
More recent advancements have focused on refining the representation of dynamic spatio-temporal features [
28]. ASTGCN [
29] incorporated spatial and temporal attention into the GCN framework to better capture subtle variations, while STSGCN [
30] applied a sliding window strategy to learn local spatio-temporal graphs. STFGNN [
31] introduced a parallel fusion of spatio-temporal features, and DSTAGNN [
32] replaced static graphs with dynamic spatio-temporal-aware graphs, addressing limitations of fixed structures. Further studies [
33,
34,
35] proposed innovative dynamic graph construction methods to adapt to the evolving nature of traffic networks and improve predictive accuracy.
Despite these advancements, many existing methods still rely on predefined or static graph structures, which restrict their ability to fully reflect the dynamic changes and multivariate heterogeneity of real-world traffic systems. This becomes especially critical when modeling the interactions among diverse features, managing complex spatio-temporal dependencies, and responding to sudden and unpredictable events. For instance, while STSGCN [
30] focuses on evolving spatial patterns, it does not explicitly address temporal dynamics. AGCRN [
36], which integrates adaptive graph construction with recurrent neural networks, improves representation capability but lacks comprehensive global information modeling.
Traffic flow is a typically complex system that is influenced not only by temporal factors (such as regular fluctuations during rush hours or holiday effects) and spatial factors (such as geographic location and road network structure) but also by various other elements such as traffic accidents, temporary road closures, and large-scale events. These factors contribute to the “heterogeneous characteristics” in traffic flow prediction, and their interactions and feedback mechanisms form a dynamically changing network. However, in such a complex and dynamic traffic environment, previous methods [
37,
38,
39,
40] have not addressed the impact of sudden traffic events on traffic flow prediction. As a result, these models struggle to effectively handle unexpected traffic incidents.
To address the limitations in extracting spatiotemporal heterogeneous features and to effectively tackle the challenges arising from dynamic traffic conditions and sudden incidents, this paper spatio-temporal fusion graph neural network based on dynamic sparse graph convolution GRU for traffic flow forecast (STFDSGCN). We enhance the spatiotemporal features of the input data through an effective data preprocessing layer. Furthermore, we introduce a novel structure, the dynamic sparse graph convolutional gated recurrent network (DSGCN-GRU), which is designed to simultaneously capture local dynamic spatiotemporal features. To further improve model performance, we incorporate a dual attention mechanism, combining gated temporal attention and spatial attention, to address the DSGCN-GRU’s shortcomings in handling anomalies and long-range dependencies. In summary, the key contributions of STFDSGCN are:
The STFDSGCN model, which integrates a gated recurrent network architecture with a combined attention mechanism, enabling effective extraction of spatiotemporal features for accurate traffic flow prediction.
The introduction of a novel dynamic sparse graph convolutional gated recurrent network (DSGCN-GRU), a unique module that embeds adaptive sparse graph convolution and graph attention blocks into gated recurrent units, allowing for the capture of local temporal dependencies and spatially heterogeneous characteristics.
The incorporation of dual attention mechanisms—gated temporal attention and spatial attention—enhancing the model’s capability to understand complex spatiotemporal patterns. This fusion improves the model’s ability to capture long-range dependencies, thus increasing the accuracy of long-term traffic flow predictions and strengthening its responsiveness to sudden changes in traffic conditions.
2. Methods
2.1. Data Structure Definition
Definition (traffic graph): the road traffic network, monitored by a variety of sensors, is represented as a graph , where denotes the set of nodes and represents the set of edges. The adjacency matrix captures the connectivity between the nodes. Additionally, the matrix is a weighted adjacency matrix that quantifies the specific weight relationships among the nodes. The edges in this graph signify the connections between the nodes, and the weights assigned to these edges reflect the distances separating the nodes.
Definition (traffic flow): traffic flow is defined as the quantity of vehicles or pedestrians passing through designated locations, such as roads or intersections, within a specific time frame. It provides insights into traffic conditions and is instrumental in determining congestion levels. In the framework of this study, the traffic flow at time t in a road network with nodes is represented by , where denotes the number of traffic flow features. Moreover, the signals across all nodes during a time interval are denoted as .
Definition (traffic flow prediction): the task of traffic flow prediction involves forecasting future traffic conditions based on historical traffic data. The data for the previous T time steps is represented as
, while the forecasted data for the subsequent
time steps is expressed as
. Mathematically, the prediction task can be seen as mapping the historical observations
to the predicted future state
, in the form:
In this context, represents the mapping function that learns to transform the historical sequence into the predicted sequence. The primary focus of this paper is on the development and optimization of this mapping function to enhance both the accuracy and practical applicability of the predictions.
2.2. Overall Structure of the Model
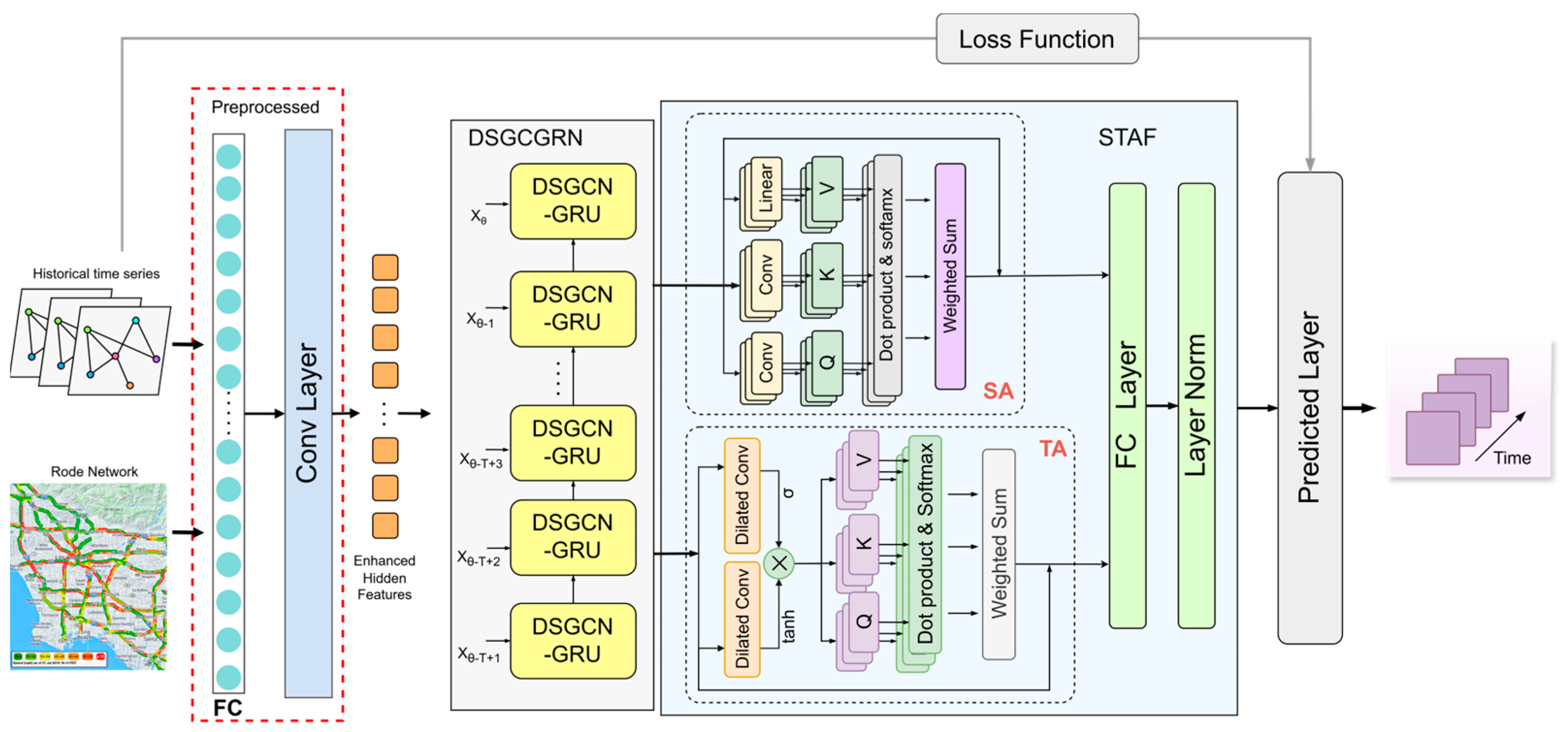
The STFDSGCN model’s overall architecture is illustrated in
Figure 1. It is primarily composed of two key components: the dynamic sparse graph convolutional gated recurrent network (DSGCGRN) and the spatio-temporal attention fusion layer (STAF). In
Figure 1, the DSGCGRN consists of multiple DSGCN-GRU layers, where each layer processes the output of the previous layer to generate a new hidden state. The STAF, as depicted in
Figure 1, includes a Temporal Multi-Head Attention Block (TA) with dilated convolution gating and a Spatial Multi-Head Attention Block (SA). Initially, traffic flow data
is input into the model. After passing through fully connected layers and convolutional layers [
41], the model produces an enhanced spatio-temporal feature representation, which is computed as follows:
The matrices and represent the weight matrices for the first and second linear layers of the fully connected layer, respectively. The activation functions used are ReLU and Sigmoid, while ⊙ denotes element-wise multiplication. The matrix represents the enhanced hidden feature representation. This is then input into the dynamic sparse graph convolutional recurrent network to capture local spatio-temporal correlations. The DSGCGRN module combines the gated recurrent unit (GRU) with dynamic sparse graph convolution (DSGCN) to effectively process spatio-temporal data, taking into account its irregularities and dynamic variations. The output from the DSGCN-GRU is subsequently passed into the attention fusion layer, which employs spatial attention (SA) and temporal attention (TA) to handle different types of information. This enhances the model’s capacity to understand both local and global spatio-temporal features, improving its ability to predict long-term traffic flow and respond to sudden traffic events. Finally, the output of the attention fusion layer is fed into the prediction layer, where it interacts with the loss function during training to generate predictions for future traffic data .
2.3. Dynamic Sparse Graph Convolutional Recurrent Network (DSGCGRN)
In real-world traffic networks, the mutual influence between traffic flows is not constant but varies over time, leading to significant correlations between roads due to dynamic traffic flow fluctuations. To capture and understand the spatial correlations in traffic data, we employ graph convolutional networks (GCNs) to model the information transmission process within dynamic spatial structures [
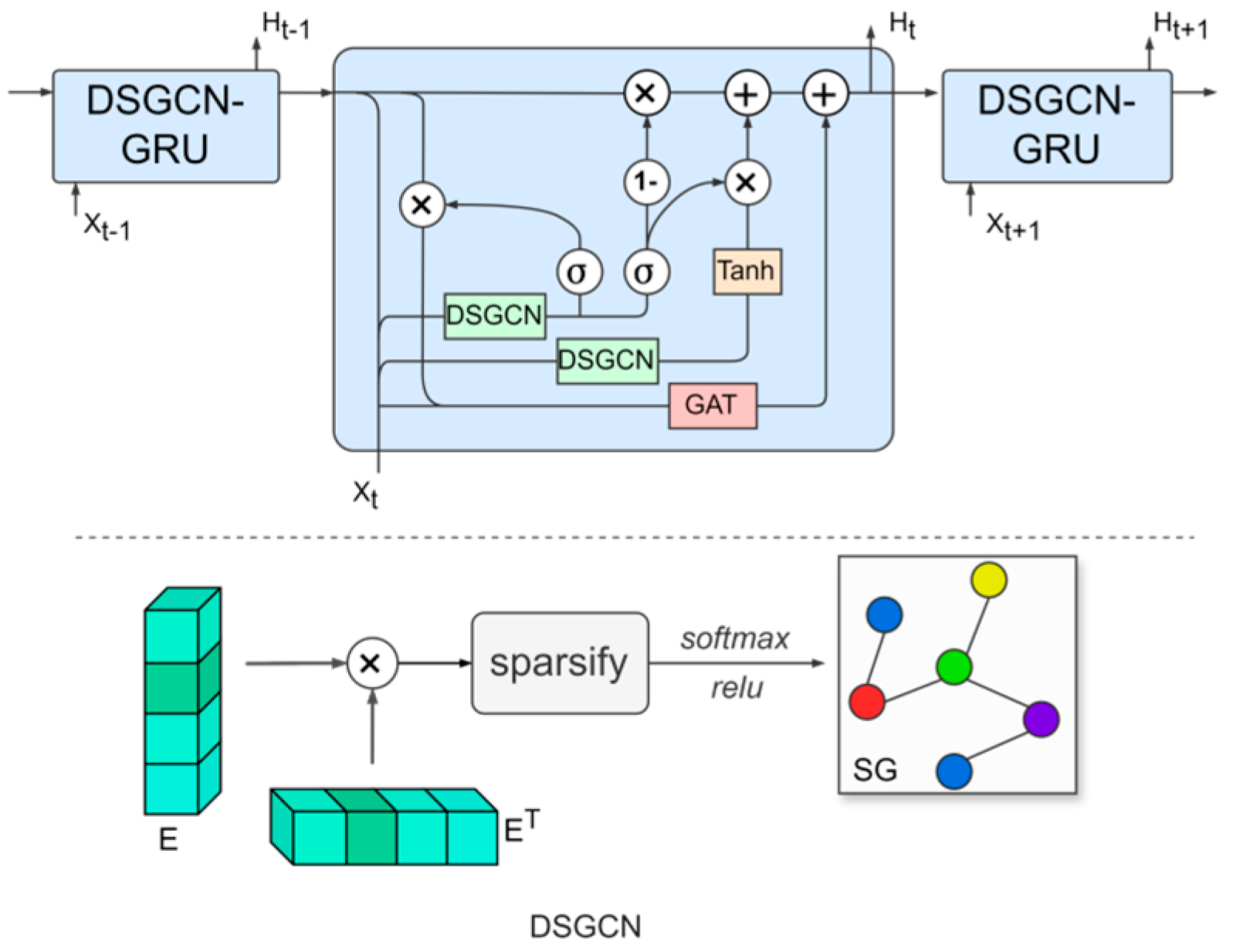
42], thereby obtaining feature representations of nodes. However, traditional GCNs are limited in their ability to handle static graph structures, which restricts their capacity to capture dynamic spatial correlations. In contrast, dynamic GCNs can adaptively generate adjacency matrices that reflect these time-varying relationships, allowing for a more accurate representation of spatial correlations in traffic flow across different time periods. To address this challenge, we propose the dynamic sparse graph convolutional gated recurrent network (DSGCGRN), as illustrated in
Figure 2.
The DSGCGRN consists of multiple layers of DSGCN-GRU structures, with each GRU unit incorporating two novel dynamic sparse graph convolution blocks and one graph attention block. By combining the strengths of dynamic sparse graph convolution (DSGCN) and gated recurrent units (GRUs), the model is able to capture both spatial and temporal correlations. The DSGCN module dynamically updates the adjacency matrix based on the evolving traffic data, thereby capturing the shifting spatial correlations in the traffic network over time. The sparse graph learning approach encourages the model to identify key, explicit connections, effectively limiting the spatial receptive field to preserve the distinctive characteristics of individual nodes [
43]. Meanwhile, the GRU component handles the processing and storage of time-series information.
First, we generate adaptive node embeddings to calculate the adjacency matrix
. Next, we apply a sparsification technique to
, keeping only the top highest similarity connections between each node and its neighboring nodes. The resulting matrix is then normalized using the softmax function to obtain the adaptive sparse adjacency matrix
. The formula for this process is defined as:
Here, is the adaptive node embedding matrix, where denotes the embedding dimension of the nodes. The function denotes the sparsification operation, and is the sparsity rate.
To enable our method to learn higher-order neighborhood information in graph data, we utilize Chebyshev polynomials [
44] to approximate the graph convolution kernel. This technique allows us to efficiently model the intricate relationships between nodes and their distant neighbors, as well as the broader global structure, without significantly increasing computational complexity. Therefore, the dynamic graph convolutional network can be defined as:
Here, represents the identity matrix, be the input graph signal, and represent the output signal after the graph convolution operation. The learnable parameters of the model are and .
In order to consider both the spatial topology and the interactions between nodes while also capturing temporal dependencies, we combine gated recurrent units (GRUs) with dynamic sparse graph generation. Specifically, we integrate dynamic graph convolution into the GRU with graph attention (GAT) gating. The overall structure is shown in
Figure 2. Given the previous hidden state
and the input data at time
,
, the gated recurrent unit can be expressed as follows:
Here, indicates the graph convolution operation, represents the sigmoid activation function, and , , , , , and are the learnable weights of the recurrent network layer. The output at time is denoted as . is the static matrix in the GAT (graph attention network) computed based on distance, is the dynamic attention coefficient matrix, and represents the learnable weight parameters.
2.4. Spatio-Temporal Attention Fusion Layer
Although the DSGCN-GRU approach, which relies on GRU, is capable of effectively capturing local temporal patterns in traffic sequence data through its internal hidden states and memory mechanisms, its forget gate and limitations in the direction of information flow hinder its ability to detect long-range spatio-temporal dependencies. Therefore, we propose a spatio-temporal attention fusion (STAF) structure to further process the output of the DSGCN-GRU network, aiming to capture long-range, multi-scale spatio-temporal patterns.
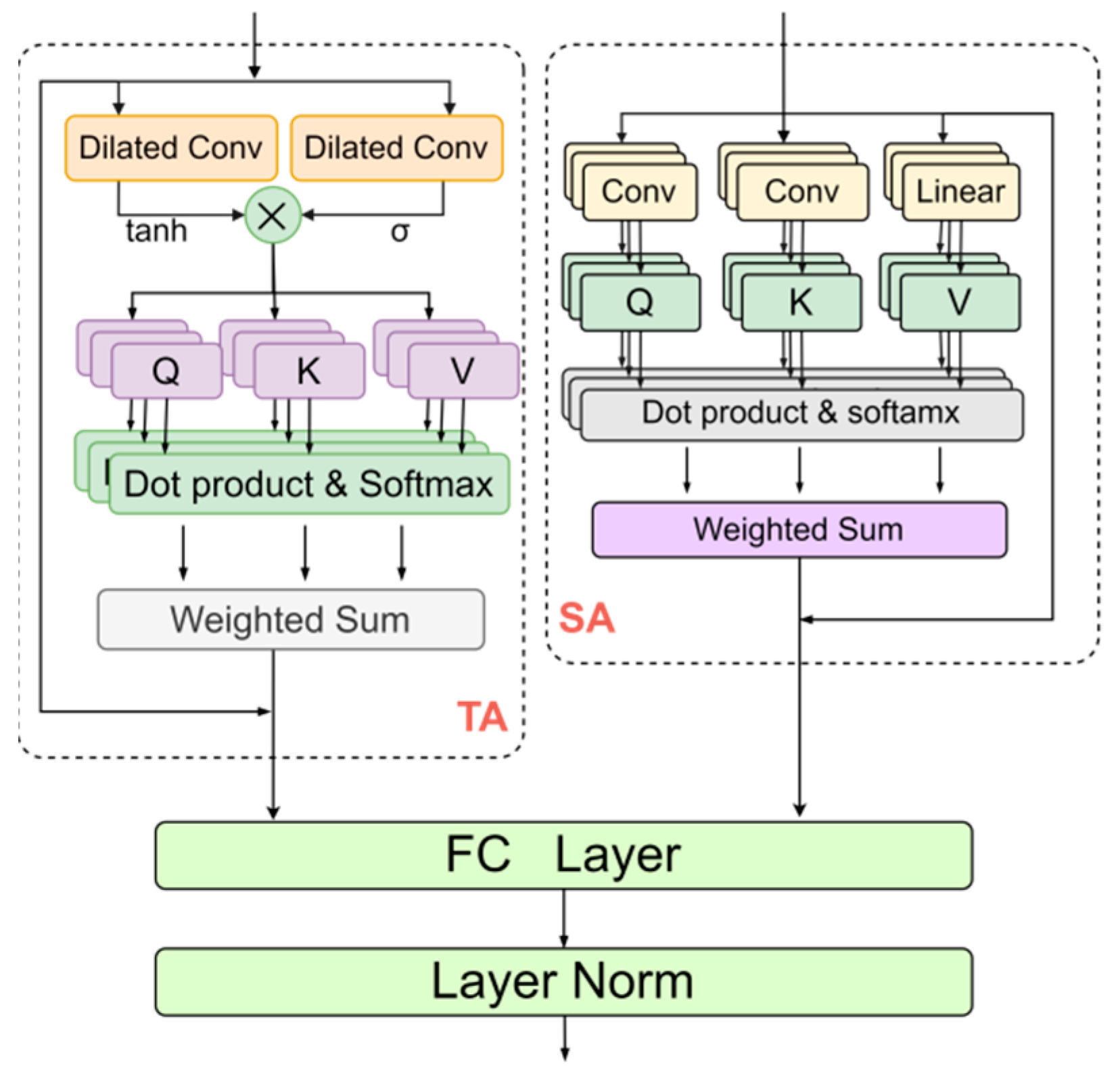
The spatio-temporal attention fusion (STAF) structure employs a parallel design, comprising a Temporal Multi-Head Attention block (TA) with dilated convolution gating and a Spatial Multi-Head Attention block (SA), as illustrated in
Figure 3. This design is intended to overcome the limitations of recurrent neural networks in processing long spatio-temporal sequences and their inability to efficiently handle sudden traffic events. Initially, the output from the DSGCN-GRU network is separately input into the TA and SA blocks to capture long-range temporal and spatial dependencies, as well as to detect local abrupt changes. The outputs of both blocks are then combined using a fully connected layer and layer normalization [
45]. The following sections offer a detailed discussion of these two modules.
2.4.1. Temporal Dilated Gated Multi-Head Self-Attention
In the temporal dimension, we propose an innovative integration of dilated convolutional gating with temporal attention to assess the significance of information propagation before passing it to the multi-head attention layer. The specifics of this approach are outlined in the TA block in
Figure 3. The Temporal Dilated Gated Multi-Head Self-Attention block (TA) consists primarily of a dilated convolution gating mechanism combined with a temporal attention mechanism. First, we apply the dilated convolutional gating structure to dynamically regulate the model’s learning and response to spatio-temporal features, effectively capturing both local and global patterns. This design enhances flexibility, enabling the model to better adapt to sudden changes in traffic conditions. The process is defined as follows:
In this context,
denotes the sigmoid activation function and
represents the input to the subsequent temporal multi-head attention layer [
46]. Next, we utilize the multi-head attention mechanism to capture dynamic temporal relationships, allowing the model to learn intricate temporal dependencies. The query
, key
, and value
matrices are derived through linear layers to compute the attention scores. This is mathematically expressed as follows:
Here
represents the learnable parameter matrices. The output of the Temporal Dilated Gated Self-Attention, denoted as
is then computed as follows:
2.4.2. Spatial Multi-Head Self-Attention
In the spatial dimension, unlike the TA block, we directly use the output of the Dynamic Sparse Graph Convolutional Recurrent Network to calculate the query
, key
, and value
matrices in order to obtain the spatial attention output, as detailed in the SA block in
Figure 3. Notably, we apply convolution operations to obtain
and
, which are defined as follows:
This method successfully captures both local and global dependencies, facilitating the efficient integration and compression of spatial information. The attention scores, along with the final output, are calculated using the multi-head self-attention mechanism, as expressed below:
Here are the learnable parameter matrices. is the output of spatial attention.
The final output of the STAF layer is defined as follows:
represents the fully connected layer operation, and represents the layer normalization operation. represents the output of the spatio-temporal attention fusion (STAF) layer.
2.5. Prediction and Loss Function
Our model can generate accurate predictions through a simple and efficient convolutional prediction layer. Specifically, we map the high-dimensional spatio-temporal features obtained from the spatio-temporal attention mechanism to a lower-dimensional space using a convolutional layer to predict future traffic sequences
. In this process, since traffic data frequently includes outliers caused by sensor malfunctions or other factors, we employ the L1 loss function to assess the deviation between predicted and actual values. The L1 loss is less affected by extreme errors, enhancing the robustness of the model. The loss function is defined as follows:
3. Experiment
3.1. Datasets
In conducting our research experiments, we rigorously used two well-known and widely applied public datasets, PeMS04 and PeMS08, as the foundation for evaluating model performance. The data used in this study are sourced from the Performance Measurement System (PeMS) of the California Department of Transportation. This system gathers and compiles data at five-minute intervals through a network of sensors installed across the road network, capturing essential traffic parameters such as vehicle speed, traffic volume, and lane occupancy. A comprehensive statistical summary of the datasets is provided in
Table 1, offering detailed insights into the data’s background and structure.
3.2. Baseline Models
Traditional time series forecasting methods: ARIMA [
4]: This model is based on the autoregressive moving average model and adds a difference term to predict the trend of traffic flow. SVR [
7]: The model uses the linear support vector regression algorithm to realize the prediction function of continuous values.
Graph neural network-based approaches: STGCN [
25]: For the first time, convolution operations are used to capture temporal relationships, and GCN is used to capture spatial relationships. DCRNN [
26]: The diffusion convolutional recurrent neural network follows the encoder-decoder structure and uses the combination of diffusion map convolutional network and GRU to predict traffic flow. GraphWaveNet [
20]: Graph WaveNet combines graph convolution with temporal convolution to capture spatiotemporal dependencies. ST-AE [
37]: An autoencoder-based traffic flow prediction method, which realizes traffic flow prediction by encoding the current traffic flow into a low-dimensional representation and directly predicting the future hidden state and then decoding and reconstructing. MSTGCN [
47]: A spatiotemporal deep learning framework with data normalization, a multi-semantic graph convolutional network, and external feature fusion is proposed to solve the data imbalance and complex spatiotemporal feature modeling problems in the traffic flow prediction of highway toll stations. ASTGCN [
32]: The attention mechanism was introduced into traffic flow prediction, and the spatial attention and temporal attention mechanisms were designed to model the spatial sum. Temporal dynamics to construct a convolutional network of spatiotemporal graphs. STSGCN [
30]: a novel spatiotemporal synchronous graph convolutional network, which uses convolution operations to capture local spatial and temporal correlations at the same time. AGCRN [
36]: The model combines a circular architecture with dynamic components to automatically learn multi-level spatiotemporal dependencies in traffic data. STFGNN [
33]: A time graph that fuses time and space modules is proposed for flow prediction. STGODE [
48]: The algorithm uses tensor ODE to model the spatiotemporal evolution law so as to support the construction of deeper networks and collaborative mining of spatiotemporal information. In order to enhance the modeling ability, the method introduces a semantic association matrix and adopts an optimized temporal convolution module to learn long-range time dependence. DSTAGNN [
32]: A new dynamic spatiotemporal perception graph replaces the predefined static graph used by the traditional graph convolution method and considers the traffic prediction from the perspective of the dynamic graph. GSTPRN [
49]: A model that integrates self-attention location map convolution, an approximate personalized propagation algorithm, and adaptive graph learning, realizing accurate spatiotemporal prediction of traffic flow through gated recirculation units. PDFormer [
50]: A dynamic spatiotemporal modeling framework is proposed, which captures multi-scale spatial dependence through the spatial self-attention module and the dual-view map masking matrix and explicitly models the information propagation delay in combination with the delay-sensing feature transformation module so as to enhance the spatiotemporal representation ability of traffic flow prediction.
3.3. Experimental Setup and Evaluation Metrics
For this experiment, we split the datasets into training, validation, and test sets in a 7:2:1 ratio. Prior to feeding the data into the model for training, all datasets were normalized using the Min-Max normalization technique. In alignment with the baseline models, we set both the historical and prediction step sizes to 12, meaning that 12 consecutive time steps (equivalent to one hour of traffic flow) from the past are used to forecast the next 12 consecutive time steps.
The model was implemented using PyTorch 2.0, with all experiments running on an NVIDIA RTX 4090D GPU (ASUS, Shanghai, China). STFDSGCN employs the Adam optimizer with a learning rate of 0.001. The batch sizes for the PeMS04 and PeMS08 datasets are set to 4 and 64, respectively, with training conducted over 200 epochs. To mitigate overfitting, an early stopping strategy with a patience value of 20 was applied.
The model’s performance is assessed using three metrics: Mean Absolute Error (MAE), Mean Absolute Percentage Error (MAPE), and root mean square error (RMSE), defined as follows:
In this context, denotes the number of samples, represents the actual value, and represents the predicted value.
3.4. Performance Comparison and Analysis
To demonstrate the superior performance of the STFDSGCN model, we conducted comparative performance experiments using the test sets of two real-world traffic flow datasets.
Table 2 summarizes the average performance of various models in predicting the next hour for the PeMS04 and PeMS08 datasets. The goal is to showcase the advantages of our model through a comprehensive performance evaluation.
For fairness and reliability, we extensively referenced and cited official records and authoritative publications of several benchmark models. STFDSGCN significantly outperforms all baseline methods on both the PeMS04 and PeMS08 datasets in most cases. On PeMS04, STFDSGCN improves the MAE and MAPE metrics by 1.5% and 1.26%, respectively, compared to the advanced DSTAGNN method. On PeMS08, STFDSGCN enhances MAE and RMSE by 5.02% and 2.63%, respectively, outperforming the state-of-the-art ST-AE method, with a 3.8% improvement in MAPE.
Our analysis indicates that models leveraging spatio-temporal graph neural networks (GNNs) show considerable performance gains over traditional linear time series forecasting methods. This improvement stems from the ability of spatio-temporal GNNs to effectively capture and utilize the spatio-temporal correlations within the data, further validating their effectiveness in traffic flow prediction. Models such as STGCN and DCRNN, which combine both temporal and spatial features, demonstrate enhanced performance. The ASTGCN model, incorporating an attention mechanism, also excels by accurately capturing long-term temporal patterns, boosting prediction accuracy. Graph WaveNet improves the understanding of temporal dynamics by integrating diffusion graph convolution with temporal convolutional networks, offering a more effective spatio-temporal feature capture.
Although STSGCN attempts to integrate spatio-temporal information in a unified manner, its reliance on a simplified sliding window strategy for time sequence handling limits its capacity to capture temporal correlations precisely, thus reducing its overall effectiveness. The STGODE and AGCRN models break away from the constraints of fixed graph structures by utilizing the adaptive or dynamic nature of spatial correlations between nodes, enhancing predictive performance. DSTAGNN introduces a dynamic spatio-temporal graph, replacing the static graph traditionally used in graph convolutions, modeling pairwise node dependencies. While it shows strong results, STFDSGCN outperforms it.
What is striking is the prediction accuracy of PDFormer, which pays more attention to the time delay of the propagation of traffic conditions between spatial locations in the traffic system and more effectively simulates the change trend of actual traffic flow. It surpasses the model we propose in every metric. However, STFDSGCN pays more attention to the spatiotemporal heterogeneity of traffic data and the impact of traffic emergencies (i.e., traffic anomalies) on spatiotemporal changes in the modeling. Although the prediction accuracy of STFDSGCN does not surpass that of PDFormer, the model training efficiency is much better than that of PDFormer.
STFDSGCN innovatively integrates a dynamic sparse graph convolutional recurrent network to capture potential spatial correlations, allowing the model to deeply explore the heterogeneous spatial features of the road network. Additionally, it uses a gated spatio-temporal attention fusion mechanism to identify critical long-term time-series information and detect unforeseen traffic incidents. This model efficiently captures spatio-temporal correlations across the entire data range, achieving superior performance compared to baseline models.
3.5. Ablation Experiment
In order to assess the contribution of various components within the STFDSGCN model, we performed ablation experiments on the PeMS08 and PeMS04 datasets. For this, we created five distinct variants of the STFDSGCN model, with their specific configurations outlined in
Table 3.
STFDSGCN w/o DG_TA: removes the temporal self-attention structure with dilated gating.
STFDSGCN w/o SA: removes the spatial self-attention structure from the model.
STFDSGCN w/o STAF: removes the spatio-temporal attention fusion module from the model.
STFDSGCN w/o SG: replaces the dynamic sparse graph in the graph convolution block with a dense graph.
STFDSGCN w/o DSGCN: replaces the dynamic sparse graph convolutional network (DSGCN) in the dynamic sparse graph convolutional recurrent network with a regular GCN.
Apart from the differences mentioned above, all other configurations of the variants remain consistent with STFDSGCN.
Figure 4 shows the ablation results based on the PeMS08 and PeMS04 datasets. STFDSGCN demonstrates outstanding performance across all evaluation metrics. First, considering the extraction of dynamic spatial heterogeneous features, the Dynamic Sparse Graph Convolutional Recurrent Network (DSGCN) has the most significant impact on model prediction, improving MAE and MAPE by 12.24% and 12.20%, respectively. This clearly demonstrates that DSGCN, compared to the standard static GCN, is better at capturing complex and dynamic spatial correlations. The sparse graph learning approach also outperforms the dense graph as it constrains the spatial scope, preserving the uniqueness of features and thereby enhancing model performance. Second, the spatio-temporal attention fusion (STAF) mechanism contributes significantly to overall improvement, with a 10.1% increase in MAE. This mechanism balances local dependencies and global correlations in spatio-temporal features. Notably, the MAE metric is highly sensitive to outliers, and the observed significant improvement in this metric strongly confirms that this module excels in handling sudden traffic flow situations. The temporal self-attention with dilated gating and the spatial self-attention structures are both indispensable to the spatio-temporal attention fusion mechanism. Removing either would lead to a deterioration in model performance.
3.6. Hyperparameter Configuration Study
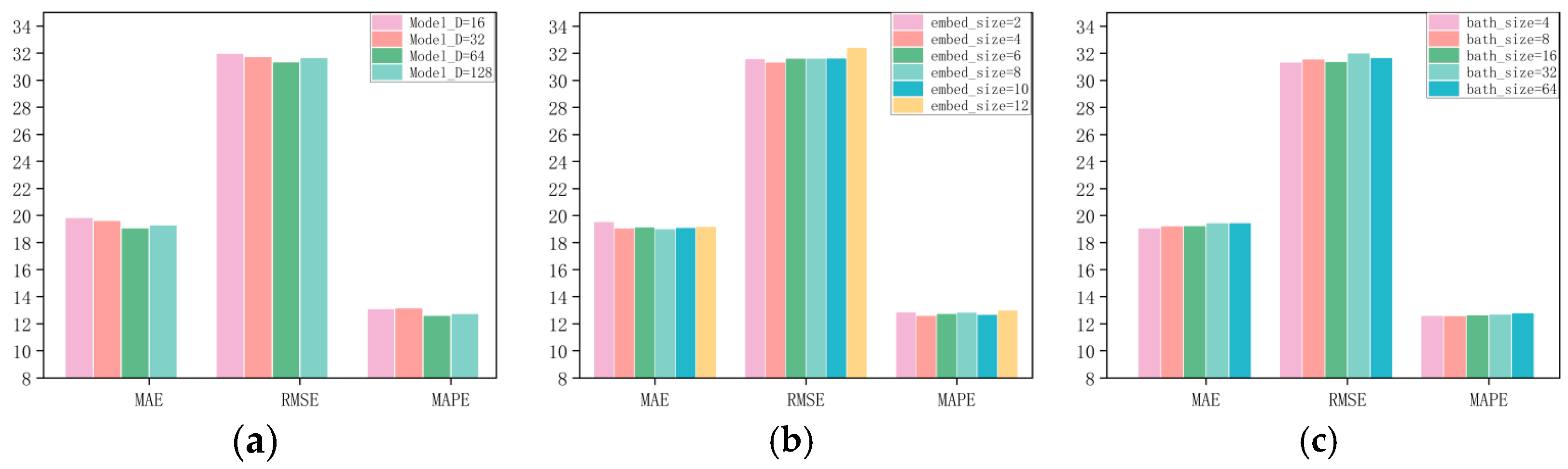
To explore how hyperparameter choices influence model performance, we conducted a set of experiments on the PeMS04 and PeMS08 datasets with various network configurations. Our results indicated that the model’s performance was particularly sensitive to adjustments in batch size (Batch_size), model dimension (Model_D), and the dimension of node embeddings (Embedded_dim). As depicted in
Figure 5a and
Figure 6a, the model achieved the best predictive accuracy when the model dimension (Model_D) was set to 64. In
Figure 5b and
Figure 6b, it is shown that the node embedding size plays a crucial role in determining the quality of node representations in the graph. The optimal values for the node embedding dimensions were found to be 4 for PeMS04 and 8 for PeMS08. A larger node embedding dimension allows the model to accommodate more parameter information, which helps to uncover and infer more comprehensive spatial correlations.
Figure 5c and
Figure 6c show the influence of batch size on model performance across different datasets. The optimal `Batch_size` for PeMS04 and PeMS08 is 4 and 64, respectively. When all hyperparameters are set to their optimal values, our model produces the best performance.
3.7. Scalability Study
We performed a comparison of the computational costs between the STFDSGCN model and various baseline models, as shown in
Table 4, using the PeMS08 dataset. While the STFDSGCN model demonstrates excellent performance, its computational cost did not increase significantly. Compared to other advanced baselines such as STGODE and DSTAGNN, STFDSGCN not only outperforms them in terms of accuracy but also significantly reduces the consumption of computational resources. While STFGNN is highly efficient and exhibits the lowest computational cost, it has some limitations in capturing long-term dependencies in time series data. PDFormer designs a more complex null attention mechanism, which leads to its complete inferiority in training efficiency compared to STFDSGCN. The main computational expense of STFDSGCN is associated with its gated spatio-temporal attention fusion structure. However, since STFDSGCN processes data in parallel within the spatio-temporal attention fusion structure, it greatly improves the model’s operational efficiency.
3.8. Discuss the Implications of the Study
The STFDSGCN model proposed in this study effectively solves the spatiotemporal dynamic modeling problem in traffic flow prediction through innovative dynamic sparse graph convolution and a gated spatiotemporal attention mechanism. In this study, two public datasets of California highways are used as practical application cases for traffic flow prediction, and the prediction accuracy is significantly better than that of existing methods under the influence of spatiotemporal heterogeneous characteristics and emergency response. These practical effects were significantly demonstrated in both the ablation experiment and the baseline comparison experiment. This work not only provides a new theoretical framework for spatiotemporal series prediction but also shows important engineering value and provides reliable technical support for the construction of smart cities. Future research can further optimize extreme weather adaptability and explore the deployment of edge computing to expand its application breadth in the field of intelligent transportation.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}