
ZZ-YOLOv11: A Lightweight Vehicle Detection Model Based on Improved YOLOv11


Abstract
Highlights
- Developed ZZ-YOLO with GEIT module and LDCD detection head, achieving 70.9% detection accuracy and 58% mAP@0.5 on KITTI and BDD100K datasets, improving accuracy by 5.7% while reducing model parameters by 34% compared to the baseline.
- Successfully integrated LAMP pruning and knowledge distillation techniques to create a lightweight vehicle detection model with only 14.1 GFLOPs computational cost.
- The proposed approach effectively addresses vehicle detection challenges in complex urban traffic scenes, significantly reducing false positives and missed detections.
- The lightweight yet accurate model design enables practical deployment in resource-constrained environments while maintaining high detection performance.
Abstract
1. Introduction
- (1)
- The GlobalEdgeInformationTransfer (GEIT) module is designed to improve the network’s focus on object edges, effectively enhancing the clarity of target classification and localization. This module can transfer the edge information extracted from shallow features to the whole network and fuse it with features of different scales.
- (2)
- A lightweight LDCD detection head is proposed to optimize the feature fusion effect while reducing the number of parameters.
- (3)
- The LAMP pruning method optimizes the network, reducing the model’s computational complexity.
- (4)
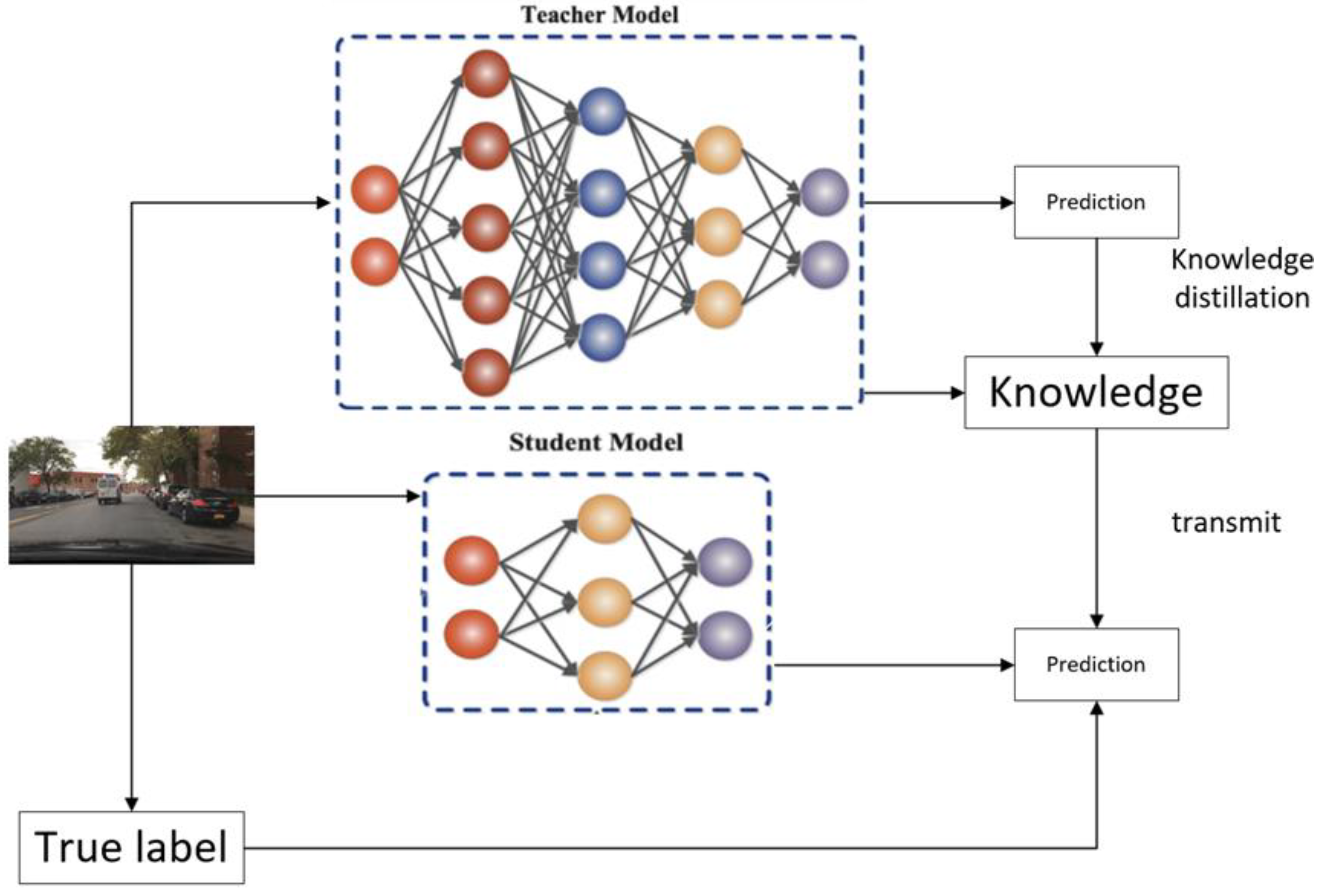
- The model distillation technique is introduced, and YOLOv11x + LDCD is used as a teacher model to guide the learning of the lightweight model after pruning, ensuring that the model performance will not be significantly degraded by pruning.
2. Materials and Methods
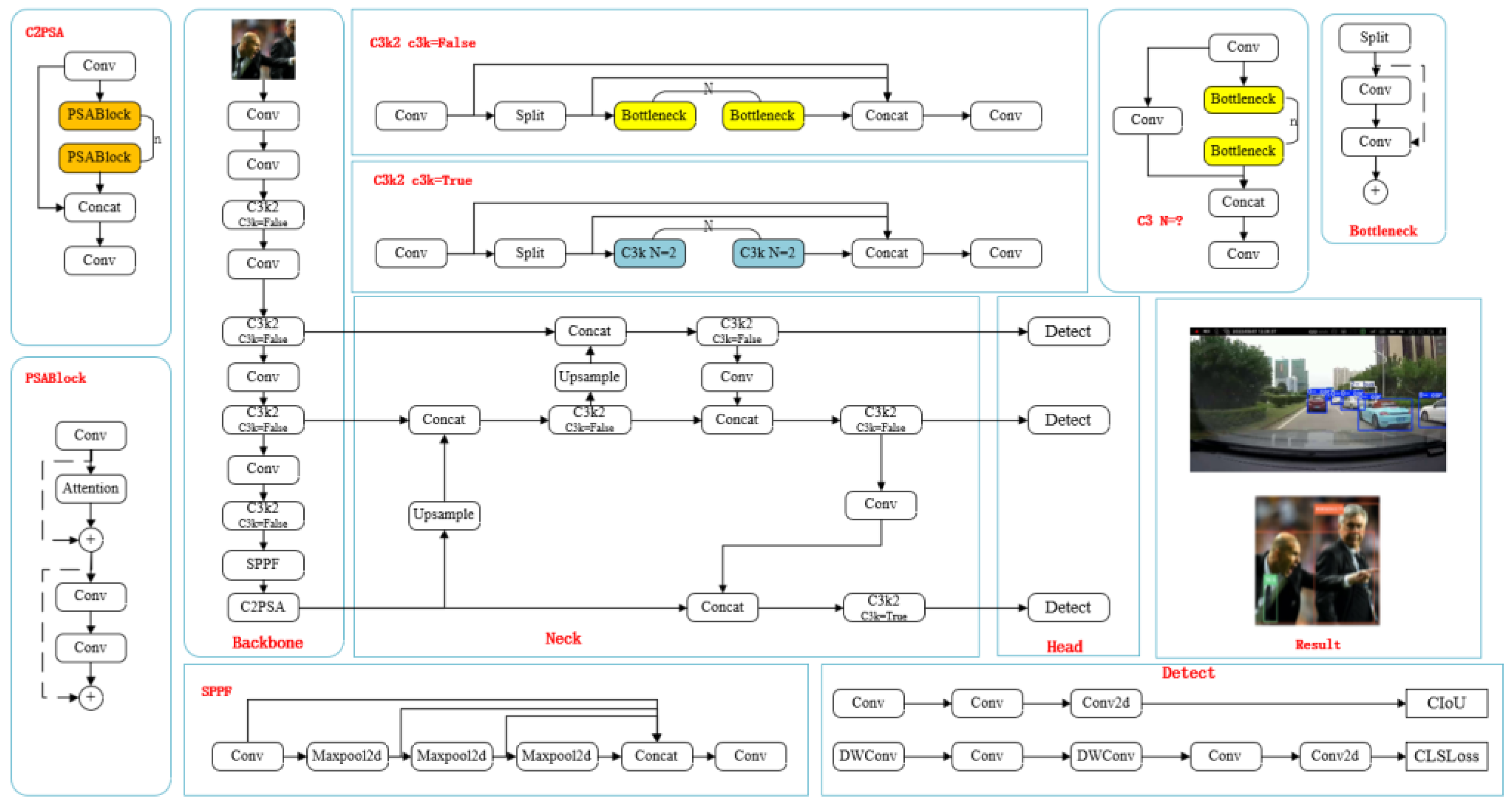
2.1. YOLO11 Introduction
2.2. Improvement of YOLOv11 Network
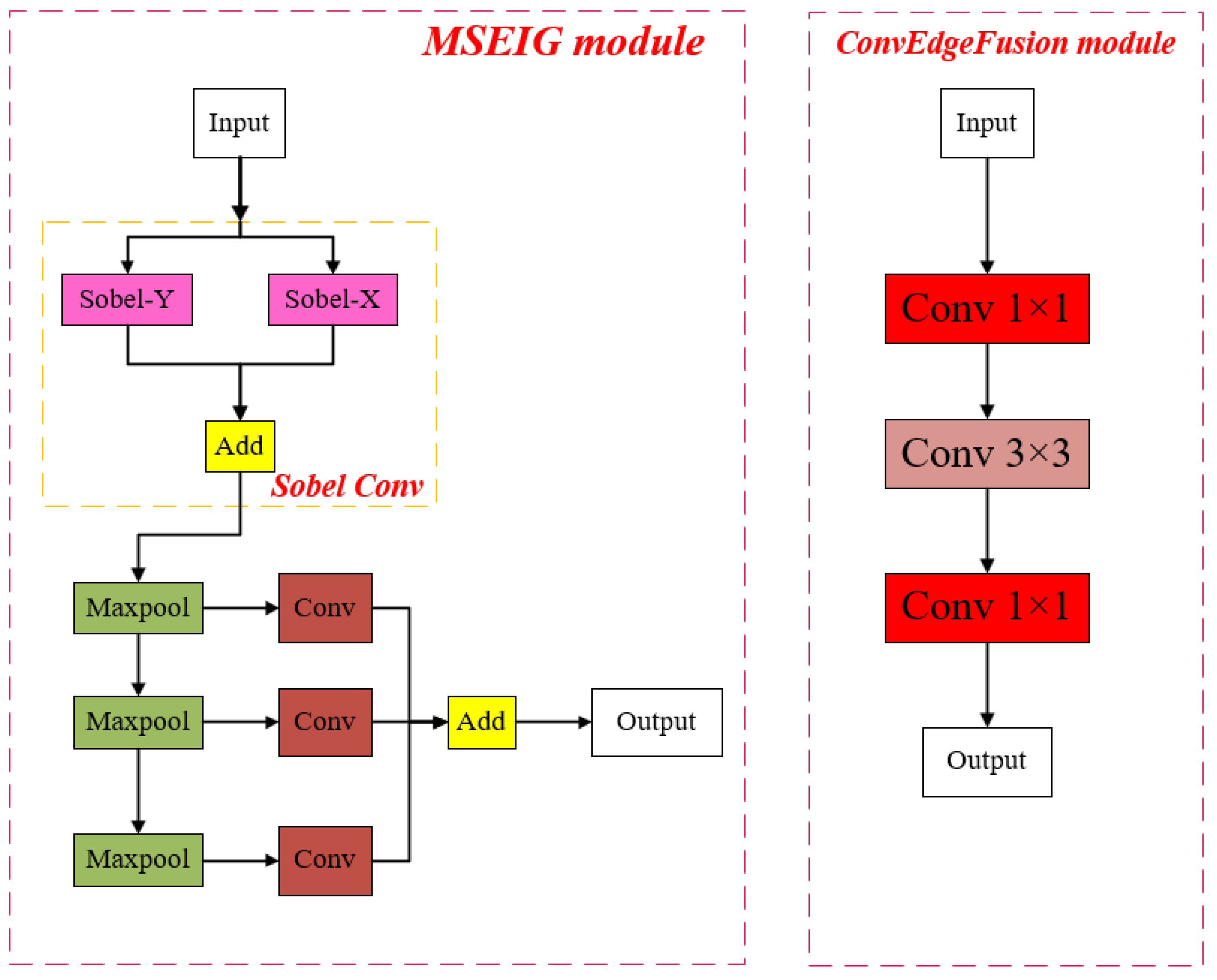
2.2.1. Global Edge Generation Transformation Module (GEIT)
Introduction to the Global Edge Generation Conversion Module
- Multiscale Edge Information Guidance Module (MSEIG)
- Optimization of the Downsampling Strategy
- Convolutional Edge Fusion Mechanisms
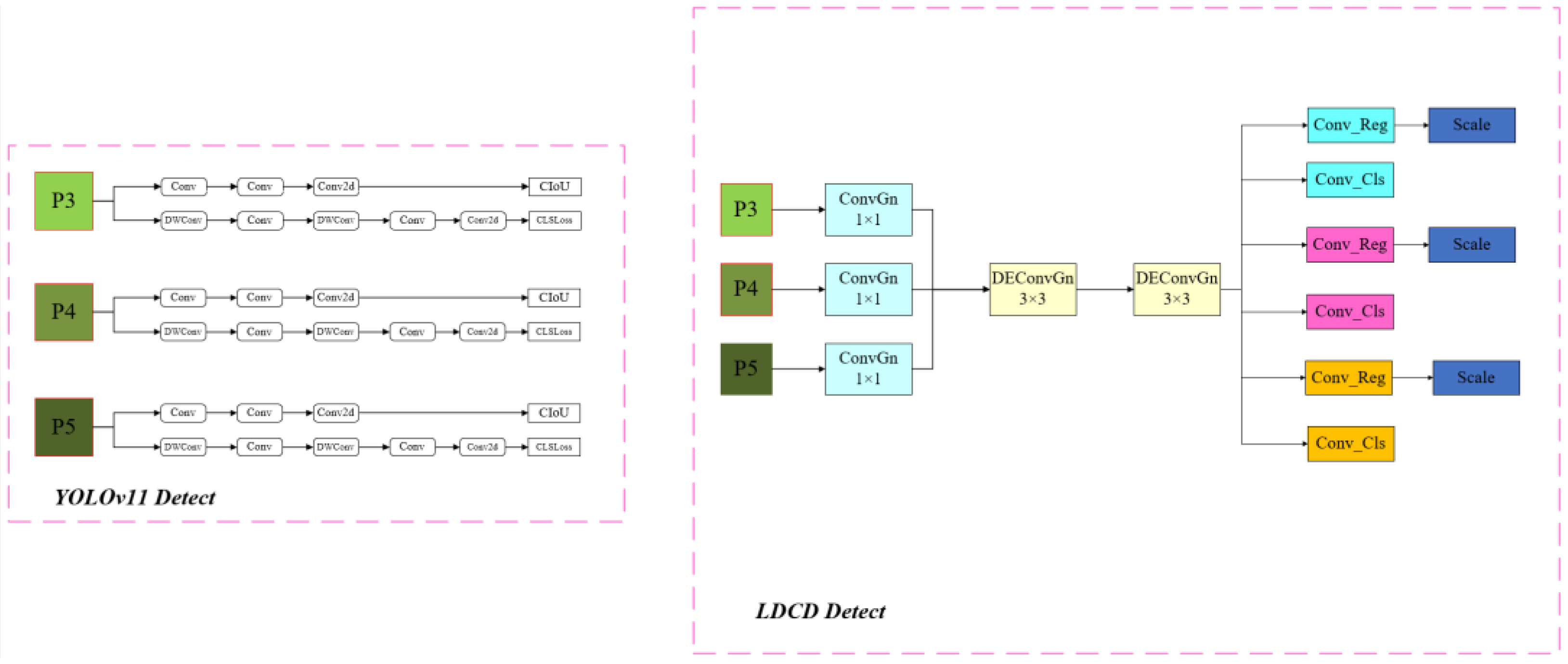
2.2.2. Lightweight LDCD Detection Head
Characteristics of the New Inspection Head
- Strategic Update of the Normalization Layer
- Lightweight Design of the Detection Head
- Introduction of Detail-Enhanced Convolution Module
- (1)
- Dual-path structure: DEConv adopts a parallel dual-path design, where one path handles the main semantic information, and the other focuses on detailed feature extraction.
- (2)
- Adaptive Feature Enhancement: Dynamically adjusts the importance of detail information through a feature-reweighting mechanism, enabling the network to intelligently focus on key detail regions based on the input content.
- (3)
- Multiscale receptive fields: Integrate different scales of receptive fields to simultaneously capture local fine structure and global context information.
- (4)
- Edge retention capability: Specially optimized to retain high-frequency information such as edges and textures, reducing the loss of detail common in traditional convolutions.
- (5)
- Pluggable design: Standard convolutional layers in an existing network can be directly replaced without drastically changing the network architecture.
2.2.3. Model Pruning
Hierarchical Adaptive Analysis
Multi-Granularity Pruning Strategies
Progressive Pruning and Monitoring
- Network Restructuring and Optimization
2.2.4. Knowledge Distillation
3. Experimental Design and Validation
3.1. Selection of Dataset and Experimental Environment
3.2. Evaluation Indicators for the Experiment
3.3. Ablation Test
3.4. Comparative Experiment
3.5. Generalization Test
3.6. Real Vehicle Tests
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, W.; Qiao, X.; Zhao, C.; Deng, T.; Yan, F. VP-YOLO: A human visual perception-inspired robust vehicle-pedestrian detection model for complex traffic scenarios. Expert Syst. Appl. 2025, 274, 126837. [Google Scholar] [CrossRef]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: High quality object detection and instance segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1483–1498. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Carrasco, D.P.; Rashwan, H.A.; García, M.Á.; Puig, D. T-YOLO: Tiny vehicle detection based on YOLO and multi-scale convolutional neural networks. Ieee Access 2021, 11, 22430–22440. [Google Scholar] [CrossRef]
- Zarei, N.; Moallem, P.; Shams, M. Fast-Yolo-rec: Incorporating Yolo-base detection and recurrent-base prediction networks for fast vehicle detection in consecutive images. IEEE Access 2022, 10, 120592–120605. [Google Scholar] [CrossRef]
- Miao, Y.; Liu, F.; Hou, T.; Liu, L.; Liu, Y. A nighttime vehicle detection method based on YOLO v3. In Proceedings of the 2020 Chinese Automation Congress (CAC), Shanghai, China, 6–8 November 2020; pp. 6617–6621. [Google Scholar]
- Zhu, J.; Li, X.; Jin, P.; Xu, Q.; Sun, Z.; Song, X. Mme-yolo: Multi-sensor multi-level enhanced yolo for robust vehicle detection in traffic surveillance. Sensors 2020, 21, 27. [Google Scholar] [CrossRef] [PubMed]
- Song, Y.; Hong, S.; Hu, C.; He, P.; Tao, L.; Tie, Z.; Ding, C. MEB-YOLO: An Efficient Vehicle Detection Method in Complex Traffic Road Scenes. Comput. Mater. Contin. 2023, 75, 5761–5784. [Google Scholar] [CrossRef]
- Huang, S.; He, Y.; Chen, X.-A. M-YOLO: A nighttime vehicle detection method combining mobilenet v2 and YOLO v3. J. Phys. Conf. Ser. 2021, 1883, 012094. [Google Scholar] [CrossRef]
- Khanam, R.; Hussain, M. Yolov11: An overview of the key architectural enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar]
- Wu, Y.; He, K. Group normalization. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Detector, A.-F.O. Fcos: A simple and strong anchor-free object detector. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 69–76. [Google Scholar]
- Chen, Z.; He, Z.; Lu, Z.-M. DEA-Net: Single image dehazing based on detail-enhanced convolution and content-guided attention. IEEE Trans. Image Process. 2024, 33, 1002–1015. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Li, G.; Zhang, Z. A Study on the Performance Improvement of a Conical Bucket Detection Algorithm Based on YOLOv8s. World Electr. Veh. J. 2024, 15, 238. [Google Scholar] [CrossRef]
- Huang, Z.; Wang, N. Like what you like: Knowledge distill via neuron selectivity transfer. arXiv 2017, arXiv:1707.01219. [Google Scholar]
- Ji, M.; Heo, B.; Park, S. Show, attend and distill: Knowledge distillation via attention-based feature matching. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; pp. 7945–7952. [Google Scholar]
- Li, X.; Li, G.; Zhang, Z.; Sun, H. Research on Improved Algorithms for Cone Bucket Detection in Formula Unmanned Competition. Sensors 2024, 24, 5945. [Google Scholar] [CrossRef]
- Jiang, H.; Zhong, J.; Ma, F.; Wang, C.; Yi, R. Utilizing an Enhanced YOLOv8 Model for Fishery Detection. Fishes 2025, 10, 81. [Google Scholar] [CrossRef]
- Sun, X.; Wu, P.; Hoi, S.C. Face detection using deep learning: An improved faster RCNN approach. Neurocomputing 2018, 299, 42–50. [Google Scholar] [CrossRef]
- Chen, Z.; Guo, H.; Yang, J.; Jiao, H.; Feng, Z.; Chen, L.; Gao, T. Fast vehicle detection algorithm in traffic scene based on improved SSD. Measurement 2022, 201, 111655. [Google Scholar] [CrossRef]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.-Y.; Yeh, I.-H.; Liao, H.-Y.M. Yolov9: Learning what you want to learn using programmable gradient information. arXiv 2024, arXiv:2402.13616. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J. Yolov10: Real-time end-to-end object detection. Adv. Neural Inf. Process. Syst. 2024, 37, 107984–108011. [Google Scholar]
- Yan, L.; Wang, Q.; Zhao, J.; Guan, Q.; Tang, Z.; Zhang, J.; Liu, D. Radiance Field Learners as UAV First-Person Viewers. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; pp. 88–107. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | P/% | mAP0.5/% | mAP0.5–0.95/% | Participant Number | Floating-Point Calculations/GFLOPs |
|---|---|---|---|---|---|
| YOLOv11s | 65.2 | 55.7 | 37.5 | 9,414,348 | 21.3 |
| YOLOv11s-LDCD | 65.6 | 57.6 | 38.1 | 8,915,751 | 19.8 |
| YOLOv11s-GEIT | 76.2 | 57 | 38.3 | 12,721,804 | 33.3 |
| YOLOv11s-GEIT-LDCD | 69.8 | 57.4 | 37.8 | 11,963,527 | 30.2 |
| YOLOv11s- GEIT-LDCD-Prune | 66.3 | 56.7 | 38.2 | 2,449,743 | 14.1 |
| YOLOv11x | 75.8 | 61 | 41.1 | 56,831,644 | 198.4 |
| YOLOv11x-LDCD | 76.9 | 61.6 | 41.7 | 54,109,719 | 193.2 |
| YOLOv11s-All | 70.9 | 58 | 39.2 | 2,449,743 | 14.1 |
| Model | P/% | mAP0.5/% | mAP0.5–0.95/% | Participant Number | Floating-Point Calculations/GFLOPs |
|---|---|---|---|---|---|
| F-RCNN | 50.1 | 46.4 | 28.5 | 284,780,223 | 186.9 |
| SSD | 56.3 | 49.5 | 30.3 | 25,934,879 | 61.9 |
| RT-DERT-X | 58.8 | 48.7 | 31.8 | 28,489,674 | 101.2 |
| RT-DERT-r50 | 60.2 | 50.5 | 32.6 | 41,897,973 | 126.1 |
| YOLOv5s | 58.4 | 49.7 | 32.3 | 7,815,164 | 18.7 |
| YOLOv6s | 59.7 | 49.8 | 33.1 | 15,976,924 | 42.8 |
| YOLOv7 | 64.2 | 54.1 | 36.8 | 29,087,126 | 102.2 |
| YOLOv8s | 64.8 | 52.1 | 34.3 | 9,829,212 | 23.4 |
| YOLOv9s | 62.3 | 53.7 | 35.2 | 6,195,196 | 22.1 |
| YOLOv10s | 58.1 | 49.4 | 32.3 | 7,219,548 | 21.4 |
| YOLOv11s | 65.2 | 55.7 | 37.5 | 9,414,348 | 21.3 |
| ours | 70.9 | 58 | 39.2 | 2,449,743 | 14.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Zhang, Z.; Li, G.; Xia, C. ZZ-YOLOv11: A Lightweight Vehicle Detection Model Based on Improved YOLOv11. Sensors 2025, 25, 3399. https://doi.org/10.3390/s25113399
Zhang Z, Zhang Z, Li G, Xia C. ZZ-YOLOv11: A Lightweight Vehicle Detection Model Based on Improved YOLOv11. Sensors. 2025; 25(11):3399. https://doi.org/10.3390/s25113399
Chicago/Turabian StyleZhang, Zhe, Zhongyang Zhang, Gang Li, and Chenxi Xia. 2025. "ZZ-YOLOv11: A Lightweight Vehicle Detection Model Based on Improved YOLOv11" Sensors 25, no. 11: 3399. https://doi.org/10.3390/s25113399
APA StyleZhang, Z., Zhang, Z., Li, G., & Xia, C. (2025). ZZ-YOLOv11: A Lightweight Vehicle Detection Model Based on Improved YOLOv11. Sensors, 25(11), 3399. https://doi.org/10.3390/s25113399