
DeepLabV3+-Based Semantic Annotation Refinement for SLAM in Indoor Environments


 ,
,
Abstract
1. Introduction
2. Materials and Methods
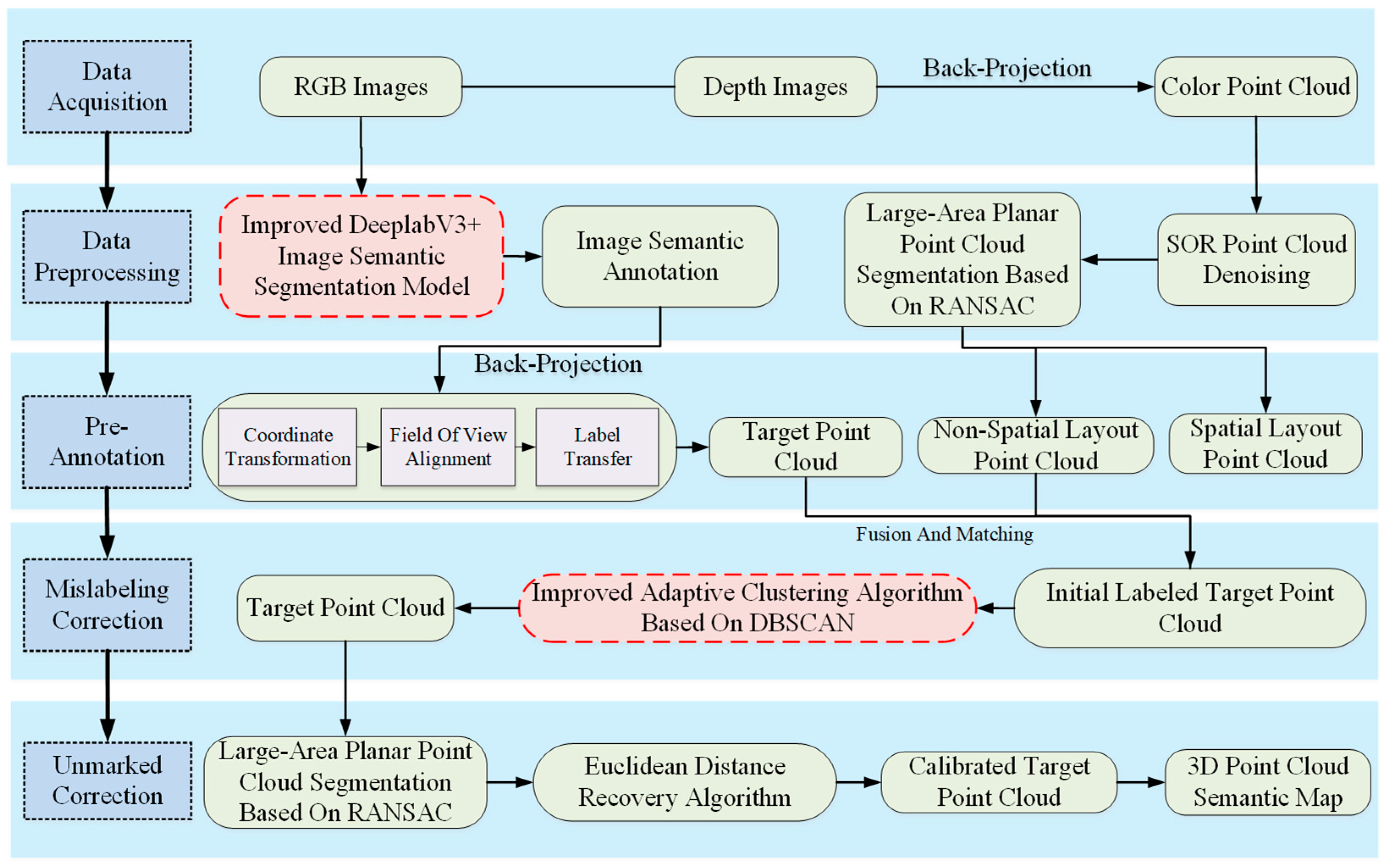
2.1. Overview of Research Methodology
- (1)
- Data Collection and 3D Reconstruction: Utilizing RGB-D sensor-based SLAM technology, we collect scene color and texture information. This technology integrates RGB and depth images to produce 3D colored point clouds, which are then used for scene reconstruction.
- (2)
- Data Processing and Optimization: The data processing phase leverages the DeepLabV3+ architecture to identify and segment objects within RGB images. Concurrently, the Random Sample Consensus (RANSAC) algorithm is employed to detect and segment extensive planes from the point clouds. Furthermore, the Statistical Outlier Removal (SOR) algorithm is utilized for data denoising, resulting in the generation of superior-quality colored point clouds.
- (3)
- Pre-Annotation Processing: Semantic information from 2D images is mapped onto 3D point clouds, and labels are transferred to produce semantically annotated point clouds. Subsequently, planar point clouds identified using the RANSAC algorithm are integrated with spatial point clouds to ensure the completeness of the dataset.
- (4)
- Mislabeling Correction: An improved adaptive DBSCAN clustering algorithm corrects initial annotation errors.
- (5)
- Unlabeled Data Processing: We reapply the RANSAC algorithm for the segmentation of large-scale planes and denoising. This is followed by the regeneration of the target point cloud using Euclidean distance calculations, which retrieves unlabeled points and guarantees the completeness of the semantic annotation.
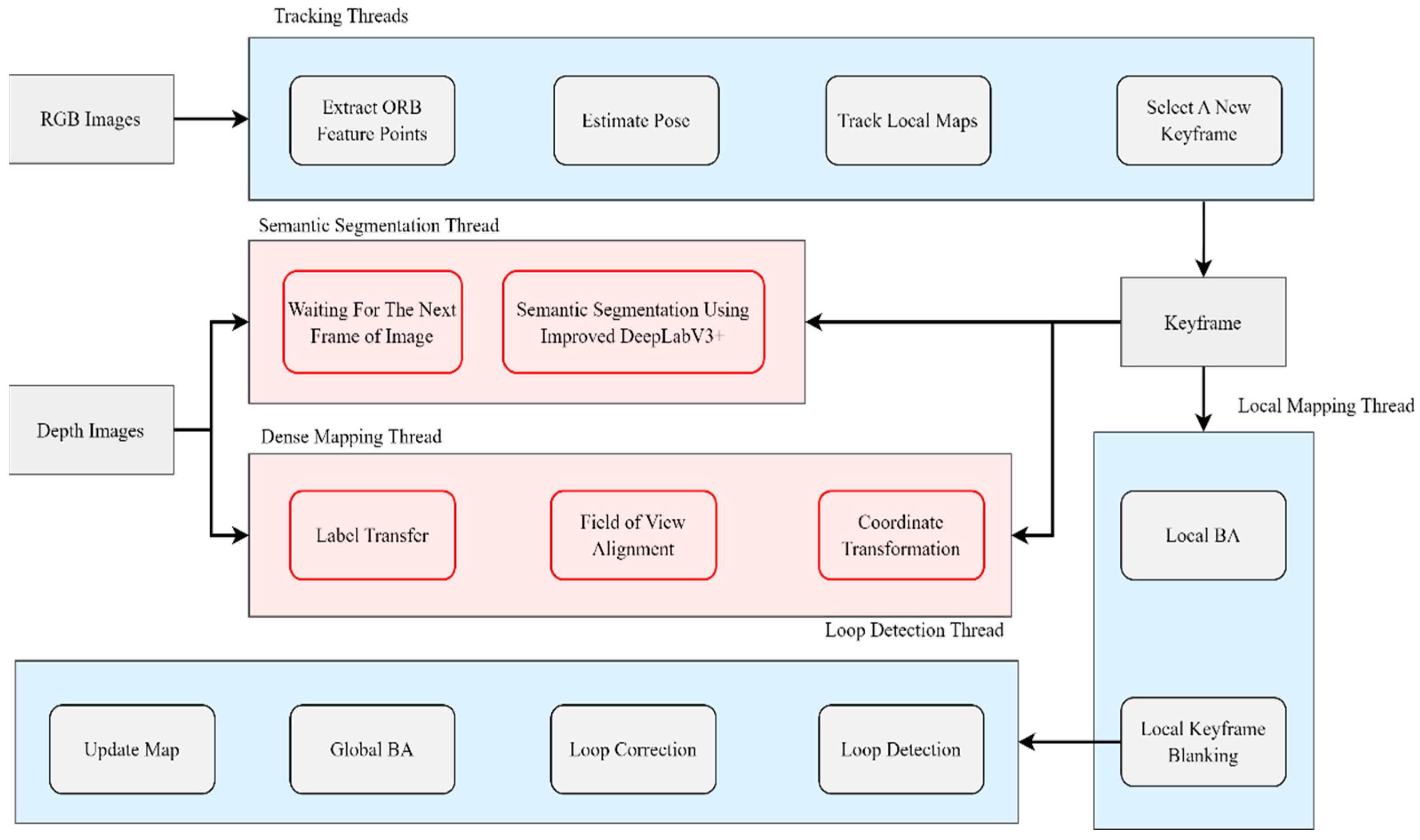
2.2. Visual SLAM System with Semantic Segmentation
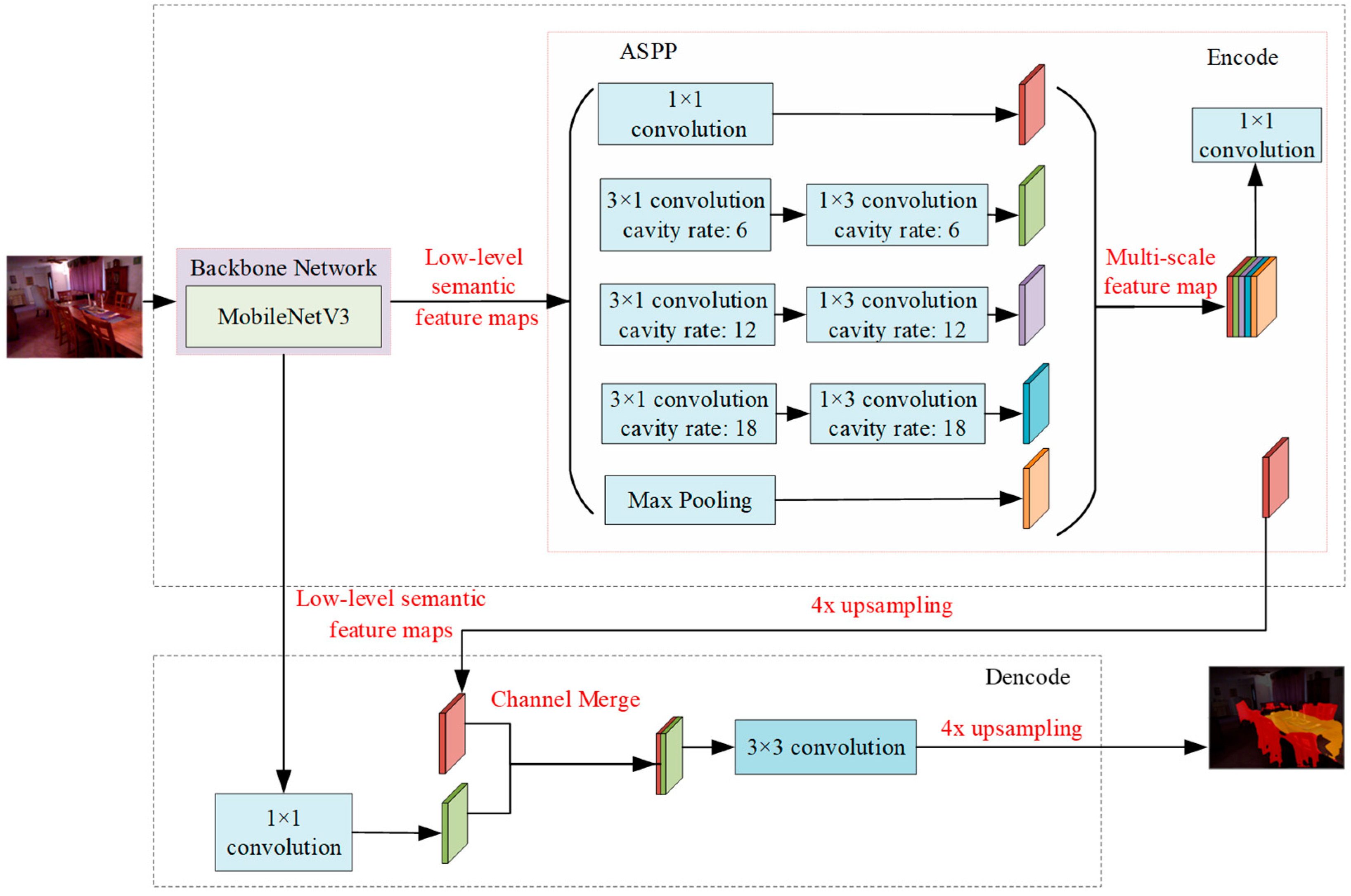
2.3. Image Semantic Segmentation Network Based on DeepLabV3+
2.4. Semantic Annotation Optimization Method for Indoor Scene Point Clouds
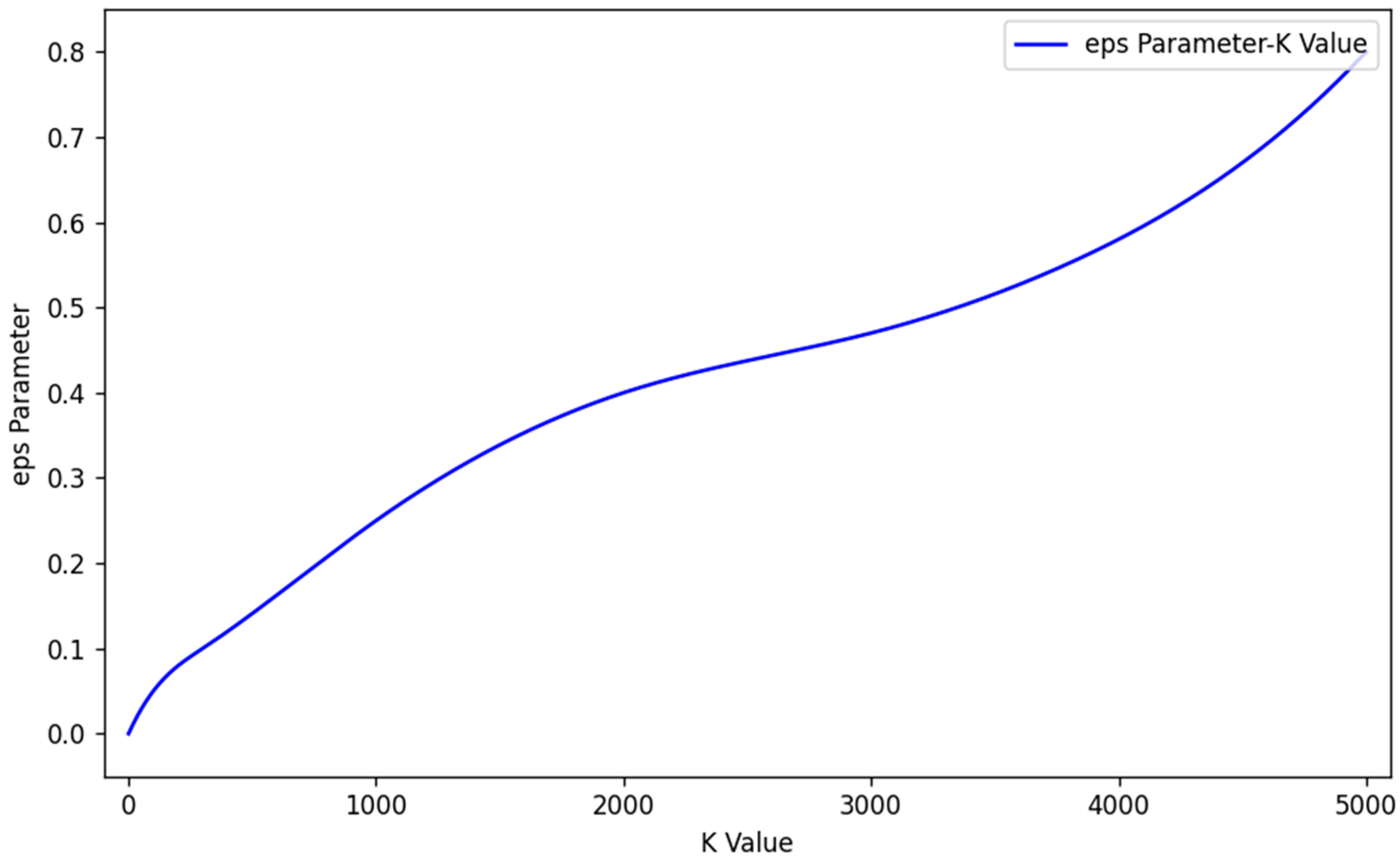
2.4.1. KD-Tree Accelerated Adaptive DBSCAN for Point Cloud Semantic Correction
- (1)
- Automatic determination of the eps parameter
- (2)
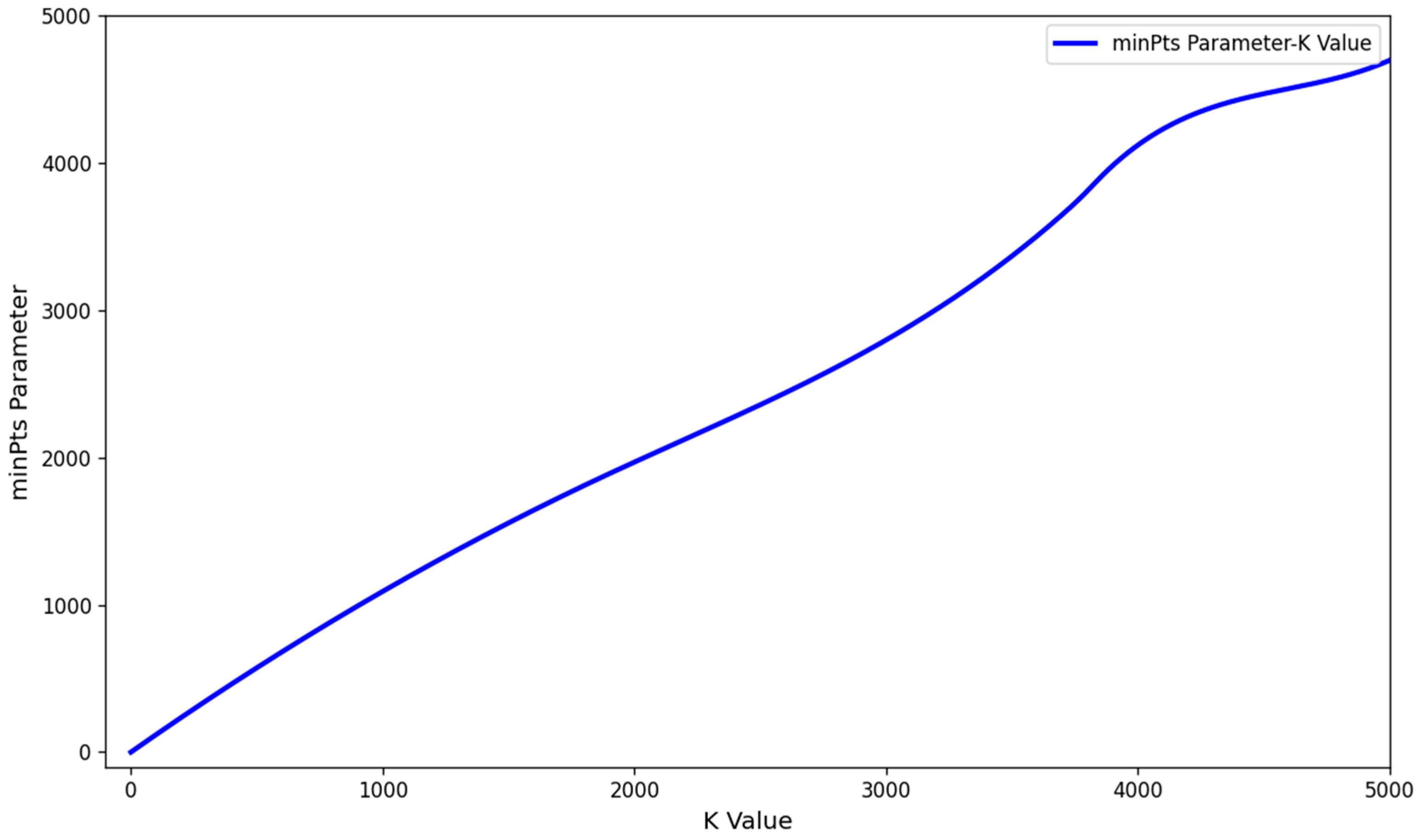
- Determination of MinPts Parameter
2.4.2. Unannotated Point Cloud Correction Based on Euclidean Distance Objective
3. Results and Discussion
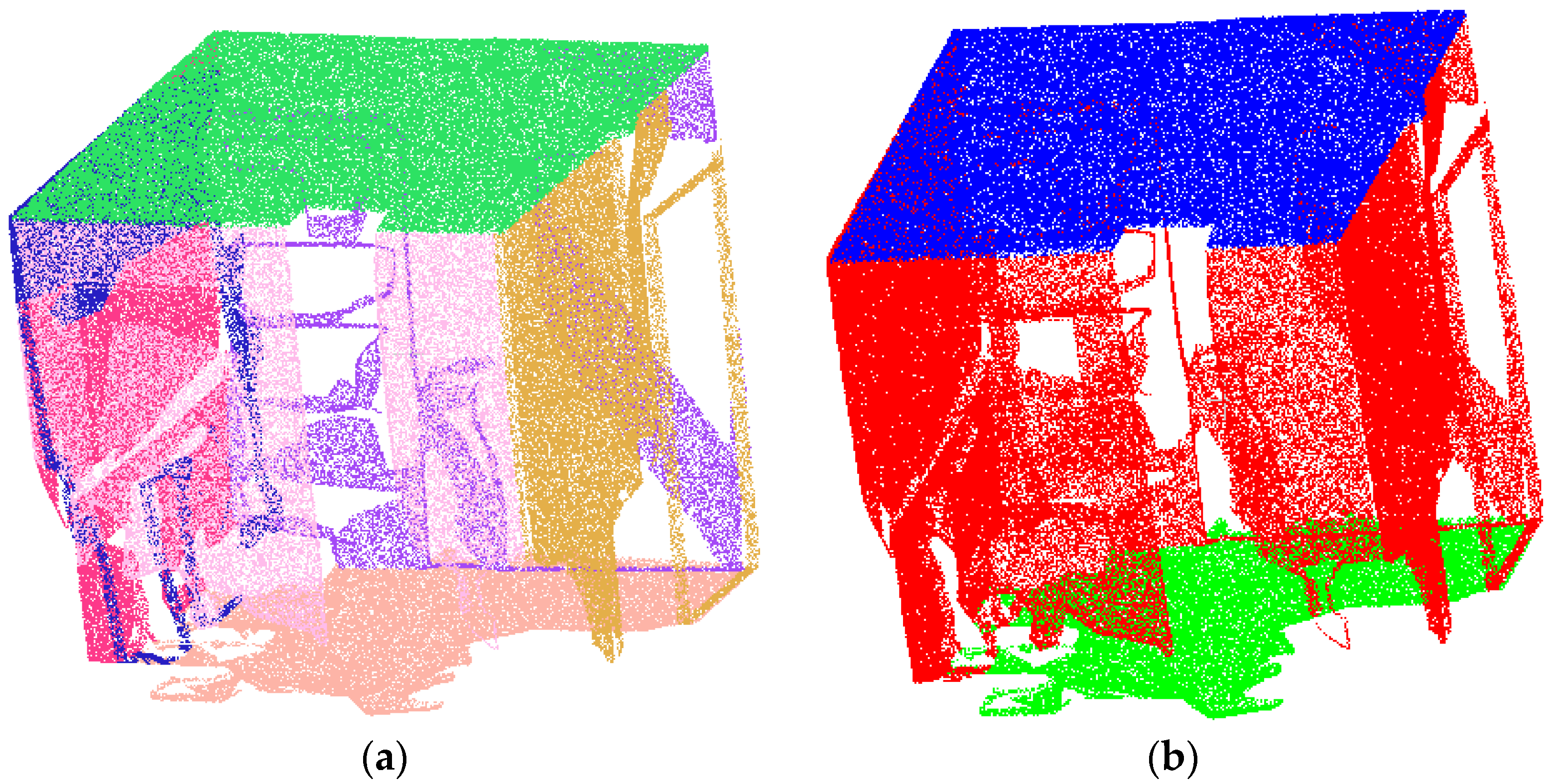
3.1. Image Segmentation and Semantic Mapping
3.2. Adaptive DBSCAN Clustering with KD-Tree Acceleration
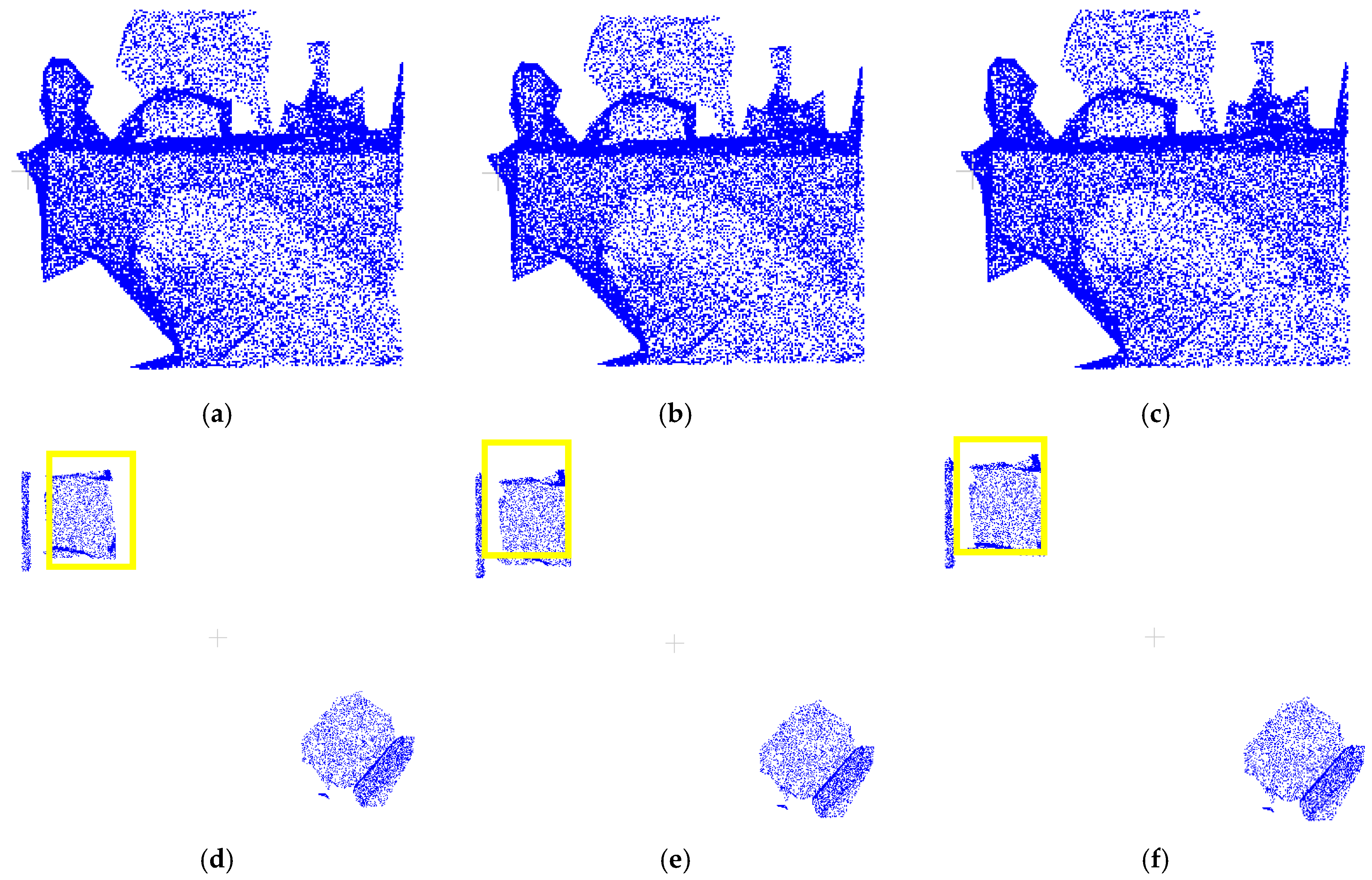
3.2.1. Analysis of Correction Effectiveness and Efficiency
3.2.2. Quantitative Analysis Results
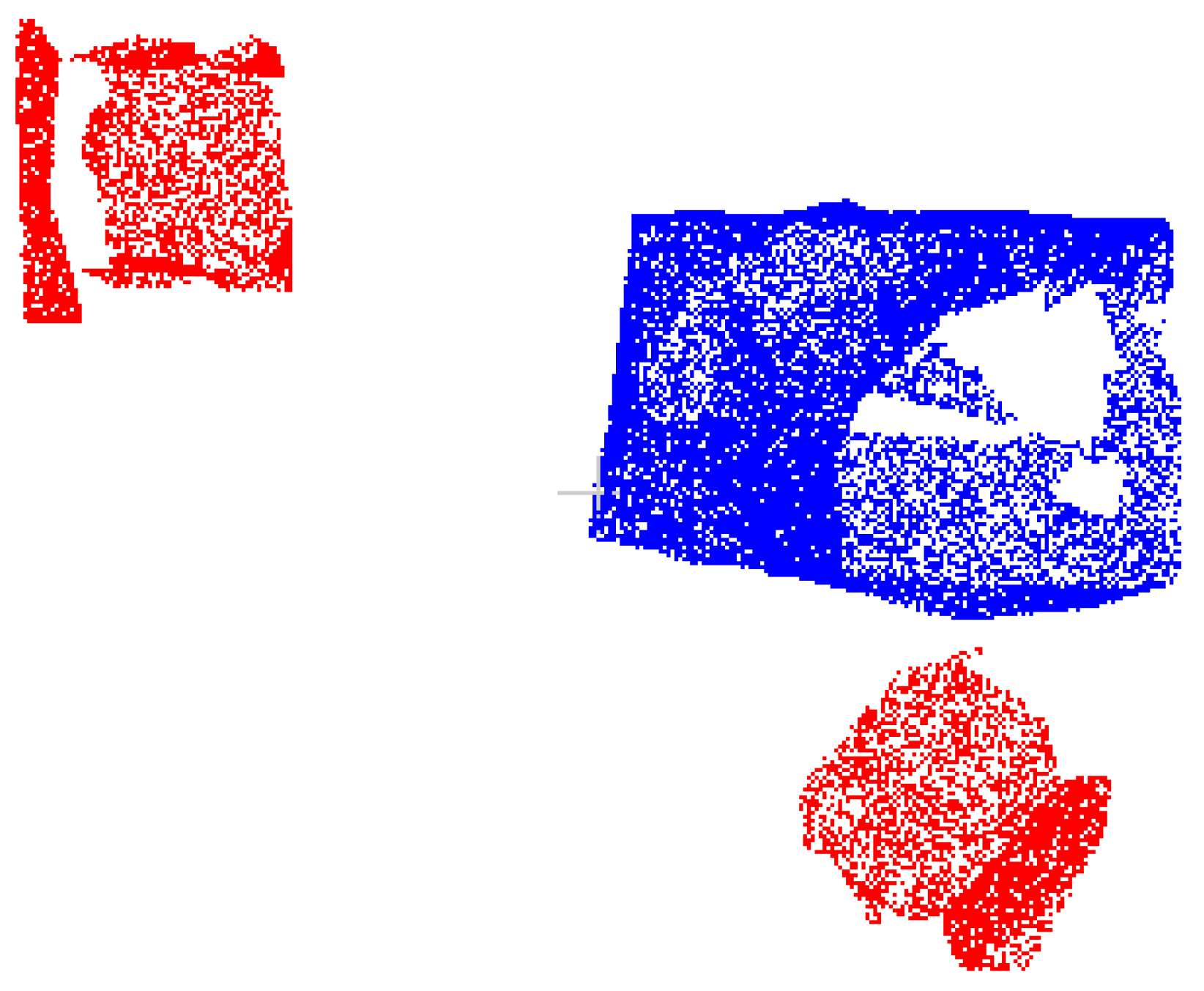
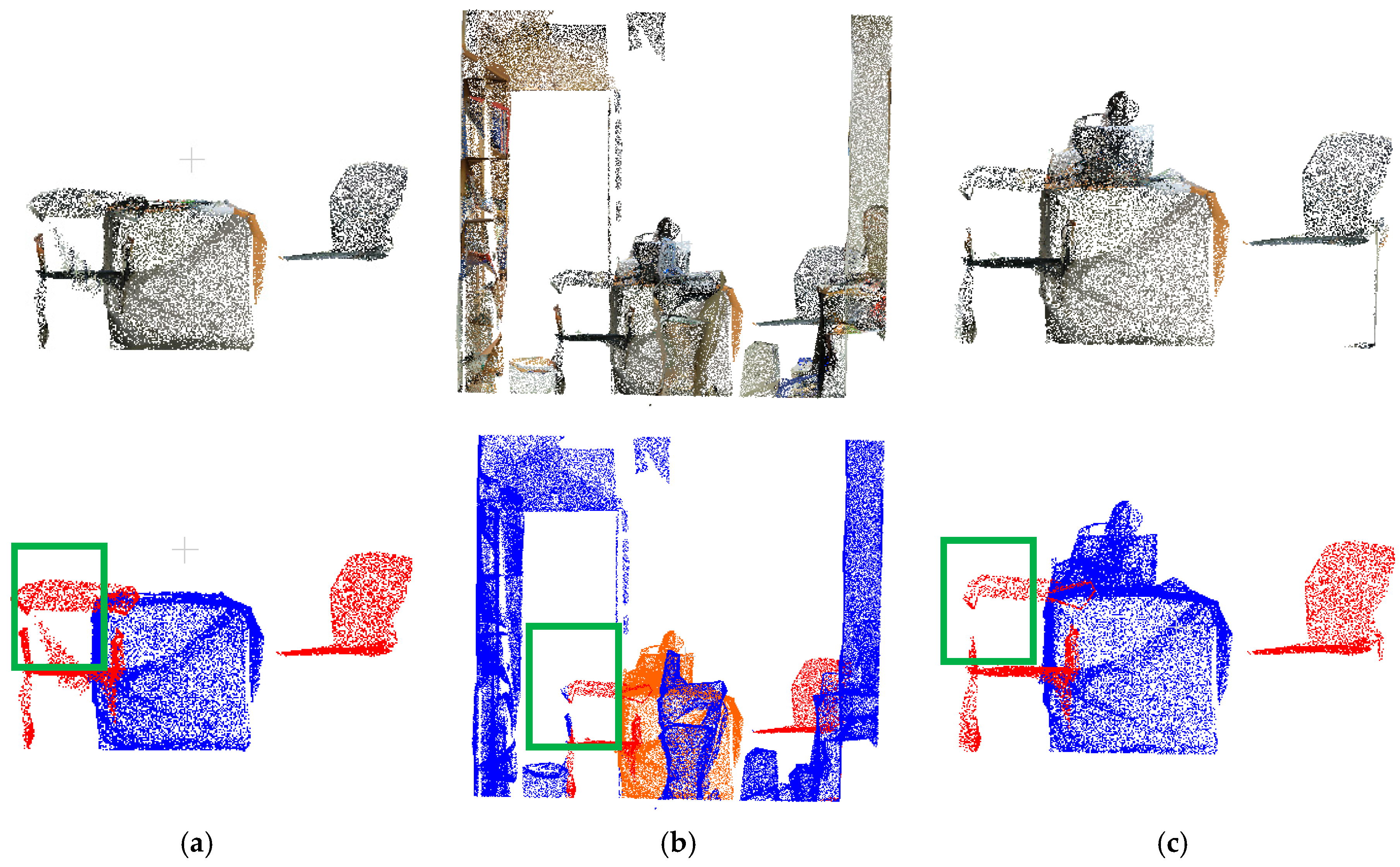
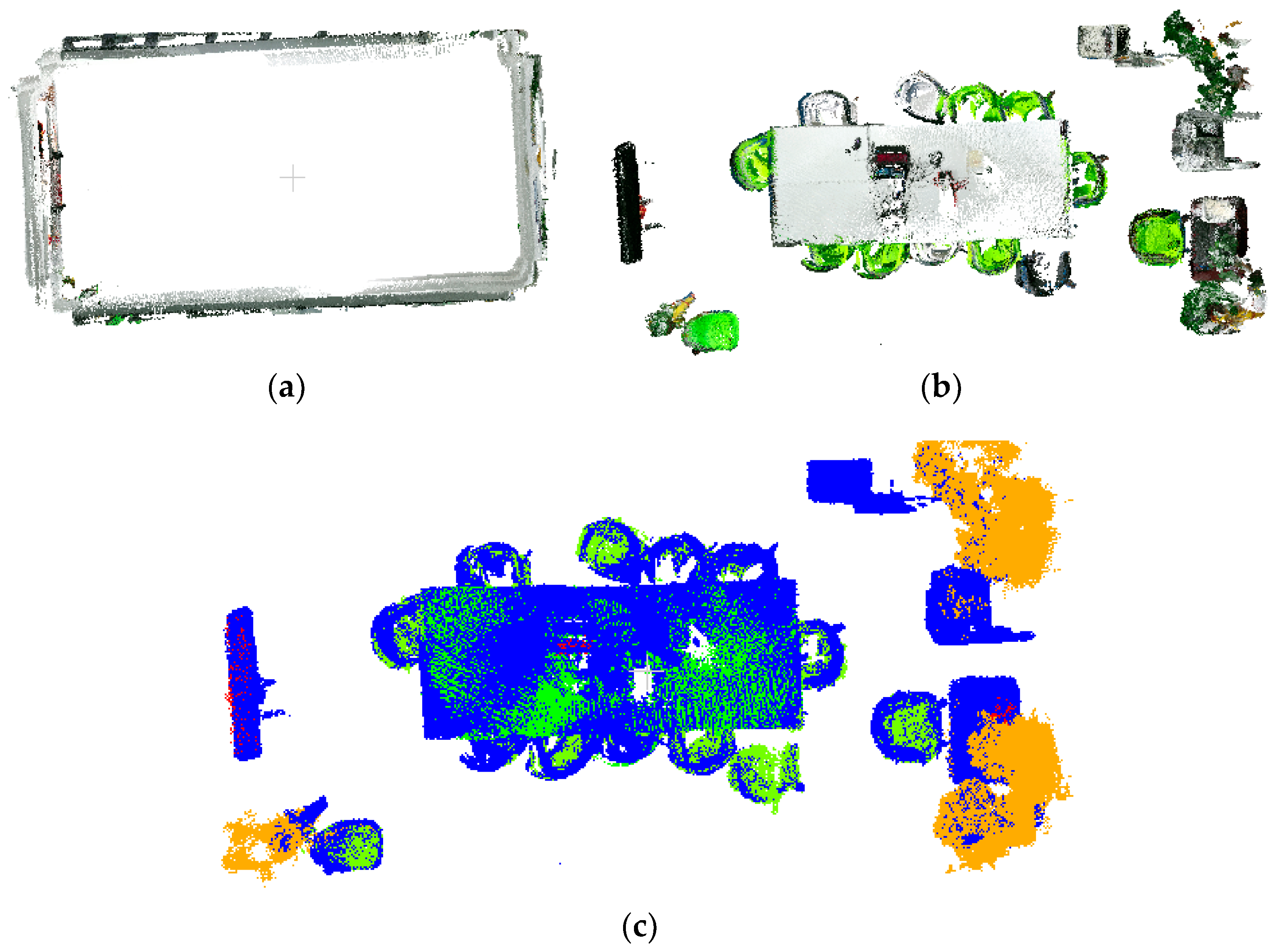
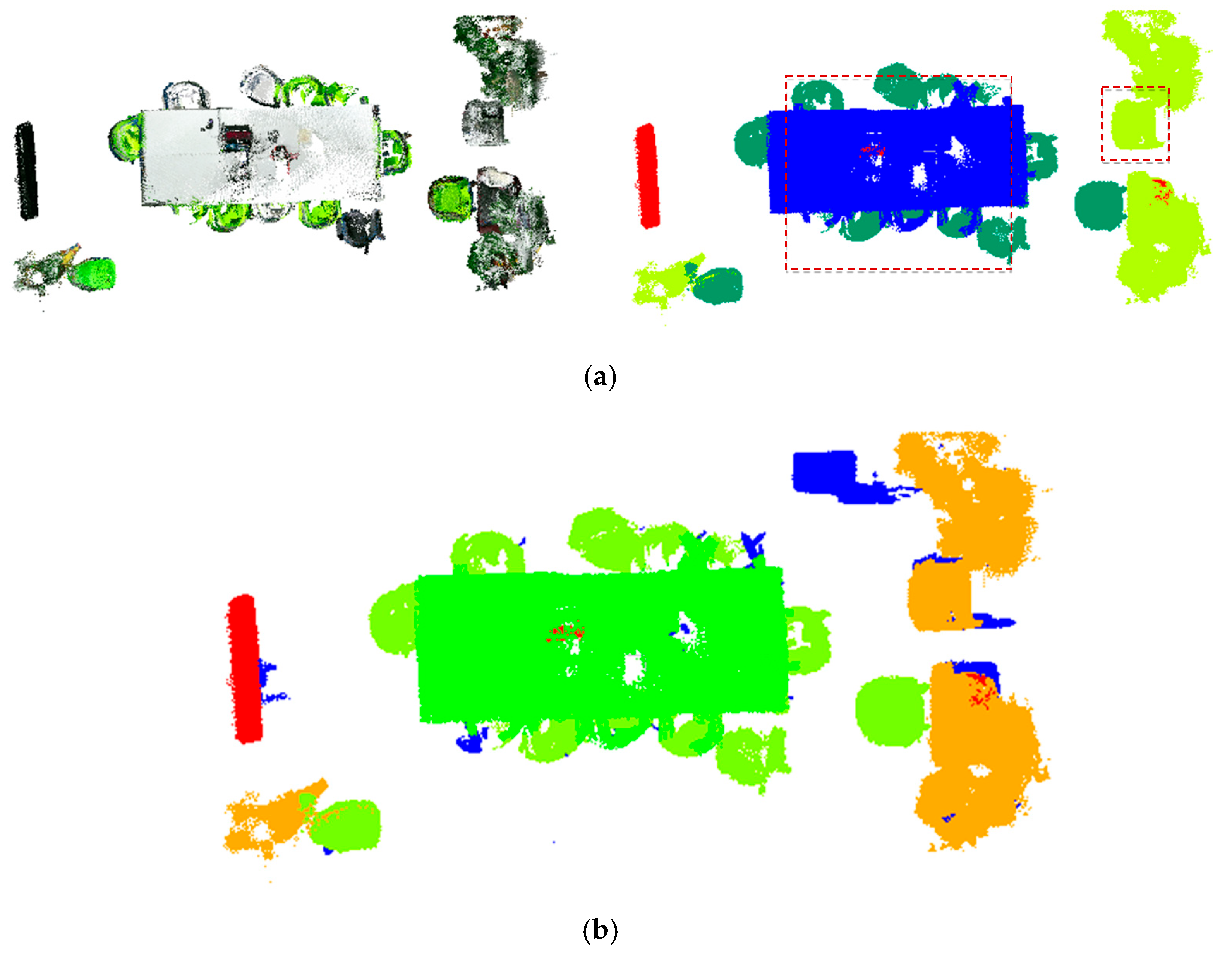
3.3. Point Cloud Regrowth for Semantic Segmentation Optimization
3.4. Real-World Validation
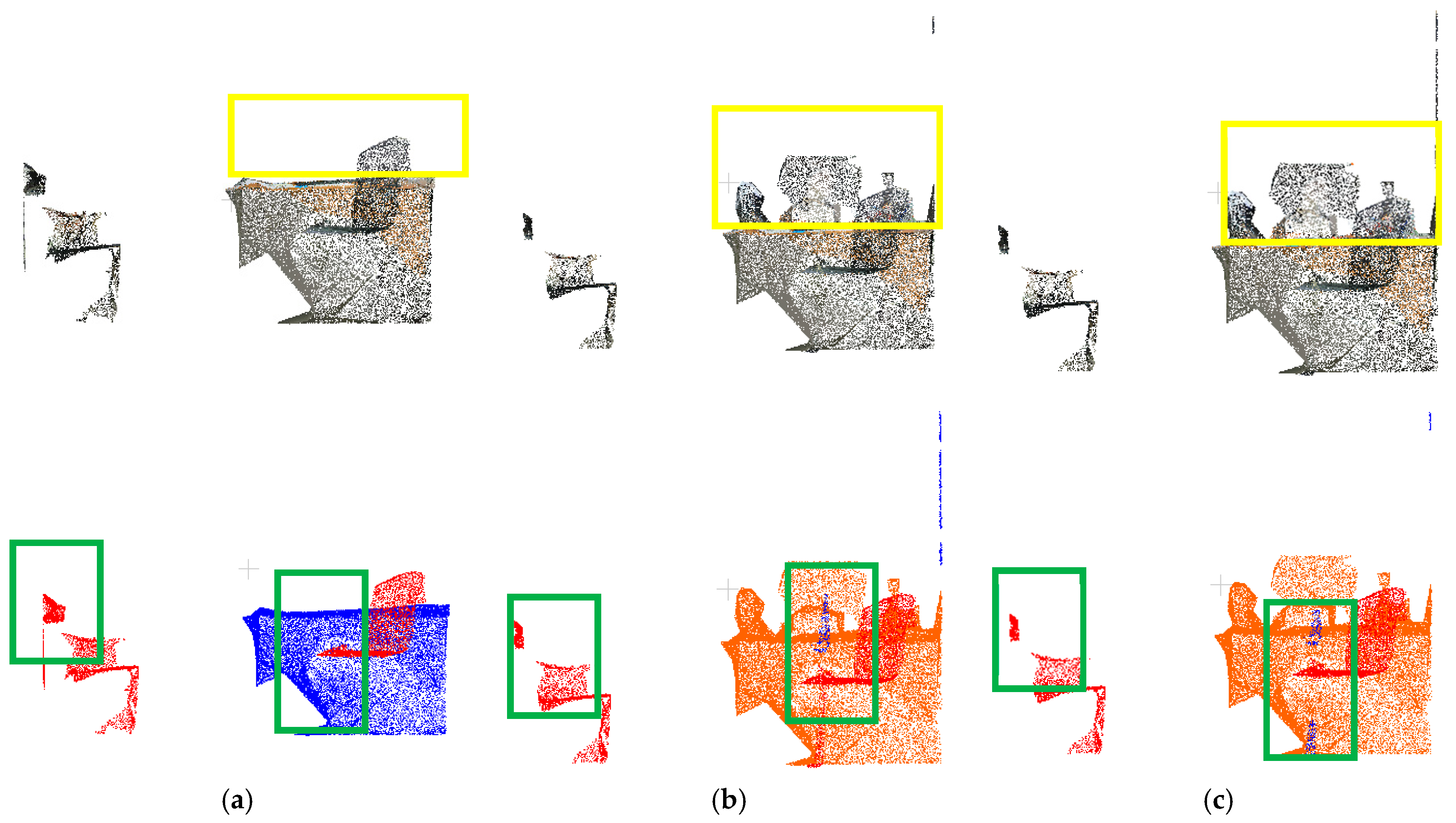
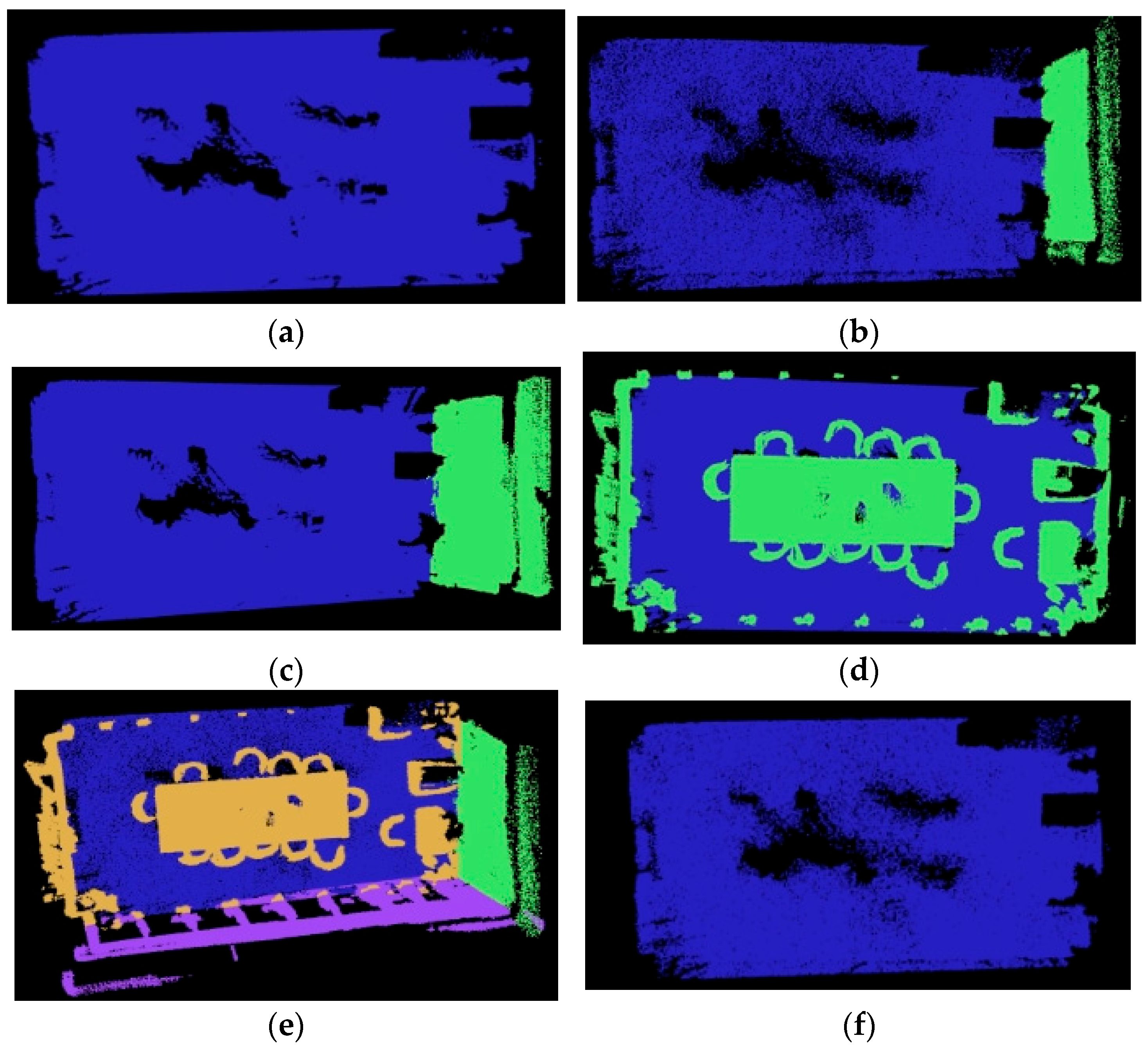
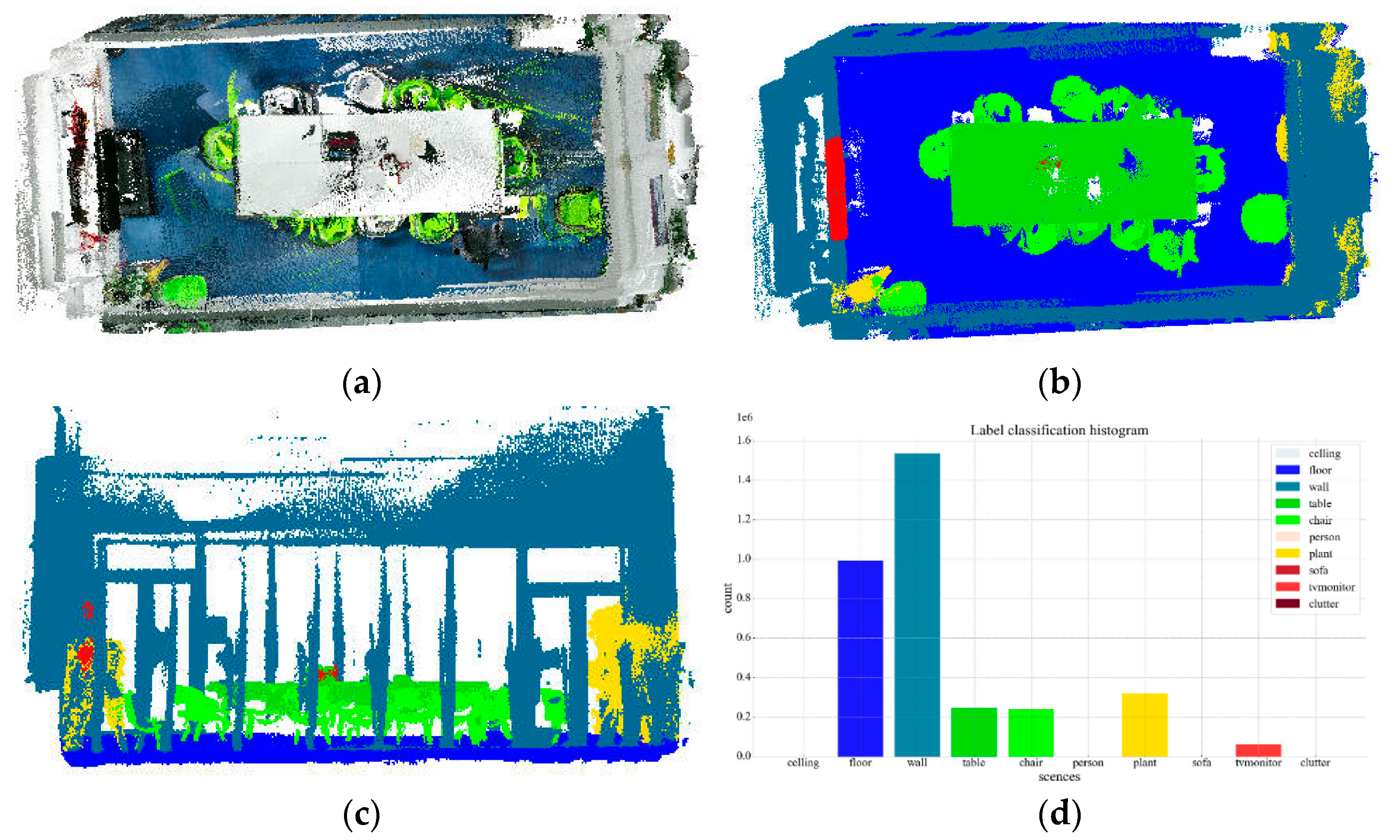
3.4.1. Point Cloud Preprocessing and Preliminary Semantic Segmentation Labeling
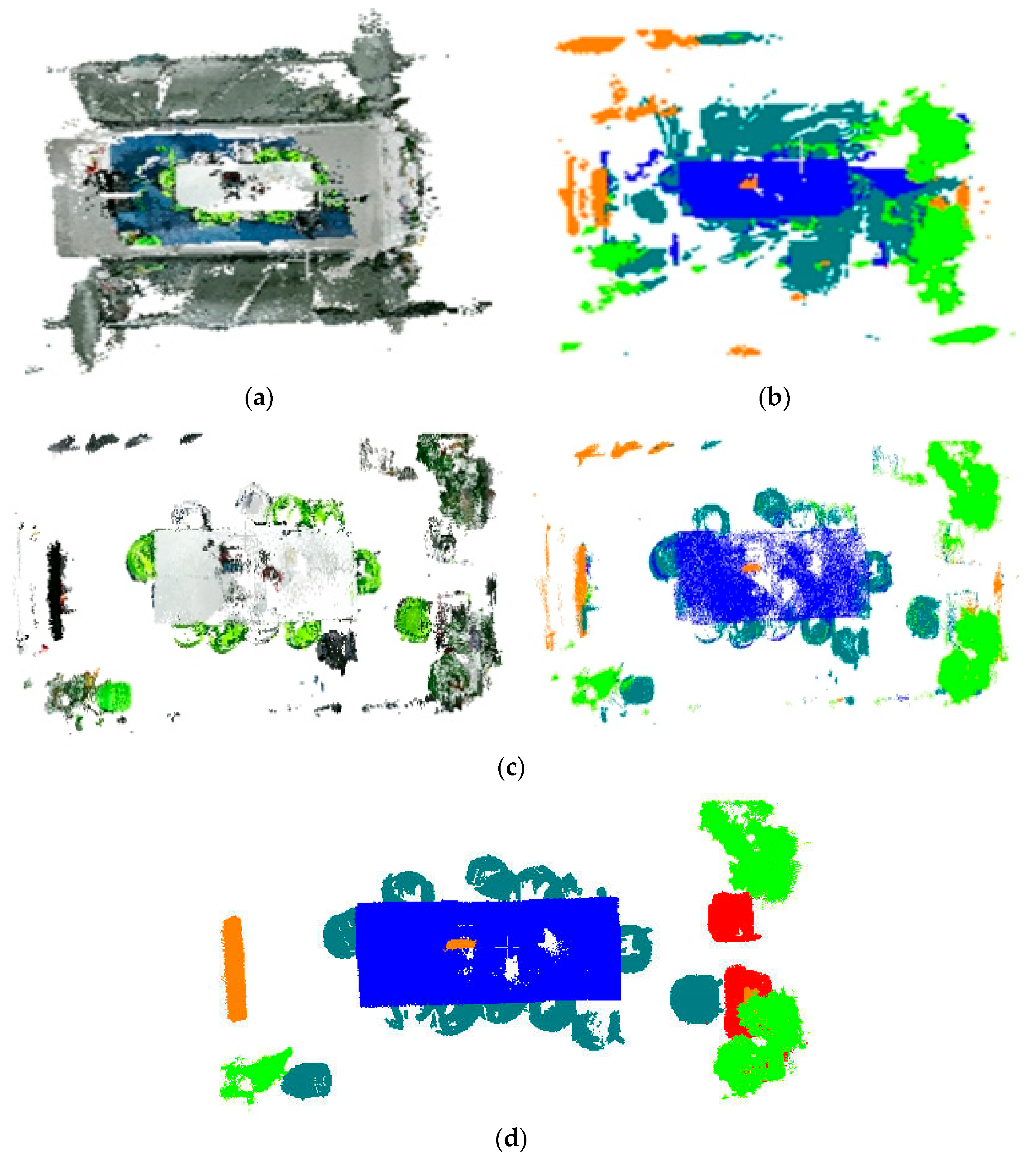
3.4.2. Point Cloud Clustering of Target Objects
3.4.3. Target Point Cloud Regrowth
3.4.4. Discussion
4. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhao, J.; Liu, S.; Li, J. Research and implementation of autonomous navigation for mobile robots based on SLAM algorithm under ROS. Sensors 2022, 22, 4172. [Google Scholar] [CrossRef] [PubMed]
- Garg, S.; Sünderhauf, N.; Dayoub, F.; Morrison, D.; Cosgun, A.; Carneiro, G.; Milford, M. Semantics for Robotic Mapping, Perception and Interaction: A Survey; Foundations and Trends in Robotics; Now Publishers: Norwell, MA, USA, 2020; Volume 8, pp. 1–224. [Google Scholar] [CrossRef]
- O’Shea, K.; Nash, R. An introduction to convolutional neural networks. arXiv 2015, arXiv:1511.08458. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 640–651. [Google Scholar]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1520–1528. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Zhou, B.; Zhao, H.; Puig, X.; Fidler, S.; Barriuso, A.; Torralba, A. Scene parsing through ade20k dataset. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 633–641. [Google Scholar]
- Poudel, R.P.; Liwicki, S.; Cipolla, R. Fast-scnn: Fast semantic segmentation network. arXiv 2019. [Google Scholar] [CrossRef]
- Xu, J.; Xiong, Z.; Bhattacharyya, S.P. PIDNet: A real-time semantic segmentation network inspired by PID controllers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 19529–19539. [Google Scholar]
- Zhang, H.; Li, F.; Xu, H.; Huang, S.; Liu, S.; Ni, L.M.; Zhang, L. Mp-former: Mask-piloted transformer for image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 18074–18083. [Google Scholar]
- Munir, M.; Avery, W.; Marculescu, R. Mobilevig: Graph-based sparse attention for mobile vision applications. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 2211–2219. [Google Scholar]
- Cai, Y.; Zhang, W.; Wu, Y.; Jin, C. Fusionformer: A concise unified feature fusion transformer for 3d pose estimation. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 900–908. [Google Scholar]
- Sang, H.; Jiang, R.; Li, X.; Wang, Z.; Zhou, Y.; He, B. Learning Cross Dimension Scene Representation for Interactive Navigation Agents in Obstacle-Cluttered Environments. IEEE Robot. Autom. Lett. 2024, 9, 6264–6271. [Google Scholar] [CrossRef]
- Zhang, R.; Wu, Y.; Jin, W.; Meng, X. Deep-Learning-Based Point Cloud Semantic Segmentation: A Survey. Electronics 2023, 12, 3642. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the KDD’96: Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996; Association for the Advancement of Artificial Intelligence: Washington, DC, USA, 1996; Volume 96, pp. 226–231. [Google Scholar]
- Liu, J.; Liu, Y.; Zhou, Y.; Wang, Y. Comparison of deep learning methods for landslide semantic segmentation based on remote sensing images. In Proceedings of the 2022 5th International Conference on Pattern Recognition and Artificial Intelligence (PRAI), Chengdu, China, 19–21 August 2022; pp. 247–251. [Google Scholar] [CrossRef]
- Liu, R.; Tao, F.; Liu, X.; Na, J.; Leng, H.; Wu, J.; Zhou, T. RAANet: A residual ASPP with attention framework for semantic segmentation of high-resolution remote sensing images. Remote Sens. 2022, 14, 3109. [Google Scholar] [CrossRef]
- Liu, B.; Zhang, B.; Feng, H.; Wu, S.; Yang, J.; Zou, Y.; Siddique, K.H. Ephemeral gully recognition and accuracy evaluation using deep learning in the hilly and gully region of the Loess Plateau in China. Int. Soil Water Conserv. Res. 2022, 10, 371–381. [Google Scholar] [CrossRef]
- Zhang, R.; Li, G.; Li, M.; Wang, L. Fusion of images and point clouds for the semantic segmentation of large-scale 3D scenes based on deep learning. ISPRS J. Photogramm. Remote Sens. 2018, 143, 85–96. [Google Scholar] [CrossRef]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Adam, H. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Kolesnikov, A.; Beyer, L.; Zhai, X. Big transfer (bit): General visual representation learning. In Proceedings of the Computer Vision–ECCV 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 491–507. [Google Scholar]
- Armeni, I.; Sener, O.; Zamir, A.R. 3d semantic parsing of large-scale indoor spaces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1534–1543. [Google Scholar]
- Liu, L. Point Cloud Segmentation Based on Adaptive DBSCAN Clustering. Master’s Thesis, Liaoning Technical University, Liaoning, China, 2021. [Google Scholar]
- Xiong, P.; Zhou, X.; Xiong, H.; Zhang, T.T. Voronoi diagram generation algorithm and application for large-scale interactive data space partition. J. Natl. Univ. Def. Technol. 2022, 44, 129–136. [Google Scholar]
- Li, Y. Image/LiDAR Data Based 3D Semantic Segmentation Using Teacher-Student Network. Master’s Thesis, Shanghai Jiao Tong University, Shanghai, China, 2020. [Google Scholar]
- Li, H. Research on Visual SLAM Based on Semantic Information in Indoor Dynamic Environment. Master’s Thesis, Beijing University of Civil Engineering and Architecture, Beijing, China, 2022. [Google Scholar]
- Guo, H. Point Cloud Library PCL from Beginner to Master; Mechanical Industry Press: Beijing, China, 2019. [Google Scholar]
- Fischler, M.A.; Bolles, R.C. Random Sample Consensus: A Paradigm for Model Fitting with Applications to Image Analysis and Automated Cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2009, 88, 303–308. [Google Scholar] [CrossRef]
- Khan, A.H.; Cao, X.; Li, S.; Katsikis, V.N.; Liao, L. BAS-ADAM: An ADAM based approach to improve the performance of beetle antennae search optimizer. IEEE/CAA J. Autom. Sin. 2020, 7, 461–471. [Google Scholar] [CrossRef]







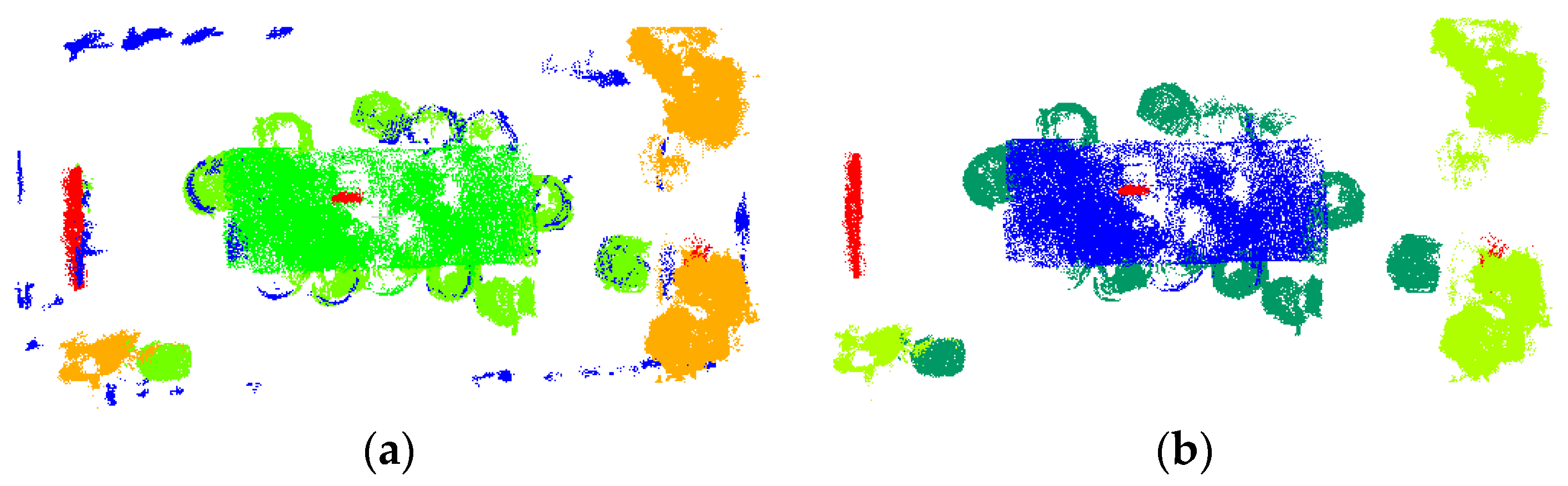

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Eps Value | MinPts Value | Param Time (s) | Table Time (s) | Chair Time (s) | |
|---|---|---|---|---|---|
| Method 1 | 0.0534556 | 53 | 42.587 | 0.21 | 0.066s |
| Method 2 | 0.0413169 | 36 | 8.731 | 0.152 | \ |
| 0.0379938 | 15 | 3.192 | \ | 0.033 |
| Model | Category | Eps | MinPts | Accuracy (%) | Precision (%) | Recall (%) | F1 Value |
|---|---|---|---|---|---|---|---|
| DeepLabV3+ | Table | \ | \ | 68.73 | 70.95 | 95.65 | 0.81 |
| Chairs | \ | \ | 86.24 | 98.07 | 87.73 | 0.93 | |
| All | \ | \ | 72.80 | 76.79 | 93.33 | 0.84 | |
| DeepLabV3+-Adaptive DBSCAN Method 1 | Table | 0.0534556 | 53 | 69.66 | 71.94 | 95.65 | 0.82 |
| Chairs | 0.0534556 | 53 | 86.46 | 98.34 | 87.73 | 0.93 | |
| All | \ | \ | 73.59 | 77.68 | 93.33 | 0.85 | |
| DeepLabV3+-Adaptive DBSCAN Method 2 | Table | 0.0413169 | 36 | 69.67 | 71.95 | 95.65 | 0.82 |
| Chairs | 0.0379938 | 15 | 87.58 | 99.81 | 87.73 | 0.93 | |
| All | \ | \ | 73.83 | 77.94 | 93.33 | 0.85 |
| Category | Radius Threshold | Accuracy (%) | Precision (%) | Recall (%) | F1 Value |
|---|---|---|---|---|---|
| Table | r1 = 0.05 | 69.67 | 71.95 | 95.65 | 0.82 |
| r1 = 0.0413169 | 69.67 | 71.95 | 95.65 | 0.82 | |
| Chairs | r1 = 0.05 | 87.86 | 99.81 | 88.01 | 0.93 |
| r1 = 0.0379938 | 87.86 | 99.81 | 88.01 | 0.93 |
| Model | Accuracy (%) | Precision (%) | Recall (%) | F1 Value |
|---|---|---|---|---|
| DeepLabV3+ (Phase I) | 72.80 | 76.79 | 93.33 | 0.84 |
| DeepLabV3+-Adaptive DBSCAN Method 2 (Phase II) | 73.83 | 77.94 | 93.33 | 0.85 |
| DeepLabV3+-Adaptive DBSCAN Method 2-Regrowth Optimization (Phase III) | 73.89 | 77.95 | 93.41 | 0.85 |
| Number | D (m) | Min | Max | Points | Planes |
|---|---|---|---|---|---|
| 1 | 0.04 | 500,000 | 100,000 | 750,784 | 1 |
| 2 | 0.08 | 500,000 | 100,000 | 1,496,337 | 2 |
| 3 | 0.10 | 500,000 | 100,000 | 1,584,185 | 2 |
| 4 | 0.12 | 500,000 | 100,000 | 1,592,514 | 2 |
| 5 | 0.10 | 250,000 | 100,000 | 2,327,828 | 4 |
| 6 | 0.10 | 250,000 | 1,500,000 | 2,327,828 | 4 |
| 7 | 0.10 | 600,000 | 1,500,000 | 993,814 | 1 |
| Category | Ceiling | Floor | Wall | Table | Chair | Person | Plant | Sofa | Tv Monitor | Clutter/Bottle |
|---|---|---|---|---|---|---|---|---|---|---|
| Tag | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| Category | Accuracy (%) | Precision (%) | Recall (%) | F1 Value |
|---|---|---|---|---|
| Table | 16.54 | 89.10 | 16.88 | 0.28 |
| Chairs | 15.17 | 70.21 | 16.22 | 0.26 |
| Plants | 63.32 | 93.62 | 66.17 | 0.78 |
| Monitors | 4.89 | 46.05 | 5.19 | 0.09 |
| All | 23.55 | 89.29 | 24.23 | 0.38 |
| Category | Points | Eps Value | MinPts Value | Parameter Estimation Time (s) | Clustering Time (s) | Total Correction Time (s) | Percentage of Corrected Points (%) |
|---|---|---|---|---|---|---|---|
| Table | 34,107 | 0.125936 | 23 | 14.126 | 0.667 | 14.793 | 94.44 |
| Chairs | 45,290 | 0.141228 | 50 | 40.112 | 1.229 | 41.341 | 92.04 |
| Plants | 117,827 | 0.20429 | 18 | 1130.32 | 19.581 | 1149.901 | 97.84 |
| Display | 10,002 | 0.115843 | 36 | 2.036 | 0.08 | 2.116 | 51.84 |
| NULL | 2068 | \ | \ | \ | \ | \ | \ |
| Total | 209,294 | \ | \ | 1186.594 | 21.557 | 1208.151 | 92.21 |
| Model | Category | Accuracy (%) | Precision (%) | Recall (%) | F1 Value |
|---|---|---|---|---|---|
| DeepLabV3+ | Table | 16.54 | 89.10 | 16.88 | 0.28 |
| Chairs | 15.17 | 70.21 | 16.22 | 0.26 | |
| Plants | 63.32 | 93.62 | 66.17 | 0.78 | |
| Monitors | 4.89 | 46.05 | 5.19 | 0.09 | |
| All | 23.55 | 89.29 | 24.23 | 0.38 | |
| DeepLabV3+-Adaptive DBSCAN | Table | 16.73 | 94.92 | 16.88 | 0.29 |
| Chairs | 15.42 | 77.05 | 16.17 | 0.27 | |
| Plants | 64.29 | 95.77 | 66.17 | 0.78 | |
| Monitors | 4.95 | 52.08 | 5.19 | 0.09 | |
| All | 23.36 | 92.30 | 23.82 | 0.38 |
| Category | Points After Clustering | Object Number | r1 Value | r2 Value | Points After Regrowth |
|---|---|---|---|---|---|
| Table | 32,209 | 1 | 0.125936 | 2.16807 | 221,940 |
| Chairs | 14,161 | 1 | 0.141228 | 1.69852 | 177,335 |
| 9008 | 2 | 1.08328 | |||
| 5127 | 3 | 0.562582 | |||
| 5075 | 4 | 0.772056 | |||
| 4688 | 5 | 1.0368 | |||
| 3625 | 6 | 0.578157 | |||
| Plants | 52,450 | 1 | 0.20429 | 1.65155 | 317,883 |
| 52,026 | 2 | 1.58817 | |||
| 10,809 | 3 | 1.14409 | |||
| Monitors | 3359 | 1 | 0.115843 | 0.850999 | 76,323 |
| 1382 | 2 | 0.450876 | |||
| 444 | 3 | 0.242609 |
| Model | Category | Accuracy (%) | Precision (%) | Recall (%) | F1 Value |
|---|---|---|---|---|---|
| DeepLabV3+ | Table | 16.54 | 89.10 | 16.88 | 0.28 |
| Chairs | 15.17 | 70.21 | 16.22 | 0.26 | |
| Potted Plants | 63.32 | 93.62 | 66.17 | 0.78 | |
| Monitors | 4.89 | 46.05 | 5.19 | 0.09 | |
| All | 23.55 | 89.29 | 24.23 | 0.38 | |
| DeepLabV3+-Adaptive DBSCAN | Table | 16.73 | 94.92 | 16.88 | 0.29 |
| Chairs | 15.42 | 77.05 | 16.17 | 0.27 | |
| Plants | 64.29 | 95.77 | 66.17 | 0.78 | |
| Monitors | 4.95 | 52.08 | 5.19 | 0.09 | |
| All | 23.36 | 92.30 | 23.82 | 0.38 | |
| DeepLabV3+-Adaptive DBSCAN-Regrowth Optimization | Table | 80.56 | 81.03 | 99.29 | 0.89 |
| Chairs | 75.10 | 91.53 | 80.71 | 0.86 | |
| Plants | 51.53 | 51.86 | 98.79 | 0.68 | |
| Monitors | 80.40 | 99.34 | 80.84 | 0.89 | |
| All | 96.82 | 97.00 | 99.80 | 0.98 |
| Model | Accuracy (%) | Precision (%) | Recall (%) | F1 Value |
|---|---|---|---|---|
| DeepLabV3+ (Phase I) | 23.55 | 89.29 | 24.23 | 0.38 |
| DeepLabV3+-Adaptive DBSCAN (Phase II) | 23.36 | 92.30 | 23.82 | 0.38 |
| DeepLabV3+-Adaptive DBSCAN-Regrowth Optimization (Phase III) | 96.82 | 97.00 | 99.80 | 0.98 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, S.; Tang, H.; Liu, C.; Yang, T.; Zhou, X.; Zlatanova, S.; Fan, J.; Tu, L.; Mao, Y. DeepLabV3+-Based Semantic Annotation Refinement for SLAM in Indoor Environments. Sensors 2025, 25, 3344. https://doi.org/10.3390/s25113344
Wei S, Tang H, Liu C, Yang T, Zhou X, Zlatanova S, Fan J, Tu L, Mao Y. DeepLabV3+-Based Semantic Annotation Refinement for SLAM in Indoor Environments. Sensors. 2025; 25(11):3344. https://doi.org/10.3390/s25113344
Chicago/Turabian StyleWei, Shuangfeng, Hongrui Tang, Changchang Liu, Tong Yang, Xiaohang Zhou, Sisi Zlatanova, Junlin Fan, Liping Tu, and Yaqin Mao. 2025. "DeepLabV3+-Based Semantic Annotation Refinement for SLAM in Indoor Environments" Sensors 25, no. 11: 3344. https://doi.org/10.3390/s25113344
APA StyleWei, S., Tang, H., Liu, C., Yang, T., Zhou, X., Zlatanova, S., Fan, J., Tu, L., & Mao, Y. (2025). DeepLabV3+-Based Semantic Annotation Refinement for SLAM in Indoor Environments. Sensors, 25(11), 3344. https://doi.org/10.3390/s25113344