
BETAV: A Unified BEV-Transformer and Bézier Optimization Framework for Jointly Optimized End-to-End Autonomous Driving


Abstract
1. Introduction
- Query-Based Interaction Mechanism: We introduce a novel query-based interaction mechanism that enables efficient fusion of multi-modal sensor signals, facilitating the extraction of explicit environmental features and implicit contextual cues for ViTs. This approach enhances perception accuracy while improving the safety and adaptability of autonomous navigation in complex real-world scenarios.
- Bézier-Parameterized Trajectory Framework: We propose an innovative trajectory representation framework utilizing Bézier curves to parameterize high-dimensional outputs, transforming discrete trajectory points into a low-dimensional and continuous representation. This approach significantly reduces the network’s learning complexity while ensuring trajectory smoothness, kinematic feasibility, and adaptability across diverse driving scenarios.
- Performance-Validated Evaluation Framework: We conducted tests on the nuScenes dataset to evaluate trajectory planning accuracy and safety while performing generalizability tests in the Carla simulator for system performance verification. The experimental results demonstrate that our method achieves superior reliability and stability in dynamic and complex scenarios compared to the state-of-the-art approaches.
2. Related Works
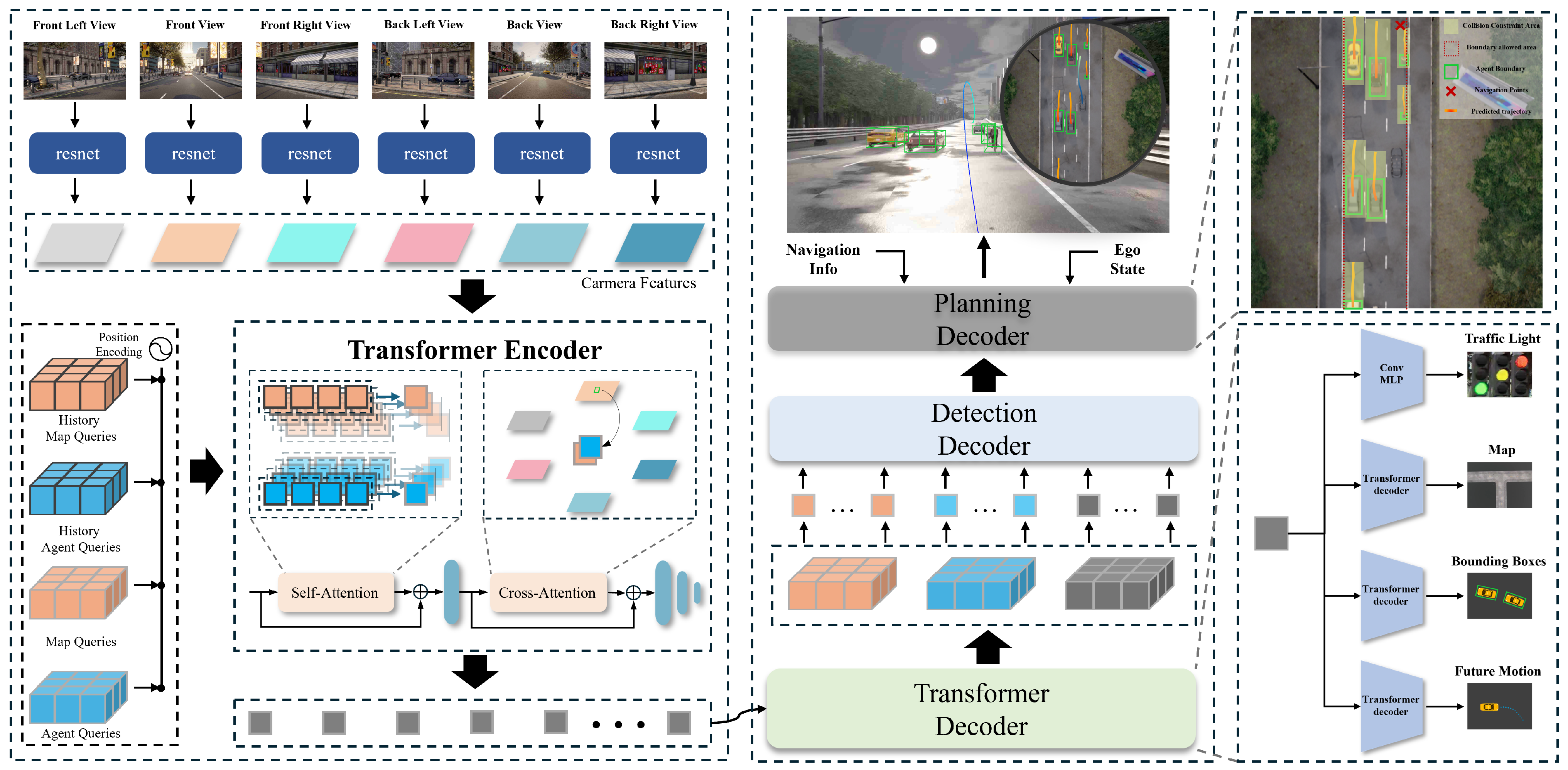
3. Methods
3.1. Problem Setting
3.2. Input and Output Parameterization
3.3. Perception and Prediction Module
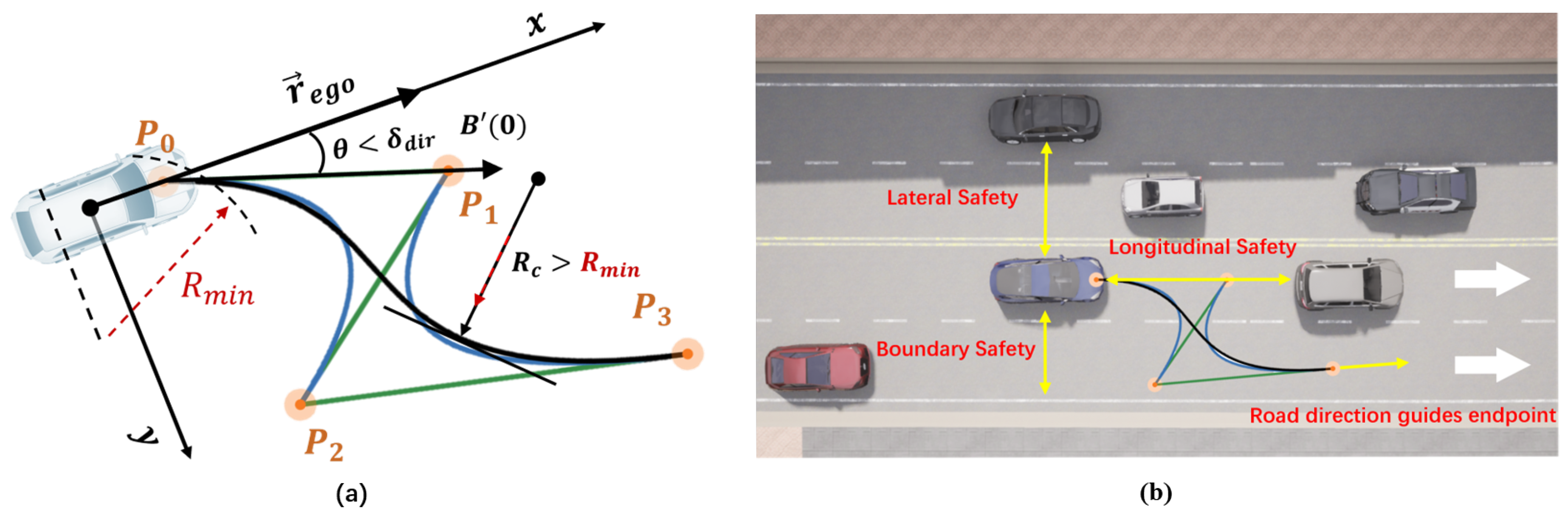
3.4. Bézier Curve-Based Trajectory Planning Module
4. End-to-End Learning
4.1. Scene Perception Loss
4.2. Planning Decoder Loss
5. Experiments
5.1. Implementation Details
5.2. Results
- NMP [52]: a holistic neural motion planning framework processes raw LiDAR data and HD maps to generate interpretable 3D detections, trajectory predictions, and a multi-modal cost volume encoding navigational preferences. It selects optimal trajectories by sampling physically feasible candidates and minimizing the learned cost function that inherently captures diverse driving scenario dynamics.
- FF [53]: a self-supervised learning framework for motion planning, bypassing object-centric scene representations by directly modeling occupancy dynamics through automatically generated freespace boundaries. The approach integrates two novel components: (1) collision-prone trajectory identification via freespace violation analysis in planning horizons, and (2) annotation-free supervision through differentiable freespace constraints in neural planner training pipelines.
- EO [54]: a motion-invariant scene representation for self-supervised trajectory forecasting using differentiable raycasting to project predicted 3D occupancy into future LiDAR sweep predictions for training. By rendering unobserved regions (occlusions) through neural volumetric reasoning, occupancy inherently disentangles ego motion from dynamic environment changes, enabling direct integration with planners to avoid non-drivable regions.
- ST-P3 [10]: an interpretable vision-based end-to-end framework (ST-P3) that jointly learns spatial–temporal features for perception, prediction, and planning through three core components: egocentric-aligned 3D geometry preservation before perception, dual-pathway motion history modeling for trajectory forecasting, and temporal refinement to enhance vision-centric planning cues. It unifies scene understanding, dynamics inference, and control reasoning within a single coherent pipeline by explicitly addressing geometry distortion, motion context aggregation, and visual feature adaptation across tasks.
- UniAD [13]: a planning-oriented unified framework that integrates full-stack driving tasks (perception, prediction, and interaction modeling) into a single network, prioritizing feature abstraction and inter-task synergy through shared queries and complementary module designs. It establishes task communication via unified interfaces to jointly optimize scene understanding, behavior reasoning, and trajectory generation in a globally coordinated manner for end-to-end planning.
- VAD [46]: an end-to-end vectorized autonomous driving framework that models driving scenes with fully vectorized representations, achieving improved safety through instance-level planning constraints and significantly faster computation compared to raster-based methods while also attaining strong baseline planning performance on the nuScenes dataset.
5.3. Ablation Study
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Parekh, D.; Poddar, N.; Rajpurkar, A.; Chahal, M.; Kumar, N.; Joshi, G.P.; Cho, W. A review on autonomous vehicles: Progress, methods and challenges. Electronics 2022, 11, 2162. [Google Scholar] [CrossRef]
- Garikapati, D.; Shetiya, S.S. Autonomous vehicles: Evolution of artificial intelligence and the current industry landscape. Big Data Cogn. Comput. 2024, 8, 42. [Google Scholar] [CrossRef]
- Padmaja, B.; Moorthy, C.V.; Venkateswarulu, N.; Bala, M.M. Exploration of issues, challenges and latest developments in autonomous cars. J. Big Data 2023, 10, 61. [Google Scholar] [CrossRef]
- Chen, L.; Platinsky, L.; Speichert, S.; Osiński, B.; Scheel, O.; Ye, Y.; Grimmett, H.; Del Pero, L.; Ondruska, P. What data do we need for training an av motion planner? In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May 2021–5 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1066–1072. [Google Scholar]
- González, D.; Pérez, J.; Milanés, V.; Nashashibi, F. A review of motion planning techniques for automated vehicles. IEEE Trans. Intell. Transp. Syst. 2015, 17, 1135–1145. [Google Scholar] [CrossRef]
- Kendall, A.; Hawke, J.; Janz, D.; Mazur, P.; Reda, D.; Allen, J.M.; Lam, V.D.; Bewley, A.; Shah, A. Learning to drive in a day. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 8248–8254. [Google Scholar]
- Xu, W.; Wang, Q.; Dolan, J.M. Autonomous vehicle motion planning via recurrent spline optimization. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May 2021–5 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 7730–7736. [Google Scholar]
- Casas, S.; Sadat, A.; Urtasun, R. Mp3: A unified model to map, perceive, predict and plan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14403–14412. [Google Scholar]
- Cui, A.; Casas, S.; Sadat, A.; Liao, R.; Urtasun, R. Lookout: Diverse multi-future prediction and planning for self-driving. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 16107–16116. [Google Scholar]
- Hu, S.; Chen, L.; Wu, P.; Li, H.; Yan, J.; Tao, D. St-p3: End-to-end vision-based autonomous driving via spatial-temporal feature learning. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 533–549. [Google Scholar]
- Chib, P.S.; Singh, P. Recent advancements in end-to-end autonomous driving using deep learning: A survey. IEEE Trans. Intell. Veh. 2023, 9, 103–118. [Google Scholar] [CrossRef]
- Chen, L.; Wu, P.; Chitta, K.; Jaeger, B.; Geiger, A.; Li, H. End-to-end autonomous driving: Challenges and frontiers. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 10164–10183. [Google Scholar] [CrossRef]
- Hu, Y.; Yang, J.; Chen, L.; Li, K.; Sima, C.; Zhu, X.; Chai, S.; Du, S.; Lin, T.; Wang, W. Planning-oriented autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 17853–17862. [Google Scholar]
- Raghu, M.; Unterthiner, T.; Kornblith, S.; Zhang, C.; Dosovitskiy, A. Do vision transformers see like convolutional neural networks? Adv. Neural Inf. Process. Syst. 2021, 34, 12116–12128. [Google Scholar]
- Guo, J.; Han, K.; Wu, H.; Tang, Y.; Chen, X.; Wang, Y.; Xu, C. Cmt: Convolutional neural networks meet vision transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12175–12185. [Google Scholar]
- Yang, K.; Zhong, M.; Fan, K.; Tan, J.; Xiao, Z.; Deng, Z. Multi-Task Traffic Scene Perception Algorithm Based on Multi-Scale Prompter. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4965636 (accessed on 20 April 2025).
- Lei, Y.; Wang, Z.; Chen, F.; Wang, G.; Wang, P.; Yang, Y. Recent advances in multi-modal 3d scene understanding: A comprehensive survey and evaluation. arXiv 2023, arXiv:2310.15676. [Google Scholar]
- Khanam, R.; Hussain, M. Yolov11: An overview of the key architectural enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Backhaus, D.; Engbert, R.; Rothkegel, L.O.; Trukenbrod, H.A. Task-dependence in scene perception: Head unrestrained viewing using mobile eye-tracking. J. Vis. 2020, 20, 3. [Google Scholar] [CrossRef]
- Liu, W.; Hua, M.; Deng, Z.; Meng, Z.; Huang, Y.; Hu, C.; Song, S.; Gao, L.; Liu, C.; Shuai, B. A systematic survey of control techniques and applications in connected and automated vehicles. IEEE Internet Things J. 2023, 10, 21892–21916. [Google Scholar] [CrossRef]
- Liang, J.; Yang, K.; Tan, C.; Wang, J.; Yin, G. Enhancing High-Speed Cruising Performance of Autonomous Vehicles Through Integrated Deep Reinforcement Learning Framework. IEEE Trans. Intell. Transp. Syst. 2025, 26, 835–848. [Google Scholar] [CrossRef]
- Liang, J.; Tian, Q.; Feng, J.; Pi, D.; Yin, G. A Polytopic Model-Based Robust Predictive Control Scheme for Path Tracking of Autonomous Vehicles. IEEE Trans. Intell. Veh. 2024, 9, 3928–3939. [Google Scholar] [CrossRef]
- Zhang, H.; Zhao, Z.; Wei, Y.; Liu, Y.; Wu, W. A self-tuning variable universe fuzzy PID control framework with hybrid BAS-PSO-SA optimization for unmanned surface vehicles. J. Mar. Sci. Eng. 2025, 13, 558. [Google Scholar] [CrossRef]
- Van, N.D.; Sualeh, M.; Kim, D.; Kim, G.W. A hierarchical control system for autonomous driving towards urban challenges. Appl. Sci. 2020, 10, 3543. [Google Scholar] [CrossRef]
- Lan, G.; Hao, Q. End-to-end planning of autonomous driving in industry and academia: 2022-2023. arXiv 2023, arXiv:2401.08658. [Google Scholar]
- Ji, H.; Liang, P.; Cheng, E. Enhancing 3D object detection with 2D detection-guided query anchors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 21178–21187. [Google Scholar]
- Wang, Y.; Guizilini, V.C.; Zhang, T.; Wang, Y.; Zhao, H.; Solomon, J. Detr3d: 3d object detection from multi-view images via 3D-to-2D queries. In Proceedings of the Conference on Robot Learning, London, UK, 8–11 November 2021; pp. 180–191. [Google Scholar]
- Liu, Y.; Wang, T.; Zhang, X.; Sun, J. Petr: Position embedding transformation for multi-view 3d object detection. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 531–548. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Chen, S.; Cheng, T.; Wang, X.; Meng, W.; Zhang, Q.; Liu, W. Efficient and robust 2d-to-bev representation learning via geometry-guided kernel transformer. arXiv 2022, arXiv:2206.04584. [Google Scholar]
- Hu, A.; Murez, Z.; Mohan, N.; Dudas, S.; Hawke, J.; Badrinarayanan, V.; Cipolla, R.; Kendall, A. Fiery: Future instance prediction in bird’s-eye view from surround monocular cameras. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 15273–15282. [Google Scholar]
- Li, Z.; Wang, W.; Li, H.; Xie, E.; Sima, C.; Lu, T.; Yu, Q.; Dai, J. BEVFormer: Learning Bird’s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers. arXiv, 2022; arXiv:2203.17270. [Google Scholar]
- Liao, B.; Chen, S.; Jiang, B.; Cheng, T.; Zhang, Q.; Liu, W.; Huang, C.; Wang, X. Lane graph as path: Continuity-preserving path-wise modeling for online lane graph construction. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; Springer: Cham, Switzerland, 2024; pp. 334–351. [Google Scholar]
- Liao, B.; Chen, S.; Wang, X.; Cheng, T.; Zhang, Q.; Liu, W.; Huang, C. Maptr: Structured modeling and learning for online vectorized hd map construction. arXiv 2022, arXiv:2208.14437. [Google Scholar]
- Liu, Z.; Chen, S.; Guo, X.; Wang, X.; Cheng, T.; Zhu, H.; Zhang, Q.; Liu, W.; Zhang, Y. Vision-based uneven bev representation learning with polar rasterization and surface estimation. In Proceedings of the Conference on Robot Learning, PMLR, Auckland, New Zealand, 14–18 December 2022; pp. 437–446. [Google Scholar]
- Zhang, Y.; Zhu, Z.; Zheng, W.; Huang, J.; Huang, G.; Zhou, J.; Lu, J. Beverse: Unified perception and prediction in birds-eye-view for vision-centric autonomous driving. arXiv 2022, arXiv:2205.09743. [Google Scholar]
- Philion, J.; Fidler, S. Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XIV 16. Springer: Cham, Switzerland, 2020; pp. 194–210. [Google Scholar]
- Roddick, T.; Kendall, A.; Cipolla, R. Orthographic feature transform for monocular 3d object detection. arXiv 2018, arXiv:1811.08188. [Google Scholar]
- Rukhovich, D.; Vorontsova, A.; Konushin, A. Imvoxelnet: Image to voxels projection for monocular and multi-view general-purpose 3d object detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 2397–2406. [Google Scholar]
- Xie, E.; Yu, Z.; Zhou, D.; Philion, J.; Anandkumar, A.; Fidler, S.; Luo, P.; Alvarez, J.M. M2 BEV: Multi-camera joint 3D detection and segmentation with unified birds-eye view representation. arXiv 2022, arXiv:2204.05088. [Google Scholar]
- Codevilla, F.; Santana, E.; López, A.M.; Gaidon, A. Exploring the limitations of behavior cloning for autonomous driving. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9329–9338. [Google Scholar]
- Prakash, A.; Chitta, K.; Geiger, A. Multi-modal fusion transformer for end-to-end autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7077–7087. [Google Scholar]
- Sadat, A.; Casas, S.; Ren, M.; Wu, X.; Dhawan, P.; Urtasun, R. Perceive, predict, and plan: Safe motion planning through interpretable semantic representations. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXIII 16. Springer: Cham, Switzerland, 2020; pp. 414–430. [Google Scholar]
- Renz, K.; Chitta, K.; Mercea, O.B.; Koepke, A.; Akata, Z.; Geiger, A. Plant: Explainable planning transformers via object-level representations. arXiv 2022, arXiv:2210.14222. [Google Scholar]
- Jiang, B.; Chen, S.; Xu, Q.; Liao, B.; Chen, J.; Zhou, H.; Zhang, Q.; Liu, W.; Huang, C.; Wang, X. Vad: Vectorized scene representation for efficient autonomous driving. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 8340–8350. [Google Scholar]
- Han, Z.; Wu, Y.; Li, T.; Zhang, L.; Pei, L.; Xu, L.; Li, C.; Ma, C.; Xu, C.; Shen, S. An efficient spatial-temporal trajectory planner for autonomous vehicles in unstructured environments. IEEE Trans. Intell. Transp. Syst. 2023, 25, 1797–1814. [Google Scholar] [CrossRef]
- Chen, W.; Chen, Y.; Wang, S.; Kong, F.; Zhang, X.; Sun, H. Motion planning using feasible and smooth tree for autonomous driving. IEEE Trans. Veh. Technol. 2023, 73, 6270–6282. [Google Scholar] [CrossRef]
- Chen, S.; Jiang, B.; Gao, H.; Liao, B.; Xu, Q.; Zhang, Q.; Huang, C.; Liu, W.; Wang, X. Vadv2: End-to-end vectorized autonomous driving via probabilistic planning. arXiv 2024, arXiv:2402.13243. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuScenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11621–11631. [Google Scholar]
- Jia, X.; Yang, Z.; Li, Q.; Zhang, Z.; Yan, J. Bench2drive: Towards multi-ability benchmarking of closed-loop end-to-end autonomous driving. arXiv 2024, arXiv:2406.03877. [Google Scholar]
- Zeng, W.; Luo, W.; Suo, S.; Sadat, A.; Yang, B.; Casas, S.; Urtasun, R. End-to-end interpretable neural motion planner. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8660–8669. [Google Scholar]
- Hu, P.; Huang, A.; Dolan, J.; Held, D.; Ramanan, D. Safe local motion planning with self-supervised freespace forecasting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12732–12741. [Google Scholar]
- Khurana, T.; Hu, P.; Dave, A.; Ziglar, J.; Held, D.; Ramanan, D. Differentiable raycasting for self-supervised occupancy forecasting. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 353–369. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | L2 (m) | Collision (%) | ||||||
|---|---|---|---|---|---|---|---|---|
| 1 s | 2 s | 3 s | Avg. | 1 s | 2 s | 3 s | Avg. | |
| NMP [52] | – | – | 2.31 | – | – | – | 1.92 | – |
| SA-NMP [52] | – | – | 2.05 | – | – | – | 1.59 | – |
| FF [53] | 0.55 | 1.20 | 2.54 | 1.43 | 0.06 | 0.17 | 1.07 | 0.43 |
| EO [54] | 0.67 | 1.36 | 2.78 | 1.60 | 0.04 | 0.09 | 0.88 | 0.33 |
| ST-P3 [10] | 1.33 | 2.11 | 2.90 | 2.11 | 0.23 | 0.62 | 1.27 | 0.71 |
| UniAD [13] | 0.48 | 0.96 | 1.65 | 1.03 | 0.05 | 0.17 | 0.71 | 0.31 |
| VAD-Tiny [46] | 0.46 | 0.76 | 1.12 | 0.78 | 0.21 | 0.35 | 0.58 | 0.38 |
| VAD-Base [46] | 0.41 | 0.70 | 1.05 | 0.72 | 0.07 | 0.17 | 0.41 | 0.22 |
| Ours | 0.45 | 0.48 | 0.54 | 0.49 | 0.04 | 0.11 | 0.33 | 0.16 |
| Scenarios | Driving Score | Route Completion | Infraction Score |
|---|---|---|---|
| Static Hazard | 37.00 | 52.63 | 0.67 |
| Dynamic Interaction | 69.16 | 95.46 | 0.72 |
| Regulated Junction | 53.28 | 99.00 | 0.53 |
| Average | 51.47 | 78.99 | 0.64 |
| w/o | w/o | w/o | w/o | w/o | L2 (Avg.) | Collision (Avg.) |
|---|---|---|---|---|---|---|
| ✓ | - | - | - | - | 0.54 | 0.23 |
| - | ✓ | - | - | - | 1.04 | 0.26 |
| - | - | ✓ | - | - | 0.98 | 0.32 |
| - | - | - | ✓ | - | 0.56 | 0.20 |
| - | - | - | - | ✓ | 0.80 | 0.26 |
| ✓ | ✓ | ✓ | ✓ | - | 0.99 | 0.32 |
| - | - | - | - | - | 0.49 | 0.16 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, R.; Chen, Z.; Fan, Y.; Gao, F.; Men, Y. BETAV: A Unified BEV-Transformer and Bézier Optimization Framework for Jointly Optimized End-to-End Autonomous Driving. Sensors 2025, 25, 3336. https://doi.org/10.3390/s25113336
Zhao R, Chen Z, Fan Y, Gao F, Men Y. BETAV: A Unified BEV-Transformer and Bézier Optimization Framework for Jointly Optimized End-to-End Autonomous Driving. Sensors. 2025; 25(11):3336. https://doi.org/10.3390/s25113336
Chicago/Turabian StyleZhao, Rui, Ziguo Chen, Yuze Fan, Fei Gao, and Yuzhuo Men. 2025. "BETAV: A Unified BEV-Transformer and Bézier Optimization Framework for Jointly Optimized End-to-End Autonomous Driving" Sensors 25, no. 11: 3336. https://doi.org/10.3390/s25113336
APA StyleZhao, R., Chen, Z., Fan, Y., Gao, F., & Men, Y. (2025). BETAV: A Unified BEV-Transformer and Bézier Optimization Framework for Jointly Optimized End-to-End Autonomous Driving. Sensors, 25(11), 3336. https://doi.org/10.3390/s25113336