
Improved YOLOv8 Network of Aircraft Target Recognition Based on Synthetic Aperture Radar Imaging Feature


Abstract
1. Introduction
- (1)
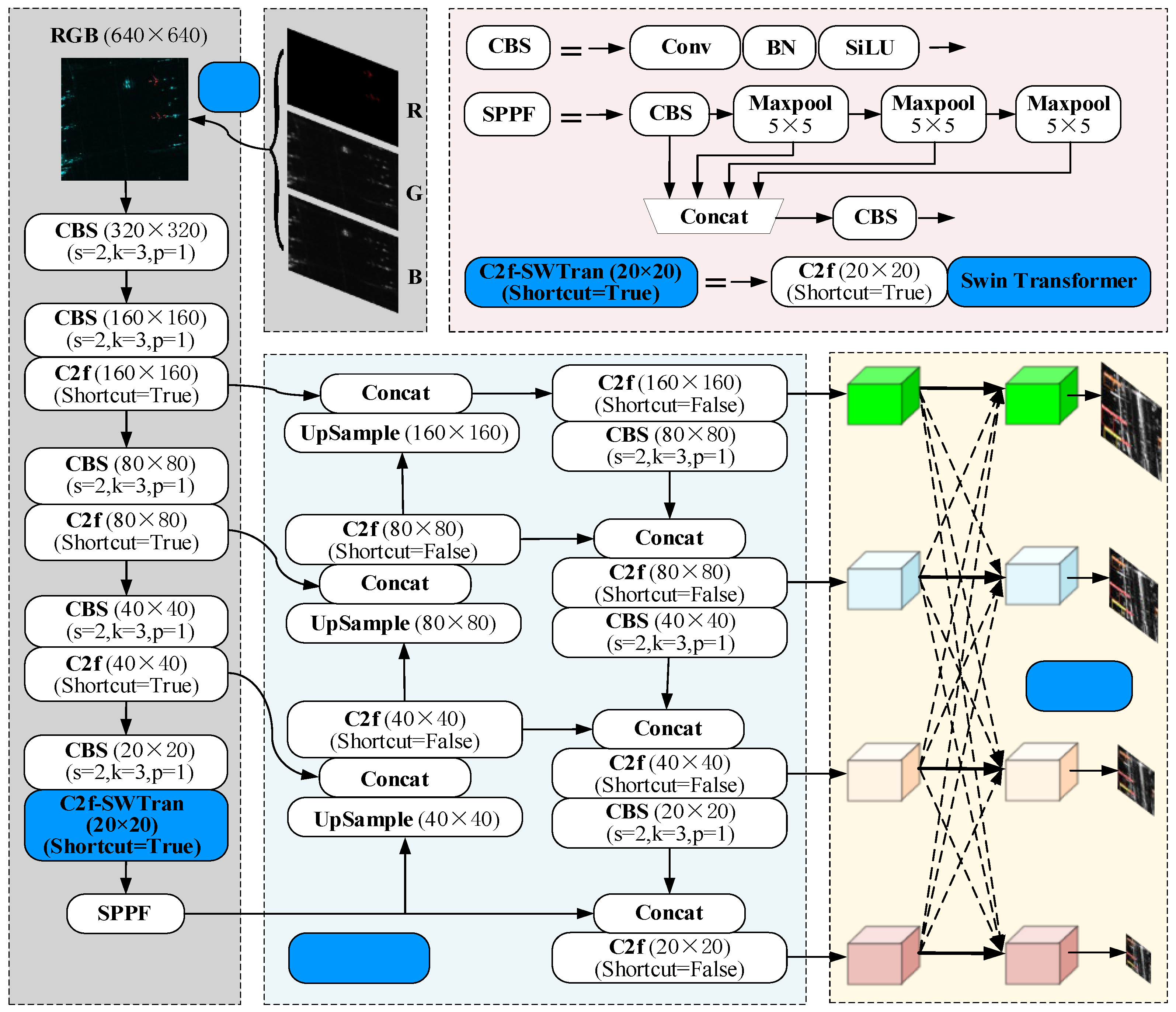
- Gray-to-RGB (GTR) conversion: We developed the GTR method to transform single-channel grayscale SAR images into three-channel RGB images. This conversion process augments the feature space available for the model, thereby reducing the tendency towards overfitting and enhancing detection accuracy.
- (2)
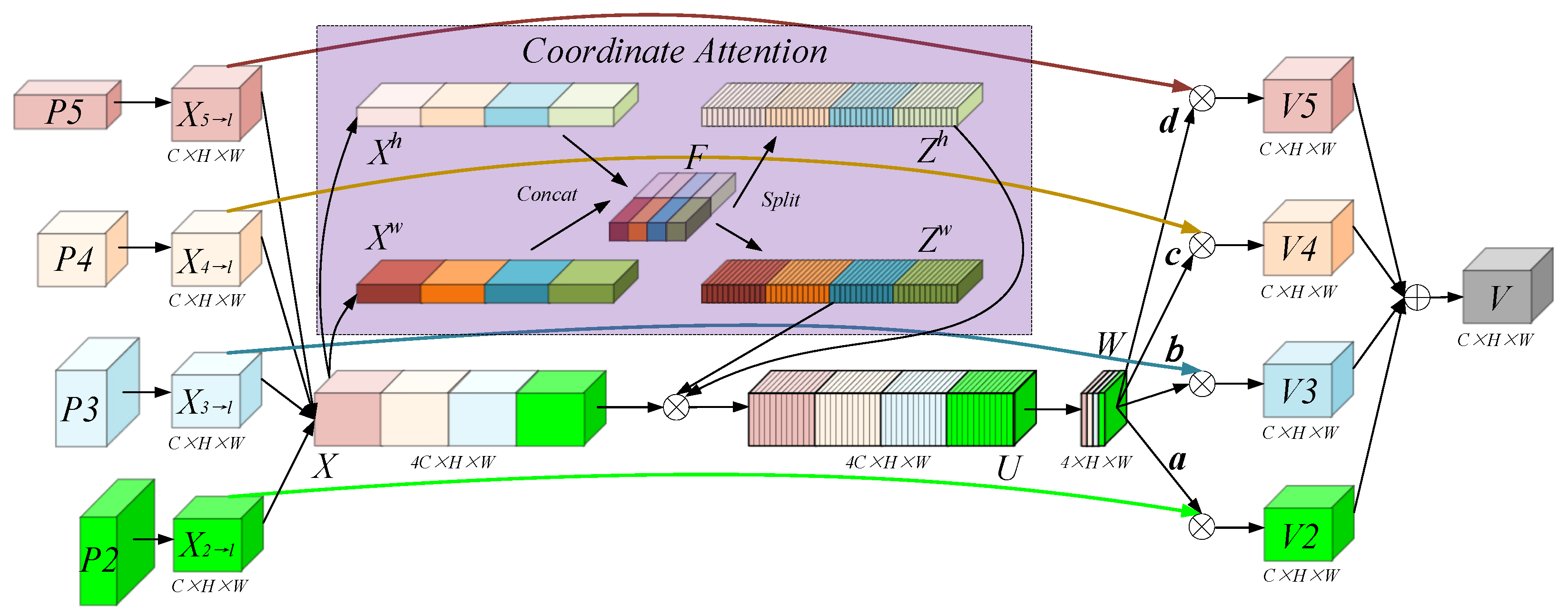
- Four-scale detectors with coordinate attention (4SDC): To address the challenge of detecting aircraft targets of varying sizes in SAR images, we introduced the 4SDC approach. This method adaptively adjusts the weights of different scale detection branches, significantly reducing missed detections of small targets and improving the model’s ability to handle multi-scale targets.
- (3)
- C2f-SWTran module integration: By incorporating the Swin Transformer mechanism into the backbone of YOLOv8, we created the C2f-SWTran module. This integration effectively captures fine-grained and global information within the imagery, leveraging a combination of self-attention and global perception mechanisms to enhance the processing of multi-scale feature maps and increase detection precision.
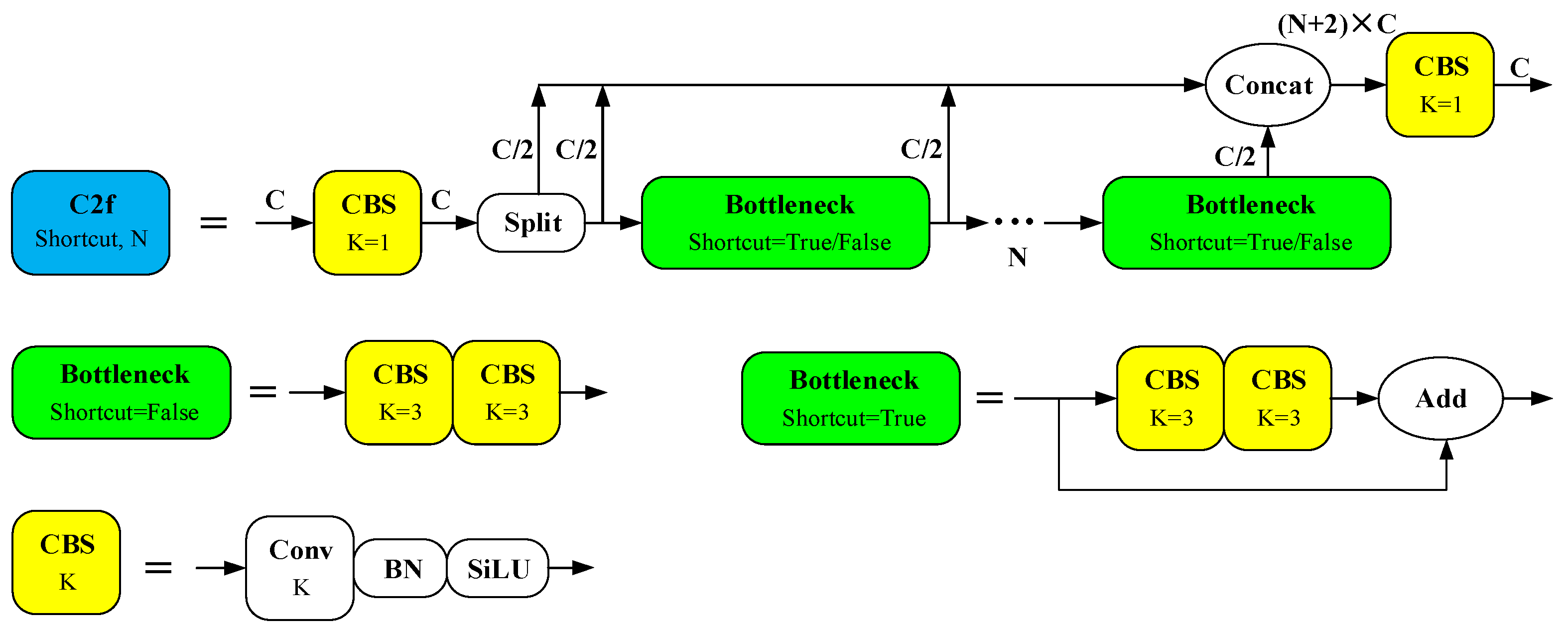
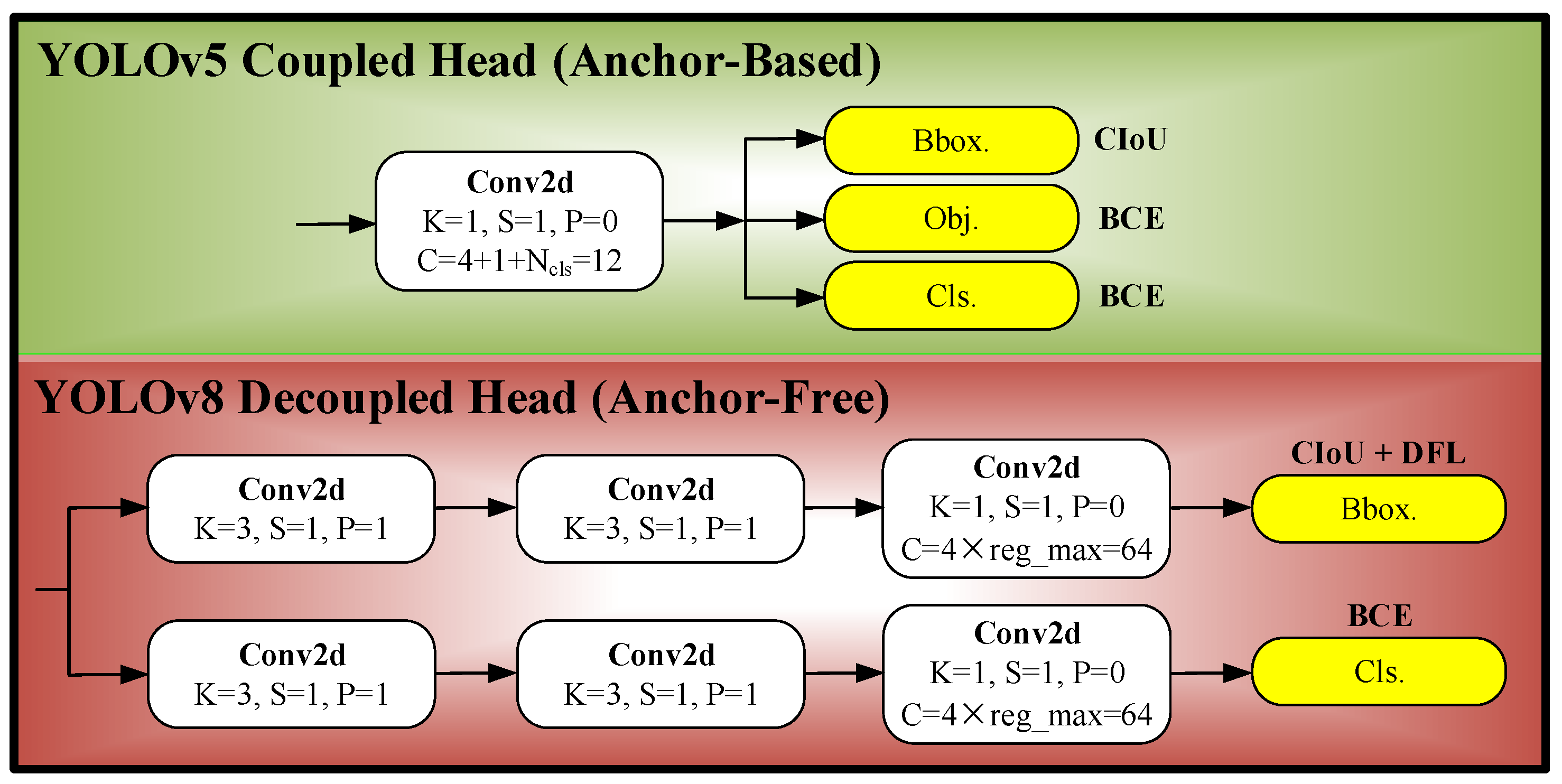
2. Preliminary: YOLOv8 Series Architecture
3. Materials and Methods
3.1. GTR Conversion
3.1.1. Corner Detection Algorithm
3.1.2. Multiplicative Noise-Filtering Algorithm
3.2. 4SDC Detection Model
3.3. C2f-SWTran Feature Extraction Module
3.4. Improved YOLOv8 Structure
4. Results
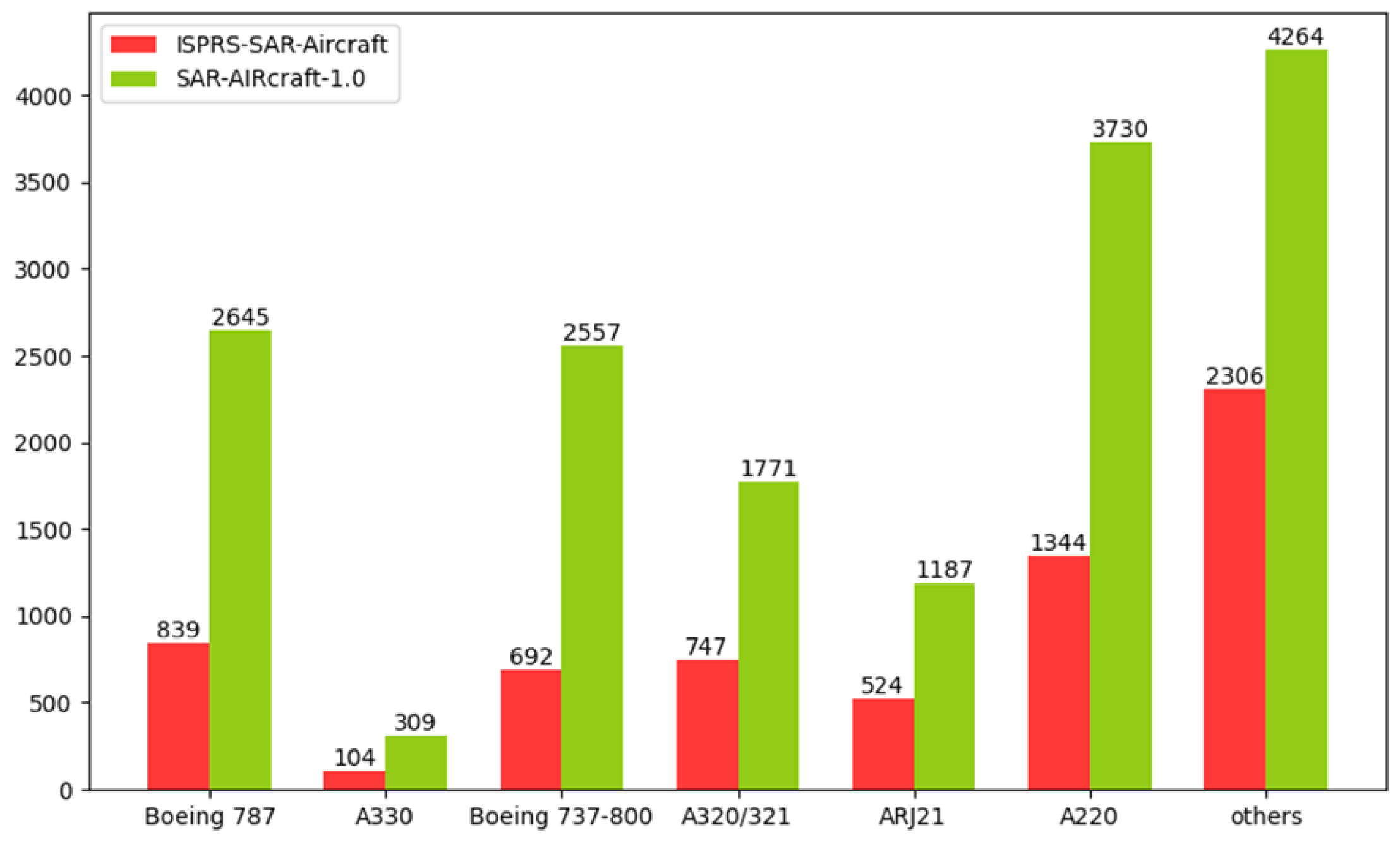
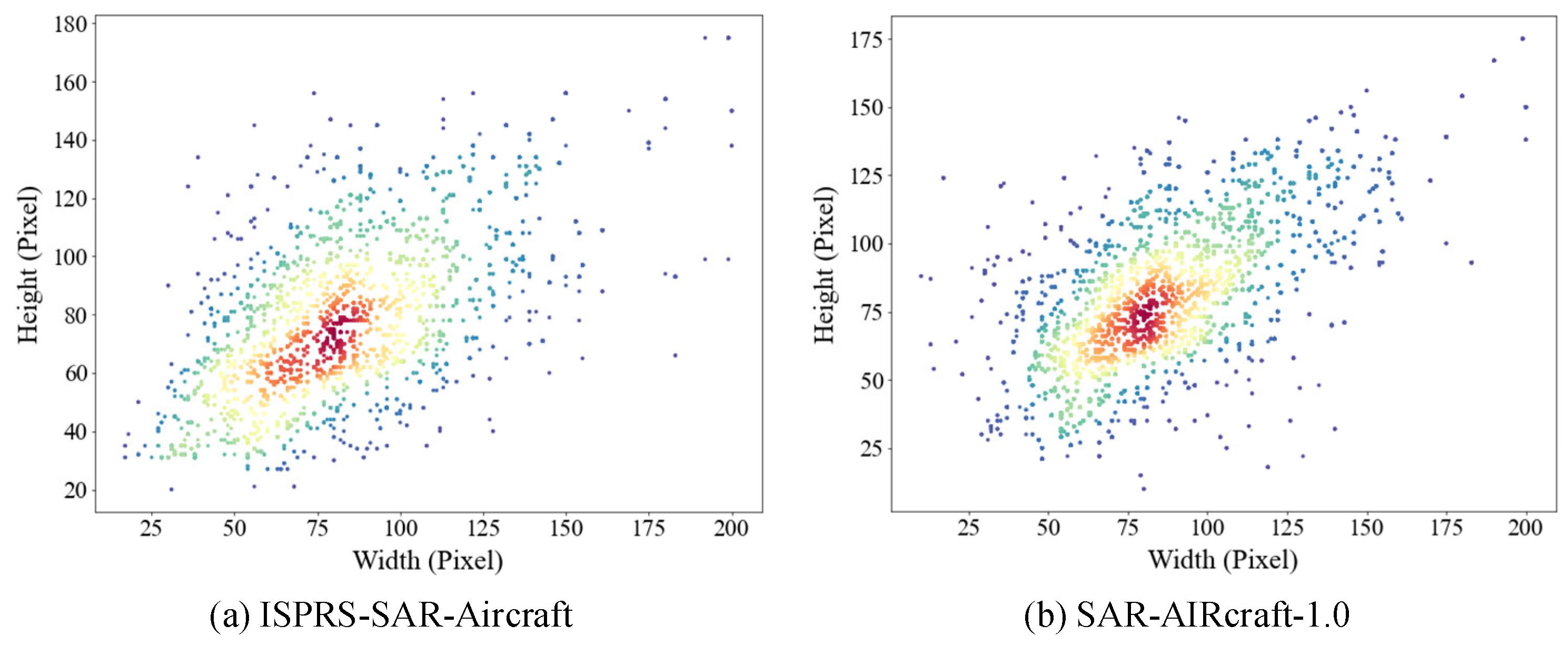
4.1. ISPRS-SAR-Aircraft Dataset and SAR-AIRcraft-1.0 Dataset
4.2. The Configuration of Our YOLOv8 Experimental Environment
4.3. Experimental Results
4.3.1. Experimental Analysis of the Enhanced Lee Algorithm
4.3.2. Experimental Analysis of GTR
4.3.3. Experimental Analysis of 4SDC Method
4.3.4. Experimental Analysis of C2f-SWTran Module
4.3.5. Comparative Analysis of Improved Algorithms with Other Algorithms
4.3.6. Discussions About Cross-Dataset Adaption
5. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yang, W.; Zhang, Z. SAR Images Target Detection Based on YOLOv5. In Proceedings of the 2021 4th International Conference on Information Communication and Signal Processing (ICICSP), Shanghai, China, 24–26 September 2021; pp. 342–347. [Google Scholar]
- Luo, R.; Zhao, L.; He, Q.; Ji, K.; Kuang, G. Intelligent Technology for Aircraft Detection and Recognition through SAR Imagery: Advancements and Prospects. J. Radars 2024, 13, 307–330. [Google Scholar] [CrossRef]
- Huang, Z.; Yao, X.; Han, J. Progress and Perspective on Physically Explainable Deep Learning for Synthetic Aperture Radar Image Interpretation. J. Radars 2022, 11, 107–125. [Google Scholar]
- Guo, X.; Xu, B. SAR-NTV-YOLOv8: A Neural Network Aircraft Detection Method in SAR Images Based on Despeckling Preprocessing. Remote Sens. 2024, 16, 3420. [Google Scholar] [CrossRef]
- Jao, J.K.; Lee, C.; Ayasli, S. Coherent spatial filtering for SAR detection of stationary targets. IEEE Trans. Aerosp. Electron. Syst. 1999, 35, 614–626. [Google Scholar]
- Smith, M.E.; Varshney, P.K. VI-CFAR: A novel CFAR algorithm based on data variability. In Proceedings of the 1997 IEEE National Radar Conference, Syracuse, NY, USA, 13–15 May 1997; pp. 263–268. [Google Scholar] [CrossRef]
- Kuttikkad, S.; Chellappa, R. Non-Gaussian CFAR techniques for target detection in high resolution SAR images. In Proceedings of the 1st IEEE International Conference on Image Processing, Austin, TX, USA, 13–16 November 1994; pp. 910–914. [Google Scholar] [CrossRef]
- Dong, G.; Kuang, G. Classification on the Monogenic Scale Space: Application to Target Recognition in SAR Image. IEEE Trans. Image Process. 2015, 24, 2527–2539. [Google Scholar] [CrossRef]
- Leng, X.; Ji, K.; Zhou, S.; Xing, X. Ship Detection Based on Complex Signal Kurtosis in Single-Channel SAR Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 57, 6447–6461. [Google Scholar] [CrossRef]
- Fu, K.; Dou, F.; Li, H.; Diao, W.; Sun, X.; Xu, G. Aircraft Recognition in SAR Images Based on Scattering Structure Feature and Template Matching. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 4206–4217. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Farhadi, A.; Redmon, J. Yolov3, An incremental improvement. In Proceedings of the Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar] [CrossRef]
- Wang, Q.; Sheng, J.; Tong, C.; Wang, Z.; Song, T.; Wang, M.; Wang, T. A Fast Facet-Based SAR Imaging Model and Target Detection Based on YOLOv5 with CBAM and Another Detection Head. Electronics 2023, 12, 4039. [Google Scholar] [CrossRef]
- Xiao, X.; Jia, H.; Xiao, P.; Wang, H. Aircraft Detection in SAR Images Based on Peak Feature Fusion and Adaptive Deformable Network. Remote Sens. 2022, 14, 6077. [Google Scholar] [CrossRef]
- Zhang, P.; Xu, H.; Tian, T.; Gao, P.; Tian, J. SFRE-Net: Scattering Feature Relation Enhancement Network for Aircraft Detection in SAR Images. Remote Sens. 2022, 14, 2076. [Google Scholar] [CrossRef]
- Jiang, Z.; Wang, Y.; Zhou, X.; Chen, L.; Chang, Y.; Song, D.; Shi, H. Small-Scale Ship Detection for SAR Remote Sensing Images Based on Coordinate-Aware Mixed Attention and Spatial Semantic Joint Context. Smart Cities 2023, 6, 1612–1629. [Google Scholar] [CrossRef]
- Sun, Z.; Dai, M.; Leng, X.; Lei, Y.; Xiong, B.; Ji, K.; Kuang, G. An anchor-free detection method for ship targets in high-resolution SAR images. IEEE Trans. Geosci. Remote Sens. 2021, 14, 7799–7816. [Google Scholar] [CrossRef]
- Zhou, W.; Yang, Y.; Zhao, M.; Hu, W. SCNet-YOLO: A symmetric convolution network for multi-scenario ship detection based on YOLOv7. J Supercomput 2025, 81, 630. [Google Scholar] [CrossRef]
- Sun, Z.; Leng, X.; Lei, Y.; Xiong, B.; Ji, K.; Kuang, G. BiFA-YOLO: A novel YOLO-based method for arbitrary-oriented ship detection in high-resolution SAR images. Remote Sens. 2021, 13, 4209. [Google Scholar] [CrossRef]
- Li, X.; Duan, W.; Fu, X.; Lv, X. R-SABMNet: A YOLOv8-Based Model for Oriented SAR Ship Detection with Spatial Adaptive Aggregation. Remote Sens. 2025, 17, 551. [Google Scholar] [CrossRef]
- Wang, J.; Liu, G.; Liu, J.; Dong, W.; Song, W. Automatic Aircraft Identification with High Precision from SAR Images Considering Multiscale Problems and Channel Information Enhancement. Remote Sens. 2024, 16, 3177. [Google Scholar] [CrossRef]
- 2021 Gaofen challenge on Automated High-Resolution Earth Observation Image Interpretation. Available online: http://gaofen-challenge.com (accessed on 1 October 2021).
- Wang, Z.; Kang, Y.; Zeng, X.; Wang, Y.; Zhang, T.; Sun, X. SAR-AIRcraft-1.0: High-resolution SAR aircraft detection and recognition dataset. J. Radars 2023, 12, 906–922. [Google Scholar] [CrossRef]
- Wang, X.; Xu, W.; Huang, P.; Tan, W. MSSD-Net: Multi-Scale SAR Ship Detection Network. Remote Sens. 2024, 16, 2233. [Google Scholar] [CrossRef]
- Glenn, J. Ultralytics YOLOv8. 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 3 May 2024).
- Zhang, C.; Bengio, S.; Hardt, M.; Recht, B.; Vinyals, O. Understanding Deep Learning Requires Rethinking Generalization. In Proceedings of the International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017; Available online: https://openreview.net/forum?id=Sy8gdB9xx (accessed on 15 October 2023).
- Wu, K.; Zhang, Z.; Chen, Z.; Liu, G. Object-Enhanced YOLO Networks for Synthetic Aperture Radar Ship Detection. Remote Sens. 2024, 16, 1001. [Google Scholar] [CrossRef]
- Cao, S.; Zhao, C.; Dong, J.; Fu, X. Ship Detection in Synthetic Aperture Radar Images under Complex Geographical Environments, Based on Deep Learning and Morphological Networks. Sensors 2024, 24, 4290. [Google Scholar] [CrossRef] [PubMed]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations (ICLR), Virtual Conference, 3–7 May 2021; Available online: https://openreview.net/forum?id=YicbFdNTTy (accessed on 10 February 2024).
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 9992–10002. [Google Scholar] [CrossRef]
- Wang, G.; Chen, Y.; An, P.; Hong, H.; Hu, J.; Huang, T. UAV-YOLOv8: A Small-Object-Detection Model Based on Improved YOLOv8 for UAV Aerial Photography Scenarios. Sensors 2023, 23, 7190. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Wang, W.; Wu, L.; Chen, S.; Hu, X.; Li, J.; Tang, J.; Yang, J. Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 6–12 December 2020. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar] [CrossRef]
- Harris, C.; Stephens, M. A combined corner and edge detector. In Proceedings of the Alvey Vision Conference, Manchester, UK, 31 August–2 September 1988; Volume 15, pp. 10–5244. [Google Scholar] [CrossRef]
- Shi, J.; Tomasi, C. Good Features to Track. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 21–23 June 1994; pp. 593–600. [Google Scholar] [CrossRef]
- Lee, J.S. Digital image enhancement and noise filtering by use of local statistics. IEEE Trans. Pattern Anal. Mach. Intell. 1980, PAMI-2, 165–168. [Google Scholar] [CrossRef]
- Frost, V.S.; Stiles, J.A.; Shanmugan, K.S.; Holtzman, J.C. A model for radar images and its application to adaptive digital filtering of multiplicative noise. IEEE Trans. Pattern Anal. Mach. Intell. 1982, PAMI-4, 157–166. [Google Scholar] [CrossRef]
- Kuan, D.T.; Sawchuk, A.A.; Strand, T.C.; Chavel, P. Adaptive noise smoothing filter for images with signal-dependent noise. IEEE Trans. Pattern Anal. Mach. Intell. 1985, PAMI-7, 165–177. [Google Scholar] [CrossRef]
- Guo, F.; Sun, C.; Sun, N.; Ma, X.; Liu, W. Integrated Quantitative Evaluation Method of SAR Filters. Remote Sens. 2023, 15, 1409. [Google Scholar] [CrossRef]
- Xie, J.; Li, Z.; Zhou, C.; Fang, Y.; Zhang, Q. Speckle Filtering of GF-3 Polarimetric SAR Data with Joint Restriction Principle. Sensors 2018, 18, 1533. [Google Scholar] [CrossRef]
- Zhang, W.G.; Liu, F.; Jiao, L.C. SAR Image Despeckling via Bilateral Filtering. Electron. Lett. 2009, 45, 781–783. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar] [CrossRef]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar] [CrossRef]
- Liu, S.; Tong, M.; He, B.; Jiang, J.; He, C. Noise-to-Convex: A Hierarchical Framework for SAR Oriented Object Detection via Scattering Keypoint Feature Fusion and Convex Contour Refinement. Electronics 2025, 14, 569. [Google Scholar] [CrossRef]
- Xia, R.; Chen, J.; Huang, Z.; Wan, H.; Wu, B.; Sun, L.; Yao, B.; Xiang, H.; Xing, M. CRTransSar: A Visual Transformer Based on Contextual Joint Representation Learning for SAR Ship Detection. Remote Sens. 2022, 14, 1488. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Configuration |
|---|---|
| Epochs | 500 |
| Batch size | 32 |
| Learning rate | 0.01 |
| Optimizer | SGD |
| Mosaic | 1.0 |
| Flipud and Fliplr | 0, 0.5 |
| Scale | 0.5 |
| Parameter | ENL | ESI |
|---|---|---|
| No | 0.962 | 1.000 |
| Lee | 1.644 | 0.302 |
| Frost | 1.305 | 0.497 |
| Kuan | 1.134 | 0.830 |
| Enhanced Lee | 1.086 | 0.883 |
| Dataset | Model | GTR | mAP50 | mAP50~95 |
|---|---|---|---|---|
| ISPRS-SAR-Aircraft | YOLOv8n | × | 0.915 | 0.699 |
| YOLOv8n | √ | 0.923 | 0.712 | |
| YOLOv8l | × | 0.920 | 0.719 | |
| YOLOv8l | √ | 0.927 | 0.731 | |
| SAR-AIRcraft-1.0 | YOLOv8n | × | 0.896 | 0.629 |
| YOLOv8n | √ | 0.905 | 0.648 | |
| YOLOv8l | × | 0.908 | 0.649 | |
| YOLOv8l | √ | 0.919 | 0.670 |
| Dataset | Model | GTR | 4SDC | mAP50 | mAP50~95 | S-aircraft mAP50~95 | L-aircraft mAP50~95 |
|---|---|---|---|---|---|---|---|
| ISPRS-SAR-Aircraft | YOLOv8n | √ | × | 0.923 | 0.712 | 0.684 | 0.726 |
| YOLOv8n | × | √ | 0.921 | 0.706 | 0.691 | 0.721 | |
| YOLOv8n | √ | √ | 0.926 | 0.718 | 0.693 | 0.728 | |
| YOLOv8l | √ | × | 0.927 | 0.731 | 0.720 | 0.736 | |
| YOLOv8l | × | √ | 0.923 | 0.725 | 0.721 | 0.725 | |
| YOLOv8l | √ | √ | 0.929 | 0.736 | 0.728 | 0.737 | |
| SAR-AIRcraft-1.0 | YOLOv8n | √ | × | 0.905 | 0.648 | 0.610 | 0.657 |
| YOLOv8n | × | √ | 0.901 | 0.637 | 0.618 | 0.643 | |
| YOLOv8n | √ | √ | 0.909 | 0.655 | 0.626 | 0.66 | |
| YOLOv8l | √ | × | 0.919 | 0.670 | 0.642 | 0.678 | |
| YOLOv8l | × | √ | 0.913 | 0.656 | 0.644 | 0.663 | |
| YOLOv8l | √ | √ | 0.922 | 0.676 | 0.656 | 0.680 |
| Dataset | Model | GTR | 4SDC | C2f SWTran | mAP50 | mAP50~95 | PARAM (MB) | GFLOPs (G) |
|---|---|---|---|---|---|---|---|---|
| ISPRS-SAR-Aircraft | YOLOv8n | × | × | × | 0.915 | 0.699 | 3.01 | 8.7 |
| YOLOv8n | × | × | √ | 0.921 | 0.705 | 3.25 | 10.4 | |
| YOLOv8n | √ | √ | × | 0.926 | 0.718 | 4.76 | 10.9 | |
| YOLOv8n | √ | × | √ | 0.925 | 0.717 | 3.25 | 10.4 | |
| YOLOv8n | × | √ | √ | 0.923 | 0.711 | 5.01 | 12.6 | |
| YOLOv8n | √ | √ | √ | 0.930 | 0.723 | 5.01 | 12.6 | |
| YOLOv8l | × | × | × | 0.920 | 0.719 | 43.6 | 165.7 | |
| YOLOv8l | × | × | √ | 0.925 | 0.726 | 44.7 | 176.3 | |
| YOLOv8l | √ | √ | × | 0.929 | 0.736 | 53.4 | 177.5 | |
| YOLOv8l | √ | × | √ | 0.928 | 0.736 | 44.7 | 176.3 | |
| YOLOv8l | × | √ | √ | 0.927 | 0.732 | 54.5 | 188.1 | |
| YOLOv8l | √ | √ | √ | 0.932 | 0.742 | 54.5 | 188.1 | |
| SAR-AIRcraft-1.0 | YOLOv8n | × | × | × | 0.896 | 0.629 | 3.01 | 8.7 |
| YOLOv8n | × | × | √ | 0.903 | 0.636 | 3.25 | 10.4 | |
| YOLOv8n | √ | √ | × | 0.909 | 0.655 | 4.76 | 10.9 | |
| YOLOv8n | √ | × | √ | 0.907 | 0.654 | 3.25 | 10.4 | |
| YOLOv8n | × | √ | √ | 0.906 | 0.650 | 5.01 | 12.6 | |
| YOLOv8n | √ | √ | √ | 0.915 | 0.661 | 5.01 | 12.6 | |
| YOLOv8l | × | × | × | 0.908 | 0.649 | 43.6 | 165.7 | |
| YOLOv8l | × | × | √ | 0.916 | 0.657 | 44.7 | 176.3 | |
| YOLOv8l | √ | √ | × | 0.922 | 0.676 | 53.4 | 177.5 | |
| YOLOv8l | √ | × | √ | 0.921 | 0.676 | 44.7 | 176.3 | |
| YOLOv8l | × | √ | √ | 0.918 | 0.666 | 54.5 | 188.1 | |
| YOLOv8l | √ | √ | √ | 0.929 | 0.683 | 54.5 | 188.1 |
| Dataset | Model | GTR | 4SDC | C2f-SWTran | mAP50 | mAP50~95 |
|---|---|---|---|---|---|---|
| ISPRS-SAR-Aircraft | Faster R-CNN | × | × | × | 0.859 | 0.557 |
| Faster R-CNN | √ | × | × | 0.876 | 0.583 | |
| SSD | × | × | × | 0.805 | 0.518 | |
| SSD | √ | × | × | 0.829 | 0.558 | |
| YOLOv3 | × | × | × | 0.866 | 0.605 | |
| YOLOv5s | × | × | × | 0.873 | 0.635 | |
| YOLOv8n | × | × | × | 0.915 | 0.699 | |
| YOLOv8n | √ | √ | √ | 0.930 | 0.723 | |
| YOLOv8l | × | × | × | 0.920 | 0.719 | |
| YOLOv8l | √ | √ | √ | 0.932 | 0.742 | |
| SAR-AIRcraft-1.0 | Faster R-CNN | × | × | × | 0.838 | 0.526 |
| Faster R-CNN | √ | × | × | 0.859 | 0.550 | |
| SSD | × | × | × | 0.795 | 0.500 | |
| SSD | √ | × | × | 0.816 | 0.529 | |
| YOLOv3 | × | × | × | 0.858 | 0.588 | |
| YOLOv5s | × | × | × | 0.865 | 0.609 | |
| SKG-DDT | × | × | × | 0.892 | 0.637 | |
| YOLOv7 | × | × | × | 0.880 | 0.625 | |
| EBPA2N | × | × | × | 0.913 | NA | |
| YOLOv8n | × | × | × | 0.896 | 0.629 | |
| YOLOv8n | √ | √ | √ | 0.915 | 0.661 | |
| YOLOv8l | × | × | × | 0.908 | 0.649 | |
| YOLOv8l | √ | √ | √ | 0.929 | 0.683 |
| Dataset | Model | Aircraft | Oil Tank | Bridge | Ship | mAP50 | mAP50~95 |
|---|---|---|---|---|---|---|---|
| MSAR-1.0 | YOLOv8n | 0.739 | 0.939 | 0.909 | 0.961 | 0.887 | 0.661 |
| Ours | 0.784 | 0.948 | 0.916 | 0.976 | 0.906 | 0.699 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Hong, W.; Liu, Y.; Yan, G.; Hu, D.; Jing, Q. Improved YOLOv8 Network of Aircraft Target Recognition Based on Synthetic Aperture Radar Imaging Feature. Sensors 2025, 25, 3231. https://doi.org/10.3390/s25103231
Wang X, Hong W, Liu Y, Yan G, Hu D, Jing Q. Improved YOLOv8 Network of Aircraft Target Recognition Based on Synthetic Aperture Radar Imaging Feature. Sensors. 2025; 25(10):3231. https://doi.org/10.3390/s25103231
Chicago/Turabian StyleWang, Xing, Wen Hong, Yunqing Liu, Guanyu Yan, Dongmei Hu, and Qi Jing. 2025. "Improved YOLOv8 Network of Aircraft Target Recognition Based on Synthetic Aperture Radar Imaging Feature" Sensors 25, no. 10: 3231. https://doi.org/10.3390/s25103231
APA StyleWang, X., Hong, W., Liu, Y., Yan, G., Hu, D., & Jing, Q. (2025). Improved YOLOv8 Network of Aircraft Target Recognition Based on Synthetic Aperture Radar Imaging Feature. Sensors, 25(10), 3231. https://doi.org/10.3390/s25103231