1. Introduction
The rapid progression of mobile communication technologies has heightened the necessity for the advanced exploration of network slicing architectures. Existing research predominantly concentrates on SFC mapping and deployment methodologies. Research on SFC deployment mostly focuses on the traditional chained SFC, and its structure and characteristics are discussed in depth. As outlined in [
1], a node-ranking mechanism is implemented at the node mapping layer, leveraging network topology attributes and neighboring node significance. For link mapping optimization, a multi-constraint link mapping model is established, with genetic algorithms employed to identify optimal mapping paths, thereby enhancing resource allocation efficacy. In reference [
2], a collaborative virtual node–link mapping algorithm is proposed to ensure the balanced utilization of the physical node and link resources in network slicing. Reference [
3] introduces a radio access network slicing-based framework for user access control and wireless resource allocation, specifically tailored for smart grid applications. In [
4], a novel delay-sensitive 5G access network slicing is proposed that can meet the demands of applications with different traffic characteristics, providing them with varying rate and delay guarantees to ensure efficient quality of service realization. However, with the continuous development of network technology and the increasing diversification of application requirements, the form and deployment mode of SFCs are characterized by more flexibility and complexity. In view of the complexity and diversity of current services, the traditional chained SFC is no longer able to fully describe and satisfy diverse service requests.
Concurrently, the effective utilization of network topology information has garnered increased attention. Current approaches predominantly utilize complex network theory to define node performance metrics through topological analysis. Reference [
5] presents a graph-theory-driven resource scheduling algorithm incorporating depth-first search optimization, which satisfies latency, data rate, and reliability requirements for power services while reducing end-to-end delays. As outlined in [
6], node importance metrics are derived from comprehensive topological evaluations of sliced and substrate networks, enabling precise node prioritization during mapping processes to optimize resource utilization.
The progressive evolution of communication technologies has exacerbated the limitations of conventional coarse-grained network slicing paradigms in addressing the escalating complexity of low-latency service requirements. This technological gap has driven substantial research focus toward fine-grained network slicing implementations. In the realization of network slicing technology, the choice of slice granularity is of high significance. References [
7,
8] show that if the granularity is too coarse, the flexibility of slices and the diversity and independence of user services will be limited, but if the granularity is too small, the management difficulty of different slices and the difficulty of sharing resources among slices will be increased. With the continuous development of various new services, the current demand for QoS is increasing, and in order to ensure better performance, it is necessary to move closer to a finer granularity. In reference [
9], the concept of link-level network slicing is proposed, necessitating resource provisioning enforcement at the physical link stratum rather than conventional slice-level abstraction. This approach enables direct resource allocation to communication links through advanced fading mitigation and interference cancellation techniques, thereby theoretically guaranteeing QoS compliance. Nevertheless, per-service link-level slice instantiation inevitably incurs resource fragmentation, diminishing infrastructure utilization efficiency. Addressing massive IoT deployments in smart environments, reference [
10] extends conventional 5G service taxonomies through micro-slice isolation mechanisms. The proposed architecture enables localized logical subnetworks between device clusters and application servers, featuring duration-aware and coverage-adaptive slice customization. Reference [
11] investigates the problem of slice-based service function chain embedding (SBSFCE) to enable end-to-end network slice deployment. Simulations show that the algorithm outperforms the benchmark algorithm. Reference [
12] uses machine learning to analyze network traffic and conducts experiments on different machine learning models. Based on these experimental results, a 5G slice management algorithm is proposed to optimize the slice resource. In reference [
13], the author proposes an MEC network slice-aware smart queuing theoretical architecture for next-generation pre-6G networks by optimizing slice resources to improve performance metrics for both online and offline scenarios. While such micro-slices permit dynamic reconfiguration via application-layer policy orchestration with elevated automation levels, their inherent control-loop latencies render them suboptimal for stringent latency-sensitive applications. Consequently, systematic methodologies for constructing and deploying fine-grained latency-constrained network slices remain an open research challenge.
Current research paradigms in network slicing resource management predominantly address singular resource types or unilateral optimization of either RAN (radio access network) or core network components, neglecting cross-domain optimization frameworks and multi-resource interdependencies. In practical deployment scenarios, heterogeneous resource allocation across multiple slices exhibits multidimensional coupling characteristics, necessitating systematic investigation of joint multi-resource orchestration strategies integrated with end-to-end RAN–core network co-optimization. Furthermore, while existing SFC deployment studies have extensively examined conventional linear service function chains through structural and characteristic analyses, the evolution of network architectures and the diversification of application requirements have precipitated the emergence of hyper-connected service graphs. These graph-structured SFCs demonstrate enhanced topological flexibility but introduce non-trivial deployment complexity, rendering traditional chain-based models inadequate for contemporary service provisioning. Consequently, pioneering research into graph-theoretic SFC deployment mechanisms becomes imperative, particularly focusing on neighborhood-aware resource coordination algorithms and topology-adaptive scheduling paradigms to achieve precise service differentiation and infrastructure efficiency maximization.
2. System Model
The advent of 6G networks has been propelled by groundbreaking advancements in communication technologies, catalyzing the emergence of mission-critical applications with sub-millisecond latency constraints and microsecond-level timing synchronization requirements. Representative use cases including relay protection systems [
14], telesurgery platforms [
15], and industrial cyber–physical control systems impose differentiated network performance thresholds [
16]. For instance, telemedicine applications mandate end-to-end latency below 20 ms, as exceeding this threshold could critically compromise surgical intervention viability. Similarly, differential protection mechanisms require 200 μs-level latency guarantees to ensure substation fault detection precision, where timing deviations exceeding 50μs may trigger protection misoperations. These stringent requirements underscore the imperative to pioneer low-latency fine-grained network slicing architectures as a cornerstone technology for 6G network infrastructure.
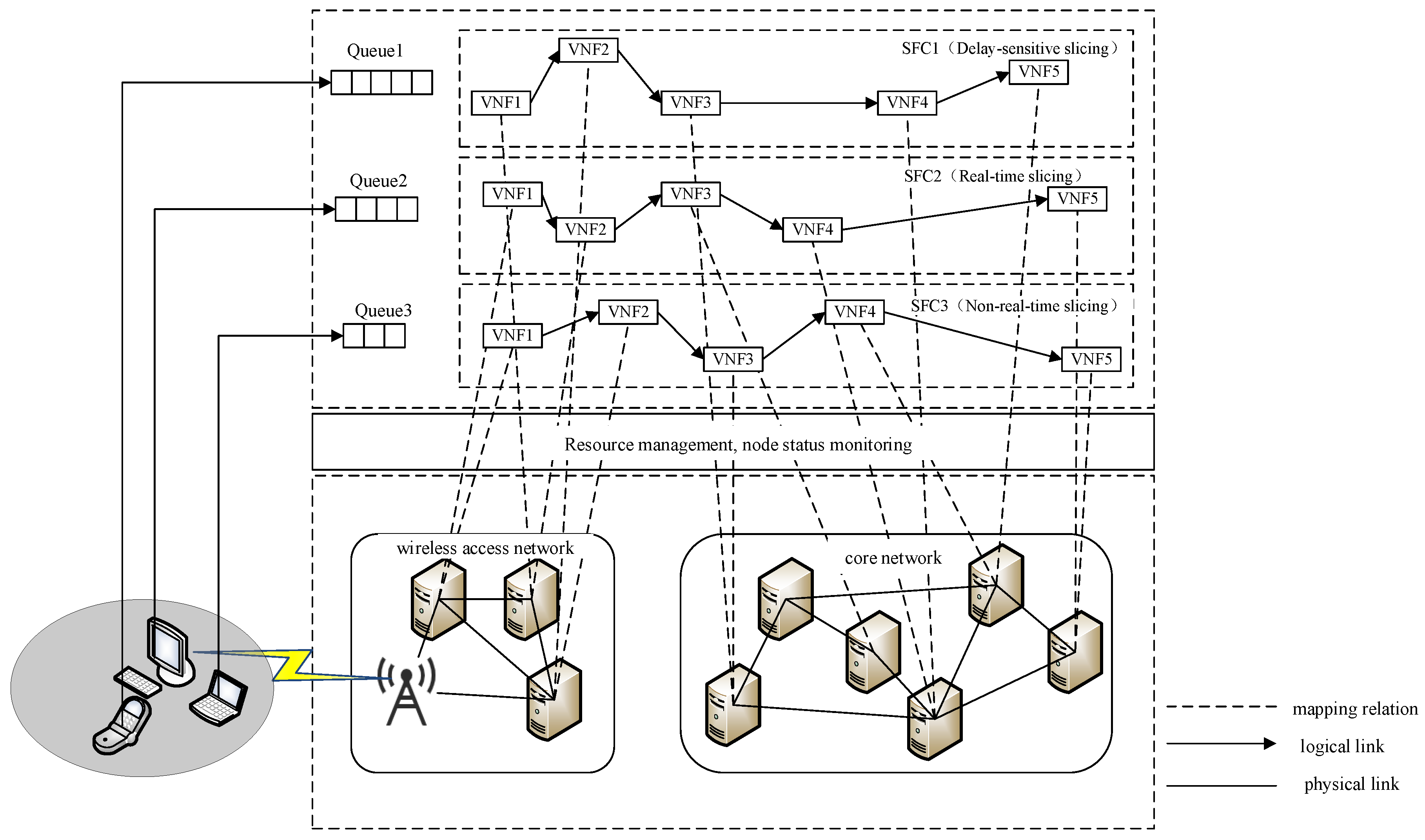
The system architecture under investigation, as depicted in
Figure 1, is formally structured through three principal strata: terminal devices, the radio access network, and the core network infrastructure. The RAN subsystem implements intelligent access technology selection mechanisms to optimize user equipment connectivity, while the core network orchestrates SFC mapping operations. Three distinct network slice categories are provisioned, all operating under latency-bound SLAs (Service-Level Agreements) but with differentiated computing and communication resource allocations: LSSs (latency-sensitive slices), RTSs (real-time slices), and NRTSs (non-real-time slices). Service reliability is strictly contingent upon the slice’s capability to satisfy predefined latency thresholds through resource reservation. Furthermore, application-specific SFCs are dynamically instantiated per slice category, ensuring service execution compliance with heterogeneous requirements. The architecture establishes deterministic E2E communication paths spanning from user terminals through base stations to core network elements, implementing coordinated resource reservation across all network strata.
Within the RAN domain, protocol layer function virtualization is achieved through DU (Distributed Unit) devices leveraging standardized server clusters, establishing a centralized processing pool. To address heterogeneous network slicing requirements, an adaptive VNF (Virtual Network Function) deployment framework is implemented across SFCs, enabling joint optimization of computational resource allocation and infrastructure utilization efficiency. Capitalizing on the inherent caching capabilities of RAN infrastructure, per-SFC packet scheduling mechanisms are provisioned at DU endpoints to refine network resource allocation granularity and maximize system throughput. In the core network stratum, the software-defined virtualization of physical switching/routing devices is realized via commodity server platforms. VNF services within SFCs are instantiated through cloud-native network functions deployed on VMs (Virtual Machines), with cross-VM elastic VNF orchestration enabling multidimensional service provisioning while maintaining optimal resource allocation efficiency across heterogeneous infrastructure.
This section conducts a systematic latency taxonomy analysis, establishing three service classification tiers with corresponding provisioning frameworks. Service instances are classified into three distinct categories: NRTS, RTS, and LSS. The classification criteria are defined through rigorous latency-bound thresholds: NRTSs accommodate applications with relaxed latency constraints exceeding 100 ms; RTSs require bounded latency between 10 ms and 100 ms to maintain service continuity; and LSSs mandate ultra-strict latency guarantees below 10 ms to support mission-critical operations. Each service category is subsequently associated with dedicated network slice configurations and resource reservation mechanisms to ensure service-specific QoS compliance. LSSs have the highest resource allocation level, which allocates dedicated PRBs (Physical Resource Blocks) and computational resources. RTSs have medium resource allocation levels, for which the system reserves a portion of bandwidth in advance. NRTSs have the lowest resource allocation priority level, and we allow resources to be shared by other slices when NRTSs are available.
The infrastructure network can be abstracted as an undirected weighted graph, denoted as . In this model, represents the set of physical nodes, which consists of two types: wireless access network nodes () and core network nodes (). represents the set of physical links, which includes two categories: physical links between wireless access network nodes () and physical links between core network nodes (), each fulfilling distinct network connectivity requirements. denotes the set of computational resources of the physical nodes, while represents the set of bandwidth resources of the physical links. The network slice request set consists of three types of slices, denoted as RNS, where RNS = RNRT∪RRT∪RCT. Here, RNRT represents non-real-time slices, RRT represents real-time slices, and RCT represents latency-sensitive slices. The set of slice type is denoted as . Each request is represented as GR = (NR, ER, CR, BR, TR). Each slice type consists of a specific set of corresponding VNFs. The VNF composition for slice is denoted as . In this section, a graph structure is employed to represent the SFC of service requests. Specifically, service requests are abstracted as a DAG , where represents the set of virtual nodes, and represents the set of virtual links.
2.1. Latency Definition
In the access network, assume that multiple Remote RRUs (Remote Radio Units) are distributed within a region, forming the set
. To efficiently manage and utilize wireless resources, the total bandwidth
Hz is divided into multiple PRBs, represented by the set
, where different PRBs are orthogonal to each other. Let
denote the power allocated by
RRU on
PRB to user
in slice
, and
represents the corresponding channel gain. It is important to note that a user can connect to more than one RRU, and different PRBs from different RRUs can be allocated to the same user. Therefore, the rate provided to user
in slice
by
RRU on
PRB can be expressed as
where
represents the bandwidth allocated by RRU
on PRB
to user
in slice
, and
denotes the noise power.
For slice , assume that the arrival of SFC packets follows a dynamic Poisson distribution, where the parameter varies over time to describe the changing arrival rate of packets in slice . Additionally, the packet size is characterized by an exponential distribution, with a mean value of .
The rate
provided by
RRU on
PRB to user
in slice
is considered the service rate
of the link. The average packet processing rate is then given by
Let the queue length of slice
in the SFC at time slot
be
. The queue update equation for the SFC on the DU side is then expressed as
Here, represents the number of data packets arriving in the time slot. Additionally, denotes the number of data packets processed in the time slot.
Based on Little’s Law, the average number of objects in a system can be derived by calculating the product of the average arrival rate of the objects and their average residence time within the system. Therefore, the queuing delay can be expressed as
The processing time required by a physical network node
after receiving a VNF data packet
is defined as the node processing latency. For slice
, this latency is expressed as
where
is defined to indicate whether the
i-th VNF is deployed on server
. Specifically,
if the
i-th VNF is deployed on server
, and
otherwise.
represents the computational processing capability of node
n in slice
, while
denotes the packet size required by the
i-th VNF
in slice
.
The time required to transmit the data packets of VNF
between physical network nodes through network links is referred to as the link transmission delay. The transmission delay for slice
is expressed as
where the
indicates whether the
i-th VNF is deployed on server
;
represents the number of hops between physical nodes
and
; and
denotes the transmission rate between physical nodes
and
.
The end-to-end delay for slice
m is equal to the sum of the node processing delay and the link transmission delay:
where
is the queueing delay of slice
in the access network,
is the total node processing delay for slice
in the access and core networks, and
is the total link transmission delay for slice
in the access and core networks.
Therefore, the objective function is
Equation (9) ensures that each VNF on the SFC can only be deployed on one generic server. Equation (10) ensures that the total computational resources required by the VNFs deployed on a given server do not exceed the total computational resources available. Equation (11) guarantees that the sum of bandwidth resources required by all virtual links mapped onto physical links does not exceed the total bandwidth of the physical link. Equation (12) requires that when two adjacent VNFs on the SFC are deployed on servers and , respectively, there must be at least one connection path between the physical links . Equations (13)–(15) use binary variables to represent the deployment status of VNFs, the mapping of virtual links, and the utilization of generic servers, respectively.
2.2. Service Function Chain Construction
Two characteristic relationships are observed between network functions: dependency-based and autonomy-preserving topologies. Upon receiving service requests, the corresponding SFC is initially instantiated through formal graph composition rules [
17]. Subsequently, a resource-aware mapping algorithm is implemented to optimally place VNFs along the SFC onto infrastructure nodes, achieving computational load balancing while maintaining service continuity constraints. Virtual machine interconnects are dynamically provisioned based on SFC requirements, establishing end-to-end service paths with customized topological configurations [
18]. Each network function is mathematically characterized by two key parameters:
, denoting the input/output bandwidth ratio, and
, representing the computational resource consumption per 1 Mb/s traffic unit. These parameters remain invariant during data plane processing, strictly adhering to preconfigured network function profiles.
In the process of constructing the SFC, the algorithm first analyzes each service request of users with precision and efficiency, independently constructing a network function dependency graph for each user [
19]. Subsequently, the algorithm uses these dependency graphs as input to build an SFC tailored to meet the specific needs of each user.
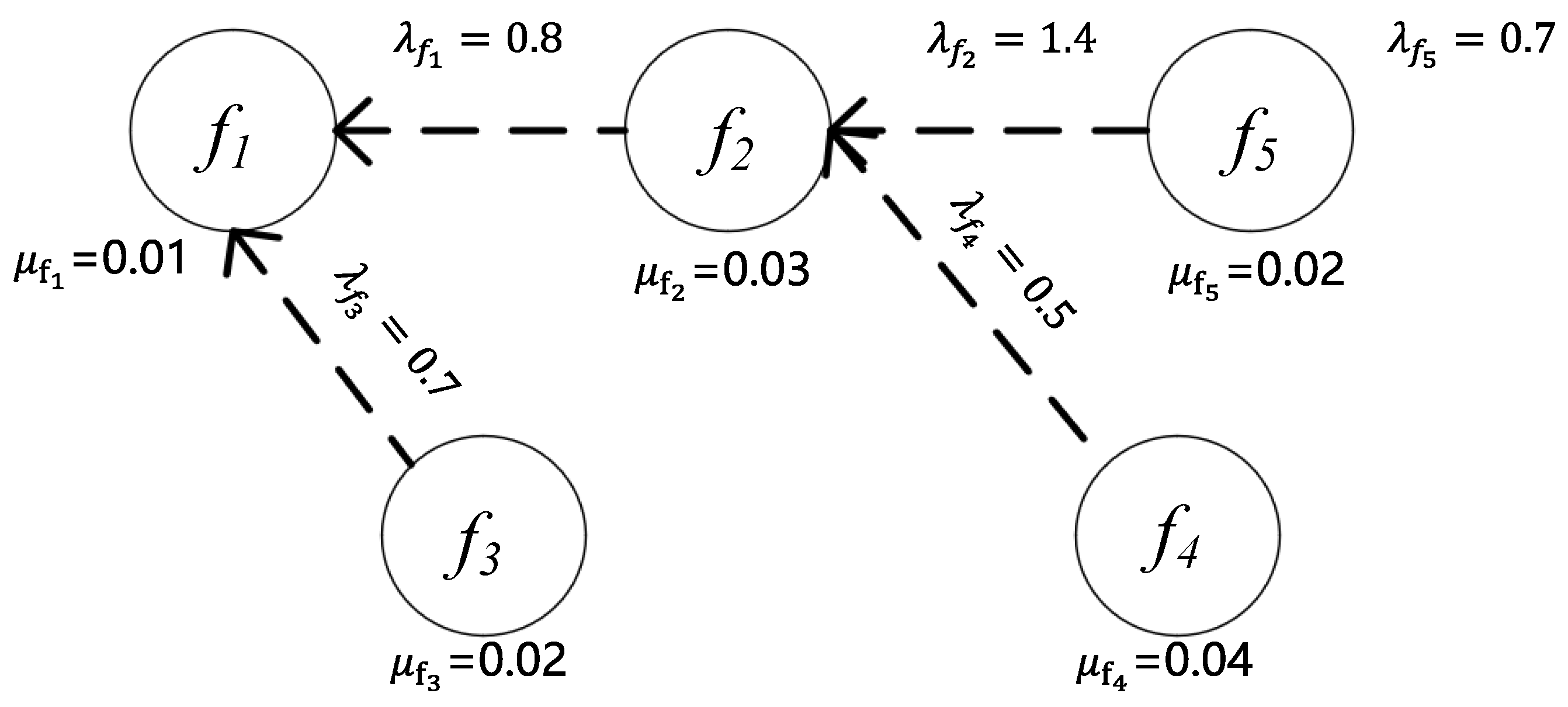
The network function dependency graph used in this section is shown in
Figure 2.
The dashed line from to indicates that in the dependency relationship between and , depends on , meaning that must be positioned after when constructing the service chain. Here, represents the ratio of output to input bandwidth, and refers to the computational resources required to process a 1 Mb/s flow.
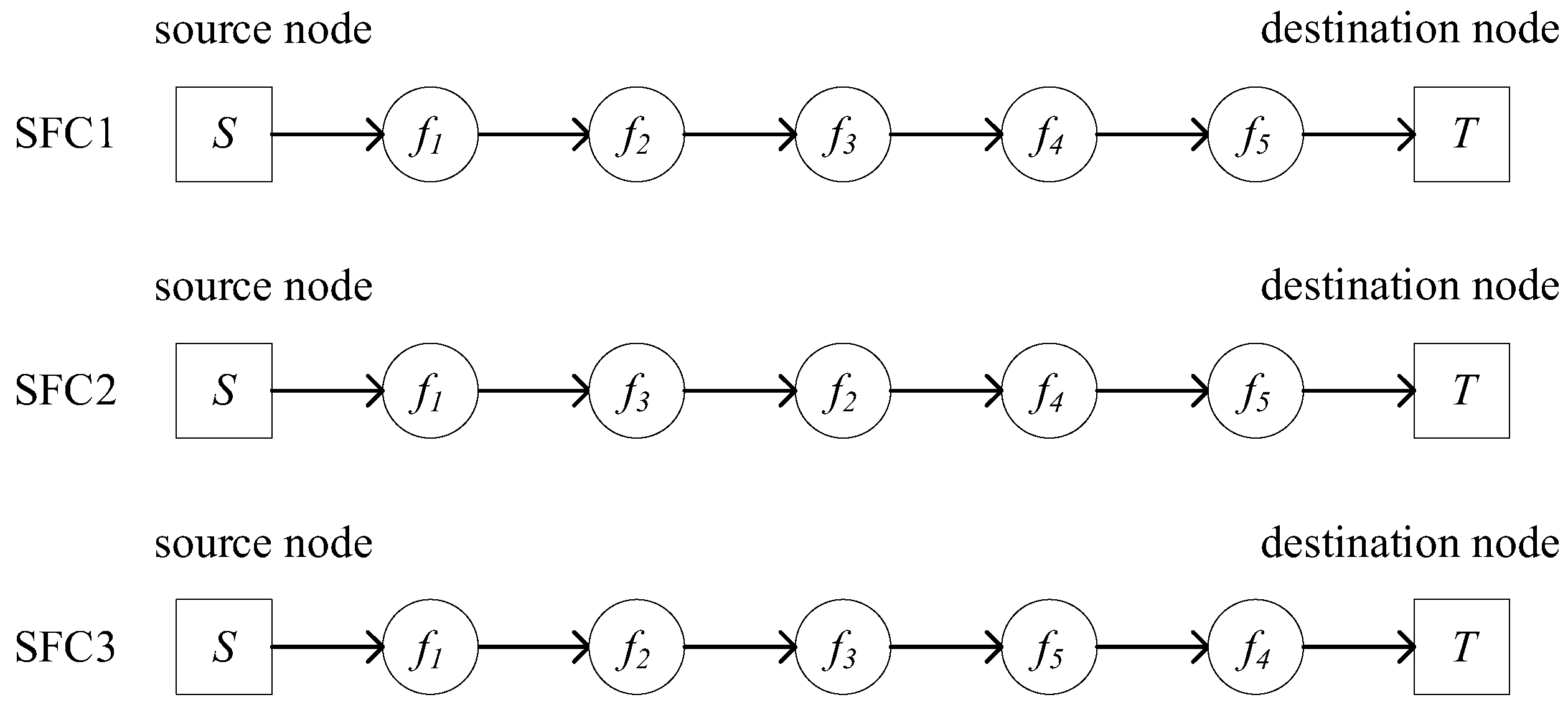
Based on
Figure 2, multiple SFC construction schemes can be generated. One such successfully constructed SFC, which satisfies both the network function dependencies and service requirements, is shown in
Figure 3. In the service request, key information includes the source node
, destination node
, initial bandwidth requirement
, and the VNF set.
In a slice network, the set of network functions is represented by
, which includes all the available VNFs on the slice. To clearly describe the dependencies between these functions, a matrix D with
rows and
columns is used to represent them:
where
represents the total computational resources required by the VNF on
, and
refers to the
K-th network request. Therefore, the following holds:
where
represents the total bandwidth resources required by the VNFs in
. Thus, the relationship can be expressed as
where
represents the evaluation value of the SFC constructed for
in terms of both computational and bandwidth resources:
Finally, the SFC corresponding to different evaluation values is selected based on the actual requirements.
The core idea of the SFC construction algorithm based on the depth-first search is as follows: Firstly, the dependencies and constraints between the VNFs within the sliced network are extracted and represented in a tree structure, where each node represents a VNF and the connections between the nodes reflect the dependencies among the VNFs. Secondly, due to the dependencies between the VNFs, they are positioned at different hierarchical levels. The algorithm selects the VNF node at the highest level as the starting point. Then, starting from this node, the algorithm traverses the tree in reverse order to reach the root node. This backtracking process aims to determine the initial path of the SFC, which is the path connecting the source node to the highest-level VNF. Once the initial SFC is determined, the algorithm proceeds to further search and add the associated sibling nodes.
The SFC mapping problem has been proven to be NP-hard, meaning that finding the optimal solution is computationally challenging [
20]. The objective of the optimization is to minimize latency by integrating the resource and topology information of the entire infrastructure network and the constructed SFCs, forming a comprehensive system state. The SFC mapping problem is inherently a complex and computationally intensive decision-making process, which aligns with the definition of an MDP (Markov Decision Process) [
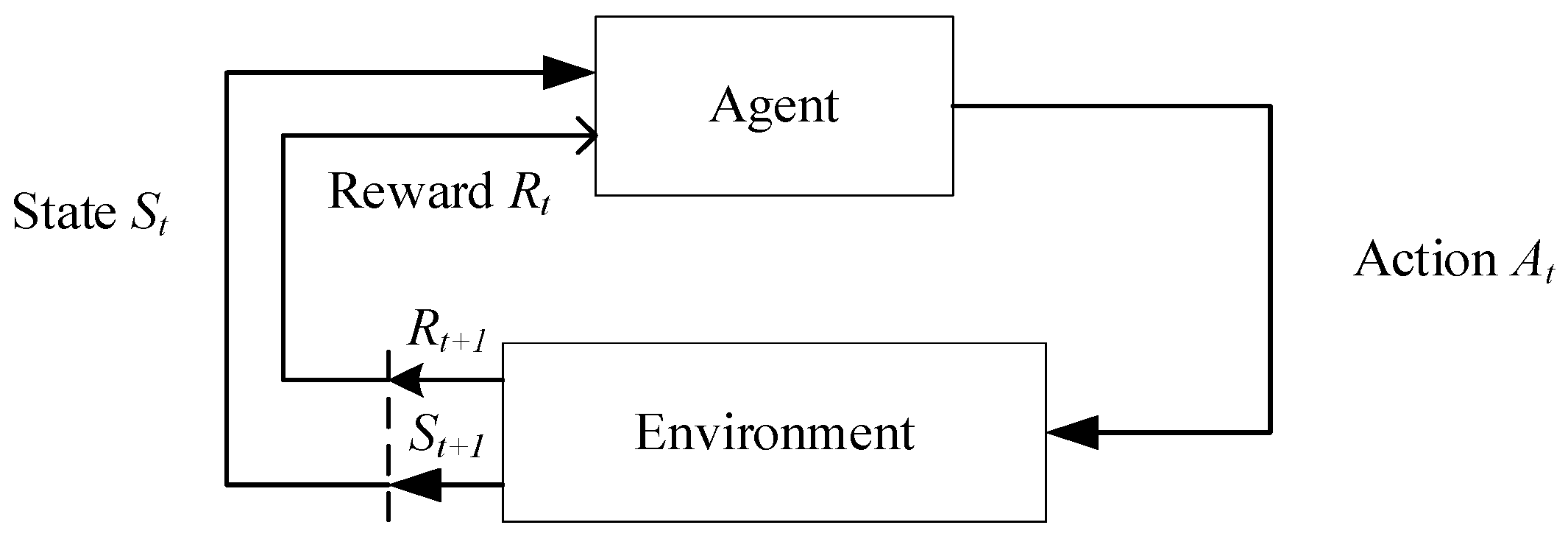
21]. Given that MDPs are effective in describing decision-making problems with state transitions and reward mechanisms, reinforcement learning methods can be employed to solve this problem. The interaction process between the agent and the environment is shown in
Figure 4.
The MDP consists of five key components, which can be abstractly represented as . represents the state space, denotes the action space, represents the state transition probability, is the reward value, and represents the discount factor. At each time step , the DRL (Deep Reinforcement Learning) agent observes the state and selects an action . After the agent acts, the environment transitions to a new state , and the agent receives a reward .
The state represents the environment at a specific time , which can be either discrete or continuous data. The set of all possible states forms the state space . Actions describe the behaviors executed by the agent at a particular moment , and the collection of all possible actions constitutes the action space . The policy is a function that determines the next action based on the current state . The state transition probability indicates the likelihood that the environment transitions to state after the agent takes action in state at time . The reward is the feedback the environment provides after the agent performs action in state . This reward is not only related to the current action but also closely tied to the resulting state at the next time step.
To evaluate the performance of the policy , the agent aims to maximize its long-term expected return by executing a sequence of actions. To achieve this objective, the concept of the state–action value function is introduced, which quantifies the long-term reward for taking a specific action in a given state. By properly defining and optimizing this function, the agent can make more informed decisions and thereby achieve higher returns. The state–action value function represents the expected return when the agent, starting from state , takes action under the policy . Its mathematical expression is given as follows: . Here, , and is the discount factor for future rewards, with . The term represents the discounted total return. The above value function can be decomposed using the Bellman equation as follows: .
2.3. Algorithmic Analysis
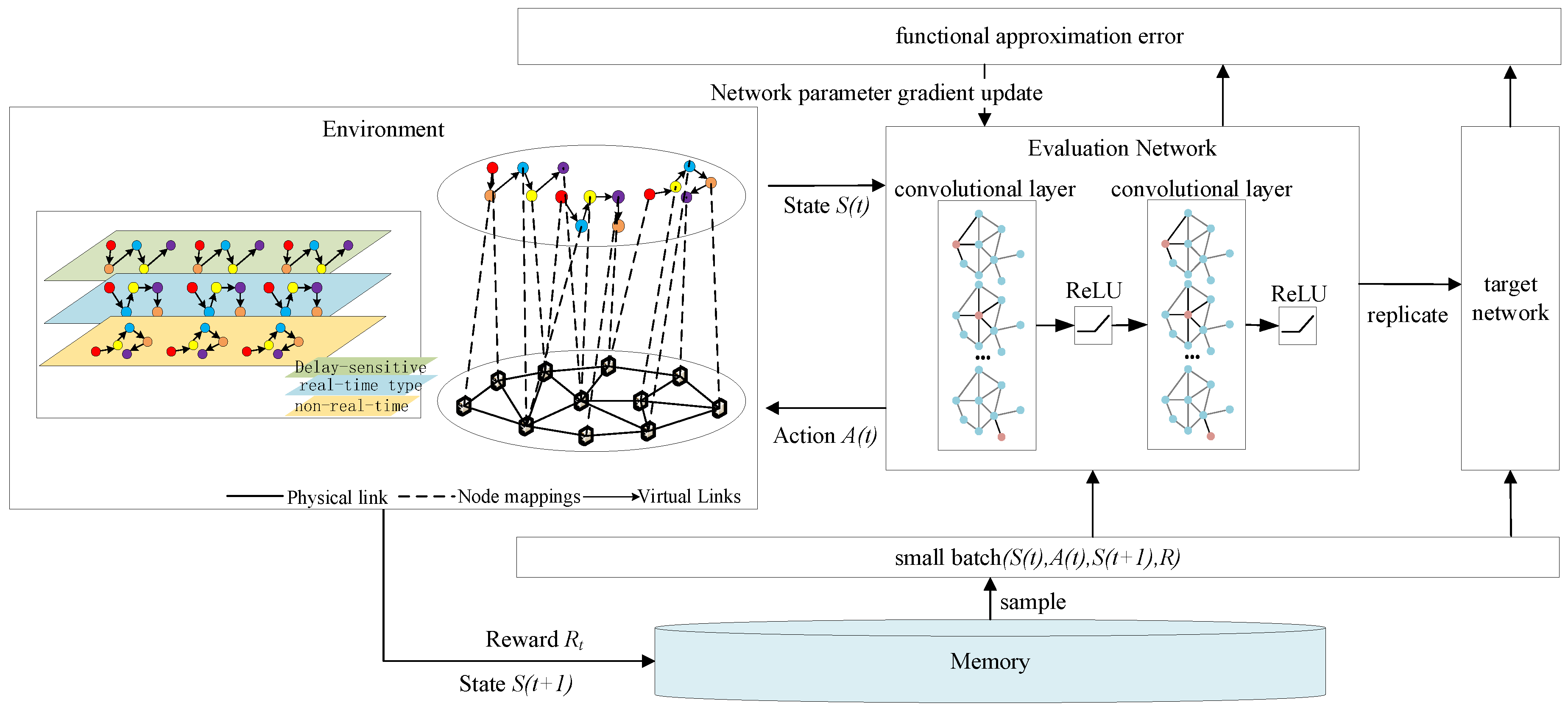
The following section illustrates the system states, actions, and reward functions in the deployment of SFCs for low-latency services within fine-grained network slicing in 6G networks. A GCN is a neural network that can directly act on domain graph structural data and can fully utilize its structural information. In the realization of network slicing technology, network topology is crucial, and a GCN can effectively handle complex network topology structure information to better realize the construction and deployment of network slices [
22]. It can rely on its powerful capabilities to help in multiple stages of the network slicing orchestration and deployment process, such as slicing design [
23], slicing deployment [
24], and slicing performance and alarm monitoring [
25]. Based on this, a GCN-based algorithm for 6G network low-latency service fine-grained network slicing is proposed.
- A.
State Space
The state space provides a comprehensive description of various resources across the network and the current processing state of each VNF, which is defined as . At time , represents the remaining computational resource vector across all nodes; shows the remaining storage resources at the nodes; and is the vector of the remaining bandwidth on the links between nodes. If two nodes are not directly connected by a link, the corresponding value of will remain 0; is a vector composed of binary variables that represent the mapping states of each node, describing the mapping states of the VNFs within the entire SFC.
- B.
Action Space
When selecting the next node for mapping, the set of selectable nodes consists of all the neighbor nodes directly connected to the current node via physical links. The action space is determined and constructed by all the VNFs currently mapped on the nodes. The vector represents the action space at time t and is defined as , where denotes the set of possible next-hop actions for all the VNFs already mapped at node .
- C.
Reward Function Definition
The agent continuously receives rewards
from the external environment to enhance its performance and train its neural network, rather than following predefined labels. Actions that result in lower latency are considered better, and the environment provides a higher positive reward for such actions. In contrast, infeasible actions (i.e., those that violate at least one constraint) are regarded as incorrect, and the environment returns a reward of 0. Thus, the reward function guides the algorithm toward optimization in the direction of minimizing latency. Based on the previous discussion, the reward
for a given action
at time
τ is defined as follows:
The strategy and target value networks of the Double DQN are improved to integrate the Double DQN with GCNs. The features of these nodes are organized into an matrix . The connections between the nodes are represented by an matrix , referred to as the adjacency matrix. This adjacency matrix and the feature matrix together form the input data for this proposed model, which will be used in subsequent analyses and computation.
In this section, modifications are made to the strategy network and the target value network in accordance with the characteristics of the GCN. We modified the layer structure of the neural network to use two convolutional layers, two activation function layers, and ReLu for the activation function. The propagation formula between the layers of the GCN is as follows:
,
,
is the identity matrix, and
is the degree matrix of
.
represents the features at each layer,
denotes the weight matrix for the connected edges, and
is the nonlinear activation function. The architecture diagram of the GCN-based low-latency service fine-grained network slicing algorithm is shown below (
Figure 5):
The Double DQN further optimizes the Q-value estimation by decoupling the action selection process from the Q-value computation process, addressing the “overestimation” issue in the DQN. Meanwhile, the GCN, by introducing the adjacency matrix, enhances the ability to extract features from the graph. The specific execution steps of the GCN-based low-latency service fine-grained slicing algorithm in a 6G network are outlined as follows:
Step 1: Initialize the capacity of the experience pool and set the initial weights of the Q-value network and the target-value network.
Step 2: Map the service function chain constructed for the current service according to Algorithm 1 during each training process, and repeat step 3 through step 5 during the network training process until the whole network reaches a converged state.
Step 3: According to the current network state , based on the predefined ε-strategy, select and execute the action in the action space and then observe the state change of the network to enter a new state .
Step 4: Obtain the reward value from the executed action and update the Q-value network parameters. Then, update the weights of the target value network.
Step 5: Deposit the samples
into the experience pool from which samples are subsequently randomly drawn for subsequent model training and updating.
| Algorithm 1: A Deep-First Search-Based Algorithm for Constructing Low-Latency Fine-Grained Network Slicing in 6G Networks |
| Input: F, D |
| Output: SFC construction scheme and its evaluation value
|
| 1: Transform the dependency D into a tree structure |
| 2: for
|
| 3: From the node where is located to find the parent node, grandfather node and root node, and put these nodes into the set ; |
| 4: . |
| 5: Assign the remaining elements in to set ; |
| 6: ; |
| 7: for |
| 8: ; |
| 9:
|
| 10: for
|
| 11: for
|
| 12: build a SFC according to the residual node rule. |
| 13: ; |
| 14: Delete the node added by . |
| 15: end for |
| 16: end for |
| 17: end for |
| 18: Equations (17) and (18) were used to compute the required computing resources and bandwidth resources. |
| 19: Equation (19) was used to compute evaluation value . |
| 20: end for |
3. Results
The time and space complexity of the proposed algorithm can be calculated in two parts: the time complexity of Algorithm 1 is
, and the space complexity is
. Algorithm 2 has a time complexity
and a space complexity
, where
is the size of the action space,
is the number of training rounds,
is the number of dependent edges, and
is the capacity of the playback experience pool, so the total time complexity of the algorithm is
and the total space complexity is
. The algorithm satisfies polynomial time in theoretical complexity and is suitable for dealing with medium-sized and below network problems.
| Algorithm 2: A GCN-Based Algorithm for Constructing Low-Latency Fine-Grained Network Slicing in 6G Networks |
| 1: Randomly reply memory to capacity D. |
| 2: Initialize the Q-network with random weights . |
| 3: Initialize the target Q-network with random weights . |
| 4: For episode to T do |
| 5: According to Algorithm 1, a dedicated network SFC with source node and end node is generated for the current service. |
| 6: With probability . |
| 7: Perform action and get the reward , observer the next state . |
| 8: Store transition in the replay memory. |
| 9: Sample random minibatch of transitions from the replay memory. |
| 10: . |
| 11: Perform a gradient step on with respect to the network parameter . |
| 12: Every step reset . |
| 13: end for |
The underlying random physical network topology is constructed using the NetworkX library. NetworkX is a package for Python 3.9; in this paper, we set the network topology as a Barabasi–Albert network by NetworkX, and the weight change of the edges is set as a sinusoidal function fluctuation mode. Other simulation parameters are set as shown in
Table 1.
The following section compares the proposed GCN-based low-latency fine-grained network slicing algorithm in 6G networks with the Double DQN algorithm.
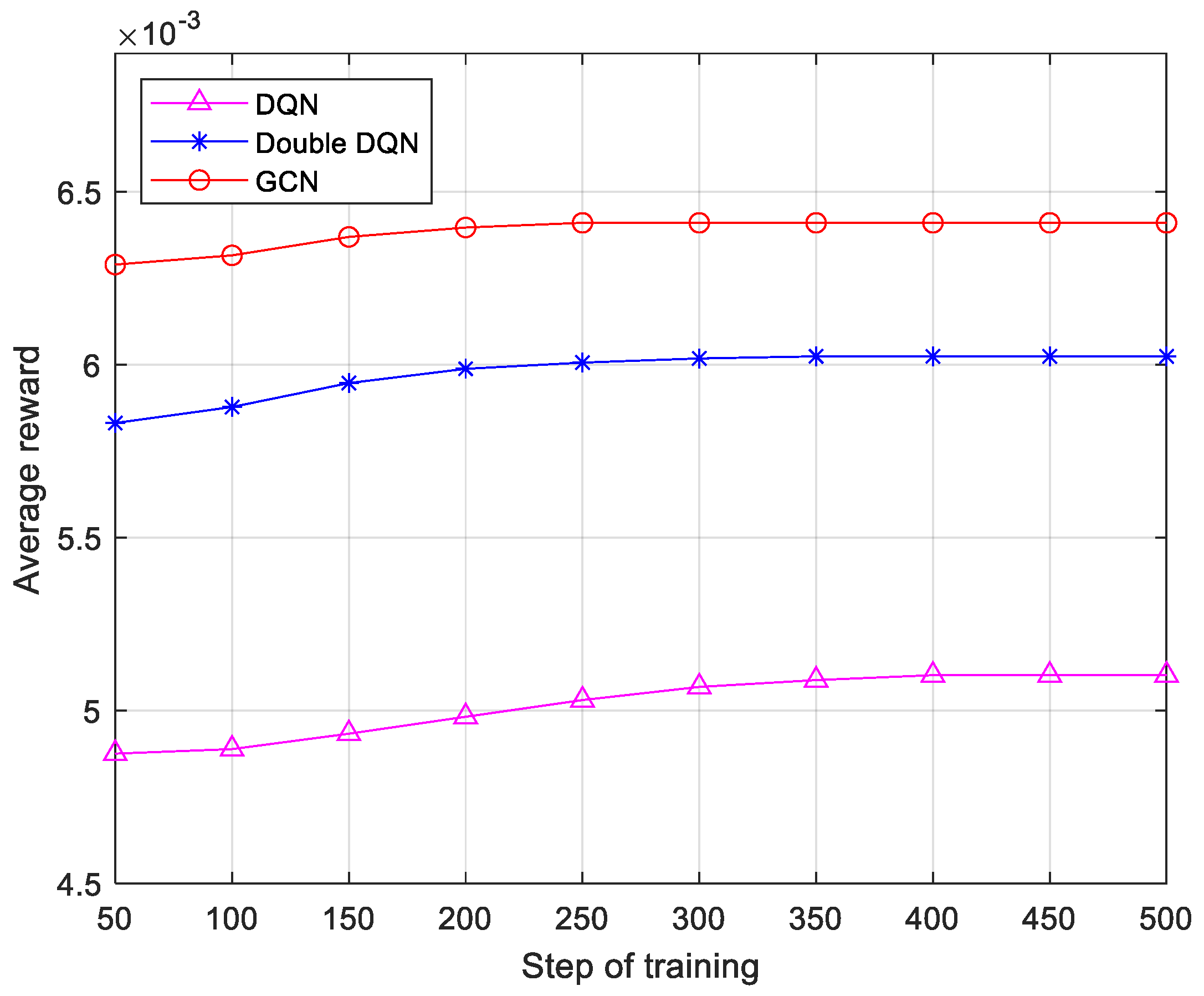
As shown in
Figure 6, the reward value in this study is defined as the inverse of transmission time. Sixth-generation networks need to support highly dynamic, low-latency services. Algorithms must quickly adjust their strategies in the rapidly changing network environment. The convergence speed directly reflects the time required for the algorithm to stabilize the optimal state from the initial state and is a key indicator of the algorithm’s real-time and adaptive ability. The simulation results show that the DQN algorithm converges at 400 training steps, the Double DQN algorithm converges at 300 training steps, and the proposed algorithm achieves convergence in just 250 steps. In addition, the algorithm proposed in this paper improves the reward by 25.74% and 8.50% over the DQN and Double DQN, respectively. This means that the algorithm proposed in this paper is more suitable for resource-sensitive communication scenarios compared to the DQN and Double DQN.
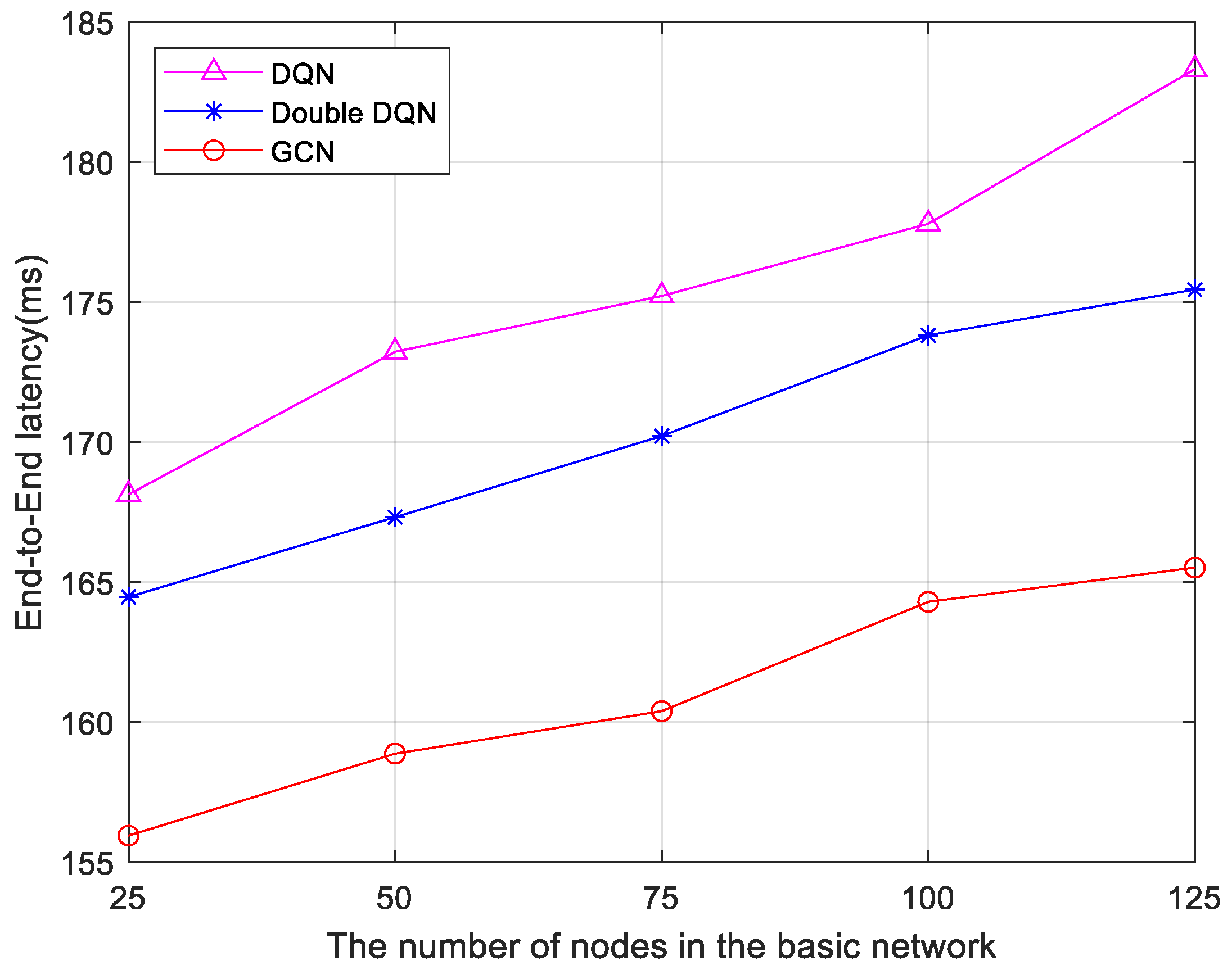
Furthermore, three algorithms are compared based on delay data under five different infrastructure network node configurations. The results are shown in
Figure 7. As the number of infrastructure network nodes increases, the end-to-end delay increases. However, the end-to-end delay of the 6G network low-latency service fine-grained slicing algorithm based on the GCN remains lower than both the Double DQN algorithm and the DQN algorithm. This is because the algorithm used in this paper itself takes into account the network topology, which has a deeper message propagation depth and has higher network scalability, so the increase in nodes has less impact on latency. This indicates that the GCN-based algorithm possesses greater stability as the number of nodes in the network topology changes.
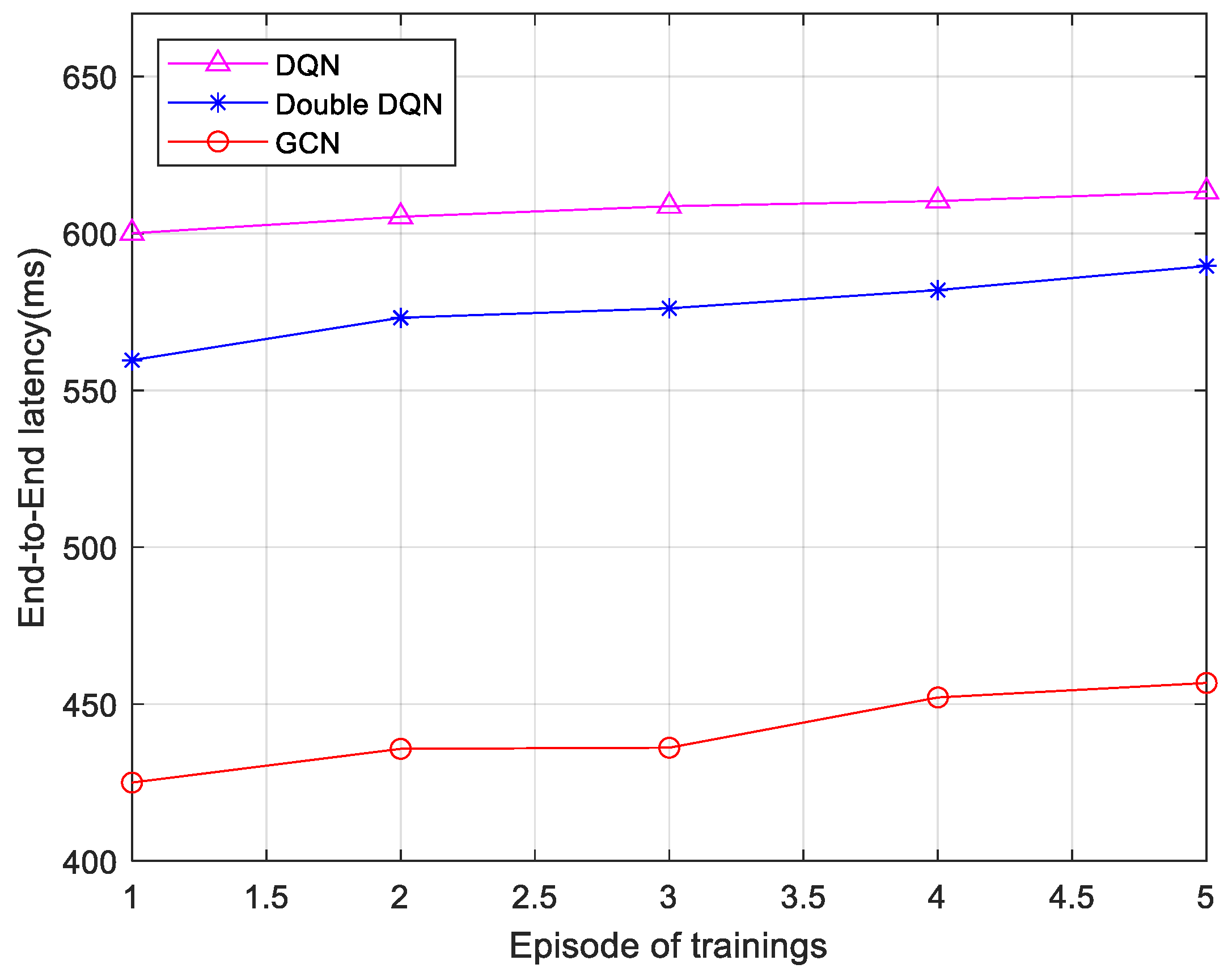
Figure 8 and
Figure 9 present comparisons of the end-to-end delay for service execution under three different algorithms, with service sizes of 25 and 75, respectively. The service size plays a crucial role in resource allocation strategies. A larger service size typically necessitates more computational and bandwidth resources, which place greater demands on the dynamism and coordination of resource allocation strategies. For each scenario, five sets of average end-to-end latency data were collected from five rounds of training, with each round consisting of 200 time steps. As observed in the figures, the end-to-end latency of all three algorithms increases as the size of the service data packet grows. The GCN-based algorithm reduces the latency by 26.92% over the DQN and 18.77% over the Double DQN when the service size is 25. When the service size is 75, this algorithm reduces the latency by 28.82% and 22.41% compared to the DQN and Double DQN, respectively. The reason for this is that the algorithm proposed in this section leverages the spectral properties of the graph and operates on the Laplace matrix to update node features, which enhances computational capability. Therefore, the end-to-end latency of the 6G network low-latency service fine-grained slicing algorithm based on the GCN is lower than that of the Double DQN algorithm and the DQN algorithm.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}