1. Introduction
The rapid development of artificial intelligence is driving various industries toward intelligent transformation [
1]. Smart classrooms, as a new teaching model, are increasingly applied in the education field. Assessing and analyzing classroom behavior is a vital component of smart classrooms [
2]. Classroom behavior not only reflects students’ learning states, but also indirectly verifies the teaching quality. Observing and evaluating students’ classroom behavior helps identify deficiencies in the teaching process and allows for targeted interventions [
3]. Therefore, this study focuses on detecting and analyzing students’ behavior throughout the classroom, aiming to provide a reference for research on classroom behavior under smart education.
Student classroom behavior detection is essentially a target detection task in computer vision [
4]. Traditional classroom behavior detection methods rely on manually observing surveillance videos, which are often limited by inefficiency, low accuracy, and observer fatigue [
5]. Consequently, researchers have explored classroom behavior detection technologies based on deep learning [
6,
7,
8] and other methods [
9,
10,
11].
In recent years, with the rapid development of deep learning technology, deep learning-based algorithms for classroom behavior detection have gained widespread application. These algorithms can be generally divided into two-stage and one-stage categories. Two-stage algorithms first generate a series of candidate regions, followed by precise classification and localization adjustments. Representative algorithms include R-CNN, Fast R-CNN, and Faster R-CNN [
12]. In contrast, one-stage algorithms directly predict the category and location of the target on the feature map, achieving both high detection accuracy and significantly enhanced detection speed. Representative algorithms include YOLO series methods [
13,
14,
15,
16,
17,
18,
19,
20] and SSD [
21]. However, in complex classroom environments with dense occlusions and multi-scale target variations, the existing algorithms tend to produce false positives and miss detections, thereby increasing the difficulty of classroom behavior detection.
To reduce the influence of irrelevant backgrounds, Li et al. [
22] proposed an improved SlowFast model for student behavior recognition. However, the model has a high parameter quantity and slow detection speed. Wang et al. [
23] proposed a novel SLBDetection-Net behavior detection method, which introduces a specific attention mechanism to prioritize the perception of learning behaviors. However, the algorithm’s complex structure and long detection time limit its suitability for real-time classroom behavior analysis. To address student occlusion issues in classroom monitoring, Zhao et al. [
24] proposed an improved Transformer-based student behavior detection model, which uses Bi-FPN to effectively fuse features from different scales. However, this model is sensitive to data variations and noise, reducing recognition accuracy. Liu et al. [
25] presented PV-YOLO, a model that adopts RFAConv as the backbone, BiFPN in the neck, and a lightweight detection head, enhancing detection accuracy for small targets. Jiao et al. [
26] proposed RS-YOLO, an algorithm that used MS-PAFPN, WS-Fusion, and SPPFormer to improve semantic feature representation and interaction, achieving excellent performance in benchmarks. Zhao et al. [
27] introduced CBPH-Net, a one-stage classroom behavior recognition method that enhances multi-scale recognition capabilities by using convolution kernels of different sizes and multi-scale features, reducing small-target information loss during sampling. However, the multi-scale feature nodes increasement raises computational costs.
In summary, in the task of dense classroom behavior detection, large target scale differences and occlusion are the main factors that limit the accuracy of student classroom behavior detection. To address these issues, this paper proposes a classroom behavior detection model. The main contributions of this paper are as follows:
- (1)
This paper proposes a classroom behavior detection model, YOLO-CBD (YOLOv10s Classroom Behavior Detection), targeting crowd occlusion and small-target detection in dense classrooms. By constructing a novel FMBNet backbone, the model enhances the capture of behavior features in densely crowds.
- (2)
To improve the detection capability for small classroom behaviors in distant instances, the AKConv deformable convolution is incorporated for feature aggregation structure to create the VACSP (VoVGSCSP + AKConv) module, replacing all C2f modules in the neck network. This modification allows the network to more precisely identify and locate occluded small targets, enhancing its handling capacity in complex scenarios.
- (3)
To address the multi-scale variations of student targets in classroom environments, this study integrates the GSConv module into the Bi-FPN feature pyramid network to resolve the loss of feature diversity after feature fusion. This optimizes the network’s multi-scale features fusion, enhancing its ability to recognize and locate targets of different scales.
- (4)
This paper modifies CIOU to Wise-IoU, enabling the network to adaptively evaluate the difficulty level of samples by dynamically adjusting the weight function, enhancing the detection performance and generalization ability.
The remainder of this paper is organized as follows:
Section 2 describes the related works, and
Section 3 provides a detailed introduction on the proposed method.
Section 4 describes the experiment setup, and
Section 5 provides the various experimental results. Finally, the conclusion is shown in
Section 6.
2. Related Works
2.1. YOLOv10
The YOLOv10 model [
28], proposed by researchers from Tsinghua University in 2024, is the latest version of the YOLO (You Only Look Once) series of object detection models. This model inherits the real-time detection advantages of the YOLO series and introduces a consistent dual assignment strategy for training without non-maximum suppression (NMS), achieving efficient end-to-end detection. Compared to previous YOLO models, YOLOv10 is highly scalable and comes in six versions—YOLOv10n, YOLOv10s, YOLOv10m, YOLOv10l, YOLOv10x, and YOLOv10b—each optimized for complex scene detection.
YOLOv10s, with its efficient backbone feature extraction network, neck feature fusion network, and multi-scale detection layer design, demonstrates the best performance in the object detection domain. It is especially suitable for detecting student behaviors in dense classroom environments, as it significantly improves detection accuracy for small targets, providing strong technical support for the development of smart classroom teaching. Therefore, this study uses YOLOv10s as the baseline model, optimizing it for dense crowd behaviors, particularly in cases of occluded behaviors among students in classrooms, significantly enhancing detection accuracy and efficiency. This improvement provides more accurate and reliable technical support for student behavior detection tasks in complex environments. However, YOLOv10 still faces challenges in extracting fine-grained features and maintaining robustness under severe occlusions or irregular spatial distributions, which motivates the architectural improvements proposed in this paper.
2.2. Student Classroom Behavior Detection
Student behavior detection is affected by various factors, such as posture, facial expressions, clothing, height, seating, classroom environment, and camera equipment, which can lead to blurred images, cluttered backgrounds, and unclear student movements. This can cause the model to misinterpret student behaviors, making it difficult to distinguish between behaviors. For example, from the machine’s perspective, hand-raising may be confused with face-touching, eye-rubbing, or head-touching, and discussions between students may resemble aimless glancing.
Apparently, if YOLOv10s’s backbone network relies solely on convolutional neural networks (CNNs) for feature extraction, it primarily captures highly localized information, overlooking long-range dependencies within image pixels and limiting the understanding of deep semantic information in complex classroom scenes. CNNs are relatively inefficient at capturing long-distance dependencies. If there is no excessive repetition of convolution operations and multiple layers stacking, long-range semantic interaction cannot be achieved.
EfficientNetV2 [
29], a network designed by Google’s team in 2021 for image classification, uses a concurrent structure that blends multi-resolution local and global features, allowing the model to learn more effective weights and enhancing its multi-scale detection performance. Unlike traditional networks, which adjust width, depth, and resolution to improve accuracy, EfficientNetV2 introduces a multi-dimensional scaling method. Firstly, it fixes available network resources at one and uses a grid search to determine the optimal balance of width, depth, and resolution. As resources increase, it proportionally scales these dimensions to ensure optimal balance. Thus, using the EfficientNetV2 architecture as the backbone for image feature extraction can enable a synergistic combination of high-level and low-level features, which help for capturing target features.
2.3. Attention Mechanism
Inspired by human perceptual processes, attention mechanisms focus on critical information areas while ignoring non-essential regions, showing excellent performance in various image processing tasks. Typically, attention mechanisms are inserted after convolutional blocks to enhance the ability to handle short- and long-term dependencies and improve learning capabilities for student behavior features in densely occluded scenes.
BiFormer is one of the most popular attention mechanisms, which maintains high internal resolution and merges a SoftMax–Sigmoid combination within the channel and spatial attention blocks [
30]. By integrating attention mechanisms into the CNN, BiFormer can automatically learn the importance of different areas, enhancing feature extraction, and ultimately improving classification and detection accuracy.
3. Methods
3.1. YOLO-CBD Architecture
As shown in
Figure 1, YOLO-CBD consists of the FMBNet backbone network, the BGC-FPN (Bi-FPN + GSConv) neck structure, and the head prediction module, enhancing the model’s capabilities in feature extraction, feature aggregation, multi-scale fusion, and final prediction. To balance detection accuracy and inference speed, the FMBNet backbone is built by integrating the Fused-MBConv module into the baseline YOLOv10s and further enhancing it with the BiFormer attention mechanism at the 3rd and 5th stages. For feature fusion, the BGC-FPN structure is constructed based on VACSP and Bi-FPN [
31], improving the integration of semantic and spatial information. In addition, the original CIoU loss used in YOLOv10s is replaced with Wise-IoU, a gradient-friendly loss function that adaptively emphasizes high-quality samples during training. This modification enables smoother gradient descent and better convergence, thereby improving localization accuracy and overall robustness.
The YOLO-CBD model takes input images with a resolution of 640 × 640. First, a 3 × 3 convolution with a stride of 2 reduces the resolution to 320 × 320. This is followed by a Fused-MBConv module that further down-samples the feature map to 160 × 160. For the P3 detection head, a 3 × 3 convolution with a stride of 2 is applied, followed by the FM-BiFormer module to enhance the perceptual capability of the model. The P4 detection head includes another 3 × 3 Fused-MBConv with a stride of 2, reducing the resolution to 40 × 40. Finally, the P5 detection head uses a 3 × 3 Fused-MBConv (stride = 2) to generate a 20 × 20 feature map, enabling accurate small-object detection in densely populated classroom environments.
3.2. FMBNet Backbone Network
EfficientNetV2 improves feature extraction ability in densely occluded scenes by adjusting the convolution modules, effectively avoiding gradient vanishing and high computational costs. Drawing from EfficientNetV2, this paper propose a mixed-scaling method in the FMBNet backbone network to achieve the best scaling factor for width, depth, and input image resolution. The FMBNet structure, comprising a convolution module, multiple Fused-MBConv modules, and FM-BiFormer modules, replaces YOLOv10s’s original backbone network, as shown in
Figure 2. The proposed backbone network better balances speed and accuracy, improving the detection performance.
In the FMBNet backbone structure, Stage 1 consists of a 3 × 3 convolutional layer with a batch normalization (BN) layer and ReLU6 activation function. Stages 2 to 18 involve stacked Fused-MBConv and FM-BiFormer modules, designed to enhance the network’s feature extraction capability through increased width and depth. Stage 3 integrates a 5 × 5 convolution with the BiFormer attention module to output large-scale features. Stage 5 also uses a 5 × 5 convolution and a BiFormer attention module to output medium-scale features. Stage 18 uses a 3 × 3 convolution layer in the Fused-MBConv module, outputting smaller-scale feature maps. To improve the pedestrian feature recognition in densely occluded environments, the BiFormer attention mechanism is incorporated into the Fused-MBConv modules in Stage 3 and Stage 5. This modification enhances the model focus on key information related to student behavior. Consequently, the extracted features in the FMBNet backbone are significantly enhanced before being fed into the neck network. The BiFormer structure is illustrated in
Figure 3.
The operations of the BiFormer mechanism are shown as follows:
Input Image Partitioning: The input image
X∈
RH×W×C is divided into
S ×
S regions, each containing
HW/
S2 feature vectors. The image
X is transformed into
Xr, which is then linearly mapped to obtain
Q,
K,
V, as shown in Equations (1)–(4).
Graph Construction for Region Routing: A directed graph is constructed to route between regions. The average values of
Q and
K are computed to yield
Qr,
Kr. An adjacency matrix is calculated to represent region-to-region correlations, forming a directed graph to identify participation relationships between different key-value pairs, as shown in Equation (5).
Graph Pruning: Each region retains only the top
k connections by trimming the correlation graph, as described in Equation (6), where the
i-th row of
Ir contains the top
k most relevant region indices for region
i.
Token-to-Token Fine-grained Attention Calculation: Fine-grained attention between tokens is then calculated, as shown in Equation (7).
Here, Kg = gather(K, Ir), Vg = gather(V, Ir) and LCE(·) are used with depthwise separable convolution via parameterized values, which is set to 5 for specific performance requirements. By employing this dual-layer routing attention mechanism, BiFormer captures both global and local feature information. Coarse-grained regions filter out unrelated key-value pairs, retaining only relevant regions for fine-grained attention interactions, thus facilitating the retention of a small subset of routing regions. Since this module uses sparse rather than down-sampling techniques, the network focuses more on regions containing small targets and extracts more precise features.
3.3. VACSP Module
In the context of detecting student behaviors in complex, densely occluded classroom environments, the YOLOv10s network can be hindered by obstructions, often focusing on local pixel positions rather than capturing essential contextual information. To leverage contextual information, stacking convolutional layers repeatedly would be ideal but poses computational inefficiencies and optimization challenges. This paper proposes a VACSP module, which integrates the VoVGSCSP module [
32] and the AKConv module [
33] and overcomes these challenges through sparse connections. The structure of VACSP and AKConv are illustrated in
Figure 4 and
Figure 5.
To enhance spatial adaptability, the AKConv module introduces a dynamic sampling mechanism that adjusts the receptive field according to the content of the input feature map. For a given kernel size, a set of base sampling coordinates Pn is first generated using predefined spatial patterns. Then, for each central point P0 in the feature map, convolution is applied at the relative positions P0 + Pn using learned weights. To further improve alignment with objects of varying shapes, AKConv incorporates a learnable offset component that predicts spatial deformations. The final sampling locations are adjusted to P0 + Pn + Δ, where Δ denotes the predicted offset values. This adaptive mechanism enables the convolution kernel to more accurately focus on semantically relevant regions and improves the extraction of discriminative features, particularly for small or irregularly shaped targets.
The VoVGSCSP module consists of three convolution blocks (CBS) for spatial feature extraction and a GSBottleneck module. As shown in
Figure 4, we replace one of the CBS convolution layers with the AKConv module, which enhances the VACSP structure with multi-scale adaptability and higher efficiency by dynamically transforming low-resolution features within each channel. The AKConv module adaptively combines multiple convolution kernels (e.g., 1 × 3, 3 × 1, and 3 × 3) using attention weights derived from global contextual features. This dynamic weighting mechanism allows the network to adjust its receptive field based on spatial content. Compared to the C2f module, AKConv introduces only 0.55 M additional parameters, maintains comparable inference speed in FPS, and improves mAP50 on small-object detection by 2.6%. Specifically, AKConv introduces flexibility into the VACSP structure by initially defining the sampling positions of the convolutional kernels based on target coordinates. It then performs 2D convolutional sampling to extract image features and calculates spatial offsets to adjust these positions. After re-sampling, reshaping, a second convolution, and normalization, the output is activated using the SiLU function. Unlike traditional convolution operations with fixed receptive fields, AKConv modifies the sampling shape for each position, enabling the network to dynamically adapt to image content. This adaptability significantly enhances the network’s ability to focus on small-target regions and extract fine-grained features under complex spatial variations.
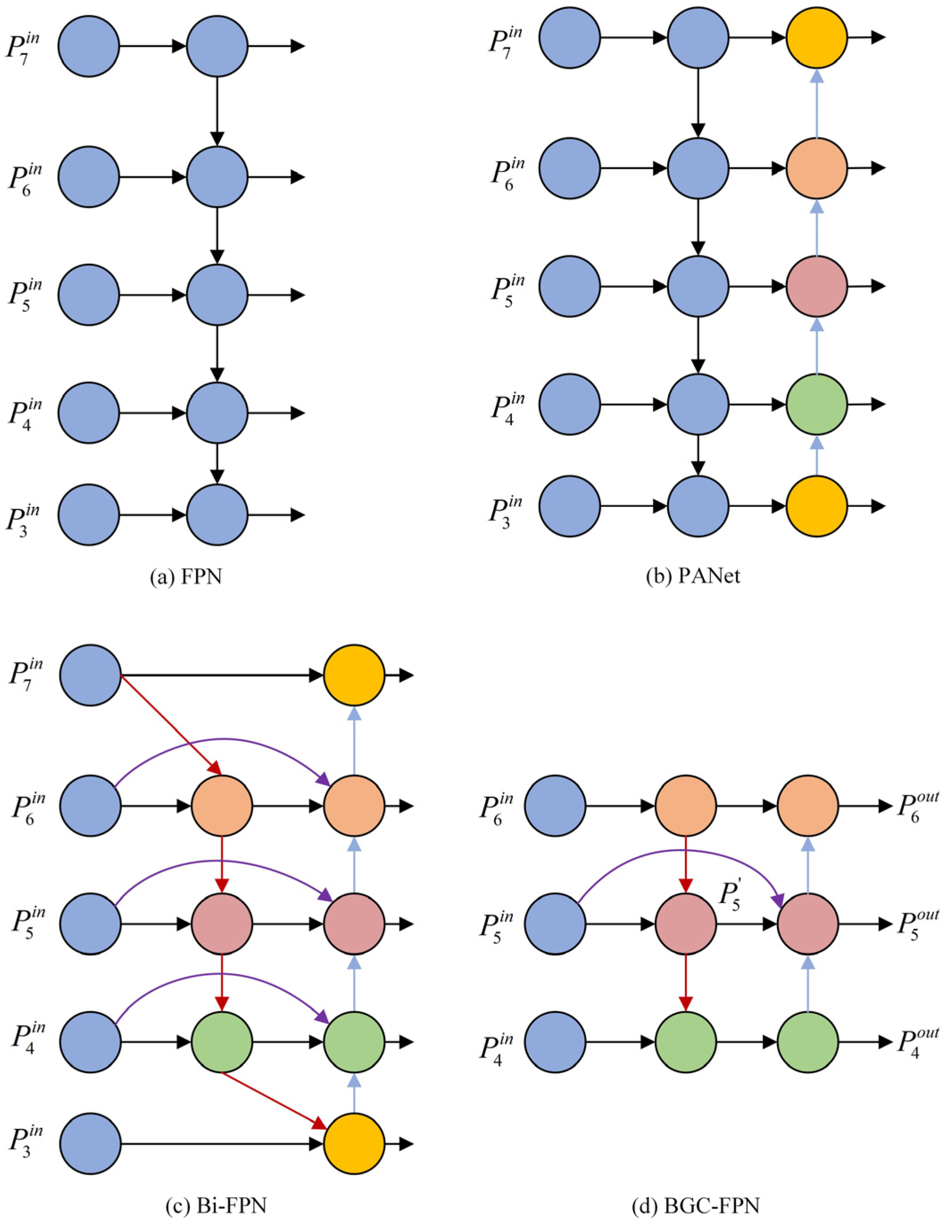
3.4. BGC-FPN Structure
The YOLOv10s model originally adopts the PANet feature fusion structure to enhance fusion performance. However, since all PAN input features are processed by the FPN, PAN lacks some original feature information, which can introduce learning biases and reduce detection accuracy. To improve the detection of attentive behaviors, this paper proposes the BGC-FPN feature pyramid network structure, integrating Bi-FPN’s feature fusion concept into YOLOv10s and replacing the neck’s standard convolution module (CBS) with the GSConv module. GSConv is a lightweight convolution that eliminates the negative impact of channel separation in feature fusion. As illustrated in
Figure 6, GSConv first applies standard convolution to the feature map, followed by depthwise separable convolution. The results are concatenated and reshuffled to recombine channels, enhancing model detection performance. The redesigned YOLOv10s neck network, as shown in
Figure 7, better suits complex student behavior detection environments.
The BGC-FPN structure differs from Bi-FPN by reducing input nodes to three effective feature layers, suitable for a simpler backbone network. Additionally, an extra edge is added through a skip connection, merging features from the feature extraction network with corresponding features from the bottom-up path, preserving shallow detail information while minimizing deep semantic loss. Compared to PANet, BGC-FPN removes nodes with only one input edge, as they do not undergo feature fusion and contribute minimally to the network. The highlighted purple sections in the structure indicate feature fusions added to increase accuracy within an acceptable range of computational costs. Traditional feature fusion methods, such as concatenation or shortcut operations, simply stack or add feature maps. However, due to varying resolutions among different feature maps, each map contributes differently to fusion. BGC-FPN utilizes a weighted feature fusion mechanism that is fast and efficient for training.
The specific example of BGC-FPN feature fusion is expressed in Equations (7) and (8), illustrating a two-feature fusion at the fifth level.
where
represents the middle node input the fifth level,
is the first node input,
w is the learned weight parameter,
Resize is the feature map sampling operation, and
Conv represents the convolution operation. Overall, BGC-FPN incorporates a weighted bi-directional, cross-scale fusion mechanism, enhancing robustness in multi-scale feature detection for classroom behavior.
3.5. Wise-IoU Loss Function
For student classroom behavior detection, the high prevalence of small targets is crucial to the overall detection performance. Traditional loss functions primarily consider the Intersection over Union (IoU) between the predicted and ground truth boxes, but often overlook classification information. By carefully designing a loss function, we can improve model detection accuracy. YOLOv10s utilizes DFL Loss and CIoU Loss for bounding box regression, where CIoU employs a monotonic focus mechanism, but lacks balance between difficult and easy samples. The presence of low-quality samples in the training dataset can negatively impact the detection performance. To address this, we introduce the Wise-IoU loss function [
34], which incorporates a dynamic non-monotonic focusing mechanism to balance samples more effectively. Wise-IoU substitutes IoU with an outlier degree assessment of anchor box quality, avoiding excessive penalization due to geometric factors (such as distance and aspect ratio), as shown in Equations (10)–(12).
Here, δ is a threshold parameter that defines the point at which the gradient gain r is maximized (i.e., when β = δ, r = 1). The parameter α controls the curvature and sharpness of the focusing mechanism. LIoU ∈ [0,1] represents the IoU loss, which will weaken the penalty term for high-quality anchor frames and strengthen their focus on centroid distance in the case of high overlap between anchor and prediction frames, and RWIoU ∈ [1,exp] represents the Wise-IoU penalty term, which strengthens the loss of ordinary-quality anchor frames. The superscript * stands for not participating in backpropagation, effectively preventing the network model from generating gradients that cannot converge. acts as a normalization factor, representing the sliding average of the increments. β stands for the degree of outlier, whose small value implies that the anchor frames are of high quality, and assigns a small gradient gain to them. In addition, smaller gradient weights are assigned to prediction boxes with large outlier values, thereby suppressing the negative impact of low-quality training samples on model optimization. Thus it can focus the bounding box regression loss to the ordinary-quality anchor frames and improve the overall performance of the network.
By balancing penalty terms based on anchor quality, the Wise-IoU function enables the network to adaptively focus on both highly relevant and mid-quality anchor boxes, which is particularly useful in tasks with complex scenes and varied target scales, like student behavior detection in classroom settings.
6. Conclusions
This paper proposes a novel classroom behavior detection model, YOLO-CBD, designed to improve detection accuracy and address the challenges of severe occlusion and multi-scale variation in complex classroom environments. Specifically, the BiFormer attention mechanism was integrated into the redesigned FMBNet back-bone to enhance feature extraction under dense occlusion. AKConv was incorporated into the VoVGSCSP module to improve small-target detection at long distances. In the neck network, the BGC-FPN structure was developed by combining Bi-FPN with GSConv, facilitating more effective multi-scale feature fusion and richer semantic information extraction. Additionally, the Wise-IoU loss function was introduced to better handle bounding box localization errors by adaptively focusing on sample difficulty. Experimental results demonstrate that YOLO-CBD achieves an mAP50 of 93.4% with a lightweight model size of approximately 9.43M parameters, meeting real-time detection requirements for classroom behavior analysis.
In future work, we plan to further reduce the model size through model compression techniques such as pruning or knowledge distillation to better meet the deployment requirements on resource-constrained edge devices. Moreover, we intend to expand the range of detected student behaviors to include actions such as writing, discussing, and answering questions, thereby improving the model’s applicability in more diverse smart classroom scenarios.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}