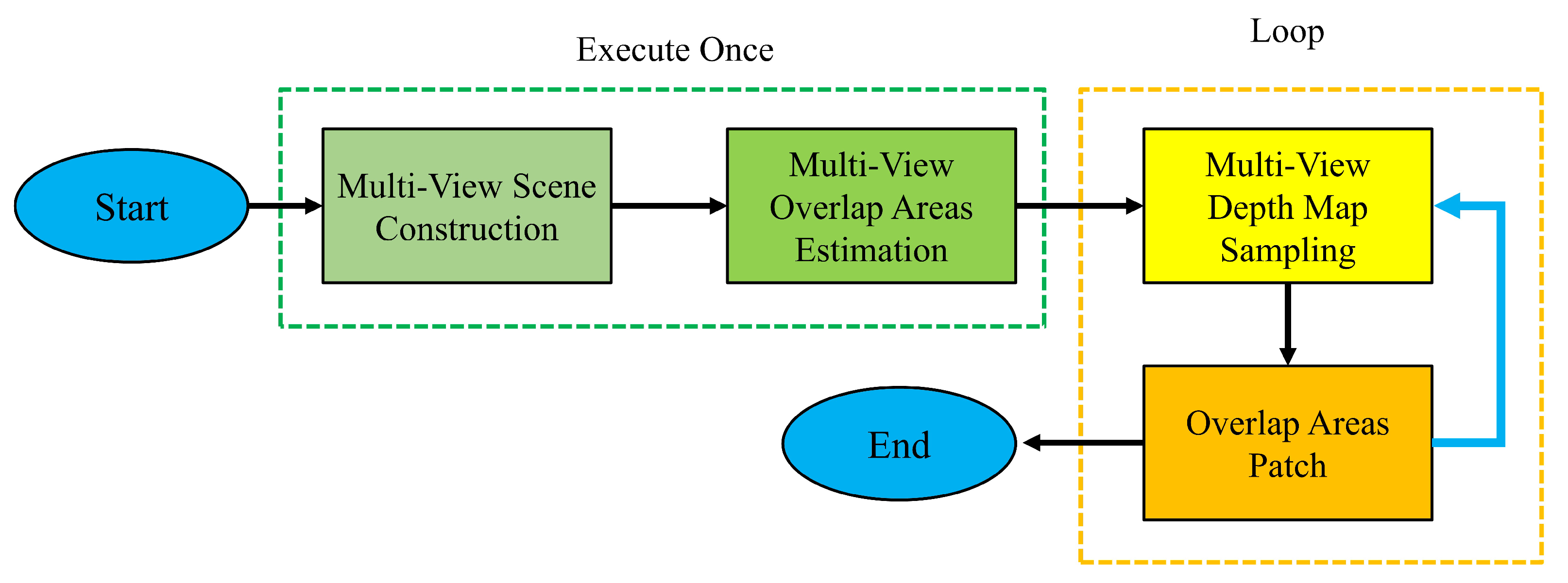
4.1. Multi-View Scene Construction
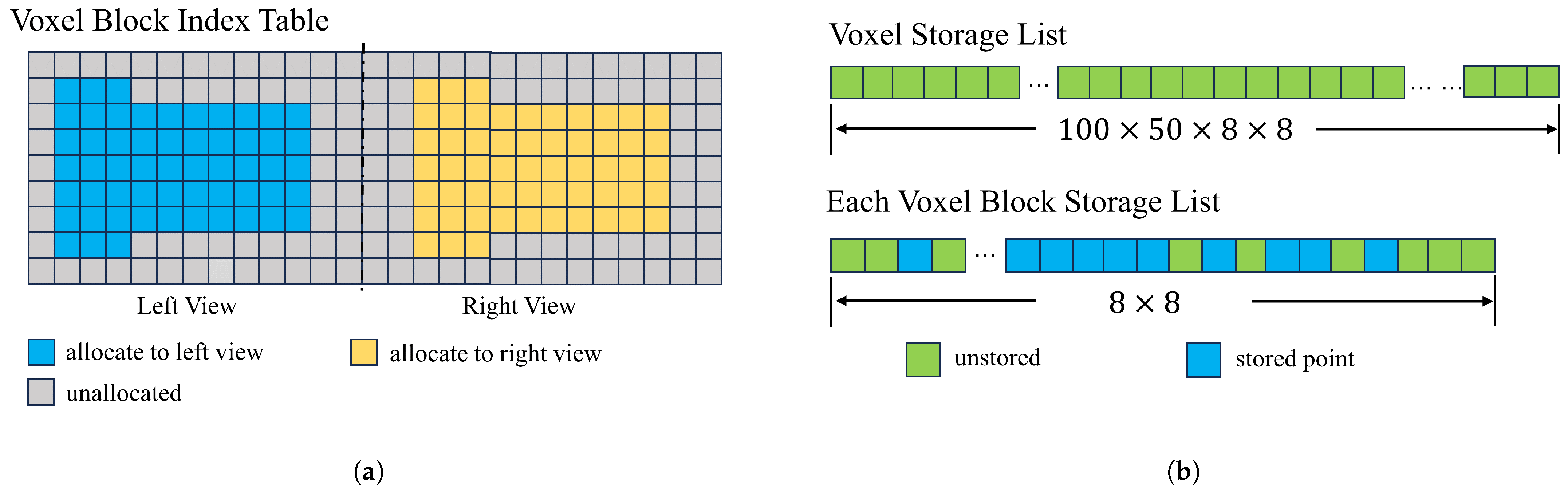
To facilitate data access and reduce conflicts between views, a two-dimensional voxel block index table is designed to manage voxel blocks of different views and the actual storage area of voxel blocks of different views; our voxel block borrows from the implementation of voxel blocks in InfiniTAM [
24]. These two structures are called voxel block index table and voxel storage list. These two data structures are shown in
Figure 3.
The voxel block index table shown in
Figure 3a is a two-dimensional table that stores information about voxel blocks, indicating whether elements are assigned to voxel blocks and whether the area of the depth map needs to be assigned to voxel blocks. In our design, different regions divided by columns will be assigned to voxel blocks in different views to avoid storage conflicts. For example, with a voxel size of 5 mm, the left and right views can be fully covered by pre-assigning a two-dimensional table with a length of 100 and a height of 50. Columns 1 through 50 are assigned to the left view and columns 51 through 100 are assigned to the right-hand view.
The voxel storage list shown in
Figure 3b is a linear table of custom voxel structures, where each element stores a three-dimensional piece of information. In other studies [
19], individual voxels require less storage space (minimum 4 bytes; our 12 bytes) but have a larger number of constituent voxel blocks. In the process of voxelizing the depth information of the chest and abdomen, only some voxels can be used. Therefore, we have improved the storage of voxel blocks from storing all the voxels of a voxel block (which requires the allocation of the length of
) to storing all the pixels of a voxel block, improved to storing only the valid voxels on each vertical column of the voxel block (only the length of
needs to be allocated); this improvement reduces the memory required for voxel storage by 96%.
When constructing the scene, you need to enter a depth map from a different perspective. Firstly, the thoracic and abdominal regions are extracted through the corresponding mask, which can avoid the interference of other regions. Secondly, for each depth map, the depth value of the effective region is traversed, and the depth value
stored by the pixel is converted to the
under the current camera coordinate by the camera internal parameter
K. Finally, the
is converted into the voxel coordinate, and the voxel coordinates in a certain range are converted into the voxel block coordinate
utilizing interception. Geometrically, the meaning of this operation is to divide the points in a certain region of space into the range of the voxel block. Formula (
1) describes this process, where
L is the side length of the voxel block.
After obtaining the coordinates of each voxel block, each voxel block is stored in the voxel block index table for easy access. The table index
is calculated by adding the distance on the negative half-axis, as shown in the Formula (
2), where
is the column offset, which in the experiment is set to half the width of the voxel index table.
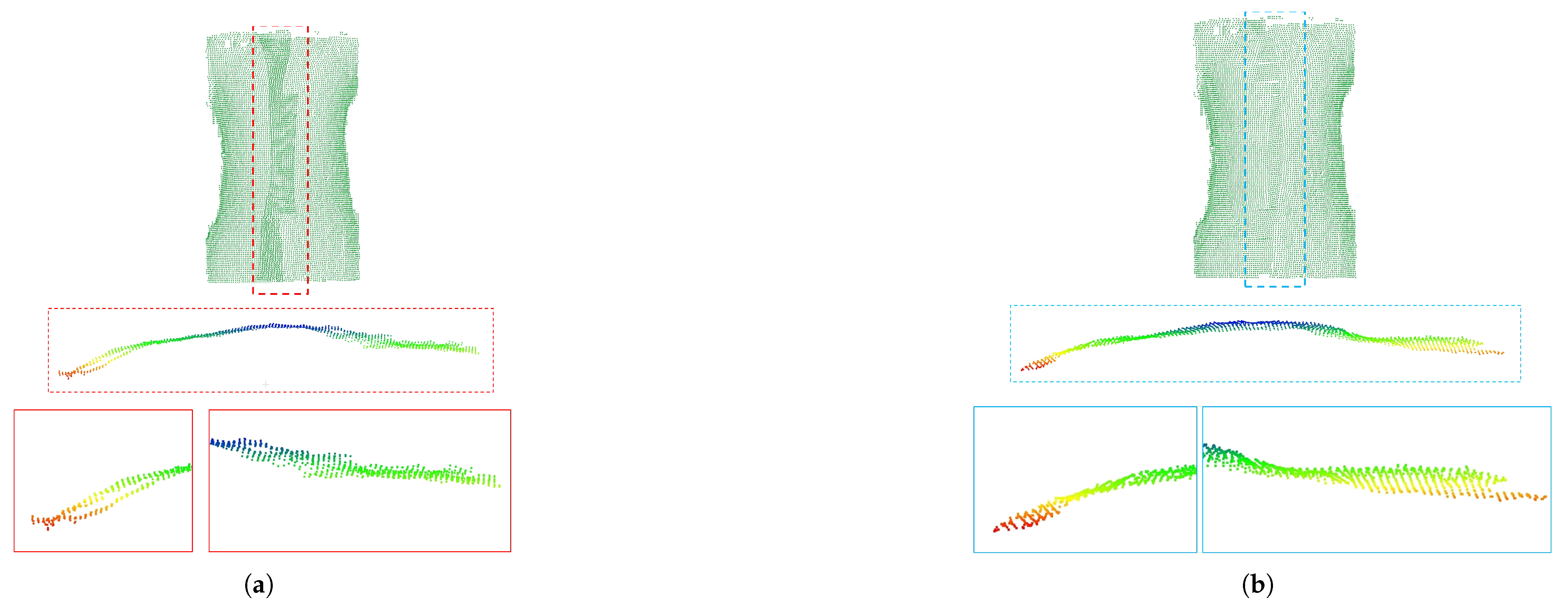
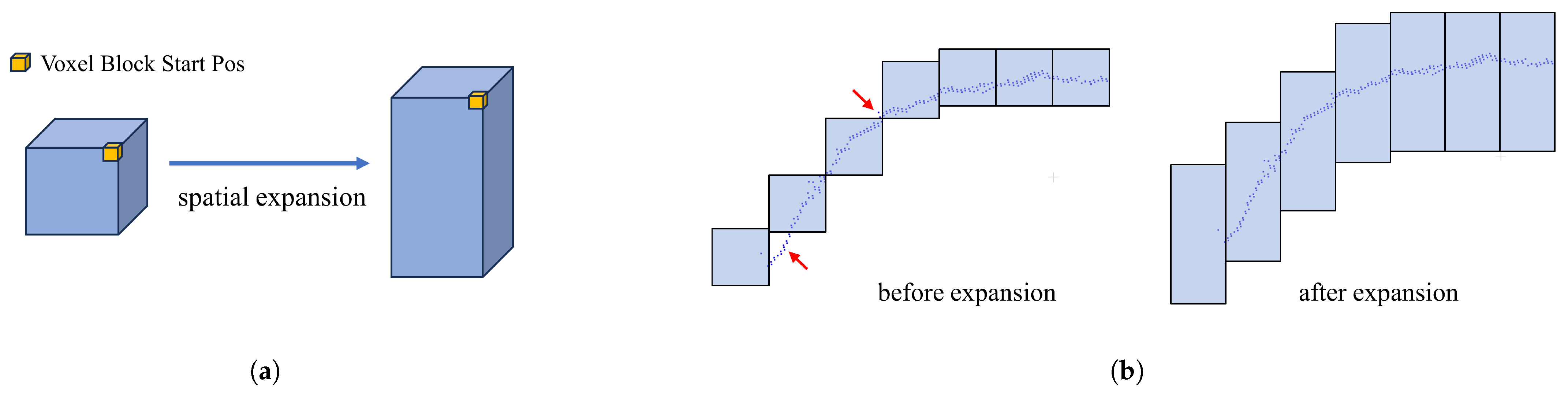
In addition, in the experiment of constructing the scene, we found that for the depth data of the human chest and abdomen with a certain curvature, missing areas that could not be covered by voxel blocks (see red arrows in
Figure 4b) appeared in some areas. This problem is probably due to type conversion during the interception of voxel block coordinates.
To solve the problem of this missing region, we solve it by optimizing the
z-axis coverage of voxel blocks. Specifically, the general voxel block size is composed of 8 × 8 × 8 voxels, whose starting and ending coordinates are
and
, respectively, near and far from the camera along the
z-axis, and decrease and increase the size of a voxel block, respectively, so that in this section, the voxel block is sized 8 × 8 × 24 with
and
coordinates. Geometrically, the cube-shaped voxel block is elongated into a column-shaped voxel block. The operation increases the coverage of each voxel block in the positive and negative directions along the
z-axis; these designs can avoid missing depth samples in subsequent procedures, as shown in
Figure 4.
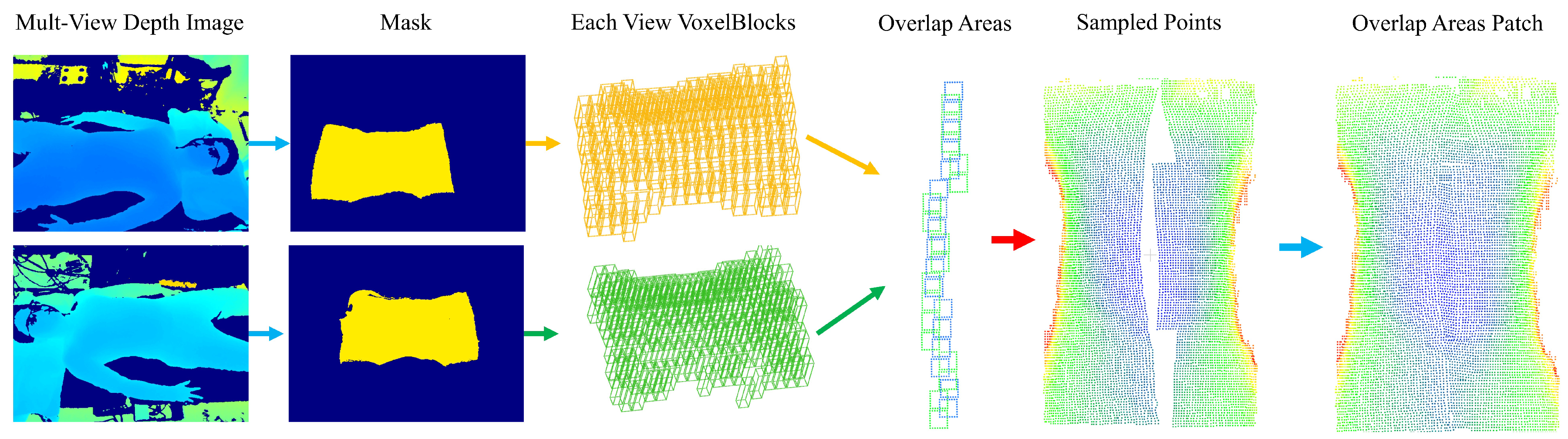
4.2. Multi-View Overlap Area Estimation
In the fusion of multi-view voxelized scenes, the obtained depth information is often redundant, especially in our scene, and the point clouds of chest and abdomen from different views will have a large overlap area. Therefore, overlapping regions are estimated in this section to determine which voxel blocks are overlapping, which voxel blocks need to be retained, and which are not required prior to the sampling step.
An easy way to think of this is to unify the voxel blocks of the left and right side views into the middle view through the rotation and translation matrix RT and treat the voxel block as a cuboid, through the three-dimensional AABB [
25] collision box algorithm, to determine whether they overlap. We initially experimented with this idea but found that the voxel blocks obtained by the algorithm were not continuous with each other in the same perspective, and there were more independent voxel blocks clustered together. Our guess is that there are more overlapping regions than independent regions in this scene.
In this study, we are inspired by the best suture algorithm [
26] in the image domain and apply the idea of this algorithm to voxel blocks of multi-view. In this algorithm, the index table of voxel blocks is regarded as 2D images taken from different perspectives, and the position information of voxel blocks stored in the index is used as the basis for judging whether there is a overlap. The steps of the algorithm are as follows.
Figure 5 shows the process of finding overlapping voxel blocks and labeled voxel blocks.
First, set the indices pointing to the voxel table in two directions, and . i corresponds to the row of the table and j corresponds to the column of the table. Because voxel blocks from different views are positioned differently in the index table when they overlap, we need to set the range of to , to , and both to .
Second, align the block of the starting voxel. The coordinates of voxel blocks in different directions can be obtained by the subscript mentioned earlier. This integer coordinate can be converted into the coordinates in the camera coordinate system and then unified into the coordinates in the world coordinate system by the rotation and translation matrix. At this time, the distance between the two coordinates on the x-axis in the world coordinate system is judged. If the distance is less than the threshold T (T = voxelSize × 8), the starting voxel block meets the requirements. If the distance is greater than the side length of the voxel block, then move the Index J in one direction (fixing in this section, moving ) until a block of eligible voxels is found.
Third, after the second step, align the starting voxel blocks in the two directions, and the overlapping region of the voxel block can be obtained by the algorithm in this step. In the voxel block index table, the overlapping voxel blocks will be marked. Algorithm 1 shows the detailed process of this step.
For more detailed logic, we used pseudocode, see Algorithm 1.
| Algorithm 1: Multi-view overlap area estimation algorithm |
![Sensors 25 03062 i001]() |
When the third step finds the collision voxel block, the column belonging to the vertical direction is moved, and then the horizontal movement alignment process is repeated. Finally, the existing valid voxel blocks are traversed to complete the search of the overlapping region of voxel blocks. While identifying the overlapping voxel blocks, the other voxel blocks are marked, and all the valid voxel blocks in the positive direction of the row index of the overlapping voxel block are set to the voxel blocks that need to be sampled; all valid voxel blocks in the negative direction are set to voxel blocks that do not require sampling.
4.3. Multi-View Depth Map Sampling
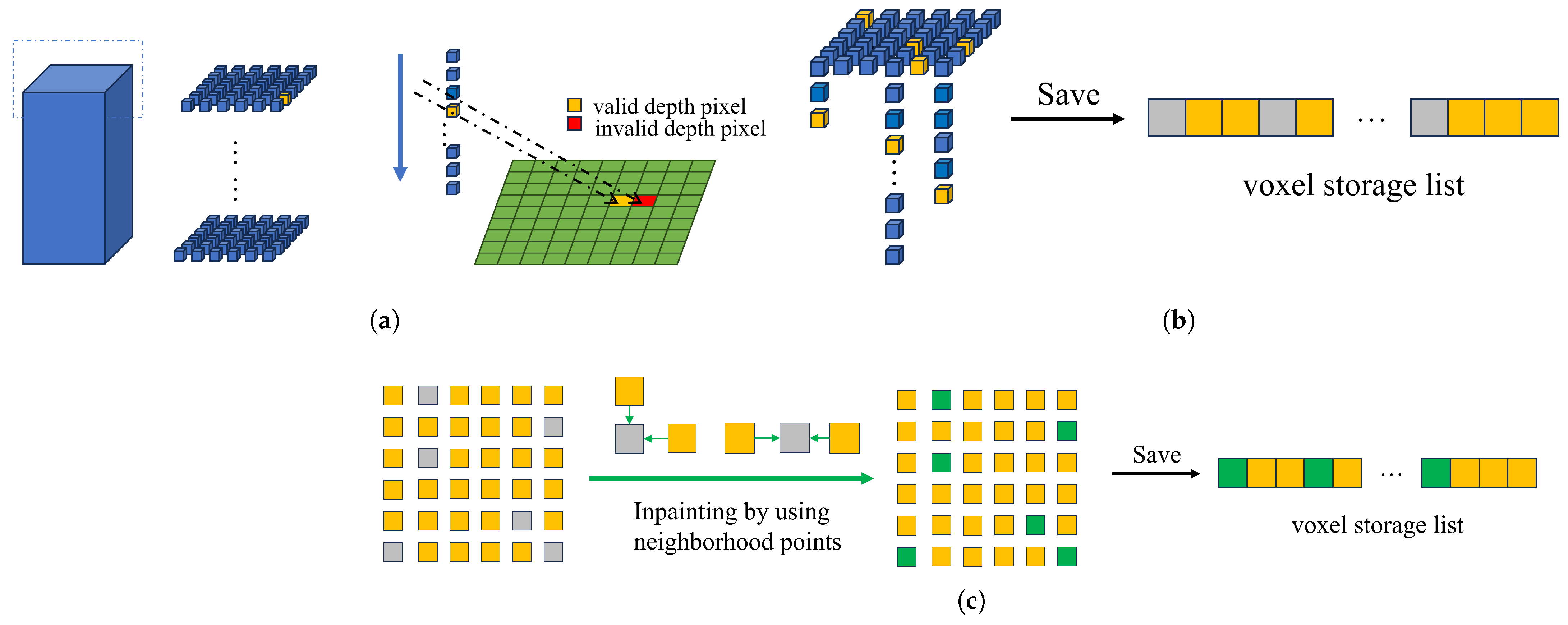
In this section, sampling is performed through voxel blocks identified as normally sampled in the voxel block index table, as shown in
Figure 6 below. The voxel block is a cube or cuboid made up of voxels measuring 8 × 8 × 24. Each voxel is a small cube with a side length of 5 mm.
As shown in
Figure 6, (a) corresponds to finding valid pixels, (b) to store 3D points, and (c) to missing 3D point inpaint. These three steps are described in detail below.
Finding valid pixels: This algorithm traverses each voxel in the voxel block and converts the coordinate information of the voxel pos into a 3D point in the camera’s view; then, a virtual depth value is obtained by projecting the intrinsic parameter matrix K of each camera to the depth map corresponding to each viewing angle. If there is a valid pixel value in the pixel coordinate corresponding to , the proximity between the depth pixel in the pixel coordinate and the depth value of the projection is judged. If the proximity is within the allowable range, a reasonable pixel value is found. This allowable range is set to the size of the side of a voxel, which is 5 mm.
Store 3D points: When the depth value is found, the coordinates of the current 3D point and the corresponding depth value are stored in the voxel storage list. In contrast to how the entire voxel block is stored in other studies (requiring
), our storage area only uses a continuous space of length
in the voxel storage list, which is used to store the entire voxel block; the voxels in the voxel block that successfully obtain the depth value are stored in the region using the row-first method. Under different views, the following Formula (
3) is also used to obtain the starting position of the continuous region to avoid the storage conflict between different voxel blocks.
Missing 3D Point Inpaint: When a voxel block sampling is completed, due to the sampling process involving several different data type conversions, there will be some situations where pixel values are missing. To this end, we add an inpainting step after sampling each voxel block. By accessing the valid points in the four-neighborhood, the points in the four-neighborhood are completed according to the three-dimensional information of the valid points.
4.4. Overlap Area Patch
After sampling multiple depth maps from different perspectives, the depth information of the corresponding region is obtained for each normally sampled voxel block. At this time, it is necessary to process the points identified as overlapping voxel blocks to finally produce a more complete human thorax and abdomen point cloud.
In a single voxel block, the original discrete 3D points can be quickly accessed by the local index of each voxel block. At the same time, 3D cameras with different viewing angles should capture the same points in the same area as close as possible in space during similar shooting times. Therefore, we transform the processing goal of the points in the overlapping region into a point completion algorithm for the overlapping region; through the similarity of the points close to each other from different perspectives and the similarity of the points in the overlapping region, the algorithm of this section is designed, and the neighborhood points can be accessed directly by the local index of voxel blocks.
The algorithm processes the points stored in the horizontally adjacent voxel blocks of the overlapping area and generates new points to fill the overlapping area by using the position information of the points near the center line in the two directions. The algorithm consists of the following steps:
The voxel blocks in the overlapping region of different views are used as the processing objects, and the sliding window method is used to process two voxel blocks at a time, which are derived from different views; there can be left–right and right–left combinations.
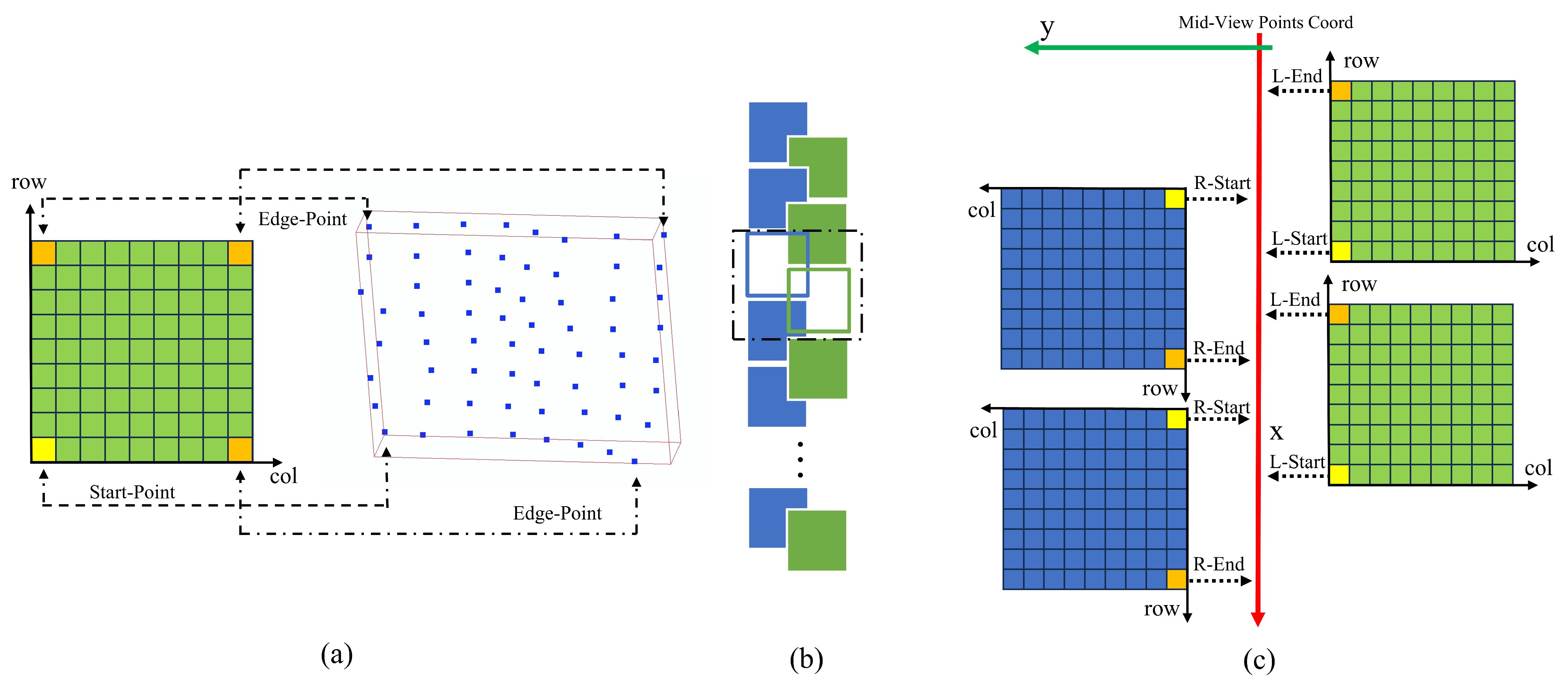
For these two voxel blocks with different views, their boundary points are extracted by the index to determine their position and overlap relationship. The definition of boundary points is shown in
Figure 7a. A voxel block stores up to 4 valid boundary points. In this section, just two of them, the end and start points on the
x-axis projection, are needed, and the different views are captured in slightly different ways.
After obtaining the start point and end point of the different views, determine whether the point pairs of the different views overlap. In the ideal case, the projection of the
x-axis from a uniform perspective, where S for L corresponds to E for R, and E for L corresponds to E for R, is unusual. In practice, the voxel blocks of l-view and r-view are partially overlapped with each other, and often overlap with two voxel blocks in the other direction. Thus, the criterion for the overlap of voxel blocks in the two directions is set to
L-Start > R-End and
R-Start > L-End, corresponding to L blocks in front of R blocks and L blocks behind R blocks, respectively, as shown in
Figure 7b.
When it is determined that two voxel blocks overlap on the
x-axis, the subscripts of one view are moved, and the stored points corresponding to the subscripts of different views are aligned on the
x-axis. In the case where LR overlaps, as shown in
Figure 7c, two cursors in the LR direction are first initialized, both pointing to the starting point, and the distance between the starting points is obtained and converted to the number of rows moved by the formula, and the r-direction cursor is moved to the new position. The cursors in the L and R directions point to the two closest points on the
x-axis; again, this is the case when the LR directions overlap, as in
Figure 8. The difference is that the first initialized cursor has R pointing to the end point and L pointing to the start point. When moving the cursor, move L’s cursor to the new position.
After the alignment in Step 4, the points pointed by the cursors in the different directions are closest on the
x-axis. At this point, calculate the distance between two points on the
y-axis; according to the size of the voxel needed to fill the number of point steps, calculate the difference between two points
, and through Formula (
4), a new point is generated by the difference between the component and the step length
k.
Repeat steps 3 through 5 to complete the completion of the overlapping region adjacent to the current two voxel blocks. After completing this pair of voxel blocks, the sliding window moves one step to continue processing another combined voxel block and finally completes all the tasks.
The concrete process of the algorithm in this section can also refer to Algorithms A1 and A2 in
Appendix A.
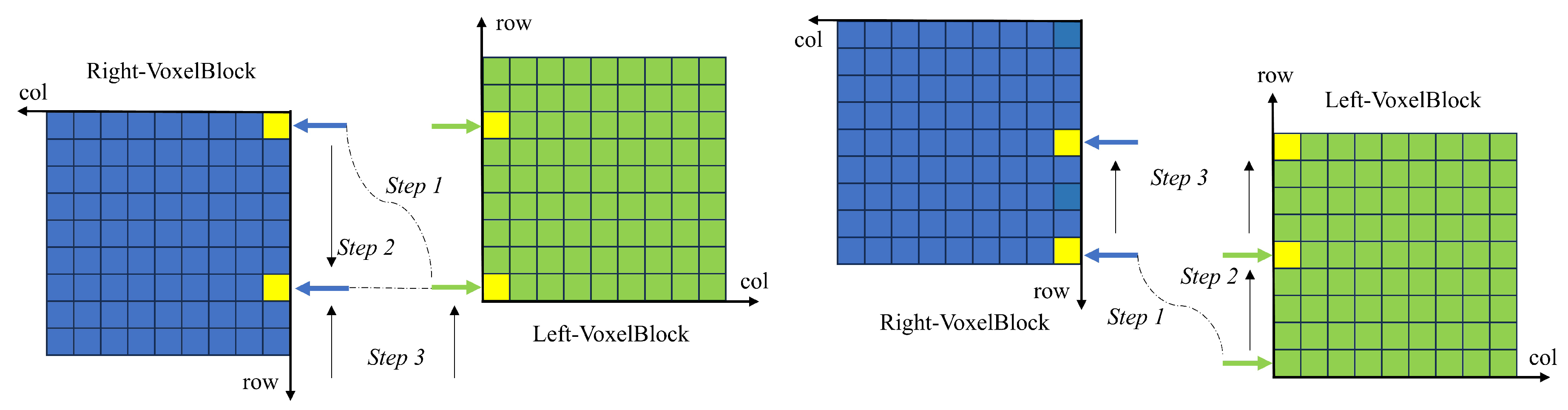
Figure 8 depicts how the cursor moves in two overlapping cases, corresponding to steps 4–5 of the above.
In
Figure 8,
Step 1 computes the vertical distance from the point on the starting line,
Step 2 converts the vertical distance to the number of steps moved, and
Step 3 completes the code by moving the cursor.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}