1. Introduction
In modern cattle farming, animal identifiability is essential for registering animal performance, health, and welfare in the context of good animal management. To this end, all animals on a farm are identified regularly, whether it is to record milk production data, provide individualised amounts of concentrate, keep track of the growth of youngstock, etc. Various affordable and effective methodologies to identify cattle by human handlers were developed in the past, such as ear tags, collars, tattoos, brand marks or RFID tags [
1,
2]. However, when studying cattle behaviour using video monitoring, none of these methods provides sufficient robustness to assure continuous identifiability of the animals. This is because it is relatively easy for the animals to strike a pose in which none of the multiple possible identification marks are visible. Moreover, all of the previously specified identification methods require to modify the animal in some way. Hence, none of these methods is used by the animals themselves to recognise herdmates. Nevertheless, the presence of a linear social hierarchy in cattle [
3] implies the identifiability of the individuals constituting a social group. Since, in contrast to pigs [
4,
5], cows only rarely use sound to communicate, they rely mainly on visual and olfactory cues to recognise each other [
6]. Among those two ’natural’ methods, vision has the most potential to develop a robust and automated re-identification system for cattle that could work from any perspective as soon as there is sufficient light to distinguish the animals from the surrounding environment.
Compared to applications and developments in humans, animal re-identification is still in its infancy. In human re-identification, large datasets are available, such as Market-1501 [
7], DukeMTMC [
8], and MSMT17 [
9]. This availability of large datasets allows the development of complex, high-performing re-identification algorithms. For example, for the Market-1501 dataset [
7], which contains 32,000 images of 1501 different identities, collected using six different cameras, rank-1 re-identification accuracies over 0.95 are reported by Chen et al. [
10], Wang et al. [
11], and Zhang et al. [
12]. To improve generalisability and to reduce the number of incorrect re-identifications, current research focuses on the re-identification of occluded persons [
12], usage of attention mechanisms [
10], and non-supervised (pre-)training [
13]. In contrast to human applications, data availability is often a limiting factor in developing highly versatile and practical algorithms for animal re-identification. In animal re-identification, most datasets only contain a limited number of animals and a limited number of images per animal. For example, the OpenCows2020 dataset of Andrew et al. [
14] includes 4736 images of 46 cows. Additionally, most studies use a standardised pose. For example, in the case of standing animals, being either top views [
14], front views [
15], lateral views or a combination of two of the aforementioned poses [
16], but never a variable animal pose.
Using a variable pose, however, adds significant complexity to the re-identification task. For example, if an animal is viewed from the side, oriented with its head to the right, one primarily observes the right flank of the animal. If the animal turns around 180°, one will primarily observe the left flank of the animal. Due to the randomness in the pied patch pattern, especially in Holstein-Friesian cattle, the left and right flank of the animal may show quite a different patch pattern. Therefore, re-identifying an animal showing its left flank by using reference images of the right flank of animals will give poor results. Previous research handled this issue by standardising the pose [
17] or using a perfect top view of the animals [
14,
18,
19]. This approach is, however, detrimental for the application of computer vision-based re-identification of cattle in commercial environments, where the ability to cope with a large variability in animal poses is an essential condition for the broad applicability of computer vision-based re-identification. As state-of-the-art methods do not meet this prerequisite, the potential use of computer vision-based re-identification on dairy farms is currently limited to the milking parlour/robot [
18], separation gates [
20], and concentrate stations. However, at these locations, the added value of computer vision-based re-identification is limited compared to highly cost-effective RFID-based re-identification.
To overcome the hurdles mentioned above, we aimed to develop an embedding-based re-identification algorithm [
16,
21] able to handle all possible poses which could be shown by cattle. Therefore, we combined two neural networks: a neural network performing simultaneous pose-estimation and behaviour classification, and a neural network which generates embeddings in a versatile way. We use an embedding-based approach rather than a classification-based method since the former obviates the need to retrain and redesign the neural network every time a new animal enters the herd. By combining the results of both networks, we can re-identify an animal, conditional on its behaviour and orientation with respect to the camera, obviating the need for a standardised animal pose.
3. Results and Discussion
Table 2 shows the rank-1 and rank-2 re-identification accuracy for re-identification without correction for the behaviour and orientation of the animals. Moreover, the rank-1 and rank-2 accuracies for seen and new individuals are compared between our dataset and the OpenCows dataset of Andrew et al. [
14]. Our embedding-based re-identification method applied to the OpenCows dataset delivers an excellent rank-1 accuracy of 0.985 for seen identities. For new identities, the rank-1 accuracy drops slightly to 0.959. However, the rank-2 accuracy is still 0.990, which indicates that most wrongly identified images result from confusion between two animals that are probably quite similar and not due to a complete failure of re-identification. The rank-1 re-identification results for seen identities in our dataset are similar to the rank-1 accuracy for new identities in the OpenCows dataset. However, for new identities in our dataset, the average rank-1 accuracy reduces to 0.822. Note the impact of the behaviour: for standing animals, the rank-1 accuracy is severely reduced to 0.777, while the rank-1 accuracy for animals lying right is still 0.890. Moreover, it takes until the rank-4 accuracy to reach a value above 0.99, indicating that a significant part of the wrongly re-identified animals is not a result of confusion between two similar individuals, but rather a complete failure to re-identify animal segments.
The large drop in rank-1 accuracy on our dataset for new identities suggests that the embedding network learns the patch pattern of each identity in the training dataset by heart. This allows the embedding network to generate similar embedding vectors for two instance segments of the same animal, even if the two images have little in common. As a result, the rank-1 accuracy for seen identities is still good. However, this strategy does not generalise, leading to a severe drop in performance when re-identification has to be performed for new identities.
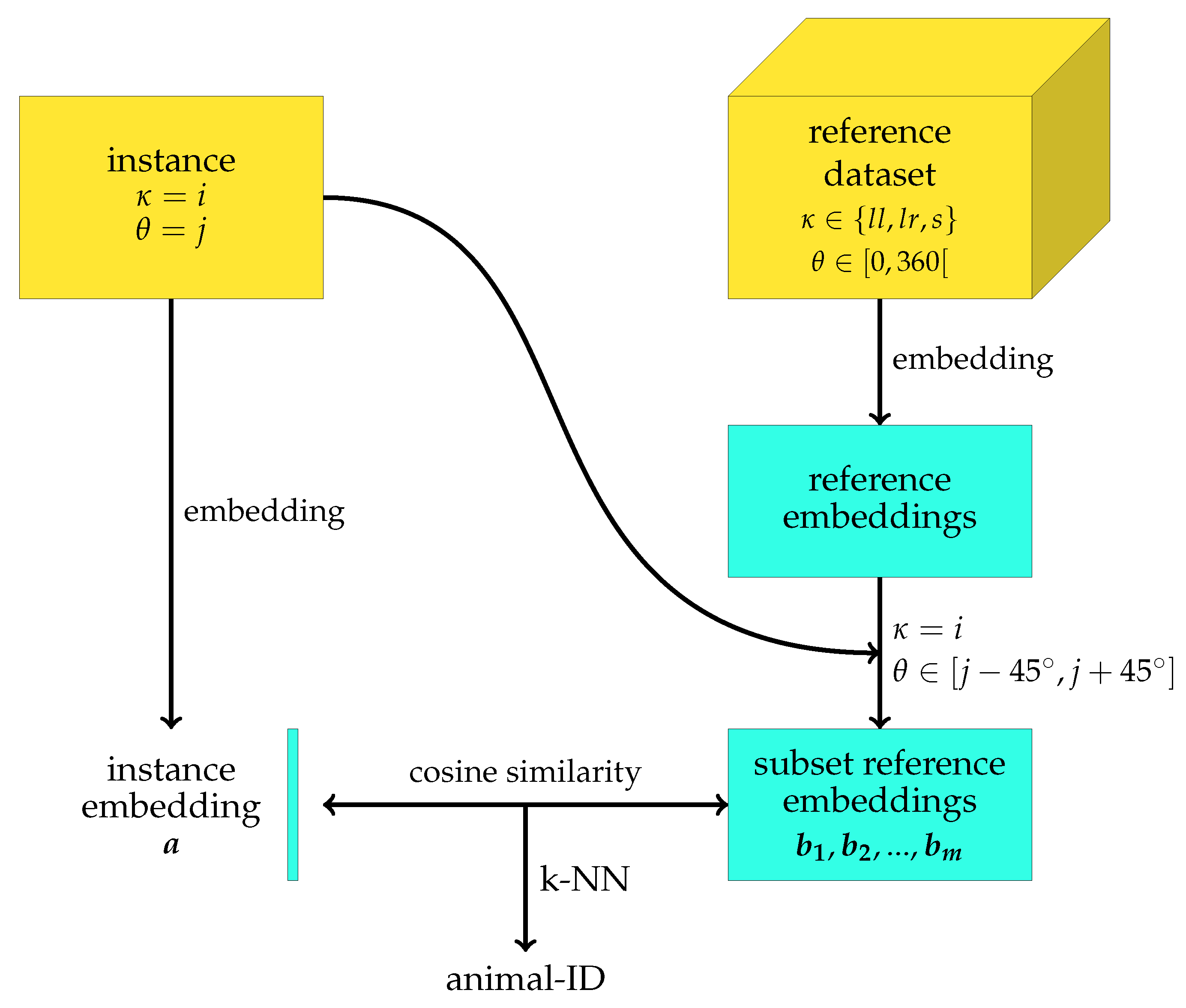
To improve the re-identification performance for unseen identities, we proposed to use metadata about the behaviour and orientation of the animal to construct a more homogeneous reference dataset for each animal segment which has to be re-identified. The results of applying this correction for orientation and behaviour are shown in
Table 3. When comparing the rank-1 accuracy with and without correction for behaviour and orientation, one can observe a significant improvement in the rank-1 accuracy with 0.072. This improvement corresponds with a 40% decrease in the number of animal segments which is wrongly re-identified. Moreover, the improvement in the rank-1 accuracy is present for all behaviours. For lying left and standing, the two behaviours with a rank-1 accuracy below 0.80, the rank-1 accuracy improves with about 0.08. For lying right, on the other hand, the improvement is with 0.052 slightly lower. Nevertheless, as the rank-1 accuracy for lying right without correction for behaviour and orientation was already 0.890, a lower improvement could be expected. If the performance improvement is, however, expressed in terms of the relative decrease in the number of wrongly re-identified instances, the performance improvement for lying left, lying right, and standing are 42%, 47%, and 36%, respectively. From this perspective, the performance improvement for lying right is even the largest of the three considered behaviours.
The differences in rank-1 accuracy between the different behaviours should, however, be interpreted carefully. From
Table 3, one could, for example, conclude that re-identification of animals lying right is significantly easier compared to the re-identification of animals lying left. However, this is not true. If one would mirror all instance segments left/right, this would result in the opposite conclusion, while both scenarios could be valid in the real world. The main cause for the differences in rank-1 accuracy between the different behaviours originates in the modest size of our test dataset, even though the number of identities in our test dataset is similar to those of test datasets used in previous research on animal re-identification [
14,
16,
18]. Knowing that for animals lying left, mostly the right flank is visible, while for animals lying right, mostly the left flank is visible, the differences in rank-1 accuracy between different behaviours rather indicate that, by chance, there are more groups of several animals in our dataset which have a similar right flank than groups of animals having a similar left flank.
Table 4 shows the rank-1 accuracies realised by the embedding network trained on all 48 identities in our dataset. This model was evaluated by determining its rank-1 accuracy with respect to the within coat-pattern group (
Table 1) re-identification for seen identities. Additionally, the overall rank-1 accuracy for re-identification of seen identities was obtained by using all 48 identities simultaneously. With regard to the within coat-pattern group rank-1 re-identification accuracy, the average rank-1 accuracy is approximately the same for r, b, rw, and rb (all 0.95–0.96) and similar to the results reported for seen identities in
Table 3. The rank-1 accuracies for the separate behaviours show larger differences, but one should consider that these rank-1 accuracies have larger estimation variances compared to the average rank-1 accuracy. For wb, all rank-1 accuracies are 1, but since this group contains only two individuals, which apparently are fairly easy to distinguish from each other, no conclusions may be drawn from this result. The wr coat-pattern group, on the other hand, reports the lowest rank-1 accuracy of all coat-pattern groups, which is about 0.08 lower than the average rank-1 accuracy of the other coat-pattern groups. This is probably because the animals in the wr class often had only a few small red patches. If several of these red patches are occluded by other animals or by the pose of the animal itself, the segmentation algorithm results in segments that barely contain any coloured patches. During annotation, we found these segments the most difficult to assign to a correct identity, since sometimes only a subtle difference in the shape of a single visible red patch delivered the necessary information to assign a segment to its correct identity. From the results in
Table 4, it can be observed that the embedding model is also struggling to some extent with this complexity. It could be argued why the same reasoning does not hold for the r and b coat-pattern groups, since all four categories r, b, wr, and wb, have in common that one of the two coat colours is present for less than 20% of the coat area. However, the few white patches of the r and b animals were nearly always located around the spine of the animals and had mostly an elongated shape. This is in contrast to the wr animals, where the red patches were mainly located at the flanks and generally had a more rounded shape. Since (1) patches located around the spine are occluded less frequently compared to patches located further from the spine and (2) more elongated patches are easier to distinguish from each other compared to rounded patches, these differences in the location and shape of coat patches are possible reasons for the observed differences in the rank-1 accuracy between the wr coat pattern group on the one hand, and the r and b coat-pattern groups on the other hand.
The rank-1 accuracies for re-identification of all 48 seen identities simultaneously are shown at the bottom of
Table 4. The average rank-1 re-identification accuracy of 0.912 is significantly lower compared to the average rank-1 re-identification accuracy of 0.971 which is reported in
Table 3 for seen animals when correcting for behaviour and orientation, as well as all but one of the other reported average rank-1 accuracies in
Table 4. This observation is expected as an increased number of possible identities goes hand in hand with a higher probability of the model being confused between two or more identities for a given animal segment. While the reported overall rank-1 re-identification accuracy is significantly lower than the value of 0.971 reported in
Table 3, the differences in the average rank-2 accuracy are much more modest: 0.972 versus 0.982 for re-identification of seen identities with 48 versus 11 possible identities. This indicates that the embedding network is more often confused between two similar individuals when the number of possible identities increases, but that the number of totally wrong re-identifications stays about the same. Compared to the small colour pattern groups with maximum 12 identities, the set of 48 possible identities is more in line with commercial group sizes of lactating dairy cows. Therefore, the obtained rank-1 re-identification accuracy for the overall group with 48 seen identities gives a better indication of the rank-1 re-identification accuracy that can be expected in practical applications. When herd sizes become even larger, up to several hundreds of animals, as is common in some parts of the world, one can expect two counteracting effects influencing the rank-1 re-identification accuracy. On the one hand, with an increasing number of animals, there is an increase in the probability of two animals having a similar coat pattern, lowering the rank-1 re-identification accuracy. On the other hand, if all animals of the herd would (initially) be used to train the re-identification algorithm, larger herd sizes will result in higher quality discriminative features being extracted by the embedding network, as will be shown later in this paper (Figure 13). The latter effect on the rank-1 re-identification accuracy will partially compensate the former, but to quantify this compensation, further research is required.
When multiple animals are present on a single camera frame, maximising the joint probability, computed by multiplication of the identity probabilities for all detected instances, offers an opportunity to leverage the rank-1 re-identification accuracy. This joint probability should be maximised under the condition that each detected instance has to be assigned a unique identity, since it is evident that an animal cannot be present twice in a single frame. This approach will reduce the probability of incorrect identification when two regularly confused animals are present simultaneously in the camera’s field of view. Hence, the average rank-1 re-identification accuracy is expected to improve. This principle of joint probability maximisation can be extended to scenarios in which animals have to be re-identified subsequently, for example, in the milking parlour. Whenever a new animal enters the milking parlour, it is possible to maximise the joint identity probability of the current and all previous animals, since each animal is expected to pass only once. Using this joint re-identification approach instead of re-identifying every animal independently, will reduce the number of incorrect re-identifications.
In most herds, new animals enter the herd on a weekly or even on a daily basis. While our embedding-based methodology is readily extendable to new identities without retraining of the embedding network, it may be evident from
Table 3 that the re-identification performance for seen identities will always be higher than for new identities. However, retraining/finetuning the embedding network for each animal entering the herd would strongly increase the energy consumption, and thus cost, of a computer vision-based re-identification algorithm. Moreover, retraining/finetuning the embedding network requires more costly hardware than is required for inference. Therefore, we suggest to apply periodically (remote) finetuning, for example, monthly, to mitigate the cost of energy consumption, while simultaneously consolidating to a large extent the improved re-identification performance for seen identities.
Figure 8 shows the first two components of a t-SNE analysis of the embeddings generated while evaluating our re-identification methodology on the overall-evaluation dataset containing all 48 different identities present in the dataset. During this experiment, an average rank-1 re-identification accuracy of 0.912 was realised (
Table 4). In
Figure 8, one can observe that the embedding vectors of most individuals form clear clusters. This is remarkable since our methodology does not require generating similar embeddings for all of the animal’s possible behaviours and orientations to achieve a good rank-1 re-identification accuracy. On the other hand, coat pattern properties such as patch size and patch edging (smooth vs. irregular) are often quite similar over the whole body. Therefore, it is not surprising the embedding network generates similar embeddings for different behaviours and orientations of an animal.
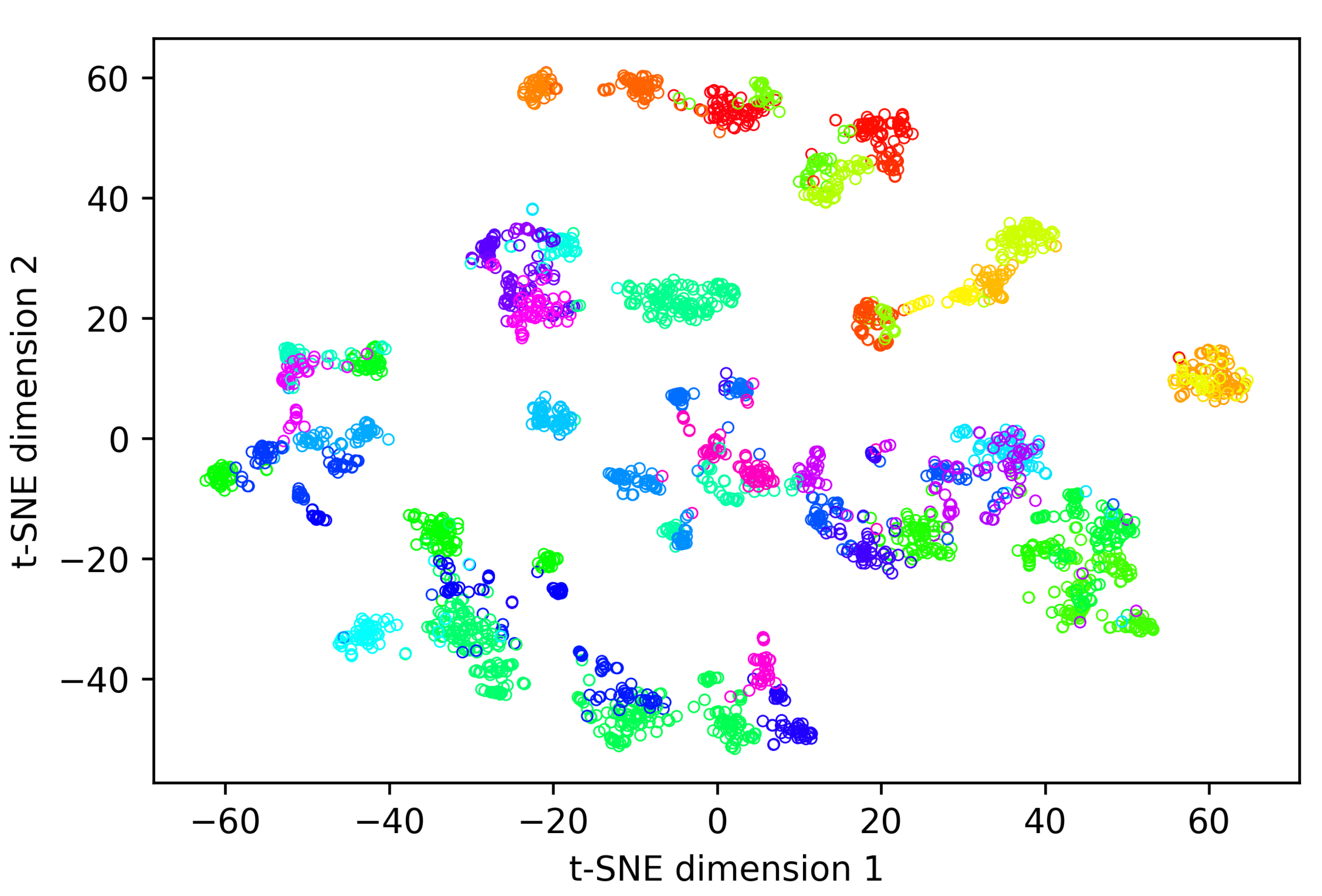
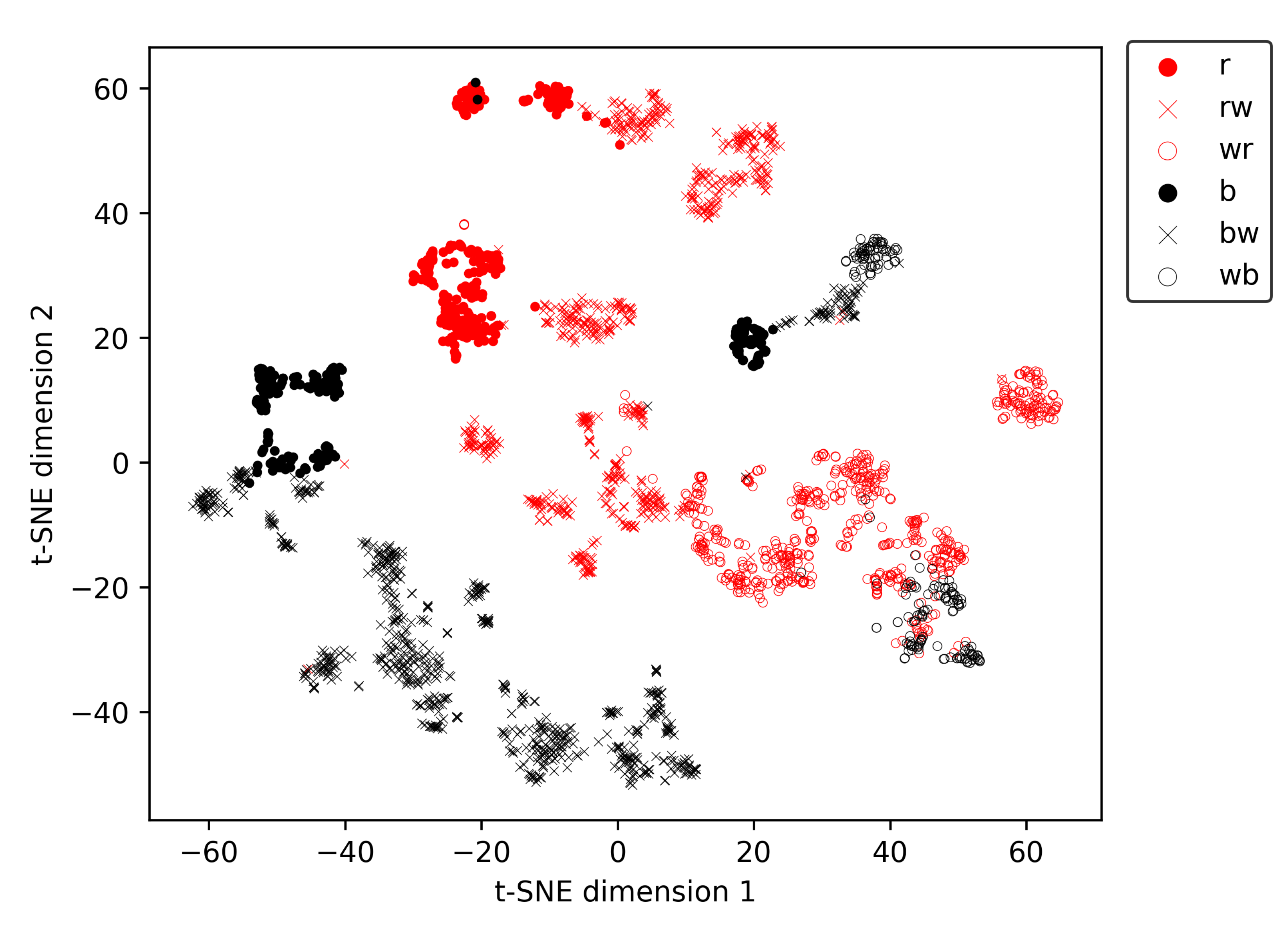
To explore the presence of metaclusters related to the coat pattern in the t-SNE vectors, we created
Figure 9, in which the marker type and colour are depending on the animal’s coat pattern (
Table 1). Ignoring the amount of white in the coats for a moment, three clear metaclusters are present in
Figure 9, each predominantly containing animals of a single hair colour. The first metacluster is located at the bottom-left of
Figure 9 and contains only black-haired animals. The second large metacluster is banana-shaped and located more centrally in the figure. This metacluster contains predominantly red-haired animals, together with instances of a single animal with a wb coat pattern. The third and smallest metacluster is positioned in the middle of the previously described banana-shaped metacluster and contains only black-haired animals. The single black-haired animal in the second, predominantly red-haired, metacluster is an almost entirely white animal with only a few small black patches, of which none have a diameter larger than 20 cm. Therefore, it is no surprise this animal ends up in the predominantly red-haired cluster. After all, there are several red-haired individuals which also have only a few small red patches in their coat, while the other wb animal in the dataset has much larger, more elongated black patches, with dimension well over 50 cm. In each metacluster, the amount of white in the coat increases along the main axis of the metacluster. For example, for the predominantly red-haired metacluster, all predominantly red-coloured animals are located at the top-left of the metacluster. More towards the right/bottom of the metacluster, the red and white (rw) coloured animals are located, while all the white and red (wr) animals are situated at the bottom-right part of the metacluster.
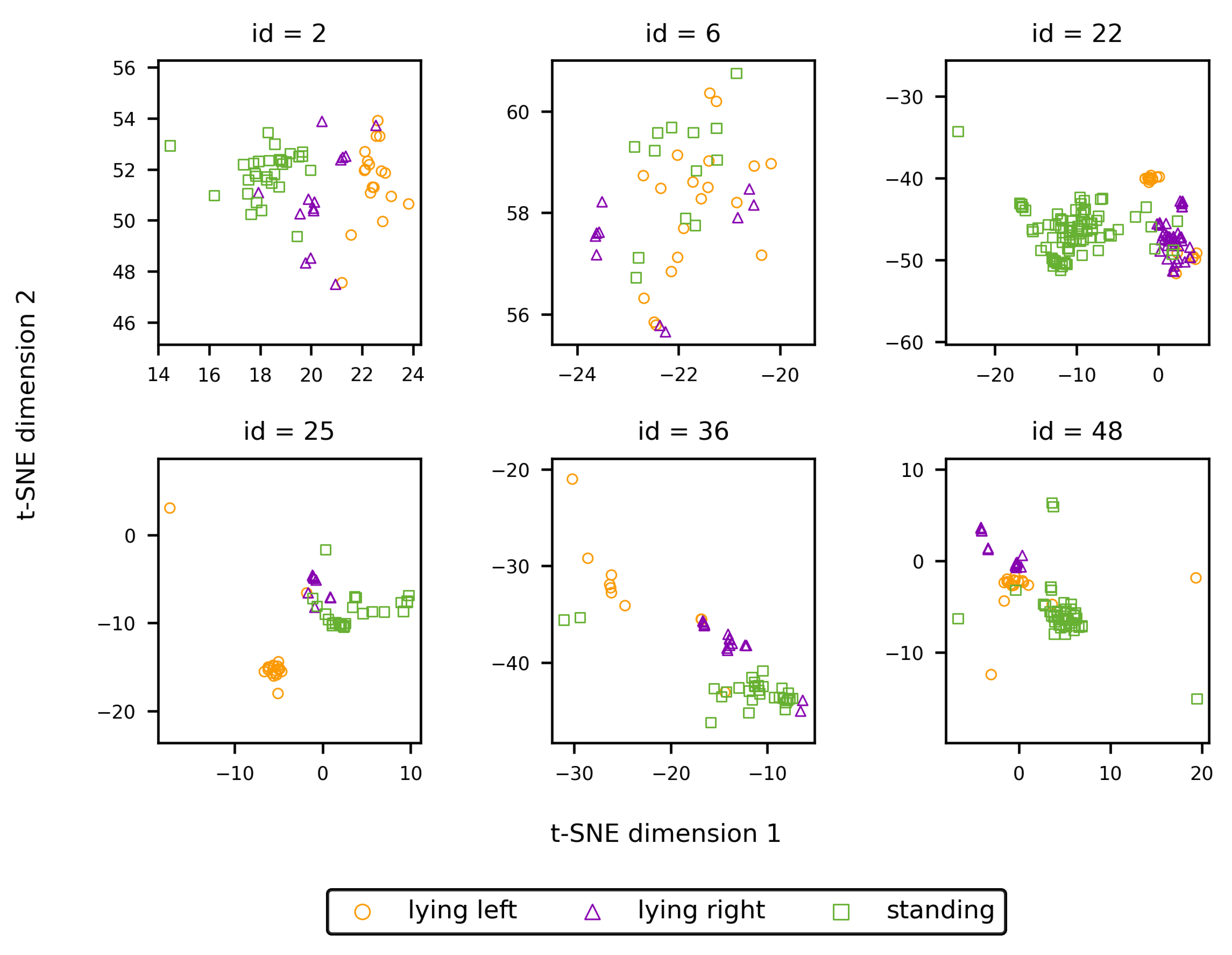
Figure 10 allows to study the embeddings of individual animals with regard to the presence of behaviour-related clusters. For most identities, some degree of clustering according to the shown behaviour is present. This apparent clustering originates from the training procedure of the embedding network, during which batches are constructed conditional on the animal’s behaviour. As a consequence, the incentive of the embedding network to generate similar embeddings for images of a single identity is also conditional on the animal’s behaviour. However, since the properties of the coat pattern are quite similar over the whole body, as mentioned earlier, similar embeddings are generated for the different behaviours. Hence, the mutual position of the cluster centres is only defined by randomness and is of no influence on the re-identification performance.
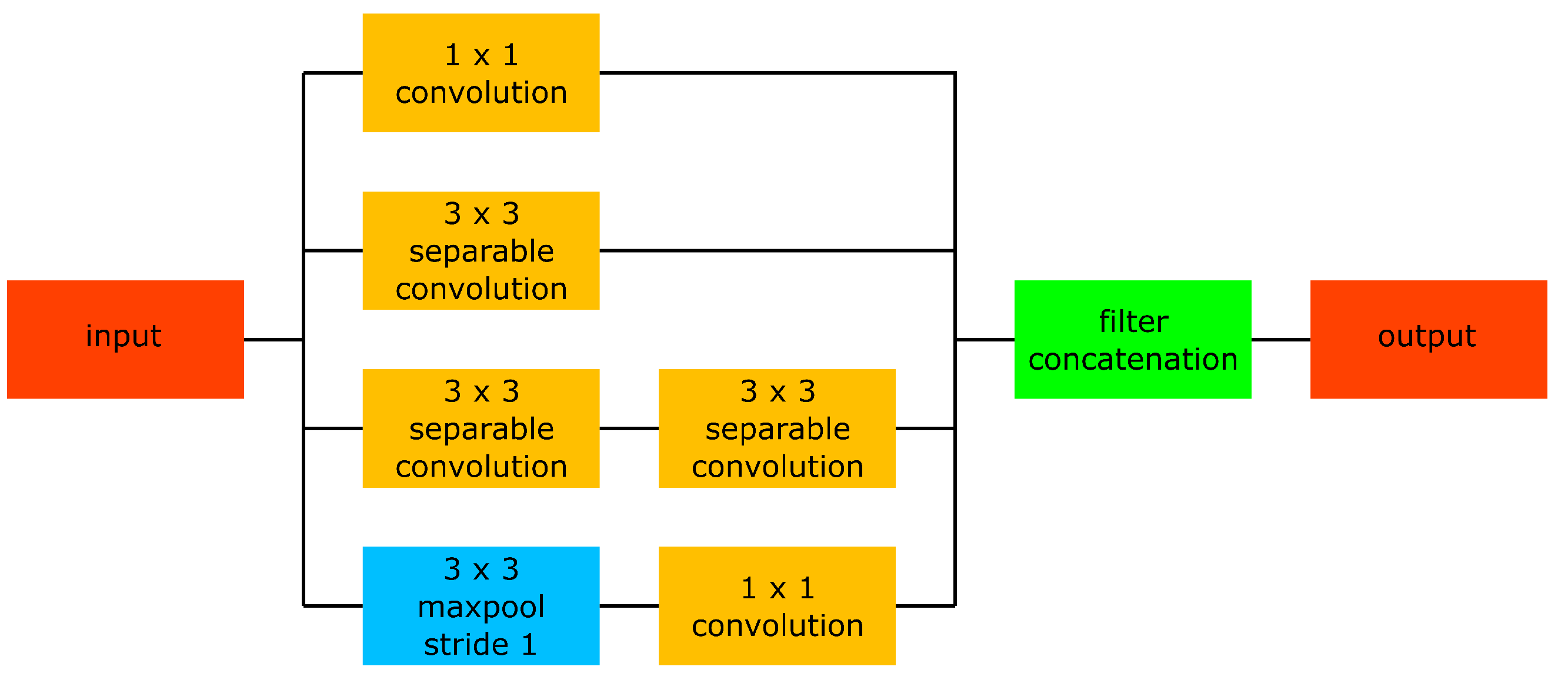
In
Table 5, the rank-1 re-identification results are shown for new identities using various backbone architectures. Furthermore, the usage of ImageNet pre-trained weights was compared with training from scratch. From this table, it is clear that our model architecture has by far the lowest number of parameters. While Inception V3 and ResNet-50 both have slightly more than 25,000 k parameters and AlexNet even has 57,134 k parameters, our network architecture has only 1160 k parameters, which is only 4.5% of the number of parameters in Inception V3. Nevertheless, nearly all models achieve similar rank-1 accuracies, varying between 0.869 and 0.894. The only exception is the Inception V3 architecture without using ImageNet pre-trained initial weights, using this backbone results in an average rank-1 accuracy of only 0.537. This rank-1 accuracy is better than the trivial rank-1 accuracy of
that would be expected in the case of random guessing, but it does not result in a re-identification model useful for practical applications. When weight initialisation is performed using ImageNet pre-trained weights, the Inception V3 backbone delivers similar results as the other backbones, indicating the network capacity is not at all an issue in restricting the realised rank-1 re-identification accuracy. Moreover, the number of inception modules in Inception V3 is quite similar to the number of inception modules in our network: 11 vs. 9. However, the design of our inception modules is slightly different from those of Inception V3 and we only use separable convolutional layers instead of the ordinary conventional convolutional layers in Inception V3. The results in
Table 5 suggest that these differences allow our embedding network to be easily trained from scratch, while this is not the case for the Inception V3 backbone. For the benchmark backbones that deliver decent results when trained from scratch (AlexNet and Resnet-50), the rank-1 accuracy does not improve significantly when using Imagenet pre-trained weights instead of randomly initialised weights. The average rank-1 accuracy for AlexNet improved slightly, while the average rank-1 accuracy for ResNet-50 slightly decreased. Moreover, the differences in the rank-1 accuracies for the individual behaviours are not coherent: some do improve, some stay about the same, and some even decline. This observation is in contrast with the results shown in
Table 3, where the rank-1 accuracies for new identities coherently increase for all behaviours. Therefore, it can be concluded that if a neural network converges without using Imagenet pre-trained initial weights, there is little performance improvement to be expected by using Imagenet pre-trained initial weights.
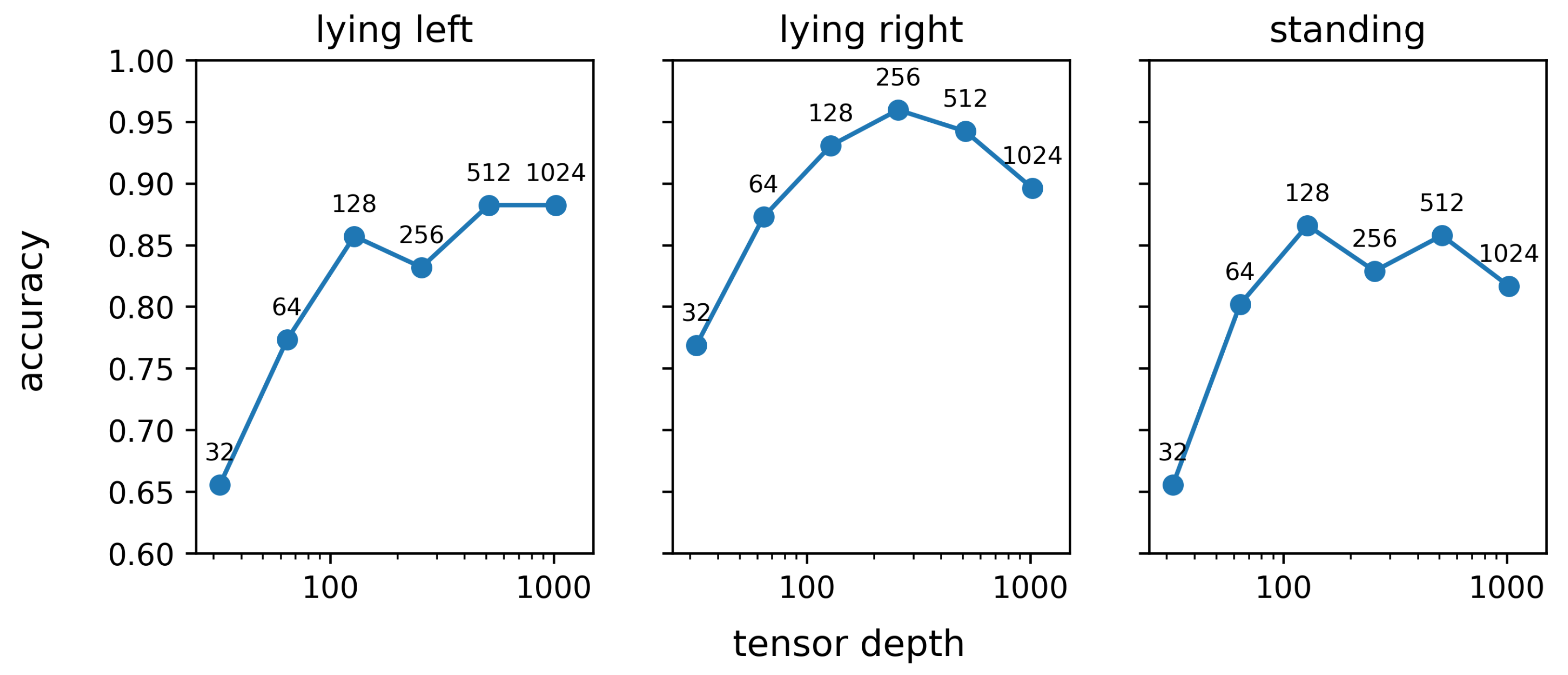
Figure 11 shows the result of the sensitivity analysis that was performed to evaluate the impact of the network capacity on the rank-1 re-identification performance. In
Figure 11, the network capacity is quantified by the depth of the tensor obtained after application of the last inception module, as elaborated in
Section 2.8. For all three studied behaviours, the rank-1 re-identification accuracy monotonously increases when the tensor depth after the last inception module increases from 32 to 128. However, a further increase in network capacity does not result in an improved re-identification performance. The average rank-1 re-identification for tensor depths of 128, 256, 512, and 1024 is relatively constant and varies between 0.87 and 0.89. The trends in the rank-1 re-identification performance in
Figure 11 for tensor depths over 128 are, therefore, mainly due to coincidence and are not coherent over the different behaviours. This observation aligns with the results in
Table 5, in which network architectures with more parameters, and thus a higher network capacity, do not result in an improved re-identification performance. On the other hand, the results visualised in
Figure 11 clearly show that below a certain threshold, lowering the network capacity inevitably results in a decrease in the re-identification performance. Based on our results, the depth of the tensor resulting from the last inception layer can thus be reduced up to 128 without any significant loss of performance. However, it is important to consider that making the network more lightweight in this way will reduce the computer memory requirements and energy consumption, but will not improve the inference speed.
Figure 12 shows the influence of the image resolution on the rank-1 re-identification performance. This figure clearly shows that a higher image resolution results in an improved re-identification performance. This observation can be explained based on the median width and height of the images in the test database, which is 297 and 263 pixels, respectively. When, for example, a 256 × 256 input image is used instead of the default 512 × 512 input image, more than half of the images have to be scaled down. The loss of resolution following from this downscaling results in a loss of apparently useful information and hence also in a loss of rank-1 re-identification performance. Given the 95% percentile of the image width and height, which is 469 and 398 pixels, respectively, it can be expected that the performance will have reached its maximum for the 512 × 512 images. Therefore, using larger input images will not lead to an improved re-identification performance.
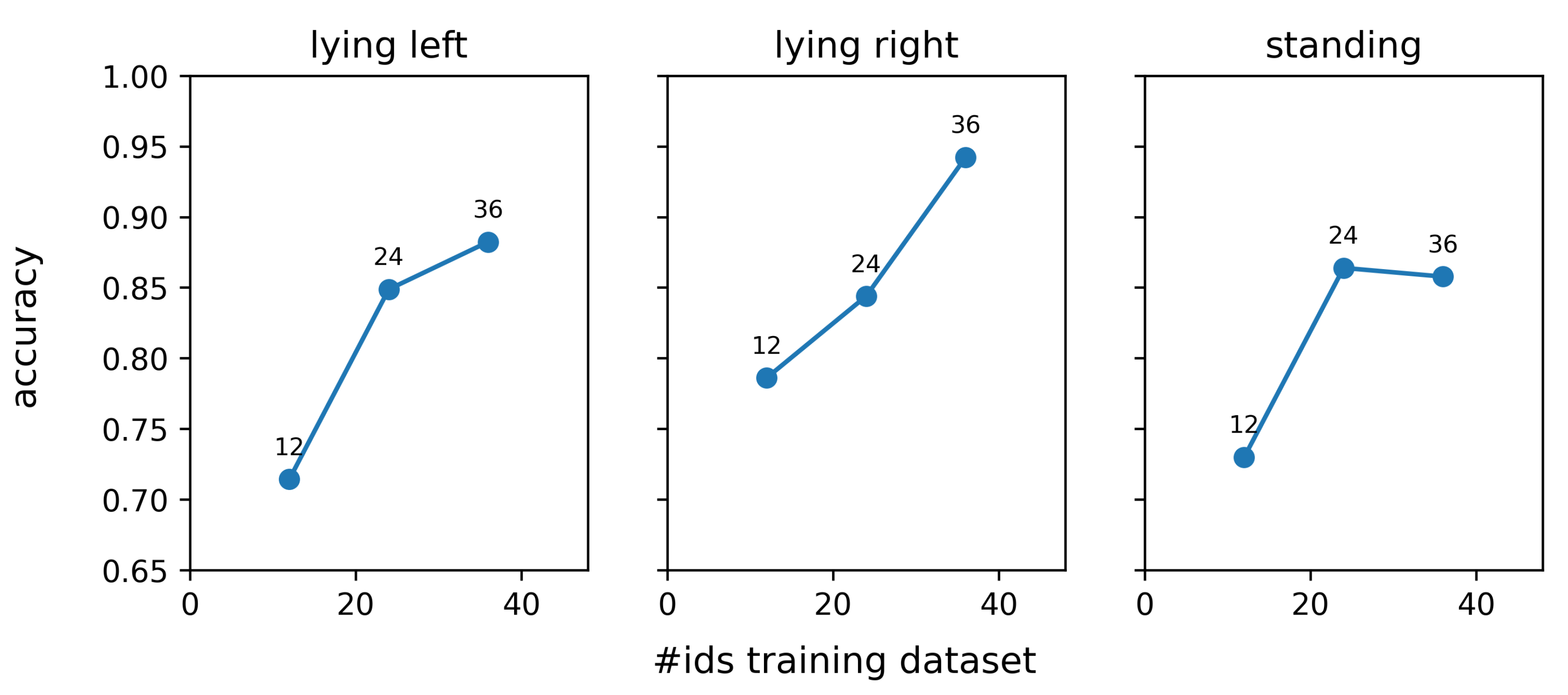
Figure 13 shows the influence of the training dataset size on the re-identification performance. For each data point in this figure, the same test dataset was used, containing 12 individuals, of which six are red and white (rw) and six are black and white (bw). It is clear from the results that a larger training dataset results in an improved re-identification performance. Adding more individuals to our dataset could thus improve the re-identification performance further. However, one has to consider that the marginal increment in the overall rank-1 re-identification performance will decrease with increasing dataset size. Previous exploratory research revealed that the amount of overfitting of the embedding network is relatively limited, and therefore, other factors are responsible for the observed performance increment. One possible reason is that the addition of new individuals to the dataset results in the presence of more similar individuals and hence requires the network to construct more efficient features.
It should be noted that the size of the training dataset reported in
Figure 13 cannot be compared directly to the datasets used in previous publications on animal re-identification [
14,
18], where re-identification was performed for a single pose only with standardised camera perspective, e.g., a top-down view of standing animals. In those previous studies, the number of actual individuals equals the number of identities “perceived” by the neural network during training. This apparently trivial assumption, however, does not hold for our research. In theory, by distinguishing three different behaviours and sampling batches from randomly selected orientation intervals of 45°, a single actual individual gives rise to
fictive individuals perceived by the network. Moreover, since the set of mirrored instances of each individual was included in the dataset as a new unique individual, the number of fictive individuals per actual individual doubles once more and becomes 48. However, in practice, the orientations of animals lying right or lying left will show a strongly bimodal distribution and, therefore, the usage of orientation intervals of 45° gives rise to eight fictive individuals for standing, two fictive individuals for lying left, and two fictive individuals for lying right, instead of eight fictive individuals for each behaviour. This results in a total of only
fictive individuals per actual individual. Since our complete training dataset contained 36 actual individuals, this corresponds to a total of 864 fictive individuals. Nevertheless, during evaluation, the number of individuals the algorithm has to distinguish is always 12, the number of actual individuals in the test dataset. Hence, the results presented in this paper can be considered as being a result of training an embedding network using a dataset of 864 (fictive) individuals and subsequently evaluating the obtained network on a test dataset containing 12 individuals.
Despite the fact that our methodology removes several hurdles for the application of computer vision-based re-identification in commercial environments, some challenges still remain. First of all, we showed that the fraction of the coat which is white is an important discriminative feature to assign the correct identity to an animal. The simultaneous presence of white and coloured patches, with a high inter-individual variation, is a typical characteristic of pied cattle breeds, such as Holstein and Fleckvieh. However, several other cattle breeds, such as Jersey, Brown Swiss, and Angus, have a homogeneous coat. It can be expected that computer vision-based re-identification will be considerably more difficult for these breeds. Secondly, our algorithm was only trained using daylight images. However, daylight images are more informative compared to night vision images, since the latter lack colour information and contain often less contrast. Therefore, night vision images are expected to result in a decrease in the re-identification performance.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}