
Domain-Adaptive Direction of Arrival (DOA) Estimation in Complex Indoor Environments Based on Convolutional Autoencoder and Transfer Learning



Abstract
1. Introduction
- 1
- CAE Model Training and Deep Feature Extraction. A CAE is initially trained on the source domain dataset, leveraging its dimensionality reduction and feature extraction capabilities. CAE’s encoder compresses high-dimensional input into low-dimensional representations, effectively mitigating multipath effects and extracting directional features critical for DOA, enhancing resilience in complex indoor settings.
- 2
- Domain Adaptation Training and Cross-Domain Feature Transfer. Domain adaptation is implemented through adversarial training and self-supervised learning to align deep features from the source to the target domain. During training, supervised learning on the source domain ensures accurate direction representation, while unsupervised learning aligns target data features through adversarial training, minimizing domain distribution discrepancies and enabling cross-domain feature transfer.
- 3
- Dataset Construction and Experimental Evaluation. Separate simulation datasets and measured datasets were constructed. A simplified multipath model is constructed to simulate and generate data with different SNRs in different environments, obtaining multiple sets of datasets. Regarding the measured data, datasets were constructed by collecting and annotating DOA data in a typical indoor environment to create the labeled source domain dataset. Additional DOA data were collected from another indoor environment, with a small portion annotated and added to the source domain, while the rest formed the unlabeled target domain dataset. Experiments on the constructed datasets confirmed the effectiveness of the proposed CAE-DANN.
2. Model
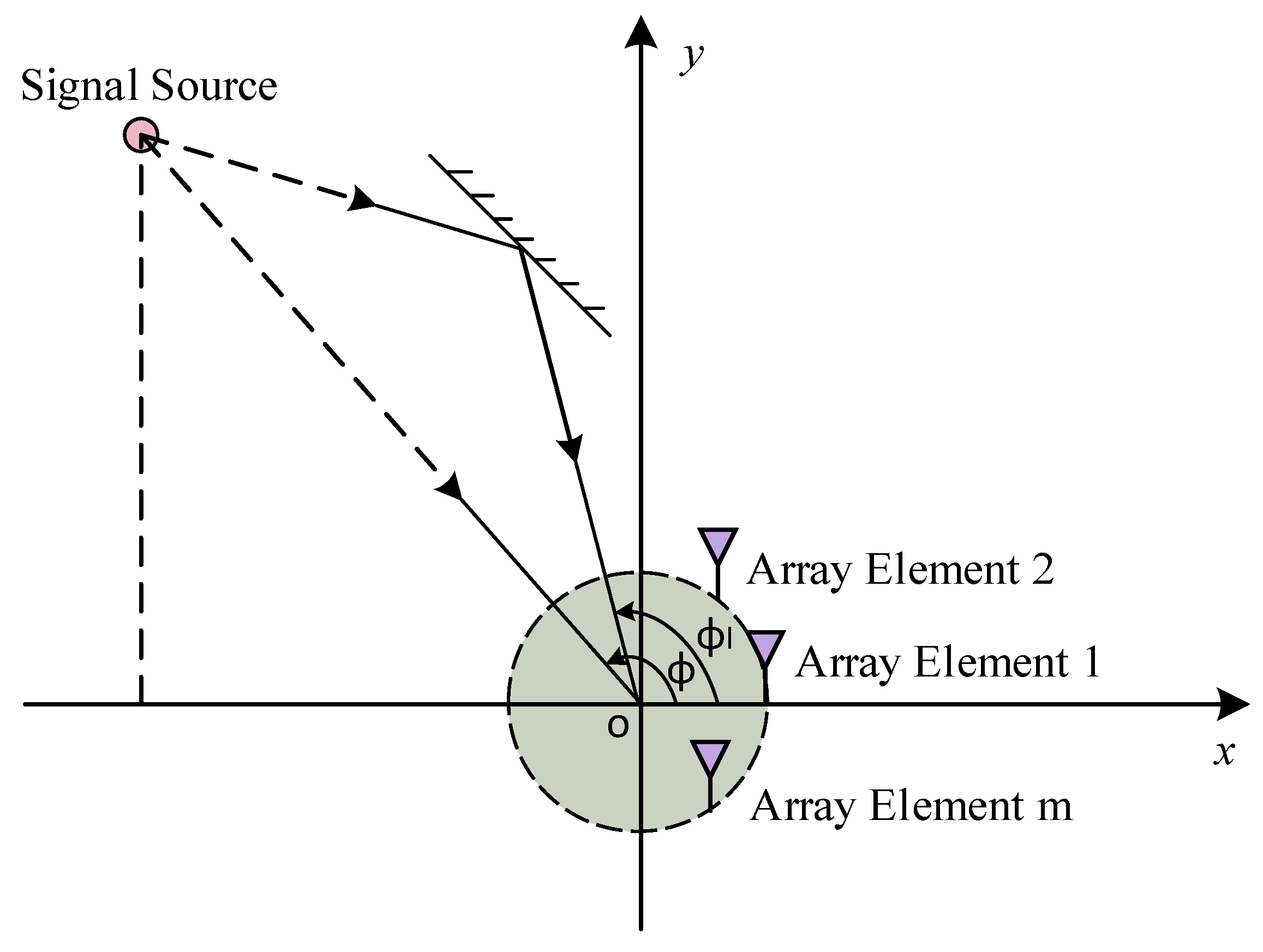
2.1. Array Model
2.2. Signal Model
3. The CAE-DANN Network
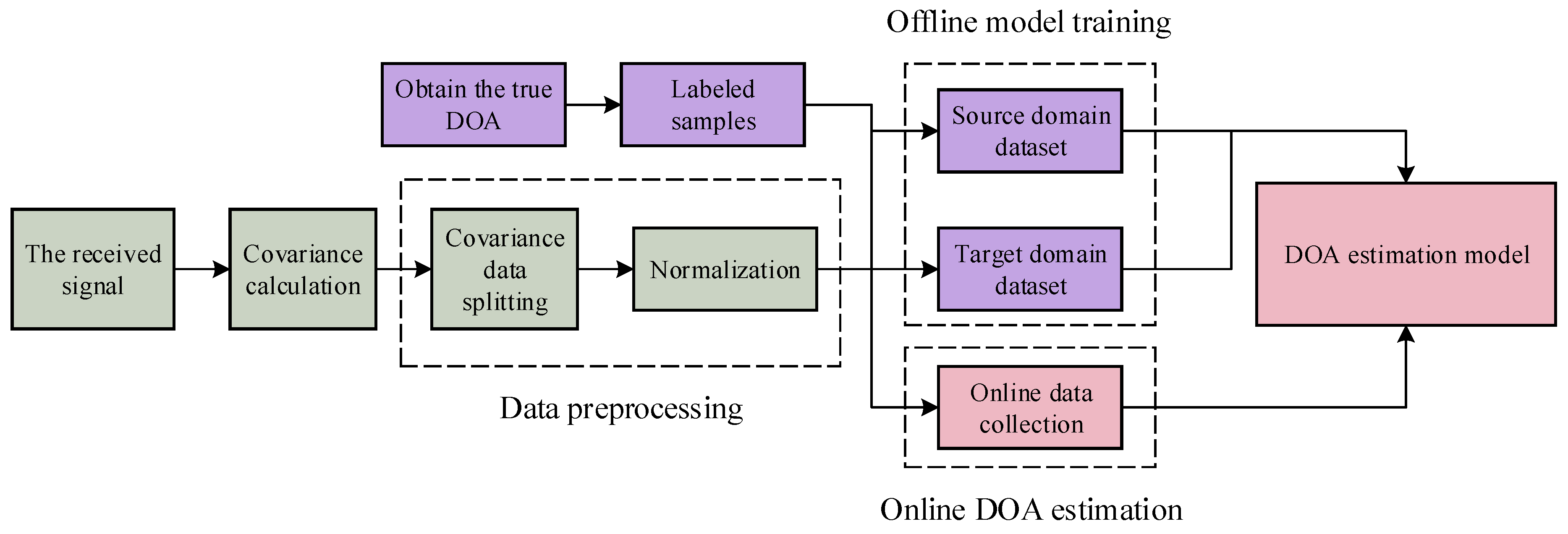
3.1. Framework for the DOA Estimation Process
3.2. Dataset Construction
3.3. Model Design and Training
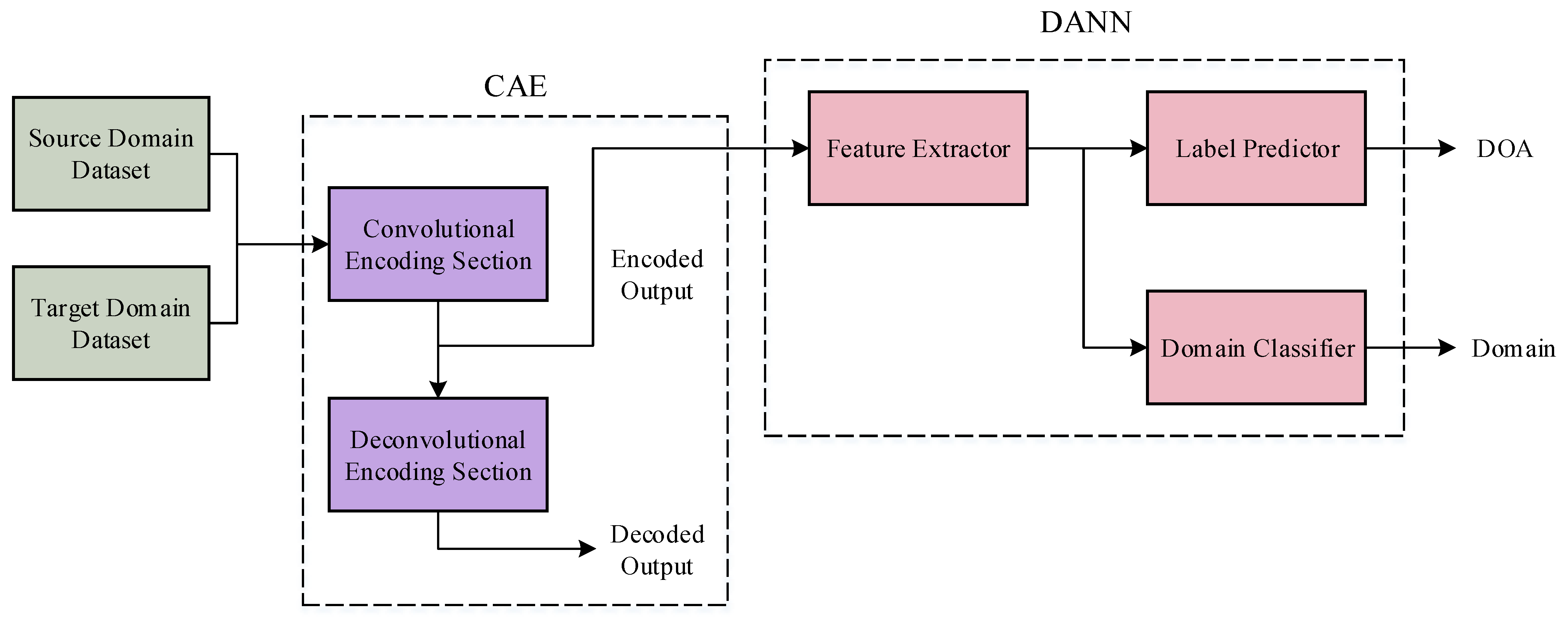
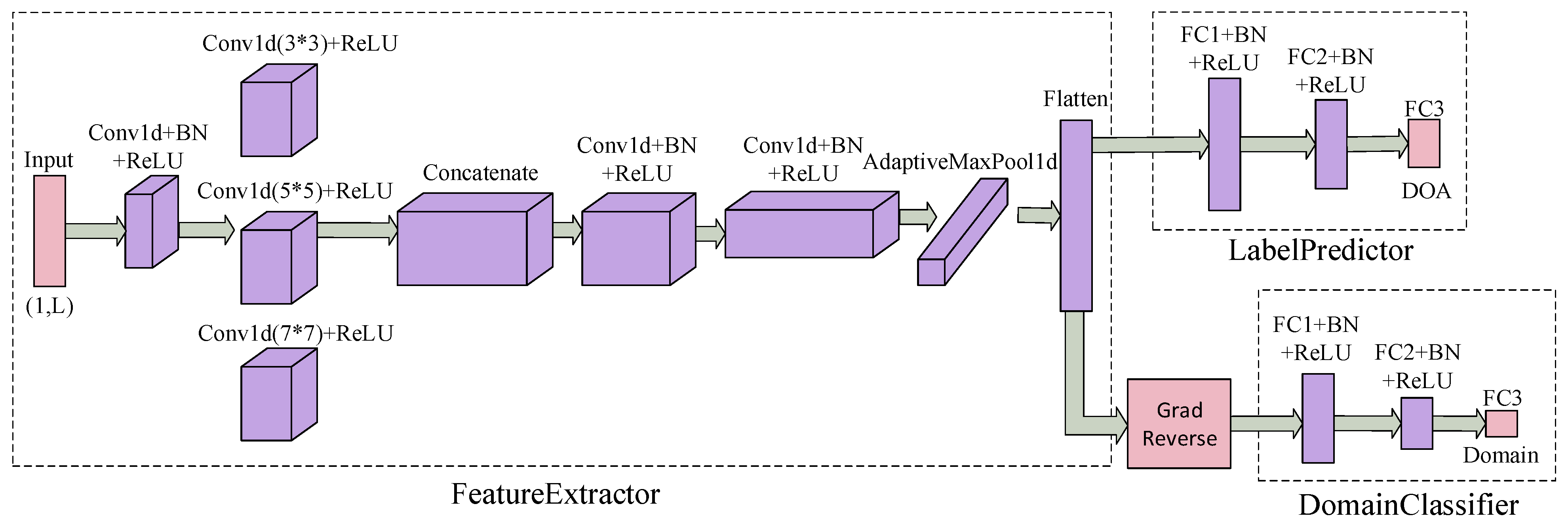
3.3.1. Overall Network Model
3.3.2. Convolutional Autoencoder
3.3.3. Domain Adversarial Neural Network
3.4. Time Complexity
4. Experiment
4.1. Simulation Experiment
4.1.1. Simulation Setup
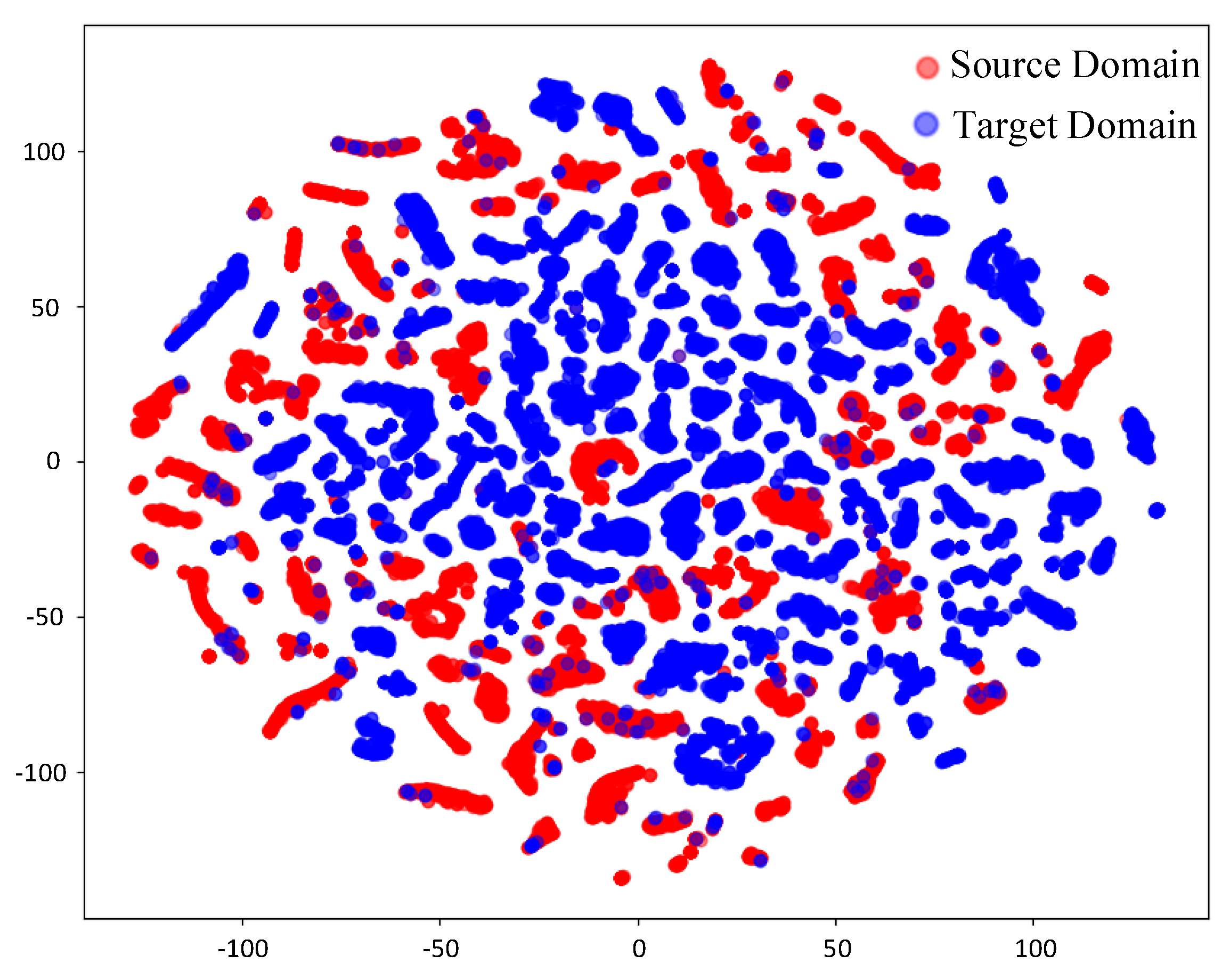
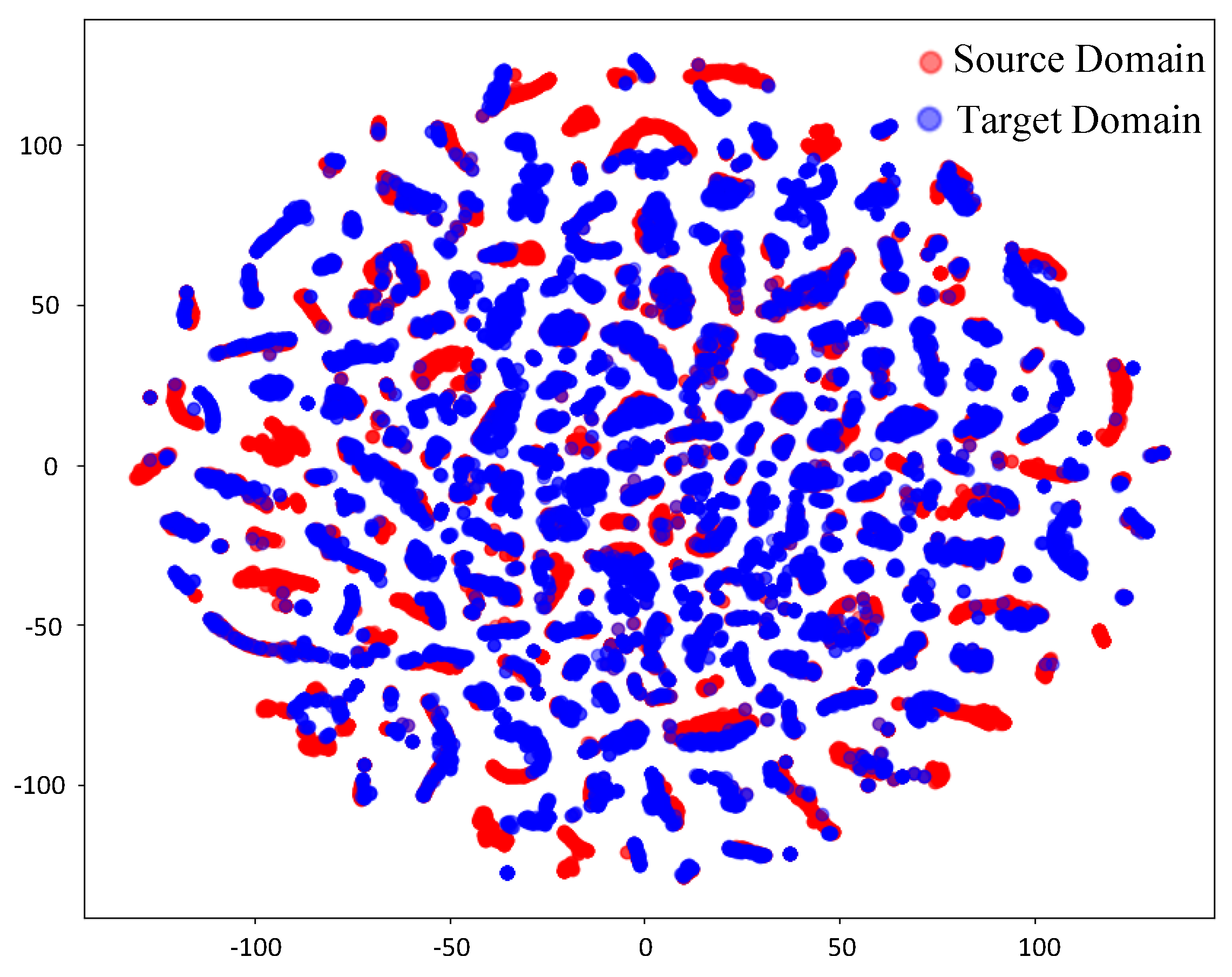
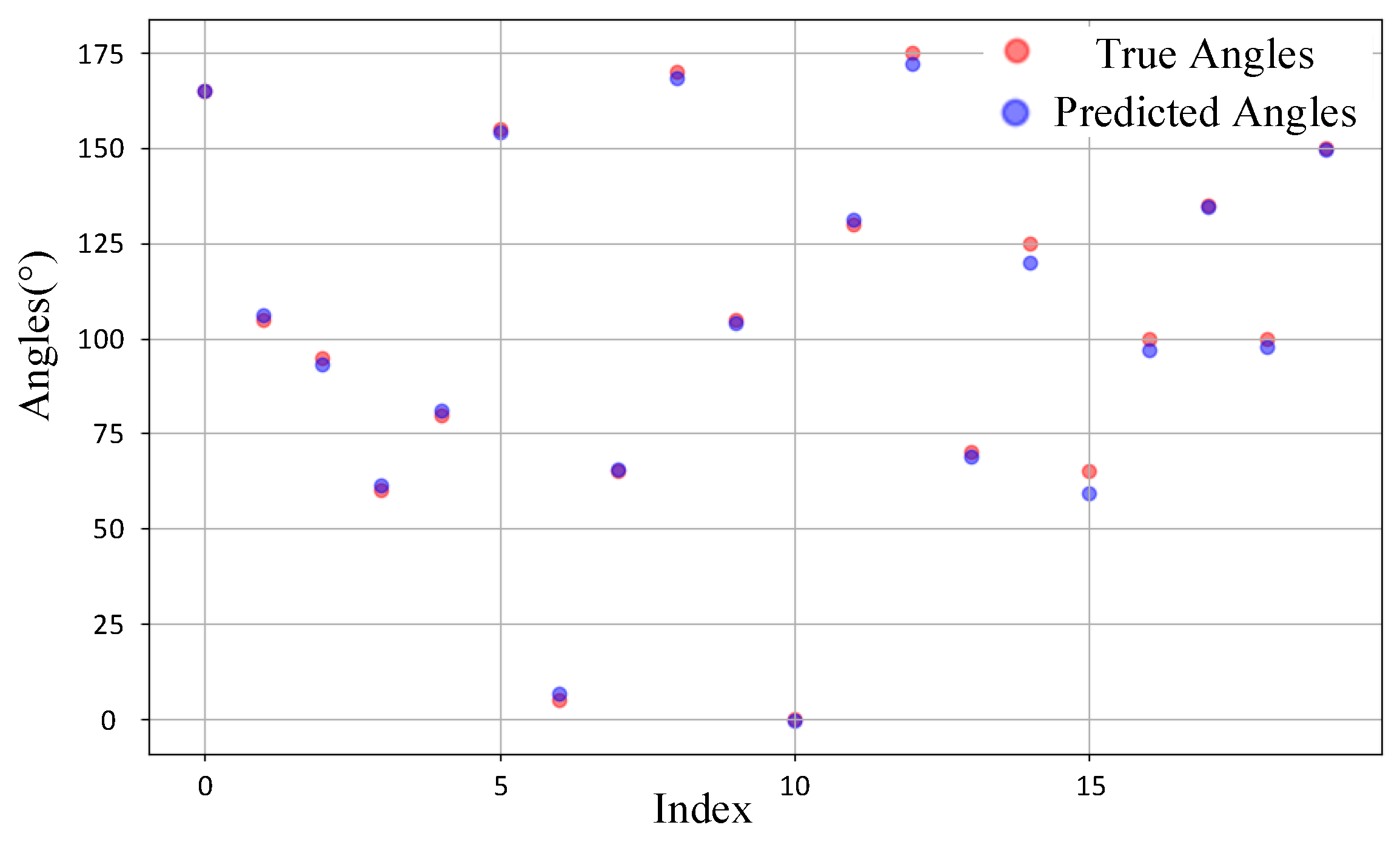
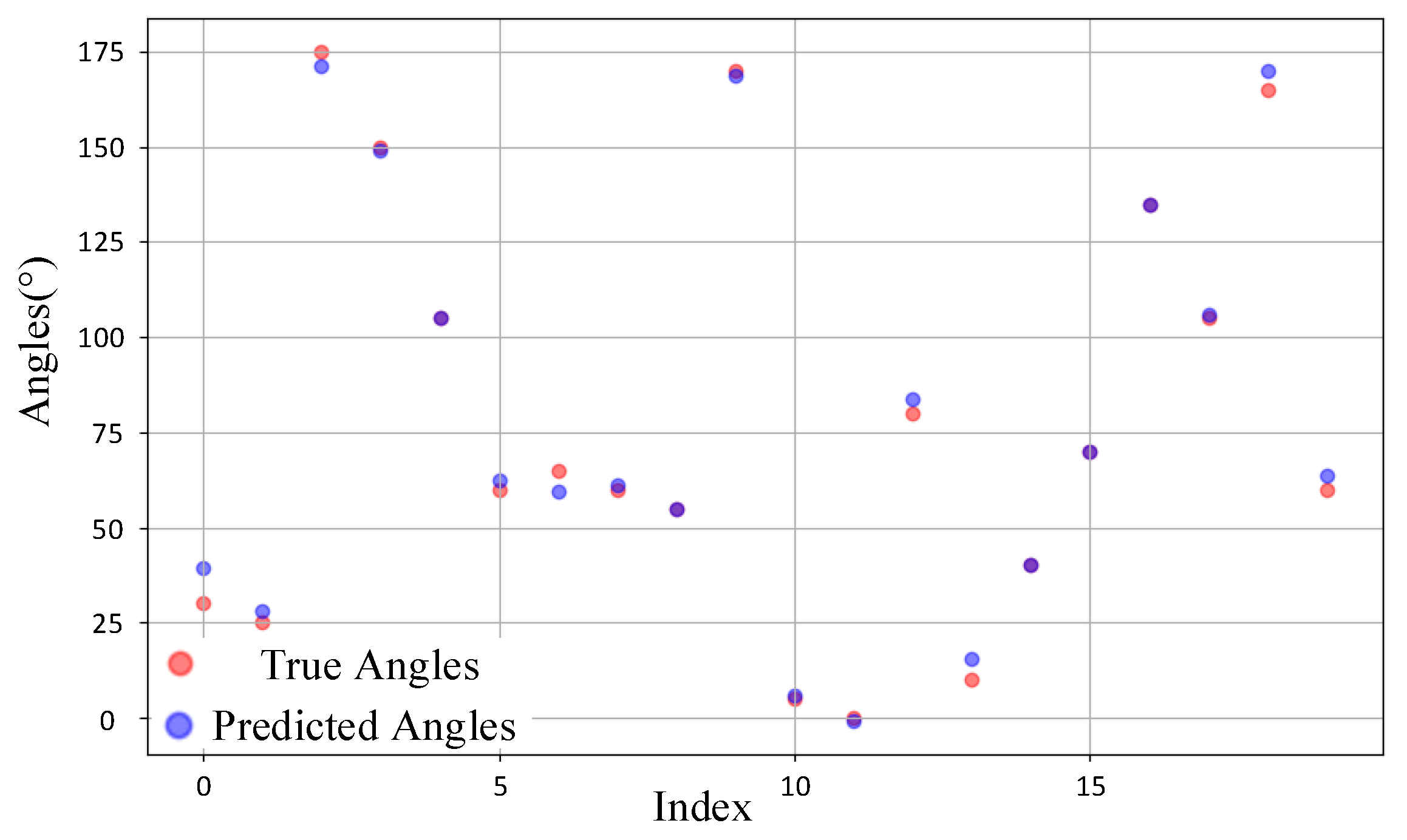
4.1.2. Simulation Results and Analysis
4.2. Measured Experiment
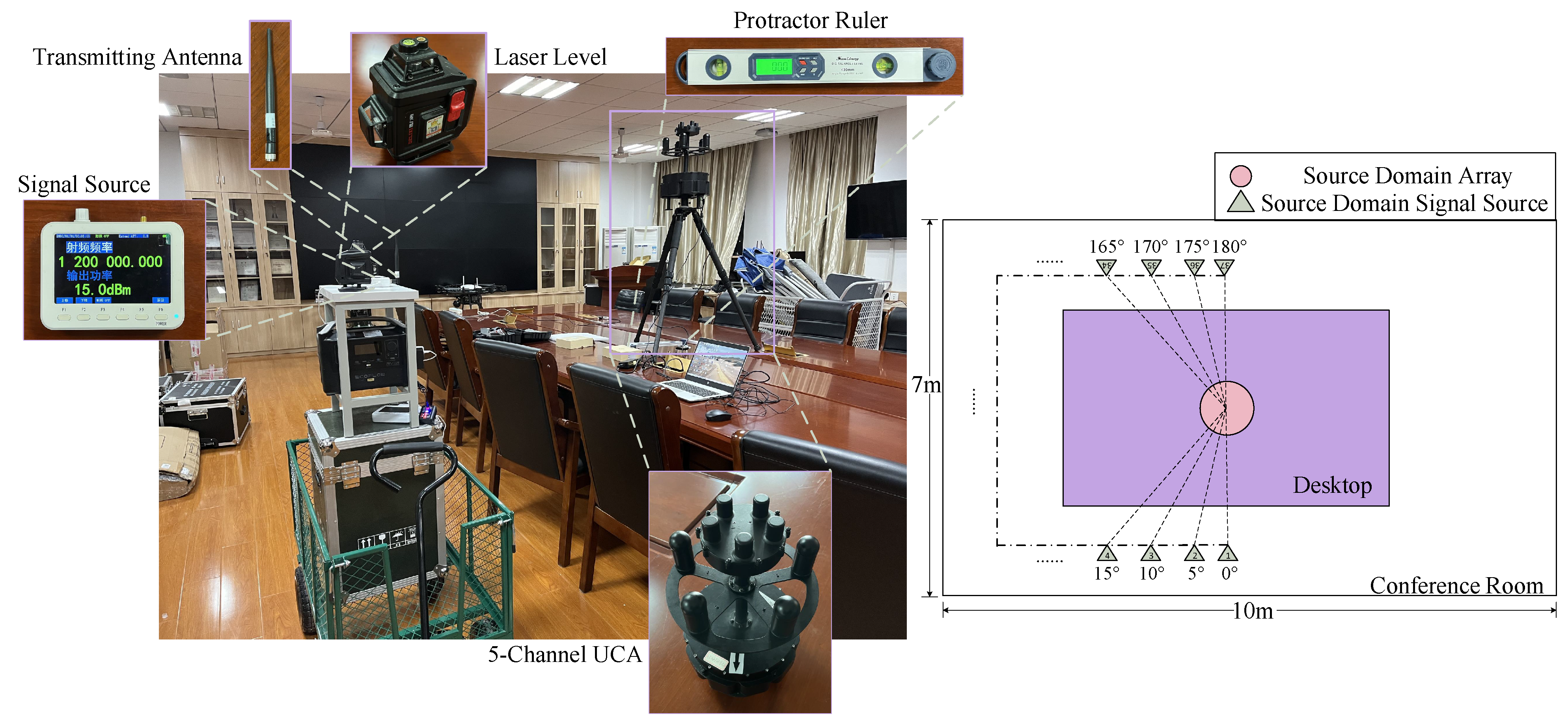
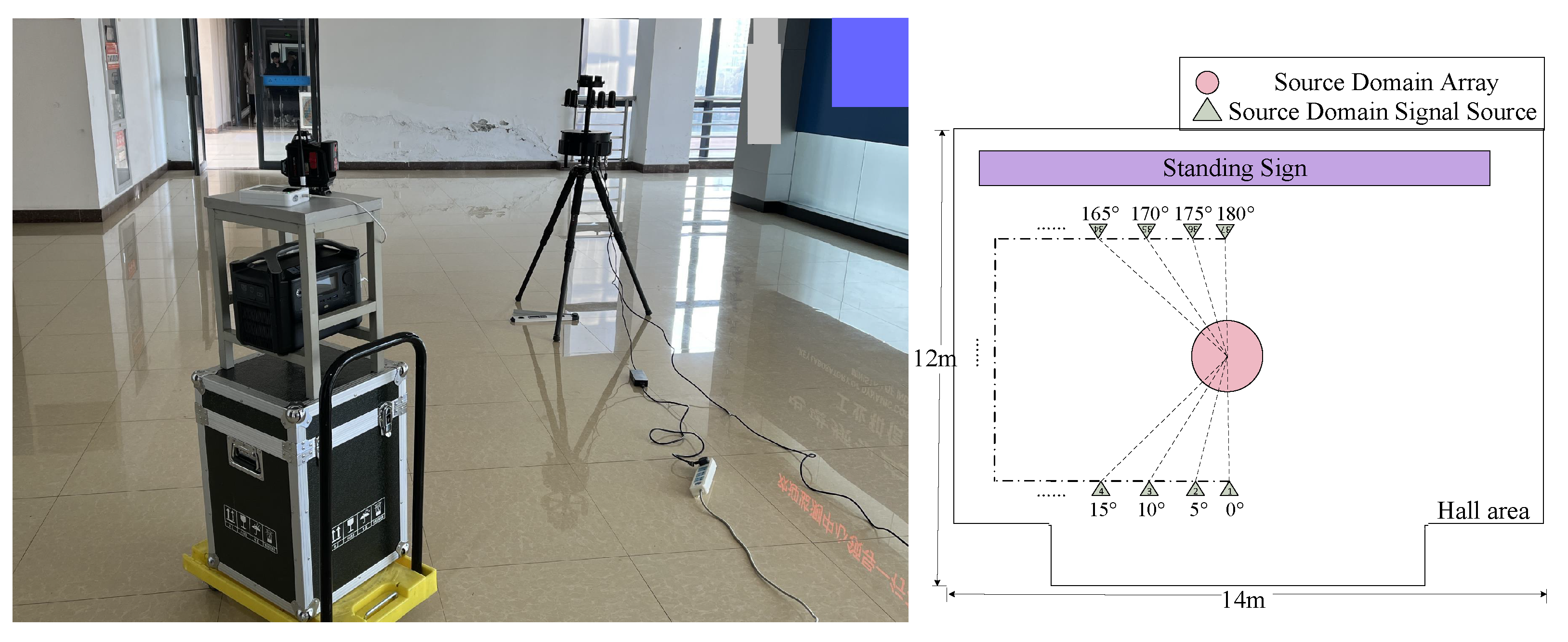
4.2.1. Measured Setup and Instruments
4.2.2. Measured Data Collection
4.2.3. Network Training Configuration
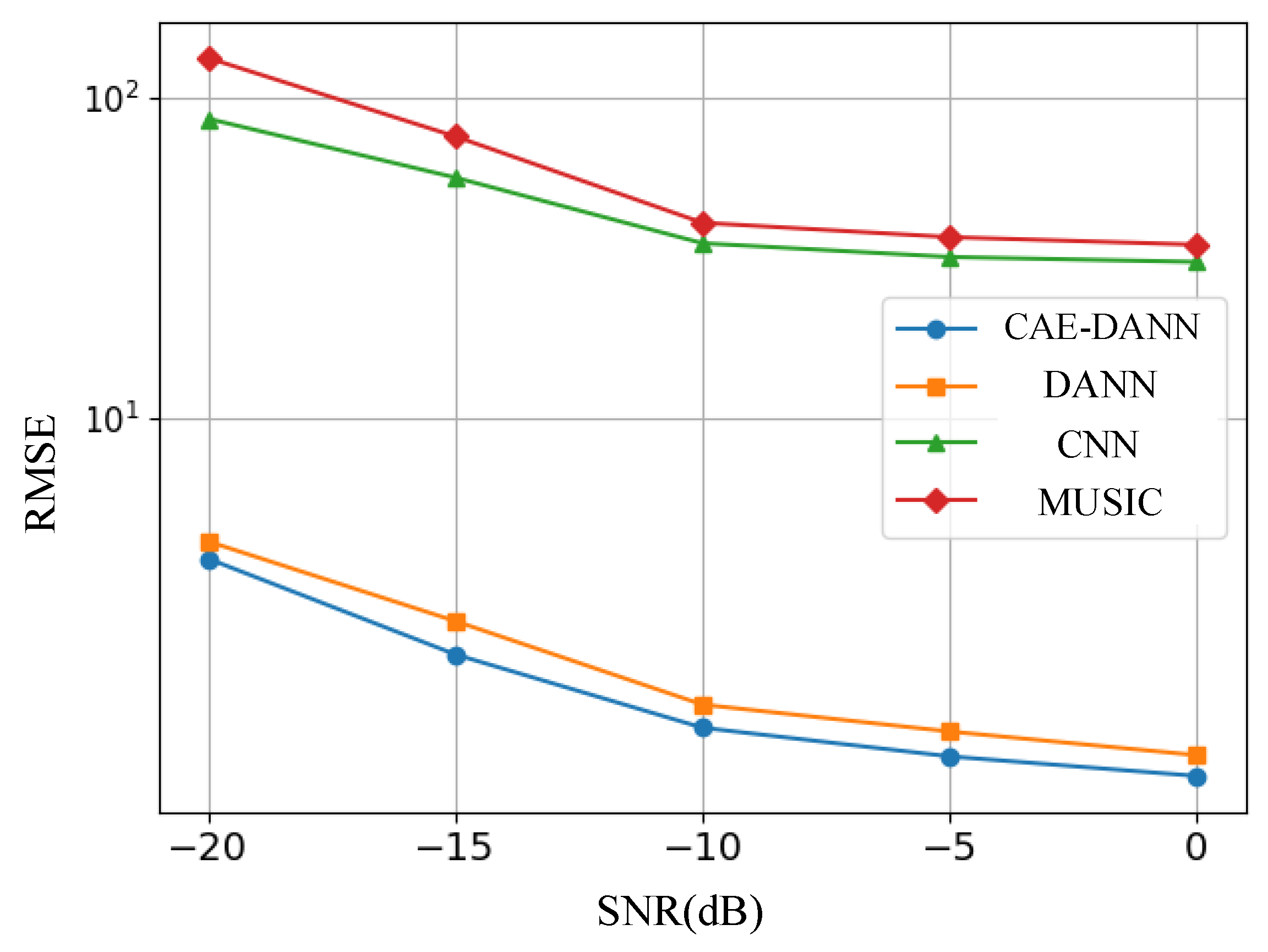
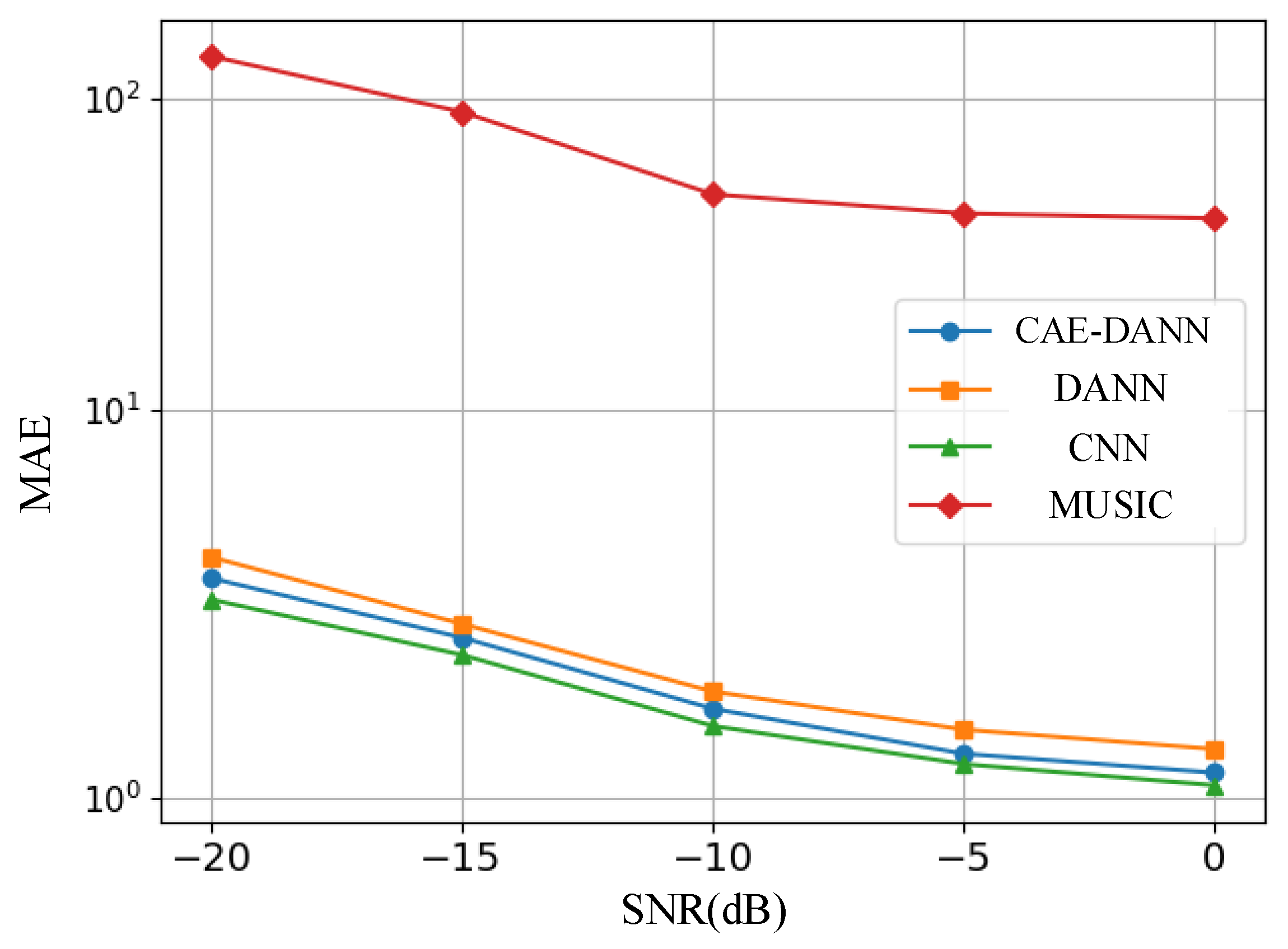
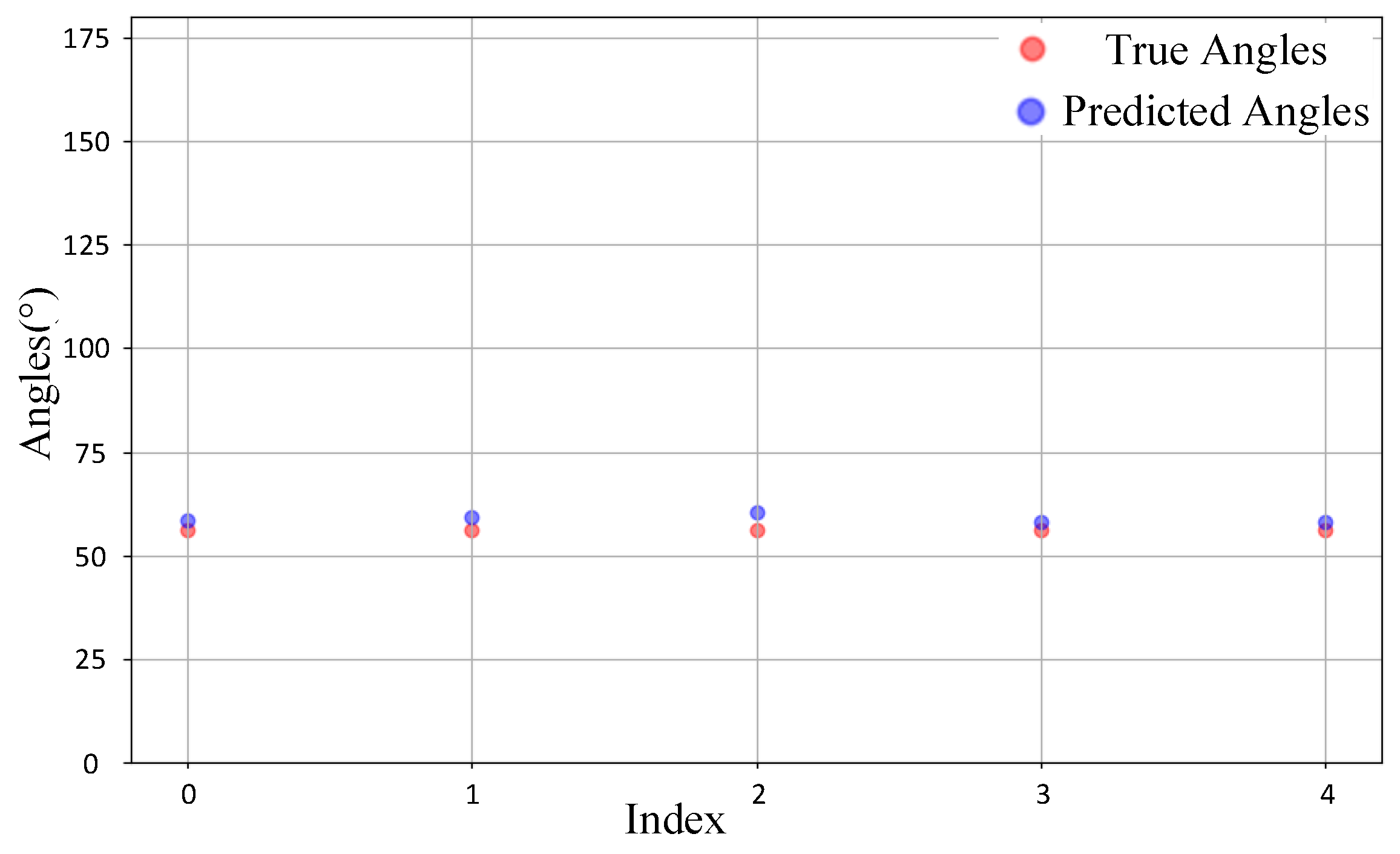
4.2.4. Measured Results and Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| LBS | Location-Based Services |
| VR | Virtual Reality |
| AR | Augmented Reality |
| DOA | Direction of Arrival |
| MUSIC | Multiple Signal Classification |
| ESPRIT | Estimation of Signal Parameters using Rotational Invariance Techniques |
| SNR | Signal-to-Noise Ratio |
| AOA | Angle of Arrival |
| AOD | Angle of Departure |
| OMP | Orthogonal Matching Pursuit |
| LAA | Lens Antenna Array |
| JADE | Joint Angle and Delay Estimation |
| TOA | Time of Arrival |
| RSSI | Received Signal Strength Indicator |
| SVM | Support Vector Machine |
| DL | Deep Learning |
| DNNs | Deep Neural Networks |
| CNN | Convolutional Neural Network |
| FSL | Few-Shot Learning |
| CAE | Convolutional Autoencoder |
| DANN | Domain-Adversarial Neural Network |
| GRL | Gradient Reversal Layers |
| MMD | Maximum Mean Discrepancy |
| UCA | Uniform Circular Array |
| LOS | Line-of-Sight |
| NLOS | Non-Line-of-Sight |
| MSE | Mean Squared Error |
| RMSE | Root Mean Squared Error |
| MAE | Mean Absolute Error |
| RF | Radio Frequency |
References
- Jayananda, P.K.V.; Seneviratne, D.H.D.; Abeygunawardhana, P.; Dodampege, L.N.; Lakshani, A.M.B. Augmented Reality Based Smart Supermarket System with Indoor Navigation using Beacon Technology (Easy Shopping Android Mobile App). In Proceedings of the 2018 IEEE International Conference on Information and Automation for Sustainability (ICIAfS), Colombo, Sri Lanka, 21–22 December 2018; pp. 1–6. [Google Scholar]
- Guo, Y.; Jiang, Q.; Xu, M.; Fang, W.; Liu, Q.; Yan, G.; Yang, Q.; Lu, H. Resonant Beam Enabled DoA Estimation in Passive Positioning System. IEEE Trans. Wirel. Commun. 2024, 23, 16290–16300. [Google Scholar] [CrossRef]
- Wan, L.; Han, G.; Shu, L.; Chan, S.; Zhu, T. The Application of DOA Estimation Approach in Patient Tracking Systems with High Patient Density. IEEE Trans. Ind. Inform. 2016, 12, 2353–2364. [Google Scholar] [CrossRef]
- Gaber, A.; Omar, A. A Study of Wireless Indoor Positioning Based on Joint TDOA and DOA Estimation Using 2-D Matrix Pencil Algorithms and IEEE 802.11ac. IEEE Trans. Wirel. Commun. 2015, 14, 2440–2454. [Google Scholar] [CrossRef]
- Al-Ardi, E.M.; Shubair, R.M.; Al-Mualla, M.E. Computationally efficient DOA estimation in a multipath environment using covariance differencing and iterative spatial smoothing. In Proceedings of the 2005 IEEE International Symposium on Circuits and Systems, Kobe, Japan, 23–26 May 2005; pp. 3805–3808. [Google Scholar]
- Anand, A.; Mukul, M.K. Comparative analysis of different direction of arrival estimation techniques. In Proceedings of the 2016 IEEE International Conference on Recent Trends in Electronics, Information & Communication Technology (RTEICT), Bangalore, India, 20–21 May 2016; pp. 343–347. [Google Scholar]
- Kılıç, B.; Arıkan, O. Capon’s Beamformer and Minimum Mean Square Error Beamforming Techniques in Direction of Arrival Estimation. In Proceedings of the 2021 29th Signal Processing and Communications Applications Conference (SIU), Istanbul, Turkey, 9–11 June 2021; pp. 1–4. [Google Scholar]
- Chai, Y. Advanced Techniques in Adaptive Beamforming for Enhanced DOA Estimation. In Proceedings of the 2024 International Wireless Communications and Mobile Computing (IWCMC), Ayia Napa, Cyprus, 27–31 May 2024; pp. 269–273. [Google Scholar]
- Gupta, P.; Aditya, K.; Datta, A. Comparison of conventional and subspace based algorithms to estimate Direction of Arrival (DOA). In Proceedings of the 2016 International Conference on Communication and Signal Processing (ICCSP), Melmaruvathur, India, 6–8 April 2016; pp. 0251–0255. [Google Scholar]
- Oumar, O.A.; Siyau, M.F.; Sattar, T.P. Comparison between MUSIC and ESPRIT direction of arrival estimation algorithms for wireless communication systems. In Proceedings of the First International Conference on Future Generation Communication Technologies, London, UK, 12–14 December 2012; pp. 99–103. [Google Scholar]
- Weber, R.J.; Huang, Y. Analysis for Capon and MUSIC DOA estimation algorithms. In Proceedings of the 2009 IEEE Antennas and Propagation Society International Symposium, North Charleston, SC, USA, 1–5 June 2009; pp. 1–4. [Google Scholar]
- Hu, Y.; Yu, X. Research on the application of compressive sensing theory in DOA estimation. In Proceedings of the 2017 IEEE International Conference on Signal Processing, Communications and Computing (ICSPCC), Xiamen, China, 22–25 October 2017; pp. 1–5. [Google Scholar]
- Shen, Q.; Liu, W.; Cui, W.; Wu, S. Underdetermined DOA Estimation Under the Compressive Sensing Framework: A Review. IEEE Access 2016, 4, 8865–8878. [Google Scholar] [CrossRef]
- Aminu, A.; Secmen, M. Performance evaluation of combined methods for the estimation of fading coefficients of uncorrelated signal sources in multipath propagation. In Proceedings of the 2014 11th International Conference on Electronics, Computer and Computation (ICECCO), Abuja, Nigeria, 29 September–1 October 2014; pp. 1–4. [Google Scholar]
- Chahbi, I.; Jouaber, B. A joint AOA, AOD and delays estimation of multipath signals based on beamforming techniques. In Proceedings of the 2010 Conference Record of the Forty Fourth Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 7–10 November 2010; pp. 603–607. [Google Scholar]
- Kaneko, K.; Sano, A. Music-like iterative DOA estimation in multipath environments. In Proceedings of the 2008 5th IEEE Sensor Array and Multichannel Signal Processing Workshop, Darmstadt, Germany, 21–23 July 2008; pp. 212–215. [Google Scholar]
- Veerendra, D.; Balamurugan, K.S.; Villagómez-Galindo, M.; Khandare, A.; Patil, M.; Jaganathan, A. Optimizing Sensor Array DOA Estimation With the Manifold Reconstruction Unitary ESPRIT Algorithm. IEEE Sens. Lett. 2023, 7, 7006804. [Google Scholar]
- Bhargav, P.R.; Nagaraju, L.; Kumar, P.K. Compressive Sensing based DOA Estimation for Multi-path Environment. In Proceedings of the 2021 IEEE International Conference on Microwaves, Antennas, Communications and Electronic Systems (COMCAS), Tel Aviv, Israel, 1–3 November 2021; pp. 309–313. [Google Scholar]
- Bazzi, A.; Slock, D.T.M.; Meilhac, L. A Newton-type Forward Backward Greedy Method for Multi-Snapshot Compressed Sensing. In Proceedings of the 2017 51st Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, USA, 29 October–1 November 2017; pp. 1178–1182. [Google Scholar]
- Hoang, T.-D.; Huang, X.; Qin, P. Low-Complexity Compressed Sensing-Aided Coherent Direction-of-Arrival Estimation for Large-Scale Lens Antenna Array. In Proceedings of the ICC 2024—IEEE International Conference on Communications, Denver, CO, USA, 9–13 June 2024; pp. 1–6. [Google Scholar]
- Pan, M.; Liu, P.; Liu, S.; Qi, W.; Huang, Y.; You, X.; Jia, X.; Li, X. Efficient Joint DOA and TOA Estimation for Indoor Positioning With 5G Picocell Base Stations. IEEE Trans. Instrum. Meas. 2022, 71, 8005219. [Google Scholar] [CrossRef]
- Florio, A.; Avitabile, G.; Coviello, G. Digital Phase Estimation through an I/Q Approach for Angle of Arrival Full-Hardware Localization. In Proceedings of the 2020 IEEE Asia Pacific Conference on Circuits and Systems (APCCAS), Ha Long, Vietnam, 8–10 December 2020; pp. 106–109. [Google Scholar]
- Liu, Y.; Li, Y.; Zhu, Y.; Niu, Y.; Jia, P. A Brief Review on Deep Learning in Application of Communication Signal Processing. In Proceedings of the 2020 IEEE 5th International Conference on Signal and Image Processing (ICSIP), Nanjing, China, 3–5 July 2020; pp. 51–54. [Google Scholar]
- Khan, A.; Wang, S.; Zhu, Z.M. Angle-of-Arrival Estimation Using an Adaptive Machine Learning Framework. IEEE Commun. Lett. 2019, 23, 294–297. [Google Scholar] [CrossRef]
- Yang, M.; Ai, B.; He, R.; Huang, C.; Ma, Z.; Zhong, Z.; Wang, J.; Pei, L.; Li, Y.; Li, J. Machine-learning-based Fast Angle-of-Arrival Recognition for Vehicular Communications. IEEE Trans. Veh. Technol. 2021, 70, 1592–1605. [Google Scholar] [CrossRef]
- Malajner, M.; Gleich, D.; Planinsic, P. Indoor AoA Estimation Using Received Signal Strength Parameter and a Support Vector Machine. In Proceedings of the 2019 International Conference on Systems, Signals and Image Processing (IWSSIP), Osijek, Croatia, 5–7 June 2019; pp. 133–137. [Google Scholar]
- Salvati, D.; Drioli, C.; Foresti, G.L. On the use of machine learning in microphone array beamforming for far - field sound source localization. In Proceedings of the 2016 IEEE 26th International Workshop on Machine Learning for Signal Processing (MLSP), Vietri sul Mare, Italy, 13–16 September 2016; pp. 1–6. [Google Scholar]
- Ge, S.G.; Li, K.; Rum, S.N.B.M. Deep Learning Approach in DOA Estimation: A Systematic Literature Review. Mob. Inf. Syst. 2021, 2021, 6392875. [Google Scholar] [CrossRef]
- Merkofer, J.P.; Revach, G.; Shlezinger, N.; van Sloun, R.J.G. Deep Augmented Music Algorithm for Data-driven DOA Estimation. In Proceedings of the ICASSP 2022—IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 3598–3602. [Google Scholar]
- Harkouss, Y. Direction of Arrival Estimation in Multipath Environments Using Deep Learning. Int. J. Commun. Syst. 2021, 34, e4882. [Google Scholar] [CrossRef]
- Kase, Y.; Nishimura, T.; Ohgane, T.; Ogawa, Y.; Kitayama, D.; Kishiyama, Y. DOA Estimation of Two Targets with Deep Learning. In Proceedings of the 2018 15th Workshop on Positioning, Navigation and Communications (WPNC), Bremen, Germany, 25–26 October 2018; pp. 1–5. [Google Scholar]
- Huang, H.; Yang, J.; Huang, H.; Song, Y.; Gui, G. Deep Learning for Super-resolution Channel Estimation and DOA Estimation Based on Massive MIMO System. IEEE Trans. Veh. Technol. 2018, 67, 8549–8560. [Google Scholar] [CrossRef]
- Chen, M.; Gong, Y.; Mao, X.P. Deep Neural Network for Estimation of Direction of Arrival with Antenna Array. IEEE Access 2020, 8, 140688–140698. [Google Scholar] [CrossRef]
- Elbir, A.M. DeepMUSIC: Multiple Signal Classification via Deep Learning. IEEE Sens. Lett. 2020, 4, 7001004. [Google Scholar] [CrossRef]
- Xiang, H.; Chen, B.; Yang, T.; Liu, D. Improved De-Multipath Neural Network Models With Self-Paced Feature-to-Feature Learning for DOA Estimation in Multipath Environment. IEEE Trans. Veh. Technol. 2020, 69, 5068–5078. [Google Scholar] [CrossRef]
- Yu, J.; Howard, W.W.; Xu, Y.; Buehrer, R.M. Model Order Estimation in the Presence of Multipath Interference Using Residual Convolutional Neural Networks. IEEE Trans. Wirel. Commun. 2024, 23, 7349–7361. [Google Scholar] [CrossRef]
- Miao, M.; Sun, Y.; Yu, J. Sparse Representation Convolutional Autoencoder for Feature Learning of Vibration Signals and its Applications in Machinery Fault Diagnosis. IEEE Trans. Ind. Electron. 2022, 69, 13565–13575. [Google Scholar] [CrossRef]
- Yu, C.; Liu, C.; Song, M.; Chang, C.-I. Unsupervised Domain Adaptation With Content-Wise Alignment for Hyperspectral Imagery Classification. IEEE Geosci. Remote Sens. Lett. 2022, 19, 5511705. [Google Scholar] [CrossRef]
- Ganin, Y.; Lempitsky, V. Unsupervised Domain Adaptation by Backpropagation. Int. Conf. Mach. Learn. 2015, 37, 1180–1189. [Google Scholar]
- Gretton, A.; Borgwardt, K.; Rasch, M.; Schölkopf, B.; Smola, A. A Kernel Two-Sample Test. J. Mach. Learn. Res. 2012, 13, 723–773. [Google Scholar]
- Long, M.; Cao, Y.; Wang, J.; Jordan, M.I. Learning Transferable Features with Deep Adaptation Networks. In Proceedings of the 32nd International Conference on Machine Learning (ICML), Lille, France, 6–11 July 2015; pp. 97–105. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Run Time |
|---|---|
| CAE-DANN | s |
| DANN | s |
| CNN | s |
| MUSIC | s |
| Parameter | Parameter Value |
|---|---|
| Optimizer | Adam |
| Learning Rate | 0.001 |
| Hidden Layers | 8 |
| Activation Function | ReLU, Sigmoid |
| Batch Size | 256 |
| Epochs | 50 |
| Parameter | Parameter Value |
|---|---|
| Optimizer | Adam |
| Learning Rate | 0.001 |
| FeatureExtractor Hidden Layers | 7 |
| LabelPredictor Hidden Layers | 3 |
| DomainClassifier Hidden Layers | 3 |
| Activation Function | ReLU |
| Batch Size | 256 |
| Epochs | 200 |
| Methods | Source Domain RMSE | Target Domain RMSE |
|---|---|---|
| CAE-DANN | 3.156 | 5.486 |
| DANN (without CAE) | 6.651 | 8.458 |
| CAE-DANN (without MMD) | 3.032 | 8.752 |
| CAE-CNN (without GRL) | 2.981 | 10.976 |
| CNN | 2.854 | 52.466 |
| MUSIC | 84.230 | 92.816 |
| Methods | Source Domain RMSE | Target Domain RMSE |
|---|---|---|
| CAE-DANN | 3.591 | 6.148 |
| DANN (without CAE) | 7.275 | 10.484 |
| CAE-DANN (without MMD) | 4.864 | 11.776 |
| CAE-CNN (without GRL) | 3.418 | 12.257 |
| CNN | 3.351 | 64.527 |
| MUSIC | 88.571 | 124.876 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shen, L.; Li, J.; Pan, J.; Shi, J.; Xu, R.; Wang, H.; Deng, W. Domain-Adaptive Direction of Arrival (DOA) Estimation in Complex Indoor Environments Based on Convolutional Autoencoder and Transfer Learning. Sensors 2025, 25, 2959. https://doi.org/10.3390/s25102959
Shen L, Li J, Pan J, Shi J, Xu R, Wang H, Deng W. Domain-Adaptive Direction of Arrival (DOA) Estimation in Complex Indoor Environments Based on Convolutional Autoencoder and Transfer Learning. Sensors. 2025; 25(10):2959. https://doi.org/10.3390/s25102959
Chicago/Turabian StyleShen, Lingyu, Jianfeng Li, Jingjing Pan, Junpeng Shi, Rui Xu, Hao Wang, and Weiming Deng. 2025. "Domain-Adaptive Direction of Arrival (DOA) Estimation in Complex Indoor Environments Based on Convolutional Autoencoder and Transfer Learning" Sensors 25, no. 10: 2959. https://doi.org/10.3390/s25102959
APA StyleShen, L., Li, J., Pan, J., Shi, J., Xu, R., Wang, H., & Deng, W. (2025). Domain-Adaptive Direction of Arrival (DOA) Estimation in Complex Indoor Environments Based on Convolutional Autoencoder and Transfer Learning. Sensors, 25(10), 2959. https://doi.org/10.3390/s25102959