1. Introduction
With the continuous acceleration of global population aging and urbanization, the incidence of cardiovascular diseases (CVDs) is steadily increasing, gradually becoming some of the diseases with the highest incidence and mortality rates [
1]. According to the relevant reports, cardiovascular diseases accounts for the largest proportion of disease-related deaths in both rural and urban residents, with CVDs accounting for 48.00% and 45.86% of deaths in rural and urban areas, respectively, in 2020 [
2]. Despite the high level of attention given to the prevention and control of cardiovascular diseases, the upward trend in their incidence has not been fundamentally reversed, making cardiovascular diseases a major global public health issue [
3].
Blood pressure (BP) is a crucial physiological indicator of the human circulatory system, comprising systolic blood pressure (SBP) and diastolic blood pressure (DBP) [
4]. Monitoring these metrics aids in evaluating an individual’s blood pressure status. Hypertension represents a significant risk factor for cardiovascular ailments, encompassing heart disease, stroke, arteriosclerosis, and various other cardiovascular complications. According to the inaugural Global Hypertension Report unveiled by the World Health Organization in 2023 [
5,
6], the global prevalence of hypertension surged from 650 million in 1990 to 1.3 billion in 2019. Consequently, the quest for achieving portable, continuous monitoring of human blood pressure to facilitate early detection, prevention, and treatment of hypertension and cardiovascular diseases has emerged as a paramount concern.
Currently, blood pressure measurement methods mainly include direct measurement, intermittent blood pressure measurement, and continuous non-invasive blood pressure measurement [
7,
8,
9]. Direct blood pressure measurement involves inserting a catheter into the artery to directly monitor real-time blood pressure data. While this method is unaffected by external noise, its invasive nature poses risks of infection and arterial damage. Intermittent blood pressure measurement methods commonly used include the auscultatory method and the oscillometric method. The auscultatory method [
10] utilizes a stethoscope to listen to blood flow sounds to determine the systolic and diastolic pressures. Although convenient, it is subject to subjective errors and may lead to the “white coat” phenomenon. Conversely, the oscillometric method [
11] automatically measures blood pressure using oscillations beneath the blood pressure cuff, offering convenience and practicality. However, the measurement method based on cuff inflation and deflation repetitively compresses the arterial blood vessels, leading to psychological discomfort and other issues. As a result, it cannot continuously track dynamic blood pressure changes and achieve accurate continuous blood pressure measurement.
In the realm of continuous blood pressure monitoring, methods based on pulse transit time (PTT) and pulse wave velocity (PWV) calculate arterial blood pressure by measuring the time or velocity required for a pulse to travel from one location to another. However, both these methods require frequent calibration to actual blood pressure values, posing limitations in terms of measurement accuracy and applicability [
12,
13]. Additionally, these methods typically necessitate at least two fully synchronized input signals (such as PPG and ECG signals) to obtain accurate physiological parameters. Ensuring strict synchronization of ECG and PPG signals in time during PTT measurements, as well as ensuring that the R peak of the ECG signal corresponds to the main peak of the PPG signal within the same cardiac cycle, significantly increases the complexity of blood pressure prediction tasks and the amount of raw data required, making them less suitable for clinical research [
14,
15,
16].
In addition to utilizing pulse wave parameters for blood pressure prediction, many researchers have explored the relationship between various physiological signals and blood pressure through the construction of mathematical models. For instance, Shi et al. [
17] combined electrical network models with tube-load models to propose a hybrid mathematical model for establishing the relationship between PPG signals and blood pressure signals. Through system identification methods, individualized continuous blood pressure measurements can be achieved. Similarly, Yi et al. [
13] established the relationship between piezoelectric pulse waves and blood pressure waves using linear and integral relationships, enabling wearable continuous blood pressure prediction without motion artifacts. These approaches, based on specific assumptions and inferences, offer strong predictive performance and interpretability by elucidating the relationship between blood pressure changes and PPG signal features. However, acquiring medical physiological datasets that encompass various physiological states is often challenging. This limitation extends to parameter tuning for the established mathematical models.
The continuous advancement of deep learning has provided new perspectives for continuous blood pressure prediction, offering an end-to-end learning paradigm that can directly learn the mapping relationship between input and output from raw data [
18]. Traditional methods require the manual extraction of physiological parameters and features from input signals, often involving complex feature engineering and data preprocessing steps, making them unsuitable for efficient and precise wearable products [
19,
20]. Deep learning models possess high-performance feature extraction capabilities and the ability to handle large-scale data, enabling them to capture individual differences and blood pressure variations without the need for complex physical modeling. Moreover, they can automatically tune parameters, laying the technical foundation for achieving accurate and continuous blood pressure monitoring [
21]. With its formidable feature extraction and information mining capabilities, deep learning has been widely employed in the field of continuous non-invasive blood pressure prediction based on PPG signals. For instance, Baek et al. [
22] utilized Convolutional Neural Networks (CNNs) with dilated and strided convolutions in both the time and frequency domains to extract features from periodic signals, achieving accurate blood pressure prediction. Sadrawi et al. [
23] employed deep convolutional autoencoders based on LeNet and U-Net architectures to transform PPG signals into ABP signals. Schrumpf et al. [
16] trained blood pressure prediction models based on PPG signals using three different deep learning models, combined with signal parameterization methods for empirical evaluation. They further fine-tuned the network models using transfer learning to successfully apply them to clinical environments for blood pressure prediction based on rPPG signals. Numerous studies [
24,
25,
26] have demonstrated a high degree of similarity between PPG and blood pressure waveforms, highlighting the significance of recovering original blood pressure waveforms for clinical research. Therefore, in addition to predicting blood pressure parameters, this study also attempted to reconstruct the original blood pressure waveform using only a single PPG signal, revealing the patterns of blood pressure changes.
Since the proposal of the U-shaped architecture (U-net) by Ronneberger et al. [
27], this model has garnered significant attention from scholars due to its highly symmetric structure and the paradigm of skip connections, and has been widely applied in the field of blood pressure prediction. Cheng et al. [
28] constructed ABP-Net for blood pressure waveform prediction through the design of the network structure, input signals, and loss functions. It allows for non-invasive estimation of physiological parameters reflecting the cardiovascular status, albeit with room for improvement in accuracy. Athaya et al. [
25] introduced new activation functions and dropout optimization to enhance the traditional U-net structure, demonstrating its potential for blood pressure prediction and potential application in sensor-based wearable devices. Ibtehaz et al. [
26] developed a dual-layer U-net model comprising an approximate network and a refinement network, achieving the precise prediction of blood pressure waveforms but falling short of meeting the A-grade criteria of the BHS standard in the systolic blood pressure prediction task. Sun et al. [
29] proposed a dual-channel encoder U-net model and incorporated an improved attention mechanism block into the encoder to address the strong periodicity and continuity characteristics of PPG signals, thereby achieving accurate and rapid blood pressure prediction.
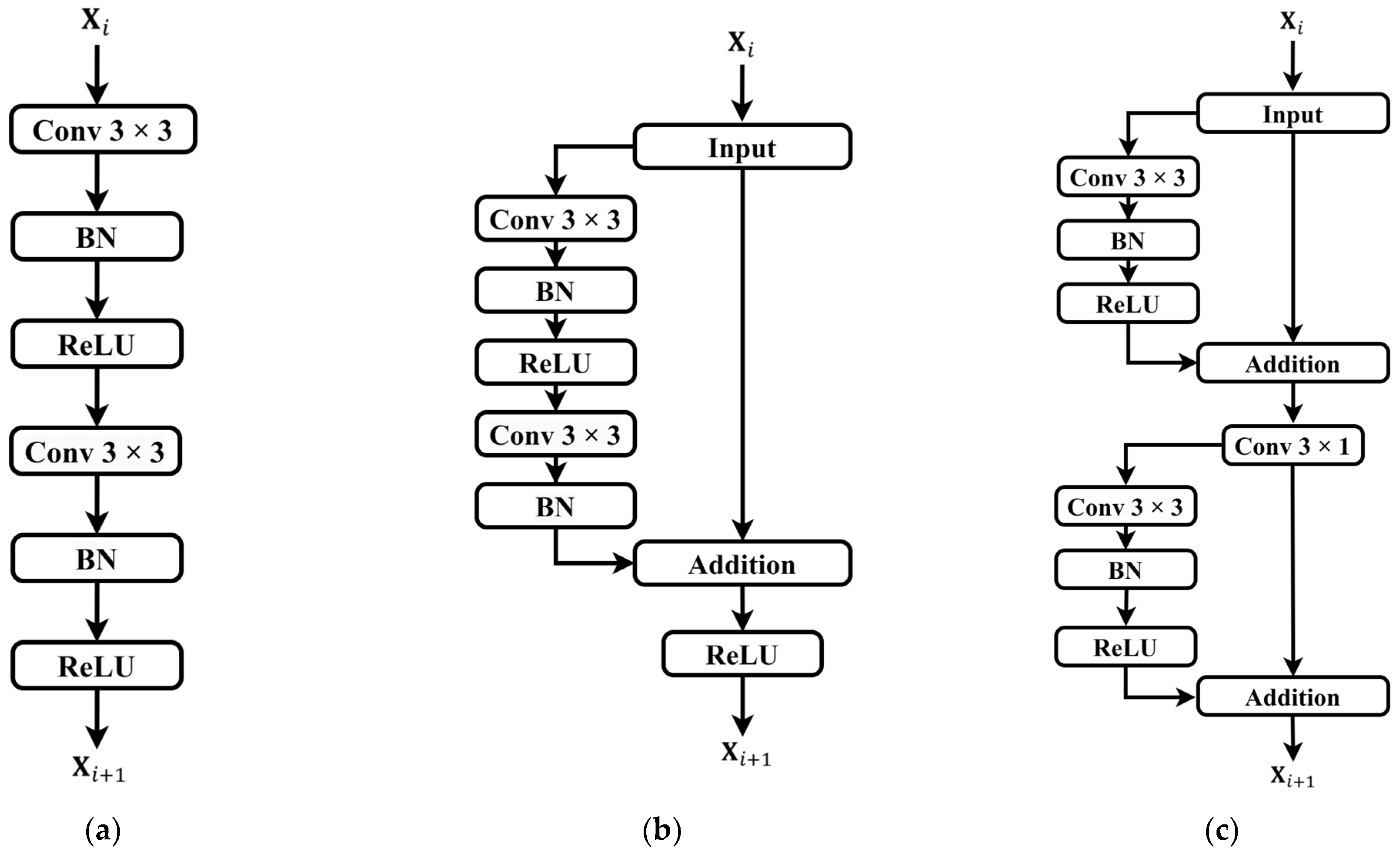
However, existing research indicates that there is still room for improvement in using the U-net model for continuous blood pressure prediction. Firstly, the direct transmission of long-distance information via skip connections for high–low-scale feature fusion may lead to information redundancy and loss. Additionally, the use of ordinary convolutions for information transmission in the upsampling and downsampling paths may result in information loss and gradient vanishing issues [
30]. Finally, the traditional U-net primarily focuses on extracting and reconstructing local features, which presents certain limitations in capturing global contextual information. However, physiological signals such as PPG signals exhibit strong temporal and continuous characteristics, posing challenges for U-net in effectively extracting their temporal features.
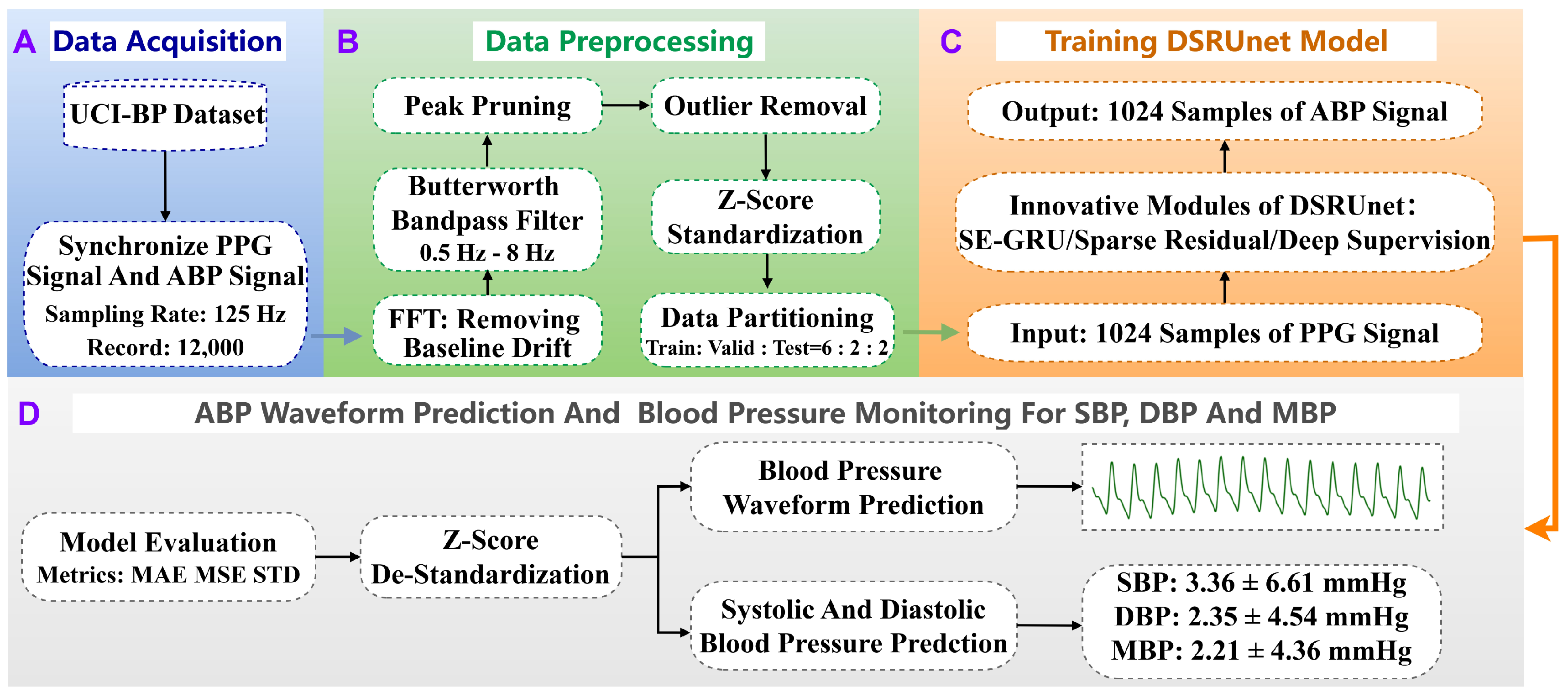
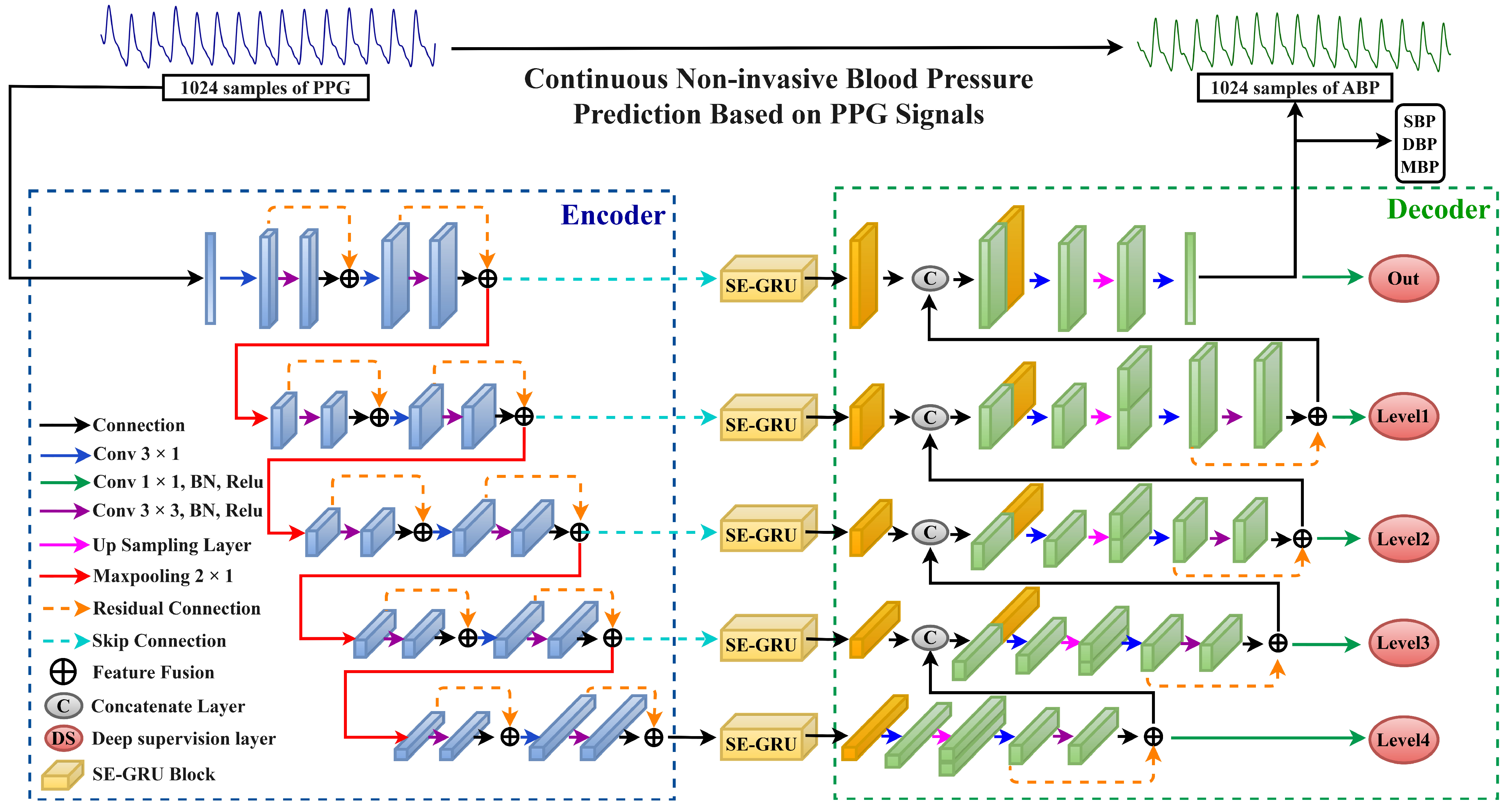
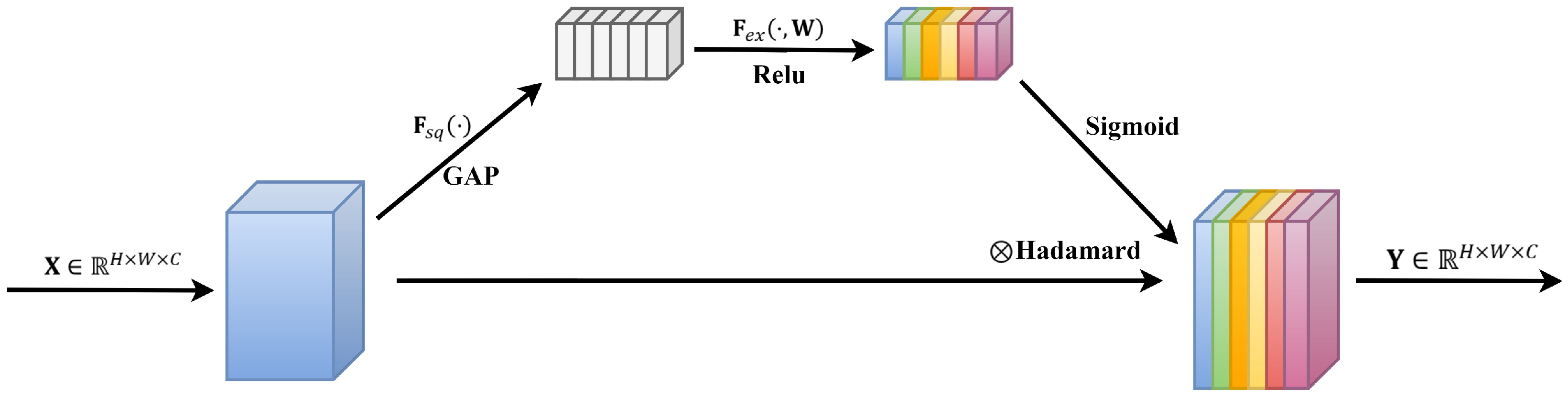
In response to the aforementioned issues, this paper proposes a novel continuous non-invasive blood pressure prediction method based on deep sparse residual U-net combined with improved SE skip connections, aiming to enable continuous blood pressure prediction using a single PPG signal. The main contributions of this work are as follows:
- (1)
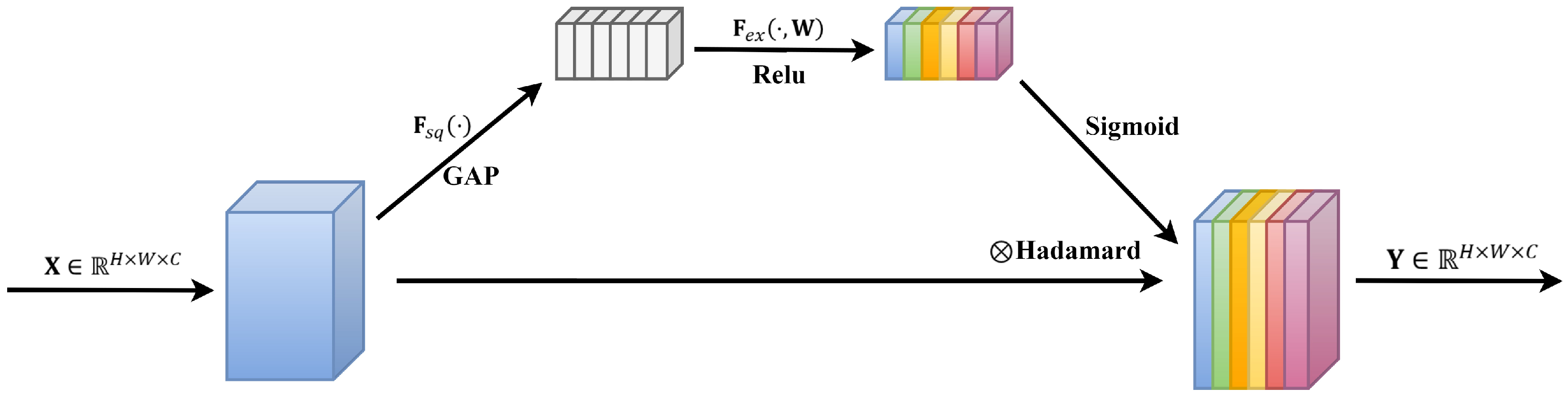
The introduction of a highly symmetric DSRUnet architecture, incorporating refined sparse residual connections to facilitate feature propagation, thereby enhancing information fusion and feature expansion for capturing subtle variations in PPG signals. To address the issue of the inability of the fully connected layers in the SE module to dynamically learn temporal data features, GRU layers are introduced to capture temporal pulse signal features by learning internal channel dependencies. Furthermore, an SE-GRU module is embedded within the skip connections for global information modeling and weighting, aimed at enhancing the discriminative and representational capabilities of essential features in the original PPG signal.
- (2)
The integration of a deep supervision mechanism by introducing additional output layers at the decoder end of the DSRUnet network, guiding the lower-level network to learn effective feature representations, thus alleviating the issue of gradient disappearance and improving the network’s training efficiency and performance.
- (3)
The proposed method not only predicts highly accurate SBP, DBP, and MBP values but also enables the accurate recovery of blood pressure waveforms from a single PPG signal. Extensive ablation experiments and comparisons with the existing research demonstrate the superior blood pressure prediction performance of the DSRUnet model proposed in this study, particularly in SBP prediction, surpassing other state-of-the-art models in terms of accuracy, thus indicating its potential applicability in wearable devices.
The remaining sections of the paper are organized as follows:
Section 2 provides a detailed description of the research methodology for continuous non-invasive blood pressure prediction based on photoplethysmography (PPG) signals. It also outlines the fundamental and innovative theories behind the proposed DSRUnet model.
Section 3 encompasses the experimental settings, dataset descriptions, establishment of evaluation metrics, and configuration of the comparative models.
Section 4 elucidates the experimental results and analysis, including assessments based on various standards, results from ablation experiments, and comparisons with existing methods.
Section 5 summarizes the research findings of the paper and outlines potential future research directions.
4. Results and Discussion
4.1. Evaluation and Analysis of Experimental Results Based on BHS Standard
The British Hypertension Society (BHS) standard [
53] is one of the international standards used to assess the accuracy of blood pressure measurement devices. It serves as a foundation for determining whether blood pressure prediction models can be applied in clinical experiments. The accuracy criteria in the BHS standard evaluation method are established based on absolute errors, requiring evaluation based on the percentage of absolute errors in the predicted values for the test samples. The thresholds are set at 5 mmHg, 10 mmHg, and 15 mmHg, and the BHS defines three grades, A, B, and C, as shown in
Table 4. The overall evaluation grade for the SBP, DBP, and MBP predictions under the three scenarios was determined using the worst result among the three sets of threshold judgment results.
Utilizing the BHS standard, the evaluation grade results for the different models are presented in
Table 5. It can be observed that the proposed DSRUnet model achieved grade A in the evaluation of its SBP, DBP, and MBP predictions according to the BHS standard. Furthermore, compared with the other models, the DSRUnet model achieved significant breakthroughs in the prediction accuracy for SBP after incorporating the improved SE-GRU module and sparse residual connection module. Specifically, the percentage of predictions below a difference of 5 mmHg exceeded 80% for the first time, and predictions below 10 mmHg exceeded 90%. Although the performance of this model in DBP and MBP prediction was slightly lower than that of Model 5 and Model 6, comparing DSRUnet with Model 6 revealed that the prediction accuracy of SBP was enhanced by 1.51%, 0.75%, and 0.34% under the three thresholds, respectively. Meanwhile, the prediction accuracy of DBP decreased by only 0.08%, 0.45%, and 0.14%, respectively. This suggests that the improvement in SBP prediction performance by DSRUnet far outweighed the decrease in DBP prediction performance. Considering the substantial difficulty in predicting SBP in blood pressure prediction tasks, this outcome is acceptable according to the hypothesis proposed by Kachuee et al. [
44,
54].
Figure 7 illustrates the distribution of absolute errors when predicting SBP, DBP, and MBP. It can be observed that the majority of absolute errors were below 2.5 mmHg, indicating that the proposed model achieved small errors in blood pressure prediction and exhibits good prediction performance, meeting the basic requirements for clinical applications [
55].
4.2. Evaluation and Analysis of Experimental Results Based on AAMI Standard
Similar to the BHS standard, the Association for the Advancement of Medical Instrumentation (AAMI) Standard [
56] serves as another benchmark for assessing the performance of medical devices. In the realm of blood pressure measurements, the AAMI standard is frequently employed to gauge the accuracy and reliability of blood pressure measuring devices. This standard imposes specific requirements regarding error limits, stipulating that the average error and standard deviation between predicted and true results should each be less than 5 mmHg and 8 mmHg, respectively. Furthermore, adherence to the AAMI standards typically necessitates a minimum sample size of 85 subjects in the study.
Table 6 presents the evaluation results of the DSRUnet model in accordance with the AAMI standard.
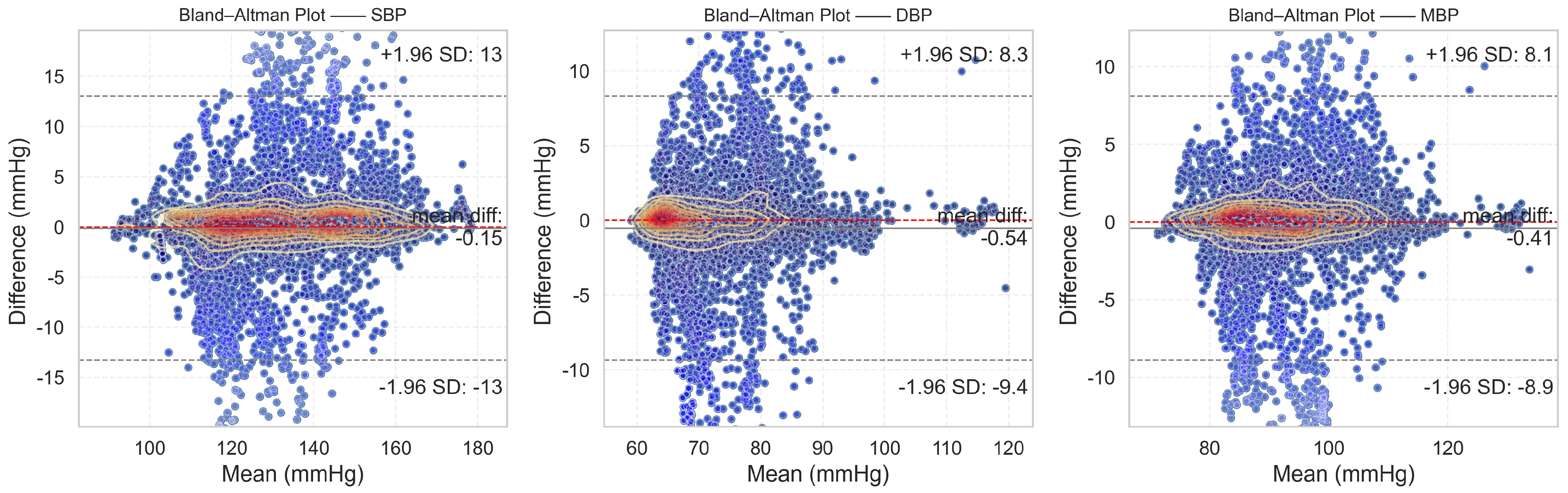
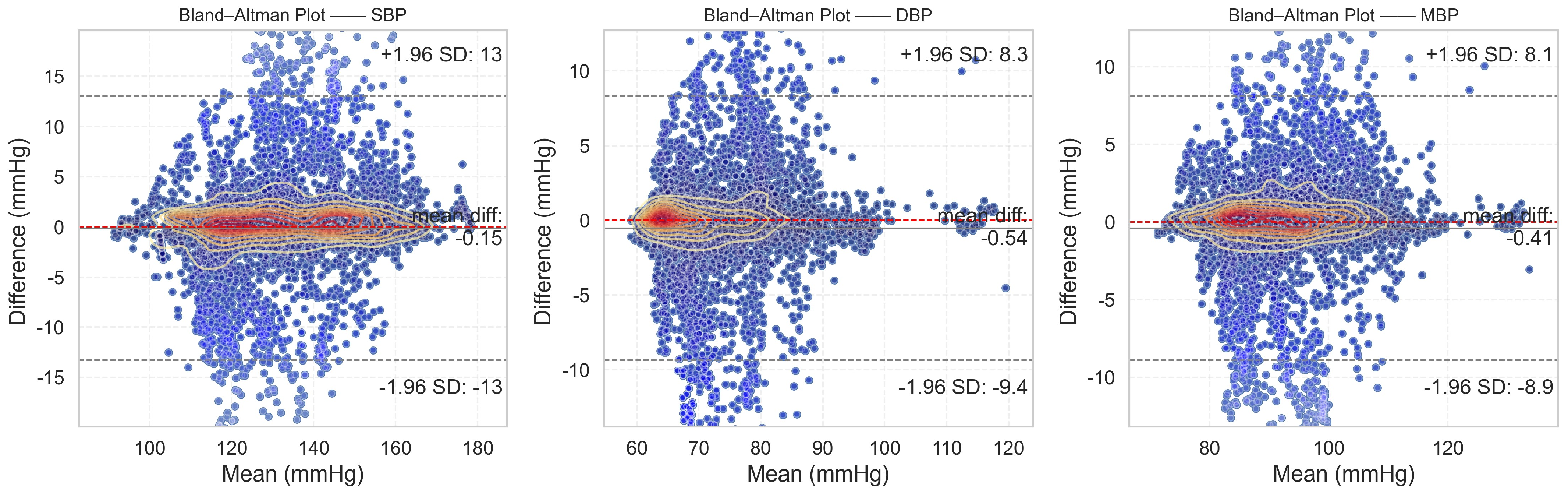
From the evaluation results, it is evident that the proposed DSRUnet model meets the AAMI standard for blood pressure prediction. Building upon this foundation, to assist researchers and medical professionals in assessing the consistency between predicted and true results, Bland–Altman plots [
57] of the predicted SBP, DBP, and MBP results are generated based on the ME and STD evaluation metrics. These plots provide a visual means to evaluate potential biases or anomalies in the predicted results and reflect the central tendency of the predictions. Bland–Altman plots utilize the standard deviation of the differences to describe the variability of the mean. The requirement for good consistency between true and predicted results is that the vast majority of differences fall within the 95% limits of agreement, defined as ±1.96 times the standard deviation of the differences. The range of this limit is
, where
and
represent the mean and standard deviation of the differences, respectively. This range can reflect the acceptable level in clinical practice.
The final results, as shown in
Figure 8, distinctly illustrate the consistency analysis of the SBP, DBP, and MBP predictions using the DSRUnet model. The majority of the errors were below 5 mmHg, with the local density heatmaps distributed near the 0 scale line. Although some samples exceeded 15 mmHg in the SBP predictions, the distribution of the local density heatmap in this scenario was the most uniform. This demonstrates that the DSRUnet model has relatively reliable performance for blood pressure prediction, particularly with a qualitative breakthrough in SBP predictions. Moreover, the results can be validated through consistency checks.
4.3. Ablation Experiment and Result Analysis
In order to comprehensively evaluate the generalization ability and predictive performance of the proposed DSRUnet model, degradation experiments were conducted based on the model evaluation metrics set in
Section 2.3 and the comparative models set in
Section 2.4, using an independent test set. The evaluation results of the different models are presented in
Table 7. To facilitate a more intuitive comparison of the ME metric differences, the absolute values of the ME results were used for comparison.
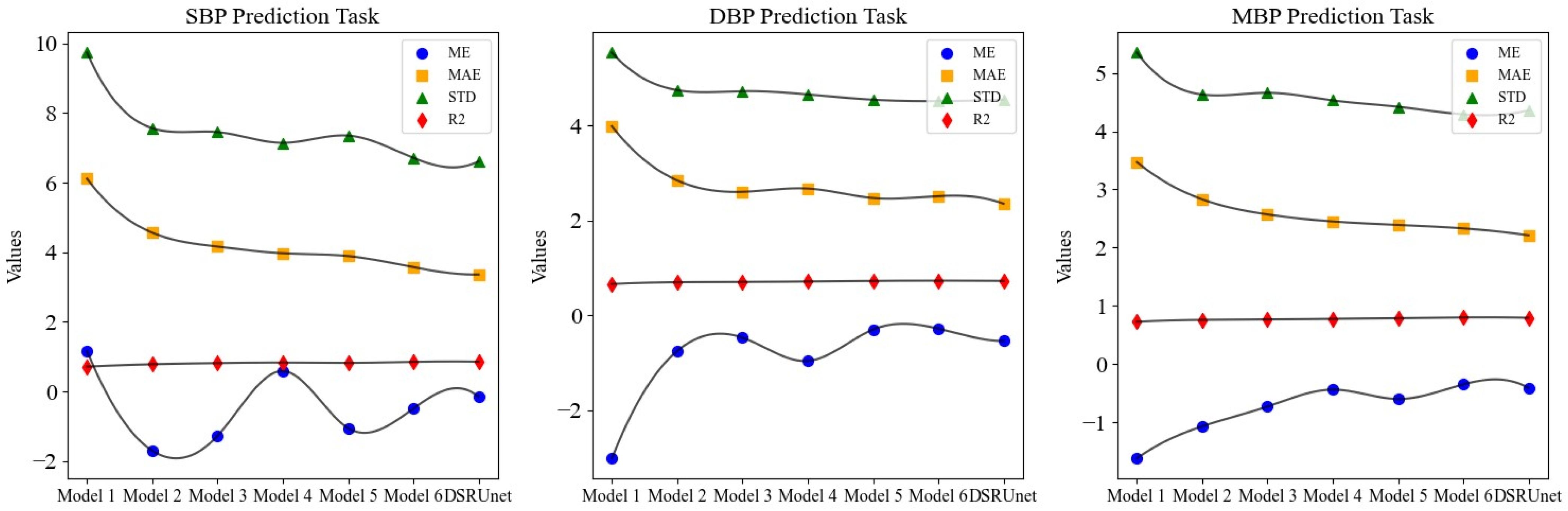
The comparison of four performance metrics across different models is illustrated in
Figure 9. It is evident that the DSRUnet model exhibited superior performance, indicating its advanced capabilities.
From the results of the ablation experiment, it can be observed that the performance the pure U-net network without any improvement modules for continuous blood pressure prediction was the poorest. In particular, the MAE for SBP predictions reached 6.11 and the STD reached 9.73, indicating very unsatisfactory results. Building upon the performance of the worst-performing Model 1, different improvement modules were progressively added for the degradation experiment.
A comprehensive comparison and analysis of the experimental results of each model, using the mean absolute error (MAE) of each prediction as the evaluation metric, validates the effectiveness of the proposed innovative modules for SBP, DBP, and MBP predictions. The specific results are as follows:
Model 2 and Model 3 have embedded traditional SE modules and improved SE-GRU modules, respectively, in the skip-connection part. Compared to Model 1, the MAE for SBP predictions was reduced by 1.55 and 1.95, respectively, for Model 2 and Model 3. Similarly, for DBP prediction, the MAE was reduced by 1.14 and 1.38, respectively. This demonstrates that improving the skip-connection method can significantly reduce blood pressure prediction errors, and introducing GRU layers to enhance SE modules can further improve the prediction accuracy and enhance the ability to extract pulse signal features.
Building upon the improved skip-connection method, the effectiveness of replacing conventional convolution modules in the sampling paths with residual modules was verified. Model 4 and Model 5 are based on Model 2 but use ordinary residual modules and sparse residual modules for feature transmission, respectively. Compared to Model 2, the MAE for SBP predictions was reduced by 0.59 and 0.67, respectively, for Model 4 and Model 5. Similarly, for DBP predictions, the MAE was reduced by 0.17 and 0.37, respectively. This indicates that replacing the original conventional convolution modules with residual modules in both the downsampling and upsampling paths can further improve the blood pressure prediction accuracy, alleviate the gradient vanishing problem, and enhance the robustness and generalization ability of the network.
From the experimental results, Model 6 and the proposed DSRUnet model emerged as the two best-performing models. Both models have improved SE-GRU modules embedded in the skip connection and residual connection modules for feature transmission were introduced. Among them, the DSRUnet model achieved the smallest MAE results for SBP, DBP, and MBP predictions, which were 3.36, 2.35, and 2.21, respectively. While Model 6 attained the best ME, STD, and R2 values for DBP and MBP predictions, considering the difficulty in SBP prediction in existing blood pressure prediction tasks, and the minor differences in DBP and MBP prediction performances (ME difference of 0.26 and 0.06, STD difference of 0.03 and 0.07, R2 difference of 0.005 and 0.006), this study selected the more accurate DSRUnet model for SBP prediction as the optimal model. This choice validates the excellent prediction performance and stability of the proposed SE-GRU module and sparse residual connection module.
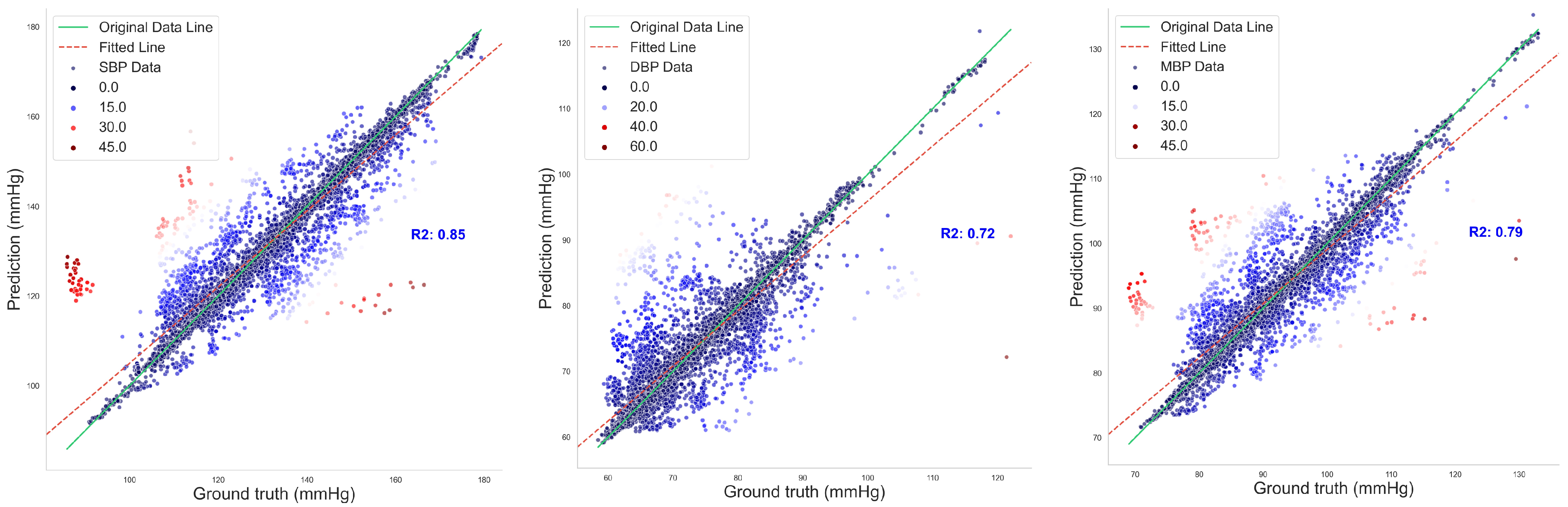
Figure 10 illustrates the regression fitting results of the proposed DSRUnet model for SBP, DBP, and MBP prediction tasks. The green solid line represents the original data line, while the red dashed line represents the fitted line. Different colors denote the degree of dispersion of the data points. It can be observed that the majority of data points exhibited small errors. Additionally, the coefficients of determination (R
2) for the SBP, DBP, and MBP prediction fitting results were 0.85, 0.72, and 0.79, respectively. From the fitting results, it can be observed that the majority of points were clustered around the line, indicating a good overall prediction performance. There were relatively few red scattered points with significant deviations.
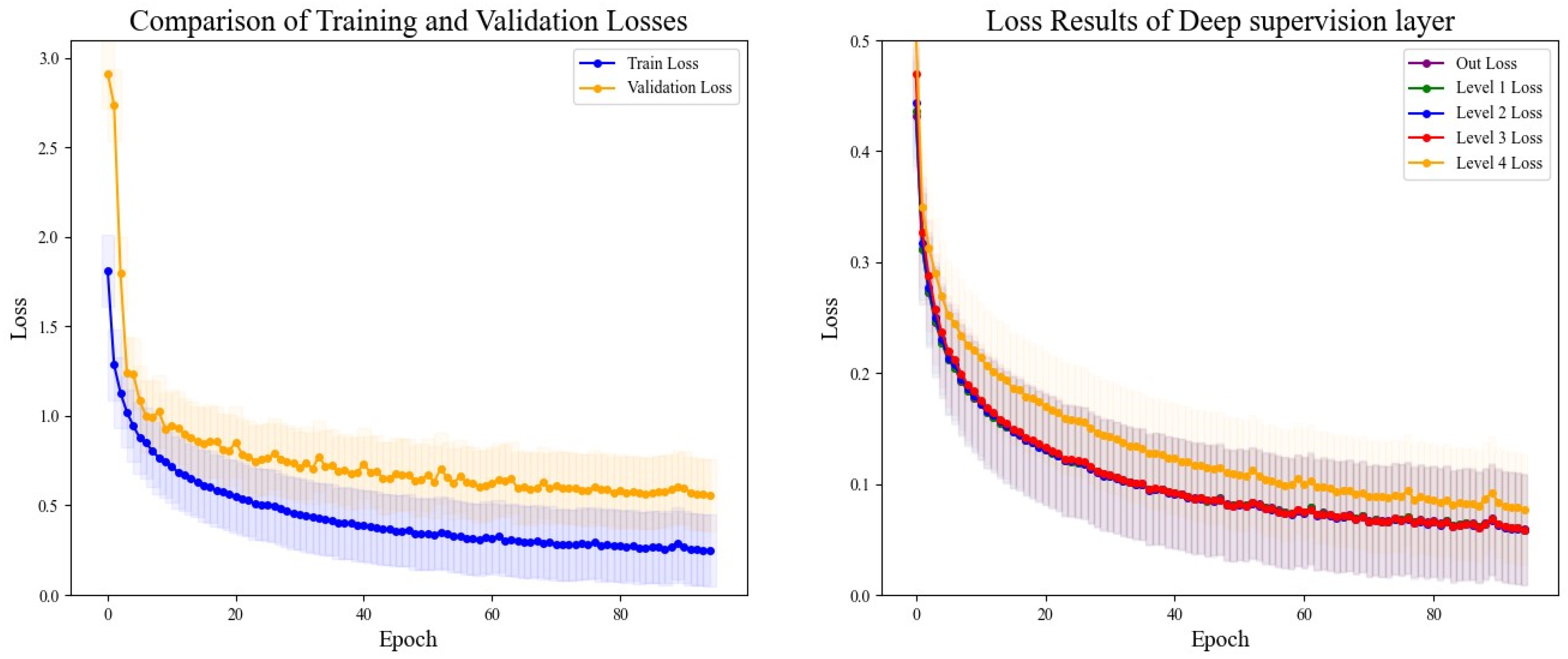
4.4. Model Loss Curves and Results of Deep Supervision Monitoring
The DSRUnet model constructed in this study introduces a deep supervision mechanism to monitor the training process of the model. Five deep supervision layers were incorporated into the encoder module to learn intermediate representations and output intermediate losses for visual analysis. Additionally, to better evaluate the performance and generalization ability of the model, and to intuitively analyze the model’s performance during training and validation, the losses using the training set and validation set were recorded for a comprehensive comparison. The final results are shown in
Figure 11.
From the comparative analysis, it is evident that the disparity between the training and validation losses was minimal, with the training loss consistently lower than the validation loss. Both exhibited a decreasing trend, which gradually approached a plateau, indicating that the model’s training process adheres to scientific principles without signs of overfitting or underfitting, thus providing valuable guidance. An analysis of the loss output from the five layers of deep supervision revealed higher losses during the initial stages of upsampling learning, coupled with slower descent rates, which could be alleviated through appropriate adjustments to the learning rate. Throughout all stages, the network’s learning efficacy progressively converged, with the loss values tending towards a smaller range, thus affirming the reliability of the model’s training process.
4.5. Comparison with Existing Methods
Comprehensively comparing the existing blood pressure prediction methods is often challenging. Different prediction methods may utilize distinct medical datasets for model training and evaluation, which could originate from diverse age groups and clinical settings with varying sampling frequencies and storage methods, resulting in significant data heterogeneity. The commonly used publicly available datasets in the field of blood pressure prediction include MIMIC-I [
58], MIMIC-II [
59], MIMIC-III [
60], UCI-BP, and the Queensland Vital Signs Dataset [
61], among others. Notably, there is a scarcity of datasets specifically tailored for blood pressure prediction tasks, with limited studies solely relying on the UCI-BP dataset, which is derived from a subset of the MIMIC-II database following preprocessing steps. Besides dataset disparities, differences in evaluation methodologies also pose challenges in comparing different methods. Various studies may opt for different evaluation metrics, and even when using the same metrics, they may employ different evaluation techniques and cross-validation strategies, leading to substantial impacts on comparison outcomes.
In light of the aforementioned considerations, in order to scientifically assess the predictive performance of the proposed DSRUnet model and determine its relative advancement compared to existing methods and models, we refer to current mainstream evaluation methodologies [
62,
63,
64]. Specifically, we conducted a comprehensive comparison by evaluating the overall models rather than isolated parameters. We strived to select methods with similar data processing procedures and evaluation workflows for a holistic assessment. This study conducted a comprehensive comparison with existing research in three aspects:
- (a)
Direct Model Comparison: Disregarding the impact of different data preprocessing methods, we included methods utilizing the MIMIC-II and MIMIC-III datasets for comparison alongside the DSRUnet model. We directly compared the DSRUnet model with existing models based on common evaluation metrics. The final comparative results are presented in
Table 8.
- (b)
Innovation Assessment Against U-net Models: The DSRUnet model proposed in this study primarily addresses the limitations of the traditional U-net model. In order to better validate the advancement of our proposed model, we considered the existing methods for blood pressure prediction based on the U-net model for a comprehensive comparison. The results are presented in
Table 9.
From
Table 8, it is evident that, disregarding various influencing factors, the proposed DSRUnet model attained the highest level among the analyzed models in terms of blood pressure prediction capability. The predicted absolute mean error (|ME|) and mean absolute error (MAE) values were significantly lower than those of most existing studies, indicating smaller prediction errors from the DSRUnet model. Particularly noteworthy is the marked improvement achieved in predicting SBP compared to similar models, which holds considerable significance for the task of blood pressure prediction given the historical challenge associated with predicting systolic pressure. Overall, although the DSRUnet model did not outperform some existing models on certain metrics (such as R
2), its performance advantage remains substantial when considering multiple indicators. It is imperative to emphasize that model performance in blood pressure prediction should not rely solely on a single metric, but should encompass various factors including accuracy, stability, and clinical applicability. Furthermore, the evaluation system of the DSRUnet model is relatively comprehensive, covering the majority of evaluation metrics and possessing the capability to recover real-time blood pressure signals from single PPG signals, a feature not commonly found in other models. This attribute gives the DSRUnet model a significant advantage in practical clinical applications, as it can provide faster and more precise blood pressure predictions.
The proposed DSRUnet model demonstrated consistent performance across different metrics, with all prediction results meeting the A-grade standards outlined by the British Hypertension Society (BHS) and also aligning with the standards set by the Association for the Advancement of Medical Instrumentation (AAMI). This underscores its promising clinical applicability in blood pressure prediction.
Table 9 presents a comparative analysis of the existing methods for continuous non-invasive blood pressure prediction based on PPG signals and U-net architectures. During the comparison, it was noted that R
2, a commonly used evaluation metric, was not calculated in these methods. Only a few studies mentioned the calculation results of the correlation coefficient (
) when performing parameter regression fitting. Therefore, we included the calculation of the correlation coefficient (
) for predicting SBP and DBP using the DSRUnet model for localized comparisons, as described in Equation (22).
where
presents the number of samples,
represents the true blood pressure value, and
represents the predicted blood pressure value.
When selecting specific comparison methods, besides considering the necessity of employing the encoder–decoder architecture of the U-net model, this study aimed to choose systems trained on similar datasets and relatively large datasets for comparison. It can be observed that the proposed method, which combines deep sparse residual U-net with improved SE skip connections, achieved superior performance compared to the majority of the U-net-based systems. Additionally, it boasts a comprehensive evaluation framework. It can accurately reconstruct blood pressure waveforms using only a single PPG signal, without the need for additional physiological signals, a feature uncommon in the existing methods. In particular, DSRUnet exhibited the lowest mean error and mean absolute error in SBP predictions, indicating a higher precision in SBP prediction compared to the existing U-net-based methods. This was achieved with only a slight compromise in DBP prediction performance. This suggests that the innovative structure of DSRUnet might be more suitable for SBP prediction, providing valuable insights for improving SBP prediction performance in the future. However, optimizing the DSRUnet structure for DBP prediction remains an area for further exploration. Furthermore, the calculated correlation coefficient () results of 0.92 and 0.86 demonstrate a strong correlation between the predicted and actual values, further validating the scientific rigor and credibility of the proposed method.
Combining the comparison results from both sections, it becomes evident that achieving optimization across all evaluation metrics in the field of continuous non-invasive blood pressure prediction is challenging. This is attributed to the inherent characteristics of blood pressure prediction tasks mentioned earlier. Moreover, the lack of a comprehensive prediction system that encompasses all feature datasets and measurement methods could be a potential avenue for future research. From this perspective, solely pursuing the “superiority” of data metrics while overlooking the fairness of evaluation brought about by the characteristics of blood pressure prediction tasks may not be highly persuasive.
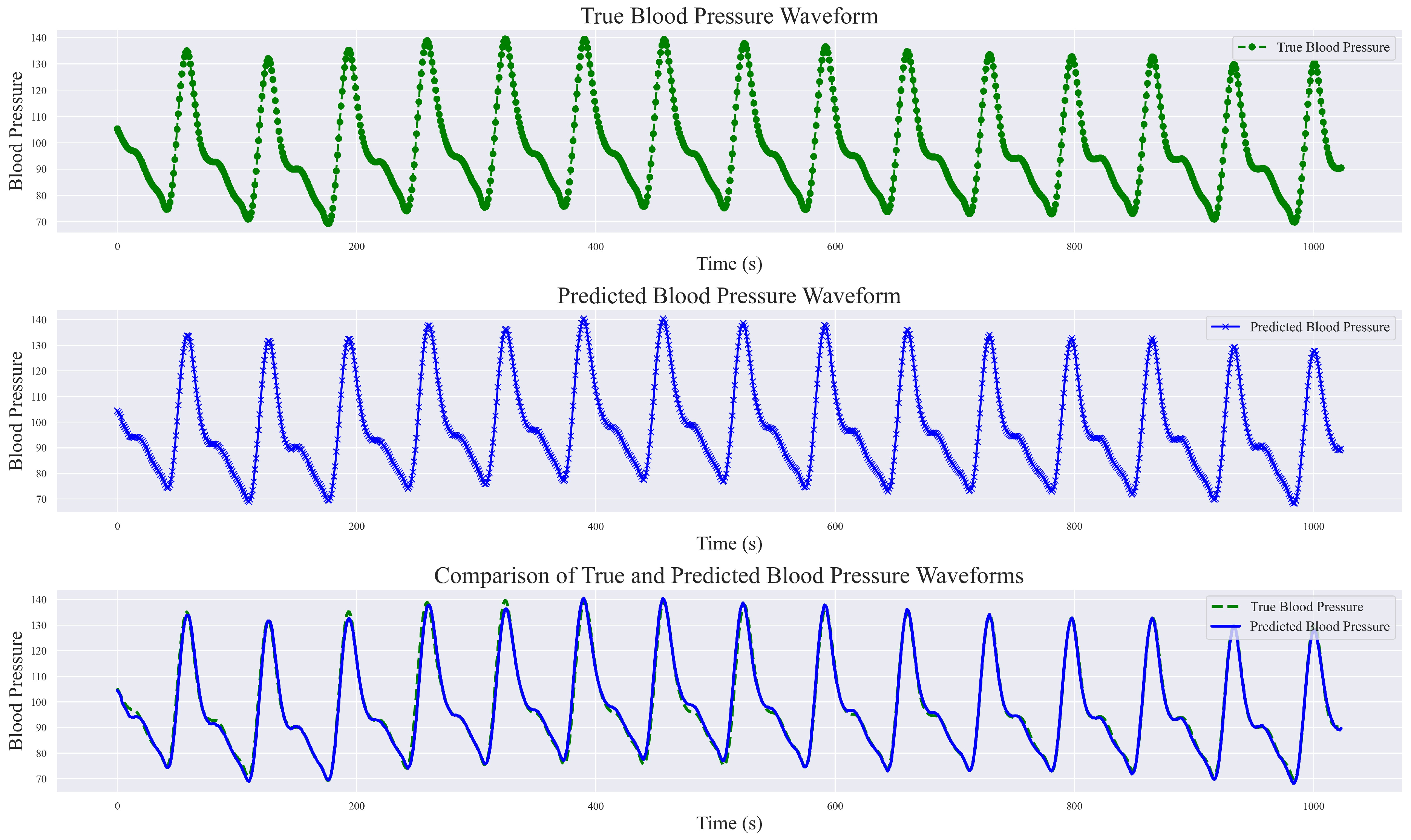
During the exploration of relevant methods, it was noted that the original input signals varied, encompassing both raw PPG signal data and raw waveform features, as well as inputs fused from multimodal information such as ECG, first-order derivatives of PPG, and second-order derivatives of PPG, among others. In this study, a singular PPG signal was employed for continuous blood pressure signal prediction. The final prediction results not only include numerical predictions but also encompass predictions of the blood pressure waveform. Analyze and present the results of a randomly selected set of sampling bands, each with a length of 1024, showcasing real blood pressure waveforms, predicted blood pressure waveforms, and a comprehensive comparison between the two, as illustrated in
Figure 12.
This study demonstrated the robust performance of the DSRUnet model in estimating blood pressure waveforms by converting input PPG signals into corresponding predicted blood pressure waveforms. A comparative analysis with real blood pressure waveforms revealed that the DSRUnet model achieved a waveform prediction MAE of 3.37 mmHg, STD of 6.33 mmHg, and R2 value of 0.91. A visual inspection of the graphs indicated that the overall shapes, amplitudes, and trends of the predicted blood pressure waveforms closely match those of the actual blood pressure waveforms. Minor discrepancies in phase and amplitude were observed only at certain peaks, troughs, and reperfusion traces, corresponding to errors in the SBP and DBP predictions. Additionally, some variations were observed in the prediction of individual systolic phases (i.e., the stage where the arterial pressure reaches its peak), which may correspond to challenges encountered in SBP prediction. Overall, the predicted blood pressure waveforms not only closely matched the real waveforms but also accurately described the systolic and diastolic processes of blood pressure changes, capturing the corresponding peak points, trough points, and rebound traces. Moreover, the predictions were unaffected by motion artifacts in the PPG signal and alleviated the phase lag issues. Generally, ABP waveforms are collected and stored invasively. Through the proposed DSRUnet model, real-time reliable ABP waveforms can be reconstructed from PPG signals acquired using optical sensors, thus expanding the possibilities for clinical applications.
5. Conclusions
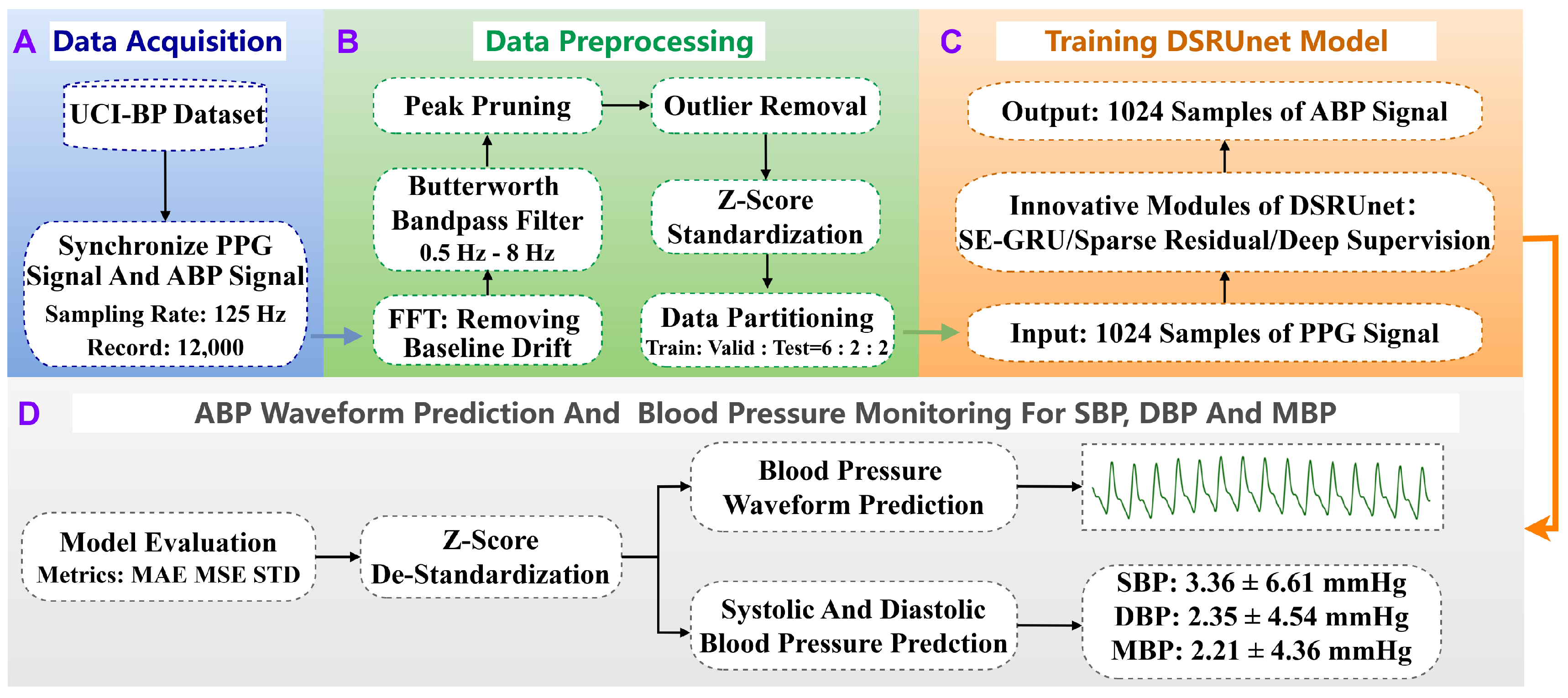
This study proposes a continuous non-invasive blood pressure prediction model, named DSRUnet, based on a deep sparse residual U-net combined with an improved SE skip connection. Utilizing only a single PPG signal, the model produced high-precision predictions of SBP, DBP, and MBP, as well as an accurate visualization of blood pressure waveforms. The integration of BP parameters and waveform patterns assists in identifying cardiovascular abnormalities, providing new possibilities for clinical research in hospitals and deployment studies for medical edge devices.
Specifically, the DSRUnet model employs a single PPG signal as the network input and utilizes an end-to-end U-net structure with highly symmetrical features for feature extraction. Sparse residual connection modules were introduced in the upsampling and downsampling paths to replace the ordinary convolutional modules to better capture subtle feature variations in the original PPG signal and preventing performance degradation. To model and weight global feature information more effectively, an improved SE-GRU module was embedded in the skip connections to extract the temporal features of the PPG signal through the GRU layer and enhancing the model’s generalization performance. Furthermore, a deep supervision mechanism was added to each layer’s output in the upsampling path to guide the learning of effective feature representations in the lower layers and alleviate the problem of gradient vanishing. Through ablation experiments on the UCI-BP dataset and comparisons with existing models, the effectiveness and advancement of the DSRUnet model were verified. When comparing with existing studies, we took into account the impact of data processing and evaluation procedures on the prediction outcomes. By establishing two sets of contrasting principles, we found that solely assessing system superiority based on prediction results is not objective. What is required for blood pressure prediction tasks is a comprehensive and adaptable system that remains stable across various data types. The experimental results indicated that the proposed DSRUnet model achieved higher prediction accuracy than most existing models, with a significant improvement in SBP prediction compared to the majority of the existing blood pressure prediction models. The model’s ability to accurately predict blood pressure waveforms is also relatively rare in existing research. Additionally, the model’s prediction results meet the A-grade standard of the BHS and fulfill the basic requirements of the AAMI standard, showing practical application potential in the field of intelligent wearable medical devices.
Building upon the traditional U-net model, this study balanced model complexity and prediction performance by optimizing the model structure. The proposed sparse residual connection modules and SE-GRU modules provide insights for researchers in other areas of blood pressure prediction, such as introducing models that can better extract temporal signal features, such as LSTM and GRU, to explore the underlying patterns between PPG signals and blood pressure signals, contributing to the field of blood pressure prediction.
In future work, we will delve deeper into the following issues:
Physiological characteristics vary from person to person, making it challenging for a single model to accurately predict blood pressure for different individuals. We will explore the mechanisms behind individual differences in blood pressure prediction tasks, considering methods such as network model optimization and transfer learning, to improve the model’s ability to generalize across individuals and resist noise interference.
In blood pressure prediction, the number of samples within the normal blood pressure range is often much larger than those within the high or low blood pressure ranges, resulting in dataset imbalance issues. In future research, we will address the problem of imbalance regression caused by insufficient datasets, and consider appropriate data preprocessing methods and data balancing techniques to enhance the prediction stability and accuracy of the blood pressure prediction model under data imbalance conditions.
The proposed DSRUnet method appears to be more focused on predicting SBP. In future research, we will consider adjusting the model structure and data processing methods to enhance the DBP prediction performance while maintaining its performance in predicting SBP. Additionally, we will explore integration with wearable devices for enhanced prediction capabilities.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}