
VELIE: A Vehicle-Based Efficient Low-Light Image Enhancement Method for Intelligent Vehicles


Abstract
1. Introduction
2. Literature Review
2.1. Traditional Methods
2.2. Learning-Based Method
2.3. LLIE in Driving Scenarios
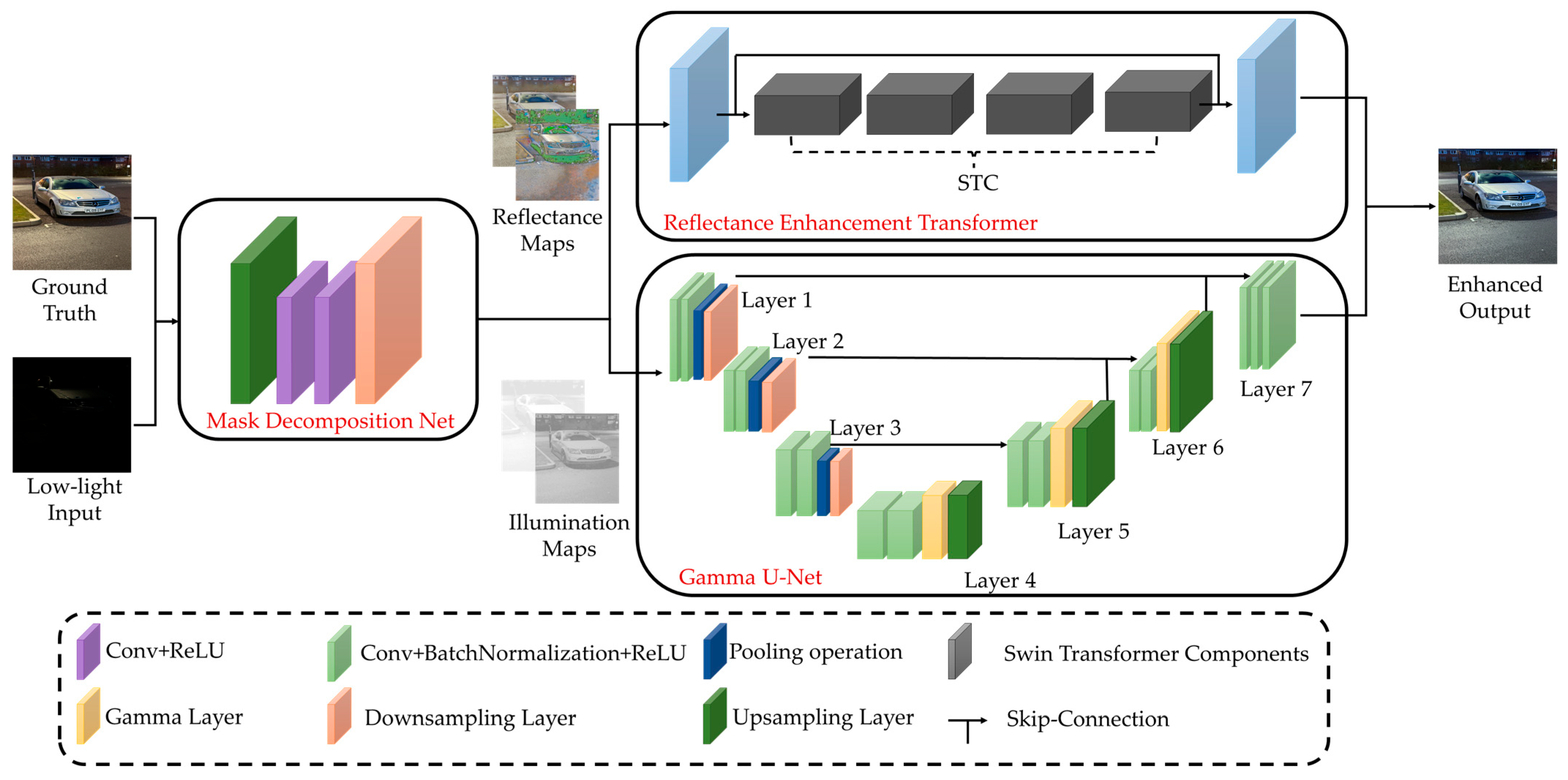
3. Method
3.1. Mask Decomposition Network (MDN)
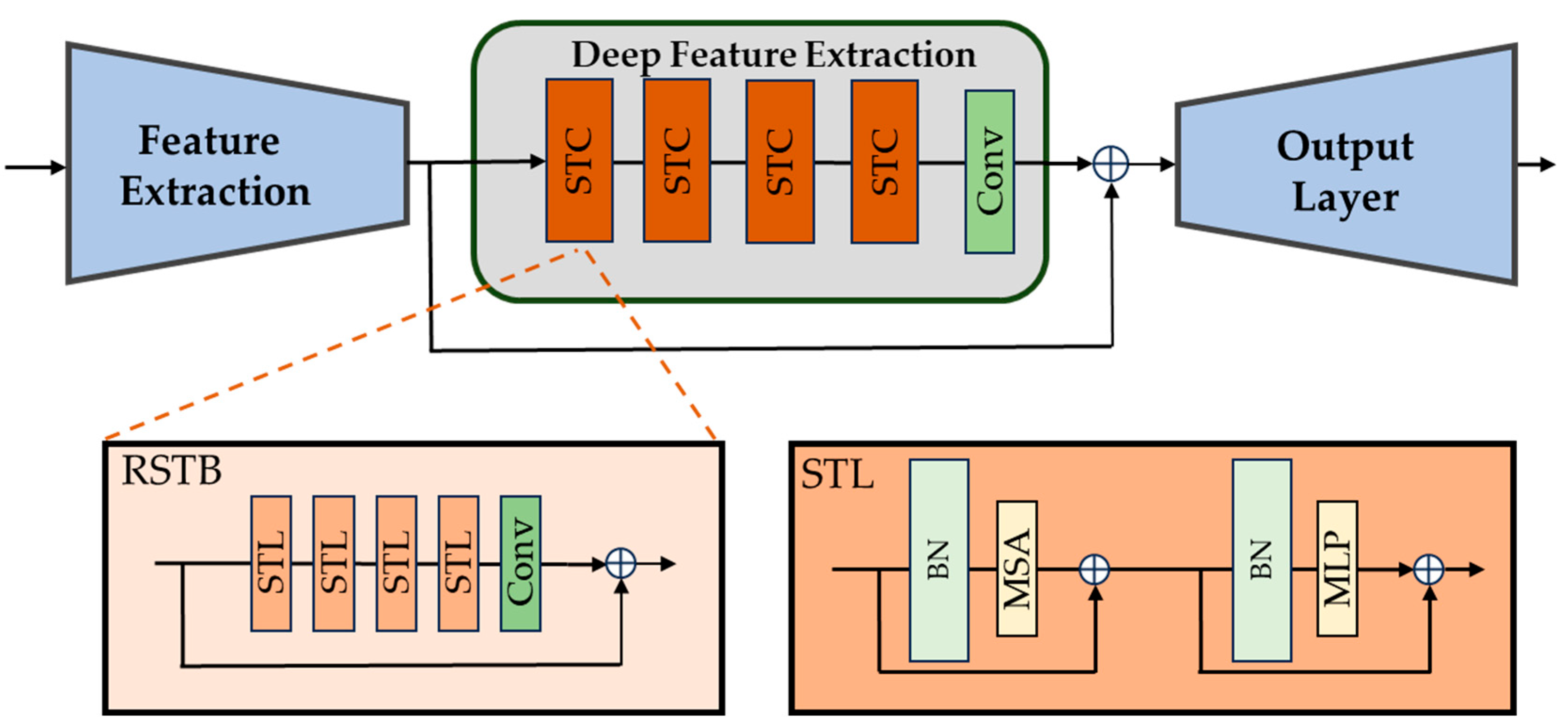
3.2. Reflectance Enhancement Transformer (RET)
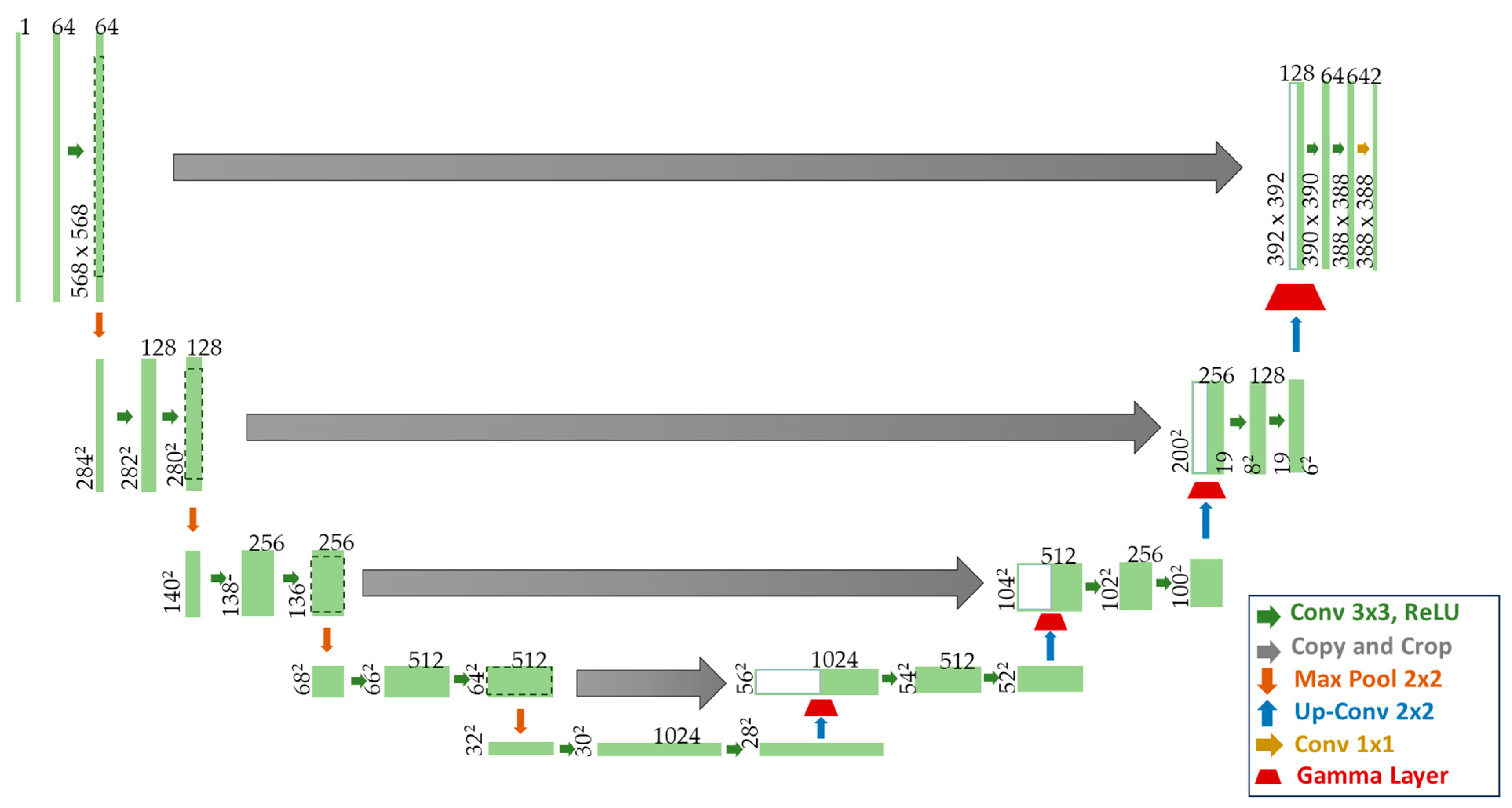
3.3. Gamma U-Net (G-UNet)
3.4. Feature Fusion Output Layer
4. Experiment
4.1. Dataset
4.2. Implementation
4.3. Enhancement Results
4.4. Impact on High-Level Perception
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gruyer, D.; Magnier, V.; Hamdi, K.; Claussmann, L.; Orfila, O.; Rakotonirainy, A. Perception, information processing and modeling: Critical stages for autonomous driving applications. Annu. Rev. Control 2017, 44, 323–341. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, X.; Li, J.; Xv, B.; Fu, R.; Chen, H.; Yang, L.; Jin, D.; Zhao, L. Multi-Modal and Multi-Scale Fusion 3D Object Detection of 4D Radar and LiDAR for Autonomous Driving. IEEE Trans. Veh. Technol. 2022, 72, 5628–5641. [Google Scholar] [CrossRef]
- Fang, W.; Zhang, G.; Zheng, Y.; Chen, Y. Multi-Task Learning for UAV Aerial Object Detection in Foggy Weather Condition. Remote Sens. 2023, 15, 4617. [Google Scholar] [CrossRef]
- Wood, J.M.; Isoardi, G.; Black, A.; Cowling, I. Night-time driving visibility associated with LED streetlight dimming. Accid. Anal. Prev. 2018, 121, 295–300. [Google Scholar] [CrossRef] [PubMed]
- Rashed, H.; Ramzy, M.; Vaquero, V.; El Sallab, A.; Sistu, G.; Yogamani, S. FuseMODNet: Real-Time Camera and LiDAR Based Moving Object Detection for Robust Low-Light Autonomous Driving. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Republic of Korea, 27–28 October 2019; pp. 2393–2402. [Google Scholar]
- Paek, D.; Kong, S.; Wijaya, K.T. K-Radar: 4D Radar Object Detection for Autonomous Driving in Various Weather Conditions. Adv. Neural Inf. Process. Syst. 2022, 35, 3819–3829. [Google Scholar] [CrossRef]
- Zhang, S.; Zhang, Y.; Jiang, Z.; Zou, D.; Ren, J.; Zhou, B. Learning to see in the dark with events. In Proceedings of the 16th European Conference on Computer Vision (ECCV 2020), Glasgow, UK, 23–28 August 2020; Springer International Publishing: Berlin/Heidelberg, Germany, 2020. Part XVIII 16. [Google Scholar] [CrossRef]
- Altay, F.; Velipasalar, S. The Use of Thermal Cameras for Pedestrian Detection. IEEE Sens. J. 2022, 22, 11489–11498. [Google Scholar] [CrossRef]
- Faramarzpour, N.; Deen, M.J.; Shirani, S.; Fang, Q.; Liu, L.W.C.; Campos, F.d.S.; Swart, J.W. CMOS-Based Active Pixel for Low-Light-Level Detection: Analysis and Measurements. IEEE Trans. Electron Devices 2007, 54, 3229–3237. [Google Scholar] [CrossRef]
- Yuantao, Z.; Mengyang, C.; Dexin, S.; Yinnian, L. TDI Technology Based on Global Shutter sCMOS Image Sensor for Low-Light-Level Imaging. Acta Opt. Sin. 2018, 38, 0911001. [Google Scholar] [CrossRef]
- Pizer, S.M.; Amburn, E.P.; Austin, J.D.; Cromartie, R.; Geselowitz, A.; Greer, T.; ter Haar Romeny, B.; Zimmerman, J.B.; Zuiderveld, K. Adaptive histogram equalization and its variations. Comput. Vis. Graph. Image Process. 1987, 39, 355–368. [Google Scholar] [CrossRef]
- Kim, Y.-T. Contrast enhancement using brightness preserving bi-histogram equalization. IEEE Trans. Consum. Electron. 1997, 43, 1–8. [Google Scholar] [CrossRef]
- Stark, J. Adaptive image contrast enhancement using generalizations of histogram equalization. IEEE Trans. Image Process. 2000, 9, 889–896. [Google Scholar] [CrossRef]
- Abdullah-Al-Wadud, M.; Kabir; Dewan, M.A.A.; Chae, O. A Dynamic Histogram Equalization for Image Contrast Enhancement. IEEE Trans. Consum. Electron. 2007, 53, 593–600. [Google Scholar] [CrossRef]
- Land, E.H.; McCann, J.J. Lightness and Retinex Theory. J. Opt. Soc. Am. 1971, 61, 1–11. [Google Scholar] [CrossRef]
- Hines, G.; Rahman, Z.U.; Jobson, D.; Woodell, G. Single-Scale Retinex Using Digital Signal Processors. In Proceedings of the Global Signal Processing Conference, Bangkok, Thailand, 6–9 December 2005; p. 1324. Available online: https://ntrs.nasa.gov/citations/20050091487 (accessed on 8 February 2024).
- Rahman, Z.; Jobson, D.J.; Woodell, G.A. Multi-scale retinex for color image enhancement. In Proceedings of the 3rd IEEE International Conference on Image Processing, Lausanne, Switzerland, 19 September 1996; Volume 3, pp. 1003–1006. [Google Scholar]
- Antonini, M.; Barlaud, M.; Mathieu, P.; Daubechies, I. Image coding using wavelet transform. IEEE Trans. Image Process. 1992, 1, 205–220. [Google Scholar] [CrossRef]
- Huang, S.-C.; Cheng, F.-C.; Chiu, Y.-S. Efficient Contrast Enhancement Using Adaptive Gamma Correction With Weighting Distribution. IEEE Trans. Image Process. 2012, 22, 1032–1041. [Google Scholar] [CrossRef] [PubMed]
- Jourlin, M.; Pinoli, J. A model for logarithmic image processing. J. Microsc. 1988, 149, 21–35. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, J.; Guo, X. Kindling the Darkness: A Practical Low-Light Image Enhancer. In Proceedings of the 27th ACM International Conference on Multimedia, Melbourne, VIC, Australia, 15 October 2019; pp. 1632–1640. [Google Scholar] [CrossRef]
- Li, P.; Tian, J.; Tang, Y.; Wang, G.; Wu, C. Deep Retinex Network for Single Image Dehazing. Available online: https://daooshee.github.io/BMVC2018website/ (accessed on 8 February 2024).
- Zhang, Y.; Guo, X.; Ma, J.; Liu, W.; Zhang, J. Beyond Brightening Low-light Images. Int. J. Comput. Vis. 2021, 129, 1013–1037. [Google Scholar] [CrossRef]
- Wu, W.; Weng, J.; Zhang, P.; Wang, X.; Yang, W.; Jiang, J. URetinex-Net: Retinex-based Deep Unfolding Network for Low-light Image Enhancement. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 5891–5900. [Google Scholar]
- Kim, B.; Lee, S.; Kim, N.; Jang, D.; Kim, D.-S. Learning Color Representations for Low-Light Image Enhancement. In Proceedings of the 2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2022; pp. 904–912. [Google Scholar]
- Xu, J.; Yuan, M.; Yan, D.-M.; Wu, T. Illumination Guided Attentive Wavelet Network for Low-Light Image Enhancement. IEEE Trans. Multimed. 2022, 25, 6258–6271. [Google Scholar] [CrossRef]
- Jiang, Y.; Gong, X.; Liu, D.; Cheng, Y.; Fang, C.; Shen, X.; Yang, J.; Zhou, P.; Wang, Z. EnlightenGAN: Deep Light Enhancement Without Paired Supervision. IEEE Trans. Image Process. 2021, 30, 2340–2349. [Google Scholar] [CrossRef]
- Gong, Y.; Liao, P.; Zhang, X.; Zhang, L.; Chen, G.; Zhu, K.; Tan, X.; Lv, Z. Enlighten-GAN for Super Resolution Reconstruction in Mid-Resolution Remote Sensing Images. Remote Sens. 2021, 13, 1104. [Google Scholar] [CrossRef]
- Wang, Y.; Wan, R.; Yang, W.; Li, H.; Chau, L.-P.; Kot, A. Low-Light Image Enhancement with Normalizing Flow. Proc. AAAI Conf. Artif. Intell. 2022, 36, 2604–2612. [Google Scholar] [CrossRef]
- Yi, X.; Xu, H.; Zhang, H.; Tang, L.; Ma, J. Diff-Retinex: Rethinking Low-light Image Enhancement with A Generative Diffusion Model. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–3 October 2023; pp. 12268–12277. [Google Scholar]
- Jiang, H.; Luo, A.; Fan, H.; Han, S.; Liu, S. Low-Light Image Enhancement with Wavelet-Based Diffusion Models. ACM Trans. Graph. 2023, 42, 1–14. [Google Scholar] [CrossRef]
- Kuang, H.; Zhang, X.; Li, Y.-J.; Chan, L.L.H.; Yan, H. Nighttime Vehicle Detection Based on Bio-Inspired Image Enhancement and Weighted Score-Level Feature Fusion. IEEE Trans. Intell. Transp. Syst. 2016, 18, 927–936. [Google Scholar] [CrossRef]
- Kuang, H.; Chen, L.; Gu, F.; Chen, J.; Chan, L.; Yan, H. Combining Region-of-Interest Extraction and Image Enhancement for Nighttime Vehicle Detection. IEEE Intell. Syst. 2016, 31, 57–65. [Google Scholar] [CrossRef]
- Li, G.; Yang, Y.; Qu, X.; Cao, D.; Li, K. A deep learning based image enhancement approach for autonomous driving at night. Knowl.-Based Syst. 2020, 213, 106617. [Google Scholar] [CrossRef]
- Lin, C.-T.; Huang, S.-W.; Wu, Y.-Y.; Lai, S.-H. GAN-Based Day-to-Night Image Style Transfer for Nighttime Vehicle Detection. IEEE Trans. Intell. Transp. Syst. 2020, 22, 951–963. [Google Scholar] [CrossRef]
- Kandula, P.; Suin, M.; Rajagopalan, A.N. Illumination-Adaptive Unpaired Low-Light Enhancement. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 3726–3736. [Google Scholar] [CrossRef]
- Cui, Z.; Li, K.; Gu, L.; Su, S.; Gao, P.; Jiang, Z.; Qiao, Y.; Harada, T. You Only Need 90K Parameters to Adapt Light: A Light Weight Transformer for Image Enhancement and Exposure Correction. arXiv 2022, arXiv:2205.14871, 238. [Google Scholar]
- Krichen, M. Convolutional Neural Networks: A Survey. Computers 2023, 12, 151. [Google Scholar] [CrossRef]
- Ali, A.M.; Benjdira, B.; Koubaa, A.; El-Shafai, W.; Khan, Z.; Boulila, W. Vision Transformers in Image Restoration: A Survey. Sensors 2023, 23, 2385. [Google Scholar] [CrossRef]
- Daubechies, I.; DeVore, R.; Foucart, S.; Hanin, B.; Petrova, G. Nonlinear approximation and (deep) ReLU networks. Constr. Approx. 2022, 55, 127–172. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar] [CrossRef]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L.; Timofte, R. SwinIR: Image Restoration Using Swin Transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1833–1844. [Google Scholar] [CrossRef]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer Normalization. arXiv 2016. Available online: https://arxiv.org/abs/1607.06450 (accessed on 8 February 2024).
- Van Erven, T.; Harremoes, P. Rényi Divergence and Kullback-Leibler Divergence. IEEE Trans. Inf. Theory 2014, 60, 3797–3820. [Google Scholar] [CrossRef]
- Horé, A.; Ziou, D. Image Quality Metrics: PSNR vs. SSIM. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 2366–2369. [Google Scholar] [CrossRef]
- Mittal, A.; Soundararajan, R.; Bovik, A.C. Making a “Completely Blind” Image Quality Analyzer. IEEE Signal Process. Lett. 2012, 20, 209–212. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Part III 18. pp. 234–241. [Google Scholar] [CrossRef]
- Ullah, F.; Ansari, S.U.; Hanif, M.; Ayari, M.A.; Chowdhury, M.E.H.; Khandakar, A.A.; Khan, M.S. Brain MR Image Enhancement for Tumor Segmentation Using 3D U-Net. Sensors 2021, 21, 7528. [Google Scholar] [CrossRef] [PubMed]
- Ai, S.; Kwon, J. Extreme Low-Light Image Enhancement for Surveillance Cameras Using Attention U-Net. Sensors 2020, 20, 495. [Google Scholar] [CrossRef] [PubMed]
- Jia, F.; Wong, W.H.; Zeng, T. DDUNet: Dense Dense U-net with Applications in Image Denoising. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 354–364. [Google Scholar] [CrossRef]
- Bloomfield, P.; Steiger, W.L. Least Absolute Deviations: Theory, Applications, and Algorithms; Birkhäuser: Boston, MA, USA, 1983; pp. 158–166. [Google Scholar] [CrossRef]
- Anaya, J.; Barbu, A. RENOIR—A dataset for real low-light image noise reduction. J. Vis. Commun. Image Represent. 2018, 51, 144–154. [Google Scholar] [CrossRef]
- Guo, X.; Li, Y.; Ling, H. LIME: Low-Light Image Enhancement via Illumination Map Estimation. Available online: https://github.com/estija/LIME (accessed on 8 February 2024).
- Sakaridis, C.; Dai, D.; Gool, L.V. Guided Curriculum Model Adaptation and Uncertainty-Aware Evaluation for Semantic Nighttime Image Segmentation. Available online: https://www.trace.ethz.ch/publications/2019/GCMA_UIoU/ (accessed on 8 February 2024).
- Fu, Z.; Yang, Y.; Tu, X.; Huang, Y.; Ding, X.; Ma, K.K. Learning a Simple Low-Light Image Enhancer From Paired Low-Light Instances. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 22252–22261. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | LOL Test Set | P-VELIE Test Set | ||
|---|---|---|---|---|
| PSNR 1 | SSIM | PSNR | SSIM | |
| CLAHE | 16.21 | 0.57 | 17.76 | 0.63 |
| MSRCR | 11.24 | 0.35 | 9.97 | 0.24 |
| RetinexNet | 16.82 | 0.43 | 12.44 | 0.39 |
| KinD++ | 21.30 | 0.82 | 21.07 | 0.79 |
| EnGAN | 17.48 | 0.65 | 19.95 | 0.70 |
| LLFlow | 25.72 | 0.91 | 20.34 | 0.83 |
| PairLIE | 19.51 | 0.74 | 17.72 | 0.69 |
| URetinexNet | 21.33 | 0.83 | 20.19 | 0.75 |
| VELIE (Ours) | 26.07 | 0.91 | 23.61 | 0.85 |
| Method | NIQE | Inference Time (s) |
|---|---|---|
| CLAHE | 4.31 | 0.47 |
| MSRCR | 8.81 | 0.22 |
| RetinexNet | 7.25 | 0.84 |
| KinD++ | 4.36 | 0.41 |
| EnGAN | 5.01 | 1.77 |
| LLFlow | 4.57 | 2.29 |
| PairLIE | 4.99 | 0.91 |
| URetinexNet | 4.33 | 1.12 |
| VELIE (Ours) | 3.97 | 0.19 |
| Method | Detection Rate | Processing Time (s) |
|---|---|---|
| CLAHE | 88.7 | 0.68 |
| MSRCR | 73.1 | 0.46 |
| RetinexNet | 77.5 | 1.02 |
| KinD++ | 86.7 | 0.62 |
| EnGAN | 92.1 | 1.97 |
| LLFlow | 84.2 | 2.52 |
| PairLIE | 92.5 | 1.21 |
| URetinexNet | 92.4 | 1.33 |
| VELIE (Ours) | 94.3 | 0.41 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ye, L.; Wang, D.; Yang, D.; Ma, Z.; Zhang, Q. VELIE: A Vehicle-Based Efficient Low-Light Image Enhancement Method for Intelligent Vehicles. Sensors 2024, 24, 1345. https://doi.org/10.3390/s24041345
Ye L, Wang D, Yang D, Ma Z, Zhang Q. VELIE: A Vehicle-Based Efficient Low-Light Image Enhancement Method for Intelligent Vehicles. Sensors. 2024; 24(4):1345. https://doi.org/10.3390/s24041345
Chicago/Turabian StyleYe, Linwei, Dong Wang, Dongyi Yang, Zhiyuan Ma, and Quan Zhang. 2024. "VELIE: A Vehicle-Based Efficient Low-Light Image Enhancement Method for Intelligent Vehicles" Sensors 24, no. 4: 1345. https://doi.org/10.3390/s24041345
APA StyleYe, L., Wang, D., Yang, D., Ma, Z., & Zhang, Q. (2024). VELIE: A Vehicle-Based Efficient Low-Light Image Enhancement Method for Intelligent Vehicles. Sensors, 24(4), 1345. https://doi.org/10.3390/s24041345