
Finger Vein Identification Based on Large Kernel Convolution and Attention Mechanism

Abstract
1. Introduction
- (1)
- Pioneering the incorporation of a large kernel solution into the FV identification task, we introduce a large kernel structure named LK Block, featuring taper connection and hybrid depthwise convolution. This innovative architecture adeptly captures the comprehensive distribution and global features of finger veins via expansive convolution operations, consequently enhancing the speed and quality of feature extraction.
- (2)
- The introduction of a module that integrates attention mechanisms and residual connections enhances information flows in channels and spaces by emulating visual attention mechanisms. This effectively mitigates limitations associated with convolutional induction bias and improves the discriminative capacity and robustness of features.
- (3)
- By leveraging a dual-channel architecture, Let-Net effectively expands the dataset, seamlessly integrating feature comparison and extraction without explicit feature extraction steps. This innovative approach yields excellent identification results without the need to extract specific areas of interest.
- (4)
- Experimental evaluations conducted across nine public datasets underscore Let-Net’s considerable advantages in the domain of FV identification. Notably, on the VERA dataset [13], characterized by its low quality, Let-Net outperforms current state-of-the-art methods by a significant margin.
2. Related Works
2.1. FV Identification Method Based on Deep Learning
2.2. Kernel Size in Convolutional Layers
2.3. Attention Mechanism
3. Proposed Method
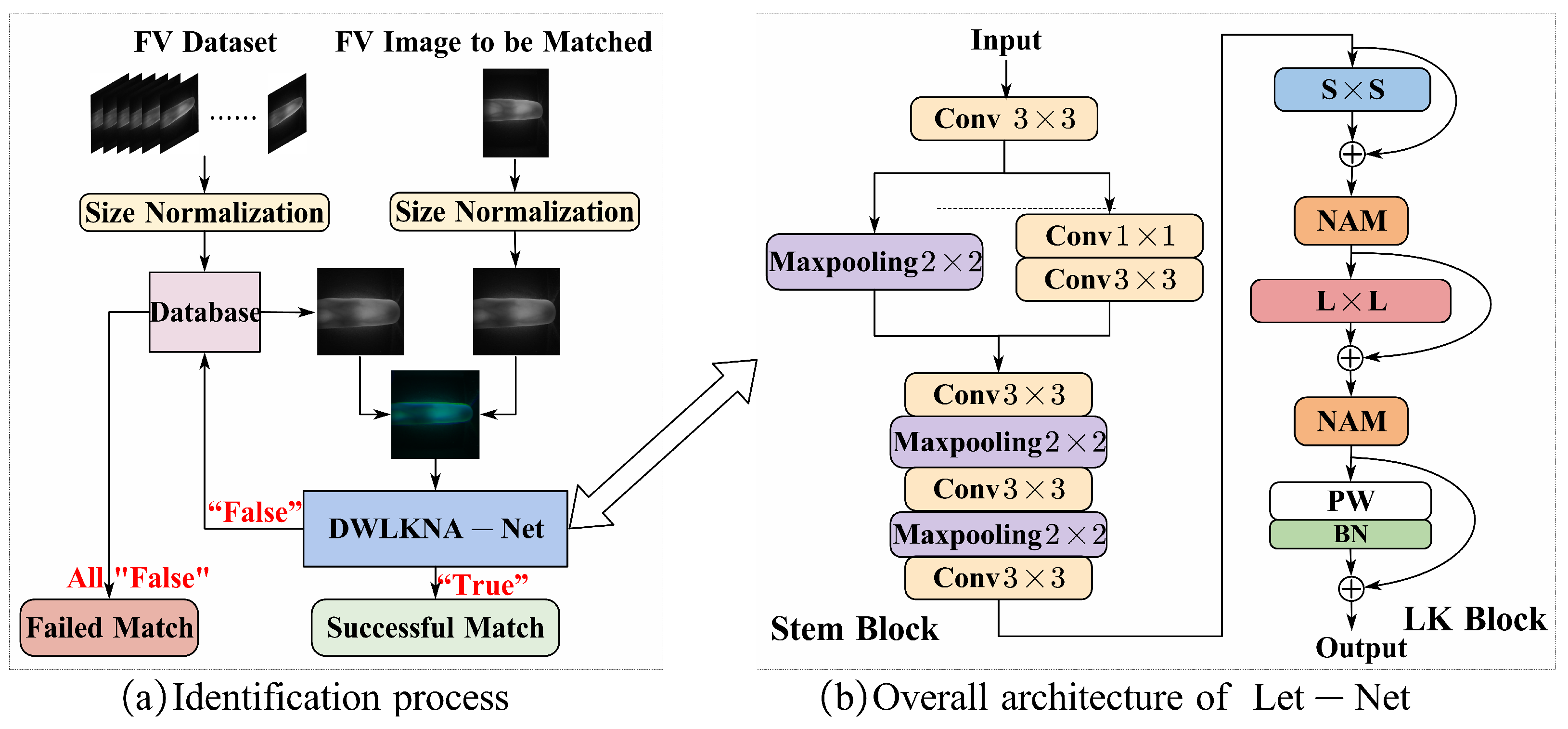
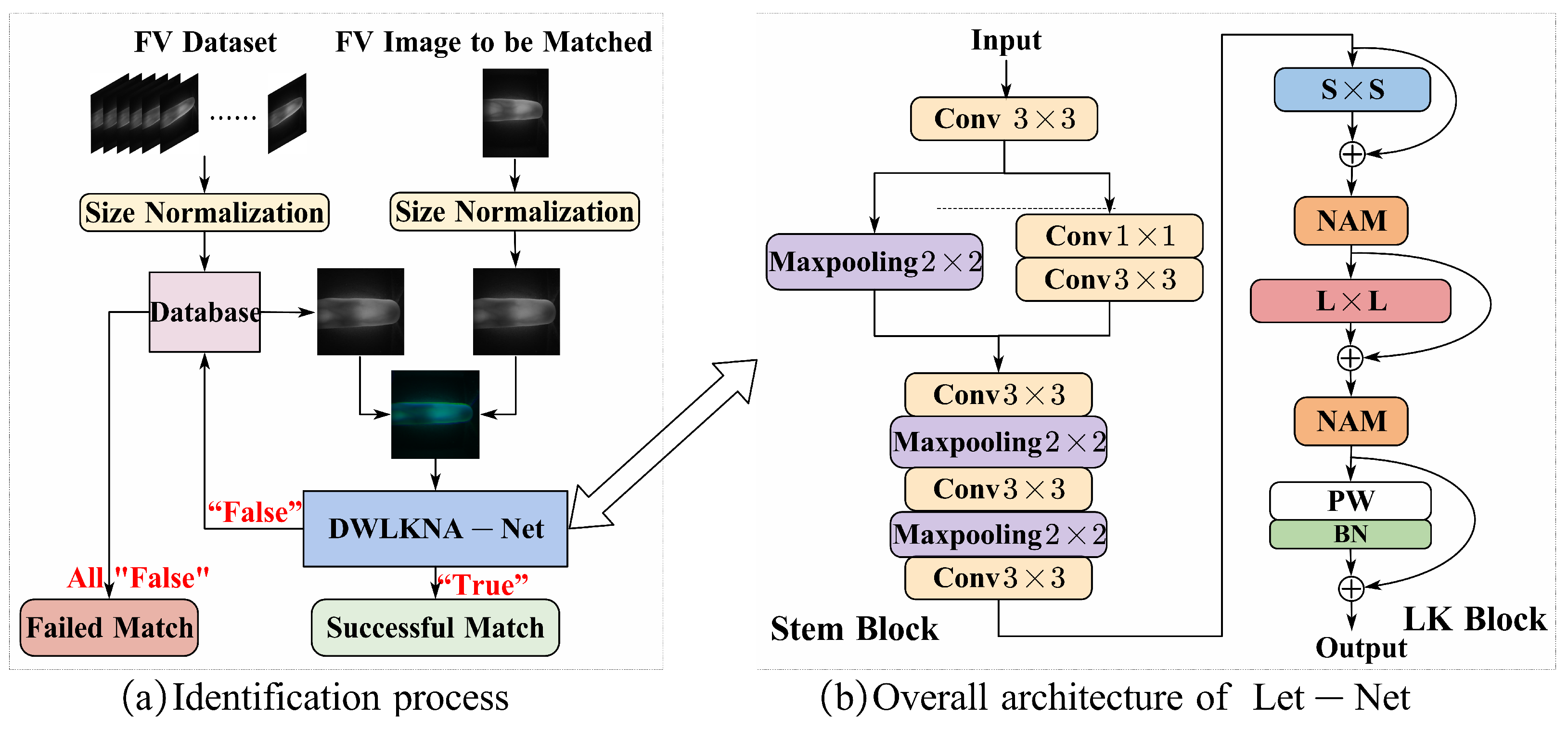
3.1. Method Flow and Overall Network Structure
3.2. Dual-Channel Network Architecture
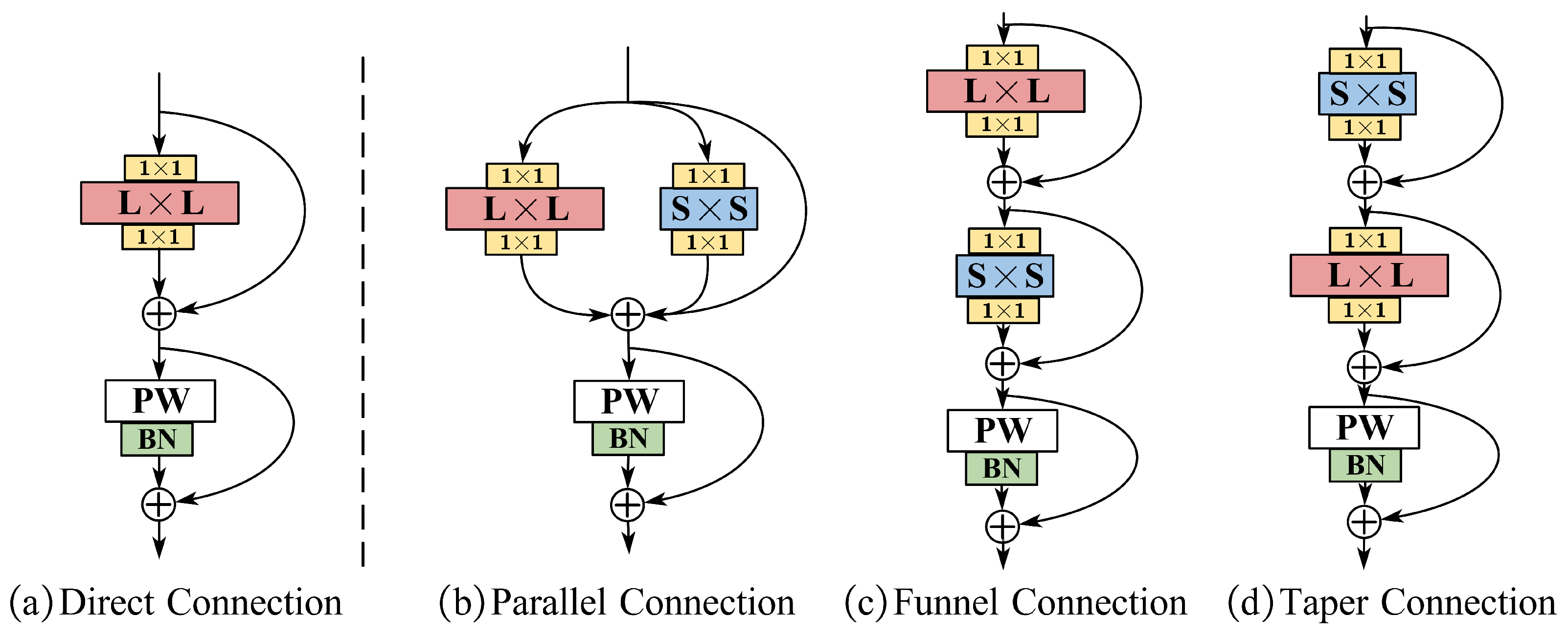
3.3. Design of the LK Block
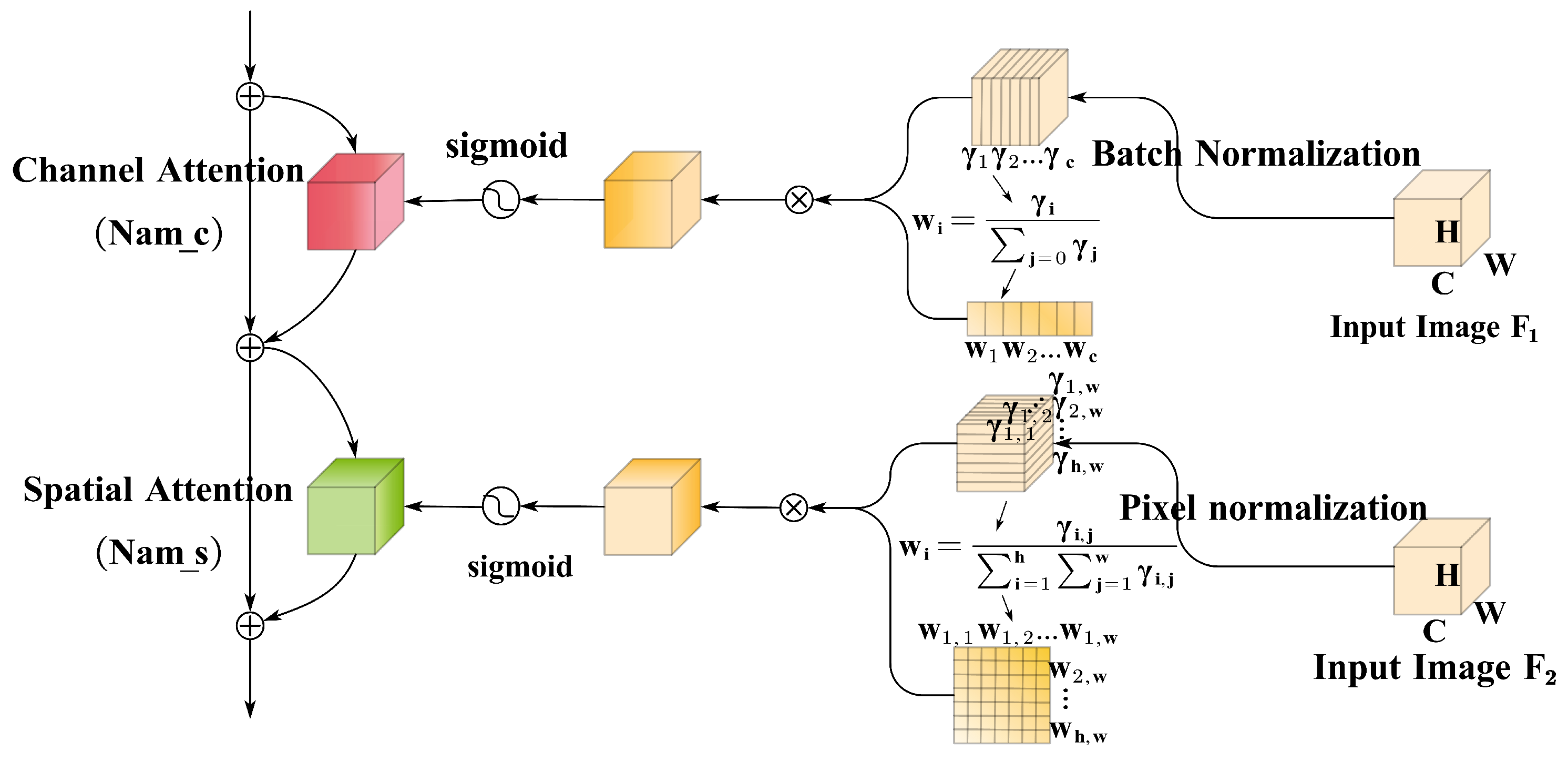
3.4. Attention Module
4. Experiment and Result Analysis
4.1. Dataset Description
- (1)
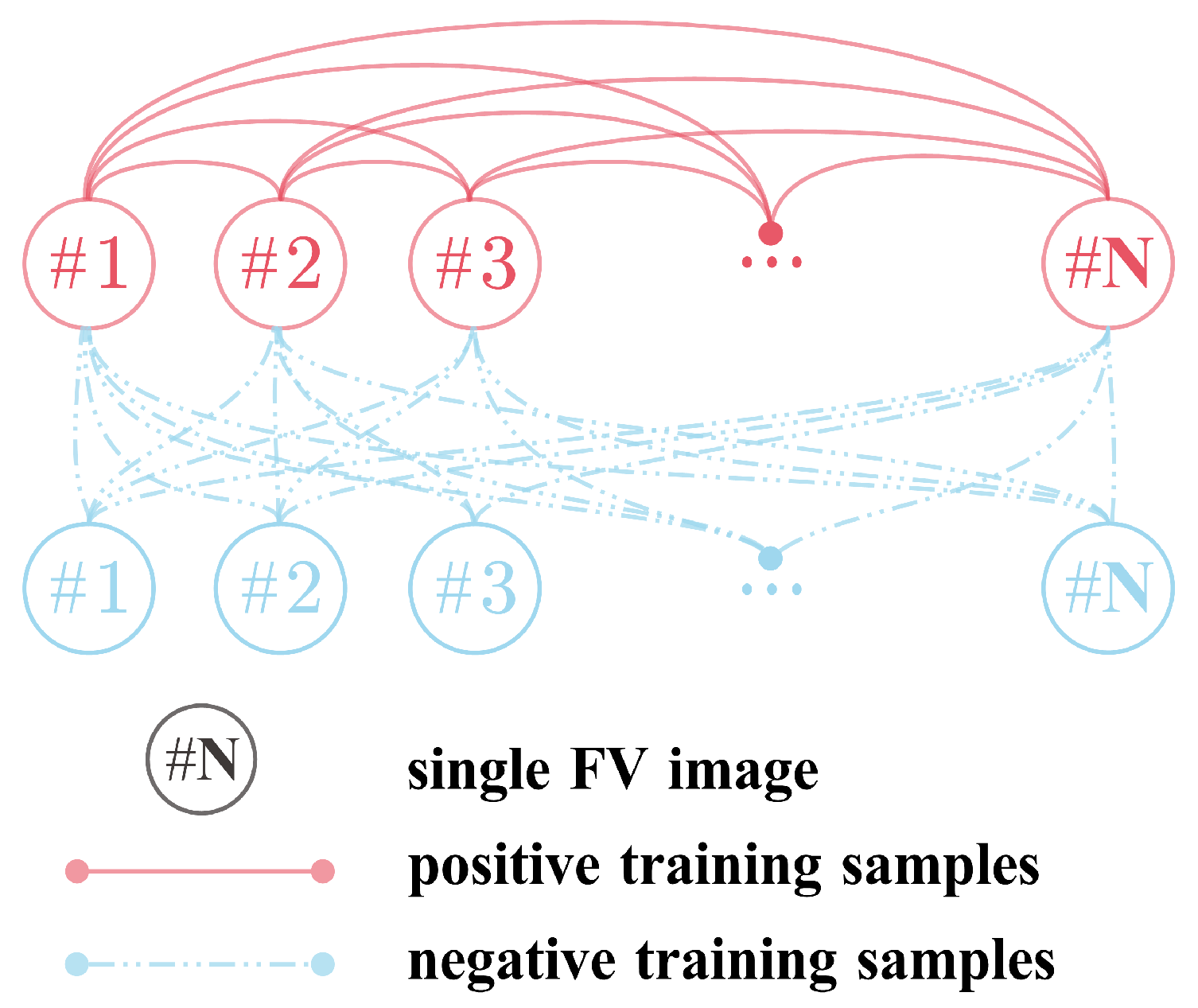
- SDUMLA: This dataset contains images of 636 fingers. Each finger is captured six times, resulting in a total of 3816 FV images. The input of the dual channels is two pictures. Two pictures belonging to the same category are combined as positive samples, and two pictures of different categories are combined as negative samples. Without considering the order of channels, a total of 9540 positive samples can be formed, and a total of 7,269,480 negative samples can be formed. Considering that the number of negative samples is much larger than the number of positive samples, 9540 negative samples were randomly downsampled. The same applies to the following datasets.
- (2)
- FV_USM: This dataset contains images of 492 fingers. Each finger was captured six times in a session, resulting in a total of 2952 FV images. (This dataset involves two stages, and only data from stage 1 is used for the experiments.)
- (3)
- HKPU_FID: This dataset contains images of 312 fingers. Each finger is captured six times, resulting in a total of 1872 FV images.
- (4)
- SCUT_RIFV: This dataset contains 606 images of fingers. Each finger is captured six times, resulting in a total of 3636 FV images. (This dataset involves three rolling poses and six illumination intensities, and only the subset under level 3 illumination with normal finger poses is used for the experiments.)
- (5)
- PLUSVein: This dataset contains images of 360 fingers, with each finger captured five times, resulting in a total of 1800 FV images.
- (6)
- MMCBNU_6000: This dataset contains images of 600 fingers. Each finger is captured ten times, resulting in a total of 6000 FV images.
- (7)
- UTFVP: This dataset contains images of 360 fingers. Each finger is captured four times, resulting in a total of 1440 FV images.
- (8)
- VERA: This dataset contains images of 220 fingers. Each finger is captured twice, resulting in a total of 440 FV images. Since the dataset is too small, we expanded it and randomly rotated and stretched each FV image to expand each finger image to 6, for a total of 1320 FV images.
- (9)
- THU_FVD: This dataset contains 610 finger images. Each finger is captured eight times, resulting in a total of 4880 FV images. (This dataset involves two stages, and only data from stage 1 is used for the experiments.)
4.2. Experimental Settings and Experimental Indicators
4.3. Results Evaluation and Comparison
4.3.1. Comparison and Evaluation with Existing FV models
4.3.2. Ablation Experiments
4.3.3. Comparative Experimental Results between Let-Net and Classic Models
4.3.4. Computational Cost
5. Summary and Outlook
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mulyono, D.; Jinn, H.S. A study of finger vein biometric for personal identification. In Proceedings of the 2008 IEEE International Symposium on Biometrics and Security Technologies, Islamabad, Pakistan, 23–24 April 2008; pp. 1–8. [Google Scholar]
- Jun, B.; Kim, D. Robust face detection using local gradient patterns and evidence accumulation. Pattern Recognit. 2012, 45, 3304–3316. [Google Scholar] [CrossRef]
- Vlachos, M.; Dermatas, E. Finger vein segmentation from infrared images based on a modified separable mumford shah model and local entropy thresholding. Comput. Math. Methods Med. 2015, 2015, 868493. [Google Scholar] [CrossRef] [PubMed]
- Yang, G.; Xi, X.; Yin, Y. Finger vein recognition based on (2D) 2 PCA and metric learning. BioMed Res. Int. 2012, 2012, 324249. [Google Scholar]
- Radzi, S.A.; Hani, M.K.; Bakhteri, R. Finger-vein biometric identification using convolutional neural network. Turk. J. Electr. Eng. Comput. Sci. 2016, 24, 1863–1878. [Google Scholar] [CrossRef]
- Yang, W.; Hui, C.; Chen, Z.; Xue, J.H.; Liao, Q. FV-GAN: Finger vein representation using generative adversarial networks. IEEE Trans. Inf. Forensics Secur. 2019, 14, 2512–2524. [Google Scholar] [CrossRef]
- Huang, J.; Luo, W.; Yang, W.; Zheng, A.; Lian, F.; Kang, W. FVT: Finger vein transformer for authentication. IEEE Trans. Instrum. Meas. 2022, 71, 5011813. [Google Scholar] [CrossRef]
- Das, R.; Piciucco, E.; Maiorana, E.; Campisi, P. Convolutional neural network for finger-vein-based biometric identification. IEEE Trans. Inf. Forensics Secur. 2018, 14, 360–373. [Google Scholar] [CrossRef]
- Yang, W.; Luo, W.; Kang, W.; Huang, Z.; Wu, Q. Fvras-net: An embedded finger-vein recognition and antispoofing system using a unified cnn. IEEE Trans. Instrum. Meas. 2020, 69, 8690–8701. [Google Scholar] [CrossRef]
- Chen, L.; Guo, T.; Li, L.; Jiang, H.; Luo, W.; Li, Z. A Finger Vein Liveness Detection System Based on Multi-Scale Spatial-Temporal Map and Light-ViT Model. Sensors 2023, 23, 9637. [Google Scholar] [CrossRef]
- Kang, W.; Lu, Y.; Li, D.; Jia, W. From noise to feature: Exploiting intensity distribution as a novel soft biometric trait for finger vein recognition. IEEE Trans. Inf. Forensics Secur. 2018, 14, 858–869. [Google Scholar] [CrossRef]
- Zhao, P.; Zhao, S.; Xue, J.H.; Yang, W.; Liao, Q. The neglected background cues can facilitate finger vein recognition. Pattern Recognit. 2023, 136, 109199. [Google Scholar] [CrossRef]
- Tome, P.; Marcel, S. On the vulnerability of palm vein recognition to spoofing attacks. In Proceedings of the 2015 IEEE International Conference on Biometrics (ICB), Phuket, Thailand, 19–22 May 2015; pp. 319–325. [Google Scholar]
- Ton, B.T.; Veldhuis, R.N. A high quality finger vascular pattern dataset collected using a custom designed capturing device. In Proceedings of the 2013 IEEE International Conference on Biometrics (ICB), Madrid, Spain, 4–7 June 2013; pp. 1–5. [Google Scholar]
- Shaheed, K.; Mao, A.; Qureshi, I.; Kumar, M.; Hussain, S.; Ullah, I.; Zhang, X. DS-CNN: A pre-trained Xception model based on depth-wise separable convolutional neural network for finger vein recognition. Expert Syst. Appl. 2022, 191, 116288. [Google Scholar] [CrossRef]
- Huang, J.; Zheng, A.; Shakeel, M.S.; Yang, W.; Kang, W. FVFSNet: Frequency-spatial coupling network for finger vein authentication. IEEE Trans. Inf. Forensics Secur. 2023, 18, 1322–1334. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Luo, W.; Li, Y.; Urtasun, R.; Zemel, R. Understanding the effective receptive field in deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2016, 29, 1–9. [Google Scholar]
- Ding, X.; Zhang, X.; Han, J.; Ding, G. Scaling up your kernels to 31 × 31: Revisiting large kernel design in cnns. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11963–11975. [Google Scholar]
- Hu, H.; Zhang, Z.; Xie, Z.; Lin, S. Local relation networks for image recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3464–3473. [Google Scholar]
- Peng, C.; Zhang, X.; Yu, G.; Luo, G.; Sun, J. Large kernel matters–improve semantic segmentation by global convolutional network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4353–4361. [Google Scholar]
- Romero, D.W.; Bruintjes, R.J.; Tomczak, J.M.; Bekkers, E.J.; Hoogendoorn, M.; van Gemert, J.C. Flexconv: Continuous kernel convolutions with differentiable kernel sizes. arXiv 2021, arXiv:2110.08059. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11976–11986. [Google Scholar]
- Mnih, V.; Heess, N.; Graves, A.; Kavukcuoglu, K. Recurrent models of visual attention. Adv. Neural Inf. Process. Syst. 2014, 27, 1–9. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- De Silva, M.; Brown, D. Multispectral Plant Disease Detection with Vision Transformer—Convolutional Neural Network Hybrid Approaches. Sensors 2023, 23, 8531. [Google Scholar] [CrossRef] [PubMed]
- Hoffer, E.; Ailon, N. Deep metric learning using triplet network. In Similarity-Based Pattern Recognition, Proceedings of the Third International Workshop, SIMBAD 2015, Copenhagen, Denmark, 12–14 October 2015; Springer: Cham, Switzerland, 2015; pp. 84–92. [Google Scholar]
- Liu, Y.; Shao, Z.; Teng, Y.; Hoffmann, N. NAM: Normalization-based attention module. arXiv 2021, arXiv:2111.12419. [Google Scholar]
- Yin, Y.; Liu, L.; Sun, X. SDUMLA-HMT: A multimodal biometric database. In Biometric Recognition, Proceedings of the 6th Chinese Conference, CCBR 2011, Beijing, China, 3–4 December 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 260–268. [Google Scholar]
- Asaari, M.S.M.; Suandi, S.A.; Rosdi, B.A. Fusion of band limited phase only correlation and width centroid contour distance for finger based biometrics. Expert Syst. Appl. 2014, 41, 3367–3382. [Google Scholar] [CrossRef]
- Kumar, A.; Zhou, Y. Human identification using finger images. IEEE Trans. Image Process. 2011, 21, 2228–2244. [Google Scholar] [CrossRef]
- Tang, S.; Zhou, S.; Kang, W.; Wu, Q.; Deng, F. Finger vein verification using a Siamese CNN. IET Biom. 2019, 8, 306–315. [Google Scholar] [CrossRef]
- Kauba, C.; Prommegger, B.; Uhl, A. Focussing the beam-a new laser illumination based data set providing insights to finger-vein recognition. In Proceedings of the 2018 IEEE 9th International Conference on Biometrics Theory, Applications and Systems (BTAS), Redondo Beach, CA, USA, 22–25 October 2018; pp. 1–9. [Google Scholar]
- Lu, Y.; Xie, S.J.; Yoon, S.; Wang, Z.; Park, D.S. An available database for the research of finger vein recognition. In Proceedings of the 2013 IEEE 6th International Congress on Image and Signal Processing (CISP), Hangzhou, China, 16–18 December 2013; Volume 1, pp. 410–415. [Google Scholar]
- Yang, W.; Qin, C.; Liao, Q. A database with ROI extraction for studying fusion of finger vein and finger dorsal texture. In Biometric Recognition, Proceedings of the 9th Chinese Conference, CCBR 2014, Shenyang, China, 7–9 November 2014; Springer: Cham, Switzerland, 2014; pp. 266–270. [Google Scholar]
- Yang, L.; Yang, G.; Xi, X.; Su, K.; Chen, Q.; Yin, Y. Finger vein code: From indexing to matching. IEEE Trans. Inf. Forensics Secur. 2018, 14, 1210–1223. [Google Scholar] [CrossRef]
- Shen, J.; Liu, N.; Xu, C.; Sun, H.; Xiao, Y.; Li, D.; Zhang, Y. Finger vein recognition algorithm based on lightweight deep convolutional neural network. IEEE Trans. Instrum. Meas. 2021, 71, 5000413. [Google Scholar] [CrossRef]
- Hou, B.; Yan, R. ArcVein-arccosine center loss for finger vein verification. IEEE Trans. Instrum. Meas. 2021, 70, 5007411. [Google Scholar] [CrossRef]
- Du, S.; Yang, J.; Zhang, H.; Zhang, B.; Su, Z. FVSR-net: An end-to-end finger vein image scattering removal network. Multimed. Tools Appl. 2021, 80, 10705–10722. [Google Scholar] [CrossRef]
- Fang, C.; Ma, H.; Li, J. A finger vein authentication method based on the lightweight Siamese network with the self-attention mechanism. Infrared Phys. Technol. 2023, 128, 104483. [Google Scholar] [CrossRef]
- Liu, J.; Chen, Z.; Zhao, K.; Wang, M.; Hu, Z.; Wei, X.; Zhu, Y.; Yu, Y.; Feng, Z.; Kim, H.; et al. Finger vein recognition using a shallow convolutional neural network. In Biometric Recognition, Proceedings of the 15th Chinese Conference, CCBR 2021, Shanghai, China, 10–12 September 2021; Springer: Cham, Switzerland, 2021; pp. 195–202. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| EER (%) | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| FV_USM | SDUMLA | MMCBNU_6000 | HKPU_FID | THU_FVD | SCUT_RIFV | UTFVP | PLUSVein | VERA | |
| FV_CNN [8] | - | 6.42 | - | 4.67 | - | - | - | - | - |
| Fvras-net [9] | 0.95 | 1.71 | 1.11 | - | - | - | - | - | - |
| FV code [36] | - | - | - | 3.33 | - | - | - | - | - |
| L-CNN [37] | - | 1.13 | - | 0.67 | - | - | - | - | - |
| ArcVein [38] | 0.25 | 1.53 | - | 1.30 | - | - | - | - | - |
| FVSR-Net [39] | - | 5.27 | - | - | - | - | - | - | - |
| S-CNN [41] | - | 2.29 | 0.47 | - | - | - | - | - | - |
| FVT [6] | 0.44 | 1.50 | 0.92 | 2.37 | 3.60 | 1.65 | 1.97 | 2.08 | 4.55 |
| L-S-CNN [40] | 0.19 | 0.59 | 0.12 | - | - | - | - | - | - |
| FVFSNet [16] | 0.20 | 1.10 | 0.18 | 0.81 | 2.15 | 0.83 | 2.08 | 1.32 | 6.82 |
| Let-Net (ours) | 0.04 | 0.15 | 0.12 | 1.54 | 2.13 | 1.12 | 1.58 | 1.12 | 3.87 |
| Method | FV_USM EER (%) | SDUMLA EER (%) | Parameters (M) | |
|---|---|---|---|---|
| Kernel Size | 99.57 | 99.10 | 0.72 | |
| 99.66 | 99.35 | 0.81 | ||
| 99.77 | 99.42 | 0.89 | ||
| 99.68 | 99.34 | 1.08 | ||
| 99.66 | 99.33 | 1.67 | ||
| Components of Let-Net | No Stem | 98.25 | 97.86 | 0.51 |
| No LK | 96.65 | 96.27 | 0.78 | |
| No NAM | 95.76 | 95.17 | 0.66 | |
| No Stem or LK | 94.71 | 94.16 | 0.52 | |
| No Stem or NAM | 93.64 | 93.11 | 0.27 | |
| No LK or NAM | 88.12 | 87.76 | 0.55 | |
| Stem, LK, and NAM | 99.77 | 99.50 | 0.89 | |
| Architecture of the LK Block | Direct Connection | 96.32 | 96.01 | 0.88 |
| Parallel Connection | 98.46 | 97.26 | 0.89 | |
| Funnel Connection | 98.26 | 97.49 | 0.89 | |
| Taper Connection | 99.77 | 99.50 | 0.89 |
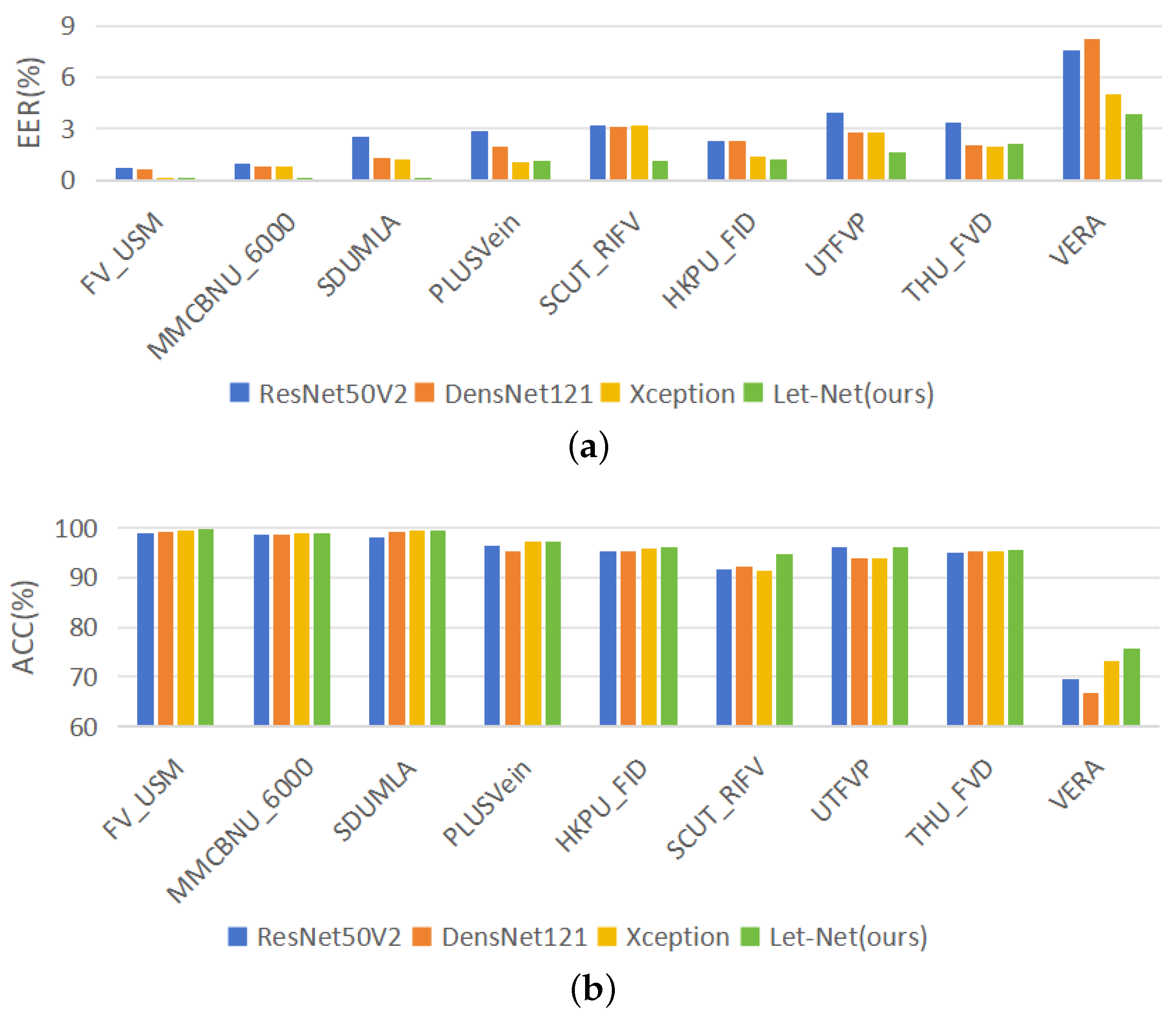
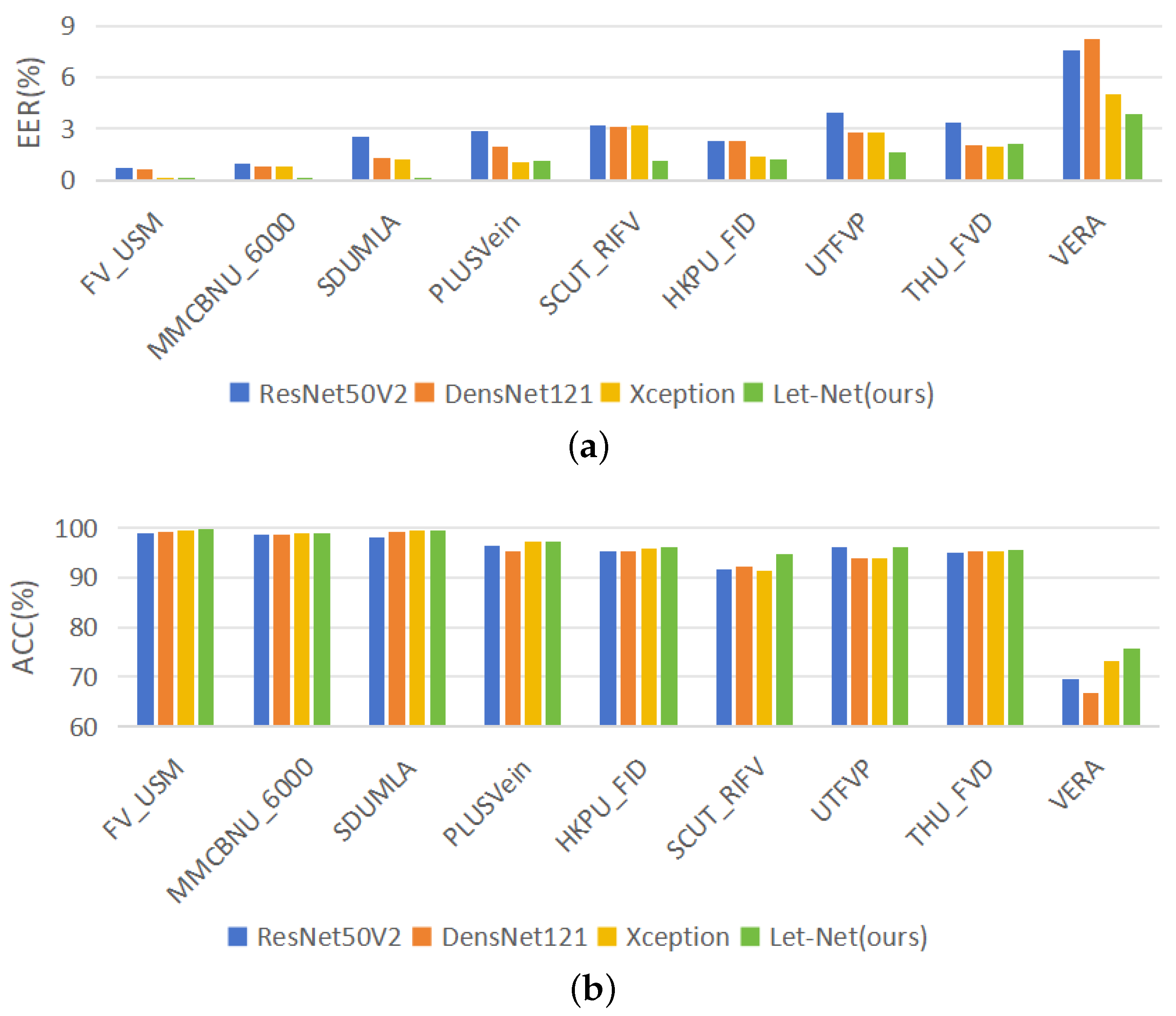
| ResNet50V2 | DensNet121 | Xception | Let-Net | |||||
|---|---|---|---|---|---|---|---|---|
| EER (%) | ACC (%) | EER (%) | ACC (%) | EER (%) | ACC (%) | EER (%) | ACC (%) | |
| MMCBNU_6000 | 0.97 | 98.63 | 0.76 | 98.60 | 0.82 | 98.86 | 0.12 | 98.84 |
| HKPU_FV | 2.26 | 95.24 | 2.27 | 95.23 | 1.36 | 95.74 | 1.21 | 96.10 |
| VERA | 7.56 | 69.66 | 8.23 | 66.75 | 5.05 | 73.11 | 3.87 | 75.60 |
| UTFVP | 3.91 | 96.24 | 2.81 | 93.74 | 2.80 | 93.80 | 1.58 | 96.18 |
| THU_FVD | 3.32 | 94.97 | 2.02 | 95.30 | 1.99 | 95.35 | 2.13 | 95.52 |
| SCUT_RIFV | 3.20 | 91.56 | 3.09 | 92.12 | 3.17 | 91.23 | 1.12 | 94.69 |
| FV_USM | 0.75 | 98.90 | 0.65 | 99.10 | 0.15 | 99.35 | 0.04 | 99.77 |
| SDUMLA | 2.52 | 98.08 | 1.31 | 99.13 | 1.18 | 99.36 | 0.15 | 99.50 |
| PLUSVein | 2.85 | 96.27 | 1.97 | 95.16 | 1.01 | 97.15 | 1.12 | 97.32 |
| Average | 3.04 | 93.28 | 2.57 | 92.79 | 1.95 | 93.77 | 1.26 | 94.84 |
| Model | Params (M) | FLOPs (G) | EER (%) * | ACC (%) * |
|---|---|---|---|---|
| ResNet50V2 | 23.63 | 6.99 | 3.04 | 93.28 |
| DensNet121 | 7.07 | 5.70 | 2.57 | 92.79 |
| Xception | 2.09 | 16.8 | 1.95 | 93.77 |
| Let-Net (ours) | 0.89 | 0.25 | 1.26 | 94.84 |
| Training (s) | Prediction (s) | Total (s) | Single Batch Time (ms) | |
|---|---|---|---|---|
| VGG16 | 10 | 5 | 15 | 48 |
| VGG19 | 12 | 6 | 18 | 55 |
| Resnet50V2 | 11 | 6 | 17 | 53 |
| InceptionV3 | 16 | 9 | 25 | 78 |
| DensNet121 | 22 | 11 | 33 | 102 |
| Xception | 19 | 6 | 25 | 77 |
| RepLKNet | 96 | 6 | 120 | 373 |
| Let-Net (ours) | 3 | 3 | 6 | 17 |
| Training (s) | Prediction (s) | Total (s) | Single Batch Time (ms) | |
|---|---|---|---|---|
| VGG16 | 13 | 7 | 20 | 48 |
| VGG19 | 15 | 8 | 23 | 55 |
| Resnet50V2 | 14 | 9 | 23 | 54 |
| InceptionV3 | 20 | 12 | 32 | 77 |
| DensNet121 | 26 | 15 | 41 | 97 |
| Xception | 25 | 7 | 32 | 78 |
| RepLKNet | 126 | 32 | 158 | 379 |
| Let-Net (ours) | 4 | 3 | 7 | 18 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, M.; Gong, Y.; Zheng, Z. Finger Vein Identification Based on Large Kernel Convolution and Attention Mechanism. Sensors 2024, 24, 1132. https://doi.org/10.3390/s24041132
Li M, Gong Y, Zheng Z. Finger Vein Identification Based on Large Kernel Convolution and Attention Mechanism. Sensors. 2024; 24(4):1132. https://doi.org/10.3390/s24041132
Chicago/Turabian StyleLi, Meihui, Yufei Gong, and Zhaohui Zheng. 2024. "Finger Vein Identification Based on Large Kernel Convolution and Attention Mechanism" Sensors 24, no. 4: 1132. https://doi.org/10.3390/s24041132
APA StyleLi, M., Gong, Y., & Zheng, Z. (2024). Finger Vein Identification Based on Large Kernel Convolution and Attention Mechanism. Sensors, 24(4), 1132. https://doi.org/10.3390/s24041132