

Dynamic Japanese Sign Language Recognition Throw Hand Pose Estimation Using Effective Feature Extraction and Classification Approach




Abstract
1. Introduction
- Novelty: We developed a distinctive JSL video dataset based on dynamic skeletons to fill a crucial void in existing resources. The dataset includes 46 static signs and their dynamic equivalents, gathered from 20 individuals. Through the use of MediaPipe estimation for skeletal data extraction, we effectively tackled challenges such as diverse backgrounds, partial obstruction, computational demands, and varying lighting conditions. This dataset not only addresses a significant research gap but also lays a solid foundation for more comprehensive and inclusive studies in the field of JSL recognition. Although most studies exclude dynamic sign languages, this study includes both dynamic and static sign languages for practical purposes. There are 46 types of signs in Japanese sign language (finger spelling) and five signs include movement. Some signs that have movement share the same shape as other static signs, for example, as in Figure 1.There are moments when the five dynamic signs share the same shape. Perhaps due to the difficulty of classification, most Japanese Sign Language recognition research removes dynamic signs, making it impossible to express these five types of dynamic signs. If even one character cannot be expressed, it means that many Japanese words will not be able to be expressed. Therefore, in this research, we target all finger spellings, including both dynamic and static, by adding a feature that captures the changes.
- Innovative Feature Extraction: Our feature extraction procedure encompasses distance, angle, variation, finger direction, and motion features, delivering a comprehensive representation of JSL signs. Through an innovative process, a constant number of these features are generated regardless of the number of frames, making classification using machine learning possible. In other words, it is possible to recognize dynamic and static signs in the same process.
- Optimized Feature Selection and Classification: Using a feature selection approach based on Random Forest (RF), we identified the most relevant features, thereby optimizing the efficiency and effectiveness of our model. Additionally, we employed a kernels-based Support Vector Machine (SVM) algorithm for classification.
- Comprehensive Evaluation: We rigorously assessed the proposed model using our newly generated dynamic JSL dataset and the widely recognized Argentine sign language dataset, LSA64. In both instances, our proposed method demonstrated superior performance compared to existing systems.
2. Related Work
3. Dataset Description
3.1. Japanese Sign Language(JSL) Dataset
3.2. Argentina Sign Language LSA64 Dataset
4. Proposed Methodology
- 1.
- Dataset Acquisition: We recorded the dataset using an RGB camera to capture Japanese Sign Language (JSL) gestures to address the unavailability of the dynamic JSL dataset.
- 2.
- Hand Pose Detection: Utilizing the MediaPipe hand pose detection approach, we extracted key points of the hand from the recorded videos.
- 3.
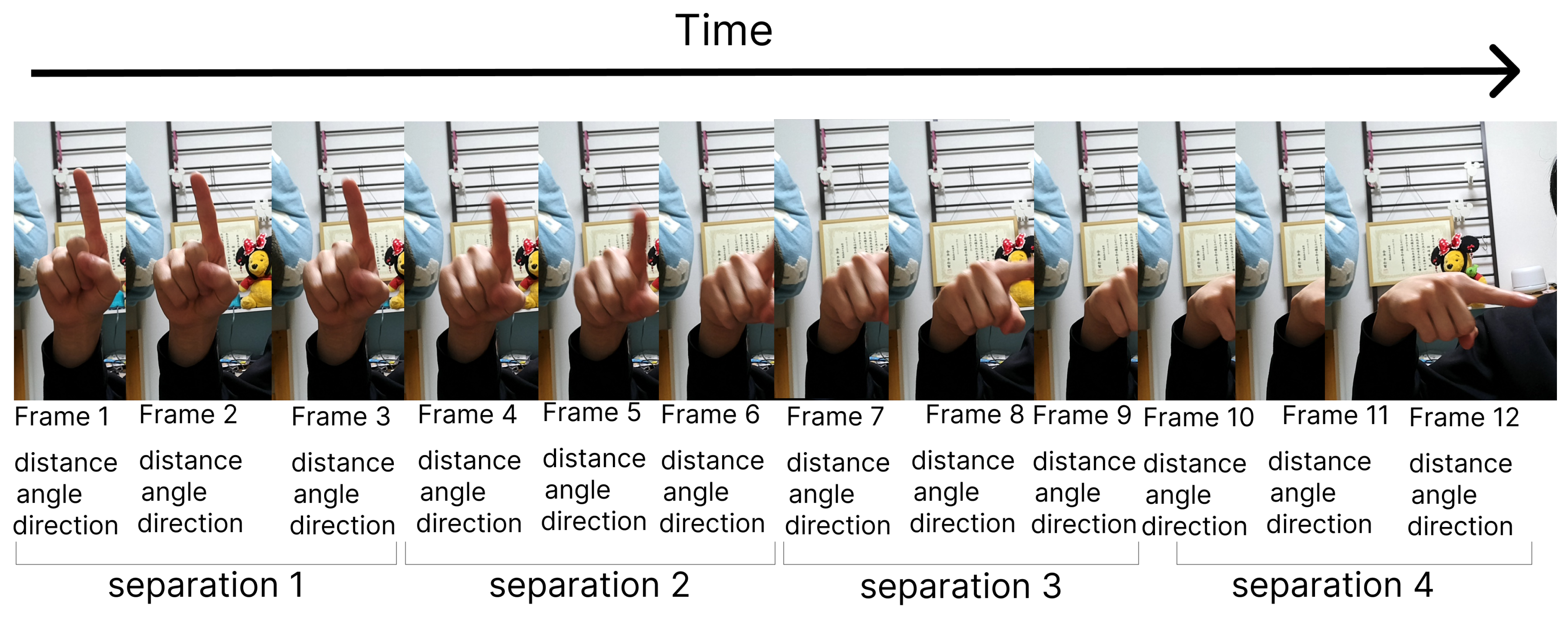
- Frame Segmentation: Each video in our study comprises approximately 12 frames, which were segmented into four distinct groups for analysis.
- 4.
- Feature Extraction: From each frame group, we extracted four types of features—distance, angle, motion, and finger direction—employing geometrical and mathematical formulas.
- 5.
- Feature Concatenation: Concatenating these extracted features, we created a comprehensive feature set that captures both static and dynamic aspects of JSL signs.Optimized Feature Selection and Classification: Using a feature selection approach based on Random Forest (RF), we identified the most relevant features from the concatenated features, thereby optimizing the efficiency and effectiveness of our model. Additionally, we employed a kernels-based Support Vector Machine (SVM) algorithm for classification.
4.1. Getting Joint Coordinates through Pose Estimation
4.2. Normalization Joint Coordinate Values
4.3. Feature Extraction
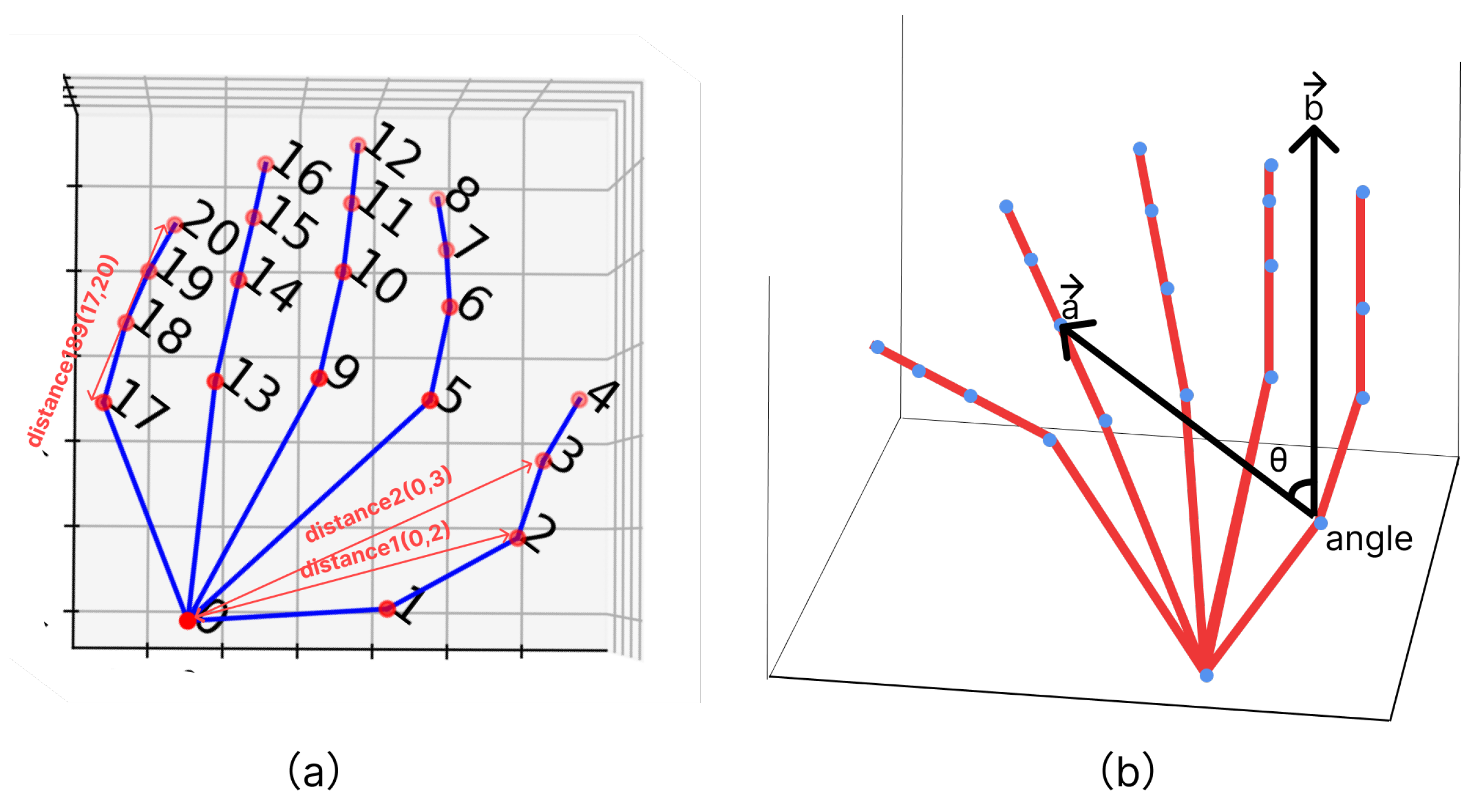
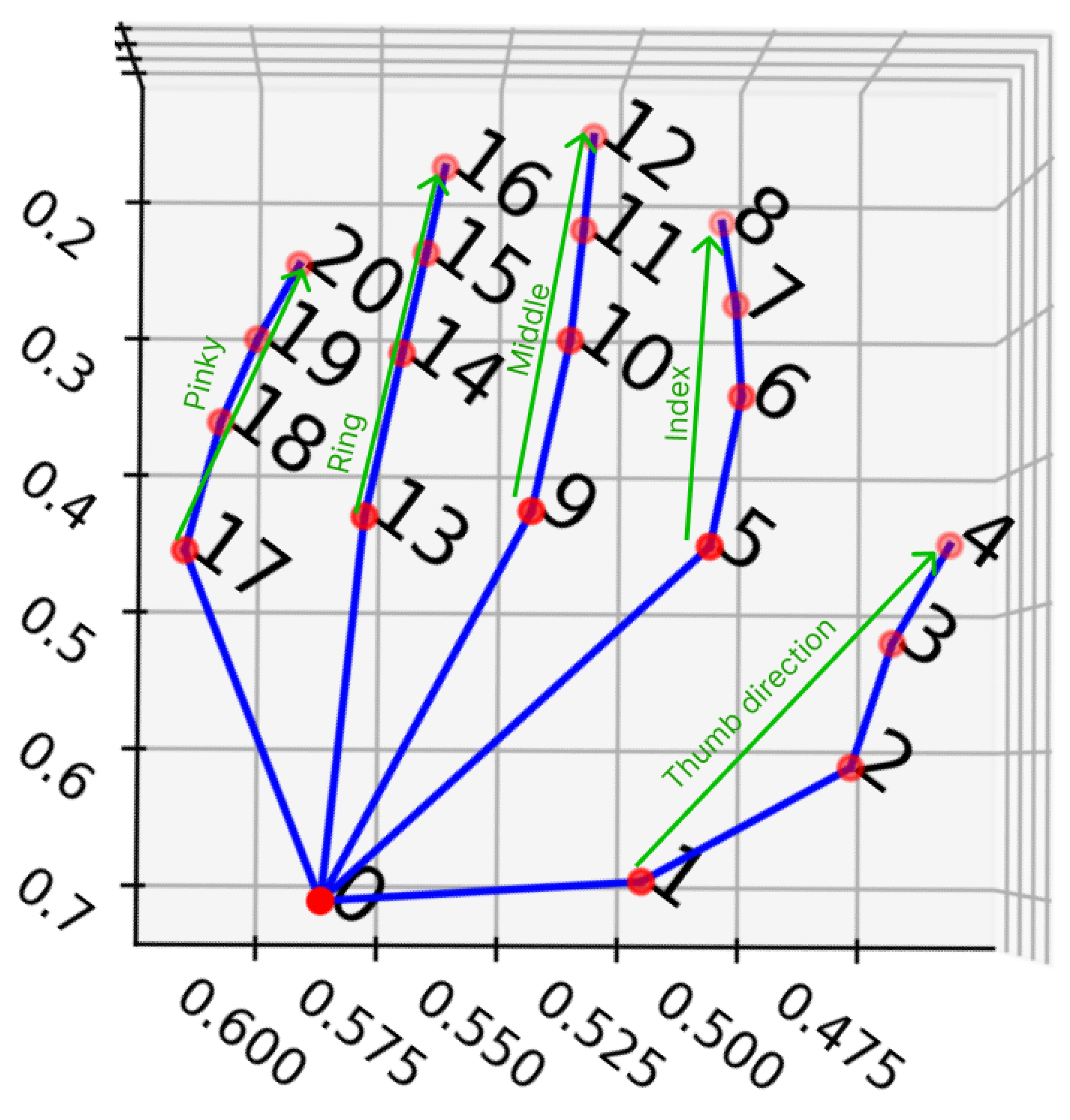
4.3.1. Distance Based Feature
4.3.2. Angle Based Features
4.3.3. Finger Direction Features
4.3.4. Motion Based Features
4.4. Combined All Features for All Frames
4.5. Feature Selection
- It draws a bootstrap samples from the training dataset
- It forms a classification tree from the bootstrap sample. To do this, it randomly selects the predictors’ sample and then splits them as the best splitting policies. The tree is grown as much as possible without pruning back. Random forest obtained a predictor for each tree.
- It collects the prediction output of the to predict the new data, then produces the final result using the majority voting system.
4.6. Classification Module
5. Experimental Performance
5.1. Environmental Setting
5.2. Ablation Study
5.3. Performance Accuracy with Proposed JSL Dataset
5.3.1. Optimal Feature Based Performance Analysis of the Proposed JSL Dataset
5.3.2. State of the Art Similar Work Comparison for the JSL Dataset
5.4. Performance Accuracy with Public LSA64 Dataset
5.5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| JSL | Japanese Sign Language |
| PCA | principal component analysis |
| HMM | Hidden Markov model |
| ANN | Artificial neural networks |
| FCA | Fuzzy classification algorithms |
| KNN | K-nearest-neighbor |
| CNN | Convolutional Neural Network |
| ASL | American Sign Language |
References
- Japan, C.O. White Paper on Persons with Disabilities 2023. Available online: https://nanbyo.jp/2023/09/12/whitepaper_disabilities/ (accessed on 8 June 2023).
- Kobayashi, H.; Ishikawa, T.; Watanabe, H. Classification of Japanese Signed Character with Pose Estimation and Machine Learning. In Proceedings of the IEICE General Conference on Information and Systems, Hiroshima, Japan, 10–13 September 2019; Rihga Royal Hotel: Shinjuku City, Tokyo, 2019. [Google Scholar]
- Ito, S.i.; Ito, M.; Fukumi, M. A Method of Classifying Japanese Sign Language using Gathered Image Generation and Convolutional Neural Networks. In Proceedings of the 2019 IEEE Intl Conf on Dependable, Autonomic and Secure Computing, Intl Conf on Pervasive Intelligence and Computing, Intl Conf on Cloud and Big Data Computing, Intl Conf on Cyber Science and Technology Congress (DASC/PiCom/CBDCom/CyberSciTech), Fukuoka, Japan, 5–8 August 2019; pp. 868–871. [Google Scholar] [CrossRef]
- Ministry of Health, Labour and Welfare of Japan. Survey on Difficulties in Living. Online. 2018. Available online: https://www.mhlw.go.jp/toukei/list/seikatsu_chousa_h28.html: (accessed on 8 June 2023).
- Ohki, J. Sign language service with IT for the Deaf people in Japan “Tech for the Deaf”. J. Inf. Process. Manag. 2014, 57, 234–242. [Google Scholar] [CrossRef]
- Miah, A.S.M.; Shin, J.; Hasan, M.A.M.; Rahim, M.A. BenSignNet: Bengali Sign Language Alphabet Recognition Using Concatenated Segmentation and Convolutional Neural Network. Appl. Sci. 2022, 12, 3933. [Google Scholar] [CrossRef]
- Miah, A.S.M.; Shin, S.J.; Hasan, M.A.M.; Rahim, M.A.; Okuyama, Y. Rotation, Translation and Scale Invariant Sign Word Recognition Using Deep Learning. Comput. Syst. Sci. Eng. 2023, 44, 2521–2536. [Google Scholar] [CrossRef]
- Miah, A.S.M.; Hasan, M.A.M.; Shin, J. Dynamic Hand Gesture Recognition using Multi-Branch Attention Based Graph and General Deep Learning Model. IEEE Access 2023, 11, 4703–4716. [Google Scholar] [CrossRef]
- Takahashi, H.; Otaga, M.; Hayashi, R. Mapping between the 2016 Survey on Difficulties in Life; Research Report FY2018; Ministry of Health, Labor and Welfare and International Classification of Functioning, Disability and Health (ICF): Fairfax, VA, USA, 2015. [Google Scholar]
- Silanon, K. Thai finger-spelling recognition using a cascaded classifier based on histogram of orientation gradient features. Comput. Intell. Neurosci. 2017, 2017, 9026375. [Google Scholar] [CrossRef] [PubMed]
- Phitakwinai, S.; Auephanwiriyakul, S.; Theera-Umpon, N. Thai sign language translation using fuzzy c-means and scale invariant feature transform. In Proceedings of the Computational Science and Its Applications–ICCSA 2008: International Conference, Perugia, Italy, 30 June –3 July 2008; Proceedings, Part II 8. Springer: Berlin/Heidelberg, Germany, 2008; pp. 1107–1119. [Google Scholar]
- Jebali, M.; Dalle, P.; Jemni, M. Extension of hidden markov model for recognizing large vocabulary of sign language. arXiv 2013, arXiv:1304.3265. [Google Scholar] [CrossRef]
- Ranga, V.; Yadav, N.; Garg, P. American sign language fingerspelling using hybrid discrete wavelet transform-gabor filter and convolutional neural network. J. Eng. Sci. Technol. 2018, 13, 2655–2669. [Google Scholar]
- Zhou, Y.; Jiang, G.; Lin, Y. A novel finger and hand pose estimation technique for real-time hand gesture recognition. Pattern Recognit. 2016, 49, 102–114. [Google Scholar] [CrossRef]
- Tao, W.; Leu, M.C.; Yin, Z. American Sign Language alphabet recognition using Convolutional Neural Networks with multiview augmentation and inference fusion. Eng. Appl. Artif. Intell. 2018, 76, 202–213. [Google Scholar] [CrossRef]
- Pariwat, T.; Seresangtakul, P. Thai finger-spelling sign language recognition using global and local features with SVM. In Proceedings of the 2017 9th international conference on knowledge and smart technology (KST), Chonburi, Thailand, 1–4 February 2017; pp. 116–120. [Google Scholar]
- Mukai, N.; Harada, N.; Chang, Y. Japanese fingerspelling recognition based on classification tree and machine learning. In Proceedings of the 2017 Nicograph International (NicoInt), Kyoto, Japan, 2–3 June 2017; pp. 19–24. [Google Scholar]
- Pigou, L.; Dieleman, S.; Kindermans, P.J.; Schrauwen, B. Sign language recognition using convolutional neural networks. In Proceedings of the Computer Vision-ECCV 2014 Workshops, Zurich, Switzerland, 6–7 and 12 September 2014; Proceedings, Part I 13; Springer: Cham, Switzerland, 2015; pp. 572–578. [Google Scholar]
- Molchanov, P.; Gupta, S.; Kim, K.; Kautz, J. Hand gesture recognition with 3D convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Shanghai, China, 20 December 2015; pp. 1–7. [Google Scholar]
- Hassan, N.; Miah, A.S.M.; Shin, J. A Deep Bidirectional LSTM Model Enhanced by Transfer-Learning-Based Feature Extraction for Dynamic Human Activity Recognition. Appl. Sci. 2024, 14, 603. [Google Scholar] [CrossRef]
- Shiraishi, Y.; Tsuchiya, T.; Kato, N.; Yoneyama, F.; Shitara, A. Fingerprint Recognition Using Multidimensional Time-series Data by Deep Learning. Tsukuba Univ. Technol. Techno Rep. 2020, 28, 58–59. [Google Scholar]
- Shin, J.; Musa Miah, A.S.; Hasan, M.A.M.; Hirooka, K.; Suzuki, K.; Lee, H.S.; Jang, S.W. Korean Sign Language Recognition Using Transformer-Based Deep Neural Network. Appl. Sci. 2023, 13, 3029. [Google Scholar] [CrossRef]
- Miah, A.S.M.; Hasan, M.A.M.; Shin, J.; Okuyama, Y.; Tomioka, Y. Multistage Spatial Attention-Based Neural Network for Hand Gesture Recognition. Computers 2023, 12, 13. [Google Scholar] [CrossRef]
- Rahim, M.A.; Miah, A.S.M.; Sayeed, A.; Shin, J. Hand gesture recognition based on optimal segmentation in human-computer interaction. In Proceedings of the 2020 3rd IEEE International Conference on Knowledge Innovation and Invention (ICKII), Kaohsiung, Taiwan, 21–23 August 2020; pp. 163–166. [Google Scholar]
- Hosoe, H.; Sako, S.; Kwolek, B. Recognition of JSL finger spelling using convolutional neural networks. In Proceedings of the 2017 Fifteenth IAPR International Conference on Machine Vision Applications (MVA), Nagoya, Japan, 8–12 May 2017; pp. 85–88. [Google Scholar]
- Funasaka, M.; Ishikawa, Y.; Takata, M.; Joe, K. Sign language recognition using leap motion controller. In Proceedings of the International Conference on Parallel and Distributed Processing Techniques and Applications (PDPTA). The Steering Committee of The World Congress in Computer Science, Computer Engineering and Applied Computing (WorldComp), Las Vegas, NV, USA, 27–30 July 2015; p. 263. [Google Scholar]
- Wakatsuki, D.; Miyake, T.; Naito, I.; et al. Study of Non-contact Recognition Method for Finger Lettering with Finger Movement. Tsukuba Univ. Technol. Techno Rep. 2013, 21, 122–123. [Google Scholar]
- Ikuno, Y.; Tonomura, Y. UbiScription: Finger gesture recognition using smartphone. In Proceedings of the IPSJ Interaction, Online, 10–12 March 2021; pp. 350–353. [Google Scholar]
- Kwolek, B.; Baczynski, W.; Sako, S. Recognition of JSL fingerspelling using Deep Convolutional Neural Networks. Neurocomputing 2021, 456, 586–598. [Google Scholar] [CrossRef]
- Kobayashi, T. Classification of Japanese Signed Character with Pose Estimation and Machine Learning. Ph.D. Thesis, Waseda University, Shinjuku City, Japan, 2019. [Google Scholar]
- Tsutsui, K. Japanese Sign Language Recognition via the Handpose Estimation and Machine Learning. Ph.D. Thesis, The University of Aizu, Aizuwakamatsu, Japan, 2022. [Google Scholar]
- Kobayashi, D.; Watanabe, Y. Kana Finger Alphabet Classification Using Skeleton Estimation and Machine Learning; Waseda University, Graduate School of Fundamental Science and Engineering: Shinjuku City, Japan, 2019. [Google Scholar]
- Ito, S.i.; Ito, M.; Fukumi, M. Japanese Sign Language Classification Using Gathered Images and Convolutional Neural Networks. In Proceedings of the 2020 IEEE 2nd Global Conference on Life Sciences and Technologies (LifeTech), Kyoto, Japan, 10–12 March 2020; pp. 349–350. [Google Scholar]
- Zhang, F.; Bazarevsky, V.; Vakunov, A.; Tkachenka, A.; Sung, G.; Chang, C.L.; Grundmann, M. Mediapipe hands: On-device real-time hand tracking. arXiv 2020, arXiv:2006.10214. [Google Scholar]
- Shin, J.; Matsuoka, A.; Hasan, M.A.M.; Srizon, A.Y. American sign language alphabet recognition by extracting feature from hand pose estimation. Sensors 2021, 21, 5856. [Google Scholar] [CrossRef]
- Chen, R.C.; Dewi, C.; Huang, S.W.; Caraka, R.E. Selecting critical features for data classification based on machine learning methods. J. Big Data 2020, 7, 52. [Google Scholar] [CrossRef]
- Noble, W.S. What is a support vector machine? Nat. Biotechnol. 2006, 24, 1565–1567. [Google Scholar] [CrossRef]
- Akiba, T.; Sano, S.; Yanase, T.; Ohta, T.; Koyama, M. Optuna: A next-generation hyperparameter optimization framework. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2623–2631. [Google Scholar]
- Huu, P.N.; Phung, N.T. Hand Gesture Recognition Algorithm Using SVM and HOGModel for Control of Robotic System. J. Robot. 2021, 2021, 3986497. [Google Scholar]
- Rahim, M.A.; Islam, M.R.; Shin, J. Non-Touch Sign Word Recognition Based on Dynamic Hand Gesture Using Hybrid Segmentation and CNN Feature Fusion. J. Robot. 2019, 9, 3790. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Equipment | Classifier | Accuracy | Target | Years |
|---|---|---|---|---|---|
| [32] | OpenPose | SVM | 63.6 | static | 2019 |
| [20] | RGB Camera | CNN and SVM | 84.7 | static | 2019 |
| [33] | RGB Camera | CNN and SVM | 86.2 | static | 2020 |
| [21] | Data Glove | CNN and SVM | 70 | static + dynamic (all) | 2020 |
| [25] | RGB Camera | CNN | 93 | static | 2017 |
| [26] | LeapMotion | decision tree | 74.7 | static | 2015 |
| [32] | Infrared TOF | SVM | 90 | static + dynamic | 2013 |
| [28] | RGB Camera | random forest | 79.2 | static | 2021 |
| [29] | RGB Camera | deep CNN | 92.1 | static | 2021 |
| [30] | OpenPose | MSVM | 65.6 96 | static + dynamic (subclass) | 2019 |
| [31] | RGB Camera | SVM | 97.8 | static | 2022 |
| Dataset Name | Classes | Recording Time 1 p/s | Average Frames | People | Age Range | Total Frames |
|---|---|---|---|---|---|---|
| JSL | 46 あ [a] ∼ん [n] | 2.00 s | 12 | 20 | 11∼48 | 11,040 |
| Name | 42 (の [no]) | 43 (も [mo]) | 44 (り [ri]) | 45 (を [wo]) | 46 (ん [n]) |
|---|---|---|---|---|---|
| Frame average | 14.75 | 8.05 | 10.2 | 9.55 | 9.37 |
| Average seconds | 3.20 | 1.74 | 2.21 | 2.1 | 2.029 |
| Starting Joint Number | Distance to the Joint Numbers | Number of Distance Based Features |
|---|---|---|
| 0 | {2,3,5,6,7,9,10,11,13,14,15,17,18,19,20} | 15 |
| 1 | {3,4,5,6,7,8,9,10,11,12, 13,14,15, 16,17,18,19,20} | 18 |
| 2 | {4,5,6,7,8,9,10,11,12, 13,14,15, 16,17,18,19,20} | 17 |
| 3 | {5,6,7,8,9,10,11,12, 13,14,15, 16,17,18,19,20} | 16 |
| 4 | {5,6,7,8,9,10,11,12, 13,14,15, 16,17,18,19,20} | 16 |
| 5 | {7,8,9,10,11,12, 13,14,15, 16,17,18,19,20} | 14 |
| 6 | {8,9,10,11,12, 13,14,15, 16,17,18,19,20} | 13 |
| 7 | {9,10,11,12, 13,14,15, 16,17,18,19,20} | 12 |
| 8 | {9,10,11,12, 13,14,15, 16,17,18,19,20} | 12 |
| 9 | {11,12, 13,14,15, 16,17,18,19,20} | 10 |
| 10 | {12, 13,14,15, 16,17,18,19,20} | 9 |
| 11 | {13,14,15, 16,17,18,19,20} | 8 |
| 12 | {13,14,15, 16,17,18,19,20} | 8 |
| 13 | {15, 16,17,18,19,20} | 6 |
| 14 | {16,17,18,19,20} | 5 |
| 15 | {17,18,19,20} | 4 |
| 16 | {17,18,19,20} | 4 |
| 17 | {19,20} | 2 |
| 18 | {20} | 1 |
| 19 | {} | 0 |
| 20 | {} | 0 |
| Joint Index | Starting Joint (P) Variable Joint (V) | Other Joints (V) | Features |
|---|---|---|---|
| 0 | 20 × 3 | ||
| 1 | 19 × 3 | ||
| 2 | 18 × 3 | ||
| 3 | 17 × 3 | ||
| 4 | 16 × 3 | ||
| 5 | 15 × 3 | ||
| 6 | , , , , , | ||
| … | … | … | … |
| 19 | |||
| 20 | 0 |
| SVM Parameters | Range |
|---|---|
| C | |
| Gamma | |
| Degree | |
| Trial | 300 |
| Dataset Name | Division | Total Feature | Input Shape | Classification Algorithm | Accuracy | Computation Time in [ms] | Device |
|---|---|---|---|---|---|---|---|
| JSL | 1 | 898 | 128 | SVM | 96.00 | 0.23 | CPU |
| JSL | 2 | 1796 | 208 | SVM | 96.80 | 0.27 | CPU |
| JSL | 2 | 1796 | (2, 835), (2, 63) | Two-Stream LSTM | 97.30 | 0.16 | GPU |
| JSL | 2 | 1796 | (2, 835), (2, 63) | Two-Stream Bi-LSTM | 97.20 | 0.19 | GPU |
| JSL | 2 | 1796 | (2, 835), (2, 63) | Two-Stream GRU | 96.99 | 0.15 | GPU |
| JSL | 2 | 1796 | (2, 835), (2, 63) | Two-Stream Bi-GRU | 97.14 | 0.17 | GPU |
| JSL | 3 | 2631 | 493 | SVM | 97.20 | 0.34 | CPU |
| JSL | 3 | 2631 | (3, 835), (2, 63) | Two-Stream LSTM | 97.34 | 0.16 | GPU |
| JSL | 3 | 2631 | (3, 835), (2, 63) | Two-Stream Bi-LSTM | 97.28 | 0.19 | GPU |
| JSL | 3 | 2631 | (3, 835), (2, 63) | Two-Stream GRU | 97.07 | 0.15 | GPU |
| JSL | 3 | 2631 | (3, 835), (2, 63) | Two-Stream Bi-GRU | 97.13 | 0.17 | GPU |
| JSL | 4 | 3529 | 550 | SVM | 97.00 | 0.37 | CPU |
| JSL | 4 | 3529 | (4, 835), (3, 63) | Two-Stream LSTM | 97.09 | 0.17 | GPU |
| JSL | 4 | 3529 | (4, 835), (3, 63) | Two-Stream Bi-LSTM | 97.19 | 0.21 | GPU |
| JSL | 4 | 3529 | (4, 835), (3, 63) | Two-Stream GRU | 96.79 | 0.15 | GPU |
| JSL | 4 | 3529 | (4, 835), (3, 63) | Two-Stream Bi-GRU | 96.99 | 0.18 | GPU |
| LSA64 | 3 | 2631 | 341 | SVM | 98.00 | 0.28 | CPU |
| LSA64 | 3 | 2631 | (3, 835), (2, 63) | Two-Stream LSTM | 97.75 | 0.16 | GPU |
| LSA64 | 3 | 2631 | (3, 835), (2, 63) | Two-Stream Bi-LSTM | 97.51 | 0.19 | GPU |
| LSA64 | 3 | 2631 | (3, 835), (2, 63) | Two-Stream GRU | 97.62 | 0.15 | GPU |
| LSA64 | 3 | 2631 | (3, 835), (2, 63) | Two-Stream Bi-GRU | 97.60 | 0.17 | GPU |
| LSA64 | 4 | 3529 | 326 | SVM | 98.40 | 0.27 | CPU |
| LSA64 | 4 | 3529 | (4, 835), (3, 63) | Two-Stream LSTM | 97.38 | 0.19 | GPU |
| LSA64 | 4 | 3529 | (4, 835), (3, 63) | Two-Stream Bi-LSTM | 97.53 | 0.23 | GPU |
| LSA64 | 4 | 3529 | (4, 835), (3, 63) | Two-Stream GRU | 97.55 | 0.16 | GPU |
| LSA64 | 4 | 3529 | (4, 835), (3, 63) | Two-Stream Bi-GRU | 97.51 | 0.18 | GPU |
| Feature | Number of Features | Accuracy |
|---|---|---|
| Distance | 760 | 93.00 |
| Angle | 2520 | 95.00 |
| Direction | 60 | 89.00 |
| All features | 3529 | 96.26 |
| Dataset | Without Variation | With Variation | SVM Tunned Parameter | ||
|---|---|---|---|---|---|
| Number of Selected Feature | Accuracy | Number of Selected Feature | Accuracy | ||
| JSL | 421 | 95.61 | 367 | 97.20 | Kernel = rbf, C = 24.61, Gamma = 0.0015 |
| LSA64 | 209 | 97.77 | 326 | 98.40 | Kernel = rbf, C = 24.61, Gamma = 0.0015 |
| No. | Labels | Accuracy | No. | Labels | Accuracy |
|---|---|---|---|---|---|
| 1 | あ (a) | 1.00 | 24 | ね (ne) | 1.00 |
| 2 | い (i) | 1.00 | 25 | の (no) | 1.00 |
| 3 | う (u) | 1.00 | 26 | は (ha) | 1.00 |
| 4 | え (e) | 1.00 | 27 | ひ (hi) | 1.00 |
| 5 | お (o) | 75.00 | 28 | ふ (he) | 1.00 |
| 6 | か (ka) | 1.00 | 29 | へ (he) | 86.00 |
| 7 | き (ki) | 1.00 | 30 | ほ (ho) | 1.00 |
| 8 | く (ku) | 1.00 | 31 | ま (ma) | 1.00 |
| 9 | け (ke) | 1.00 | 32 | み (mi) | 1.00 |
| 10 | こ (ko) | 71.00 | 33 | む (mu) | 1.00 |
| 11 | さ (sa) | 1.00 | 34 | め (me) | 1.00 |
| 12 | し (si) | 1.00 | 35 | も (mo) | 1.00 |
| 13 | す (su) | 1.00 | 36 | や (ya) | 75.00 |
| 14 | せ (se) | 1.00 | 37 | ゆ (yu) | 1.00 |
| 15 | そ (so) | 1.00 | 38 | よ (yo) | 1.00 |
| 16 | た (ta) | 1.00 | 39 | ら (ra) | 1.00 |
| 17 | ち (ti) | 1.00 | 40 | り (ri) | 1.00 |
| 18 | つ (tu) | 1.00 | 41 | る (ru) | 1.00 |
| 19 | て (te) | 1.00 | 42 | れ (re) | 1.00 |
| 20 | と (to) | 1.00 | 43 | ろ (ro) | 1.00 |
| 21 | な (na) | 1.00 | 44 | わ (wa) | 1.00 |
| 22 | に (ni) | 1.00 | 45 | を (wo) | 75.00 |
| 23 | ぬ (nu) | 1.00 | 46 | ん (n) | 1.00 |
| Reference | Recording Device | Features | Algorithm Name | Result Score [%] | Type of Sign |
|---|---|---|---|---|---|
| Ikuno et al. [28] | RGB Camera | random forest | 79.20 | static | |
| Kwolek et al. [29] | RGB Camera | deep CNN | 92.10 | static | |
| Kobayashi et al. [30] | Open Pose | MSVM | 65.00 96.00 | static + dynamic | |
| Proposed method | Camera | Distance, Angle, Finger Direction, Motion | SVM | 97.20 | Static + dynamic |
| No. | Labels | Accuracy | No. | Labels | Accuracy |
|---|---|---|---|---|---|
| 1 | Opaque | 1.00 | 22 | Water | 1.00 |
| 2 | Red | 1.00 | 23 | Food | 91.00 |
| 3 | Green | 1.00 | 24 | Argentina | 1.00 |
| 4 | Yellow | 1.00 | 25 | Uruguay | 1.00 |
| 5 | Bright | 1.00 | 26 | Country | 1.00 |
| 6 | Light-blue | 90.00 | 27 | Last name | 1.00 |
| 7 | Colors | 1.00 | 28 | Where | 83.00 |
| 8 | Pink | 1.00 | 29 | Birthday | 1.00 |
| 9 | Women | 1.00 | 30 | Hungry | 92.00 |
| 10 | Enemy | 1.00 | 31 | Ship | 1.00 |
| 11 | Son | 1.00 | 32 | None | 1.00 |
| 12 | Man | 83.00 | 33 | Name | 1.00 |
| 13 | Away | 1.00 | 34 | Patience | 1.00 |
| 14 | Drawer | 1.00 | 35 | Perfume | 1.00 |
| 15 | Born | 89.00 | 36 | Deaf | 1.00 |
| 16 | Learn | 1.00 | 37 | Candy | 1.00 |
| 17 | Call | 1.00 | 38 | Chewing-gum | 1.00 |
| 18 | Skimmer | 1.00 | 39 | Shut down | 1.00 |
| 19 | Bitter | 1.00 | 40 | Buy | 1.00 |
| 20 | Sweet milk | 1.00 | 41 | Realize | 79.00 |
| 21 | Milk | 1.00 | 42 | Find | 1.00 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kakizaki, M.; Miah, A.S.M.; Hirooka, K.; Shin, J. Dynamic Japanese Sign Language Recognition Throw Hand Pose Estimation Using Effective Feature Extraction and Classification Approach. Sensors 2024, 24, 826. https://doi.org/10.3390/s24030826
Kakizaki M, Miah ASM, Hirooka K, Shin J. Dynamic Japanese Sign Language Recognition Throw Hand Pose Estimation Using Effective Feature Extraction and Classification Approach. Sensors. 2024; 24(3):826. https://doi.org/10.3390/s24030826
Chicago/Turabian StyleKakizaki, Manato, Abu Saleh Musa Miah, Koki Hirooka, and Jungpil Shin. 2024. "Dynamic Japanese Sign Language Recognition Throw Hand Pose Estimation Using Effective Feature Extraction and Classification Approach" Sensors 24, no. 3: 826. https://doi.org/10.3390/s24030826
APA StyleKakizaki, M., Miah, A. S. M., Hirooka, K., & Shin, J. (2024). Dynamic Japanese Sign Language Recognition Throw Hand Pose Estimation Using Effective Feature Extraction and Classification Approach. Sensors, 24(3), 826. https://doi.org/10.3390/s24030826