1. Introduction
The integration of IoT and RL creates an intelligent and adaptive control system for greenhouses. IoT sensors provide a constant flow of accurate information, which RL algorithms then process to optimize growing conditions. Automated systems implement the decisions made by RL, and the system constantly improves on the basis of the results obtained. This synergy allows for more efficient resource management, increased productivity, and better adaptation to changing conditions, which is crucial in the current context of climate change and food security. By combining the data collection capabilities of IoT with the decision-making power of RL, greenhouse operators can create a self-improvement system that continuously adapts to changing environmental conditions and plant needs. This integration not only improves crop yield and quality but also contributes to sustainable agriculture practices by optimizing resource use. As climate change continues to pose challenges to traditional farming methods, the integrated IoT-RL approach in greenhouses offers a promising solution to ensure food security in an environmentally responsible way. This paper is structured as follows.
Section 2 provides a comprehensive review of the literature, highlighting key contributions and future research directions in the use of reinforcement learning (RL) for energy management in greenhouses.
Section 3 presents materials and methods. In
Section 3.1, we present the proposed model, detailing the integration of IoT and RL technologies for optimized climate control in greenhouses.
Section 3.2 discusses the methodology, including the phases of development of control strategies, IoT infrastructure design, dataset generation, and the application of digital models and RL algorithms. The IoT infrastructure is proposed in
Section 3.3. In
Section 3.4, we analyze the generation of dataset and the materials used.
Section 3.5 proposes the RL algorithm based on the model.
Section 3.6 implements and evaluates the RL agent, comparing its performance with traditional control methods. Finally,
Section 4 and
Section 5 conclude the article, summarizing the findings and discussing the implications for future research and practical applications in greenhouse management.
Automated greenhouse systems require the meticulous configuration of diverse parameters to guarantee that the actuators execute the designated functions accurately. This configuration entails the determination of appropriate set-points for various subsystems including climate, lighting, and irrigation control. Typically, these parameters and control rules are reactive. In recent years, numerous studies have advanced models based on set-point selection strategies employing various heuristic or artificial intelligence paradigms coupled with the implementation of predictive solutions. The application of reinforcement learning (RL) to greenhouse management has gained significant attention in recent years due to its potential to optimize energy usage and automate various control processes. This section provides an overview of the most relevant studies categorized by their approaches and contributions.
2. Literature Review
The use of reinforcement learning (RL) in the energy management of greenhouses and precision agriculture techniques has evolved significantly. This analysis is based on the references provided, which highlight key contributions in this field. Future research directions are also discussed. This paper reviews key contributions to the field, analyzes their contributions, and discusses future research directions.
Kiumarsi et al. [
1] present a comprehensive survey and implementation guidelines for optimal and autonomous control using RL. They discuss applications in complex systems, emphasizing their potential to enhance energy efficiency and reduce operational costs in greenhouses. Perera et al. [
2] review various applications of RL in energy management from generation to consumption. They highlight specific cases of intelligent greenhouses that use RL to optimize energy use. Wang et al. [
3] present an RL controller based on recurring neural networks based on Long Short-Term Memory (LSTM) for microgrid management with potential applications in greenhouses.
Kazmi et al. [
4] explore the use of deep RL for optimal control in hybrid energy systems of buildings, which is applicable to energy management in greenhouses. Ruelens et al. [
5] examine the application of RL in electric water heaters with direct implications for energy management in greenhouses.
Zhang et al. [
6] discuss the developments and future challenges in precision agriculture, including the integration of RL for better resource management in greenhouses. Liu et al. [
6] provide a comprehensive review of RL applications in smart agriculture, highlighting various use cases and the potential benefits of RL in optimizing agricultural processes, including greenhouse energy management.
Mason et al. [
7] review the applications of RL in smart grids, discussing how these methods can be applied to improve energy management and efficiency in interconnected systems such as greenhouses. Hosseinloo et al. [
8] explore data-driven predictive control using RL for energy efficiency and comfort management in buildings with potential applications in greenhouses to optimize climate control systems. Sun et al. [
9] present a study on multi-agent RL for the integrated energy management of interconnected microgrids, which is applicable to complex greenhouse energy systems. Alani et al. [
10] discuss the opportunities and challenges of RL-based energy management for smart homes and buildings with insights applicable to greenhouse energy systems.
Fu et al. [
11] survey the applications of RL in building energy management, providing information relevant to greenhouse energy systems. Mauree et al. [
12] review data-driven and machine learning models for building energy performance prediction, fault detection, and optimization, all of which are applicable to greenhouse energy management. Kazmi et al. [
13] discuss the application of multi-agent RL for building energy management with potential benefits for greenhouse systems. Yang et al. [
14] explore energy optimization in smart home buildings using deep RL, providing information for greenhouse energy management.
Ruelens et al. [
15] discuss learning sequential decision making for the optimal control of thermally activated resources, which is applicable to greenhouse energy systems. Vázquez-Canteli and Henze [
16] discuss the integration of reinforcement learning with predictive control of the model for the response to demand in buildings, which can be applied to optimize energy management in greenhouses. Sutton and Barto [
17] discuss the application of RL in real-world games, providing insights that can be adapted to complex energy management systems in greenhouses. Peters et al. [
18] discuss a reinforcement learning approach to autonomous vehicles, which can provide insights for autonomous control in greenhouse energy systems. Kar et al. [
19] present QD learning, which is a collaborative Q-learning approach that can be applied to cooperative energy management strategies in greenhouses.
Sierla et al. [
20] review reinforcement learning applications in urban energy systems, which can provide valuable information for energy management in greenhouse environments. Vázquez-Canteli and Nagy [
21] discuss reinforcement learning for demand response, which is highly relevant for dynamic energy management in greenhouses. Mauree et al. [
12] review assessment methods for urban environments, providing methodologies that can be adapted to evaluate energy performance in greenhouses.
2.1. Future Research Directions
Despite significant advancements, several areas require further exploration to fully implement RL in greenhouse energy management.
Integration with IoT: The integration of RL with IoT devices can enhance real-time data acquisition and decision-making processes in greenhouses. Future research should focus on developing seamless IoT-RL integration frameworks.
Scalability: Research on scaling RL solutions to larger, more complex greenhouse systems is necessary to ensure widespread adoption. Studies should address computational challenges and the ability to handle large datasets.
Interdisciplinary Approaches: Combining RL with other AI techniques, such as genetic algorithms and fuzzy logic, could yield more robust energy management solutions. The exploration of hybrid models that leverage the strengths of different AI paradigms is essential.
Environmental Adaptability: Developing RL algorithms capable of adapting to diverse environmental conditions will be crucial for global applications. This includes designing algorithms that can learn and adapt to changing weather patterns, pest infestations, and other environmental variables.
Economic Viability: Studies on the cost-effectiveness of RL implementations in greenhouses can drive commercial interest and investment. Future research should focus on performing cost–benefit analyses and developing business models that highlight the economic advantages of RL-based energy management systems.
User-Friendly Interfaces: Developing user-friendly interfaces and control systems for greenhouse operators is vital for the practical implementation of RL. Research should focus on creating intuitive dashboards and control panels that allow operators to easily interact with and oversee RL systems.
Sustainability Metrics: Future work should also explore the development of sustainability metrics that RL systems can optimize. This includes not only energy efficiency but also water usage, pesticide application, and overall environmental impact.
Policy and Regulatory Compliance: Research should address how RL systems can be designed to comply with local and international policies and regulations concerning energy usage and environmental protection.
Data Privacy and Security: With the increasing use of IoT and RL, ensuring data privacy and security is essential. Future research should develop robust security protocols to protect sensitive data in greenhouse management systems.
Real-World Case Studies: Conducting real-world case studies and pilot projects can provide valuable insights into the practical challenges and benefits of implementing RL in greenhouses. These studies can help refine RL models and identify best practices for successful adoption.
2.2. Literature Review Conclusions
The RL paradigm has shown significant potential to optimize energy management in greenhouses and precision agriculture techniques. From optimal autonomous control to deep RL, the reviewed references indicate a growing trend toward intelligent, adaptive solutions that promote energy efficiency and sustainability. Future research should focus on integrating RL with IoT, scalability, interdisciplinary approaches, environmental adaptability, economic viability, user-friendly interfaces, sustainability metrics, policy compliance, data privacy and security, and real-world case studies to further advance this technological evolution.
In conclusion, the field of reinforcement learning for greenhouse management has made significant progress, yet challenges remain. Future research should focus on improving scalability, integrating advanced technologies, and developing hybrid models to fully realize the potential of RL in this domain.
3. Materials and Methods
3.1. Model Proposed
The reinforcement learning (RL) problem involves a digital agent exploring an environment to achieve a specific goal. In the field of automated greenhouses, it is about managing environmental conditions and crop growth while optimizing resources and inputs. RL is based on the hypothesis that all goals can be characterized by maximizing the expected cumulative reward. The agent must learn to perceive and manipulate the state of the environment through its actions to optimize this reward. In the model presented in this work, the agent performs control actions to adjust the set-points, ensuring that the internal conditions of the greenhouse stay within the predefined maximum and minimum limits. By doing so, the agent optimizes the management of resources such as water, energy, and inputs, leading to improved plant growth.
Figure 1 shows the application scenario of the RL paradigm.
The system must be able to collect relevant data, establish the necessary sensors and communication protocols, and manage them appropriately using the IOT paradigm.
The proposed model uses a layered architecture (
Figure 2) to integrate the services and functionalities of the platform (IoT + RL). In an agricultural facility, whether newly constructed or already operational, monitoring and actuation devices are installed and interfaced with the processing and control layer. The following provides a detailed description of each layer.
In the physical layer, IoT sensors/actuators, human–machine interfaces (HMIs) and machine-to-machine interfaces (MMIs) are installed. The farmer and technicians can act by entering data and requests. The processing layer filters data, executes control actions, and communicates with the upper layer.
The control layer embedded devices receive data from the upper layer to manage the different processes and perform control and maintenance actions. This layer must provide the necessary support to communicate the data to the sensor/actuators installed.
The interoperability layer integrates different RL agents connected to digital twin algorithms. The model proposes the development of RL agents to optimize the use of set-point values in various control loops within an automated facility. The RL agent modifies the set-point values to achieve one or more specified objectives, such as maintaining environmental conditions, improving electrical consumption, reducing water use, and optimizing renewable energy use. This process operates automatically and can be analyzed through an interface where users can test control strategies. This interface enables simulations on a digital twin model that replicates different states based on the knowledge acquired from the analyzed data obtained from IoT network sensors. In this layer, the deployment of RL agents, the development of digital twin functionalities, and the implementation of user interfaces are executed.
In the application layer, applications are designed and developed on different platforms (mobile phones, business networks, computers, etc.). In each of them, a relationship is defined between the user and the type of access allowed.
3.1.1. Development in an Automated Greenhouse
Greenhouses provide a controlled environment for plant cultivation, allowing for improved growth and productivity compared to traditional open-field agriculture. However, managing a greenhouse efficiently involves complex decision-making processes to balance resource usage, such as water and energy, with the optimal growing conditions for plants. Traditional management methods often rely on predefined schedules and heuristics, which may not adapt well to dynamic environmental conditions and changing plant needs.
Reinforcement learning (RL) offers a promising solution to this challenge by enabling systems to learn optimal strategies through interactions with the environment. RL algorithms can adapt to changing conditions and learn from experience, making them well suited to the dynamic and complex nature of greenhouse management. By continuously adjusting actions based on observed outcomes, RL can optimize resource usage while maintaining or improving crop yields.
One of the scenarios where the model can be applied is in energy management. In the case of the use of this work, the model is based on a reinforcement learning algorithm in the management of greenhouse energy. Specifically, the model employs a prediction model to forecast the greenhouse’s environmental conditions throughout the day. Based on these predictions, they implement a reinforcement learning (RL) algorithm that rewards minimal energy usage to regulate the greenhouse’s temperature. The algorithm refines the temperature control loop by optimizing the choice of the input point for the existing regulation loop. In essence, the algorithm adjusts the set point value to optimize energy consumption while maintaining the selected minimum and maximum temperature thresholds.
Incorporating climate predictions into the RL model can further enhance its performance by allowing anticipatory adjustments.
Reinforcement learning (RL) offers a promising approach to energy consumption by learning from the environment and making data-driven decisions. This study focuses on the Q-learning algorithm, a model-free RL method, to determine the connection and disconnection of the air conditioning system.
3.1.2. Methodology
The proposed system uses the Q-learning algorithm to make watering decisions based on real-time data from IoT sensors. The states, variables, actions, and reward function are designed to reflect the dynamics of the greenhouse environment. The methods are indicated in
Table 1.
3.2. Phase 1: Control Strategies (Set-Point in the Environmental Regulation Loop)
Reinforcement learning (RL) techniques can optimize air conditioning connection strategies by making decisions based on continuous feedback from plants and the environment. Various sensors (energy consumption, temperature, humidity, weather data, etc.), actuators, and a data processing unit must be used. In
Table 2, different strategies and their relationship with IoT technologies are shown.
The selection of the appropriate irrigation strategy for greenhouse cultivation depends on various factors, including crop type, environmental conditions, and resource availability. Strategies based on substrate moisture, evapotranspiration, and VPD offer customized approaches to optimize water use, improve crop performance, and promote sustainable agricultural practices.
3.3. Phase 2: IoT Infrastructure
The IoT infrastructure is designed with the strategy of being interoperable with existing greenhouse subsystems: climate, lighting, irrigation, etc. To achieve this, it is designed and developed at two levels.
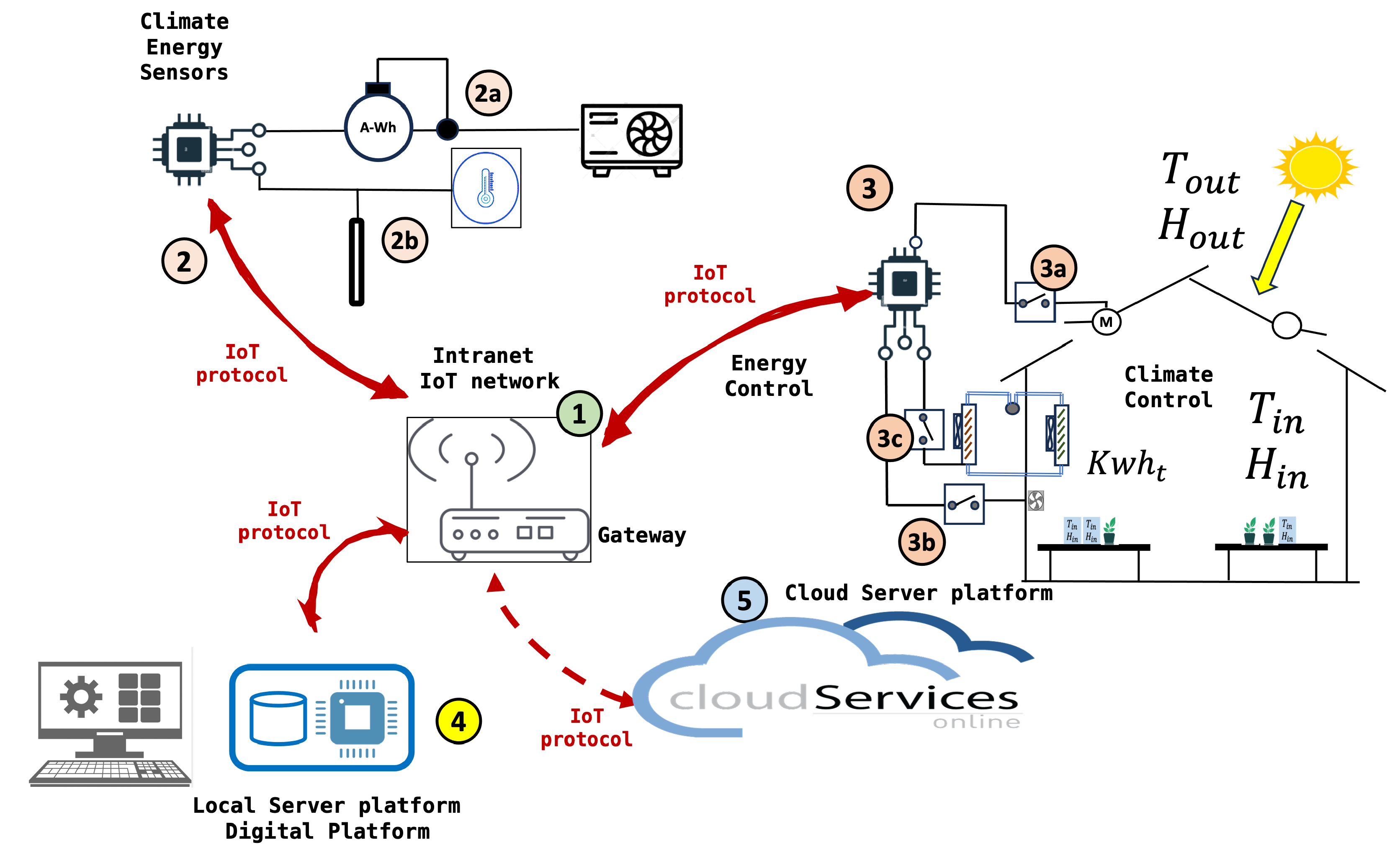
Figure 3 describes the Internet of Things (IoT) network.
Table 3 contains the identification of the components according to this figure. The sequence of events and data sequence are listed below.
Climate energy data are captured and stored in the system.
Sensors collect environmental conditions.
The data are sent to the gateway, which then transmits it to the local server and cloud services.
The data are stored on the local server. The datasets are created with the main variables.
Local and cloud services allow remote monitoring and control of the system.
The prediction of the environmental conditions in the next few hours is obtained.
With the data and predictions, the learning algorithm is executed.
The algorithm proposes a modification of the set-point by increasing or decreasing its value, using the values of the reinforcements or Q values.
Table 3.
Identification of components in the IoT network for a solar energy management system.
Table 3.
Identification of components in the IoT network for a solar energy management system.
| Number | Component Description |
|---|
| 1 | IoT Gateway or Router: This device acts as a central communication point between various sensors and devices and the cloud server. It uses IoT protocols to transmit data. |
| 2 | Sensors and Meters: These devices collect data from different sources: |
| 2a | Energy meter (A-Wh) that measures the amount of energy consumed. |
| 2b | Temperature sensor (thermostat) that measures the ambient temperature. |
| 3 | Solar Energy Controller: This component receives data from the sensors and manages the distribution of energy. |
| 3a | Inverter that converts solar energy from direct current (DC) to alternating current (AC). |
| 3b | Batteries for energy storage. |
| 3c | Switches and fuses for protection. |
| 4 | Local Server or Database: Stores and processes data locally. It is where all the data are collected for processing before being sent to the cloud. |
| 5 | Cloud Services: The data are sent to the cloud for additional storage and analysis. Cloud services can provide interfaces to monitor and control the system. |
| M | Monitoring Computer: Allows users to interact with the system, probably through a graphical interface for real-time monitoring and control of the system. |
3.4. Phase 3: Dataset Generation
Datasets generated from IoT sensors provide a rich source of information for decision makers. These datasets enable real-time monitoring and analysis, allowing for informed decision making based on accurate and up-to-date information. In greenhouse facilities, IoT sensor traffic data can be used to optimize traffic flow, reduce congestion, and improve public transportation systems. Generating high-quality datasets from IoT sensor data requires addressing issues related to data quality and consistency. Sensors can produce noisy or incomplete data, which can affect the accuracy and reliability of the datasets. Implementing robust data preprocessing and cleaning techniques is essential to ensure the integrity of the datasets.
Temperature and humidity sensors are located inside and outside the greenhouse, monitoring the weather forecast and energy consumption. The methodology for data capture is outlined below:
Sensor Placement. Strategically place sensors to capture a representative sample of environmental conditions within the greenhouse. This includes placing sensors at various depths and locations throughout the greenhouse to monitor microclimates.
Data Logging and Transmission. Utilize data loggers and wireless networks to ensure continuous data capture and transmission. This includes setting up a reliable network infrastructure that can handle the data volume and frequency required for RL applications.
Data Storage. Implement a centralized data storage solution, preferably cloud-based, to store the large volumes of data generated by the sensors. Ensure the storage system supports efficient data retrieval and processing.
Data Prepossessing, Cleaning, and Normalization. Address issues related to missing values, sensor malfunctions, and noise in the data. Techniques such as interpolation and filtering should be applied to ensure data quality and consistency. Normalise sensor data to a common scale to facilitate accurate analysis and model training. This step is crucial for integrating diverse data types into a cohesive dataset.
Materials and Methods
Data capture was carried out on a hemp crop in a technical greenhouse (
Figure 4) with the following characteristics: glass greenhouse of 50 m
2 (5 × 10 m) each. All of them have an automatic climate and irrigation control system with the following equipment:
Humidifier with osmosis water mist.
Air conditioners to heat and cool the modules. Twin, Triple Mitsubishi PUHZ-P200YKA three-phase classic inverter Nominal cooling capacity (Min.–Max.) kW 19.00 Nominal heat capacity (Min.–Max.) kW 22.40.
Thermal shading screen.
Extractor fan and zenithal opening windows with anti-trip mesh.
Artificial light lamps to increase net assimilation.
Micro-sprinkler and drip or flood irrigation system.
Temperature and humidity probes.
Electrical, compressed air, mains water and osmosed water connections.
Embedded device (raspberrypi4) that deploys an intranet (WiFi, Bluetooth Low Energy) for communication, monitoring, and control.
Electric energy meter in three-phase and single-phase circuits (shelly 3 EM). This consumption meter communicates with the embedded system through the WiFi and IP protocol.
Communication to web servers to obtain the temperature prediction in the greenhouse area.
Figure 4.
Industrial greenhouse used to deploy the IoT data. A control intranet has been deployed with embedded devices and communications based on IoT protocols (WiFi and MQTT).
Figure 4.
Industrial greenhouse used to deploy the IoT data. A control intranet has been deployed with embedded devices and communications based on IoT protocols (WiFi and MQTT).
This work develops and tests a low-cost sensor/actuator network platform, based on the Internet of Things, integrating machine-to-machine and human–machine interface protocols used in [
22]. The system integrated Internet of Things (IoT) paradigms, ubiquitous sensor networks, and edge computing to create a smart agricultural environment. Implementation (
Figure 4) included machine-to-machine and human–machine interface protocols to enable seamless communication, data capture (
Figure 5) and control processes considering a precision agriculture scenario.
3.5. Phase 4: Digital Model and RL Algorithm
RL involves an agent learning to make sequential decisions through interaction with its environment to maximize cumulative rewards. In the context of greenhouse control, RL offers a promising framework to optimize energy use while maintaining the configured maximum and minimum temperature conditions. The theoretical model serves to support decision making at a given moment. The objective is to start from prior knowledge that allows the system to initiate decision making more effectively. From the initial configuration of the RL algorithm, the system will adapt to the specific conditions of the installation, optimizing control as feedback information is obtained on the evolution of the system compared to its previous behavior. It is therefore about introducing a finer regulation that is capable of improving the existing one by adapting to the specific conditions of the installation.
3.5.1. Greenhouse Model Based in Differential Equations
There is knowledge and mathematical models of the behavior of temperature in a greenhouse. These models provide a good starting point for defining reward policies and functions. For all these reasons, the RL model is based on the knowledge already acquired to, from there, introduce improvements and optimize current operation. The behavior of the temperature inside a greenhouse is influenced by several factors, including the external temperature, solar radiation, and the thermal dynamics of the greenhouse itself. Here, we present a mathematical model to simulate the dynamics of the greenhouse temperature.
The thermal model of a greenhouse when both heating and cooling are applied can be described by the following differential equation.
To discretize this equation for algorithmic application, we consider a time step
. The temperature change over the time step from
t to
can be approximated as
Substituting this into the differential equation gives
Solving for
, we obtain the following
The meaning of all variables is shown in
Table 4.
This discretized equation can be used to iteratively compute the inside temperature of the greenhouse in discrete time steps for the purpose of applying control algorithms. This model is simple, and the results give us a first analysis of trends and future strategies. In the scenario of an RL algorithm, the actions taken depend on the value of the set temperature. The actions that can be taken are shown in the
Table 5.
3.5.2. Greenhouse Model Based in Predictions
This model has two parts. In the first case, the behavior of the greenhouse temperature in the next moments of time is predicted on the basis of IoT data and the machine learning paradigm. Once the future value of the temperature inside the greenhouse is calculated, the best possible action for regulation is taken.
The interior temperature of a greenhouse based on external climatic conditions and historically can be obtained with several models, including linear regression, decision tree, gradient boost, random forest, and neural networks, which can be compared to identify the most accurate and consistent predictive model.
The dataset used consists of climatic data collected from a greenhouse over several months. The variables include the following:
TE: Exterior Temperature;
HRE: Exterior Relative Humidity;
RGE: Exterior Global Radiation;
VV: Wind Speed;
DV: Wind Direction;
LL: Rainfall;
TI: Interior Temperature;
HRI: Interior Relative Humidity.
The data are resampled to intervals that are configured according to the installation, and lag features are created to incorporate historical data into the prediction model.
The actions taken are shown in
Table 6.
3.5.3. Reinforcement Learning Deployment
Reinforcement learning (RL) is a subfield of machine learning where an agent learns to make decisions by interacting with an environment to maximize a cumulative reward. In the context of controlling the temperature of a greenhouse, an RL agent can learn when to turn the heater on or off to maintain the desired temperature and minimize energy consumption.
The RL model consists of the following elements:
State (s): Represents the current situation of the environment. In our case, the state can include the internal temperature of the greenhouse, the external temperature, and solar radiation.
Action (a): The decision taken by the agent in each state. In our case, actions are turning the heater on () or off ().
Reward (r): The feedback received by the agent after taking an action in a state. The reward can be a function of the internal temperature and energy consumption.
Policy (): The strategy followed by the agent to make decisions. The policy maps states to actions.
Value (): The expected value of the cumulative reward starting from state s following policy .
Q-Value (): The expected value of the cumulative reward starting from state s taking action a and following policy .
The goal of the RL agent is to learn an optimal policy that maximizes the cumulative reward. This is formalized in the optimal control problem in a Markov Decision Process (MDP).
3.6. Phase 5: Training and Methods
To start with prior knowledge and avoid the initial errors introduced by RL, actions, functions, and reward policies are analyzed first through simulation and then using real data obtained in the cultivation process. Firstly, an analysis is carried out using differential equations that model the climatic behavior in a greenhouse and then apply it with the data obtained in the greenhouse.
The method used for the RL algorithm applied to a greenhouse model is based on differential equations.
The RL agent intervenes in the control process through the following steps:
Observe Current State: The agent observes the current state , which includes the internal temperature (), the external temperature (), and solar radiation ().
Select Action: Based on its policy , the agent chooses an action (turn the heater on or off).
Apply Action: The chosen action is applied to the environment.
Observe Reward and Next State: The agent receives a reward and observes the next state .
Update Policy: The agent updates its policy using the learning algorithm, such as Q-learning.
By formulating temperature control as a sequential decision-making problem, RL algorithms can adaptively adjust based on real-time environmental data and set-point conditions. One crucial aspect in applying RL to temperature control is the choice of state representation, which captures relevant information about the environment for decision making.
The process is based on the technician’s previous configuration and a theoretical model of temperature behavior on which the RL algorithm performs the calculations. This model can be based on energy balances or be a model obtained by studying the behavior of greenhouse conditions.
Selecting an appropriate state representation is essential to allow the RL agent to effectively learn and adapt its cotrol policies to achieve optimal performance under varying environmental conditions. Furthermore, the careful selection of control actions is equally important, as it determines how the RL agent interacts with the environment. By choosing suitable control actions, such as adjusting the temperature set-point, the RL agent can effectively optimize energy usage. Finally, algorithms are developed to optimize the reward functions associated with states and actions, ensuring that the RL agent learns to make decisions that lead to the most favorable outcomes. This approach allows the development of intelligent control systems capable of dynamically responding to changing environmental conditions and ambient conditions needs.
The Q-learning algorithm has five actions (
Table 5).
Table 8 describes examples of potential reward functions applicable in RL algorithms.
An appropriate RL algorithm, such as Q-learning, deep Q network (DQN), or posterior policy optimization (PPO), should be chosen based on the complexity of the task and the available computational resources, where the following apply:
, , and are weight coefficients that can be tuned.
E is the energy consumption penalty.
is the current inside temperature.
is the set-point temperature.
where
and
are the maximum and minimum allowable temperatures, respectively.
5. Conclusions
The results obtained in this work align with the findings of previous studies [
1] which also highlight the potential of RL to improve energy efficiency in complex systems such as greenhouses. This work provides an expanded method to apply the integration of RL with IoT considering the participation and knowledge of users (technicians and farmers), the use of non-proprietary hardware and communication protocols. The model can also be implemented both in operating facilities and in new designs.
The integration of Internet of Things (IoT) protocols and reinforcement learning (RL) methodologies has been shown to be effective in managing and optimizing greenhouse operations for industrial hemp cultivation. This combination not only enhances operational efficiency but also maintains selected temperatures and optimizes energy consumption more effectively than classical control methods. By reducing the need for constant human intervention, this technological integration minimizes labor costs and increases scalability for larger agricultural enterprises.
The RL-based control system shows significant energy savings while maintaining the desired temperature ranges, outperforming traditional fixed set-point control systems. Specifically, the study shows energy savings of up to 45% during cooling processes and 25.93% during heating processes. In addition, this new control approach simplifies the workload of technicians by eliminating the need for complex analyses to achieve the same results, allowing them to focus on higher-level oversight and maintenance tasks.
Integration with IoT plays a crucial role in this setup, enabling real-time data acquisition and seamless communication between various greenhouse subsystems. IoT devices collect and transmit environmental data that RL algorithms use to make informed dynamic adjustments to greenhouse conditions. This IoT integration ensures that the RL model can adapt to changing conditions promptly and accurately, thus optimizing resource use and improving overall system responsiveness.
RL algorithms are capable of adaptively adjusting set-point temperatures based on real-time data and predictions, leading to optimized energy consumption and better maintenance of desired environmental conditions. The study validates the practical implementation of RL models in automated greenhouses in the real world, showcasing their ability to scale and adapt to different types of crops and environmental conditions. These conclusions highlight the potential of combining IoT and RL technologies to improve the efficiency, scalability, and sustainability of greenhouse operations, particularly for industrial hemp cultivation.



 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}