

Knowledge Graph-Based In-Context Learning for Advanced Fault Diagnosis in Sensor Networks


Abstract
1. Introduction
- We construct a unique fault text dataset that includes domain-specific expertise. This dataset includes approximately 1000 instances that encompass fault modes, causal analyses, and maintenance strategies. This dataset summarizes expert diagnostic knowledge, compensating for the lack of general availability of fault text datasets.
- We introduce KG-ICL, a method designed for fault cause analysis. We employ a DGCNN to construct a DSKG and use the LES metric to retrieve task-related knowledge. By means of predefined prompt templates, we obtain task-related demonstrations. Through KG-ICL, the structured knowledge contained in a knowledge graph (KG) can be provided to LLMs, offering them a referenceable background of domain-specific expertise for text analysis.
- We apply the KG-ICL method in a specific domain as an example, thereby validating the feasibility and soundness of the proposed approach in practical applications. Through a series of experiments, we systematically compare the performance of three types of prompts—without prompts, domain-relevant but not task-related prompts, and task-related prompts—using various LLMs.
2. Related Work
2.1. LLMs and In-Context Learning
2.2. KGs and LLMs
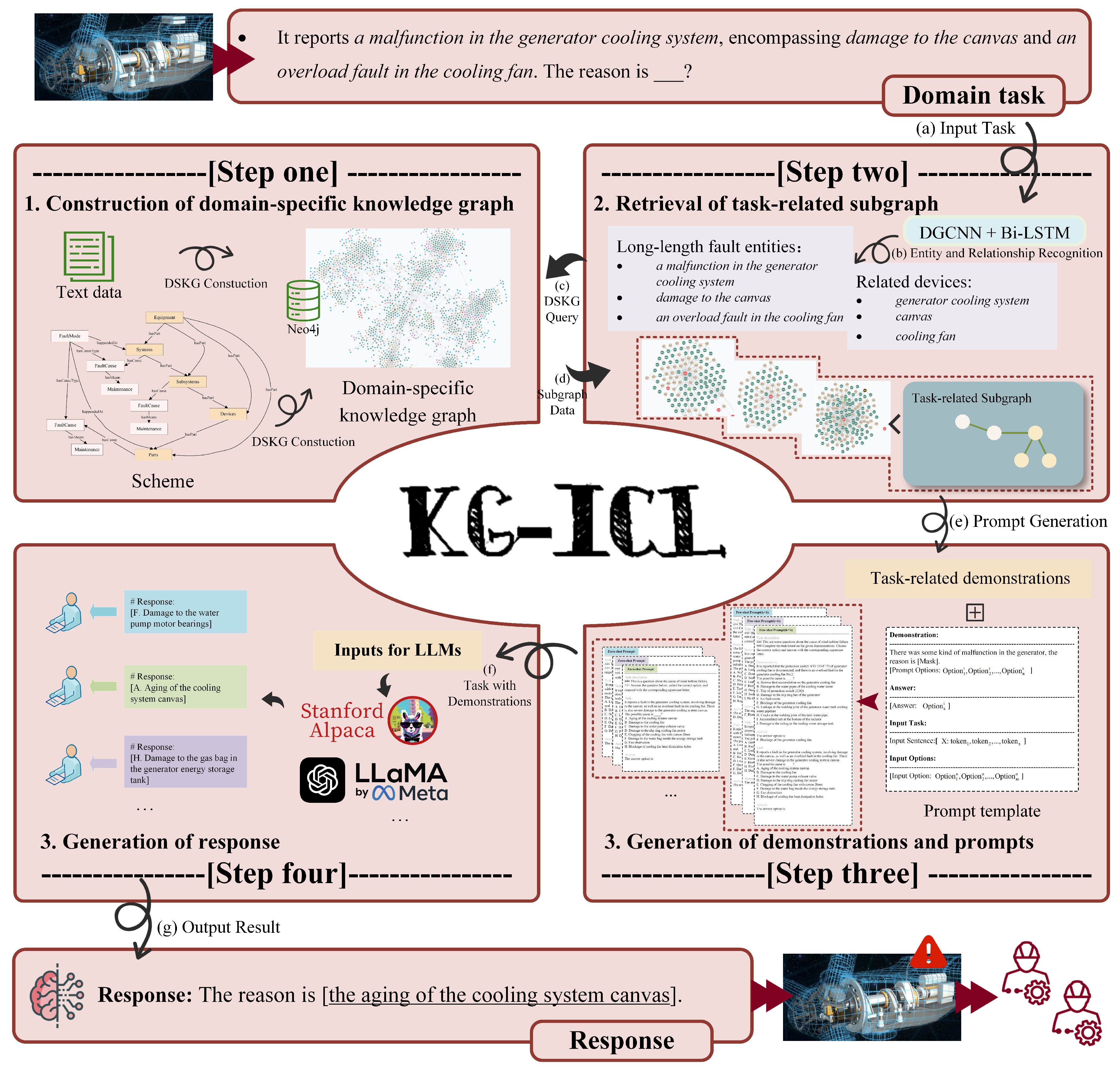
3. Methodology
3.1. Dataset
- : dataset for DSKG construction.
- : dataset for testing.
3.2. DSKG Construction
3.2.1. Schema Layer
3.2.2. Construction of the DSKG
| Algorithm 1: Process of Building DSKG |
| Input:: Dataset Output:: SPO list of entities and relationships
|
3.3. Prompt Construction
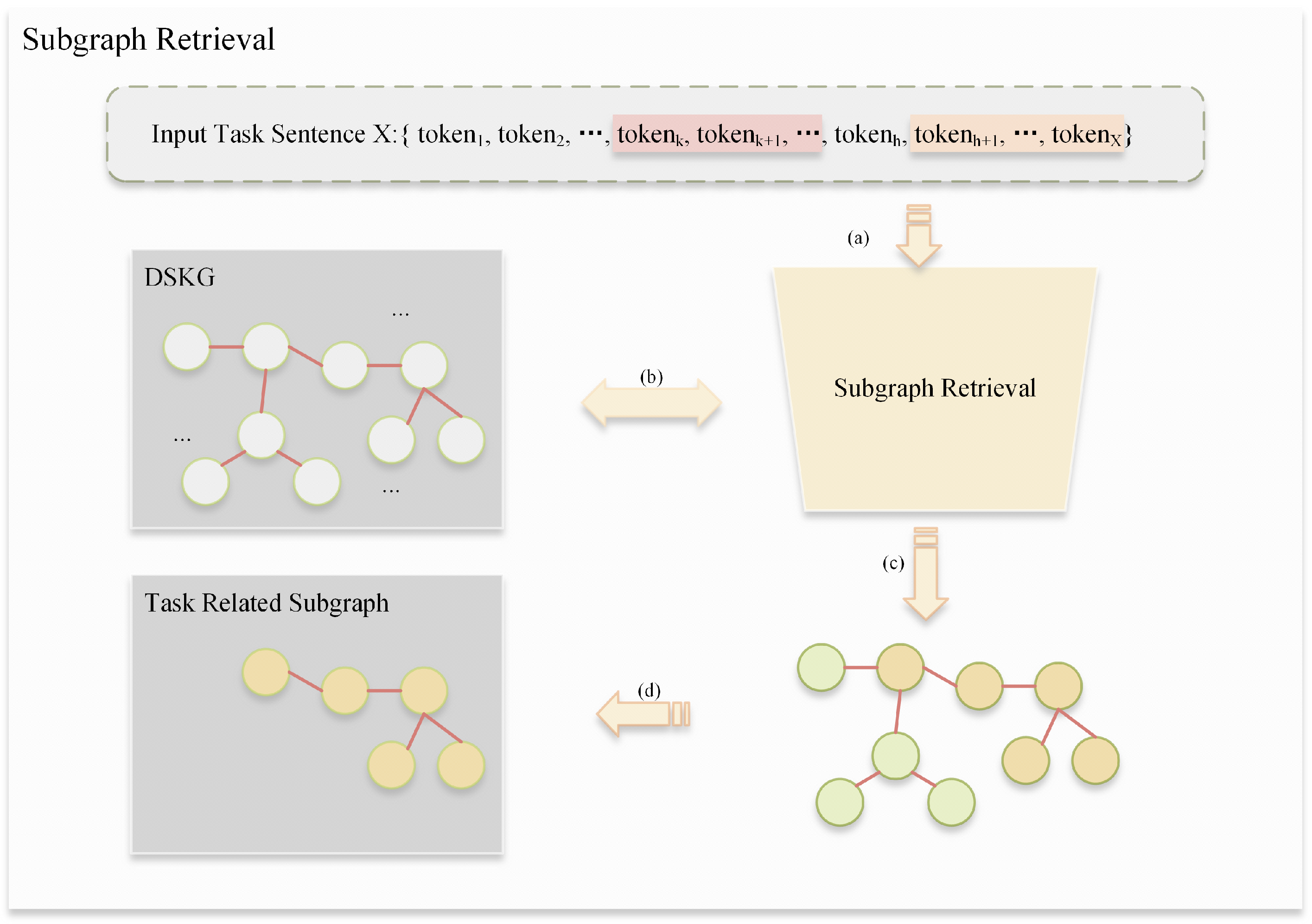
3.3.1. Subgraph Retrieval
3.3.2. Prompt Construction
4. Experiments
4.1. Experimental Setting
4.2. Evaluation
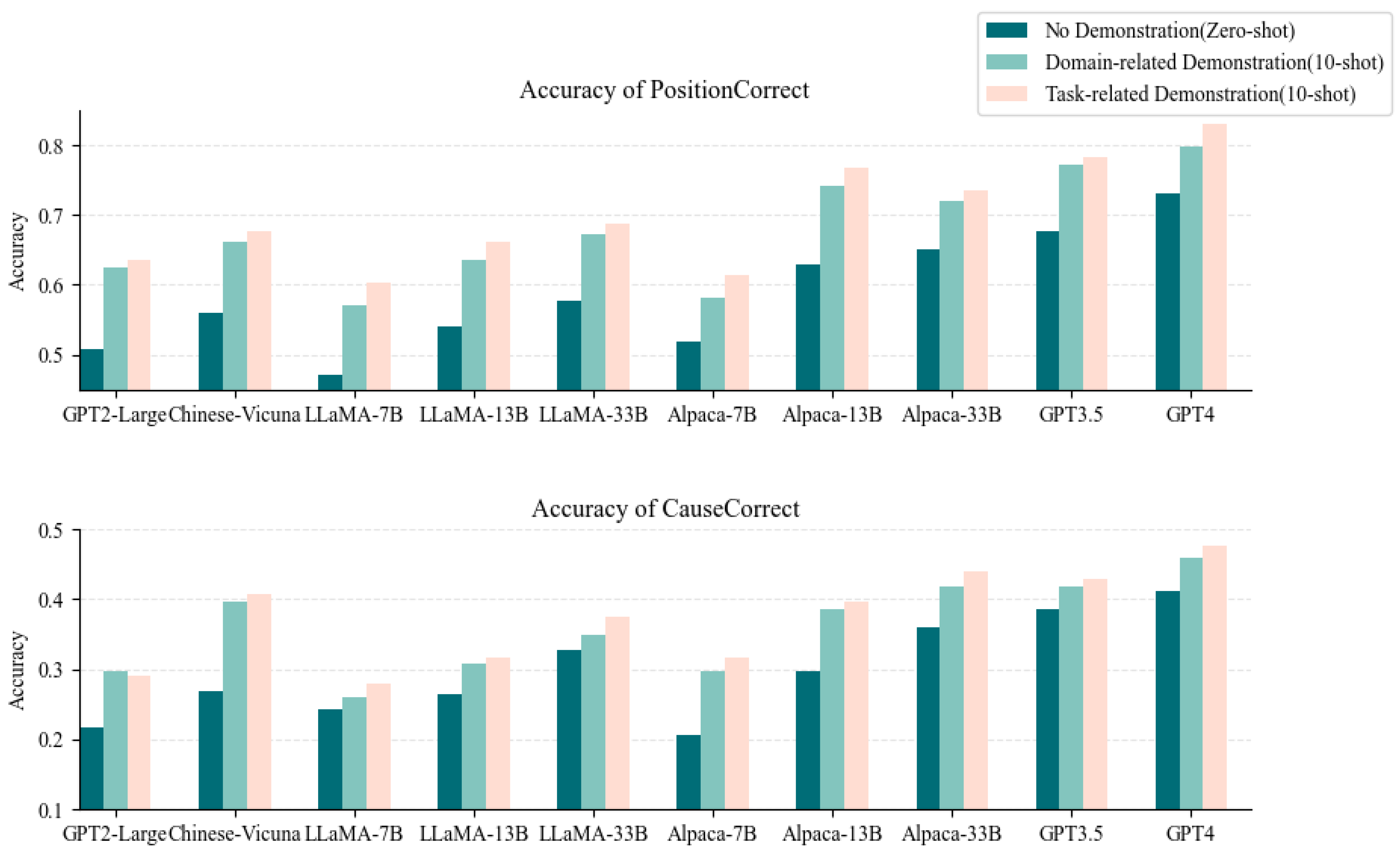
4.3. Results
5. Discussion
5.1. Cross-Validation Experiments
5.2. Ablation Study on the LES Component
6. Conclusions
- Enriching prompt templates with KGs yields superior results in terms of demonstration quality compared to manual approaches.
- The integration of KGs when generating prompts leads to more task-relevant prompts.
- The integration of structured knowledge from KGs into prompts enhances the accuracy of the content generated by LLMs.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kauf, C.; Ivanova, A.A.; Rambelli, G.; Chersoni, E.; She, J.S.; Chowdhury, Z.; Fedorenko, E.; Lenci, A. Event knowledge in large language models: The gap between the impossible and the unlikely. Cogn. Sci. 2023, 47, e13386. [Google Scholar] [CrossRef] [PubMed]
- Ott, S.; Hebenstreit, K.; Liévin, V.; Hother, C.E.; Moradi, M.; Mayrhauser, M.; Praas, R.; Winther, O.; Samwald, M. ThoughtSource: A central hub for large language model reasoning data. Sci. Data 2023, 10, 528. [Google Scholar] [CrossRef] [PubMed]
- Xiao, Y.; Zheng, S.; Shi, J.; Du, X.; Hong, J. Knowledge graph-based manufacturing process planning: A state-of-the-art review. J. Manuf. Syst. 2023, 70, 417–435. [Google Scholar] [CrossRef]
- Bu, K.; Liu, Y.; Ju, X. Efficient utilization of pre-trained models: A review of sentiment analysis via prompt learning. Knowl.-Based Syst. 2023, 283, 111148. [Google Scholar] [CrossRef]
- Fang, Y.; Zhang, Q.; Zhang, N.; Chen, Z.; Zhuang, X.; Shao, X.; Fan, X.; Chen, H. Knowledge graph-enhanced molecular contrastive learning with functional prompt. Nat. Mach. Intell. 2023, 5, 542–553. [Google Scholar] [CrossRef]
- Hu, L.; Liu, Z.; Zhao, Z.; Hou, L.; Nie, L.; Li, J. A survey of knowledge enhanced pre-trained language models. IEEE Trans. Knowl. Data Eng. 2023, 36, 1413–1430. [Google Scholar] [CrossRef]
- Sun, P.Z.; Bao, Y.; Ming, X.; Zhou, T. Knowledge-driven industrial intelligent system: Concept, reference model, and application direction. IEEE Trans. Comput. Soc. Syst. 2022, 10, 1465–1478. [Google Scholar] [CrossRef]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Liu, P.; Yuan, W.; Fu, J.; Jiang, Z.; Hayashi, H.; Neubig, G. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. ACM Comput. Surv. 2023, 55, 1–35. [Google Scholar] [CrossRef]
- Lee, S.; Lee, J.; Bae, C.H.; Choi, M.S.; Lee, R.; Ahn, S. Optimizing Prompts using In-Context Few-Shot Learning for Text-to-Image Generative Models. IEEE Access 2024, 12, 2660–2673. [Google Scholar] [CrossRef]
- Han, X.; Zhao, W.; Ding, N.; Liu, Z.; Sun, M. Ptr: Prompt tuning with rules for text classification. AI Open 2022, 3, 182–192. [Google Scholar] [CrossRef]
- Gao, T.; Fisch, A.; Chen, D. Making pre-trained language models better few-shot learners. arXiv 2020, arXiv:2012.15723. [Google Scholar]
- Lester, B.; Al-Rfou, R.; Constant, N. The power of scale for parameter-efficient prompt tuning. arXiv 2021, arXiv:2104.08691. [Google Scholar]
- Liu, X.; Zheng, Y.; Du, Z.; Ding, M.; Qian, Y.; Yang, Z.; Tang, J. GPT understands, too. AI Open 2023, 5, 208–215. [Google Scholar] [CrossRef]
- Gu, Y.; Han, X.; Liu, Z.; Huang, M. Ppt: Pre-trained prompt tuning for few-shot learning. arXiv 2021, arXiv:2109.04332. [Google Scholar]
- Hu, S.; Ding, N.; Wang, H.; Liu, Z.; Wang, J.; Li, J.; Wu, W.; Sun, M. Knowledgeable prompt-tuning: Incorporating knowledge into prompt verbalizer for text classification. arXiv 2021, arXiv:2108.02035. [Google Scholar]
- Min, S.; Lyu, X.; Holtzman, A.; Artetxe, M.; Lewis, M.; Hajishirzi, H.; Zettlemoyer, L. Rethinking the Role of Demonstrations: What Makes In-Context Learning Work? In Proceedings of the EMNLP, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 1048–11064. [Google Scholar]
- Yoo, K.M.; Kim, J.; Kim, H.J.; Cho, H.; Jo, H.; Lee, S.W.; Lee, S.g.; Kim, T. Ground-Truth Labels Matter: A Deeper Look into Input-Label Demonstrations. In Proceedings of the EMNLP, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 2422–2437. [Google Scholar]
- Wang, L.; Zhao, W.; Wei, Z.; Liu, J. SimKGC: Simple contrastive knowledge graph completion with pre-trained language models. arXiv 2022, arXiv:2203.02167. [Google Scholar]
- Lo, P.C.; Lim, E.P. A transformer framework for generating context-aware knowledge graph paths. Appl. Intell. 2023, 53, 23740–23767. [Google Scholar] [CrossRef]
- Zhang, N.; Xu, X.; Tao, L.; Yu, H.; Ye, H.; Qiao, S.; Xie, X.; Chen, X.; Li, Z.; Li, L.; et al. Deepke: A deep learning based knowledge extraction toolkit for knowledge base population. arXiv 2022, arXiv:2201.03335. [Google Scholar]
- Wang, X.; Gao, T.; Zhu, Z.; Zhang, Z.; Liu, Z.; Li, J.; Tang, J. KEPLER: A unified model for knowledge embedding and pre-trained language representation. Trans. Assoc. Comput. Linguist. 2021, 9, 176–194. [Google Scholar] [CrossRef]
- Liu, W.; Zhou, P.; Zhao, Z.; Wang, Z.; Ju, Q.; Deng, H.; Wang, P. K-bert: Enabling language representation with knowledge graph. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 2901–2908. [Google Scholar]
- Zhang, Z.; Han, X.; Liu, Z.; Jiang, X.; Sun, M.; Liu, Q. ERNIE: Enhanced language representation with informative entities. arXiv 2019, arXiv:1905.07129. [Google Scholar]
- Lin, B.Y.; Chen, X.; Chen, J.; Ren, X. Kagnet: Knowledge-aware graph networks for commonsense reasoning. arXiv 2019, arXiv:1909.02151. [Google Scholar]
- Guu, K.; Lee, K.; Tung, Z.; Pasupat, P.; Chang, M. Retrieval augmented language model pre-training. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 3929–3938. [Google Scholar]
- Pan, S.; Luo, L.; Wang, Y.; Chen, C.; Wang, J.; Wu, X. Unifying large language models and knowledge graphs: A roadmap. IEEE Trans. Knowl. Data Eng. 2024, 36, 3580–3599. [Google Scholar] [CrossRef]
- Ben-David, E.; Oved, N.; Reichart, R. PADA: Example-based Prompt Learning for on-the-fly Adaptation to Unseen Domains. Trans. Assoc. Comput. Linguist. 2022, 10, 414–433. [Google Scholar] [CrossRef]
- Chen, L.; Cai, Z.; Jiang, Z.; Sun, L.; Childs, P.; Zuo, H. A knowledge graph-based bio-inspired design approach for knowledge retrieval and reasoning. J. Eng. Des. 2024, 1–31. [Google Scholar] [CrossRef]
- Hu, Z.; Li, X.; Pan, X.; Wen, S.; Bao, J. A question answering system for assembly process of wind turbines based on multi-modal knowledge graph and large language model. J. Eng. Des. 2023, 1–25. [Google Scholar] [CrossRef]
- Zhou, B.; Bao, J.; Chen, Z.; Liu, Y. KGAssembly: Knowledge graph-driven assembly process generation and evaluation for complex components. Int. J. Comput. Integr. Manuf. 2022, 35, 1151–1171. [Google Scholar] [CrossRef]
- Wang, C.; Liu, Y.; Guo, T.; Li, D.; He, T.; Li, Z.; Yang, Q.; Wang, H.; Wen, Y. Systems engineering issues for industry applications of large language model. Appl. Soft Comput. 2024, 151, 111165. [Google Scholar]
- Guo, Q.; Cao, S.; Yi, Z. A medical question answering system using large language models and knowledge graphs. Int. J. Intell. Syst. 2022, 37, 8548–8564. [Google Scholar] [CrossRef]
- Zhu, S.; Cheng, X.; Su, S. Knowledge-based question answering by tree-to-sequence learning. Neurocomputing 2020, 372, 64–72. [Google Scholar] [CrossRef]
- Du, H.; Zhang, X.; Wang, M.; Chen, Y.; Ji, D.; Ma, J.; Wang, H. A contrastive framework for enhancing knowledge graph question answering: Alleviating exposure bias. Knowl.-Based Syst. 2023, 280, 110996. [Google Scholar] [CrossRef]
- Xia, L.; Li, C.; Zhang, C.; Liu, S.; Zheng, P. Leveraging error-assisted fine-tuning large language models for manufacturing excellence. Robot. -Comput. -Integr. Manuf. 2024, 88, 102728. [Google Scholar] [CrossRef]
- Mayer, C.W.; Ludwig, S.; Brandt, S. Prompt text classifications with transformer models! An exemplary introduction to prompt-based learning with large language models. J. Res. Technol. Educ. 2023, 55, 125–141. [Google Scholar] [CrossRef]
- Zhou, B.; Li, X.; Liu, T.; Xu, K.; Liu, W.; Bao, J. CausalKGPT: Industrial structure causal knowledge-enhanced large language model for cause analysis of quality problems in aerospace product manufacturing. Adv. Eng. Inform. 2024, 59, 102333. [Google Scholar] [CrossRef]
- Shin, E.; Ramanathan, M. Evaluation of prompt engineering strategies for pharmacokinetic data analysis with the ChatGPT large language model. J. Pharmacokinet. Pharmacodyn. 2024, 51, 101–108. [Google Scholar] [CrossRef]
- Zhang, K.; Zhou, F.; Wu, L.; Xie, N.; He, Z. Semantic understanding and prompt engineering for large-scale traffic data imputation. Inf. Fusion 2024, 102, 102038. [Google Scholar] [CrossRef]
- Song, R.; Liu, Z.; Chen, X.; An, H.; Zhang, Z.; Wang, X.; Xu, H. Label prompt for multi-label text classification. Appl. Intell. 2023, 53, 8761–8775. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Params | Model | Params |
|---|---|---|---|
| GPT-2-Large | 774 M | Chinese-Alpaca-pro | 7 B |
| Chinese-Vicuna | 7 B | Chinese-Alpaca-pro | 13 B |
| Chinese-LLaMA-plus | 7 B | Chinese-Alpaca-pro | 33 B |
| Chinese-LLaMA-plus | 13 B | ChatGPT (GPT-3.5) | 175 B |
| Chinese-LLaMA-plus | 33 B | GPT-4 | 1.8 T |
| Model | k | Method | Method | ||||
|---|---|---|---|---|---|---|---|
| 1-shot | 0.307 | 0.529 | 0.280 | 0.540 | |||
| 3-shot | 0.275 | 0.556 | 0.270 | 0.561 | |||
| GPT-2-Large | 5-shot | ICL | 0.270 | 0.571 | KG-ICL | 0.259 | 0.582 |
| 8-shot | 0.275 | 0.603 | 0.270 | 0.614 | |||
| 10-shot | 0.296 | 0.624 | 0.291 | 0.635 | |||
| 1-shot | 0.286 | 0.582 | 0.286 | 0.593 | |||
| 3-shot | 0.312 | 0.603 | 0.296 | 0.614 | |||
| Chinese-Vicuna | 5-shot | ICL | 0.360 | 0.630 | KG-ICL | 0.413 | 0.646 |
| 8-shot | 0.413 | 0.646 | 0.354 | 0.651 | |||
| 10-shot | 0.397 | 0.661 | 0.407 | 0.677 | |||
| 1-shot | 0.228 | 0.503 | 0.254 | 0.508 | |||
| 3-shot | 0.228 | 0.540 | 0.259 | 0.545 | |||
| Chinese-LLaMA-7B | 5-shot | ICL | 0.275 | 0.545 | KG-ICL | 0.243 | 0.550 |
| 8-shot | 0.212 | 0.561 | 0.243 | 0.571 | |||
| 10-shot | 0.259 | 0.571 | 0.280 | 0.603 | |||
| 1-shot | 0.291 | 0.577 | 0.286 | 0.582 | |||
| 3-shot | 0.296 | 0.587 | 0.275 | 0.593 | |||
| Chinese-LLaMA-13B | 5-shot | ICL | 0.254 | 0.603 | KG-ICL | 0.270 | 0.614 |
| 8-shot | 0.302 | 0.614 | 0.333 | 0.624 | |||
| 10-shot | 0.307 | 0.635 | 0.317 | 0.661 | |||
| 1-shot | 0.312 | 0.582 | 0.270 | 0.603 | |||
| 3-shot | 0.296 | 0.619 | 0.280 | 0.630 | |||
| Chinese-LLaMA-33B | 5-shot | ICL | 0.333 | 0.640 | KG-ICL | 0.296 | 0.656 |
| 8-shot | 0.360 | 0.667 | 0.333 | 0.656 | |||
| 10-shot | 0.349 | 0.672 | 0.376 | 0.688 | |||
| 1-shot | 0.238 | 0.534 | 0.243 | 0.540 | |||
| 3-shot | 0.275 | 0.550 | 0.280 | 0.556 | |||
| Chinese-Alpaca-7B | 5-shot | ICL | 0.243 | 0.550 | KG-ICL | 0.238 | 0.566 |
| 8-shot | 0.275 | 0.550 | 0.286 | 0.582 | |||
| 10-shot | 0.296 | 0.582 | 0.317 | 0.614 | |||
| 1-shot | 0.323 | 0.667 | 0.418 | 0.677 | |||
| 3-shot | 0.349 | 0.698 | 0.354 | 0.704 | |||
| Chinese-Alpaca-13B | 5-shot | ICL | 0.397 | 0.709 | KG-ICL | 0.339 | 0.720 |
| 8-shot | 0.360 | 0.720 | 0.370 | 0.725 | |||
| 10-shot | 0.386 | 0.741 | 0.397 | 0.767 | |||
| 1-shot | 0.360 | 0.661 | 0.370 | 0.667 | |||
| 3-shot | 0.354 | 0.683 | 0.418 | 0.688 | |||
| Chinese-Alpaca-33B | 5-shot | ICL | 0.365 | 0.693 | KG-ICL | 0.365 | 0.704 |
| 8-shot | 0.402 | 0.714 | 0.392 | 0.720 | |||
| 10-shot | 0.418 | 0.720 | 0.439 | 0.735 | |||
| 1-shot | 0.386 | 0.693 | 0.402 | 0.720 | |||
| 3-shot | 0.354 | 0.725 | 0.429 | 0.730 | |||
| ChatGPT-3.5 | 5-shot | ICL | 0.365 | 0.741 | KG-ICL | 0.429 | 0.746 |
| 8-shot | 0.418 | 0.746 | 0.413 | 0.757 | |||
| 10-shot | 0.418 | 0.772 | 0.429 | 0.783 | |||
| 1-shot | 0.455 | 0.741 | 0.423 | 0.751 | |||
| 3-shot | 0.429 | 0.772 | 0.450 | 0.767 | |||
| GPT-4 | 5-shot | ICL | 0.450 | 0.772 | KG-ICL | 0.434 | 0.783 |
| 8-shot | 0.466 | 0.794 | 0.476 | 0.794 | |||
| 10-shot | 0.460 | 0.799 | 0.476 | 0.831 |
| Accuracy | Method | GPT-2-Large | Chinese-Vicuna | LLaMA-7B |
|---|---|---|---|---|
| No demonstrations | 0.254 | 0.296 | 0.212 | |
| ICL | 0.249 | 0.360 | 0.243 | |
| KG-ICL | 0.270 | 0.397 | 0.275 | |
| No demonstrations | 0.513 | 0.614 | 0.534 | |
| ICL | 0.556 | 0.630 | 0.571 | |
| KG-ICL | 0.577 | 0.661 | 0.635 | |
| Accuracy | Method | LLaMA-13B | LLaMA-33B | Alpaca-7B |
| No demonstrations | 0.148 | 0.328 | 0.249 | |
| ICL | 0.238 | 0.349 | 0.259 | |
| KG-ICL | 0.265 | 0.376 | 0.270 | |
| No demonstrations | 0.593 | 0.577 | 0.656 | |
| ICL | 0.640 | 0.672 | 0.667 | |
| KG-ICL | 0.667 | 0.688 | 0.683 | |
| Accuracy | Method | Alpaca-13B | Alpaca-33B | GPT-3.5 |
| No demonstrations | 0.296 | 0.360 | 0.386 | |
| ICL | 0.365 | 0.370 | 0.365 | |
| KG-ICL | 0.397 | 0.392 | 0.413 | |
| No demonstrations | 0.630 | 0.651 | 0.677 | |
| ICL | 0.698 | 0.667 | 0.741 | |
| KG-ICL | 0.709 | 0.709 | 0.757 | |
| Accuracy | Method | GPT-4 | ||
| No demonstrations | 0.413 | |||
| ICL | 0.460 | |||
| KG-ICL | 0.476 | |||
| No demonstrations | 0.730 | |||
| ICL | 0.799 | |||
| KG-ICL | 0.831 |
| Models | Domain-Related vs. No (%) | Task-Related (KG-ICL) vs. Domain-Related |
|---|---|---|
| GPT-2-Large | ↑ 11.6 | ↑1.1 |
| Chinese-Vicuna | ↑1.0 | ↑1.6 |
| Chinese-LLaMA-7B | ↑1.0 | ↑3.2 |
| Chinese-LLaMA-13B | ↑9.5 | ↑2.6 |
| Chinese-LLaMA-33B | ↑9.5 | ↑1.6 |
| Chinese-Alpaca-7B | ↑6.3 | ↑3.2 |
| Chinese-Alpaca-13B | ↑11.1 | ↑2.6 |
| Chinese-Alpaca-33B | ↑6.9 | ↑6.9 |
| GPT-3.5 | ↑9.5 | ↑1.1 |
| GPT-4 | ↑6.9 | ↑3.2 |
| Models | Domain-Related vs. No (%) | Task-Related (KG-ICL) vs. Domain-Related |
|---|---|---|
| GPT-2-Large | ↑7.9 | ↓0.5 |
| Chinese-Vicuna | ↑12.7 | ↑1.0 |
| Chinese-LLaMA-7B | ↑1.6 | ↑2.1 |
| Chinese-LLaMA-13B | ↑4.2 | ↑1.0 |
| Chinese-LLaMA-33B | ↑2.1 | ↑2.7 |
| Chinese-Alpaca-7B | ↑9.0 | ↑2.1 |
| Chinese-Alpaca-13B | ↑9.0 | ↑1.1 |
| Chinese-Alpaca-33B | ↑5.8 | ↑2.1 |
| GPT-3.5 | ↑3.2 | ↑1.1 |
| GPT-4 | ↑4.7 | ↑1.6 |
| Dataset | ACCCause Correct | ACCPosition Correct |
|---|---|---|
| D_g, D_t | ||
| D_g1, D_t1 | ||
| D_g2, D_t2 | ||
| D_g3, D_t3 |
| Model | 1-Shot | 3-Shot | 5-Shot | 8-Shot | 10-Shot | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| KG-ICL |
KG-ICL
(LES) | KG-ICL |
KG-ICL
(LES) | KG-ICL |
KG-ICL
(LES) | KG-ICL |
KG-ICL
(LES) | KG-ICL |
KG-ICL
(LES) | |
| GPT-2-Large | 0.513 | 0.540 | 0.556 | 0.561 | 0.561 | 0.582 | 0.587 | 0.614 | 0.603 | 0.635 |
| Chinese-Vicuna | 0.571 | 0.593 | 0.603 | 0.614 | 0.624 | 0.646 | 0.646 | 0.651 | 0.661 | 0.677 |
| LLaMa-7B | 0.492 | 0.508 | 0.503 | 0.545 | 0.534 | 0.550 | 0.556 | 0.571 | 0.566 | 0.603 |
| LLaMa-13B | 0.556 | 0.582 | 0.577 | 0.593 | 0.593 | 0.614 | 0.603 | 0.624 | 0.640 | 0.661 |
| LLaMa-33B | 0.571 | 0.603 | 0.624 | 0.630 | 0.640 | 0.656 | 0.651 | 0.656 | 0.677 | 0.688 |
| Alpaca-7B | 0.524 | 0.540 | 0.550 | 0.556 | 0.556 | 0.566 | 0.577 | 0.582 | 0.608 | 0.614 |
| Alpaca-13B | 0.640 | 0.667 | 0.693 | 0.704 | 0.704 | 0.720 | 0.709 | 0.725 | 0.741 | 0.767 |
| Alpaca-33B | 0.651 | 0.667 | 0.677 | 0.688 | 0.683 | 0.704 | 0.709 | 0.720 | 0.714 | 0.735 |
| GPT-3.5 | 0.693 | 0.720 | 0.725 | 0.730 | 0.741 | 0.746 | 0.751 | 0.757 | 0.767 | 0.783 |
| GPT-4 | 0.735 | 0.751 | 0.757 | 0.767 | 0.772 | 0.783 | 0.794 | 0.794 | 0.815 | 0.831 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, X.; Wang, J.; Han, Y.; Li, W. Knowledge Graph-Based In-Context Learning for Advanced Fault Diagnosis in Sensor Networks. Sensors 2024, 24, 8086. https://doi.org/10.3390/s24248086
Xie X, Wang J, Han Y, Li W. Knowledge Graph-Based In-Context Learning for Advanced Fault Diagnosis in Sensor Networks. Sensors. 2024; 24(24):8086. https://doi.org/10.3390/s24248086
Chicago/Turabian StyleXie, Xin, Junbo Wang, Yu Han, and Wenjuan Li. 2024. "Knowledge Graph-Based In-Context Learning for Advanced Fault Diagnosis in Sensor Networks" Sensors 24, no. 24: 8086. https://doi.org/10.3390/s24248086
APA StyleXie, X., Wang, J., Han, Y., & Li, W. (2024). Knowledge Graph-Based In-Context Learning for Advanced Fault Diagnosis in Sensor Networks. Sensors, 24(24), 8086. https://doi.org/10.3390/s24248086