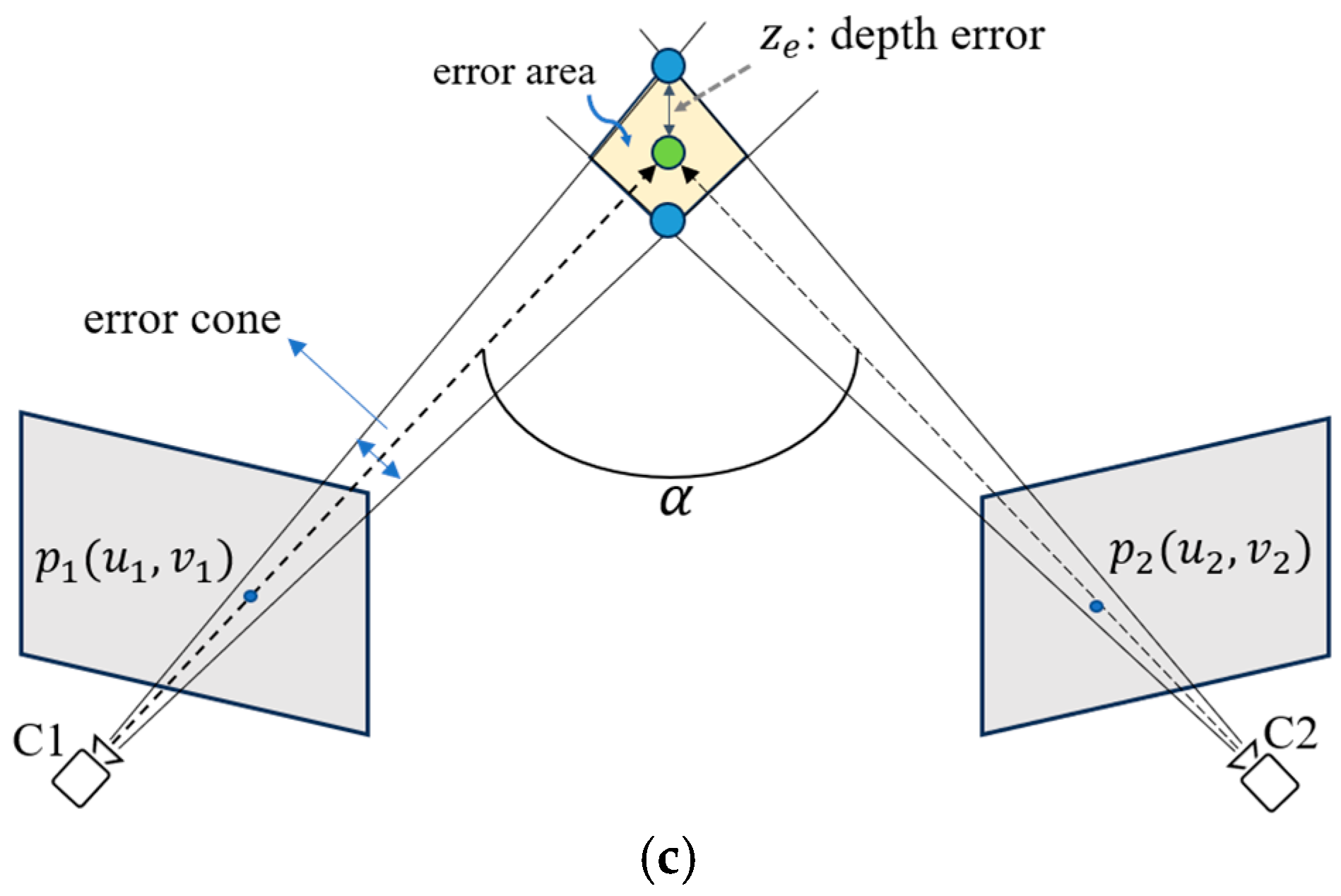
The ambiguity of depth prediction from a single RGB image remains a significant challenge in 3D human pose estimation, as monocular images inherently lack sufficient depth cues to accurately infer joint positions in 3D space. In many computer vision tasks, this depth ambiguity is resolved by using multiple cameras from different viewpoints, leveraging the triangulation principle or multi-view geometry (
Figure 1a shows an example of two views) to estimate 3D information. However, the use of multiple real cameras in real-world applications (especially during the inference stage) presents several drawbacks, such as increased computational costs, hardware and space requirements, and system complexity (e.g., camera calibration is required).
Figure 2 illustrates our proposed network architecture. In
Figure 2a, the architecture is divided into two stages. The first stage is composed of a two-stream sub-network (real stream and virtual stream) that is designed to predict enhanced 2D skeletons with several viewpoints. As depicted in
Figure 1b,
N virtual cameras are arranged to encircle the target human by rotating around the
z-axis. The “real” viewpoint (the blue one) represents the viewing direction corresponding to a real camera arranged in the system configuration, while the “virtual” viewpoints (the white ones) refer to the hypothesized ones without real cameras arranged therein. The second stage consists of several modules, including the cropped-to-original coordinate transform (COCT) module, depth denoising (DD) module, and fusion module (FM), to fuse the multiple enhanced 2D skeletons and lift them to form the final regressed 3D skeleton. The detailed design of each stage and module is given in the following subsections.
3.1. Stage 1: Real-Net and Virtual-Net
To overcome these limitations, we draw inspiration from the multi-view approach but aim to eliminate the need for multiple real cameras in realistic operation. Instead, we introduce virtual viewpoints to simulate the benefits of multi-view systems. By using virtual viewpoints, we can provide in-depth information from various perspectives, effectively addressing the depth ambiguity inherent in single-view geometry. In the first stage of our architecture, networks are designed to predict semi-3D human skeletons, which involve joints’ 2D image coordinates and relative depths from multiple real and virtual viewpoints. These predictions are then lifted to the full 3D space and integrated into the second-stage network to produce an accurate 3D human skeleton. This approach allows us to take advantage of multi-view geometry without the need for complex and resource-intensive setups with multiple real cameras. In this section, the detailed design of our Real-Net and Virtual-Net is provided.
Traditional two-stage 3D human pose estimation approaches often propose the prediction of pure 2D skeletons in the first stage by using HRNet [
24], CPN [
25], or other networks. However, we are motivated (based on our prior work [
26]) to predict the “semi-3D skeleton” (or “enhanced 2D skeleton”, which includes 2D image coordinates and relative depth for each joint) rather than the traditional pure 2D skeletons. This semi-3D or enhanced 2D skeleton was also adopted in some other research [
15] and might result in better accuracy once further converted/refined/lifted to a real 3D skeleton (i.e., with
x,
y, and
z coordinates).
Considering the fact that there are no real cameras with virtual viewpoints (i.e., no real images are captured), our system predicts only the relative depth
d (with respect to a “root” joint) of each joint in virtual viewpoints, but not their 2D image coordinates (
u,
v). These predicted relative depths
(
n-th virtual view) are embedded in the 2D skeleton
of the real camera
, thus forming
N + 1 enhanced 2D skeletons
,
n = 0, …,
N. That is, the first-stage network predicts the real-view 2D skeleton
, as well as each joint’s relative depth
in all
N + 1 viewpoints, as demonstrated in
Figure 2a. The embedding of virtual-view depths into the real-view 2D skeleton has two advantages: lessening the prediction loading of the network and focusing on the ambiguity of the predicted depths.
The purpose of the Real-Net stream is to predict the enhanced 2D skeleton, which is denoted as
,
j = 1, …,
J (number of joints; here,
J = 18). The input of the Real-Net is a single RGB image with a cropped size of
pixels. The output of the Real-Net is a number (18) of 3D heatmaps of size
, where the spatial (in
u and
v) and the depth (
d) dimensions are quantized into 64 levels. Each output element is transformed via the Softmax operator to reveal its probability of being the
j-th joint. Via a Soft_argmax layer [
27], it is easy to calculate the
J predicted 2D joints with depths (
u,
v,
d), forming an output of
. Note that Soft_argmax is capable of transforming the heatmap to a regressed value, sharing the advantages of both heatmap (differentiable and easy convergence) and regression (end-to-end training with accessible output ground truths) approaches. The quantization into 64 levels in the (
u,
v,
d) dimensions comes from considerations regarding speed and memory consumption.
The Virtual-Net stream, which differs from the Real-Net stream, is primarily designed to predict the relative depths of skeletal joints from multiple virtual viewpoints, which are denoted as
. Additionally, it also predicts the 2D skeletal joint coordinates
in the real viewpoint. As illustrated in
Figure 2b, the virtual net stream consists of one encoder and two decoders, which process the same input image as the Real-Net.
The first decoder (Dec_1) generates N depth maps, each of size (64 × J), where J is the number of joints. Each depth map represents 3D tensors in terms of (depth, u-coordinate, and joint) and reveals the predicted depths for each joint at every possible u-coordinate. The relative depths for each joint j are obtained by mapping these depth maps with the joint coordinate predicted by the Real-Net.
The second decoder (Dec_2) generates (18 × N) heatmaps, each of size (64 × 64), representing the 2D joint locations in the real viewpoint. The final 2D skeletal joint coordinates are extracted using a soft-argmax operator that is applied to these heatmaps, similar to the process in the Real-Net.
The outputs from the Virtual-Net, i.e., the relative depths in virtual viewpoints and 2D joint coordinates in the real viewpoint, are then combined to form . This combined output is subsequently fed into the second stage for further processing.
The 2D skeletal joints
from the Real-Net and Virtual-Net are predicted based on the same ground truths and, thus, are expected to be approximate, while the ground truths of the relative depths in multiple virtual viewpoints are computed by geometrically rotating the real-view skeleton around the
z-axis, as shown in
Figure 1b. In this study, the network of ResNeXt-50 is chosen as the backbone of both the Real-Net and Virtual-Net.
3.2. Stage 2-1: Cropped-to-Original Coordinate Transform (COCT)
Accurate 3D human pose estimation requires the capture of both local and global image features. While local features provide detailed information about individual body parts, the global context is essential for resolving ambiguities among varying viewpoints. Traditionally, the input to a deep learning network is an ROI containing the target human, which is cropped from the original image and probably resized. Correspondingly, the 3D skeleton ground truth for training will remain the same, or the 2D skeleton ground truth will be transformed from the original coordinate system to the cropped image space. These cropping and resizing procedures will, however, cause the loss of global context information.
The scenario of
Figure 3 shows three persons, P1–P3, with the same pose while standing at different positions in the camera coordinate space. Due to the characteristics of the camera perspectives, their 2D appearances exhibit some tiny differences (e.g., different self-occlusions or different horizontal projection lengths), hence resulting in different 2D skeletons. Nevertheless, their 3D poses, which are described by the relative 3D coordinates of each joint with respect to the selected root joint, are actually all the same. After image cropping for the ROI, the global context information (e.g., the location of the human: central, left, or right side) is lost and exists implicitly only in tiny perspective differences that might not be easily detected by the deep learning network.
To help the network learn global context information, a cropped-to-original coordinate transform (COCT) module is proposed in this study to provide explicit information on the original image coordinates. In both the training and inference phases, we transform the 2D skeletons from the cropped to the original image space by referring to the offset vector
) (in the original coordinate system) of the left-top corner of the ROI image based on the following equations:
where
are the normalized coordinates (0~1.0) predicted after the network,
are the width and height of the cropped ROI,
are the width and height of the original image, and (
are the normalized coordinates (0~1.0) in the original image space after the transformation.
This COCT-transformed skeleton of the real view is then concatenated with the predicted enhanced 2D skeleton in the cropped image space (see
Figure 2c, the first and second branches) before being passed to the second-stage network. This dual representation (i.e., (
and (
)
leverages the advantages of both the global (in the original image space) and the local (in the cropped image space) contexts, providing the following second-stage network with richer and more comprehensive input data.
3.4. Stage 2-3: Fusion Module (FM)
In the second stage, the fusion module (FM) is composed of parallel embedding networks that accept the depth-denoised enhanced 2D skeletons from all real and virtual viewpoints and a fusion network, as illustrated in
Figure 2c. The embedding networks are used to transform the enhanced 2D skeletons to a high-dimensional feature space (from
J × 3 to
J ×
D,
D = 256), and they are then concatenated and fed to the fusion network that follows. The embedding network can be implemented via an MLP (multiple-layer perceptron), which is a simple yet powerful feed-forward neural network that learns nonlinear relationships between the inputs and outputs. MLPs are often implemented as fully connected (FC) layers. The embedding networks can also be implemented in terms of a GCN (graph convolutional network) [
29], which considers a human skeleton input as a graph with vertices (i.e., joints) connected via an adjacency matrix (specified with the standard connection of human skeletal joints via bones). GCNs capture the spatial relationships between connected joints, making them highly effective for modeling human poses and extracting their features. In the experimental section, we will provide a detailed ablation study on the performance of 3D skeleton estimation by using different kinds of embedding networks.
As shown in
Figure 2c, after the parallel embedding networks, the triplet outputs
from all real and virtual viewpoint branches are concatenated together and flattened to form a 1D array (of dimension
J ×
D × (
N + 2)). In this way, the 2D spatial and depth information in the real and virtual viewpoints is combined. These concatenated data are then passed to a fusion network that follows for regression to a 3D human skeleton. Our fusion network is implemented in terms of densely and fully connected (DenseFC) layers, as proposed in the form of the DenseNet in [
30]. Our fusion network architecture, DenseFC, is illustrated in
Figure 4a, where the input is a set of
N + 2 skeletal features (256 × (
N + 2)), and the output provides the 3D skeleton (
J × 3). Each block of this network is composed of a linear module followed by batch normalization, PReLU activation for nonlinear mapping, and a Dropout layer for regularization, but the last one contains only one linear module. These layers progressively refine the features, capturing intricate relationships between joints while mitigating overfitting. Dense connections ensure efficient feature reuse and mitigate vanishing gradient issues, facilitating deeper learning. This fusion network can also be designed by using a GCN [
29], as shown in
Figure 4b. By leveraging both the local joint information from the embedding network and the global spatial context from the fusion network, the FM is capable of combining depth information from multiple viewpoints. This approach reduces depth ambiguity and enhances the accuracy of 3D pose estimation, even from a single RGB image. To study the effects of different types of networks that can be used to design the fusion network, detailed ablation studies will be described in the experimental section.
3.5. Data Preprocessing and Virtual-Viewpoint Skeleton Generation
Both the input and output ground-truth data need to be well-prepared before training. Normalization, as a data preprocessing step, is used to transform the image and skeletal data into a common scale without distortions or information loss. For an image input, the popular z-score normalization is performed based on the mean
μ and variance
for each of the R/G/B channels, where
μ = (123.68, 116.28, 103.53) and
σ = (58.40, 57.12, 57.38) are derived from the ImageNet dataset. For the enhanced 2D skeleton, the image coordinate
and the relative depth
of each joint need to be normalized to a common scale [0, 1.0] by dividing a normalization constant—256 pixels, 256 pixels, and 1000 mm, respectively—due to the different measurement units. Since
will be derived from the 3D heatmap (64 × 64 × 64) or the 3D depth map (64 ×
J ×
N) (as illustrated in
Figure 2b) by applying a Soft-argmax or a lookup operation, the normalized (
u,
v,
d) should be multiplied by 64 for the loss function calculation in training.
Similarly, we normalize the 3D skeleton ground truth in the second stage to the range of [−1, 1] by subtracting the root joint coordinates (here, “Pelvis” is selected as the root joint) and dividing the result by 1000 mm.
To obtain the ground truths of relative depths in virtual viewpoints, the
j-th joint of the real-view 3D skeleton
can be transformed into the virtual viewpoint. The
j-th joint of the 3D skeleton in the virtual viewpoint
is denoted as
, and
can be obtained as follows:
where
and
represent the rotation and translation matrices for transformation between the real and the
n-th virtual cameras. From {
},
j = 1, …
J, the relative depth of joint
can be calculated. Note that
and
can be determined based on the viewpoint planning shown in
Figure 1b.
3.6. Loss Functions
The loss function plays a pivotal role in guiding the learning process of a deep learning network, as it ensures that the predictions progressively align with the ground truths. Given the two-stage architecture of our method, we employ an independent multi-stage loss design. This approach ensures that each stage is optimized separately, allowing focused improvements in both the 2D + relative depth and the 3D pose estimation processes without the need to combine losses from different stages.
In the first stage, the training is further divided into two independent training processes: Real-Net and Virtual-Net. Real-Net is trained using the mean absolute error (MAE) between the predicted joints and their ground truths, as expressed below.
where
is the predicted enhanced 2D skeletal joint,
is the ground truth, and
is the joint index.
The loss function of the Virtual-Net is composed of both 2D and depth prediction losses.
where
denotes the predicted 2D skeleton in the virtual viewpoint
,
is the corresponding ground truth (inherited from the real viewpoint
),
denotes the predicted relative depth value,
denotes the corresponding ground truth,
n is the virtual viewpoint index, and
and
are the hyperparameters.
The loss function of the second stage includes both joint and bone losses. The use of joint loss makes our network capable of learning the precise joint coordinates, while bone loss makes our network learn the skeleton’s spatial characteristics, which is helpful in enhancing the physical constraints between adjacent joints. To be consistent in the description of the joint loss, the bone loss is defined based on a bone vector pointing from a predefined starting joint to an ending joint.
Figure 5 depicts all of the physical bones defined by Human3.6M (16 in total) and some virtual ones (6 in total) defined in our work. The virtual bones are connections between joints that are symmetric in the human skeleton, such as the left shoulder and right shoulder, left hip and right hip, etc. The total loss functions for the training of the second stage are defined as follows.
where
and
denote the prediction and the ground truth of the 3D coordinates for the joint
, respectively;
and
denote the prediction and the ground truth of the
k-th bone vector, respectively; and
and
are the hyperparameters for bone loss and joint loss, respectively. When calculating the losses, the
smoothL1 metric, which is expressed in Equation (12), was used.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}