
Analytical Equations for the Prediction of the Failure Mode of Reinforced Concrete Beam–Column Joints Based on Interpretable Machine Learning and SHAP Values

 , ,
, ,  ,
,  and
and
Abstract
1. Introduction
2. Materials and Methods
2.1. Dataset Overview and Feature Engineering
- The joint type: This categorical variable described whether the joint was “interior”, i.e., beams are attached on two opposing sides, or “exterior”.
- : The compressive strength of the concrete, measured in MPa.
- : The amount of transverse reinforcement, i.e., stirrups, in the joint, expressed as a percentage of its area.
- : The yield strength of the stirrups in the joint, measured in MPa.
- : The amount of longitudinal reinforcement in the beam and column, respectively, expressed as a percentage of the respective cross-sectional areas.
- : The yield strength of the longitudinal reinforcement in the beam and column, respectively, measured in MPa.
- : The height (h) and width (b) of the beam and column, respectively, measured in mm.
- ALF: The axial load factor, i.e., the axial load applied to the column normalized to the respective compressive strength .
- The failure mode: This was the dependent variable in the present study and took two distinct values. Specifically, the value “Joint Shear” (“JS”) corresponded to cases where the joint failed suddenly in a brittle, shear manner and the beam had not yet reached its yield capacity. Accordingly, the value “Beam Yield-Joint Shear” (“BY-JS”) pertained to specimens wherein the ductile flexural yielding of the beam reinforcement preceded the brittle shear failure of the joint [3].
2.2. Machine Learning Modeling
2.3. Shapley Additive Explanations (SHAP Values)
3. Results
3.1. XGBoost Classification Results
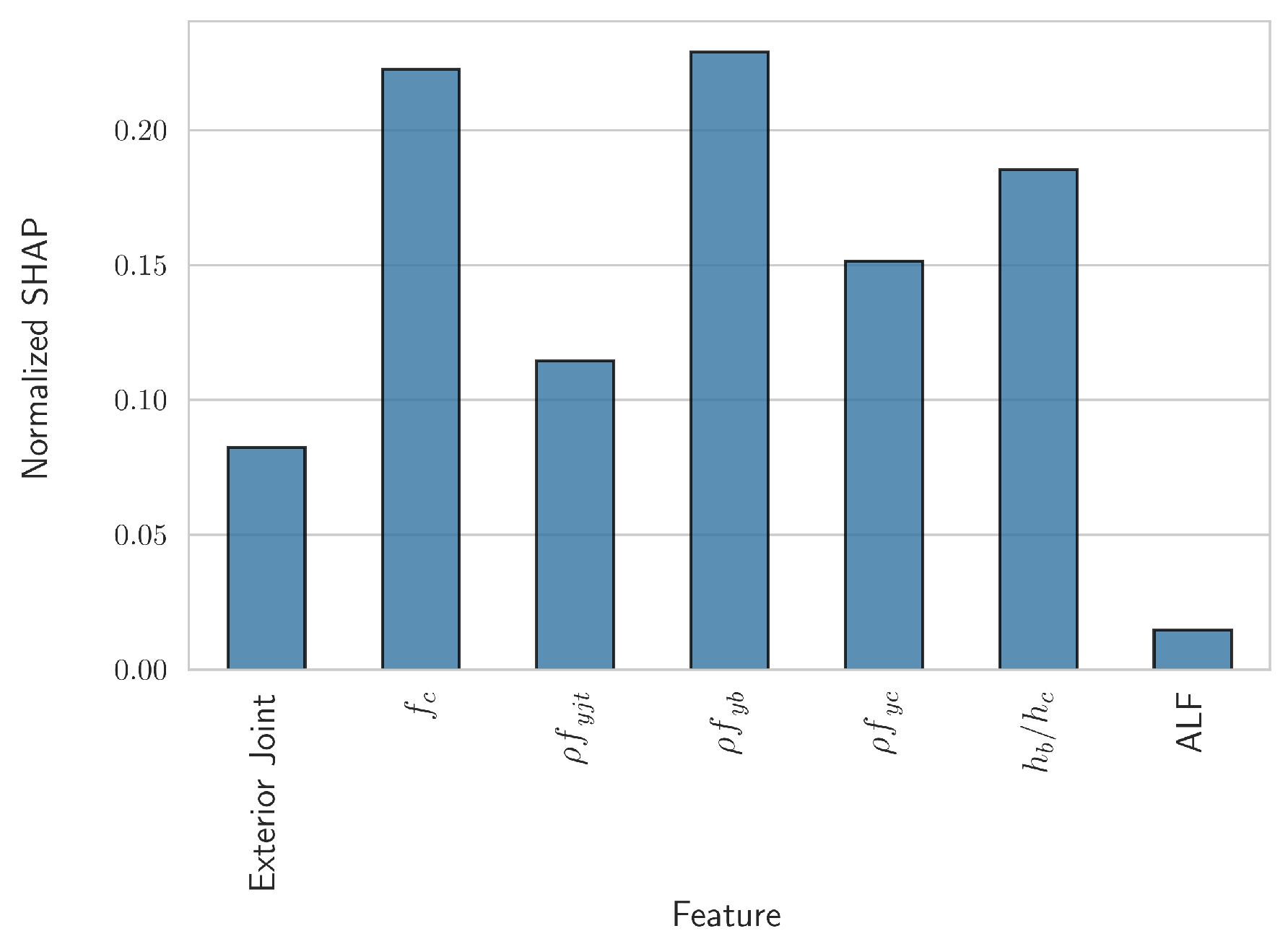
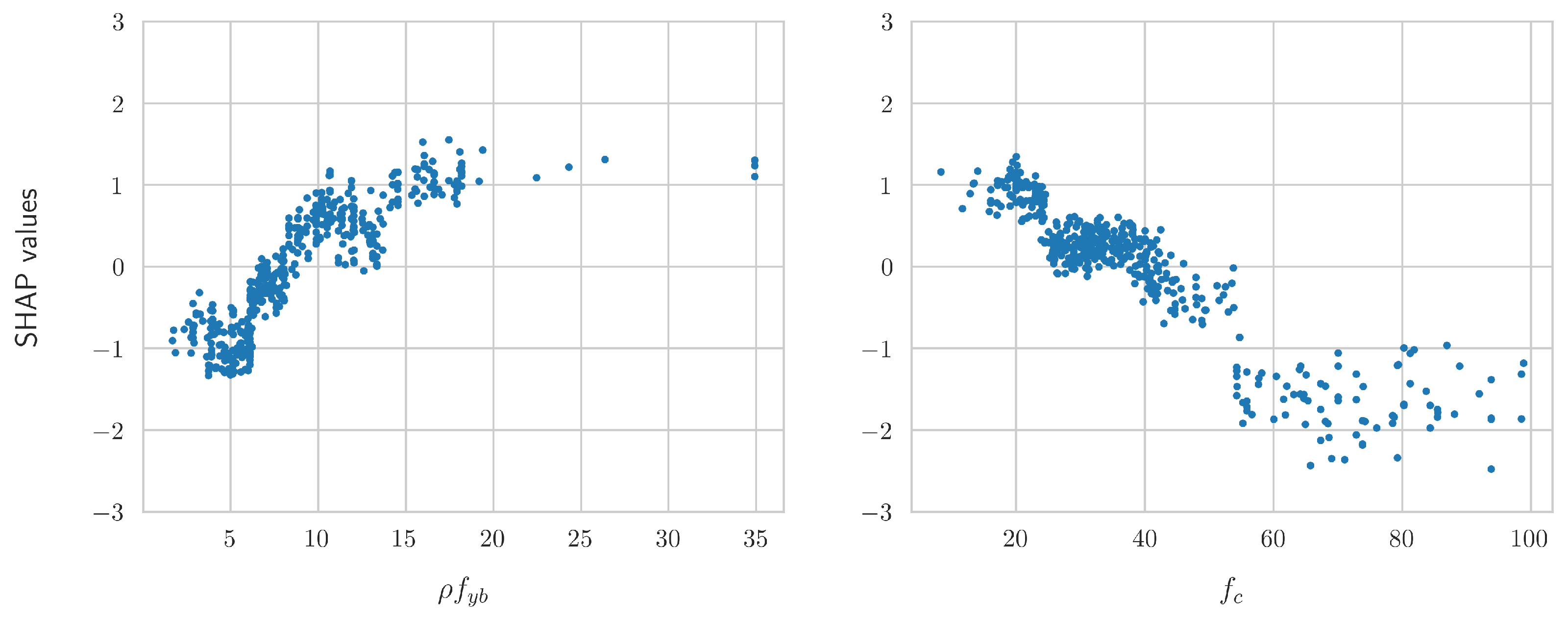
3.2. Derivation of Analytical Equations
4. Summary and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| RC | Reinforced concrete |
| ML | Machine learning |
| ANN | Artifical neural network |
| SHAP | SHapley Additive exPlanations |
| k-NN | k-nearest neighbors |
| SVM | Support vector machine |
| OLS | Ordinary least squares |
| XGBoost | eXtreme Gradient Boosting |
| P-R | Precision–recall |
| AUC | Area under the curve |
References
- Najafgholipour, M.; Dehghan, S.; Dooshabi, A.; Niroomandi, A. Finite element analysis of reinforced concrete beam-column connections with governing joint shear failure mode. Lat. Am. J. Solids Struct. 2017, 14, 1200–1225. [Google Scholar] [CrossRef]
- Karabini, M.; Karampinis, I.; Rousakis, T.; Iliadis, L.; Karabinis, A. Machine Learning Ensemble Methodologies for the Prediction of the Failure Mode of Reinforced Concrete Beam–Column Joints. Information 2024, 15, 647. [Google Scholar] [CrossRef]
- Kuang, J.; Wong, H. Behaviour of Non-seismically Detailed Beam-column Joints under Simulated Seismic Loading: A Critical Review. In Proceedings of the Fib Symposium on Concrete Structures: The Challenge of Creativity, Avignon, France, 26–28 April 2004. [Google Scholar]
- Braga, F.; Caprili, S.; Gigliotti, R.; Salvatore, W. Hardening slip model for reinforcing steel bars. Earthq. Struct. 2015, 9, 503–539. [Google Scholar] [CrossRef]
- Recommendations for Design of Beam-Column Connections in Monolithic Reinforced Concrete Structures (ACI 352R-02); Technical Report; American Concrete Institute: Indianapolis, IN, USA, 2002.
- Retrofitting of Concrete Structures by Externally Bonded FRPs with Emphasis on Seismic Applications (FIB-35); Technical Report; The International Federation for Structural Concrete: Lausanne, Switzerland, 2002.
- EN 1992 Eurocode 2 Part 1-1; General Rules and Rules for Buildings. Technical Report; European Committee for Standardization: Brussels, Belgium, 2004.
- Karayannis, C.G.; Sirkelis, G.M. Strengthening and rehabilitation of RC beam–column joints using carbon-FRP jacketing and epoxy resin injection. Earthq. Eng. Struct. Dyn. 2008, 37, 769–790. [Google Scholar] [CrossRef]
- Tsonos, A.; Stylianidis, K. Pre-seismic and post-seismic strengthening of reinforced concrete structural subassemblages using composite materials (FRP). In Proceedings of the 13th Hellenic Concrete Conference, Rethymno, Greece, 25–27 October 1999; Volume 1, pp. 455–466. [Google Scholar]
- Park, R.; Paulay, T. Reinforced Concrete Structures; John Wiley & Sons: Hoboken, NJ, USA, 1991. [Google Scholar]
- Tsonos, A.G. Cyclic load behaviour of reinforced concrete beam-column subassemblages of modern structures. WIT Trans. Built Environ. 2005, 81, 11. [Google Scholar]
- Antonopoulos, C.P.; Triantafillou, T.C. Experimental investigation of FRP-strengthened RC beam-column joints. J. Compos. Constr. 2003, 7, 39–49. [Google Scholar] [CrossRef]
- Nikolić, Ž.; Živaljić, N.; Smoljanović, H.; Balić, I. Numerical modelling of reinforced-concrete structures under seismic loading based on the finite element method with discrete inter-element cracks. Earthq. Eng. Struct. Dyn. 2017, 46, 159–178. [Google Scholar] [CrossRef]
- Thai, H.T. Machine learning for structural engineering: A state-of-the-art review. Structures 2022, 38, 448–491. [Google Scholar] [CrossRef]
- Kaveh, A. Applications of Artificial Neural Networks and Machine Learning in Civil Engineering. Stud. Comput. Intell. 2024, 1168, 472. [Google Scholar]
- Kotsovou, G.M.; Cotsovos, D.M.; Lagaros, N.D. Assessment of RC exterior beam-column Joints based on artificial neural networks and other methods. Eng. Struct. 2017, 144, 1–18. [Google Scholar] [CrossRef]
- Suwal, N.; Guner, S. Plastic hinge modeling of reinforced concrete Beam-Column joints using artificial neural networks. Eng. Struct. 2024, 298, 117012. [Google Scholar] [CrossRef]
- Mangalathu, S.; Jeon, J.S. Classification of failure mode and prediction of shear strength for reinforced concrete beam-column joints using machine learning techniques. Eng. Struct. 2018, 160, 85–94. [Google Scholar] [CrossRef]
- Oviedo, F.; Ferres, J.L.; Buonassisi, T.; Butler, K.T. Interpretable and explainable machine learning for materials science and chemistry. Accounts Mater. Res. 2022, 3, 597–607. [Google Scholar] [CrossRef]
- Marie, H.S.; Abu El-hassan, K.; Almetwally, E.M.; El-Mandouh, M.A. Joint shear strength prediction of beam-column connections using machine learning via experimental results. Case Stud. Constr. Mater. 2022, 17, e01463. [Google Scholar] [CrossRef]
- Gao, X.; Lin, C. Prediction model of the failure mode of beam-column joints using machine learning methods. Eng. Fail. Anal. 2021, 120, 105072. [Google Scholar] [CrossRef]
- Karampinis, I.; Morfidis, K.; Iliadis, L. Derivation of Analytical Equations for the Fundamental Period of Framed Structures Using Machine Learning and SHAP Values. Appl. Sci. 2024, 14, 9072. [Google Scholar] [CrossRef]
- Verdonck, T.; Baesens, B.; Óskarsdóttir, M.; vanden Broucke, S. Special issue on feature engineering editorial. Mach. Learn. 2024, 113, 3917–3928. [Google Scholar] [CrossRef]
- Ahsan, M.M.; Mahmud, M.P.; Saha, P.K.; Gupta, K.D.; Siddique, Z. Effect of data scaling methods on machine learning algorithms and model performance. Technologies 2021, 9, 52. [Google Scholar] [CrossRef]
- Lee, H.; Yun, S. Strategies for Imputing Missing Values and Removing Outliers in the Dataset for Machine Learning-Based Construction Cost Prediction. Buildings 2024, 14, 933. [Google Scholar] [CrossRef]
- Ghosh, K.; Bellinger, C.; Corizzo, R.; Branco, P.; Krawczyk, B.; Japkowicz, N. The class imbalance problem in deep learning. Mach. Learn. 2024, 113, 4845–4901. [Google Scholar] [CrossRef]
- Kumar, P.; Bhatnagar, R.; Gaur, K.; Bhatnagar, A. Classification of imbalanced data: Review of methods and applications. IOP Conf. Ser. Mater. Sci. Eng. 2021, 1099, 012077. [Google Scholar] [CrossRef]
- Wongvorachan, T.; He, S.; Bulut, O. A comparison of undersampling, oversampling, and SMOTE methods for dealing with imbalanced classification in educational data mining. Information 2023, 14, 54. [Google Scholar] [CrossRef]
- Jeong, D.H.; Kim, S.E.; Choi, W.H.; Ahn, S.H. A comparative study on the influence of undersampling and oversampling techniques for the classification of physical activities using an imbalanced accelerometer dataset. Healthcare 2022, 10, 1255. [Google Scholar] [CrossRef] [PubMed]
- Sen, P.C.; Hajra, M.; Ghosh, M. Supervised classification algorithms in machine learning: A survey and review. In Emerging Technology in Modelling and Graphics: Proceedings of the IEM Graph 2018; Springer: Singapore, 2020; pp. 99–111. [Google Scholar]
- Kotsiantis, S.B.; Zaharakis, I.D.; Pintelas, P.E. Machine learning: A review of classification and combining techniques. Artif. Intell. Rev. 2006, 26, 159–190. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Erion, G.; Chen, H.; DeGrave, A.; Prutkin, J.M.; Nair, B.; Katz, R.; Himmelfarb, J.; Bansal, N.; Lee, S.I. From local explanations to global understanding with explainable AI for trees. Nat. Mach. Intell. 2020, 2, 56–67. [Google Scholar] [CrossRef]
- Lundberg, S.; Su-In, L. A unified approach to interpreting model predictions. arXiv 2017, arXiv:1705.07874. [Google Scholar]
- Linardatos, P.; Papastefanopoulos, V.; Kotsiantis, S. Explainable AI: A review of machine learning interpretability methods. Entropy 2020, 23, 18. [Google Scholar] [CrossRef] [PubMed]
- Shapley, L. Notes on the n-Person Game-II: The Value of an n-Person Game; RAND Corporation: Santa Monica, CA, USA, 1951. [Google Scholar]
- Aas, K.; Jullum, M.; Løland, A. Explaining individual predictions when features are dependent: More accurate approximations to Shapley values. Artif. Intell. 2021, 298, 103502. [Google Scholar] [CrossRef]
- Norton, E.C.; Dowd, B.E. Log odds and the interpretation of logit models. Health Serv. Res. 2018, 53, 859–878. [Google Scholar] [CrossRef] [PubMed]
- Raschka, S. An overview of general performance metrics of binary classifier systems. arXiv 2014, arXiv:1410.5330. [Google Scholar]
- Allgaier, J.; Pryss, R. Cross-Validation Visualized: A Narrative Guide to Advanced Methods. Mach. Learn. Knowl. Extr. 2024, 6, 1378–1388. [Google Scholar] [CrossRef]
- Karampinis, I.; Iliadis, L.; Karabinis, A. Rapid Visual Screening Feature Importance for Seismic Vulnerability Ranking via Machine Learning and SHAP Values. Appl. Sci. 2024, 14, 2609. [Google Scholar] [CrossRef]
- Buckland, M.; Gey, F. The relationship between recall and precision. J. Am. Soc. Inf. Sci. 1994, 45, 12–19. [Google Scholar] [CrossRef]
- Gordon, M.; Kochen, M. Recall-precision trade-off: A derivation. J. Am. Soc. Inf. Sci. 1989, 40, 145–151. [Google Scholar] [CrossRef]
- Sofaer, H.R.; Hoeting, J.A.; Jarnevich, C.S. The area under the precision-recall curve as a performance metric for rare binary events. Methods Ecol. Evol. 2019, 10, 565–577. [Google Scholar] [CrossRef]
- Miao, J.; Zhu, W. Precision-recall curve (PRC) classification trees. Evol. Intell. 2022, 15, 1545–1569. [Google Scholar] [CrossRef]
- Fan, J.; Upadhye, S.; Worster, A. Understanding receiver operating characteristic (ROC) curves. Can. J. Emerg. Med. 2006, 8, 19–20. [Google Scholar] [CrossRef]
- Yang, S.; Berdine, G. The receiver operating characteristic (ROC) curve. Southwest Respir. Crit. Care Chronicles 2017, 5, 34–36. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Set | Testing Set | |||
|---|---|---|---|---|
| BY-JS | JS | BY-JS | JS | |
| Precision | ||||
| Recall | ||||
| F1-Score | ||||
| Accuracy | ||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Karampinis, I.; Karabini, M.; Rousakis, T.; Iliadis, L.; Karabinis, A. Analytical Equations for the Prediction of the Failure Mode of Reinforced Concrete Beam–Column Joints Based on Interpretable Machine Learning and SHAP Values. Sensors 2024, 24, 7955. https://doi.org/10.3390/s24247955
Karampinis I, Karabini M, Rousakis T, Iliadis L, Karabinis A. Analytical Equations for the Prediction of the Failure Mode of Reinforced Concrete Beam–Column Joints Based on Interpretable Machine Learning and SHAP Values. Sensors. 2024; 24(24):7955. https://doi.org/10.3390/s24247955
Chicago/Turabian StyleKarampinis, Ioannis, Martha Karabini, Theodoros Rousakis, Lazaros Iliadis, and Athanasios Karabinis. 2024. "Analytical Equations for the Prediction of the Failure Mode of Reinforced Concrete Beam–Column Joints Based on Interpretable Machine Learning and SHAP Values" Sensors 24, no. 24: 7955. https://doi.org/10.3390/s24247955
APA StyleKarampinis, I., Karabini, M., Rousakis, T., Iliadis, L., & Karabinis, A. (2024). Analytical Equations for the Prediction of the Failure Mode of Reinforced Concrete Beam–Column Joints Based on Interpretable Machine Learning and SHAP Values. Sensors, 24(24), 7955. https://doi.org/10.3390/s24247955