1. Introduction
In the field of modern control engineering, with the rapid development of industrial automation, robotics, and smart manufacturing, control systems are facing increasingly complex challenges [
1]. These systems not only need to achieve high precision and performance in complicated operational environments, but they must also possess strong adaptability and robustness to handle constantly changing external conditions and various uncertainties. They must operate seamlessly in environments that are both complex and subject to frequent and unpredictable changes. High precision and performance are crucial, especially in applications such as aerospace, automotive manufacturing, and medical robotics, where even the slightest deviation can have significant consequences. However, achieving these goals is only part of the challenge. Modern control systems must also possess strong adaptability and robustness, which are essential to maintaining optimal performance in the face of fluctuating environmental conditions, unknown disturbances, and system uncertainties.
This adaptability is particularly important in dynamic environments, where variables such as load, temperature, and external forces may change unpredictably. Robustness ensures that control systems can continue to operate effectively in the presence of noise, sensor errors, or inaccuracies in modeling. Although traditional control methods, such as PID controllers, are widely used due to their simplicity and effectiveness in linear, time-invariant systems, they often struggle to meet the demands of more advanced applications that require real-time adjustments and learning capabilities [
2]. Another widely used control method is Linear Quadratic Regulator (LQR), which provides optimal control strategies by balancing system performance and control energy. LQR achieves this by minimizing a quadratic cost function that penalizes state errors and control effort [
3,
4,
5]. While LQR is highly effective for linear systems with well-defined models, it has limitations when applied to more complex, nonlinear, or time-varying systems. Its assumption of linearity limits its use in many real-world situations where system dynamics can change unpredictably. These conventional methods rely on fixed parameters, which can limit their effectiveness in situations where adaptability and continuous improvement are needed. In highly complex systems, traditional controllers may struggle to handle nonlinearity, time-varying dynamics, or external disturbances, resulting in performance degradation and operational inefficiency.
More advanced control strategies with learning abilities have become essential to overcoming these limitations [
6,
7,
8]. Among these approaches, Iterative Learning Control (ILC) has gained considerable attention due to its ability to improve performance over time by using data from previous cycles. This makes ILC well suited for systems that perform repetitive tasks, such as robotic arms, automated manufacturing processes, or any system that repeats operations in each cycle [
9,
10,
11,
12]. By adjusting control actions based on past results, ILC gradually reduces tracking errors, improving the system’s accuracy and efficiency. However, despite its advantages, the performance of traditional ILC can decline significantly in dynamic or unpredictable environments, as it typically relies on a fixed system model that may not account for changes or disturbances.
The study by Cao et al. introduced modified P-type indirect ILC designed to handle nonlinear systems with mismatched uncertainties and matched disturbances [
13]. The method employs a learning-based disturbance estimator to transform the system into an input-to-state stable form, enabling compensation for dynamic mismatched uncertainties. Additionally, modified P-type ILC is implemented to enhance tracking performance for non-repetitive trajectories. Experimental results demonstrate the effectiveness of this approach, with tracking errors being significantly reduced in complex systems such as continuous stirred tank reactors and flight simulators.
In addition to ILC, gradient descent is another well-known optimization method widely used to fine-tune system parameters by minimizing a cost function [
14]. This cost function typically includes essential factors such as output error, control energy, and system stability. Gradient descent is commonly used across various fields due to its general applicability. However, in control systems, gradient descent is typically applied non-iteratively, focusing solely on optimizing current parameters without fully utilizing feedback from previous cycles. This lack of iterative learning limits gradient descent’s effectiveness in dynamic environments where continuous adjustments are necessary. While gradient descent works well for optimizing single objectives in relatively stable settings, it becomes less effective in control systems that require adaptation and iterative refinement.
Although ILC and gradient descent differ in many ways, they share similar strategies in updating control inputs and system parameters iteratively to improve performance. This similarity has led researchers to explore combining the strengths of both ILC and gradient descent to create hybrid control methods that address the limitations of each approach. By merging the iterative learning features of ILC with the optimization properties of gradient descent, these hybrid strategies can improve the adaptability and robustness of control systems, especially in environments that experience frequent changes or disturbances.
Sago and Adachi presented a gradient-based ILC algorithm for linear discrete-time systems which addresses the limitations of existing ILC schemes. It provides convergence conditions based on system uncertainties, ensuring exponential decay of input error and improving applicability in uncertain systems [
15]. Owens et al. introduced a robust gradient-based ILC algorithm and provided conditions for monotonic convergence in the presence of model uncertainties. This approach ensures that tracking errors decrease consistently, making it suitable for dynamic environments. Their work addresses the practical challenges of modeling errors, contributing to the development of more reliable and adaptable control systems [
16]. Chu et al. proposed a predictive gradient-based ILC algorithm that extends traditional ILC by incorporating predicted future trials in addition to past trial data. This approach significantly improves convergence speed and robustness to model uncertainties, offering better predictive control capabilities [
17]. Huo et al. presented a model-free gradient-based ILC algorithm for nonlinear systems, eliminating the need for system model identification. The algorithm achieves monotonic convergence to zero error and matches the performance of model-based ILC in stroke rehabilitation, with better tracking than linear model-free ILC [
18]. He and Pu proposed a novel gradient-based ILC algorithm to enhance proportional-type traditional ILC by addressing its parameter sensitivity. Their algorithm mimics the gradient descent process, ensuring reliable convergence and reducing parameter dependence, making it more robust than traditional ILC [
19]. Developing these hybrid methods offers a promising approach to improving system performance in complex, real-world applications.
Different from the common control objective, which focuses on minimizing the error between actual and desired outputs, this paper also considers the effect of input energy consumption. Drawing inspiration from LQR’s approach to optimizing performance, we aim to extend these principles by integrating the iterative learning capabilities of ILC with the optimization strengths of gradient descent.
This paper introduces Green ILC, a novel hybrid control strategy that combines the characteristics of ILC with the optimization strengths of gradient descent. Green ILC is designed to balance tracking accuracy and energy use through a cost function that minimizes both tracking error and control effort. By using gradient-based updates, Green ILC iteratively improves control inputs over time while optimizing energy consumption. This makes Green ILC particularly useful in applications where energy efficiency is critical, such as robotics, manufacturing, and industrial process control. By combining iterative learning and optimization, Green ILC offers a more adaptable and efficient solution for control systems in dynamic environments, significantly reducing energy consumption while maintaining satisfactory tracking performance.
The rest of this paper is organized as follows:
Section 2 explains the theoretical background and mathematical development of Green ILC.
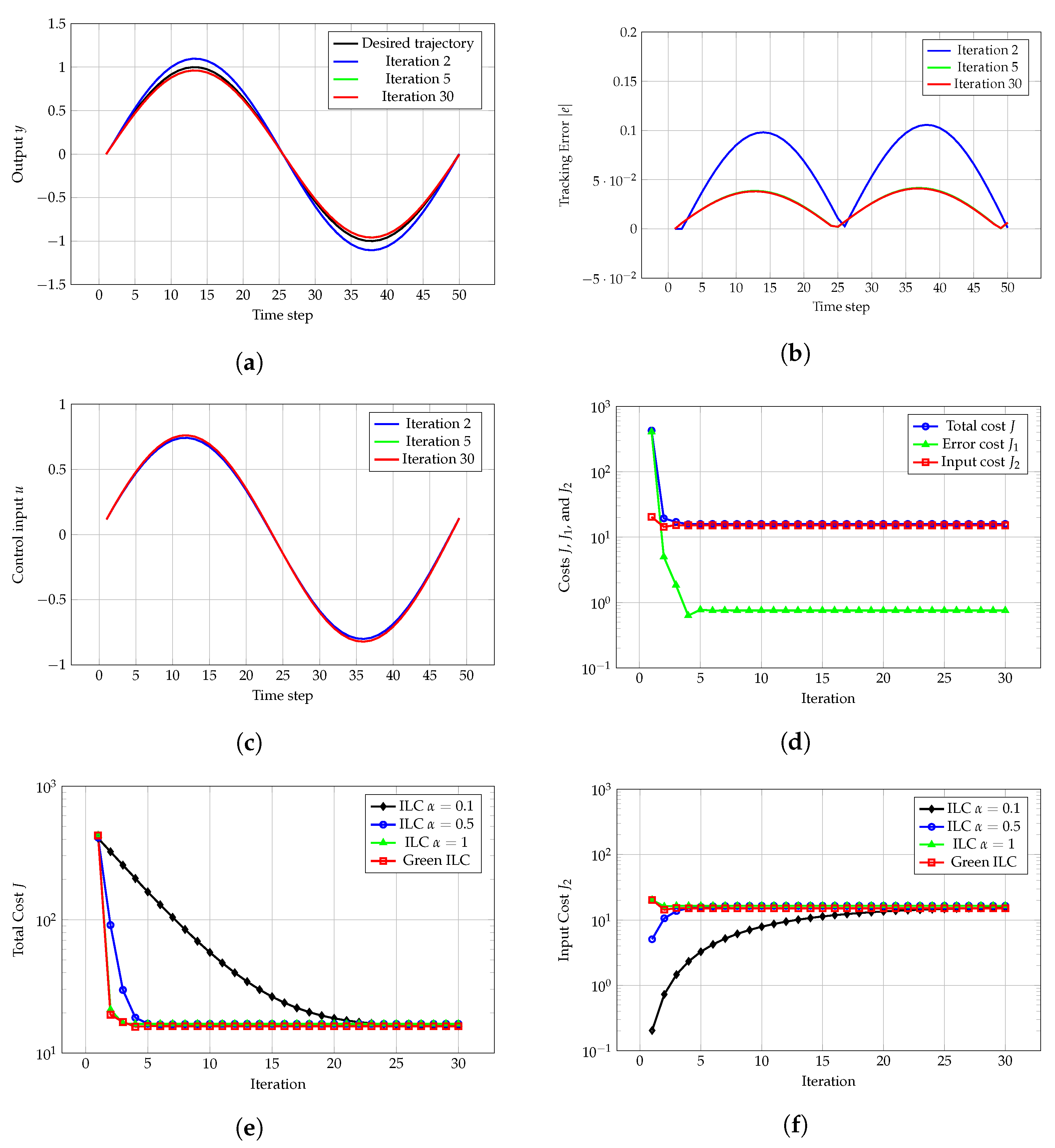
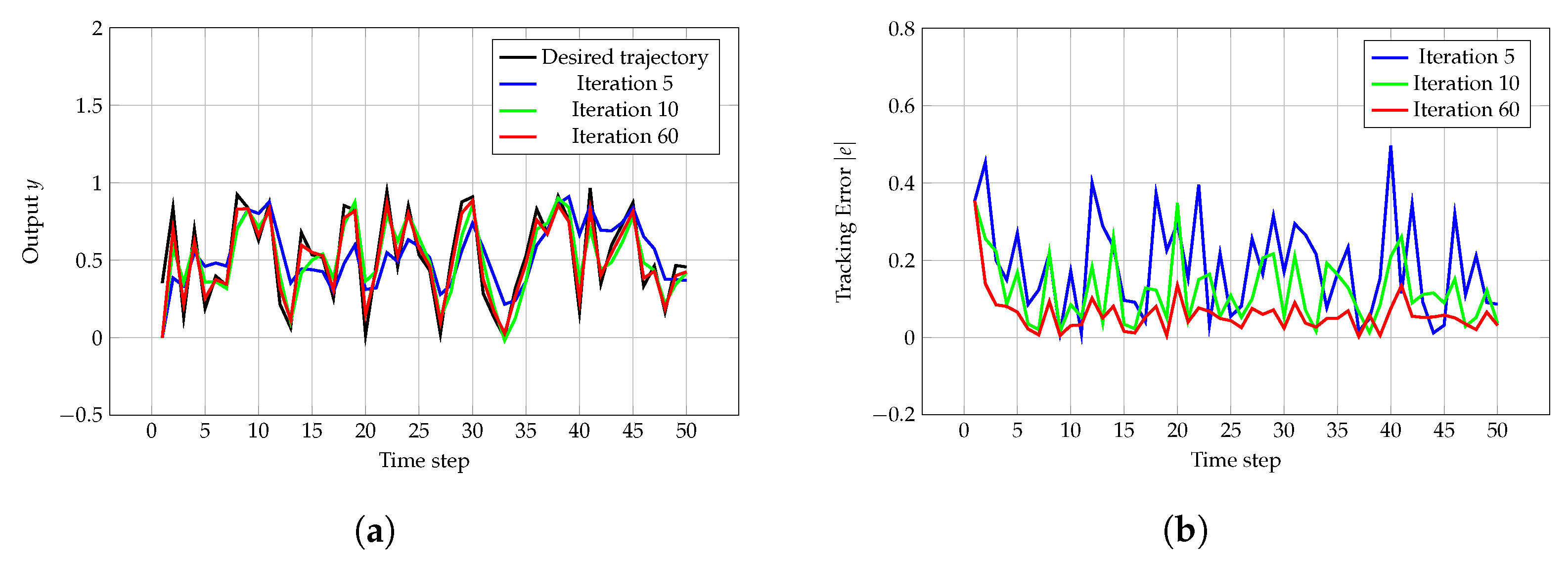
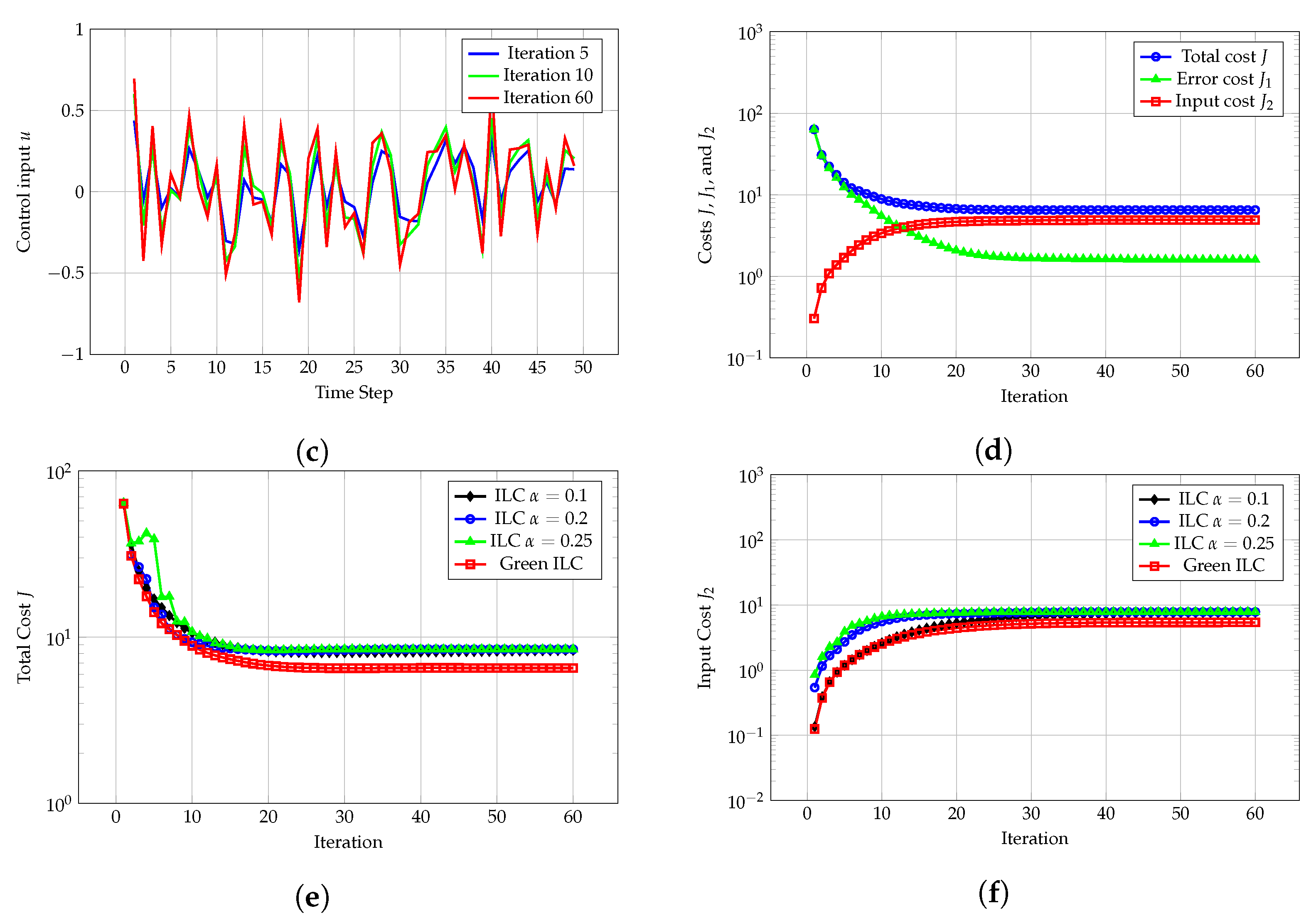
Section 3 presents the simulation results, demonstrating its performance and comparing it with traditional ILC.
Section 4 discusses Green ILC’s performance in detail, and
Section 5 concludes the paper by summarizing the key contributions of this research.
4. Discussion
Green ILC combines the strengths of gradient descent optimization and the ILC strategy, leading to significant reductions in energy consumption while maintaining good system performance. However, compared with traditional ILC, Green ILC may show a slight decrease in tracking accuracy. This method optimizes control inputs and tracking errors, prioritizing energy efficiency over precision. As a result, it may not be the best choice for applications where high precision is crucial, but it is highly effective in cases where managing energy use is the main concern.
The main advantage of Green ILC is its ability to significantly reduce control energy consumption, especially in energy-intensive systems. By balancing tracking accuracy with control inputs, Green ILC helps avoid excessive energy usage, which can lead to actuator wear or failure. In many repetitive-task applications, such as robotics, automated manufacturing, and process control, Green ILC provides acceptable tracking accuracy while saving energy by reducing control effort. Additionally, Green ILC can handle certain unknown disturbances that traditional LQR methods cannot manage, increasing its robustness and expanding its range of practical applications.
In Green ILC, the weighting matrices and are pivotal in balancing tracking errors and control energy. By dynamically adjusting these matrices based on system states and performance requirements, Green ILC achieves adaptive optimization of control strategies, thereby enhancing system robustness and reliability. For instance, in robotics, Green ILC can modify the weighting matrices to meet specific task demands, such as precise assembly or high-speed material handling. In manufacturing, it optimizes energy consumption and efficiency across production lines, accommodating various product specifications. In Unmanned Aerial Vehicles (UAVs), Green ILC’s dynamic adjustment of and significantly improves system reliability and broadens its application scope. During missions in complex terrains or under variable weather conditions, increasing the weight of emphasizes trajectory tracking accuracy, ensuring flight safety. Conversely, for long-distance missions, elevating the weight of reduces energy consumption, thereby extending flight duration. This flexibility allows Green ILC to adapt to diverse scenarios, including logistics, environmental monitoring, and disaster relief, thereby enhancing UAV system reliability and versatility. In aerospace applications, Green ILC demonstrates substantial potential. During satellite deployment, increasing the weight of ensures precise positioning. For extended space missions, adjusting to lower energy consumption can prolong operational lifespan. This adaptability makes Green ILC suitable for various aerospace tasks, such as satellite orbit control, spacecraft docking, and planetary exploration, thereby improving system reliability and expanding its range of applications.
Furthermore, Green ILC addresses sensitivity to initial conditions through its adaptive learning mechanism. By integrating the iterative refinement capabilities of traditional ILC with the optimization strengths of gradient descent, Green ILC dynamically adjusts control inputs based on feedback from previous iterations. This adaptive process allows the system to progressively correct deviations caused by suboptimal initial conditions, leading to improved convergence and performance over time. As a result, Green ILC reduces the impact of initial state variations, ensuring robust and consistent control outcomes across different starting points.
However, in high-dimensional nonlinear systems, ILC methods, including Green ILC, can encounter challenges related to computational efficiency and convergence speed. For instance, the study [
20] examines the difficulties in achieving robust convergence in the presence of non-repetitive uncertainties, underscoring the limitations of ILC approaches in complex nonlinear environments.
To assess actuator reliability and safety, it is essential to evaluate actuator wear by assessing input energy variance and thermal stability. High variance in input energy indicates fluctuating loads, leading to increased wear. Monitoring this variance provides insights into the actuator’s degree of wear. Green ILC optimizes control strategies to reduce energy consumption, thereby decreasing load fluctuations and operating temperatures. This reduction not only minimizes wear but also enhances thermal stability, indirectly extending the actuator’s service life and improving reliability and safety.
Both papers [
18,
19] provide experimental results confirming the advantages of gradient-based ILC methods, supporting the performance improvements introduced by Green ILC. The paper [
18] validates a model-free gradient ILC in stroke rehabilitation tasks, achieving monotonic convergence with tracking errors up to 1000 times smaller than traditional linear model-free ILC methods. The paper [
19] demonstrates a reduction in the standard deviation of normalized steady-state errors from 0.224 in traditional proportional ILC to 0.009 in gradient-based ILC, showcasing enhanced robustness and adaptability for nonlinear systems. These findings, together with the energy optimization and tracking improvements of Green ILC, underscore the ability of gradient-based methods to outperform traditional ILC by enhancing convergence, reducing errors, and addressing energy efficiency in complex control problems.
The Green ILC method is based on the assumption of a known linear model with fixed matrices , , and . While this framework offers mathematical simplicity and ensures convergence, it restricts the method’s applicability to systems with nonlinear or uncertain dynamics. In practical applications, linear models are often used as approximations of system behavior within specific operating ranges. To overcome these limitations, future research could focus on developing adaptive or model-free extensions, which would allow the method to handle time-varying or nonlinear systems effectively. Furthermore, integrating Green ILC with robust control strategies or predictive techniques could significantly enhance its applicability and adaptability in dynamic and complex environments.
5. Conclusions
In this paper, Green ILC is introduced as an innovative hybrid control strategy that effectively optimizes energy consumption while maintaining satisfactory tracking accuracy. By combining the principles of gradient descent optimization with iterative learning, the algorithm delivers significant improvements in convergence speed and energy efficiency compared with traditional ILC methods. Simulation results highlight reductions in energy usage and enhanced robustness in dynamic environments.
The practical applications of Green ILC are extensive, spanning robotic manipulators, UAVs, and aerospace systems, where energy efficiency and system reliability are of paramount importance. To maximize its potential in power system design, adaptive weighting strategies should be employed to minimize energy fluctuations and reduce actuator wear. Integrating Green ILC with renewable energy systems could improve stability under variable power conditions, making it a valuable solution for sustainable energy management.
Future research should focus on extending the applicability of Green ILC to nonlinear and time-varying systems, incorporating predictive models to enhance adaptability, and validating its performance in real-world scenarios. These advancements would further establish Green ILC as a practical approach to addressing energy-efficient control challenges.



{kind=link}
{kind=link}
{kind=link}
{kind=link}