Re-Parameterization After Pruning: Lightweight Algorithm Based on UAV Remote Sensing Target Detection


Abstract
1. Introduction
2. Materials
2.1. Lightweight CNN Models
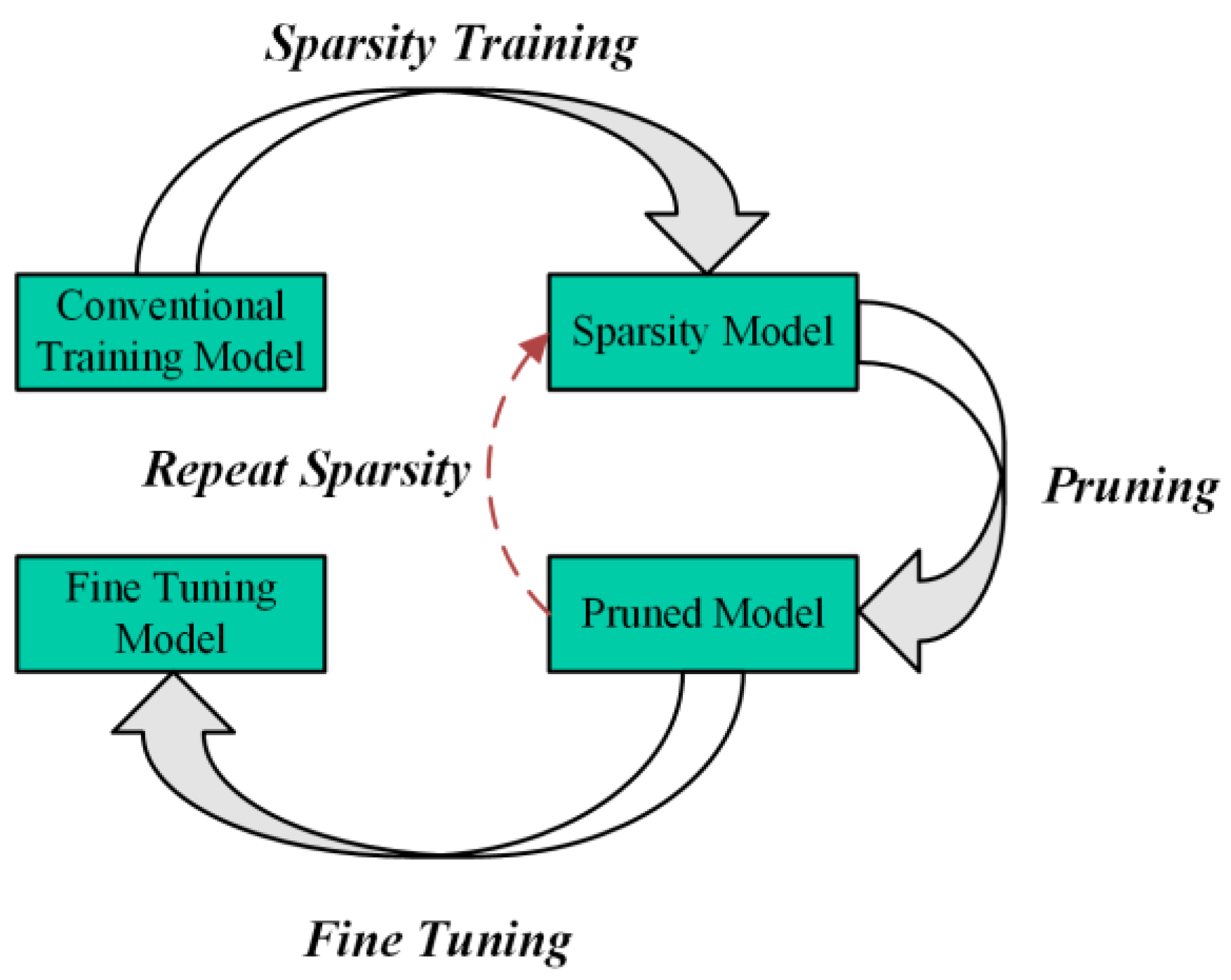
2.2. Model Pruning
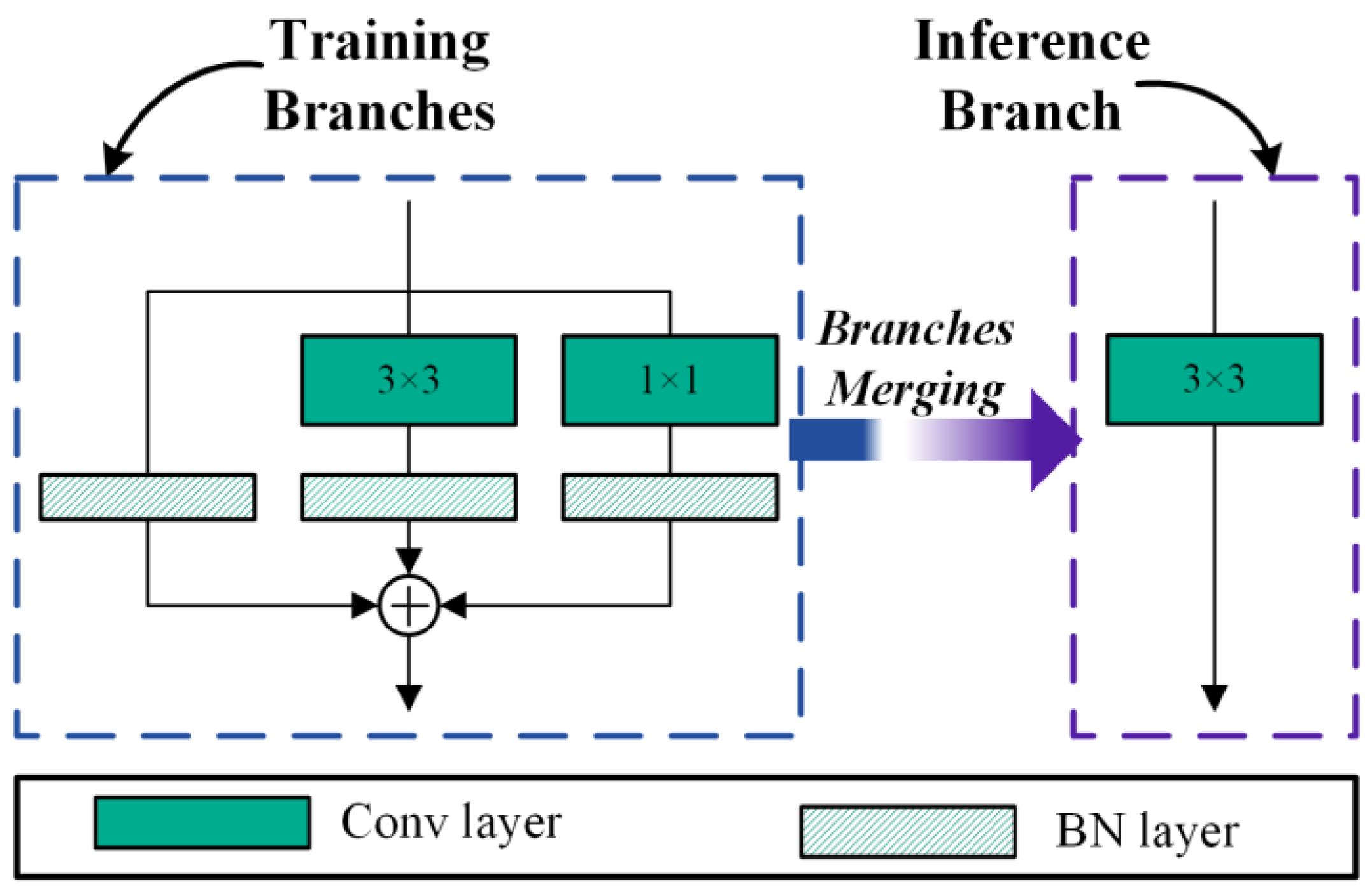
2.3. Model Re-Parameterization
3. Methods
3.1. Proposed the PR-YOLO Model
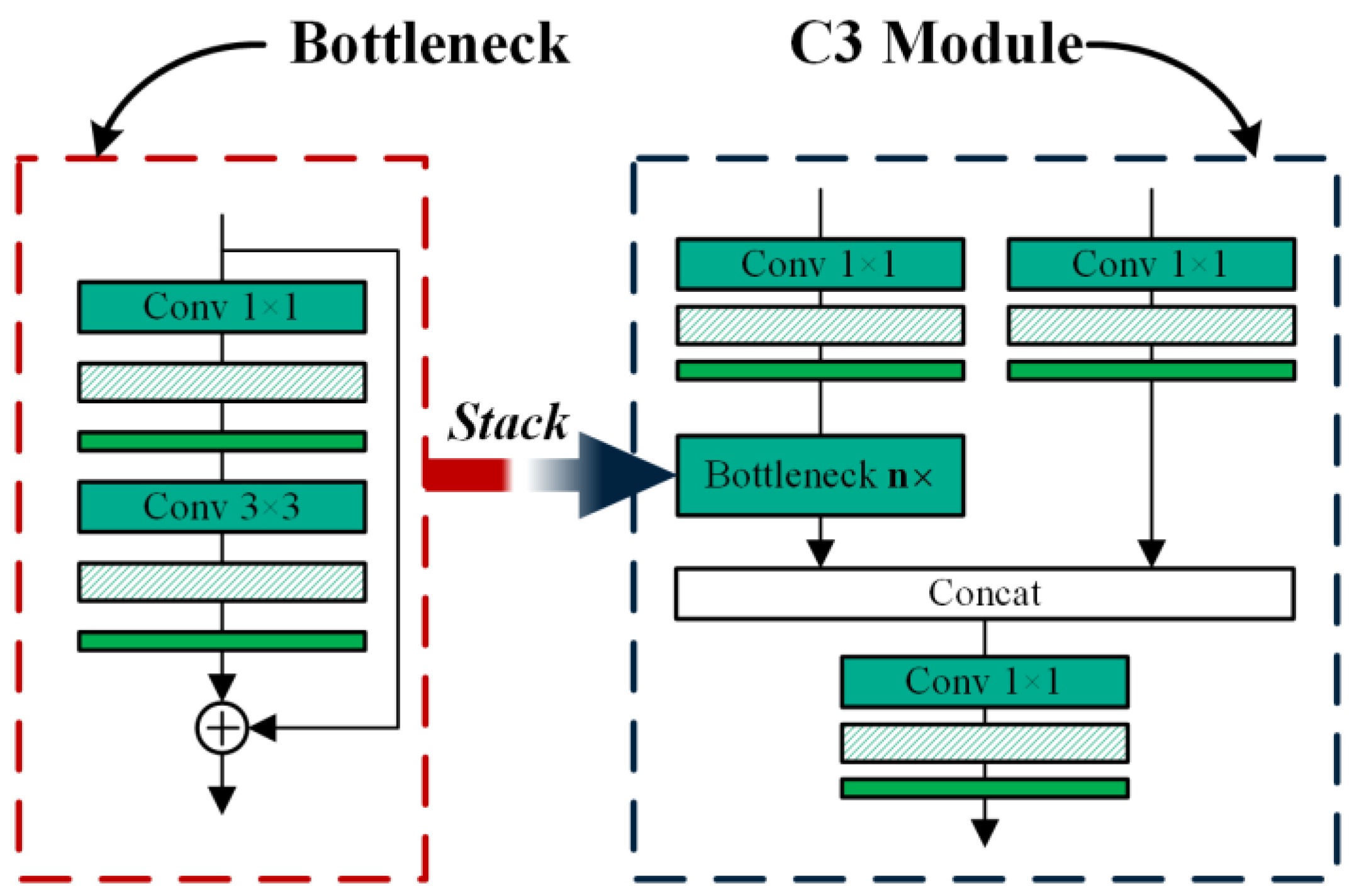
3.1.1. Backbone Network Improvement
3.1.2. Regression Loss Function Improvement
3.2. Re-Parameterization Towards the Larger Kernel
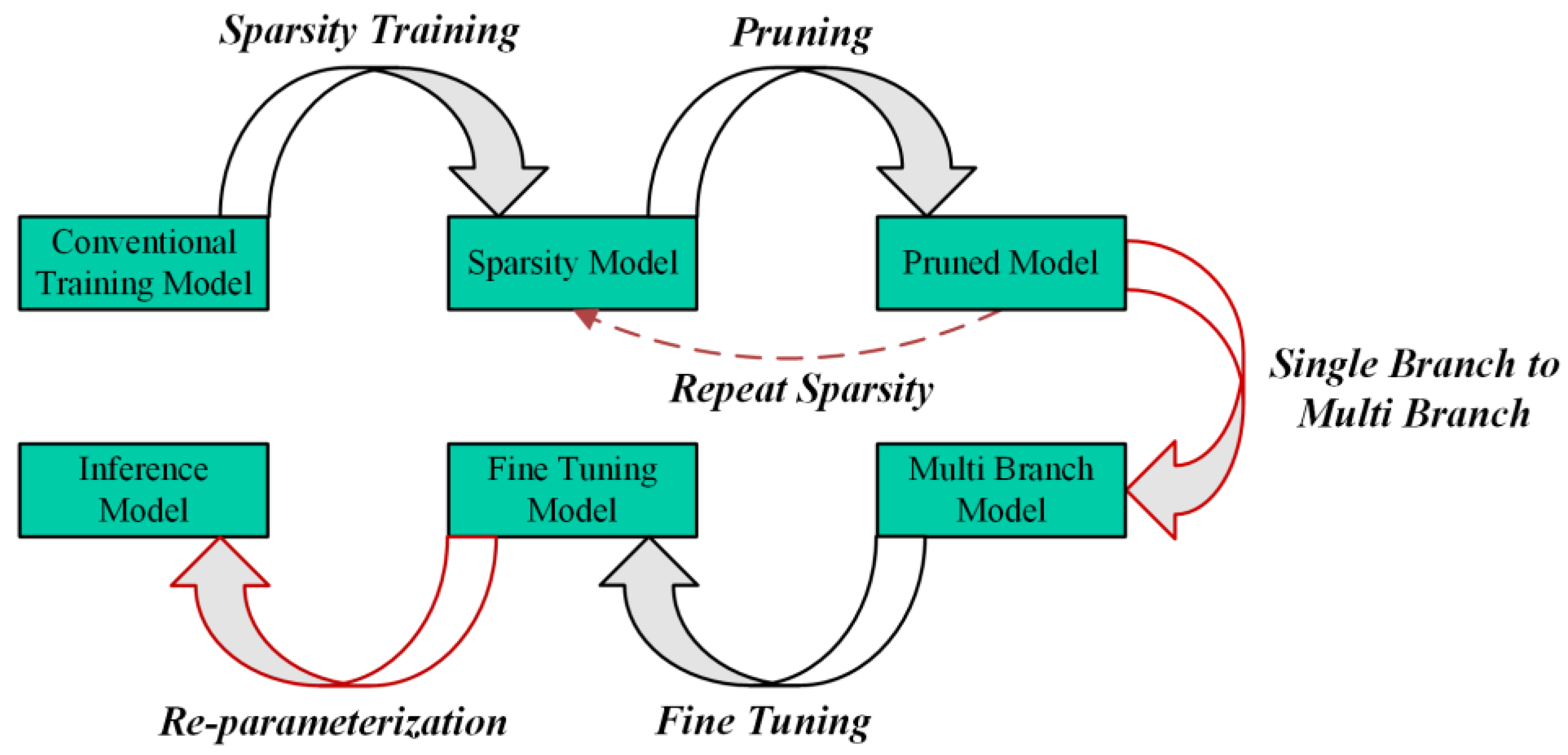
3.3. Pruning and Fine-Tuning Process Improvement
4. Experiments
4.1. Experimental Details
Evaluating Indicators
4.2. Training and Validation Datasets
4.3. Experimental Results
4.3.1. Ablation Experiments
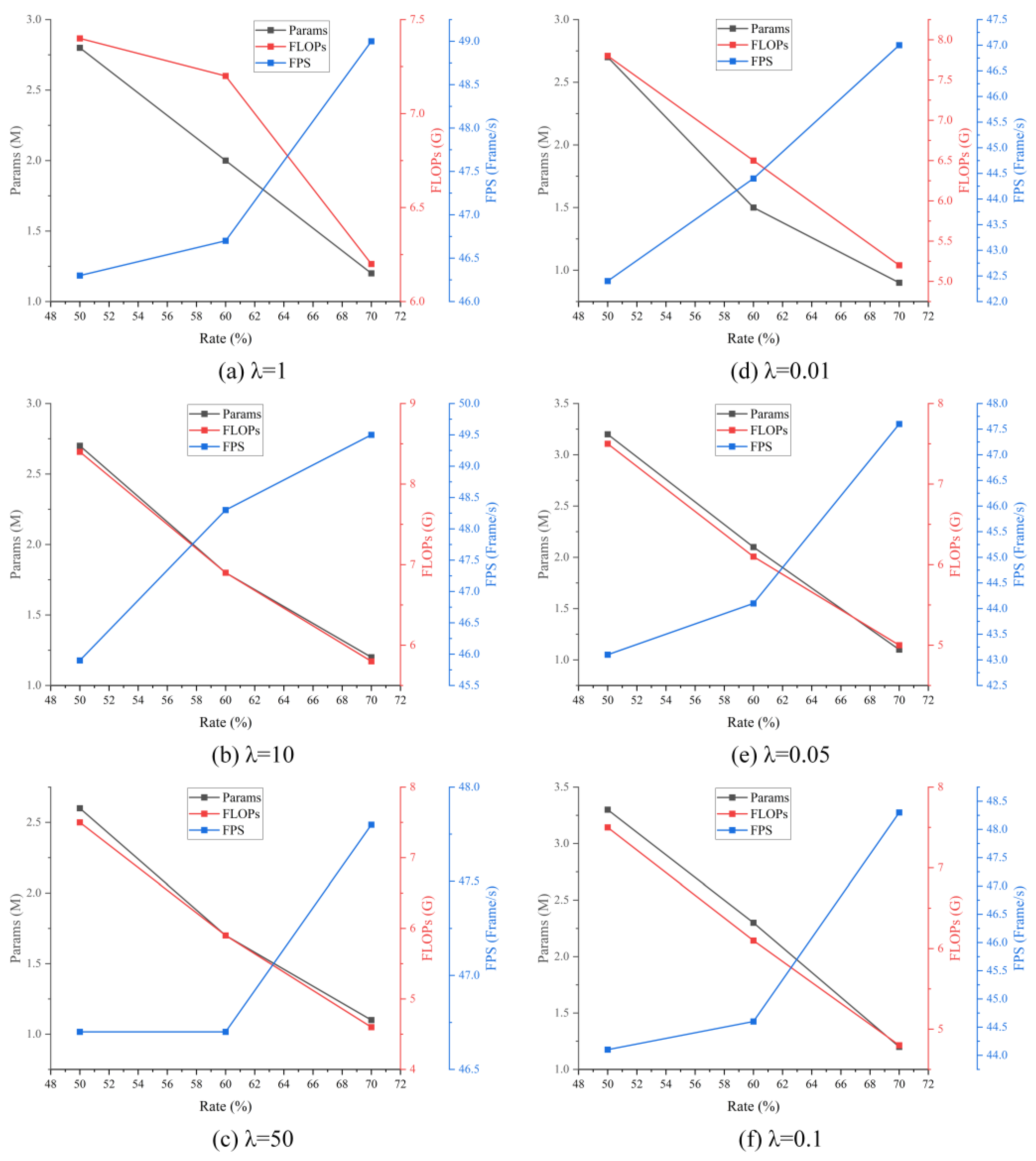
4.3.2. Model Compression Experiment
4.3.3. Fine-Tuning and Re-Parameterization Experiment
4.3.4. The Comparison Results with Related Algorithms
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yang, S.; Luo, P.; Loy, C.C.; Tang, X. Wider Face: A Face Detection Benchmark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5525–5533. [Google Scholar]
- Wang, J.; Chen, Y.; Dong, Z.; Gao, M. Improved YOLOv5 Network for Real-Time Multi-Scale Traffic Sign Detection. Neural Comput. Appl. 2023, 35, 7853–7865. [Google Scholar] [CrossRef]
- Dong, X.; Yan, S.; Duan, C. A Lightweight Vehicles Detection Network Model Based on YOLOv5. Eng. Appl. Artif. Intell. 2022, 113, 104914. [Google Scholar] [CrossRef]
- Sun, X.; Wang, P.; Wang, C.; Liu, Y.; Fu, K. PBNet: Part-based Convolutional Neural Network for Complex Composite Object Detection in Remote Sensing Imagery. ISPRS J. Photogramm. Remote Sens. 2021, 173, 50–65. [Google Scholar] [CrossRef]
- Ma, A.; Wan, Y.; Zhong, Y.; Wang, J.; Zhang, L. SceneNet: Remote sensing scene classification deep learning network using multi-objective neural evolution architecture search. ISPRS J. Photogramm. Remote Sens. 2021, 172, 171–188. [Google Scholar] [CrossRef]
- Wan, Y.; Zhong, Y.; Ma, A.; Wang, J.; Zhang, L. E2SCNet: Efficient Multiobjective Evolutionary Automatic Search for Remote Sensing Image Scene Classification Network Architecture. IEEE Trans. Neural Netw. Learn. Syst. 2024, 35, 7752–7766. [Google Scholar] [CrossRef]
- Liu, Z.; Chen, C.; Huang, Z.; Chang, Y.; Liu, L.; Pei, Q. A Low-Cost and Lightweight Real-Time Object-Detection Method Based on UAV Remote Sensing in Transportation Systems. Remote Sens. 2024, 16, 3712. [Google Scholar] [CrossRef]
- Liu, S.; Cao, L.; Li, Y. Lightweight Pedestrian Detection Network for UAV Remote Sensing Images Based on Strideless Pooling. Remote Sens. 2024, 16, 2331. [Google Scholar] [CrossRef]
- Tan, L.; Lv, X.; Lian, X.; Wang, G. YOLOv4_Drone: UAV image target detection based on an improved YOLOv4 algorithm. Comput. Electr. Eng. 2021, 93, 107261. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, Y.; Shi, Z.; Zhang, Y.; Gao, R. Unmanned Aerial Vehicle Object Detection Based on Information-Preserving and Fine-Grained Feature Aggregation. Remote Sens. 2024, 16, 2590. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the 2016 European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Liao, H.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding Yolo Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Huang, R.; Pedoeem, J.; Chen, C. YOLO-LITE: A Real-Time Object Detection Algorithm Optimized for Non-GPU Computers. In Proceedings of the 2018 IEEE International Conference on Big Data, Seattle, WA, USA, 10–13 December 2018. [Google Scholar]
- Wong, A.; Famuori, M.; Shafiee, M.J.; Li, F.; Chwyl, B.; Chung, J. YOLO Nano: A Highly Compact You Only Look Once Convolutional Neural Network for Object Detection. In Proceedings of the 2019 Fifth Workshop on Energy Efficient Machine Learning and Cognitive Computing—NeurIPS Edition, Vancouver, BC, Canada, 13 December 2019. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, W.; Li, Y.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.; Bochkovskiy, A.; Liao, H.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Howard, A.; Sandler, M.; Chen, B.; Wang, W.; Chen, L.; Tan, M. Searching for MobileNetV3. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. GhostNet: More Features From Cheap Operations. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Sun, C.; Wang, X.; Liu, Z.; Wang, Y.; Zhang, L.; Zhong, Y. SiamOHOT: A Lightweight Dual Siamese Network for Onboard Hyperspectral Object Tracking via Joint Spatial–Spectral Knowledge Distillation. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–12. [Google Scholar] [CrossRef]
- Li, X.; Wang, Z.; Geng, S.; Wang, L.; Zhang, H.; Liu, L.; Li, D. Yolov3-Pruning(transfer): Real-Time Object Detection Algorithm Based on Transfer Learning. J. Real-Time Image Process. 2022, 19, 839–852. [Google Scholar] [CrossRef]
- Wu, D.; Lv, S.; Jiang, M.; Song, H. Using channel pruning-based YOLO v4 deep learning algorithm for the real-time and accurate detection of apple flowers in natural environments. Comput. Electron. Agric. 2020, 178, 105742. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, P.; Zhao, Z.; Su, F. Pruned-YOLO: Learning Efficient Object Detector Using Model Pruning. In Proceedings of the 30th International Conference on Artificial Neural Networks, Bratislava, Slovakia, 14–17 September 2021; Springer International Publishing: Cham, Switzerland, 2021. [Google Scholar]
- Gupta, C.; Gill, N.; Gulia, P.; Chatterjee, J. A Novel Finetuned YOLOv6 Transfer Learning Model for Real-Time Object Detection. J. Real-Time Image Process. 2023, 20, 42. [Google Scholar] [CrossRef]
- Iandola, F.; Han, S.; Moskewicz, M.; Ashraf, K.; Dally, W.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Tan, M.; Chen, B.; Pang, R.; Vasudevan, V.; Sandler, M.; Howard, A.; Le, Q. MnasNet: Platform-Aware Neural Architecture Search for Mobile. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Tang, Y.; Han, K.; Guo, J.; Xu, C.; Xu, C.; Wang, Y. GhostNetv2: Enhance Cheap Operation with Long-Range Attention. Adv. Neural Inf. Process. Syst. 2022, 35, 9969–9982. [Google Scholar]
- Vasu, A.; Gabriel, J.; Zhu, J.; Tuzel, O.; Ranjan, A. MobileOne: An Improved One Millisecond Mobile Backbone. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Chen, J.; Kao, S.; He, H.; Zhuo, W.; Wen, S.; Lee, C.; Chan, S. Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Diracnets: Training very deep neural networks without skip-connections. arXiv 2017, arXiv:1706.00388. [Google Scholar]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. RepVGG: Making VGG-style ConvNets Great Again. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Chen, C.; Guo, Z.; Zeng, H.; Xiong, P.; Dong, J. Repghost: A Hardware-Efficient Ghost Module via Re-parameterization. arXiv 2022, arXiv:2211.06088. [Google Scholar]
- Liu, Z.; Li, J.; Shen, Z.; Huang, G.; Yan, S.; Zhang, C. Learning efficient convolutional networks through network slimming. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Cao, Y.; He, Z.; Wang, L.; Wang, W.; Yuan, Y.; Zhang, D. VisDrone-DET2021: The vision meets drone object detection challenge results. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Training Server | Embedded Platform |
|---|---|---|
| Device name | DELL Precision R7920 | Jetson AGX Xavier |
| CPU | Intel Xeon(R) Gold 6254 CPU @ 3.10 GHz × 72 | 64-bit 8-core CPU (ARMv8.2) |
| GPU | Quadro RTX 8000 48 G × 2 | 512-core Volta GPU with Tensor Cores |
| RAM | DELL 64G × 2 | 16 G |
| Dataset | Anchor Box | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| VisDrone | 5, 5 | 7, 11 | 15, 9 | 12, 19 | 29, 16 | 22, 31 | 54, 30 | 38, 55 | 91, 76 |
| DIOR | 10, 15 | 30, 12 | 15, 36 | 46, 37 | 55, 109 | 130, 127 | 119, 252 | 340, 208 | 323, 412 |
| Hyperparameter | Conventional Training | Sparse Training | Fine-Tuning Training |
|---|---|---|---|
| Optimizer | SGD | Adam | AdamW |
| Batch size | 32 | 32 | 32 |
| Input size | 640 × 640 | 640 × 640 | 640 × 640 |
| Mosaic | True | True | True |
| Initial learning rate | 0.01 | 0.01 | 0.0032 |
| Final learning rate | 0.01 | 0.01 | 0.12 |
| Warmup epochs | 3 | 3 | 2 |
| Warmup bias learning rate | 0.1 | 0.1 | 0.05 |
| Warmup momentum | 0.8 | 0.8 | 0.5 |
| Weight decay | 0.0005 | 0.0005 | 0.00036 |
| Momentum | 0.937 | 0.937 | 0.843 |
| V3 | ECA | FocalEIoU | OPF | RPF | Params (M) | FLOPs (G) | mAP@0.5 (%) | mAP@0.5:0.95 (%) | FPS (Frame/s) |
|---|---|---|---|---|---|---|---|---|---|
| 20.9 | 48.0 | 38.1/79.4 | 21.8/57.8 | 29/17 | |||||
| ✔ | 11.9 | 20.0 | 33.5/79.1 | 18.3/56.6 | 37/27 | ||||
| ✔ | ✔ | 10.4 | 20.0 | 34.1/79.4 | 18.7/56.6 | 38/27 | |||
| ✔ | ✔ | ✔ | 10.4 | 20.0 | 34.3/79.0 | 19.3/57.5 | 38/27 | ||
| ✔ | ✔ | ✔ | ✔ | 1.2/1.5 | 6.2/6.5 | 35.8/79.8 | 20.3/58.1 | 49/44 | |
| ✔ | ✔ | ✔ | ✔ | 36.2/79.8 | 20.7/58.6 |
| Backbone | Params (M) | FLOPs (G) | mAP@0.5 (%) | mAP@0.5:0.95 (%) | FPS (Frame/s) |
|---|---|---|---|---|---|
| GhostNetV1 | 12.7 | 20.0 | 28.9/77.0 | 15.2/53.6 | 25/25 |
| GhostNetV2 | 18.7 | 22.2 | 32.6/76.4 | 17.4/52.2 | 22/19 |
| ShuffleNetV2 | 10.9 | 19.5 | 30.4/77.2 | 16.2/54.4 | 33/26 |
| MobileOne | 17.3 | 32.8 | 33.6/77.5 | 18.5/54.7 | 32/19 |
| FasterNet | 11.6 | 22.3 | 33.1/76.5 | 17.9/53.4 | 41/30 |
| MobileNetV3 | 11.9 | 20.0 | 33.5/79.1 | 18.3/56.6 | 37/27 |
| Method | Params (M) | FLOPs (G) | mAP@0.5 (%) | mAP@0.5:0.95 (%) | FPS (Frame/s) |
|---|---|---|---|---|---|
| SSDLite-MV2 | 3.2 | 2.8 | 20.0/66.9 | 10.4/42.9 | 27/26 |
| YOLOv3-MV2 | 3.7 | 6.6 | 24.8/70.0 | 11.7/43.1 | 31/29 |
| YOLOv4-Tiny | 5.9 | 16.2 | 24.3/68.3 | 13.5/42.4 | 48/49 |
| YOLOv5s | 7.0 | 16.0 | 33.1/78.3 | 17.6/54.3 | 45/39 |
| YOLOv6n | 4.6 | 11.3 | 31.9/40.7 | 18.3/24.4 | 42/41 |
| YOLOv7-Tiny | 6.0 | 13.1 | 37.1/78.3 | 18.9/55.4 | 45/44 |
| YOLOv8n | 3.0 | 8.1 | 34.3/78.5 | 20.2/58.1 | - |
| YOLOXs | 8.9 | 13.3 | 32.7/75.7 | 17.9/49.7 | 25/25 |
| Ours | 1.2/1.5 | 6.2/6.5 | 36.2/79.8 | 20.7/58.6 | 49/44 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Y.; Song, P.; Wang, Y.; Cao, L. Re-Parameterization After Pruning: Lightweight Algorithm Based on UAV Remote Sensing Target Detection. Sensors 2024, 24, 7711. https://doi.org/10.3390/s24237711
Yang Y, Song P, Wang Y, Cao L. Re-Parameterization After Pruning: Lightweight Algorithm Based on UAV Remote Sensing Target Detection. Sensors. 2024; 24(23):7711. https://doi.org/10.3390/s24237711
Chicago/Turabian StyleYang, Yang, Pinde Song, Yongchao Wang, and Lijia Cao. 2024. "Re-Parameterization After Pruning: Lightweight Algorithm Based on UAV Remote Sensing Target Detection" Sensors 24, no. 23: 7711. https://doi.org/10.3390/s24237711
APA StyleYang, Y., Song, P., Wang, Y., & Cao, L. (2024). Re-Parameterization After Pruning: Lightweight Algorithm Based on UAV Remote Sensing Target Detection. Sensors, 24(23), 7711. https://doi.org/10.3390/s24237711