
Artificial Intelligence in Audiology: A Scoping Review of Current Applications and Future Directions

 ,
,  ,
,  , ,
, ,  and
and 
Abstract
1. Introduction
2. Materials and Methods
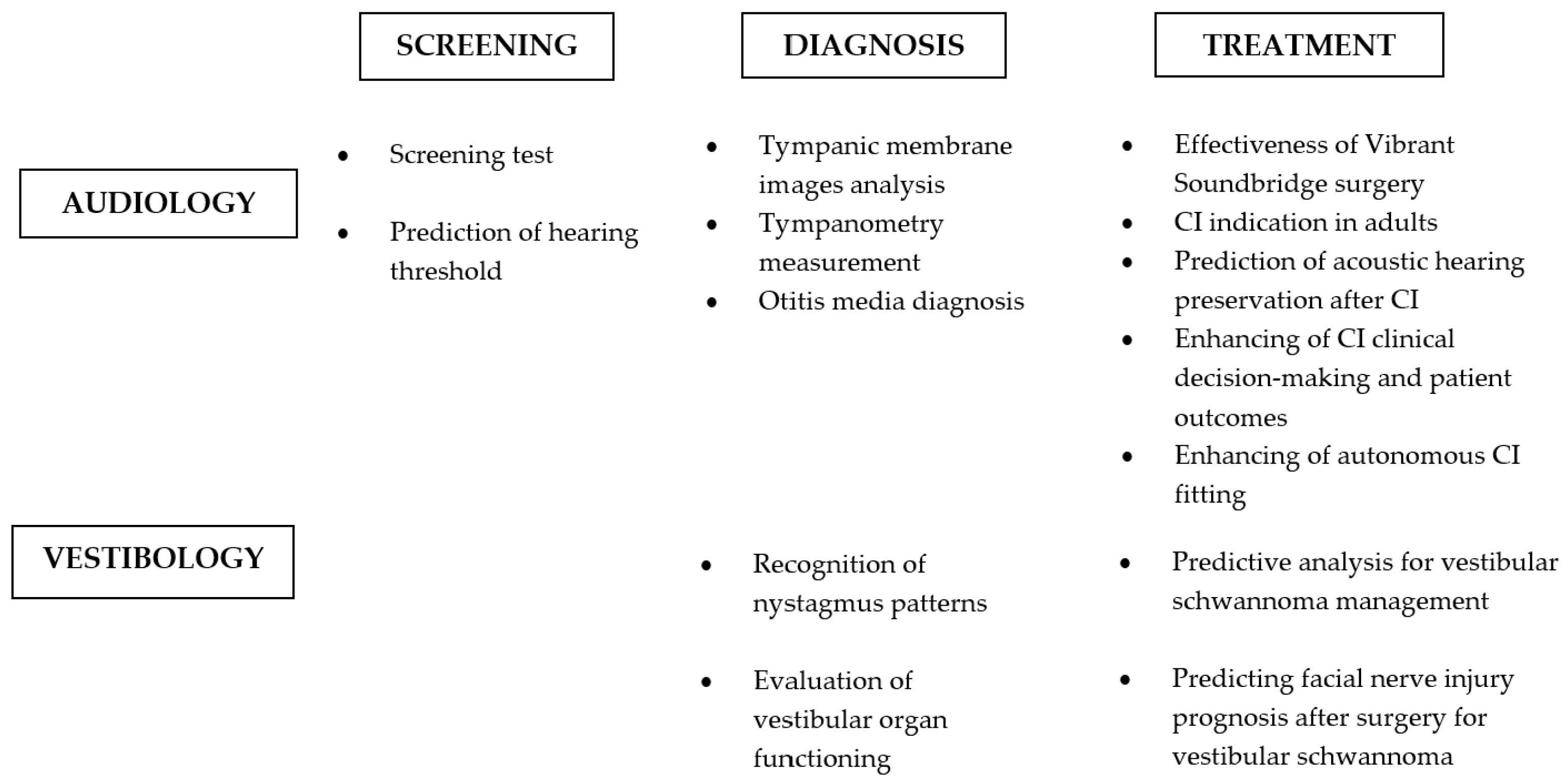
3. Results
Application Fields and Technical Approaches
4. Discussion
4.1. Hearing Tests
4.2. Vestibular Diagnostics
4.3. Temporal Bone Radiology
4.3.1. AI Models in Temporal Bone Radiology: General Principles
4.3.2. Automated Temporal Bone Image Segmentation
4.3.3. AI and Radiological Imaging of Middle Ear Diseases
4.3.4. AI and Radiological Imaging of Inner Ear
4.4. Therapeutic and Prognostic Tools
4.4.1. Expert Systems for Counseling and Peer Support in Chronic Audiological Diseases
4.4.2. AI-Assisted Therapy and Hearing Rehabilitation
4.4.3. AI-Based Prognostic Models
4.5. AI-Driven Augmented Sensors in Audiology
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Oremule, B.; Saunders, G.H.; Kulk, K.; d’Elia, A.; Bruce, I.A. Understanding, experience, and attitudes towards artificial intelligence technologies for clinical decision support in hearing health: A mixed-methods survey of healthcare professionals in the UK. J. Laryngol. Otol. 2024, 138, 928–935. [Google Scholar] [CrossRef] [PubMed]
- Muthukrishnan, N.; Maleki, F.; Ovens, K.; Reinhold, C.; Forghani, B.; Forghani, R. Brief history of artificial intelligence. Neuroimaging Clin. N. Am. 2020, 30, 393–399. [Google Scholar] [CrossRef] [PubMed]
- Garcia, E.V.; Taylor, A.; Halkar, R.; Folks, R.; Krishnan, M.; Cooke, C.D.; Dubovsky, E. RENEX: An expert system for the interpretation of 99mTc-MAG3 scans to detect renal obstruction. J. Nucl. Med. 2006, 47, 320–329. [Google Scholar] [PubMed]
- Frosolini, A.; Franz, L.; Benedetti, S.; Vaira, L.A.; de Filippis, C.; Gennaro, P.; Marioni, G.; Gabriele, G. Assessing the accuracy of ChatGPT references in head and neck and ENT disciplines. Eur. Arch. Otorhinolaryngol. 2023, 280, 5129–5133. [Google Scholar] [CrossRef]
- Koyama, H. Machine learning application in otology. Auris Nasus Larynx 2024, 51, 666–673. [Google Scholar] [CrossRef]
- Choi, R.Y.; Coyner, A.S.; Kalpathy-Cramer, J.; Chiang, M.F.; Campbell, J.P. Introduction to machine learning, neural networks, and deep learning. Transl. Vis. Sci. Technol. 2020, 9, 14. [Google Scholar]
- Liu, X.; Faes, L.; Kale, A.U.; Wagner, S.K.; Fu, D.J.; Bruynseels, A.; Mahendiran, T.; Moraes, G.; Shamdas, M.; Kern, C.; et al. A comparison of deep learning performance against health-care professionals in detecting diseases from medical imaging: A systematic review and meta-analysis. Lancet Digit. Health 2019, 1, e271–e297. [Google Scholar] [CrossRef]
- Mohamed, A.A.; Lucke-Wold, B. Text-to-video generative artificial intelligence: Sora in neurosurgery. Neurosurg. Rev. 2024, 47, 272. [Google Scholar] [CrossRef]
- Paladugu, P.S.; Ong, J.; Nelson, N.; Kamran, S.A.; Waisberg, E.; Zaman, N.; Kumar, R.; Dias, R.D.; Lee, A.G.; Tavakkoli, A. Generative adversarial networks in medicine: Important considerations for this emerging innovation in artificial intelligence. Ann. Biomed. Eng. 2023, 51, 2130–2142. [Google Scholar] [CrossRef]
- OpenAI. ChatGPT (Version GPT-4) [Large Language Model]. OpenAI. 2023. Available online: https://www.openai.com/ (accessed on 9 September 2024).
- Frosolini, A.; Catarzi, L.; Benedetti, S.; Latini, L.; Chisci, G.; Franz, L.; Gennaro, P.; Gabriele, G. The role of Large Language Models (LLMs) in providing triage for maxillofacial trauma cases: A preliminary study. Diagnostics 2024, 14, 839. [Google Scholar] [CrossRef]
- Milne-Ives, M.; de Cock, C.; Lim, E.; Shehadeh, M.H.; de Pennington, N.; Mole, G.; Normando, E.; Meinert, E. The effectiveness of artificial intelligence conversational agents in health care: Systematic review. J. Med. Internet Res. 2020, 22, e20346. [Google Scholar] [CrossRef] [PubMed]
- Vaira, L.A.; Lechien, J.R.; Abbate, V.; Allevi, F.; Audino, G.; Beltramini, G.A.; Bergonzani, M.; Boscolo-Rizzo, P.; Califano, G.; Cammaroto, G.; et al. Validation of the Quality Analysis of Medical Artificial Intelligence (QAMAI) tool: A new tool to assess the quality of health information provided by AI platforms. Eur. Arch. Otorhinolaryngol. 2024, 281, 6123–6131. [Google Scholar] [CrossRef] [PubMed]
- Alter, I.L.; Chan, K.; Lechien, J.; Rameau, A. An introduction to machine learning and generative artificial intelligence for otolaryngologists-head and neck surgeons: A narrative review. Eur. Arch. Otorhinolaryngol. 2024, 281, 2723–2731. [Google Scholar] [CrossRef] [PubMed]
- Rapoport, N.; Pavelchek, C.; Michelson, A.P.; Shew, M.A. Artificial Intelligence in Otology and Neurotology. Otolaryngol. Clin. N. Am. 2024, 57, 791–802. [Google Scholar] [CrossRef] [PubMed]
- Aghakhani, A.; Yousefi, M.; Yekaninejad, M.S. Machine learning models for predicting sudden sensorineural hearing loss outcome: A systematic review. Ann. Otol. Rhinol. Laryngol. 2024, 133, 268–276. [Google Scholar] [CrossRef]
- Ma, T.; Wu, Q.; Jiang, L.; Zeng, X.; Wang, Y.; Yuan, Y.; Wang, B.; Zhang, T. Artificial intelligence and machine (deep) learning in otorhinolaryngology: A bibliometric analysis based on VOSviewer and CiteSpace. Ear Nose Throat J. 2023, 01455613231185074. [Google Scholar] [CrossRef]
- Bonnefon, J.F.; Rahwan, I.; Shariff, A. The moral psychology of artificial intelligence. Annu. Rev. Psychol. 2024, 75, 653–675. [Google Scholar] [CrossRef]
- Tricco, A.C.; Lillie, E.; Zarin, W.; O’Brien, K.K.; Colquhoun, H.; Levac, D.; Moher, D.; Peters, M.D.; Horsley, T.; Weeks, L.; et al. PRISMA extension for scoping reviews (PRISMA-ScR): Checklist and explanation. Ann. Intern. Med. 2018, 169, 467–473. [Google Scholar] [CrossRef]
- Bonadonna, F. HyperShell: An expert system shell in a hypermedia environment—Application in medical audiology. Med. Inform. 1990, 15, 105–114. [Google Scholar] [CrossRef]
- Juhola, M.; Viikki, K.; Laurikkala, J.; Auramo, Y.; Kentala, E.; Pyykkö, I. Application of artificial intelligence in audiology. Scand. Audiol. Suppl. 2001, 52, 97–99. [Google Scholar] [CrossRef]
- McCullagh, P.; Wang, H.; Zheng, H.; Lightbody, G.; McAllister, G. A comparison of supervised classification methods for auditory brainstem response determination. Stud. Health Technol. Inform. 2007, 129, 1289–1293. [Google Scholar] [PubMed]
- Rasku, J.; Pyykkö, I.; Levo, H.; Kentala, E.; Manchaiah, V. Disease profiling for computerized peer support of Ménière’s disease. JMIR Rehabil. Assist. Technol. 2015, 2, e9. [Google Scholar] [CrossRef] [PubMed]
- Song, X.D.; Wallace, B.M.; Gardner, J.R.; Ledbetter, N.M.; Weinberger, K.Q.; Barbour, D.L. Fast, continuous audiogram estimation using machine learning. Ear Hear. 2015, 36, e326–e335. [Google Scholar] [CrossRef] [PubMed]
- Masino, A.J.; Grundmeier, R.W.; Pennington, J.W.; Germiller, J.A.; Crenshaw, E.B., 3rd. Temporal bone radiology report classification using open source machine learning and natural language processing libraries. BMC Med. Inform. Decis. Mak. 2016, 16, 65. [Google Scholar] [CrossRef]
- Pyykkő, I.; Manchaiah, V.; Levo, H.; Kentala, E.; Juhola, M. Internet-based peer support for Ménière’s disease: A summary of web-based data collection, impact evaluation, and user evaluation. Int. J. Audiol. 2017, 56, 453–463. [Google Scholar] [CrossRef]
- Programming Cochlear Implant with Artificial Intelligence. ClinicalTrials.gov Identifier NCT03700268. Available online: https://clinicaltrials.gov/study/NCT03700268 (accessed on 4 September 2024).
- Sanchez Lopez, R.; Bianchi, F.; Fereczkowski, M.; Santurette, S.; Dau, T. Data-driven approach for auditory profiling and characterization of individual hearing loss. Trends Hear. 2018, 22, 2331216518807400. [Google Scholar] [CrossRef]
- Barbour, D.L.; Howard, R.T.; Song, X.D.; Metzger, N.; Sukesan, K.A.; DiLorenzo, J.C.; Snyder, B.R.D.; Chen, J.Y.; Degen, E.A.; Buchbinder, J.M.; et al. Online machine learning audiometry. Ear Hear. 2019, 40, 918–926. [Google Scholar] [CrossRef]
- Buhl, M.; Warzybok, A.; Schädler, M.R.; Lenarz, T.; Majdani, O.; Kollmeier, B. Common Audiological Functional Parameters (CAFPAs): Statistical and compact representation of rehabilitative audiological classification based on expert knowledge. Int. J. Audiol. 2019, 58, 231–245. [Google Scholar] [CrossRef]
- Lee, J.Y.; Choi, S.-H.; Chung, J.W. Automated classification of the tympanic membrane using a convolutional neural network. Appl. Sci. 2019, 9, 1827. [Google Scholar] [CrossRef]
- McKearney, R.M.; MacKinnon, R.C. Objective auditory brainstem response classification using machine learning. Int. J. Audiol. 2019, 58, 224–230. [Google Scholar] [CrossRef]
- Buhl, M.; Warzybok, A.; Schädler, M.R.; Majdani, O.; Kollmeier, B. Common Audiological Functional Parameters (CAFPAs) for single patient cases: Deriving statistical models from an expert-labelled data set. Int. J. Audiol. 2020, 59, 534–547. [Google Scholar] [CrossRef] [PubMed]
- Charih, F.; Bromwich, M.; Mark, A.E. Data-driven audiogram classification for mobile audiometry. Sci. Rep. 2020, 10, 3962. [Google Scholar] [CrossRef] [PubMed]
- Crowson, M.G.; Franck, K.H.; Rosella, L.C.; Chan, T.C.Y. Predicting depression from hearing loss using machine learning. Ear Hear. 2021, 42, 982–989. [Google Scholar] [CrossRef] [PubMed]
- Crowson, M.G.; Lee, J.W.; Hamour, A.; Mahmood, R.; Babier, A.; Lin, V.; Tucci, D.L.; Chan, T.C.Y. AutoAudio: Deep learning for automatic audiogram interpretation. J. Med. Syst. 2020, 44, 163. [Google Scholar] [CrossRef] [PubMed]
- Heisey, K.L.; Walker, A.M.; Xie, K.; Abrams, J.M.; Barbour, D.L. Dynamically masked audiograms with machine learning audiometry. Ear Hear. 2020, 41, 1692–1702. [Google Scholar] [CrossRef]
- Losorelli, S.; Kaneshiro, B.; Musacchia, G.A.; Blevins, N.H.; Fitzgerald, M.B. Factors influencing classification of frequency following responses to speech and music stimuli. Hear. Res. 2020, 398, 108101. [Google Scholar] [CrossRef]
- Meeuws, M.; Pascoal, D.; Janssens de Varebeke, S.; De Ceulaer, G.; Govaerts, P.J. Cochlear implant telemedicine: Remote fitting based on psychoacoustic self-tests and artificial intelligence. Cochlear Implants Int. 2020, 21, 260–268. [Google Scholar] [CrossRef]
- Saak, S.K.; Hildebrandt, A.; Kollmeier, B.; Buhl, M. Predicting Common Audiological Functional Parameters (CAFPAs) as interpretable intermediate representation in a clinical decision-support system for audiology. Front. Digit. Health 2020, 2, 596433. [Google Scholar] [CrossRef]
- Balling, L.W.; Mølgaard, L.L.; Townend, O.; Nielsen, J.B.B. The collaboration between hearing aid users and artificial intelligence to optimize sound. Semin. Hear. 2021, 42, 282–294. [Google Scholar] [CrossRef]
- Buhl, M.; Warzybok, A.; Schädler, M.R.; Kollmeier, B. Sensitivity and specificity of automatic audiological classification using expert-labelled audiological data and Common Audiological Functional Parameters. Int. J. Audiol. 2021, 60, 16–26. [Google Scholar] [CrossRef]
- Ellis, G.M.; Souza, P.E. Using machine learning and the National Health and Nutrition Examination Survey to classify individuals with hearing loss. Front. Digit. Health 2021, 3, 723533. [Google Scholar] [CrossRef] [PubMed]
- Rahme, M.; Folkeard, P.; Scollie, S. Evaluating the accuracy of step tracking and fall detection in the Starkey Livio artificial intelligence hearing aids: A pilot study. Am. J. Audiol. 2021, 30, 182–189. [Google Scholar] [CrossRef] [PubMed]
- Rodrigo, H.; Beukes, E.W.; Andersson, G.; Manchaiah, V. Exploratory data mining techniques (decision tree models) for examining the impact of internet-based cognitive behavioral therapy for tinnitus: Machine learning approach. J. Med. Internet Res. 2021, 23, e28999. [Google Scholar] [CrossRef] [PubMed]
- Hart, B.N.; Jeng, F.C. A Demonstration of machine learning in detecting frequency following responses in American neonates. Percept. Mot. Skills 2021, 128, 48–58. [Google Scholar] [CrossRef]
- Koyama, H.; Mori, A.; Nagatomi, D.; Fujita, T.; Saito, K.; Osaki, Y.; Yamasoba, T.; Doi, K. Machine learning technique reveals prognostic factors of vibrant soundbridge for conductive or mixed hearing loss patients. Otol. Neurotol. 2021, 42, e1286–e1292. [Google Scholar] [CrossRef]
- Kyong, J.S.; Suh, M.W.; Han, J.J.; Park, M.K.; Noh, T.S.; Oh, S.H.; Lee, J.H. Cross-modal cortical activity in the brain can predict cochlear implantation outcome in adults: A machine learning study. J. Int. Adv. Otol. 2021, 17, 380–386. [Google Scholar] [CrossRef]
- Li, L.P.; Han, J.Y.; Zheng, W.Z.; Huang, R.J.; Lai, Y.H. Improved environment-aware-based noise reduction system for cochlear implant users based on a knowledge transfer approach: Development and usability study. J. Med. Internet Res. 2021, 23, e25460. [Google Scholar] [CrossRef]
- Liu, Y.; Xu, R.; Gong, Q. Maximising the ability of stimulus-frequency otoacoustic emissions to predict hearing status and thresholds using machine-learning models. Int. J. Audiol. 2021, 60, 263–273. [Google Scholar] [CrossRef]
- Luengen, M.; Garrelfs, C.; Adiloǧlu, K.; Krueger, M.; Cauchi, B.; Markert, U.; Typlt, M.; Kinkel, M.; Schultz, C. Connected hearing devices and audiologists: The user-centered development of digital service innovations. Front. Digit. Health 2021, 3, 739370. [Google Scholar] [CrossRef]
- Profant, O.; Bureš, Z.; Balogová, Z.; Betka, J.; Fík, Z.; Chovanec, M.; Voráček, J. Decision making on vestibular schwannoma treatment: Predictions based on machine-learning analysis. Sci. Rep. 2021, 11, 18376. [Google Scholar] [CrossRef]
- Schlee, W.; Langguth, B.; Pryss, R.; Allgaier, J.; Mulansky, L.; Vogel, C.; Spiliopoulou, M.; Schleicher, M.; Unnikrishnan, V.; Puga, C.; et al. Using big data to develop a clinical decision support system for tinnitus treatment. Curr. Top. Behav. Neurosci. 2021, 51, 175–189. [Google Scholar] [CrossRef] [PubMed]
- Shafieibavani, E.; Goudey, B.; Kiral, I.; Zhong, P.; Jimeno-Yepes, A.; Swan, A.; Gambhir, M.; Buechner, A.; Kludt, E.; Eikelboom, R.H.; et al. Predictive models for cochlear implant outcomes: Performance, generalizability, and the impact of cohort size. Trends Hear. 2021, 25, 23312165211066174. [Google Scholar] [CrossRef] [PubMed]
- Skidmore, J.; Xu, L.; Chao, X.; Riggs, W.J.; Pellittieri, A.; Vaughan, C.; Ning, X.; Wang, R.; Luo, J.; He, S. Prediction of the functional status of the cochlear nerve in individual cochlear implant users using machine learning and electrophysiological measures. Ear Hear. 2021, 42, 180–192. [Google Scholar] [CrossRef] [PubMed]
- Ting, P.J.; Ruan, S.J.; Li, L.P. Environmental noise classification with inception-dense blocks for hearing aids. Sensors 2021, 21, 5406. [Google Scholar] [CrossRef] [PubMed]
- Wasmann, J.A.; Lanting, C.P.; Huinck, W.J.; Mylanus, E.A.M.; van der Laak, J.W.M.; Govaerts, P.J.; Swanepoel, W.; Moore, D.R.; Barbour, D.L. Computational audiology: New approaches to advance hearing health care in the digital age. Ear Hear. 2021, 42, 1499–1507. [Google Scholar] [CrossRef]
- Wimalarathna, H.; Ankmnal-Veeranna, S.; Allan, C.; Agrawal, S.K.; Samarabandu, J.; Ladak, H.M.; Allen, P. Comparison of machine learning models to classify Auditory Brainstem Responses recorded from children with Auditory Processing Disorder. Comput. Methods Programs Biomed. 2021, 200, 105942. [Google Scholar] [CrossRef]
- Wu, Z.; Lin, Z.; Li, L.; Pan, H.; Chen, G.; Fu, Y.; Qiu, Q. Deep learning for classification of pediatric otitis media. Laryngoscope 2021, 131, E2344–E2351. [Google Scholar] [CrossRef]
- Anderson, S.R.; Jocewicz, R.; Kan, A.; Zhu, J.; Tzeng, S.; Litovsky, R.Y. Sound source localization patterns and bilateral cochlear implants: Age at onset of deafness effects. PLoS ONE 2022, 17, e0263516. [Google Scholar] [CrossRef]
- Anh, D.T.; Takakura, H.; Asai, M.; Ueda, N.; Shojaku, H. Application of machine learning in the diagnosis of vestibular disease. Sci. Rep. 2022, 12, 20805. [Google Scholar] [CrossRef]
- Buhl, M. Interpretable Clinical Decision Support System for Audiology Based on Predicted Common Audiological Functional Parameters (CAFPAs). Diagnostics 2022, 12, 463. [Google Scholar] [CrossRef]
- Buhl, M.; Akin, G.; Saak, S.; Eysholdt, U.; Radeloff, A.; Kollmeier, B.; Hildebrandt, A. Expert validation of prediction models for a clinical decision-support system in audiology. Front. Neurol. 2022, 13, 960012. [Google Scholar] [CrossRef] [PubMed]
- Hoppe, U.; Hocke, T.; Iro, H. Age-Related Decline of Speech Perception. Front. Aging Neurosci. 2022, 14, 891202. [Google Scholar] [CrossRef] [PubMed]
- Hülsmeier, D.; Kollmeier, B. How much individualization is required to predict the individual effect of suprathreshold processing deficits? Assessing Plomp’s distortion component with psychoacoustic detection thresholds and FADE. Hear. Res. 2022, 426, 108609. [Google Scholar] [CrossRef] [PubMed]
- Lenatti, M.; Moreno-Sánchez, P.A.; Polo, E.M.; Mollura, M.; Barbieri, R.; Paglialonga, A. Evaluation of machine learning algorithms and explainability techniques to detect hearing Loss from a speech-in-noise screening test. Am. J. Audiol. 2022, 31, 961–979. [Google Scholar] [CrossRef] [PubMed]
- Madahana, M.C.I.; Nyandoro, O.T.C.; Khoza-Shangase, K.; Moroe, N.F. From manual to fully-automated systems and the impact of artificial intelligence: Effects of changes in mining practices on occupational noise-induced hearing loss in Africa. In Occupational Noise-Induced Hearing Loss: An African Perspective; Khoza-Shangase, K., Ed.; AOSIS: Cape Town, South Africa, 2022. [Google Scholar]
- Madahana, M.C.; Khoza-Shangase, K.; Moroe, N.; Nyandoro, O.; Ekoru, J. Application of machine learning approaches to analyse student success for contact learning and emergency remote teaching and learning during the COVID-19 era in speech-language pathology and audiology. S. Afr. J. Commun. Disord. 2022, 69, e1–e13. [Google Scholar] [CrossRef]
- McKearney, R.M.; Bell, S.L.; Chesnaye, M.A.; Simpson, D.M. Auditory brainstem response detection using machine learning: A comparison with statistical detection methods. Ear Hear. 2022, 43, 949–960. [Google Scholar] [CrossRef]
- McMurray, B.; Sarrett, M.E.; Chiu, S.; Black, A.K.; Wang, A.; Canale, R.; Aslin, R.N. Decoding the temporal dynamics of spoken word and nonword processing from EEG. NeuroImage 2022, 260, 119457. [Google Scholar] [CrossRef]
- Ntlhakana, L.; Khoza-Shangase, K. Machine learning models: Predictive tools for occupational noise-induced hearing loss in the South African mining industry. In Preventive Audiology: An African Perspective; Khoza-Shangase, K., Ed.; AOSIS: Cape Town, South Africa, 2022. [Google Scholar]
- Pitathawatchai, P.; Chaichulee, S.; Kirtsreesakul, V. Robust machine learning method for imputing missing values in audiograms collected in children. Int. J. Audiol. 2022, 61, 66–77. [Google Scholar] [CrossRef]
- Saak, S.; Huelsmeier, D.; Kollmeier, B.; Buhl, M. A flexible data-driven audiological patient stratification method for deriving auditory profiles. Front. Neurol. 2022, 13, 959582. [Google Scholar] [CrossRef]
- Sandström, J.; Myburgh, H.; Laurent, C.; Swanepoel, W.; Lundberg, T. A Machine learning approach to screen for otitis media using digital otoscope images labelled by an expert panel. Diagnostics 2022, 12, 1318. [Google Scholar] [CrossRef]
- Sundgaard, J.V.; Bray, P.; Laugesen, S.; Harte, J.; Kamide, Y.; Tanaka, C.; Christensen, A.N.; Paulsen, R.R. A Deep learning approach for detecting otitis media from wideband tympanometry measurements. IEEE J. Biomed. Health Inform. 2022, 26, 2974–2982. [Google Scholar] [CrossRef] [PubMed]
- Wasmann, J.W.; Pragt, L.; Eikelboom, R.; Swanepoel, W. Digital approaches to automated and machine learning assessments of hearing: Scoping review. J. Med. Internet Res. 2022, 24, e32581. [Google Scholar] [CrossRef] [PubMed]
- Wimalarathna, H.; Ankmnal-Veeranna, S.; Allan, C.; Agrawal, S.K.; Samarabandu, J.; Ladak, H.M.; Allen, P. Machine learning approaches used to analyze auditory evoked responses from the human auditory brainstem: A systematic review. Comput. Methods Programs Biomed. 2022, 226, 107118. [Google Scholar] [CrossRef] [PubMed]
- Zeng, J.; Kang, W.; Chen, S.; Lin, Y.; Deng, W.; Wang, Y.; Chen, G.; Ma, K.; Zhao, F.; Zheng, Y.; et al. A deep learning approach to predict conductive hearing loss in patients with otitis media with effusion using otoscopic images. JAMA Otolaryngol. Head Neck Surg. 2022, 148, 612–620. [Google Scholar] [CrossRef] [PubMed]
- Abousetta, A.; El Kholy, W.; Hegazy, M.; Kolkaila, E.; Emara, A.; Serag, S.; Ismail, O. A scoring system for cochlear implant candidate selection using artificial intelligence. Hear. Balance Commun. 2023, 21, 114–121. [Google Scholar] [CrossRef]
- Amiri, S.; Abdolali, F.; Neshastehriz, A.; Nikoofar, A.; Farahani, S.; Firoozabadi, L.A.; Askarabad, Z.A.; Cheraghi, S. A machine learning approach for prediction of auditory brain stem response in patients after head-and-neck radiation therapy. J. Cancer Res. Ther. 2023, 19, 1219–1225. [Google Scholar] [CrossRef]
- Balan, J.R.; Rodrigo, H.; Saxena, U.; Mishra, S.K. Explainable machine learning reveals the relationship between hearing thresholds and speech-in-noise recognition in listeners with normal audiograms. J. Acoust. Soc. Am. 2023, 154, 2278–2288. [Google Scholar] [CrossRef]
- Bragg, P.G.; Norton, B.M.; Petrak, M.R.; Weiss, A.D.; Kandl, L.M.; Corrigan, M.L.; Bahner, C.L.; Matsuoka, A.J. Application of supervised machine learning algorithms for the evaluation of utricular function on patients with Meniere’s disease: Utilizing subjective visual vertical and ocular-vestibular-evoked myogenic potentials. Acta Otolaryngol. 2023, 143, 262–273. [Google Scholar] [CrossRef]
- Cao, Z.; Chen, F.; Grais, E.M.; Yue, F.; Cai, Y.; Swanepoel, W.; Zhao, F. Machine learning in diagnosing middle ear disorders using tympanic membrane images: A meta-analysis. Laryngoscope 2023, 133, 732–741. [Google Scholar] [CrossRef]
- Doborjeh, M.; Liu, X.; Doborjeh, Z.; Shen, Y.; Searchfield, G.; Sanders, P.; Wang, G.Y.; Sumich, A.; Yan, W.Q. Prediction of tinnitus treatment outcomes based on EEG sensors and TFI score using deep learning. Sensors 2023, 23, 902. [Google Scholar] [CrossRef]
- Gathman, T.J.; Choi, J.S.; Vasdev, R.M.S.; Schoephoerster, J.A.; Adams, M.E. Machine learning prediction of objective hearing loss with demographics, clinical factors, and subjective hearing status. Otolaryngol. Head Neck Surg. 2023, 169, 504–513. [Google Scholar] [CrossRef] [PubMed]
- Jin, F.Q.; Huang, O.; Kleindienst Robler, S.; Morton, S.; Platt, A.; Egger, J.R.; Emmett, S.D.; Palmeri, M.L. A hybrid deep learning approach to identify preventable childhood hearing loss. Ear Hear. 2023, 44, 1262–1270. [Google Scholar] [CrossRef] [PubMed]
- Kong, S.; Huang, Z.; Deng, W.; Zhan, Y.; Lv, J.; Cui, Y. Nystagmus patterns classification framework based on deep learning and optical flow. Comput. Biol. Med. 2023, 153, 106473. [Google Scholar] [CrossRef]
- Mahey, P.; Toussi, N.; Purnomu, G.; Herdman, A.T. Generative Adversarial Network (GAN) for simulating electroencephalography. Brain Topogr. 2023, 36, 661–670. [Google Scholar] [CrossRef]
- Mohsen, S.; Sadeghijam, M.; Talebian, S.; Pourbakht, A. Use of some relevant parameters for primary prediction of brain activity in idiopathic tinnitus based on a machine learning application. Audiol. Neurootol. 2023, 28, 446–457. [Google Scholar] [CrossRef]
- Petsiou, D.P.; Martinos, A.; Spinos, D. Applications of artificial intelligence in temporal bone imaging: Advances and future challenges. Cureus 2023, 15, e44591. [Google Scholar] [CrossRef]
- Ramzi, G.; McLoughlin, I.; Palaniappan, R. Did you hear that? Detecting aditory events with EEGNet. In Proceedings of the 2023 45th Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Sydney, Australia, 24–27 July 2023; pp. 1–4. [Google Scholar] [CrossRef]
- Saeed, H.S.; Fergie, M.; Mey, K.; West, N.; Caye-Thomasen, P.; Nash, R.; Saeed, S.R.; Stivaros, S.M.; Black, G.; Bruce, I.A. Enlarged vestibular aqueduct and associated inner ear malformations: Hearing loss prognostic factors and data modeling from an international cohort. J. Int. Adv. Otol. 2023, 19, 454–460. [Google Scholar] [CrossRef]
- Schroeer, A.; Andersen, M.R.; Rank, M.L.; Hannemann, R.; Petersen, E.B.; Rønne, F.M.; Strauss, D.J.; Corona-Strauss, F.I. Assessment of vestigial auriculomotor activity to acoustic stimuli using electrodes in and around the ear. Trends Hear. 2023, 27, 23312165231200158. [Google Scholar] [CrossRef]
- Schuerch, K.; Wimmer, W.; Dalbert, A.; Rummel, C.; Caversaccio, M.; Mantokoudis, G.; Gawliczek, T.; Weder, S. An intracochlear electrocochleography dataset—From raw data to objective analysis using deep learning. Sci. Data 2023, 10, 157. [Google Scholar] [CrossRef]
- Seifer, A.K.; Dorschky, E.; Küderle, A.; Moradi, H.; Hannemann, R.; Eskofier, B.M. EarGait: Estimation of temporal gait parameters from hearing aid integrated inertial sensors. Sensors 2023, 23, 6565. [Google Scholar] [CrossRef]
- Wathour, J.; Govaerts, P.J.; Lacroix, E.; Naïma, D. Effect of a CI programming fitting tool with artificial intelligence in experienced cochlear implant patients. Otol. Neurotol. 2023, 44, 209–215. [Google Scholar] [CrossRef] [PubMed]
- Wathour, J.; Govaerts, P.J.; Derue, L.; Vanderbemden, S.; Huaux, H.; Lacroix, E.; Deggouj, N. Prospective comparison between manual and computer-assisted (FOX) cochlear implant fitting in newly implanted patients. Ear Hear. 2023, 44, 494–505. [Google Scholar] [CrossRef] [PubMed]
- Yang, T.H.; Chen, Y.F.; Cheng, Y.F.; Huang, J.N.; Wu, C.S.; Chu, Y.C. Optimizing age-related hearing risk predictions: An advanced machine learning integration with HHIE-S. BioData Min. 2023, 16, 35. [Google Scholar] [CrossRef]
- Yu, F.; Wu, P.; Deng, H.; Wu, J.; Sun, S.; Yu, H.; Yang, J.; Luo, X.; He, J.; Ma, X.; et al. A questionnaire-based ensemble learning model to predict the diagnosis of vertigo: Model development and validation study. J. Med. Internet Res. 2022, 24, e34126. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, M.A.O.; Satar, Y.A.; Darwish, E.M.; Zanaty, E.A. Synergistic integration of multi-view brain networks and advanced machine learning techniques for auditory disorders diagnostics. Brain Inform. 2024, 11, 3. [Google Scholar] [CrossRef] [PubMed]
- Carlson, M.L.; Carducci, V.; Deep, N.L.; DeJong, M.D.; Poling, G.L.; Brufau, S.R. AI model for predicting adult cochlear implant candidacy using routine behavioral audiometry. Am. J. Otolaryngol. 2024, 45, 104337. [Google Scholar] [CrossRef]
- Chen, P.Y.; Yang, T.W.; Tseng, Y.S.; Tsai, C.Y.; Yeh, C.S.; Lee, Y.H.; Lin, P.H.; Lin, T.C.; Wu, Y.J.; Yang, T.H.; et al. Machine learning-based longitudinal prediction for GJB2-related sensorineural hearing loss. Comput. Biol. Med. 2024, 176, 108597. [Google Scholar] [CrossRef]
- Chua, K.W.; Yeo, H.K.H.; Tan, C.K.L.; Martinez, J.C.; Goh, Z.H.; Dritsas, S.; Simpson, R.E. A novel ear impression-taking method using structured light imaging and machine learning: A pilot proof of concept study with patients’ feedback on prototype. J. Clin. Med. 2024, 13, 1214. [Google Scholar] [CrossRef]
- Deroche, M.L.D.; Wolfe, J.; Neumann, S.; Manning, J.; Hanna, L.; Towler, W.; Wilson, C.; Bien, A.G.; Miller, S.; Schafer, E.; et al. Cross-Modal Plasticity in Children with cochlear implant: Converging evidence from EEG and functional near-infrared spectroscopy. Brain Commun. 2024, 6, fcae175. [Google Scholar] [CrossRef]
- Dou, Z.; Li, Y.; Deng, D.; Zhang, Y.; Pang, A.; Fang, C.; Bai, X.; Bing, D. Pure tone audiogram classification using deep learning techniques. Clin. Otolaryngol. 2024, 49, 595–603. [Google Scholar] [CrossRef]
- Heman-Ackah, S.M.; Blue, R.; Quimby, A.E.; Abdallah, H.; Sweeney, E.M.; Chauhan, D.; Hwa, T.; Brant, J.; Ruckenstein, M.J.; Bigelow, D.C.; et al. A multi-institutional machine learning algorithm for prognosticating facial nerve injury following microsurgical resection of vestibular schwannoma. Sci. Rep. 2024, 14, 12963. [Google Scholar] [CrossRef] [PubMed]
- Jedrzejczak, W.W.; Kochanek, K. Comparison of the audiological knowledge of three chatbots: ChatGPT, Bing Chat, and Bard. Audiol. Neurootol. 2024, 13, 1–7. [Google Scholar] [CrossRef] [PubMed]
- Jedrzejczak, W.W.; Skarzynski, P.H.; Raj-Koziak, D.; Sanfins, M.D.; Hatzopoulos, S.; Kochanek, K. ChatGPT for tinnitus information and support: Response accuracy and retest after three and six months. Brain Sci. 2024, 14, 465. [Google Scholar] [CrossRef] [PubMed]
- Kohler, I.; Perrotta, M.V.; Ferreira, T.; Eagleman, D.M. Cross-modal sensory boosting to improve high-frequency hearing loss: Device development and validation. JMIRx Med. 2024, 5, e49969. [Google Scholar] [CrossRef] [PubMed]
- Liang, S.; Xu, J.; Liu, H.; Liang, R.; Guo, Z.; Lu, M.; Liu, S.; Gao, J.; Ye, Z.; Yi, H. Automatic recognition of auditory brainstem response waveforms using a deep learning-based framework. Otolaryngol. Head Neck Surg. 2024, 171, 1165–1171. [Google Scholar] [CrossRef]
- Madahana, M.C.I.; Ekoru, J.E.D.; Sebothoma, B.; Khoza-Shangase, K. Development of an artificial intelligence based occupational noise induced hearing loss early warning system for mine workers. Front. Neurosci. 2024, 18, 1321357. [Google Scholar] [CrossRef]
- Sadegh-Zadeh, S.A.; Soleimani Mamalo, A.; Kavianpour, K.; Atashbar, H.; Heidari, E.; Hajizadeh, R.; Roshani, A.S.; Habibzadeh, S.; Saadat, S.; Behmanesh, M.; et al. Artificial intelligence approaches for tinnitus diagnosis: Leveraging high-frequency audiometry data for enhanced clinical predictions. Front. Artif. Intell. 2024, 7, 1381455. [Google Scholar] [CrossRef]
- Simon, A.; Bech, S.; Loquet, G.; Østergaard, J. Cortical linear encoding and decoding of sounds: Similarities and differences between naturalistic speech and music listening. Eur. J. Neurosci. 2024, 59, 2059–2074. [Google Scholar] [CrossRef]
- Soylemez, E.; Avci, I.; Yildirim, E.; Karaboya, E.; Yilmaz, N.; Ertugrul, S.; Tokgoz-Yilmaz, S. Predicting noise-induced hearing loss with machine learning: The influence of tinnitus as a predictive factor. J. Laryngol. Otol. Published Online 2024, 1–18. [Google Scholar] [CrossRef]
- Twinomurinzi, H.; Myburgh, H.; Barbour, D.L. Active transfer learning for audiogram estimation. Front. Digit. Health 2024, 6, 1267799. [Google Scholar] [CrossRef]
- Wang, C.; Young, A.S.; Raj, C.; Bradshaw, A.P.; Nham, B.; Rosengren, S.M.; Calic, Z.; Burke, D.; Halmagyi, G.M.; Bharathy, G.K.; et al. Machine learning models help differentiate between causes of recurrent spontaneous vertigo. J. Neurol. 2024, 271, 3426–3438. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Mo, C.; Chen, Y.; Dai, X.; Wang, H.; Shen, X. Exploring the performance of ChatGPT-4 in the Taiwan audiologist qualification examination: Preliminary observational study highlighting the potential of AI chatbots in hearing care. JMIR Med. Educ. 2024, 10, e55595. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Yao, X.; Wang, D.; Ye, C.; Xu, L. A machine learning screening model for identifying the risk of high-frequency hearing impairment in a general population. BMC Public Health 2024, 24, 1160. [Google Scholar] [CrossRef] [PubMed]
- Yin, Z.; Kuang, Z.; Zhang, H.; Guo, Y.; Li, T.; Wu, Z.; Wang, L. Explainable AI method for tinnitus diagnosis via neighbor-augmented knowledge graph and traditional Chinese medicine: Development and validation study. JMIR Med. Inform. 2024, 12, e57678. [Google Scholar] [CrossRef] [PubMed]
- Zeitler, D.M.; Buchlak, Q.D.; Ramasundara, S.; Farrokhi, F.; Esmaili, N. Predicting acoustic hearing preservation following cochlear implant surgery using machine learning. Laryngoscope 2024, 134, 926–936. [Google Scholar] [CrossRef]
- Liu, Y.; Gong, Q. Deep learning models for predicting hearing thresholds based on swept-tone stimulus-frequency otoacoustic emissions. Ear Hear. 2024, 45, 465–475. [Google Scholar] [CrossRef]
- Szaleniec, J.; Wiatr, M.; Szaleniec, M.; Składzień, J.; Tomik, J.; Oleś, K.; Tadeusiewicz, R. Artificial neural network modelling of the results of tympanoplasty in chronic suppurative otitis media patients. Comput. Biol. Med. 2013, 43, 16–22. [Google Scholar] [CrossRef]
- Fang, Y.; Wu, J.; Wang, Q.; Qiu, S.; Bozoki, A.; Liu, M. Source-free collaborative domain adaptation via multi-perspective feature enrichment for functional MRI analysis. Pattern Recognit. 2025, 157, 110912. [Google Scholar] [CrossRef]
- Deo, R.C. Machine learning in medicine. Circulation 2015, 132, 1920–1930. [Google Scholar] [CrossRef]
- Handelman, G.S.; Kok, H.K.; Chandra, R.V.; Razavi, A.H.; Lee, M.J.; Asadi, H. eDoctor: Machine learning and the future of medicine. J. Intern. Med. 2018, 284, 603–619. [Google Scholar] [CrossRef]
- An, Q.; Rahman, S.; Zhou, J.; Kang, J.J. A comprehensive review on machine learning in healthcare industry: Classification, restrictions, opportunities and challenges. Sensors 2023, 23, 4178. [Google Scholar] [CrossRef] [PubMed]
- Jiao, R.; Zhang, Y.; Ding, L.; Cai, R.; Zhang, J. Learning with limited annotations: A survey on deep semi-supervised learning for medical image segmentation. arXiv 2022, arXiv:2207.10085. [Google Scholar] [CrossRef] [PubMed]
- Wang, D.; Zhang, Y.; Zhang, K.; Wang, L. FocalMix: Semi-supervised learning for 3D medical image detection. arXiv 2020, arXiv:2007.02701. [Google Scholar]
- Liu, Y.; Logan, B.; Liu, N.; Xu, Z.; Tang, J.; Wang, Y. Deep reinforcement learning for dynamic treatment regimes on medical registry data. Healthc. Inform. 2017, 2017, 380–385. [Google Scholar] [PubMed]
- Zhachow, S.; Zilske, M.; Hege, H.C. 3D Reconstruction of Individual Anatomy from Medical Image Data: Segmentation and Geometry Processing. In Proceedings of the 25. ANSYS Conference & CADFEM Users’ Meeting, Dresden, Germany, 21–23 November 2007. [Google Scholar]
- Ke, J.; Lv, Y.; Ma, F.; Du, Y.; Xiong, S.; Wang, J.; Wang, J. Deep learning-based approach for the automatic segmentation of adult and pediatric temporal bone computed tomography images. Quant. Imaging Med. Surg. 2023, 13, 1577–1591. [Google Scholar] [CrossRef]
- Franz, L.; Isola, M.; Bagatto, D.; Tuniz, F.; Robiony, M. A Novel approach to skull-base and orbital osteotomies through virtual planning and navigation. Laryngoscope 2019, 129, 823–831. [Google Scholar] [CrossRef]
- European Society of Radiology (ESR). Current practical experience with artificial intelligence in clinical radiology: A survey of the European Society of Radiology. Insights Imaging 2022, 13, 107. [Google Scholar] [CrossRef]
- Wu, H.; Liu, J.; Chen, G.; Liu, J.; Chen, G.; Liu, W.; Hao, R.; Liu, L.; Ni, G.; Liu, Y.; et al. Automatic semicircular canal segmentation of CT volumes using improved 3D UNet with attention mechanism. Comput. Intell. Neurosci. 2021, 2021, 9654059. [Google Scholar] [CrossRef]
- Heutink, F.; Koch, V.; Verbist, B.; van der Woude, W.J.; Mylanus, E.; Huinck, W.; Sechopoulos, I.; Caballo, M. Multi-scale deep learning framework for cochlea localization, segmentation and analysis on clinical ultra-high-resolution CT images. Comput. Methods Programs Biomed. 2020, 191, 105387. [Google Scholar] [CrossRef]
- Lingam, R.K.; Bassett, P. A Meta-analysis on the diagnostic performance of non-echoplanar diffusion-weighted imaging in detecting middle ear cholesteatoma: 10 years on. Otol. Neurotol. 2017, 38, 521–528. [Google Scholar] [CrossRef]
- Boucher, F.; Liao, E.; Srinivasan, A. Diffusion-weighted imaging of the head and neck (including temporal bone). Magn. Reson. Imaging Clin. N. Am. 2021, 29, 205–232. [Google Scholar] [CrossRef] [PubMed]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 785–794. [Google Scholar] [CrossRef]
- Yasaka, K.; Furuta, T.; Kubo, T.; Maeda, E.; Katsura, M.; Sato, J.; Ohtomo, K. Full and hybrid iterative reconstruction to reduce artifacts in abdominal CT for patients scanned without arm elevation. Acta Radiol. 2017, 58, 1085–1093. [Google Scholar] [CrossRef] [PubMed]
- Higaki, T.; Nakamura, Y.; Tatsugami, F.; Nakaura, T.; Awai, K. Improvement of image quality at CT and MRI using deep learning. Jpn. J. Radiol. 2019, 37, 73–80. [Google Scholar] [CrossRef]
- Fujita, N.; Yasaka, K.; Hatano, S.; Sakamoto, N.; Kurokawa, R.; Abe, O. Deep learning reconstruction for high-resolution computed tomography images of the temporal bone: Comparison with hybrid iterative reconstruction. Neuroradiology 2024, 66, 1105–1112. [Google Scholar] [CrossRef]
- Ogawa, M.; Kisohara, M.; Yamamoto, T.; Shibata, S.; Ojio, Y.; Mochizuki, K.; Tatsuta, A.; Iwasaki, S.; Shibamoto, Y. Utility of unsupervised deep learning using a 3D variational autoencoder in detecting inner ear abnormalities on CT images. Comput. Biol. Med. 2022, 147, 105683. [Google Scholar] [CrossRef]
- Belle, V.; Papantonis, I. Principles and practice of explainable machine learning. Front. Big Data 2021, 4, 688969. [Google Scholar] [CrossRef]
- Asadi-Lari, M.; Tamburini, M.; Gray, D. Patients’ needs, satisfaction, and health related quality of life: Towards a comprehensive model. Health Qual. Life Outcomes 2004, 2, 32. [Google Scholar] [CrossRef]
- Wathour, J.; Govaerts, P.J.; Deggouj, N. From manual to artificial intelligence fitting: Two cochlear implant case studies. Cochlear Implants Int. 2020, 21, 299–305. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
| Journals | Number of Publications (%) | Study Design | Number of Publications (%) |
|---|---|---|---|
| Ear and Hearing | 13 (12.5%) | Observational | 71 (68.3%) |
| International Journal of Audiology | 6 (5.8%) | Development and Validation | 17 (16.3%) |
| Frontiers in Digital Health | 4 (3.8%) | Reviews | 9 (8.7%) |
| Others | 81 (88.7%) | Clinical Trials | 3 (2.9%) |
| Surveys | 2 (1.9%) | ||
| Case Reports and Study Protocols | 2 (1.9%) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Frosolini, A.; Franz, L.; Caragli, V.; Genovese, E.; de Filippis, C.; Marioni, G. Artificial Intelligence in Audiology: A Scoping Review of Current Applications and Future Directions. Sensors 2024, 24, 7126. https://doi.org/10.3390/s24227126
Frosolini A, Franz L, Caragli V, Genovese E, de Filippis C, Marioni G. Artificial Intelligence in Audiology: A Scoping Review of Current Applications and Future Directions. Sensors. 2024; 24(22):7126. https://doi.org/10.3390/s24227126
Chicago/Turabian StyleFrosolini, Andrea, Leonardo Franz, Valeria Caragli, Elisabetta Genovese, Cosimo de Filippis, and Gino Marioni. 2024. "Artificial Intelligence in Audiology: A Scoping Review of Current Applications and Future Directions" Sensors 24, no. 22: 7126. https://doi.org/10.3390/s24227126
APA StyleFrosolini, A., Franz, L., Caragli, V., Genovese, E., de Filippis, C., & Marioni, G. (2024). Artificial Intelligence in Audiology: A Scoping Review of Current Applications and Future Directions. Sensors, 24(22), 7126. https://doi.org/10.3390/s24227126