Abstract
Animal pose estimation is crucial for animal health assessment, species protection, and behavior analysis. It is an inevitable and unstoppable trend to apply deep learning to animal pose estimation. In many practical application scenarios, pose estimation models must be deployed on edge devices with limited resource. Therefore, it is essential to strike a balance between model complexity and accuracy. To address this issue, we propose a lightweight network model, i.e., MPE-HRNet, by improving Lite-HRNet. The improvements are threefold. Firstly, we improve Spatial Pyramid Pooling-Fast and apply it and the improved version to different branches. Secondly, we construct a feature extraction module based on a mixed pooling module and a dual spatial and channel attention mechanism, and take the feature extraction module as the basic module of MPE-HRNet. Thirdly, we introduce a feature enhancement stage to enhance important features. The experimental results on the AP-10K dataset and the Animal Pose dataset verify the effectiveness and efficiency of MPE-HRNet.
1. Introduction
Animal pose estimation aims to identify and locate the key points of animal bodies. It plays a crucial role in assessing animal health [1], protecting endangered species [2], and analyzing animal behavior [3]. With the advancement of deep learning technology, it has been an inevitable trend to apply the technology to animal pose estimation. Deep-learning-based solutions can be categorized into bottom-up solutions and top-down solutions [4]. The bottom-up solutions detect key points and then cluster the key points to generate specific poses [5,6]. Although these solutions are relatively fast, they cannot guarantee accuracy in complex scenes. Different from the bottom-up solutions, the top-down solutions [7,8,9] identify individual animal objects, and then estimate the poses of these objects, yielding higher accuracy [5,6].
A lot of effort has been devoted to the top-down solutions [10,11]. For example, some researchers utilize large network models, such as Hourglass [12] and HRNet [8], to achieve higher accuracy at the cost of high complexity [13,14,15,16,17,18,19]. In many practical application scenarios, pose estimation models must be deployed on edge devices. Edge devices are always equipped with limited resource. They are unable to leverage the advantages of large models since they cannot provide the resource that large models need. Inspired by ShuffleNet [20], Yu et al. [9] proposed a lightweight version of HRNet, i.e., Lite-HRNet. Lite-HRNet can estimate the poses of human beings with relatively high speed and accuracy. However, it shows an obvious drop in accuracy when estimating the poses of animals of multiple species. That happens because of two reasons. The first reason is that animals of different species possess different anatomical structures, resulting in significant variations in their poses. The second reason is that Lite-HRNet sacrifices accuracy in favor of a light network structure.
In this paper, we propose a lightweight network to estimate the poses of multiple species on edge devices with higher accuracy. We name the lightweight network MPE-HRNet and construct it by improving Lite-HRNet from three aspects. Firstly, we improve Spatial Pyramid Pooling-Fast (SPPF) and propose SPPF. We apply SPPF and SPPF to different branches in order to enrich the receptive fields of feature maps and mitigate the impact of feature loss caused by pooling operations. Secondly, we propose a mixed pooling module (MPM) and a dual spatial and channel attention mechanism (DSCA). Leveraging MPM and DSAM, we construct a mixed feature extraction (MFE) block with two different versions. Thirdly, we design a feature enhancement (FE) stage, and append it as the last stage of MPE-HRNet. The main contributions of this work are as follows.
- We propose SPPF. Comparing with SPPF, SPPF has a stronger feature extraction capability and lower computational load.
- We propose MPM and DSCA. Based on MPM and DSCA, we design MFE block which possesses strong feature extraction capabilities.
- We design the FE stage and take it as the final stage of MPE-HRNet. This stage is introduced to emphasize the semantic feature in the output feature map of MPE-HRNet.
2. Related Works
This section presents the significant advancements in animal pose estimation and two important techniques of deep learning. Firstly, Section 2.1 summarizes the research status of animal pose estimation. Secondly, Section 2.2 addresses the evolution and application of attention mechanisms. Finally, Section 2.3 discusses the advantage and the development of spatial pyramid pooling (SPP).
2.1. Animal Pose Estimation
Traditional solutions [21] for animal pose estimation involve obtaining behavioral data through manual observation or attaching sensors to animals. These methods incur high labor costs and implementation difficulties, along with challenges related to equipment vulnerability and data collection for rare species. Deep-learning-based pose estimation solutions can effectively alleviate these problems [22]. These solutions can be classified into bottom-up solutions and top-down solutions. Considering accuracy, this paper solely focuses on the top-down solutions.
To improve accuracy, large network models have been introduced to some of the top-down solutions. Graving et al. [17] developed a software toolkit based on Hourglass and DenseNet [23] to estimate keypoint locations with subpixel precision. Zhou et al. [16] improved Hourglasses to model the differences and spatial correlations between mouse body parts. Wang et al. [13] designed a grouped pig pose estimation model which exploited HRNet [24] to predict the heatmap of keypoints of pigs. Fan et al. [14] and Zhao et al. [18] also exploited HRNet. They constructed a pose estimation network for cattle and Jinling ducks, respectively. He et al. [15] combined Vision Transformer (ViT) [25] and HRNet, and constructed a model for birds. The above solutions are only applicable in scenarios involving single-species pose estimation.
In multispecies pose estimation scenarios, Gong et al. [19] applied dynamic convolution and a receptive field block to HRNet, thereby significantly enhancing the feature extraction of quadrupeds. In order to address the challenges in animal data annotation, Liao et al. [26] proposed THANet to transfer human pose estimation to animal pose estimation. Different from the solution of Liao et al. [26], Hu and Liu [27] utilized a language–image contrastive learning model to address the challenges, while Zeng et al. [28] employed a semi-supervised method with MVCRNet to utilize unlabeled data. All these solutions exploit large models. In many practical application scenarios, models are always deployed on edge devices. Because of the limited memory and computing power, large models are not suitable for those devices. We try to make a trade-off between accuracy and complexity, and design a lightweight model to run animal pose estimation on edge devices with relatively high accuracy.
2.2. Attention Mechanism
Attention mechanism [29] allows models to focus on important areas in an image by mimicking the human visual system. It calculates a weight matrix for an input feature map and depends on the weight matrix to highlight the important features and weaken the irrelevant features in the feature map. SENet [30], ECANet [31], FcaNet [32], and CBAM [33] are all attention mechanisms.
SENet is composed of a squeeze module and an excitation module. The squeeze module extracts global spatial information from input feature maps and then compresses these feature maps using global average pooling. The excitation module uses a fully connected layer to capture the relationships among these compressed feature maps and output an attention weight matrix for the input feature maps. Wang et al. [31] believe that the fully connected layer in the excitation module increases the complexity of SENet. They replaced the fully connected layer with a 1D convolution, from which they came up with ECANet. Qin et al. [32] also made improvements to SENet. They replaced the global average pooling with the following operations: grouping the feature maps and then processing the grouped feature maps with a 2D discrete cosine transform function. CBAM is a hybrid attention mechanism that combines the channel features and spatial features of input feature maps to figure out where to focus and what to focus on.
2.3. Spatial Pyramid Pooling
Convolutional neural networks (CNNs) [34] often require input images to meet a special requirement of size to ensure that the fully connected layer can output feature vectors of a specific size. Traditional methods exploit cropping and stretching to generate images of a specific size, but this can result in image distortion and information loss. SPP [35] utilizes pooling operations of different scales to transform images of different sizes into a specific size, thus avoiding stretching or cropping images. Chen et al. [36] replaced the pooling layers in SPP with multiple dilated convolutions with different dilation factors to generate feature maps with larger receptive fields. Jocher [37] improved SPP and proposed SPPF. SPPF exploits multiple concatenated pooling layers of the same scale to process input feature maps, and fuses the pooling results in parallel to improve speed.
3. Proposed Algorithm
In this section, we illustrate the proposed MPE-HRNet. We outline the structure of MPE-HRNet in Section 3.1, and then elaborate the improved version of SPPF in Section 3.2. After representing the details of MFE block in Section 3.3, we describe the feature enhancement stage in Section 3.4.
3.1. Architecture of MPE-HRNet
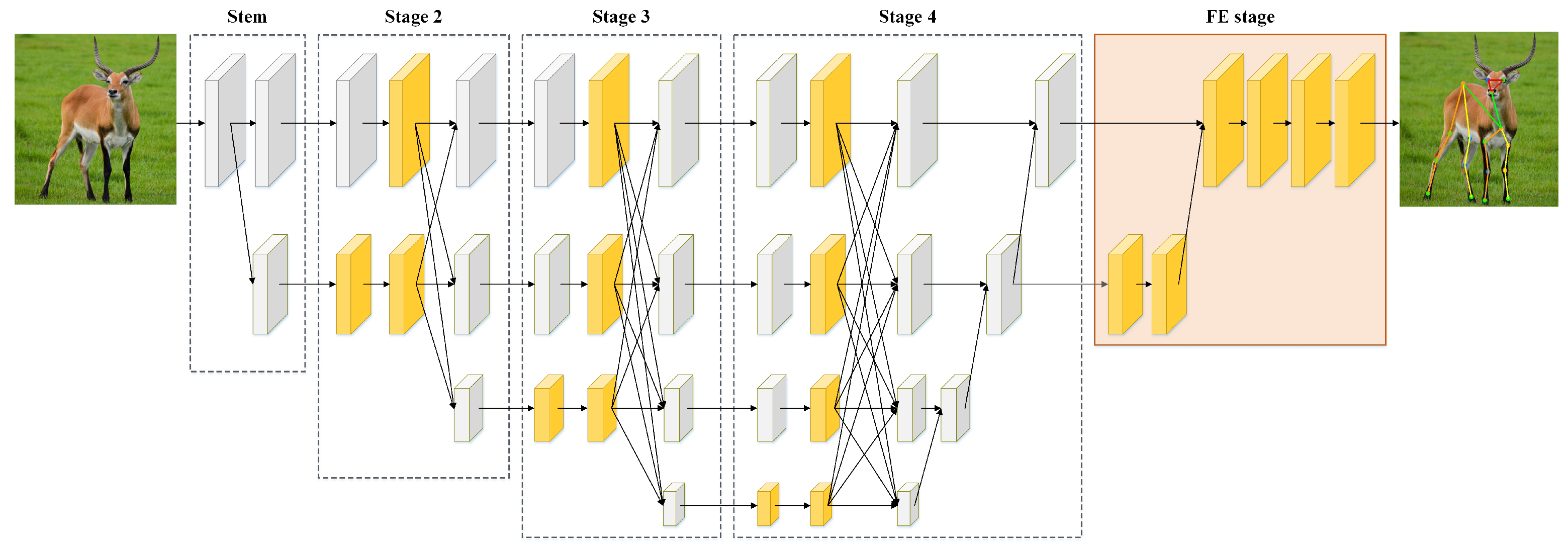
To construct a lightweight network for accurately estimating the poses of multiple animal species, we improved Lite-HRNet and proposed MPE-HRNet. The improvements include optimizing branches with SPPF, SPPF and MFE block, and introducing a feature enhancement (FE) stage. The branch optimization is designed to enhance the feature extraction and representation capabilities of MPE-HRNet. The introduction of the FE stage aims to enhance the important features in the final outputs of MPE-HRNet. Figure 1 and Table 1 show the architecture and the details of MPE-HRNet, respectively.
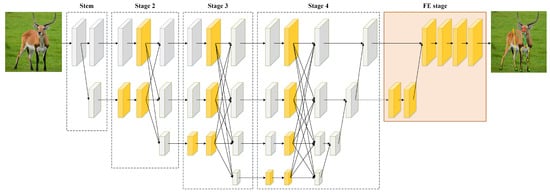
Figure 1.
Overall architecture of MPE-HRNet. MPE-HRNet includes five stages. MFE block and SPPF/SPPF are applied to stages 2 to 4. FE stage is appended as the final stage. The yellow cuboids describe the feature maps processed by our improvements.

Table 1.
Structure details of MPE-HRNet.
As Figure 1 and Table 1 show, stage stem only creates a new branch with a conv2d block and a shuffle block. Both stage 2 and stage 3 create a new branch, and apply SPPF to the branches created by the previous stage of each of them. They stack multiple MFE blocks to extract features from all the branches except the ones created by themselves. Similar to stage 2 and stage 3, stage 4 also applies stacked MFE blocks to branches. The difference is that stage 4 does not create any new branches, and it applies SPPF instead of SPPF to the branch created by its previous stage. Stage FE is quite different from the former four stages. It is introduced to enhance the features output by stage 4.
3.2. SPPF+
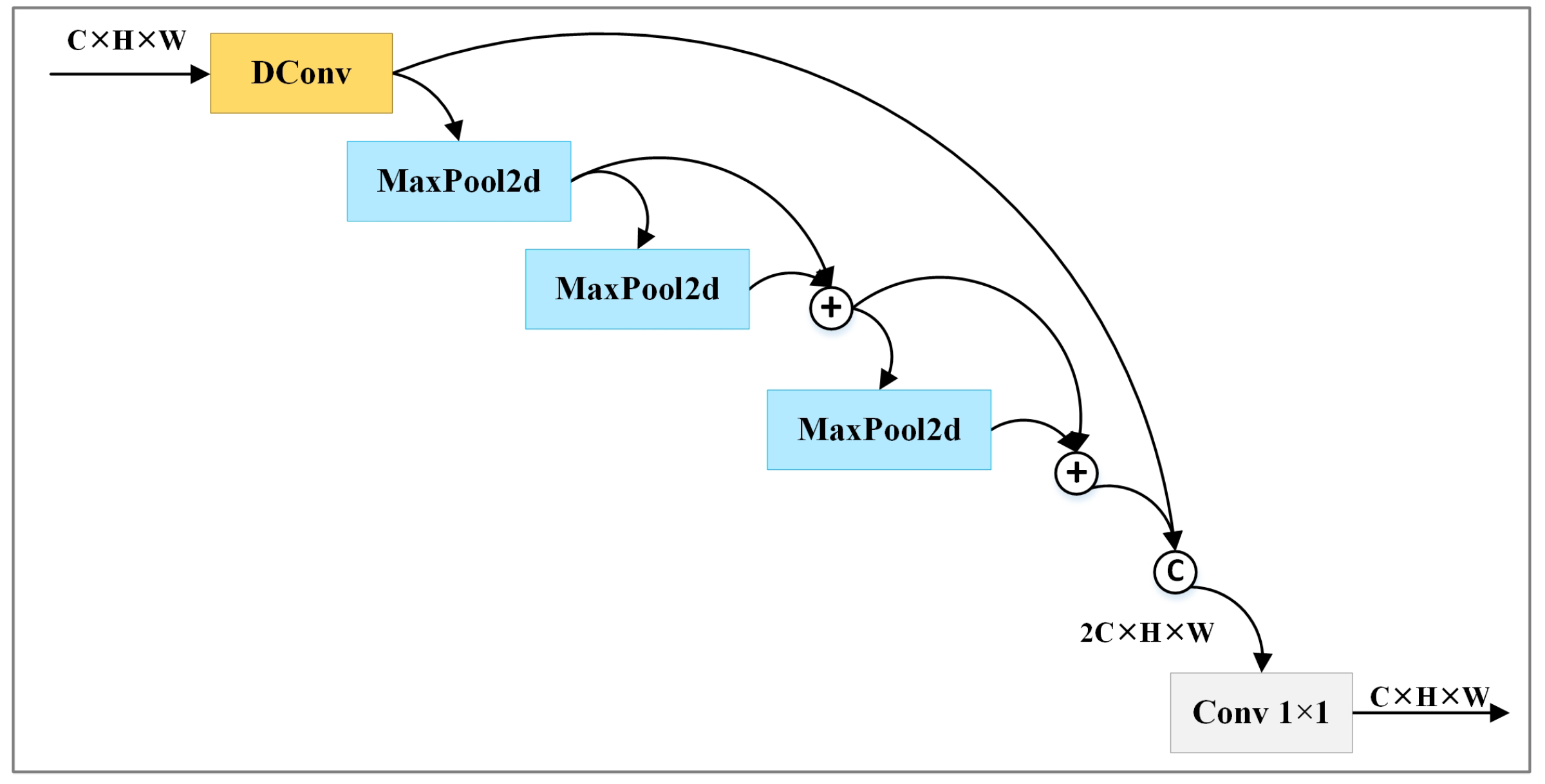
Lite-HRNet utilizes downsampling to create new branches. However, downsampling can only generate feature maps with limited receptive fields. It could probably also lose some important features. SPPF can generate feature maps with rich receptive fields by extracting multiple features of varying scales and fusing them together. However, SPPF has three obvious limitations. Firstly, 1 × 1 convolution struggles to extract complex features. Secondly, pooling operations also lose some features. Finally, concat operation increases computational complexity. To address these issues, we improve SPPF and propose SPPF.
In order to enhance the ability to extract features, SPPF replaces the 1 × 1 convolution with a depthwise separable convolution. To ensure that the feature maps generated by pooling operations contain rich features, SPPF inserts fusion operations among the sequential pooling operations. Concretely, it fuses the results of the initial two pooling operations, and then processes the fused results with the last pooling operation. To reduce the computational complexity caused by the concatenation operation, SPPF refrains from concatenating the feature maps produced by the pooling operations with the one yielded by the depthwise separable convolution. Instead, it fuses the results of the last pooling operation with the fused results of the first two pooling operations, and then concatenates the fused results with the results of the depthwise separable convolution. SPPF employs ADD operations to achieve fusion.
Figure 2 illustrates the architecture of SPPF. denotes the outputs of SPPF with the given input , which includes multiple channels. It is computed according to Equation (1). In the equation, represents 1 × 1 convolution, denotes the concatenation operation, describes depthwise separable convolution, and represents a series of max pooling operations. is calculated according to Equations (2)–(5).
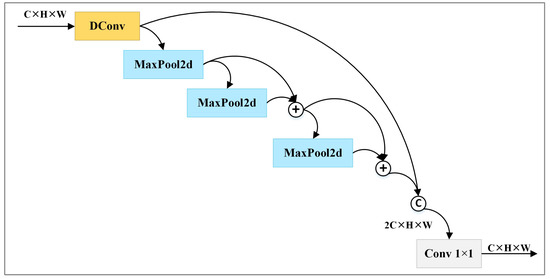
Figure 2.
Structures of SPPF. © and ⊕ represent concat operation and add operation, respectively.
3.3. Mixed Feature Extraction Block
Lite-HRNet exploits the conditional channel weight block (CCW) to extract features. The CCW includes two weight calculation functions, and . employs average pooling to generate low-resolution feature maps, which may loss some important details. neglects spatial information when computing weight matrices, which is crucial for localizing keypoints. To address these issues, we propose WGM along with DSCA, and construct the MFE block based on them, which serves as the foundational module for feature extraction.
3.3.1. Weight Generation Module
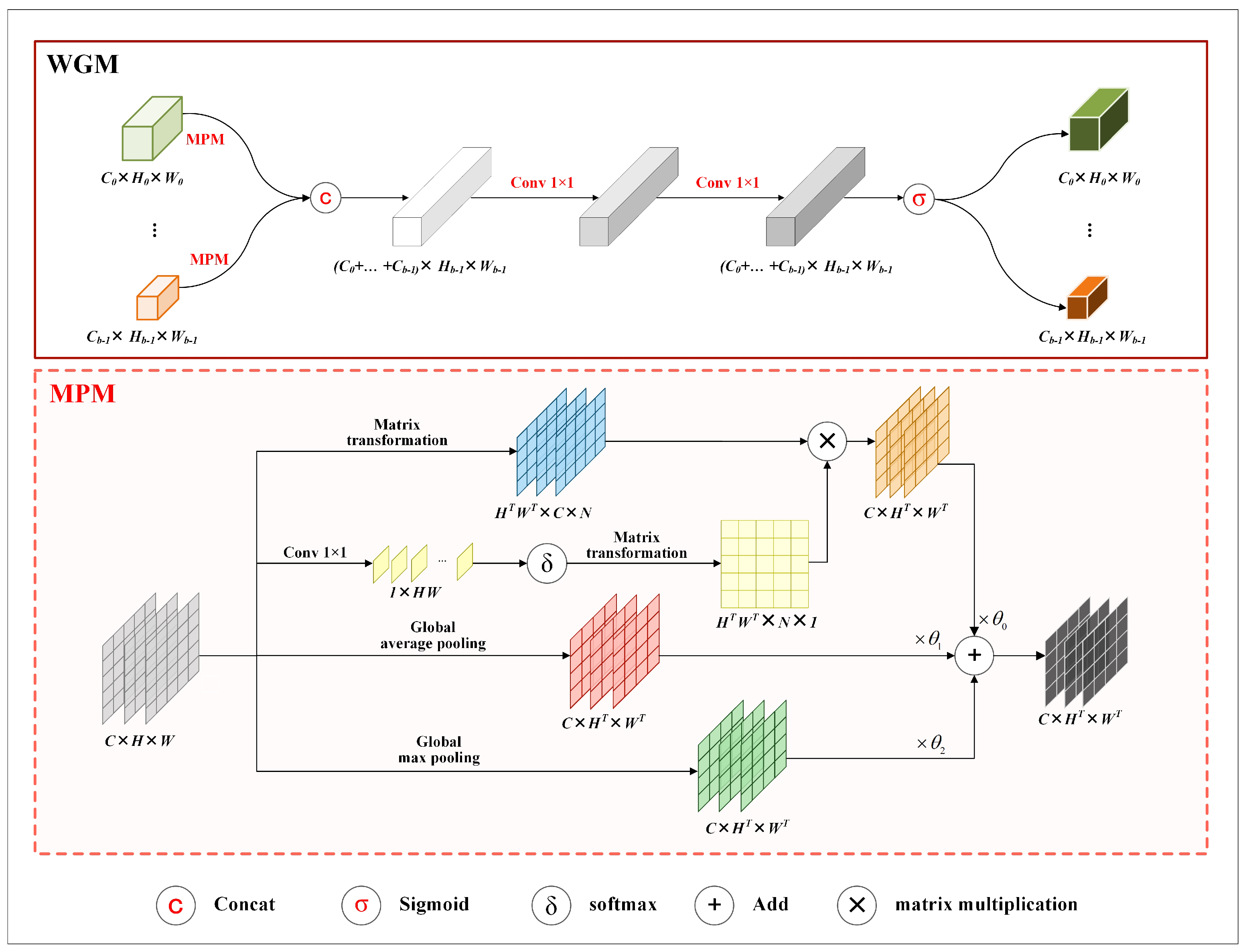
To alleviate the feature loss caused by average pooling operation in , we propose a mixed pooling module (MPM) and construct WGM by replacing the pooling operation in with MPM. Figure 3 shows the structure of WGM.
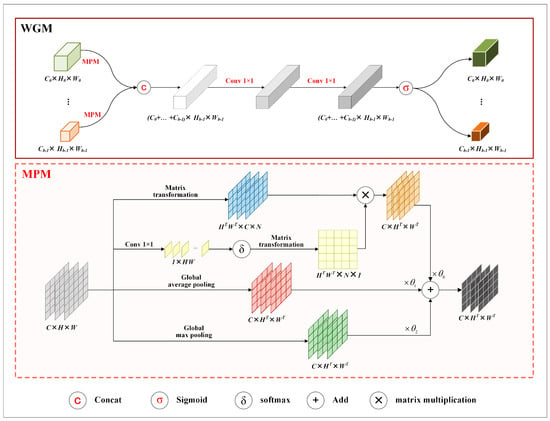
Figure 3.
Structure of WGM. The top part shows the structure of WGM, and the bottom part describes the structure of MPM. Matrix transformation represents a series of operations, e.g., reshaping, unsqueezing, and permuting, on the dimensions or sizes of three−dimensional matrices. and denote the height and width of a transformed matrix, and N is calculated by dividing by .
In the figure, the area surrounded by dashed lines illustrates the details of MPM. As the figure shows, MPM consists of a context-aware branch, an average pooled branch, and a maximum pooled branch. The three branches are designed to capture spatial contextual features, highlight local prominent features, and preserve global features, respectively.
The context-aware branch uses a point-wise convolution to extract spatial contextual features, followed by a activation to generate a weight matrix. Subsequently, the weight matrix and the input feature maps undergo matrix transformations and multiplication to map the spatial contextual features into the input feature maps.
Taking as the input of MPM, can be described as (), where c denotes the total number of channels in . The output of MPM is denoted as . It is calculated according to Equation (6). In the equation, denotes the results of the i-th branch in MPM. It is calculated by Equation (7). In the equation, and separately describe global average pooling and global max pooling; denotes the function, and represents matrix transformation.
Figure 3 also shows the structure of WGM. According to the figure, WGM first performs mixed pooling on input feature maps and then concatenates the pooled results. After that, it processes the concatenated results using two sequential 1 × 1 convolutions, followed by a sigmoid function to the outputs of the convolutions to generate weight matrices.
Taking as the input of WGM, can be described as (), where b denotes the total number of the existing branches in the corresponding stage. Moreover, , comprises multiple channel feature maps. For the given input , the result of WGM is denoted as . is calculated by Equation (8). In the equation, denotes the upsampling operation, and represents the sigmoid function. , WGM calculates a weight matrix for each channel feature map in .
3.3.2. Dual Spatial and Channel Attention Module
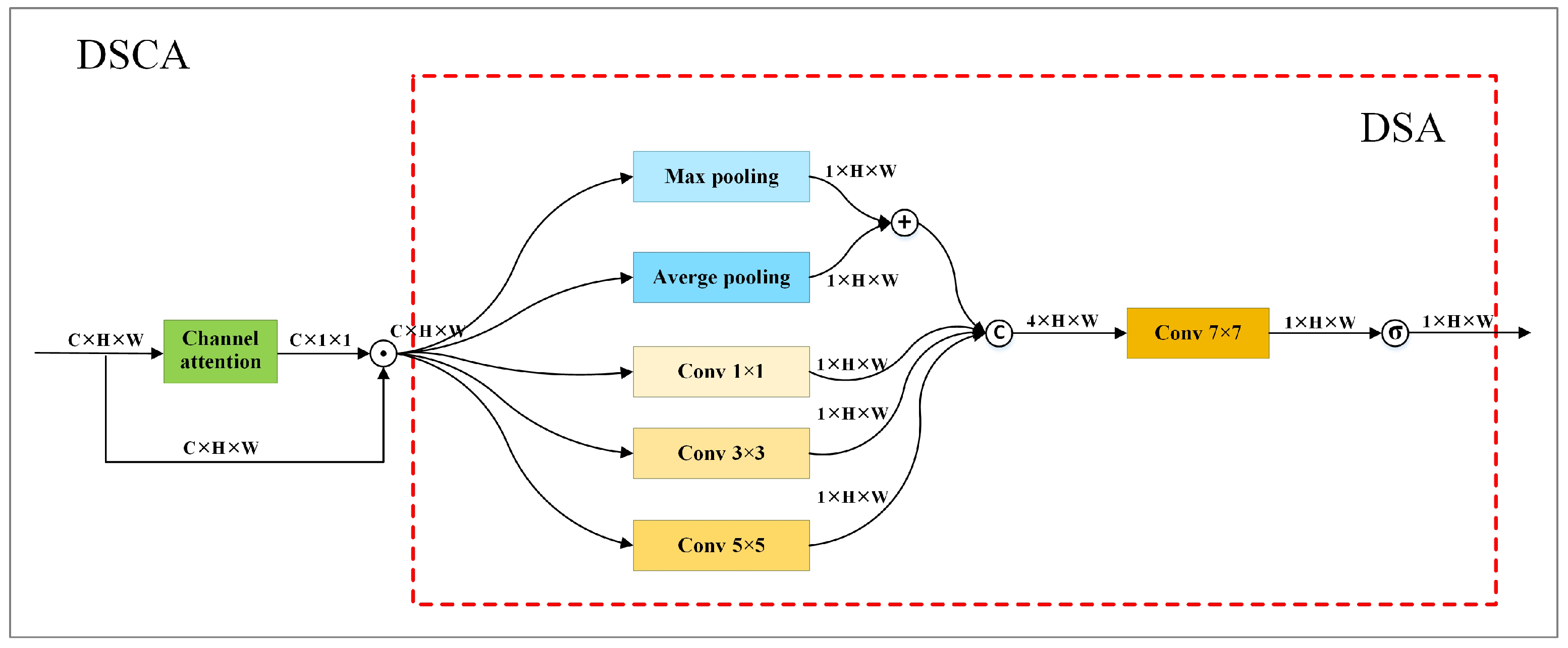
Each stage includes both low-resolution branches and high-resolution branches with channel and spatial features. Channel features are richer than spatial features in low-resolution feature maps, while both channel features and spatial features are rich in high-resolution feature maps. calculates weights based solely on channel features. It does not capitalize on spatial features which are vital for keypoint localization. To leverage both channel and spatial features for weight calculation, we introduce a dual spatial attention module (DSA) and a hybrid attention mechanism, i.e., DSCA. DSCA is constructed by combining DSA with a channel attention module. Figure 4 shows the structure of DSCA.
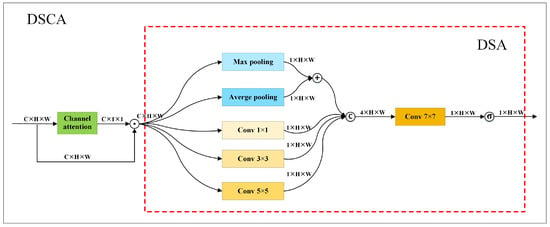
Figure 4.
Structure of DSCA. It comprises a channel attention module and a DSA module. The area surrounded by red dashed lines describes the structure of DSA. ⨀ represents element-wise multiplication.
DSA utilizes four branches to extract spatial features. The first branch processes each input feature map with max and average pooling, then performs a weighted sum. The second, third, and fourth branches separately use a 1 × 1 convolution, a 3 × 3 convolution, and a 5 × 5 convolution to process each feature map and generate spatial features of various receptive fields. The first and second branches extract global spatial features, capturing the overall structure and layout relationships in each input feature map to obtain higher-level, more abstract semantic information. The third and fourth branches focus on extracting local spatial features, enhancing the attention to different regions within an input image.
After extracting spatial features, DSA concatenates the output of each branch and employs a 7 × 7 convolution to process the concatenated results. It generates a spatial attention weight matrix by applying sigmoid activation function to the results of the 7 × 7 convolution. Given the input with c channels, the result of DSA is calculated according to Equation (9). In the equation, denotes sigmoid function, describes the convolution, represents the operation to concatenate the results of the four branches, and depicts the results of the i-th branch. is calculated according to Equation (10) in which and describe max pooling and average pooling, respectively.
denotes the outputs of DSCA. It can be calculated according to Equation (11). In this equation, represents the output of a channel attention module, and ⊙ denotes element-wise multiplication. To simultaneously utilize both channel and spatial features for weight calculation, we utilize DSCA to replace to compute weights.
3.3.3. Mixed Feature Extraction Block
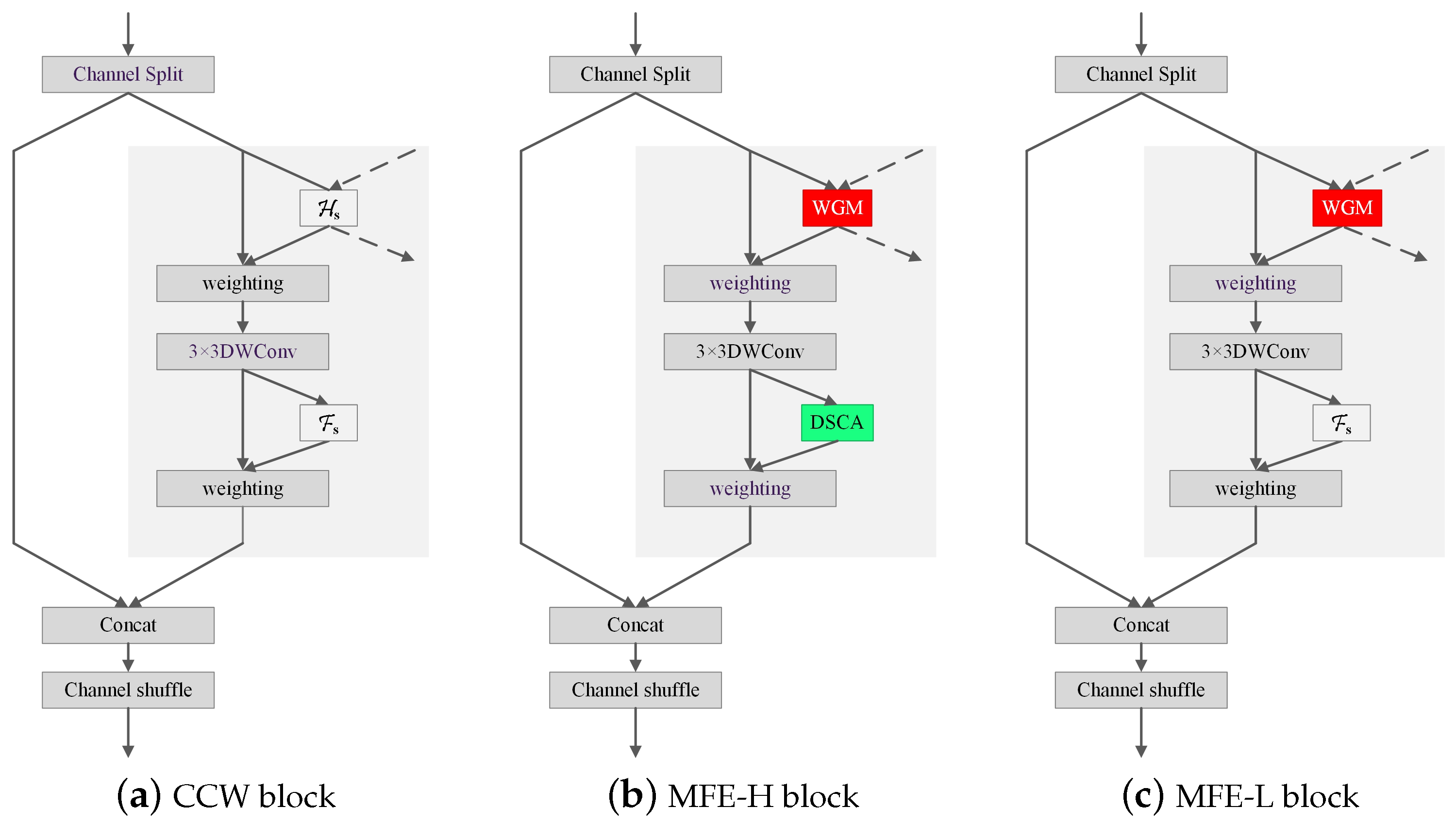
We construct MFE block by substituting with WGM and with DSCA, respectively. MFE has two architectures, namely, MFE-H and MFE-L, which utilize WGM and DSCA in different manners. MFE-H utilizes both WGM and DSCA, while MFE-L only uses WGM. Figure 5 compares the structures of MFE block with CCW block.
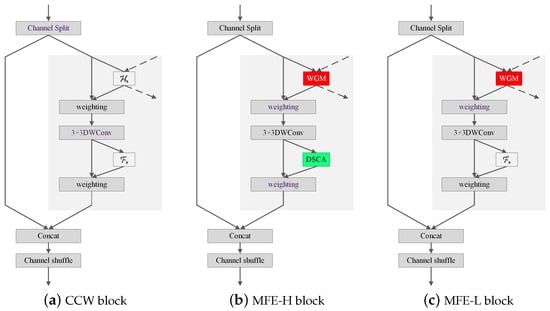
Figure 5.
Structures of MFE. Both MFE-H and MFE-L exploit WGM to generate weighted feature maps as the input of the 3 × 3 DWConv. MFE-H also utilizes the proposed DSCA to generate the weighted feature maps involving in the concat operation, while MFE-L still utilizes to generated weighted feature maps.
High-resolution branches are rich in both channel and spatial features, while low- resolution branches are rich only in channel features. Thus, we apply MFE-H to the two highest-resolution branches and MFE-L to the others.
3.4. Feature Enhancement Stage
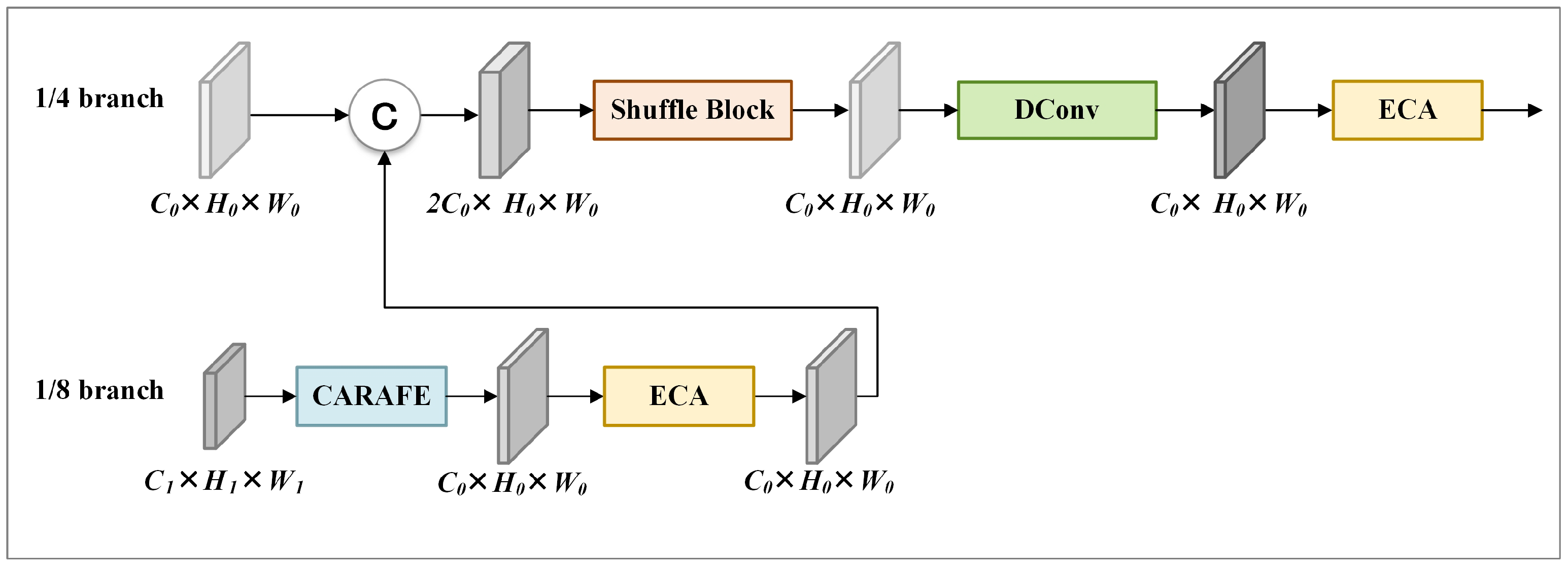
Lite-HRNet uses bilinear interpolation in stage 4 to perform upsampling and feature fusion step by step from the 1/32 branch, until generating the output feature maps of the 1/4 branch, which is used for generating heatmaps and locating keypoints. However, bilinear interpolation only considers the subpixel neighborhood and generates feature maps within small receptive fields, which is incapable of capturing the rich semantic information needed for pose estimation. Therefore, we introduce the FE stage to capture more semantic information.
Figure 6 illustrates the structure of the FE stage. The FE stage utilizes content-aware reassembly of features (CARAFE) [38] to upsample input feature maps from 1/8 to 1/4 resolution. Then, it uses the efficient channel attention module (ECA) to process the generated feature maps, and fuses the processed results with the input feature maps at 1/4 resolution. Finally, it processes the fused results sequentially with shuffle block, depthwise separable convolutions, and ECA to create feature maps for heatmap generation and keypoint localization.
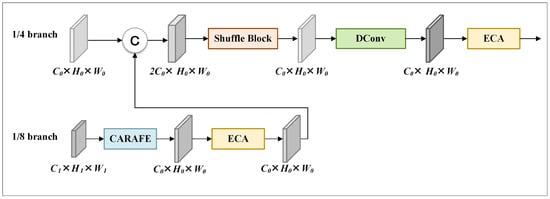
Figure 6.
Structure of FE stage. The cuboids represent feature maps. © denotes concat operation.
4. Experiments
In this section, we conduct experiments on two public benchmark datasets to evaluate MPE-HRNet. Firstly, we represent the details of datasets, training, and evaluation metrics in Section 4.1. Secondly, we analyze the ablation experiments in Section 4.2 and comparative experiments in Section 4.3, respectively. Finally, we discuss the limitation of HRNet in Section 4.4.
4.1. Experimental Settings
Dataset. We use two datasets, i.e., AP-10K [39] and Animal Pose [40], to evaluate our solution. AP-10K dataset is the a large-scale dataset for animal pose estimation. It includes 10,015 images collected from 23 families and 54 species of animals. The AP-10K dataset contains a total of 13,028 instances, each of which is labeled with 17 key points to describe poses. Table 2 shows the details of those keypoints. In our experiments, the AP-10K dataset is divided into train set, validation set, and test set. The three datasets include 7010 images, 1002 images, and 2003 images, respectively. The Animal Pose dataset contains 4608 images collected from dog, cat, cow, horse, and sheep species. It includes 6117 instances annotated with 20 keypoints. The Animal Pose dataset is also divided into train set, validation set, and test set. Each of these sets include 2798 images, 810 images, and 1000 images, respectively.
Table 2.
Definitions of keypoints.
Training. All the training is carried out on the same server which is equipped with 5 NVIDIA GeForce RTX 3090 GPUs sourced from Santa Clara, CA, USA, and 376 GB of Kingston memory sourced from Fountain Valley, CA, USA. Our solution and all the comparative solutions are implemented in Python 3.8.19, and executed on PyTorch 2.5.0 framework. Multiple data augmentations are adopted in the training, which include random horizontal flip, random rotation from −80 to 80 degrees, random scaling by a factor of 0.5–1.5, and random body part augmentation generating animals with only the upper or lower part of a body.
To ensure the fairness of training processes, the training parameters, batch_size and the number of epochs, are separately set to 64 and 260, while all the other training parameters are configured with their default values. All parameters are updated by Adam optimizer combined with warm-up learning strategy. Learning rate is configured to at the first 170 epochs and reduced to and at the 170th and 200th epochs, respectively.
Evaluation metrics. Object keypoint similarity (OKS) is a widely accepted criterion for pose estimation. It is calculated according to Equation (12). In the equation, describes the Euclidean distance between the model prediction and the ground truth of keypoint i, denotes the visibility flag of the ground truth of the key point, s represents the scale of the animal object, and describes the constant to control the fall-off of the keypoint.
We use the average precision (AP), (AP at OKS = 0.5), (AP at OKS = 0.75), (AP for medium objects: 322 < area < 962), (AP for large objects: area > 962), and average recall (AR) to evaluate the accuracy of models. AP is regarded as the main metric for accuracy. In addition, we use Params (M) to evaluate complexity, and use FLOPs (G) and inference time (ms) to evaluate speed.
4.2. Ablation Experiments
To analyze the effectiveness of the improvements in this work, we carry out a series of ablation experiments.
4.2.1. Selection of SPPF+ and SPPF
SPPF+ fuses the feature maps generated by different pooling operations by add operation. Add operation adds feature maps related to the same channel. It can merge multiple groups of feature maps generated by different pooling operations into one group, thus reducing parameters for subsequent operations. However, it also results in feature loss. Fortunately, the feature loss could be alleviated if the feature maps involving the same add operation are much similar to each other.
For the feature maps generated by the stacked pooling operations in SPPF, the similarity between the feature maps related to the same channel increases with the increase in their resolutions. Therefore, SPPF is more suitable for the branches of high resolutions. SPPF does not suffer from the issue. MPE-HRNet contains multiple branches of different resolutions. In order to improve accuracy through the proper use of SPPF and SPPF in these branches, we carry out the experiments in which SPPF/SPPF are added at the beginning of different branches.
Table 3 records the experiment results of Lite-HRNet and its variants only involving SPPF, SPPF, or both of them. +SPPF denotes the variant with SPPF in the 1/8, 1/16, and 1/32 branches. +SPPF and SPPF describes the variant version with SPPF in the 1/8 branch and SPPF in the 1/16 and 1/32 branches. +SPPF and SPPF represent the variant version with +SPPF in the 1/8 and 1/16 branches and SPPF in the 1/32 branch. +SPPF indicates the variant version with SPPF in the 1/8, 1/16, and 1/32 branches. From the experimental results, it can be observed that inserting SPPF in the 1/8 and 1/16 branches and SPPF in the 1/32 branch yields the best results. In the following experiments, we configure SPPF and SPPF according to the best results.
Table 3.
Effectiveness study of SPPF and SPPF.
4.2.2. Effectiveness Study of All the Improvements
We design five different models to evaluate the effectiveness of each improvement and describe the corresponding experiment results in Table 4. All these results are generated on the AP-10K dataset. In the table, Model0 denotes the original version of Lite-HRNet, while Model1 to Model4 describe different variants of the original version. Model1 and Model2 separately denote the variant with MFE-L in all the branches and the variant with MFE-L in 1/16 and 1/32 branches and MFE-H in 1/4 and 1/8 branches. Model3 represents the variant with MFE-L in 1/16 and 1/32 branches, MFE-H in 1/4 and 1/8 branches, and FE stage.
Table 4.
Effectiveness study of all the improvements.
According to Table 4, Model1 and Model2 achieved improvements in AP, AR, parameters, and FLOPs(G) separately compared to Model0 and Model1, indicating that the introduction of MFE-L and MFE-H helped to improve the performance of Lite-HRNet. Model3 also achieved performance improvements in the above four evaluation metrics compared with Model2, which verified the effectiveness of the collaboration of MFE-L, MFE-H, and FE stage in improving the performance of Lite-HRNet.
Model4 describes the variant with MFE-L, MFE-H, the new stage, and /SPPF. It executes with a higher performance compared with Model3, which verified the effectiveness of all the improvements proposed in this work.
4.3. Performance Comparison
4.3.1. Comparison on AP-10K Dataset
We carry out experiments to evaluate the detection accuracy and speed of MPE-HRNet by comparing it with nine important pose estimation solutions, including CSPNeXt-t [41], CSPNeXt-s, ShuffleNetV1 [20], ShuffleNetV2 [42], MobileNetV2 [43], MobileNetV3 [44], Dite-HRNet [45], Lite-HRNet, and DARK [46]. DARK utilizes Lite-HRNet to generate heatmaps but performs post-processing in a different way to the other solutions. All the solutions are lightweight solutions.
Table 5 shows the results of these solutions on the AP-10K validation set. According to the table, MPE-HRNet obtained the highest AP, , , , , and AR. Compared with ShuffleNetV2, ShuffleNetV1, MobileNetV2, MobileNetV3, CSPNeXt-t, Dite-HRNet, Lite-HRNet, DARK, and CSPNeXt-s, it improved AP in animal pose estimation by 8.8%, 8.5%, 6.4%, 5.5%, 5.3%, 2.3%, 2.2%, 2.0%, and 1.5%, respectively. It also achieved improvements when any of the other metrics was used. It is obvious that MPE-HRNet outperformed all the comparative solutions in accuracy.
Table 5.
Results on the AP-10K validation set.
We aimed to strike a balance between accuracy and complexity, striving to carefully manage the complexity of MPE-HRNet during its design process. In all the solutions, DARK and Lite-HRNet have the least Params, and Dite-HRNet has the lowest FLOPs. Comparing with these two solutions, MPE-HRNet does not increase Params and FLOPs too much while obtaining an improvement in accuracy. Concretely, it has only 0.43 M more parameters than DARK and Lite-HRNet, and 0.29 G more FLOPs than Dite-HRNet, respectively. Comparing with ShuffleNet, MobileNet, and CSPNeXt, MPE-HRNet has the least Params and the lowest FLOPs(G). The inference time of MPE-HRNet is 1.74 ms longer than that of DARK and 1.62 ms longer than Lite-HRNet, indicating a slight increase with negligible impact.
Table 6 shows the results on the AP-10K test set. According to the table, MPE-HRNet still achieved the highest AP in all the comparison solutions. Comparing with ShuffleNetV2, ShuffleNetV1, MobileNetV2, MobileNetV3, CSPNeXt-t, Dite-HRNet, Lite-HRNet, DARK, and CSPNeXt-s, it improved AP by 8.4%, 7.9%, 4.9%, 4.9%, 4.6%, 1.4%, 1.3%, 1.4%, and 1.1%, respectively. MPE-HRNet also exhibited the highest , , , , and AR in all the other comparison solutions except DARK. Although DARK surpasses our method in the metric, it falls behind MPE-HRNet in all the other metrics. Considering all the metrics, MPE-HRNet outperforms all comparison solutions on the test set.
Table 6.
Results on the AP-10K test set.
We also compared MPE-HRNet with ResNet-101, HRNet-W32, and RFB-HRNet. The latter three solutions are based on large models. According to the results in Table 7, these three solutions exhibit a higher accuracy than MPE-HRNet. However, they also have many more Params than MPE-HRNet. In many practical application scenarios, pose estimation models are required to be deployed on edge devices. Large models struggle to perform optimally on edge devices due to the inability of these devices to provide the resources required by the models.
Table 7.
Comparison with solutions based on large models.
4.3.2. Comparison on Animal Pose Dataset
We also conducted experiments on the Animal Pose dataset. In these experiments, we compared MPE-HRNet with ShuffleNetV2, MobileNetV2, and CSPNeXt-s. The corresponding results are recorded in Table 8. Similar to the results on the AP-10K dataset, MPE-HRNet also achieved the highest AP on the Animal Pose dataset, demonstrating the effectiveness of MPE-HRNet in improving accuracy.
Table 8.
Results on the Animal Pose dataset.
4.4. Limitation Discussion
While MPE-HRNet obtains accuracy improvements, it still suffers from two obvious limitations. The first limitation is that MPE-HRNet does not perform well in complex occlusion scenes. The second limitation is that the accuracy of MPE-HRNet needs to be improved.
Complex occlusion limitation. We chose twelve images with different scenes and depicted the corresponding results of MPE-HRNet in Figure 7. These images were shot at different distances and angles. They include various animals belonging to different species. Some of them even include shadow and object occlusions. According to Figure 7b,e,h, MPE-HRNet performed well in the images including multiple objects even if those objects are different sizes. It also performed well in the scenario where shadow exists, according to Figure 7i. MPE-HRNet can still work well in the scenario where some parts of bodies are occluded lightly, as Figure 7j,k show. However, it does not work well in the scenario where complex occlusion exists, as Figure 7f shows.

Figure 7.
Example qualitative results of the AP-10K.
Accuracy limitation. According to Section 4.3.1 and Section 4.3.2, MPE-HRNet obtains accuracy improvements compared with lightweight models such as Dark, Lite-HRNet, and so on. However, MPE-HRNet exhibits a relatively low accuracy when compared with the solutions based on large models. In addition, MPE-HRNet improves accuracy by 1.4%, 1.3%, and 1.4% compared with Dark, Lite-HRNet, and Dite-HRNet, respectively. However, it increases parameters by 38% (0.43 M), 38% (0.43 M), and 31% (0.37 M) compared with the three solutions, respectively. Compared to the improvement in accuracy, the increase in parameters is more pronounced. Nonetheless, the number of parameters of MPE-HRNet is only 1.56 M. MPE-HRNet is still a lightweight model. However, MPE-HRNet does not exhibit any advantage in accuracy compared to large models. It is necessary to improve MPE-HRNet to obtain higher accuracy.
5. Conclusions
In this work, we focused on the problem of estimating the poses of multiple species with high accuracy in real scenarios. To deal with this problem, we constructed a lightweight network by improving Lite-HRNet. Concretely, we proposed SPPF and applied it as well as SPPF to all branches. We proposed MPM and DSCA, and constructed MFE block by applying them together. We also designed a new stage to enhance the features in the feature map output by MPE-HRNet. The experimental results on the AP-10K dataset and the Animal Pose dataset verified the effectiveness of our work. In the future, we will focus on the problem of animal pose estimation involving complex occlusions.
Author Contributions
Conceptualization, J.S., J.L. and W.W.; methodology, J.S., Y.J. and W.W.; formal analysis, J.S.; investigation, Y.J. and W.W.; resources, J.S. and Y.J.; data curation, Y.J.; writing—original draft preparation, J.S., Y.J. and W.W.; writing—review and editing, J.S., Y.J. and W.W.; visualization, Y.J.; supervision, J.S., J.L. and W.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded in part by Junwei Luo and the National Natural Science Foundation of China (Grant No. 61972134) and the Innovative and Scientific Research Team of Henan Polytechnic University (No. T2021-3).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The datasets used in this article are publicly available. The AP-10K dataset can be accessed at https://drive.google.com/file/d/1-FNNGcdtAQRehYYkGY1y4wzFNg4iWNad/view (accessed on 15 May 2024), and the Animal Pose dataset is available at https://openxlab.org.cn/datasets/OpenDataLab/animalpose (accessed on 4 October 2024).
Conflicts of Interest
Author Wei Wang was employed by the company CSSC Haifeng Aviation Technology Co., Ltd. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Harding, E.J.; Paul, E.S.; Mendl, M. Cognitive bias and affective state. Nature 2004, 427, 312. [Google Scholar] [CrossRef] [PubMed]
- Zuffi, S.; Kanazawa, A.; Berger-Wolf, T.; Black, M.J. Three-D Safari: Learning to Estimate Zebra Pose, Shape, and Texture from Images “In the Wild”. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5359–5368. [Google Scholar]
- Anderson, T.L.; Donath, M. Animal behavior as a paradigm for developing robot autonomy. Robot. Auton. Syst. 1990, 6, 145–168. [Google Scholar] [CrossRef]
- Jiang, L.; Lee, C.; Teotia, D.; Ostadabbas, S. Animal pose estimation: A closer look at the state-of-the-art, existing gaps and opportunities. Comput. Vis. Image Underst. 2022, 222, 103483. [Google Scholar] [CrossRef]
- Cheng, B.; Xiao, B.; Wang, J.; Shi, H.; Huang, T.S.; Zhang, L. Higherhrnet: Scale-aware representation learning for bottom-up human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5386–5395. [Google Scholar]
- Chao, W.; Duan, F.; Du, P.; Zhu, W.; Jia, T.; Li, D. DEKRV2: More accurate or fast than DEKR. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; pp. 1451–1455. [Google Scholar]
- Xiao, B.; Wu, H.; Wei, Y. Simple baselines for human pose estimation and tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 466–481. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 5693–5703. [Google Scholar]
- Yu, C.; Xiao, B.; Gao, C.; Yuan, L.; Zhang, L.; Sang, N.; Wang, J. Lite-hrnet: A lightweight high-resolution network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 10440–10450. [Google Scholar]
- Li, C.; Lee, G.H. From synthetic to real: Unsupervised domain adaptation for animal pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 1482–1491. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. Realtime multi-person 2d pose estimation using part affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7291–7299. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked hourglass networks for human pose estimation. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 483–499. [Google Scholar]
- Wang, Z.; Zhou, S.; Yin, P.; Xu, A.; Ye, J. GANPose: Pose estimation of grouped pigs using a generative adversarial network. Comput. Electron. Agric. 2023, 212, 108119. [Google Scholar] [CrossRef]
- Fan, Q.; Liu, S.; Li, S.; Zhao, C. Bottom-up cattle pose estimation via concise multi-branch network. Comput. Electron. Agric. 2023, 211, 107945. [Google Scholar] [CrossRef]
- He, R.; Wang, X.; Chen, H.; Liu, C. VHR-BirdPose: Vision Transformer-Based HRNet for Bird Pose Estimation with Attention Mechanism. Electronics 2023, 12, 3643. [Google Scholar] [CrossRef]
- Zhou, F.; Jiang, Z.; Liu, Z.; Chen, F.; Chen, L.; Tong, L.; Yang, Z.; Wang, H.; Fei, M.; Li, L.; et al. Structured context enhancement network for mouse pose estimation. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 2787–2801. [Google Scholar] [CrossRef]
- Graving, J.M.; Chae, D.; Naik, H.; Li, L.; Koger, B.; Costelloe, B.R.; Couzin, I.D. DeepPoseKit, a software toolkit for fast and robust animal pose estimation using deep learning. eLife 2019, 8, e47994. [Google Scholar] [CrossRef]
- Zhao, S.; Bai, Z.; Meng, L.; Han, G.; Duan, E. Pose Estimation and Behavior Classification of Jinling White Duck Based on Improved HRNet. Animals 2023, 13, 2878. [Google Scholar] [CrossRef]
- Gong, Z.; Zhang, Y.; Lu, D.; Wu, T. Vision-Based Quadruped Pose Estimation and Gait Parameter Extraction Method. Electronics 2022, 11, 3702. [Google Scholar] [CrossRef]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6848–6856. [Google Scholar]
- Maselyne, J.; Adriaens, I.; Huybrechts, T.; De Ketelaere, B.; Millet, S.; Vangeyte, J.; Van Nuffel, A.; Saeys, W. Measuring the drinking behaviour of individual pigs housed in group using radio frequency identification (RFID). Animal 2016, 10, 1557–1566. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; Fan, Q.; Liu, S.; Zhao, C. DepthFormer: A High-Resolution Depth-Wise Transformer for Animal Pose Estimation. Agriculture 2022, 12, 1280. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Sun, K.; Zhao, Y.; Jiang, B.; Cheng, T.; Xiao, B.; Liu, D.; Mu, Y.; Wang, X.; Liu, W.; Wang, J. High-resolution representations for labeling pixels and regions. arXiv 2019, arXiv:1904.04514. [Google Scholar]
- Xu, Y.; Zhang, J.; Zhang, Q.; Tao, D. Vitpose: Simple vision transformer baselines for human pose estimation. Adv. Neural Inf. Process. Syst. 2022, 35, 38571–38584. [Google Scholar]
- Liao, J.; Xu, J.; Shen, Y.; Lin, S. THANet: Transferring Human Pose Estimation to Animal Pose Estimation. Electronics 2023, 12, 4210. [Google Scholar] [CrossRef]
- Hu, X.; Liu, C. Animal Pose Estimation Based on Contrastive Learning with Dynamic Conditional Prompts. Animals 2024, 14, 1712. [Google Scholar] [CrossRef] [PubMed]
- Zeng, X.; Zhang, J.; Zhu, Z.; Guo, D. MVCRNet: A Semi-Supervised Multi-View Framework for Robust Animal Pose Estimation with Minimal Labeled Data. 2024; preprint. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Qin, Z.; Zhang, P.; Wu, F.; Li, X. Fcanet: Frequency channel attention networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 783–792. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Jocher, G. YOLOv5 by Ultralytics. 2020. Available online: https://zenodo.org/records/7347926 (accessed on 11 April 2024).
- Wang, J.; Chen, K.; Xu, R.; Liu, Z.; Loy, C.C.; Lin, D. Carafe: Content-aware reassembly of features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3007–3016. [Google Scholar]
- Yu, H.; Xu, Y.; Zhang, J.; Zhao, W.; Guan, Z.; Tao, D. Ap-10K: A benchmark for animal pose estimation in the wild. arXiv 2021, arXiv:2108.12617. [Google Scholar]
- Cao, J.; Tang, H.; Fang, H.S.; Shen, X.; Lu, C.; Tai, Y.W. Cross-Domain Adaptation for Animal Pose Estimation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Jiang, T.; Lu, P.; Zhang, L.; Ma, N.; Han, R.; Lyu, C.; Li, Y.; Chen, K. Rtmpose: Real-time multi-person pose estimation based on mmpose. arXiv 2023, arXiv:2303.07399. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Li, Q.; Zhang, Z.; Xiao, F.; Zhang, F.; Bhanu, B. Dite-HRNet: Dynamic lightweight high-resolution network for human pose estimation. arXiv 2022, arXiv:2204.10762. [Google Scholar]
- Zhang, F.; Zhu, X.; Dai, H.; Ye, M.; Zhu, C. Distribution-aware coordinate representation for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7093–7102. [Google Scholar]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).