
Fusion Attention for Action Recognition: Integrating Sparse-Dense and Global Attention for Video Action Recognition


Abstract
1. Introduction
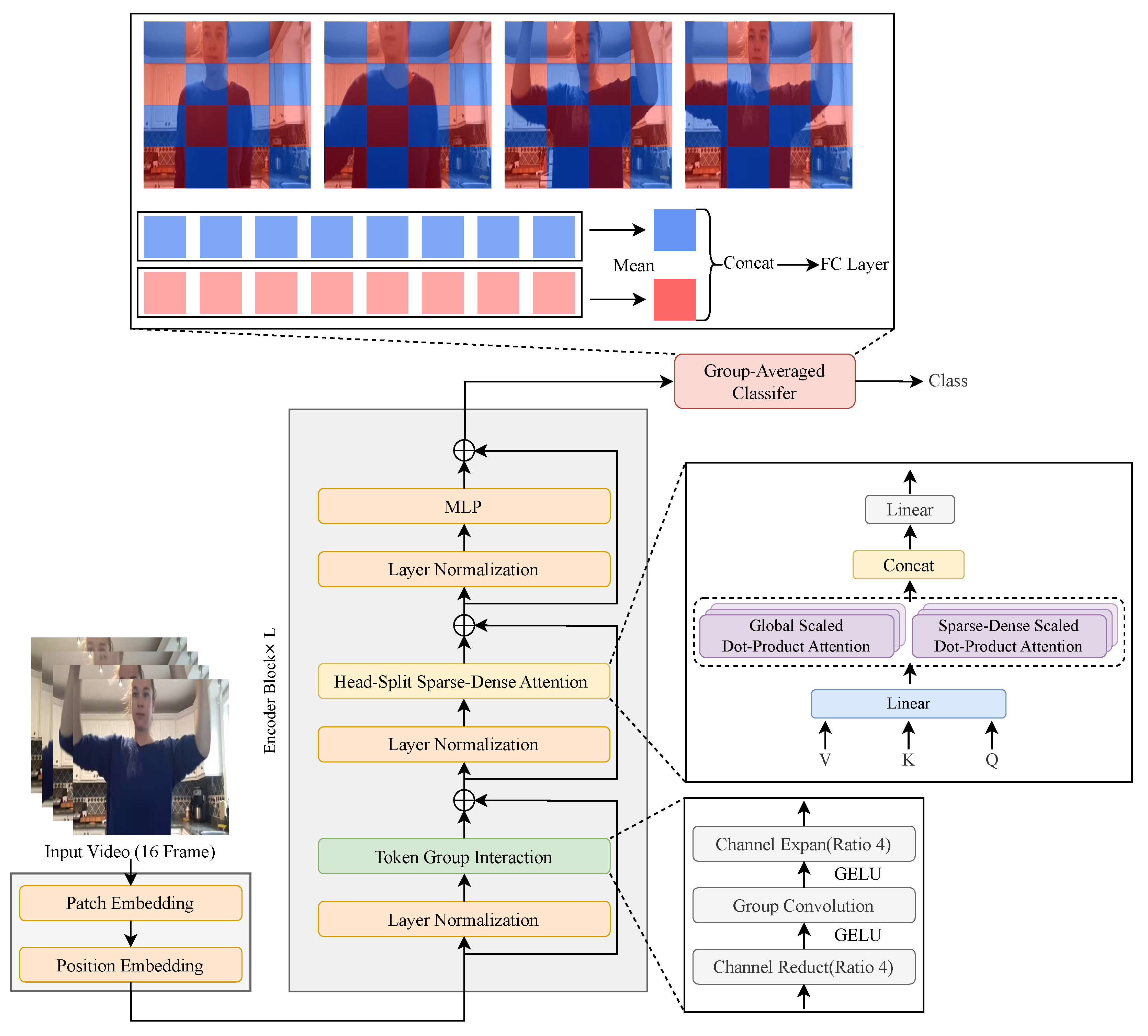
- For effective video action recognition, we propose a new FAR consisting of head-split sparse-dense attention, token–group interaction, and group-averaged classifier to mitigate temporal redundancy and effectively capture spatio-temporal features.
2. Related Work
3. Methodology
3.1. Video Vision Transformer
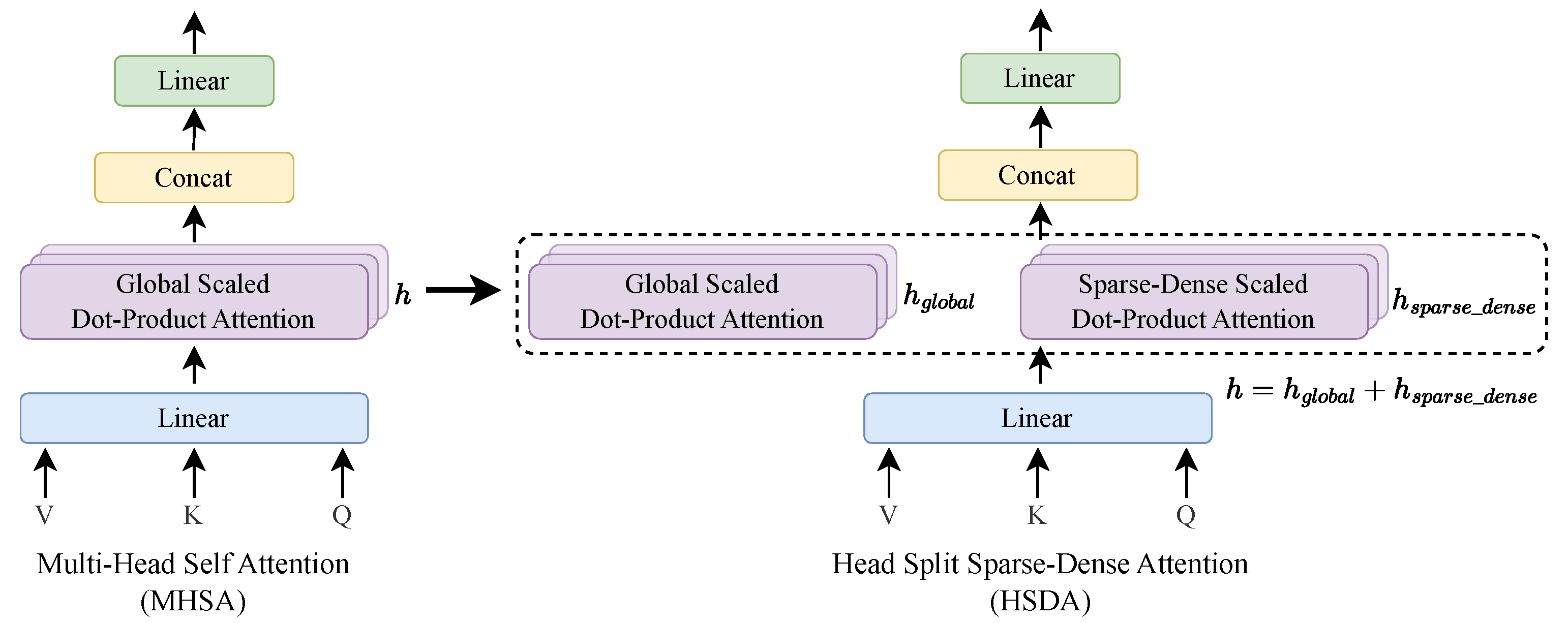
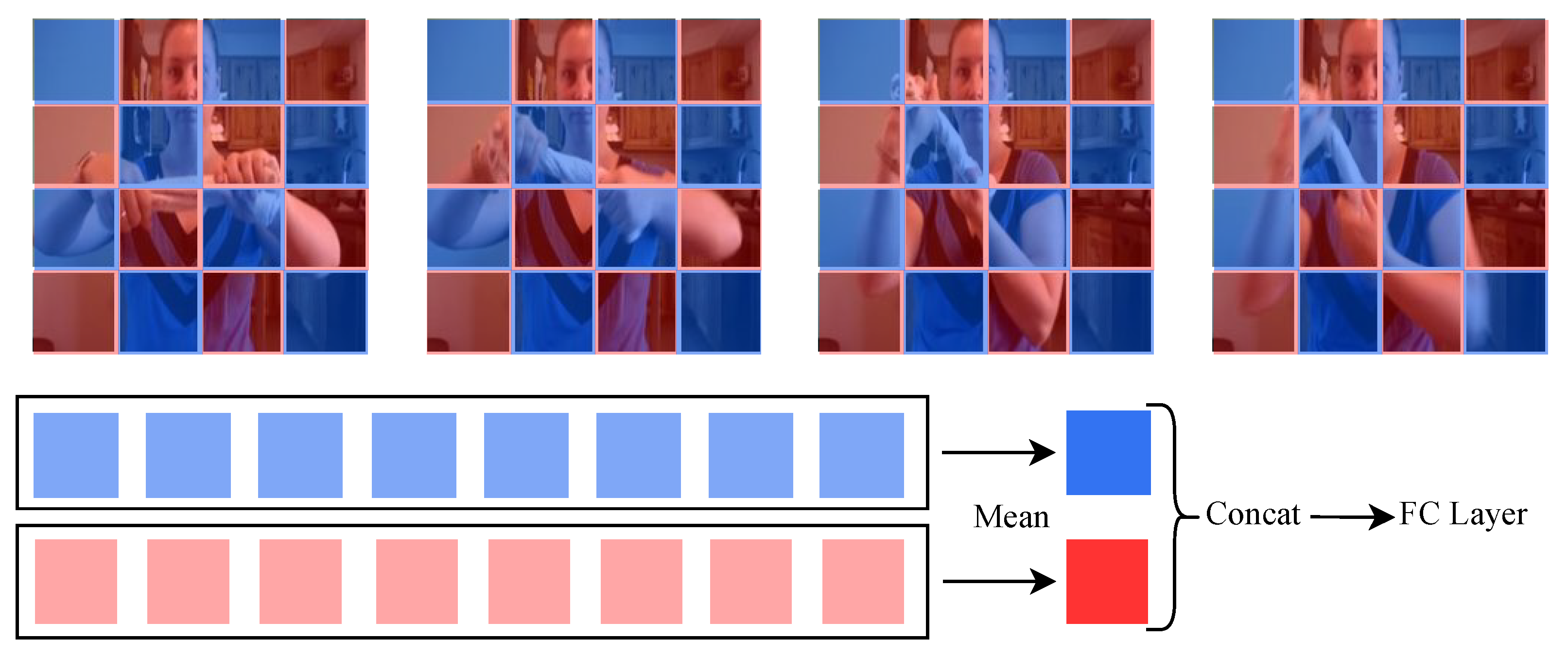
3.2. Proposed Method
3.3. Fusion Attention for Action Recognition (FAR)
4. Experiments
4.1. Datasets
4.2. Implementation Details
4.3. Ablation Study
4.4. Comparisons with Previous Methods
4.5. Qualitative Comparison
5. Conclusions
Limitations and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf (accessed on 2 July 2024).
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Dehghani, M.; Djolonga, J.; Mustafa, B.; Padlewski, P.; Heek, J.; Gilmer, J.; Steiner, A.P.; Caron, M.; Geirhos, R.; Alabdulmohsin, I.; et al. Scaling vision transformers to 22 billion parameters. In Proceedings of the International Conference on Machine Learning, PMLR, Honolulu, HI, USA, 23–29 July 2023; pp. 7480–7512. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Wang, R.; Chen, D.; Wu, Z.; Chen, Y.; Dai, X.; Liu, M.; Yuan, L.; Jiang, Y.G. Masked video distillation: Rethinking masked feature modeling for self-supervised video representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 6312–6322. [Google Scholar]
- Liu, Z.; Ning, J.; Cao, Y.; Wei, Y.; Zhang, Z.; Lin, S.; Hu, H. Video swin transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 3202–3211. [Google Scholar]
- Arnab, A.; Dehghani, M.; Heigold, G.; Sun, C.; Lučić, M.; Schmid, C. Vivit: A video vision transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 6836–6846. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–12 December 2015; pp. 4489–4497. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. arXiv 2017, arXiv:1705.07750. [Google Scholar]
- Feichtenhofer, C.; Fan, H.; Malik, J.; He, K. Slowfast networks for video recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6202–6211. [Google Scholar]
- Bertasius, G.; Wang, H.; Torresani, L. Is space-time attention all you need for video understanding? In Proceedings of the ICML, Online, 18–24 July 2021; Volume 2, p. 4. [Google Scholar]
- Li, K.; Wang, Y.; Gao, P.; Song, G.; Liu, Y.; Li, H.; Qiao, Y. Uniformer: Unified transformer for efficient spatiotemporal representation learning. arXiv 2022, arXiv:2201.04676. [Google Scholar]
- Fan, H.; Xiong, B.; Mangalam, K.; Li, Y.; Yan, Z.; Malik, J.; Feichtenhofer, C. Multiscale vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 6824–6835. [Google Scholar]
- Zhang, Z.; Tao, D. Slow feature analysis for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 436–450. [Google Scholar] [CrossRef] [PubMed]
- Tong, Z.; Song, Y.; Wang, J.; Wang, L. Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training. Adv. Neural Inf. Process. Syst. 2022, 35, 10078–10093. [Google Scholar]
- Feichtenhofer, C.; Li, Y.; He, K. Masked autoencoders as spatiotemporal learners. Adv. Neural Inf. Process. Syst. 2022, 35, 35946–35958. [Google Scholar]
- Goyal, R.; Ebrahimi Kahou, S.; Michalski, V.; Materzynska, J.; Westphal, S.; Kim, H.; Haenel, V.; Fruend, I.; Yianilos, P.; Mueller-Freitag, M.; et al. The “Something Something” Video Database for Learning and Evaluating Visual Common Sense. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Kay, W.; Carreira, J.; Simonyan, K.; Zhang, B.; Hillier, C.; Vijayanarasimhan, S.; Viola, F.; Green, T.; Back, T.; Natsev, P.; et al. The kinetics human action video dataset. arXiv 2017, arXiv:1705.06950. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Qiu, Z.; Yao, T.; Mei, T. Learning spatio-temporal representation with pseudo-3d residual networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5533–5541. [Google Scholar]
- Huang, Z.; Zhang, S.; Pan, L.; Qing, Z.; Tang, M.; Liu, Z.; Ang, M.H., Jr. TAda! temporally-adaptive convolutions for video understanding. arXiv 2021, arXiv:2110.06178. [Google Scholar]
- Huang, Z.; Zhang, S.; Pan, L.; Qing, Z.; Zhang, Y.; Liu, Z.; Ang, M.H., Jr. Temporally-adaptive models for efficient video understanding. arXiv 2023, arXiv:2308.05787. [Google Scholar]
- Liu, Z.; Wang, L.; Wu, W.; Qian, C.; Lu, T. Tam: Temporal adaptive module for video recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 13708–13718. [Google Scholar]
- Wang, L.; Tong, Z.; Ji, B.; Wu, G. Tdn: Temporal difference networks for efficient action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1895–1904. [Google Scholar]
- Jiang, B.; Wang, M.; Gan, W.; Wu, W.; Yan, J. Stm: Spatiotemporal and motion encoding for action recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2000–2009. [Google Scholar]
- Li, Y.; Ji, B.; Shi, X.; Zhang, J.; Kang, B.; Wang, L. Tea: Temporal excitation and aggregation for action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 909–918. [Google Scholar]
- Wu, Z.; Xiong, C.; Ma, C.Y.; Socher, R.; Davis, L.S. Adaframe: Adaptive frame selection for fast video recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1278–1287. [Google Scholar]
- Korbar, B.; Tran, D.; Torresani, L. Scsampler: Sampling salient clips from video for efficient action recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6232–6242. [Google Scholar]
- Wu, W.; He, D.; Tan, X.; Chen, S.; Wen, S. Multi-agent reinforcement learning based frame sampling for effective untrimmed video recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6222–6231. [Google Scholar]
- Zhi, Y.; Tong, Z.; Wang, L.; Wu, G. Mgsampler: An explainable sampling strategy for video action recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1513–1522. [Google Scholar]
- Tu, S.; Dai, Q.; Wu, Z.; Cheng, Z.Q.; Hu, H.; Jiang, Y.G. Implicit temporal modeling with learnable alignment for video recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 19936–19947. [Google Scholar]
- Wang, L.; Huang, B.; Zhao, Z.; Tong, Z.; He, Y.; Wang, Y.; Wang, Y.; Qiao, Y. VideoMAE V2: Scaling Video Masked Autoencoders with Dual Masking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 14549–14560. [Google Scholar]
- Dong, X.; Bao, J.; Zheng, Y.; Zhang, T.; Chen, D.; Yang, H.; Zeng, M.; Zhang, W.; Yuan, L.; Chen, D.; et al. Maskclip: Masked self-distillation advances contrastive language-image pretraining. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 10995–11005. [Google Scholar]
- Zheng, Y.; Yang, H.; Zhang, T.; Bao, J.; Chen, D.; Huang, Y.; Yuan, L.; Chen, D.; Zeng, M.; Wen, F. General facial representation learning in a visual-linguistic manner. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18697–18709. [Google Scholar]
- Bao, H.; Dong, L.; Piao, S.; Wei, F. Beit: Bert pre-training of image transformers. arXiv 2021, arXiv:2106.08254. [Google Scholar]
- Dong, X.; Bao, J.; Zhang, T.; Chen, D.; Zhang, W.; Yuan, L.; Chen, D.; Wen, F.; Yu, N.; Guo, B. Peco: Perceptual codebook for bert pre-training of vision transformers. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 552–560. [Google Scholar]
- Tan, H.; Lei, J.; Wolf, T.; Bansal, M. Vimpac: Video pre-training via masked token prediction and contrastive learning. arXiv 2021, arXiv:2106.11250. [Google Scholar]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16000–16009. [Google Scholar]
- Xie, Z.; Zhang, Z.; Cao, Y.; Lin, Y.; Bao, J.; Yao, Z.; Dai, Q.; Hu, H. Simmim: A simple framework for masked image modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 9653–9663. [Google Scholar]
- Wei, C.; Fan, H.; Xie, S.; Wu, C.Y.; Yuille, A.; Feichtenhofer, C. Masked feature prediction for self-supervised visual pre-training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 14668–14678. [Google Scholar]
- Ryali, C.; Hu, Y.T.; Bolya, D.; Wei, C.; Fan, H.; Huang, P.Y.; Aggarwal, V.; Chowdhury, A.; Poursaeed, O.; Hoffman, J.; et al. Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles. In Proceedings of the 2023 International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023. [Google Scholar]
- Huang, G.; Sun, Y.; Liu, Z.; Sedra, D.; Weinberger, K.Q. Deep networks with stochastic depth. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 646–661. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Shlens, J.; Le, Q.V. Randaugment: Practical automated data augmentation with a reduced search space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 702–703. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. Cutmix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6023–6032. [Google Scholar]
- Li, Y.; Wu, C.Y.; Fan, H.; Mangalam, K.; Xiong, B.; Malik, J.; Feichtenhofer, C. Mvitv2: Improved multiscale vision transformers for classification and detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4804–4814. [Google Scholar]
- Wang, R.; Chen, D.; Wu, Z.; Chen, Y.; Dai, X.; Liu, M.; Jiang, Y.G.; Zhou, L.; Yuan, L. Bevt: Bert pretraining of video transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 14733–14743. [Google Scholar]
- Girdhar, R.; El-Nouby, A.; Singh, M.; Alwala, K.V.; Joulin, A.; Misra, I. Omnimae: Single model masked pretraining on images and videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 10406–10417. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| FAR (VideoMAE) | FAR (MVD) | |||
|---|---|---|---|---|
| Config | Sth-Sth V2 | Kinetics-400 | Sth-Sth V2 | Kinetics-400 |
| optimizer | AdamW | AdamW | ||
| learning rate | (S), (B) | (S), (B) | ||
| lr schedule | cosine decay | cosine decay | ||
| weight decay | 0.05 | 0.05 | ||
| momentum | = 0.9, 0.999 | = 0.9, 0.999 | ||
| batch size | 384 | 384 (S), 512 (B) | 384 | |
| accumulation step | 8 (S), 16 (B) | 6 (S), 16 (B) | 6 (S), 4 (B) | 6 (S), 16 (B) |
| warmup epochs | 5 | 5 | ||
| training epochs | 40 (S), 30 (B) | 150 (S), 100 (B) | 40 (S), 30 (B) | 150 (S), 75 (B) |
| drop path [46] | 0.1 | 0.1 | ||
| layer-wise lr decay [39] | 0.7 (S), 0.75 (B) | 0.75 | 0.7 (S), 0.75 (B) | 0.75 |
| repeated augmentation | 2 | 2 (S), 1 (B) | 2 | |
| flip augmentation | no | yes | no | yes |
| RandAug [47] | (9, 0.5) | (9, 0.5) | ||
| label smoothing [48] | 0.1 | 0.1 | ||
| mixup [49] | 0.8 | 0.8 | ||
| cutmix [50] | 1.0 | 1.0 | ||
| Type | Top-1 (%) | Top-5 (%) | FLOPS (G) |
|---|---|---|---|
| Global | 70.7 | 92.8 | 56.9 |
| Sparse-Dense | 70.0 | 92.5 | 45.6 |
| Temporal | 47.5 | 76.5 | 34.4 |
| Head-Split Temporal | 68.4 | 91.6 | 45.7 |
| Head-Split Sparse-Dense | 70.6 | 92.9 | 51.3 |
| Type | Top-1 (%) | Top-5 (%) | FLOPS (G) | Param (M) |
|---|---|---|---|---|
| w/o Bottleneck | 70.6 | 92.9 | 51.3 | 22.0 |
| Bottleneck w Group | 70.9 | 93.1 | 53.5 | 23.4 |
| Bottleneck w/o Group | 71.0 | 93.0 | 57.4 | 25.9 |
| Type | Top-1 (%) | Top-5 (%) | FLOPS (G) | Param (M) |
|---|---|---|---|---|
| Global-Mean | 70.9 | 93.1 | 53.5 | 23.4 |
| Group-Mean | 71.1 | 92.9 | 53.5 | 23.4 |
| Ratio (Global:Sparse-Dense) | Top-1 (%) | Top-5 (%) | FLOPS (G) |
|---|---|---|---|
| 1:1 | 71.1 | 92.9 | 53.5 |
| 2:1 | 70.7 | 92.9 | 55.4 |
| 1:2 | 70.7 | 93.0 | 51.6 |
| Token–Group Interaction Position | Top-1 (%) | Top-5 (%) | FLOPS (G) |
|---|---|---|---|
| Before Attention | 71.1 | 92.9 | 53.5 |
| After Attention | 70.8 | 92.9 | 53.5 |
| After MLP | 70.7 | 92.4 | 53.5 |
| Method | Extra Data | Backbone | Flops (G) | Top-1 (%) | Top-5 (%) |
|---|---|---|---|---|---|
| supervised | |||||
| SlowFast [14] | K400 | ResNet101 | 106 × 3 | 63.1 | 87.6 |
| MViTv1 [17] | - | MViTv1-B | 455 × 3 | 67.7 | 90.9 |
| MViTv2 [51] | K400 | MViTv2-B | 225 × 3 | 70.5 | 92.7 |
| TimeSformer [15] | IN-21K | ViT-B | 196 × 3 | 59.5 | N/A |
| ViViT FE [11] | IN-21K | ViT-L | 995 × 12 | 65.9 | 89.9 |
| Video Swin [10] | IN-21K + K400 | Swin-B | 321 × 3 | 69.6 | 92.7 |
| self-supervised | |||||
| VIMPAC [41] | HowTo100M | ViT-L | N/A × 30 | 68.1 | N/A |
| BEVT [52] | IN-1K + K400 | Swin-B | 321 × 3 | 70.6 | N/A |
| MaskFeat [44] | K400 | MViT-L | 2828 × 3 | 74.4 | 94.6 |
| ST-MAE [20] | K400 | ViT-L | 598 × 3 | 72.1 | 93.9 |
| OmniMAE [53] | IN-1K | ViT-B | 180 × 6 | 69.5 | N/A |
| IN-1K + K400 | ViT-B | 180 × 6 | 69.0 | N/A | |
| our implementation | |||||
| VideoMAE [19] | - | ViT-S | 57 × 6 | 66.7 | 90.3 |
| - | ViT-B | 180 × 6 | 70.2 | 92.2 | |
| MVD [9] | IN-1K + K400 | ViT-S | 57 × 6 | 70.7 | 92.8 |
| IN-1K + K400 | ViT-B | 180 × 6 | 73.2 | 94.0 | |
| FAR (VideoMAE) | - | ViT-S | 53 × 6 | 66.9 | 90.4 |
| - | ViT-B | 176 × 6 | 70.4 | 92.1 | |
| FAR (MVD) | IN-1K + K400 | ViT-S | 53 × 6 | 71.1 | 92.9 |
| IN-1K + K400 | ViT-B | 176 × 6 | 73.3 | 93.9 |
| Method | Extra Data | Backbone | Flops (G) | Top-1 (%) | Top-5 (%) |
|---|---|---|---|---|---|
| supervised | |||||
| SlowFast [14] | - | R101+NL | 234 × 30 | 79.8 | 93.9 |
| MViTv1 [17] | - | MViTv1-B | 170 × 5 | 80.2 | 94.4 |
| TimeSformer [15] | IN-21K | ViT-L | 2380 × 3 | 80.7 | 94.7 |
| ViViT FE [11] | JFT-300M | ViT-L | 3980 × 3 | 83.5 | 94.3 |
| Video Swin [10] | IN-1K | Swin-B | 282 × 12 | 80.6 | 94.6 |
| self-supervised | |||||
| VIMPAC [41] | HowTo100M | ViT-L | N/A × 30 | 77.4 | N/A |
| BEVT [52] | IN-1K | Swin-B | 282 × 12 | 81.1 | N/A |
| MaskFeat [44] | - | MViT-S | 71 × 10 | 82.2 | 95.1 |
| ST-MAE [20] | - | ViT-B | 180 × 21 | 81.3 | 94.9 |
| OmniMAE [53] | IN-1K | ViT-B | 180 × 15 | 80.8 | N/A |
| our implementation | |||||
| VideoMAE [19] | - | ViT-S | 57 × 15 | 79.0 | 93.9 |
| - | ViT-B | 180 × 15 | 80.0 | 94.5 | |
| MVD [9] | IN-1K | ViT-S | 57 × 15 | 80.9 | 94.8 |
| IN-1K | ViT-B | 180 × 15 | 83.4 | 95.8 | |
| FAR (VideoMAE) | - | ViT-S | 53 × 15 | 79.4 | 94.0 |
| - | ViT-B | 176 × 15 | 80.4 | 94.5 | |
| FAR (MVD) | IN-1K | ViT-S | 53 × 15 | 81.1 | 94.9 |
| IN-1K | ViT-B | 176 × 15 | 83.6 | 95.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, H.-W.; Choi, Y.-S. Fusion Attention for Action Recognition: Integrating Sparse-Dense and Global Attention for Video Action Recognition. Sensors 2024, 24, 6842. https://doi.org/10.3390/s24216842
Kim H-W, Choi Y-S. Fusion Attention for Action Recognition: Integrating Sparse-Dense and Global Attention for Video Action Recognition. Sensors. 2024; 24(21):6842. https://doi.org/10.3390/s24216842
Chicago/Turabian StyleKim, Hyun-Woo, and Yong-Suk Choi. 2024. "Fusion Attention for Action Recognition: Integrating Sparse-Dense and Global Attention for Video Action Recognition" Sensors 24, no. 21: 6842. https://doi.org/10.3390/s24216842
APA StyleKim, H.-W., & Choi, Y.-S. (2024). Fusion Attention for Action Recognition: Integrating Sparse-Dense and Global Attention for Video Action Recognition. Sensors, 24(21), 6842. https://doi.org/10.3390/s24216842