1. Introduction
The evolution of intelligent transportation systems (ITSs) has increasingly underscored the importance of integrating connected and automated driving technologies, with V2X communications emerging as a critical enabler. V2X technology has garnered significant attention from both academic and industrial sectors, as it plays a pivotal role in enhancing road safety and transportation efficiency [
1]. Within this domain, Cellular Vehicle-to-Everything (C-V2X) technology, encompassing long-term evolution (LTE) and fifth-generation New Radio (5G-NR) standards, facilitates the seamless information exchange between vehicles, roadside units (RSUs), and vulnerable road users (VRUs) [
2,
3,
4].
The initial C-V2X specifications, introduced in 3GPP Release 14 (Rel-14), featured two operational Modes: the network-based Mode 3, which utilizes the LTE-Uu interface for vehicle-to-network communication, and direct Mode 4, which enables device-to-device communication via the PC5 interface. Despite its advantages, LTE-V2X does not fully satisfy the stringent requirements for autonomous driving, particularly those associated with ultra-reliable low-latency communication (URLLC). In response, 3GPP initiated the standardization of 5G NR in two phases; Phase 1 (Rel-15) focused on enhanced mobile broadband (eMBB) and preliminary URLLC studies, while Phase 2 (Rel-16 onwards) emphasized URLLC and network performance enhancements. 5G-NR-V2X, which extends beyond broadcast transmissions, supports both unicast and multicast transmissions. Like C-V2X, 5G-NR-V2X operates in two transmission Modes: Mode 1 (centralized) and Mode 2 (decentralized). In Mode 1, resource scheduling is managed by the base station (enB) when vehicles are within coverage areas, whereas in Mode 2, vehicles autonomously reserve resources using the SB-SPS algorithm in out-of-coverage regions. 5G-NR-V2X Mode 2 introduces a mandatory re-evaluation mechanism that includes both the SB-SPS and DS schemes. The SB-SPS scheme is inherited from LTE-V2X with minor modifications, while the DS scheme is a new reservation-less approach that requires selecting new transmission resources for each generated message [
1,
5,
6].
To date, only a few studies have examined the performance of the SB-SPS scheme in 5G-NR-V2X Mode 2, revealing that increased vehicular traffic density and aperiodic traffic with varying data sizes lead to inefficiencies in the SB-SPS method. These inefficiencies result in poor radio resource utilization (RRU) and a higher probability of resource collisions, particularly when a vehicle fails to transmit a message in an intended slot due to a collision. To address these limitations, novel artificial intelligence (AI)-based solutions and alternative techniques have been proposed. Conversely, there has been limited analysis of the DS scheme. Machine learning has proven invaluable across various domains, including vehicular communications, offering optimal solutions through advanced algorithms. Several studies have employed machine learning to address challenges in V2X communications, such as optimizing resource allocation in C-V2X Mode 4 to mitigate network contention and reducing the signaling overhead in C-V2X Mode 3 [
5]. Cutting-edge AI techniques, including machine learning and deep learning, are providing innovative solutions to wireless communication challenges, particularly through the application of deep neural networks in supervised, unsupervised, and reinforcement learning settings [
6,
7].
Despite the extensive efforts to apply machine learning techniques to address the challenges in 5G-NR-V2X Mode 2, achieving significant breakthroughs remains challenging [
8,
9,
10]. This paper presents a novel approach to resolving persistent collision issues in 5G-NR-V2X Mode 2 by implementing the SEAC reinforcement learning (RL) technique. Our research exclusively focuses on optimizing Mode 2 communication within the European V2X framework, particularly for Cooperative Awareness Messages (CAMs) and Collective Perception Messages (CPMs), which are safety-critical and transmitted more frequently than other message types. Our objective is to reduce collisions during resource reselection and to enhance packet reception ratios.
The remainder of this paper is organized as follows:
Section 2 reviews the literature on SB-SPS and DS, as well as related work.
Section 3 introduces the proposed SEAC technique, and the methodology employed.
Section 4 describes the simulation environment,
Section 5 presents the results and their analysis, and
Section 6 concludes the paper.
The main findings of this paper are as follows:
The performance of the SB-SPS scheme can significantly deteriorate in the presence of aperiodic traffic, especially with increasingly stringent packet delay budget (PDB) constraints. However, it remains the optimal solution for serving fixed-size periodic traffic, provided that the reservation periodicity aligns with the traffic generation period;
Conversely, the performance of the DS scheme remains independent of PDB requirements, making it most effective for handling both fixed- and variable-size aperiodic traffic under low or average density conditions;
Although the DS scheme performs better than SB-SPS in aperiodic traffic scenarios, its effectiveness diminishes as traffic density increases due to the random selection of transmission resources, leading to higher collision probabilities;
The SEAC strategy consistently outperforms both SB-SPS and DS schemes, particularly in aperiodic traffic scenarios, by improving reliability, reducing collisions, and enhancing resource utilization.
2. Overview of 5G-NR-V2X Mode 2
In 5G-NR-V2X Mode 2, communication systems utilize the physical (PHY) layer for signal transmission and the medium access control (MAC) layer for managing access to the communication medium. The 3GPP also devoted significant efforts to the MAC sublayer to develop a new resource allocation Mode, known as 5G-NR-V2X Mode 2. The MAC layer employs two main resource allocation schemes: SB-SPS and DS.
SB-SPS operates by allowing vehicles to periodically reserve subchannels for a fixed number of transmissions, defined by the reselection counter
and the resource reservation interval (RRI). Vehicles using the SB-SPS scheme periodically reserve the selected subchannel(s) for a number of
consecutive transmissions. The time between consecutive reservations is called the resource reservation interval (RRI), and 5G-NR-V2X Mode 2 supports any RRI value in the {0, [1:1:99], [100:100:1000]} ms range, where in the [x:y:z] notation, x denotes the minimum allowed value; z, the maximum; and y, the incremental step between consecutive values. Vehicles employ the SCI to broadcast the adopted RRI configuration and to inform neighboring vehicles about their next reservation. Depending on the selected RRI, the value of the
is set as follows: if RRI ≥ 100 ms,
is randomly set between the [5, 15] interval [
1,
5].
After every transmission, the value of the
is decremented by one, and when
= 0, the ego vehicle selects new subchannels with probability 1 − P, where P is the keep probability; P ∈ [0, 0.8]. On the other hand, vehicles using the DS scheme select new subchannels every time a new message is generated, and they are not allowed to place any reservations. In other words, DS is the reservation-less variant of the SB-SPS scheme, which sets
= 1 and P = 0. Despite being characterized by a totally different reservation policy, the SB-SPS and DS schemes employ the same resource reselection process (illustrated in
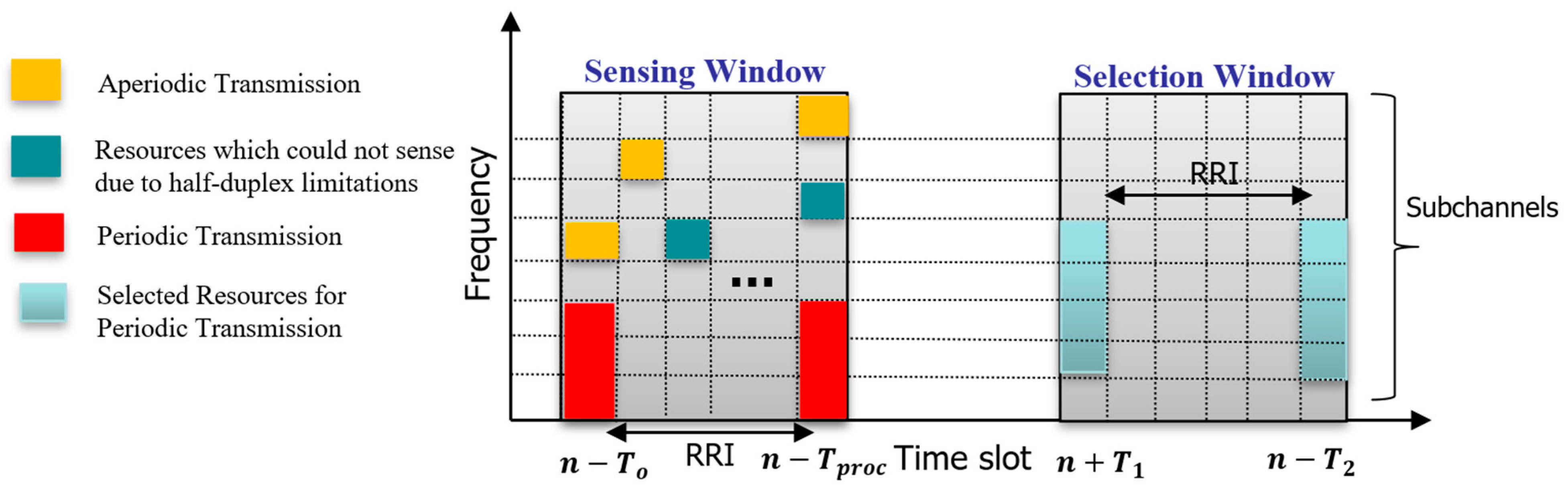
Figure 1). The ego vehicle’s subchannel selection process involves two main phases: the sensing window and the selection window, as shown in
Figure 1. During the sensing window, which spans from
to
depending on the subcarrier spacing (SCS), the ego vehicle identifies and excludes subchannels reserved by neighboring vehicles if the reservation signal exceeds a certain Reference Signal Received Power (RSRP) threshold. Additionally, subchannels previously used by the ego vehicle during this period are excluded due to half-duplex limitations.
In the selection window, which extends from to based on the SCS and the PDB, the ego vehicle compiles a list of candidate subchannels. If the list does not cover at least a set percentage (β%) of the window, the RSRP threshold is increased by 3 dB, and the process is repeated. Depending on the priority of the TB, β can be set to 20, 35, or 50. Once an adequate list is determined, the ego vehicle randomly selects adjacent subchannels to accommodate its transmission needs.
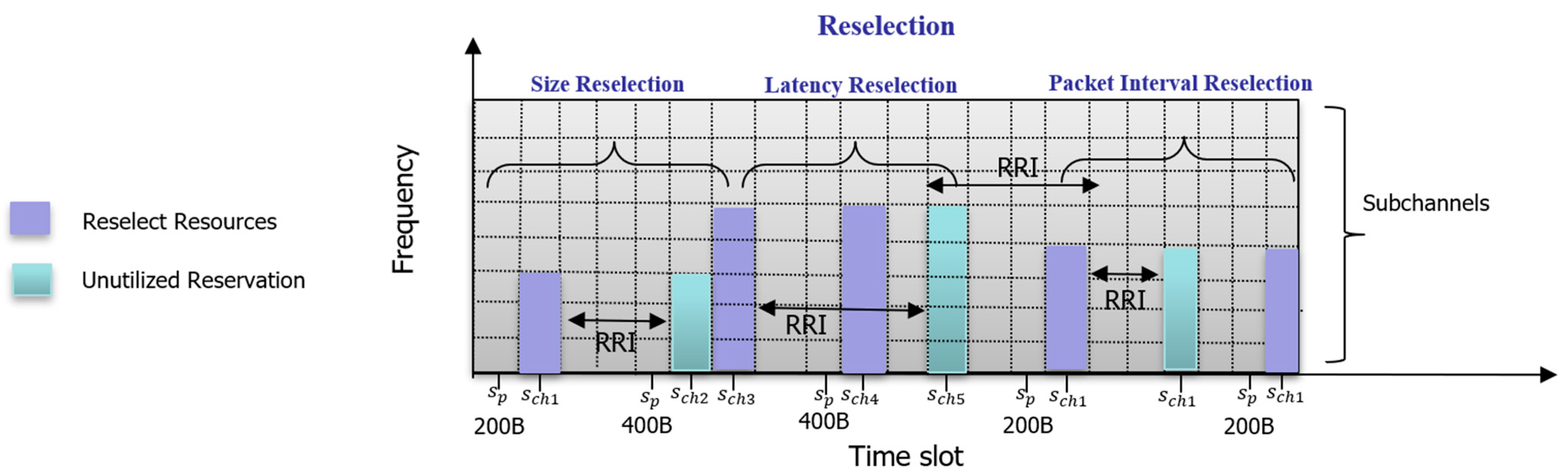
However, SB-SPS has notable limitations:
Persistent collisions: Periodic reservations can result in repeated collisions if multiple vehicles reserve the same resources;
Inefficiency with variable traffic: SB-SPS struggles to accommodate aperiodic or variable-sized data, leading to unutilized reservations and higher collision probabilities;
Latency issues: The fixed periodic nature of SB-SPS does not adapt well to varying latency requirements, causing delays for latency-sensitive applications.
Figure 2 illustrates these problems in the SB-SPS resource selection process, showing how issues like size reselection, latency reselection, and packet interval reselection lead to inefficiencies.
DS in vehicular networks allows vehicles to randomly select subchannels for each transmitted message without prior reservations, assuming that all subchannels within the selection window are available, as shown in
Table 1. This method, like a multichannel slotted Aloha strategy, operates independently of the selection window’s width and PDB. The collision probability under DS is primarily influenced by the message generation rate and size, making it an efficient approach that minimizes collision risks, particularly when only a subset of vehicles adopts this scheme.
DS on the other hand, involves the random selection of new subchannels for each transmission without pre-reserving resources. This scheme better handles aperiodic and variable traffic but faces the following significant challenges:
High collision probability: Random selection increases collision risk, especially in dense traffic scenarios;
Lack of coordination: Real-time resource selection can lead to inefficient subchannel usage and higher interference;
PDB issues: DS does not explicitly consider the PDB for individual packets, potentially missing strict latency requirements for delay-sensitive applications, leading to delays and suboptimal performance.
The current landscape of research on resource allocation strategies in 5G-NR-V2X Mode 2, as summarized in the comparison in
Table 2, highlights significant efforts to address the limitations of the SB-SPS and DS techniques, particularly in handling aperiodic traffic and periodic traffic. In
Table 2, a cross (✗) indicates that the technique is not included in the respective study, while a checkmark (✓) signifies that it is included. Various approaches, including Multi-Agent Actor–Critic (IAC, SEAC) [
2], deep reinforcement learning (Q-learning) [
5,
9,
10], and SB-SPS with lookahead mechanisms [
11,
12,
13], have been explored to improve reliability, reduce collisions, and enhance resource utilization in V2X communications. However, despite these advances, no existing work has fully addressed the challenges associated with SB-SPS in aperiodic traffic, nor has there been substantial exploration of DS, especially under conditions of high traffic density where the likelihood of collisions increases due to the random resource selection inherent in DS [
14,
15].
This work addresses these gaps by proposing a SEAC reinforcement learning technique that not only overcomes the limitations of SB-SPS but also enhances the reliability and resource utilization in aperiodic environments. As demonstrated by the results, SEAC significantly outperforms both SB-SPS and DS, particularly in scenarios where the traffic density is high, proving to be a superior method for reducing collisions and optimizing resource allocation.
3. System Design and the Proposed SEAC-Based Resource Allocation Methodology
In this work, we focus specifically on aperiodic traffic in 5G-NR-V2X Mode 2, which presents unique challenges in resource allocation. Traditional methods like SB-SPS and DS have limitations in this context. SB-SPS struggles with variations in message size, packet generation latency, and the intervals between packet generations, leading to underutilized resources and frequent collisions. On the other hand, while DS is more flexible in handling aperiodic and variable-sized traffic, it has a high collision probability in environments with dense vehicular traffic. Moreover, DS does not consider packet delay budget (PDB) constraints, which are crucial for latency-sensitive applications such as autonomous driving and real-time video streaming [
16,
17].
To address these challenges, we propose the Shared Experience Actor–Critic (SEAC) reinforcement learning technique, which optimizes resource allocation in aperiodic traffic scenarios by overcoming the limitations of both SB-SPS and DS. SEAC leverages shared experiences among vehicular agents to reduce collisions and to improve resource utilization. It dynamically allocates resources by considering both real-time decisions and long-term impacts, ensuring sustained performance in high-density vehicular environments [
18].
Figure 3 provides a general framework that illustrates both the existing (DS and SB-SPS) and the proposed SEAC techniques for a better understanding. While this figure includes a comparison of the traditional and proposed methods, the main focus of our work is on aperiodic traffic and how SEAC enhances resource allocation in such scenarios. The decision-making process shown in the figure is based on the traffic type (aperiodic vs. periodic), with SEAC addressing the challenges specifically associated with aperiodic traffic.
In the 5G-NR-V2X Mode 2 network, the radio resource allocation task is addressed through a fully decentralized multi-agent networked MDP. Vehicular agents operate in a shared road traffic environment, constantly exchanging CAMs and CPMs. These messages provide critical information such as position, distance to neighboring vehicles, and forecasts of object locations. This decentralized model bases its actions on each agent’s local observations and assigns rewards specific to each agent’s context. The primary objective for all agents is to ensure the successful transmission of V2X messages within the selected radio resources while avoiding collisions with other agents. By employing experience-sharing techniques, the agents enhance their learning capabilities, gaining valuable insights from the actions and outcomes experienced by their peers [
18]. Our approach utilizes gated recurrent unit (GRU) layers to process and forecast the state information, optimizing resource allocation decisions and improving the overall network efficiency. To formulate an MDP, the components—state, action, reward, and experience—must be clearly defined in the context of radio resource allocation.
3.1. Network State Representation
In 5G-NR-V2X Mode 2 networks, the state includes essential information for each vehicle’s decision making regarding radio resource allocation. Accurate observation and processing of these parameters are crucial for efficient collision-free communication in vehicular networks.
The state
at a given time t includes the following components:
3.1.1. Distance to Neighboring Vehicles (Δd)
This parameter represents the distance between the ego vehicle and its neighboring vehicles. This is crucial for the reuse of radio resources, as distant vehicles can use the same resources without causing interference
3.1.2. Forecast Indicator of the Possibility of an Object (I_sf)
This indicator reflects the likelihood of aperiodic traffic within the vehicle’s sensor field of view (FOV). Derived from Cooperative Perception Messages (CPMs), it helps in predicting potential traffic events and adjusting resource allocation.
3.1.3. Radio Resource Occupancy () in the Previous 1 s Time Window
This parameter indicates the number of resource blocks (RBs) occupied in each subchannel
k and timeslot
m within the selection window
[
19,
20].
The number of resource blocks occupied in subchannel k and timeslot m are given by
where
k is the set of subchannels, and
m is the set of timeslots.
We capture the temporal variations of these parameters over the previous time window using a GRU-based recurrent neural network (RNN). These components are captured and processed in the system using gated recurrent units (GRUs). The GRUs track temporal variations in these parameters and use them as multi-dimensional inputs to predict future states, aiding in more informed decision making regarding resource allocation.
3.2. Resource Management Decisions
The action space for each agent in our resource scheduler is defined by the available radio resource pool, denoted as
where k represents the number of subchannels (each consisting of groups of resource blocks (RBs)), and m represents the number of slots. Furthermore, the total channel bandwidth is 20 MHz, operating in the 5.9 GHz ITS band. We also incorporate a reselection counter
as per ETSI specifications, with a range uniformly distributed between 5 and 15 [
20]. This counter determines the duration for which a vehicle holds the selected resources for future transmissions. The system operates under design constraints such as channel bandwidth (20 MHz), V2X transmission power (0 to 23 dBm), and an RSRP threshold of −128 dBm. These constraints ensure that radio resources are efficiently allocated and that the signal strength is sufficient for reliable communication.
Each vehicle, with a mean speed of 140 km/h (and standard deviation of 3 km/h), selects one radio resource from and one category of the value. The action selection mechanism aims to achieve the following:
Select a radio resource and decide the duration for using the same resource for future transmissions, based on the V2X data traffic pattern forecasted by the GRU layers;
Detect potential resource collision risks and re-evaluate the resource selection within the PDB;
Avoid scheduling the same resource for subsequent transmissions after detecting collisions in one of the intended slots and inform other agents to avoid the same resource;
Adapt based on the V2X data traffic pattern to ensure that reserved resources are utilized efficiently.
The actor network selects a radio resource based on the softmax probability values. The critic network evaluates the impact of the selected action by computing the state value after the environment transitions to a new state. This continuous evaluation by the critic network provides feedback to the actor network, helping it to refine its policy and make more effective resource allocation decisions.
3.3. Performance Feedback Mechanism
The critic component in our model plays a crucial role in evaluating the actions taken by the actor within the N-step actor–critic framework. It provides a value function estimate, which helps in assessing the quality of the actions in terms of expected rewards. The critic network receives the current state and action as inputs and outputs the value of the resulting state.
3.3.1. Immediate Reward
The reward for each agent at time is calculated based on the following criteria:
The reward = if no collisions are detected and the resource allocation latency is
The reward if collisions are detected but successfully re-evaluated within ;
The reward if the agent cannot reselect resources within due to multiple neighboring vehicles choosing the same resource.
is the number of successful transmissions for the agent;
is the number of re-evaluated successful transmissions;
is the number of failed transmissions;
is the resource allocation latency;
is the packet delay budget.
3.3.2. Cumulative Rewards in the N-Step Actor–Critic Framework
The N-step actor–critic framework computes the cumulative reward
over
N steps to balance immediate rewards and long-term performance.
where
is the cumulative reward at time step ;
is the discount factor;
is the immediate reward at time step is the estimated value of the state at time step ;
N represents the number of steps used in the N-step actor–critic method, where cumulative rewards are calculated over N time steps to balance between immediate and future rewards.
The immediate rewards provide a short-term measure of success for each action taken, focusing on the success of individual transmissions and collision avoidance. These rewards are accumulated over N steps to form the cumulative reward , which evaluates the long-term impact of actions on the resource allocation efficiency and overall network performance. This dual approach ensures that the model not only makes effective immediate decisions but also optimizes for future states.
3.4. Cumulative Learning Process
Each vehicular agent takes independent actions based on its local observations of the environment. These actions are influenced by the agent’s policy, which is continuously refined through interactions with the environment. After executing each action, the agent receives a reward (either positive or negative) that reflects the immediate impact of its decision.
The sequence of states, actions, and rewards generated by the agent over multiple time steps constitutes an ”on-policy” trajectory, which is referred to as experience. This experience captures the agent’s interactions with the environment and is crucial for updating the policy and value functions, ensuring that the agent adapts to changing network conditions and traffic patterns
State transitions: The changes in the agent’s state after taking actions, such as moving from one radio resource to another;
Actions: The specific radio resource selections and reselection decisions made by the agent;
Immediate rewards: The rewards received based on the success of transmissions, collisions, and resource allocation latencies;
Cumulative rewards: The cumulative impact of actions over multiple time steps, which are used to update the agent’s policy.
3.5. SEAC-Based Resource Allocation Algorithm
In this section, we detail the SEAC methodology for efficient resource allocation in 5G-NR-V2X Mode 2 networks. The SEAC approach leverages a multi-agent setup, as depicted in
Figure 4, where each vehicular agent learns to optimize its resource allocation strategy while sharing experiences with other agents to enhance the overall system performance.
The SEAC model efficiently allocates communication resources among vehicles by employing both actor and critic networks. The actor network is responsible for selecting actions based on the current state
provided by the 5G-NR-V2X Mode 2 environment. The actor network generates an action
using its online policy network
, which is subsequently executed in the environment. This action influences the environment, leading to a new state
and a corresponding reward
[
21,
22].
The critic network evaluates the selected actions by computing the value function, providing feedback to the actor network. It consists of two Q-values: the online network and the target value network. The online value network calculates the Q-value , while the target value network computes the target Q-value , where helps in refining the value function
Figure 4 illustrates the Shared Experience Actor–Critic (SEAC) mechanism, where vehicles collaborate to improve resource allocation through shared learning in a 5G-NR-V2X environment. The process begins with each vehicle observing its environment state and using the actor network to select a resource allocation action. The critic network then evaluates this action by calculating a
Q-value that reflects the effectiveness of the resource allocation. The outcome (state–action–reward tuple) is stored in a local experience pool for future training. To further enhance learning, vehicles share their experiences via V2V communication, which are aggregated into a shared experience pool, enabling each vehicle to learn from both its own and others’ experiences. This shared learning improves the overall decision-making and resource optimization process.
The actor and critic networks are updated through a process involving gradient calculations (policy gradient for the actor and Q-value gradient for the critic) based on the critic’s feedback. Soft updates are applied to ensure stable learning, adjusting the target policy and value networks gradually. The temporal difference (TD) error is computed to refine the critic’s evaluations, ensuring accurate learning over time. This iterative process allows vehicles to continuously refine their policies, leading to more efficient resource allocation and improved network performance by leveraging both local and shared experiences.
The TD error is crucial in evaluating the difference between the expected value of the current state–action pair and the value after observing the outcome. This error helps in refining the value function.
The TD error can be expressed as
where
is the immediate reward at time t;
is the discount factor;
is the target value for the next state–action pair;
is the current estimate of the state–action value.
The critic’s value function is updated based on the TD error, and the actor’s policy is refined using the policy gradient calculated by the critic. Soft updates are applied to the target policy network and the target value network, ensuring smooth transitions and stable learning by gradually moving the parameters toward those of the online networks.
To ensure training stability, the parameter update for the critic’s value network is given by
where
Similarly, the update for the actor network parameters is
where
To ensure stability during training, soft updates are performed on the target networks, gradually moving their parameters closer to those of the online networks:
where
The actor and critic networks work together, with the critic providing feedback via the TD error to guide the actor’s policy adjustments and to refine the value function. By leveraging both the local and shared experiences, the SEAC framework enables vehicles to improve their decision making for resource allocation in the 5G-NR-V2X networks. Soft updates maintain network stability by preventing drastic changes to the parameters of the target networks. This method allows the SEAC model to manage resource allocation effectively, minimizing collisions and congestion in high-traffic environments. By continuously sharing experiences and adjusting policies based on feedback, the framework adapts to varying traffic conditions and optimizes communication channels in dynamic V2X environments.
Multi-Agent MDP Model
The SEAC algorithm builds on the actor–critic framework in a multi-agent MDP model to address the limited information in decentralized systems. The MDP components include the state
representing the shared environment where all agents operate, actions
taken by each agent that together form a joint action space
, and rewards
given to each agent based on the state and actions. The system then transitions to the next state, which is influenced by the collective actions of all the agents. In SEAC, agents share their experiences—comprising state, action, and reward information—with other agents. This allows each agent to update its actor–critic model using both local and shared experiences, leading to improved decision making and more efficient resource allocation in future states [
23].
The SEAC framework integrates actor and critic networks for effective learning. The actor network, parameterized by ϕ, selects actions based on the current state, while the critic network, parameterized by θ, evaluates these actions by estimating the value function.
Agents leverage both their own and others’ experiences through a shared experience pool. This off-policy learning approach adjusts the actor and critic loss functions to incorporate diverse interactions, enhancing the adaptability and resource allocation efficiency in dynamic environments.
In SEAC, agents share their experiences through a common experience pool, enhancing the learning efficiency. The goal is to determine policies
that maximize the total reward over time
:
where
is the discount factor, and
is the reward obtained by agent
i at time
t. The main objective for all agents is to maximize the expected reward:
where
denotes the policies of all agents except
i.
Each agent adjusts its strategy by minimizing losses in both the actor and critic networks, taking into account the partial observability of the environment. The actor network’s loss, which guides how it changes its policy, is defined as
where
are the actor’s network parameters;
is the value function computed by the critic network, is the target value function.
The critic network’s loss function, which helps in evaluating actions, is
Here, is the online value network, and is the target value network.
The target value
is calculated using
where
is the reward obtained by agent i at time t;
is the discount factor;
is the target value for the next state–action pair.
In SEAC, each agent not only learns from its own experiences but also incorporates experiences from other agents. This shared experience is considered “off-policy” data. The actor and critic losses are extended to include the off-policy experiences as follows:
The actor loss with experience sharing is
where
represents the probability of taking action given the observation and the actor network parameters ;
is the immediate reward received by agent i at time t;
is the discount factor;
is the target Q-value at the next state using the next action and the target network parameters ;
is the standard actor loss for agent i without experience sharing;
is the ratio of the policy probabilities of another agent k to that of agent i. This ratio adjusts how much influence the experiences of other agents should have on the current agent i’s policy.
The critic loss with experience sharing is
where
is the standard critic loss for agent i without experience sharing;
is the squared error between the predicted Q-value and the target value . This is a common loss function for training critic networks in reinforcement learning.
The hyperparameter
adjusts how much influence the shared experiences have. The loss functions for the actor and critic are modified to include contributions from other agents, which are controlled by the hyperparameter λ. This approach ensures that the policy and value functions are updated not only based on the agent’s own experience but also by considering the experiences of other agents in the network [
24,
25].
By continuously updating policies and value functions based on real-time feedback, the SEAC ensures efficient and responsive resource allocation. The experience sharing mechanism allows agents to adjust their strategies, leading to better handling of traffic variability and ensuring that resources are allocated effectively without causing congestion or wastage.
4. Simulation Environments
The operation and performance of the SB-SPS, DS, and SEAC schemes were evaluated using the WiLabV2X simulator. This simulator provides an accurate implementation of 5G-NR-V2X Mode 2, adhering closely to the 3GPP specifications and evaluation guidelines.
For artificial intelligence (AI)-based allocation, we extended the existing simulation environment by a deep reinforcement learning (DRL) environment that executes the AI-based scheduler [
26,
27,
28]. In this section, we discuss selected aspects of the evaluation methodology and the simulator implementation design [
29,
30,
31,
32].
4.1. AI-Driven Resource Management
In the simulation environment for evaluating AI-based radio resource allocation, the WiLabV2X simulator is employed, supporting the unmanaged mode for Cellular V2X communication. This simulator is primarily utilized to benchmark the performance of existing resource allocation techniques under unmanaged network conditions. For the AI-based resource allocation aspect, custom coding is developed independently, leveraging advanced deep reinforcement learning methodologies.
The dataset, encompassing parameters such as the distance to neighboring vehicles, forecast indicators, and radio resource occupancy, is meticulously prepared and imported. These parameters define the states crucial for training the reinforcement learning model. The state space incorporates factors like the number of radio resources occupied and the specific actions taken. The reward structure is designed to reflect the efficiency and effectiveness of resource usage, providing positive reinforcement for optimal allocations and penalties for suboptimal decisions.
4.2. Model Architecture
The core of the AI-based approach is a GRU model with two layers, which captures temporal dependencies and makes accurate future state predictions. The model architecture includes convolutional layers for feature extraction, GRU layers for sequential data processing, and fully connected layers for the final decision making.
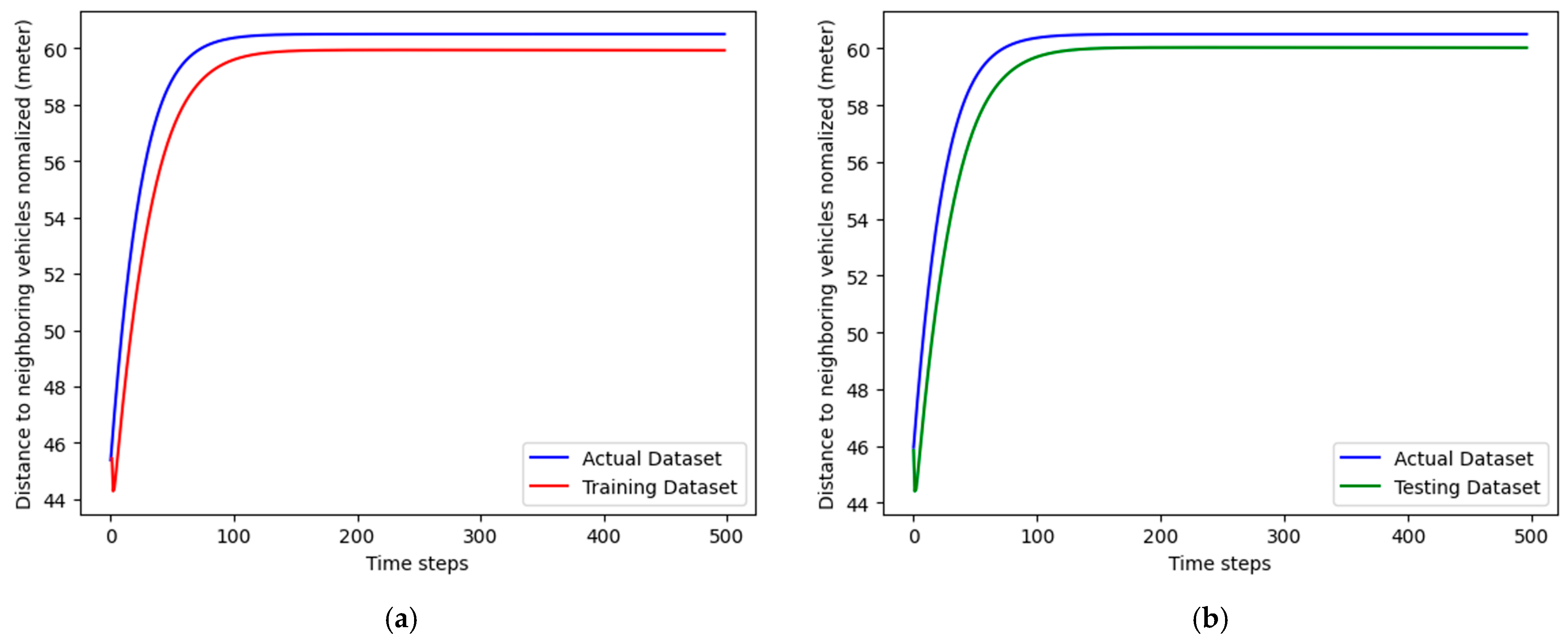
The model trains and tests using a dataset split, with the training focused on optimizing parameters to reduce loss functions, such as the mean absolute percentage error (MAPE). The training process includes multiple epochs, with the model’s performance evaluated on both training and testing datasets to ensure generalization.
4.3. Simulation Parameters
The study is conducted on a simulated 2 km long highway segment with 3 lanes in each direction, totaling 6 lanes. Vehicles in the simulation maintain a mean speed of 140 km/h, with a standard deviation of 3 km/h. The system operates under the 5G-NR-V2X network with an OFDM numerology set to μ = 1, corresponding to a subcarrier spacing (SCS) of 15 kHz and a symbol time (ts) of 0.5 ms. The traffic type is aperiodic, with variable data size. The 5G-NR-V2X Mode 2 radios are configured to function within a 20 MHz channel in the 5.9 GHz ITS band, using QPSK modulation. Subchannels are organized into 12 resource blocks (RBs) each, resulting in 4 available subchannels per time slot. The transmission power is adjustable between 0 and 23 dBm, while the receiver sensitivity is set to −103.5 dBm. The simulation accounts for a proximity broadcast range of 500 m, with the resource reservation interval (RRI) set to 100 ms. The operational mode remains unmanaged, with an initial RSRP threshold of −128 dBm and a retention probability (P) of 0 for the SB-SPS scheme. These settings are detailed in
Table 3.
The evaluation in this study utilizes a variety of V2X message types and simulation parameters to assess the performance of different scheduling mechanisms [
28]. The key message types considered are Cooperative Awareness Messages (CAMs) and Collective Perception Messages (CPMs), as illustrated in
Table 4. CAMs, defined in ETSI TS 103 900 V2.0.0 (July 2022), provide continuous updates on vehicle status and kinematics, typically at a frequency of 1–10 Hz with a payload size of around 400 bytes. CPMs, described in ETSI TS 103 324 V2.1.1 (Jun 2023), enable the sharing of sensor-based environmental perceptions, including detected and classified objects. These messages are also transmitted at a frequency of 1–10 Hz, with payloads of up to 1000 bytes [
29].
4.4. Performance Metrics
In this study, the performance of the SEAC reinforcement learning technique is compared with traditional SB-SPS and DS schemes using the following metrics:f
Packet reception ratio (PRR): The PRR measures the percentage of correctly received and decoded transmission bursts (TBs) compared to the total transmitted TBs. It is evaluated as a function of the distance (D) between transmitting and receiving vehicles, providing insight into the reliability of communications over varying distances.
where
Radio resource utilization (RRU): This metric evaluates the efficiency with which the communication system uses the available radio spectrum. It reflects the effectiveness of resource management in maintaining high network performance and minimizing wasted resources.
where
Probability of resource collision (PRC): This metric assesses the likelihood of multiple vehicles selecting the same radio resources simultaneously, causing communication collisions. A high PRC indicates frequent resource contention, leading to degraded network performance. Minimizing the PRC is essential for efficient spectrum utilization and reliable communication, especially in dense traffic scenarios.
where
is the number of instances where multiple vehicles selected the same resource, causing a collision;
is the total number of attempts made by vehicles to access the resources.
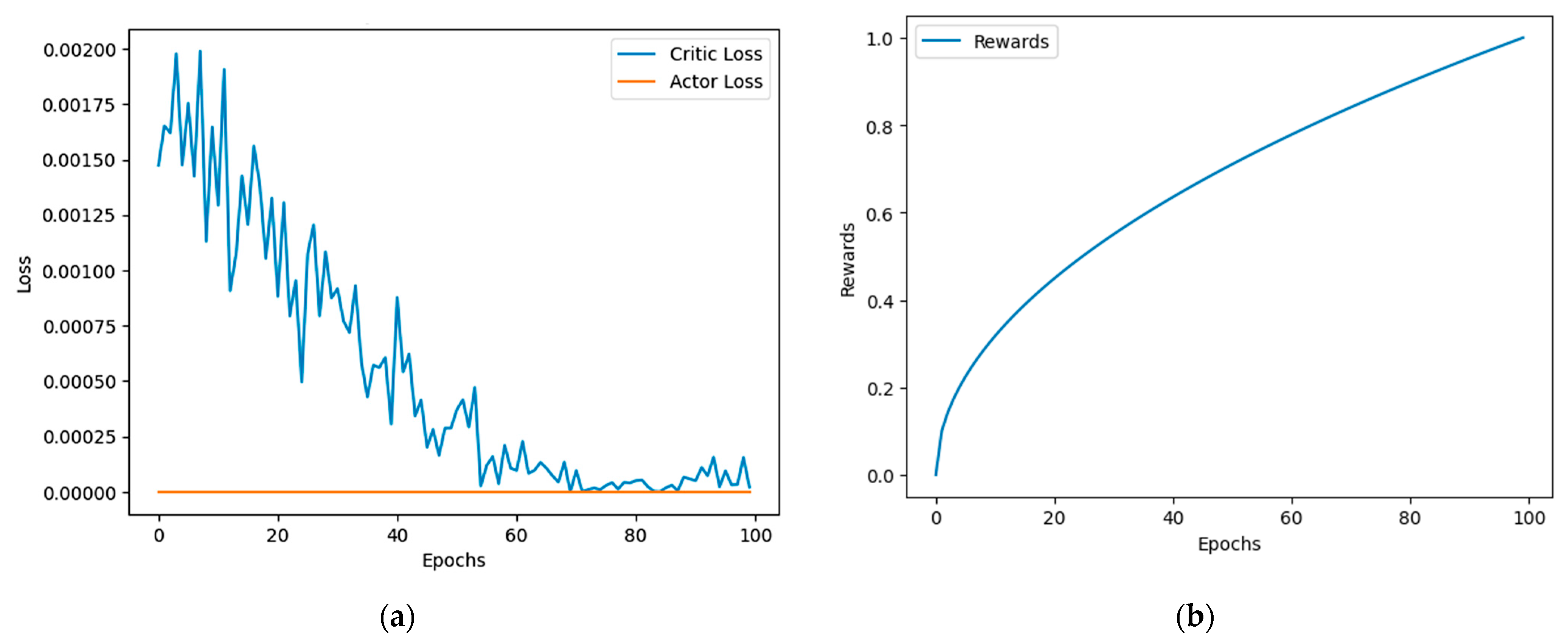
In addition to these metrics, the effectiveness of the SEAC technique is further demonstrated through training graphs, illustrating the model’s learning progress. These graphs provide a visual representation of how well the SEAC model improves its resource allocation decisions over time, showcasing its potential advantages over traditional methods.
6. Conclusions
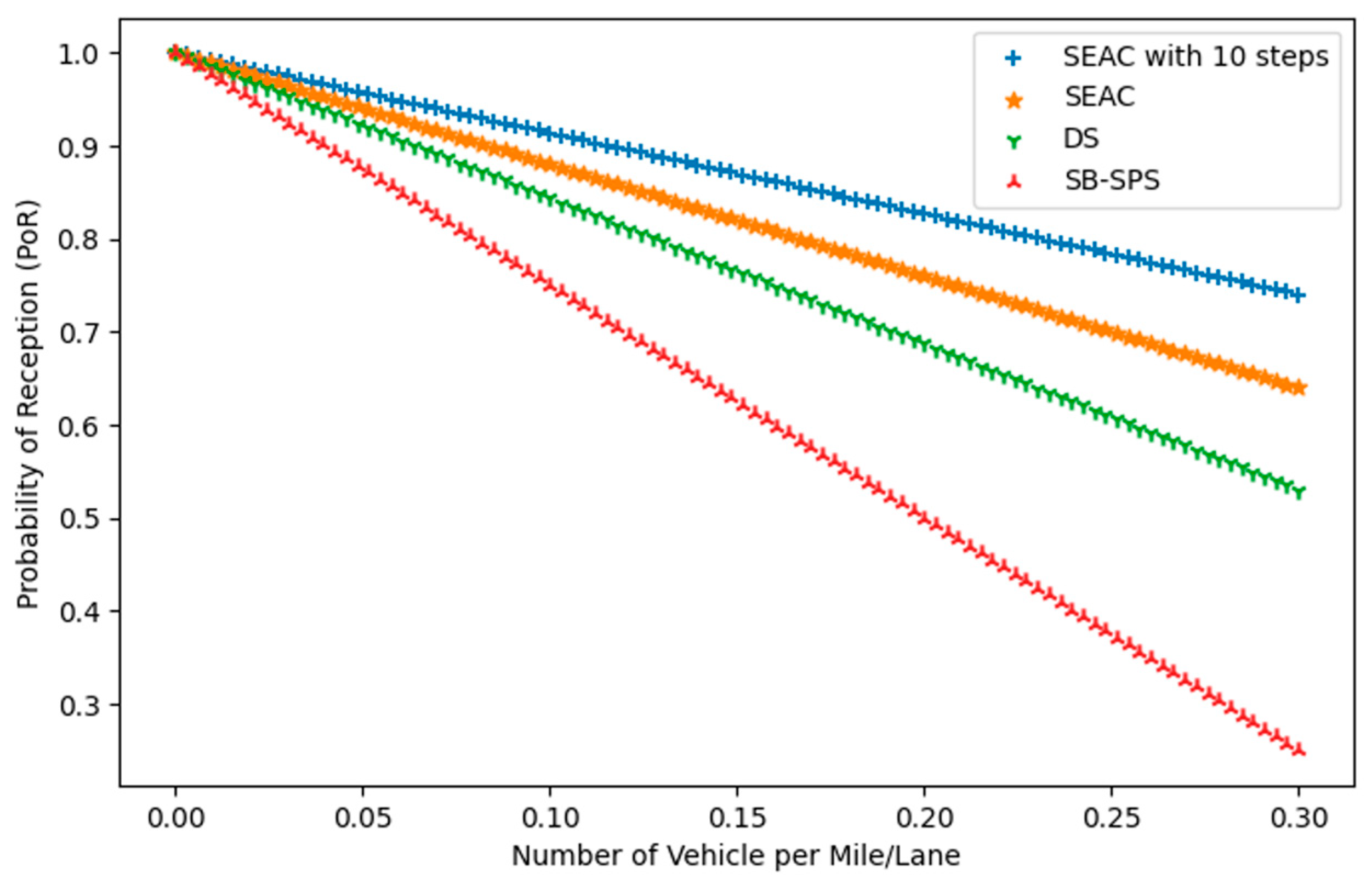
This study explores the challenges of resource allocation in 5G-NR-V2X Mode 2 networks, particularly under aperiodic traffic conditions, and proposes the SEAC technique as a solution. Our findings indicate that traditional approaches, such as SB-SPS and DS, exhibit notable limitations, especially in high-density scenarios, where resource collisions and inefficiencies are pronounced. Under high-traffic conditions, a SEAC model with N steps achieves an RRU of approximately 70.36%, representing a 60.01% improvement over SB-SPS and a 32.12% improvement over DS. SEAC also maintains a POR of around 0.85 as the vehicular density increases, which is 10–15% higher than DS and 20–25% higher than SB-SPS. Additionally, SEAC demonstrates a PRC that is 15–20% lower than DS and 20–30% lower than SB-SPS in high-density environments. The SEAC method, leveraging reinforcement learning in a multi-agent environment, shows a clear advantage in optimizing resource allocation. These results underscore SEAC’s potential to enhance the reliability and efficiency of V2X communications, which are critical for the advancement of autonomous driving technologies. Future research can explore the combination of SEAC with other AI-based techniques, as well as its application in diverse vehicular scenarios, including urban environments with complex traffic dynamics. By addressing these challenges, the SEAC technique has the potential to play a pivotal role in shaping the future of ITSs.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}