
UNeXt: An Efficient Network for the Semantic Segmentation of High-Resolution Remote Sensing Images


Abstract
1. Introduction
- This paper summarizes the existing methods that combine a CNN and ViT for remote sensing image segmentation, uncovering their shared shortcomings, namely, CNN’s inability to model global information and the substantial increase in computational cost brought by VIT. The limited input size of high-resolution remote sensing images constrains global information modeling.
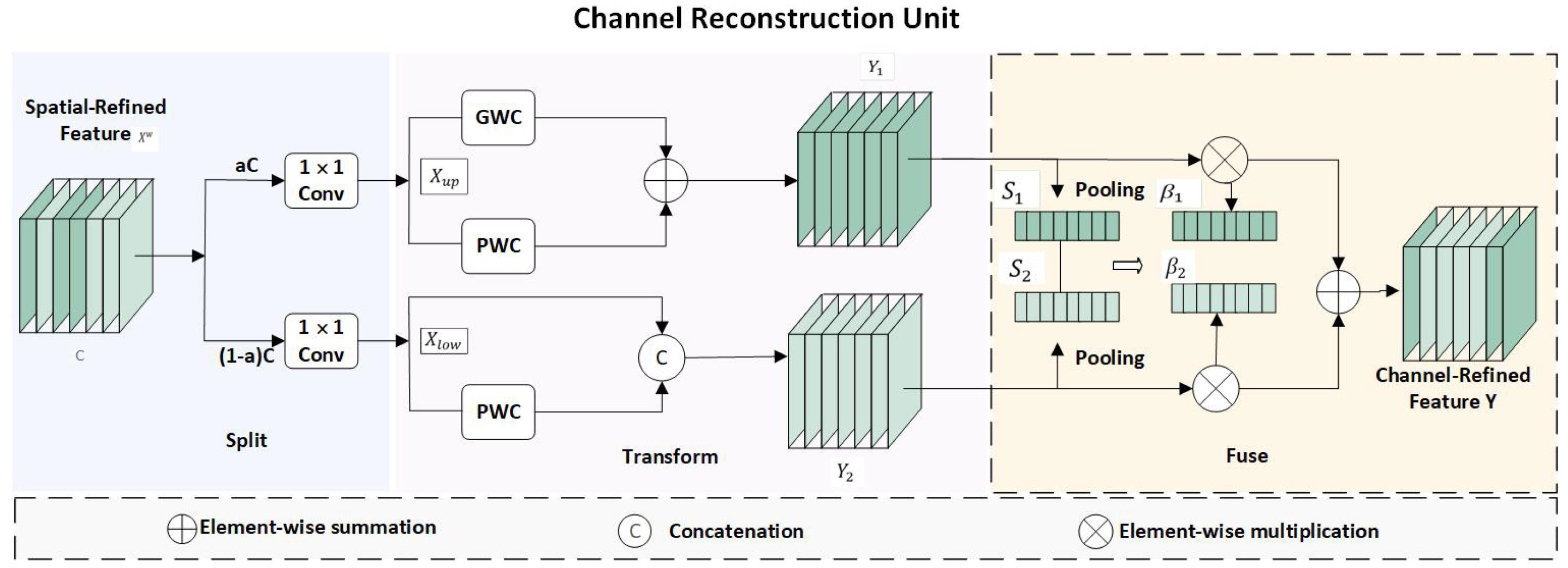
- To achieve more efficient remote information interaction, we devised a novel and efficient feature fusion module, the SFFB (SC Fuse Block), which incorporates spatial and channel reconstruction convolutions, consisting of an SRU (Spatial Reconstruction Unit) and CRU (Channel Reconstruction Unit). The SRU reduces spatial redundancy through the separate–reconstruct method, while the CRU reduces channel redundancy using the segment–transform–fuse method.
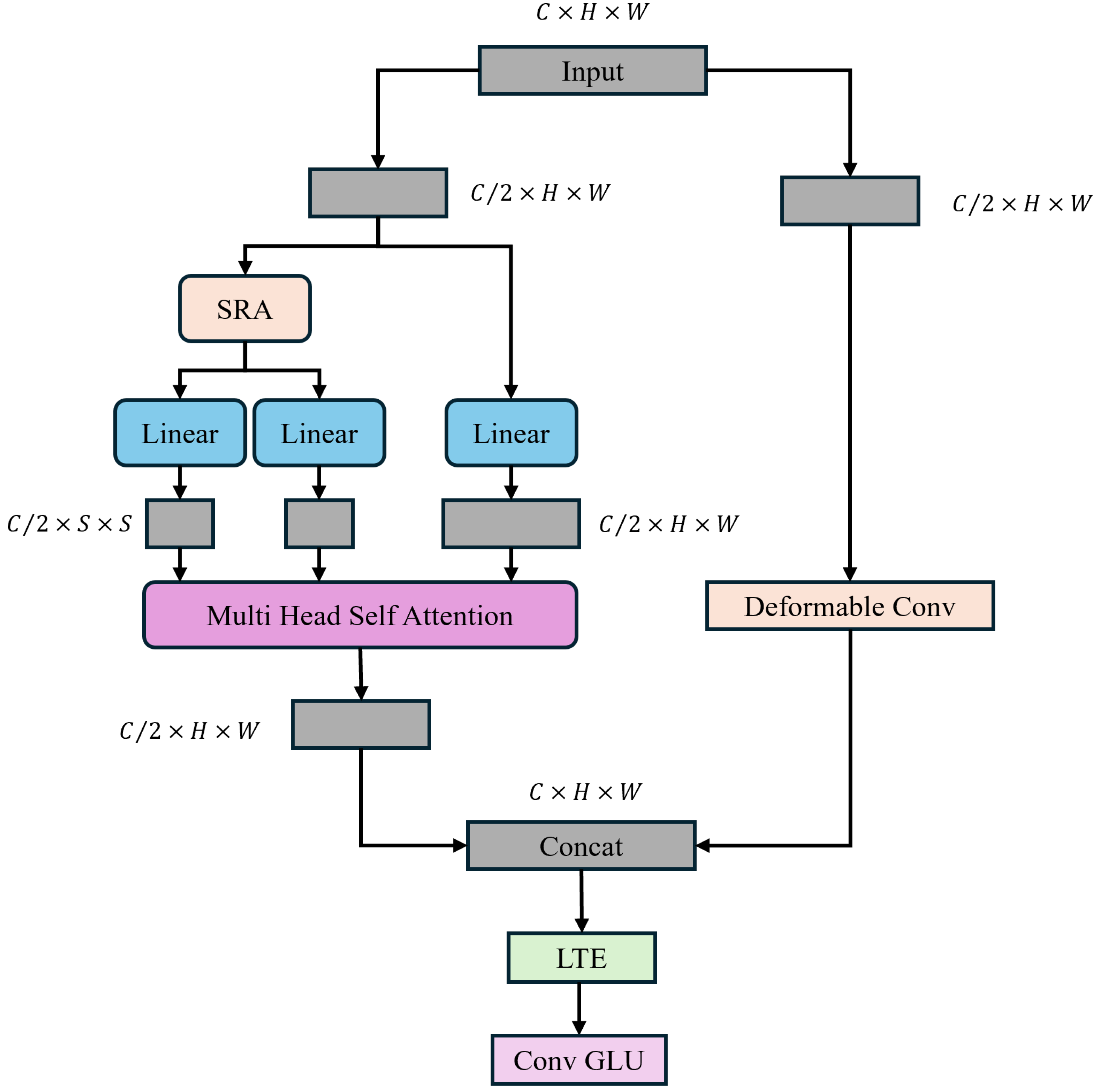
- To enhance the generalization capability of the Transformer, we designed a novel decoding structure, TransNeXt, which captures multi-scale information through internal multi-scale convolutions and utilizes Spatial Reduction Attention (SRA) to help the Transformer better capture spatial relationships in images, improve the modeling of spatial structures near image boundaries, and effectively improve the segmentation accuracy of elongated objects and object edges while reducing computational costs through channel compression and expansion as well as the combination of residual connections.
2. Materials and Methods
2.1. Materials
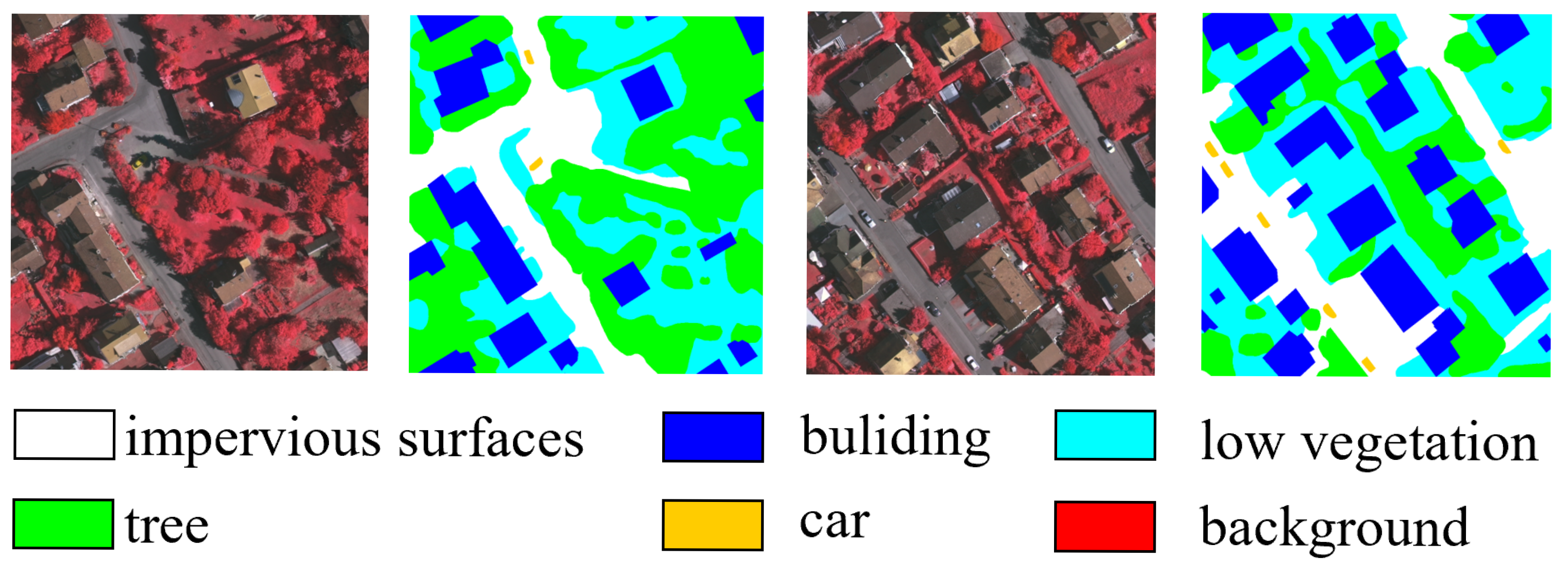
2.1.1. Vaihingen Datasets
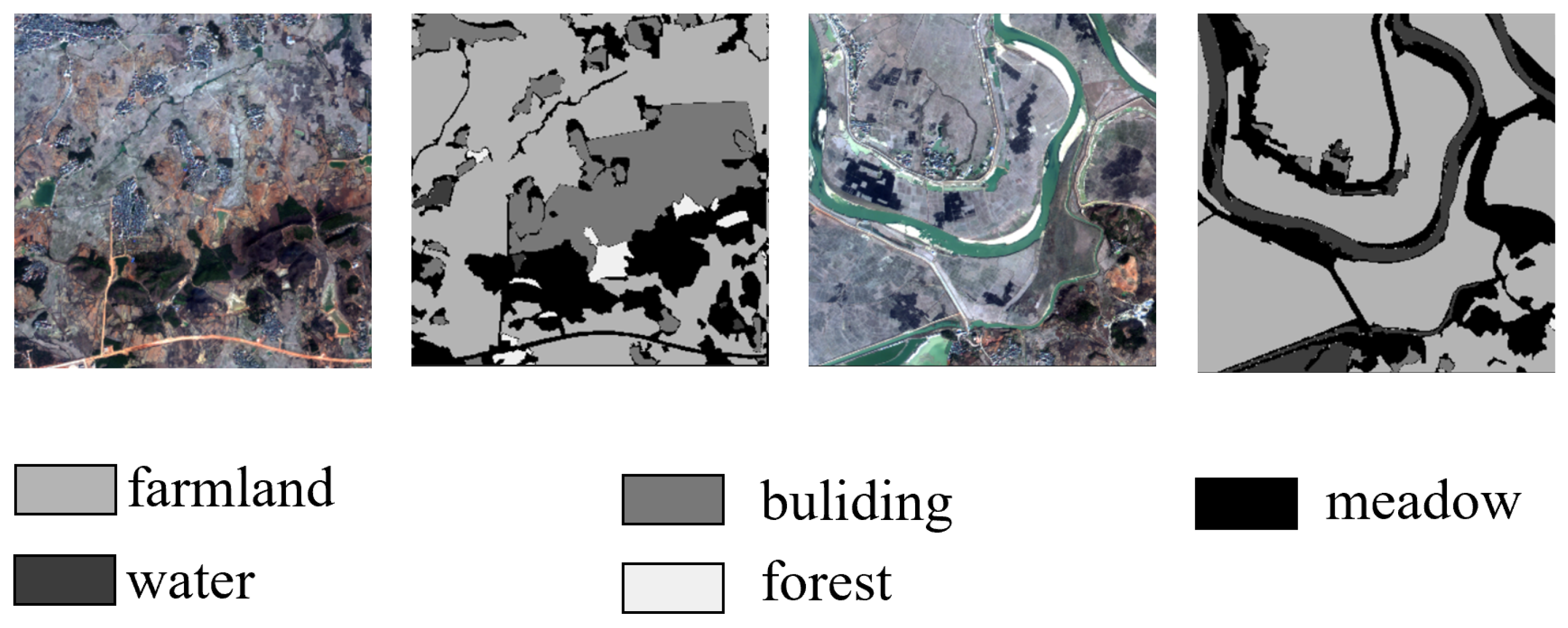
2.1.2. GID-5 Datasets
2.2. Methods
2.2.1. Implementation Details
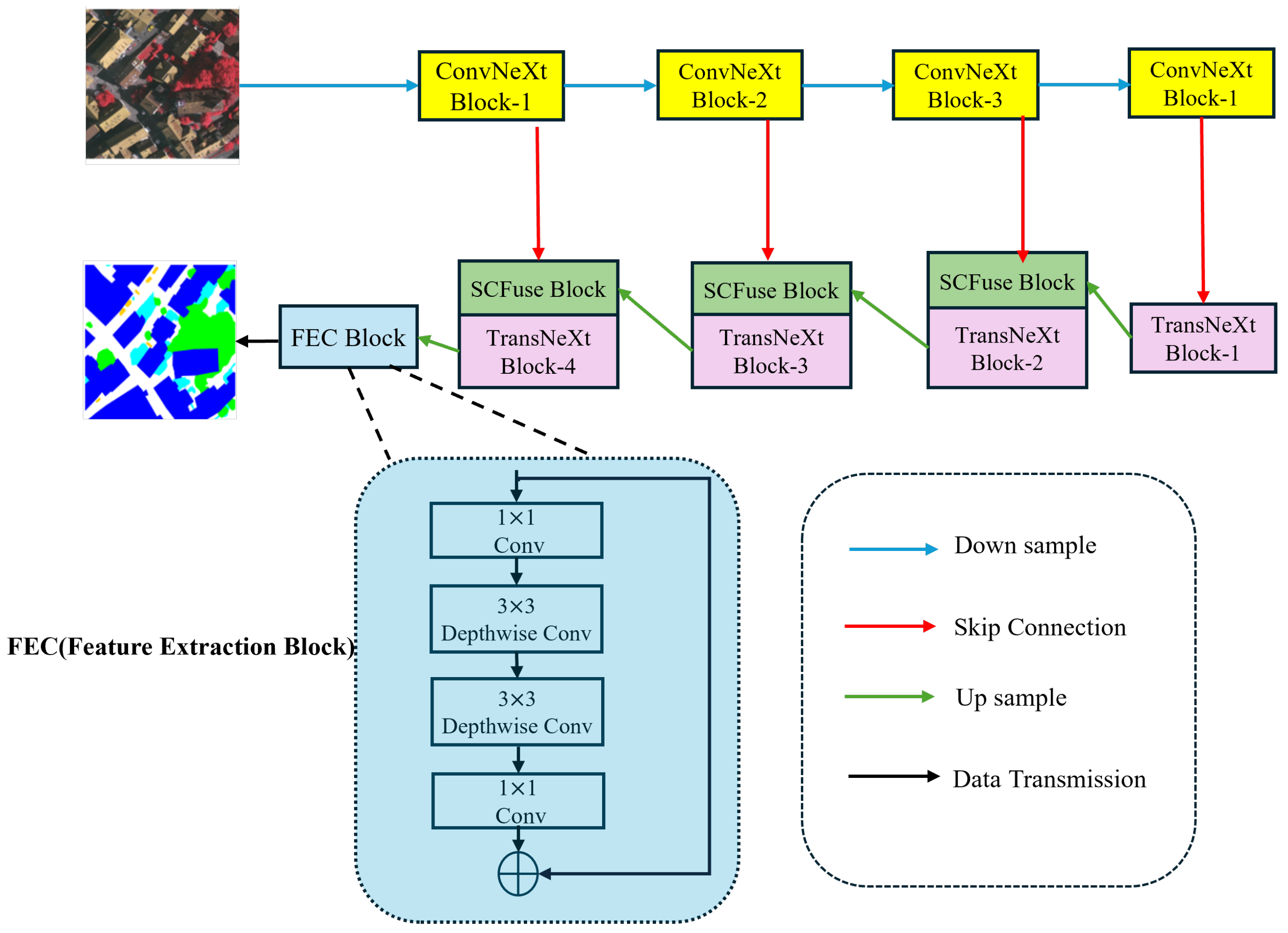
2.2.2. Overall Network Structure
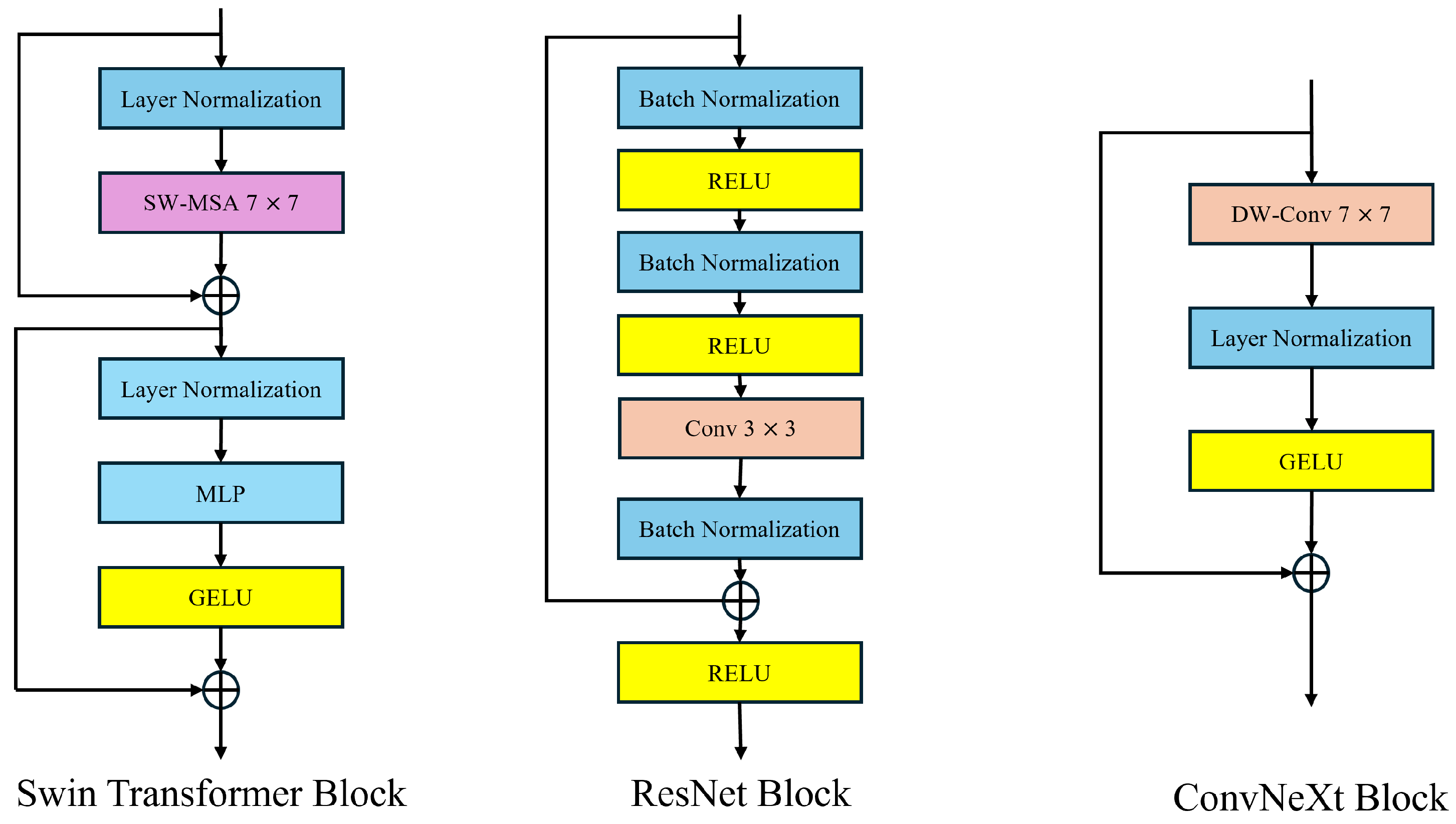
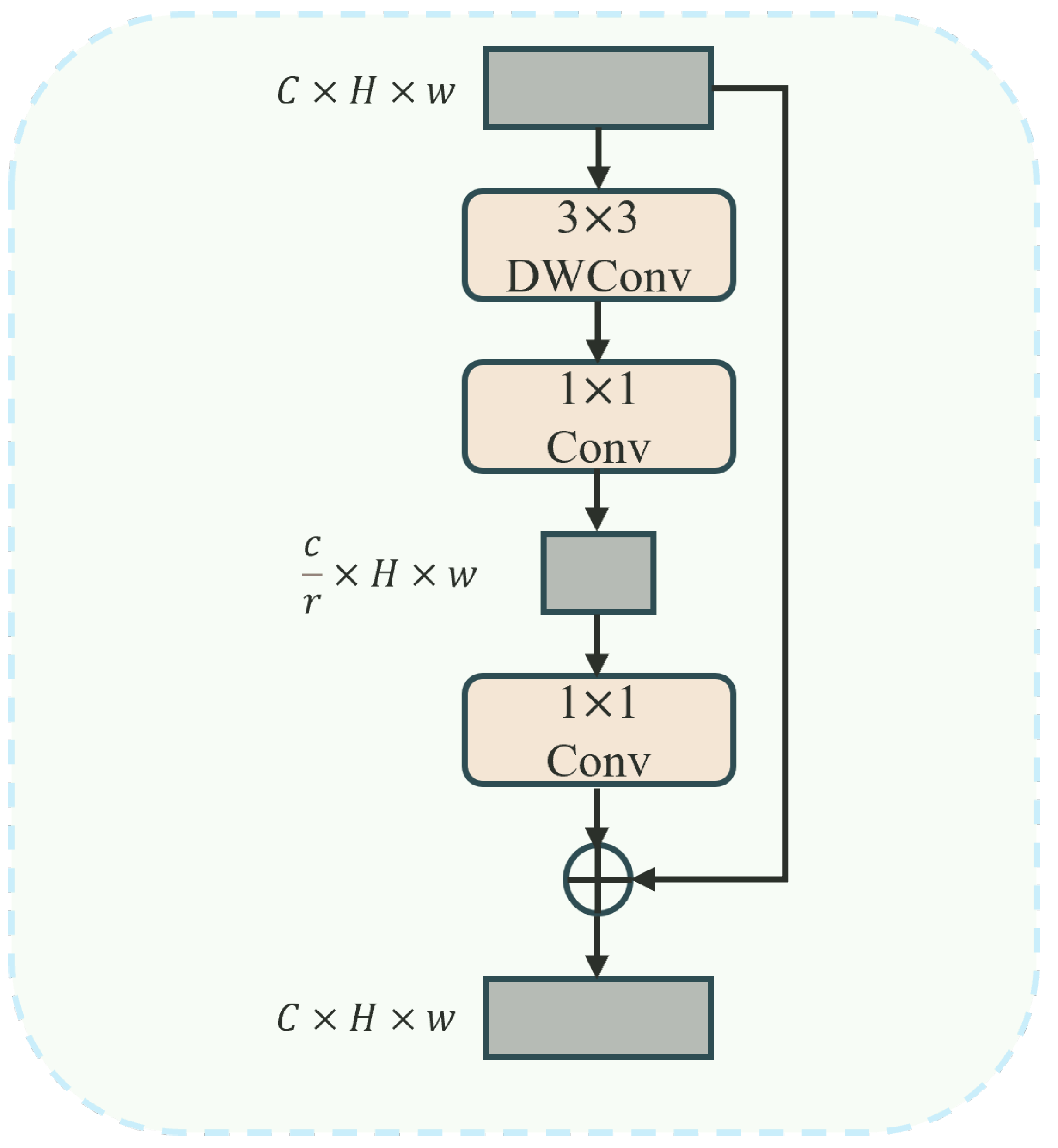
2.2.3. Convnext Module
2.2.4. SC Fuse Module
2.2.5. TransNeXt Module
3. Experiments and Results
Comparative Experiments
4. Ablation Study
5. Complexity Analysis
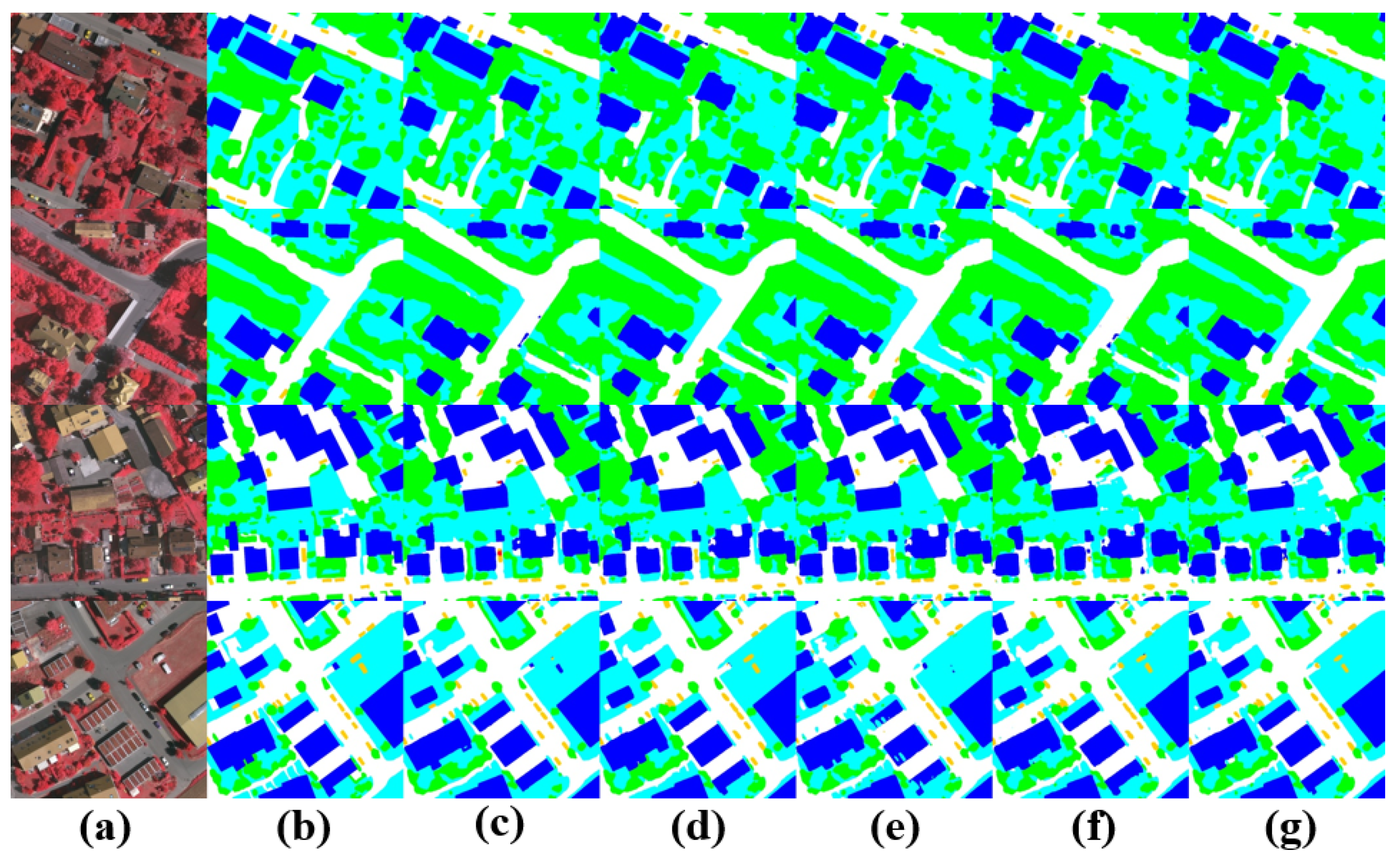
6. Results Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, X.; Jiao, L.; Li, L.; Tang, X.; Guo, Y. Deep multi-level fusion network for multi-source image pixel-wise classification. Knowl. Based Syst. 2021, 221, 106921. [Google Scholar] [CrossRef]
- Liu, X.; Jiao, L.; Li, L.; Cheng, L.; Liu, F.; Yang, S.; Hou, B. Deep Multiview Union Learning Network for Multisource Image Classification. IEEE Trans. Cybern. 2022, 52, 4534–4546. [Google Scholar] [CrossRef] [PubMed]
- Zhao, P. Research on Application of Agricultural Remote Sensing Technology in Big Data Era. In Proceedings of the 2022 IEEE 2nd International Conference on Electronic Technology, Communication and Information (ICETCI), Online Conference, 27–29 May 2022; pp. 1270–1272. [Google Scholar] [CrossRef]
- AlQallaf, N.; Bhatti, S.; Suett, R.; Aly, S.G.; Khalil, A.S.G.; Ghannam, R. Visualising Climate Change using Extended Reality: A Review. In Proceedings of the 2022 29th IEEE International Conference on Electronics, Circuits and Systems (ICECS), Glasgow, UK, 24–26 October 2022; pp. 1–4. [Google Scholar] [CrossRef]
- Yu, Y.; Bao, Y.; Wang, J.; Chu, H.; Zhao, N.; He, Y.; Liu, Y. Crop Row Segmentation and Detection in Paddy Fields Based on Treble-Classification Otsu and Double-Dimensional Clustering Method. Remote. Sens. 2021, 13, 901. [Google Scholar] [CrossRef]
- Sheikh, R.; Milioto, A.; Lottes, P.; Stachniss, C.; Bennewitz, M.; Schultz, T. Gradient and Log-based Active Learning for Semantic Segmentation of Crop and Weed for Agricultural Robots. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 1350–1356. [Google Scholar] [CrossRef]
- Andrade, R.B.; da Costa, G.A.O.P.; Mota, G.L.A.; Ortega, M.X.; Feitosa, R.Q.; Soto, P.J.; Heipke, C. Evaluation of Semantic Segmentation Methods for Deforestation Detection in the Amazon. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, 43, 1497–1505. [Google Scholar] [CrossRef]
- O’Neill, S.J.; Boykoff, M.; Niemeyer, S.; Day, S.A. On the use of imagery for climate change engagement. Glob. Environ. Chang. Hum. Policy Dimens. 2013, 23, 413–421. [Google Scholar] [CrossRef]
- Schumann, G.J.; Brakenridge, G.R.; Kettner, A.J.; Kashif, R.; Niebuhr, E. Assisting Flood Disaster Response with Earth Observation Data and Products: A Critical Assessment. Remote Sens. 2018, 10, 1230. [Google Scholar] [CrossRef]
- Bi, H.; Xu, F.; Wei, Z.; Han, Y.; Cui, Y.; Xue, Y.; Xu, Z. An Active Deep Learning Approach for Minimally-Supervised Polsar Image Classification. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 3185–3188. [Google Scholar] [CrossRef]
- Wang, T.; Xu, C.; Liu, B.; Yang, G.; Zhang, E.; Niu, D.; Zhang, H. MCAT-UNet: Convolutional and Cross-Shaped Window Attention Enhanced UNet for Efficient High-Resolution Remote Sensing Image Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 9745–9758. [Google Scholar] [CrossRef]
- Chen, X.; Li, Z.; Jiang, J.; Han, Z.; Deng, S.; Li, Z.; Fang, T.; Huo, H.; Li, Q.; Liu, M. Adaptive Effective Receptive Field Convolution for Semantic Segmentation of VHR Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 3532–3546. [Google Scholar] [CrossRef]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. UNet++: A Nested U-Net Architecture for Medical Image Segmentation. Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support. In Proceedings of the 4th International Workshop, DLMIA 2018, and 8th International Workshop, ML-CDS 2018, Held in Conjunction with MICCAI 2018, Granada, Spain, 20 September 2018; Volume 11045, pp. 3–11. [Google Scholar]
- Huang, G.; Liu, Z.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2261–2269. [Google Scholar]
- Diakogiannis, F.I.; Waldner, F.; Caccetta, P.; Wu, C. ResUNet-a: A deep learning framework for semantic segmentation of remotely sensed data. arXiv 2019, arXiv:1904.00592. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Zhang, C.; Fang, S.; Duan, C.; Meng, X.; Atkinson, P.M. UNetFormer: A UNet-like transformer for efficient semantic segmentation of remote sensing urban scene imagery. ISPRS J. Photogramm. Remote Sens. 2021, 190, 196–214. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar] [CrossRef]
- He, P.; Jiao, L.; Shang, R.; Wang, S.; Liu, X.; Quan, D.; Yang, K.; Zhao, D. MANet: Multi-Scale Aware-Relation Network for Semantic Segmentation in Aerial Scenes. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3141–3149. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar] [CrossRef]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep High-Resolution Representation Learning for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3349–3364. [Google Scholar] [CrossRef] [PubMed]
- Berroukham, A.; Housni, K.; Lahraichi, M. Vision Transformers: A Review of Architecture, Applications, and Future Directions. In Proceedings of the 2023 7th IEEE Congress on Information Science and Technology (CiSt), Agadir/Essaouira, Morocco, 16–22 December 2023; pp. 205–210. [Google Scholar] [CrossRef]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Xu, L.; Liu, H.; Cui, Q.; Luo, B.; Li, N.; Chen, Y.; Tang, Y. UGTransformer: Unsupervised Graph Transformer Representation Learning. In Proceedings of the 2023 International Joint Conference on Neural Networks (IJCNN), Gold Coast, Australia, 18–23 June 2023; pp. 1–8. [Google Scholar] [CrossRef]
- He, X.; Zhou, Y.; Zhao, J.; Zhang, D.; Yao, R.; Xue, Y. Swin Transformer Embedding UNet for Remote Sensing Image Semantic Segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Peng, P.; Xu, T.; Huang, B.; Li, J. HAFNet: Hierarchical Attentive Fusion Network for Multispectral Pedestrian Detection. Remote Sens. 2023, 15, 2041. [Google Scholar] [CrossRef]
- Shi, D. TransNeXt: Robust Foveal Visual Perception for Vision Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 17773–17783. [Google Scholar]
- Markus Gerke, I. Use of the Stair Vision Library within the ISPRS 2D Semantic Labeling Benchmark (Vaihingen); University of Twente: Enschede, The Netherlands, 2014. [Google Scholar]
- Dittrich, B.; Huebschle, C.B.; Proepper, K.; Dietrich, F.; Stolper, T.; Holstein, J. The generalized invariom database (GID). Acta Crystallogr. Sect. Struct. Sci. Cryst. Eng. Mater. 2013, 69, 91–104. [Google Scholar] [CrossRef]
- Wang, W.; Zhang, Y.; Wang, X.; Li, J. A Boundary Guided Cross Fusion Approach for Remote Sensing Image Segmentation. IEEE Geosci. Remote Sens. Lett. 2024, 21, 1–5. [Google Scholar] [CrossRef]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A ConvNet for the 2020s. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 11966–11976. [Google Scholar] [CrossRef]
- Li, J.; Wen, Y.; He, L. Scconv: Spatial and channel reconstruction convolution for feature redundancy. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 6153–6162. [Google Scholar]
- Liu, Y. A Hybrid CNN-TransXNet Approach for Advanced Glomerular Segmentation in Renal Histology Imaging. Int. J. Comput. Intell. Syst. 2024, 17, 126. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Duan, C.; Zhang, C.; Meng, X.; Fang, S. A novel transformer based semantic segmentation scheme for fine-resolution remote sensing images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Backbone | F1 (%) | Evaluation Index | |||||
|---|---|---|---|---|---|---|---|---|
| Surface | Building | Low | Tree | Car | MF1 | MIoU | ||
| MANet | ResNet50 | 91.4 | 93.6 | 82.4 | 88.5 | 88.7 | 90.4 | 82.7 |
| DeepLabV3+ | ResNet50 | 91.7 | 94.8 | 83.0 | 89.1 | 88.4 | 87.9 | 82.4 |
| ABCNet | ResNet18 | 92.7 | 95.2 | 83.5 | 89.7 | 77.7 | 86.7 | 77.1 |
| Unetformer | ResNet18 | 92.7 | 95.3 | 84.9 | 90.6 | 85.3 | 89.5 | 82.7 |
| ST-UNet | / | 93.5 | 96.0 | 85.6 | 90.8 | 86.6 | 90.3 | 83.1 |
| DC-Swin | Swin-T | 94.1 | 96.2 | 85.8 | 90.4 | 87.6 | 90.7 | 83.2 |
| UNeXt | ConvNeXt-T | 96.0 | 96.2 | 85.4 | 90.3 | 90.8 | 91.8 | 84.9 |
| Model | Backbone | F1 (%) | Evaluation Index | |||||
|---|---|---|---|---|---|---|---|---|
| Surface | Building | Low | Tree | Car | MF1 | MIoU | ||
| MANet | ResNet50 | 92.4 | 73.9 | 62.5 | 88.5 | 88.7 | 86.6 | 82.7 |
| DeepLabV3+ | ResNet50 | 91.6 | 73.8 | 63.2 | 89.1 | 88.4 | 87.9 | 80.1 |
| ABCNet | ResNet18 | 92.5 | 74.3 | 63.4 | 89.7 | 77.7 | 86.8 | 79.1 |
| Unetformer | ResNet18 | 93.4 | 73.4 | 64.7 | 90.6 | 85.3 | 85.5 | 82.7 |
| ST-UNet | / | 93.1 | 75.2 | 63.8 | 92.8 | 84.5 | 87.5 | 81.1 |
| DC-Swin | Swin-T | 94.1 | 76.2 | 65.8 | 93.4 | 87.2 | 87.7 | 81.2 |
| UNeXt | ConvNeXt-T | 95.2 | 75.4 | 68.4 | 96.3 | 84.5 | 89.6 | 84.2 |
| Model | Backbone | Params (MB) | FLOPs (Gbps) | Vaihingen | GID5 | ||
|---|---|---|---|---|---|---|---|
| MIoU (%) | MF1 (%) | MIoU (%) | MF1 (%) | ||||
| Transformer-Based | VIL-M | 40.5 | 45.3 | 83.6 | 88.9 | 81.3 | 89.4 |
| Focal-T | 61.4 | 74.2 | 84.1 | 90.4 | 82.4 | 88.2 | |
| DeiT-S | 42.7 | 53.3 | 83.3 | 90.9 | 82.5 | 89.1 | |
| CSwin-T | 41.9 | 49.6 | 83.8 | 91.3 | 82.1 | 88.5 | |
| Swin-T | 38.2 | 37.6 | 84.3 | 91.2 | 83.5 | 87.6 | |
| CNN-Based | ResNet 18 | 23.9 | 18.5 | 84.1 | 89.7 | 83.6 | 88.4 |
| ResNet 50 | 190.2 | 100.3 | 82.7 | 90.3 | 82.1 | 86.2 | |
| VAN-Base | 36.5 | 40.2 | 84.3 | 91.4 | 83.9 | 87.1 | |
| Convnext-T | 38.4 | 34.2 | 84.9 | 91.8 | 84.2 | 89.6 | |
| Model | Vaihingen | GID5 | ||
|---|---|---|---|---|
| MIoU (%) | MF1 (%) | MIoU (%) | MF1 (%) | |
| Baseline | 79.2 | 88.0 | 82.1 | 88.5 |
| Baseline+SCFB | 80.2 | 88.7 | 83.0 | 89.0 |
| Baseline+Transnext | 81.8 | 89.8 | 83.8 | 89.0 |
| Baseline+SCFB+Transnext | 84.9 | 91.8 | 84.2 | 89.6 |
| Model | Params (MB) | Potsdam | Vaihingen | ||
|---|---|---|---|---|---|
| Speed (FPS) | MIoU (%) | Speed (FPS) | MIoU (%) | ||
| MANet | 35.9 | 90 | 82.7 | 91 | 82.7 |
| DeepLabV3+ | 41.2 | 85 | 82.4 | 95 | 80.1 |
| ABCNet | 14.0 | 110 | 77.1 | 110 | 79.1 |
| Unetformer | 11.7 | 135 | 82.7 | 135 | 82.7 |
| ST-UNet | 160.97 | 12 | 83.1 | 14 | 81.1 |
| DC-Swin | 45.6 | 54 | 83.2 | 56 | 81.2 |
| UNeXt | 38.4 | 97 | 84.9 | 99 | 84.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chang, Z.; Xu, M.; Wei, Y.; Lian, J.; Zhang, C.; Li, C. UNeXt: An Efficient Network for the Semantic Segmentation of High-Resolution Remote Sensing Images. Sensors 2024, 24, 6655. https://doi.org/10.3390/s24206655
Chang Z, Xu M, Wei Y, Lian J, Zhang C, Li C. UNeXt: An Efficient Network for the Semantic Segmentation of High-Resolution Remote Sensing Images. Sensors. 2024; 24(20):6655. https://doi.org/10.3390/s24206655
Chicago/Turabian StyleChang, Zhanyuan, Mingyu Xu, Yuwen Wei, Jie Lian, Chongming Zhang, and Chuanjiang Li. 2024. "UNeXt: An Efficient Network for the Semantic Segmentation of High-Resolution Remote Sensing Images" Sensors 24, no. 20: 6655. https://doi.org/10.3390/s24206655
APA StyleChang, Z., Xu, M., Wei, Y., Lian, J., Zhang, C., & Li, C. (2024). UNeXt: An Efficient Network for the Semantic Segmentation of High-Resolution Remote Sensing Images. Sensors, 24(20), 6655. https://doi.org/10.3390/s24206655