
DenseFusion-DA2: End-to-End Pose-Estimation Network Based on RGB-D Sensors and Multi-Channel Attention Mechanisms


Abstract
1. Introduction
2. Related Work
3. Methodology
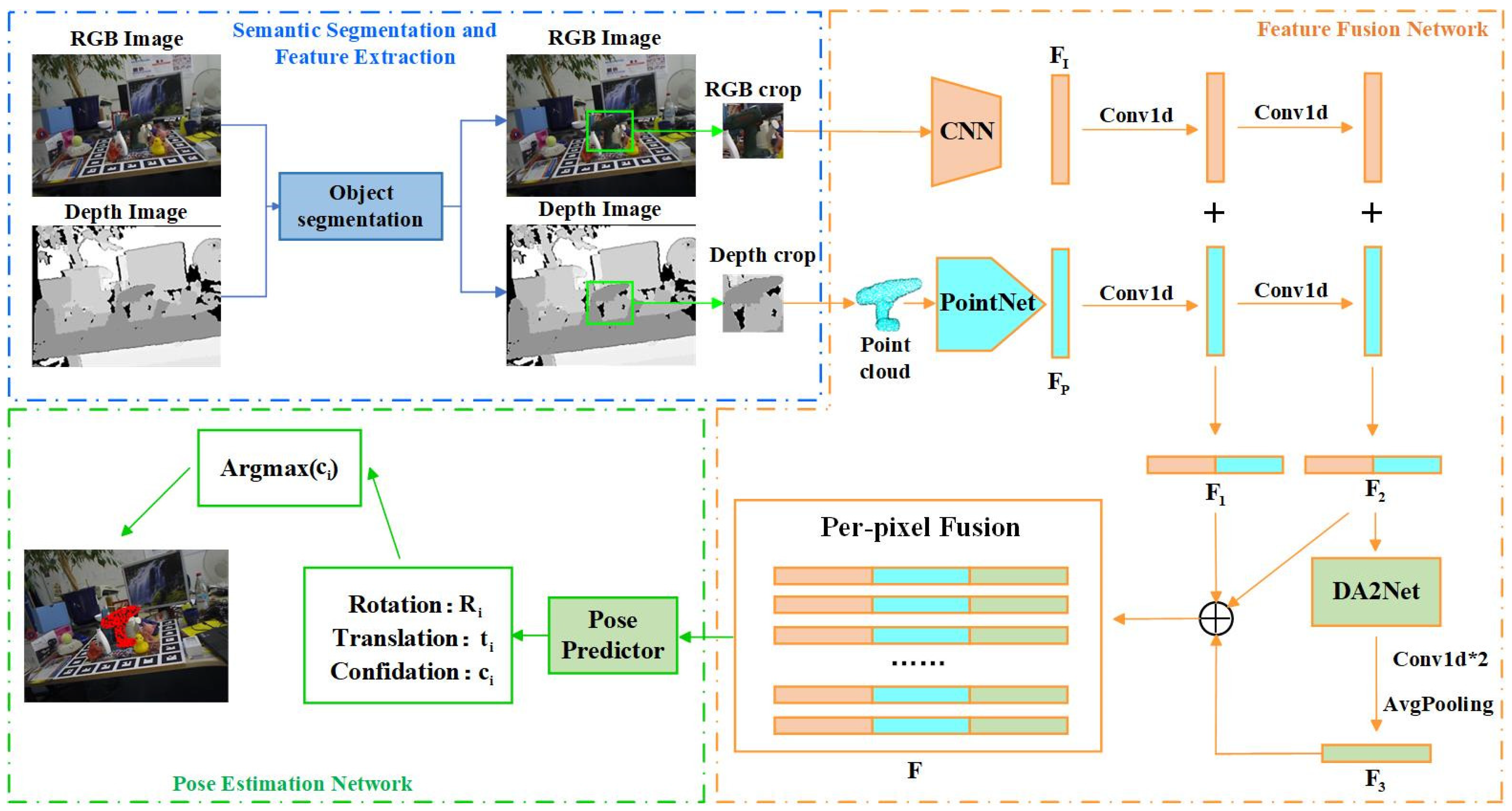
3.1. Method Overview
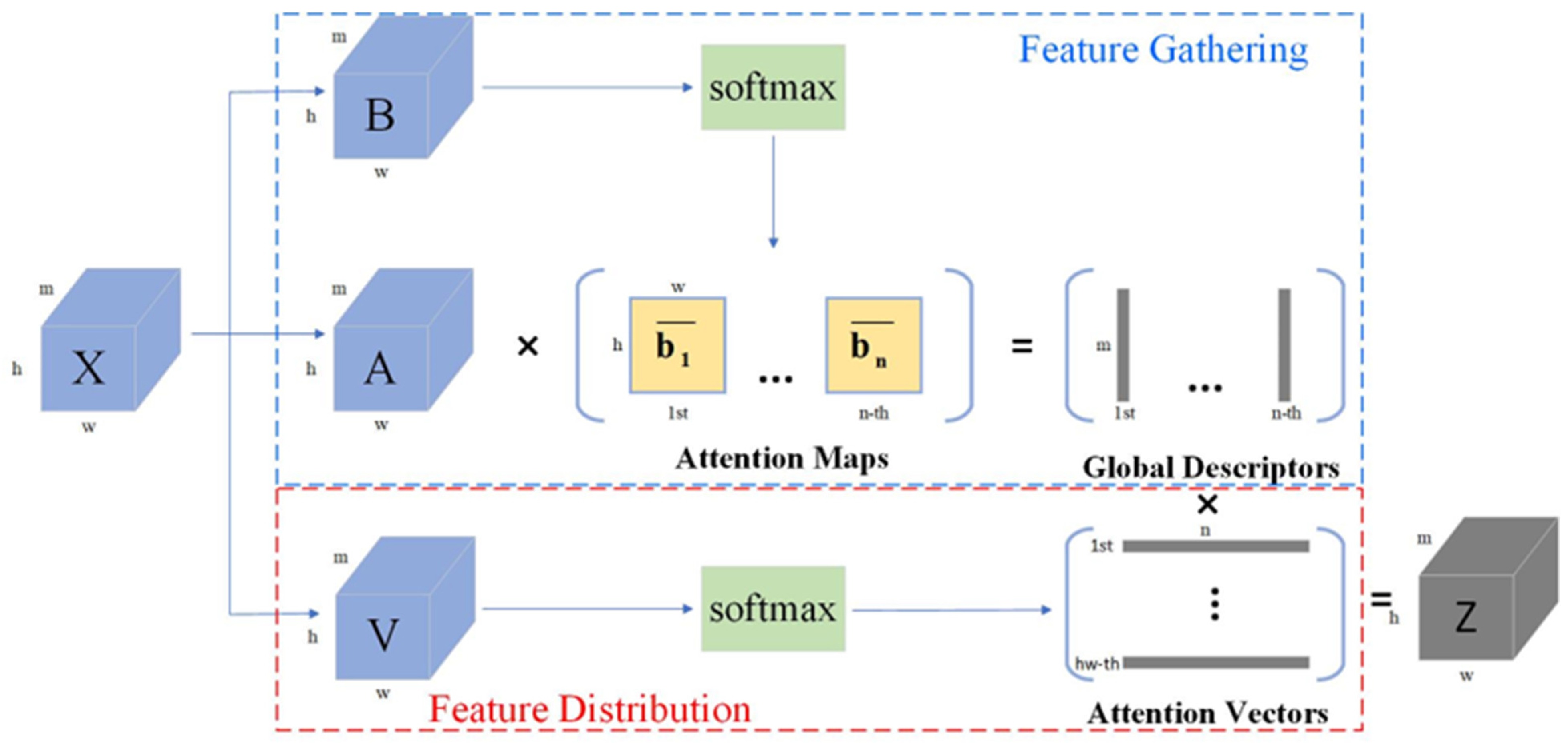
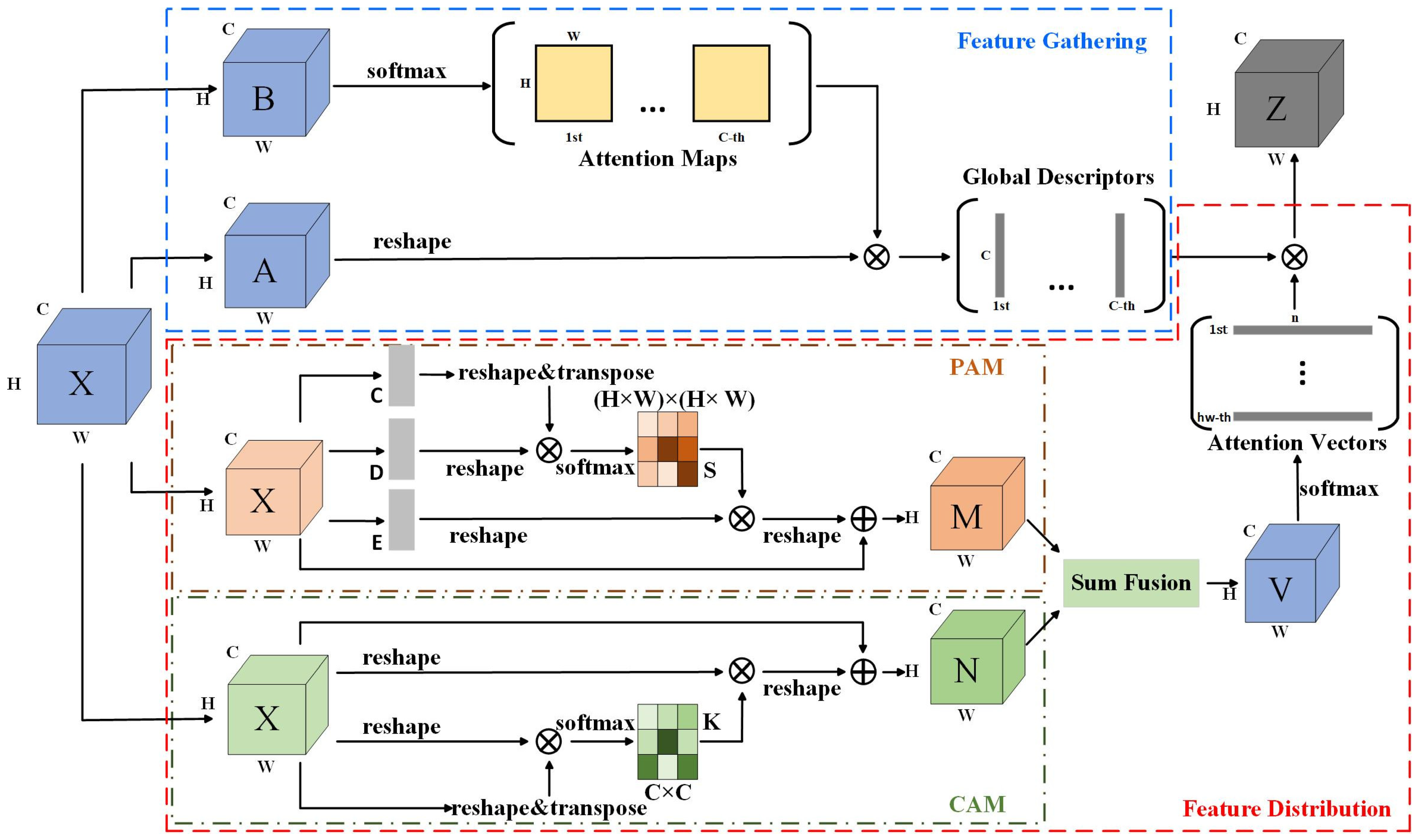
3.2. Multi-Channel Attention Mechanism DA2Net
3.2.1. Attention Module
3.2.2. DA2Net
3.3. Improved Feature-Fusion Network
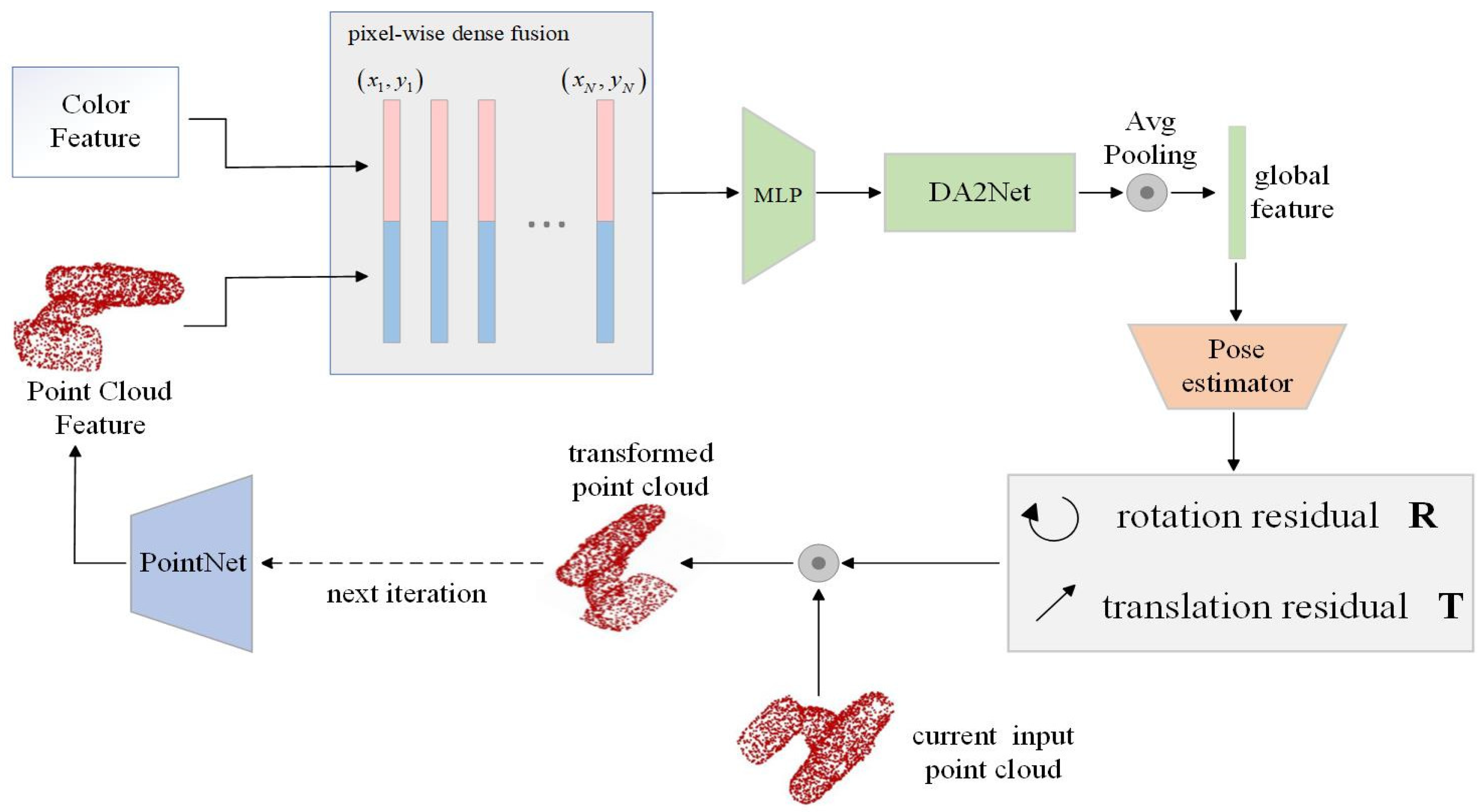
3.4. Improved Iterative Refinement Network DA2iter
4. Experiments
4.1. Loss Function
4.2. Evaluation Indicators
4.3. Results
4.3.1. Results on the LineMOD Dataset
- (1)
- Contrast experiment
- (2)
- Ablation experiment
4.3.2. Results on the Occlusion LineMOD Dataset
4.3.3. Results on the HR-Vision Dataset
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tremblay, J.; To, T.; Sundaralingam, B.; Xiang, Y.; Fox, D.; Birchfield, S. Deep object pose estimation for semantic robotic grasping of household objects. arXiv 2018, arXiv:1809.10790. [Google Scholar]
- Bohg, J.; Morales, A.; Asfour, T.; Kragic, D. Data-driven grasp synthesis—A survey. IEEE Trans. Robot. 2013, 30, 289–309. [Google Scholar] [CrossRef]
- Chen, X.; Kundu, K.; Zhang, Z.; Ma, H.; Fidler, S.; Urtasun, R. Monocular 3d object detection for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2147–2156. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? the kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- You, Y.; Wang, Y.; Chao, W.L.; Garg, D.; Pleiss, G.; Hariharan, B.; Campbell, M.; Weinberger, K.Q. Pseudo-lidar++: Accurate depth for 3d object detection in autonomous driving. arXiv 2019, arXiv:1906.06310. [Google Scholar]
- Marchand, E.; Uchiyama, H.; Spindler, F. Pose estimation for augmented reality: A hands-on survey. IEEE Trans. Vis. Comput. Graph. 2015, 22, 2633–2651. [Google Scholar] [CrossRef] [PubMed]
- Ababsa, F.; Mallem, M. Robust camera pose estimation using 2d fiducials tracking for real-time augmented reality systems. In Proceedings of the 2004 ACM SIGGRAPH International Conference on Virtual Reality Continuum and its Applications in Industry, Singapore, 16–18 June, 2004; pp. 431–435. [Google Scholar]
- Rusinkiewicz, S.; Levoy, M. Efficient variants of the ICP algorithm. In Proceedings of the Proceedings Third International Conference on 3-D Digital Imaging and Modeling, Quebec City, QC, Canada, 28 May–1 June 2001; pp. 145–152. [Google Scholar]
- Ng, P.C.; Henikoff, S. SIFT: Predicting amino acid changes that affect protein function. Nucleic Acids Res. 2003, 31, 3812–3814. [Google Scholar] [CrossRef] [PubMed]
- Bay, H.; Tuytelaars, T.; Van Gool, L. Surf: Speeded up robust features. In Proceedings of the Computer Vision–ECCV 2006: 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; Proceedings, Part I 9. Springer: Berlin/Heidelberg, Germany, 2006; pp. 404–417. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Lepetit, V.; Moreno-Noguer, F.; Fua, P. EP n P: An accurate O (n) solution to the P n P problem. Int. J. Comput. Vis. 2009, 81, 155–166. [Google Scholar] [CrossRef]
- Yanagi, T.; Okamoto, K.; Takita, S. Effects of blue, red, and blue/red lights of two different PPF levels on growth and morphogenesis of lettuce plants. Int. Symp. Plant Prod. Closed Ecosyst. 1996, 440, 117–122. [Google Scholar] [CrossRef] [PubMed]
- Wei, A.H.; Chen, B.Y. Robotic object recognition and grasping with a natural background. Health Inform. J. 2020, 17. [Google Scholar] [CrossRef]
- Chen, Y.; Kalantidis, Y.; Li, J.; Yan, S.; Feng, J. A2-nets: Double attention networks. Adv. Neural Inf. Process. Syst. 2018. [Google Scholar] [CrossRef]
- Wang, C.; Xu, D.; Zhu, Y.; Martín-Martín, R.; Lu, C.; Fei-Fei, L.; Savarese, S. Densefusion: 6d object pose estimation by iterative dense fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3343–3352. [Google Scholar]
- Qiao, S.; Wang, Y.; Li, J. Real-time human gesture grading based on OpenPose. In Proceedings of the 2017 10th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Shanghai, China, 14–16 October 2017; pp. 1–6. [Google Scholar]
- Fang, H.S.; Li, J.; Tang, H.; Xu, C.; Zhu, H.; Xiu, Y.; Li, Y.-L.; Lu, C. Alphapose: Whole-body regional multi-person pose estimation and tracking in real-time. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 7157–7173. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep high-resolution representation learning for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3349–3364. [Google Scholar] [CrossRef] [PubMed]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honoulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. Adv. Neural Inf. Process. Syst. 2017, 30, 5105–5114. [Google Scholar]
- Diao, Z.; Wang, X.; Zhang, D.; Liu, Y.; Xie, K.; He, S. Dynamic spatial-temporal graph convolutional neural networks for traffic forecasting. Proc. AAAI Conf. Artif. Intell. 2019, 33, 890–897. [Google Scholar] [CrossRef]
- Zhao, H.; Jiang, L.; Jia, J.; Torr, P.H.; Koltun, V. Point transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 16259–16268. [Google Scholar]
- Han, K.; Xiao, A.; Wu, E.; Guo, J.; Xu, C.; Wang, Y. Transformer in transformer. Adv. Neural Inf. Process. Syst. 2021, 34, 15908–15919. [Google Scholar]
- Xiang, Y.; Schmidt, T.; Narayanan, V.; Fox, D. Posecnn: A convolutional neural network for 6d object pose estimation in cluttered scenes. arXiv 2017, arXiv:1711.00199. [Google Scholar]
- Chen, W.; Jia, X.; Chang, H.J.; Duan, J.; Leonardis, A. G2l-net: Global to local network for real-time 6d pose estimation with embedding vector features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 4233–4242. [Google Scholar]
- He, Y.; Huang, H.; Fan, H.; Chen, Q.; Sun, J. Ffb6d: A full flow bidirectional fusion network for 6d pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 3003–3013. [Google Scholar]
- Yuan, H.; Veltkamp, R.C. 6D object pose estimation with color/geometry attention fusion. In Proceedings of the 2020 16th International Conference on Control, Automation, Robotics and Vision (ICARCV), Shenzhen, China, 13–15 December 2020; pp. 529–535. [Google Scholar]
- Zou, L.; Huang, Z.; Wang, F.; Yang, Z.; Wang, G. CMA: Cross-modal attention for 6D object pose estimation. Comput. Graph. 2021, 97, 139–147. [Google Scholar] [CrossRef]
- Xu, D.; Anguelov, D.; Jain, A. Pointfusion: Deep sensor fusion for 3d bounding box estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Auckland, New Zealand, 20–23 April 2018; pp. 244–253. [Google Scholar]
- Peng, S.; Liu, Y.; Huang, Q.; Zhou, X.; Bao, H. PVNet: Pixel-wise voting network for 6DoF object pose estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 44, 3212–3223. [Google Scholar] [CrossRef] [PubMed]
- Kehl, W.; Manhardt, F.; Tombari, F.; Ilic, S.; Navab, N. Ssd-6d: Making rgb-based 3d detection and 6d pose estimation great again. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1521–1529. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3146–3154. [Google Scholar]
- Calli, B.; Singh, A.; Walsman, A.; Srinivasa, S.; Abbeel, P.; Dollar, A.M. The ycb object and model set: Towards common benchmarks for manipulation research. In Proceedings of the 2015 International Conference on Advanced Robotics (ICAR), Istanbul, Turkey, 27–31 July 2015; pp. 510–517. [Google Scholar]
- Brachmann, E.; Krull, A.; Michel, F.; Gumhold, S.; Shotton, J.; Rother, C. Learning 6d object pose estimation using 3d object coordinates. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014, Proceedings, Part II 13; Springer International Publishing: Cham, Switzerland, 2014; pp. 536–551. [Google Scholar]
- Hinterstoisser, S.; Holzer, S.; Cagniart, C.; Ilic, S.; Konolige, K.; Navab, N.; Lepetit, V. Multimodal templates for real-time detection of texture-less objects in heavily cluttered scenes. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 858–865. [Google Scholar]
- Buch, A.G.; Kiforenko, L.; Kraft, D. Rotational subgroup voting and pose clustering for robust 3d object recognition. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4137–4145. [Google Scholar]
- Vidal, J.; Lin, C.Y.; Martí, R. 6D pose estimation using an improved method based on point pair features. In Proceedings of the 2018 4th International Conference on Control, Automation and Robotics (Iccar), Auckland, New Zealand, 20–23 April 2018; pp. 405–409. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PointFusion [30] | SSD6D [32] _ICP | PVNet [31] | PoseCNN [25] | DenseFusion [16] | FFB6D [27] | Ours | |
|---|---|---|---|---|---|---|---|
| ape | 71.8 | 64.8 | 42.9 | 76.4 | 85.9 | 97.6 | 90.3 |
| ben. | 78.5 | 78.9 | 99.5 | 97.0 | 93.6 | 99.3 | 98.5 |
| cam | 61.0 | 78.0 | 85.7 | 93.5 | 91.1 | 99.0 | 96.2 |
| can | 59.7 | 85.7 | 95.5 | 96.5 | 95.2 | 98.7 | 97.1 |
| cat | 77.3 | 70.2 | 79.5 | 82.1 | 95.3 | 99.2 | 94.8 |
| drill. | 50.2 | 72.5 | 94.1 | 95.3 | 90.0 | 98.5 | 96.5 |
| duck | 63.1 | 66.4 | 50.8 | 78.0 | 87.5 | 97.8 | 98.1 |
| egg | 97.4 | 100.0 | 99.7 | 97.1 | 99.8 | 100.0 | 99.5 |
| glue | 97.9 | 100.0 | 94.9 | 99.2 | 99.8 | 100.0 | 100.0 |
| hole. | 70.0 | 48.9 | 81.7 | 52.8 | 90.3 | 98.7 | 95.0 |
| iron | 84.8 | 77.2 | 97.6 | 97.3 | 95.5 | 98.4 | 97.8 |
| lamp | 60.9 | 72.7 | 98.3 | 97.5 | 94.7 | 99.7 | 97.5 |
| pho. | 75.4 | 78.5 | 92.0 | 87.5 | 94.9 | 99.7 | 96.8 |
| MEAN | 72.9 | 76.4 | 85.6 | 88.4 | 93.3 | 98.9 | 96.7 |
| Ape | Ben. | Cam | Can | Cat | Drill. | Duck | Egg | Glue | Hole. | Iron | Lamp | Pho. | MEAN | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DF(iter) + DA2Net | 86.3 | 94.8 | 90.2 | 95.2 | 94.9 | 93.8 | 90.4 | 99.2 | 99.5 | 92.1 | 95.9 | 95.5 | 96.0 | 94.1 |
| DF(DA2iter) | 88.0 | 94.2 | 95.6 | 95.9 | 94.1 | 93.1 | 88.3 | 99.8 | 99.5 | 93.9 | 98.0 | 96.0 | 96.9 | 94.8 |
| Ours | 90.3 | 98.5 | 96.2 | 97.1 | 94.8 | 96.5 | 98.1 | 99.5 | 100 | 95.0 | 97.8 | 97.5 | 96.8 | 96.7 |
| Ape | Ben. | Cam | Can | Cat | Drill. | Duck | Egg | Glue | Hole. | Iron | Lamp | Pho. | MEAN | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DF + A2-Nets [15] | 86.0 | 97.2 | 95.4 | 95.7 | 94.4 | 86.6 | 91.4 | 99.8 | 99.5 | 94.9 | 98.5 | 96.8 | 97.0 | 95.4 |
| DF + DANet [37] | 84.1 | 95.0 | 93.8 | 96.1 | 95.9 | 91.1 | 91.6 | 99.6 | 99.8 | 92.7 | 96.9 | 95.5 | 95.2 | 94.4 |
| Ours | 90.3 | 98.5 | 96.2 | 97.1 | 94.8 | 96.5 | 98.1 | 99.5 | 100 | 95.0 | 97.8 | 97.5 | 96.8 | 96.7 |
| Ape | Can | Cat | Driller | Duck | Eggbox | Glue | Hole. | MEAN | |
|---|---|---|---|---|---|---|---|---|---|
| FFB6D [27] | 47.2 | 85.2 | 45.7 | 81.4 | 53.9 | 70.2 | 60.1 | 85.9 | 66.2 |
| PoseCNN [25] + ICP | 76.2 | 87.4 | 52.2 | 90.3 | 77.7 | 72.2 | 76.7 | 91.4 | 78.0 |
| DenseFusion [16] | 73.2 | 88.6 | 72.2 | 92.5 | 59.6 | 94.2 | 92.6 | 78.7 | 81.4 |
| Ours | 82.8 | 90.5 | 71.4 | 93.2 | 68.1 | 95.5 | 94.7 | 79.2 | 84.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, H.; Wan, G.; Li, X.; Wang, C.; Zhang, H.; Liu, B. DenseFusion-DA2: End-to-End Pose-Estimation Network Based on RGB-D Sensors and Multi-Channel Attention Mechanisms. Sensors 2024, 24, 6643. https://doi.org/10.3390/s24206643
Li H, Wan G, Li X, Wang C, Zhang H, Liu B. DenseFusion-DA2: End-to-End Pose-Estimation Network Based on RGB-D Sensors and Multi-Channel Attention Mechanisms. Sensors. 2024; 24(20):6643. https://doi.org/10.3390/s24206643
Chicago/Turabian StyleLi, Hanqi, Guoyang Wan, Xuna Li, Chengwen Wang, Hong Zhang, and Bingyou Liu. 2024. "DenseFusion-DA2: End-to-End Pose-Estimation Network Based on RGB-D Sensors and Multi-Channel Attention Mechanisms" Sensors 24, no. 20: 6643. https://doi.org/10.3390/s24206643
APA StyleLi, H., Wan, G., Li, X., Wang, C., Zhang, H., & Liu, B. (2024). DenseFusion-DA2: End-to-End Pose-Estimation Network Based on RGB-D Sensors and Multi-Channel Attention Mechanisms. Sensors, 24(20), 6643. https://doi.org/10.3390/s24206643