
Key Synchronization Method Based on Negative Databases and Physical Channel State Characteristics of Wireless Sensor Network


Abstract
1. Introduction
- Avoidance of Confidential Information Leakage: NDPCS-KS avoids reliance on Certificate Authorities (CAs) or Public Key Infrastructure (PKI), eliminating the need for pre-distributed keys or dependence on centralized key servers. It dynamically generates keys based on the current state of the physical channels, ensuring no confidential information is transmitted over the network in the key exchange process, preventing the leakage of secrets.
- Security key exchange mechanism: By leveraging the isolation of the physical channels, NDPCS-KS prevents attackers from eavesdropping on the main channel’s state information to obtain initial key seeds. For the first time, the NDB is employed in the IKE process of WSNs to generate encryption keys. The irreversible nature of the NDB prevents the attackers from generating legitimate keys.
- Resistance to Attacks: NDPCS-KS resists replay attacks, identity forgery, and data packet tampering, ensuring data integrity and reliability. Compared to traditional key exchange mechanisms, it offers higher security and flexibility.
- Extensive Experimental Validation: Extensive experiments have been conducted to compare the effectiveness and feasibility of NDPCS-KS with other methods, demonstrating its effective performance and capability to resist various attacks.
2. Related Work
2.1. Current State of Research on Key Generation in WSNs
2.2. Introduction on Key Negotiation and Quantization
2.3. Introduction and Current State of Research on Negative Databases
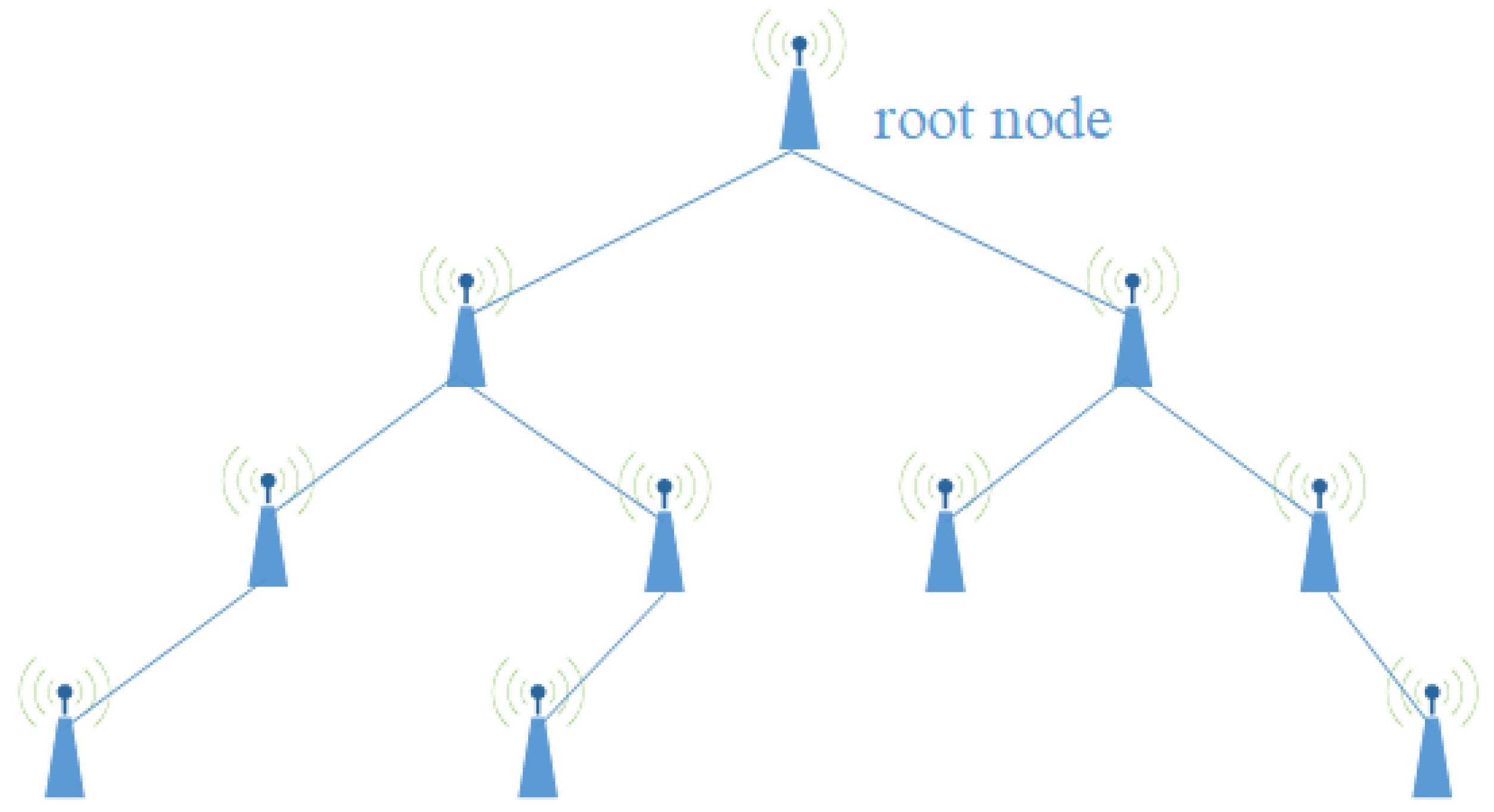
3. System Model
4. Key Technologies and Algorithms
4.1. Network Initialization
- Measurement and Quantization of CSI Samples (RSSI): A pair of sensors measures their CSI samples contained in the received pilot signals as follows:where and represent the ith CSI sample measured by sensors a and b, respectively. represents noise, and N is the number of samples. Due to the reciprocity of the channel, sensors a and b can detect highly correlated CSI measurements, which exhibit similar fluctuation patterns. These patterns are primarily determined by the distance and interference factors in the physical channel connecting a and b. Suppose an attacker, Eve, is beyond the coherence distance from either a or b. She will observe entirely different fluctuation patterns [39,40], preventing her from eavesdropping on similar CSI and thus synchronizing the same initial key seed.The measured CSI samples are then coded into binary sequences as follows:where and represent the ith quantized CSI value of sensors a and sensor b, respectively. if , otherwise .
- Grouping, Hamming Encoding, and Hashing: The quantized CSI sequences are divided into multiple groups as follows:where and represent the kth group of quantized CSI values of sensor a and sensor b, respectively. k is the group index, and m is the number of samples per group. Each group of data is then encoded using the Hamming code (7,4) as follows:The Hamming code (7,4) is chosen for its single-bit error correction, making it suitable for mild noise in sensor networks. It provides high efficiency with low complexity, which is ideal for resource-constrained devices. In the network environment considered, where channel variation is minimal, Hamming ensures reliable communication without added overhead. In more complex environments, stronger error correction codes like Reed–Solomon or LDPC may be needed for higher noise and error levels. Then, the encoded groups are hashed as follows:where and represent the hash values of the kth encoded group of sensors a and b, respectively.
- Error Detection and Correction: When sensors a and b exchange hash values to detect inconsistencies between groups, if , it indicates that group k contains errors. In such cases, Hamming decoding and correction are applied. Specifically, the syndrome is calculated usingwhere is the parity-check matrix of the Hamming code. The matrix is used to determine the positions of errors in the encoded data by comparing it with the transmitted codeword. If the syndrome is non-zero, it indicates the presence of an error. The position of the error j is located, and the error is corrected by flipping the bit:Equation (7) ensures that inconsistencies between the hash values are detected and corrected appropriately.
- Generation of the Initial Key Seeds: After correcting all errors, both sensors concatenate the corrected CSI sequences and hash the result to generate shared initial key seeds. The concatenation of all corrected groups is expressed aswhere represents the corrected sequence of group k, and K represents the total number of the groups. The shared initial key seed is then generated by hashing the concatenated result:
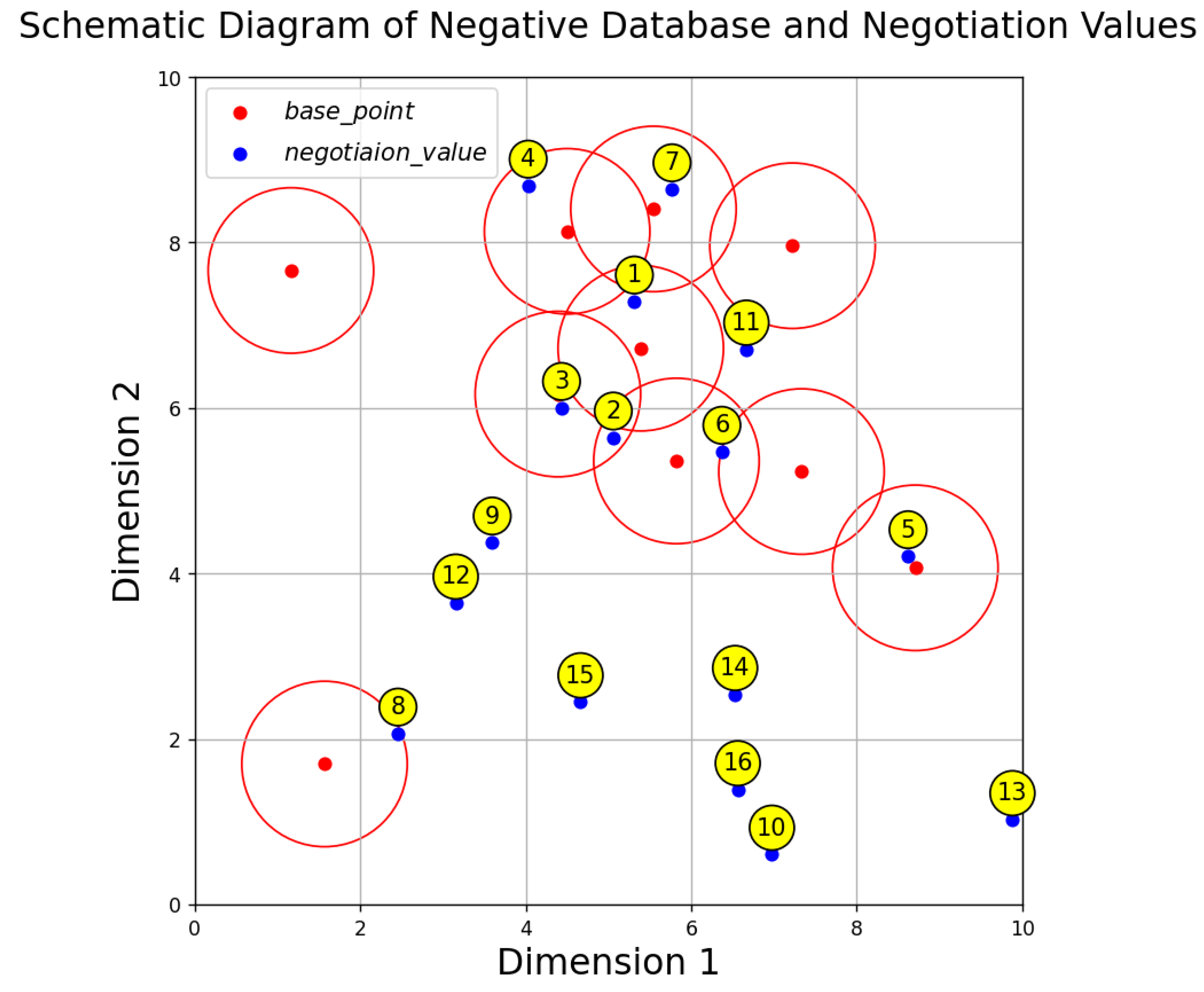
4.2. Negative Databases and Negotiation Key Generation
4.2.1. Negative Database Generation
- Initialization and Generating the Initial Hash Seed: Initially, a and b retrieve in their local , respectively. Then, is calculated based on :
- Setting the Initial Hash State: Set the initial hash state to :
- Generating as follows:in which the current hash state and are employed to generate the next hash state . Here, concat(x, y) concatenates two inputs, x and y, by appending the second input y to the first input x.
- Generating the Coordinate Pairs for : the coordinates and are generated as follows:here, the function rounds the number x to n decimal places. function converts a string x representing a hexadecimal number (base 16) into a decimal integer (base 10). function generates the hexadecimal representation of the hash value H.
- For
- “” returns a 64-character hexadecimal string.
- “[:8]” extracts the first eight characters, and these eight characters have a hexadecimal value range from “00000000” to “FFFFFFFF”.
- “” converts the hexadecimal string to a decimal integer with values ranging from 0 to (i.e., ).
- For and
- extracts the first eight characters for calculating .
- extracts the next eight characters for calculating .
- Since SHA256 generates a 64-character hexadecimal hash value, and each character represents 4 bits, totaling 256 bits (32 bytes). Extracting any eight characters (32 bits) is sufficient to represent any value between 0 and (i.e., ), fully covering the required range.
- This ratio ranges from 0 to 1 because the numerator’s maximum value is (i.e., ) and the denominator is also .
- Result after Multiplying by 10
- Multiplying the above ratio by 10 scales the range to 0 to 10.
- Final Rounding to 5 Decimal Places
- The “Round(…, 5)” function rounds the value to five decimal places. Therefore, the final values of and range from 0.00000 to 9.99999.
4.2.2. Negotiation Key Generation
4.3. Second Negotiation for Communication Key Generation
| Algorithm 1 Key Generation Method based on Negative Database |
| 1: Input: |
| 2: Output: Returns a byte array representing the communication key, |
| 3: |
| 4: |
| 5: |
| 6: for to 25 do |
| 7: update the hash state to using Equation (13). |
| 8: NDB_base[i] = , calculated using Equation (14). |
| 9: end for |
| 10: |
| 11: for to 128 do |
| 12: update the hash state to using Equation (15) |
| 13: negotiation_KEY[i] = , calculated using Equation (16). |
| 14: end for |
| 15: for each base_point in NDB_base do |
| 16: calculate the density of base_point using Equation (17). |
| 17: dynamically adjust the radius of base_point using Equation (18). |
| 18: end for |
| 19: |
| 20: for each negotiation_value = in negotiation_KEY do |
| 21: filter to obtain filtered_key[j] using Equation (19). |
| 22: end for |
| 23: convert to a binary string |
| 24: return |
4.4. Identity Verification Mechanism Based on SHA256
| Algorithm 2 Identity Verification Mechanism Based on SHA256 |
| 1: Input: and encrypted message |
| 2: Output: communication key or false |
| 3: calculated using Equation (20) |
| 4: for each initial key seed in of parent node b do |
| 5: calculated using Equation (20) |
| 6: if = then |
| 7: calculate using Algorithm 1 |
| 8: return |
| 9: else |
| 10: return false |
| 11: end if |
| 12: end for |
4.5. Lightweight Anti-Replay Mechanism Based on Timestamps and Rolling Hash Tokens
| Algorithm 3 Lightweight Anti-Replay Mechanism Based on Timestamps and Rolling Hash Tokens |
| 1: Input: , , |
| 2: Output: replay attack detected or not |
| 3: using as input to Algorithm 2 to generate |
| 4: ← using |
| 5: ← |
| 6: if current system time then |
| 7: return replay attack detected |
| 8: else |
| 9: return true |
| 10: end if |
| 11: for each token in of sensor b do |
| 12: if token = then |
| 13: return replay attack detected |
| 14: break |
| 15: else |
| 16: push onto |
| 17: if size exceeds limit n then |
| 18: pop the oldest token from |
| 19: end if |
| 20: end if |
| 21:end for |
4.6. Data Transmission Process Between Nodes
5. Security Analysis
5.1. Key Space Size
5.2. Key Security
- Let S be the initial key seed and let denote a hash function (specifically SHA256).
- Let be a set of n baseline points generated based on S.
- Let be a set of m negotiation value points generated.
- Assume the initial filtering radius is R, the adjustment value is , the high density threshold is , and the low density value is . All these parameters are pre-shared by all nodes in the sensor network.
6. Experiments
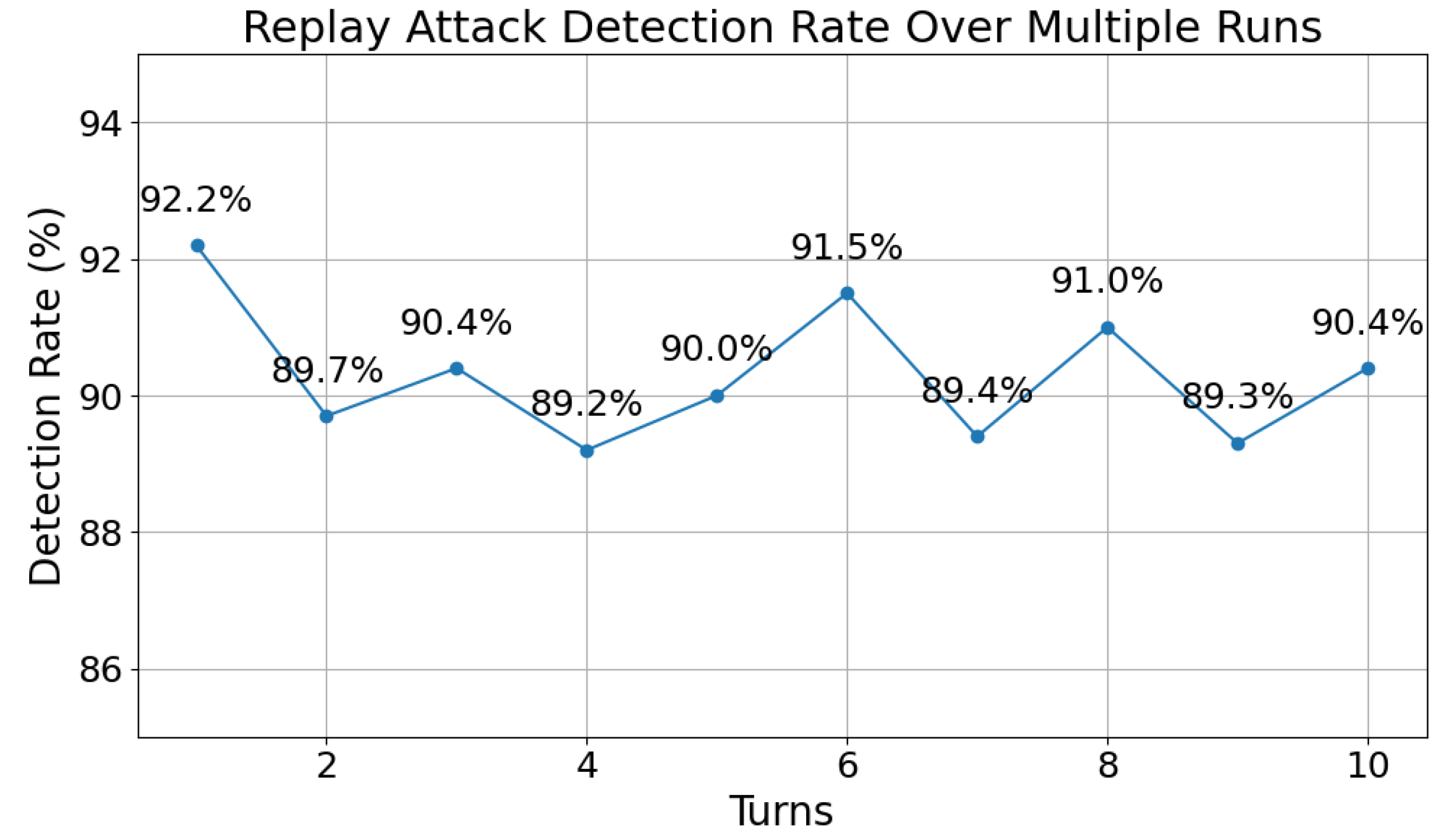
- Simulated replay attacks and calculated detection accuracy.
- Simulated attacks involving tampering and forging transmission packets and calculated detection accuracy.
- The randomness of NDPCS-KS was validated through probabilistic statistics, Monte Carlo simulations, and entropy statistics experiments. Additionally, the NIST Statistical Test Suite [42] was used to test the randomness of the keys generated by NDPCS-KS.
6.1. Replay Attack Detection Accuracy
6.2. Tampering and Forging of Transmission Packets Detection Accuracy
6.3. Performance Analysis
6.4. Randomness Analysis
6.4.1. Probabilistic Statistics
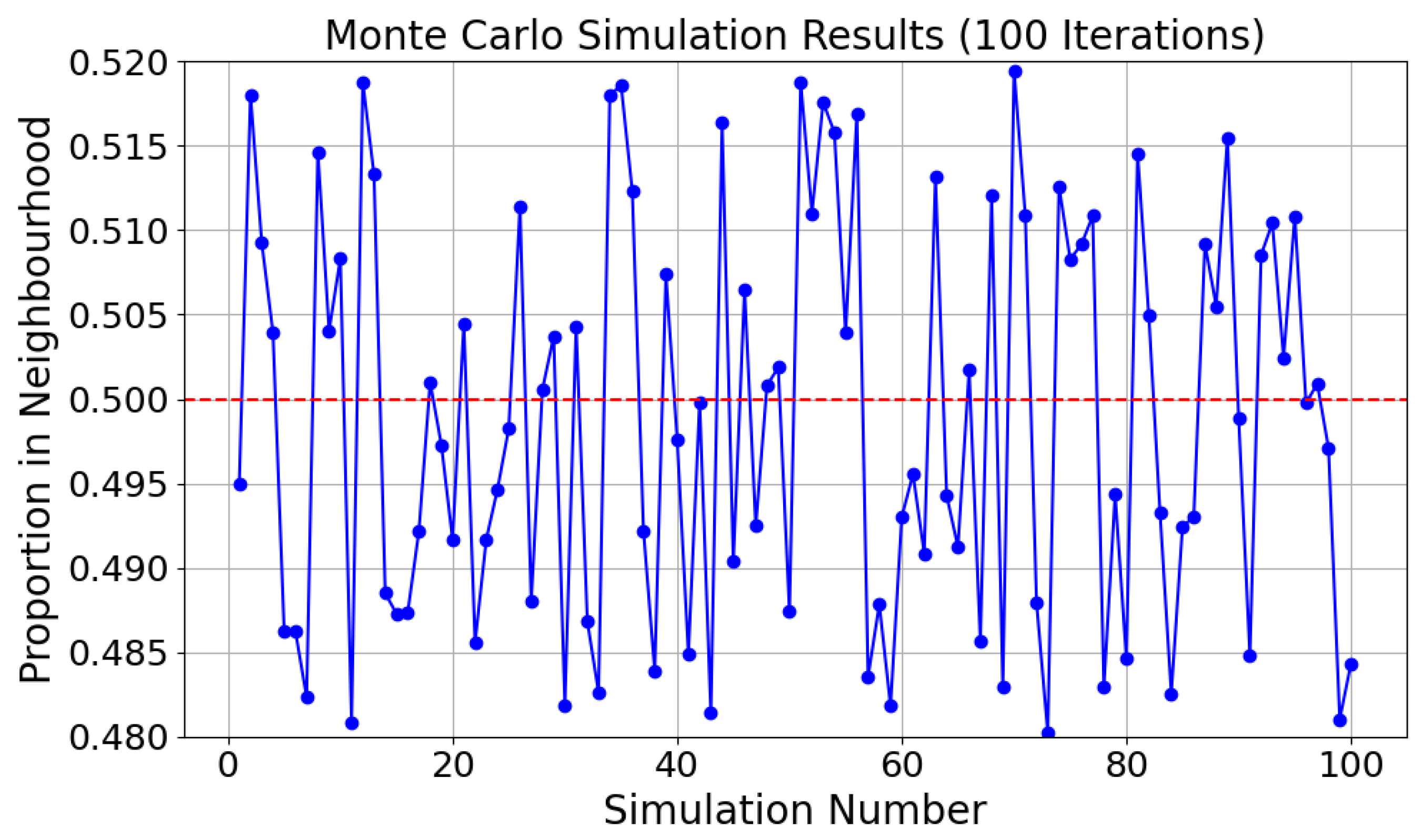
6.4.2. Monte Carlo Simulations
- Random generation of : 25 are randomly generated within the continuous two-dimensional space [0, 10] × [0, 10].
- Random generation of : A point is randomly generated within the same two-dimensional interval, and whether this point falls within the neighborhood of any is determined.
- Consideration of overlapping neighborhoods: The neighborhood of each may overlap with other , which increases the complexity of calculating the probability that a single point falls within a neighborhood.
- Generate : Randomly generate 25 in the two-dimensional interval [0, 10] × [0, 10].
- Generate random points: Generate many random points within the same range.
- Calculate neighborhood hits: For each random point, check whether it falls within the neighborhood of any .
- Estimate probability: Calculate the proportion of random points within at least one neighborhood.
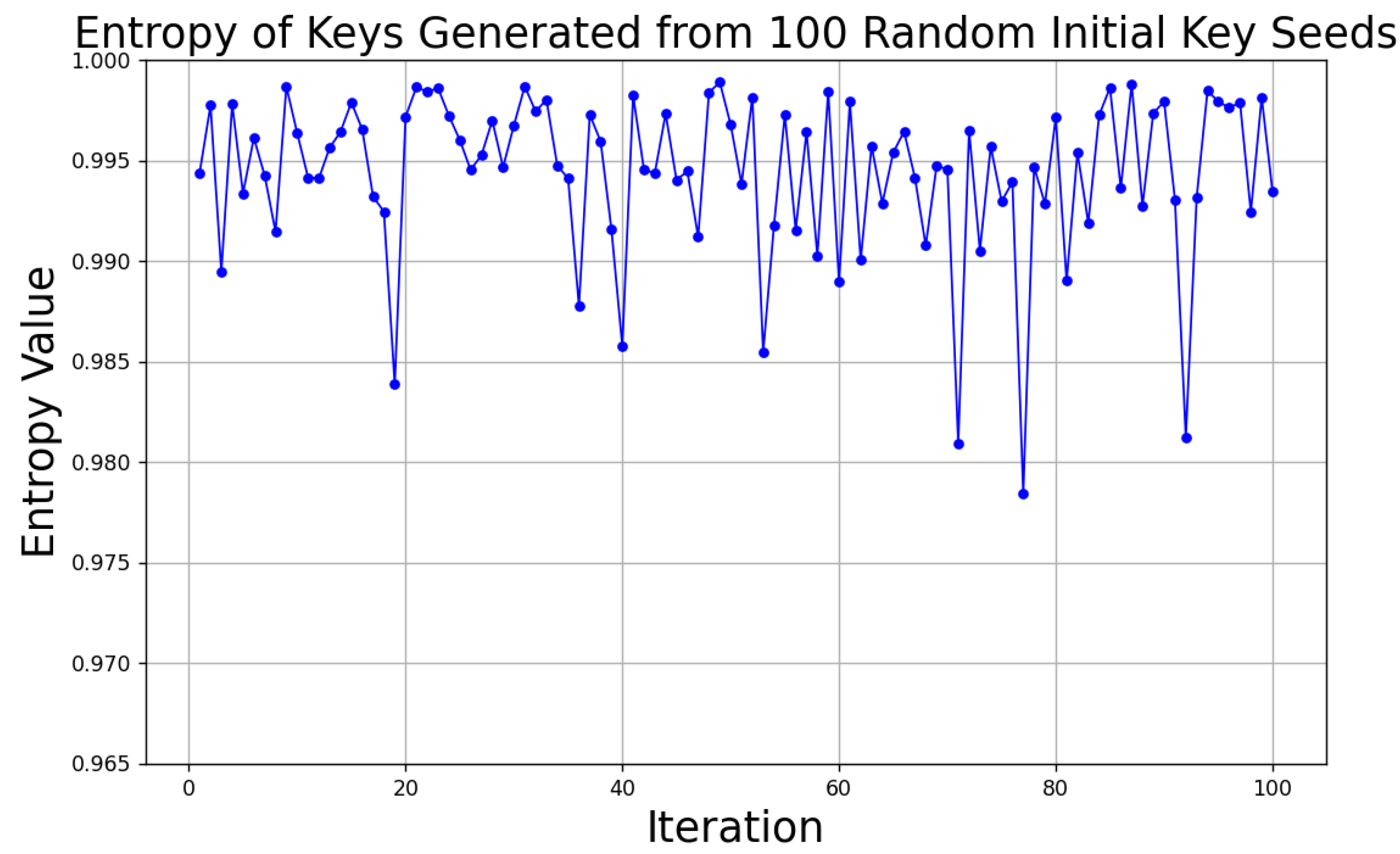
6.4.3. Entropy Statistics
6.4.4. NIST Statistical Test Suite
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Al-Fuqaha, A.; Guizani, M.; Mohammadi, M.; Aledhari, M.; Ayyash, M. Internet of Things: A Survey on Enabling Technologies, Protocols, and Applications. IEEE Commun. Surv. Tutor. 2015, 17, 2347–2376. [Google Scholar] [CrossRef]
- Shafique, K.; Khawaja, B.A.; Sabir, F.; Qazi, S.; Mustaqim, M. Internet of Things (IoT) for Next-Generation Smart Systems: A Review of Current Challenges, Future Trends and Prospects for Emerging 5G-IoT Scenarios. IEEE Access 2020, 8, 23022–23040. [Google Scholar] [CrossRef]
- Lombardi, M.; Pascale, F.; Santaniello, D. Internet of Things: A General Overview Between Architectures, Protocols and Applications. Information 2021, 12, 87. [Google Scholar] [CrossRef]
- Abiodun, O.I.; Oluwaranti, A.; Misra, S.; Chamola, V. A Review on the Security of the Internet of Things: Challenges and Solutions. Wirel. Pers. Commun. 2021, 119, 2603–2637. [Google Scholar] [CrossRef]
- Lin, Y.; Xie, Z.; Chen, T.; Cheng, X.; Wen, H. Image Privacy Protection Scheme Based on High-Quality Reconstruction DCT Compression and Nonlinear Dynamics. Expert Syst. Appl. 2024, 257, 124891. [Google Scholar] [CrossRef]
- Shen, S.; Chen, X.; Duan, H.; Zhang, J.; Xiang, Y. Differential Game-Based Strategies for Preventing Malware Propagation in Wireless Sensor Networks. IEEE Trans. Inf. Forensics Secur. 2014, 9, 1962–1973. [Google Scholar] [CrossRef]
- Chen, L.; Ji, J.; Zhang, Z. Wireless Network Security; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Zhou, L.; Kang, M.; Chen, W. Lightweight Security Transmission in Wireless Sensor Networks Through Information Hiding and Data Flipping. Sensors 2022, 22, 823. [Google Scholar] [CrossRef]
- Dai, H.; Xu, H. Key Predistribution Approach in Wireless Sensor Networks Using LU Matrix. IEEE Sens. J. 2010, 10, 1399–1409. [Google Scholar] [CrossRef]
- Kuang, W. Improved Random Key Pre-Distribution Scheme for Wireless Sensor Networks. Chin. J. Sens. Actuators 2010, 10, 225–234. [Google Scholar]
- Yin, L.; Liu, Q.; Liang, W.; Shen, H.; Yang, Y. Secure Pairwise Key Establishment for Key Predistribution in Wireless Sensor Networks. In Proceedings of the 2012 International Conference on Computer Science and Service System, Nanjing, China, 22–24 June 2012; pp. 1018–1021. [Google Scholar]
- Renyi, S. Dynamic Nonlinear Key Distribution in Wireless Sensor Networks. J. Yanbian Univ. 2011. Available online: http://en.cnki.com.cn/Article_en/CJFDTOTAL-YBDZ201103022.htm (accessed on 2 August 2024).
- Chen, S.; Zhang, H.; Wang, Q. Dynamic Key Management Scheme in Wireless Sensor Networks. In High Performance Networking, Computing, and Communication Systems: Second International Conference ICHCC 2011, Singapore, 5–6 May 2011, Selected Papers; Communications in Computer and Information Science; Springer: Berlin/Heidelberg, Germany, 2011; Volume 163. [Google Scholar]
- Yousefpoor, M.S.; Barati, H. DSKMS: A Dynamic Smart Key Management System Based on Fuzzy Logic in Wireless Sensor Networks. Wirel. Netw. 2020, 26, 2515–2535. [Google Scholar] [CrossRef]
- Xiong, H.; Li, X.; Gao, S.; Zhang, J.; Zhao, H. Efficient Secret Key Generation Scheme of Physical Layer Security Communication in Ubiquitous Wireless Networks. IET Commun. 2021, 15, 1123–1132. [Google Scholar] [CrossRef]
- Altun, U.; Emekligil, M.; Ozger, M. Scalable Secret Key Generation for Wireless Sensor Networks. IEEE Syst. J. 2022, 16, 6031–6041. [Google Scholar] [CrossRef]
- Wei, X.; Saha, D. KNEW: Key Generation Using Neural Networks From Wireless Channels. In Proceedings of the 2022 ACM Workshop on Wireless Security and Machine Learning, New Orleans, LA, USA, 18 March 2022; pp. 1–6. [Google Scholar]
- Rangarajan, J.; Sharma, N.; Gope, P.; Kundu, S. Crypto Analysis With Modified Diffie–Hellman Key Exchange Based Sensor Node Security Improvement in Wireless Sensor Networks. In Proceedings of the 2023 Third International Conference on Artificial Intelligence and Smart Energy (ICAIS), Coimbatore, India, 24–26 March 2023; pp. 1–5. [Google Scholar]
- Moara-Nkwe, K.; Masek, P.; Barcelo-Ordinas, J.M.; De Poorter, E. A Novel Physical Layer Secure Key Generation and Refreshment Scheme for Wireless Sensor Networks. IEEE Access 2018, 6, 11374–11387. [Google Scholar] [CrossRef]
- Ji, Z.; Huang, H.; Zhang, J.; Yang, F.; Wen, H. Physical-Layer-Based Secure Communications for Static and Low-Latency Industrial Internet of Things. IEEE Internet Things J. 2022, 9, 18392–18405. [Google Scholar] [CrossRef]
- Aldaghri, N.; Mahdavifar, H. Physical Layer Secret Key Generation in Static Environments. IEEE Trans. Inf. Forensics Secur. 2020, 15, 2692–2705. [Google Scholar] [CrossRef]
- Chen, Y.; Li, X.; Du, X.; Zhao, H. Physical Layer Key Generation Scheme for MIMO System Based on Feature Fusion Autoencoder. IEEE Internet Things J. 2023, 10, 14886–14895. [Google Scholar] [CrossRef]
- Chen, Y.; Li, X.; Du, X.; Zhao, H. Physical Layer Secret Key Generation Based on Bidirectional Convergence Feature Learning Convolutional Network. IEEE Internet Things J. 2023, 10, 14846–14855. [Google Scholar] [CrossRef]
- Wunder, G.; Nieman, K.; Dahmen, T. Mimicking DH Key Exchange Over a Full Duplex Wireless Channel via Bisparse Blind Deconvolution. In Proceedings of the 2023 6th International Conference on Advanced Communication Technologies and Networking (CommNet), Marrakech, Morocco, 16–18 May 2023; pp. 1–5. [Google Scholar]
- Cao, Z.; Lin, Z.; Zhou, X.; Niu, H. Eliminating Privacy Amplification in Secret Key Generation from Wireless Channels. In Proceedings of the 2015 10th International Conference on Communications and Networking in China (ChinaCom), Shanghai, China, 15–17 August 2015; pp. 1–5. [Google Scholar]
- Hua, Y. Generalized Channel Probing and Generalized Pre-processing for Secret Key Generation. IEEE Trans. Signal Process. 2023, 71, 1067–1082. [Google Scholar] [CrossRef]
- Li, G.; Xia, Y.; Chen, Y.; Zhang, Z. The Optimal Preprocessing Approach for Secret Key Generation from OFDM Channel Measurements. In Proceedings of the 2016 IEEE Globecom Workshops (GC Wkshps), Washington, DC, USA, 4–8 December 2016; pp. 1–6. [Google Scholar]
- Li, G.; Zhang, Z.; Liu, L.; Xia, Y.; Chen, Y. High-Agreement Uncorrelated Secret Key Generation Based on Principal Component Analysis Preprocessing. IEEE Trans. Commun. 2018, 66, 3022–3034. [Google Scholar] [CrossRef]
- Wang, X.; Cao, Z.; Li, G.; Zhou, X. Secret Key Extraction with Quantization Randomness Using Hadamard Matrix on QuaDRiGa Channel. In Information and Communications Security: 17th International Conference, ICICS 2015, Beijing, China, 9–11 December 2015, Revised Selected Papers; Zhou, J., Ed.; Springer: Cham, Switzerland, 2016; pp. 1–12. [Google Scholar]
- Horie, S.; Watanabe, O. Hard Instance Generation for SAT. In Proceedings of the 8th International Symposium on Algorithms and Computation (ISAAC ’97), Singapore, 17–19 December 1997; pp. 21–30. [Google Scholar]
- Hwang, M.-S.; Li, L.-H. A New Remote User Authentication Scheme Using Smart Cards. IEEE Trans. Consum. Electron. 2000, 46, 28–30. [Google Scholar] [CrossRef]
- Esponda, F.; Forrest, S.; Helman, P. Negative Representations of Information. Int. J. Inf. Secur. 2009, 8, 331–345. [Google Scholar] [CrossRef]
- Esponda, F.; Ackley, E.; Forrest, S.; Helman, P. Protecting Data Privacy Through Hard-to-Reverse Negative Databases. Int. J. Inf. Secur. 2007, 6, 403–415. [Google Scholar] [CrossRef]
- Barthel, W.; Hartmann, A.K.; Leone, M.; Ricci-Tersenghi, F.; Weigt, M.; Zecchina, R. Hiding Solutions in Random Satisfiability Problems: A Statistical Mechanics Approach. Phys. Rev. Lett. 2002, 88, 188701. [Google Scholar] [CrossRef]
- Achlioptas, D.; Jia, H.; Moore, C. Hiding Satisfying Assignments: Two Are Better Than One. J. Artif. Intell. Res. 2005, 24, 623–639. [Google Scholar] [CrossRef]
- Liu, R.; Luo, W.; Wang, X. A Hybrid of the Prefix Algorithm and the Q-Hidden Algorithm for Generating Single Negative Databases. In Proceedings of the 2011 IEEE Symposium on Computational Intelligence in Cyber Security (CICS), Paris, France, 11–15 April 2011; pp. 36–43. [Google Scholar]
- Liu, R.; Luo, W.; Yue, L. The P-Hidden Algorithm: Hiding Single Databases More Deeply. Immune Comput. 2014, 2, 43–55. [Google Scholar]
- Zhao, D.; Du, D.; Liang, Y.; Xu, D.; Ji, S. A Fine-Grained Algorithm for Generating Hard-to-Reverse Negative Databases. In Proceedings of the 2015 International Workshop on Artificial Immune Systems (AIS), Taormina, Italy, 21–22 October 2015; pp. 1–8. [Google Scholar]
- Zhang, J.; Mao, J.; Li, X.; Yao, W. Experimental Study on Channel Reciprocity in Wireless Key Generation. In Proceedings of the 2016 IEEE 17th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Edinburgh, UK, 3–6 July 2016; pp. 1–5. [Google Scholar]
- Klement, F.; Voss, P.; Koller, F.; Obermeier, S.; Parzinger, M.; Hollick, M. Keep Your Enemies Closer: On the Minimal Distance of Adversaries When Using Channel-Based Key Extraction in SISO 6G Systems. In Proceedings of the 2023 19th International Conference on Wireless and Mobile Computing, Networking and Communications (WiMob), Thessaloniki, Greece, 9–11 October 2023; pp. 445–451. [Google Scholar]
- Beaulieu, R.; Shors, D.; Smith, J.; Treatman-Clark, S.; Weeks, B.; Wingers, L. The SIMON and SPECK Lightweight Block Ciphers. In Proceedings of the 52nd Annual Design Automation Conference (DAC ’15), San Francisco, CA, USA, 8–12 June 2015; pp. 1–6. [Google Scholar]
- National Institute of Standards and Technology. NIST Statistical Test Suite. Available online: https://csrc.nist.gov/publications/detail/sp/800-22/rev-1a/final (accessed on 30 June 2024).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| DB | U-DB | NDB |
|---|---|---|
| 001 | ||
| 000 | 010 | 0*1 |
| 111 | 011 | *11 |
| 100 | 10* | |
| 101 | ||
| 110 |
| Term | Definition |
|---|---|
| Main channels | The legitimate channels between any pair of sensor nodes |
| The communication key between child node a and parent node b | |
| Message x encrypted with | |
| Message x decrypted with | |
| The initial key seed is negotiated via CSI between nodes a and b, with indicating a as the child node and b as the parent node | |
| Represents the ith bit of , where a is the child node of b | |
| used by node a to communicate with node b at time t | |
| Initial key seeds library maintained by each node | |
| The two-dimensional baseline points of the NDB | |
| All elements form an sequence | |
| Represents the ith element of | |
| The two-dimensional negotiation values | |
| All elements form the negotiation key for NDB second negotiation | |
| Represents the jth element of | |
| R | The initial filtering radius |
| The adjustment value for dynamic radius adjusting | |
| The adjusted filtering radius | |
| A sequence representing the communication key | |
| The jth bit of the communication key, which can be 0 or 1 | |
| Identity verification value calculated by child node a sending information | |
| Identity verification value calculated by parent node b receiving information | |
| A library of rolling hash tokens maintained by each sensor | |
| A timestamp includes the generation time and the token expiration time | |
| A token calculated by sensor a using SHA256 with as input, sent to sensor b |
| Test Name | p-Value | Proportion Passing |
|---|---|---|
| Frequency Test | 0.350485 | 10/10 |
| Block Frequency Test | 0.534146 | 9/10 |
| Cumulative Sums Test 1 | 0.739918 | 10/10 |
| Cumulative Sums Test 2 | 0.911413 | 10/10 |
| Runs Test | 0.213309 | 9/10 |
| Longest Run Test | 0.350485 | 10/10 |
| Rank Test | 0.350485 | 10/10 |
| FFT Test | 0.534146 | 10/10 |
| Non-Overlapping Template Test 1 | 0.122325 | 10/10 |
| Non-Overlapping Template Test 2 | 0.350485 | 10/10 |
| Non-Overlapping Template Test 3 | 0.739918 | 10/10 |
| Non-Overlapping Template Test 4 | 0.534146 | 10/10 |
| Non-Overlapping Template Test 5 | 0.739918 | 9/10 |
| Overlapping Template Test | 0.739918 | 10/10 |
| Universal Statistical Test | 0.534146 | 10/10 |
| Approximate Entropy Test | 0.534146 | 10/10 |
| Random Excursions Test 1 | — | 3/4 |
| Random Excursions Test 2 | — | 4/4 |
| Random Excursions Test 3 | — | 4/4 |
| Serial Test 1 | 0.739918 | 10/10 |
| Serial Test 2 | 0.739918 | 10/10 |
| Linear Complexity Test | 0.035174 | 10/10 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pu, H.; Chen, W.; Wang, H.; Bao, S. Key Synchronization Method Based on Negative Databases and Physical Channel State Characteristics of Wireless Sensor Network. Sensors 2024, 24, 6217. https://doi.org/10.3390/s24196217
Pu H, Chen W, Wang H, Bao S. Key Synchronization Method Based on Negative Databases and Physical Channel State Characteristics of Wireless Sensor Network. Sensors. 2024; 24(19):6217. https://doi.org/10.3390/s24196217
Chicago/Turabian StylePu, Haoyang, Wen Chen, Hongchao Wang, and Shenghong Bao. 2024. "Key Synchronization Method Based on Negative Databases and Physical Channel State Characteristics of Wireless Sensor Network" Sensors 24, no. 19: 6217. https://doi.org/10.3390/s24196217
APA StylePu, H., Chen, W., Wang, H., & Bao, S. (2024). Key Synchronization Method Based on Negative Databases and Physical Channel State Characteristics of Wireless Sensor Network. Sensors, 24(19), 6217. https://doi.org/10.3390/s24196217