1. Introduction
In the past few decades, the enhancement of remote sensing technologies has impacted several fields by making it convenient to incorporate high-resolution multispectral (HRMS) images. These images are important for instances like detecting land [
1], monitoring targets [
2], and semantic segmentation [
3], among others [
4]. However, satellite sensor imaging systems are still limited in their ability to provide remote sensing images with high spatial as well as high spectral resolution. Usually, these systems obtain low-spatial-resolution multispectral (LRMS) images and high-spatial-resolution panchromatic (PAN) images by using different sensors [
5]. As a result of these constraints, there has been the development of what is known as pansharpening technology. This technique improves the spatial resolution of multispectral images with the help of panchromatic images and produces high-resolution multispectral images.
Existing pansharpening methodologies are broadly classified into two categories: conventional and deep learning (DL)-based methods. Traditional methods are mainly the component substitution (CS) method [
6], the multiresolution analysis (MRA) method [
7], and the variational optimization (VO) method [
8]. All of these techniques utilize different approaches to solve the problem of increasing the spatial resolution of multispectral images, and they differ in their performance and difficulty.
CS algorithms work in the following way: the MS image is first upsampled and then projected onto a certain space, where the image is separated into spatial and spectral components. The spatial components of this image are then replaced with the panchromatic (PAN) images, which are endowed with more spatial details. The last step is to perform an inverse transformation on the LRMS image to generate the HRMS image. CS algorithms that are worth mentioning are intensity–hue saturation transform (IHS) [
9], partial replacement adaptive CS (PRACS) [
10], and Brovey [
11]. However, these methods generally cause serious spectral distortion in the fused images since the MS spatial bands are replaced by the PAN details without proper reference to compatibility.
Techniques derived from MRA commonly utilize a high-pass filter for extracting detailed information from PAN images. Then, these details are fused into LRMS images to generate HRMS images. Some of the well-known algorithms in this class are the adaptive weighted Laplacian pyramid (AWLP) [
12], modulation transfer-function-generalized Laplacian pyramid (MTF_GLP) [
13], and induction scaling approach (Indusion) [
14], among others. However, these methods have some limitations, such as spatial distortions (e.g., blurring) or artifact formation, which affect the image quality.
VO in the context of remote sensing image fusion that utilizes variational theory as its method is called variational optimization. These methods work on the basis of the smoothness of the image and apply certain conditions on image reconstruction. These constraints form the basis of the formation of an energy functional to be used in solving image processing problems. This process results in the attainment of the final image based on minimizing the value of the generalized function, as stated in [
15]. Some of the well-known VO algorithms are P+XS methods [
16], Bayesian-based methods [
17], and sparse-representation-based methods [
18]. However, they also have a significant disadvantage: the time needed for their execution is much longer compared to other methods, which is why their further development and application in high-speed applications is limited.
DL uses neural networks to simulate the learning process of the human brain; it trains models with large amounts of data in order to automatically extract features, recognize patterns, and perform classification and prediction tasks. In recent years, deep learning has been widely applied in the field of image processing, such as SAR image change detection [
19], cross-view intelligent person searches [
20], landslide extraction [
21], shadow detection in remote sensing imagery [
22], and building height extraction [
23].
Convolutional neural networks (CNNs), as key models in the field of deep learning, are considered one of the most valuable approaches in the pansharpening domain because of their ability to extract features and their effective generalization. Based on the introduction of CNNs in the field of super-resolution reconstruction of remote sensing images [
24], Masi et al. [
25] proposed the first DL-based pansharpening work with a three-layer convolutional network model (PNN). This model paved the way for other developments in the area of study. After this innovation, the research community came up with better CNN models. For instance, the multi-scale and multi-depth CNN (MSDCNN) [
26] is intended for multi-scale and multi-depth feature extraction through networks that operate on shallow and deep information layers. Xu et al. [
27] later improved it by adding a residual module to form a residual-network-based PNN (DRPNN). This method also improves detail capture by applying residual learning. Another significant improvement was described in [
28], wherein an end-to-end method is used to insert obtained details into the upsampled multispectral images to improve overall image quality. Jin [
29] designed a full-depth feature fusion network (FDFNet) consisting of three branches (MS branch, PAN branch, and fusion branch). The MS branch extracts spectral information from MS images; the PAN branch extracts rich texture and detail information from PAN images. The information extracted by these two branches is injected into the fusion branch, achieving full-depth fusion of the network. In addition, Zhang [
30] proposed LAGConv as a new convolution kernel that learns the local context with global harmonics to overcome the issue of spatial discontinuity and to balance global and local features. Jun Da et al. [
31] introduced the cascaded multi-receptive learning residual block (CML) to learn features from multiple receptive fields in a structured manner in order to improve pansharpening performance. The cross spectral–spatial fusion network (CSSFN) [
32] uses a two-stage residual network structure to extract information at different scales from MS and PAN images and uses a cross-spectral–spatial attention block (CSSAB) to interact with spatial information and spectral information, improving the quality of the fusion results.
Despite the significant advancements achieved by deep-learning-based pansharpening methods, there are notable challenges that still need to be addressed:
Overlooking of size variability: Some methodologies, exemplified by the works of [
27] and [
31], operate under the assumption that changes in the sizes of MS and PAN images do not impact the fusion outcomes. This assumption fails to consider the variable information content present in MS and PAN images at different scales, and the networks often utilize simplistic, single-stage fusion. This approach can overlook critical details necessary for high-quality fusion.
Undifferentiated feature handling: Techniques such as the one mentioned in [
30] process stacked feature maps of MS and PAN images as uniform inputs into the feature extraction network or utilize identical subnetworks for both MS and PAN feature extraction (such as [
29]). This method does not account for the inherent differences between spectral and spatial features, potentially leading to a lack of model interpretability and underutilization of the unique characteristics each feature type offers.
Overlooking of redundancy: Most existing methods (such as [
32]) perform feature fusion after feature extraction, during which the generation of redundant information is inevitable. However, these methods lack consideration for eliminating redundant information, resulting in a decrease in the quality of the fused results.
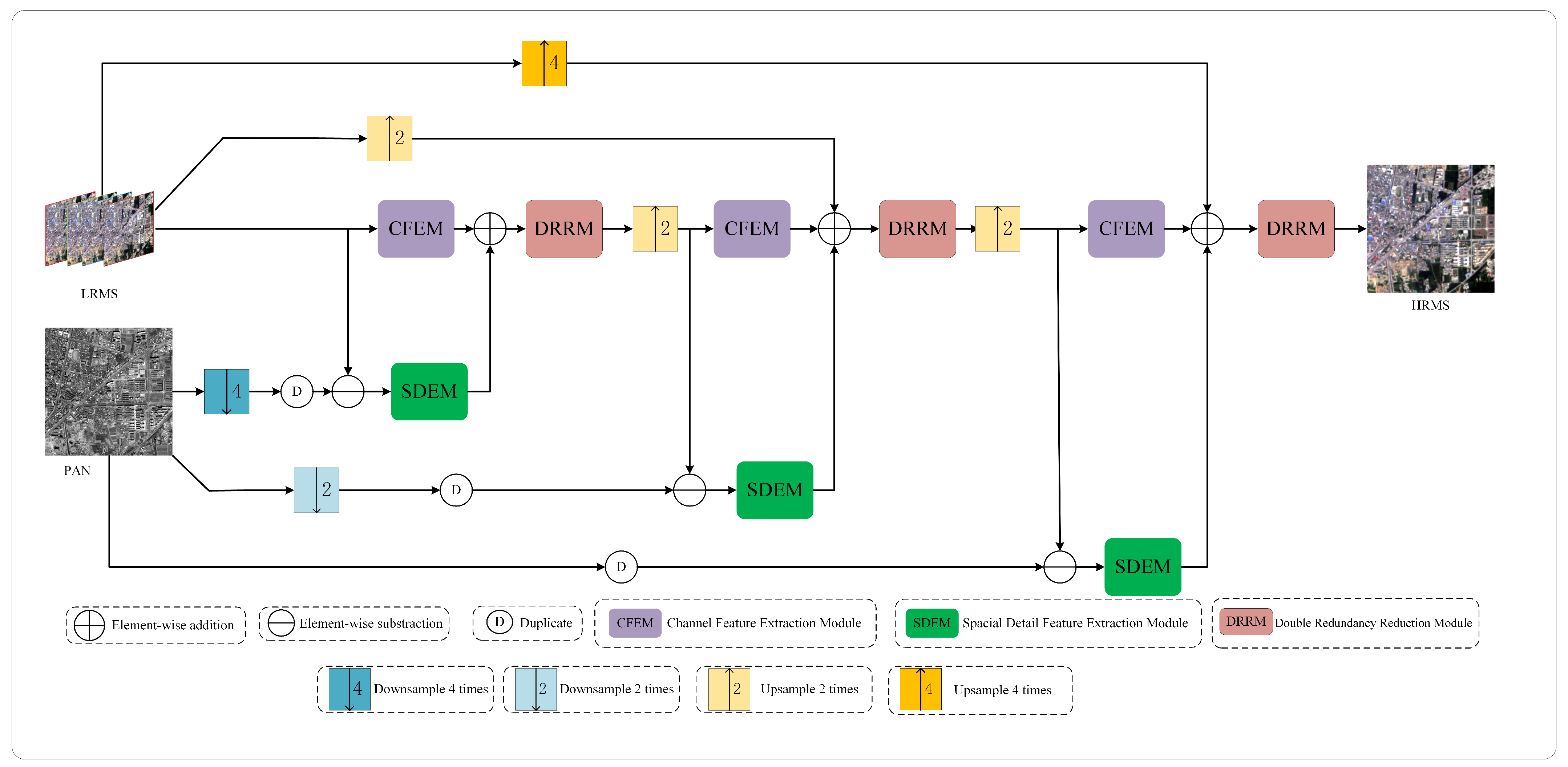
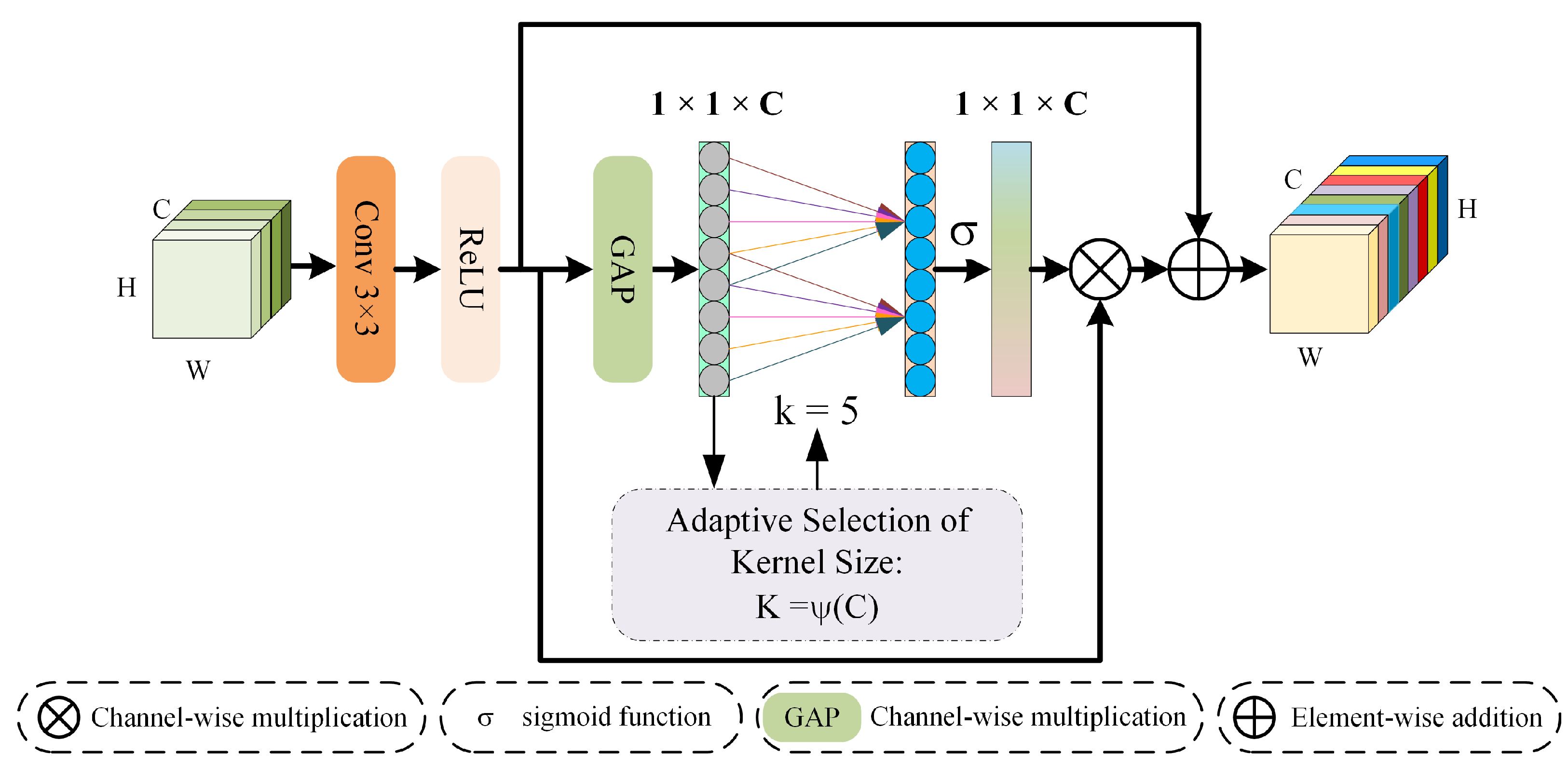
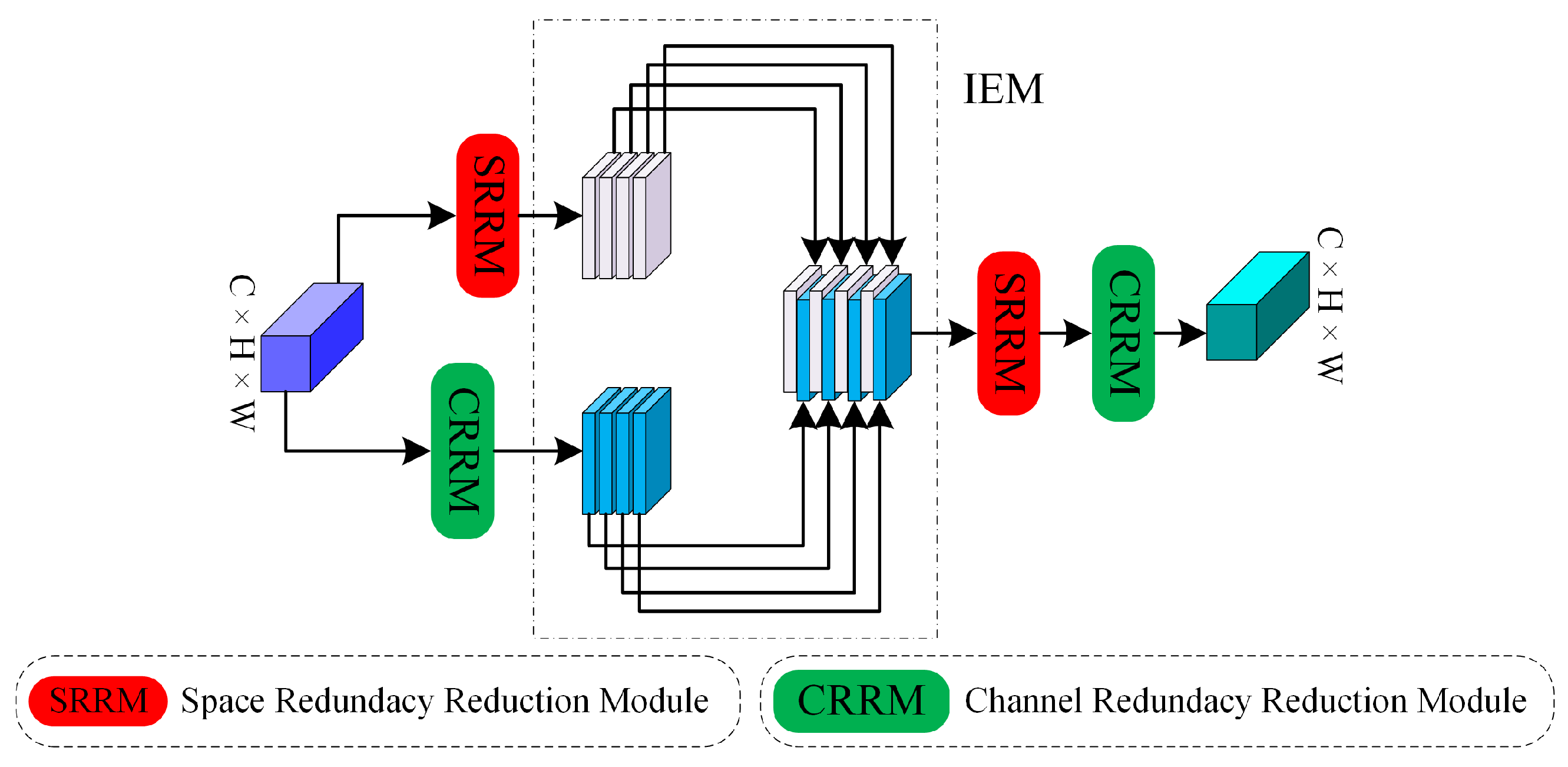
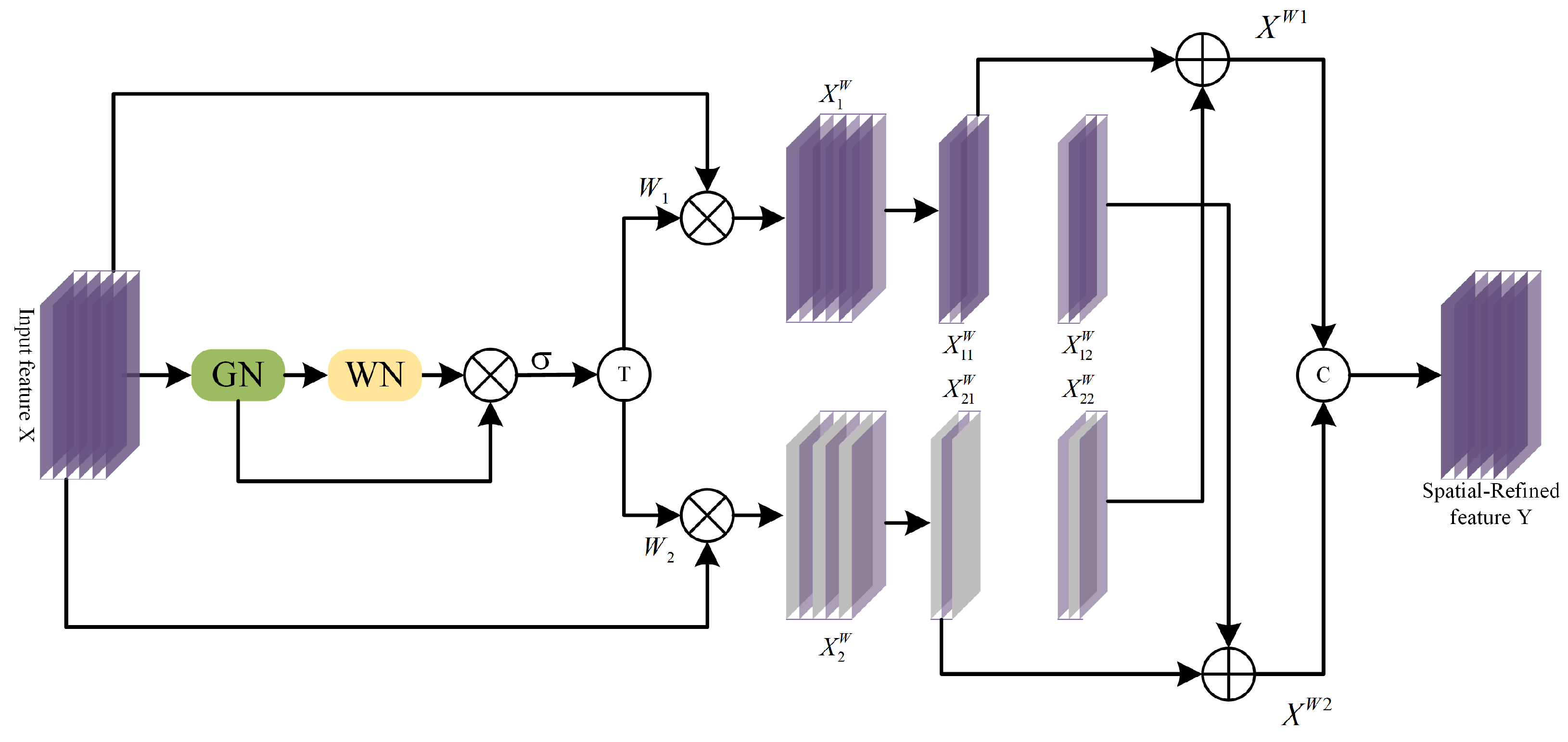
In response to the above issues, instead of adopting a simple end-to-end single-stage fusion network, we propose a multi-stage fusion pansharpening network based on detail injection with redundancy reduction that can fully extract spectral and spatial information from MS and PAN images at different resolutions. In order to obtain richer spectral information from MS images, we design an efficient channel feature extraction module (CFEM) to model spectral features by learning the relationships between feature map channels. In order to obtain sufficient spatial details from PAN images without introducing additional redundant information, inspired by partial convolution (PConv) [
33] and spatial attention (SA) [
34], we design a space detail extraction module (SDEM). At the end of each stage, we reconstruct the previously extracted features. Specifically, the fusion features obtained by this module are first subjected to spatial and channel redundancy reduction operations to obtain feature maps with spatial and channel enhancement, respectively. These two sets of feature maps undergo comprehensive interaction followed by sequential operations to reduce spatial and channel redundancy. Experimental results on the datasets collected by the QuickBird (QB), GaoFen1 (GF1), and WorldView2 (WV2) satellites show that our proposed method has a certain level of improvement in performance compared to other methods, and the number of parameters used is relatively small. Our contributions are summarized as follows:
A multi-stage progressive pansharpening framework is introduced to address both the spectral and spatial dimensions across varying resolutions in order to incrementally refine the fused image’s spectral and spatial attributes while maintaining stability throughout the pansharpening process.
A spatial detail extraction module and a channel feature extraction module are developed to proficiently learn and distinguish between the characteristics of spectral and spatial information. Concurrently, a detail injection technique is employed to enhance the model’s interpretability.
The designed DRRM mitigates redundancy within both the spatial and channel dimensions of the feature maps’ post-detail injection, fostering enhanced interaction among diverse information streams. This approach not only enriches the spectral and spatial representations in the fusion outcomes but also effectively addresses the issue of feature redundancy.
5. Conclusions
The proposed remote sensing image pansharpening network is a novel one based on a three-stage progressive fusion network. In each stage, the output image is upsampled to twice the size of the input image and a channel attention mechanism is incorporated to enhance spectral features. Additionally, an SDEM is employed to precisely extract spatial details from the PAN image. At the end of each stage, there is information reconstruction by means of a DRRM that enhances the features that were obtained in the prior stage. A comparative analysis with state-of-the-art methods and experiments conducted on both real and synthetic datasets demonstrate that the proposed method surpasses its competitors in terms of subjective and objective evaluation criteria while utilizing fewer parameters. Moreover, the results of ablation studies also support the importance of the channel feature extraction module (CFEM), the SDEM, and the DRRM; on the other hand, extra experiments on the network architecture also prove the advantages of the multi-stage approach.
For future work, the network model that is proposed in this study will be applied to other remote sensing areas like object detection and land classification. Modifications to the proposed network structure will be done in order to fit the requirements of the system. Moreover, it is also observed that the network model has shown superb performance on the simulated dataset, but there is scope for improvement when dealing with real datasets. In the future, research and development will remain devoted to these areas to improve the model’s efficiency. In addition, in order to save computing resources, we will attempt to design new models that can train on datasets from multiple satellites that have been combined into a mixed dataset.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}