RSE-YOLOv8: An Algorithm for Underwater Biological Target Detection

Abstract
1. Introduction
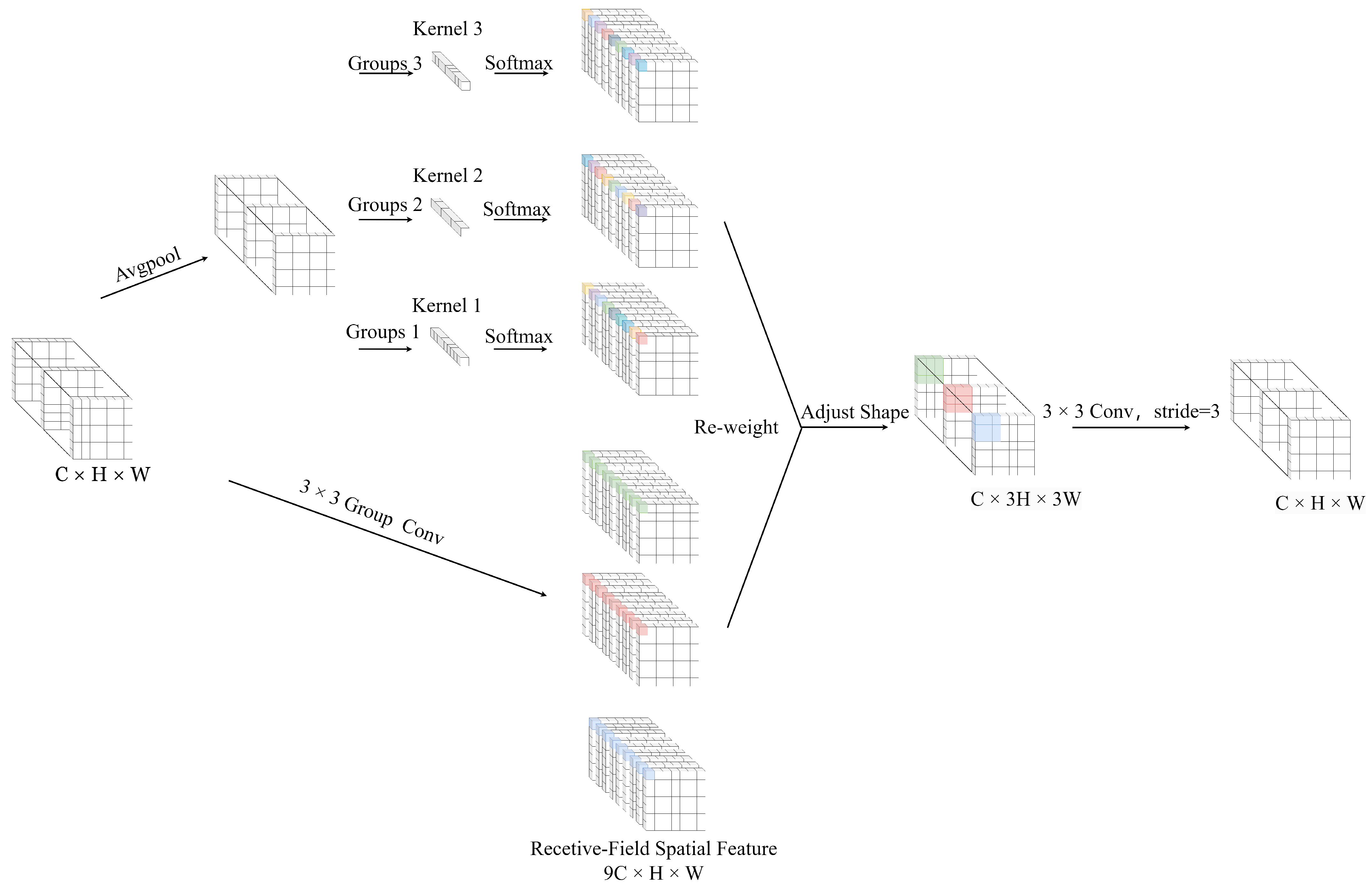
- This paper introduces an efficient receptive field attention convolution that enables the new convolution to fully account for the importance of different receptive fields. This design addresses the issue of parameter sharing and enhances the model’s sensitivity to variations in underwater environmental channel information, thereby tackling the problem of underwater image distortion caused by light absorption and scattering. Additionally, the introduction of the Global Average Pooling (GAP) layer enables the model to better capture global information from the image, thereby improving the identification of key features.
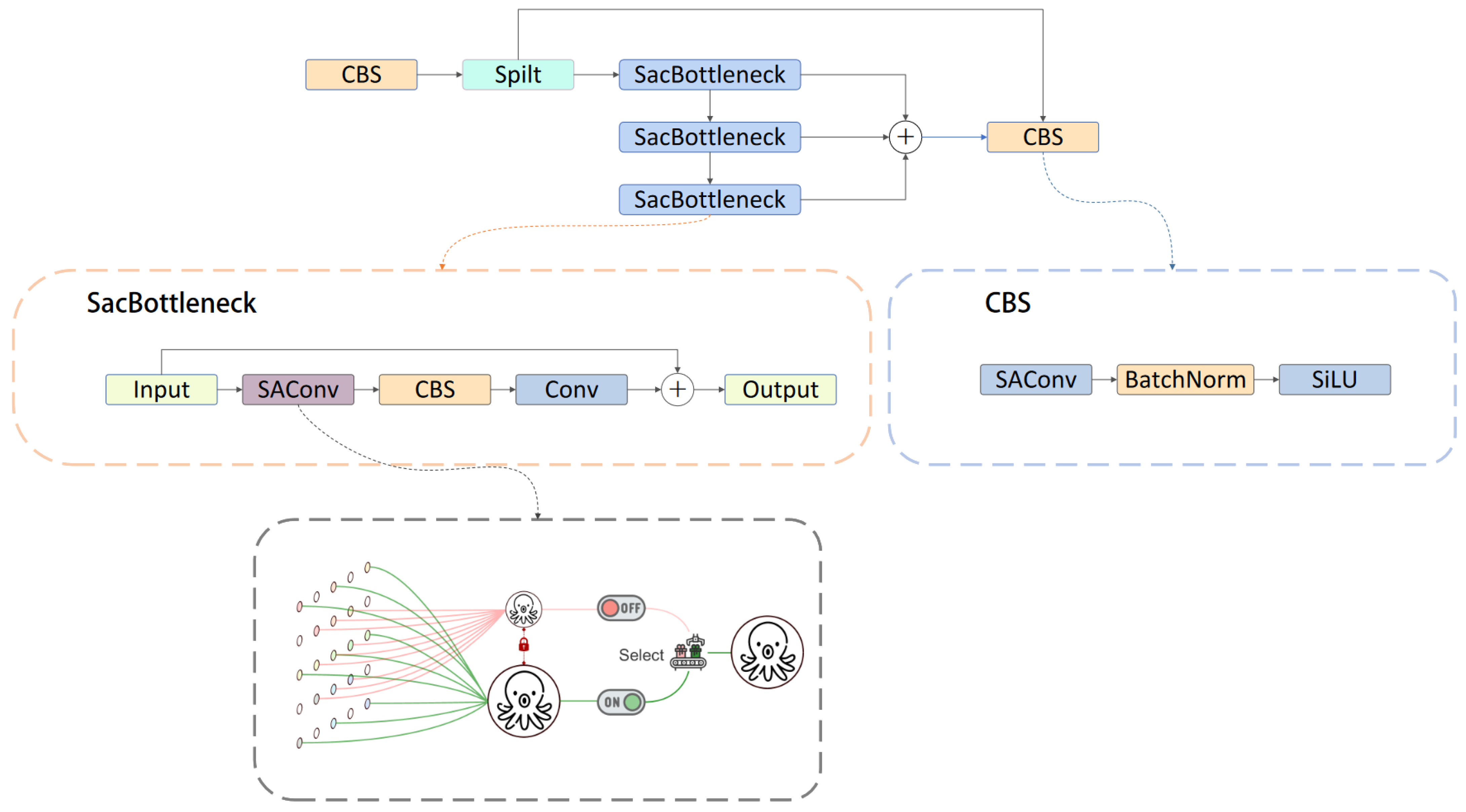
- In this paper, the C2f module is redesigned to incorporate SAConv (switchable atrous convolution), which allows for the flexible adjustment of the atrous rate within the same network layer. This modification enables the network to observe features at different scales through convolutional kernels with two different dilation rates, thereby improving its ability to address the challenge of large scale differences in underwater targets.
- Compared to traditional spatial pyramid pooling, this paper proposes a new ESPPF structure that reduces the depth of spatial pyramid pooling while expanding the module’s width to enable parallel pooling. This approach enhances the efficiency of feature fusion and reduces the number of model parameters, which is of significant importance for underwater target detection applications and embedded devices.
2. Related Works
3. Materials and Methods
3.1. Materials
3.1.1. YOLOv8 Detection Algorithm
3.1.2. RFAConv Module
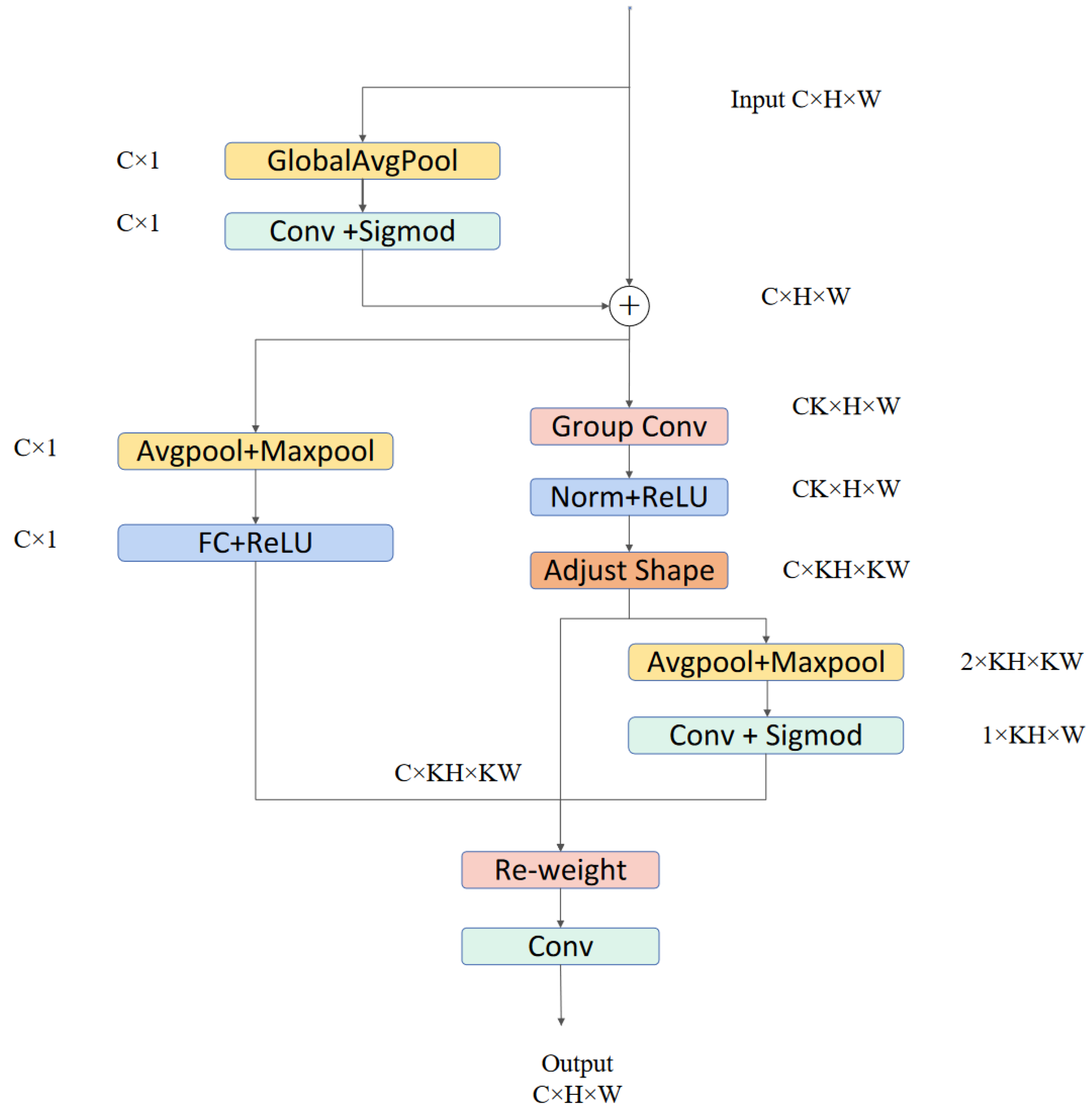
3.1.3. SAConv Module
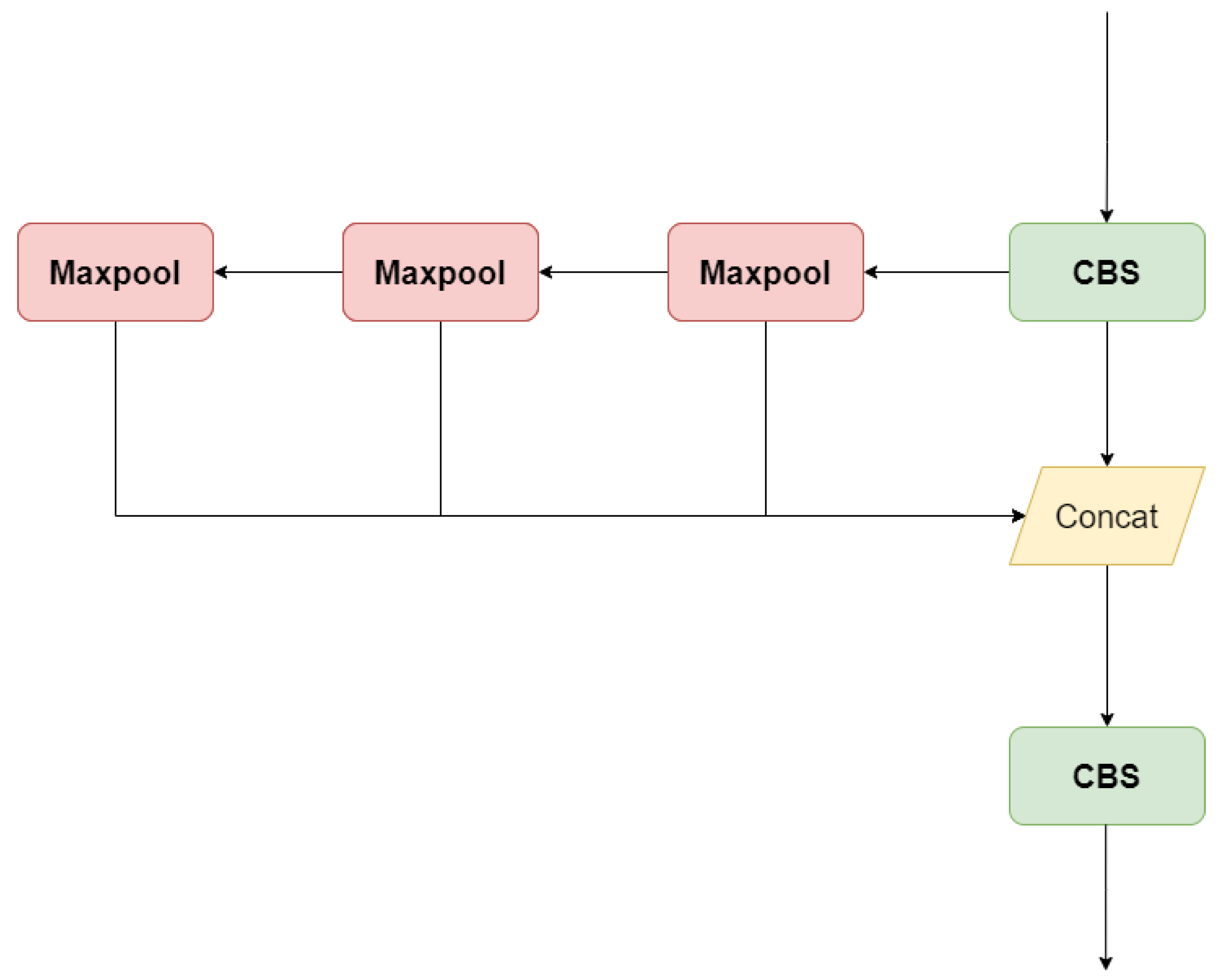
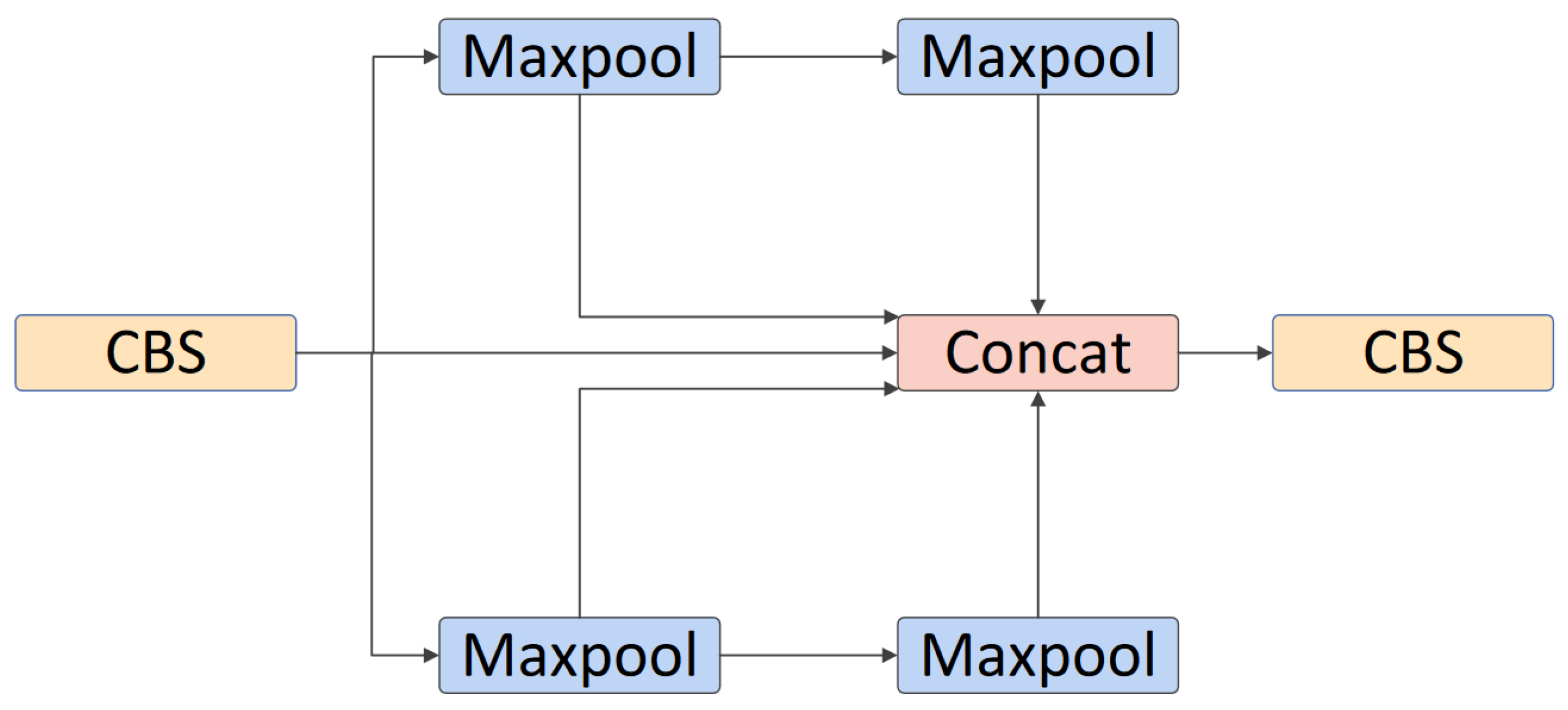
3.1.4. SPPF Module
3.2. The Proposed RSE-YOLOv8
3.2.1. RFESEConv Module
3.2.2. C2f_SAConv Module
3.2.3. ESPPF Module
4. Experimentation and Analysis
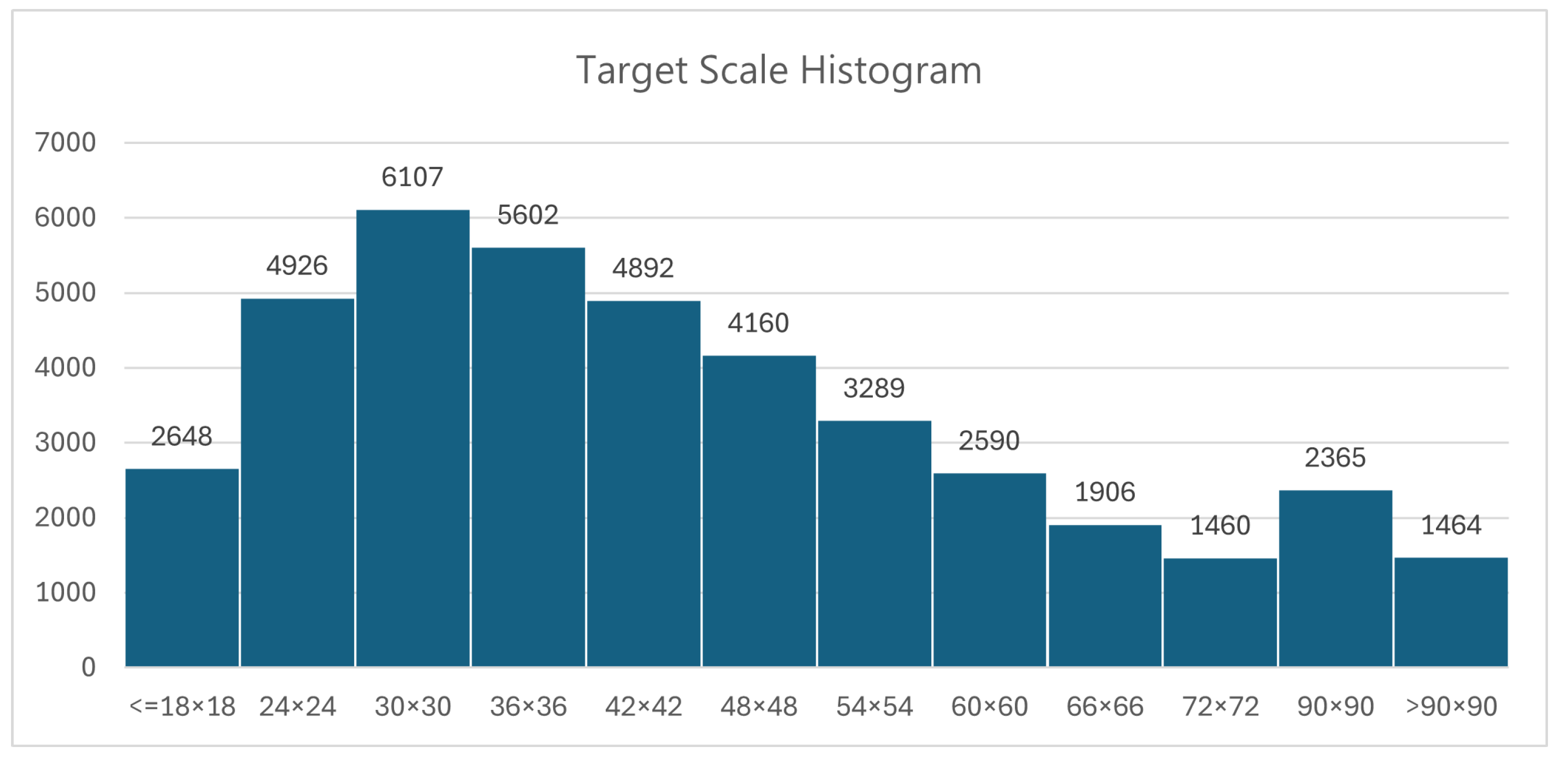
4.1. Experimental Dataset
4.2. Experimental Settings
4.3. Evaluation Indicators
4.4. Ablation Experiment
4.5. Contrast Experiment
4.6. Analysis of Improvement Effects
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Popper, A.N.; Hawkins, A.D.; Thomsen, F. Taking the animals’ perspective regarding anthropogenic underwater sound. Trends Ecol. Evol. 2020, 35, 787–794. [Google Scholar] [CrossRef]
- Sala, E.; Knowlton, N. Global marine biodiversity trends. Annu. Rev. Environ. Resour. 2006, 31, 93–122. [Google Scholar] [CrossRef]
- Zhang, Z.; Qu, Y.; Wang, T.; Zhang, X.; Zhang, L. An improved YOLOv8n used for fish detection in natural water environments. Animals 2024, 14, 2022. [Google Scholar] [CrossRef]
- Li, L.; Shi, G.; Jiang, T. Fish detection method based on improved YOLOv5. Aquac. Int. 2023, 31, 2513–2530. [Google Scholar] [CrossRef]
- Jia, R.; Lv, B.; Chen, J.; Zhang, X.; Liu, L. Underwater object detection in marine ranching based on improved YOLOv8. J. Mar. Sci. Eng. 2023, 12, 55. [Google Scholar] [CrossRef]
- Liu, R.; Fan, X.; Zhu, M.; Zhang, J. Real-world underwater enhancement: Challenges, benchmarks, and solutions under natural light. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 4861–4875. [Google Scholar] [CrossRef]
- Fatan, M.; Daliri, M.R.; Mohammad Shahri, A. Underwater cable detection in the images using edge classification based on texture information. In Measurement; Elsevier BV: Amsterdam, The Netherlands, 2016; Volume 91, pp. 309–317. [Google Scholar]
- Mathias, A.; Dhanalakshmi, S.; Kumar, R.; Narayanamoorthi, R. Underwater object detection based on bi-dimensional empirical mode decomposition and Gaussian Mixture Model approach. In Ecological Informatics; Elsevier BV: Amsterdam, The Netherlands, 2021; Volume 66, p. 101469. [Google Scholar]
- Xu, S.; Zhang, M.; Song, W.; Wang, X. A systematic review and analysis of deep learning-based underwater object detection. Neurocomputing 2023, 527, 204–232. [Google Scholar] [CrossRef]
- Dakhil, R.A.; Khayeat, A.R.H. Review on deep learning techniques for underwater object detection. In Data Science and Machine Learning; Academy and Industry Research Collaboration Center (AIRCC): Chennai, India, 2022. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Liu, C.; Tao, Y.; Liang, J.; Zhao, X. Object detection based on YOLO network. In Proceedings of the 2018 IEEE 4th Information Technology and Mechatronics Engineering Conference (ITOEC), Chongqing, China, 14–16 December 2018; pp. 799–803. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single shot multi-box detector. In Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Zou, Z.; Chen, K.; Shi, Z.; Li, X. Object detection in 20 years: A survey. Proc. IEEE 2023, 111, 257–276. [Google Scholar] [CrossRef]
- Fu, C.; Liu, R.; Fan, X.; Zhang, J. Rethinking general underwater object detection: Datasets, challenges, and solutions. Neurocomputing 2023, 517, 243–256. [Google Scholar] [CrossRef]
- Song, S.; Zhu, J.; Li, X.; Sun, C. Integrate MSRCR and mask R-CNN to recognize underwater creatures on small sample datasets. IEEE Access 2020, 8, 172848–172858. [Google Scholar] [CrossRef]
- Seese, M.; Mishra, S.; Tang, J. Fish detection and classification using convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 7177–7187. [Google Scholar]
- Liu, Y.; Wang, S. A quantitative detection algorithm based on improved faster R-CNN for marine benthos. Ecol. Inform. 2021, 61, 101228. [Google Scholar] [CrossRef]
- Cai, S.; Li, G.; Shan, Y. Underwater object detection using collaborative weakly supervision. Comput. Electr. Eng. 2022, 102, 108159. [Google Scholar] [CrossRef]
- Ye, X.; Luo, K.; Wang, H.; Zhang, Y. An advanced AI-based lightweight two-stage underwater structural damage detection model. Adv. Eng. Inform. 2024, 62, 102553. [Google Scholar] [CrossRef]
- Li, J.; Xu, W.; Deng, L.; Yang, S. Deep learning for visual recognition and detection of aquatic animals: A review. Rev. Aquac. 2022, 15, 409–433. [Google Scholar] [CrossRef]
- Hu, K.; Lu, F.; Lu, M.; Deng, Z.; Liu, Y.; Wang, Z. A marine object detection algorithm based on SSD and feature enhancement. Complexity 2020, 2020, 5476142. [Google Scholar] [CrossRef]
- Zhang, J.; Zhu, L.; Xu, L.; Zhang, X. MFFSSD: An enhanced SSD for underwater object detection. In Proceedings of the 2020 Chinese Automation Congress (CAC), Shanghai, China, 6–8 November 2020. [Google Scholar]
- Hao, W.; Xiao, N. Research on underwater object detection based on improved YOLOv4. In Proceedings of the 2021 8th International Conference on Information, Cybernetics, and Computational Social Systems (ICCSS), Beijing, China, 10–12 December 2021. [Google Scholar]
- Zhou, H.; Kong, M.; Yuan, H.; Li, S. Real-time underwater object detection technology for complex underwater environments based on deep learning. Ecol. Inform. 2024, 82, 102680. [Google Scholar] [CrossRef]
- Tan, A.; Guo, T.; Zhao, Y.; Wang, Y.; Li, X. Object detection based on polari-zation image fusion and grouped convolutional attention network. Vis. Comput. 2023, 40, 3199–3215. [Google Scholar] [CrossRef]
- Guntha, P.; Beaulah, P.M.R. A Comprehensive Review on Underwater Object Detection Techniques. In Proceedings of the 2024 International Conference on Computing and Data Science (ICCDS), Chennai, India, 26–27 April 2024. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning Deep Features for Discriminative Localization (Version 1). arXiv 2015. [Google Scholar] [CrossRef]
- Wang, G.; Chen, Y.; An, P.; Hong, H.; Hu, J.; Huang, T. UAV-YOLOv8: A Small-Object-Detection Model Based on Improved YOLOv8 for UAV Aerial Photography Scenarios. Sensors 2023, 23, 7190. [Google Scholar] [CrossRef] [PubMed]
- Feng, C.; Zhong, Y.; Gao, Y.; Scott, M.R.; Huang, W. TOOD: Task-aligned One-stage Object Detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Zhang, X.; Liu, C.; Yang, D.; Song, T.; Ye, Y.; Li, K.; Song, Y. RFAConv: Innovating spatial attention and standard convolutional operation. arXiv 2023, arXiv:2304.03198. [Google Scholar]
- Papandreou, G.; Kokkinos, I.; Savalle, P.A. Modeling local and global deformations in deep learning: Epitomic convolution, multiple instance learning, and sliding window detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 390–399. [Google Scholar]
- Liang-Chieh, C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A. Semantic image segmentation with deep convolutional nets and fully connected CRFs. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Qiao, S.; Chen, L.C.; Yuille, A. Detectors: Detecting objects with recursive feature pyramid and switchable atrous convolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10213–10224. [Google Scholar]
- Scott, E. SPPF-style parsing from Earley recognisers. Electron. Notes Theor. Comput. Sci. 2008, 203, 53–67. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, W.; Bai, L.; Ren, P. Metalantis: A Comprehensive Underwater Image Enhancement Framework. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5618319. [Google Scholar] [CrossRef]
- Kassri, N.; Ennouaary, A.; Bah, S. Efficient Squeeze-and-Excitation-Enhanced Deep Learning Method for Automatic Modulation Classification. Int. J. Adv. Comput. Sci. Appl. 2024, 15, 536. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design (Version 1). arXiv 2021, arXiv:2103.02907. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need (Version 7). arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network In Network (Version 3). arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Pan, P.; Shao, M.; He, P.; Hu, L.; Zhao, S.; Huang, L.; Zhou, L.; Zhang, J. Lightweight cotton diseases real-time detection model for resource-constrained devices in natural environments. Front. Plant Sci. 2024, 15, 1383863. [Google Scholar] [CrossRef]
- Li, X.; Sun, H.; Song, T.; Zhang, T.; Meng, Q. A method of underwater bridge structure damage detection method based on a lightweight deep convolutional network. IET Image Process. 2022, 16, 3893–3909. [Google Scholar] [CrossRef]
- Ding, X.; Zhang, X.; Han, J.; Ding, G. Diverse branch block: Building a convolution as an inception-like unit. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10886–10895. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollár, P. Microsoft COCO: Common Objects in Context (Version 3). arXiv 2014, arXiv:1405.0312. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection (Version 2). arXiv 2017, arXiv:1708.02002. [Google Scholar]
- Yu, Y.; Lee, S.; Choi, Y.; Kim, G. CurlingNet: Compositional Learning between Images and Text for Fashion IQ Data (Version 2). arXiv 2020, arXiv:2003.12299. [Google Scholar]
- Li, X.; Wang, W.; Wu, L.; Chen, S.; Hu, X.; Li, J.; Tang, J.; Yang, J. Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection (Version 1). arXiv 2020, arXiv:2006.04388. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| YOLOv8n | C2f_SAConv | RFESEconv | ESPPF | mAP@0.5 | mAP@0.5:0.95 | Param (M) | FLOPS (G) | Speed |
|---|---|---|---|---|---|---|---|---|
| √ | 0.759 | 0.415 | 3.00 | 8.10 | 82.71 | |||
| √ | √ | 0.771 | 0.426 | 3.20 | 9.00 | 61.06 | ||
| √ | √ | √ | 0.775 | 0.431 | 3.70 | 7.30 | 63.62 | |
| √ | √ | √ | √ | 0.78 | 0.434 | 3.57 | 7.10 | 90.98 |
| Recall | Precision | mAP@0.5 | mAP@0.5:0.95 | Param (M) | FLOPS (G) | |
|---|---|---|---|---|---|---|
| Faster-RCNN | 0.489 | 0.37 | 0.616 | 0.267 | 82.3 | 25.1 |
| SSD | 0.793 | 0.48 | 0.600 | 0.276 | 13.5 | 15.2 |
| YOLOv3-tiny | 0.695 | 0.77 | 0.734 | 0.379 | 12.1 | 18.9 |
| YOLOv5n | 0.693 | 0.75 | 0.745 | 0.406 | 2.5 | 7.1 |
| YOLOv5s | 0.724 | 0.77 | 0.768 | 0.425 | 9.0 | 23.9 |
| YOLOv8 | 0.698 | 0.78 | 0.759 | 0.415 | 3.0 | 8.1 |
| YOLOV6 | 0.632 | 0.76 | 0.713 | 0.375 | 4.2 | 11.8 |
| Ours | 0.718 | 0.78 | 0.780 | 0.434 | 3.5 | 7.1 |
| Recall | Precision | mAP@0.5 | mAP@0.5:0.95 | Param (M) | FLOPS (G) | |
|---|---|---|---|---|---|---|
| Faster-RCNN | 0.564 | 0.376 | 0.690 | 0.325 | 82.3 | 25.1 |
| SSD | 0.638 | 0.540 | 0.676 | 0.337 | 13.5 | 15.2 |
| YOLOv3-tiny | 0.764 | 0.818 | 0.822 | 0.455 | 12.1 | 18.9 |
| YOLOv5n | 0.752 | 0.817 | 0.828 | 0.473 | 2.5 | 7.1 |
| YOLOv5s | 0.785 | 0.824 | 0.844 | 0.492 | 9.0 | 23.9 |
| YOLOv8 | 0.763 | 0.816 | 0.832 | 0.484 | 3.0 | 8.10 |
| YOLOv6 | 0.750 | 0.817 | 0.824 | 0.471 | 4.2 | 11.8 |
| Ours | 0.786 | 0.827 | 0.853 | 0.498 | 3.5 | 7.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, P.; Zhao, L.; Li, H.; Xue, X.; Liu, H. RSE-YOLOv8: An Algorithm for Underwater Biological Target Detection. Sensors 2024, 24, 6030. https://doi.org/10.3390/s24186030
Song P, Zhao L, Li H, Xue X, Liu H. RSE-YOLOv8: An Algorithm for Underwater Biological Target Detection. Sensors. 2024; 24(18):6030. https://doi.org/10.3390/s24186030
Chicago/Turabian StyleSong, Peihang, Lei Zhao, Heng Li, Xiaojun Xue, and Hui Liu. 2024. "RSE-YOLOv8: An Algorithm for Underwater Biological Target Detection" Sensors 24, no. 18: 6030. https://doi.org/10.3390/s24186030
APA StyleSong, P., Zhao, L., Li, H., Xue, X., & Liu, H. (2024). RSE-YOLOv8: An Algorithm for Underwater Biological Target Detection. Sensors, 24(18), 6030. https://doi.org/10.3390/s24186030