Abstract
For nonlinear systems with uncertain state time delays, an adaptive neural optimal tracking control method based on finite time is designed. With the help of the appropriate LKFs, the time-delay problem is handled. A novel nonquadratic Hamilton–Jacobi–Bellman (HJB) function is defined, where finite time is selected as the upper limit of integration. This function contains information on the state time delay, while also maintaining the basic information. To meet specific requirements, the integral reinforcement learning method is employed to solve the ideal HJB function. Then, a tracking controller is designed to ensure finite-time convergence and optimization of the controlled system. This involves the evaluation and execution of gradient descent updates of neural network weights based on a reinforcement learning architecture. The semi-global practical finite-time stability of the controlled system and the finite-time convergence of the tracking error are guaranteed.
1. Introduction
Adaptive intelligent control algorithms have developed rapidly with the advancement of intelligent approximation technology, especially in neural networks (NN) and fuzzy logic systems (FLS), and have achieved a series of excellent research results [1,2,3,4,5,6,7,8,9]. This has also significantly motivated many scholars to explore the adaptive control algorithm, laying a solid foundation for using the corresponding control theory algorithm in the field of practical engineering applications.
Considering that control and decision-making problems are essentially optimization problems, and optimal control plays a key role in engineering applications, the research on intelligent majorization control algorithms in this paper has a certain role in promoting practical engineering applications. In view of the importance of optimal control, many scholars have conducted extensive research on optimal control algorithms and have obtained certain achievements, mainly including two optimization methods [10,11], adaptive dynamic programming (ADP) methods [12] and reinforcement learning (RL) methods [13].
The ADP approach could realize the online approximation of the optimal target by the recursive numerical method without relying on the control algorithm of the model [14,15,16,17,18,19]. Using NNs, the performance function, designed control laws, and the uncertain part of the nonlinear system could be approximated, which helps solve the HJB function; then, the optimal stability is guaranteed. Similar to the learning mechanism of mammals, the reinforcement learning mechanism aims to regulate both the critic and action adaptive laws in order to control the long-term interaction cost of the environment. The action NNs could modify the action laws, while the critic NNs reduce the virtual energy of the long-term storage function. Thanks to the interoperability of the operating mechanism, refs. [20,21,22,23,24] have made outstanding contributions to online optimization control and model-free optimization control.
Although previous ADP-based methods perform well for non-linear systems without time delays, achieving the ideal control effect on time-delayed non-linear systems is often challenging. Therefore, research on this topic has generated interest among experts and scholars and has achieved preliminary results. However, the time delay in the form of nonlinear interference is a major obstacle to applications of control theory algorithms. Some scholars have paid attention to this and have achieved certain results. Regarding existing methods, there are two main forms of system delay: state and input [25].
State time delays are mainly found in intricate engineering systems, for example, wheeled mobile robot (WMR) systems and chemical engineering, which are hysteresis induced by internal propagation of signals during system motion. With assistance from the Lyapunov–Krasovskii functional (LKF) [25,26,27], the influence caused by the state time delay is overcome, and superior control algorithms are designed.
Due to the contradiction between the convergence characteristics of existing optimization algorithms in infinite time and the fast convergence requirements of actual engineering systems, it has greatly inhibited the practical application and promotion of intelligent optimization algorithms. Therefore, in recent years, some scholar award research has focused on the study of convergence speed and convergence domain equilibrium. The existing breakthrough theoretical research results on infinite convergence algorithms [28,29,30,31,32,33] have promoted the research process of finite-time convergence control algorithms to a certain extent and also reflect the necessity of studying the algorithm from the side. At the same time, they also point out the key and difficult issues faced by finite-time convergence control research.
To meet the finite-time or finite-horizon domain convergence characteristics of actual engineering requirements, some scholars have begun relevant research. For nonlinear discrete systems, researchers use the ADP-based approach to solve the finite-time domain convergence problem [34,35], which greatly stimulates the authors’ research passion for finite-time convergence optimization control algorithms.
Different from finite-horizon convergence, besides guaranteeing the time domain of system convergence, finite-time convergence also increases the speed and accuracy of system convergence. However, the existing research is not perfect and is still in its infancy, but some studies with excellent performance have been obtained [36,37,38,39,40,41,42,43,44,45]. Up to now, the finite-time optimization algorithm, considering both convergence speed and convergence precision as well as considering energy consumption, is basically absent. Therefore, based on the previous research, this paper not only considers the state delay, but also considers the input delay, and uses the ADP method to effectively resolve the finite-time optimal tracking control problem of the controlled target.
An adaptive finite-time online optimal tracking control method based on neural networks is designed for uncertain nonlinear systems with state time delays. Firstly, the initial nonlinear system is extended to an augmentation system, which contains tracking error and target expectation information, and a novel discounted performance function is presented. Secondly, a Hamiltonian function is constructed, and the appropriate LKFs are used to resolve the problem of state delay. Then, for the solution of the ideal HJB function, this paper introduces the method of integral reinforcement learning (IRL). Finally, by designing the optimal control strategy and optimizing the control adaptive law, the semi-global practical finite-time stability (SGPFS) lemma, not only is the influence of time delays eliminated, but the stability of uncertain nonlinear systems is guaranteed. The main innovative work includes:
- (1)
- The time-delay effect is incorporated into the strategy design process to address the finite-time convergence issues.
- (2)
- The problem caused by the state time delay is solved simultaneously in the optimal control process.
- (3)
- The optimal control policy guarantees that the target control system achieves optimal control within a finite time.
2. System Description and Preliminaries
Considering the state time-delayed nonlinear system as
where the delayed dynamics is one known function vector with an unknown time delay . For the sake of simplicity in subsequent expressions, except for the hysteresis term , and other variables are omitted. denotes the input function, denotes the state function, denotes the system control input, and denotes the external perturbation function.
Considering the state and the input time delays in system (1), the appropriate LKF is introduced to deal with the state time-delay problem, respectively. And according to Remark 1 in [26], only when the delayed dynamics are known, one can obtain with and .
The following scientific assumptions are made, and corresponding lemmas are given to ensure that the subsequent design process achieves the expected control objectives.
Assumption 1.
Both function and are continuously differentiable. For the time-delay function , its Jacobi matrix satisfies the Lipchitz condition with .
Assumption 2.
The boundedness of the unknown input transfer function can be obtained as . Similarly, ; can be used to present the boundedness of the activation functions in hidden layers of NNs and the functional approximation error .
Lemma 1
([44]). For any states ,
, if the positive constant satisfies , we have
Lemma 2
([39]). For the nonlinear system , if (3) holds,
where is a smooth positive definite function, , , , one can further obtain that the nonlinear system is SGPFS.
In this paper, by designing an adaptive NN-based optimal controller such that , the output of the system could track well in a finite time. The two main types of neural networks used in this paper include critic neural networks and action neural networks. The critic neural network is used for the estimation of the long-term utility function, while the action neural network is used to ensure the stability of the system and the solution of the optimal control inputs of the system.
3. Controller Design and Stability Analysis
This section is divided into subheadings, which provide a concise and precise description of the experimental results and their interpretation, as well as the experimental conclusions that can be drawn. Depicted in Figure 1, in this section, we design an optimal controller, which ensures the optimal control of the system and converges within a finite time. By transforming the initial system into an augmented system, which tracks errors and targets expected information, a novel discounted performance function is presented. Furthermore, a Hamiltonian function is constructed, and the time-delay problem will be solved by using the appropriate LKFs. Then, by introducing the IRL method to the Hamiltonian function, a finite-time optimal tracking controller based on neural networks is designed. Finally, the adaptive law of the appropriate evaluator and the adaptive law of the action NN are designed; the target system’s SGPFS can be ensured.
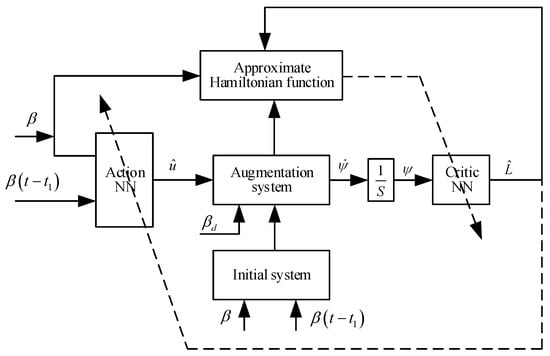
Figure 1.
Finite time convergence adaptive optimal tracking control algorithm structure drawing.
3.1. System Transformation
Considering the nonstrict nonlinear system (1), we developed a controller using a neural network to enable the system to follow the desired trajectory. Firstly, the tracking error system can be design as
Then, find the (4) derivative, and we can obtain
Assumption 3.
The target-given trajectory with the initial state as is bounded, and can be rewritten into the form of (6) by a command generator function that satisfies the Lipschitz continuity property.
The algorithm is expected to adopt a new type of discounted performance function, which includes both tracking error terms and expected trajectories and time-delay terms. Therefore, we constructed the following widening system.
where , , , , .
Furthermore, the novel discounted performance function is
where , is the discount factor, with is a constant, and , where is a matrix that is positive definite, and satisfies , and the semi-global uniform convergence in (7) can be ensured with .
Based on [46,47,48,49,50,51,52], and taking the input constraints into consideration, the nonquadratic functional is proposed as
where is the saturation input, and , is a non-quadratic matrix.
3.2. Virtual Control
In this part, based on the Hamiltonian function, which is established based on the discounted performance function, the virtual optimal controller will be designed.
To obtain the tracking Bellman equation, we used the Leibniz rule and (9) to obtain
Then, we moved the right-hand side of Equation (10) to the left-hand side of the equation and substituted it into Equation (8) to finally obtain Equation (11)
In addition, we designed the optimal cost function in (12) from
the following conditions should be guaranteed
Based on (11) and [53], and the finite-time convergence theory [34], the optimal control input defined as
According to (13) and [44,53], the ideal optimal control input is abbreviated as
where is a constant greater than zero and .
Then, together with (14), (9) can be written as the following form
where and .
The Hamiltonian function can be written as the following form
Furthermore, (17) can be written as
To deal with the challenges brought by online tracking control, the optimal value should be solved using (17). Furthermore, the optimal control policy is shown in (14).
3.3. State Time Delay
Choosing the appropriate LKFs solves the problem caused by the state time delay, which laid the foundation for the application of the IRL algorithm.
According to Assumption 2 in [36] and Remark 5 in [15], the IRL method can be used to solve the , only when the function , and satisfy that
where , , and are positive constants, with and .
Considering the function and the known function satisfy the Lipchitz condition, and Assumption 2, (19) and (21) can be guaranteed. However, the state time delay is uncertain, and the boundedness of (20) cannot be obtained. In addition, because of the uncertain state time delay, the uncertain function cannot be approximated using NN.
In order to better complete the controller design, the problem caused by the state time delay will be handled first. Defining the new function as
and (22) can be written in the following form
where , and both and are positive integers.
By Assumption 1, the mean-value theorem is introduced to . Therefore, one obtains
where , .
The error function caused by can be obtained as
Defining the augmented system states as
then, we can write system (24) as follows
To guarantee that system (27) is uniformly ultimately bounded (UUB), the following lemma is proposed.
Lemma 3.
If the dimension of the state vector matches that of the function , where .
converges to a compact set exponentially, where the Lyapunov function satisfies
where , . In addition, the uniformly ultimately boundedness of system (28) can be guaranteed.
Proof.
Inspired by the research in [26], the following proof process is given. Defining the initial state of (28) as , we obtain
If the system exponentially converges to a compact set, then
where positive constants satisfy , , and .
Furthermore, the Lyapunov function is
Submitting (32) to (33), we obtain
Considering the fact that , we obtain
where , , .
Moreover, we can obtain
where and . If a sufficiently small-time interval is chosen, will be sufficiently large to ensure that is a positive constant.
Based on, (35) and (36), one has
where
Furthermore, we can obtain the Lyapunov function (23), and guarantee the UUB of system (23), which is composed by n subsystems similar to (28)
Substituting (36) for (40), one has
Similarly, one has
when and are selected large enough, the ultimate boundedness of can be assured for any initial condition within a bounded set, guaranteeing the UUB of system states are guaranteed.
The proof is competed. □
3.4. Critic NN and Value Function Approximation
In summary, the boundedness of (19)–(21) can be obtained. The IRL method will be extended to the solution of in the following section.
When the IRL interval is choose as , (8) can be written as the following form
Assuming that (8) is a continuous smooth function, and its gradient are approximated as
where is the constant-target online estimate parameter vector, in which is the quantity of neurons within the neural network, and and are the activation function of the critic NN and approximate error, respectively.
Assumption 4.
The boundedness of the activation function and assessment of the error of the critic NN and their gradient can be obtained as , and , and , respectively.
When the IRL interval is , the Bellman equation induced in the critic NN estimated value, can be expressed as
where
The constraint on (46) can be derived based on Assumption 4, i.e., .
To derive the approximate tracking Bellman function, the approximation of the neural network is evaluated to obtain
where is the estimation of the critic law .
Therefore, the estimation of (46) is
where the reinforcement learning reward is denoted by
To reduce the approximation error, we give a function in (51) from
We can obtain the following expression using the Gradient descent method.
where represents the learning rate of the critic neural network.
Considering , (46) and (49), we have
3.5. Action NN and Controller Design
According to (45), the optimal control input, i.e., (14) is as follows
To solve the issue in the tracking HJB induced , we obtain
In addition, we obtain
Equation (16) becomes
Then, (46) can be rewritten as
where
To obtain the limitation of the HJB proximity error, we can use the boundary proximity error. In addition, when NN is selected, the construction cannot be changed. We can only solve this problem by uncertain weights of NN.
Approximating the control input (55) by critic NN, we have
where is the estimated value of .
However, the function of (61) is only to estimate the current critical NN weight, which fails to keep the system (1) stable. Hence, to guarantee the stability of the system and solve the optimal control strategy, we introduce another NN as the action NN.
where represents the weight vector of the action neural network, denoting the present evaluation value of .
Then, the interval IRL Bellman equation error is estimated as
where
Therefore, (52) can be rewritten as
defining the input assessment error as
To minimize (66), we use the following formula
We can utilize the gradient descent method to derive the following equation
where , and is a positive design variable.
3.6. Stability Analysis
According to the proposed lemmas and assumptions, the following theorem is given to analyze the effectiveness of the proposed algorithm.
Theorem 1.
Based on the definition in [43], Lemma 1–4, Assumptions 1–4, and the design of the proposed control policy (62) and the control laws, (65) and (68), the proposed optimal tracking control algorithm ensures that the partially uncertain nonlinear system (1) is SGPFS.
Proof of Theorem 1.
The candidate function of the Lyapunov function is designed as
where and is given in (8) as the optimal value function. Then, the provided expressions are applicable:
Based on (24) and (31), the first derivative of can be given as
Using Young’s inequality , one has
where .
Based on (44), the first derivative of is
Considering (57), with the IRL interval chosen small enough, we have , , , and is a sufficiently small positive constant.
Then, (76) can be written as
Based on (54) we have
Then, the approximate of (54) is
And, for the first difference of (71)
Using Cauchy’s mean value theorem, (81) changed into
Based on (68) and (66), we have
Then, the first derivative of is
where
By using Cauchy’s mean value theorem, we have
Above all, the first difference of (69)
where , , , , , and .
To make the finite-time convergence, we deal with the equation and add and subtract several terms on the right side
To make the system (1) stable, and the finite time, we consider Lemma 1. Therefore, the constant must be greater than zero.
and there are the following formulas:
with
then
Taking Lemma 1 to , and , as , and , or , or , or with , and . Then, we have
Considering (94)–(97), (88) can be rewritten as
Inspired by reference [45], we have , if , , , , .
where
Based on (89)–(93), (99)–(101), and the lemma in [39], the boundedness of all singles in the closed loop nonstrict system is SGPFS for .
Furthermore, by using (62), we obtain the optimal control strategy, which guarantees that the target nonlinear system system’s state and the stability of input delays are maintained, and that the tracking error converges to a sufficiently small neighborhood around zero.
The proof is completed. □
4. Results of Simulation Example
The WMR system [54] in Figure 2 illustrates the effectiveness of the proposed algorithm.
where represent the robot mass, and denotes the rotational inertia around the motion center. is the angle between the robot speed and the axis, and is the angle of inclination of the ground environment where the robot is located.
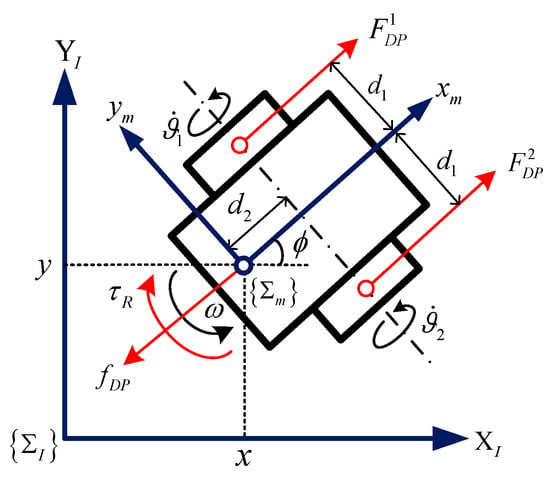
Figure 2.
The structure of the wheeled mobile robot.
Then, rewrite (102) as a vector form
where, according to [55], we have , , , , , , , .
Considering the symmetry of the quality matrix and incorporating the time delay in the state, the state-space form can be used to represent the dynamic system of WMR.
where , is an unknown function, and denotes the resistance torque with the same effect and unknown resistance.
The desired trajectories indicate the forward and steering angular velocity, are given as and .
Depending on the actual WMR system, the initial values are , and , and , , , and , in this simulation. Then, the following simulation results are presented.
With the state time delay handled by appropriate LKFs, the impact of delay is successfully suppressed. From Figure 3 and Figure 4, we can obtain that the tracking performance of the proposed algorithm has good tracking performance.
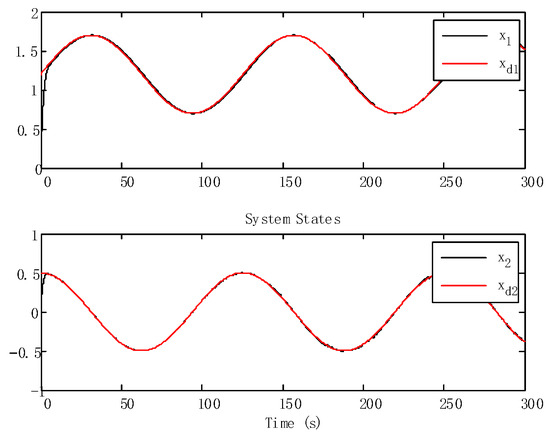
Figure 3.
Tracking trajectories of the states.
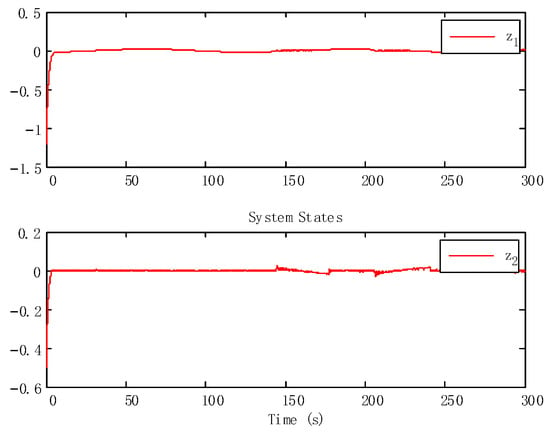
Figure 4.
Tracking errors.
In addition, the adaptive update of the critic and the action can be reflected in Figure 5 and Figure 6, which ensures the boundedness of the adaptive law. Moreover, the tracking trajectory of the WMR is shown in Figure 7. According to the process, the signal in the wheeled mobile robotic system is SGPFS. Compared with previous work [56], with similar control effects, this paper additionally considers finite-time control and the final simulation results achieve finite-time convergence, reflecting the control advantages of the proposed algorithm.
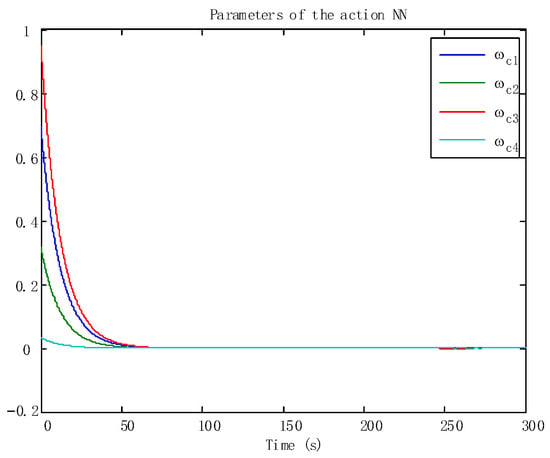
Figure 5.
The adaptive laws of the action NNs.
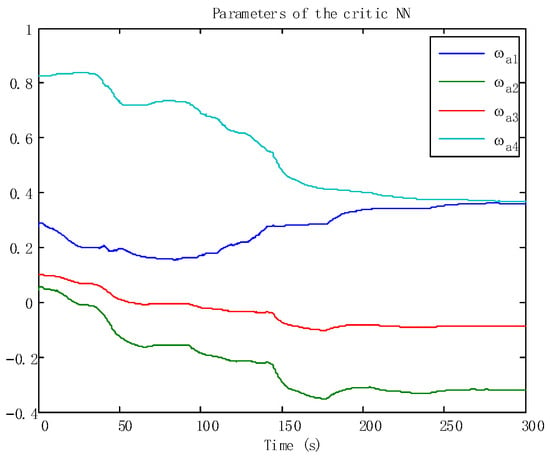
Figure 6.
The adaptive laws of the critic NNs.
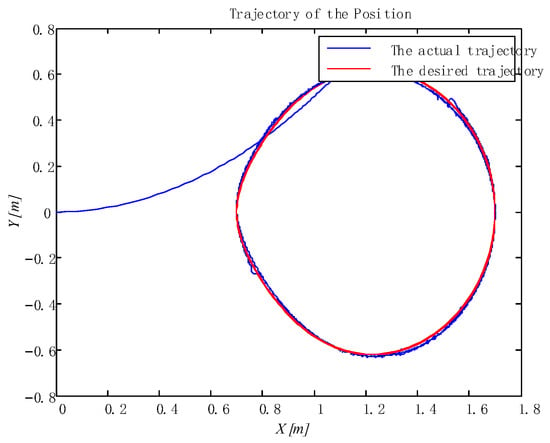
Figure 7.
Tracking trajectories of the position.
5. Conclusions
A finite-time adaptive online optimization tracking control algorithm was suggested for nonlinear systems incorporating state time delays. By using appropriate LKFs, the issue arising from time delays in both state and input variables has been resolved. Then, a novel nonquadratic HJB function was defined, where finite time was selected as the upper limit of integration, which contains information of the state time delay on the premise of containing the basic information. With the premise of meeting specific requirements, the ideal HJB function was solved by using the IRL method. Furthermore, the SGPFS was guaranteed with the definition of the optimal control policy and the update of the adaptations of the critic and action NNs.
Author Contributions
Conceptualization, S.L.; methodology, S.L.; software, S.L.; validation, S.L.; formal analysis, S.L.; investigation, S.L.; resources, S.L.; data curation, S.L.; writing—original draft preparation, S.L.; writing—review and editing, S.L., T.R., L.D. and L.L.; visualization, S.L.; supervision, S.L., L.D. and L.L.; project administration, S.L.; funding acquisition, S.L. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported in part by the National Natural Science Foundation of China under Grant 62203198 and Grant 62173173, in part by the Doctoral Startup Fund of Liaoning University of Technology under Grant XB2021010, in part by the Liaoning Revitalization Talents Program under Grant XLYC1907050/XLYC2203094 and in part by the key project of “Unveiling the List and Leading the Command” in Liaoning Province under Grant JBGS2022005.
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Liu, Y.J.; Li, J.; Tong, S.C.; Chen, C.L.P. Neural network control-based adaptive learning design for nonlinear systems with full state constraints. IEEE Trans. Neural Netw. Learn. Syst. 2016, 27, 1562–1571. [Google Scholar] [PubMed]
- Wu, C.W.; Liu, J.X.; Xiong, Y.Y.; Wu, L.G. Observer-based adaptive fault-tolerant tracking control of nonlinear nonstrict-feedback systems. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 3022–3033. [Google Scholar] [PubMed]
- Gao, T.T.; Liu, Y.J.; Liu, L.; Li, D.P. Adaptive neural network-based control for a class of nonlinear pure-feedback systems with time-varying full state constraints. IEEE/CAA J. Autom. Sin. 2018, 5, 923–933. [Google Scholar]
- Li, D.P.; Chen, C.L.P.; Liu, Y.J.; Tong, S.C. Neural network controller design for a class of nonlinear delayed systems with time-varying full-state constraints. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 2625–2636. [Google Scholar] [PubMed]
- Liu, L.; Wang, Z.S.; Yao, X.S.; Zhang, H.G. Echo state networks based data-driven adaptive fault tolerant control with its application to electromechanical system. IEEE/ASME Trans. Mechatron. 2018, 23, 1372–1382. [Google Scholar]
- Ge, S.S.; Hang, C.C.; Zhang, T. Adaptive neural network control of nonlinear systems by state and output feedback. IEEE Trans. Syst. Man Cybern. Part B Cybern. 1999, 29, 818–828. [Google Scholar]
- Wen, G.X.; Ge, S.S.; Chen, C.L.P.; Tu, F.W.; Wang, S.N. Adaptive tracking control of surface vessel using optimized backstepping technique. IEEE Trans. Cybern. 2019, 49, 3420–3431. [Google Scholar] [PubMed]
- Jagannathan, S.; He, P. Neural-network-based state feedback control of a nonlinear discrete-time system in nonstrict feedback form. IEEE Trans. Neural Netw. 2008, 19, 2073–2087. [Google Scholar] [PubMed]
- Liu, L.; Liu, Y.J.; Tong, S.C. Fuzzy based multi-error constraint control for switched nonlinear systems and its applications. IEEE Trans. Fuzzy Syst. 2019, 27, 1519–1531. [Google Scholar]
- Bertsekas, D.P.; Tsitsiklis, J.N. Neuro-dynamic programming: An overview. In Proceedings of the 1995 34th IEEE Conference on Decision and Control, New Orleans, LA, USA, 13–15 December 1995; Volume 1, pp. 560–564. [Google Scholar]
- Lewis, F.L.; Liu, D. Reinforcement Learning and Approximate Dynamic Programming for Feedback Control; John Wiley & Sons: New York, NY, USA, 2013. [Google Scholar]
- Zhang, H.G.; Liu, D.R.; Luo, Y.H.; Wang, D. Adaptive Dynamic Programming for Control: Algorithms and Stability; Springer: London, UK, 2013. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Wen, G.X.; Chen, C.L.P.; Ge, S.S.; Yang, H.L.; Liu, X.G. Optimized adaptive nonlinear tracking control using actor-critic reinforcement learning strategy. IEEE Trans. Ind. Inform. 2019, 15, 4969–4977. [Google Scholar]
- Modares, H.; Lewis, F.L. Optimal tracking control of nonlinear partially-unknown constrained-input systems using integral reinforcement learning. Automatica 2014, 50, 1780–1792. [Google Scholar]
- Vamvoudakis, K.G. Event-triggered optimal adaptive control algorithm for continuous-time nonlinear systems. IEEE/CAA J. Autom. Sin. 2014, 1, 282–293. [Google Scholar]
- Wang, D.; Liu, D.R.; Wei, Q.L.; Zhao, D.; Jin, N. Optimal control of unknown nonaffine nonlinear discrete-time systems based on adaptive dynamic programming. Automatica 2012, 48, 1825–1832. [Google Scholar]
- Liu, D.R.; Wei, Q.L. Policy iteration adaptive dynamic programming algorithm for discrete-time nonlinear systems. IEEE Trans. Neural Netw. Learn. Syst. 2014, 25, 621–634. [Google Scholar] [PubMed]
- Wei, Q.L.; Liu, D.R. A novel iterative adaptive dynamic programming for discrete-time nonlinear systems. IEEE Trans. Autom. Sci. Eng. 2014, 11, 1176–1190. [Google Scholar]
- Cao, Y.; Ni, K.; Kawaguchi, T.; Hashimoto, S. Path following for autonomous mobile robots with deep reinforcement learning. Sensors 2024, 24, 561. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Ding, L.; Gao, H.B.; Liu, Y.J.; Li, N.; Deng, Z.Q. Reinforcement learning neural network-based adaptive control for state and input time-delayed wheeled mobile robots. IEEE Trans. Syst. Man Cybern. Syst. 2018, 50, 4171–4182. [Google Scholar]
- Luy, N.T.; Thanh, N.T.; Tri, H.M. Reinforcement learning-based intelligent tracking control for wheeled mobile robot. Trans. Inst. Meas. Control 2014, 36, 868–877. [Google Scholar]
- Li, S.; Ding, L.; Gao, H.B.; Liu, Y.J.; Huang, L.; Deng, Z.Q. ADP-based online tracking control of partially uncertain time-delayed nonlinear system and application to wheeled mobile robots. IEEE Trans. Cybern. 2020, 50, 3182–3194. [Google Scholar] [PubMed]
- Shih, P.; Kaul, B.C.; Jagannathan, S.; Drallmeier, J.A. Reinforcement-learning-based output-feedback control of nonstrict nonlinear discrete-time systems with application to engine emission control. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2009, 39, 1162–1179. [Google Scholar]
- Wei, Q.L.; Zhang, H.G.; Liu, D.R.; Zhao, Y. An optimal control scheme for a class of discrete-time nonlinear systems with time delays using adaptive dynamic programming. Acta Autom. Sin. 2010, 36, 121–129. [Google Scholar]
- Na, J.; Herrmann, G.; Ren, X.; Barber, P. Adaptive discrete neural observer design for nonlinear systems with unknown time-delay. Int. J. Robust Nonlinear Control 2011, 21, 625–647. [Google Scholar]
- Li, D.P.; Liu, Y.J.; Tong, S.C.; Chen, C.L.P.; Li, D.J. Neural networks- based adaptive control for nonlinear state constrained systems with input delay. IEEE Trans. Cybern. 2019, 49, 1249–1258. [Google Scholar] [PubMed]
- Chen, C.L.P.; Wen, G.X.; Liu, Y.J.; Wang, F.Y. Adaptive consensus control for a class of nonlinear multiagent time-delay systems using neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2014, 25, 1217–1226. [Google Scholar]
- Li, H.; Wang, L.J.; Du, H.P.; Boulkroune, A. Adaptive fuzzy backstepping tracking control for strict-feedback systems with input delay. IEEE Trans. Fuzzy Syst. 2017, 25, 642–652. [Google Scholar]
- Wang, D.; Zhou, D.H.; Jin, Y.H.; Qin, S.J. Adaptive generic model control for a class of nonlinear time-varying processes with input time delay. J. Process Control 2004, 14, 517–531. [Google Scholar]
- Li, D.P.; Li, D.J. Adaptive neural tracking control for an uncertain state constrained robotic manipulator with unknown time-varying delays. IEEE Trans. Syst. Man Cybern. Syst. 2018, 48, 2219–2228. [Google Scholar]
- Iglehart, D.L. Optimality of (s, S) policies in the infinite horizon dynamic inventory problem. Manag. Sci. 1963, 9, 259–267. [Google Scholar]
- Sondik, E.J. The optimal control of partially observable Markov processes over the infinite horizon: Discounted costs. Oper. Res. 1978, 26, 282–304. [Google Scholar]
- Keerthi, S.S.; Gilbert, E.G. Optimal infinite-horizon feedback laws for a general class of constrained discrete-time systems: Stability and moving-horizon approximations. J. Optim. Theory Appl. 1988, 57, 265–293. [Google Scholar]
- Chen, H.; Allgöwer, F. A quasi-infinite horizon nonlinear model predictive control scheme with guaranteed stability. Automatica 1998, 34, 1205–1217. [Google Scholar]
- Vamvoudakis, K.G.; Lewis, F.L. Online actor–critic algorithm to solve the continuous-time infinite horizon optimal control problem. Automatica 2010, 46, 878–888. [Google Scholar]
- Wei, Q.L.; Liu, D.R.; Yang, X. Infinite horizon self-learning optimal control of nonaffine discrete-time nonlinear systems. IEEE Trans. Neural Netw. Learn. Syst. 2015, 26, 866–879. [Google Scholar] [PubMed]
- Wang, D.; Liu, D.R.; Wei, Q.L. Finite-horizon neuro-optimal tracking control for a class of discrete-time nonlinear systems using adaptive dynamic programming approach. Neurocomputing 2012, 78, 14–22. [Google Scholar]
- Wang, F.Y.; Jin, N.; Liu, D.; Wei, Q.L. Adaptive dynamic programming for finite-horizon optimal control of discrete-time nonlinear systems with ε-error bound. IEEE Trans. Neural Netw. 2011, 22, 24–36. [Google Scholar]
- Liu, X.; Gao, Z. Robust finite-time fault estimation for stochastic nonlinear systems with Brownian motions. J. Frankl. Inst. 2017, 354, 2500–2523. [Google Scholar]
- Liu, L.; Liu, Y.J.; Tong, S.C. Neural networks-based adaptive finite-time fault-tolerant control for a class of strict-feedback switched nonlinear systems. IEEE Trans. Cybern. 2019, 49, 2536–2545. [Google Scholar] [PubMed]
- Wang, F.; Zhang, X.; Chen, B.; Lin, C.; Li, X.; Zhang, J. Adaptive finite-time tracking control of switched nonlinear systems. Inf. Sci. 2017, 421, 126–135. [Google Scholar]
- Wang, F.; Chen, B.; Liu, X.; Lin, C. Finite-time adaptive fuzzy tracking control design for nonlinear systems. IEEE Trans. Fuzzy Syst. 2018, 26, 1207–1216. [Google Scholar]
- Wang, F.; Chen, B.; Lin, C.; Zhang, J.; Meng, X. Adaptive neural network finite-time output feedback control of quantized nonlinear systems. IEEE Trans. Cybern. 2018, 48, 1839–1848. [Google Scholar] [PubMed]
- Ren, H.; Ma, H.; Li, H.; Wang, Z. Adaptive fixed-time control of nonlinear mass with actuator faults. IEEE/CAA J. Autom. Sin. 2023, 10, 1252–1262. [Google Scholar]
- Wang, N.; Tong, S.C.; Li, Y.M. Observer -based adaptive fuzzy control of nonlinear non-strict feedback system with input delay. Int. J. Fuzzy Syst. 2018, 20, 236–245. [Google Scholar]
- Zhu, Z.; Xia, Y.Q.; Fu, M.Y. Attitude stabilization of rigid spacecraft with finite-time convergence. Int. J. Robust Nonlinear Control 2011, 21, 686–702. [Google Scholar]
- Hardy, G.H.; Littlewood, J.E.; Polya, G. Inequalities; Cambridge University Press: Cambridge, UK, 1952. [Google Scholar]
- Chen, B.; Liu, X.P.; Liu, K.F.; Lin, C. Fuzzy approximation-based adaptive control of nonlinear delayed systems with unknown dead-zone. IEEE Trans. Fuzzy Syst. 2014, 22, 237–248. [Google Scholar]
- Qian, C.; Lin, W. Non-Lipschitz continuous stabilizers for nonlinear systems with uncontrollable unstable linearization. Syst. Control Lett. 2001, 42, 185–200. [Google Scholar]
- Adhyaru, D.M.; Kar, I.N.; Gopal, M. Bounded robust control of nonlinear systems using neural network–based HJB solution. Neural Comput. Appl. 2011, 20, 91–103. [Google Scholar]
- Lyshevski, S.E. Optimal control of nonlinear continuous-time systems: Design of bounded controllers via generalized nonquadratic functionals. In Proceedings of the 1998 American Control Conference. ACC (IEEE Cat. No. 98CH36207), Philadelphia, PA, USA, 26 June 1998; Volume 1, pp. 205–209. [Google Scholar]
- Abu-Khalaf, M.; Lewis, F.L. Nearly optimal control laws for nonlinear systems with saturating actuators using a neural network HJB approach. Automatica 2005, 41, 779–791. [Google Scholar]
- Li, S.; Wang, Q.; Ding, L.; An, X.; Gao, H.; Hou, Y.; Deng, Z. Adaptive NN-based finite-time tracking control for wheeled mobile robots with time-varying full state constraints. Neurocomputing 2020, 403, 421–430. [Google Scholar]
- Ding, L.; Huang, L.; Li, S.; Gao, H.; Deng, H.; Li, Y.; Liu, G. Definition and application of variable resistance coefficient for wheeled mobile robots on deformable terrain. IEEE Trans. Robot. 2020, 36, 894–909. [Google Scholar]
- Li, S.; Li, D.P.; Liu, Y.J. Adaptive neural network tracking design for a class of uncertain nonlinear discrete-time systems with unknown time-delay. Neurocomputing 2015, 168, 152–159. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).