Research on the Method of Foreign Object Detection for Railway Tracks Based on Deep Learning

Abstract
1. Introduction
- The railway lane detection method has been improved to extract the entire track area of interest for this paper, establishing a track boundary model that provides important support for the division of dangerous areas on the track.
- The YOLOv5s model has been improved for the detection of small objects at long distances, improving cases of missed detections and false alarms and enhancing the detection accuracy and positioning accuracy of the model.
- Extensive experimental evaluations have been conducted on the proposed method, using multiple performance metrics for comprehensive assessment and comparison. Meanwhile, self-built railway foreign object incursion data has been used for recognition and incursion behavior judgment to verify the practicality of the proposed method in real-world scenarios.
2. Foreign Object Incursion Detection Method
2.1. Establishment of Track Clearance Model
2.1.1. Method of Track Extraction
2.1.2. Feature Extraction
2.1.3. Track Line Fitting
2.1.4. Track Boundary Model
2.2. Foreign Object Detection
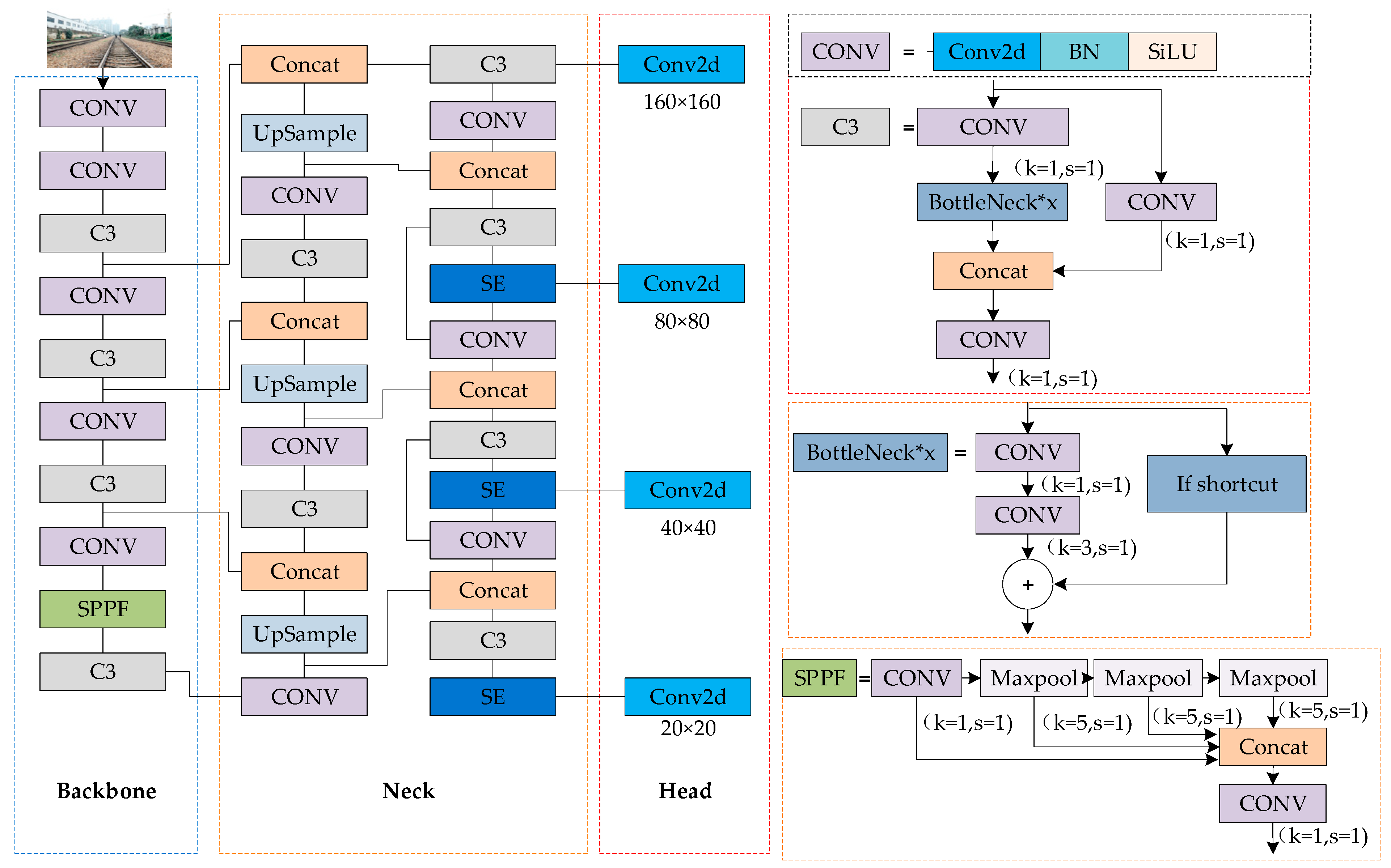
2.2.1. The Improved YOLOv5s Model
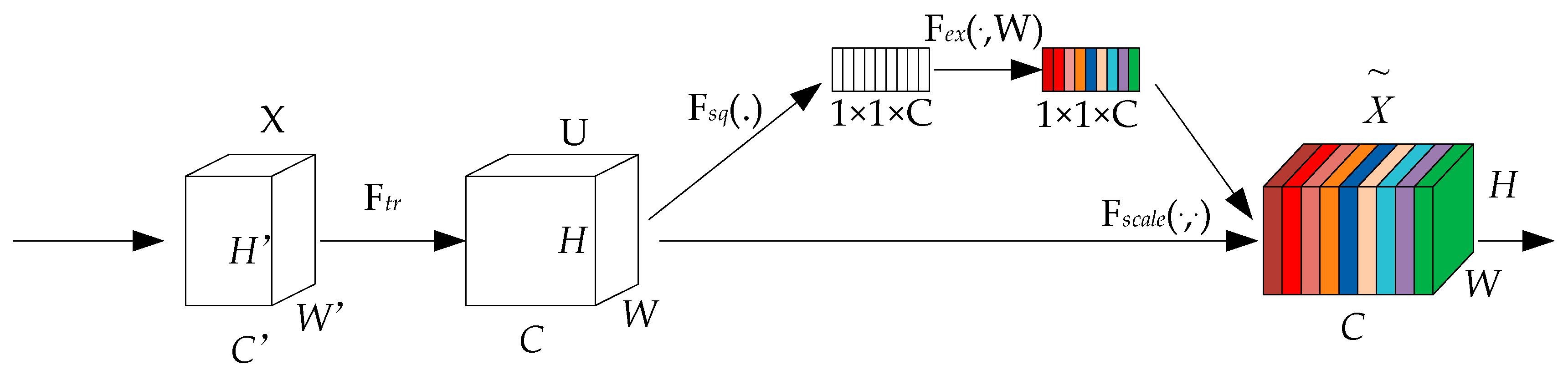
2.2.2. SE Module Attention Mechanism
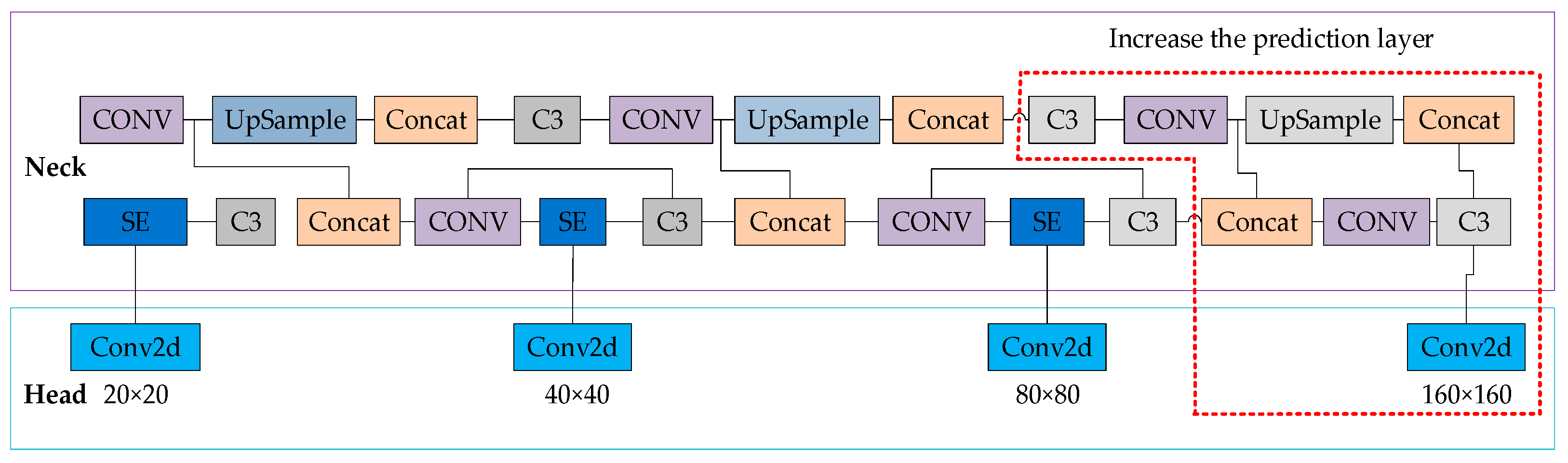
2.2.3. Add a Prediction Layer
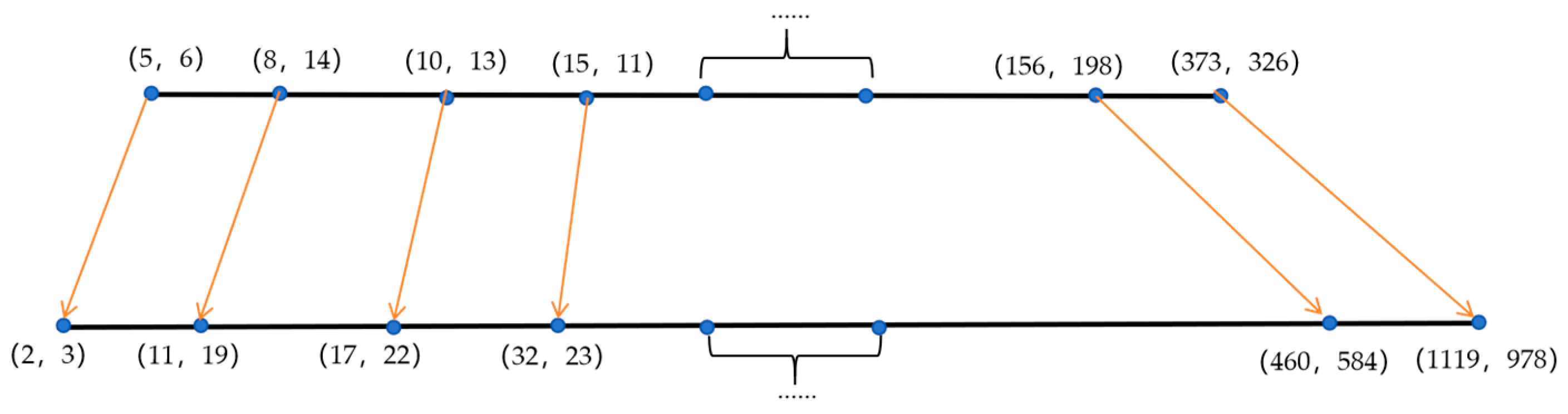
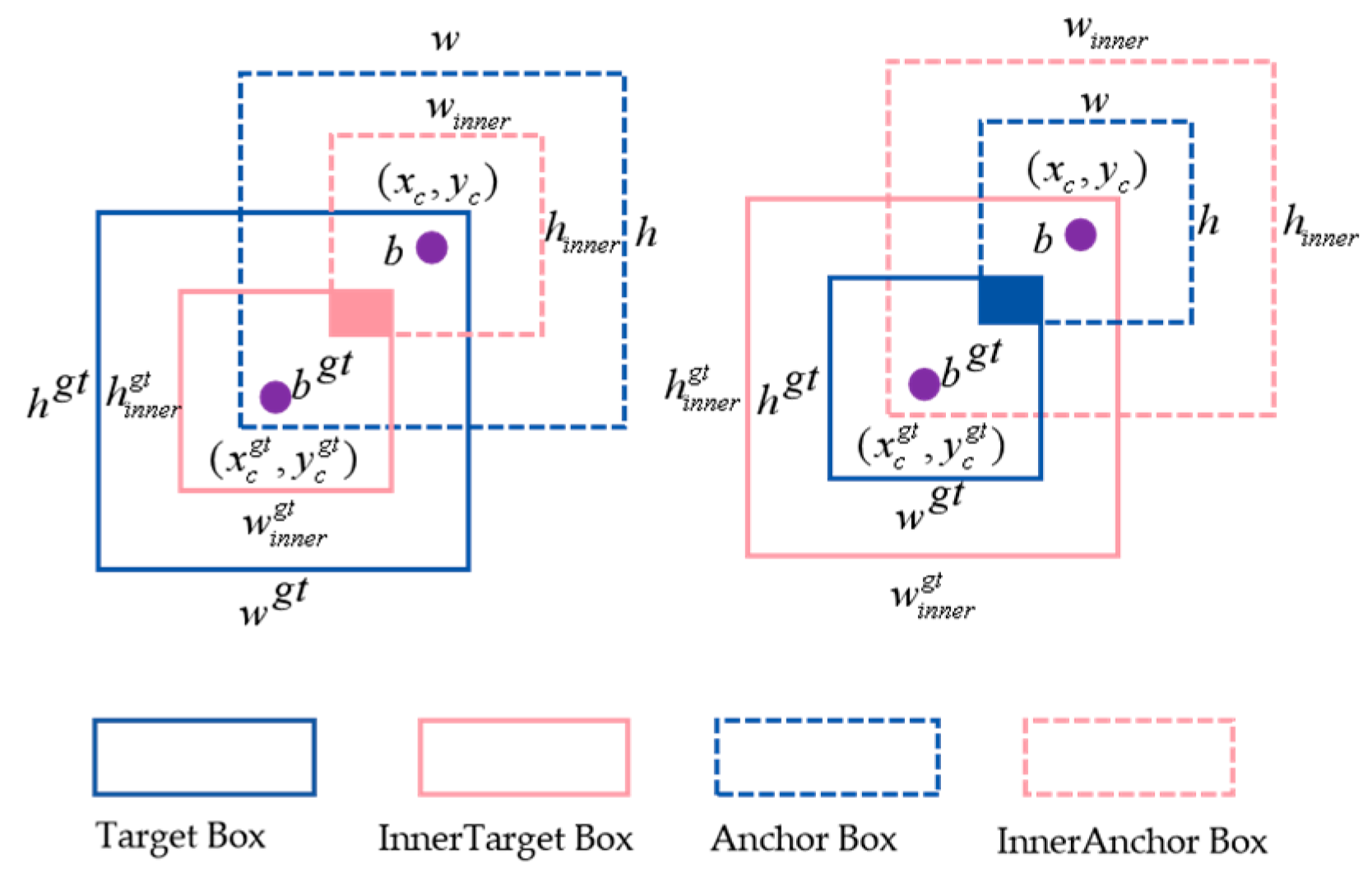
2.2.4. Improve the Anchor Box
2.2.5. Improvement of the Loss Function
3. Experiments and Results
3.1. Dataset and Experimental Environment
3.1.1. Foreign Object Invasion Dataset
3.1.2. Railway Track Division
3.1.3. Training Configurations and Evaluation Metrics
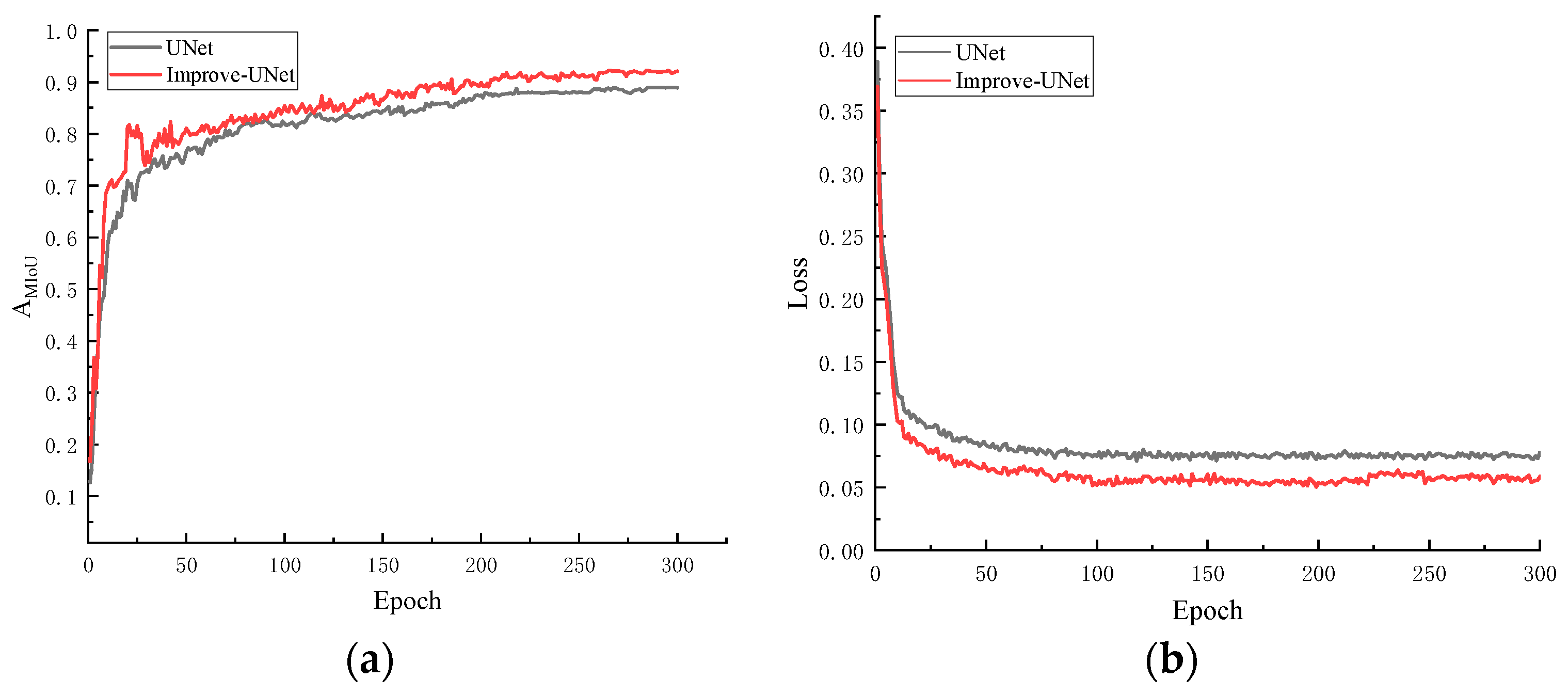
3.2. Segmentation Results of Railway Tracks
3.3. Analysis of the Results for Model Performance
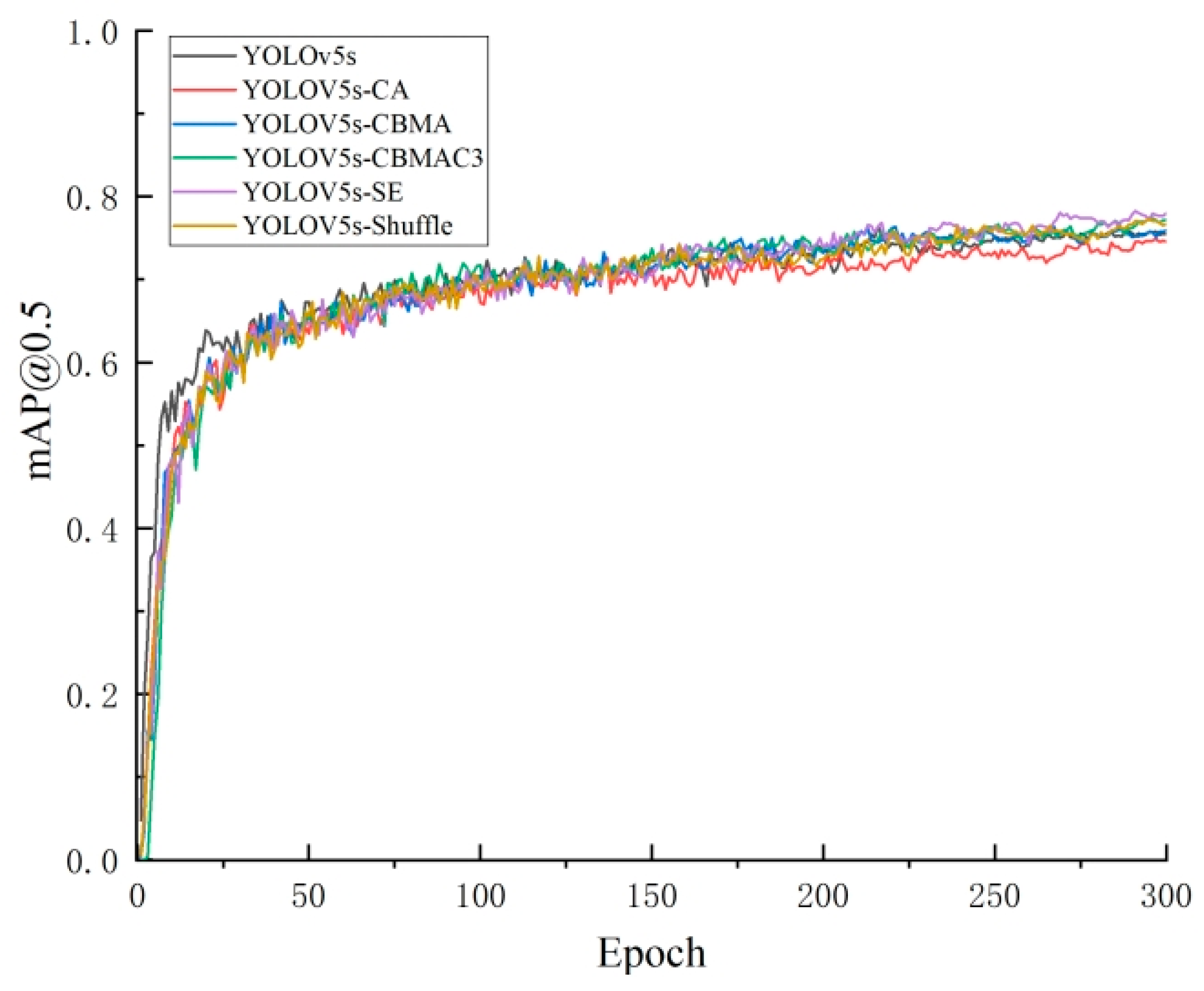
3.3.1. Comparative Analysis of Attention Mechanisms
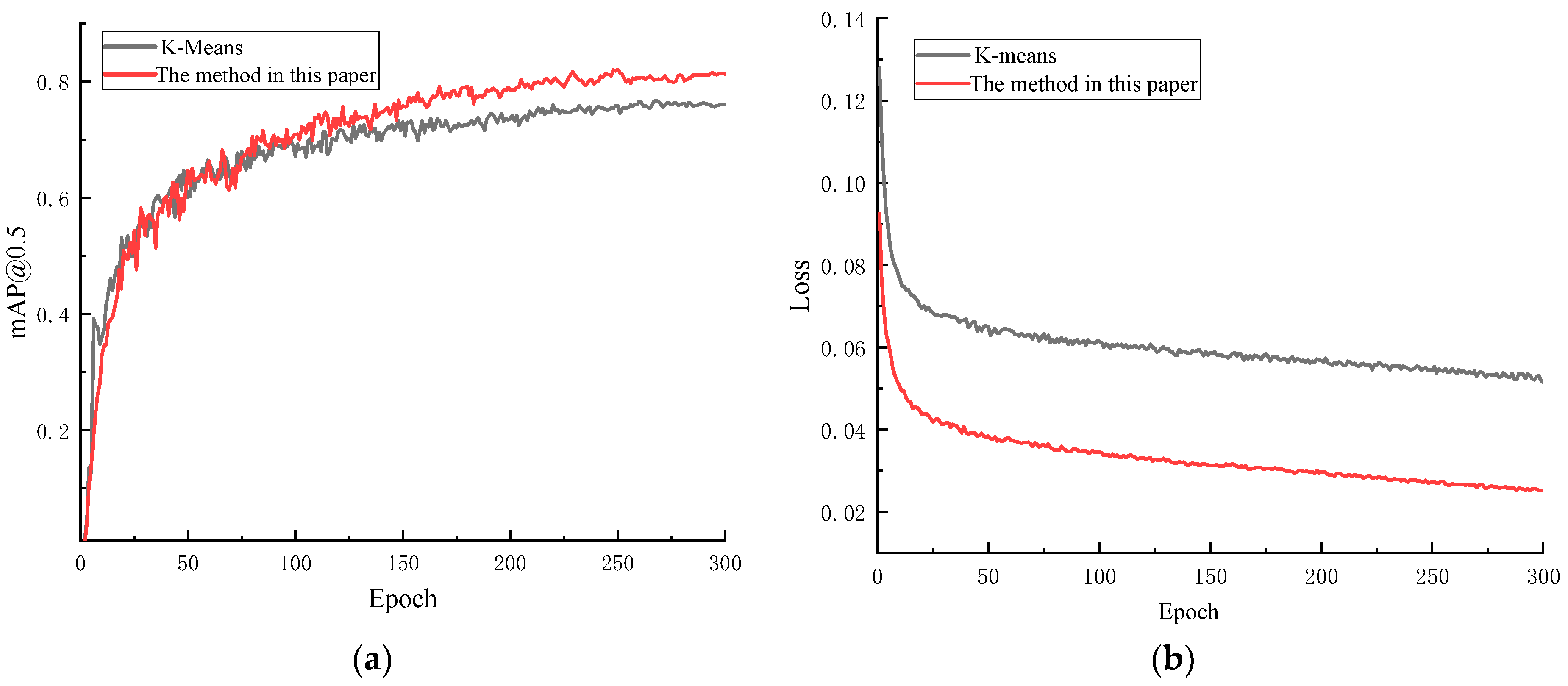
3.3.2. Comparative Analysis of Anchor Boxes
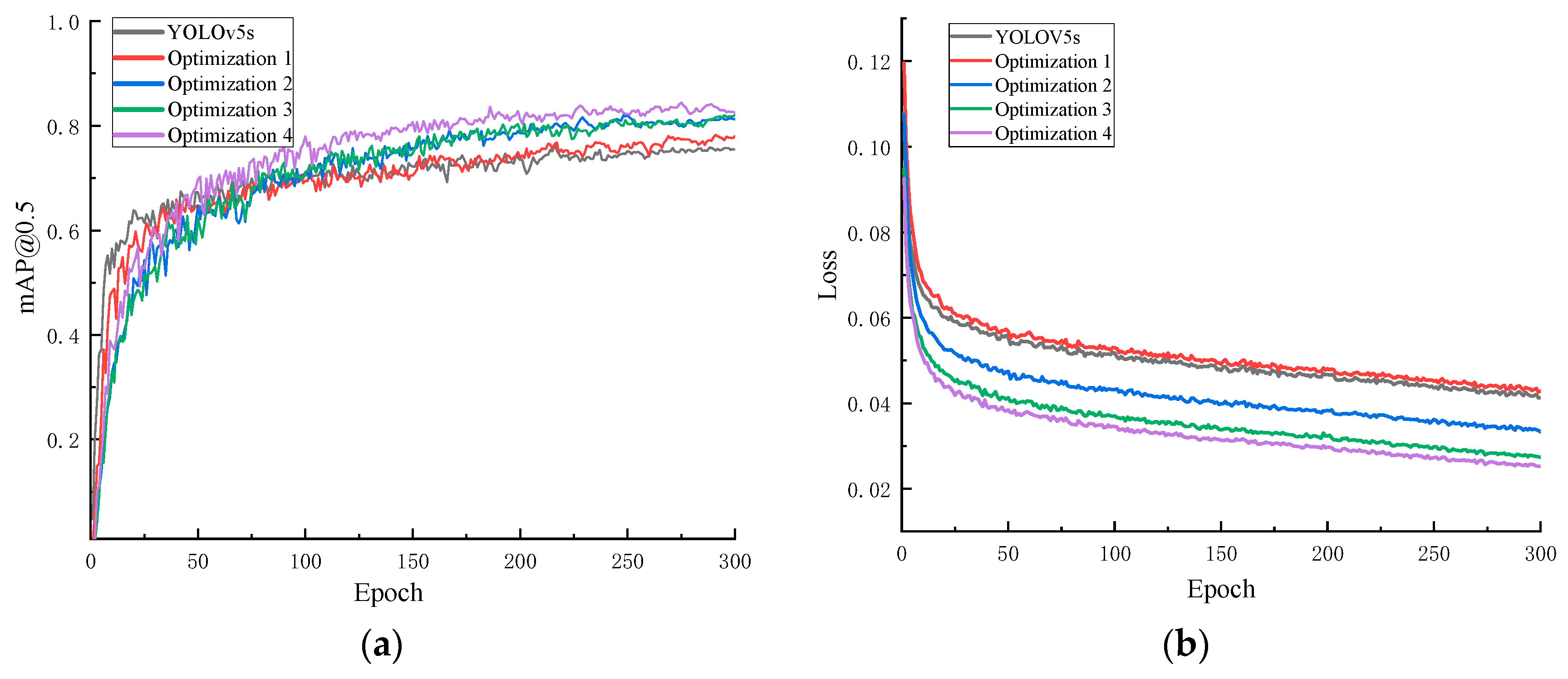
3.3.3. Comparative Analysis of Model Recognition Accuracy
3.3.4. Analysis of Bounding Box Localization Accuracy
3.4. Judgment of Foreign Object Encroachment Behavior
4. Conclusions
- By utilizing an improved UNet semantic segmentation network and the least squares method, a linear equation for the railway track is determined, and a track boundary model is established. Through a self-constructed segmentation dataset, the improved UNet segmentation model achieved a value of 91.8%, representing a 3.9% improvement compared to the previous version. The extracted track edges are clearer and more complete.
- The improved YOLOv5s foreign object detection model incorporates the SE attention mechanism, adds a prediction layer, and modifies the anchor boxes and loss function. It achieves feature weighting processing with relatively low computational cost, and the detection accuracy of the model is improved by 7.4%. The proposed detection model outperforms Faster R-CNN, SSD, YOLOv3, and YOLOv8s in terms of average precision for small object detection, enabling long-distance foreign object detection.
- The proposed combination of the railway boundary model and the object detection model provides an effective solution for the identification and localization of foreign object encroachment on railway tracks. Through experimental validation, this method can accurately determine foreign object encroachment behaviors. Moreover, the model only requires evaluation of specific feature points of the detection box, resulting in relatively low computational complexity and demonstrating practical usefulness. It can provide strong technical support for railway transportation safety.
- Further work could involve collecting a more comprehensive and detailed dataset of different foreign object types, such as animals, as well as acquiring data from special environments with low illumination and low resolution to improve recognition accuracy. Additionally, exploring the integration of lidar or infrared images with video images to enhance foreign object recognition accuracy in special environments is a promising direction.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Singh, P.; Dulebenets, M.; Pasha, J.; Ernesto, D.; Gonzalez, S.; Lau, Y.; Kampmann, R. Deployment of Autonomous Trains in Rail Transportation: Current Trends and Existing Challenges. IEEE Access 2021, 9, 91427–91461. [Google Scholar] [CrossRef]
- Wang, T.; Zhang, Z.; Tsui, K.-L. A Deep Generative Approach for Rail Foreign Object Detections via Semisupervised Learning. IEEE Trans. Ind. Inf. 2023, 19, 459–468. [Google Scholar]
- Simonović, M.; Banić, M.; Stamenković, D.; Franke, M.; Michels, K.; Schoolmann, I.; Ristić-Durrant, D.; Ulianov, C.; Dan-Stan, S.; Plesa, A.; et al. Toward the Enhancement of Rail Sustainability: Demonstration of a Holistic Approach to Obstacle Detection in Operational Railway Environments. Sustainability 2024, 16, 2613. [Google Scholar] [CrossRef]
- Meng, H.; Wang, S.; Gao, C.; Liu, F. Research on Recognition Method of Railway Perimeter Intrusions Based on Φ-OTDR Optical Fiber Sensing Technology. IEEE Sens. J. 2021, 21, 9852–9859. [Google Scholar] [CrossRef]
- Catalano, A.; Bruno, F.A.; Galliano, C.; Pisco, M.; Persiano, G.V.; Cutolo, A.; Cusano, A. An optical fiber intrusion detection system for railway security. Sens. Actuators A Phys. 2017, 253, 91–100. [Google Scholar] [CrossRef]
- Fredin-Knutzén, J.; Gergö, H.; Andersson, A.L.; Sokolowski, M. A pilot study evaluating the effectiveness of preventing railway suicides by mid-track fencing, which restrict easy access to high-speed train tracks. J. Saf. Res. 2022, 83, 232–237. [Google Scholar] [CrossRef] [PubMed]
- Gregor, S.; Beavan, G.; Culbert, A.; Kan John, P.; Ngo, N.V.; Keating, B.; Radwan, I. Patterns of pre-crash behaviour in railway suicides and the effect of corridor fencing: A natural experiment in New South Wales. Int. J. Inj. Control Saf. Promot. 2019, 26, 423–430. [Google Scholar] [CrossRef] [PubMed]
- Cui, J.; Qin, Y.; Wu, Y.; Shao, C.; Yang, H. Skip Connection YOLO Architecture for Noise Barrier Defect De tection Using UAV-Based Images in High-Speed Railway. IEEE Trans. Intell. Transp. Syst. 2023, 24, 12180–12195. [Google Scholar] [CrossRef]
- Guan, L.; Jia, L.; Xie, Z.; Yin, C. A Lightweight Framework for Obstacle Detection in the Railway Image Based on Fast Region Proposal and Improved YOLO-Tiny Network. IEEE Trans. Instrum. Meas. 2022, 71, 1–16. [Google Scholar] [CrossRef]
- Wu, Y.; Meng, F.; Qin, Y.; Qian, Y.; Xu, F.; Jia, L. UAV imagery based potential safety hazard evaluation for high-speed railroad using Real-time instance segmentation. Adv. Eng. Inf. 2023, 55, 101819. [Google Scholar] [CrossRef]
- Li, M.; Peng, B.; Liu, J.; Zhai, D. RBNet: An Ultrafast Rendering-Based Architecture for Railway Defect Segmentation. IEEE Trans. Instrum. Meas. 2023, 72, 1–8. [Google Scholar] [CrossRef]
- Ye, T.; Zheng, Z.; Li, X.; Zhao, Z.; Gao, X. An Efficient Few-Shot Object Detection Method for Railway Intrusion via Fine-Tune Approach and Contrastive Learning. IEEE Trans. Instrum. Meas. 2023, 72, 1–13. [Google Scholar] [CrossRef]
- Wei, X.; Wei, D.; Suo, D.; Jia, L.; Li, Y. Multi-Target Defect Identification for Railway Track Line Based on Image Processing and Improved YOLOv3 Model. IEEE Access 2020, 8, 61973–61988. [Google Scholar] [CrossRef]
- Ye, T.; Zhang, J.; Zhao, Z.; Zhou, F. Foreign Body Detection in Rail Transit Based on a Multi-Mode Feature-Enhanced Convolutional Neural Network. IEEE Trans. Intell. Transp. Syst. 2022, 23, 18051–18063. [Google Scholar] [CrossRef]
- Ristić-Durrant, D.; Franke, M.; Michels, K. A Review of Vision-Based On-Board Obstacle Detection and Distance Estimation in Railways. Sensors 2021, 21, 3452. [Google Scholar] [CrossRef] [PubMed]
- Gong, X.; Chen, X.; Zhong, Z.; Chen, W. Enhanced Few-Shot Learning for Intrusion Detection in Railway Video Surveillance. IEEE Trans. Intell. Transp. Syst. 2022, 23, 11301–11313. [Google Scholar] [CrossRef]
- Qin, Y.; He, D.; Jin, Z.; Chen, Y.; Shan, S. An Improved Deep Learning Algorithm for Obstacle Detection in Complex Rail Transit Environments. IEEE Sens. J. 2024, 24, 4011–4022. [Google Scholar] [CrossRef]
- Ye, T.; Zhao, Z.; Wang, S.; Zhou, F.; Gao, X. A Stable Lightweight and Adaptive Feature Enhanced Convolution Neural Network for Efficient Railway Transit Object Detection. IEEE Trans. Intell. Transp. Syst. 2022, 23, 17952–17965. [Google Scholar] [CrossRef]
- Nan, Z.; Zhu, G.; Zhang, X.; Lin, X.; Yang, Y. Development of a High-Precision Lidar System and Improvement of Key Steps for Railway Obstacle Detection Algorithm. Remote Sens. 2024, 16, 1761. [Google Scholar] [CrossRef]
- Wang, S.; Wang, Y.; Chang, Y.; Zhao, R.; She, Y. EBSE-YOLO: High Precision Recognition Algorithm for Small Target Foreign Object Detection. IEEE Access 2023, 11, 57951–57964. [Google Scholar] [CrossRef]
- Yu, Z.; Liu, L.; Wang, W.; Zhang, L.; Zhao, X. DALNet: A Rail Detection Network Based on Dynamic Anchor Line. IEEE Trans. Instrum. Meas. 2024, 73, 1–14. [Google Scholar] [CrossRef]
- Weng, Y.; Huang, X.; Chen, X.; He, J.; Li, Z.; Yi, H. Research on Railway Track Extraction Method Based on Edge Detection and Attention Mechanism. IEEE Access 2024, 12, 26550–26561. [Google Scholar] [CrossRef]
- Dong, Q.; Chen, X.; Jiang, L.; Wang, L.; Chen, J.; Zhao, Y. Semantic Segmentation of Remote Sensing Images Depicting Environmental Hazards in High-Speed Rail Network Based on Large-Model Pre-Classification. Sensors 2024, 24, 1876. [Google Scholar] [CrossRef]
- Chen, J.; Wei, D.; Teng, L.; Tian, L.; Wang, H. All-weather road drivable area segmentation method based on CycleGAN. Vis. Comput. 2023, 39, 5135–5151. [Google Scholar]
- Li, Z.; Yuan, J.; Li, G.; Wang, H.; Li, X.; Li, D.; Wang, X. RSI-YOLO: Object Detection Method for Remote Sensing Images Based on Improved YOLO. Sensors 2023, 23, 6414. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Chen, P.; Huan, Y.; Dai, L.; Xu, F.; Hu, H. Railway obstacle intrusion warning mechanism integrating YOLO-based detection and risk assessment. J. Ind. Inf. Integr. 2024, 38, 100571. [Google Scholar] [CrossRef]
- Qiu, Y.; Liu, J.; Liu, H. Railway Track Multi-component Segmentation Based on Residual Contextual Transformer. IEEE Sens. J. 2024, 5, 3403137. [Google Scholar] [CrossRef]
- Liu, Y.; Wu, Y.; Ma, Z.; Zhou, Y.; Li, G.; Jian, X.; Meng, S. CNN and Binocular Vision-Based Target Detection and Ranging Framework of Intelligent Railway System. IEEE Trans. Instrum. Meas. 2024, 73, 1–11. [Google Scholar] [CrossRef]
- Yuki, F.; Daisuke, D.; Yasutomo, K.; Ichiro, I.; Hiroshi, M.; Hiroki, M.; Nozomi, N. Soft-Boundary Label Relaxation with class placement constraints for semantic segmentation of the railway environment. Pattern Recognit. Lett. 2021, 150, 258–264. [Google Scholar]
- Wang, C.; Li, X.; Chen, P.; Xie, Y.; Liu, W. Spatial pattern and developing mechanism of railway geo-systems based on track gauge: A case study of Eurasia. J. Geogr. Sci. 2020, 8, 1283–1306. [Google Scholar] [CrossRef]
- Lv, H.; Yan, H.; Liu, K.; Zhou, Z.; Jing, J. YOLOv5-AC: Attention Mechanism-Based Lightweight YOLOv5 for Track Pedestrian Detection. Sensors 2022, 22, 5903. [Google Scholar] [CrossRef] [PubMed]
- Zhou, J.; Su, T.; Li, K.; Dai, J. Small Target-YOLOv5: Enhancing the Algorithm for Small Object Detection in Drone Aerial Imagery Based on YOLOv5. Sensors 2024, 24, 134. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, H.; Pei, L.; Yu, W. CDNet: A real-time and robust crosswalk detection network on Jetson nano based on YOLOv5. Neural Comput. 2022, 34, 10719–10730. [Google Scholar] [CrossRef]
- Qu, Z.; Gao, L.; Wang, S.; Yin, H.; Yi, T. An improved YOLOv5 method for large objects detection with multi-scale feature cross-layer fusion network. Image Vis. Comput. 2022, 125, 104518. [Google Scholar] [CrossRef]
- Hong, Z.; Yang, T.; Tong, X.; Zhang, Y.; Jiang, S.; Zhou, R.; Han, Y.; Wang, J.; Yang, S.; Liu, S. Multi-Scale Ship Detection From SAR and Optical Imagery Via A More Accurate YOLOv3. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 6083–6101. [Google Scholar] [CrossRef]
- Chen, J.; Xie, Y.; Qian, Z.; Chen, K.; Zhen, M.; Hu, X. Power Adapter Appearance Defect Detection Based on Task Feature Decoupling YOLOv8n. IEEE Access 2024, 12, 60070–60080. [Google Scholar] [CrossRef]
- Wu, D.; Guo, Z.; Li, A.; Yu, C.; Gao, C.; Sang, N. Conditional Boundary Loss for Semantic Segmentation. IEEE Trans. Image Process. 2023, 32, 3717–3731. [Google Scholar] [CrossRef]
- Li, W.; Lambert-Garcia, R.; Getley, A.C.M.; Kim, K.; Bhagavath, S.; Majkut, M.; Rack, A.; Lee, P.; Leung, C.L.A. AM-SegNet for additive manufacturing in situ X-ray image segmentation and feature quantification. Virtual Phys. Prototyp. 2024, 19, e2325572. [Google Scholar] [CrossRef]
- Zheng, X.; Zou, J.; Du, S.; Zhong, P. Small Target Detection in Refractive Panorama Surveillance Based on Improved YOLOv8. Sensors 2024, 24, 819. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name of Sub-Dataset | Quantity/Images | Number of Objects |
|---|---|---|
| Daytime Application Dataset | 1056 | 3852 |
| Nighttime Application Dataset | 896 | 2736 |
| Extreme Weather Application Dataset | 582 | 1116 |
| Bounding Box Size | Quantity | Proportion |
|---|---|---|
| [0, 50] | 4517 | 75.10% |
| [50, 100] | 693 | 11.52% |
| [100, 200] | 457 | 7.60% |
| [200, 300] | 227 | 3.77% |
| [300, 400] | 113 | 1.88% |
| [400, 800] | 8 | 0.13% |
| mAP@0.5 (%) | Precision (%) | Recall (%) | FLOPs/G | |
|---|---|---|---|---|
| YOLOv5s | 75.7 | 81.7 | 72.5 | 15.8 |
| YOLOv5s-CA | 74.2 | 85.9 | 69.7 | 15.8 |
| YOLOv5s-CBMA | 76.0 | 81.5 | 72.5 | 15.9 |
| YOLOv5s-CBMAC3 | 77.2 | 88.3 | 72.7 | 22.6 |
| YOLOv5s-SE | 77.9 | 89.3 | 70.8 | 15.8 |
| YOLOv5s-Shuffle | 77.1 | 88.2 | 72.6 | 15.8 |
| Experimental Group | SE | Adding a Prediction Layer | Modifying the Anchor Box | Loss Function | mAP@0.5 (%) | Precision (%) | Recall (%) | FPS |
|---|---|---|---|---|---|---|---|---|
| YOLOv5s | 75.7 | 81.7 | 72.5 | 84.3 | ||||
| Optimization 1 | √ | 77.9 | 84.3 | 70.8 | 90.9 | |||
| Optimization 2 | √ | √ | 81.4 | 82.7 | 74.9 | 93.3 | ||
| Optimization 3 | √ | √ | √ | 82.0 | 87.0 | 75.3 | 109.5 | |
| Optimization 4 | √ | √ | √ | √ | 83.1 | 89.3 | 76.0 | 111.1 |
| Experimental Group | SE | Adding a Prediction Layer | Modifying the Anchor Box | Loss Function | mAP@0.5 (%) | Precision (%) | Recall (%) | FPS |
|---|---|---|---|---|---|---|---|---|
| YOLOv5s | 75.7 | 81.7 | 72.5 | 84.3 | ||||
| YOLOv5s-S | √ | 77.9 | 84.3 | 70.8 | 90.9 | |||
| YOLOv5s-P | √ | 80.1 | 86.7 | 73.5 | 82.1 | |||
| YOLOv5s-B | √ | 79.8 | 84.3 | 74.7 | 123.6 | |||
| YOLOv5s-L | √ | 77.4 | 82.7 | 73.2 | 85.7 | |||
| YOLOv5s-PBL | √ | √ | √ | 80.1 | 84.2 | 74.6 | 102.7 | |
| YOLOv5s-SBL | √ | √ | √ | 79.2 | 83.1 | 73.7 | 105.3 | |
| YOLOv5s-SPL | √ | √ | √ | 81.7 | 86.5 | 74.9 | 98.8 | |
| YOLOv5s-SPB | √ | √ | √ | 82.0 | 87.0 | 75.3 | 109.5 | |
| YOLOv5s-SPBL | √ | √ | √ | √ | 83.1 | 89.3 | 76.0 | 111.1 |
| Model | Backbone | Input Pixel (s) | mAP@0.5 (%) | Precision (%) | Recall (%) | FPS |
|---|---|---|---|---|---|---|
| Faster R-CNN | Resnet50 | 1000 × 600 | 76.7 | 84.7 | 71.7 | 56.4 |
| SSD | VGG16 | 300 × 300 | 75.4 | 81.3 | 73.4 | 62.1 |
| YOLOv3 | CPSDarknet53 | 608 × 608 | 74.9 | 80.8 | 71.6 | 82.1 |
| YOLOv7 | CPSDarknet53 | 640 × 640 | 76.6 | 83.1 | 72.9 | 84.7 |
| YOLOv8s | CPSDarknet53 | 640 × 640 | 76.8 | 83.6 | 73.1 | 85.2 |
| YOLOv8s-tiny | EfficientNetV3 | 640 × 640 | 77.2 | 85.2 | 73.8 | 94.6 |
| YOLOv5s | CPSDarknet53 | 640 × 640 | 75.7 | 81.7 | 72.5 | 84.3 |
| YOLOv5s-ghostNet | GhostNetV2 | 640 × 640 | 76.6 | 82.8 | 73.2 | 90.2 |
| The method in this paper | The Algorithm | 640 × 640 | 83.1 | 89.3 | 76.0 | 111.1 |
| Detected Object | Model | Bounding Box Coordinates | Label Box Coordinates | IoU (%) |
|---|---|---|---|---|
| Car | YOLOv5s | (2490.5, 412, 53, 24) | (2487.5, 409, 57, 27) | 72.81% |
| The method in this paper | (2485, 408, 55, 28) | 80.13% | ||
| Person 1 | YOLOv5s | (2784.5, 434, 29, 72) | (2780, 435, 31, 74) | 83.75% |
| The method in this paper | (2788, 434, 32, 76) | 85.07% | ||
| Person 2 | YOLOv5s | (2646, 446, 34, 82) | (2647, 445, 38, 84) | 80.62% |
| The method in this paper | (2643.5, 447, 37, 86) | 82.76% | ||
| Person 3 | YOLOv5s | (2416, 443, 34, 80) | (2418, 450, 39, 91) | 84.83% |
| The method in this paper | (2415.5, 447, 35, 84) | 86.74% |
| Type of Foreign Object | Vertex Coordinates | Center Coordinates | Boundary Encroachment | Type of Encroachment |
|---|---|---|---|---|
| Car | Upper Left (2667, 2965) | (2712.5, 2990) | Yes | Left Boundary Encroachment and Center Point Encroachment |
| Lower Left (2667, 3015) | Yes | |||
| Upper Right (2758, 2965) | Yes | |||
| Lower Right (2758, 3015) | Yes | |||
| Person 1 | Upper Left (2763, 2979) | (2820.5, 3099.5) | Yes | Center Point Encroachment |
| Lower Left (2763, 3220) | Yes | |||
| Upper Right (2878, 2979) | Yes | |||
| Lower Right (2878, 3220) | Yes | |||
| Person 2 | Upper Left (2876, 2968) | (2931, 3088) | Yes | Center Point Encroachment |
| Lower Left (2876,3208) | Yes | |||
| Upper Right (2986,2968) | Yes | |||
| Lower Right (2986,3208) | Yes |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ning, S.; Ding, F.; Chen, B. Research on the Method of Foreign Object Detection for Railway Tracks Based on Deep Learning. Sensors 2024, 24, 4483. https://doi.org/10.3390/s24144483
Ning S, Ding F, Chen B. Research on the Method of Foreign Object Detection for Railway Tracks Based on Deep Learning. Sensors. 2024; 24(14):4483. https://doi.org/10.3390/s24144483
Chicago/Turabian StyleNing, Shanping, Feng Ding, and Bangbang Chen. 2024. "Research on the Method of Foreign Object Detection for Railway Tracks Based on Deep Learning" Sensors 24, no. 14: 4483. https://doi.org/10.3390/s24144483
APA StyleNing, S., Ding, F., & Chen, B. (2024). Research on the Method of Foreign Object Detection for Railway Tracks Based on Deep Learning. Sensors, 24(14), 4483. https://doi.org/10.3390/s24144483