
SRE-YOLOv8: An Improved UAV Object Detection Model Utilizing Swin Transformer and RE-FPN



Abstract
1. Introduction
- (1)
- An enhanced CSPDarknet53 backbone network is introduced, leveraging the Swin Transformer architecture. This integration aims to better preserve contextual information.
- (2)
- The original FPN structure is replaced with the RE-FPN, a lighter and more efficient residual feature fusion pyramid structure. Additionally, an SOD layer is integrated to bolster the adeptness of the model in detecting objects of various scales, particularly small objects.
- (3)
- A Dynamic Head, equipped with multiple attention modules, is introduced to direct the model’s focus towards densely populated areas containing small objects. This facilitates the extraction of additional features from small objects. Experimental results demonstrate that our SRE-YOLOv8 model performs well and reaches a level of high accuracy in the specific dataset.
2. Literature Review
2.1. SOD Based on CNN
2.2. Emergence of Vision Transformer
3. Proposed Method
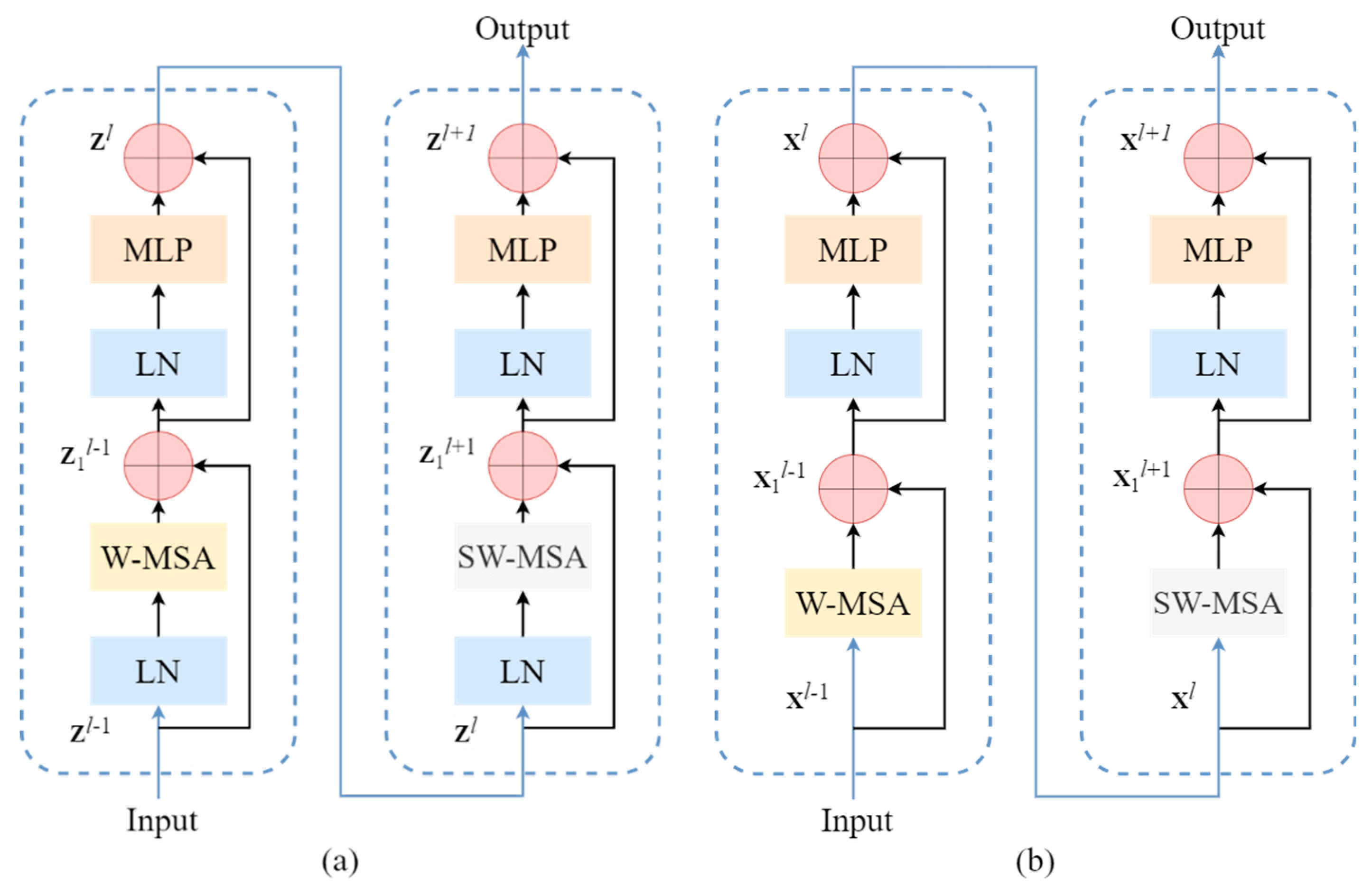
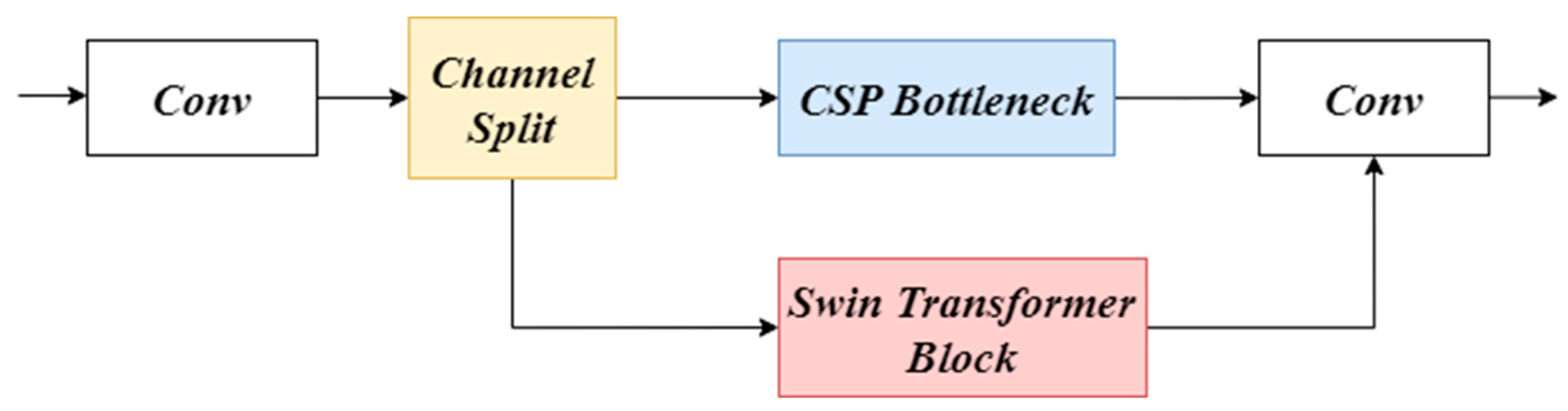
3.1. Improved Swin Transformer Module
3.2. Lightweight Residual Feature Pyramid Network
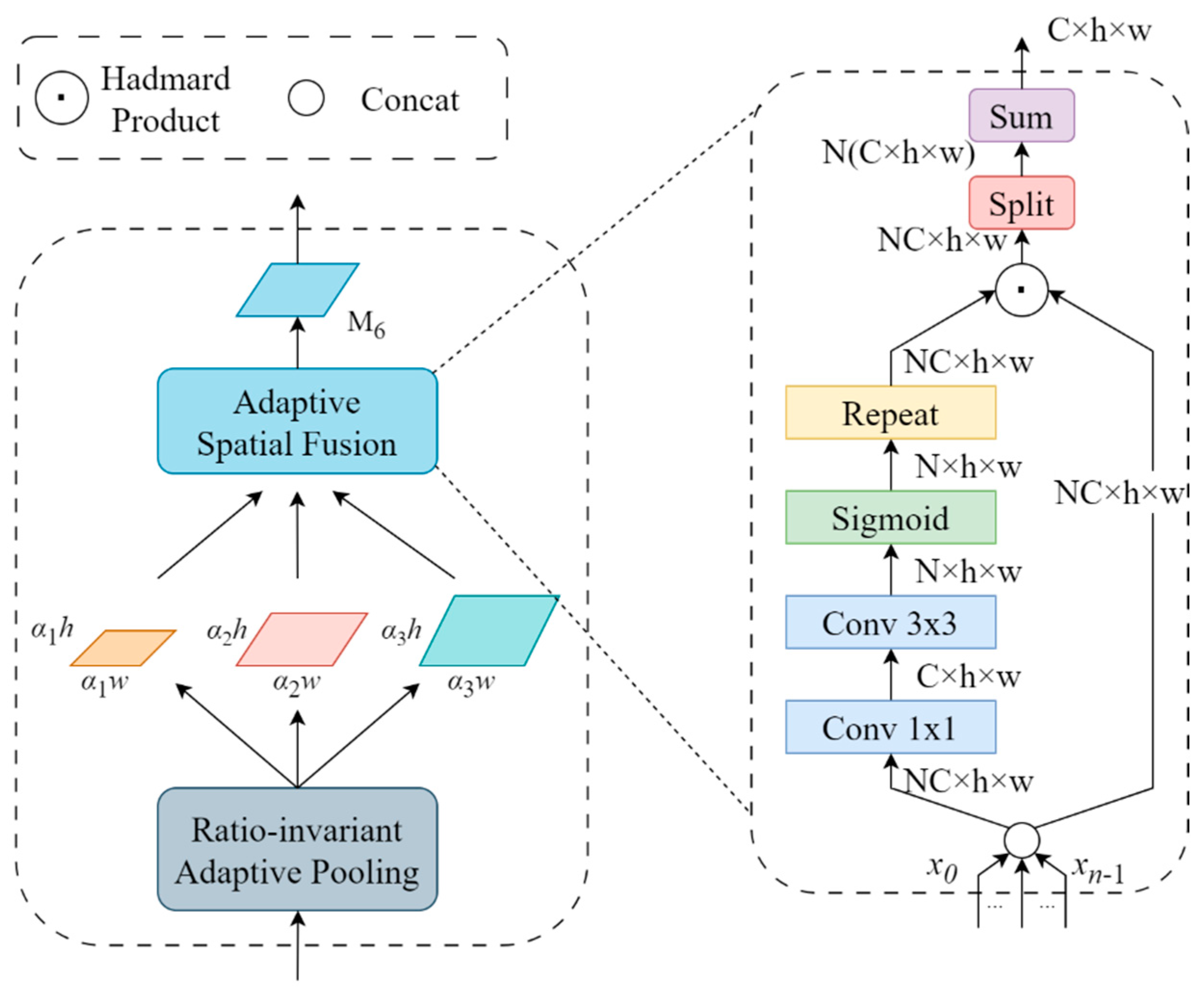
3.2.1. Residual Feature Augmentation Module
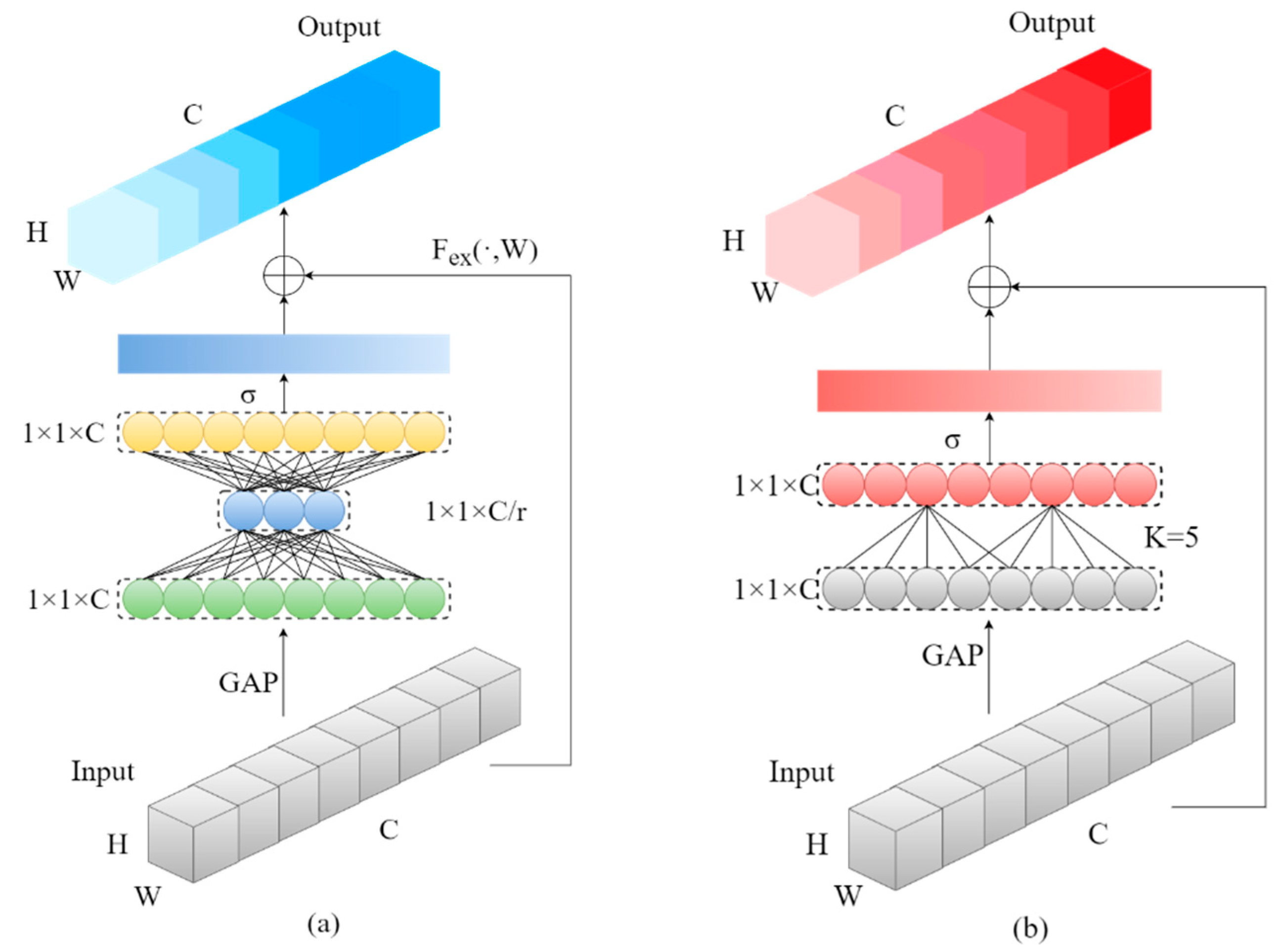
3.2.2. Introduction of Lightweight Attention Mechanism
3.3. Adding Small Object Detection Layer
3.4. Dynamic Head
4. Experiment
4.1. Dataset
4.2. Experimental Environment and Parameter Settings
4.3. Evaluation Metrics
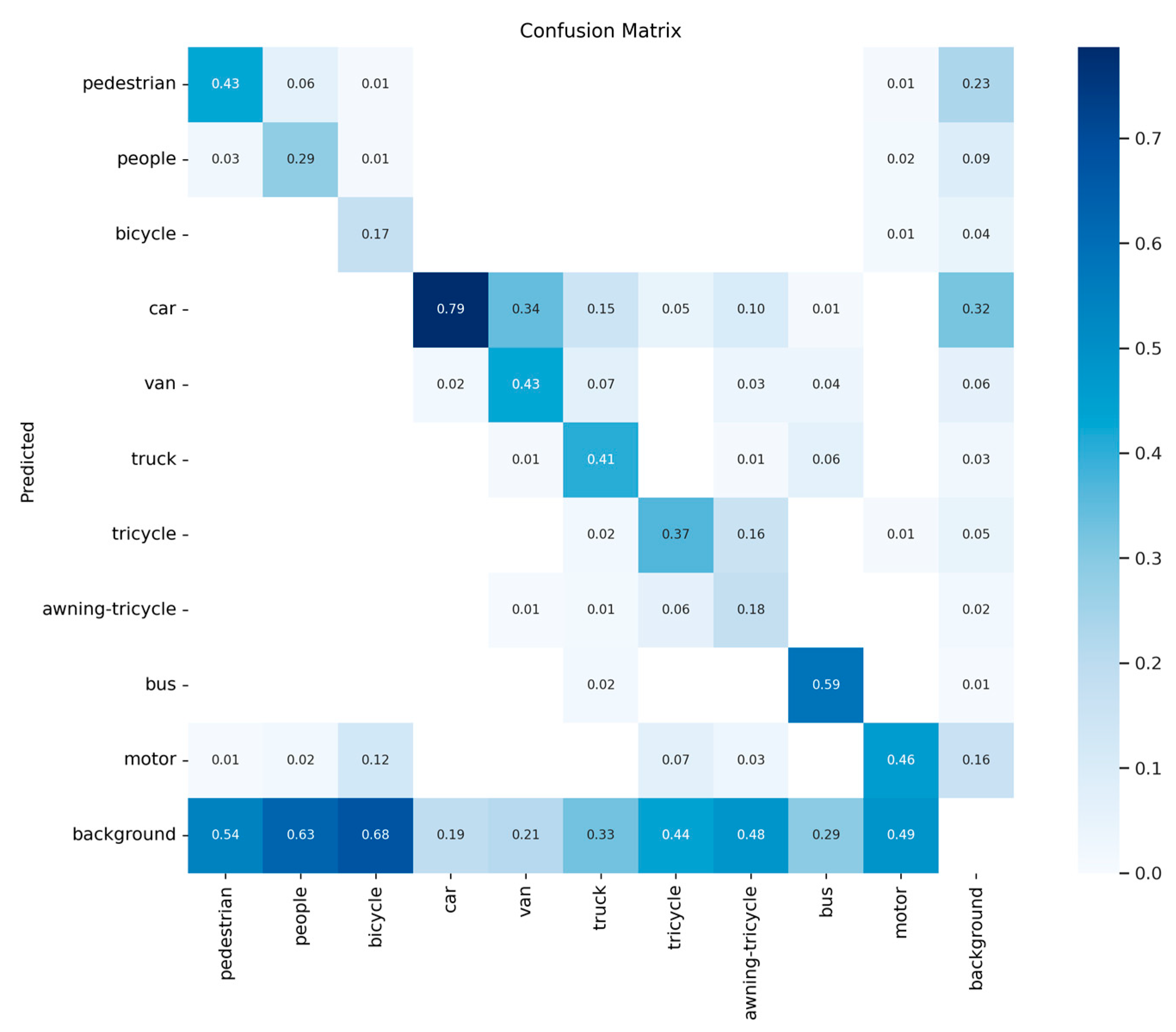
4.4. Experiment Result
5. Discussion
5.1. Comparative Tests with YOLOv8
5.2. Comparative Analysis of C2f-ST Module
5.3. Comparative Analysis of RE-FPN Structure
5.4. Ablation Experiment
5.5. Comparative Experiments with Other Models
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| UAVs | Unmanned aerial vehicles |
| SOD | Small object detection |
| RE-FPN | Residual Feature Augmentation |
| C2f | Cross-stage Partial Bottleneck with 2 convolutions |
| DW Conv | Depthwise convolution |
| LN | Layer Normalization |
| GELU | Gaussian Error Linear Unit |
| MLP | Multi-layer perceptron |
| W-MSA | Window Multi-head Self-Attention |
| SW-MSA | Shifted Window Multi-Head Self-Attention |
| ASF | Adaptive Spatial Fusion |
| GAP | Global Average Pooling |
| mAP | Mean average precision |
| AP-S | Average precision for small objects |
References
- Leng, J.; Mo, M.; Zhou, Y.; Ye, Y.; Gao, C.; Gao, X. Recent advances in drone-view object detection. J. Image Graph. 2023, 28, 2563–2586. [Google Scholar]
- Zhang, Q.; Zhang, H.; Lu, X. Adaptive Feature Fusion for Small Object Detection. Appl. Sci. 2022, 12, 11854. [Google Scholar] [CrossRef]
- Chen, P.; Wang, J.; Zhang, Z.; He, C. Small object detection in aerial images based on feature aggregation and multiple cooperative features interaction. J. Electron. Meas. Instrum. 2023, 37, 183–192. [Google Scholar]
- Lowe, D. Distinctive image features from scale-invariant key-points. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; IEEE: Piscataway, NJ, USA, 2005; pp. 886–893. [Google Scholar]
- Gao, Y.; Zhang, P.; Yang, H. GraphNAS++: Distributed architecture search for graph neural networks. IEEE Trans. Knowl. Data Eng. 2022, 35, 6973–6987. [Google Scholar] [CrossRef]
- Gao, Y.; Zhang, P.; Zhou, C. HGNAS++: Efficient architecture search for heterogeneous graph neural networks. IEEE Trans. Knowl. Data Eng. 2023, 35, 9448–9461. [Google Scholar] [CrossRef]
- Shi, Y.; Shi, Y. Advances in Big Data Analytics: Theory, Algorithms and Practices; Springer: Berlin/Heidelberg, Germany, 2022; pp. 3–21. [Google Scholar]
- Olson, D.L.; Shi, Y.; Shi, Y. Introduction to Business Data Mining; McGraw-Hill/Irwin: New York, NY, USA, 2007; pp. 203–205. [Google Scholar]
- Shi, Y.; Tian, Y.; Kou, G. Optimization Based Data Mining: Theory and Applications; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2011; pp. 154–156. [Google Scholar]
- Tien, J.M. Internet of things, real-time decision making, and artificial intelligence. Ann. Data Sci. 2017, 4, 149–178. [Google Scholar] [CrossRef]
- Li, J.; Liu, Y. An Efficient Data Analysis Framework for Online Security Processing. J. Comput. Netw. Commun. 2021, 2021, 9290853. [Google Scholar] [CrossRef]
- Li, J.; Li, C.; Tian, B. DAF: An adaptive computing framework for multimedia data streams analysis. Intell. Data Anal. 2020, 24, 1441–1453. [Google Scholar] [CrossRef]
- Osco, L.P.; Junior, J.M.; Ramos, A.P.M. A review on deep learning in UAV remote sensing. Int. J. Appl. Earth Obs. Geoinf. 2021, 102, 102456. [Google Scholar] [CrossRef]
- Albahli, S.; Nawaz, M.; Javed, A.; Irtaza, A. An improved faster-RCNN model for handwritten character recognition. Arab. J. Sci. Eng. 2021, 46, 8509–8523. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single Shot Multibox Detector. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Gong, H.; Mu, T.; Li, Q.; Dai, H.; Li, C.; He, Z.; Wang, W.; Han, F.; Tuniyazi, A.; Li, H. Swin-Transformer-Enabled YOLOv5 with Attention Mechanism for Small Object Detection on Satellite Images. Remote Sens. 2022, 14, 2861. [Google Scholar] [CrossRef]
- Zhang, Z.; Lu, X.; Cao, G.; Yang, Y.; Jiao, L.; Liu, F. ViT-YOLO: Transformer-Basd YOLO for Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 2799–2808. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 9992–10002. [Google Scholar]
- Guo, C.; Fan, B.; Zhang, Q.; Xiang, S.; Pan, C. AugFPN: Improving Multi-Scale Feature Learning for Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 12592–12601. [Google Scholar]
- Dai, X.; Chen, Y.; Xiao, B.; Chen, D.; Liu, M.; Yuan, L.; Zhang, L. Dynamic head: Unifying object detection heads with attentions. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 7369–7378. [Google Scholar]
- Zhang, J.; Lei, J.; Xie, W.; Fang, Z.; Li, Y.; Du, Q. SuperYOLO: Super resolution assisted object detection in multimodal remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5605415. [Google Scholar] [CrossRef]
- Maktab, D.O.; Razaak, M.; Remagnino, P. Enhanced single shot small object detector for aerial imagery using super-resolution, feature fusion and deconvolution. Sensors 2022, 22, 4339. [Google Scholar] [CrossRef]
- Liu, Z.; Gao, X.; Wan, Y.; Wang, J.; Lyu, H. An Improved YOLOv5 Method for Small Object Detection in UAV Capture Scenes. IEEE Access 2023, 11, 14365–14374. [Google Scholar] [CrossRef]
- Qi, X.; Chai, R.; Gao, Y. Algorithm of Reconstructed SPPCSPC and Optimized Downsampling for Small Object Detection. Comput. Eng. Appl. 2023, 59, 159–166. [Google Scholar]
- Kim, M.; Jeong, J.; Kim, S. ECAP-YOLO: Efficient channel attention pyramid YOLO for small object detection in aerial image. Remote Sens. 2021, 13, 4851. [Google Scholar] [CrossRef]
- Wang, G.; Chen, Y.; An, P.; Hong, H.; Hu, J.; Huang, T. UAV-YOLOv8: A small-object-detection model based on improved YOLOv8 for UAV aerial photography scenarios. Sensors 2023, 23, 7190. [Google Scholar] [CrossRef]
- Jawaharlalnehru, A.; Sambandham, T.; Sekar, V.; Ravikumar, D.; Loganathan, V.; Kannadasan, R.; Alzamil, Z.S. Target object detection from Unmanned Aerial Vehicle (UAV) images based on improved YOLO algorithm. Electronics 2022, 11, 2343. [Google Scholar] [CrossRef]
- Tian, Y.; Wang, Y.; Wang, J.; Wang, X.; Wang, F.Y. Key problems and progress of vision transformers: The state of the art and prospects. Acta Autom. Sin. 2022, 48, 957–979. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Houlsby, N. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tao, D. A survey on vision transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 87–110. [Google Scholar] [CrossRef]
- Xu, Y.; Yang, Y.; Zhang, L. DeMT: Deformable mixer transformer for multi-task learning of dense prediction. Proc. AAAI Conf. Artif. Intell. 2023, 37, 3072–3080. [Google Scholar] [CrossRef]
- He, X.; Zhou, Y.; Zhao, J.; Zhang, D.; Yao, R.; Xue, Y. Swin transformer embedding UNet for remote sensing image semantic segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4408715. [Google Scholar] [CrossRef]
- Jiang, X.; Wu, Y. Remote Sensing Object Detection Based on Convolution and Swin Transformer. IEEE Access 2023, 11, 38643–38656. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Springer International Publishing: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Wu, H.; Xiao, B.; Codella, N.; Liu, M.; Dai, X.; Yuan, L.; Zhang, L. Cvt: Introducing convolutions to vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; IEEE: Piscataway, NJ, USA, 2021. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450 2016. [Google Scholar]
- Li, X.Y.; Fu, H.T.; Niu, W.T. Multi-Modal Pedestrian Detection Algorithm Based on Deep Learning. J. Xi’an Jiaotong Univ. 2022, 56, 61–70. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Ren, Z.; Yu, Z.; Yang, X.; Liu, M.Y.; Lee, Y.J.; Schwing, A.G.; Kautz, J. Instance-aware, context-focused, and memory-efficient weakly supervised object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar]
- Zhao, Y. Research on Road Environment Perception Based on Deep Learning. Master’s Thesis, Shijiazhuang Tiedao University, Shijiazhuang, China, 2023. [Google Scholar]
- Wang, K.Z.; Xu, Y.F.; Zhou, S.B. Image Dehazing Model Combined with Contrastive Perceptual Loss and Fusion Attention. Comput. Eng. 2023, 49, 207–214. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Li, Y.; Chen, Y.; Wang, N.; Zhang, Z. Scale-aware trident networks for object detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Li, Y.; Chen, Y.; Wang, N.; Zhang, Z. Bridging the gap between networks for object detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Ahmed, A.; Tangri, P.; Panda, A.; Ramani, D.; Karmakar, S. Vfnet: A convolutional architecture for accent classification. In Proceedings of the 2019 IEEE 16th India Council International Conference (INDICON), Rajkot, India, 13–15 December 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Yu, G.; Chang, Q.; Lv, W.; Xu, C.; Cui, C.; Ji, W.; Ma, Y. PP-PicoDet: A better real-time object detector on mobile devices. arXiv 2021, arXiv:2111.00902. [Google Scholar]
- Wang, C.Y.; Yeh, I.H.; Liao, H.Y.M. YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information. arXiv 2024, arXiv:2402.13616. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter Item | Value |
|---|---|
| Optimizer | SGD |
| Momentum Parameter | 0.941 |
| Weight Decay Coefficient | 0.0004 |
| Initial Learning Rate | 0.011 |
| Epoch | 200 |
| Image Size | 640 × 640 |
| Batch Size | 32 |
| Method | Ped | Peo | Bic | Car | Van | Tru | Tri | Awi | Bus | Mot | mAP@0.5 (%) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| YOLOv8 | 40.3 | 23.1 | 10.2 | 67.4 | 35.1 | 26.9 | 11.7 | 10.1 | 31.3 | 32.1 | 29.3 |
| SRE-YOLOv8 (Ours) | 50.2 | 36.6 | 14.1 | 79.5 | 36.5 | 31.9 | 23.3 | 19.6 | 45.5 | 47.7 | 38.5 |
| Feature Extraction Module | FLOPs (G) | Precision (%) | Recall (%) | mAP |
|---|---|---|---|---|
| C2f | 15.8 | 38.6 | 28.1 | 29.3 |
| C2f_MixConv | 28.5 | 37.5 | 31.4 | 33.5 |
| C2f_DefConv | 28.1 | 38.1 | 30.6 | 34.6 |
| C2f_CrossConv | 27.9 | 37.3 | 29.1 | 33.9 |
| C2f-ST | 27.4 | 39.5 | 32.6 | 35.1 |
| Feature Fusion Structures | Parameter (M) | mAP (%) | FPS |
|---|---|---|---|
| FPN | 33.5 | 29.3 | 59 |
| SE-FPN | 41.9 | 36.7 | 39 |
| BiFPN | 42.1 | 36.9 | 42 |
| RE-FPN | 38.6 | 36.1 | 54 |
| Improvement Method | Experiment | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | ||
| C2f-ST | - | √ | - | - | - | √ | √ | √ | |
| RE-FPN | - | - | √ | - | - | √ | √ | √ | |
| Small Object Detection Layer | - | - | - | √ | - | - | √ | √ | |
| Dynamic Head | - | - | - | - | √ | - | - | √ | |
| Evaluation Indicator | mAP (%) | 29.3 | 34.1 (+4.8) | 31.2 (+1.9) | 29.6 (+0.3) | 31.0 (+1.7) | 36.2 (+5.9) | 38.1 (+7.8) | 38.5 (+8.2) |
| AP-S (%) | 17.4 | 20.5 (+3.1) | 18.5(+1.1) | 17.9(+0.5) | 18.1(+0.7) | 21.5(+4.1) | 21.9(+4.5) | 22.3 (+4.9) | |
| Precision (%) | 38.6 | 39.5 (+0.9) | 38.2 (−0.4) | 40.0 (+1.4) | 38.9 (+0.3) | 39.7 (+1.1) | 40.5 (+1.9) | 41.3 (+2.7) | |
| Recall (%) | 28.1 | 32.6 (+4.5) | 29.4 (+1.3) | 29.6 (+1.5) | 28.8 (+0.7) | 33.1 (+5.0) | 34.1 (+6.0) | 34.9 (+6.8) | |
| FPS | 59 | 55 | 58 | 56 | 57 | 54 | 53 | 53 | |
| Model | Ped | Peo | Bic | Car | Van | Tru | Tri | Awi | Bus | Mot | mAP@0.5 (%) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| CenterNet [46] | 21.1 | 25.1 | 4.3 | 57.5 | 15.1 | 15.0 | 12.0 | 5.3 | 23.7 | 16.4 | 19.5 |
| Fcos [47] | 34.6 | 26.6 | 7.7 | 69.3 | 28.4 | 24.0 | 13.8 | 6.7 | 28.3 | 33.4 | 27.3 |
| Tridentnets [48] | 27.9 | 24.1 | 7.4 | 73 | 35.1 | 27.8 | 17.9 | 8.4 | 46.3 | 33.3 | 30.3 |
| ATSS [49] | 35.8 | 21.9 | 9.6 | 73.3 | 34.7 | 28.1 | 18.1 | 10.2 | 46.3 | 34.9 | 31.3 |
| VFNet [50] | 38.9 | 31.6 | 11.3 | 72.4 | 34.8 | 28.5 | 19.3 | 9.5 | 43.4 | 37.0 | 32.7 |
| PP-PicoDet-L [51] | 40.2 | 35.3 | 12.8 | 75.6 | 35.4 | 29.3 | 21.1 | 12.1 | 44.3 | 36.3 | 34.2 |
| YOLOv9-c [52] | 49.1 | 35.4 | 14.8 | 78.5 | 36.8 | 30.5 | 23.6 | 19.2 | 44.6 | 47.1 | 38.1 |
| SRE-YOLOv8(Ours) | 50.2 | 36.6 | 14.1 | 79.5 | 36.5 | 31.9 | 23.3 | 19.6 | 45.5 | 47.7 | 38.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Zhang, J.; Shao, Y.; Liu, F. SRE-YOLOv8: An Improved UAV Object Detection Model Utilizing Swin Transformer and RE-FPN. Sensors 2024, 24, 3918. https://doi.org/10.3390/s24123918
Li J, Zhang J, Shao Y, Liu F. SRE-YOLOv8: An Improved UAV Object Detection Model Utilizing Swin Transformer and RE-FPN. Sensors. 2024; 24(12):3918. https://doi.org/10.3390/s24123918
Chicago/Turabian StyleLi, Jun, Jiajie Zhang, Yanhua Shao, and Feng Liu. 2024. "SRE-YOLOv8: An Improved UAV Object Detection Model Utilizing Swin Transformer and RE-FPN" Sensors 24, no. 12: 3918. https://doi.org/10.3390/s24123918
APA StyleLi, J., Zhang, J., Shao, Y., & Liu, F. (2024). SRE-YOLOv8: An Improved UAV Object Detection Model Utilizing Swin Transformer and RE-FPN. Sensors, 24(12), 3918. https://doi.org/10.3390/s24123918