
EMA-YOLO: A Novel Target-Detection Algorithm for Immature Yellow Peach Based on YOLOv8


Abstract
1. Introduction
2. Materials
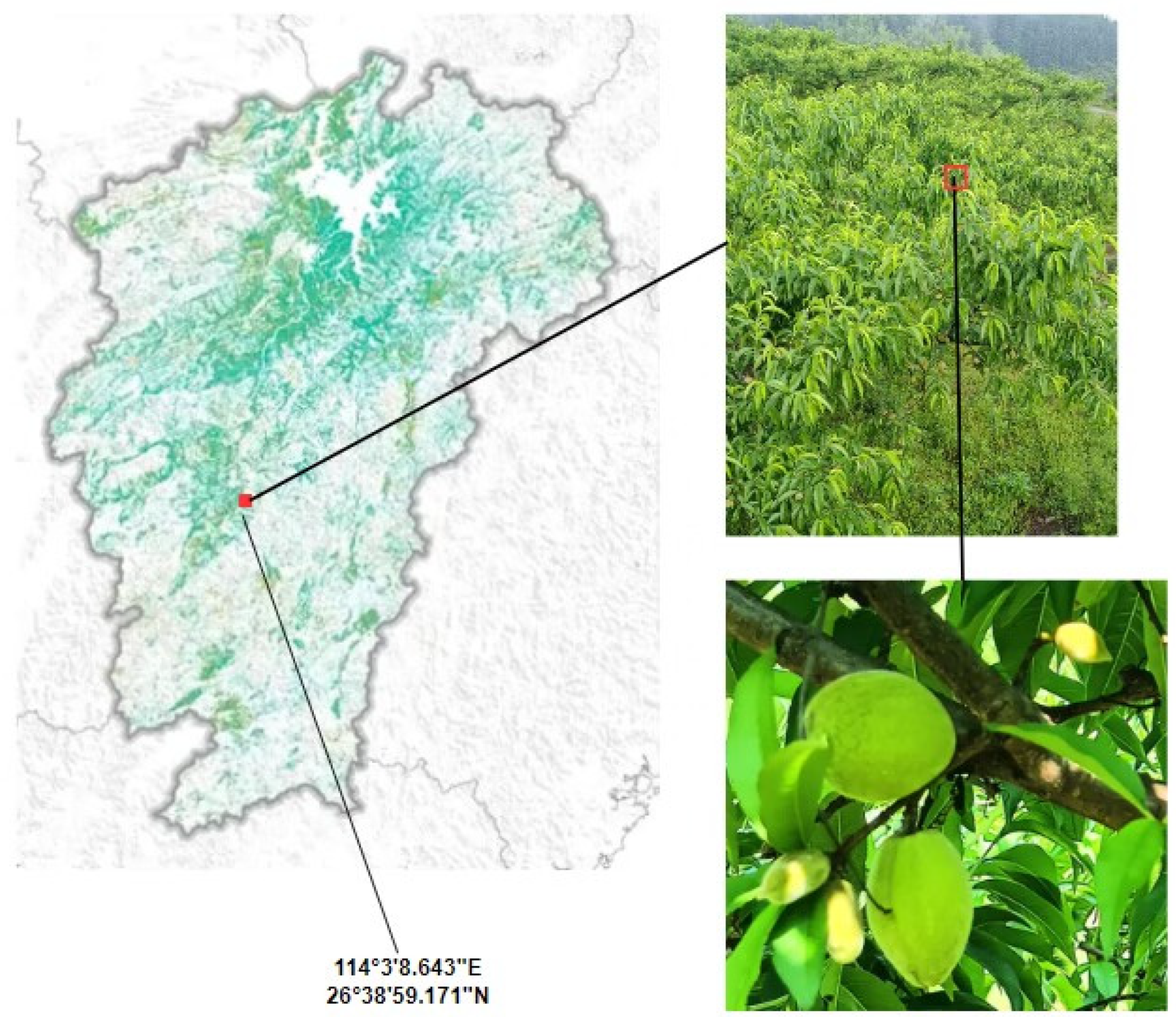
2.1. Data Acquisition
2.2. Data Augmentation
3. Method
3.1. YOLOv8
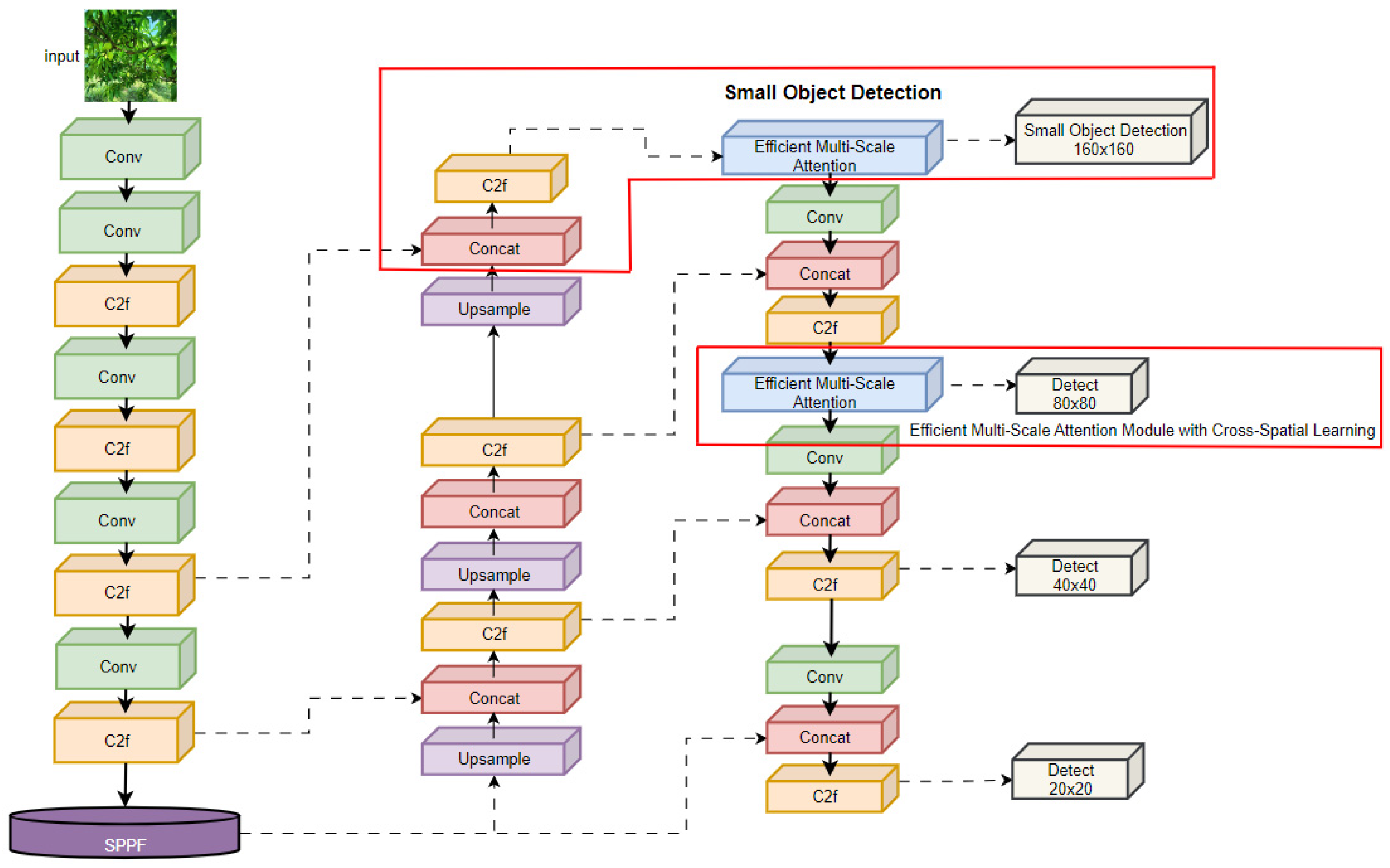
3.2. EMA-YOLO
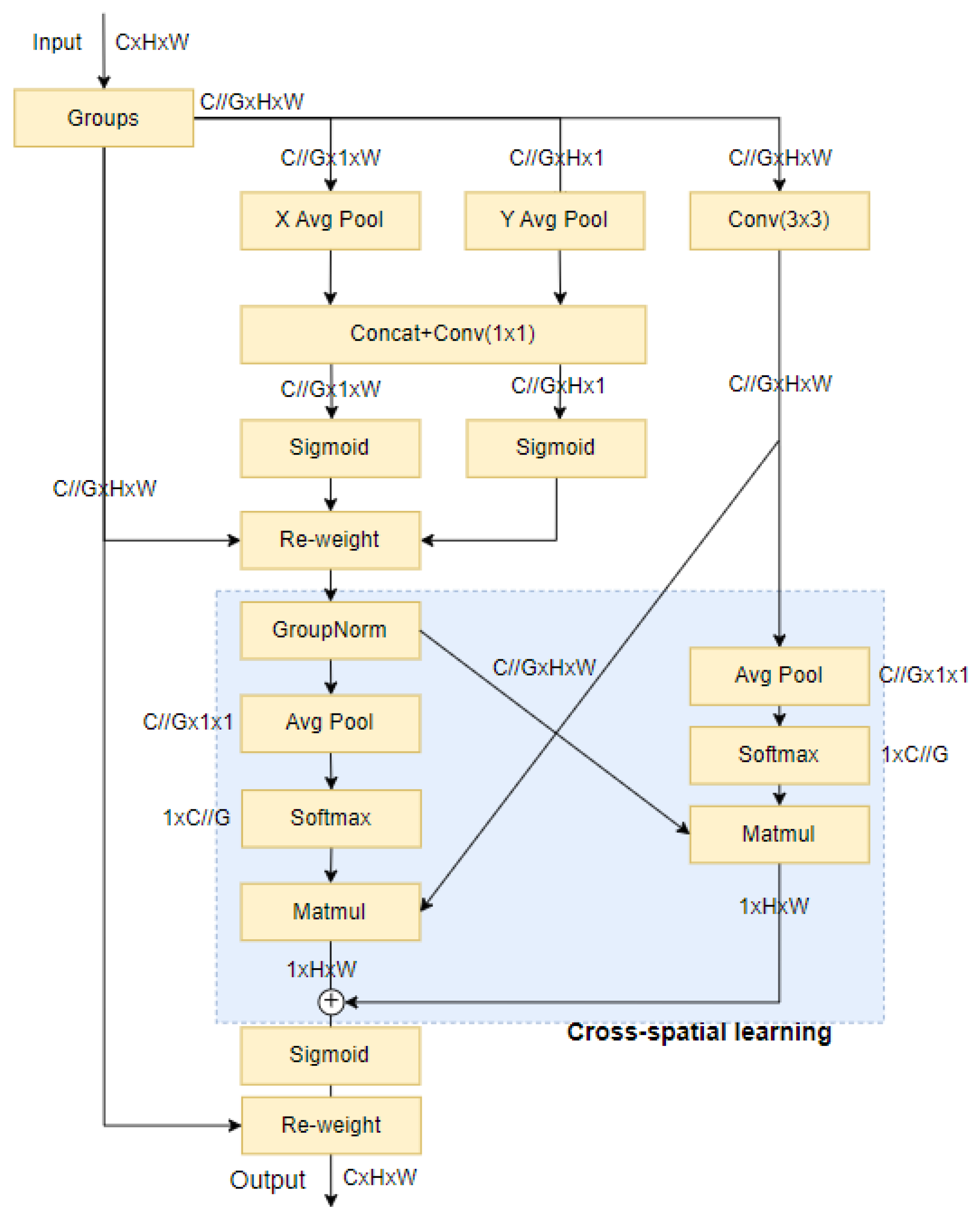
3.2.1. EMA Attention Mechanism
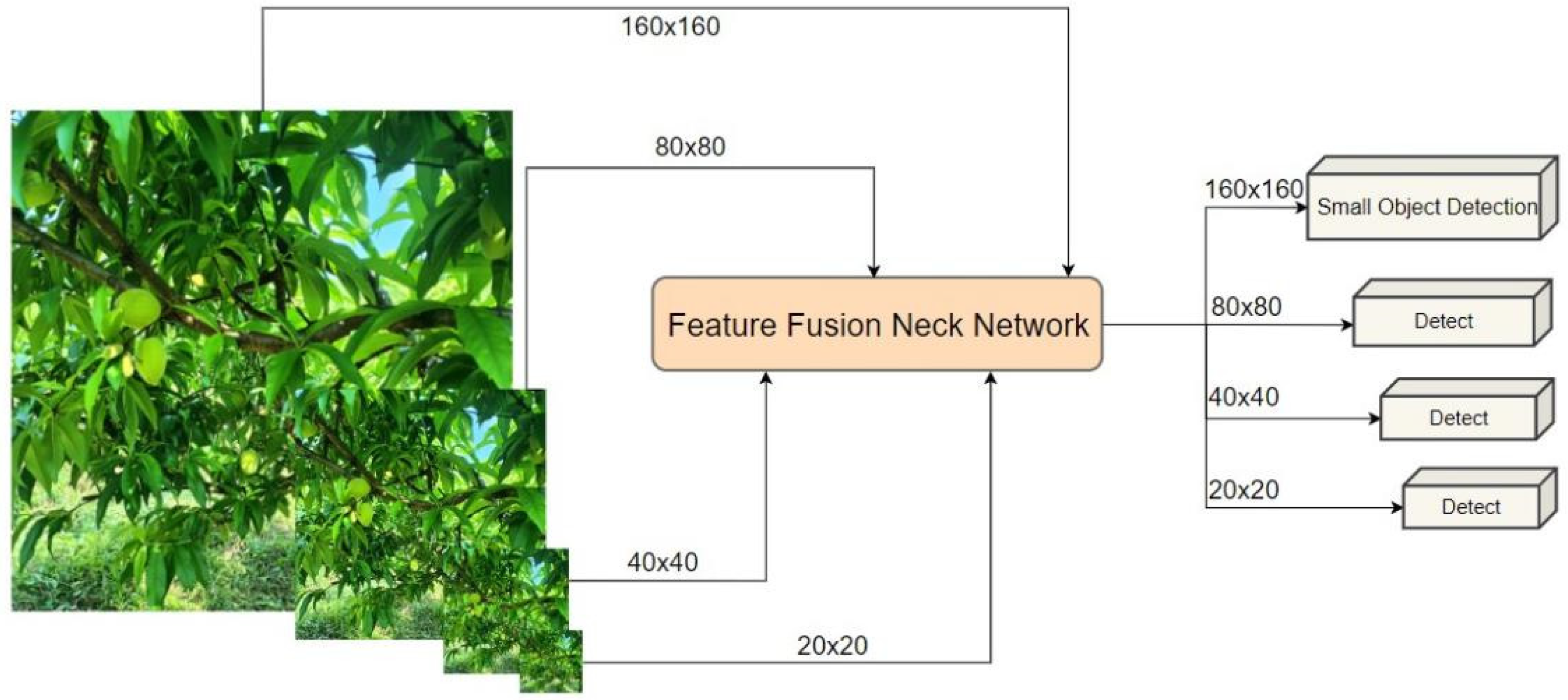
3.2.2. Incorporate the Small-Object Detection Head
3.2.3. EIoU Loss Function
3.3. Experimental Parameters
3.4. Evaluation Metrics
4. Experimental Results and Analysis
4.1. Experimental Result
4.2. Ablation Experiment
4.3. Comparison of Different Networks
4.4. Comparison at Different Shooting Distances
4.5. Comparison of Different Light Intensities
4.6. Comparison of Different Densities
4.7. Comparison of Computational Load
4.8. Discussion
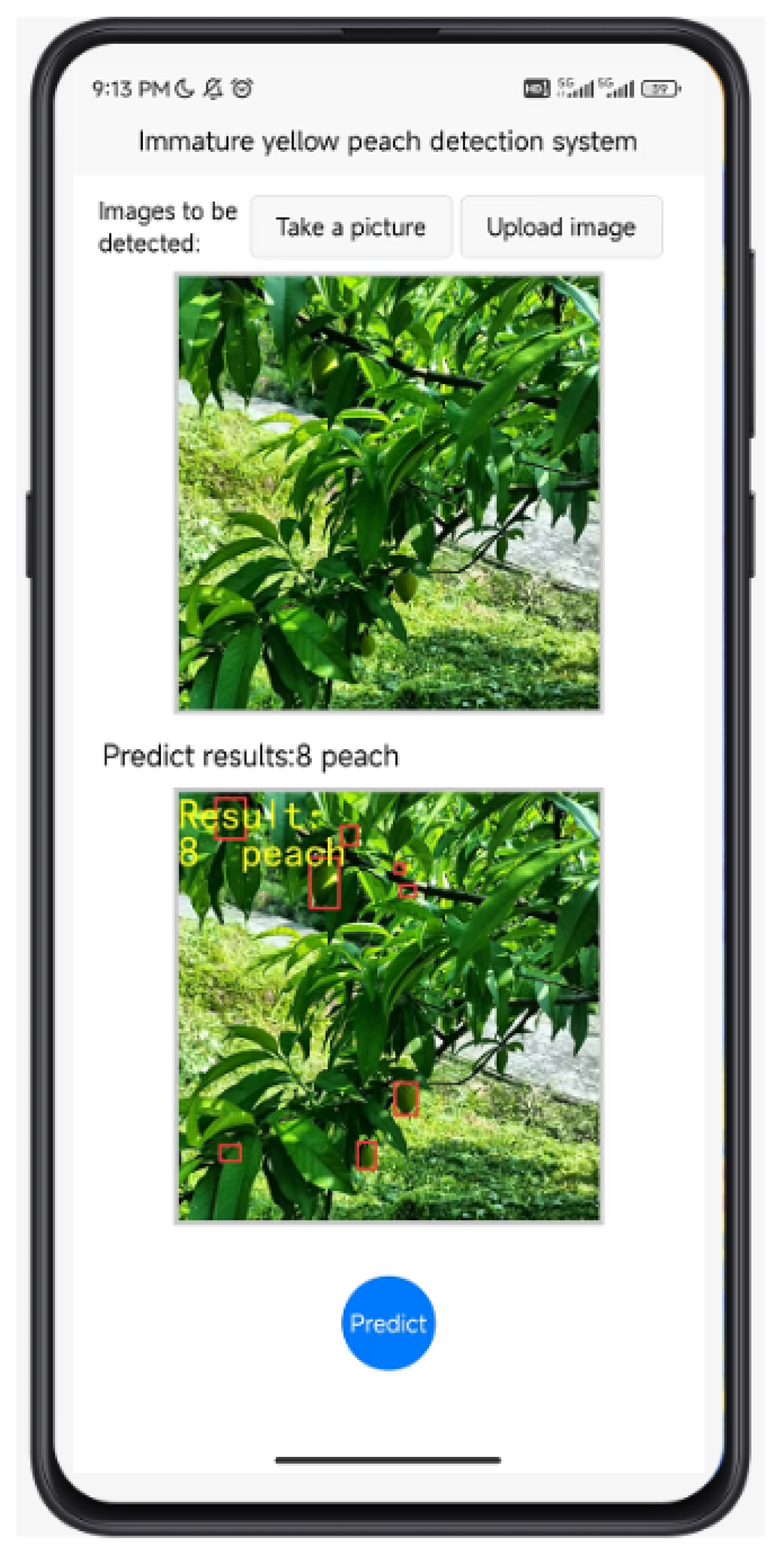
5. Application of Our Method
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cao, Z.; Zhou, D.; Ge, X.; Luo, Y.; Su, J. The role of essential oils in maintaining the postharvest quality and preservation of peach and other fruits. J. Food Biochem. 2022, 46, e14513. [Google Scholar] [CrossRef] [PubMed]
- Wu, P.; Yuan, L.; Fan, Z.; Wu, E.; Chen, X.; Wang, Z. The introduction performance and supporting cultivation techniques of Jinxiu yellow peach in Hubei Huanggang. Fruit Tree Pract. Technol. Inf. 2022, 335, 17–19. [Google Scholar]
- Huang, Y.; Zhang, W.; Zhang, Q.; Li, G.; Shan, Y.; Su, D.; Zhu, X. Effects of Pre-harvest Bagging and Non-bagging Treatment on Postharvest Storage Quality of Yellow-Flesh Peach. J. Chin. Inst. Food Sci. Technol. 2021, 21, 231–242. [Google Scholar]
- Yuan, X.; Zhao, P.; Li, D. Nursery tree seedling detection and counting based on YOLOv3 network. J. For. Eng. 2022, 7, 174–179. [Google Scholar]
- Rahnemoonfar, M.; Sheppard, C. Deep Count: Fruit Counting Based on Deep Simulated Learning. Sensors 2017, 17, 905. [Google Scholar] [CrossRef] [PubMed]
- Li, W.; Wang, D.; Ning, Z.; Lu, M.; Qin, P. Survey of Fruit Object Detection Algorithms in Computer Vision. Comput. Mod. 2022, 322, 87–95. [Google Scholar]
- Song, Z.; Liu, Y.; Zheng, L.; Tie, J.; Wang, J. Identification of green citrus based on improved YOLOV3 in natural environment. J. Chin. Agric. Mech. 2021, 42, 159–165. [Google Scholar]
- Hao, J.; Bing, Z.; Yang, S.; Yang, J.; Sun, L. Detection of green walnut by improved YOLOv3. Trans. Chin. Soc. Agric. Eng. 2022, 38, 183–190. [Google Scholar]
- Song, H.; Wang, Y.; Wang, Y.; Lv, S.; Jiang, M. Camellia oleifera Fruit Detection in Natural Scene Based on YOLO v5s. Trans. Chin. Soc. Agric. Mach. 2022, 53, 234–242. [Google Scholar]
- Zhang, Z.; Luo, M.; Guo, S.; Liu, G.; Li, S.; Zhang, Y. Cherry Fruit Detection Method in Natural Scene Based on Improved YOLOv5. Trans. Chin. Soc. Agric. Mach. 2022, 53, 232–240. [Google Scholar]
- Lv, J.; Li, S.; Zeng, M.; Dong, B. Detecting bagged citrus using a Semi-Supervised SPM-YOLOv5. Trans. Chin. Soc. Agric. Eng. 2022, 38, 204–211. [Google Scholar]
- Xie, J.; Peng, J.; Wang, J.; Chen, B.; Jing, T.; Sun, D.; Gao, P.; Wang, W.; Lu, J.; Yetan, R.; et al. Litchi Detection in a Complex Natural Environment Using the YOLOv5-Litchi Model. Agronomy 2022, 12, 3054. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, W.; Yu, J.; He, L.; Chen, J.; He, Y. Complete and accurate holly fruits counting using YOLOX object detection. Comput. Electron. Agric. 2022, 198, 107062. [Google Scholar] [CrossRef]
- Tang, R.; Lei, Y.; Luo, B.; Zhang, J.; Mu, J. YOLOv7-Plum:Advancing Plum Fruit Detection in Natural Environments with Deep Learing. Plants 2023, 12, 2883. [Google Scholar] [CrossRef]
- Liu, P.; Yin, H. YOLOv7-Peach: An Algorithm for Immature Small Yellow Peaches Detection in Complex Natural Environments. Sensors 2023, 23, 5096. [Google Scholar] [CrossRef] [PubMed]
- Zhao, K.; Jin, X.; Wang, Y. Survey on few-shot learning. Ruan Jian Xue Bao/J. Softw. 2021, 32, 349–369. [Google Scholar]
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef]
- Chen, W.; Jia, X.; Zhu, X.; Ran, E.; Wei, Y. G-YOLO v7:Target Detection Algorithm for UAV Aerial Images. J. Optoelectron. Laser 2024, 55, 3205–3209. [Google Scholar]
- Zhang, Z.; Zhou, J.; Jiang, Z.; Han, H. Lightweight Apple Recognition Method in Natural Orchard Environment Based on Improved YOLO v7 Model. Trans. Chin. Soc. Agric. Mach. 2024, 55, 231–242+262. [Google Scholar]
- Yi, S.; Li, J.; Zhang, P.; Wang, D. Detecting and counting of spring-see citrus using YOLOv4 network model and recursive fusion of features. Trans. Chin. Soc. Agric. Eng. 2021, 37, 161–169. [Google Scholar]
- Gao, A.; Liang, X.; Xia, C.; Zhang, C. A dense pedestrian detection algorithm with improved YOLOv8. J. Graph. 2023, 44, 890–898. [Google Scholar]
- Ouyang, D.; He, S.; Zhan, J.; Guo, H.; Huang, Z.; Luo, M.; Zhang, G. Efficient Multi-Scale Attention Module with Cross-Spatial Learning. In Proceedings of the ICASSP 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design; IEEE: Piscataway, NJ, USA, 2021; pp. 13708–13717. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. AAAI Conf. Artif. Intell. 2019, 34, 12993–13000. [Google Scholar] [CrossRef]
- Zhang, Y.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and Efficient IOU Loss for Accurate Bounding Box Regression. Neurocomputing 2022, 506, 146–157. [Google Scholar] [CrossRef]
- Wu, H.; Wu, H.; Sun, Y.; Yan, C. Pilot Workload Assessment Based on Improved KNN Algorithms. Aeronaut. Comput. Tech. 2022, 52, 77–81. [Google Scholar]
- Zhang, X.; Jing, M.; Yuan, Y.; Yin, Y.; Li, K.; Wang, C. Tomato seedling classification detection using improved YOLOv3-Tiny. Trans. Chin. Soc. Agric. Eng. 2022, 38, 221–229. [Google Scholar]
- Zhou, H.; Jin, S.; Zhou, L.; Guo, Z.; Sun, M. Recognizing of camellia oleifera fruits in natural environment using multi-modal images. Trans. Chin. Soc. Agric. Eng. 2023, 39, 175–182. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Zand, M.; Etemad, A.; Greenspan, M. ObjectBox: From Centers to Boxes for Anchor-Free Object Detection. Eur. Conf. Comput. Vis. 2022, 13670, 390–406. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision-ECCV, Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; Volume 9905, pp. 21–37. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Grdient-based Localization. Int. J. Comput. Vis. 2020, 128, 336–359. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experiment | Data Augmentation | EMA | Small Object Detection | EIoU | mAP |
|---|---|---|---|---|---|
| A | 79.9% | ||||
| B | √ | 81.5% | |||
| C | √ | √ | 82.6% | ||
| D | √ | √ | √ | 83.5% | |
| E | √ | √ | √ | √ | 84.1% |
| Target-Detection Model | mAP | P | R | F1 | mAP@.5:95 |
|---|---|---|---|---|---|
| SDD-VGG | 0.540 | 0.933 | 0.170 | 0.288 | 0.225 |
| YOLOv3 | 0.739 | 0.820 | 0.665 | 0.734 | 0.370 |
| YOLOv4s | 0.749 | 0.813 | 0.650 | 0.722 | 0.364 |
| YOLOv5n | 0.685 | 0.787 | 0.610 | 0.687 | 0.312 |
| YOLOv7n | 0.769 | 0.793 | 0.697 | 0.742 | 0.371 |
| YOLOv7-Peach | 0.804 | 0.793 | 0.730 | 0.760 | 0.396 |
| YOLOv8n | 0.799 | 0.821 | 0.708 | 0.760 | 0.418 |
| ObjectBox | 0.699 | 0.838 | 0.614 | 0.709 | 0.339 |
| EMA-YOLO(ours) | 0.841 | 0.836 | 0.744 | 0.787 | 0.447 |
| Models | Different Conditions | Scenario | Ground Truth | Predicted | Missed |
|---|---|---|---|---|---|
| YOLOv8 | Short distance | (a) | 8 | 8 | 0 |
| (b) | 4 | 3 | 1 | ||
| Moderate distance | (a) | 12 | 9 | 3 | |
| (b) | 21 | 18 | 3 | ||
| Long distance | (a) | 21 | 14 | 7 | |
| (b) | 43 | 33 | 10 | ||
| EMA-YOLO(ours) | Short distance | (a) | 8 | 8 | 0 |
| (b) | 4 | 4 | 0 | ||
| Moderate distance | (a) | 12 | 10 | 2 | |
| (b) | 21 | 20 | 1 | ||
| Long distance | (a) | 21 | 20 | 1 | |
| (b) | 43 | 41 | 2 |
| Models | Different Conditions | Scenario | Ground Truth | Predicted | Missed |
|---|---|---|---|---|---|
| YOLOv8 | Strong light | (a) | 7 | 6 | 1 |
| (b) | 12 | 12 | 0 | ||
| Moderate light | (a) | 12 | 11 | 1 | |
| (b) | 14 | 12 | 2 | ||
| Dim light | (a) | 35 | 28 | 7 | |
| (b) | 33 | 23 | 10 | ||
| EMA-YOLO(ours) | Strong light | (a) | 7 | 7 | 0 |
| (b) | 12 | 12 | 0 | ||
| Moderate light | (a) | 12 | 12 | 0 | |
| (b) | 14 | 13 | 1 | ||
| Dim light | (a) | 35 | 32 | 3 | |
| (b) | 33 | 31 | 2 |
| Models | Different Conditions | Scenario | Ground Truth | Predicted | Missed |
|---|---|---|---|---|---|
| YOLOv8 | Sparse | (a) | 12 | 12 | 0 |
| (b) | 7 | 5 | 2 | ||
| Moderately dense | (a) | 40 | 35 | 5 | |
| (b) | 42 | 36 | 6 | ||
| Extremely dense | (a) | 167 | 145 | 22 | |
| (b) | 131 | 117 | 14 | ||
| EMA-YOLO(ours) | Sparse | (a) | 12 | 12 | 0 |
| (b) | 7 | 7 | 0 | ||
| Moderately dense | (a) | 40 | 38 | 2 | |
| (b) | 42 | 40 | 2 | ||
| Extremely dense | (a) | 167 | 162 | 5 | |
| (b) | 131 | 127 | 4 |
| Model and Module | Params/M | FLOPs/G |
|---|---|---|
| YOLOv8n(X) | 12.04 | 8.9 |
| X+P2 Detect(Y) | 12.79 | 17.4 |
| Y+EMA(Z) | 12.80 | 17.6 |
| Z+EIoU | 12.80 | 17.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, D.; Xiong, H.; Liao, Y.; Wang, H.; Yuan, Z.; Yin, H. EMA-YOLO: A Novel Target-Detection Algorithm for Immature Yellow Peach Based on YOLOv8. Sensors 2024, 24, 3783. https://doi.org/10.3390/s24123783
Xu D, Xiong H, Liao Y, Wang H, Yuan Z, Yin H. EMA-YOLO: A Novel Target-Detection Algorithm for Immature Yellow Peach Based on YOLOv8. Sensors. 2024; 24(12):3783. https://doi.org/10.3390/s24123783
Chicago/Turabian StyleXu, Dandan, Hao Xiong, Yue Liao, Hongruo Wang, Zhizhang Yuan, and Hua Yin. 2024. "EMA-YOLO: A Novel Target-Detection Algorithm for Immature Yellow Peach Based on YOLOv8" Sensors 24, no. 12: 3783. https://doi.org/10.3390/s24123783
APA StyleXu, D., Xiong, H., Liao, Y., Wang, H., Yuan, Z., & Yin, H. (2024). EMA-YOLO: A Novel Target-Detection Algorithm for Immature Yellow Peach Based on YOLOv8. Sensors, 24(12), 3783. https://doi.org/10.3390/s24123783