
Virtual Sensing of Key Variables in the Hydrogen Production Process: A Comparative Study of Data-Driven Models


Abstract
1. Introduction
- (1)
- The developed DVBPCA considers both process dynamics and transportation delays of energies and materials. Concretely, the finite impulse response (FIR) method is employed to model the dynamics of the hydrogen production process. And the transportation delays related to the EVs are automatically determined by differential evolution (DE). Moreover, the DVBPCA is able to make full use of the correlations between KVs for performance enhancement.
- (2)
- The moving window (MW) approach is employed for updating the DVBPCA with the latest online process information, which effectively captures the time-varying characteristics of the hydrogen production process in real-time.
- (3)
- A comparative study of data-driven virtual sensors is implemented for the hydrogen production process, which is sparsely mentioned in the predecessors’ research. Furthermore, the performance of the developed MW-DVBPCA is verified by the real-life natural gas steam reforming hydrogen production process.
2. Variational Inference
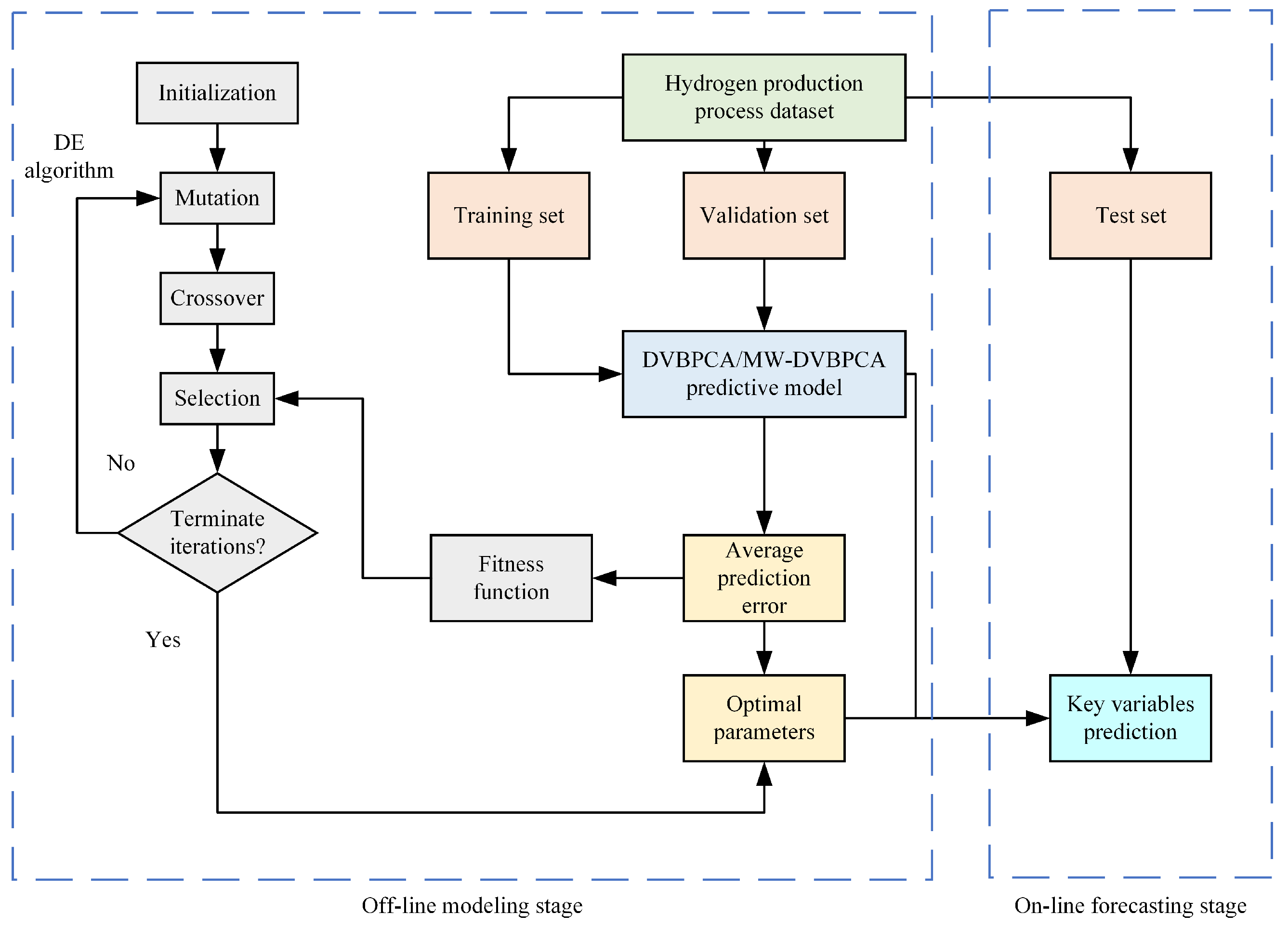
3. Dynamic Variational Bayesian Principal Component Analysis Based on Moving Window
3.1. Time-Delayed Moving Average Model
3.2. Dynamic Variational Bayesian Principal Component Analysis
| Algorithm 1 Pseudocode for the DVBPCA. |
|
3.3. Moving Window-Based Dynamic Variational Bayesian Principal Component Analysis
3.4. Differential Evolutionary-Based Model Selection
4. Case Studies and Comparisons
4.1. Natural Gas Steam Reforming Hydrogen Production Process
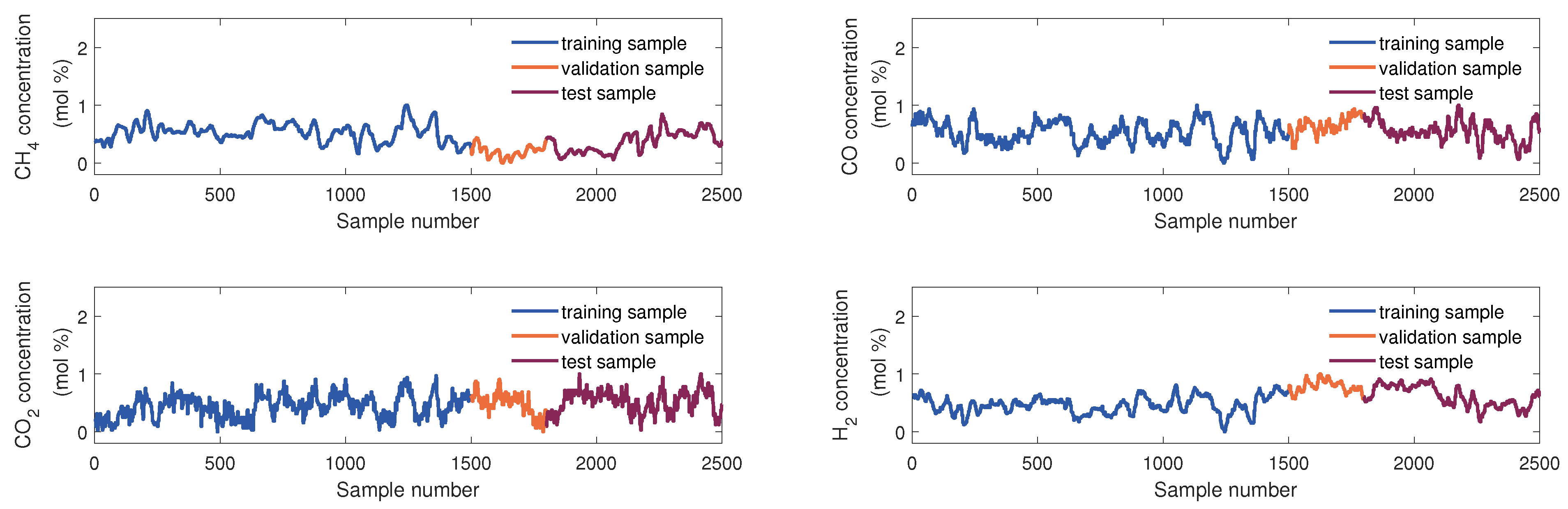
4.2. Explanatory Variable Selection and Data Collection
4.3. Evaluation Metrics
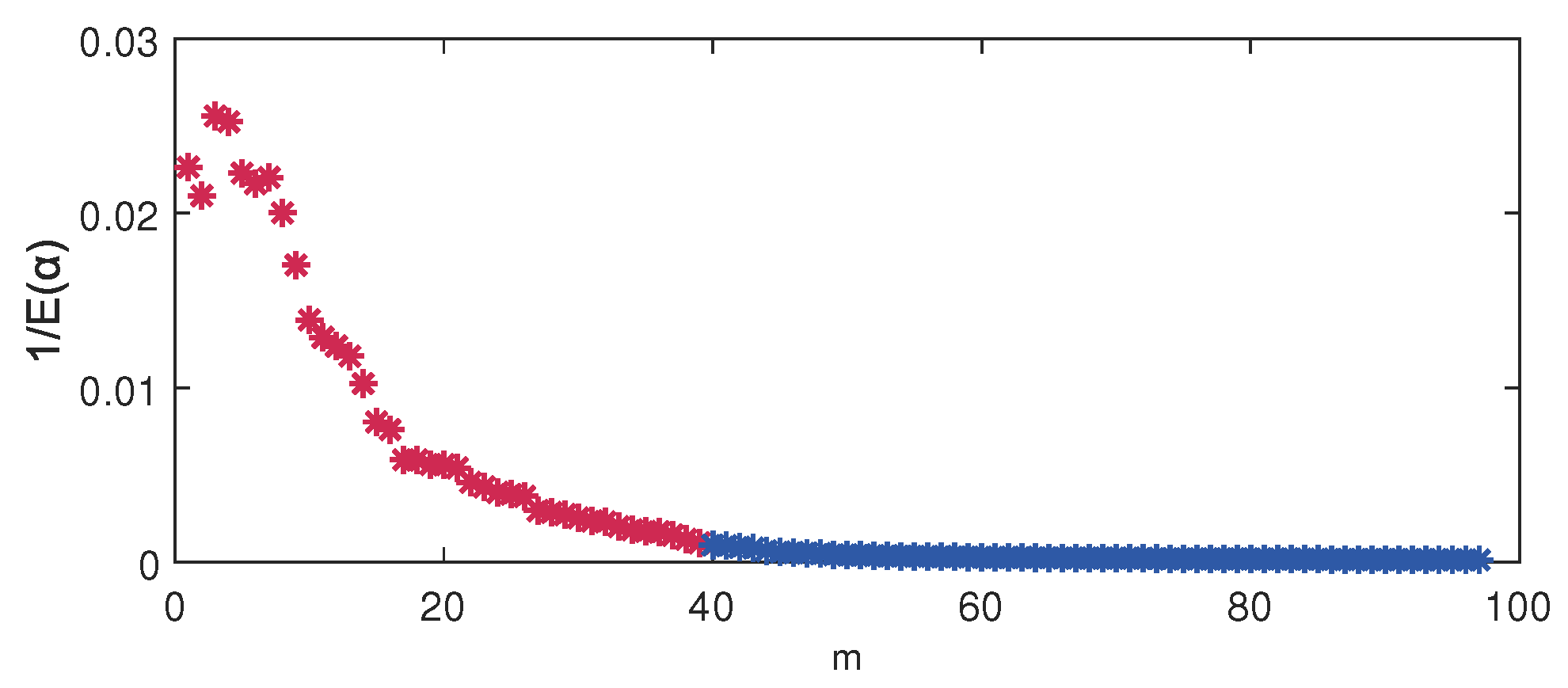
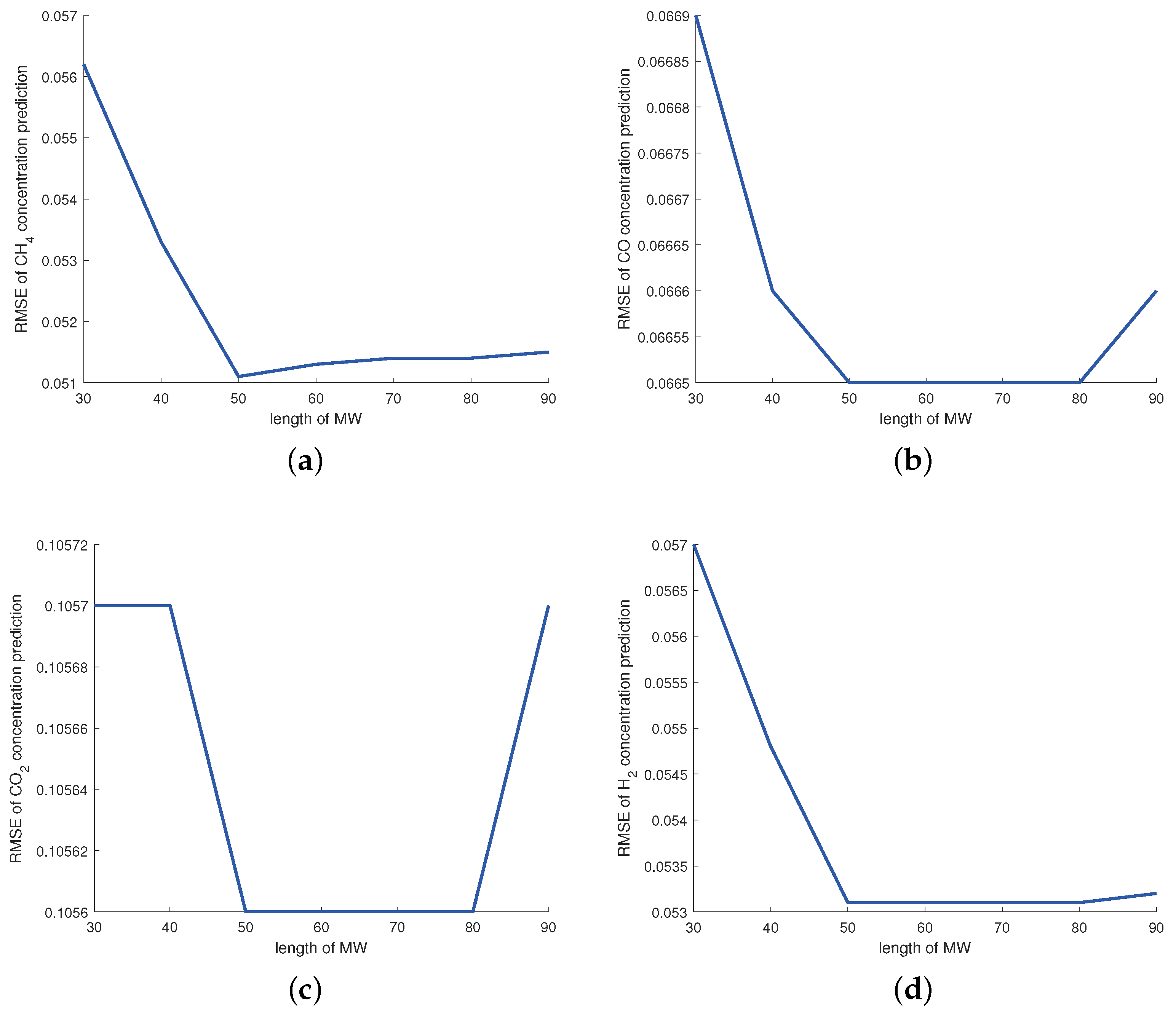
4.4. Parameter Selection
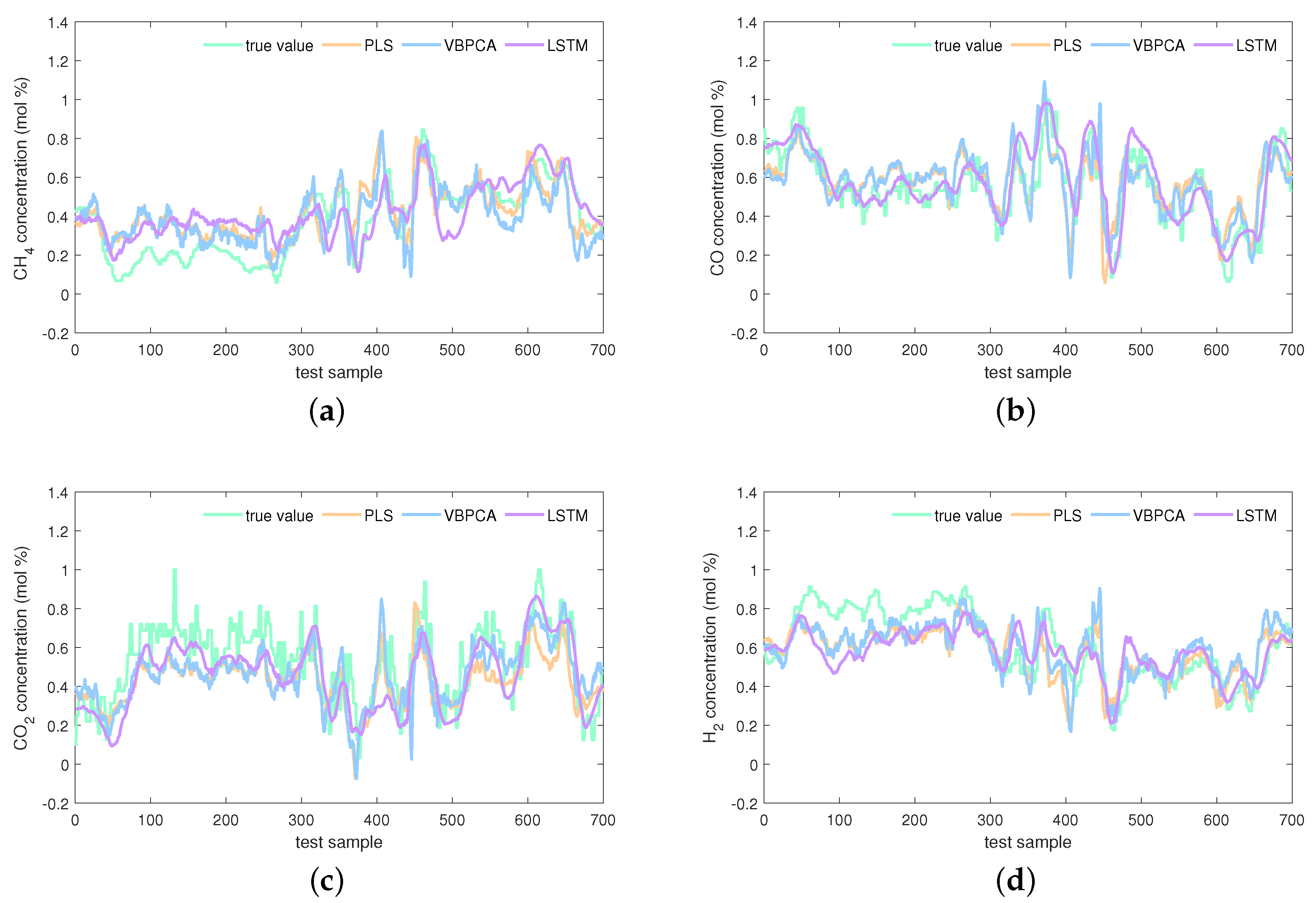
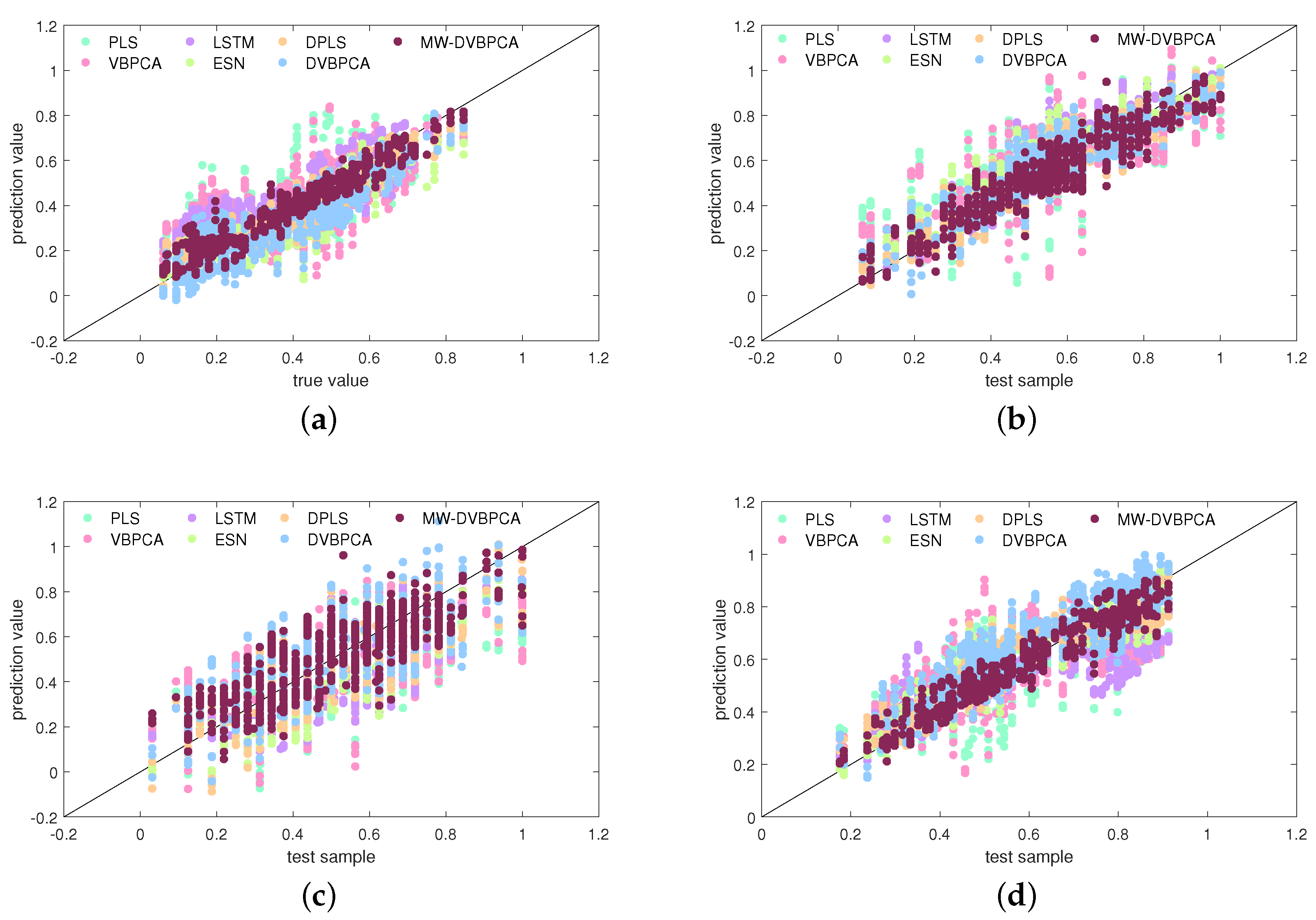
4.5. Results and Analysis
4.6. Computational Efficiency Analysis
5. Conclusions and Outlook
- Robust methods. The probabilistic model in this article is based on the traditional Gaussian distribution assumption, which is susceptible to outliers. Therefore, the training set must be cleaned to remove outliers. However, some outliers are indistinctive and challenging to detect and remove. To this end, finding a probability distribution insensitive to the noise and outliers can help improve the generalization performance of predictive models. Typically, Student’s t distribution with heavier tails is a candidate choice. As a result, designing a robust virtual sensor based on Student’s t distribution is worth investigating.
- Data-driven approaches fused with process knowledge. In fact, the states (or the hidden variables) of the system are influenced by variables characterizing materials and energies fed into the process. Conventional virtual sensors take all observed variables as inputs and the KVs as outputs, which makes it difficult to describe the true causality between variables of the hydrogen production process, weakening the interpretability and generalization abilities. A causal virtual sensor can better reflect the process mechanism and thus estimate the KVs more accurately. Therefore, equipping the MW-DVBPCA model with the causality of process variables of the hydrogen production process is desirable.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lee, C.; Li, S.; Chen, C.; Huang, Y.; Wang, Y. Real-time microscopic monitoring of flow, voltage and current in the proton exchange membrane water electrolyzer. Sensors 2018, 18, 867. [Google Scholar] [CrossRef] [PubMed]
- Ji, M.; Wang, J. Review and comparison of various hydrogen production methods based on costs and life cycle impact assessment indicators. Int. J. Hydrogen Energy 2021, 46, 38612–38635. [Google Scholar] [CrossRef]
- Chen, Y. Technical progress and development trend of hydrogen production from natural gas. Coal Chem. Ind. 2020, 43, 130–133. [Google Scholar]
- Yao, L.; Ge, Z. Deep learning of semisupervised process data with hierarchical extreme learning machine and soft sensor application. IEEE Trans. Ind. Electron. 2017, 65, 1490–1498. [Google Scholar] [CrossRef]
- Cao, Q.; Chen, S.; Zhang, D.; Xiang, W. Research on soft sensing modeling method of gas turbine’s difficult-to-measure parameters. J. Mech. Sci. Technol. 2022, 36, 4269–4277. [Google Scholar] [CrossRef]
- Dogan, A.; Birant, D. Machine learning and data mining in manufacturing. Expert Syst. Appl. 2021, 166, 114060. [Google Scholar] [CrossRef]
- Suthar, K.; Shah, D.; Wang, J.; He, Q.P. Next-generation virtual metrology for semiconductor manufacturing: A feature-based framework. Comput. Chem. Eng. 2019, 127, 140–149. [Google Scholar] [CrossRef]
- Liu, C.; Wang, K.; Wang, Y.; Xie, S.; Yang, C. Deep nonlinear dynamic feature extraction for quality prediction based on spatiotemporal neighborhood preserving SAE. IEEE Trans. Instrum. Meas. 2021, 70, 1–10. [Google Scholar] [CrossRef]
- Sadeghian, A.; Jan, N.M.; Wu, O.; Huang, B. Robust probabilistic principal component regression with switching mixture Gaussian noise for soft sensing. Chemom. Intell. Lab. Syst. 2022, 222, 104491. [Google Scholar] [CrossRef]
- Shao, W.; Ge, Z.; Song, Z. Semisupervised Bayesian Gaussian mixture models for non-Gaussian soft sensor. IEEE Trans. Cybern. 2019, 51, 3455–3468. [Google Scholar] [CrossRef]
- Yang, F.; Liang, Q.; Zhao, J.; Qiao, R. Hydrogen production from ammonia pyrolysis reforming and prediction model of ammonia decomposition rate. J. Ordnance Equip. Eng. 2022, 43, 277–280,285. [Google Scholar]
- Huang, X.; Zhao, B.; Zhang, H.; Zhang, R.; Wang, B.; Liu, H. Parameters research for hydrogen production of methane steam reforming under concentrated radiation. Chem. Eng. Oil Gas. 2021, 50, 58–65. [Google Scholar]
- Zhou, H.; Ma, Y.; Wang, K.; Li, H.; Meng, W.; Xie, J.; Li, G.; Zhang, D.; Wang, D.; Zhao, Y. Optimization and analysis of coal-to-methanol process by integrating chemical looping air separation and hydrogen technology. Chem. Ind. Eng. Prog. 2022, 41, 5332–5341. [Google Scholar]
- Yin, S.; Rodriguez-Andina, J.J.; Jiang, Y. Real-Time Monitoring and Control of Industrial Cyberphysical Systems: With Integrated Plant-Wide Monitoring and Control Framework. IEEE Ind. Electron. Mag. 2019, 13, 38–47. [Google Scholar] [CrossRef]
- Ye, Y.; Ren, J.; Wu, X.; Ou, G.; Jin, H. Data-driven soft-sensor modelling for air cooler system pH values based on a fast search pruned-extreme learning machine. Asia-Pac. J. Chem. Eng. 2017, 12, 186–195. [Google Scholar] [CrossRef]
- Yuan, X.; Qi, S.; Shardt, Y.A.; Wang, Y.; Yang, C.; Gui, W. Soft sensor model for dynamic processes based on multichannel convolutional neural network. Chemom. Intell. Lab. Syst. 2020, 203, 104050. [Google Scholar] [CrossRef]
- Wei, C.; Song, Z. Real-time forecasting of subsurface inclusion defects for continuous casting slabs: A data-driven comparative study. Sensors 2023, 23, 5415. [Google Scholar] [CrossRef]
- Tong, W.; Wei, B. Soft sensing modeling of methane content in conversion reaction based on GA-BP. Automat. Instrum. 2016, 31, 7–10. [Google Scholar]
- Zamaniyan, A.; Joda, F.; Behroozsarand, A.; Ebrahimi, H. Application of artificial neural networks (ANN) for modeling of industrial hydrogen plant. Int. J. Hydrogen Energy 2013, 38, 6289–6297. [Google Scholar] [CrossRef]
- Ögren, Y.; Tóth, P.; Garami, A.; Sepman, A.; Wiinikka, H. Development of a vision-based soft sensor for estimating equivalence ratio and major species concentration in entrained flow biomass gasification reactors. Appl. Energy 2018, 226, 450–460. [Google Scholar] [CrossRef]
- Fang, X.; Ding, Z.; Shu, X. Hydrogen yield prediction model of hydrogen production from low rank coal based on support vector machine optimized by genetic algorithm. J. China Coal Soc. 2010, 35, 205–209. [Google Scholar]
- Zhao, Y.; Song, H.; Guo, Y.; Zhao, L.; Sun, H. Super short term combined power prediction for wind power hydrogen production. Energy Rep. 2022, 8, 1387–1395. [Google Scholar] [CrossRef]
- Koc, R.; Kazantzis, N.K.; Ma, Y.H. A process dynamic modeling and control framework for performance assessment of Pd/alloy-based membrane reactors used in hydrogen production. Int. J. Hydrogen Energy 2011, 36, 4934–4951. [Google Scholar] [CrossRef]
- Pan, F.; Cheng, X.; Wu, X.; Wang, X.; Gong, J. Thermodynamic design and performance calculation of the thermochemical reformers. Energies 2019, 12, 3693. [Google Scholar] [CrossRef]
- Sharma, Y.C.; Kumar, A.; Prasad, R.; Upadhyay, S.N. Ethanol steam reforming for hydrogen production: Latest and effective catalyst modification strategies to minimize carbonaceous deactivation. Renew. Sustain. Energy Rev. 2017, 74, 89–103. [Google Scholar] [CrossRef]
- Blei, D.M.; Kucukelbir, A.; McAuliffe, J.D. Variational inference: A review for statisticians. J. Am. Stat. Assoc. 2017, 112, 859–877. [Google Scholar] [CrossRef]
- Oh, H.S.; Kim, D.G. Bayesian principal component analysis with mixture priors. J. Korean Stat. Soc. 2010, 39, 387–396. [Google Scholar] [CrossRef]
- Liu, Y.; Hu, N.; Wang, H.; Li, P. Soft chemical analyzer development using adaptive least-squares support vector regression with selective pruning and variable moving window size. Ind. Eng. Chem. Res. 2009, 48, 5731–5741. [Google Scholar] [CrossRef]
- Yao, L.; Ge, Z. Refining data-driven soft sensor modeling framework with variable time reconstruction. J. Process Control 2020, 87, 91–107. [Google Scholar] [CrossRef]
- Geladi, P.; Kowalski, B.R. Partial least-squares regression: A tutorial. Anal. Chim. Acta 1986, 185, 1–17. [Google Scholar] [CrossRef]
- Sherstinsky, A. Fundamentals of recurrent neural network (RNN) and long short-term memory (LSTM) network. Phys. D 2020, 404, 132306. [Google Scholar] [CrossRef]
- Chen, Q.; Zhang, A.; Huang, T.; He, Q.; Song, Y. Imbalanced dataset-based echo state networks for anomaly detection. Neural Comput. Appl. 2020, 32, 3685–3694. [Google Scholar] [CrossRef]
- Ricker, N.L. The use of biased least-squares estimators for parameters in discrete-time pulse-response models. Ind. Eng. Chem. Res. 1988, 27, 343–350. [Google Scholar] [CrossRef]
- Shao, W.; Ge, Z.; Yao, L.; Song, Z. Bayesian nonlinear Gaussian mixture regression and its application to virtual sensing for multimode industrial processes. IEEE Trans. Automat. Sci. Eng. 2019, 17, 871–885. [Google Scholar] [CrossRef]
- Rodríguez-Fdez, I.; Canosa, A.; Mucientes, M.; Bugarín, A. STAC: A web platform for the comparison of algorithms using statistical tests. In Proceedings of the 2015 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), Istanbul, Turkey, 2–5 August 2015. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| EV | Description |
|---|---|
| U1 | Flow of fuel natural gas into primary reformer |
| U2 | Flow of fuel off gas into primary reformer |
| U3 | Pressure of fuel off gas at the exit of heat exchanger 3 |
| U4 | Pressure of furnace flue gas at primary reformer’s exit |
| U5 | Temperature of fuel off gas at the exit of heat exchanger 3 |
| U6 | Temperature of fuel natural gas at pre-heater’s exit |
| U7 | Temperature of process gas at primary reformer’s entrance |
| U8 | Temperature of furnace flue gas at primary reformer’s top left |
| U9 | Temperature of furnace flue gas at primary reformer’s top right |
| U10 | Temperature of mixed furnace flue gas at primary reformer’s top |
| U11 | Temperature of transformed gas at primary reformer’s left exit |
| U12 | Temperature of transformed gas at primary reformer’s right exit |
| U13 | Temperature of transformed gas at primary reformer’s exit |
| RMSE | MAE | RMSE | MAE | ||||
|---|---|---|---|---|---|---|---|
| ➀ | PLS | 0.1915 | −0.1329 | 0.1643 | 0.1944 | −0.0975 | 0.1483 |
| VBPCA | 0.2061 | −0.2566 | 0.1703 | 0.2054 | −0.2259 | 0.1592 | |
| LSTM | 0.1567 | 0.2733 | 0.1373 | 0.1351 | 0.5370 | 0.1080 | |
| ESN | 0.1150 | 0.6088 | 0.0965 | 0.1148 | 0.6173 | 0.0968 | |
| DPLS | 0.0942 | 0.7373 | 0.0770 | 0.0956 | 0.7348 | 0.0764 | |
| DVBPCA | 0.0827 | 0.7975 | 0.0704 | 0.0826 | 0.8018 | 0.0662 | |
| MW-DVBPCA | 0.0525 | 0.9186 | 0.0388 | 0.0709 | 0.8538 | 0.0533 | |
| ➁ | PLS | 0.1348 | 0.4623 | 0.1077 | 0.1352 | 0.4687 | 0.1067 |
| VBPCA | 0.1339 | 0.4694 | 0.1092 | 0.1315 | 0.4976 | 0.1052 | |
| LSTM | 0.1227 | 0.5543 | 0.1051 | 0.0829 | 0.8128 | 0.0606 | |
| ESN | 0.0955 | 0.7301 | 0.0759 | 0.0912 | 0.7582 | 0.0730 | |
| DPLS | 0.0777 | 0.8215 | 0.0647 | 0.0732 | 0.8444 | 0.0587 | |
| DVBPCA | 0.0673 | 0.8659 | 0.0536 | 0.0719 | 0.8497 | 0.0574 | |
| MW-DVBPCA | 0.0511 | 0.9228 | 0.0368 | 0.0665 | 0.8717 | 0.0515 | |
| RMSE | MAE | RMSE | MAE | ||||
|---|---|---|---|---|---|---|---|
| ➀ | PLS | 0.1930 | 0.0095 | 0.1536 | 0.1882 | −0.0729 | 0.1612 |
| VBPCA | 0.1913 | 0.0264 | 0.1521 | 0.1973 | −0.1792 | 0.1660 | |
| LSTM | 0.1562 | 0.3949 | 0.1293 | 0.1302 | 0.4863 | 0.1118 | |
| ESN | 0.1152 | 0.6471 | 0.0946 | 0.1057 | 0.6616 | 0.0895 | |
| DPLS | 0.1346 | 0.5185 | 0.1099 | 0.0955 | 0.7237 | 0.0779 | |
| DVBPCA | 0.1145 | 0.6514 | 0.0906 | 0.0796 | 0.8080 | 0.0676 | |
| MW-DVBPCA | 0.1103 | 0.6765 | 0.0858 | 0.0548 | 0.9090 | 0.0425 | |
| ➁ | PLS | 0.1724 | 0.2094 | 0.1400 | 0.1320 | 0.4722 | 0.1090 |
| VBPCA | 0.1648 | 0.2777 | 0.1361 | 0.1289 | 0.4964 | 0.1065 | |
| LSTM | 0.1352 | 0.5137 | 0.1094 | 0.1292 | 0.4943 | 0.1015 | |
| ESN | 0.1230 | 0.5978 | 0.1007 | 0.0823 | 0.7948 | 0.0678 | |
| DPLS | 0.1156 | 0.6448 | 0.0934 | 0.0790 | 0.8107 | 0.0669 | |
| DVBPCA | 0.1119 | 0.6670 | 0.0859 | 0.0752 | 0.8285 | 0.0605 | |
| MW-DVBPCA | 0.1056 | 0.7036 | 0.0835 | 0.0531 | 0.9146 | 0.0403 | |
| KV | Hypothesis | Decision | |
|---|---|---|---|
| concentration | |||
| concentration | |||
| concentration | |||
| concentration | |||
| PLS | 3.44 | <0.01 |
| VBPCA | 11.49 | <0.01 |
| LSTM | 3893.01 | 0.04 |
| ESN | 264.38 | <0.01 |
| DPLS | 255.83 | <0.01 |
| DVBPCA | 210.16 | <0.01 |
| MW-DVBPCA | 1877.91 | 0.06 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yao, Y.; Xing, Y.; Zuo, Z.; Wei, C.; Shao, W. Virtual Sensing of Key Variables in the Hydrogen Production Process: A Comparative Study of Data-Driven Models. Sensors 2024, 24, 3143. https://doi.org/10.3390/s24103143
Yao Y, Xing Y, Zuo Z, Wei C, Shao W. Virtual Sensing of Key Variables in the Hydrogen Production Process: A Comparative Study of Data-Driven Models. Sensors. 2024; 24(10):3143. https://doi.org/10.3390/s24103143
Chicago/Turabian StyleYao, Yating, Yupeng Xing, Ziteng Zuo, Chihang Wei, and Weiming Shao. 2024. "Virtual Sensing of Key Variables in the Hydrogen Production Process: A Comparative Study of Data-Driven Models" Sensors 24, no. 10: 3143. https://doi.org/10.3390/s24103143
APA StyleYao, Y., Xing, Y., Zuo, Z., Wei, C., & Shao, W. (2024). Virtual Sensing of Key Variables in the Hydrogen Production Process: A Comparative Study of Data-Driven Models. Sensors, 24(10), 3143. https://doi.org/10.3390/s24103143