

Novel Approach Combining Shallow Learning and Ensemble Learning for the Automated Detection of Swallowing Sounds in a Clinical Database

 , ,
, ,
Abstract
1. Introduction
2. Proposed Method
2.1. Recording Database
2.2. Detection of Loud Events from Recorded Data
2.3. Feature Extraction
2.4. Classification of Loud Events Using Machine Learning Models
2.4.1. Support Vector Machine
2.4.2. Multi-Layer Perceptron
2.4.3. Ensemble Learning Model
2.5. Evaluation of Loud Event Classification with K-Fold Cross-Validation
3. Results
Results of Evaluating Performance of Swallowing-Sound and Non-Swallowing-Sound Event Classification System
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Clavé, P.; Terré, R.; de Kraa, M.; Serra, M. Approaching Oropharyngeal Dysphagia. Rev. Esp. Enferm. Dig. 2004, 96, 119–131. [Google Scholar] [CrossRef] [PubMed]
- Aslam, M.; Vaezi, M.F. Dysphagia in the Elderly. Gastroenterol. Hepatol. 2013, 9, 784–795. [Google Scholar]
- Sura, L.; Madhavan, A.; Carnaby, G.; Crary, M.A. Dysphagia in the Elderly: Management and Nutritional Considerations. Clin. Interv. Aging 2012, 7, 287–298. [Google Scholar] [PubMed]
- Nawaz, S.; Tulunay-Ugur, O.E. Dysphagia in the Older Patient. Otolaryngol. Clin. N. Am. 2018, 51, 769–777. [Google Scholar] [CrossRef] [PubMed]
- Kertscher, B.; Speyer, R.; Palmieri, M.; Plant, C. Bedside Screening to Detect Oropharyngeal Dysphagia in Patients with Neurological Disorders: An Updated Systematic Review. Dysphagia 2014, 29, 204–212. [Google Scholar] [CrossRef] [PubMed]
- Walton, J.; Silva, P. Physiology of Swallowing. Surgery 2018, 36, 529–534. [Google Scholar]
- Sherman, V.; Flowers, H.; Kapral, M.K.; Nicholson, G.; Silver, F.; Martino, R. Screening for Dysphagia in Adult Patients with Stroke: Assessing the Accuracy of Informal Detection. Dysphagia 2018, 33, 662–669. [Google Scholar] [CrossRef] [PubMed]
- Giraldo-Cadavid, L.F.; Leal-Leaño, L.R.; Leon-Basantes, G.A.; Bastidas, A.R.; Garcia, R.; Ovalle, S.; Abondano-Garavito, J.E. Accuracy of Endoscopic and Videofluoroscopic Evaluations of Swallowing for Oropharyngeal Dysphagia. Laryngoscope 2017, 127, 2002–2010. [Google Scholar] [CrossRef] [PubMed]
- Fattori, B.; Giusti, P.; Mancini, V.; Grosso, M.; Barillari, M.R.; Bastiani, L.; Molinaro, S.; Nacci, A. Comparison Between Videofluoroscopy, Fiberoptic Endoscopy and Scintigraphy for Diagnosis of Oro-Pharyngeal Dysphagia. Acta Otorhinolaryngol. Ital. 2016, 36, 395–402. [Google Scholar] [CrossRef]
- Wu, C.H.; Hsiao, T.Y.; Chen, J.C.; Chang, Y.C.; Lee, S.Y. Evaluation of Swallowing Safety with Fiberoptic Endoscope: Comparison with Videofluoroscopic Technique. Laryngoscope 1997, 107, 396–401. [Google Scholar]
- Horiguchi, S.; Suzuki, Y. Screening Tests in Evaluating Swallowing Function. JMAJ 2011, 54, 31–34. [Google Scholar]
- Ozaki, K.; Kagaya, H.; Yokoyama, M.; Saitoh, E.; Okada, S.; González-Fernández, M.; Palmer, J.B.; Uematsu, A.H. The Risk of Penetration or Aspiration During Videofluoroscopic Examination of Swallowing Varies Depending on Food Types. Tohoku J. Exp. Med. 2010, 220, 41–46. [Google Scholar] [CrossRef]
- Helliwell, K.; Hughes, V.J.; Bennion, C.M.; Manning-Stanley, A. The Use of Videofluoroscopy (VFS) and Fibreoptic Endoscopic Evaluation of Swallowing (FEES) in the Investigation of Oropharyngeal Dysphagia in Stroke Patients: A Narrative Review. Radiography 2023, 29, 284–290. [Google Scholar] [CrossRef] [PubMed]
- Takahashi, N.; Kikutani, T.; Tamura, F.; Groher, M.; Kuboki, T. Videoendoscopic Assessment of Swallowing Function to Predict the Future Incidence of Pneumonia of the Elderly. J. Oral Rehabil. 2012, 39, 429–437. [Google Scholar] [CrossRef]
- Leslie, P.; Drinnan, M.J.; Finn, P.; Ford, G.A.; Wilson, J.A. Reliability and Validity of Cervical Auscultation: A Controlled Comparison Using Videofluoroscopy. Dysphagia 2004, 19, 231–240. [Google Scholar] [CrossRef]
- Borr, C.; Hielscher-Fastabend, M.; Lücking, A. Reliability and Validity of Cervical Auscultation. Dysphagia 2007, 22, 225–234. [Google Scholar] [CrossRef]
- Lagarde, M.L.J.; Kamalski, D.M.A.; van den Engel-Hoek, L. The Reliability and Validity of Cervical Auscultation in the Diagnosis of Dysphagia: A Systematic Review. Clin. Rehabil. 2016, 30, 199–207. [Google Scholar] [CrossRef]
- Dudik, J.M.; Kurosu, A.; Coyle, J.L.; Sejdić, E. Dysphagia and Its Effects on Swallowing Sounds and Vibrations in Adults. Biomed. Eng. OnLine 2018, 17, 69. [Google Scholar] [CrossRef]
- Takahashi, K.; Groher, M.E.; Michi, K. Methodology for Detecting Swallowing Sounds. Dysphagia 1994, 9, 54–62. [Google Scholar] [CrossRef] [PubMed]
- Rayneau, P.; Bouteloup, R.; Rouf, C.; Makris, P.; Moriniere, S. Automatic Detection and Analysis of Swallowing Sounds in Healthy Subjects and in Patients with Pharyngolaryngeal Cancer. Dysphagia 2021, 36, 984–992. [Google Scholar] [CrossRef]
- Frakking, T.T.; Chang, A.B.; Carty, C.; Newing, J.; Weir, K.A.; Schwerin, B.; So, S. Using an Automated Speech Recognition Approach to Differentiate Between Normal and Aspirating Swallowing Sounds Recorded from Digital Cervical Auscultation in Children. Dysphagia 2022, 37, 1482–1492. [Google Scholar] [CrossRef]
- Sarraf Shirazi, S.; Buchel, C.; Daun, R.; Lenton, L.; Moussavi, Z. Detection of Swallows with Silent Aspiration Using Swallowing and Breath Sound Analysis. Med. Biol. Eng. Comput. 2012, 50, 1261–1268. [Google Scholar] [CrossRef]
- Khlaifi, H.; Istrate, D.; Demongeot, J.; Malouche, D. Swallowing Sound Recognition at Home Using GMM. IRBM 2018, 39, 407–412. [Google Scholar] [CrossRef]
- Kuramoto, N.; Ichimura, K.; Jayatilake, D.; Shimokakimoto, T.; Hidaka, K.; Suzuki, K. Deep Learning-Based Swallowing Monitor for Realtime Detection of Swallow Duration. In Proceedings of the 2020 42nd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Montreal, QC, Canada, 20–24 July 2020; Volume 2020, pp. 4365–4368. [Google Scholar]
- Khalifa, Y.; Coyle, J.L.; Sejdić, E. Non-invasive Identification of Swallows via Deep Learning in High Resolution Cervical Auscultation Recordings. Sci. Rep. 2020, 10, 8704. [Google Scholar] [CrossRef]
- Suzuki, T.; Ogata, J.; Tsunakawa, T.; Nishida, M.; Nishimura, M. Bottleneck Feature-Mediated DNN-Based Feature Mapping for Throat Microphone Speech Recognition. In Proceedings of the 2018 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Honolulu, HI, USA, 12–15 November 2018; pp. 1738–1741. [Google Scholar]
- Yagi, N.; Nagami, S.; Lin, M.K.; Yabe, T.; Itoda, M.; Imai, T.; Oku, Y. A Noninvasive Swallowing Measurement System Using a Combination of Respiratory Flow, Swallowing Sound, and Laryngeal Motion. Med. Biol. Eng. Comput. 2017, 55, 1001–1017. [Google Scholar] [CrossRef] [PubMed]
- Movahedi, F.; Kurosu, A.; Coyle, J.L.; Perera, S.; Sejdić, E. A Comparison Between Swallowing Sounds and Vibrations in Patients with Dysphagia. Comput. Methods Programs Biomed. 2017, 144, 179–187. [Google Scholar] [CrossRef] [PubMed]
- Cichero, J.A.; Murdoch, B.E. The Physiologic Cause of Swallowing Sounds: Answers from Heart Sounds and Vocal Tract Acoustics. Dysphagia 1998, 13, 39–52. [Google Scholar] [CrossRef]
- Ancilin, J.; Milton, A. Improved Speech Emotion Recognition with Mel Frequency Magnitude Coefficient. Appl. Acoust. 2021, 179, 108046. [Google Scholar] [CrossRef]
- Kerkeni, L.; Serrestou, Y.; Mbarki, M.; Raoof, K.; Mahjoub, M.A.; Cleder, C. Automatic Speech Emotion Recognition Using Machine Learning; IntechOpen: London, UK, 2019. [Google Scholar] [CrossRef]
- Nayak, S.S.; Darji, A.D.; Shah, P.K. Machine Learning Approach for Detecting COVID-19 from Speech Signal Using Mel Frequency Magnitude Coefficient. Signal Image Video Process. 2023, 17, 3155–3162. [Google Scholar] [CrossRef]
- Zhao, H.; Jiang, Y.; Wang, S.; He, F.; Ren, F.; Zhang, Z.; Yang, X.; Zhu, C.; Yue, J.; Li, Y.; et al. Dysphagia Diagnosis System with Integrated Speech Analysis from Throat Vibration. Expert Syst. Appl. 2022, 204, 117496. [Google Scholar] [CrossRef]
- Ribeiro, V.H.A.; Reynoso-Meza, G. Ensemble Learning Toolbox: Easily Building Custom Ensembles in MATLAB; Version 1.0.0; MathWorks: Beijing, China, 2020. [Google Scholar]
- Chicco, D.; Jurman, G. The Advantages of the Matthews Correlation Coefficient (MCC) over F1 Score and Accuracy in Binary Classification Evaluation. BMC Genom. 2020, 21, 6. [Google Scholar] [CrossRef] [PubMed]
- Nakamura, A.; Saito, T.; Ikeda, D.; Ohta, K.; Mineno, H.; Nishimura, M. Automatic Detection of Chewing and Swallowing. Sensors 2021, 21, 3378. [Google Scholar] [CrossRef] [PubMed]
- Sazonov, E.S.; Makeyev, O.; Schuckers, S.; Lopez-Meyer, P.; Melanson, E.L.; Neuman, M.R. Automatic Detection of Swallowing Events by Acoustical Means for Applications of Monitoring of Ingestive Behavior. IEEE Trans. Biomed. Eng. 2010, 57, 626–633. [Google Scholar] [CrossRef] [PubMed]
- Jayatilake, D.; Ueno, T.; Teramoto, Y.; Nakai, K.; Hidaka, K.; Ayuzawa, S.; Eguchi, K.; Matsumura, A.; Suzuki, K. Smartphone-Based Real-Time Assessment of Swallowing Ability from the Swallowing Sound. IEEE J. Transl. Eng. Health Med. 2015, 3, 2900310. [Google Scholar] [CrossRef] [PubMed]
- Honda, T.; Baba, T.; Fujimoto, K.; Goto, T.; Nagao, K.; Harada, M.; Honda, E.; Ichikawa, T. Characterization of Swallowing Sound: Preliminary Investigation of Normal Subjects. PLoS ONE 2016, 11, e0168187. [Google Scholar] [CrossRef] [PubMed]
- Ohyado, S. Cervical Auscultation. Jpn. J. Gerodontol. 2013, 28, 331. [Google Scholar]
- Miyagi, S.; Sugiyama, S.; Kozawa, K.; Moritani, S.; Sakamoto, S.I.; Sakai, O. Classifying Dysphagic Swallowing Sounds with Support Vector Machines. Healthcare 2020, 8, 103. [Google Scholar] [CrossRef] [PubMed]
- Suzuki, K.; Shimizu, Y.; Ohshimo, S.; Oue, K.; Saeki, N.; Sadamori, T.; Tsutsumi, Y.; Irifune, M.; Shime, N. Real-Time Assessment of Swallowing Sound Using an Electronic Stethoscope and an Artificial Intelligence System. Clin. Exp. Dent. Res. 2022, 8, 225–230. [Google Scholar] [CrossRef]
- Golabbakhsh, M.; Rajaei, A.; Derakhshan, M.; Sadri, S.; Taheri, M.; Adibi, P. Automated Acoustic Analysis in Detection of Spontaneous Swallows in Parkinson’s Disease. Dysphagia 2014, 29, 572–577. [Google Scholar] [CrossRef]
- Santoso, L.F.; Baqai, F.; Gwozdz, M.; Lange, J.; Rosenberger, M.G.; Sulzer, J.; Paydarfar, D. Applying Machine Learning Algorithms for Automatic Detection of Swallowing from Sound. In Proceedings of the 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Berlin, Germany, 23–27 July 2019; pp. 2584–2588. [Google Scholar]
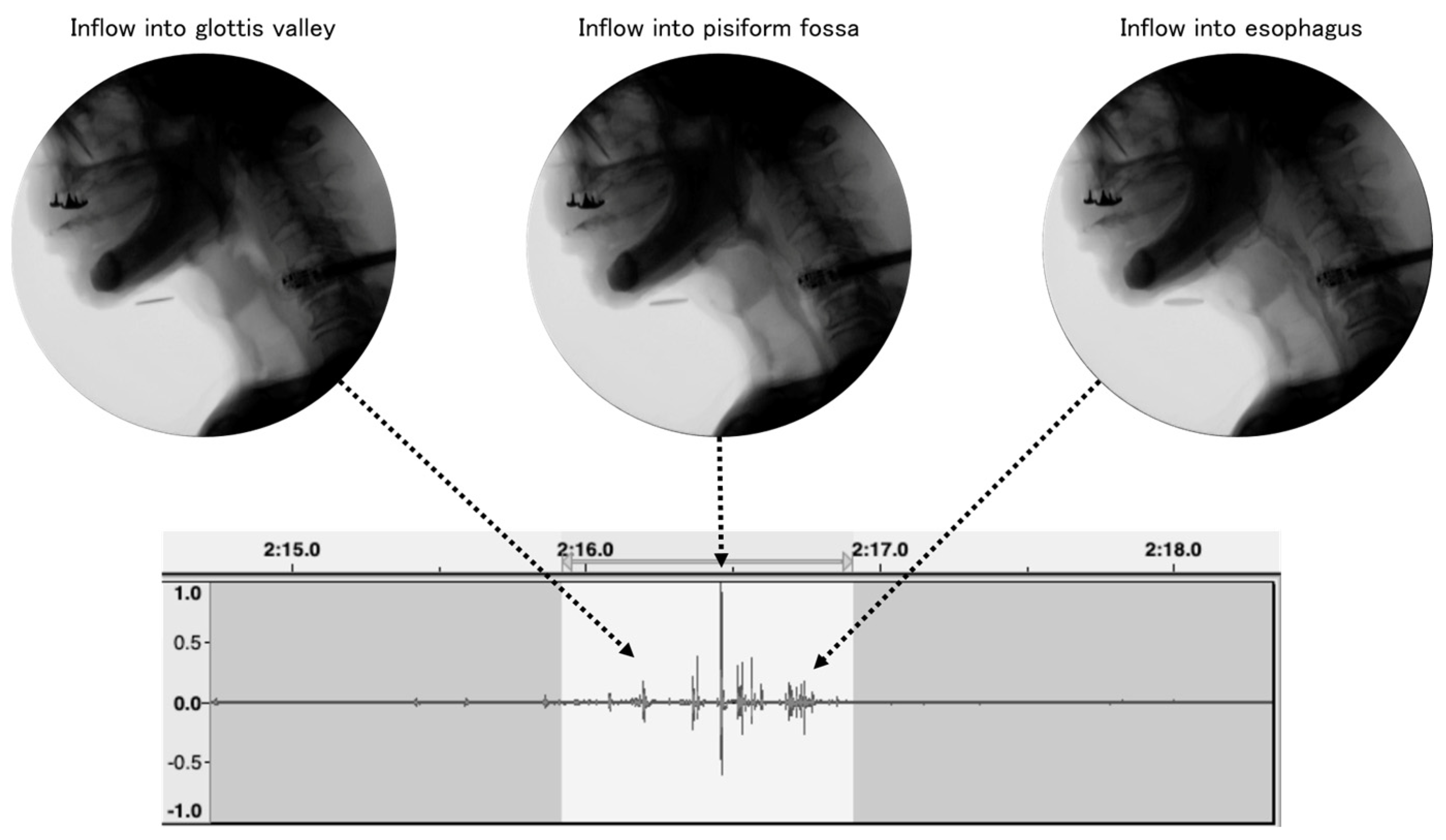
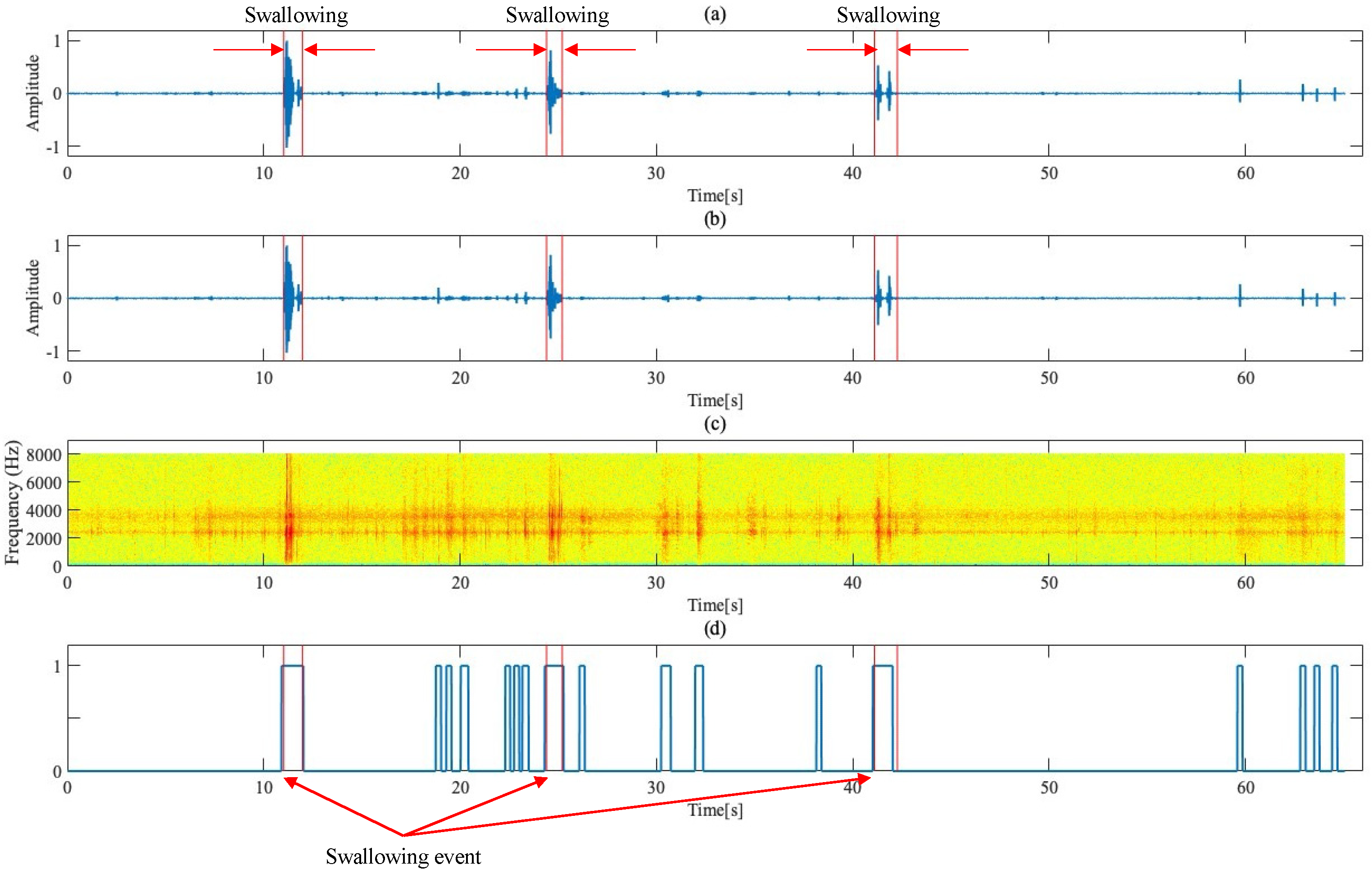



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sound Event | Total |
|---|---|
| Swallowing | 234 |
| Respiration | 41 |
| Cough | 38 |
| Voice·Speech | 224 |
| Environmental sounds, rustling sound | 394 |
| Total | 931 |
| Mean | Standard Deviation | Median | Range | Skewness | Dynamic Features | Number of Feature Dimension | |
|---|---|---|---|---|---|---|---|
| MFCC P1 | ○ | 12 | |||||
| MFCC P2 | ○ | ○ | 24 | ||||
| MFCC P3 | ○ | ○ | ○ | 36 | |||
| MFCC P4 | ○ | ○ | ○ | ○ | 48 | ||
| MFCC P5 | ○ | ○ | ○ | ○ | ○ | 60 | |
| MFCC P6 | ○ | ○ | ○ | ○ | ○ | ○ | 120 |
| MIMC P1 | ● | 40 | |||||
| MFMC P2 | ● | ● | 80 | ||||
| MFMC P3 | ● | ● | ● | 120 | |||
| MFMC P4 | ● | ● | ● | ● | 160 | ||
| MFMC P5 | ● | ● | ● | ● | ● | 200 | |
| MFMC P6 | ● | ● | ● | ● | ● | ● | 400 |
| MIX P1 | ○● | ○● | ○● | ○● | ○● | 260 | |
| MIX P2 | ○● | ○● | ○● | ○● | ○● | ○● | 520 |
| Feature Pattern | SVM | MLP | ELM | |||
|---|---|---|---|---|---|---|
| F1 Score | Accuracy [%] | F1 Score | Accuracy [%] | F1 Score | Accuracy [%] | |
| MFCC P1 | 0.57 | 77.74 | 0.71 | 84.61 | 0.73 h | 86.10 |
| MFCC P2 | 0.84 h | 91.98 | 0.82 | 90.82 | 0.84 h | 92.29 |
| MFCC P3 | 0.85 h | 92.20 | 0.83 | 91.15 | 0.85 h | 92.27 |
| MFCC P4 | 0.87 | 93.79 | 0.88 h | 93.56 | 0.87 | 93.16 |
| MFCC P5 | 0.88 | 93.93 | 0.88 | 94.16 | 0.89 h | 94.23 |
| MFCC P6 | 0.87 | 93.39 | 0.88 h | 94.17 | 0.88 h | 93.91 |
| MFMC P1 | 0.55 | 79.64 | 0.67 | 84.11 | 0.71 h | 84.88 |
| MFMC P2 | 0.78 | 88.74 | 0.80 h | 89.00 | 0.79 | 88.96 |
| MFMC P3 | 0.79 | 89.43 | 0.81 | 90.23 | 0.83 h | 90.61 |
| MFMC P4 | 0.84 | 91.79 | 0.84 | 91.45 | 0.86 h | 93.04 |
| MFMC P5 | 0.87 h | 93.14 | 0.85 | 91.75 | 0.86 | 92.89 |
| MFMC P6 | 0.87 | 93.48 | 0.89 h | 94.66 | 0.89 h | 94.40 |
| MIX P1 | 0.87 | 93.62 | 0.89 h | 94.43 | 0.89 h | 94.16 |
| MIX P2 | 0.88 | 93.88 | 0.89 | 94.77 | 0.90 h | 95.24 |
| Machine Learning Model | Feature Pattern | F1 Score | Accuracy [%] | Sensitivity [%] | Specificity [%] | PPV [%] | NPV [%] |
|---|---|---|---|---|---|---|---|
| SVM | MFCC P5 MIX P2 | 0.88 | 93.93 | 86.65 | 96.26 | 88.78 | 95.43 |
| 0.88 | 93.88 | 87.80 | 96.21 | 88.09 | 95.57 | ||
| MLP | MFMC P6 | 0.89 | 94.66 | 88.89 | 96.64 | 90.09 | 96.22 |
| ELM | MIX P2 | 0.90 | 95.24 | 90.14 | 96.88 | 91.09 | 96.83 |
| Performance Metrics | Class 0 | Class 0 | Class 1 | Class 1 |
|---|---|---|---|---|
| Mean | SD | Mean | SD | |
| Accuracy [%] | 95.2 | 0.7 | 95.2 | 0.7 |
| Sensitivity [%] | 93.74 | 4.67 | 91.66 | 4.34 |
| Specificity [%] | 94.24 | 3.77 | 96.31 | 1.96 |
| F1 score | 0.92 | 0.04 | 0.91 | 0.02 |
| PPV [%] | 89.95 | 5.35 | 89.68 | 4.96 |
| NPV [%] | 96.94 | 1.52 | 97.21 | 1.13 |
| References | Data Sets | Feature Sets | Method | Result |
|---|---|---|---|---|
| Sazonov et al. (2010) [37] | 13 healthy subjects 7 obese subjects | Wavelet Packet Decomposition (WPD) Mel Scale Fourier Spectrum (msFS) | Machine learning (SVM) | Average weighted accuracy 84.7% |
| Jayatilake et al. (2015) [38] | 70 subjects with dysphagia 15 healthy subjects | ― | Based on wavelet transform and zero crossing rate | Accuracy Water swallowing: 79.3% Dry or salvia swallowing: 83.7% |
| Khlaifi et al. (2018) [23] | 14 healthy subjects | Mel Frequency Cepstral Coefficient (MFCC) | Machine learning (GMM) | Recognition rate UTC database: 84.57% Grenoble database: 95.94% |
| Kuramoto et al. (2020) [24] | Healthy subjects and subjects with dysphagia: in total, 226 subject | Spectrogram from swallowing sound | Machine learning (CNN) | Accuracy: 97.3% |
| Ours | 74 subjects with dysphagia | Mel Frequency Cepstrum Coefficient (MFCC) Mel Frequency Magnitude Coefficient (MFMC) | Machine learning (ensemble learning model) | F1-micro average: approximately 0.92 Accuracy: 95.20% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kimura, S.; Emoto, T.; Suzuki, Y.; Shinkai, M.; Shibagaki, A.; Shichijo, F. Novel Approach Combining Shallow Learning and Ensemble Learning for the Automated Detection of Swallowing Sounds in a Clinical Database. Sensors 2024, 24, 3057. https://doi.org/10.3390/s24103057
Kimura S, Emoto T, Suzuki Y, Shinkai M, Shibagaki A, Shichijo F. Novel Approach Combining Shallow Learning and Ensemble Learning for the Automated Detection of Swallowing Sounds in a Clinical Database. Sensors. 2024; 24(10):3057. https://doi.org/10.3390/s24103057
Chicago/Turabian StyleKimura, Satoru, Takahiro Emoto, Yoshitaka Suzuki, Mizuki Shinkai, Akari Shibagaki, and Fumio Shichijo. 2024. "Novel Approach Combining Shallow Learning and Ensemble Learning for the Automated Detection of Swallowing Sounds in a Clinical Database" Sensors 24, no. 10: 3057. https://doi.org/10.3390/s24103057
APA StyleKimura, S., Emoto, T., Suzuki, Y., Shinkai, M., Shibagaki, A., & Shichijo, F. (2024). Novel Approach Combining Shallow Learning and Ensemble Learning for the Automated Detection of Swallowing Sounds in a Clinical Database. Sensors, 24(10), 3057. https://doi.org/10.3390/s24103057