
Accurate Path Loss Prediction Using a Neural Network Ensemble Method


Abstract
1. Introduction
- A neural network ensemble model capable of accurately predicting path loss is proposed. In the proposed model, multiple ANNs are trained with different hyperparameters, including the number of hidden layers, number of neurons in each hidden layer, and type of activation function, thereby enhancing the diversity among the integrated ANNs. The final prediction results of the model were then obtained by integrating the prediction results from the ANNs.
- The entire process of predicting path loss using the proposed method is presented. The dataset splitting, feature scaling, and hyperparameter optimization processes have been detailed. Based on the results of the hyperparameter optimization process, the top-ranking ANNs can be determined. These results and the pseudocode for the proposed method can simplify re-implementation.
- The proposed neural network ensemble model was quantitatively evaluated on a public dataset. Additionally, for benchmarking, nine ML-based path loss prediction methods were tested: SVM, k-NN, RF, decision tree, multiple linear regression, Least Absolute Shrinkage and Selection Operator (LASSO), ridge regression, Elastic Net, and ANNs.
2. Related Work
2.1. Non-ANN-Based Path Loss Prediction
2.2. ANN-Based Path Loss Prediction
3. Proposed Method
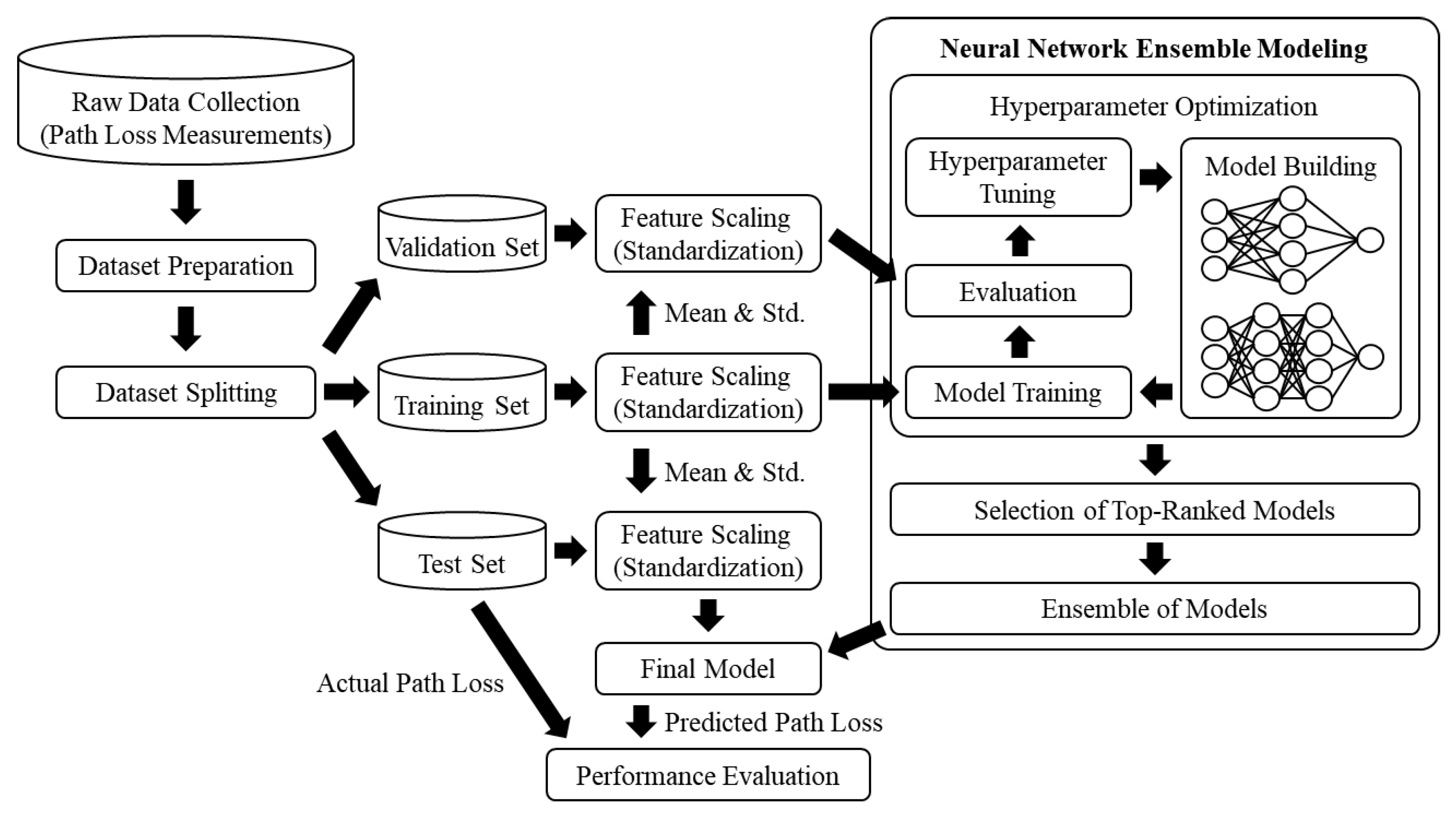
3.1. Overall Process
3.2. Dataset Preparation
3.3. Dataset Splitting and Feature Scaling
3.4. Hyperparameter Optimization
3.5. Ensemble of Artificial Neural Networks
| Algorithm 1 Pseudocode for the proposed neural network ensemble method |
| Input:
Dataset D Output: Final ensemble model E
|
4. Experimental Setup
4.1. Evaluation Metrics
4.2. Implementation of Benchmark Methods
4.2.1. SVM-Based Path Loss Prediction Method
4.2.2. k-NN-Based Path Loss Prediction Method
4.2.3. RF-Based Path Loss Prediction Method
4.2.4. DT-Based Path Loss Prediction Method
4.2.5. MLR-Based Path Loss Prediction Method
4.2.6. LASSO-Based Path Loss Prediction Method
4.2.7. Ridge-Based Path Loss Prediction Method
4.2.8. Elastic Net-Based Path Loss Prediction Method
4.2.9. ANN-Based Path Loss Prediction Method
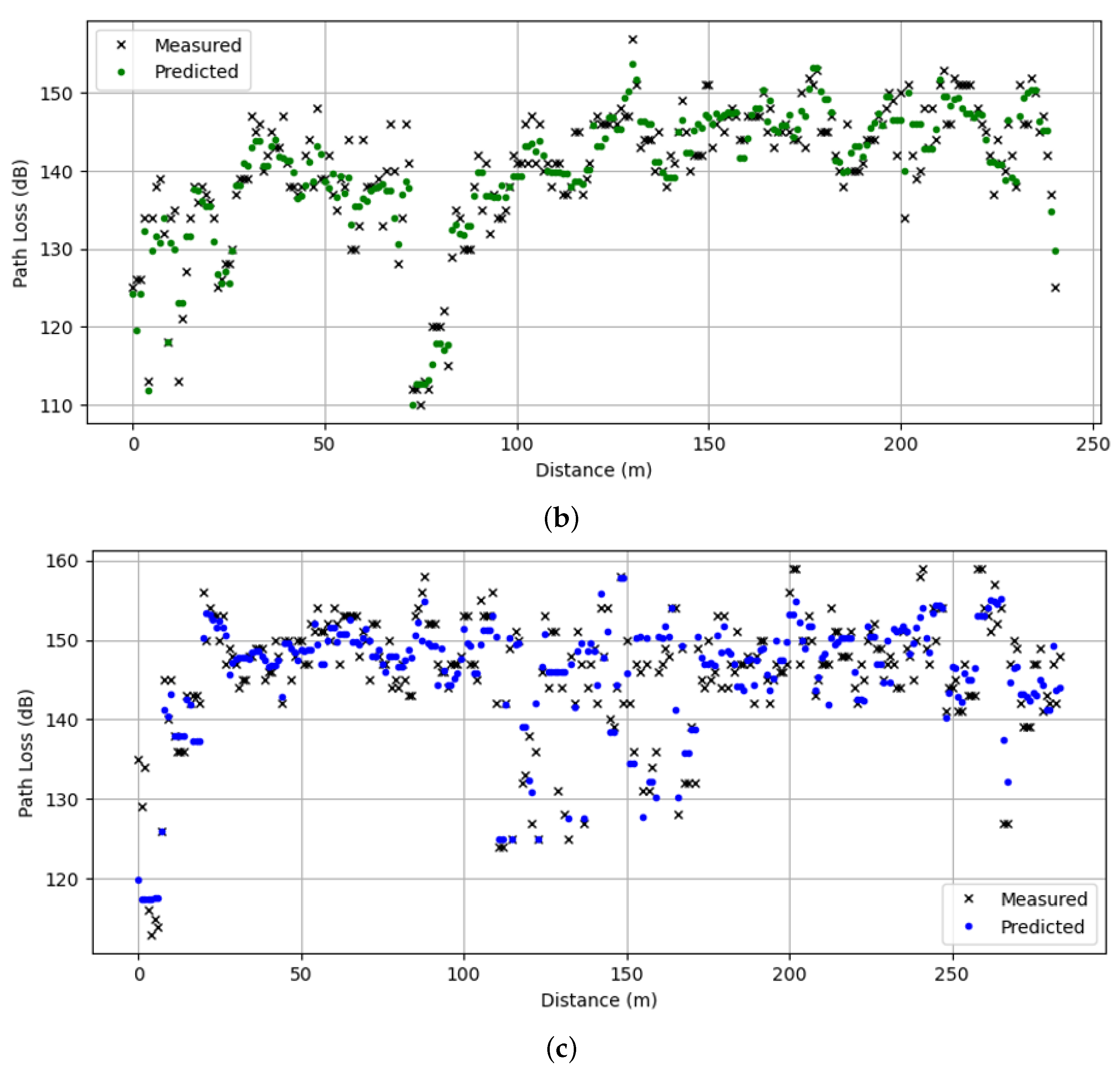
5. Results and Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Son, H.; Lee, S. Bandwidth and region division for broadband multi-cell networks. IEEE Commun. Lett. 2006, 10, 360–362. [Google Scholar]
- Kwon, B.; Kim, S.; Lee, H.; Lee, S. A downlink power control algorithm for long-term energy efficiency of small cell network. Wirel. Netw. 2015, 21, 2223–2236. [Google Scholar] [CrossRef]
- Kwon, B.; Kim, S.; Jeon, D.; Lee, S. Iterative interference cancellation and channel estimation in evolved multimedia broadcast multicast system using filter-bank multicarrier-quadrature amplitude modulation. IEEE Trans. Broadcast. 2016, 62, 864–875. [Google Scholar] [CrossRef]
- Kwon, B.; Kim, S.; Lee, S. Scattered reference symbol-based channel estimation and equalization for FBMC-QAM systems. IEEE Trans. Commun. 2017, 65, 3522–3537. [Google Scholar] [CrossRef]
- Kwon, B.; Lee, S. Cross-antenna interference cancellation and channel estimation for MISO-FBMC/QAM-based eMBMS. Wirel. Netw. 2018, 24, 3281–3293. [Google Scholar] [CrossRef]
- Loh, W.R.; Lim, S.Y.; Rafie, I.F.M.; Ho, J.S.; Tze, K.S. Intelligent base station placement in urban areas with machine learning. IEEE Antennas Wirel. Propag. Lett. 2023, 22, 2220–2224. [Google Scholar] [CrossRef]
- Srinivasa, S.; Haenggi, M. Path loss exponent estimation in large wireless networks. In Proceedings of the IEEE Information Theory and Applications Workshop, La Jolla, CA, USA, 8–13 February 2009; pp. 124–129. [Google Scholar]
- Egli, J.J. Radio propagation above 40 MC over irregular terrain. Proc. IRE 1957, 45, 1383–1391. [Google Scholar] [CrossRef]
- Hata, M. Empirical formula for propagation loss in land mobile radio services. IEEE Trans. Veh. Technol. 1980, 29, 317–325. [Google Scholar] [CrossRef]
- Longley, A.G. Prediction of Tropospheric Radio Transmission Loss over Irregular Terrain: A Computer Method-1968; Institute for Telecommunication Sciences: Boulder, CO, USA, 1968; pp. 1–147. [Google Scholar]
- Okumura, Y. Field strength and its variability in VHF and UHF land-mobile radio service. Rev. Electr. Commun. Lab. 1968, 16, 825–873. [Google Scholar]
- 3GPP. Study on Channel Model for Frequencies from 0.5 to 100 GHz (Release 16) V16.1.0; Technical Report; Rep. TR 38.901; 3GPP: Sophia Antipolis, France, 2020. [Google Scholar]
- Zhu, Q.; Wang, C.X.; Hua, B.; Mao, K.; Jiang, S.; Yao, M. 3GPP TR 38.901 Channel Model. In The Wiley 5G Ref: The Essential 5G Reference Online; Wiley Press: Hoboken, NJ, USA, 2021; pp. 1–35. [Google Scholar]
- Riviello, D.G.; Di Stasio, F.; Tuninato, R. Performance analysis of multi-user MIMO schemes under realistic 3GPP 3-D channel model for 5G mmwave cellular networks. Electronics 2022, 11, 330. [Google Scholar] [CrossRef]
- Green, D.; Yun, Z.; Iskander, M.F. Path loss characteristics in urban environments using ray-tracing methods. IEEE Antennas Wirel. Propag. Lett. 2017, 16, 3063–3066. [Google Scholar] [CrossRef]
- Qian, J.; Wu, Y.; Saleem, A.; Zheng, G. Path loss model for 3.5 GHz and 5.6 GHz bands in cascaded tunnel environments. Sensors 2022, 22, 4524. [Google Scholar] [CrossRef] [PubMed]
- Timmins, I.J.; O’Young, S. Marine communications channel modeling using the finite-difference time domain method. IEEE Trans. Veh. Technol. 2008, 58, 2626–2637. [Google Scholar] [CrossRef]
- Kwon, B.; Kim, J.; Lee, K.; Lee, Y.K.; Park, S.; Lee, S. Implementation of a virtual training simulator based on 360° multi-view human action recognition. IEEE Access 2017, 5, 12496–12511. [Google Scholar] [CrossRef]
- Kwon, B.; Song, H.; Lee, S. Accurate blind Lempel-Ziv-77 parameter estimation via 1-D to 2-D data conversion over convolutional neural network. IEEE Access 2020, 8, 43965–43979. [Google Scholar] [CrossRef]
- Kwon, B.; Lee, S. Human skeleton data augmentation for person identification over deep neural network. Appl. Sci. 2020, 10, 4849. [Google Scholar] [CrossRef]
- Kwon, B.; Lee, S. Ensemble learning for skeleton-based body mass index classification. Appl. Sci. 2020, 10, 7812. [Google Scholar] [CrossRef]
- Kwon, B.; Lee, S. Joint swing energy for skeleton-based gender classification. IEEE Access 2021, 9, 28334–28348. [Google Scholar] [CrossRef]
- Kwon, B.; Huh, J.; Lee, K.; Lee, S. Optimal camera point selection toward the most preferable view of 3-d human pose. IEEE Trans. Syst. Man, Cybern. Syst. 2022, 52, 533–553. [Google Scholar] [CrossRef]
- Kwon, B.; Kim, T. Toward an online continual learning architecture for intrusion detection of video surveillance. IEEE Access 2022, 10, 89732–89744. [Google Scholar] [CrossRef]
- Cambria, E.; White, B. Jumping NLP curves: A review of natural language processing research. IEEE Comput. Intell. Mag. 2014, 9, 48–57. [Google Scholar] [CrossRef]
- Otter, D.W.; Medina, J.R.; Kalita, J.K. A survey of the usages of deep learning for natural language processing. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 604–624. [Google Scholar] [CrossRef] [PubMed]
- Deng, J.; Ren, F. A survey of textual emotion recognition and its challenges. IEEE Trans. Affect. Comput. 2023, 14, 49–67. [Google Scholar] [CrossRef]
- Liu, Y.; Bi, S.; Shi, Z.; Hanzo, L. When machine learning meets big data: A wireless communication perspective. IEEE Veh. Technol. Mag. 2019, 15, 63–72. [Google Scholar] [CrossRef]
- Sun, Y.; Peng, M.; Zhou, Y.; Huang, Y.; Mao, S. Application of machine learning in wireless networks: Key techniques and open issues. IEEE Commun. Surv. Tutorials 2019, 21, 3072–3108. [Google Scholar] [CrossRef]
- Yang, H.; Xie, X.; Kadoch, M. Machine learning techniques and a case study for intelligent wireless networks. IEEE Netw. 2020, 34, 208–215. [Google Scholar] [CrossRef]
- Zhu, G.; Liu, D.; Du, Y.; You, C.; Zhang, J.; Huang, K. Toward an intelligent edge: Wireless communication meets machine learning. IEEE Commun. Mag. 2020, 58, 19–25. [Google Scholar] [CrossRef]
- Hu, S.; Chen, X.; Ni, W.; Hossain, E.; Wang, X. Distributed machine learning for wireless communication networks: Techniques, architectures, and applications. IEEE Commun. Surv. Tutorials 2021, 23, 1458–1493. [Google Scholar] [CrossRef]
- Li, J.; Zhang, X. Deep reinforcement learning-based joint scheduling of eMBB and URLLC in 5G networks. IEEE Wirel. Commun. Lett. 2020, 9, 1543–1546. [Google Scholar] [CrossRef]
- Xu, Y.; Xu, W.; Wang, Z.; Lin, J.; Cui, S. Load balancing for ultradense networks: A deep reinforcement learning-based approach. IEEE Internet Things J. 2019, 6, 9399–9412. [Google Scholar] [CrossRef]
- Spantideas, S.T.; Giannopoulos, A.E.; Kapsalis, N.C.; Kalafatelis, A.; Capsalis, C.N.; Trakadas, P. Joint energy-efficient and throughput-sufficient transmissions in 5G cells with deep Q-learning. In Proceedings of the IEEE International Mediterranean Conference on Communications and Networking (MeditCom), Athens, Greece, 7–10 September 2021; pp. 265–270. [Google Scholar]
- Kaloxylos, A.; Gavras, A.; Camps, D.; Ghoraishi, M.; Hrasnica, H. AI and ML–Enablers for beyond 5G Networks. 5G PPP Technol. Board 2021, 1, 1–145. [Google Scholar]
- Li, X.; Fang, J.; Cheng, W.; Duan, H.; Chen, Z.; Li, H. Intelligent power control for spectrum sharing in cognitive radios: A deep reinforcement learning approach. IEEE Access 2018, 6, 25463–25473. [Google Scholar] [CrossRef]
- Ostlin, E.; Zepernick, H.J.; Suzuki, H. Macrocell path-loss prediction using artificial neural networks. IEEE Trans. Veh. Technol. 2010, 59, 2735–2747. [Google Scholar] [CrossRef]
- Isabona, J.; Srivastava, V.M. Hybrid neural network approach for predicting signal propagation loss in urban microcells. In Proceedings of the IEEE Region 10 Humanitarian Technology Conference (R10-HTC), Agra, India, 21–23 December 2016; pp. 1–5. [Google Scholar]
- Fernandes, L.C.; Soares, A.J.M. A hybrid model for path loss calculation in urban environment. In Proceedings of the 17th International Conference on the Computation of Electromagnetic Fields (COMPUMAG), Florianópolis, Brazil, 22–26 November 2009; pp. 460–461. [Google Scholar]
- Piacentini, M.; Rinaldi, F. Path loss prediction in urban environment using learning machines and dimensionality reduction techniques. Comput. Manag. Sci. 2011, 8, 371–385. [Google Scholar] [CrossRef]
- Timoteo, R.D.; Cunha, D.C.; Cavalcanti, G.D. A proposal for path loss prediction in urban environments using support vector regression. In Proceedings of the 10th Advanced International Conference on Telecommunications (AICT), Paris, France, 20–24 July 2014; pp. 1–5. [Google Scholar]
- Gideon, K.; Nyirenda, C.; Temaneh-Nyah, C. Echo state network-based radio signal strength prediction for wireless communication in northern Namibia. IET Commun. 2017, 11, 1920–1926. [Google Scholar] [CrossRef]
- Famoriji, O.J.; Shongwe, T. Path Loss Prediction in Tropical Regions using Machine Learning Techniques: A Case Study. Electronics 2022, 11, 2711. [Google Scholar] [CrossRef]
- Wen, J.; Zhang, Y.; Yang, G.; He, Z.; Zhang, W. Path loss prediction based on machine learning methods for aircraft cabin environments. IEEE Access 2019, 7, 159251–159261. [Google Scholar] [CrossRef]
- Moreta, C.E.G.; Acosta, M.R.C.; Koo, I. Prediction of digital terrestrial television coverage using machine learning regression. IEEE Trans. Broadcast. 2019, 65, 702–712. [Google Scholar] [CrossRef]
- Elmezughi, M.K.; Salih, O.; Afullo, T.J.; Duffy, K.J. Comparative analysis of major machine-learning-based path loss models for enclosed indoor channels. Sensors 2022, 22, 4967. [Google Scholar] [CrossRef]
- Oroza, C.A.; Zhang, Z.; Watteyne, T.; Glaser, S.D. A machine-learning-based connectivity model for complex terrain large-scale low-power wireless deployments. IEEE Trans. Cogn. Commun. Netw. 2017, 3, 576–584. [Google Scholar] [CrossRef]
- Sollich, P.; Krogh, A. Learning with ensembles: How overfitting can be useful. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Denver, CO, USA, 27–30 November 1995; pp. 190–196. [Google Scholar]
- Kuncheva, L.I.; Whitaker, C.J. Measures of diversity in classifier ensembles and their relationship with the ensemble accuracy. Mach. Learn. 2003, 51, 181–207. [Google Scholar] [CrossRef]
- Brown, G.; Wyatt, J.; Harris, R.; Yao, X. Diversity creation methods: A survey and categorisation. Inf. Fusion 2005, 6, 5–20. [Google Scholar] [CrossRef]
- Adeva, J.J.G.; Beresi, U.C.; Calvo, R.A. Accuracy and diversity in ensembles of text categorisers. CLEI Electron. J. 2005, 8, 1–12. [Google Scholar]
- Karra, D.; Goudos, S.K.; Tsoulos, G.V.; Athanasiadou, G. Prediction of received signal power in mobile communications using different machine learning algorithms: A comparative study. In Proceedings of the IEEE Panhellenic Conference on Electronics & Telecommunications (PACET), Volos, Greece, 8–9 November 2019; pp. 1–4. [Google Scholar]
- Ho, T.K. Random decision forests. In Proceedings of the IEEE International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; pp. 278–282. [Google Scholar]
- Ho, T.K. The random subspace method for constructing decision forests. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 832–844. [Google Scholar]
- Lee, J.Y.; Kang, M.Y.; Kim, S.C. Path loss exponent prediction for outdoor millimeter wave channels through deep learning. In Proceedings of the IEEE Wireless Communications and Networking Conference (WCNC), Marrakesh, Morocco, 15–18 April 2019; pp. 1–5. [Google Scholar]
- Wu, L.; He, D.; Guan, K.; Ai, B.; Briso-Rodríguez, C.; Shui, T.; Liu, C.; Zhu, L.; Shen, X. Received power prediction for suburban environment based on neural network. In Proceedings of the IEEE International Conference on Information Networking (ICOIN), Barcelona, Spain, 7–10 January 2020; pp. 35–39. [Google Scholar]
- Chang, P.R.; Yang, W.H. Environment-adaptation mobile radio propagation prediction using radial basis function neural networks. IEEE Trans. Veh. Technol. 1997, 46, 155–160. [Google Scholar] [CrossRef]
- Sotiroudis, S.P.; Goudos, S.K.; Gotsis, K.A.; Siakavara, K.; Sahalos, J.N. Application of a composite differential evolution algorithm in optimal neural network design for propagation path-loss prediction in mobile communication systems. IEEE Antennas Wirel. Propag. Lett. 2013, 12, 364–367. [Google Scholar] [CrossRef]
- Popescu, I.; Kanstas, A.; Angelou, E.; Nafornita, L.; Constantinou, P. Applications of generalized RBF-NN for path loss prediction. In Proceedings of the 13th IEEE International Symposium on Personal, Indoor and Mobile Radio Communications, Lisbon, Portugal, 18 September 2002; pp. 484–488. [Google Scholar]
- Zaarour, N.; Kandil, N.; Hakem, N.; Despins, C. Comparative experimental study on modeling the path loss of an UWB channel in a mine environment using MLP and RBF neural networks. In Proceedings of the IEEE International Conference on Wireless Communications in Underground and Confined Areas, Clermont-Ferrand, France, 28–30 August 2012; pp. 1–6. [Google Scholar]
- Cheng, F.; Shen, H. Field strength prediction based on wavelet neural network. In Proceedings of the 2nd IEEE International Conference on Education Technology and Computer, Shanghai, China, 22–24 June 2010; pp. 255–258. [Google Scholar]
- Balandier, T.; Caminada, A.; Lemoine, V.; Alexandre, F. 170 MHz field strength prediction in urban environment using neural nets. In Proceedings of the 6th IEEE International Symposium on Personal, Indoor and Mobile Radio Communications, Toronto, ON, Canada, 27–29 September 1995; pp. 120–124. [Google Scholar]
- Panda, G.; Mishra, R.K.; Palai, S.S. A novel site adaptive propagation model. IEEE Antennas Wirel. Propag. Lett. 2005, 4, 447–448. [Google Scholar] [CrossRef]
- Kalakh, M.; Kandil, N.; Hakem, N. Neural networks model of an UWB channel path loss in a mine environment. In Proceedings of the 75th IEEE Vehicular Technology Conference (VTC Spring), Yokohama, Japan, 6–9 May 2012; pp. 1–5. [Google Scholar]
- Azpilicueta, L.; Rawat, M.; Rawat, K.; Ghannouchi, F.M.; Falcone, F. A ray launching-neural network approach for radio wave propagation analysis in complex indoor environments. IEEE Trans. Antennas Propag. 2014, 62, 2777–2786. [Google Scholar] [CrossRef]
- Ayadi, M.; Zineb, A.B.; Tabbane, S. A UHF path loss model using learning machine for heterogeneous networks. IEEE Trans. Antennas Propag. 2017, 65, 3675–3683. [Google Scholar] [CrossRef]
- Popoola, S.I.; Jefia, A.; Atayero, A.A.; Kingsley, O.; Faruk, N.; Oseni, O.F.; Abolade, R.O. Determination of neural network parameters for path loss prediction in very high frequency wireless channel. IEEE Access 2019, 7, 150462–150483. [Google Scholar] [CrossRef]
- Ebhota, V.C.; Isabona, J.; Srivastava, V.M. Environment-adaptation based hybrid neural network predictor for signal propagation loss prediction in cluttered and open urban microcells. Wirel. Pers. Commun. 2019, 104, 935–948. [Google Scholar] [CrossRef]
- Zhang, Y.; Wen, J.; Yang, G.; He, Z.; Wang, J. Path loss prediction based on machine learning: Principle, method, and data expansion. Appl. Sci. 2019, 9, 1908. [Google Scholar] [CrossRef]
- Wu, D.; Zhu, G.; Ai, B. Application of artificial neural networks for path loss prediction in railway environments. In Proceedings of the 5th IEEE International ICST Conference on Communications and Networking in China, Beijing, China, 25–27 August 2010; pp. 1–5. [Google Scholar]
- Zineb, A.B.; Ayadi, M. A multi-wall and multi-frequency indoor path loss prediction model using artificial neural networks. Arab. J. Sci. Eng. 2016, 41, 987–996. [Google Scholar] [CrossRef]
- Liu, J.; Jin, X.; Dong, F.; He, L.; Liu, H. Fading channel modelling using single-hidden layer feedforward neural networks. Multidimens. Syst. Signal Process. 2017, 28, 885–903. [Google Scholar] [CrossRef]
- Gómez-Pérez, P.; Crego-García, M.; Cuiñas, I.; Caldeirinha, R.F. Modeling and inferring the attenuation induced by vegetation barriers at 2G/3G/4G cellular bands using artificial neural networks. Measurement 2017, 98, 262–275. [Google Scholar] [CrossRef]
- Adeogun, R. Calibration of stochastic radio propagation models using machine learning. IEEE Antennas Wirel. Propag. Lett. 2019, 18, 2538–2542. [Google Scholar] [CrossRef]
- Kuno, N.; Takatori, Y. Prediction method by deep-learning for path loss characteristics in an open-square environment. In Proceedings of the IEEE International Symposium on Antennas and Propagation (ISAP), Busan, Republic of Korea, 23–26 October 2018; pp. 1–2. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Kuno, N.; Yamada, W.; Sasaki, M.; Takatori, Y. Convolutional neural network for prediction method of path loss characteristics considering diffraction and reflection in an open-square environment. In Proceedings of the IEEE URSI Asia-Pacific Radio Science Conference (AP-RASC), New Delhi, India, 9–15 March 2019; pp. 1–3. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Ahmadien, O.; Ates, H.F.; Baykas, T.; Gunturk, B.K. Predicting path loss distribution of an area from satellite images using deep learning. IEEE Access 2020, 8, 64982–64991. [Google Scholar] [CrossRef]
- Bal, M.; Marey, A.; Ates, H.F.; Baykas, T.; Gunturk, B.K. Regression of large-scale path loss parameters using deep neural networks. IEEE Antennas Wirel. Propag. Lett. 2022, 21, 1562–1566. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ates, H.F.; Hashir, S.M.; Baykas, T.; Gunturk, B.K. Path loss exponent and shadowing factor prediction from satellite images using deep learning. IEEE Access 2019, 7, 101366–101375. [Google Scholar] [CrossRef]
- Sani, U.S.; Malik, O.A.; Lai, D.T.C. Improving path loss prediction using environmental feature extraction from satellite images: Hand-crafted vs. convolutional neural network. Appl. Sci. 2022, 12, 7685. [Google Scholar] [CrossRef]
- Popoola, S.I.; Atayero, A.A.; Arausi, O.D.; Matthews, V.O. Path loss dataset for modeling radio wave propagation in smart campus environment. Data Brief 2018, 17, 1062–1073. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Longitude | Latitude | Elevation (m) | Altitude (m) | Clutter Height (m) | Distance (m) | Path Loss (dB) | |
|---|---|---|---|---|---|---|---|
| Count | 2169 | 2169 | 2169 | 2169 | 2169 | 2169 | 2169 |
| Mean | 3.1638 | 6.6745 | 54.39 | 54.80 | 5.81 | 443.83 | 143.18 |
| Std | 0.0038 | 0.0025 | 5.89 | 3.91 | 2.77 | 270.23 | 9.21 |
| Min | 3.1559 | 6.6676 | 45.00 | 49.00 | 4.00 | 2.00 | 104.00 |
| 25% | 3.1606 | 6.6730 | 49.00 | 52.00 | 4.00 | 250.00 | 139.00 |
| 50% | 3.1634 | 6.6745 | 54.00 | 54.00 | 6.00 | 384.00 | 145.00 |
| 75% | 3.1670 | 6.6757 | 59.00 | 57.00 | 6.00 | 668.00 | 149.00 |
| Max | 3.1706 | 6.6789 | 64.00 | 64.00 | 16.00 | 1132.00 | 162.00 |
| Rank | # Hidden Layers (M) | # Neurons in Each Hidden Layer (N) | Activation Function | Mean Squared Error (MSE) |
|---|---|---|---|---|
| 1 | 3 | 12 | sigmoid | 34.33 |
| 2 | 2 | 10 | sigmoid | 35.81 |
| 3 | 2 | 19 | sigmoid | 36.03 |
| 4 | 2 | 23 | sigmoid | 36.10 |
| 5 | 2 | 17 | sigmoid | 36.43 |
| 6 | 2 | 8 | sigmoid | 36.52 |
| 7 | 2 | 24 | sigmoid | 36.59 |
| 8 | 2 | 7 | sigmoid | 36.70 |
| 9 | 2 | 12 | sigmoid | 36.73 |
| 10 | 1 | 22 | tanh | 36.80 |
| 11 | 2 | 16 | sigmoid | 36.83 |
| 12 | 2 | 22 | sigmoid | 36.94 |
| 13 | 2 | 13 | sigmoid | 37.04 |
| 14 | 3 | 15 | sigmoid | 37.11 |
| 15 | 2 | 15 | sigmoid | 37.13 |
| 16 | 2 | 11 | sigmoid | 37.41 |
| 17 | 2 | 14 | sigmoid | 37.52 |
| 18 | 2 | 6 | sigmoid | 37.56 |
| 19 | 2 | 25 | sigmoid | 37.82 |
| 20 | 1 | 15 | tanh | 37.83 |
| Hyperparameter | Search Range | Determined Value |
|---|---|---|
| kernel | {“linear”, “poly”, “rbf”, “sigmoid”} | “poly” |
| degree | {1, 2, 3, 4, 5} | 2 |
| gamma | {“scale”, “auto”} | “scale” |
| coef0 | {0.0, 0.1, 0.2, 0.3, 0.4, 0.5} | 0.2 |
| C | {0.001, 0.01, 0.1, 1, 10, 100, 1000} | 0.1 |
| shrinking | {True, False} | True |
| Hyperparameter | Search Range | Determined Value |
|---|---|---|
| n_neighbors | {2, 3, 4, 5, 6, 7, 8, 9, 10} | 5 |
| weights | {“uniform”, “distance”} | “uniform” |
| leaf_size | {10, 20, 30, 40, 50} | 10 |
| metric | {“minkowski”, “euclidean”, “cityblock”} | “minkowski” |
| Hyperparameter | Search Range | Determined Value |
|---|---|---|
| n_estimators | {10, 20, 30, 40, 50, 60, 70, 80, 90, 100} | 100 |
| criterion | {“squared_error”, “absolute_error”, “friedman_mse”, “poisson”} | “absolute_error” |
| max_depth | {3, 4, 5, 6, 7, 8, 9, 10} | 8 |
| Hyperparameter | Search Range | Determined Value |
|---|---|---|
| criterion | {“squared_error”, “friedman_mse”, “absolute_error”, “poisson”} | “friedman_mse” |
| splitter | {“best”, “random”} | “random” |
| max_depth | {3, 4, 5, 6, 7, 8, 9, 10} | 8 |
| Hyperparameter | Search Range | Determined Value |
|---|---|---|
| fit_intercept | {True, False} | True |
| copy_X | {True, False} | True |
| positive | {True, False} | False |
| Hyperparameter | Search Range | Determined Value |
|---|---|---|
| alpha | {0.001, 0.01, 0.1, 1, 10, 100} | 0.1 |
| fit_intercept | {True, False} | True |
| copy_X | {True, False} | True |
| warm_start | {True, False} | True |
| positive | {True, False} | False |
| Hyperparameter | Search Range | Determined Value |
|---|---|---|
| alpha | {0.001, 0.01, 0.1, 1, 10, 100} | 10 |
| fit_intercept | {True, False} | True |
| copy_X | {True, False} | True |
| positive | {True, False} | False |
| Hyperparameter | Search Range | Determined Value |
|---|---|---|
| alpha | {0.001, 0.01, 0.1, 1, 10, 100} | 10 |
| l1_ratio | {0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9} | 0.1 |
| fit_intercept | {True, False} | True |
| copy_X | {True, False} | False |
| warm_start | {True, False} | False |
| positive | {True, False} | False |
| Reference | # Neurons in the 1st Hidden Layer | # Neurons in the 2nd Hidden Layer | Activation Function |
|---|---|---|---|
| [38] | 7 | 3 | tanh |
| [63] | 10 | 10 | tanh |
| [65] | 80 | None | tanh |
| [68] | 9 | None | tanh |
| [70] | 4 | None | tanh |
| [71] | 10 | None | sigmoid |
| [72] | 3 | None | sigmoid |
| [73,75] | 20 | None | sigmoid |
| [74] | 57 | None | sigmoid |
| # ANNs (T) | MSE | RMSE | MAE | MAPE | MSLE | RMSLE | |
|---|---|---|---|---|---|---|---|
| 4 | 25.4125 | 5.0411 | 3.1862 | 0.0229 | 0.0013 | 0.0362 | 0.6918 |
| 8 | 22.6888 | 4.7633 | 2.9207 | 0.0209 | 0.0012 | 0.0342 | 0.7248 |
| 12 | 17.3473 | 4.1650 | 2.2916 | 0.0163 | 0.0009 | 0.0298 | 0.7896 |
| 16 | 13.1180 | 3.6219 | 1.7190 | 0.0123 | 0.0007 | 0.0260 | 0.8409 |
| 20 | 8.6529 | 2.9416 | 1.2753 | 0.0090 | 0.0004 | 0.0210 | 0.8951 |
| 24 | 9.3429 | 3.0566 | 1.3956 | 0.0099 | 0.0005 | 0.0219 | 0.8867 |
| 28 | 9.0502 | 3.0084 | 1.3400 | 0.0095 | 0.0005 | 0.0215 | 0.8902 |
| 32 | 10.0002 | 3.1623 | 1.4605 | 0.0104 | 0.0005 | 0.0226 | 0.8787 |
| 36 | 9.4920 | 3.0809 | 1.4201 | 0.0101 | 0.0005 | 0.0221 | 0.8849 |
| 40 | 9.7920 | 3.1292 | 1.4149 | 0.0101 | 0.0005 | 0.0224 | 0.8812 |
| Method | MSE | RMSE | MAE | MAPE | MSLE | RMSLE | |
|---|---|---|---|---|---|---|---|
| SVM | 59.2186 | 7.6954 | 5.3799 | 0.0397 | 0.0032 | 0.0569 | 0.2818 |
| k-NN | 11.7490 | 3.4277 | 2.4983 | 0.0178 | 0.0006 | 0.0248 | 0.8575 |
| RF | 20.0194 | 4.4743 | 3.1856 | 0.0228 | 0.0010 | 0.0320 | 0.7572 |
| DT | 22.4978 | 4.7432 | 3.5409 | 0.0253 | 0.0012 | 0.0340 | 0.7271 |
| MLR | 60.9421 | 7.8065 | 5.8778 | 0.0427 | 0.0033 | 0.0571 | 0.2609 |
| LASSO | 62.0635 | 7.8780 | 5.9153 | 0.0430 | 0.0033 | 0.0576 | 0.2473 |
| Ridge | 61.0068 | 7.8107 | 5.8782 | 0.0428 | 0.0033 | 0.0572 | 0.2601 |
| ElasticNet | 80.6553 | 8.9808 | 6.6842 | 0.0488 | 0.0043 | 0.0655 | 0.0218 |
| [38] | 82.7867 | 9.0987 | 6.7748 | 0.0495 | 0.0044 | 0.0663 | −0.0040 |
| [63] | 51.1670 | 7.1531 | 5.3816 | 0.0387 | 0.0027 | 0.0516 | 0.3794 |
| [65] | 53.2452 | 7.2969 | 5.5224 | 0.0401 | 0.0028 | 0.0532 | 0.3542 |
| [68] | 45.5829 | 6.7515 | 5.0839 | 0.0367 | 0.0024 | 0.0487 | 0.4472 |
| [70] | 66.3351 | 8.1446 | 5.9073 | 0.0430 | 0.0035 | 0.0591 | 0.1955 |
| [71] | 48.0863 | 6.9344 | 5.2745 | 0.0380 | 0.0025 | 0.0501 | 0.4168 |
| [72] | 64.6372 | 8.0397 | 5.8128 | 0.0423 | 0.0034 | 0.0583 | 0.2161 |
| [73,75] | 51.1208 | 7.1499 | 5.4451 | 0.0394 | 0.0027 | 0.0518 | 0.3800 |
| [74] | 60.2464 | 7.7619 | 5.8966 | 0.0428 | 0.0032 | 0.0567 | 0.2693 |
| Proposed | 8.6529 | 2.9416 | 1.2753 | 0.0090 | 0.0004 | 0.0210 | 0.8951 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kwon, B.; Son, H. Accurate Path Loss Prediction Using a Neural Network Ensemble Method. Sensors 2024, 24, 304. https://doi.org/10.3390/s24010304
Kwon B, Son H. Accurate Path Loss Prediction Using a Neural Network Ensemble Method. Sensors. 2024; 24(1):304. https://doi.org/10.3390/s24010304
Chicago/Turabian StyleKwon, Beom, and Hyukmin Son. 2024. "Accurate Path Loss Prediction Using a Neural Network Ensemble Method" Sensors 24, no. 1: 304. https://doi.org/10.3390/s24010304
APA StyleKwon, B., & Son, H. (2024). Accurate Path Loss Prediction Using a Neural Network Ensemble Method. Sensors, 24(1), 304. https://doi.org/10.3390/s24010304