


A Machine Learning Model Based on GRU and LSTM to Predict the Environmental Parameters in a Layer House, Taking CO2 Concentration as an Example


Abstract
:1. Introduction
2. Materials and Methods
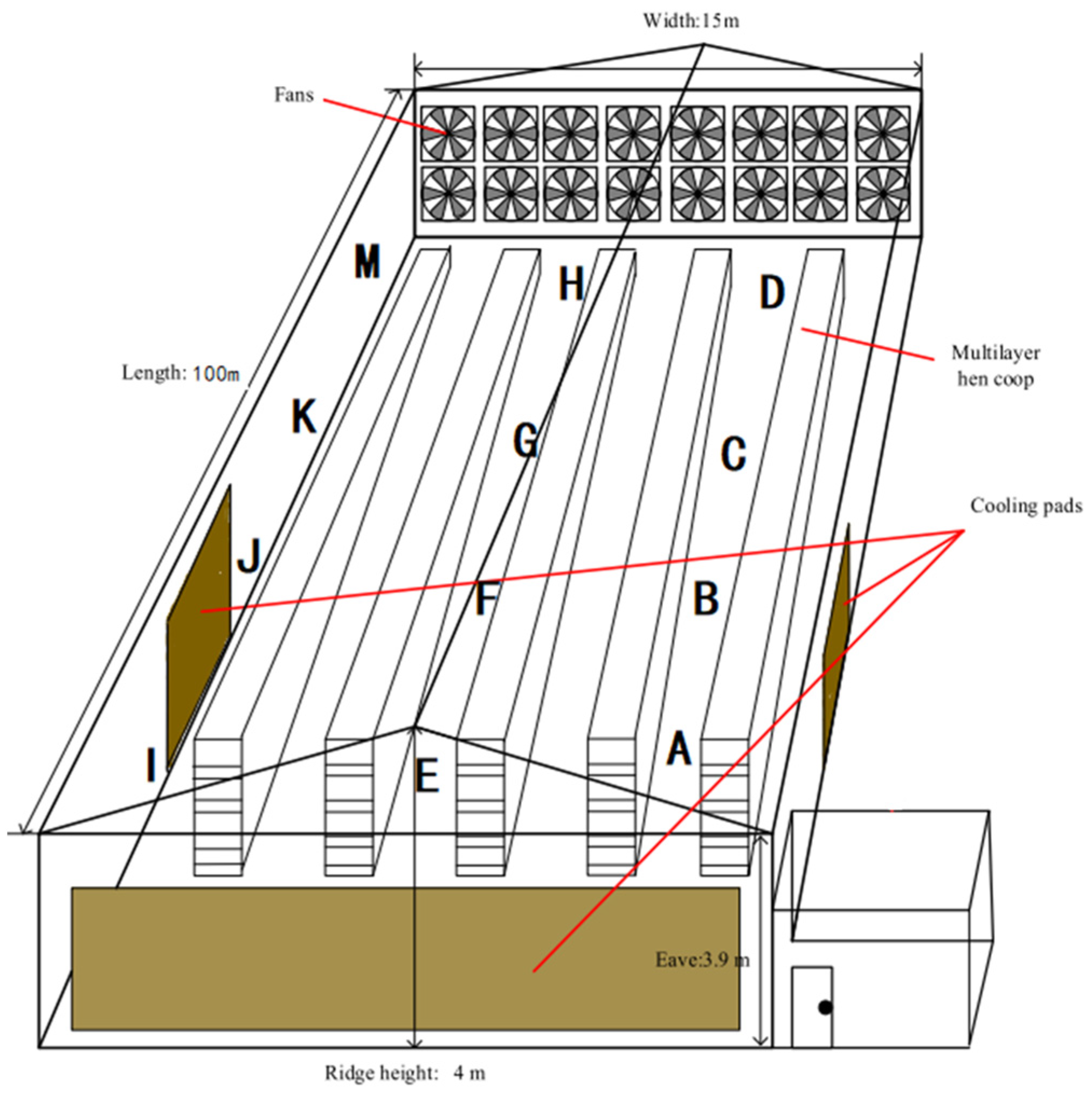
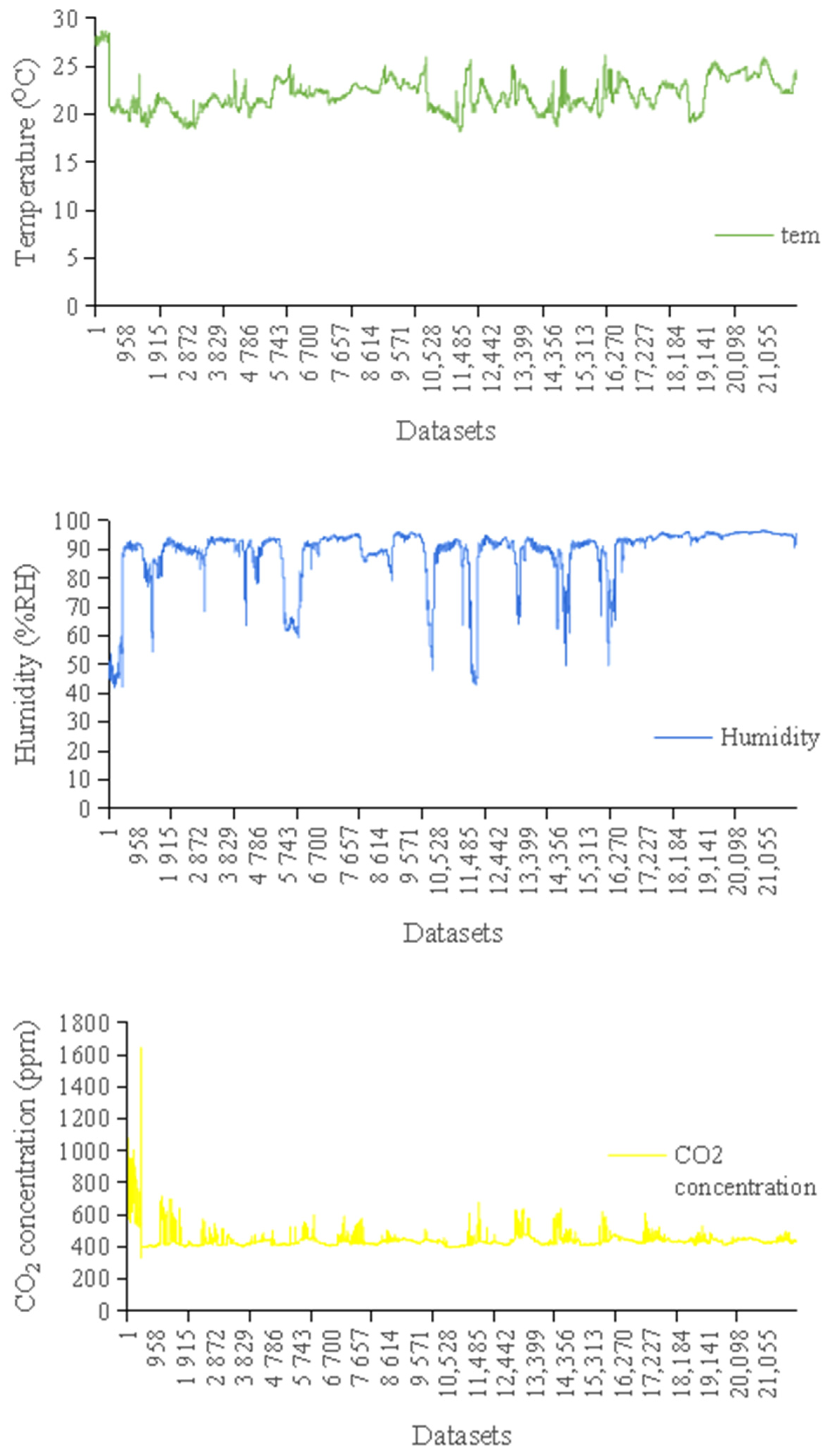
2.1. Data Acquisition
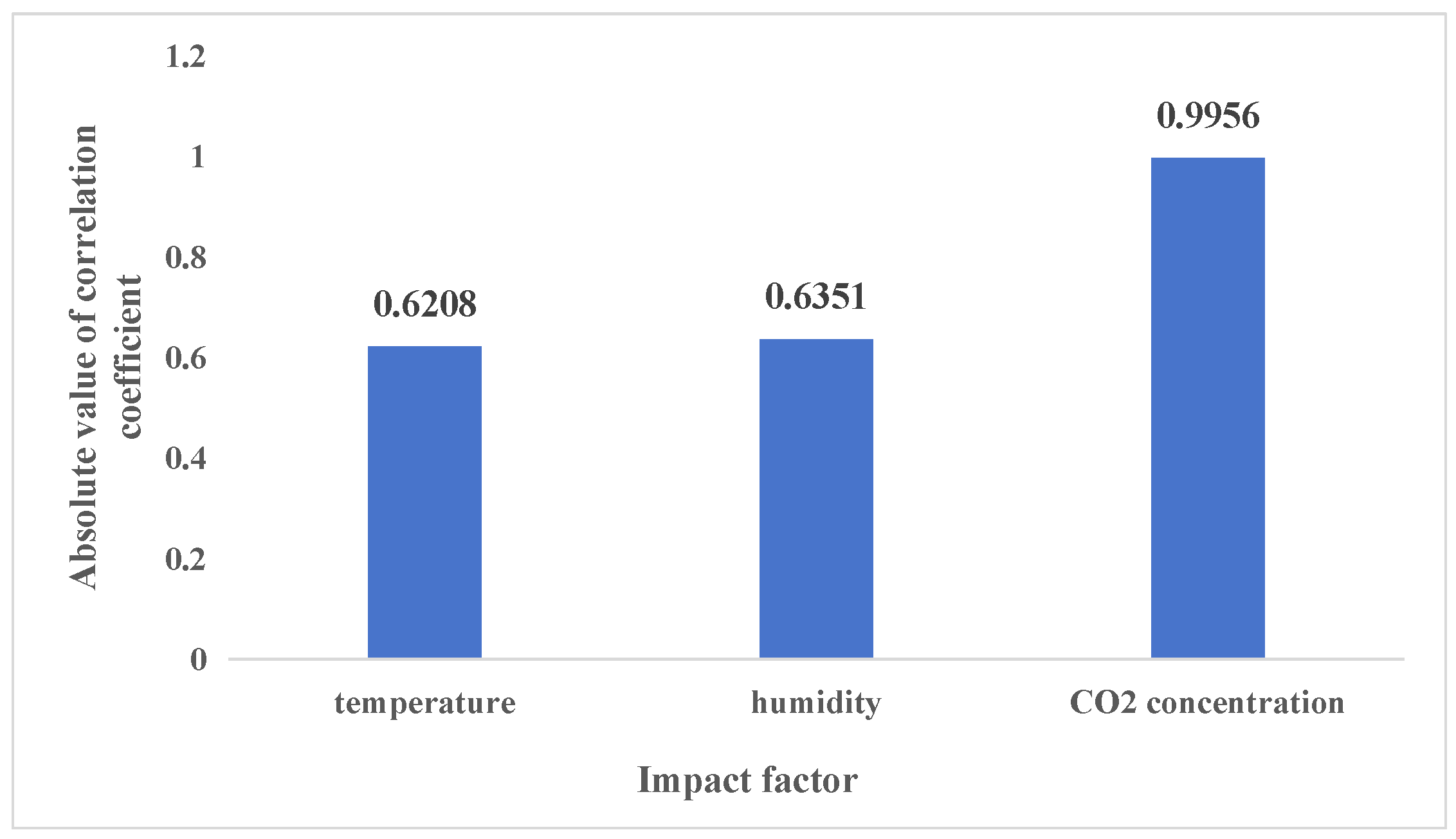
2.2. Correlation Coefficient
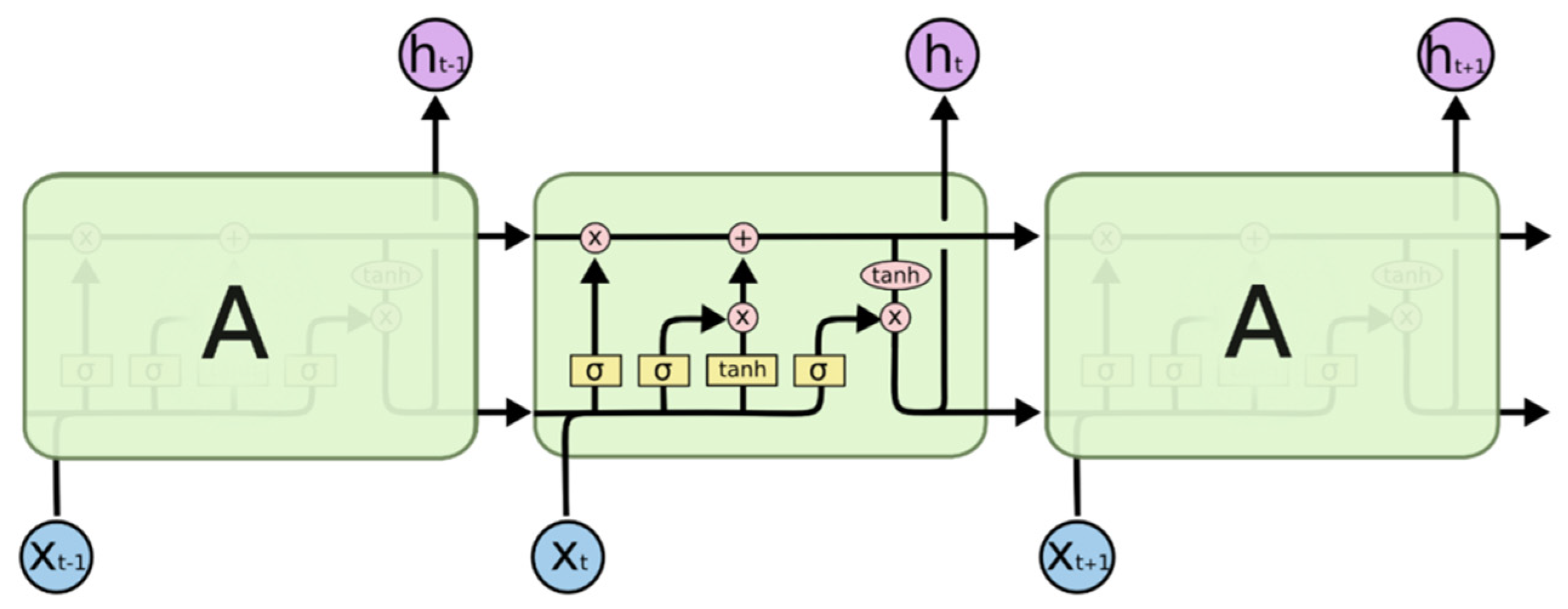
2.3. LSTM
2.3.1. Forget Gate
2.3.2. Input Gate
2.3.3. Output Gate
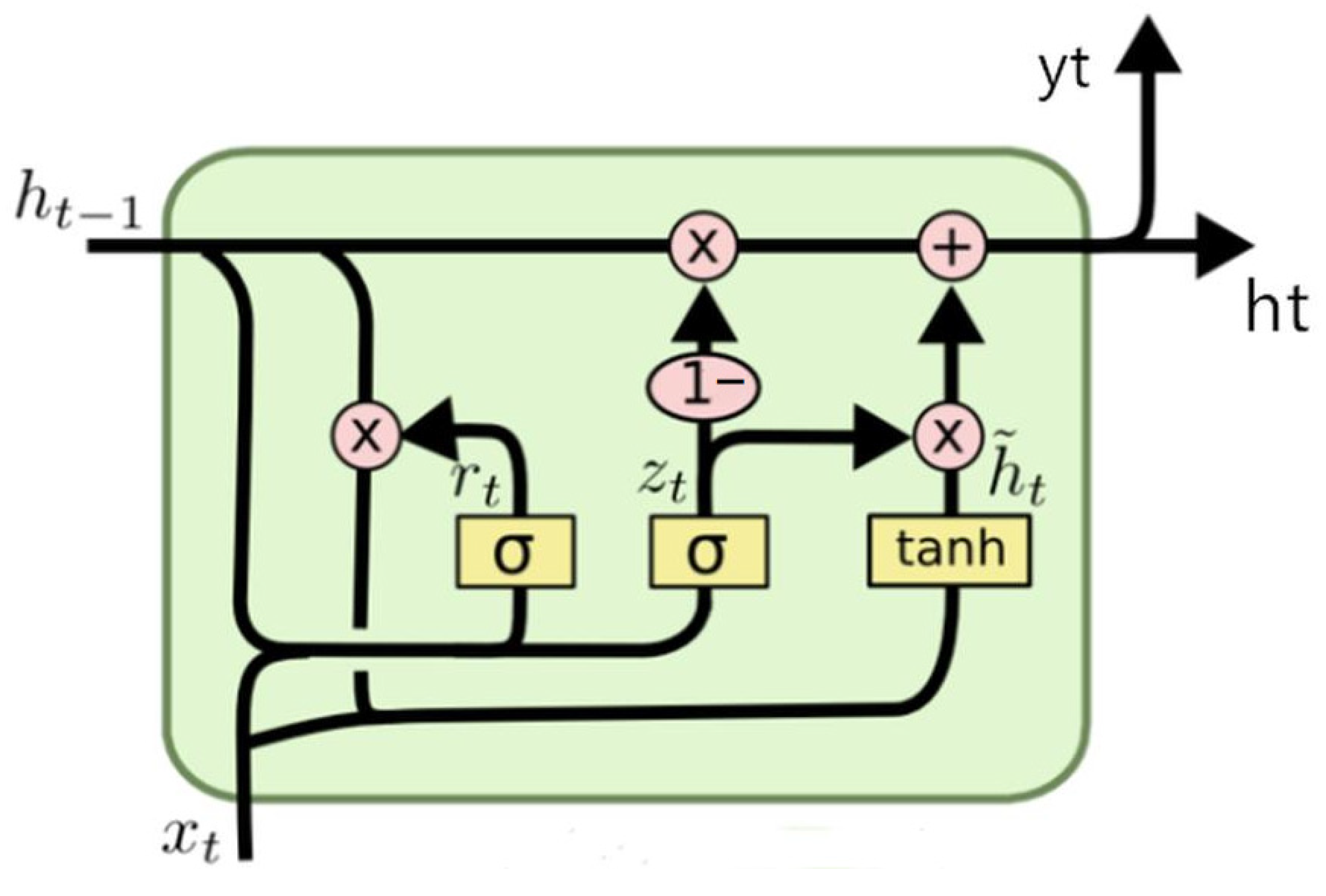
2.4. GRU
2.4.1. Update Gate
2.4.2. Reset Gate
2.5. Model Construction
- (1)
- Hardware and software of the workstation
- (2)
- Obtaining the datasets
- (3)
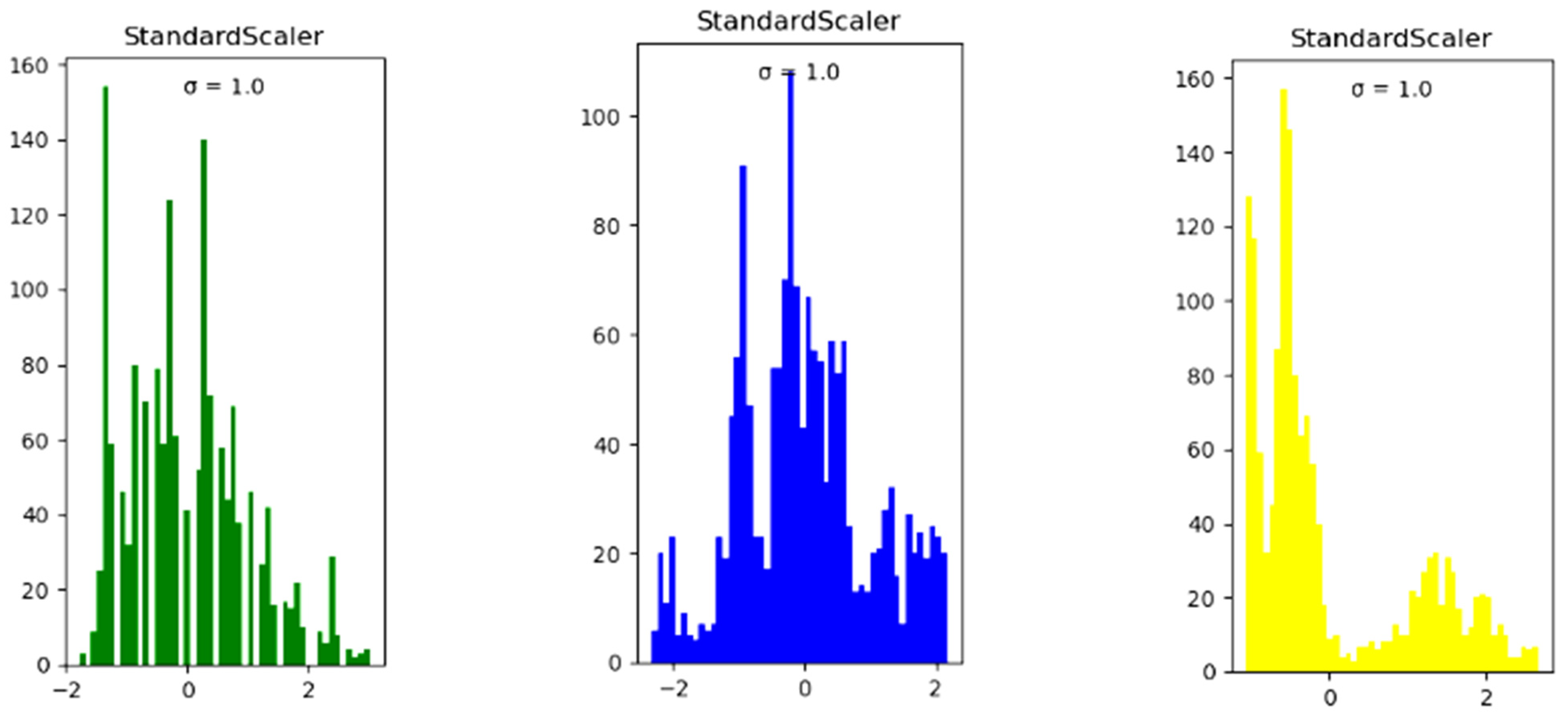
- Data pre-processing
- (4)
- Time series: sliding window method
- (5)
- Dataset partitioning
- (6)
- Construction of network models
- (7)
- Hyperparameters:
- (8)
- Hyperparameter optimization
- (9)
- Network training
- (10)
- Inspecting training process information
- (11)
- Forecasting
3. Results
3.1. Evaluation Indicators
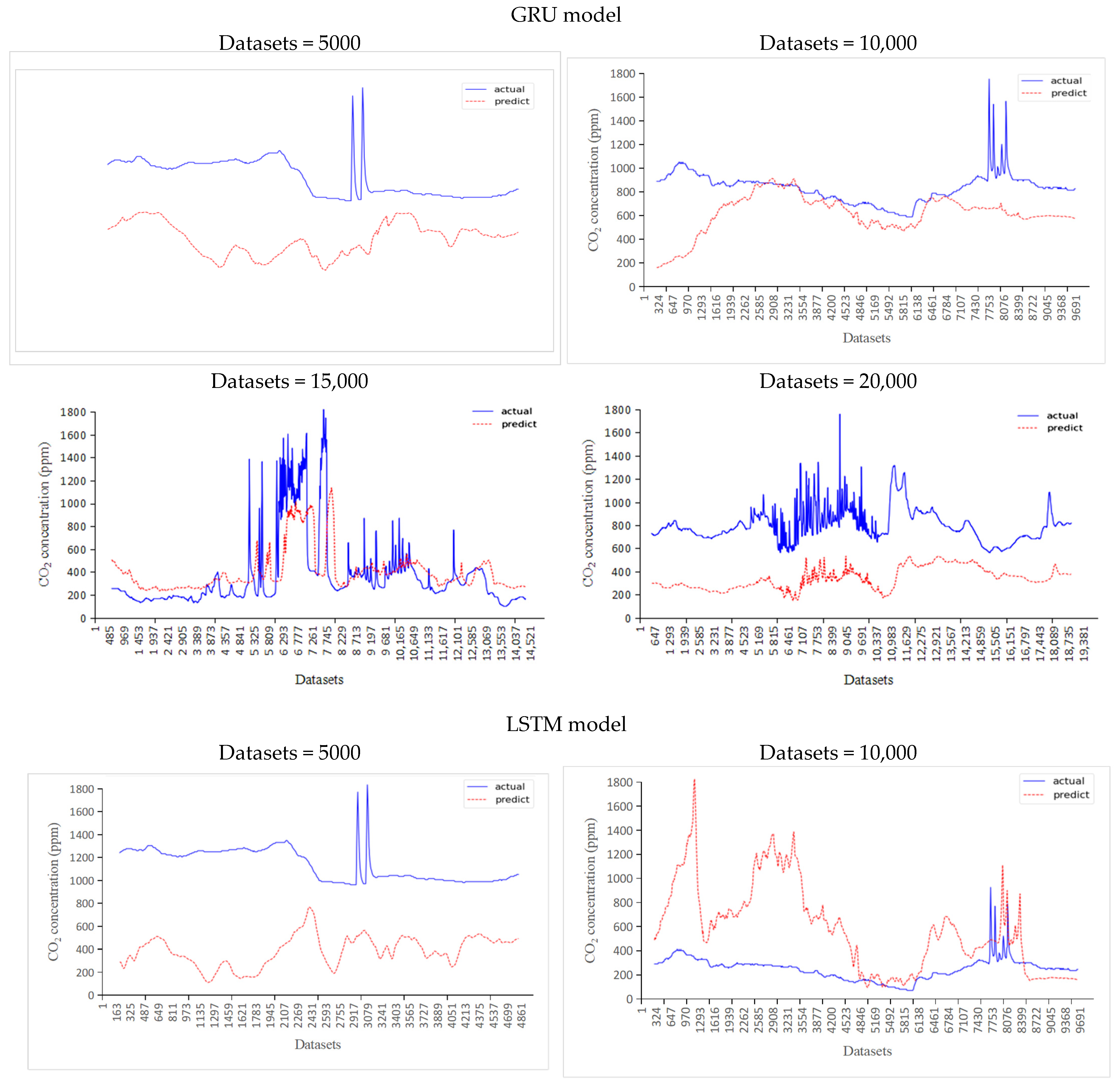
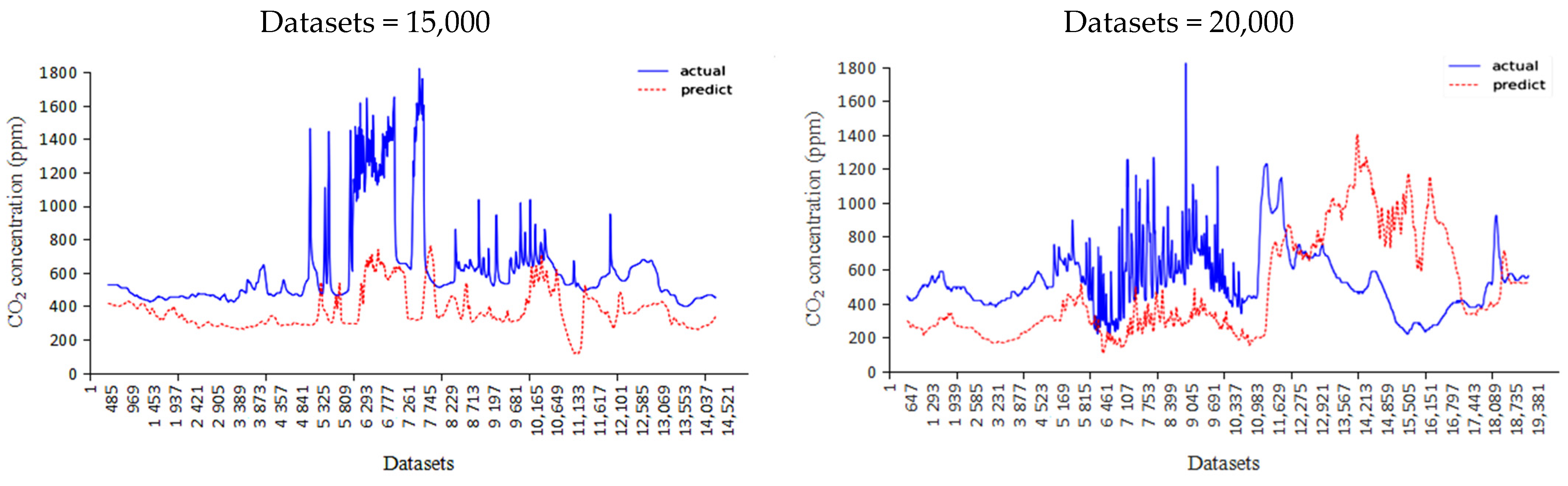
3.2. Predictive Evaluation
3.3. Evaluation of Model Performance by Plotting Training and Validation Loss Curves
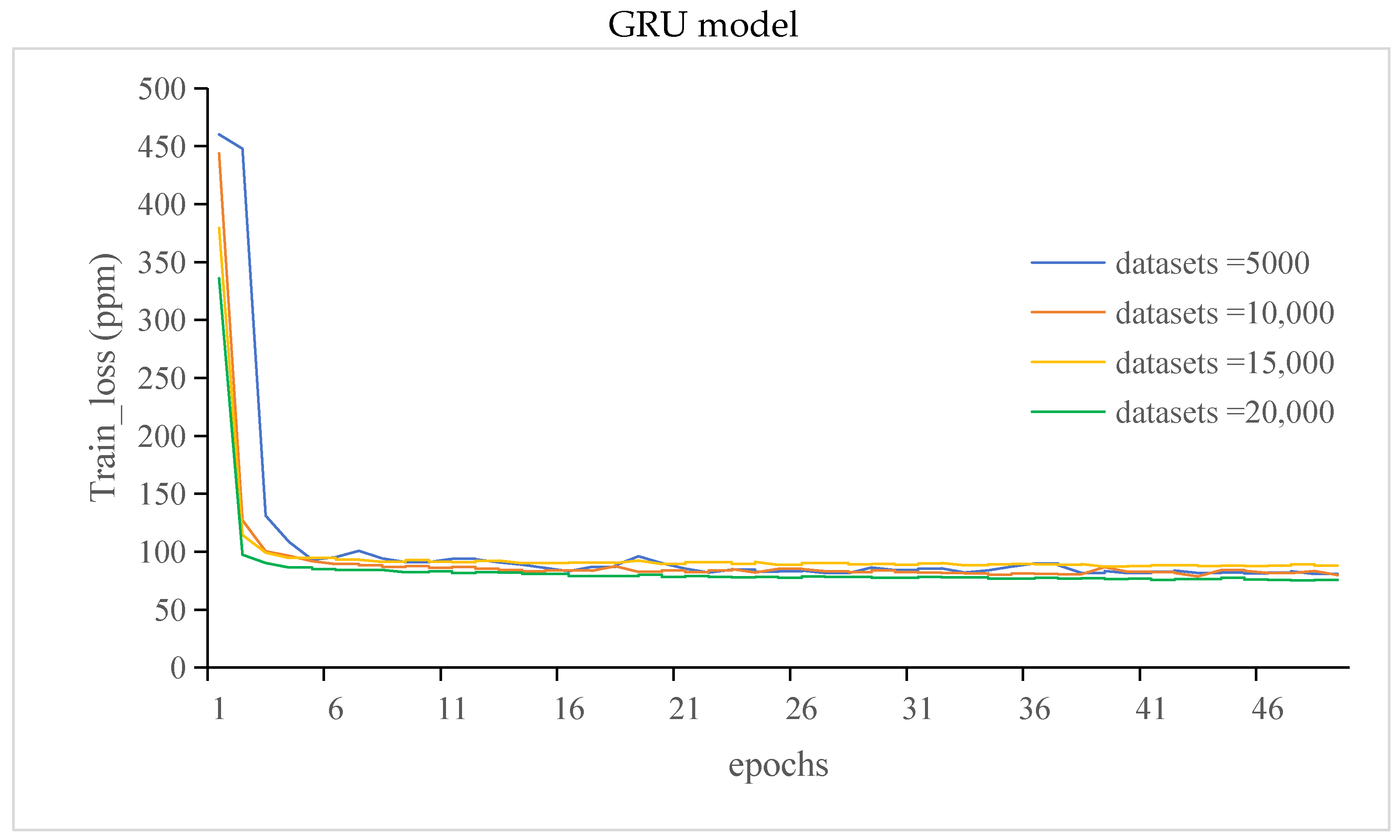
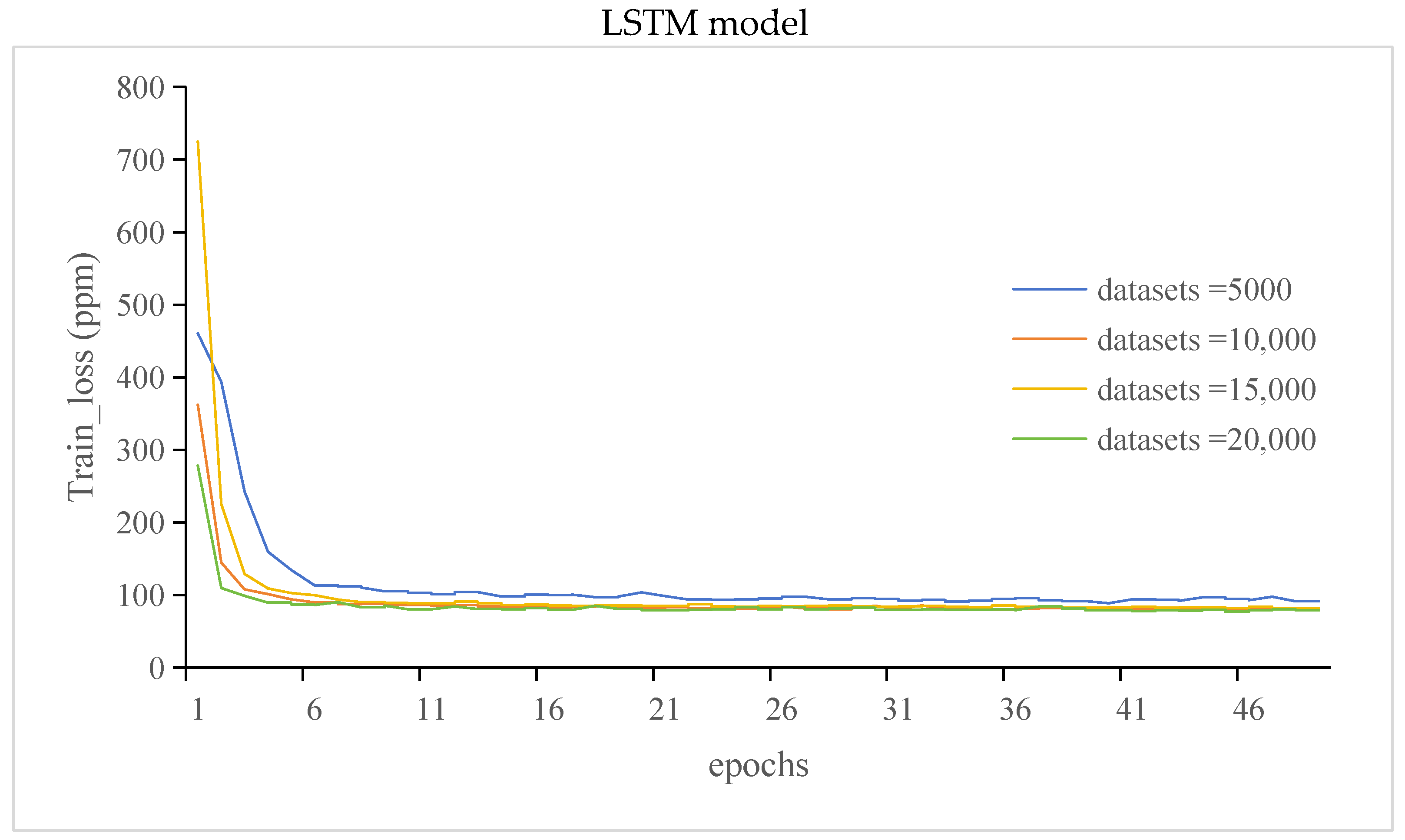
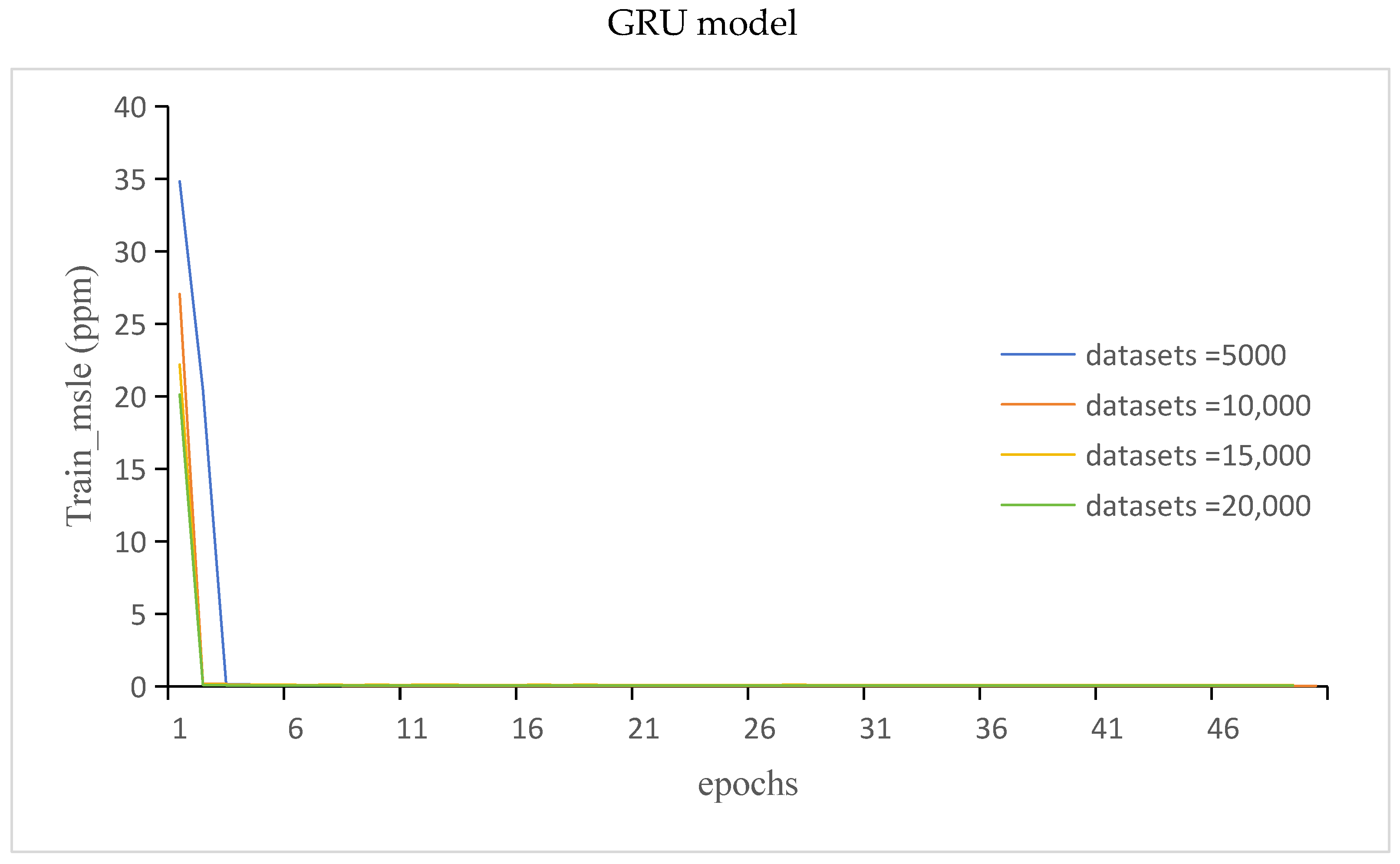
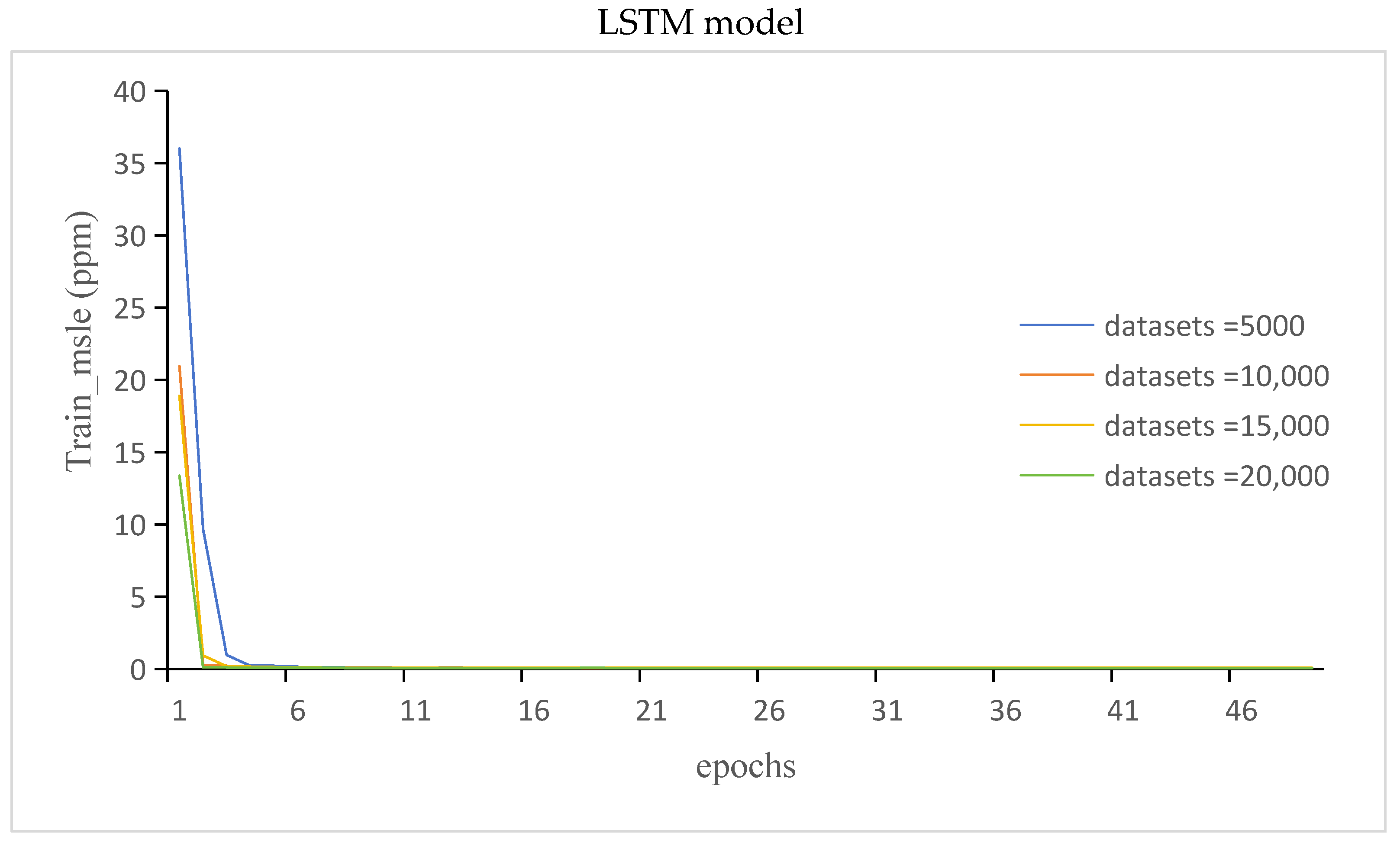
3.3.1. The Train_Loss and Train_Msle of the GRU Model and LSTM Model
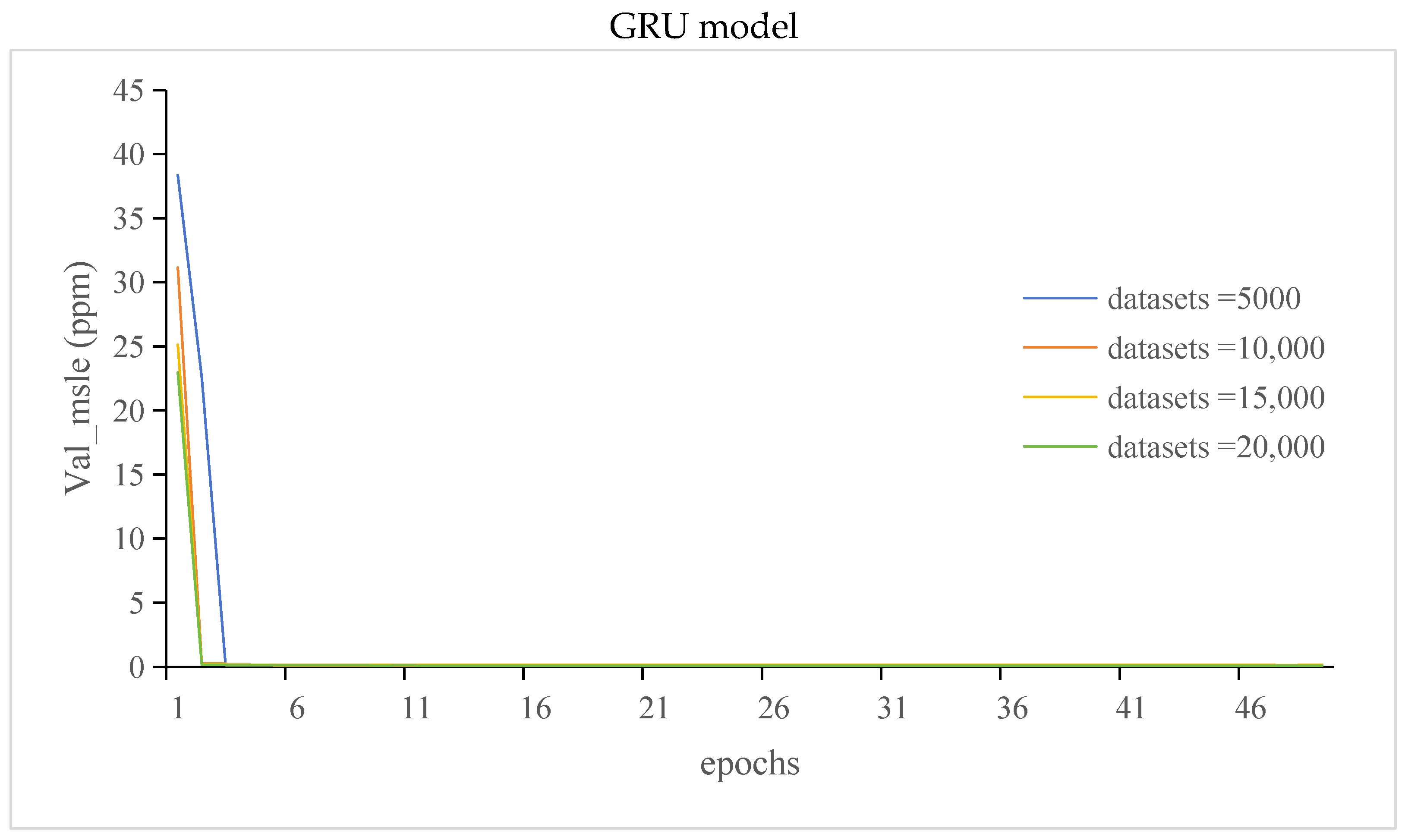
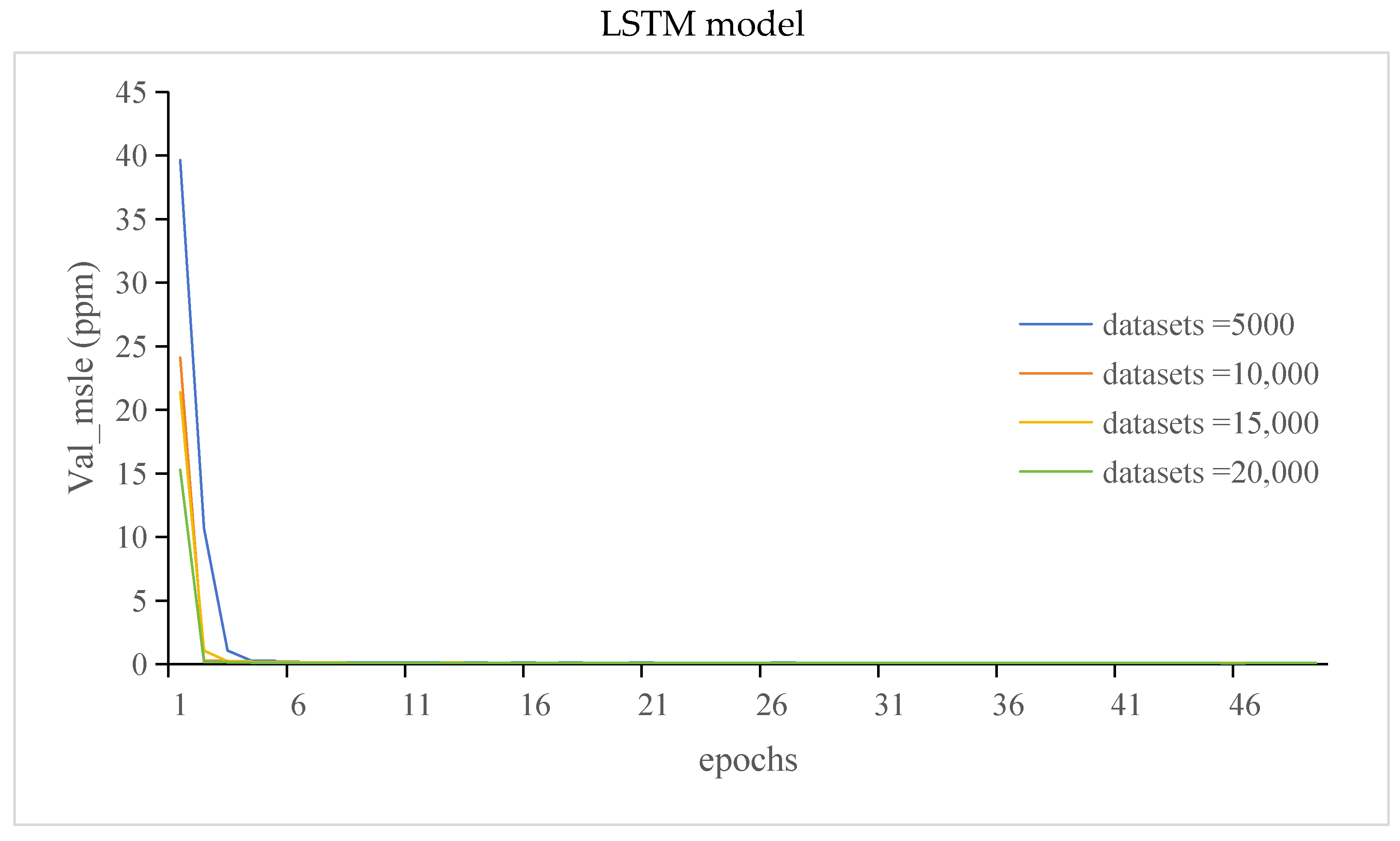
3.3.2. The Val_Loss and Val_Msle of GRU Model and LSTM Model
3.3.3. Overfitting Check by Cross-Validation
3.3.4. Model Application
4. Discussion
5. Conclusions
- (1)
- In this study, an extensive examination of the performance of GRU and LSTM models in predicting environmental parameters, specifically the CO2 concentration in a layer house, provided significant insights and contributions to the field of predictive modeling for agricultural and environmental applications.
- (2)
- According to the correlation coefficients, the layer house temperature, humidity, and CO2 concentration were selected as the feature data, and a model for predicting the CO2 concentration in a layer house was constructed based on the GRU and LSTM.
- (3)
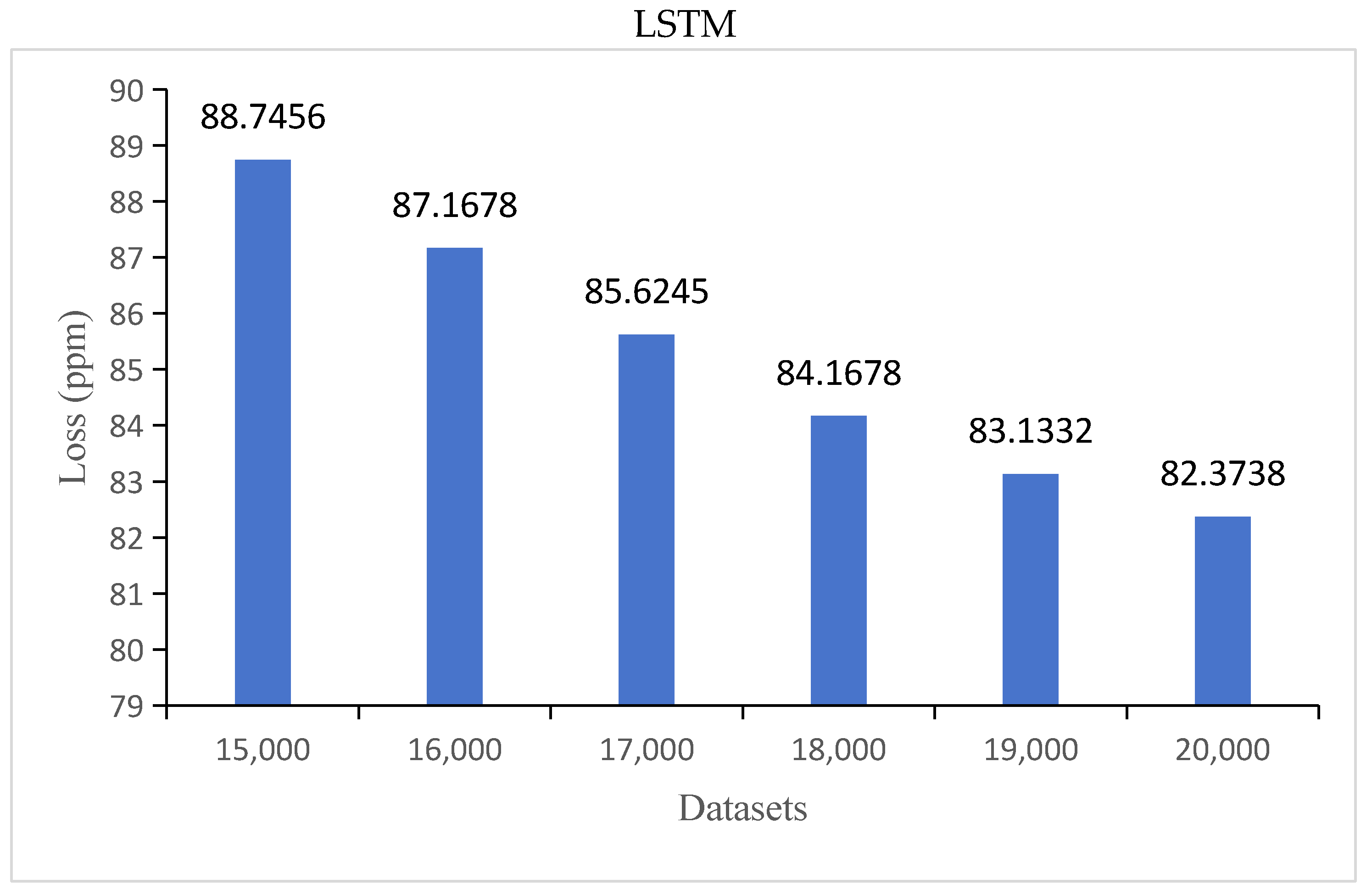
- Different datasets were selected, and the corresponding prediction results were obtained. The training and validation errors of the GRU and LSTM models were analyzed. The results showed that there was an optimal range of the number of datasets for the prediction model, and the loss of the model was minimal within this range
- (4)
- MAE between the predicted and label values was used as the loss function, and MSLE was used as a metric for monitoring the networks. MAE and MSLE were retained for each iteration during training. For each iteration, the loss and monitoring metrics of both the training set and validation set were plotted. The evaluate(∙) function was used to calculate the loss and monitoring metrics for the entire test set to obtain a timescale for each true value.
- (5)
- While increasing the dataset size yielded an improvement in prediction accuracy for both GRU and LSTM models, the findings noted a decline in prediction accuracy for the GRU model when 20,000 datasets were utilized. This suggests that the GRU model’s performance might plateau or decline beyond a certain dataset threshold, indicating a limitation in handling larger datasets. We will focus on solving this problem in future work.
- (6)
- The datasets for this study were collected between June and July 2023. In future research, the collection time of the datasets will be extended to four seasons to improve the applicability and robustness of the model.
- (7)
- This study will address the computational efficiency issue of the model in future work.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, Q.; Liu, P.; Liu, Z.; An, L.; Wang, M.; Wu, Z. Main Factors Influencing the Ammonia Emission of Poultry House. China Poult. 2017, 39, 45–49. [Google Scholar] [CrossRef]
- Zhao, Y. Effects of Carbon Dioxide Concentration on Performance, Blood Biochemical Indexes and Nutrient Metabolism of Laying Hens. Master’s Thesis, Hebei Agricultural University, Baoding, China, 2018. [Google Scholar]
- Burns, R.T.; Li, H.; Xin, H.; Gates, R.S.; Overhults, D.G.; Earnest, J.; Moody, L.B. Greenhouse Gas (GHG) Emissions from Broiler Houses in the Southeastern United States; American Society of Agricultural and Biological Engineers: St. Joseph, MI, USA, 2008; p. 1. [Google Scholar] [CrossRef]
- Kilic, I.; Yaslioglu, E. Ammonia and carbon dioxide concentrations in a layer house. Asian-Australas. J. Anim. Sci. 2014, 27, 1211. [Google Scholar] [CrossRef] [PubMed]
- Morgan, R.J.; Wood, D.J.; Van Heyst, B.J. The development of seasonal emission factors from a Canadian commercial laying hen facility. Atmos. Environ. 2014, 86, 1–8. [Google Scholar] [CrossRef]
- Taheri, S.; Razban, A. Learning-based CO2 concentration prediction: Application to indoor air quality control using demand-controlled ventilation. Build. Environ. 2021, 205, 108164. [Google Scholar] [CrossRef]
- Ma, C.F.; Xie, Q.J.; Wang, S.C. A prediction model for environmental factors in a pig house based on statistical learning and deep learning. J. Shanxi Agric. Univ. Nat. Sci. Ed. 2022, 42, 24–32. [Google Scholar] [CrossRef]
- Baghban, A.; Bahadori, A.; Mohammadi, A.H.; Behbahaninia, A. Prediction of CO2 loading capacities of aqueous solutions of absorbents using different computational schemes. Int. J. Greenh. Gas Control. 2017, 57, 143–161. [Google Scholar] [CrossRef]
- Zarzycki, K.; Ławryńczuk, M. Long Short-Term Memory Neural Networks for Modeling Dynamical Processes and Predictive Control: A Hybrid Physics-Informed Approach. Sensors 2023, 23, 8898. [Google Scholar] [CrossRef]
- Chen, K.; Zhou, Y.; Dai, F. A LSTM-based method for stock returns prediction: A case study of China stock market. In Proceedings of the 2015 IEEE International Conference on Big Data, Santa Clara, CA, USA, 29 October–1 November 2015; pp. 2823–2824. [Google Scholar] [CrossRef]
- Zha, W.; Liu, Y.; Wan, Y.; Luo, R.; Li, D.; Yang, S.; Xu, Y. Forecasting monthly gas field production based on the CNN-LSTM model. Energy 2022, 260, 124889. [Google Scholar] [CrossRef]
- Karim, F.; Majumdar, S.; Darabi, H.; Chen, S. LSTM fully convolutional networks for time series classification. IEEE Access 2017, 6, 1662–1669. [Google Scholar] [CrossRef]
- Zhao, Z.; Chen, W.; Wu, X.; Chen, P.C.; Liu, J. LSTM network: A deep learning approach for short-term traffic forecast. IET Intell. Transp. Syst. 2017, 11, 68–75. [Google Scholar] [CrossRef]
- Liu, Q.; Wang, P.; Sun, J.; Li, R.; Li, Y. Wireless Channel Prediction of GRU Based on Experience Replay and Snake Optimizer. Sensors 2023, 23, 6270. [Google Scholar] [CrossRef] [PubMed]
- Asuero, A.G.; Sayago, A.; González, A.G. The correlation coefficient: An overview. Crit. Rev. Anal. Chem. 2006, 36, 41–59. [Google Scholar] [CrossRef]
- Taylor, R. Interpretation of the correlation coefficient: A basic review. J. Diagn. Med. Sonogr. 1990, 6, 35–39. [Google Scholar] [CrossRef]
- van Aert, R.C.; Goos, C. A critical reflection on computing the sampling variance of the partial correlation coefficient. Res. Synth. Methods 2023, 14, 520–525. [Google Scholar] [CrossRef] [PubMed]
- Sherstinsky, A. Fundamentals of recurrent neural network (RNN) and long short-term memory (LSTM) network. Phys. D Nonlinear Phenom. 2020, 40, 132306. [Google Scholar] [CrossRef]
- Shewalkar, A.; Nyavanandi, D.; Ludwig, S.A. Performance evaluation of deep neural networks applied to speech recognition: RNN, LSTM and GRU. J. Artif. Intell. Soft Comput. Res. 2019, 9, 235–245. [Google Scholar] [CrossRef]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.C. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. arXiv 2015. [Google Scholar] [CrossRef]
- Fu, R.; Zhang, Z.; Li, L. Using LSTM and GRU neural network methods for traffic flow prediction. In Proceedings of the 31st Youth Academic Annual Conference of Chinese Association of Automation (YAC), Wuhan, China, 11–13 November 2016; pp. 324–328. [Google Scholar] [CrossRef]
- Shahid, F.; Zameer, A.; Muneeb, M. Predictions for COVID-19 with deep learning models of LSTM, GRU and Bi-LSTM. Chaos Solitons Fractals 2020, 140, 110212. [Google Scholar] [CrossRef]
- Zhang, Z.; Robinson, D.; Tepper, J. Detecting hate speech on twitter using a convolution-gru based deep neural network. In The Semantic Web, Proceedings of the 15th International Conference, ESWC, Heraklion, Greece, 3–7 June 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 745–760. [Google Scholar] [CrossRef]
- Athiwaratkun, B.; Stokes, J.W. Malware classification with LSTM and GRU language models and a character-level CNN. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 2482–2486. [Google Scholar] [CrossRef]
- Gao, S.; Huang, Y.; Zhang, S.; Han, J.; Wang, G.; Zhang, M.; Lin, Q. Short-term runoff prediction with GRU and LSTM networks without requiring time step optimization during sample generation. J. Hydrol. 2020, 589, 125188. [Google Scholar] [CrossRef]
- Staudemeyer, R.C.; Morris, E.R. Understanding LSTM—A tutorial into long short-term memory recurrent neural networks. arXiv 2019. [Google Scholar] [CrossRef]
- Graves, A.; Fernández, S.; Schmidhuber, J. Bidirectional LSTM networks for improved phoneme classification and recognition. In International Conference on Artificial Neural Networks; Springer: Berlin/Heidelberg, Germany, 2005; pp. 799–804. [Google Scholar] [CrossRef]
- Gers, F.A.; Schmidhuber, J.; Cummins, F. Learning to forget: Continual prediction with LSTM. Neural Comput. 2000, 12, 2451–2471. [Google Scholar] [CrossRef]
- Greff, K.; Srivastava, R.K.; Koutník, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A search space odyssey. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 2222–2232. [Google Scholar] [CrossRef]
- Yang, S.; Yu, X.; Zhou, Y. Lstm and gru neural network performance comparison study: Taking yelp review dataset as an example. In Proceedings of the International Workshop on Electronic Communication and Artificial Intelligence (IWECAI), Shanghai, China, 12–14 June 2020; pp. 98–101. [Google Scholar] [CrossRef]
- Agarap, A.F.M. A neural network architecture combining gated recurrent unit (GRU) and support vector machine (SVM) for intrusion detection in network traffic data. In Proceedings of the 10th International Conference on Machine Learning and Computing, Macau, China, 26–28 February 2018; pp. 26–30. [Google Scholar] [CrossRef]
- Dey, R.; Salem, F.M. Gate-variants of gated recurrent unit (GRU) neural networks. In Proceedings of the 60th International Midwest Symposium on Circuits and Systems (MWSCAS), Boston, MA, USA, 6–9 August 2017; pp. 1597–1600. [Google Scholar] [CrossRef]
- Bansal, T.; Belanger, D.; McCallum, A. Ask the gru: Multi-task learning for deep text recommendations. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016; pp. 107–114. [Google Scholar] [CrossRef]
- Sajjad, M.; Khan, Z.A.; Ullah, A.; Hussain, T.; Ullah, W.; Lee, M.Y.; Baik, S.W. A novel CNN-GRU-based hybrid approach for short-term residential load forecasting. IEEE Access 2020, 8, 143759–143768. [Google Scholar] [CrossRef]





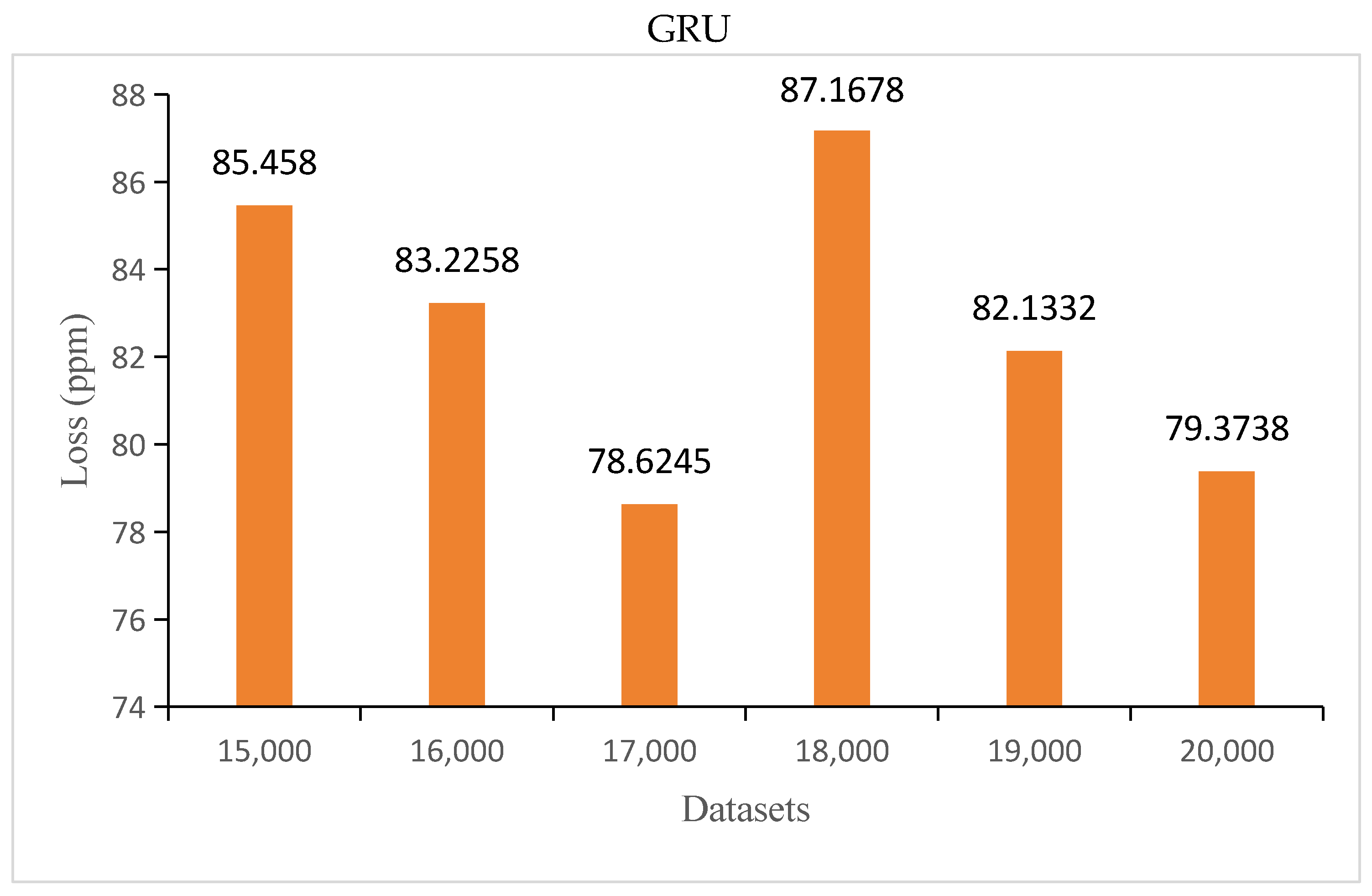

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model: “GRU” | ||
|---|---|---|
| Layer (type) | Output Shape | Parameter |
| input_4 (InputLayer) | [(None, 20, 5)] | 0 |
| gru_3 (GRU) | (None, 20, 8) | 360 |
| dropout_12 (Dropout) | (None, 20, 8) | 0 |
| gru_4 (GRU) | (None, 20, 16) | 1248 |
| dropout_13 (Dropout) | (None, 20, 16) | 0 |
| gru_5 (GRU) | (None, 32) | 4800 |
| dropout_14 (Dropout) | (None, 32) | 0 |
| dense_6 (Dense) | (None, 16) | 528 |
| dropout_15 (Dropout) | (None, 16) | 0 |
| dense_7 (Dense) | (None, 1) | 17 |
| Total parameters: 6953 | ||
| Trainable parameters: 6953 | ||
| Non-trainable parameters: 0 |
| Hyperparameters | Value |
|---|---|
| timestep | 1 |
| batch_size | 32 |
| feature_size | 1 |
| hidden_size | 256 |
| output_size | 1 |
| num_layers | 2 |
| epochs | 100 |
| best_loss | 0 |
| learning_rate | 0.0003 |
| Model | Datasets | Train_Loss | Val_Loss |
|---|---|---|---|
| LSTM | 5000 | 90.8156 | 91.6452 |
| 10,000 | 88.0604 | 89.8628 | |
| 15,000 | 86.0255 | 87.3469 | |
| 20,000 | 84.8316 | 85.3657 | |
| GRU | 5000 | 80.7534 | 82.4733 |
| 10,000 | 78.8040 | 80.3956 | |
| 15,000 | 76.4618 | 78.3562 | |
| 20,000 | 79.3265 | 80.6643 |
| Fan Opening Basis | Actual Value and Measuring Time of Carbon Dioxide Concentration in Layer House | Predict Value and Corresponding Time of Carbon Dioxide Concentration in Layer House | Status of Fan |
|---|---|---|---|
| Predicted value of carbon dioxide concentration | 495.8376 ppm 09:10:25 | 499.2168 ppm 09:11:25 | Off |
| 495.3592 ppm 09:10:40 | 500.0410 ppm 09:11:40 | Off | |
| 499.9687 ppm 09:11:40 | 503.6828 ppm 09:12:40 | On | |
| 499.2547 ppm 09:11:55 | 495.3158 ppm 09:12:55 | Off | |
| Actual value of carbon dioxide concentration | 499.6548 ppm 09:10:40 | Off | |
| 500.1364 ppm 09:11:40 | On | ||
| 500.0129 ppm 09:11:50 | On | ||
| 499.3159 ppm 09:12:00 | Off |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, X.; Yang, L.; Xue, H.; Li, L.; Yu, Y. A Machine Learning Model Based on GRU and LSTM to Predict the Environmental Parameters in a Layer House, Taking CO2 Concentration as an Example. Sensors 2024, 24, 244. https://doi.org/10.3390/s24010244
Chen X, Yang L, Xue H, Li L, Yu Y. A Machine Learning Model Based on GRU and LSTM to Predict the Environmental Parameters in a Layer House, Taking CO2 Concentration as an Example. Sensors. 2024; 24(1):244. https://doi.org/10.3390/s24010244
Chicago/Turabian StyleChen, Xiaoyang, Lijia Yang, Hao Xue, Lihua Li, and Yao Yu. 2024. "A Machine Learning Model Based on GRU and LSTM to Predict the Environmental Parameters in a Layer House, Taking CO2 Concentration as an Example" Sensors 24, no. 1: 244. https://doi.org/10.3390/s24010244
APA StyleChen, X., Yang, L., Xue, H., Li, L., & Yu, Y. (2024). A Machine Learning Model Based on GRU and LSTM to Predict the Environmental Parameters in a Layer House, Taking CO2 Concentration as an Example. Sensors, 24(1), 244. https://doi.org/10.3390/s24010244