
Adaptive Global Power-of-Two Ternary Quantization Algorithm Based on Unfixed Boundary Thresholds
Abstract
:1. Introduction
1.1. Background
1.2. Existing Methods and Problems
1.3. Contributions of This Paper
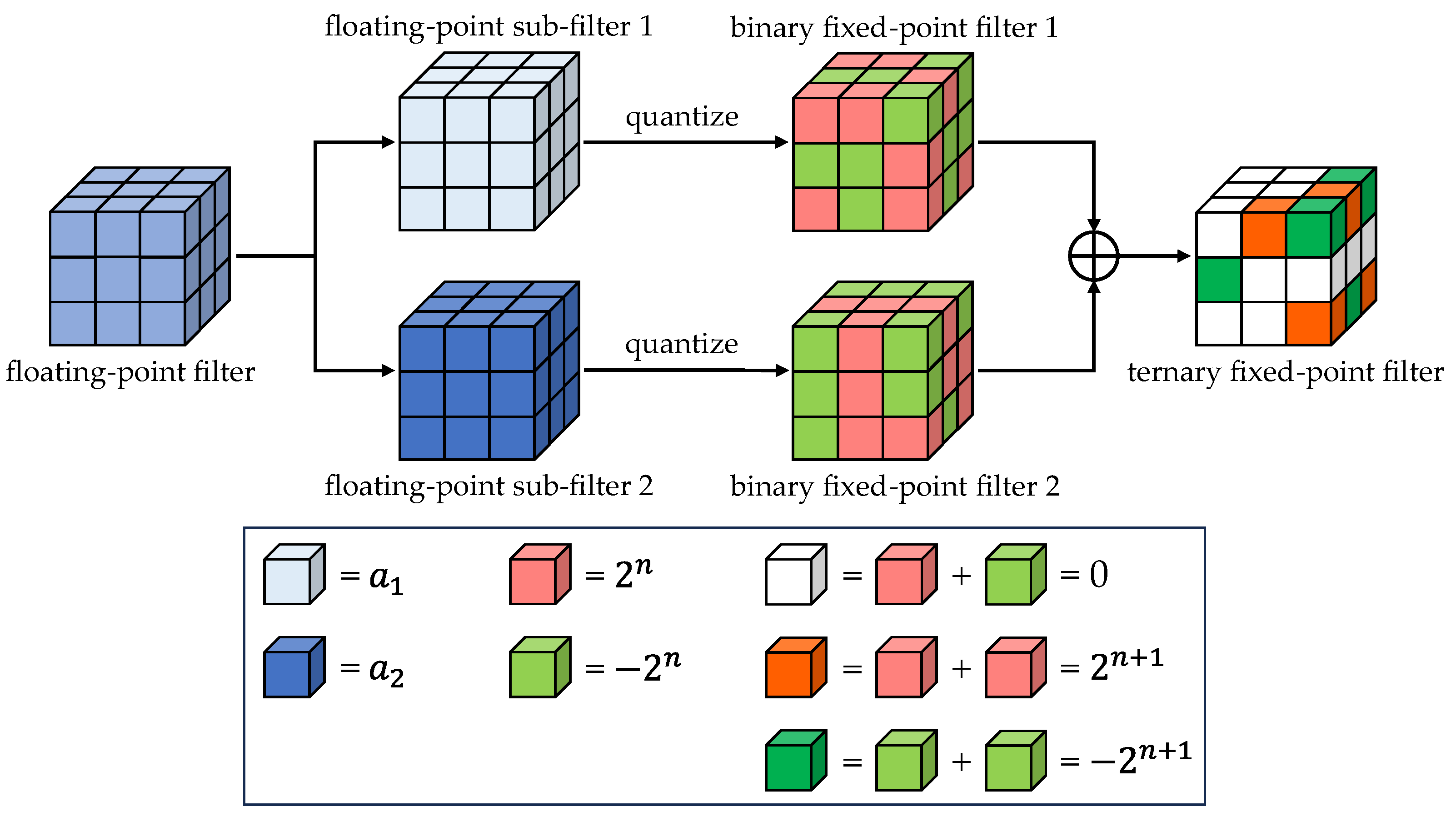
- This paper analyzes the nonglobal quantization and fixed quantization threshold problems in existing ternary quantization methods and formulates a new power-of-two ternary quantization strategy with unfixed boundary thresholds based on the global CNN quantization architecture proposed in our previous study [46]. This new quantization strategy decomposes each filter in a CNN model into two subfilters. By minimizing the Euclidean distance, the two subfilters are binarized into a power-of-two form. According to the matrix additivity, the two binary filters are combined into one ternary filter to complete the power-of-two CNN ternary quantization, and the restrictions on CNN performance due to fixed boundary thresholds and intervals are removed.
- This paper formulates a general power-of-two quantization strategy based on unfixed thresholds. By decomposing each filter into multiple filters and performing binarization and accumulation, the power-of-two ternary quantization strategy with unfixed thresholds can be extended to any bit width quantization.
- Ternary and other bit width quantization experiments were conducted on mainstream CNN models, such as VGG-16 [7], ResNet-18, ResNet-20, ResNet-56 [60], and GoogLeNet [61], in two image classification data sets: CIFAR10 [62] and Mini-ImageNet [63]. The results were compared and evaluated quantitatively and qualitatively with some state-of-the-art algorithms in order to verify the effectiveness and versatility of the proposed APTQ and APQ algorithms.
2. Proposed Method
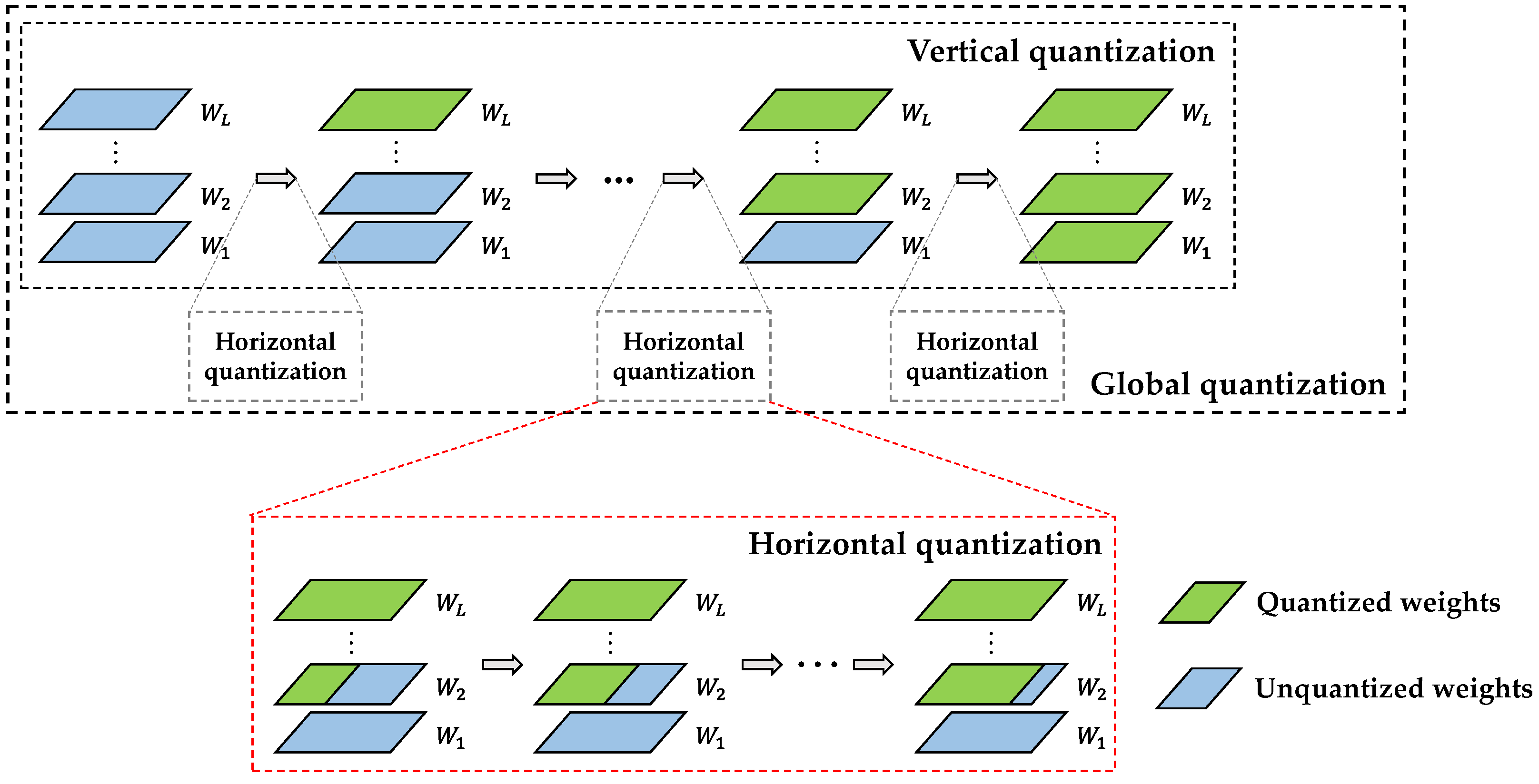
2.1. Global Power-of-Two Ternary Quantization Based on Unfixed Boundary Thresholds (APTQ)
2.1.1. APTQ Quantization Strategy
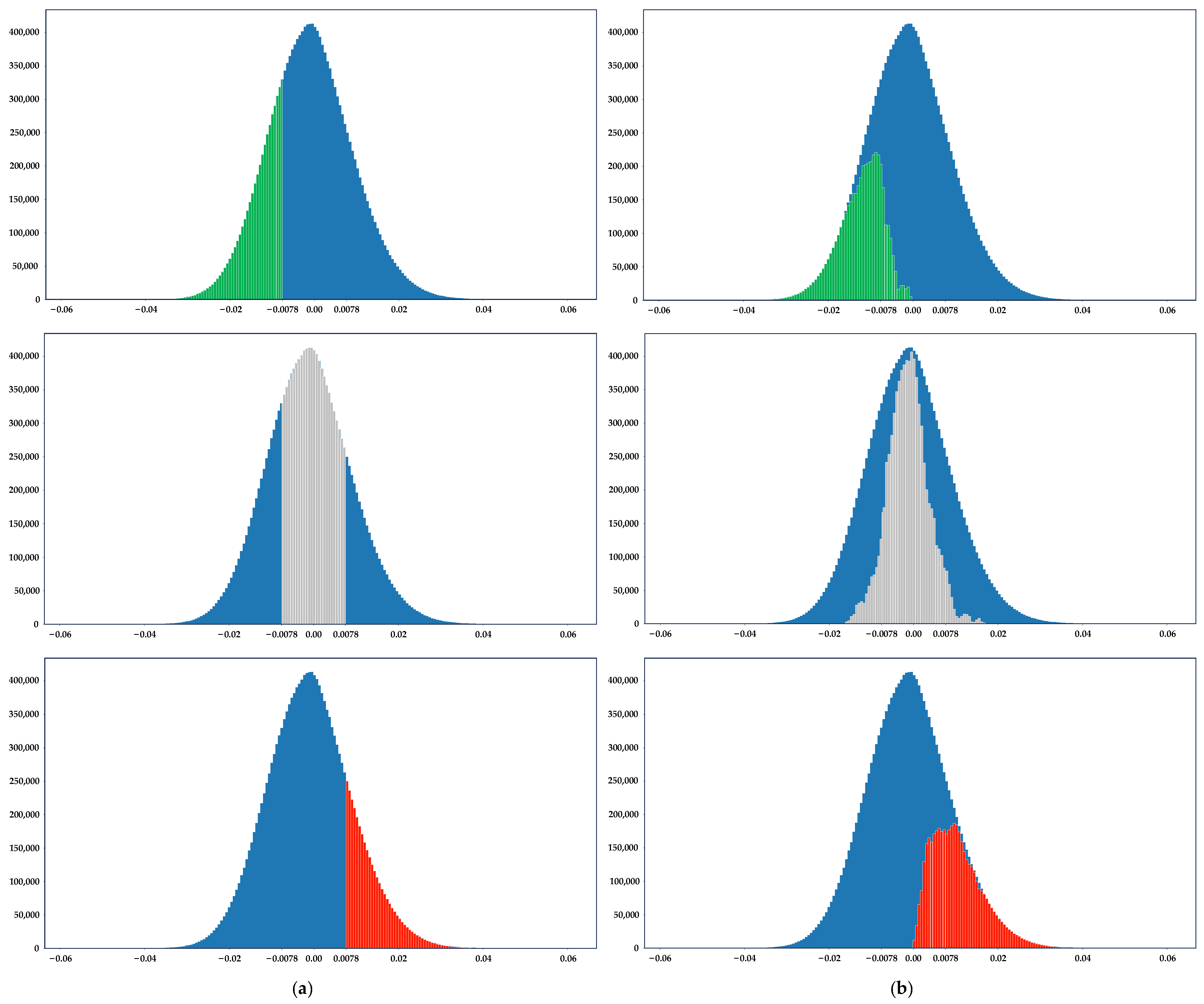
2.1.2. Weight Distribution Characteristics of APTQ Quantization Strategy
2.1.3. APTQ Global Retraining Process
| Algorithm 1: Adaptive Global Power-of-two Ternary Quantization Based on Unfixed Boundary Thresholds (APTQ) |
| Input: 32-bit floating-point CNN model |
| Output: Power-of-two ternary quantization CNN model |
| 1: Grouping weights by layer: Sort filters by their L1 norm and divide them into M groups |
| 2: for do |
| 3: Split all filters in the same layer into two subfilters using Formulas (8) and (9) |
| 4: for do |
| 5: Determine the optimal quantization scale factor using Formulas (12)–(14), (16) and (17), and complete power-of-two binary quantization of the two subfilters |
| 6: Remerge the subfilters using Formula (18) to complete the power-of-two ternary quantization based on unfixed boundary thresholds |
| 7: Retrain the network, keep the quantized layers fixed, and update unquantized weights in other layers |
| 8: end for |
| 9: end for |
2.2. Universal Global Power-of-Two Quantization Based on Unfixed Boundary Thresholds (APQ)
| Algorithm 2: Universal Global Power-of-Two Quantization Based on Unfixed Boundary Thresholds (APQ) |
| Input: 32-bit floating-point CNN model |
| Output: Power-of-two h-bit quantization CNN model |
| 1: Grouping weights by layer: Sort filters by their L1 norm and divide them into M groups |
| 2: for do |
| 3: Split all filters in the same layer into subfilters using Formulas (19) and (20) |
| 4: for do |
| 5: Determine the optimal quantization scale factor using Formulas (21)–(23), and complete power-of-two binary quantization of the H subfilters |
| 6: Merge the binary subfilters and approximate all values to the nearest power-of-two by using Formulas (24)–(26), completing the h-bit power-of-two quantization of the original filter. |
| 7: Retrain the network, keep the quantized layers fixed, and update unquantized weights in other layers |
| 8: end for |
| 9: end for |
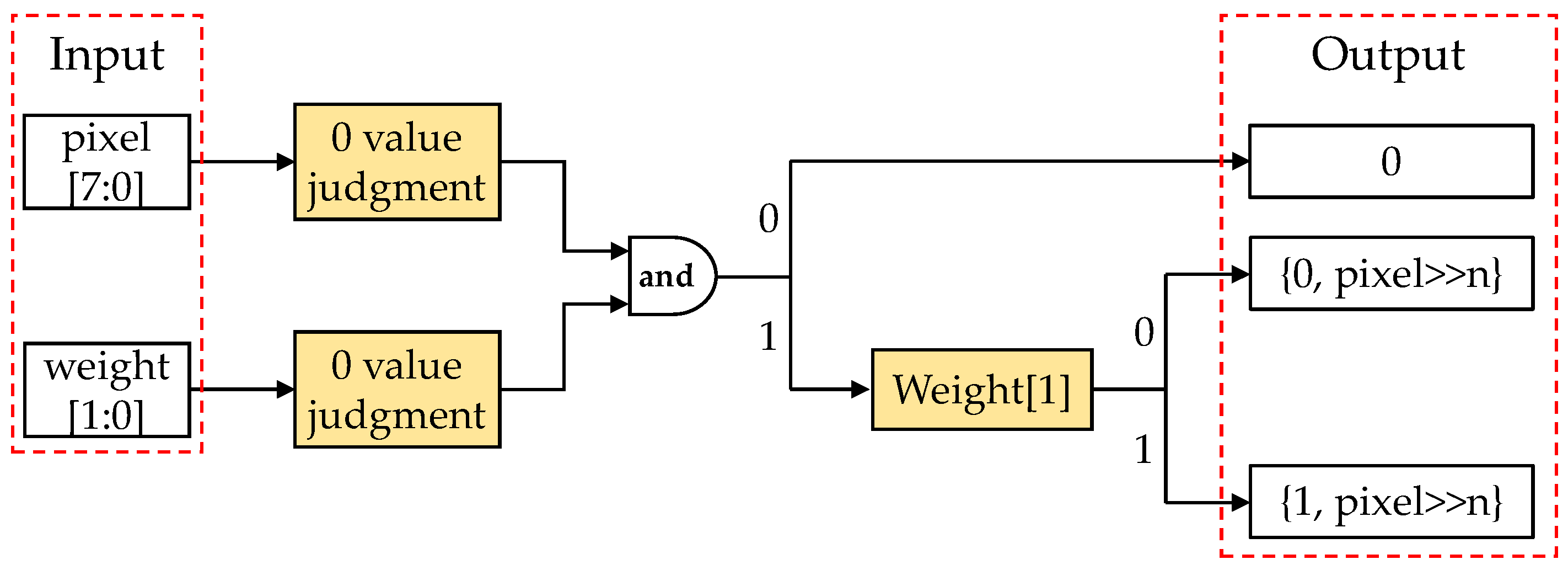
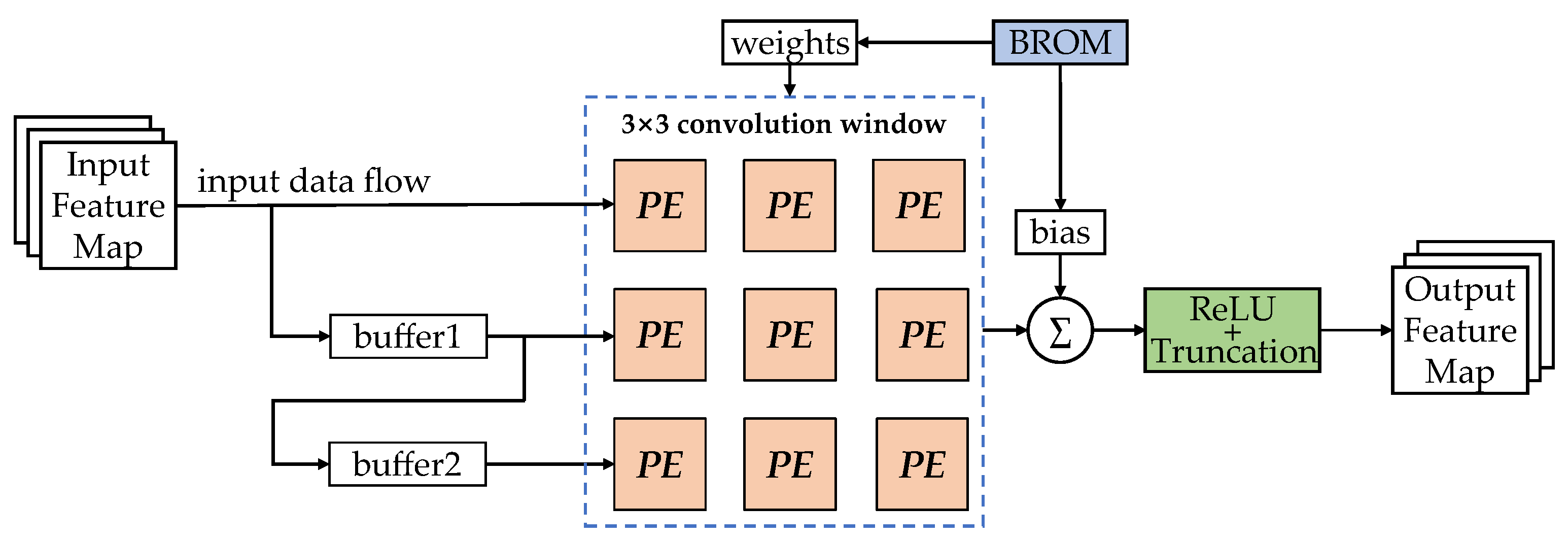
2.3. APTQ and APQ Dedicated Convolutional Computation Module in Edge Chips
3. Experiments
3.1. APTQ Quantization Performance Testing
3.1.1. Implementation Details
3.1.2. APTQ Quantization Performance Comparison
3.2. APQ Quantization Performance Testing
3.3. Hardware Performance Evaluation
3.3.1. Implementation Details
3.3.2. Hardware Design Comparative Testing
4. Limitation Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yan, S.-R.; Pirooznia, S.; Heidari, A.; Navimipour, N.J.; Unal, M. Implementation of a Product-Recommender System in an IoT-Based Smart Shopping Using Fuzzy Logic and Apriori Algorithm. In IEEE Transactions on Engineering Management; IEEE: Toulouse, France, 2022. [Google Scholar]
- Garcia, A.J.; Aouto, A.; Lee, J.-M.; Kim, D.-S. CNN-32DC: An Improved Radar-Based Drone Recognition System Based on Convolutional Neural Network. ICT Express 2022, 8, 606–610. [Google Scholar] [CrossRef]
- Saha, D.; De, S. Practical Self-Driving Cars: Survey of the State-of-the-Art. Preprints 2022. [Google Scholar] [CrossRef]
- Lyu, Y.; Bai, L.; Huang, X. ChipNet: Real-Time LiDAR Processing for Drivable Region Segmentation on an FPGA. IEEE Trans. Circuits Syst. I Regul. Pap. 2019, 66, 1769–1779. [Google Scholar] [CrossRef]
- Shi, W.; Cao, J.; Zhang, Q.; Li, Y.; Xu, L. Edge Computing: Vision and Challenges. Internet Things J. IEEE 2016, 3, 637–646. [Google Scholar] [CrossRef]
- McEnroe, P.; Wang, S.; Liyanage, M. A Survey on the Convergence of Edge Computing and AI for UAVs: Opportunities and Challenges. IEEE Internet Things J. 2022, 9, 15435–15459. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Thakur, P.S.; Sheorey, T.; Ojha, A. VGG-ICNN: A Lightweight CNN Model for Crop Disease Identification. Multimed. Tools Appl. 2023, 82, 497–520. [Google Scholar] [CrossRef]
- Wang, H.; Chen, X.; Zhang, T.; Xu, Z.; Li, J. CCTNet: Coupled CNN and Transformer Network for Crop Segmentation of Remote Sensing Images. Remote Sens. 2022, 14, 1956. [Google Scholar] [CrossRef]
- Liu, X.; Yang, J.; Zou, C.; Chen, Q.; Cai, C. Collaborative Edge Computing With FPGA-Based CNN Accelerators for Energy-Efficient and Time-Aware Face Tracking System. IEEE Trans. Comput. Soc. Syst. 2021, 9, 252–266. [Google Scholar] [CrossRef]
- Saranya, M.; Archana, N.; Reshma, J.; Sangeetha, S.; Varalakshmi, M. Object Detection and Lane Changing for Self Driving Car Using Cnn. In Proceedings of the 2022 International Conference on Communication, Computing and Internet of Things (IC3IoT), Chennai, India, 10–11 March 2022; pp. 1–7. [Google Scholar]
- Rashid, N.; Demirel, B.U.; Al Faruque, M.A. AHAR: Adaptive CNN for Energy-Efficient Human Activity Recognition in Low-Power Edge Devices. IEEE Internet Things J. 2022, 9, 13041–13051. [Google Scholar] [CrossRef]
- Yu, Z.; Lu, Y.; An, Q.; Chen, C.; Li, Y.; Wang, Y. Real-Time Multiple Gesture Recognition: Application of a Lightweight Individualized 1D CNN Model to an Edge Computing System. IEEE Trans. Neural Syst. Rehabil. Eng. 2022, 30, 990–998. [Google Scholar] [CrossRef] [PubMed]
- Choquette, J.; Gandhi, W.; Giroux, O.; Stam, N.; Krashinsky, R. NVIDIA A100 Tensor Core GPU: Performance and Innovation. IEEE Micro 2021, 41, 29–35. [Google Scholar] [CrossRef]
- Zhang, C.; Li, P.; Sun, G.; Guan, Y.; Cong, J. Optimizing FPGA-Based Accelerator Design for Deep Convolutional Neural Networks. In Proceedings of the 2015 ACM/SIGDA International Symposium, Monterey, CA, USA, 22–24 February 2015. [Google Scholar]
- Xilinx. 7 Series FPGAs Configuration User Guide (UG470); Xilinx: San Jose, CA, USA, 2018. [Google Scholar]
- Huang, W.; Wu, H.; Chen, Q.; Luo, C.; Zeng, S.; Li, T.; Huang, Y. FPGA-Based High-Throughput CNN Hardware Accelerator With High Computing Resource Utilization Ratio. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 4069–4083. [Google Scholar] [CrossRef] [PubMed]
- Wong, D.L.T.; Li, Y.; John, D.; Ho, W.K.; Heng, C.-H. An Energy Efficient ECG Ventricular Ectopic Beat Classifier Using Binarized CNN for Edge AI Devices. IEEE Trans. Biomed. Circuits Syst. 2022, 16, 222–232. [Google Scholar] [CrossRef] [PubMed]
- Yan, P.; Xiang, Z. Acceleration and Optimization of Artificial Intelligence CNN Image Recognition Based on FPGA. In Proceedings of the 2022 IEEE 6th Information Technology and Mechatronics Engineering Conference (ITOEC), Chongqing, China, 4–6 March 2022; Volume 6, pp. 1946–1950. [Google Scholar]
- Pan, H.; Sun, W. Nonlinear Output Feedback Finite-Time Control for Vehicle Active Suspension Systems. IEEE Trans. Ind. Inform. 2019, 15, 2073–2082. [Google Scholar] [CrossRef]
- Kim, H.; Choi, K.K. A Reconfigurable CNN-Based Accelerator Design for Fast and Energy-Efficient Object Detection System on Mobile FPGA; IEEE Access: Toulouse, France, 2023. [Google Scholar]
- Sze, V.; Chen, Y.-H.; Yang, T.-J.; Emer, J.S. Efficient Processing of Deep Neural Networks: A Tutorial and Survey. Proc. IEEE 2017, 105, 2295–2329. [Google Scholar] [CrossRef]
- Rizqyawan, M.I.; Munandar, A.; Amri, M.F.; Utoro, R.K.; Pratondo, A. Quantized Convolutional Neural Network toward Real-Time Arrhythmia Detection in Edge Device. In Proceedings of the 2020 International conference on radar, antenna, microwave, electronics, and telecommunications (ICRAMET), Tangerang, Indonesia, 18–20 November 2020; pp. 234–239. [Google Scholar]
- Capotondi, A.; Rusci, M.; Fariselli, M.; Benini, L. CMix-NN: Mixed Low-Precision CNN Library for Memory-Constrained Edge Devices. IEEE Trans. Circuits Syst. II Express Briefs 2020, 67, 871–875. [Google Scholar] [CrossRef]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, R. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices; IEEE: Salt Lake City, UT, USA, 2018; pp. 6848–6856. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Han, S.; Pool, J.; Tran, J.; Dally, W.J. Learning Both Weights and Connections for Efficient Neural Networks; MIT Press: Cambridge, MA, USA, 2015. [Google Scholar]
- Gao, S.; Huang, F.; Cai, W.; Huang, H. Network Pruning via Performance Maximization. In Proceedings of the 2021 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Kuala Lumpur, Malaysia, 20–25 June 2021. [Google Scholar]
- Jaderberg, M.; Vedaldi, A.; Zisserman, A. Speeding up Convolutional Neural Networks with Low Rank Expansions. arXiv 2014, arXiv:1405.3866. [Google Scholar]
- Dettmers, T. 8-Bit Approximations for Parallelism in Deep Learning. arXiv 2015, arXiv:1511.04561. [Google Scholar]
- Courbariaux, M.; Bengio, Y. BinaryNet: Training Deep Neural Networks with Weights and Activations Constrained to +1 or −1. arXiv 2016, arXiv:1602.02830. [Google Scholar]
- Rastegari, M.; Ordonez, V.; Redmon, J.; Farhadi, A. XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks. In European Conference on Computer Vision; Springer International Publishing: Cham, Switzerland, 2016. [Google Scholar]
- Zhou, A.; Yao, A.; Guo, Y.; Xu, L.; Chen, Y. Incremental Network Quantization: Towards Lossless CNNs with Low-Precision Weights. arXiv 2017, arXiv:1702.03044. [Google Scholar]
- Yamamoto, K. IEEE COMP SOC Learnable Companding Quantization for Accurate Low-Bit Neural Networks; IEEE: Piscataway, NJ, USA, 2021; pp. 5027–5036. [Google Scholar]
- Krishnamoorthi, R. Quantizing Deep Convolutional Networks for Efficient Inference: A Whitepaper. arXiv 2018, arXiv:1806.08342. [Google Scholar]
- Jacob, B.; Kligys, S.; Chen, B.; Zhu, M.; Tang, M.; Howard, A.; Adam, H.; Kalenichenko, D. Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference. In Proceedings of the 2018 IEEE conference on computer vision and pattern recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 2704–2713. [Google Scholar]
- Kuzmin, A.; Baalen, M.V.; Ren, Y.; Nagel, M.; Peters, J.; Blankevoort, T. FP8 Quantization: The Power of the Exponent. Adv. Neural Inf. Process. Syst. 2022, 35, 14651–14662. [Google Scholar]
- Zhu, F.; Gong, R.; Yu, F.; Liu, X.; Wang, Y.; Li, Z.; Yang, X.; Yan, J. Towards Unified Int8 Training for Convolutional Neural Network. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1969–1979. [Google Scholar]
- Choi, J.; Wang, Z.; Venkataramani, S.; Chuang, P.I.-J.; Srinivasan, V.; Gopalakrishnan, K. Pact: Parameterized Clipping Activation for Quantized Neural Networks. arXiv 2018, arXiv:1805.06085. [Google Scholar]
- Li, F.; Zhang, B.; Liu, B. Ternary Weight Networks. arXiv 2016, arXiv:1605.04711. [Google Scholar]
- Zhu, C.; Han, S.; Mao, H.; Dally, W.J. Trained Ternary Quantization. arXiv 2016, arXiv:1612.01064. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Li, Y.; Dong, X.; Zhang, S.Q.; Bai, H.; Chen, Y.; Wang, W. Rtn: Reparameterized Ternary Network. Proc. AAAI Conf. Artif. Intell. 2020, 34, 4780–4787. [Google Scholar] [CrossRef]
- Gong, R.; Liu, X.; Jiang, S.; Li, T.; Yan, J. Differentiable Soft Quantization: Bridging Full-Precision and Low-Bit Neural Networks. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Chin, H.-H.; Tsay, R.-S.; Wu, H.-I. An Adaptive High-Performance Quantization Approach for Resource-Constrained CNN Inference. In Proceedings of the 2022 IEEE 4th International Conference on Artificial Intelligence Circuits and Systems (AICAS), Incheon, Republic of Korea, 13–15 June 2022; pp. 336–339. [Google Scholar]
- Sui, X.; Lv, Q.; Bai, Y.; Zhu, B.; Zhi, L.; Yang, Y.; Tan, Z. A Hardware-Friendly Low-Bit Power-of-Two Quantization Method for CNNs and Its FPGA Implementation. Sensors 2022, 22, 6618. [Google Scholar] [CrossRef]
- Choukroun, Y.; Kravchik, E.; Kisilev, P. Low-Bit Quantization of Neural Networks for Efficient Inference. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- NVIDIA. 8-Bit Inference with TensorRT; NVIDIA: Santa Clara, CA, USA, 2017. [Google Scholar]
- Liu, C.; Ding, W.; Chen, P.; Zhuang, B.; Wang, Y.; Zhao, Y.; Zhang, B.; Han, Y. RB-Net: Training Highly Accurate and Efficient Binary Neural Networks with Reshaped Point-Wise Convolution and Balanced Activation. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 6414–6424. [Google Scholar] [CrossRef]
- Hong, W.; Chen, T.; Lu, M.; Pu, S.; Ma, Z. Efficient Neural Image Decoding via Fixed-Point Inference. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 3618–3630. [Google Scholar] [CrossRef]
- Baskin, C.; Liss, N.; Schwartz, E.; Zheltonozhskii, E.; Giryes, R.; Bronstein, A.M.; Mendelson, A. Uniq: Uniform Noise Injection for Non-Uniform Quantization of Neural Networks. ACM Trans. Comput. Syst. (TOCS) 2021, 37, 1–15. [Google Scholar] [CrossRef]
- Han, S.; Mao, H.; Dally, W.J. Deep Compression: Compressing Deep Neural Network with Pruning, Trained Quantization and Huffman Coding. In Proceedings of the 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Nagel, M.; Amjad, R.A.; Van Baalen, M.; Louizos, C.; Blankevoort, T. Up or down? Adaptive Rounding for Post-Training Quantization. Proc. Int. Conf. Mach. Learn. PMLR 2020, 119, 7197–7206. [Google Scholar]
- Kumar, A.; Sharma, A.; Bharti, V.; Singh, A.K.; Singh, S.K.; Saxena, S. MobiHisNet: A Lightweight CNN in Mobile Edge Computing for Histopathological Image Classification. IEEE Internet Things J. 2021, 8, 17778–17789. [Google Scholar] [CrossRef]
- Meng, J.; Venkataramanaiah, S.K.; Zhou, C.; Hansen, P.; Whatmough, P.; Seo, J. Fixyfpga: Efficient Fpga Accelerator for Deep Neural Networks with High Element-Wise Sparsity and without External Memory Access. In Proceedings of the 2021 31st International Conference on Field-Programmable Logic and Applications (FPL), Dresden, Germany, 30 August–3 September 2021; pp. 9–16. [Google Scholar]
- Li, Z.; Ni, B.; Li, T.; Yang, X.; Zhang, W.; Gao, W. Residual Quantization for Low Bit-Width Neural Networks. IEEE Trans. Multimed. 2021, 25, 214–227. [Google Scholar] [CrossRef]
- Venieris, S.I.; Christos-Savvas, B. fpgaConvNet: Mapping Regular and Irregular Convolutional Neural Networks on FPGAs. IEEE Trans. Neural Netw. Learn. Syst. 2018, 30, 326–342. [Google Scholar] [CrossRef]
- Zhu, C.; Huang, K.; Yang, S.; Zhu, Z.; Zhang, H.; Shen, H. An Efficient Hardware Accelerator for Structured Sparse Convolutional Neural Networks on FPGAs. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2020, 28, 1953–1965. [Google Scholar] [CrossRef]
- Li, Y.; Dong, X.; Wang, W. Additive Powers-of-Two Quantization: An Efficient Non-Uniform Discretization for Neural Networks. In Proceedings of the International Conference on Learning Representations (ICLR), Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images. In Handbook of Systemic Autoimmune Diseases; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Wierstra, D. Matching Networks for One Shot Learning. In Proceedings of the 30th Conference on Neural Information Processing Systems (NIPS 2016), Barcelona, Spain, 5–10 December 2016; Volume 29. [Google Scholar]
- Vanholder, H. Efficient Inference with Tensorrt. In Proceedings of the GPU Technology Conference, San Jose, CA, USA, 4–7 April 2016; Volume 1. [Google Scholar]
- Nagel, M.; van Baalen, M.; Blankevoort, T.; Welling, M. Data-Free Quantization through Weight Equalization and Bias Correction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1325–1334. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 60, 84–90. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the Conference and Workshop on Neural Information Processing Systems 2019, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Zhang, D.; Yang, J.; Ye, D.; Hua, G. Lq-Nets: Learned Quantization for Highly Accurate and Compact Deep Neural Networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 365–382. [Google Scholar]
- Zhou, S.; Ni, Z.; Zhou, X.; Wen, H.; Wu, Y.; Zou, Y. DoReFa-Net: Training Low Bitwidth Convolutional Neural Networks with Low Bitwidth Gradients. arXiv 2016, arXiv:1606.06160. [Google Scholar]
- Bai, Y.; Wang, Y.-X.; Liberty, E. Proxquant: Quantized Neural Networks via Proximal Operators. arXiv 2018, arXiv:1810.00861. [Google Scholar]
- Asim, F.; Park, J.; Azamat, A.; Lee, J. CSQ: Centered Symmetric Quantization for Extremely Low Bit Neural Networks. In Proceedings of the International Conference on Learning Representations 2022, New Orleans, LA, USA, 19–20 June 2022. [Google Scholar]
- Kulkarni, U.; Hosamani, A.S.; Masur, A.S.; Hegde, S.; Vernekar, G.R.; Chandana, K.S. A Survey on Quantization Methods for Optimization of Deep Neural Networks. In Proceedings of the 2022 International Conference on Automation, Computing and Renewable Systems (ICACRS), Pudukkottai, India, 13–15 December 2022; pp. 827–834. [Google Scholar]
- Xilinx. Vivado Design Suite User Guide: Synthesis. White Pap. 2021, 5, 30. [Google Scholar]
- Li, J.; Un, K.-F.; Yu, W.-H.; Mak, P.-I.; Martins, R.P. An FPGA-Based Energy-Efficient Reconfigurable Convolutional Neural Network Accelerator for Object Recognition Applications. IEEE Trans. Circuits Syst. II Express Briefs 2021, 68, 3143–3147. [Google Scholar] [CrossRef]
- Yuan, T.; Liu, W.; Han, J.; Lombardi, F. High Performance CNN Accelerators Based on Hardware and Algorithm Co-Optimization. IEEE Trans. Circuits Syst. I Regul. Pap. 2020, 68, 250–263. [Google Scholar] [CrossRef]
- Bouguezzi, S.; Fredj, H.B.; Belabed, T.; Valderrama, C.; Faiedh, H.; Souani, C. An Efficient FPGA-Based Convolutional Neural Network for Classification: Ad-MobileNet. Electronics 2021, 10, 2272. [Google Scholar] [CrossRef]
- Renda, A.; Frankle, J.; Carbin, M. Comparing Fine-Tuning and Rewinding in Neural Network Pruning. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Quantized Weight | Recoding Weight |
|---|---|
| 01 | |
| 0 | 00 |
| 11 |
| Quantized Weight | Recoding Weight |
|---|---|
| 001 | |
| 010 | |
| 011 | |
| 0 | 000 |
| 111 | |
| 110 | |
| 101 |
| CNN | Weight Decay | Momentum | Learning Rate | Batch Size |
|---|---|---|---|---|
| AlexNet | 0.0005 | 0.9 | 0.01 | 256 |
| VGG-16 | 0.0005 | 0.9 | 0.01 | 128 |
| ResNet-18 | 0.0005 | 0.9 | 0.01 | 128 |
| ResNet-20 | 0.0001 | 0.9 | 0.1 | 256 |
| ResNet-56 | 0.0001 | 0.9 | 0.1 | 128 |
| GoogLeNet | 0.0002 | 0.9 | 0.01 | 128 |
| CNN | Method | Top-1 Accuracy | Top-5 Accuracy | Decrease in Top-1/Top-5 Error |
|---|---|---|---|---|
| AlexNet | Baseline | 82.96% | 99.09% | |
| GSNQ | 80.95% | 98.71% | −2.01%/−0.38% | |
| APTQ | 82.25% | 99.01% | −0.71%/−0.08% | |
| VGG-16 | Baseline | 88.74% | 99.59% | |
| GSNQ | 87.14% | 99.28% | −1.60%/−0.31% | |
| APTQ | 88.18% | 99.46% | −0.56%/−0.13% | |
| ResNet-18 | Baseline | 89.72% | 99.69% | |
| GSNQ | 88.91% | 99.40% | −0.81%/−0.29% | |
| APTQ | 89.20% | 99.60% | −0.52%/−0.09% | |
| ResNet-20 | Baseline | 91.60% | 99.76% | |
| GSNQ | 90.91% | 99.61% | −0.69%/−0.15% | |
| APTQ | 91.21% | 99.66% | −0.39%/−0.10% | |
| ResNet-56 | Baseline | 93.20% | 99.80% | |
| GSNQ | 92.92% | 99.69% | −0.28%/−0.11% | |
| APTQ | 93.07% | 99.74% | −0.13%/−0.06% | |
| GoogLeNet | Baseline | 90.04% | 99.91% | |
| GSNQ | 89.02% | 99.66% | −1.02%/−0.25% | |
| APTQ | 89.63% | 99.75% | −0.41%/−0.16% |
| CNN | Method | Top-1 Accuracy | Top-5 Accuracy | Decrease in Top-1/Top-5 Error |
|---|---|---|---|---|
| AlexNet | Baseline | 70.11% | 88.18% | |
| GSNQ | 67.12% | 87.77% | −2.99%/−0.41% | |
| APTQ | 68.99% | 88.18% | −1.12%/0.00% | |
| VGG-16 | Baseline | 72.03% | 91.25% | |
| GSNQ | 70.00% | 90.85% | −2.03%/−0.40% | |
| APTQ | 71.11% | 91.10% | −0.92%/−0.15% | |
| ResNet-18 | Baseline | 74.16% | 91.96% | |
| GSNQ | 73.17% | 91.40% | −0.99%/−0.56% | |
| APTQ | 73.79% | 91.71% | −0.37%/−0.25% | |
| GoogLeNet | Baseline | 76.68% | 92.01% | |
| GSNQ | 75.52% | 91.58% | −1.16%/−0.43% | |
| APTQ | 75.98% | 91.95% | −0.70%/−0.06% |
| CNN | Method | Top-1 Accuracy | Top-5 Accuracy | Decrease in Top-1/Top-5 Error |
|---|---|---|---|---|
| AlexNet | Baseline | 61.21% | 86.99% | |
| GSNQ | 59.03% | 84.65% | −2.18%/−0.51% | |
| APTQ | 60.49% | 84.99% | −0.72%/−0.20% | |
| VGG-16 | Baseline | 75.09% | 91.56% | |
| GSNQ | 73.51% | 90.01% | −1.58%/−1.55% | |
| APTQ | 74.66% | 90.52% | −0.43%/−1.04% | |
| ResNet-18 | Baseline | 76.76% | 92.16% | |
| GSNQ | 75.19% | 91.06% | −1.57%/−1.10% | |
| APTQ | 75.98% | 92.00% | −0.78%/−0.16% | |
| GoogLeNet | Baseline | 78.91% | 93.10% | |
| GSNQ | 77.89% | 92.61% | −1.02%/−0.49% | |
| APTQ | 78.29% | 92.96% | −0.62%/−0.14% |
| CNN | Method | Top-1 Accuracy | Decrease in Top-1 Error |
|---|---|---|---|
| VGG-16 | Baseline | 88.74% | |
| TWN | 86.19% | −2.55% | |
| DSQ | 88.09% | −0.65% | |
| LQ-Net | 88.00% | −0.74% | |
| APTQ | 88.18% | −0.56% | |
| ResNet-18 | Baseline | 89.72% | |
| TWN | 87.11% | −2.61% | |
| LQ-Net | 87.16% | −2.56% | |
| DSQ | 89.25% | −0.47% | |
| APTQ | 89.20% | −0.52% | |
| ResNet-20 | Baseline | 91.60% | |
| DoReFa-Net | 88.20% | −3.40% | |
| PACT | 89.70% | −1.90% | |
| LQ-Net | 90.20% | −1.40% | |
| ProxQuant | 90.06% | −1.54% | |
| APoT | 91.00% | −0.60% | |
| CSQ | 91.22% | −0.38% | |
| APTQ | 91.21% | −0.39% | |
| ResNet-56 | Baseline | 93.20% | |
| PACT | 92.50% | −0.70% | |
| APoT | 92.90% | −0.30% | |
| APTQ | 93.07% | −0.13% |
| ResNet-20 | TWN | LQ-Net | APoT | GSNQ | APTQ |
|---|---|---|---|---|---|
| L2 Distance | 12.15 | 11.30 | 11.31 | 10.65 | 9.38 |
| CNN | Method | Top-1 Accuracy | ||
|---|---|---|---|---|
| 5-bit | 4-bit | 3-bit | ||
| ResNet-20 (baseline: 91.60%) | DoReFa-Net | — | 90.5% | 89.9% |
| PACT | — | 91.7% | 91.1% | |
| LQ-Net | — | — | 91.6% | |
| APoT | — | 92.3% | 92.2% | |
| GSNQ | — | 92.42% | 91.96% | |
| APQ | 92.42% | 92.36% | 92.16% | |
| ResNet-56 (baseline: 93.20%) | APoT | — | 94.0% | 93.9% |
| GSNQ | — | 94.0% | 93.62% | |
| APQ | 93.99% | 93.88% | 93.67% | |
| CNNs | CNN Models Storage Space | ||
|---|---|---|---|
| Baseline | After APQ (3-Bit) | After APTQ (2-Bit) | |
| VGG-16 | 114.4 Mb | 10.7 Mb | 7.2 Mb |
| ResNet-20 | 4.5 Mb | 0.4 Mb | 0.3 Mb |
| ResNet-56 | 14.2 Mb | 1.3 Mb | 0.9 Mb |
| Modules | Bit Width | LUT | FF | DSP |
|---|---|---|---|---|
| Module 1: based on multiplication (implemented using on-chip DSP) | 8-bit | 428 | 392 | 9 |
| Module 1: based on multiplication (implemented using on-chip DSP) | 3-bit | 250 | 268 | 9 |
| Module 2: based on multiplication (implemented using on-chip LUT) | 3-bit | 402 | 226 | 0 |
| Module 3: based on APQ | 3-bit | 263 | 237 | 0 |
| Module 1: based on multiplication (implemented using on-chip DSP) | 2-bit | 158 | 191 | 9 |
| Module 2: based on multiplication (implemented using on-chip LUT) | 2-bit | 262 | 158 | 0 |
| Module 4: based on APTQ | 2-bit | 168 | 167 | 0 |
| Modules | Bit Width | LUT | FF | DSP |
|---|---|---|---|---|
| Module 1: based on multiplication (implemented using on-chip DSP) | 8-bit | 14,548/8.46% | 11,226/3.27% | 288/32.00% |
| Module 1: based on multiplication (implemented using on-chip DSP) | 3-bit | 8675/5.05% | 9332/2.71% | 288/32.00% |
| Module 2: based on multiplication (implemented using on-chip LUT) | 3-bit | 14,028/8.16% | 7901/2.30% | 0/0.00% |
| Module 3: based on APQ | 3-bit | 8510/4.95% | 8270/2.41% | 0/0.00% |
| Module 1: based on multiplication (implemented using on-chip DSP) | 2-bit | 5243/3.05% | 6479/1.88% | 288/32.00% |
| Module 2: based on multiplication (implemented using on-chip LUT) | 2-bit | 8475/4.93% | 5370/1.56% | 0/0.00% |
| Module 4: based on APTQ | 2-bit | 5862/3.41% | 5799/1.69% | 0/0.00% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sui, X.; Lv, Q.; Ke, C.; Li, M.; Zhuang, M.; Yu, H.; Tan, Z. Adaptive Global Power-of-Two Ternary Quantization Algorithm Based on Unfixed Boundary Thresholds. Sensors 2024, 24, 181. https://doi.org/10.3390/s24010181
Sui X, Lv Q, Ke C, Li M, Zhuang M, Yu H, Tan Z. Adaptive Global Power-of-Two Ternary Quantization Algorithm Based on Unfixed Boundary Thresholds. Sensors. 2024; 24(1):181. https://doi.org/10.3390/s24010181
Chicago/Turabian StyleSui, Xuefu, Qunbo Lv, Changjun Ke, Mingshan Li, Mingjin Zhuang, Haiyang Yu, and Zheng Tan. 2024. "Adaptive Global Power-of-Two Ternary Quantization Algorithm Based on Unfixed Boundary Thresholds" Sensors 24, no. 1: 181. https://doi.org/10.3390/s24010181
APA StyleSui, X., Lv, Q., Ke, C., Li, M., Zhuang, M., Yu, H., & Tan, Z. (2024). Adaptive Global Power-of-Two Ternary Quantization Algorithm Based on Unfixed Boundary Thresholds. Sensors, 24(1), 181. https://doi.org/10.3390/s24010181