Abstract
In order to solve low-quality problems such as data anomalies and missing data in the condition monitoring data of hydropower units, this paper proposes a monitoring data quality enhancement method based on HDBSCAN-WSGAIN-GP, which improves the quality and usability of the condition monitoring data of hydropower units by combining the advantages of density clustering and a generative adversarial network. First, the monitoring data are grouped according to the density level by the HDBSCAN clustering method in combination with the working conditions, and the anomalies in this dataset are detected, recognized adaptively and cleaned. Further combining the superiority of the WSGAIN-GP model in data filling, the missing values in the cleaned data are automatically generated by the unsupervised learning of the features and the distribution of real monitoring data. The validation analysis is carried out by the online monitoring dataset of the actual operating units, and the comparison experiments show that the clustering contour coefficient (SCI) of the HDBSCAN-based anomaly detection model reaches 0.4935, which is higher than that of the other comparative models, indicating that the proposed model has superiority in distinguishing between the valid samples and anomalous samples. The probability density distribution of the data filling model based on WSGAIN-GP is similar to that of the measured data, and the KL dispersion, JS dispersion and Hellinger’s distance of the distribution between the filled data and the original data are close to 0. Compared with the filling methods such as SGAIN, GAIN, KNN, etc., the effect of data filling with different missing rates is verified, and the RMSE error of data filling with WSGAIN-GP is lower than that of other comparative models. The WSGAIN-GP method has the lowest RMSE error under different missing rates, which proves that the proposed filling model has good accuracy and generalization, and the research results in this paper provide a high-quality data basis for the subsequent trend prediction and state warning.
1. Introduction
As the significance of hydropower units in modern power systems grows, the urgency for accurate condition monitoring and prediction increases. However, the quality of monitoring data in hydropower units is often compromised due to interference, abnormalities or failures in data acquisition and transmission links, leading to issues like data anomalies and missing data. These problems hamper the accuracy and reliability of condition monitoring data [1].
Traditional clustering methods such as K-Means [2,3,4,5,6,7,8], subspace clustering [9,10,11,12] and Mean-Shift [13,14,15,16] struggle to adapt to the varying distributions of monitoring and collection data in industrial settings. Furthermore, statistical feature-based methods like the Lyddane criterion [17,18] and the quartile method [19,20,21] are limited in their accuracy due to the fluctuating operating conditions of hydropower units, which affect the signal amplitude. Density-based clustering methods, such as Density-Based Spatial Clustering with Noise Applications (DBSCAN) [22,23,24], the Local Outlier Factor Algorithm (LOF) [25,26], Density Estimation Based Clustering (DENCLUE) [27], hierarchical agglomerative clustering (HAC) [28] and On-Point Sorting Clustering Methods (OPTICS) [29,30], although capable of extracting clusters of arbitrary shapes and recognizing noise, still face challenges in parameter selection and do not fully meet the current needs. The Hierarchical Density-Based Spatial Clustering with Noise Applications (HDBSCAN) [31,32,33,34,35,36], which integrates the advantages of these methods and addresses the parameter selection issue, has shown promising results in application verification.
The condition monitoring of missing values has a great impact on both dimensionality reduction analysis and model training, and the timely handling of missing data is crucial for intelligent decision making [1,37]. Data augmentation is a technical tool for generating new data samples by transforming or processing the original data while keeping the data labels unchanged. It is widely used in the fields of machine learning and deep learning to enhance the generalization ability of models and mitigate the overfitting problem, especially in the case of data scarcity, which is of great practical significance. Missing data filling is an important task in data processing, the goal of which is to estimate or fill the missing values in a dataset by a reasonable method to improve the availability and quality of the dataset. In recent years, traditional statistical methods, machine learning-based methods, time series data filling methods, multiple filling methods and so on have been mainly developed.
Traditional data filling methods, including mean filling and local interpolation, often fail to account for temporal dependencies between samples, resulting in a suboptimal filling accuracy. Adhikari et al.’s comprehensive survey [37] underscores the importance of accurate data handling in IoT for intelligent decision-making, specifically highlighting the inadequacy of many methods in addressing temporal correlations. Little and Rubin [38] illuminate the utility of mean filling in missing data analysis, yet also point out its limitations in maintaining the inherent structure and relationships within datasets. Ratolojanahary et al. [39] demonstrate improvements in multiple imputation for datasets with high rates of missingness but note the challenge of capturing temporal dependencies. Goodfellow et al. [40], in their pioneering work on GANs, opened avenues for data augmentation but faced challenges with unstable training, impacting the quality of imputed data. Kim et al. [41] discuss the potential of deep learning methods, including GANs, in complex data structures, yet identify overfitting and the neglect of time-related characteristics as issues. Haliduola et al. [42] approach missing data imputation in clinical trials using clustering and oversampling to enhance neural network performance but do not fully address the temporal aspects of data series. Zhang et al. [43] show progress in handling sequential data for time series imputation yet struggle with accurately reflecting temporal dynamics in variable datasets. Verma and Kumar [44] acknowledge the importance of capturing temporal sequences in healthcare data using LSTM networks but also highlight the computational complexities involved. Azur et al. [45] explore multiple imputation methods, revealing their limitations in handling datasets with significant time series elements. Finally, Song and Wan [46] highlight the effectiveness of certain interpolation methods in specific contexts but indicate their general inadequacy in capturing time-dependent data patterns. Together, these studies contribute to our understanding of the challenges in data imputation, particularly in capturing temporal dependencies, which is crucial for advancing the field. These studies collectively illustrate that while traditional data filling methods have evolved and improved in various ways, a significant gap remains in accurately addressing the temporal dependencies in data series. This gap underscores the need for more advanced and nuanced approaches to data imputation.
To overcome these limitations, Generative Adversarial Networks (GANs) [47,48,49,50] have been introduced in the field of data generation, capable of learning data distributions and generating synthetic data with features of real data. GANs can learn the distribution of data and generate synthetic data with real data features. In the data augmentation field, many studies have shown that GANs can be used to generate more data samples. Specifically, GANs can be trained on the original dataset to obtain a generative model. Then, the generative model is used to generate more data samples, which can be used to augment the original dataset, increase the number of data samples and improve the model’s generalization ability. However, traditional GANs have problems such as unstable training and mode collapse during the training process. To overcome the issues of traditional GANs, Wasserstein Generative Adversarial Networks (WGANs) were introduced [51,52,53]. By introducing the Wasserstein distance to measure the distance between generated data and real data, WGANs improve training stability and the quality of generated data. Furthermore, to increase the diversity of generated data, Gradient Penalty was introduced into WGAN, forming Wasserstein Generative Adversarial Networks with Gradient Penalty (WGAN-GP) [54,55,56,57]. Based on the GAN and WGAN architectures, dedicated generative imputation networks were developed for data imputation, namely, the Generative Adversarial Imputation Network (GAIN) [58] and Wasserstein Generative Adversarial Imputation Network (WGAIN) [59]. The Slim Generative Adversarial Imputation Network (SGAIN), a lightweight generative imputation network architecture without a hint matrix, was proposed as an improvement on the GAIN. To address the issues of traditional GANs in SGAIN, the Wasserstein Slim Generative Adversarial Imputation Network (WSGAIN) was further improved, along with the Wasserstein Slim Generative Adversarial Imputation Network with Gradient Penalty (WSGAIN-GP) [59].
In this study, we introduce a novel approach for enhancing the quality and usability of the condition monitoring data of hydroelectric units, addressing the limitations of traditional methods, such as inadequate accuracy, disregard for temporal dependencies and obscured data distribution characteristics. Our methodology uniquely integrates two advanced data processing techniques: anomaly detection using the HDBSCAN clustering method and data imputation through the WSGAIN-GP generative model. This combination not only retains the intrinsic characteristics of the data but also significantly improves their completeness and utility. The HDBSCAN clustering method effectively groups monitoring data according to density levels, enabling the precise identification of outliers, which is crucial for accurate data enhancement. Following this, the WSGAIN-GP generative model, utilizing unsupervised self-learning, adeptly approximates the distribution characteristics of real monitoring data. This is instrumental in generating high-quality substitutes for missing data, thereby addressing the gap left by traditional methods. Our contribution is noteworthy in that we are the first to apply these sophisticated methods to the realm of hydropower unit condition monitoring. By doing so, we not only preserve the fidelity of the data but also augment its integrity and applicability. The enhanced data quality and accuracy provided by our approach lay a solid foundation for the more reliable condition monitoring and prediction of hydropower units. This advancement is a step forward in realizing intelligent warnings for hydropower unit conditions, ultimately contributing positively to the maintenance and operational efficiency of these units. This paper delves into the specifics of our quality enhancement methodology, using the HDBSCAN clustering method and the WSGAIN-GP generative model, and presents experimental evidence demonstrating its significant impact on improving data quality and accuracy in hydroelectric unit condition monitoring.
2. Related Theory and Methods
2.1. HDBSCAN Clustering Approach
HDBSCAN (Hierarchical Density-Based Spatial Clustering of Applications with Noise), an extension of the DBSCAN algorithm proposed by Campello et al. [60,61], is a density-based clustering method particularly effective for datasets with varying densities. Unlike DBSCAN, which relies on a uniform density threshold across the dataset, HDBSCAN identifies clusters of different densities by constructing a density tree, providing robustness against noise and outliers. The workflow of the HDBSCAN algorithm is illustrated in Figure 1.
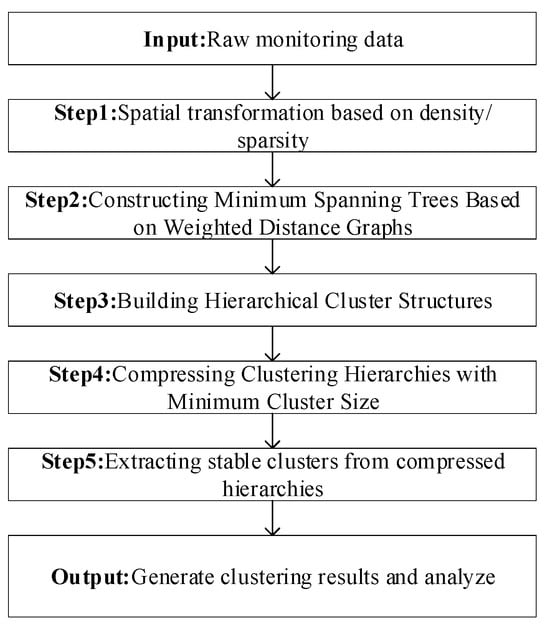
Figure 1.
HDBSCAN algorithm flow chart.
The HDBSCAN algorithm follows these steps [32,33,34,35]:
Definition: The core distance represents the distance from the current point to its k-th nearest neighbor. For a border point (BP), is infinite because in s Eps, making it meaningless. For a core point (CP), is the minimum radius that ensures exactly MinPts samples in s Eps, i.e., the Euclidean distance between point x and the k-th nearest neighbor () that satisfies . defines the minimum number of samples for a cluster. If the number of samples in a formed cluster is below this threshold, it is considered a noise (outlier) point. represents the minimum number of samples that must be included in the neighborhood of one point when calculating the density and minimum distance. and are hyperparameters that need to be set for the HDBSCAN algorithm, as shown in Equations (1) and (2).
Reachable Distance (RD): Point is a CP, and is any point. The RD between and , denoted as d_, is the maximum value between the core distance of x and the Euclidean distance between and , as shown in Equation (3).
Mutual Reachable Distance (MRD): MRD requires both points and to be CPs; otherwise, it is meaningless. It represents the maximum value between the core distances and of the two points and the Euclidean distance between them, as shown in Equation (4).
By transforming the dataset in space, the distances between dense points are reduced, while the distances involving sparse points are enlarged.
Step 1. Space Transformation: Utilizing density estimation to segregate low-density data from high-density data, reducing the impact of noise.
Step 2. Minimum Spanning Tree Construction: Building a tree graph from the weighted graph of transformed data points.
Step 3. Build a Hierarchical Clustering Structure: Creating a hierarchical structure by sorting and categorizing the edges in the tree.
Step 4. Tree Pruning and Compression: Limiting clusters based on , refining the tree structure.
Step 5. Cluster Extraction: Selecting the most stable clusters based on local density estimates and cluster stability calculations. The goal of density-based clustering algorithms is to find the region with the highest density. The local density effective estimate λ for point x can be represented by the reciprocal of , as shown in Equation (5).
denotes the maximum λ value of point x departing from cluster , and represents the minimum λ value of point x belonging to cluster . The stability of cluster is defined as shown in Equation (6):
Select the final data clusters based on stability, generate clustering results and identify outlier points based on the clustering results.
The calculation formula for the data missing rate is defined as Equation (7):
where n is the number of existing data samples, and N is the number of data samples that should exist based on the date–time interval and sampling storage interval.
Since it is difficult to directly determine whether the measured data are an abnormal sample, in order to objectively evaluate the effect of anomaly detection, the Silhouette Coefficient Index (SCI) is used as a quantitative evaluation index. The SCI allows for a quantitative comparison of clustering results from the perspective of data distribution in cases lacking support from true data labels. It is defined as Equation (8):
where represents the average distance between the i-th sample and other samples in the same cluster, reflecting the cohesion of samples within the cluster. represents the average distance between the i-th sample and all samples in the nearest neighboring cluster, reflecting the separation between clusters. and a larger SCI value indicate a smaller intra-cluster distance and larger inter-cluster distance, representing a better clustering effectiveness.
2.2. WSGAIN-GP Algorithm
The development of WSGAIN-GP as an advanced tool for data estimation and imputation is grounded in the progressive evolution of Generative Adversarial Networks (GAN) and their variants. This method is an extension of the foundational GAIN model, further refined by subsequent iterations such as SGAIN and WSGAIN, culminating in a sophisticated approach for data imputation.
Originally, the GAIN network introduced a generator to create missing data and a discriminator to distinguish between real and imputed data. This adversarial training process involves the discriminator minimizing classification loss, while the generator aims to maximize the misclassification rate of the discriminator. In this framework, GAIN’s discriminator receives additional data through a ‘hint’ mechanism, albeit at the cost of increased computational demands. SGAIN, a more streamlined version of GAIN, eliminates the Hint Generator and the associated Hint Matrix, thereby simplifying the architecture [62,63]. This approach adopts a two-layer neural network structure for both the generator and discriminator, in contrast to GAIN’s three-layer setup, as detailed by Goodfellow et al. [40].
Building upon SGAIN, WSGAIN addresses challenges such as pattern collapse and gradient vanishing. It does so by incorporating the Wasserstein distance to measure discrepancies between real and generated data, thereby enhancing the stability of the training process. Further improving upon WSGAIN, the WSGAIN-GP model introduces a gradient penalty technique, moving away from weight clipping. This modification, as part of the loss function, enhances the overall efficacy of the network [59]. The network architecture of WSGAIN-GP is depicted in Figure 2 of the manuscript.
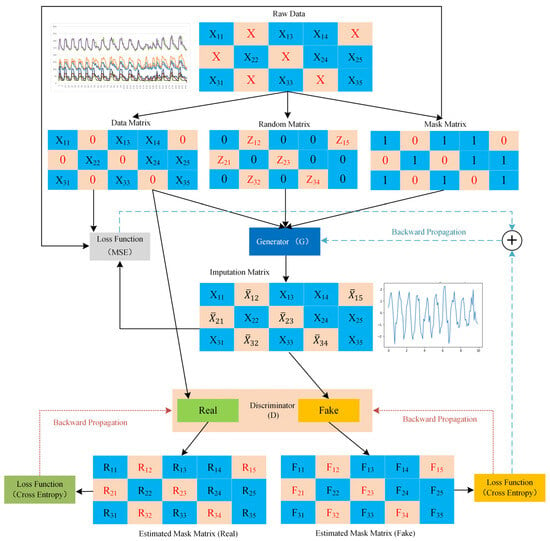
Figure 2.
Structure of the WSGAIN-GP network.
Assuming a d-dimensional spatial dataset , the data vector is a random variable taking values in the dataset , and its distribution is defined as . The mask vector is a random vector taking values in . Define a new data space and a new random variable . Then, as shown in Equation (9):
where * does not belong to any and represents an unobserved value. Therefore, the mask vector indicates which elements of X have been observed, and can be used to recover . Define the dataset , where is a copy of and corresponds to the recovered . The goal of data estimation imputation is to supplement every unobserved value in based on the conditional distribution . Define as the output vector estimated for each and as the final estimated result vector, as shown in Equation (10).
Generator (G) Model: The generator (G) takes and random noise variable as inputs and outputs the estimated matrix . is a d-dimensional variable, , where each has non-missing values from , and missing values in are replaced by random noise values. represents an output of a function that samples random values from a continuous uniform distribution, commonly configured to use the interval , as shown in Equations (11) and (12):
The loss function is expressed as shown in Equation (13[M1] ):
Discriminator (D) Model: The discriminator (D) is a crucial component in adversarial games. Its task is to receive samples from the generator or from the real dataset and attempt to classify them as either real samples or fake samples (samples generated by the generator). The goal is to correctly classify samples, i.e., accurately distinguish between real and generated samples. Training improves the discriminator’s ability to discern real from fake. Since the goal of WSGAIN-GP is to eliminate weight clipping due to weight trimming [64], there is no weight trimming. To improve training, a gradient penalty is included as a component of the loss function , as shown in Equations (14) and (15).
The detailed steps of the WSGAIN-GP algorithm are shown in Algorithm 1 [59].
| Algorithm 1. Pseudo-code of the WSGAIN-GP algorithm | |
| 1 | Input: X //Data sets with missing values |
| 2 | Output: //The populated dataset |
| 3 | Parameters: , ,,, |
| 4 | M //Equation (9) |
| 5 | For do |
| 6 | For extra do |
| 7 | Draw mb samples from X , M , N , |
| 8 | For do |
| 9 | |
| 10 | |
| 11 | //Equation (14) |
| 12 | End |
| 13 | // Discriminator optimization: update the discriminator D by Adam or RMSprop or SGD |
| 14 | |
| 15 | End |
| 16 | //Generator optimization: updating the generator G via Adam or RMSprop or SGD |
| 17 | |
| 18 | End |
| 19 | |
| 20 | |
| 21 | |
3. Enhancement Methodology Flow of Hydropower Unit Condition Monitoring Data Based on HDBSCAN-WSGAIN-GP
A monitoring data quality enhancement method based on HDBSCAN-WSGAIN-GP improves the quality and usability of hydropower unit condition monitoring data by combining the advantages of density clustering and a generative adversarial network. The quality enhancement process of hydropower unit monitoring data based on HDBSCAN-WSGAIN-GP is shown in Figure 3. The detailed steps are as follows:
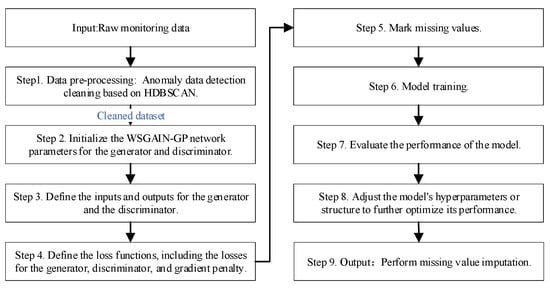
Figure 3.
Quality Enhancement Process of Hydropower Unit Monitoring Data Based on HDBSCAN-WSGAIN-GP.
Step 1. Data pre-processing: Anomaly data detection cleaning based on HDBSCAN.
Step 2. Initialize the network parameters for the generator and discriminator.
Step 3. Define the inputs and outputs for the generator and the discriminator.
Step 4. Define the loss functions, including the losses for the generator, discriminator and gradient penalty.
Step 5. Mark missing values and construct mask vector M.
Step 6. During model training, alternate between training the generator network and the discriminator network, updating model parameters by optimizing the loss functions, which include both the generator and discriminator losses. The generator is used to generate estimated values for imputing missing data, while the discriminator evaluates the difference between generated data and real data.
Step 7. After each training epoch, evaluate the performance of the model, including the imputation effectiveness of the generator and the discrimination accuracy of the discriminator.
Step 8. Based on the evaluation results, adjust the model’s hyperparameters or structure to further optimize its performance, ultimately obtaining an efficient WSGAIN-GP model for imputing missing data.
Step 9. Perform missing value imputation: using the trained WSGAIN-GP model, merge the imputed data generated by the generator with the existing data in the original dataset to obtain a complete dataset, thereby achieving the imputation of missing data.
To quantitatively assess the consistency of the filled data sequence with the original data sequence in terms of the distribution and characteristics, KL Divergence, JS Divergence and Hellinger Distance are introduced to quantify the similarity between two distributions, as shown in Equations (16)–(18):
KL Divergence, JS Divergence and Hellinger Distance are all non-negative. KL Divergence ranges from 0 to ∞, while JS Divergence and Hellinger Distance range from 0 to 1. Smaller values of these three metrics indicate a greater similarity between two distributions, with a value of 0 indicating complete similarity.
4. Case Analysis
4.1. Data Collection
In order to validate the effectiveness of the proposed method, this study conducted an analysis using the actual operational monitoring data of a mixed-flow hydropower unit in a fengtan hydropower station in the Central China region. The data anomaly detection and data imputation methods were tested separately. The unit parameters are presented in Table 1.

Table 1.
Parameter table of an experimental unit [65].
The unit is equipped with an online monitoring system, which utilizes monitoring equipment to continuously collect, monitor and automatically record various state parameters such as the vibration, deflection, pressure pulsation, air gap, stator temperature, oil level, active power, water level and rotational speed during the operation of the unit. This enables real-time access to the current operating status of the unit. The time series grouping of online monitoring data for this unit is illustrated in Figure 4.
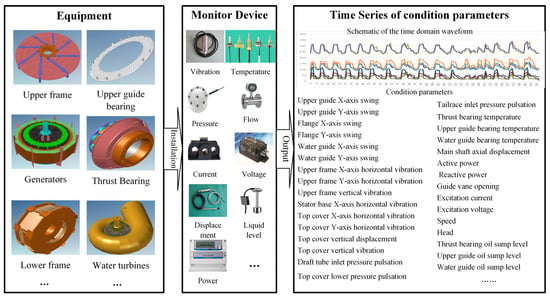
Figure 4.
Time series of online monitoring data for hydropower units.
To demonstrate the process of the proposed method and validate its effectiveness, this study has chosen the swing monitoring parameters as an example. The same procedure can be applied to other parameters. Specifically, we obtained the upper guide swing deflection data (S), corresponding head (H) and active power (P) of the unit from 3 April 2020 to 4 August 2021 from the unit’s condition online monitoring system of the Fengtan hydropower station. As illustrated in Figure 5, due to the characteristic of having a high sampling frequency but low data storage frequency in the online monitoring system of hydroelectric units, the actual time interval of the stored measured data is 15 min, amounting to a total of 26,245 samples. The overall missing rate δ of the original dataset is calculated to be 0.438. The missing data within the dataset are represented as NAN.
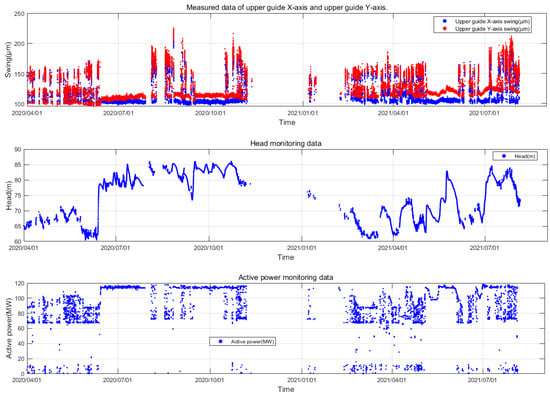
Figure 5.
Unit Measurement Dataset from Fengtan Hydropower Station Unit 2.
From Figure 5, it can be observed that the amplitude variation pattern of the upper guide swing deflection (S) is complex. This complexity is attributed to its coupling with factors such as changes in operational parameters and noise. The water head (H) exhibits long-term low-frequency fluctuation characteristics, primarily influenced by seasonal changes in the external environment. The active power output of the unit (P) displays short-term high-frequency fluctuation characteristics. This is mainly due to the fact that the unit’s output is dynamically and flexibly adjusted in real time based on the load demand from the grid side. During this adjustment process, the vibration characteristics of the unit are taken into consideration, aiming to avoid operating conditions with intense vibrations. Therefore, when conducting anomaly detection for unit parameters, it is imperative to consider the coupled analysis of the actual operational characteristics of the unit. In this study, the influence of operational parameters H and P on the operational state parameter S is simultaneously considered. By combining these operational parameters, the measured data of the hydroelectric unit are structured into a three-dimensional dataset , as illustrated in Figure 6.
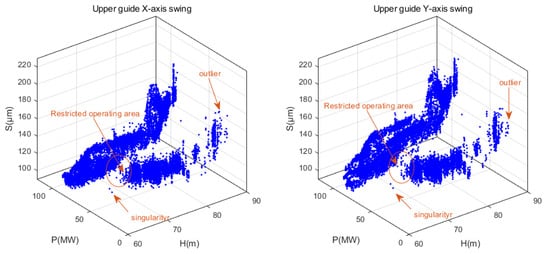
Figure 6.
Three-dimensional dataset of upper guide swing and operating condition parameters from Fengtan Hydropower Station Unit 2.
4.2. Anomaly Detection
The original data samples were fed into the HDBSCAN model, and the computed results are depicted in Figure 7a and Figure 8a. The HDBSCAN method adaptively identified effective data clusters and marked outliers, including singular points and anomalous points, as noise points. By removing these noise points from the original data samples, a denoised and valid dataset was obtained. This denoised dataset will be further input into the WSGAIN-GP model for missing data imputation.
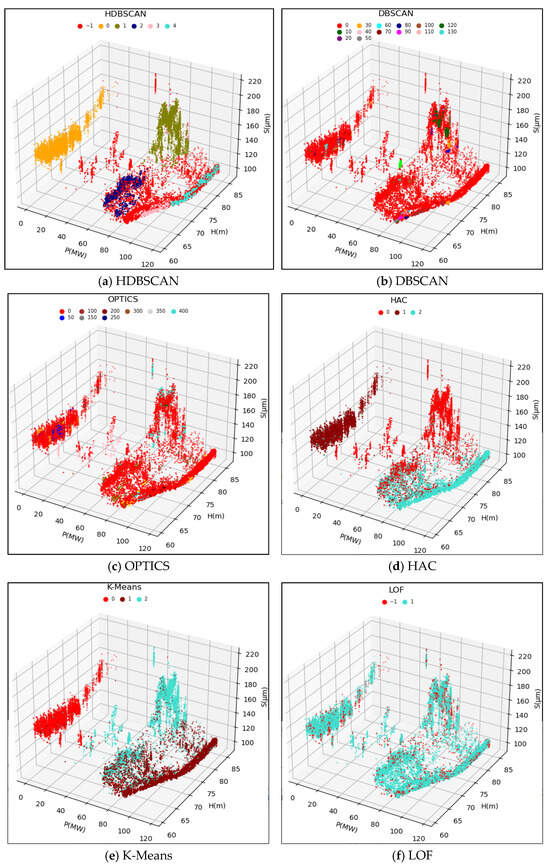
Figure 7.
Clustering results of different anomaly detection methods for the upper guide X-axis swing.
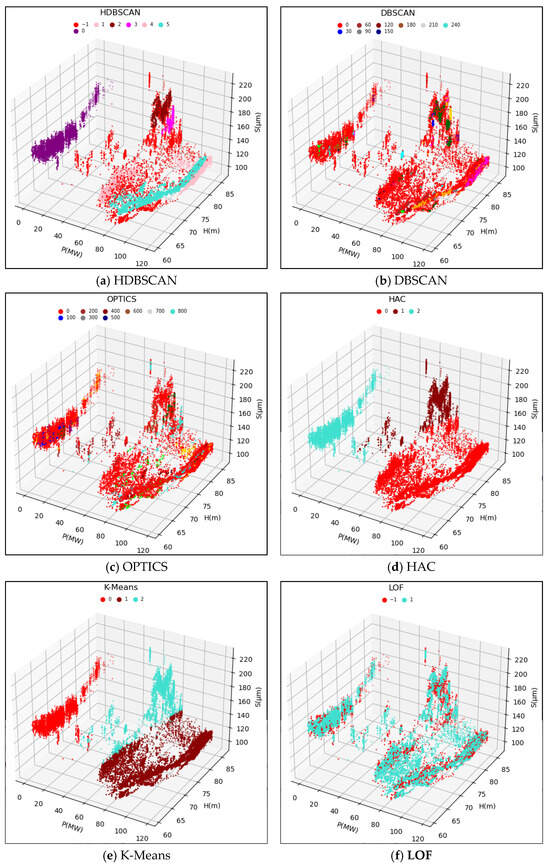
Figure 8.
Clustering results of different anomaly detection methods for the upper guide Y-axis swing.
To validate the effectiveness of the HDBSCAN anomaly detection method, this study compared the results with those of other methods such as DBSCAN, OPTICS, LOF, HAC and K-Means. Based on the methodology principles and references [24,25,26,27,28,29,30], some of the initial parameters for these comparative methods are shown in Table 2. The performance of different methods is evaluated in terms of the silhouette coefficient index, and the parameters are optimally tuned by a grid search method.
Table 2.
Initialization parameters for different detection methods.
The clustering results of the different methods compared are shown in Figure 7 and Figure 8 as (b)~(f), respectively.
Different detection methods are used to detect anomalies for the 3D dataset , consisting of a head, active and upward-guided X-axis swing, and , consisting of a head, active and upward-guided Y- axis swing, respectively, and the computation of the Profile Coefficient Indicator (SCI) standardized example is shown in Table 3.
Table 3.
Comparison table of the results of different testing methods.
Combined with the clustering effect graph and the contour coefficient comparison data table, the HDBSCAN method has the highest contour coefficient in the comparison of the two dataset calculations, and at the same time, it can detect and recognize the effective data and abnormal data better, and the clusters divided into clusters are more in line with the actual operating conditions.
4.3. Data Filling
The missing rate of the noise reduced dataset detected by the HDBSCAN method and the noise reduced dataset are further input into the trained WSGAIN-GP model for missing value filling.
The literature [56] shows that when the missing rate is greater than 50%, the accuracy of the WSGAIN-GP method of filling is significantly greater than that of other methods such as KNN and spline interpolation. According to the literature and several experiments, the network parameters of the WSGAIN-GP model involving the generator and the adversary are shown in Table 4.
Table 4.
WSGAIN-GP Network Structure Parameter Settings.
The initialization assignments of the main parameters of the WSGAIN-GP model are shown in Table 5
Table 5.
WSGAIN-GP Model Initialization Parameter Settings.
Based on the model training, incomplete data sequences were input for data filling, and the results of the WSGAIN-GP-filled Upper Guide swing, head and active are shown in Figure 9.
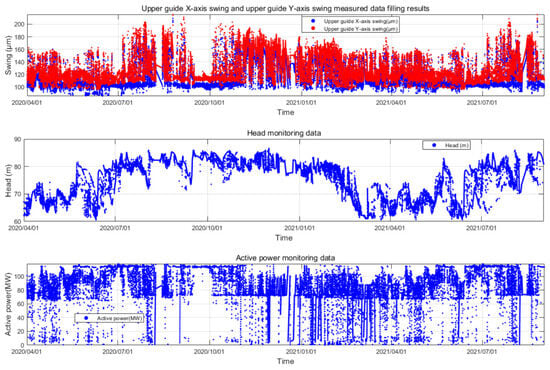
Figure 9.
Results of WSGAIN-GP filled head, active and upward-guided swing.
The relative frequency distribution of the measured data after filling the enhancement is shown in Figure 10.
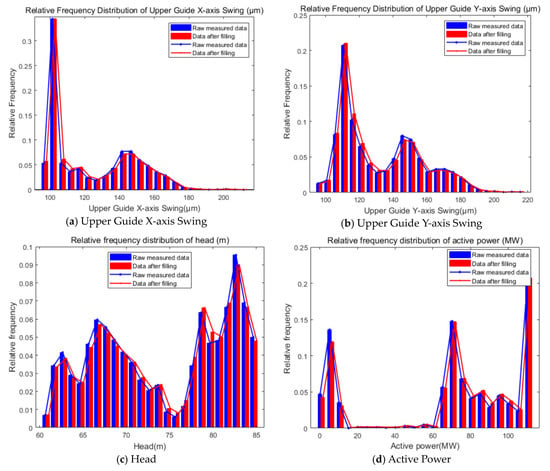
Figure 10.
Relative frequency distributions after filling in the enhancement with measured data.
Combined with the filling results in Figure 9 and Figure 10, it can be seen that the distribution of the data after filling by the WSGAIN-GP model is closer to the distribution of the measured values, which indicates that the filling method is able to better safeguard the data characteristics and distribution, and the quantitative indexes of the differences in the data distribution are shown in Table 6. The KL dispersion, JS dispersion and Hellinger distance of the data distributions before and after the filling of the upper guide swing, head and active power are close to 0, which indicates that the WSGAIN-GP filling model is able to learn the distribution and characteristics of the real data better and guarantees the accuracy of the generated data.
Table 6.
Difference in distribution between post-fill and measured data.
In order to further validate the superiority of the proposed data filling method and at the same time study the performance of different data filling methods with different missing rates, the short-term complete state sequence dataset of hydropower units in the case study is selected for comparative analysis. For the comparison experimental dataset, the sampling interval is 30 min, and the sampling start and end time is from 7:00 p.m. on 12 June 2020 to 7:00 p.m. on 25 July 2020, with a total length of 43 days and a total of 2064 measured complete data samples, as shown in Figure 11. Non-complete sequences with different missing rates were generated by random missing, the missing rates were taken as 10%, 30%, 50% and 70%, respectively, considering the engineering reality, and the comparison methods were chosen as SGAIN, GAIN and KNN.
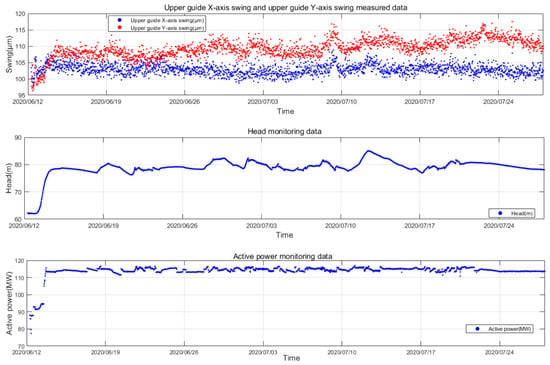
Figure 11.
A complete short-term state sequence dataset for hydropower units.
The Root Mean Square Error (RMSE) was used to measure the accuracy of the data filling results, as shown in Equation (19).
where N denotes the number of samples, represents the filled value output by the model and denotes the measured true value.
The filling results of the different methods for different missing rates for the upper guide X-axis swing, head and active power of the hydroelectric units are shown in Figure 12, Figure 13, Figure 14 and Figure 15, and the horizontal X-axis serial numbers represent the serial numbers of the original samples in chronological order.
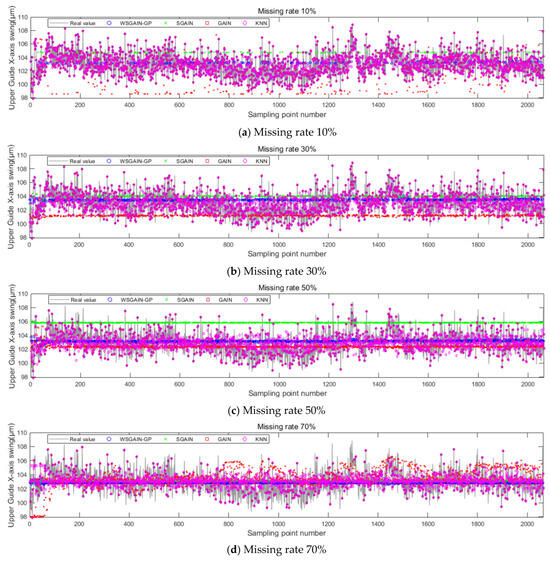
Figure 12.
Filling results of each method for the upper guide X-axis swing at different missing rates.
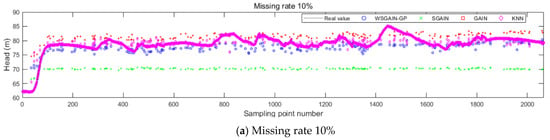
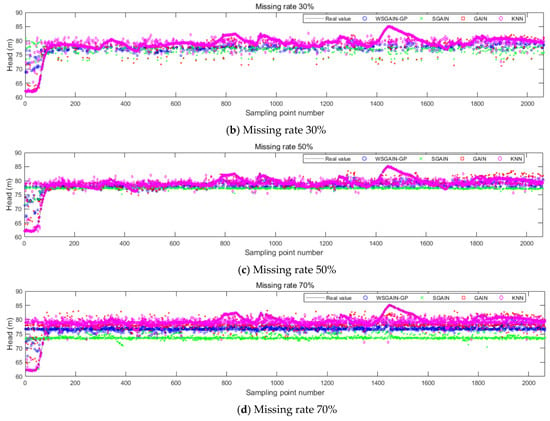
Figure 13.
Filling results of each method for the head at different missing rates.
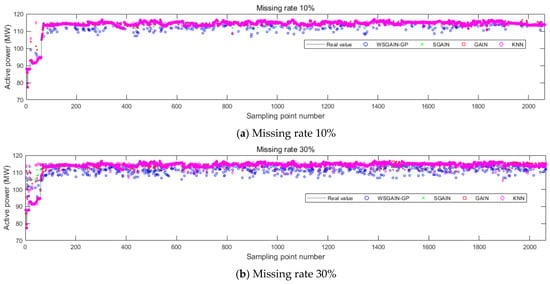
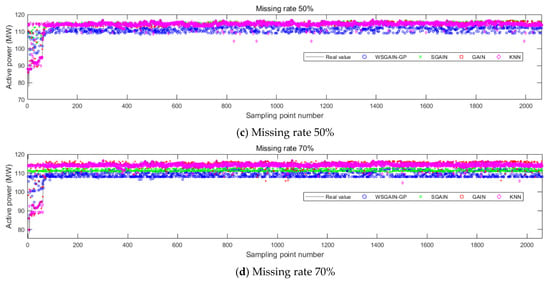
Figure 14.
Filling results of each method for active power at different missing rates.
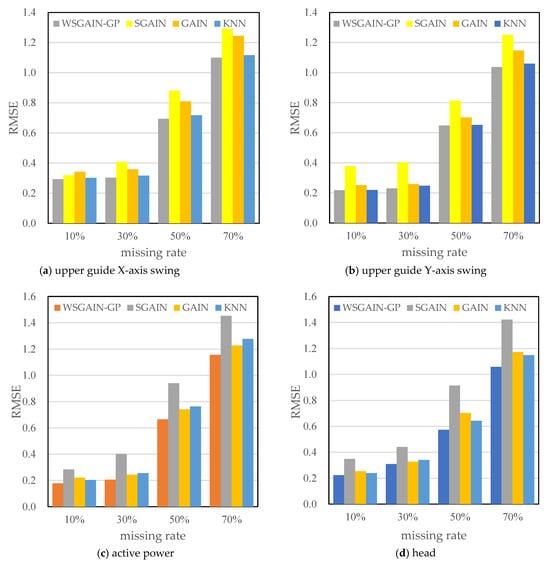
Figure 15.
Comparison of filling errors (RMSE) for different methods.
In order to eliminate the effect of non-complete sequence differences generated randomly according to the missing rate, set the number of repetitive trials to 1000 times, each time, respectively, according to a different missing rate-generated non-complete sequences, using different methods to fill, observe and record the error of each experiment and, ultimately, the average error of the 1000 experiments as the final error. The error results are shown in Table 7.
Table 7.
Evaluation of the effectiveness of different methods for filling errors in hydropower unit monitoring data.
The statistical plots of the filling errors of each method for the upper guide X-axis swing, upper guide Y-axis swing, head and active power of the hydropower units are shown in Figure 14.
Based on the comparison with Figure 11, Figure 12, Figure 13 and Figure 14 and Table 7, it is evident that the WSGAIN-GP method for missing data imputation consistently yields the lowest error across various data missing rates, with an average reduction in the root mean square error of 0.0936, thereby demonstrating the highest accuracy. This method shows commendable effectiveness in filling gaps for hydroelectric unit state parameters with a high randomness, such as the pendulum swing, as well as operational parameters like the active power and head. The WSGAIN-GP model employs a generative adversarial network structure, wherein the interplay between the generator and discriminator approximates the distribution of real data. By generating data, the model is able to complete the missing parts of the monitoring data, resulting in a more complete and continuous dataset.
5. Conclusions
In addressing issues such as anomalies and missing data that compromise the quality of condition monitoring datasets in hydropower units, this chapter introduces a method for enhancing data quality through the integration of HDBSCAN-WSGAIN-GP. This method capitalizes on the strengths of density clustering and generative adversarial networks to enhance the reliability and utility of the condition monitoring data.
Initially, the HDBSCAN clustering method categorizes the monitoring data based on density levels, aligned with operational conditions, to adaptively detect and cleanse anomalies in the dataset. Furthermore, the WSGAIN-GP model, through its data imputation capabilities, employs unsupervised learning to understand and replicate the features and distribution patterns of actual monitoring data, thereby generating values for missing data.
The validation analysis, conducted using an online monitoring dataset from real operational units, provides compelling evidence of the method’s effectiveness:
(1) Comparative experiments reveal that the clustering contour coefficient (SCI) of the anomaly detection model based on HDBSCAN achieves 0.4935, surpassing those of other comparative models, thereby demonstrating its superior ability in distinguishing between valid and anomalous samples.
(2) The probability density distribution of the data imputation model based on WSGAIN-GP closely mirrors that of the measured data. Notably, the Kullback–Leibler (KL) divergence, Jensen–Shannon (JS) divergence and Hellinger’s distance metrics, when comparing the distribution between the imputed and original data, approach values near zero, indicating a high degree of accuracy in data representation.
(3) Through comparative analyses with other filling methods, including SGAIN, GAIN and KNN, the WSGAIN-GP model demonstrates superior effectiveness in data imputation across various rates of missing data. The Root Mean Square Error (RMSE) of the WSGAIN-GP consistently outperforms other models, particularly noted in its lowest RMSE across different missing data rates. This confirms the high accuracy and generalization capability of the proposed imputation model.
The findings and methodologies presented in this study lay a robust foundation for high-quality data, crucial for subsequent trend prediction and state warnings in the context of hydropower unit monitoring.
Author Contributions
Conceptualization, F.Z., J.G. and F.Y.; methodology, F.Z. and J.G.; software, F.Z.; validation, F.Y., Y.Q. and P.W.; formal analysis, F.Z.; investigation, F.Y., Y.Q. and F.C.; resources, J.G.; data curation, F.Z. and Y.G.; writing—original draft preparation, F.Z.; writing—review and editing, J.G. and F.Y.; visualization, F.Z., Y.Q. and P.W.; supervision, J.G. and F.Y.; project administration, F.Y.; funding acquisition, J.G. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the National Key Research and Development Program of China under Grant No. 2020YFB1709700, entitled “Key Technologies Research and Development of Intelligent Operation and Maintenance for High-Security Equipment”.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The raw/processed data cannot be shared at this time. Due to the nature of this research, the participants of this study did not agree that their data be shared publicly.
Acknowledgments
The authors gratefully acknowledge the support of the National Key Research and Development Program of China (Grant No. 2020YFB1709700).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Zhang, Y.; Thorburn, P. Handling missing data in near real-time environmental monitoring: A system and a review of selected methods. Future Gener. Comput. Syst. 2022, 128, 63–72. [Google Scholar] [CrossRef]
- Tao, Y.; Wang, Y. Improved K-means based anomaly data detection for wind turbine. For. Electron. Meas. Technol. 2023, 42, 141–148. [Google Scholar] [CrossRef]
- Liu, M.; He, X.; Qin, R.; Jiang, H.; Meng, X. Anomaly detection of distribution network voltage data based on improved K-means clustering k-value selection algorithm. Electr. Power Sci. Technol. 2022, 37, 91–99. [Google Scholar] [CrossRef]
- Liu, F.; Liu, R.; Dong, Z. Anomalous dynamic data detection method for smart meters based on k-means clustering. Electron. Des. Eng. 2023, 31, 84–88. [Google Scholar] [CrossRef]
- Liu, M.; Yuan, X.; Tong, F. Research on clustering optimization algorithm for high-dimensional power data. Sci. Technol. Bull. 2021, 37, 50–55. [Google Scholar] [CrossRef]
- Wang, Y.; Ma, J.; Gao, N.; Wen, Q.; Sun, L.; Guo, H. Federated fuzzy k-means for privacy-preserving behavior analysis in smart grids. Appl. Energy 2023, 331, 120396. [Google Scholar] [CrossRef]
- Li, H.; Li, K. A method for recognizing station-household relationship based on discrete wavelet transform and fuzzy K-mean clustering. Electr. Power. 2022, 37, 430–440. [Google Scholar] [CrossRef]
- Li, W.; Wang, X.; Shi, J. Smart Grid Demand-side Response Model Based on Fuzzy Clustering Analysis. J. Phys. Conf. Ser. 2022, 2355, 012059. [Google Scholar] [CrossRef]
- Fang, M.; Gao, W.; Feng, Z. Deep robust multi-channel learning subspace clustering networks. Image Vis. Comput. 2023, 137, 104769. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, Y. Adaptive weighted multi-view subspace clustering algorithm based on latent representation. Comput. Knowl. Technol. 2023, 19, 10–15. [Google Scholar] [CrossRef]
- Li, S.; Xu, X. Multi-view subspace clustering algorithm based on information entropy weighting. J. Shaanxi Univ. Sci. Technol. 2023, 41, 207–214. [Google Scholar] [CrossRef]
- Shi, L.; Ma, C.; Yang, Y.; Jin, M. Anomaly detection algorithm based on SSC-BP neural network. Comput. Sci. 2021, 48, 357–363. [Google Scholar]
- Shi, S.; Zhang, L.; Zhang, B.; Wu, H.; Lian, X.; Du, S. A non-intrusive load identification method based on Mean-shift clustering and twin networks. Electr. Drives 2022, 52, 67–74. [Google Scholar]
- Li, Y.; Hu, J.; Lai, J.; Wang, W.; Yang, F. Partial discharge anomaly detection in switchgear based on mean-drift clustering. Electr. Drives 2022, 52, 63–69. [Google Scholar]
- Xiang, J.; Li, L. A collaborative filtering recommendation algorithm incorporating PCA dimensionality reduction and mean drift clustering. J. Nanjing Univ. Posts Telecommun. Nat. Sci. Ed. 2023, 03, 90–95. [Google Scholar] [CrossRef]
- Chen, J.; Wang, L.; Ju, Y. A method for assessing the impact of large-scale new energy on power grid line loss based on Mean-shift clustering. Power Supply 2021, 38, 59–64+76. [Google Scholar] [CrossRef]
- Zhang, Z. Research on dissimilarity rejection method for passive direction finding accuracy test. Syst. Simul. Technol. 2019, 15, 152–155. [Google Scholar] [CrossRef]
- Wu, Y.; Yang, N.; Pan, X.; Wang, W. Temperature and humidity detection system based on Leyet criterion and data fusion. Sci. Technol. Bull. 2017, 33, 96–99. [Google Scholar] [CrossRef]
- Zhao, X.; Li, B. Application of outlier detection method in civil aviation alarm. J. Nanjing Univ. Aeronaut. Astronaut. 2017, 49, 524–530. [Google Scholar] [CrossRef]
- Ma, L.; Geng, Y.; Yuan, N.; Duan, X. Wind turbine anomaly data cleaning method based on quartiles and CFSFDP. Electr. Power Sci. Eng. 2023, 39, 9–16. [Google Scholar] [CrossRef]
- Wu, Y.; Zhang, J.; Deng, F.; Huang, S. Identification of wind farm power anomaly data based on variance rate of change criterion-quadratic. Power Eng. Technol. 2023, 42, 141–148. [Google Scholar]
- Syed, D.; Punit, G. Fault aware task scheduling in cloud using min-min and DBSCAN. IoT Cyber-Phys. Syst. 2024, 4, 68–76. [Google Scholar] [CrossRef]
- Yang, Y.; Hu, R. Construction and application of anomaly identification model of average price of electricity sales based on DBSCAN algorithm. Zhejiang Electr. Power 2023, 42, 72–78. [Google Scholar] [CrossRef]
- Zhou, N.; Ma, H.; Chen, J.; Fang, Q.; Jiang, Z.; Li, C. Equivalent Modeling of LVRT Characteristics for Centralized DFIG Wind Farms Based on PSO and DBSCAN. Energies 2023, 16, 2551. [Google Scholar] [CrossRef]
- Wang, H.; Yang, S.; Liu, Y.; Li, Q. A novel abnormal data detection method based on dynamic adaptive local outlier factor for the vibration signals of rotating parts. Meas. Sci. Technol. 2023, 34, 085118. [Google Scholar] [CrossRef]
- Lv, Z.; Di, L.; Chen, C.; Zhang, B.; Li, N. A Fast Density Peak Clustering Method for Power Data Security Detection Based on Local Outlier Factors. Processes 2023, 11, 2036. [Google Scholar] [CrossRef]
- Khader, M.; Al-Naymat, G. Discovery of arbitrary-shapes clusters using DENCLUE algorithm. Int. Arab J. Inf. Technol. 2020, 17, 629–634. [Google Scholar] [CrossRef]
- Murtagh, F.; Contreras, P. Algorithms for hierarchical clustering: An overview. In Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery; John Wiley & Sons: Hoboken, NJ, USA, 2012; Volume 2, pp. 86–97. [Google Scholar] [CrossRef]
- Pan, Q.; Lin, Q.; Liu, Z.; Liu, T.; Zhang, Z.; He, Z. A method for identifying thunderstorm monoliths from radar data based on OPTICS clustering algorithm. Meas. Sci. Technol. 2022, 50, 623–629. [Google Scholar] [CrossRef]
- Li, T.; Wu, Z.; Liu, H. A homologous identification method for voltage dips based on Hausdorff distance and OPTICS clustering. China Test 2022, 48, 110–116+172. [Google Scholar]
- Campello, R.; Moulavi, D.; Zimek, A.; Sander, J. Hierarchical density estimates for data clustering, visualization, and outlier detection. ACM Trans. Knowl. Discov. Data 2015, 10, 5. [Google Scholar] [CrossRef]
- McInnes, L.; Healy, J.; Astels, S. Hdbscan: Hierarchical density based clustering. Open Source Softw. 2017, 2, 205. [Google Scholar] [CrossRef]
- Stewart, G.; Al-Khassaweneh, M. An implementation of the HDBSCAN* clustering algorithm. Appl. Sci. 2022, 12, 2405. [Google Scholar] [CrossRef]
- Wang, L.; Chen, P.; Chen, L.; Mou, J. Ship AIS trajectory clustering: An HDBSCAN-based approach. J. Mar. Sci. Eng. 2021, 9, 566. [Google Scholar] [CrossRef]
- Syed, T. Parallelization of Hierarchical Density-Based Clustering using MapReduce. Master’s Thesis, University of Alberta, Edmonton, AB, Canada, 2015. [Google Scholar] [CrossRef]
- Fahim, A. A varied density-based clustering algorithm. J. Comput. Sci. 2023, 66, 101925. [Google Scholar] [CrossRef]
- Adhikari, D.; Jiang, W.; Zhan, J.; He, Z.; Rawat, D.; Aickelin, U.; Khorshdi, H. A comprehensive survey on imputation of missing data in internet of things. ACM Comput. Surv. 2022, 55, 133. [Google Scholar] [CrossRef]
- Little, R.; Rubin, D. Statistical Analysis with Missing Data; John Wiley & Sons: Hoboken, NJ, USA, 2019. [Google Scholar]
- Ratolojanahary, R.; Ngouna, R.; Medjaher, K.; Junca-Bourié, J.; Dauriac, F.; Sebilo, M. Model selection to improve multiple imputation for handling high rate missingness in a water quality dataset. Expert Syst. Appl. 2019, 131, 299–307. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 139–144. [Google Scholar]
- Kim, J.; Tae, D.; Seok, J. A survey of missing data imputation using generative adversarial networks. In Proceedings of the 2020 International conference on artificial intelligence in information and communication (ICAIIC), Fukuoka, Japan, 19–21 February 2020; pp. 454–456. [Google Scholar] [CrossRef]
- Haliduola, H.; Bretz, F.; Mansmann, U. Missing data imputation in clinical trials using recurrent neural network facilitated by clustering and oversampling. Biom. J. 2022, 64, 863–882. [Google Scholar] [CrossRef]
- Zhang, J.; Mu, X.; Fang, J.; Yang, Y. Time series imputation via integration of revealed information based on the residual shortcut connection. IEEE Access 2019, 7, 102397–102405. [Google Scholar] [CrossRef]
- Verma, H.; Kumar, S. An accurate missing data prediction method using LSTM based deep learning for health care. In Proceedings of the 20th International Conference on Distributed Computing and Networking, Bangalore, India, 4–7 January 2019; pp. 371–376. [Google Scholar] [CrossRef]
- Azur, M.J.; Stuart, E.; Frangakis, C.; Leaf, P. Multiple imputation by chained equations: What is it and how does it work? Int. J. Methods Psychiatr. Res. 2011, 20, 40–49. [Google Scholar] [CrossRef]
- Song, L.; Wan, J. A comparative study of interpolation methods for missing data. Stat. Decis. Mak. 2020, 36, 10–14. [Google Scholar] [CrossRef]
- Mallik, M.; Tesfay, A.; Allaert, B.; Kassi, R.; Egea-Lopez, E.; Molina-Garcia-Pardo, J.; Clavier, L. Towards Outdoor Electromagnetic Field Exposure Mapping Generation Using Conditional GANs. Sensors 2022, 22, 9643. [Google Scholar] [CrossRef]
- Zhang, Z.; Jiang, Q.; Zhan, Y.; Hou, X.; Zheng, Y.; Cui, Y. A small-sample rolling bearing fault classification method based on VAE-GAN data enhancement algorithm. At. Energy Sci. Technol. 2023, 57, 228–237. [Google Scholar] [CrossRef]
- Lv, Y.; Sun, S.; Zhao, Q.; Tian, J.; Li, C. Research on Intelligent Identification Method of Power Grid Missing Data Based on Improved Generation Countermeasure Network with Multi-dimensional Feature Analysis. In International Conference on Big Data and Security; Springer: Singapore, 2021; pp. 696–706. [Google Scholar] [CrossRef]
- Zhang, P.; Xue, Y.; Song, R.; Yang, Y.; Wang, C.; Yang, L. A Method of Integrated Energy Metering Simulation Data Generation Algorithm Based on Variational Autoencoder WGAN. J. Phys. Conf. Ser. (IOP) 2022, 2195, 012031. [Google Scholar] [CrossRef]
- Su, Y.; Meng, L.; Xu, T.; Kong, X.; Lan, X.; Li, Y. Optimized WGAN fault diagnosis method for wind turbine gearboxes under unbalanced dataset. J. Sol. Energy 2022, 43, 148–155. [Google Scholar] [CrossRef]
- Zang, H.; Guo, J.; Huang, M.; Wei, Z.; Sun, G.; Zhao, J. Recognition of bad data in power system based on improved Wasserstein generative adversarial network. Power Autom. Equip. 2022, 42, 50–56+110. [Google Scholar] [CrossRef]
- Lu, S.; Dong, C.; Gu, C.; Zheng, B.; Liu, Z.; Xie, Q.; Xie, J. A WGAN-GP data enhancement method for local discharge pattern recognition. South. Power Grid Technol. 2022, 16, 55–60. [Google Scholar] [CrossRef]
- Sun, X.; Sheng, Y.; Chen, S.; Zuo, D. Bearing health diagnosis method based on WGAN-GP. Mech. Manuf. Autom. 2023, 52, 109–113. [Google Scholar] [CrossRef]
- Qin, J.; Gao, F.; Wang, Z.; Liu, L.; Ji, C. Arrhythmia Detection Based on WGAN-GP and SE-ResNet1D. Electronics 2022, 11, 3427. [Google Scholar] [CrossRef]
- Neves, D.; Alves, J.; Naik, M.; Proença, A.; Prasser, F. From missing data imputation to data generation. J. Comput. Sci. 2022, 61, 101640. [Google Scholar] [CrossRef]
- Yoon, J.; Jordon, J.; Schaar, M. Gain: Missing data imputation using generative adversarial nets. In Proceedings of the 35th International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 5689–5698. [Google Scholar]
- Friedjungová, M.; Vašata, D.; Balatsko, M.; Jiřina, M. Missing features reconstruction using a wasserstein generative adversarial imputation network. In International Conference on Computational Science; Springer International Publishing: Cham, Switzerland, 2020; pp. 225–239. [Google Scholar] [CrossRef]
- Neves, D.; Naik, M.; Proença, A. SGAIN, WSGAIN-CP and WSGAIN-GP: Novel GAN methods for missing data imputation. In International Conference on Computational Science; Springer International Publishing: Cham, Switzerland, 2021; pp. 98–113. [Google Scholar] [CrossRef]
- McInnes, L.; Healy, J. Accelerated hierarchical density based clustering. In Proceedings of the 2017 IEEE International Conference on Data Mining Workshops (ICDMW), New Orleans, LA, USA, 18–21 November 2017; pp. 33–42. [Google Scholar] [CrossRef]
- Campello, R.; Moulavi, D.; Sander, J. Density-based clustering based on hierarchical density estimates. In Pacific-Asia Conference on Knowledge Discovery and Data Mining; Springer: Berlin/Heidelberg, Germany, 2013; pp. 160–172. [Google Scholar] [CrossRef]
- Van Buuren, S. Flexible Imputation of Missing Data; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]
- Gao, S.; Zhao, W.; Wan, C.; Jiang, H.; Ding, Y.; Xue, S. Missing data imputation framework for bridge structural health monitoring based on slim generative adversarial networks. Measurement 2022, 204, 112095. [Google Scholar] [CrossRef]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A. Improved training of wasserstein gans. Adv. Neural Inf. Process. Syst. 2017, 30, 5767–5777. [Google Scholar]
- Chen, H.; Fang, X. Treatment of Turbine Blade Cracks in Unit No. 2 of Fengtan Hydropower Station. Mech. Electr. Technol. Hydropower Station. 2012, 35, 3. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).