1. Introduction
Training neural networks is usually conducted using different gradient descent-based algorithms such as stochastic gradient descent or the Adam optimizer [
1]. This type of training involves many passes through the entire data, usually on the order of 100–300, which makes it very slow. Moreover, the results of this training are sensitive to a number of tuning parameters such as the learning rate and the minibatch size, as well as the manner in which these parameters are changed during the training iterations (e.g., the learning rate schedule). For these reasons, many training runs are usually conducted (on the order of 10 or more) with different parameter and schedule combinations, and the most successful one is used to obtain the final model. The fact that the training takes at least 100 epochs and that, usually, at least 10 training runs are used to find a good combination implies that to train a neural network well, one must use at least 1000 passes through the data, which can be computationally expensive.
These computational reasons serve as motivation for studying a novel method for training two-layer neural networks with the square loss that needs as little as 10 passes through all the data. The method is capable of obtaining a loss that is smaller than the losses obtained by the well-tuned gradient descent algorithms and has better generalization when the number of inputs is small.
In [
2], it is mentioned that “practitioners find that narrow neural nets cannot be solved well”. Our work confirms this statement experimentally, at least for neural networks (NNs) with a small number of inputs, and shows that the proposed approach can find better local minima of the loss. This work can enable a wider use of shallow NNs for many computation restricted applications. The authors of [
2] also point out that the test error of an algorithm can be decomposed into the representation error, optimization error and generalization error. This work addresses the optimization error for a narrow type of NNs, namely, the two-layer NNs with ReLU-like activation and the square loss. Even though the scope is narrow, we show that in some cases, the optimization capabilities of the proposed method greatly outperform those of the standard gradient descent methods.
The contributions of this work are the following:
It introduces a method for training a two-layer NN with leaky ReLU-like activation and the square loss analytically by solving ordinary least squares (OLS) equations alternatively for each layer, while keeping the activation pattern of the neurons fixed. The neuron activation pattern is a binary matrix indicating what hidden neurons fire (have non-zero activation) for each observation. It is described in
Section 2.2.
It conducts experiments on real and simulated data to see in what conditions the proposed method outperforms standard gradient-based optimization, such as the standard stochastic gradient descent, the Adam optimizer and the LBFGS algorithm. These experiments indicate that the proposed analytic method is faster and obtains lower loss minima when the number of observations is not very large or when the input dimension is small.
The paper is organized as follows:
Section 1 gives an overview of the related work.
Section 2 introduces the proposed analytic minimization method that involves fitting each layer while keeping the other layer fixed. The experimental results on real and simulated data, as well as an ablation study, are presented in
Section 3. The paper finishes with conclusions and future work in
Section 4.
Related Work
Critical points of deep linear NNs (with no activation function) with the square loss have been studied in [
3]. For deep linear NNs, the authors proved that every local minimum is also a global minimum, and all other critical points are saddle points. The authors have also studied the critical points of one hidden layer NNs with ReLU activation and the square loss but only in certain regions of the parameter space. They have characterized the critical points in the entire space only for an NN with one hidden node. Moreover, they have made no attempt to provide an explicit algorithm for finding the critical points. In contrast, this work presents a simple and efficient algorithm that finds the critical points for the two layers, alternatively, while keeping the neuron firing pattern fixed.
Recent work [
4] has shown that training certain two-layer NNs with the square loss and stochastic gradient descent together with adequate regularization can find the global optimum of the loss function. However, these networks must have smooth and bounded activation functions, such as the sigmoid or tanh activation, and not the ReLU activation. The proof uses a Poincare-type inequality for Villani functions [
5,
6], which was proved in [
6].
Some works [
7,
8] relax the NNs to be able to use convex optimization and obtain global solutions. The first work [
7] is aimed at CNNs where the shared filters are represented as low rank constraints, which are relaxed for convex optimization. The second work [
8] focuses on two-layer ReLU networks, and using convex duality, it shows that the two-layer ReLU network can be globally optimized with a second order cone program with a computation complexity of
, where
r is the rank of the input data matrix (which is usually
for large
N). This is polynomial time in sample size
N but exponential in the input dimension
d, so it can be prohibitive for large
N and
d. They also prove that the exponential complexity in
d cannot be improved unless P = NP. In contrast, the algorithm introduced in this paper is faster, being
, where
h is the number of hidden nodes, but it does not guarantee a global optimum. The convex relaxation idea was further improved in [
9], where faster approximate algorithms were proposed based on gated ReLU models. However, the algorithm is gradient-based, relying on the accelerated proximal gradient method. To their advantage, the method can be applied to arbitrary loss functions, not only the square loss needed for our method.
Other works [
10,
11] try to develop algorithms for learning NNs in polynomial time, under the assumption that the bias terms of the hidden nodes are 0. In [
10], the authors focus on two-layer NNs with ReLU activation under the assumption that the true weight matrix of the hidden nodes is full rank. They give an algorithm that is polynomial in
N and
d but exponential in the number of hidden nodes
h that guarantees finding the true coefficients under certain assumptions. However, the algorithm is based on Independent Component Analysis and not on loss minimization. Again, our algorithm is cubic in the number of hidden nodes
h at the cost of a lack of a global optimum guarantee.
The zero bias assumption is relaxed in [
12], under the assumption that the weight matrix of the hidden nodes has linearly independent columns. Their algorithm is based on tensor decomposition and not on optimizing a loss function. It runs in polynomial time in
N,
h and
d and recovers the true coefficients, up to a permutation and within a given error
, given sufficiently many samples. However, the most important drawback is that the algorithm assumes there is no noise in the target data, so it cannot be used in practice. This kind of no noise assumption is also used in [
13], where the authors show that it is possible to recover a deep ReLU NN, including its architecture, weights and biases, from the network output alone, up to an isomorphism. For that, they rely on the piecewise linear regions of the network output, which are defined by the neuron firing patterns that are also used in our work.
An argument could be made that the Broyden–Fletcher–Goldfarb–Shanno (BFGS) [
14] and LBFGS (limited memory BFGS) [
15] algorithms, which use an approximation of the inverse Hessian matrix, are somehow close competitors to the proposed method. However, these algorithms do not freeze the neuron firing pattern at each iteration and instead try to search for the optimum in the energy landscape of the original parameter space. The problem with these approaches is that the energy landscape has many points where the inverse Hessian is infinite because of the non-differentiable nature of the piecewise linear ReLU activation. For this reason, the BFGS and LBFGS algorithms explode near the local optima, as can be easily observed experimentally. In contrast, by freezing the neuron firing pattern in our work, the analytic solution was observed experimentally to always exist for some data (three of the five real datasets from experiments) and usually exists for the rest of the data.
Table 1 presents an overview of the above mentioned works, with their computation complexities, types of loss function they optimize and whether they provide global optimum guarantees or not.
2. Materials and Methods
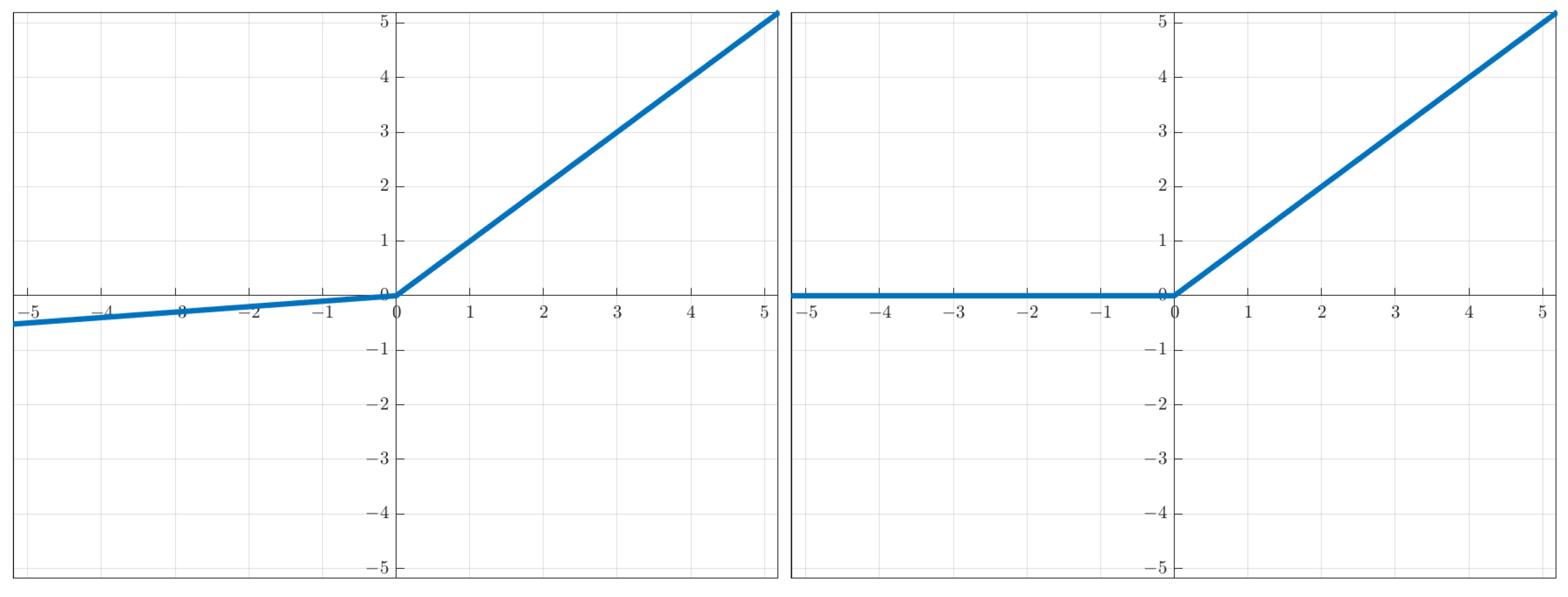
This work will focus on two-layer ReLU networks:
where
is an input vector,
is the
matrix of weights for the hidden layer and
is the
matrix of weights of the output layer and
are the biases for the
c outputs. The activation functions of interest are the leaky ReLU type
, with
. In the experiments, we will look at the ReLU (
) and the leaky ReLU (
) (
Figure 1).
Given observations
, the square loss function for these networks is:
where
is the Frobenius norm.
We will use the standard notation denoting by
the matrix of observations
and by
the matrix of outputs, with
as rows and
as columns,
where
is the vector of targets for the
j-th output.
We will use an algorithm that minimizes the loss (
1) by alternately finding the critical points of the loss in terms of
and
, where for the critical points with respect to
, the neuron firing pattern is kept frozen. The procedure is described in Algorithm 1.
| Algorithm 1 Analytic Minimization (ANMIN) |
Input: Training data .
Output: Trained network parameter vectors .
- 1:
Initialize randomly - 2:
Fit using Equation ( 4). - 3:
Compute loss - 4:
for to E do - 5:
Update and - 6:
Compute using Equation ( 7) and using Equation ( 8) - 7:
if then - 8:
Solve - 9:
else - 10:
Obtain by SVD such that - 11:
If , set - 12:
Obtain - 13:
end if - 14:
Reshape vector into matrix - 15:
Fit using Equation ( 4). - 16:
Compute loss - 17:
if then - 18:
Set - 19:
Set - 20:
end if - 21:
end for
|
The threshold controls when the linear system can be solved numerically. In practice, we take 10,000.
2.1. Fitting the Output Layer Weights
Fitting the output layer weight matrix
is simple for OLS, using
as the input. Since the square loss is a sum of the square losses over the output variables,
can be solved separately for each output variable:
2.2. Fitting the Hidden Layer Weights
Let be the binary firing pattern matrix, indicating what hidden neurons fire for each observation. Here, is the elementwise indicator operator. Let , where is the matrix with all entries 1.
Then, the neural network response for training observation
, is
where
is the
i-th row of
, “∗” is the elementwise multiplication and
is the
i-th row of
. Then, all responses can be written as
Adding the firing pattern
to the loss function parameters gives
Let
which are
matrices that can be computed incrementally using batches.
Let
be the
matrix with the cell
.
The following Theorem describes the linear system of equations that need to be solved in order to find the critical points of the loss function with respect to analytically.
Theorem 1. If the matrix from Equation (5) is fixed, the critical points with respect to of the loss function from Equation (5) are solutions of the equation:where is the matrix unraveled. Proof. The loss (
5) can also be written as
therefore,
Then, the loss function can be written using Equation (
7) as
This is a quadratic function in
, and by setting its gradient with respect to
to zero, we obtain Equation (
9). □
2.3. Computation Complexity
The computation complexity of the analytic minimization algorithm ANMIN described in Algorithm 1 can be easily calculated as follows.
Computing the input for solving is and fitting is . Computing each matrix is , so computing is . Fitting is . Since there are a fixed number of iterations, the whole algorithm is , so it is linear in N and c but cubic in d and h.
2.4. Datasets Used
Real data experiments will be conducted on three datasets from the UC Irvine Machine Learning repository [
16] and two datasets that were specially generated for two computer vision tasks. These five datasets are summarized in
Table 2.
From the UC Irvine Machine Learning repository [
16] were used the abalone, bike-sharing and year prediction MSD datasets, all three being regression datasets.
The abalone dataset is about predicting the age of abalone from its physical measurements. It has 4177 observations and 7 features, so it is a low dimensional dataset.
The bike-sharing dataset is about predicting the hourly and daily bike rental counts in a bike rental system. The hourly count was used, containing 17,379 observations and 14 features. The feature that counts the number of registered users was removed since it is very strongly correlated with the response, and the remaining 13 features were used for prediction.
The year Prediction MSD dataset is about predicting the release year of a song from audio features extracted from the song. It contains 515,345 observations and 90 features.
Another dataset was generated based on the single-shape deep SDF task from [
17]. It is about predicting the value of a signed distance transform (SDF) matrix from the pixel coordinates
. The input shape used was the first mask image of the Weizmann horse dataset [
18], shown in
Figure 2, left, from which the SDF was computed. Taking all pixels’ coordinates of the image as inputs and their corresponding SDF values as targets, a dataset with 73,080 observations and two features was obtained.
All these regression datasets are about predicting a single output. To evaluate the performance of ANMIN for predicting multiple outputs, the NN was used as a denoising autoencoder (DAE). In this case, the desired outputs consist of natural image patches, and the inputs are the same patches corrupted by noise. The patches were extracted from an image from the Berkeley dataset [
19], shown in
Figure 2, right. Using a step size of 3, from the image were extracted 15,912 overlapping patches of size
. Thus, the data have 15,912 observations, 225 inputs and 225 outputs. The outputs are the original image patches, and the inputs are the same image patches corrupted with Gaussian noise with standard deviation
.
For all datasets, one hundred random splits of the data into an 80% train set and 20% test set were generated.
A two-layer NN with h hidden nodes and ReLU or Leaky ReLU activation was trained on the training parts of the random splits using different training algorithms and then tested on the corresponding test sets. The number of hidden nodes was , except for the DAE data, where it was to obtain a low dimensional representation.
2.5. Methods Compared
The proposed ANMIN algorithm was compared with the stochastic gradient descent algorithm, the Adam optimizer [
1] and the LBFGS algorithm [
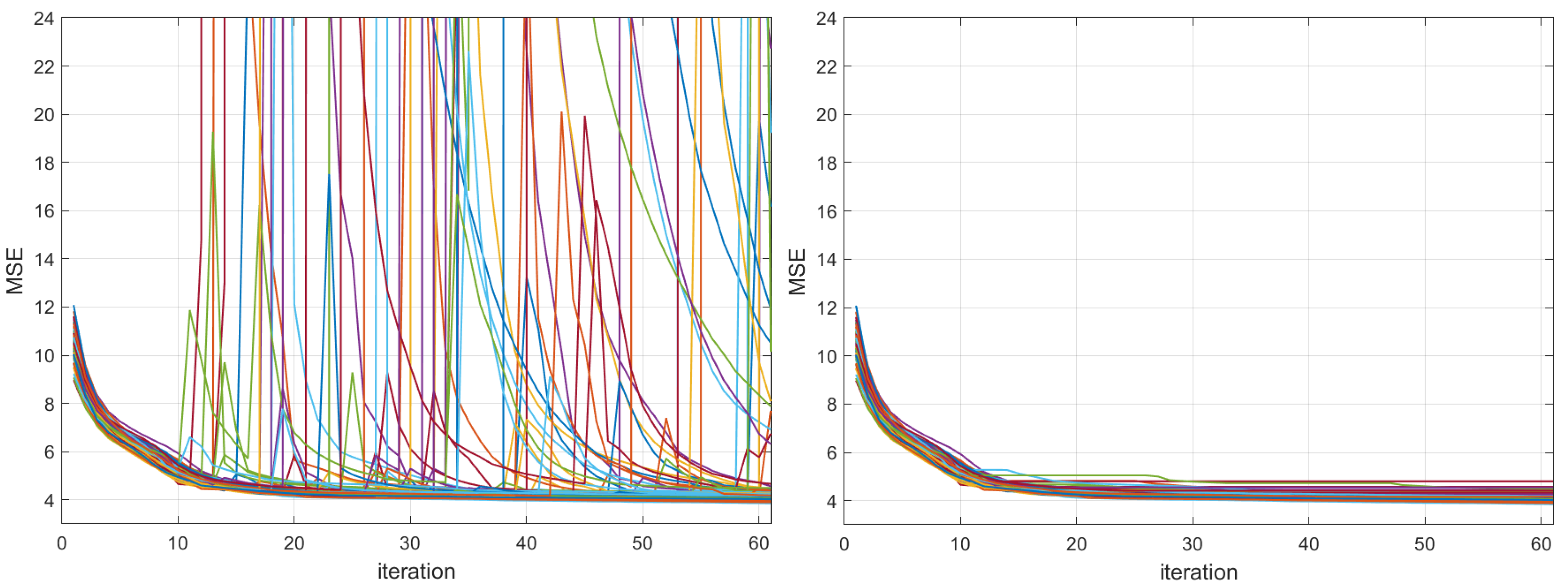
15]. The main focus is the SGD and Adam because the LBFGS blows up to values as large as
many times during optimization, as one can see in
Figure 3, left, for the abalone dataset, where 100 training losses are plotted. For this reason, for the LBFGS algorithm, for each run, the model that obtained the smallest training MSE was extracted and used for testing. The same approach was used for ANMIN (lines 17–20 of Algorithm 1).
ANMIN and Adam were experimented with two activation functions: ReLU () and leaky ReLU (), while LBFGS and SGD were experimented only with ReLU. The methods with leaky ReLU are called ANMIN-L and Adam-L in experiments.
2.6. Implementation Details
All algorithms were implemented in PyTorch. The experiments were conducted on a Core I7 computer with 32 Gb RAM and GeForce 3080 GPU.
The SGD and Adam were trained for 300 epochs. The initial learning rate for Adam was 0.03, while for SGD, it was tuned for each dataset individually to avoid the loss blowing up and to obtain a small final loss value. The learning rate was decreased by a factor of 10 after every 100 epochs. The ANMIN algorithm was run for 30 iterations. The LBFGS was run for 60 iterations with a learning rate of 0.01.
For Adam and SGD, a batch size of 256 was used except for Year Prediction MSD, where a batch of 2048 was used. For LBFGS, a batch size of 100,000 was used. For ANMIN, a batch size of 256 was used. The batch size is used in the ANMIN to accumulate the matrices
from Equation (
6), so different batch sizes result in identical solutions, and we have observed that the computation time is approximately the same for batch sizes between 128 and 2048. The value of the shrinkage parameter
for ANMIN was
.
3. Results and Discussion
Experiments are conducted on multiple real datasets to obtain insight about when the ANMIN method works well compared to regular gradient-based training and when it does not. We will see that the advantages of ANMIN are more clear when the input dimension is small relative to the number of hidden neurons. Then, simulations will be conducted on a nonlinear dataset where the input dimension and the number of observations can be modified as desired.
3.1. Real Data Experiments
The results as training, test MSEs and training and test
are collected in
Table 3. The best result and the results that obtained a
p-value of
based on a paired
t-test significance comparison with the best results are shown in bold.
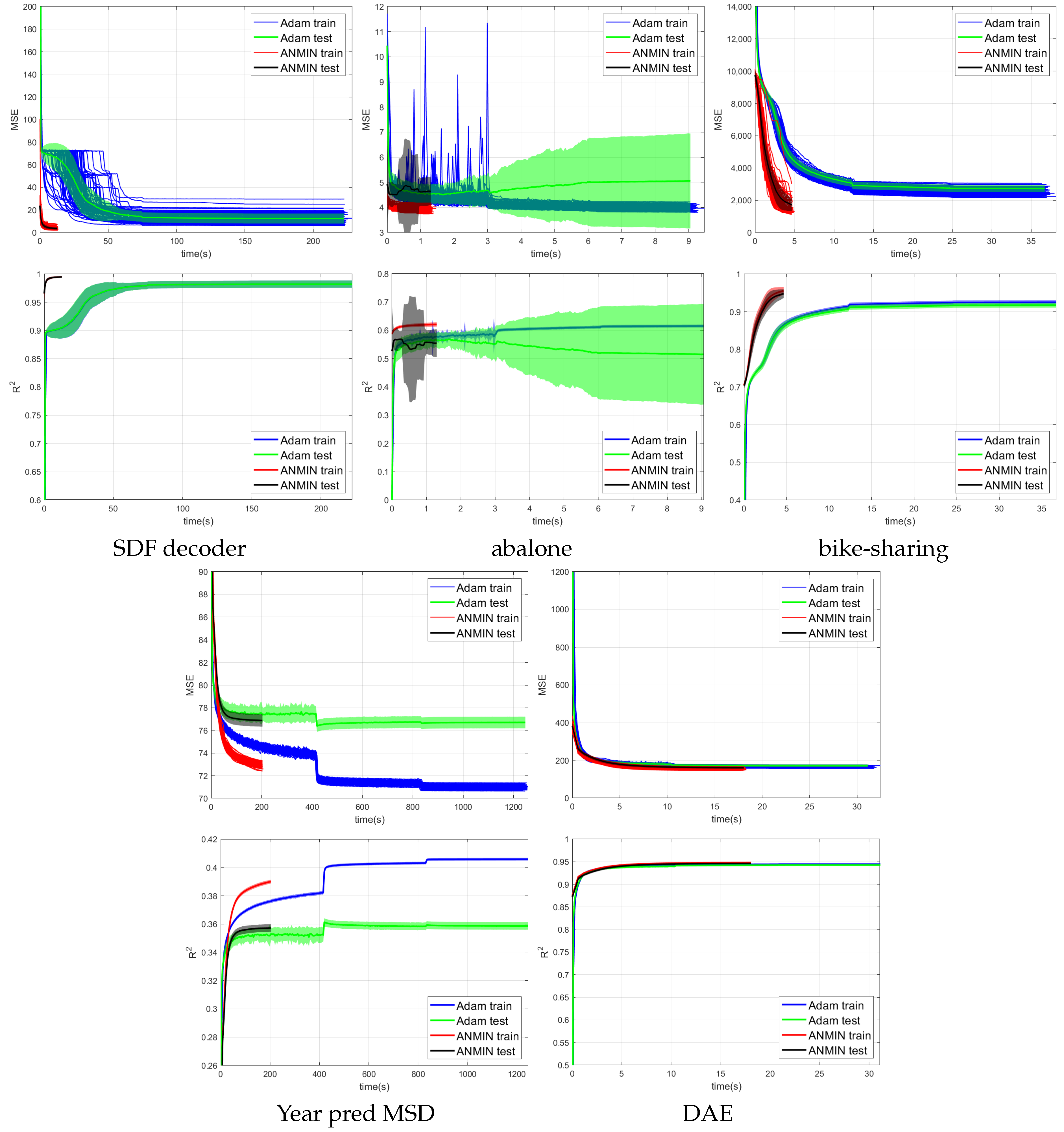
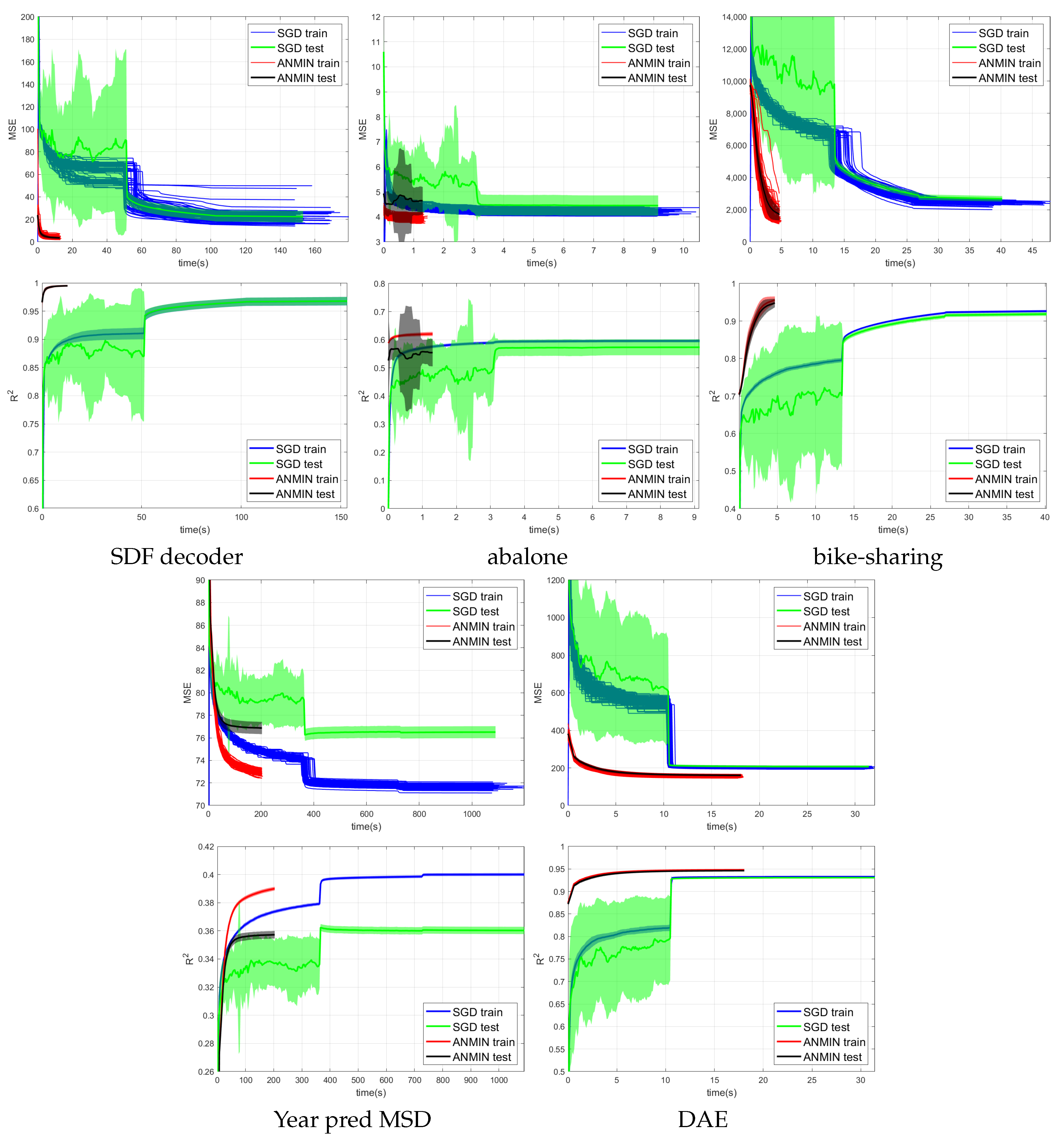
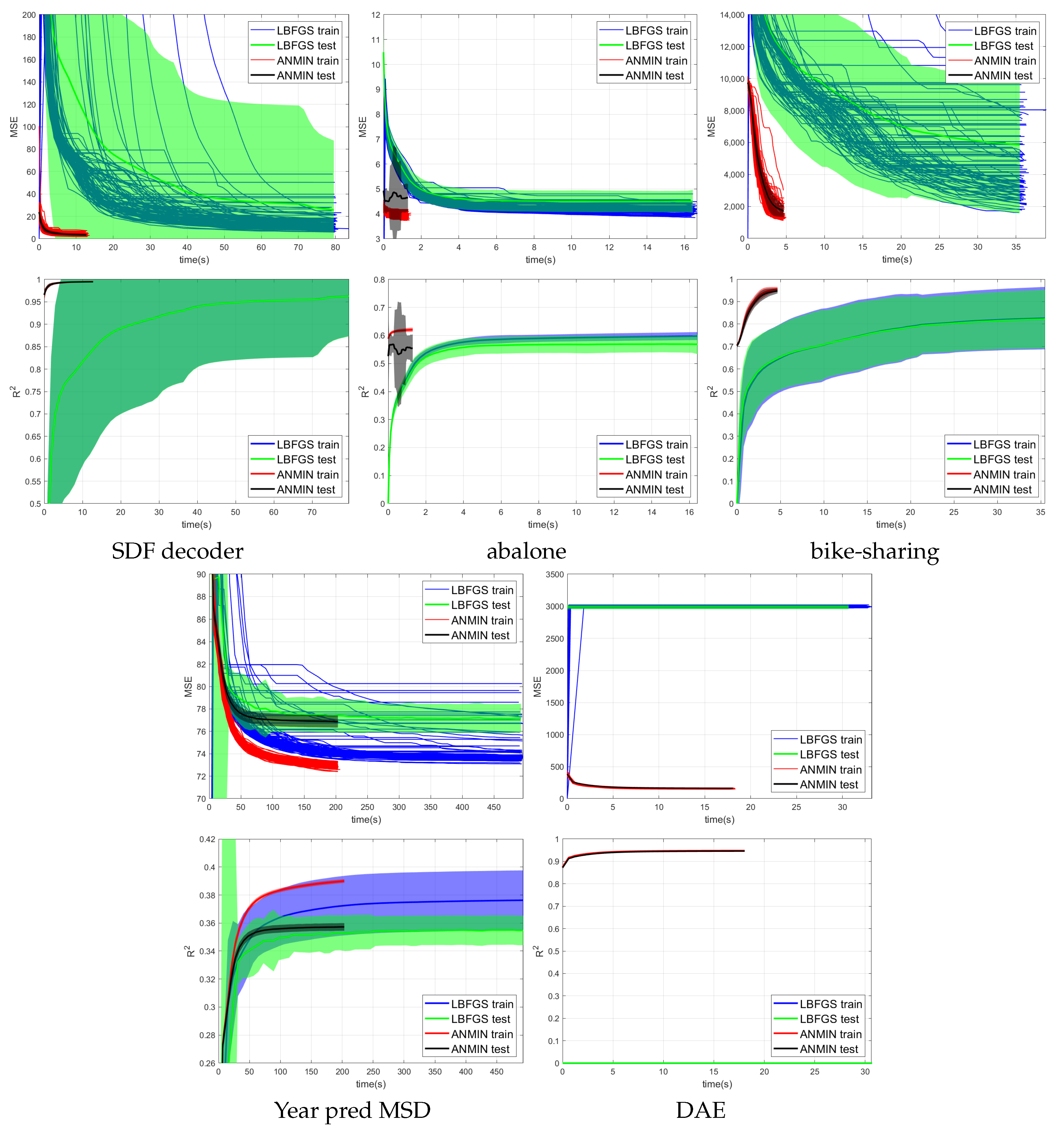
Figure 4,
Figure 5 and
Figure 6 show the training MSE loss and average
curves for NNs with ReLU activation trained with the ANMIN method vs. Adam, SGD and LBFGS methods, respectively, on all 100 random splits. Additionally are shown the mean test MSE and
curves with their standard deviation. The test MSEs and
for ANMIN and LBFGS are based on the model with the smallest training MSE loss.
Looking at the MSE loss values in
Figure 4,
Figure 5 and
Figure 6 and
Table 3, one can see that the ANMIN method obtains significantly lower train loss values than Adam, SGD and LBFGS on four out of the five datasets. It obtains significantly lower test MSEs than Adam and LBFGS on four datasets and than SGD on three datasets. Moreover, it is never significantly outperformed on the test set by either SGD, Adam or LBFGS on any of the five datasets. The LBFGS algorithm performs very well only on abalone and is decent on Year Prediction MSD. It performs very poorly on the other three datasets.
Looking at the
values from
Figure 4,
Figure 5 and
Figure 6 and
Table 3, we can see that the ANMIN method obtains significantly higher train
values than SGD, Adam and LBFGS on four out of the five datasets. It obtains significantly higher test
than Adam or LBFGS on four datasets and than SGD on three datasets. ANMIN is significantly outperformed by Adam and SGD on one dataset.
What do the datasets where the ANMIN method outperforms Adam and SGD have in common? One can notice that the one-output datasets in question all have low dimensional inputs,
. Thus, the real data experiments seem to support the hypothesis that ANMIN has an advantage over standard gradient-based optimization when the input dimension of the data (hence the number of parameters in the hidden layer) is small. This hypothesis will be further explored in the simulations in
Section 3.2. In that case, it seems that SGD and Adam have a hard time exploring the low dimensional parameter space and finding a deeper local optimum. Indeed, on the smallest dimensional dataset, which is the SDF decoder, ANMIN’s MSE was about three times smaller than SGD’s and Adam’s. On abalone and bike-sharing, the other two datasets with small numbers of features, ANMIN again significantly outperformed Adam and SGD on the training set, but SGD somehow generalized better on the test set for abalone.
The LBFGS algorithm did not do well on all datasets except for abalone, and in almost all cases, its training MSE values were so high that it was the worst of all methods evaluated.
The computation times for the methods evaluated are shown in
Table 4. Comparing computation times, one can see from
Figure 4 that a train loss value as large as the final Adam loss is obtained by ANMIN in 5–10 times less time on the three low-dimensional datasets, and more iterations bring even more improvements to the loss values. Even the total computation times (30 ANMIN iterations vs. 300 Adam) show a computation advantage for the ANMIN method, in the range of two times faster for the DAE to more than seven times for the three low-dimensional datasets.
These experiments indicate that the ANMIN method might have an advantage in some cases, e.g., when the input dimension d is small. This hypothesis is further investigated in the next section.
3.2. Simulations
In this section, simulations will be conducted to test the hypothesis that the advantage of ANMIN vs. Adam is more clear when the input dimension is small.
The simulated data has sampled from and . The dimension d was taken from . A number of observations were sampled for training and an equal number for testing.
The model is a two-layer NN with hidden nodes and ReLU activation. It is worth noting that the model does not fit the data well when d is large.
The model was trained with 30 iterations of ANMIN (Algorithm 1). For comparison, it was also trained with 300 iterations of the Adam optimizer [
1], starting with learning rate
, which was reduced by 10 every 100 iterations. The batch size was 256.
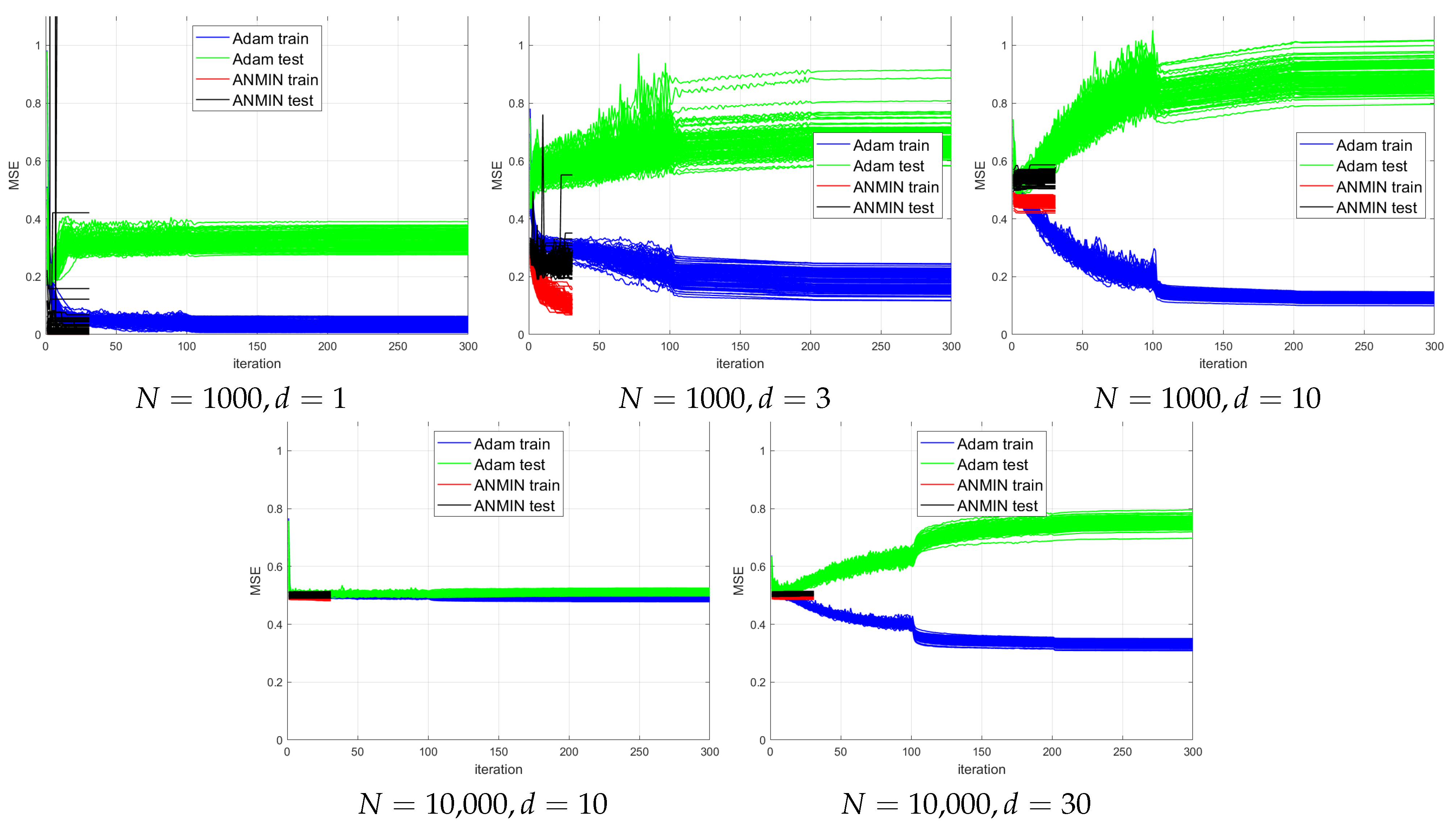
The plots of the MSE vs. iteration for 100 consecutive runs for different combinations of
n and
d are shown in
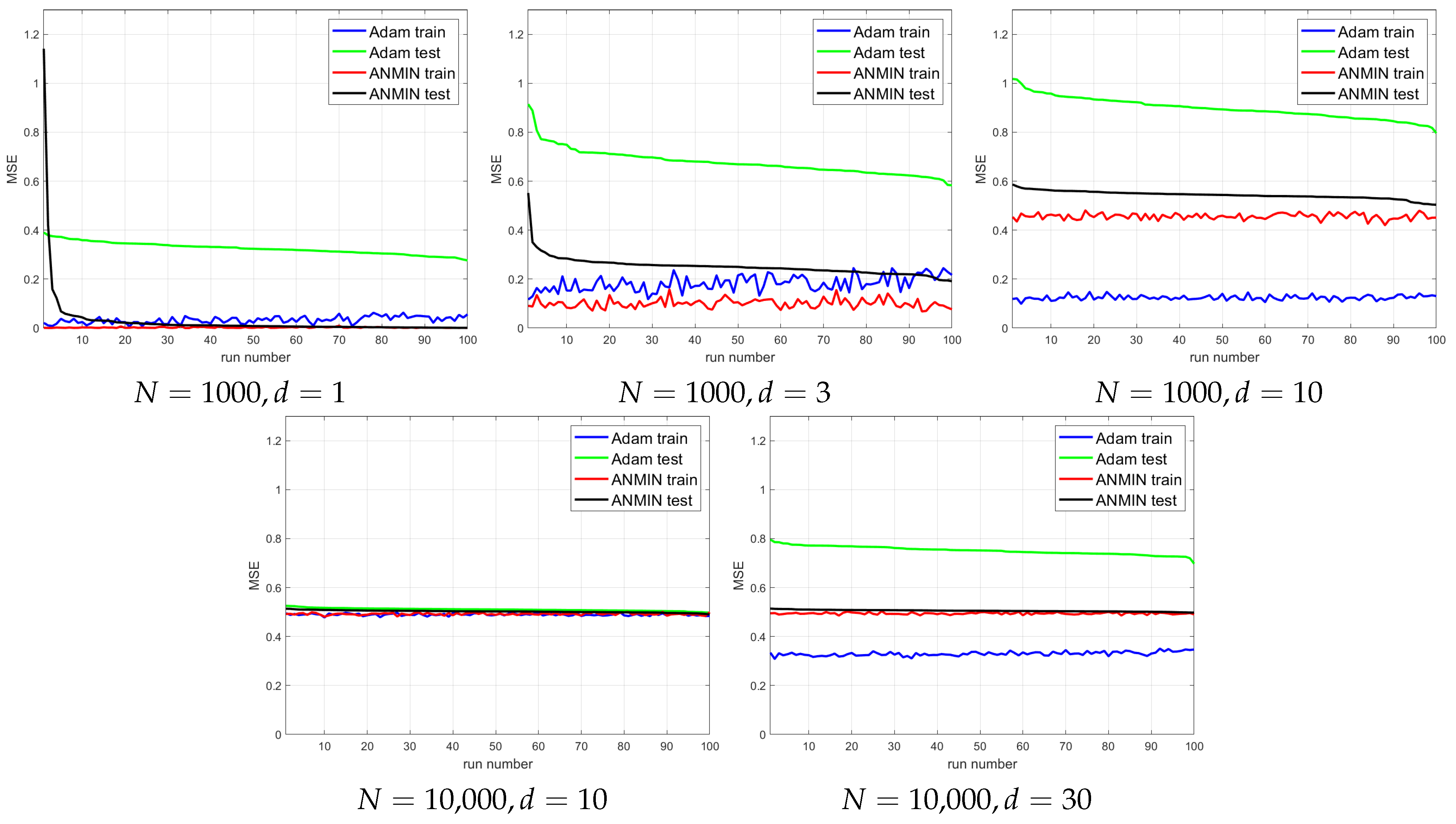
Figure 7. For a better visualization,
Figure 8 plots the train and test MSEs obtained by the two methods over the 100 runs, where the runs are sorted by decreasing test MSE for each method independently. This type of display can allow one to observe any trend between the train and test MSEs for each method. It would also allow one to obtain a better idea of the distribution of the test MSEs.
One can see that for small , the ANMIN can obtain both train and test loss values smaller than Adam. For , Adam obtains a smaller training loss, but it overfits more than ANMIN. In all situations, the ANMIN method obtains smaller test MSE values.
3.3. Ablation Study
This section investigates how the design decisions made for Algorithm 1 affect its performance. The design decisions that will be investigated are:
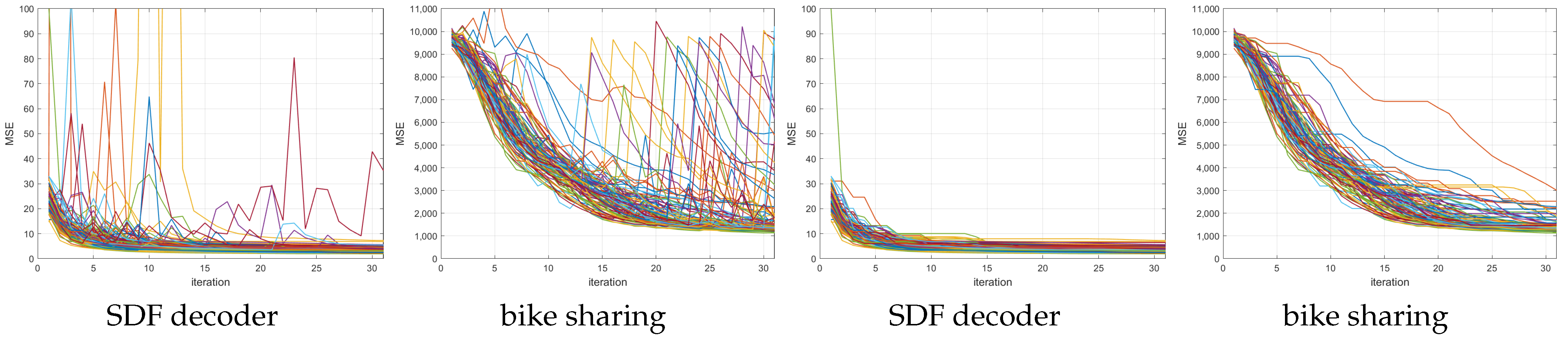
The ablation experiments are conducted on the bike-sharing dataset, which exhibits smaller log determinant values and therefore is more difficult to optimize. The results are summarized in
Table 5.
In Experiment 1, the ANMIN algorithm is stopped the first time when the log determinant is less than −10,000 and the final loss is reported.
In Experiment 2, at each iteration when the log determinant is less than −10,000, the matrix is re-initialized with random values. The model with minimum train loss over all iterations is reported with its training and test loss values.
In Experiment 3, the algorithm is run as described in Algorithm 1, except that the final model is reported instead of the model with minimum loss over the iterations.
Experiment 4 is exactly as described in Algorithm 1.
From
Table 5, one can see that both the minimum over the iterations and the use of a pseudoinverse instead of a random restart help in obtaining a small final loss.
Figure 9 shows the MSE training loss values for the SDF decoder and bike-sharing datasets obtained at each iteration (left) and the minimum MSE obtained so far (right). One can see that the MSE loss at each iteration sometimes jumps (usually when the log determinant is small or
). However, the jumps are much smaller than those of the LBFGS method. This is because after each update of the matrix
, which can result in jumps, the matrix
is also updated to minimize the MSE.
3.4. Diagnosing the ANMIN Algorithm
As opposed to gradient-based algorithms, the ANMIN method offers some capabilities to diagnose the energy landscape during the optimization. For that, the condition number of
or the log determinant
can be used to see how degenerate the local optimum that the ANMIN reaches is when fitting the hidden nodes
.
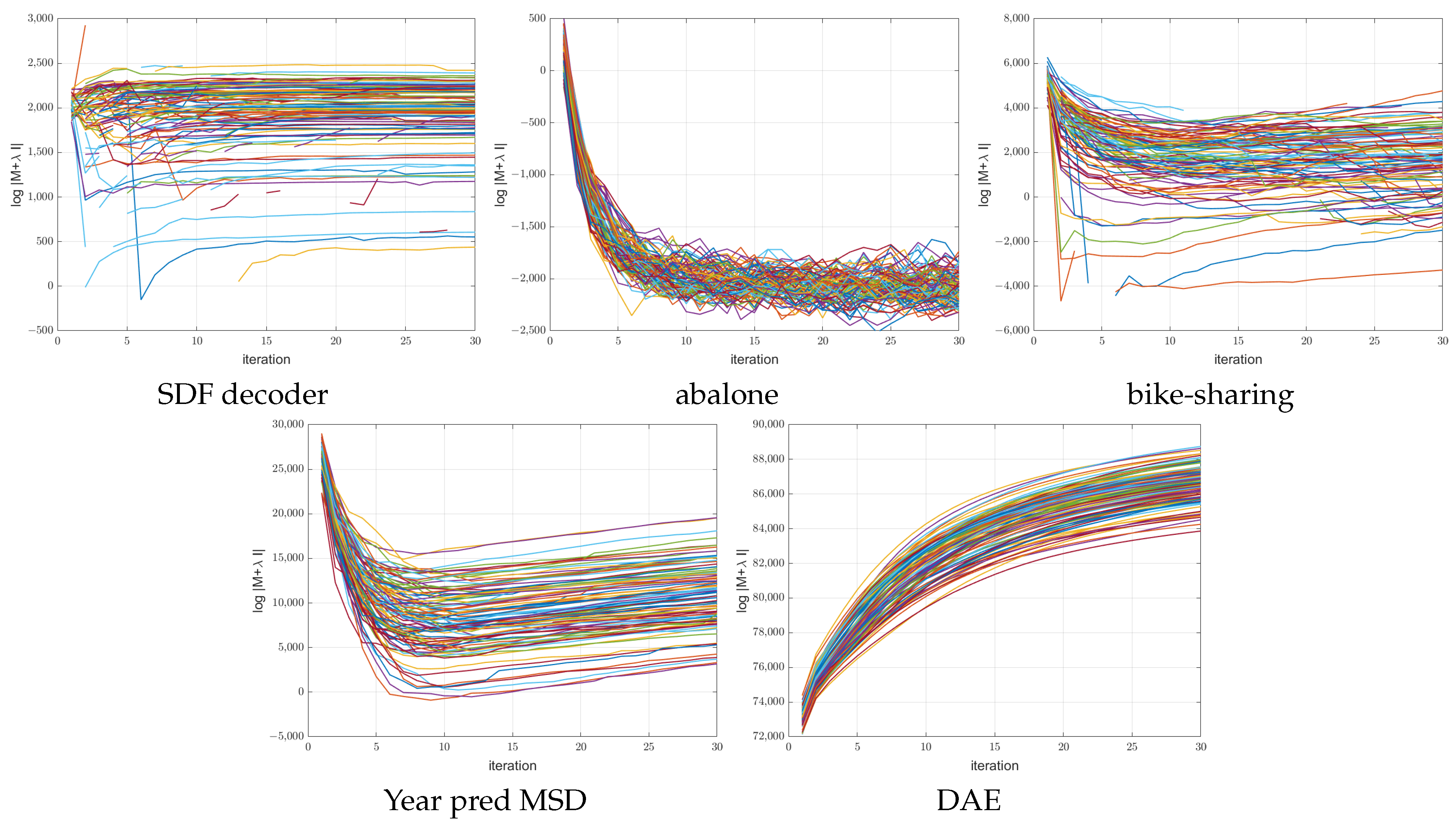
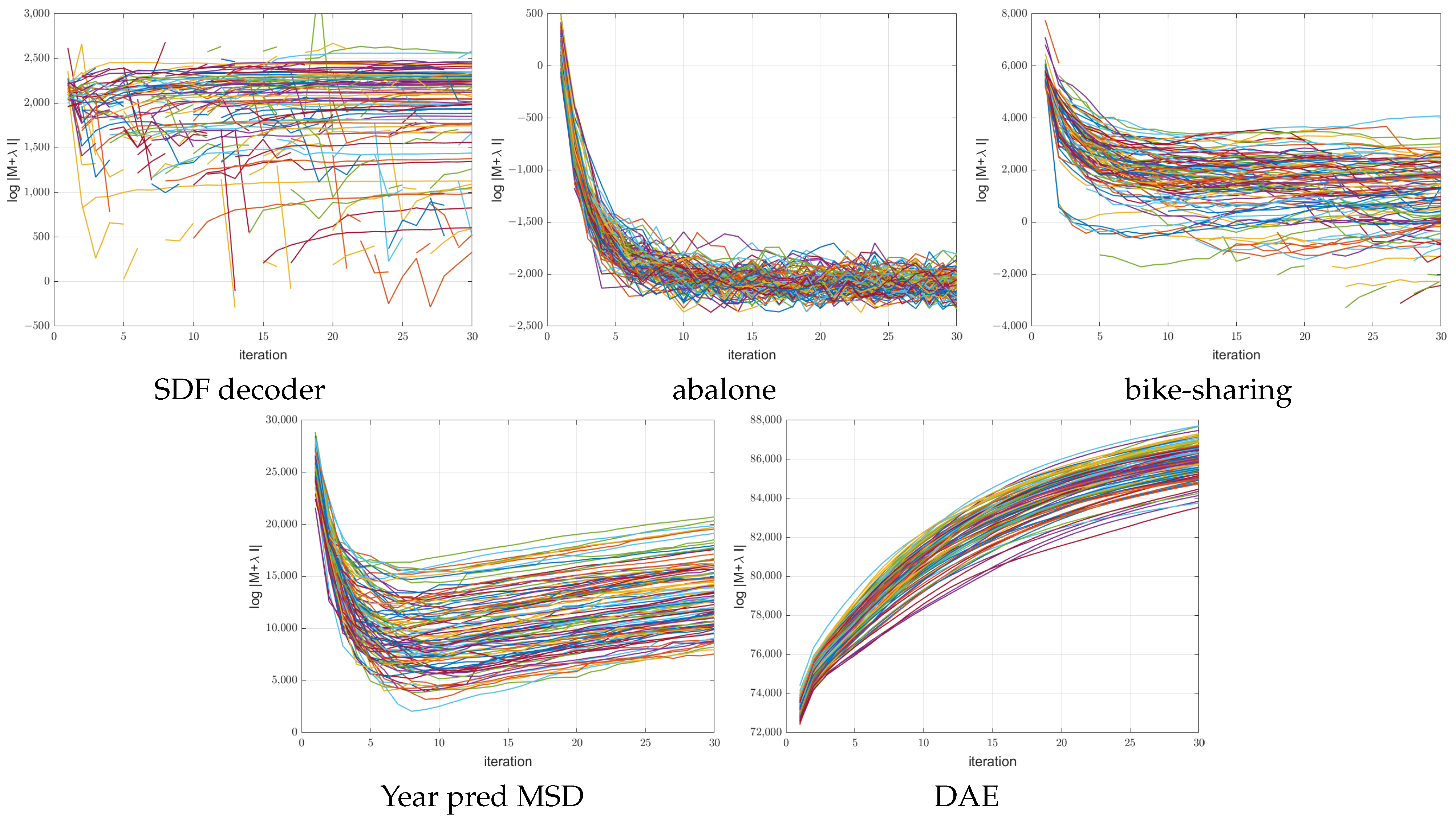
Figure 10 and
Figure 11 show the log determinant values
encountered during optimization for the 100 ANMIN runs on the random splits for the ReLU and leaky ReLU activations respectively. Some curves are broken because the log determinant is
at some iterations. One can see that for the one-output datasets, the log determinant has a tendency to decrease, while for the multiple-output DAE problem, the log determinant increases with the iterations. For the low-dimensional datasets (abalone and bike-sharing) the log determinant reaches a very small value, which makes the matrix
close to singular and the solution of Equation (
9) less stable.
4. Conclusions
This paper introduced a method for training a two-layer NN with ReLU or leaky ReLU-like activation using the square loss by alternatively fitting the coefficients of each layer, while keeping the other layer and the activation pattern of the neurons fixed.
Experiments indicate that the method can obtain in some cases (e.g., when the input dimension is small) strong minima of the loss function that go beyond the capabilities of those obtained by gradient descent optimization. It can do so with a relatively small number of iterations (10–30), which means that it can work with large datasets that do not fit in the computer’s memory.
This work is experimental in nature, in that we introduce an algorithm and we observe that it works well experimentally, but we provide no proofs or theoretical guarantees that it will always work under certain assumptions.
This work can usher the possibility of using shallow NNs for many computation-sensitive applications by providing better optimization capabilities for shallow NNs that go beyond those of gradient descent algorithms.
It is known that tree ensembles, such as boosted trees and random forests, can be mapped to two-layer neural networks [
20,
21]. In this respect, this work can potentially enable better algorithms for training such deep ensembles by loss minimization, which are better at minimizing the loss and more computationally efficient.
However, the method has certain limitations since it involves the inversion of a matrix of size . This can limit the applicability of the method when the input dimension and the number of neurons are both large (e.g., 30,000). This drawback can be addressed by sparse neuron connections, where not all neurons are connected to all inputs, or by large-scale implementations that use multiple GPUs.
In the future, we plan to apply the ANMIN method to shape analysis using NNs and to large-scale object detection applications.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}