

Integrating Visual and Network Data with Deep Learning for Streaming Video Quality Assessment

 , ,
, , 
Abstract
1. Introduction
1.1. The ITU-T P.1203 Standard
- Mode 0: Display resolution, frame rate, instantaneous video bitrate
- Mode 1: All of Mode 0, frame type/frame size (bytes)
- Mode 2 and 3: All of mode 1. It also involves detailed parsing of partial or complete bitstream.
1.2. Deep Learning in Image/Video QoE Estimation
2. Materials and Methods
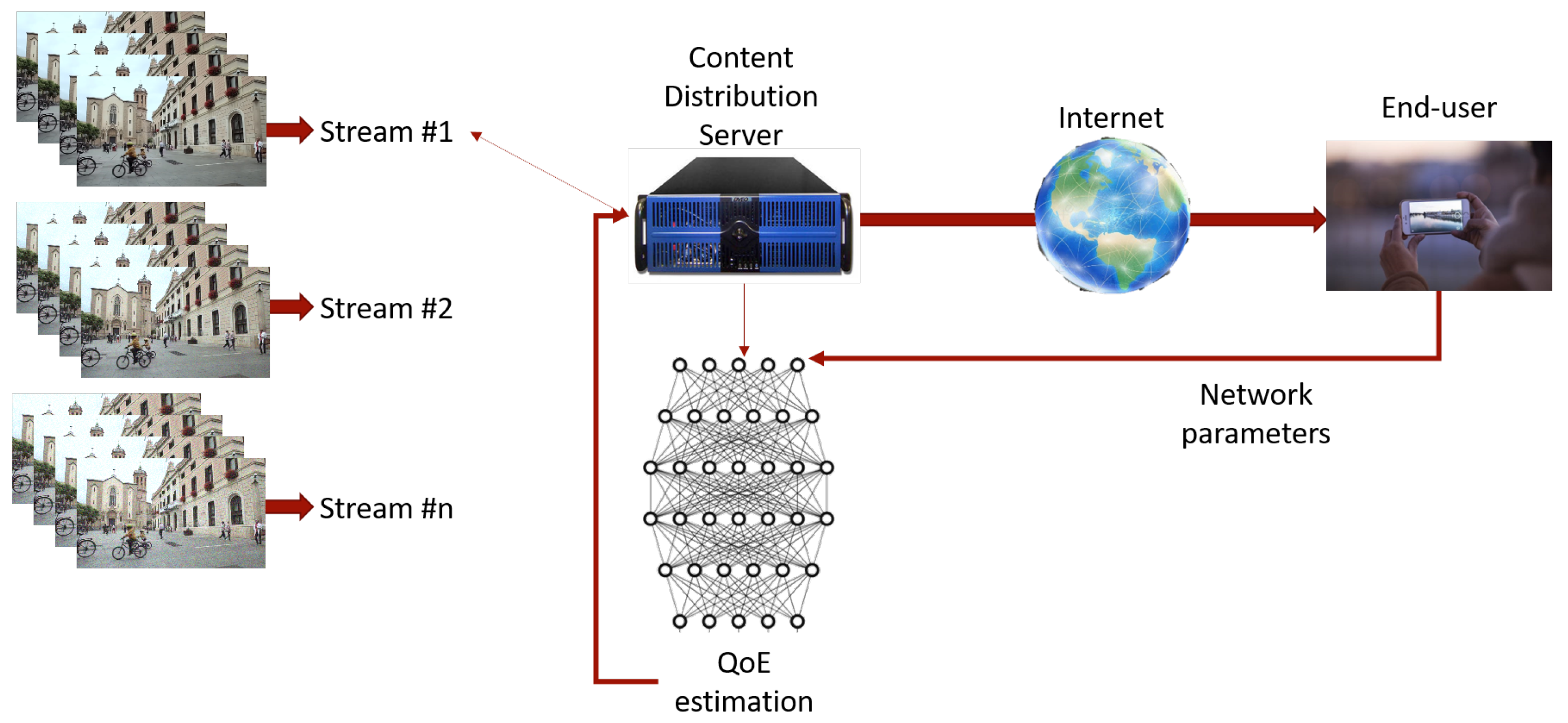
2.1. Proposed Framework and Implementation Methodology
- It does not require dedicated services running on the client.
- It does not introduce additional complexity to the client side.
- It does not suffer from lag due to the delays caused by the feedback channel.
- The CDS;
- The network/Internet;
- The client.
- The entire sequence (full video);
- Spatially localized features (sv-patch);
- Temporally localized features (tv-patch);
- Spatiotemporally localized features (stv-patch).
- Convolutional layers: These are responsible for learning the input’s feature representation. These layers consist of several kernels which produce feature maps [61].
- Pooling layers: These layers reduce the height and width of the features and they are applied after the convolutional layers [62].
- Fully connected layers: These layers map the output of the previous layer onto the neuron of the current layer [63].
2.2. Specifying and Training a DNN Model for QoE Assessment
2.2.1. Proposed Model
2.2.2. Model Training
2.3. Dataset Analysis
- Four types of no-reference image quality scores (estimated per frame after removing black bars and rebuffered frame), including PSNR, SSIM and VMAF;
- Information related to the video reproduction such as video and playback duration and number of frames;
- Information related to visual content including width, height, frame rate, the QP value, scene cuts and the compression bitrate;
- Information related to network conditions such as rebuffering frames, number of events and duration, throughput and lastly the MOS, both retrospective and continuous.
3. Results
3.1. PatchVQ Model
3.2. P.1203 Model
3.3. The Proposed Model
3.4. Comparison of the Approaches
3.5. Ablation Study
4. Discussion
- Approaches that consider network conditions lead to significantly higher prediction performance, compared to visual-only methods when investigating dynamic video streaming conditions.
- Exploiting semantic information encoded in videos through deep learning methods can significantly increase performance, compared to approaches that focus on the networking aspect only.
- It is possible to introduce both visual and network-related information into a unified deep learning model that can be trained in an end-to-end fashion.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Cisco. Cisco Annual Internet Report (2018–2023); White Paper; Technical Report; Cisco: San Jose, CA, USA, 2020. [Google Scholar]
- Comserve. Video Streaming Market Size 2021 Industry Statistics, Emerging Technologies, Business Challenges, Segmentation, Explosive Factors, of Revenue Expansion and Strategies 2023. 2021. Available online: https://www.comserveonline.com/news-releases/video-streaming-market-size-2021-industry-statistics-emerging-technologies-business-challenges-segmentation-explosive-factors-of-revenue-expansion-and-strategies-2023/10023098 (accessed on 11 October 2022).
- Bampis, C.; Li, Z.; Katsavounidis, I.; Bovik, A. Recurrent and Dynamic Models for Predicting Streaming Video Quality of Experience. IEEE Trans. Image Process. 2018, 27, 3316–3331. [Google Scholar] [CrossRef] [PubMed]
- Bhargava, A.; Martin, J.; Babu, S.V. Comparative Evaluation of User Perceived Quality Assessment of Design Strategies for HTTP-Based Adaptive Streaming. ACM Trans. Appl. Percept. 2019, 16, 1–20. [Google Scholar] [CrossRef]
- Seufert, M.; Wehner, N.; Casas, P. Studying the Impact of HAS QoE Factors on the Standardized QoE Model P.1203. In Proceedings of the 2018 IEEE 38th International Conference on Distributed Computing Systems (ICDCS), Vienna, Austria, 2–6 July 2018; pp. 1636–1641. [Google Scholar] [CrossRef]
- Gatimu, K.; Dhamodaran, A.; Johnson, T. Experimental study of QoE improvements towards adaptive HD video streaming using flexible dual TCP-UDP streaming protocol. Multimed. Syst. 2020, 26, 479–493. [Google Scholar] [CrossRef]
- Spiteri, K.; Sitaraman, R.; Sparacio, D. From Theory to Practice: Improving Bitrate Adaptation in the DASH Reference Player. ACM Trans. Multimed. Comput. Commun. Appl. 2019, 15, 1–29. [Google Scholar] [CrossRef]
- ITU. ITU-T Rec. P.10/G.100 (11/2017) Vocabulary for Performance, Quality of Service and Quality of Experience. 2017. Available online: https://www.itu.int/rec/T-REC-P.10-201711-I/en (accessed on 11 October 2022).
- Kim, G.H. QoE Unfairness in Dynamic Adaptive Streaming over HTTP. In Advances in Computer Science and Ubiquitous Computing; Park, J.J., Park, D.S., Jeong, Y.S., Pan, Y., Eds.; Springer: Singapore, 2020; pp. 586–591. [Google Scholar]
- Cofano, G.; Cicco, L.D.; Zinner, T.; Nguyen-Ngoc, A.; Tran-Gia, P.; Mascolo, S. Design and Performance Evaluation of Network-Assisted Control Strategies for HTTP Adaptive Streaming. ACM Trans. Multimed. Comput. Commun. Appl. 2017, 13, 1–24. [Google Scholar] [CrossRef]
- Kua, J.; Armitage, G.; Branch, P. A Survey of Rate Adaptation Techniques for Dynamic Adaptive Streaming Over HTTP. IEEE Commun. Surv. Tutor. 2017, 19, 1842–1866. [Google Scholar] [CrossRef]
- Pantos, R.; May, W. HTTP Live Streaming. RFC 8216. 2017. Available online: https://www.rfc-editor.org/info/rfc8216 (accessed on 11 October 2022).
- Yu, P.; Liu, F.; Geng, Y.; Li, W.; Qiu, X. An objective multi-layer QoE Evaluation for TCP video streaming. In Proceedings of the 2015 IFIP/IEEE International Symposium on Integrated Network Management (IM), Ottawa, ON, Canada, 11–15 May 2015; pp. 1255–1260. [Google Scholar] [CrossRef]
- Taraghi, B.; Bentaleb, A.; Timmerer, C.; Zimmermann, R.; Hellwagner, H. Understanding Quality of Experience of Heuristic-Based HTTP Adaptive Bitrate Algorithms. In Proceedings of the 31st ACM Workshop on Network and Operating Systems Support for Digital Audio and Video, Istanbul, Turkey, 28 September 2021. [Google Scholar] [CrossRef]
- Ntoa, S.; Margetis, G.; Antona, M.; Stephanidis, C. User experience evaluation in intelligent environments: A comprehensive framework. Technologies 2021, 9, 41. [Google Scholar] [CrossRef]
- Gao, P.; Zhang, P.; Smolic, A. Quality Assessment for Omnidirectional Video: A Spatio-Temporal Distortion Modeling Approach. IEEE Trans. Multimed. 2022, 24, 1–16. [Google Scholar] [CrossRef]
- Liu, X.; Zhang, Y.; Hu, S.; Kwong, S.; Kuo, C.C.J.; Peng, Q. Subjective and Objective Video Quality Assessment of 3D Synthesized Views With Texture/Depth Compression Distortion. IEEE Trans. Image Process. 2015, 24, 4847–4861. [Google Scholar] [CrossRef]
- Mangla, T.; Zegura, E.; Ammar, M.; Halepovic, E.; Hwang, K.W.; Jana, R.; Platania, M. VideoNOC: Assessing Video QoE for Network Operators Using Passive Measurements. In Proceedings of the 9th ACM Multimedia Systems Conference, Amsterdam, The Netherlands, 12–15 June 2018. [Google Scholar] [CrossRef]
- Liu, K.H.; Liu, T.J.; Liu, H.H.; Pei, S.C. Spatio-Temporal Interactive Laws Feature Correlation Method to Video Quality Assessment. In Proceedings of the 2018 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), San Diego, CA, USA, 23–27 July 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Moldovan, A.N.; Ghergulescu, I.; Muntean, C.H. A novel methodology for mapping objective video quality metrics to the subjective MOS scale. In Proceedings of the 2014 IEEE International Symposium on Broadband Multimedia Systems and Broadcasting, Beijing, China, 25–27 June 2014; pp. 1–7. [Google Scholar] [CrossRef]
- Zhang, Y.; Gao, X.; He, L.; Lu, W.; He, R. Objective Video Quality Assessment Combining Transfer Learning With CNN. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 2716–2730. [Google Scholar] [CrossRef]
- Vlaović, J.; Vranješ, M.; Grabić, D.; Samardžija, D. Comparison of Objective Video Quality Assessment Methods on Videos with Different Spatial Resolutions. In Proceedings of the 2019 International Conference on Systems, Signals and Image Processing (IWSSIP), Osijek, Croatia, 5–7 June 2019; pp. 287–292. [Google Scholar] [CrossRef]
- Shahid, M.; Rossholm, A.; Lövström, B.; Zepernick, H.J. No-reference image and video quality assessment: A classification and review of recent approaches. EURASIP J. Image Video Process. 2014, 2014, 40. [Google Scholar] [CrossRef]
- Sara, U.; Akter, M.; Uddin, M. Image Quality Assessment through FSIM, SSIM, MSE and PSNR—A Comparative Study. J. Comput. Commun. 2019, 7, 8–18. [Google Scholar] [CrossRef]
- García, B.; López-Fernández, L.; Gortázar, F.; Gallego, M. Practical Evaluation of VMAF Perceptual Video Quality for WebRTC Applications. Electronics 2019, 8, 854. [Google Scholar] [CrossRef]
- Varga, D. No-Reference Video Quality Assessment Based on the Temporal Pooling of Deep Features. Neural Process. Lett. 2019, 50, 2595–2608. [Google Scholar] [CrossRef]
- Masli, A.A.; Ahmed, F.Y.H.; Mansoor, A.M. QoS-Aware Scheduling Algorithm Enabling Video Services in LTE Networks. Computers 2022, 11, 77. [Google Scholar] [CrossRef]
- Tisa-Selma; Bentaleb, A.; Harous, S. Video QoE Inference with Machine Learning. In Proceedings of the 2021 International Wireless Communications and Mobile Computing (IWCMC), Harbin, China, 28 June–2 July 2021; pp. 1048–1053. [Google Scholar] [CrossRef]
- Taha, M.; Canovas, A.; Lloret, J.; Ali, A. A QoE adaptive management system for high definition video streaming over wireless networks. Telecommun. Syst. 2021, 77, 63–81. [Google Scholar] [CrossRef]
- Taha, M.; Ali, A. Smart algorithm in wireless networks for video streaming based on adaptive quantization. Concurr. Comput. Pract. Exp. 2023, 35, e7633. [Google Scholar] [CrossRef]
- Zhou, W.; Min, X.; Li, H.; Jiang, Q. A brief survey on adaptive video streaming quality assessment. J. Vis. Commun. Image Represent. 2022, 86, 103526. [Google Scholar] [CrossRef]
- Szabo, G.; Racz, S.; Malomsoky, S.; Bolle, A. Potential Gains of Reactive Video QoE Enhancement by App Agnostic QoE Deduction. In Proceedings of the 2016 IEEE Global Communications Conference (GLOBECOM), Washington, DC, USA, 4–8 December 2016; pp. 1–7. [Google Scholar] [CrossRef]
- Robitza, W.; Göring, S.; Raake, A.; Lindegren, D.; Heikkilä, G.; Gustafsson, J.; List, P.; Feiten, B.; Wüstenhagen, U.; Garcia, M.N.; et al. HTTP adaptive streaming QoE estimation with ITU-T rec. P. 1203: Open databases and software. In Proceedings of the 9th ACM Multimedia Systems Conference, Amsterdam, The Netherlands, 12–15 June 2018. [Google Scholar] [CrossRef]
- Bermudez, H.F.; Martinez-Caro, J.M.; Sanchez-Iborra, R.; Arciniegas, J.; Cano, M.D. Live video-streaming evaluation using the ITU-T P.1203 QoE model in LTE networks. Comput. Netw. 2019, 165, 106967. [Google Scholar] [CrossRef]
- Robitza, W.; Kittur, D.G.; Dethof, A.M.; Görin, S.; Feiten, B.; Raake, A. Measuring YouTube QoE with ITU-T P.1203 Under Constrained Bandwidth Conditions. In Proceedings of the 2018 Tenth International Conference on Quality of Multimedia Experience (QoMEX), Cagliari, Italy, 29 May–1 June 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Raake, A.; Garcia, M.N.; Robitza, W.; List, P.; Göring, S.; Feiten, B. A bitstream-based, scalable video-quality model for HTTP adaptive streaming: ITU-T P.1203.1. In Proceedings of the QoMEX, Erfurt, Germany, 31 May–2 June 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–6. [Google Scholar]
- Satti, S.; Schmidmer, C.; Obermann, M.; Bitto, R.; Agarwal, L.; Keyhl, M. P.1203 evaluation of real OTT video services. In Proceedings of the 2017 Ninth International Conference on Quality of Multimedia Experience (QoMEX), Erfurt, Germany, 31 May–2 June 2017; pp. 1–3. [Google Scholar] [CrossRef]
- Ramachandra Rao, R.R.; Göring, S.; Vogel, P.; Pachatz, N.; Jose, J.; Villarreal, V.; Robitza, W.; List, P.; Feiten, B.; Raake, A. Adaptive video streaming with current codecs and formats: Extensions to parametric video quality model ITU-T P.1203. EI 2019, 31, 314-1–314-7. [Google Scholar] [CrossRef]
- Barman, N.; Martini, M.G. QoE modeling for HTTP adaptive video streaming–a survey and open challenges. IEEE Access 2019, 7, 30831–30859. [Google Scholar] [CrossRef]
- Izima, O.; de Fréin, R.; Malik, A. A Survey of Machine Learning Techniques for Video Quality Prediction from Quality of Delivery Metrics. Electronics 2021, 10, 2851. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Liu, F.; Yang, W.; Peng, S.; Zhou, J. A Survey of Convolutional Neural Networks: Analysis, Applications, and Prospects. IEEE Trans. Neural Netw. Learn. Syst. 2021, 12, 6999–7019. [Google Scholar] [CrossRef]
- Bosse, S.; Maniry, D.; Müller, K.R.; Wiegand, T.; Samek, W. Deep Neural Networks for No-Reference and Full-Reference Image Quality Assessment. IEEE Trans. Image Process. 2018, 27, 206–219. [Google Scholar] [CrossRef]
- Kim, J.; Zeng, H.; Ghadiyaram, D.; Lee, S.; Zhang, L.; Bovik, A.C. Deep Convolutional Neural Models for Picture-Quality Prediction: Challenges and Solutions to Data-Driven Image Quality Assessment. IEEE Signal Process. Mag. 2017, 34, 130–141. [Google Scholar] [CrossRef]
- Tao, X.; Duan, Y.; Xu, M.; Meng, Z.; Lu, J. Learning QoE of Mobile Video Transmission With Deep Neural Network: A Data-Driven Approach. IEEE J. Sel. Areas Commun. 2019, 37, 1337–1348. [Google Scholar] [CrossRef]
- Chen, B.; Zhu, L.; Li, G.; Fan, H.; Wang, S. Learning Generalized Spatial-Temporal Deep Feature Representation for No-Reference Video Quality Assessment. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 1903–1916. [Google Scholar] [CrossRef]
- Zhang, H.; Dong, L.; Gao, G.; Hu, H.; Wen, Y.; Guan, K. DeepQoE: A Multimodal Learning Framework for Video Quality of Experience (QoE) Prediction. IEEE Trans. Multimed. 2020, 22, 3210–3223. [Google Scholar] [CrossRef]
- Tran, H.T.T.; Nguyen, D.; Thang, T.C. An Open Software for Bitstream-Based Quality Prediction in Adaptive Video Streaming. In Proceedings of the MMSys’20, 11th ACM Multimedia Systems Conference, Istanbul, Turkey, 8–11 June 2020; pp. 225–230. [Google Scholar] [CrossRef]
- Eswara, N.; Ashique, S.; Panchbhai, A.; Chakraborty, S.; Sethuram, H.P.; Kuchi, K.; Kumar, A.; Channappayya, S.S. Streaming Video QoE Modeling and Prediction: A Long Short-Term Memory Approach. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 661–673. [Google Scholar] [CrossRef]
- Gadaleta, M.; Chiariotti, F.; Rossi, M.; Zanella, A. D-DASH: A Deep Q-Learning Framework for DASH Video Streaming. IEEE Trans. Cogn. Commun. Netw. 2017, 3, 703–718. [Google Scholar] [CrossRef]
- Zhu, H.; Li, L.; Wu, J.; Dong, W.; Shi, G. MetaIQA: Deep Meta-Learning for No-Reference Image Quality Assessment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Sun, S.; Yu, T.; Xu, J.; Lin, J.; Zhou, W.; Chen, Z. GraphIQA: Learning Distortion Graph Representations for Blind Image Quality Assessment. IEEE Trans. Multimed. 2022. [Google Scholar] [CrossRef]
- Liu, J.; Zhou, W.; Li, X.; Xu, J.; Chen, Z. LIQA: Lifelong Blind Image Quality Assessment. IEEE Trans. Multimed. 2022, 1–16. [Google Scholar] [CrossRef]
- Pessemier, T.D.; Moor, K.D.; Joseph, W.; Marez, L.D.; Martens, L. Quantifying the Influence of Rebuffering Interruptions on the User’s Quality of Experience During Mobile Video Watching. IEEE Trans. Broadcast. 2013, 59, 47–61. [Google Scholar] [CrossRef]
- Ying, Z.; Mandal, M.; Ghadiyaram, D.; of Texas at Austin, A.B.U.; Facebook, A. Patch-VQ: ‘Patching Up’ the Video Quality Problem. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 14014–14024. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NA, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Shafiq, M.; Gu, Z. Deep Residual Learning for Image Recognition: A Survey. Appl. Sci. 2022, 12, 8972. [Google Scholar] [CrossRef]
- Bharati, P.; Pramanik, A. Deep Learning Techniques—R-CNN to Mask R-CNN: A Survey. In Proceedings of the 2019 Computational Intelligence in Pattern Recognition (CIPR); Springer: Singapore, 2020; pp. 657–668. [Google Scholar]
- Saleem, M.A.; Senan, N.; Wahid, F.; Aamir, M.; Samad, A.; Khan, M. Comparative Analysis of Recent Architecture of Convolutional Neural Network. Math. Probl. Eng. 2022, 2022, 7313612. [Google Scholar] [CrossRef]
- Tsagkatakis, G.; Aidini, A.; Fotiadou, K.; Giannopoulos, M.; Pentari, A.; Tsakalides, P. Survey of Deep-Learning Approaches for Remote Sensing Observation Enhancement. Sensors 2019, 19, 3929. [Google Scholar] [CrossRef]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, G.; Cai, J.; et al. Recent advances in convolutional neural networks. Pattern Recognit. 2018, 77, 354–377. [Google Scholar] [CrossRef]
- Romano, A.M.; Hernandez, A.A. Enhanced Deep Learning Approach for Predicting Invasive Ductal Carcinoma from Histopathology Images. In Proceedings of the 2019 2nd International Conference on Artificial Intelligence and Big Data (ICAIBD), Chengdu, China, 25–28 May 2019; pp. 142–148. [Google Scholar]
- Sakr, G.E.; Mokbel, M.; Darwich, A.; Khneisser, M.N.; Hadi, A. Comparing deep learning and support vector machines for autonomous waste sorting. In Proceedings of the 2016 IEEE International Multidisciplinary Conference on Engineering Technology (IMCET), Beirut, Lebanon, 14–16 November 2016; pp. 207–212. [Google Scholar]
- Hara, K.; Kataoka, H.; Satoh, Y. Learning Spatio-Temporal Features with 3D Residual Networks for Action Recognition. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshops (ICCVW), Venice, Italy, 22–29 October 2017; pp. 3154–3160. [Google Scholar]
- Kay, W.; Carreira, J.; Simonyan, K.; Zhang, B.; Hillier, C.; Vijayanarasimhan, S.; Viola, F.; Green, T.; Back, T.; Natsev, P.; et al. The Kinetics Human Action Video Dataset. arXiv 2017, arXiv:1705.06950. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the NIPS’15: 28th International Conference on Neural Information Processing Systems—Volume 1, Cambridge, MA, USA, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Ying, Z.; Niu, H.; Gupta, P.; Mahajan, D.; Ghadiyaram, D.; Bovik, A. From Patches to Pictures (PaQ-2-PiQ): Mapping the Perceptual Space of Picture Quality. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Advances in Neural Information Processing Systems; Cortes, C., Lawrence, N., Lee, D., Sugiyama, M., Garnett, R., Eds.; Curran Associates, Inc.: New York, NY, USA, 2015; Volume 28. [Google Scholar]
- Chao, Y.W.; Vijayanarasimhan, S.; Seybold, B.; Ross, D.A.; Deng, J.; Sukthankar, R. Rethinking the Faster R-CNN Architecture for Temporal Action Localization. In Proceedings of theIEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Ismail Fawaz, H.; Lucas, B.; Forestier, G.; Pelletier, C.; Schmidt, D.F.; Weber, J.; Webb, G.I.; Idoumghar, L.; Muller, P.A.; Petitjean, F. InceptionTime: Finding AlexNet for time series classification. Data Min. Knowl. Discov. 2020, 34, 1936–1962. [Google Scholar] [CrossRef]
- Bampis, C.G.; Li, Z.; Katsavounidis, I.; Huang, T.Y.; Ekanadham, C.; Bovik, A.C. Towards perceptually optimized adaptive video streaming-a realistic quality of experience database. IEEE Trans. Image Process. 2021, 30, 5182–5197. [Google Scholar] [CrossRef] [PubMed]
- Duanmu, Z.; Rehman, A.; Wang, Z. A Quality-of-Experience Database for Adaptive Video Streaming. IEEE Trans. Broadcast. 2018, 64, 474–487. [Google Scholar] [CrossRef]
- Bampis, C.G.; Li, Z.; Moorthy, A.K.; Katsavounidis, I.; Aaron, A.; Bovik, A.C. Study of Temporal Effects on Subjective Video Quality of Experience. IEEE Trans. Image Process. 2017, 26, 5217–5231. [Google Scholar] [CrossRef] [PubMed]
- Bampis, C.; Li, Z.; Moorthy, A.; Katsavounidis, I.; Aaron, A.; Bovik, A. Live Netflix Video Quality of Experience Database. 2016. Available online: https://live.ece.utexas.edu/research/LIVE_NFLXStudy/nflx_index.html (accessed on 11 October 2022).
- Sinno, Z.; Bovik, A.C. Large-Scale Study of Perceptual Video Quality. IEEE Trans. Image Process. 2019, 28, 612–627. [Google Scholar] [CrossRef]
- Riiser, H.; Endestad, T.; Vigmostad, P.; Griwodz, C.; Halvorsen, P. Video Streaming Using a Location-Based Bandwidth-Lookup Service for Bitrate Planning. ACM Trans. Multimed. Comput. Commun. Appl. 2012, 8, 1–19. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mode 0 | Mode 1 | Mode 2 * | Mode 3 * |
|---|---|---|---|
| (metadata only): bitrate, frame rate and resolution | (frame header data only): all of mode 0 plus frame types and sizes | (bitstream data, 2%): all of mode 1 plus 2% of the QP values of all frames | (bitstream data, 100 %): all of mode 1 plus QP values of all frames |
| Cycle ID | Test LCC | Test SRCC | Test Loss |
|---|---|---|---|
| 1 | 0.90 | 0.91 | 5.84 |
| 2 | 0.90 | 0.89 | 6.62 |
| 3 | 0.85 | 0.84 | 7.47 |
| 4 | 0.94 | 0.93 | 4.61 |
| 5 | 0.54 | 0.55 | 13.38 |
| 6 | 0.72 | 0.71 | 12.65 |
| 7 | 0.75 | 0.75 | 9.59 |
| 8 | 0.90 | 0.90 | 9.13 |
| 9 | 0.70 | 0.70 | 11.0 |
| 10 | 0.78 | 0.76 | 10.37 |
| 11 | 0.80 | 0.77 | 11.60 |
| 12 | 0.65 | 0.65 | 12.10 |
| Test LCC | Test SRCC | Test Loss |
|---|---|---|
| 0.11 | 0.11 | 1.75 |
| Test LCC | Test SRCC | Test Loss |
|---|---|---|
| 0.77 | 0.76 | 10.84 |
| P.1203 m = 0 | P.1203 m = 1 | P.1203 m = 2,3 | PatchVQ | Proposed Model * | |
|---|---|---|---|---|---|
| LCC | 0.55 | 0.46 | 0.75 | 0.42 | 0.77 |
| SRCC | 0.51 | 0.49 | 0.76 | 0.40 | 0.76 |
| Loss | 46.24 | 34.97 | 15.44 | 23.45 | 10.84 |
| Network Parameters | Network Parameters and Visual Information | |
|---|---|---|
| LCC | 0.77 | 0.77 |
| SRCC | 0.77 | 0.77 |
| Loss | 15.88 | 10.84 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Margetis, G.; Tsagkatakis, G.; Stamou, S.; Stephanidis, C. Integrating Visual and Network Data with Deep Learning for Streaming Video Quality Assessment. Sensors 2023, 23, 3998. https://doi.org/10.3390/s23083998
Margetis G, Tsagkatakis G, Stamou S, Stephanidis C. Integrating Visual and Network Data with Deep Learning for Streaming Video Quality Assessment. Sensors. 2023; 23(8):3998. https://doi.org/10.3390/s23083998
Chicago/Turabian StyleMargetis, George, Grigorios Tsagkatakis, Stefania Stamou, and Constantine Stephanidis. 2023. "Integrating Visual and Network Data with Deep Learning for Streaming Video Quality Assessment" Sensors 23, no. 8: 3998. https://doi.org/10.3390/s23083998
APA StyleMargetis, G., Tsagkatakis, G., Stamou, S., & Stephanidis, C. (2023). Integrating Visual and Network Data with Deep Learning for Streaming Video Quality Assessment. Sensors, 23(8), 3998. https://doi.org/10.3390/s23083998