
Development and Validation of an Explainable Machine Learning-Based Prediction Model for Drug–Food Interactions from Chemical Structures


 ,
, 

Abstract
1. Introduction
2. Materials and Methods
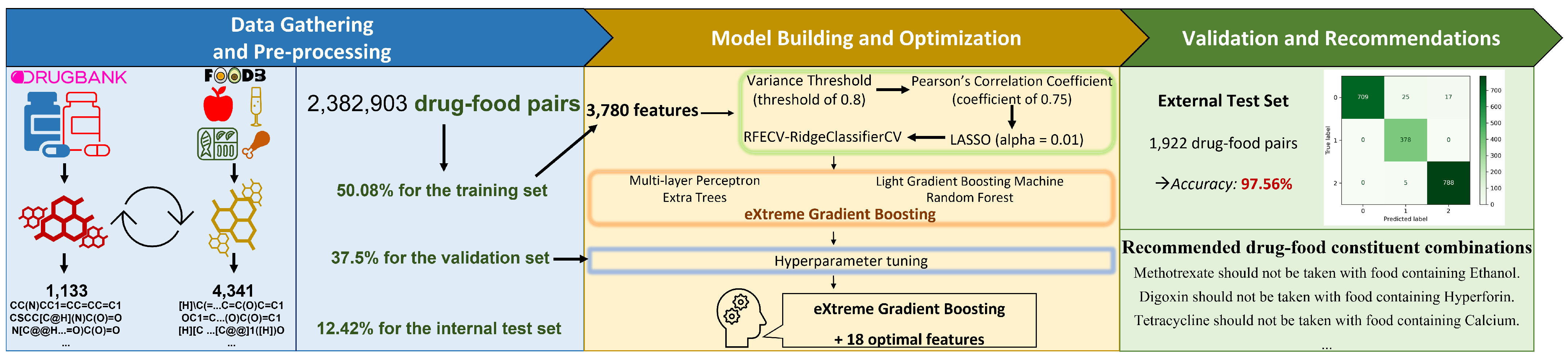
2.1. Data Gathering and Pre-Processing
2.1.1. Data Gathering
2.1.2. Data Pre-Processing
2.1.3. Labeling of DFIs Ground Truth
- Positive interactions (Class 1): (1) if two of the following conditions are met simultaneously. (a) If a drug compound in combination with a food compound, and the food compound increases the extent of absorption, increases bioavailability, increases peak concentrations, and decreases time to peak concentrations of the drug; (b) no adverse effect or toxicity for human health has been observed from DrugBank annotations. (2) If the DrugBank annotations indicate that when the drug compound is taken with the food compound, the food compound will benefit the patient (e.g., food reduces irritation, take with food to reduce nausea, food decreases the risk of gastrointestinal side effects, etc.) despite not specifying the interaction information in terms of pharmacokinetics, the pharmacodynamics of the drug. (3) If DrugBank annotations indicate “take after meals”, “take after a meal”, or “take with food” although they do not specify the information on pharmacokinetics, pharmacodynamics, or patient benefits when taking that drug with food compounds.
- Negative interactions (Class 0): (1) if two of the following conditions are met simultaneously. (a) If the drug is taken with food, but food reduces the extent of absorption, reduces bioavailability, decreases peak concentrations, and increases time to peak concentrations of the drug; (b) at least one adverse effect or toxicity for human health has been described from DrugBank annotations. (2) If the DrugBank annotations indicate that when the drug compound is taken with the food compound, the food compound will cause harm to the patient regardless of the interaction information in terms of pharmacokinetics and the pharmacodynamics of the drug. If DrugBank annotations contain the words “avoid”, “Take separately from meals”, “take on an empty stomach” or “take before a meal” regardless of the information on pharmacokinetics, pharmacodynamics, or benefits when taking that drug with food compounds.
- Non-significant interactions (Class 2): (1) if DrugBank annotations do not fall into the above two categories. (2) If DrugBank annotations state “take with or without food”, “take consistently with regard to food” regardless of pharmacokinetic or pharmacodynamic interaction information.
2.2. Model Building and Optimization
2.2.1. Feature Extraction
2.2.2. Feature Selection
2.3. Model Training
2.4. Validation and Recommendations
2.5. Evaluation Metrics
3. Results
3.1. 4341 Food Compounds and 1133 Drug Compounds from DrugBank and FooDB
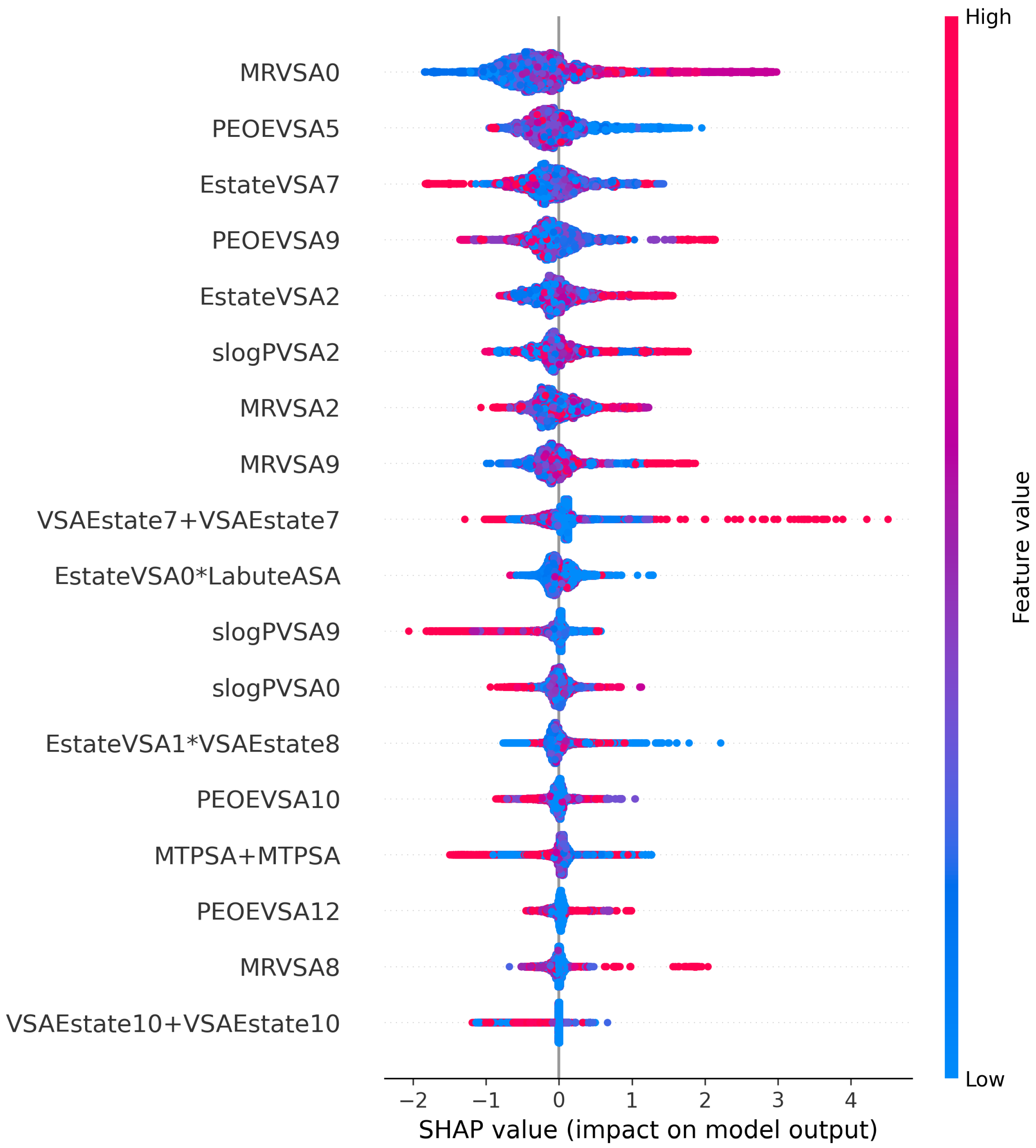
3.2. 18 Selected Features Can Improve the Prediction
3.3. Performance Improvement Via Hyper-Parameter Tuning
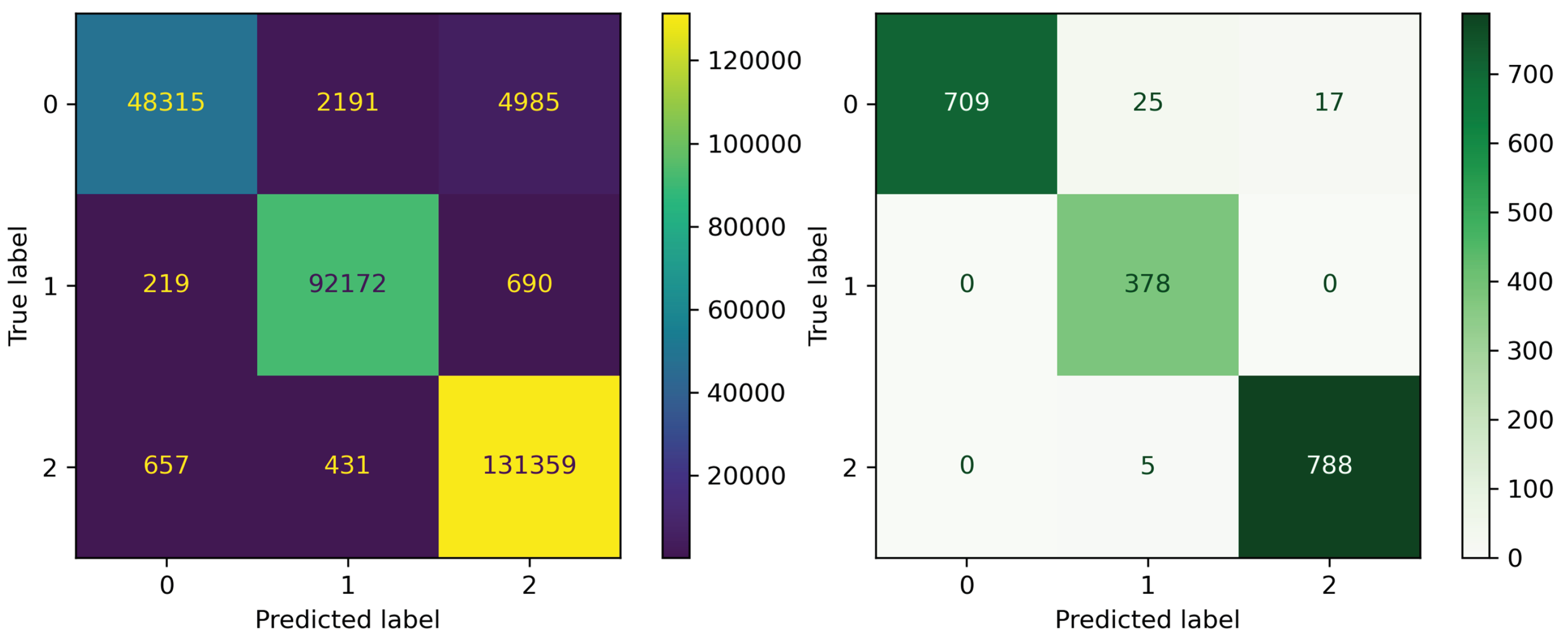
3.4. Evaluating the Performance Results of the Final Models on External Test Set
3.5. Interpretation of Eighteen Optimal Features
3.6. The Interpretation of our Model to Clinical Physicians, Pharmacists, and Patients
4. Discussions
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bushra, R.; Aslam, N.; Khan, A.Y. Food-drug interactions. Oman Med. J. 2011, 26, 77. [Google Scholar] [CrossRef] [PubMed]
- Edwards, I.R.; Aronson, J.K. Adverse drug reactions: Definitions, diagnosis, and management. Lancet 2000, 356, 1255–1259. [Google Scholar] [CrossRef] [PubMed]
- Kantor, E.D.; Rehm, C.D.; Haas, J.S.; Chan, A.T.; Giovannucci, E.L. Trends in prescription drug use among adults in the United States from 1999–2012. JAMA 2015, 314, 1818–1830. [Google Scholar] [CrossRef]
- Sutherland, J.J.; Daly, T.M.; Liu, X.; Goldstein, K.; Johnston, J.A.; Ryan, T.P. Co-prescription trends in a large cohort of subjects predict substantial drug-drug interactions. PLoS ONE 2015, 10, e0118991. [Google Scholar] [CrossRef] [PubMed]
- Ryu, J.Y.; Kim, H.U.; Lee, S.Y. Deep learning improves prediction of drug–drug and drug–food interactions. Proc. Natl. Acad. Sci. USA 2018, 115, E4304–E4311. [Google Scholar] [CrossRef]
- Huang, S.M.; Lesko, L.J. Drug-Drug, Drug—Dietary Supplement, and Drug—Citrus Fruit and Other Food Interactions: What Have We Learned? J. Clin. Pharmacol. 2004, 44, 559–569. [Google Scholar] [CrossRef]
- Onakpoya, I.J.; Heneghan, C.J.; Aronson, J.K. Post-marketing withdrawal of 462 medicinal products because of adverse drug reactions: A systematic review of the world literature. BMC Med. 2016, 14, 10. [Google Scholar] [CrossRef]
- Nassar, A.; Talaat, R.E.; Tokuno, H. Drug interactions: Concerns and current approaches. IDrugs Investig. Drugs J. 2007, 10, 47–52. [Google Scholar]
- Fuhr, U.; Kummert, A.L. The fate of naringin in humans: A key to grapefruit juice-drug interactions? Clin. Pharmacol. Ther. 1995, 58, 365–373. [Google Scholar] [CrossRef]
- Bailey, D.D.G.; Dresser, G.K. Interactions between grapefruit juice and cardiovascular drugs. Am. J. Cardiovasc. Drugs 2004, 4, 281–297. [Google Scholar] [CrossRef]
- Tan, C.S.S.; Lee, S.W.H. Warfarin and food, herbal or dietary supplement interactions: A systematic review. Br. J. Clin. Pharmacol. 2021, 87, 352–374. [Google Scholar] [CrossRef] [PubMed]
- Holbrook, A.M.; Pereira, J.A.; Labiris, R.; McDonald, H.; Douketis, J.D.; Crowther, M.; Wells, P.S. Systematic overview of warfarin and its drug and food interactions. Arch. Intern. Med. 2005, 165, 1095–1106. [Google Scholar] [CrossRef] [PubMed]
- Pedersen, F.; Hamberg, O.; Hess, K.; Ovesen, L. The effect of dietary vitamin K on warfarin-induced anticoagulation. J. Intern. Med. 1991, 229, 517–520. [Google Scholar] [CrossRef] [PubMed]
- Humphreys, J.H.; Warner, A.; Costello, R.; Lunt, M.; Verstappen, S.M.; Dixon, W.G. Quantifying the hepatotoxic risk of alcohol consumption in patients with rheumatoid arthritis taking methotrexate. Ann. Rheum. Dis. 2017, 76, 1509–1514. [Google Scholar] [CrossRef]
- McClain, C.J.; Kromhout, J.P.; Peterson, F.J.; Holtzman, J.L. Potentiation of acetaminophen hepatotoxicity by alcohol. JAMA 1980, 244, 251–253. [Google Scholar] [CrossRef]
- Price, S.; James, C.; Deighton, C. Methotrexate use and alcohol. Clin. Exp. Rheumatol.-Incl Suppl. 2010, 28, S114. [Google Scholar]
- Koski, A.; Ojanperä, I.; Vuori, E. Interaction of alcohol and drugs in fatal poisonings. Hum. Exp. Toxicol. 2003, 22, 281–287. [Google Scholar] [CrossRef]
- Koski, A.; Ojanperä, I.; Vuori, E. Alcohol and benzodiazepines in fatal poisonings. Alcohol. Clin. Exp. Res. 2002, 26, 956–959. [Google Scholar] [CrossRef]
- Zimmerman, H.J.; Maddrey, W.C. Acetaminophen (paracetamol) hepatotoxicity with regular intake of alcohol: Analysis of instances of therapeutic misadventure. Hepatology 1995, 22, 767–773. [Google Scholar] [CrossRef]
- Choi, J.H.; Ko, C.M. Food and drug interactions. J. Lifestyle Med. 2017, 7, 9. [Google Scholar] [CrossRef]
- Karagiannis, D.; Mitsis, K.; Nikita, K.S. Development of a Low-Power IoMT Portable Pillbox for Medication Adherence Improvement and Remote Treatment Adjustment. Sensors 2022, 22, 5818. [Google Scholar] [CrossRef] [PubMed]
- Cheng, F.; Zhao, Z. Machine learning-based prediction of drug–drug interactions by integrating drug phenotypic, therapeutic, chemical, and genomic properties. J. Am. Med. Inform. Assoc. 2014, 21, e278–e286. [Google Scholar] [CrossRef] [PubMed]
- Akamine, D.; Michel Filho, K.; Peres, C.M. Drug–nutrient interactions in elderly people. Curr. Opin. Clin. Nutr. Metab. Care 2007, 10, 304–310. [Google Scholar] [CrossRef] [PubMed]
- Mason, P. Important drug–nutrient interactions. Proc. Nutr. Soc. 2010, 69, 551–557. [Google Scholar] [CrossRef]
- Mallet, L.; Spinewine, A.; Huang, A. The challenge of managing drug interactions in elderly people. Lancet 2007, 370, 185–191. [Google Scholar] [CrossRef]
- Chan, L.N. Drug-nutrient interactions. J. Parenter. Enter. Nutr. 2013, 37, 450–459. [Google Scholar] [CrossRef]
- Jensen, K.; Ni, Y.; Panagiotou, G.; Kouskoumvekaki, I. Developing a molecular roadmap of drug-food interactions. PLoS Comput. Biol. 2015, 11, e1004048. [Google Scholar] [CrossRef]
- Riedmaier, A.E.; DeMent, K.; Huckle, J.; Bransford, P.; Stillhart, C.; Lloyd, R.; Alluri, R.; Basu, S.; Chen, Y.; Dhamankar, V.; et al. Use of physiologically based pharmacokinetic (PBPK) modeling for predicting drug-food interactions: An industry perspective. AAPS J. 2020, 22, 15. [Google Scholar] [CrossRef]
- Sugano, K.; Kataoka, M.; da Costa Mathews, C.; Yamashita, S. Prediction of food effect by bile micelles on oral drug absorption considering free fraction in intestinal fluid. Eur. J. Pharm. Sci. 2010, 40, 118–124. [Google Scholar] [CrossRef]
- Gu, C.H.; Li, H.; Levons, J.; Lentz, K.; Gandhi, R.B.; Raghavan, K.; Smith, R.L. Predicting effect of food on extent of drug absorption based on physicochemical properties. Pharm. Res. 2007, 24, 1118–1130. [Google Scholar] [CrossRef]
- Mathias, N.; Xu, Y.; Vig, B.; Kestur, U.; Saari, A.; Crison, J.; Desai, D.; Vanarase, A.; Hussain, M. Food effect in humans: Predicting the risk through in vitro dissolution and in vivo pharmacokinetic models. AAPS J. 2015, 17, 988–998. [Google Scholar] [CrossRef] [PubMed]
- Christiansen, M.L.; Müllertz, A.; Garmer, M.; Kristensen, J.; Jacobsen, J.; Abrahamsson, B.; Holm, R. Evaluation of the use of Göttingen minipigs to predict food effects on the oral absorption of drugs in humans. J. Pharm. Sci. 2015, 104, 135–143. [Google Scholar] [CrossRef] [PubMed]
- Kondo, H.; Shinoda, T.; Nakashima, H.; Watanabe, T.; Yokohama, S. Characteristics of the gastric pH profiles of unfed and fed cynomolgus monkeys as pharmaceutical product development subjects. Biopharm. Drug Dispos. 2003, 24, 45–51. [Google Scholar] [CrossRef] [PubMed]
- Qin, C.; Li, Y.; Zhang, Y.; Liu, L.; Wu, Z.; Weng, P. Insights into oat polyphenols constituent against advanced glycation end products mechanism by spectroscopy and molecular interaction. Food Biosci. 2021, 43, 101313. [Google Scholar] [CrossRef]
- Vamathevan, J.; Clark, D.; Czodrowski, P.; Dunham, I.; Ferran, E.; Lee, G.; Li, B.; Madabhushi, A.; Shah, P.; Spitzer, M.; et al. Applications of machine learning in drug discovery and development. Nat. Rev. Drug Discov. 2019, 18, 463–477. [Google Scholar] [CrossRef]
- Segura-Bedmar, I.; Martinez, P.; de Pablo-Sánchez, C. Using a shallow linguistic kernel for drug–drug interaction extraction. J. Biomed. Inform. 2011, 44, 789–804. [Google Scholar] [CrossRef]
- Vo, T.H.; Nguyen, N.T.K.; Le, N.Q.K. Improved prediction of drug-drug interactions using ensemble deep neural networks. Med. Drug Discov. 2023, 17, 100149. [Google Scholar] [CrossRef]
- Rahman, M.M.; Vadrev, S.M.; Magana-Mora, A.; Levman, J.; Soufan, O. A novel graph mining approach to predict and evaluate food-drug interactions. Sci. Rep. 2022, 12, 1061. [Google Scholar] [CrossRef]
- Wishart, D.S.; Knox, C.; Guo, A.C.; Shrivastava, S.; Hassanali, M.; Stothard, P.; Chang, Z.; Woolsey, J. DrugBank: A comprehensive resource for in silico drug discovery and exploration. Nucleic Acids Res. 2006, 34, D668–D672. [Google Scholar] [CrossRef]
- Schwartz, J.; Awale, M.; Reymond, J.L. SMIfp (SMILES fingerprint) chemical space for virtual screening and visualization of large databases of organic molecules. J. Chem. Inf. Model. 2013, 53, 1979–1989. [Google Scholar] [CrossRef]
- Vilar, S.; Harpaz, R.; Uriarte, E.; Santana, L.; Rabadan, R.; Friedman, C. Drug—Drug interaction through molecular structure similarity analysis. J. Am. Med. Inform. Assoc. 2012, 19, 1066–1074. [Google Scholar] [CrossRef] [PubMed]
- Vilar, S.; Uriarte, E.; Santana, L.; Lorberbaum, T.; Hripcsak, G.; Friedman, C.; Tatonetti, N.P. Similarity-based modeling in large-scale prediction of drug-drug interactions. Nat. Protoc. 2014, 9, 2147–2163. [Google Scholar] [CrossRef] [PubMed]
- Dong, J.; Yao, Z.J.; Zhang, L.; Luo, F.; Lin, Q.; Lu, A.P.; Chen, A.F.; Cao, D.S. PyBioMed: A python library for various molecular representations of chemicals, proteins and DNAs and their interactions. J. Cheminformatics 2018, 10, 11. [Google Scholar] [CrossRef] [PubMed]
- Landrum, G. RDKit: A software suite for cheminformatics, computational chemistry, and predictive modeling. Greg Landrum 2013, 8, 31. [Google Scholar]
- Ertl, P.; Rohde, B.; Selzer, P. Fast calculation of molecular polar surface area as a sum of fragment-based contributions and its application to the prediction of drug transport properties. J. Med. Chem. 2000, 43, 3714–3717. [Google Scholar] [CrossRef]
- Gasteiger, J.; Marsili, M. Iterative partial equalization of orbital electronegativity—A rapid access to atomic charges. Tetrahedron 1980, 36, 3219–3228. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B Methodol. 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Tsai, C.Y.; Huang, H.T.; Cheng, H.C.; Wang, J.; Duh, P.J.; Hsu, W.H.; Stettler, M.; Kuan, Y.C.; Lin, Y.T.; Hsu, C.R.; et al. Screening for Obstructive Sleep Apnea Risk by Using Machine Learning Approaches and Anthropometric Features. Sensors 2022, 22, 8630. [Google Scholar] [CrossRef]
- Le, N.Q.K.; Do, D.T.; Hung, T.N.K.; Lam, L.H.T.; Huynh, T.T.; Nguyen, N.T.K. A computational framework based on ensemble deep neural networks for essential genes identification. Int. J. Mol. Sci. 2020, 21, 9070. [Google Scholar] [CrossRef]
- Chen, M.; Yang, X.; Lai, X.; Kang, J.; Gan, H.; Gao, Y. Structural Investigation for optimization of anthranilic acid derivatives as partial FXR agonists by in silico approaches. Int. J. Mol. Sci. 2016, 17, 536. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. In Advances in Neural Information Processing Systems 30, Proceedings of the Annual Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Curran Associates, Inc.: Red Hook, NY, USA, 2018; Volume 30. [Google Scholar]
- Neuvonen, P. Interactions with the absorption of tetracyclines. Drugs 1976, 11, 45–54. [Google Scholar] [CrossRef] [PubMed]
- Kuang, Y.; Jia, H.; Miyanaga, K.; Tanji, Y. Effect of milk on antibacterial activity of tetracycline against Escherichia coli and Staphylococcus aureus isolated from bovine mastitis. Appl. Microbiol. Biotechnol. 2009, 84, 135–142. [Google Scholar] [CrossRef]
- Whiting-O’Keefe, Q.E.; Fye, K.H.; Sack, K.D. Methotrexate and histologic hepatic abnormalities: A meta-analysis. Am. J. Med. 1991, 90, 711–716. [Google Scholar] [CrossRef] [PubMed]
- Malatjalian, D.; Ross, J.; Williams, C.; Colwell, S.; Eastwood, B. Methotrexate hepatotoxicity in psoriatics: Report of 104 patients from Nova Scotia, with analysis of risks from obesity, diabetes and alcohol consumption during long term follow-up. Can. J. Gastroenterol. 1996, 10, 369–375. [Google Scholar] [CrossRef] [PubMed]
- Weathermon, R.; Crabb, D.W. Alcohol and medication interactions. Alcohol Res. Health 1999, 23, 40. [Google Scholar]
- Johne, A.; Brockmöller, J.; Bauer, S.; Maurer, A.; Langheinrich, M.; Roots, I. Pharmacokinetic interaction of digoxin with an herbal extract from St John’s wort (Hypericum perforatum). Clin. Pharmacol. Ther. 1999, 66, 338–345. [Google Scholar] [CrossRef]
- Paine, M.F.; Criss, A.B.; Watkins, P.B. Two major grapefruit juice components differ in intestinal CYP3A4 inhibition kinetic and binding properties. Drug Metab. Dispos. 2004, 32, 1146–1153. [Google Scholar] [CrossRef]
- Takanaga, H.; Ohnishi, A.; Murakami, H.; Matsuo, H.; Higuchi, S.; Urae, A.; Irie, S.; Furuie, H.; Matsukuma, K.; Kimura, M.; et al. Relationship between time after intake of grapefruit juice and the effect on pharmacokinetics and pharmacodynamics of nisoldipine in healthy subjects. Clin. Pharmacol. Ther. 2000, 67, 201–214. [Google Scholar] [CrossRef]
- Kupferschmidt, H.H.; Ha, H.R.; Ziegler, W.H.; Meier, P.J.; Krähenbühl, S. Interaction between grapefruit juice and midazolam in humans. Clin. Pharmacol. Ther. 1995, 58, 20–28. [Google Scholar] [CrossRef]
- Goho, C. Oral midazolam-grapefruit juice drug interaction. Pediatr. Dent. 2001, 23, 365. [Google Scholar]
- Johnson, M.A. Influence of vitamin K on anticoagulant therapy depends on vitamin K status and the source and chemical forms of vitamin K. Nutr. Rev. 2005, 63, 91–97. [Google Scholar] [CrossRef] [PubMed]
- Milić, N.; Milošević, N.; Kon, S.G.; Božić, T.; Abenavoli, L.; Borrelli, F. Warfarin interactions with medicinal herbs. Nat. Prod. Commun. 2014, 9, 1934578X1400900835. [Google Scholar] [CrossRef]
- Hu, Z.; Yang, X.; Ho, P.C.L.; Chan, S.Y.; Heng, P.W.S.; Chan, E.; Duan, W.; Koh, H.L.; Zhou, S. Herb-drug interactions: A literature review. Drugs 2005, 65, 1239–1282. [Google Scholar] [CrossRef] [PubMed]
- Otles, S.; Senturk, A. Food and drug interactions: A general review. Acta Sci. Pol. Technol. Aliment. 2014, 13, 89–102. [Google Scholar] [CrossRef] [PubMed]
- Devan, P.; Khare, N. An efficient XGBoost–DNN-based classification model for network intrusion detection system. Neural Comput. Appl. 2020, 32, 12499–12514. [Google Scholar] [CrossRef]
- Lin, S.; Zhang, G.; Wei, D.Q.; Xiong, Y. DeepPSE: Prediction of polypharmacy side effects by fusing deep representation of drug pairs and attention mechanism. Comput. Biol. Med. 2022, 149, 105984. [Google Scholar] [CrossRef] [PubMed]
- Lin, S.; Wang, Y.; Zhang, L.; Chu, Y.; Liu, Y.; Fang, Y.; Jiang, M.; Wang, Q.; Zhao, B.; Xiong, Y.; et al. MDF-SA-DDI: Predicting drug–drug interaction events based on multi-source drug fusion, multi-source feature fusion and transformer self-attention mechanism. Briefings Bioinform. 2022, 23, bbab421. [Google Scholar] [CrossRef]
- Le, N.Q.K. Potential of deep representative learning features to interpret the sequence information in proteomics. Proteomics 2021, 22, e2100232. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Classifier | Accuracy | STD |
|---|---|---|
| XGBoost | 0.9675 | 0.0005 |
| LGBM | 0.9671 | 0.0004 |
| RF | 0.9651 | 0.0002 |
| ET | 0.9589 | 0.0004 |
| MLP | 0.9561 | 0.0050 |
| Parameter | Default Setting | Hyper-Tuned Values | Optimal Value |
|---|---|---|---|
| n_estimators | 100 | [50, 100, 150, 200] | 150 |
| max_depth | 6 | [3, 4, 5, 6, 8, 10, 12, 15] | 6 |
| gamma | 0 | [0.0, 0.1, 0.2, 0.3, 0.4] | 0.4 |
| colsample_bytree | 1 | [0.3, 0.4, 0.5, 0.7] | 0.3 |
| min_child_weight | 1 | [1, 3, 5, 7] | 5 |
| learning_rate | 0.1 | [0.05, 0.1, 0.15, 0.2, 0.25, 0.3] | 0.2 |
| Algorithms | Before Tuning | After Tuning |
|---|---|---|
| XGBoost | 0.9673 | 0.9677 |
| MLP | 0.9589 | 0.9623 |
| LGBM | 0.9671 | 0.9673 |
| ET | 0.9586 | 0.9611 |
| RF | 0.9651 | 0.9662 |
| Types of DFIs | Internal Test | External Test | ||||||
|---|---|---|---|---|---|---|---|---|
| Accuracy | Recall | Precision | F1-Score | Accuracy | Recall | Precision | F1-Score | |
| Negative DFIs | 0.9714 | 0.8707 | 0.9822 | 0.9231 | 0.9781 | 0.9441 | 1.0 | 0.9712 |
| Positive DFIs | 0.9874 | 0.9902 | 0.9723 | 0.9811 | 0.9844 | 1.0 | 0.9265 | 0.9618 |
| Non-significant DFIs | 0.9759 | 0.9918 | 0.9586 | 0.9749 | 0.9886 | 0.9937 | 0.9789 | 0.9862 |
| Drug–Food Compound | Adverse Effect(s) | Model’s Recommendation | References |
|---|---|---|---|
| Tetracycline + Calcium | Calcium reduces the absorption rate of Tetracycline. | Tetracycline should not be taken with food containing Calcium. | Neuvonen et al. [52], Kuang et al. [53] |
| Methotrexate + Ethanol | Ethanol increases the risk for liver damage while taking Methotrexate. | Methotrexate should not be taken with food containing Ethanol. | Whiting-O’Keefe et al. [54], Price et al. [16], Malatjalian et al. [55], Humphreys et al. [14] |
| Diazepam + Ethanol | Ethanol may increase the central nervous depressant effect of diazepam, leading to dizziness, nausea, lost of consciousness, even coma, or death. | Diazepam should not be taken with food containing Ethanol. | Koski et al. [17,18] |
| Nitroglycerin + Ethanol | Drinking alcohol while taking this medication increases the risk for dangerously low blood pressure and Disulfiram-Like Reactions. | Nitroglycerin should not be taken with food containing Ethanol. | Weathermon et al. [56] |
| Digoxin + Hyperforin | St. John’s wort may decrease levels of the medication and reduce its effectiveness. Hyperforin is a natural compound extracted from the St. John’s wort (Hypericum perforatum) plant. | Digoxin should not be taken with food containing Hyperforin. | Johne et al. [57] |
| Nisoldipine + Bergamottin | Grapefruit juice can increase the serum concentrations and oral bioavailability of Nisoldipine due to the inhibitant effect to CYP3A4. Bergamottin is the most abundant of furanocoumarins present in grapefruit juice. | Nisoldipin should not be taken with food containing Bergamottin. | Paine et al. [58], Takanaga et al. [59] |
| Midazolam + Licofuranocoumarin | Grapefruit juice is contraindicated when taking Midazolam orally since it contains Furanocoumarin compounds that can inhibit CYP3A4. This will increase bioavailability and change the pharmacodynamics of Midazolam, leading to excessive levels of sedation for the patients. | Midazolam should not be taken with food containing Licofuranocoumarin. | Kupferschmidt et al. [60], Goho et al. [61] |
| Warfarin + Vitamin K1 2,3-epoxide | Vitamin K can make Warfarin less effective, which means that Warfarin could not prevent a dangerous blood clot. | Warfarin should not be taken with food containing Vitamin K1 2,3-epoxide. | Pedersen et al. [13], Johnson et al. [62] |
| Warfarin + Dimethyl disulfide | Herbs can increase the risk of bleeding if one is taking Warfarin as an anticoagulant. Dimethyl disulfide is one of the components found in herbs. | Warfarin should not be taken with food containing Dimethyl disulfide | Milić et al. [63], Hu et al. [64] |
| Methods-Architectures | Advantages | Disadvantages | Performances |
|---|---|---|---|
| DeepDDI [5] - Deep Neural Network. | Leveraging the structural similarity of food constituents to interacting drugs to predict accurately DFIs. | Predicting DFIs indirectly and may omit some food constituents | Not clearly stated. |
| FDMine [38] - Graph mining approach. | Harnessing the similarity data from various subnetworks and merging the information on food items and their compound compositions in a homogeneous graph. | Investigating fewer drug compounds. Hard to reproduce. | Highest precision: 0.84 |
| Ours - Simple classification algorithms. | Direct predictions from SMILES descriptions of drugs and food compounds. High reproducibility. | Not built on state-of-the-art architectures. | External test set Precision: 0.9265 to 1.0. Recall: 0.9441 to 1.0. F1-score: 0.9618 to 0.9862. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kha, Q.-H.; Le, V.-H.; Hung, T.N.K.; Nguyen, N.T.K.; Le, N.Q.K. Development and Validation of an Explainable Machine Learning-Based Prediction Model for Drug–Food Interactions from Chemical Structures. Sensors 2023, 23, 3962. https://doi.org/10.3390/s23083962
Kha Q-H, Le V-H, Hung TNK, Nguyen NTK, Le NQK. Development and Validation of an Explainable Machine Learning-Based Prediction Model for Drug–Food Interactions from Chemical Structures. Sensors. 2023; 23(8):3962. https://doi.org/10.3390/s23083962
Chicago/Turabian StyleKha, Quang-Hien, Viet-Huan Le, Truong Nguyen Khanh Hung, Ngan Thi Kim Nguyen, and Nguyen Quoc Khanh Le. 2023. "Development and Validation of an Explainable Machine Learning-Based Prediction Model for Drug–Food Interactions from Chemical Structures" Sensors 23, no. 8: 3962. https://doi.org/10.3390/s23083962
APA StyleKha, Q.-H., Le, V.-H., Hung, T. N. K., Nguyen, N. T. K., & Le, N. Q. K. (2023). Development and Validation of an Explainable Machine Learning-Based Prediction Model for Drug–Food Interactions from Chemical Structures. Sensors, 23(8), 3962. https://doi.org/10.3390/s23083962