
EDPNet: An Encoding–Decoding Network with Pyramidal Representation for Semantic Image Segmentation

 ,
,  , ,
, ,  , , and
, , and 
Abstract
1. Introduction
2. Related Work
2.1. Traditional Segmentation
2.2. Machine Learning-Based Segmentation
2.3. Deep Learning-Based Segmentation
2.4. Unresolved Issues
2.5. Novel Contributions
- (a)
- We propose EDPNet, a novel convolutional neural network tailored for the semantic image segmentation task. EDPNet is a hybrid network that combines the encoder–decoder structure and the pyramidal representation at multiple scales to aggregate context-aware augmented features for precise boundary delineation.
- (b)
- We introduce an auxiliary loss function at the end of the proposed network’s feature extraction module to supervise the model output. Auxiliary loss can optimize the parameters of the convolution layers which are far away from the main loss and accelerate learning progress for the main task, significantly improving the network’s overall performance.
3. Methodology
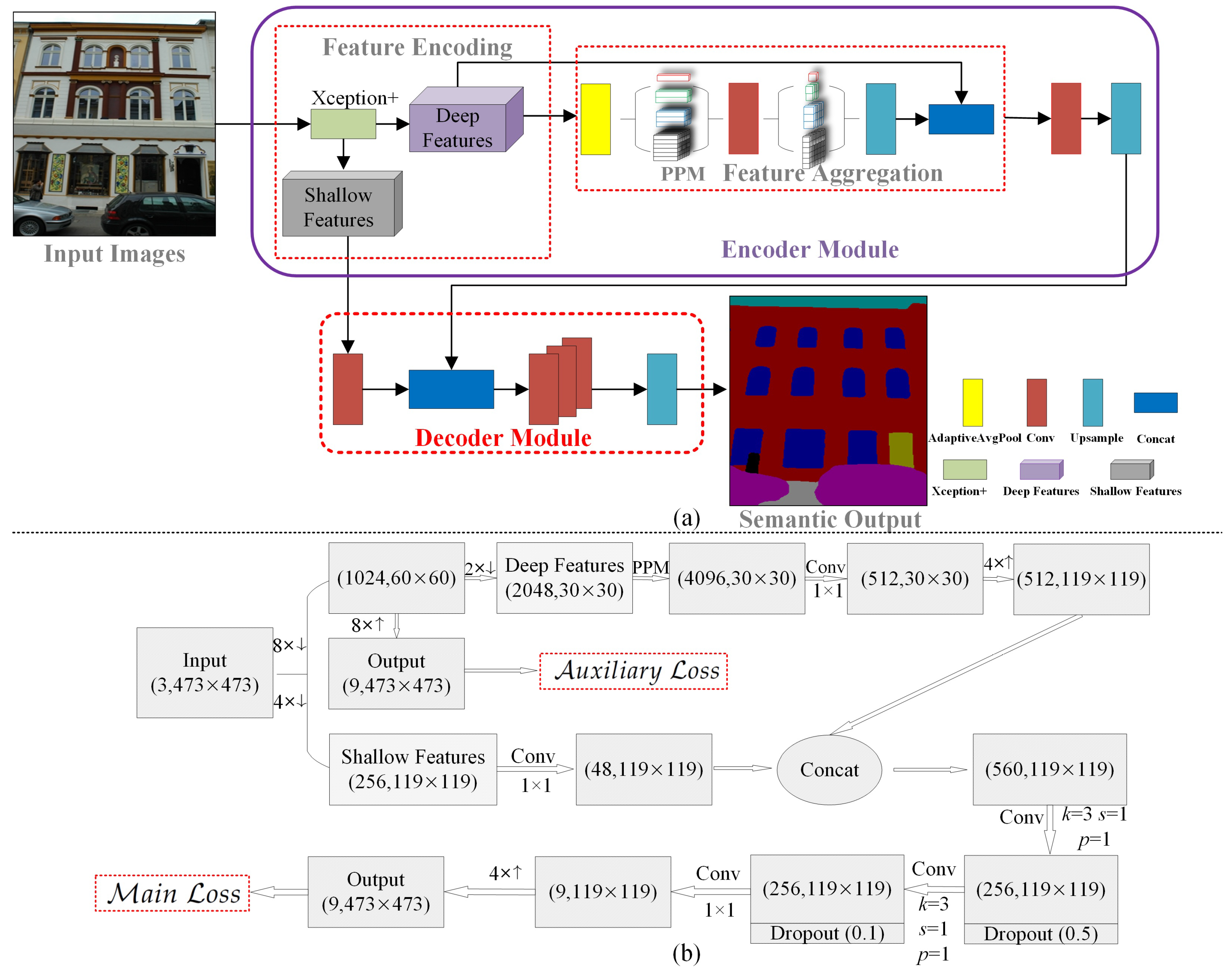
3.1. EDPNet Framework
3.2. Encoding Module
- (1)
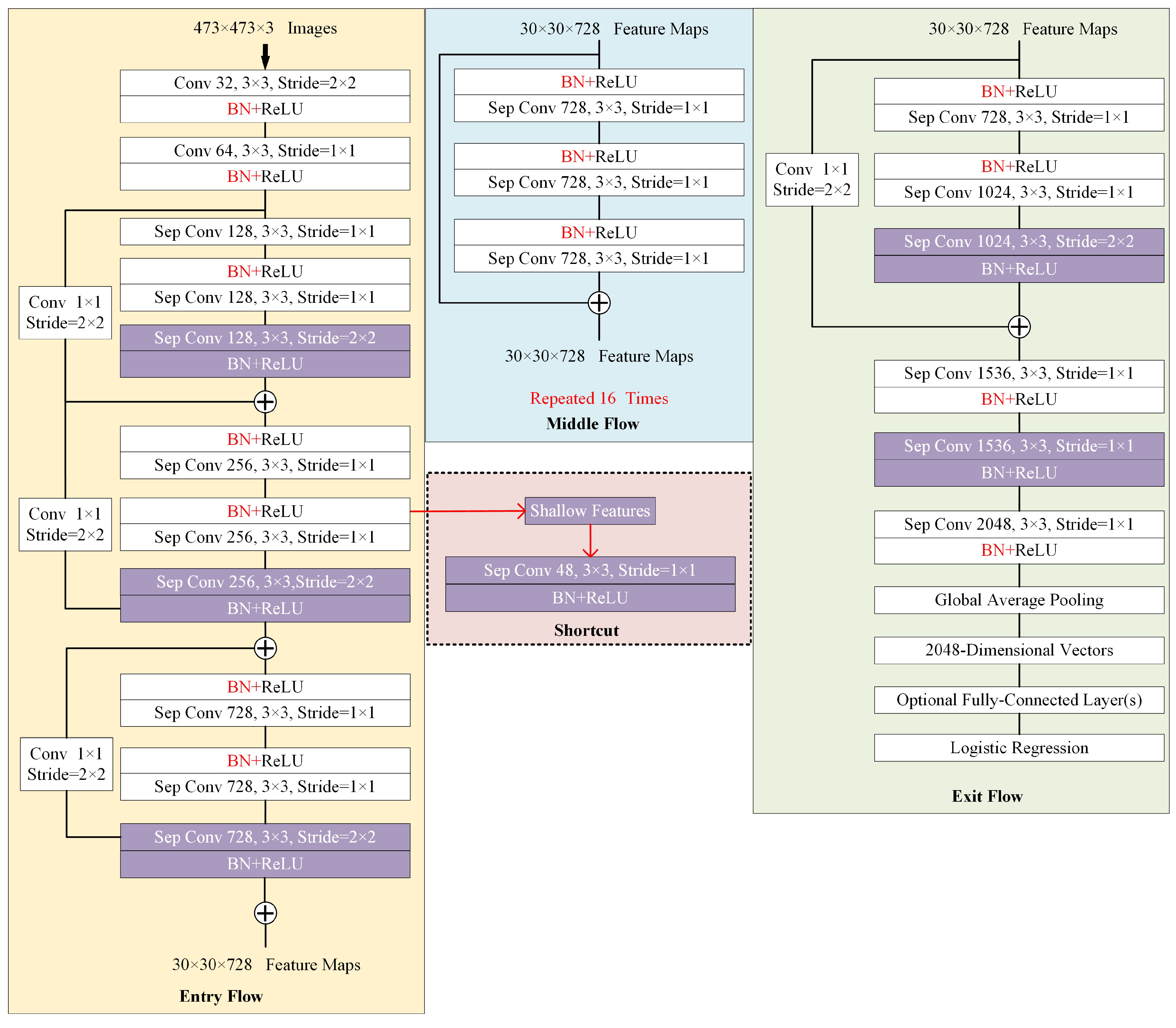
- Feature Extraction: As the basic structure of the semantic segmentation network, the feature extraction module directly determines deep-level semantics and low-level appearance information embedded in the extracted feature maps. Most semantic image segmentation networks employ classic networks such as VGG [55], ResNet [44], and Xception [56] as backbones for feature encoding and integration. These networks have demonstrated excellent performance in various recognition problems based on the large-scale ImageNet benchmark [57] and prove the abilities of feature representation and aggregation. In addition, these networks have a powerful transfer learning ability by loading a pre-trained ImageNet model to accelerate convergence and improve network performance. As light-weighted Xception is more efficient and exhibits powerful encoding ability compared with VGG and ResNet, in the proposed EDPNet, we adopt Xception as a backbone for initial feature extraction and representation. Inspired by works [56,58], we enhance the original Xception module to further strengthen the feature encoding ability. The enhanced module, called Xception+, includes the following significant enhancements: (i) The original Xception network uses downsampling operators such as stride convolutions or pooling layers to encode the feature representations. While these enlarge the receptive field size to perceive high-level semantics, they also increase the loss of spatial information, especially for deep feature maps. To guarantee a large-sized receptive field and relieve the spatial information loss, we substitute the Xception’s pooling structures with depthwise separable convolutions with 3 × 3 filters and a stride of 2 to retain more details. The changes are illustrated by rectangles with purple backgrounds in Figure 2. (ii) We draw out a shortcut block from “Entry Flow” block in Figure 2 to retain shallow features with detailed appearance information and make fusions with encoder outputs (see Figure 1) with rich semantics.
- (2)
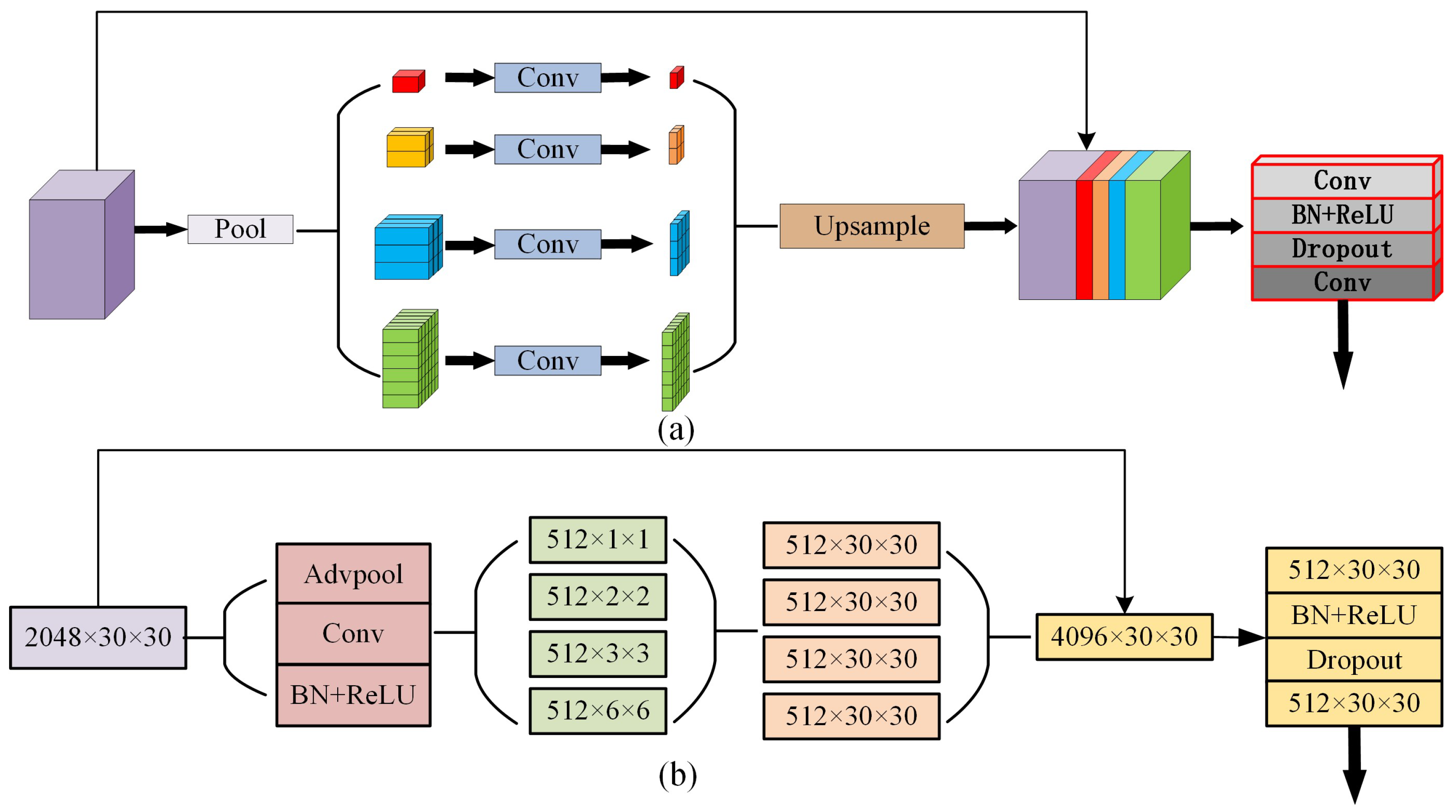
- Feature Aggregation: After extracting feature maps using Xception+, we further enhance global feature representation at different contextual scales by embedding a pyramidal aggregation module into EDPNet. Pyramidal structures can better encode global context feature maps to relieve semantic image segmentation problems, such as mismatched relationships, confusion categories, and inconspicuous classes. In addition, by the multiple-level representations, the aggregated features can significantly parse complex scenarios, especially for the scenery context with different shape sizes of geographical entities because the multi-level representation is easier to retain global contextual information compared to tandem pooling networks.
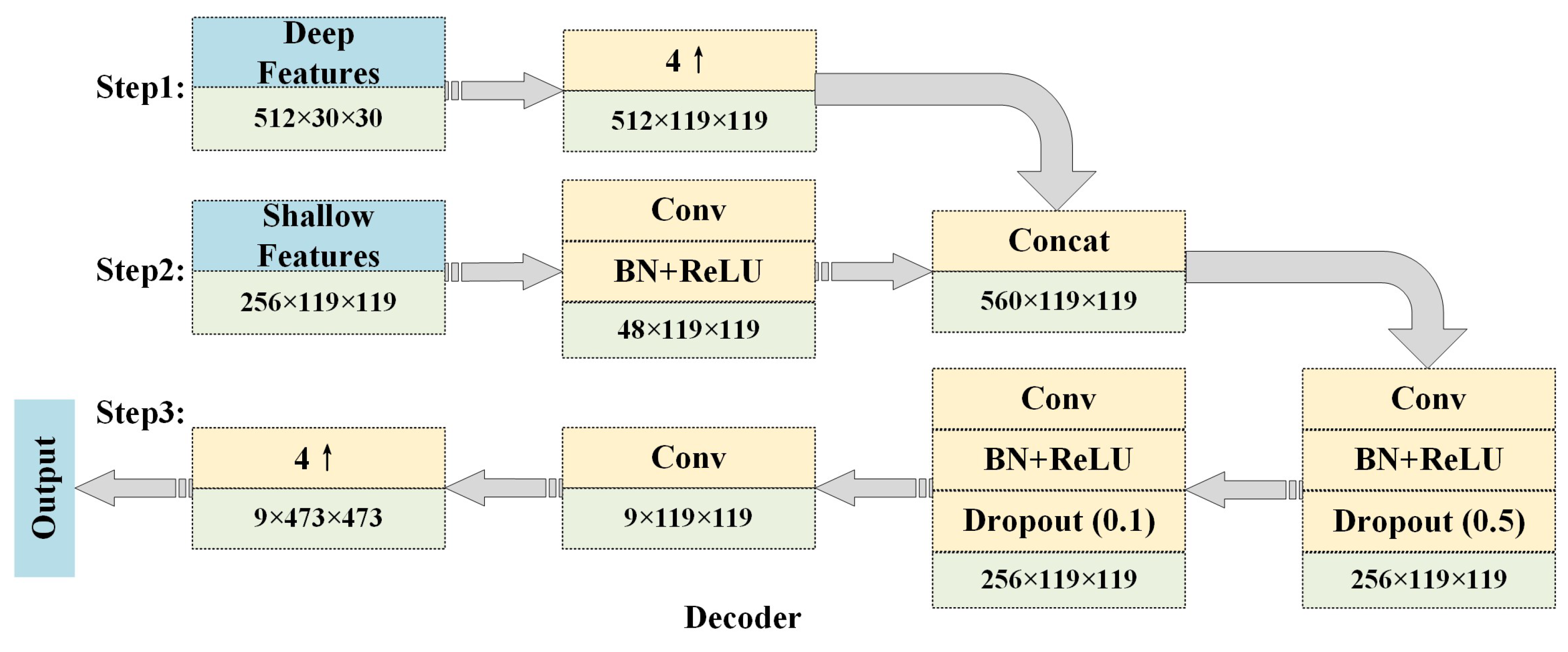
3.3. Decoding Module
4. Performance Evaluation
4.1. Dataset Specification
4.2. Experimental Environment
4.3. Evaluation Metrics
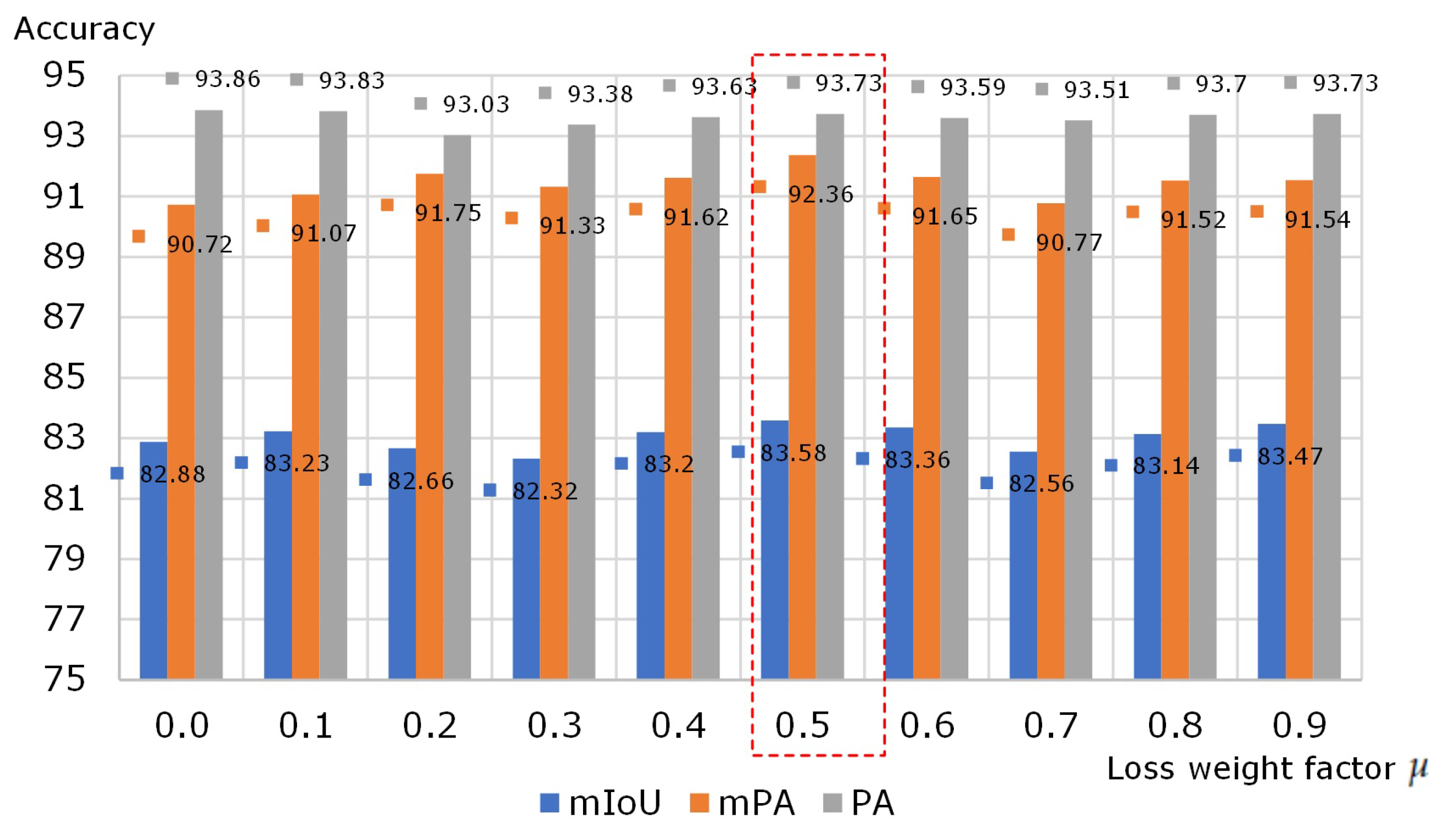
4.4. Parameters Setting
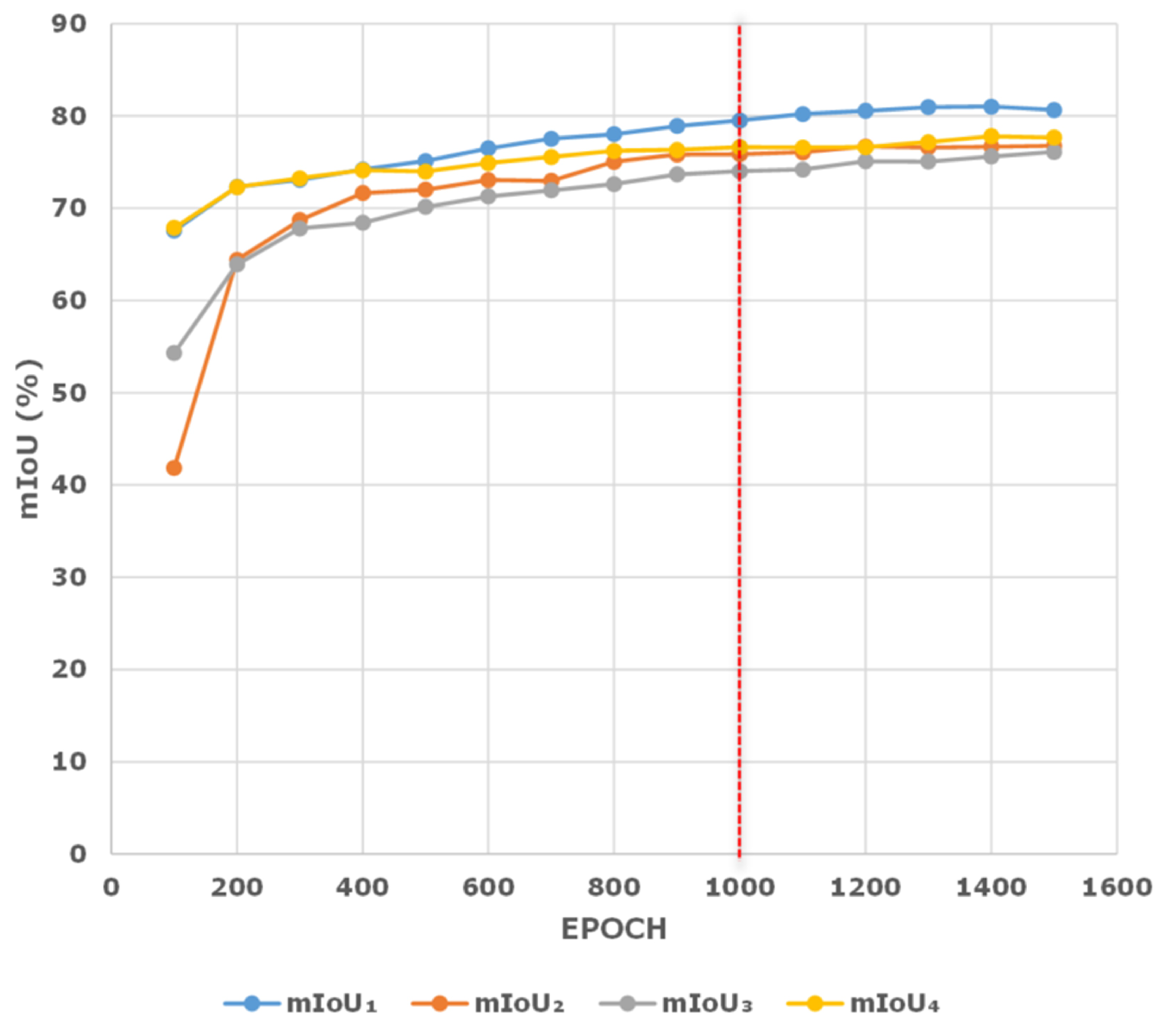
4.5. Ablation Experiments
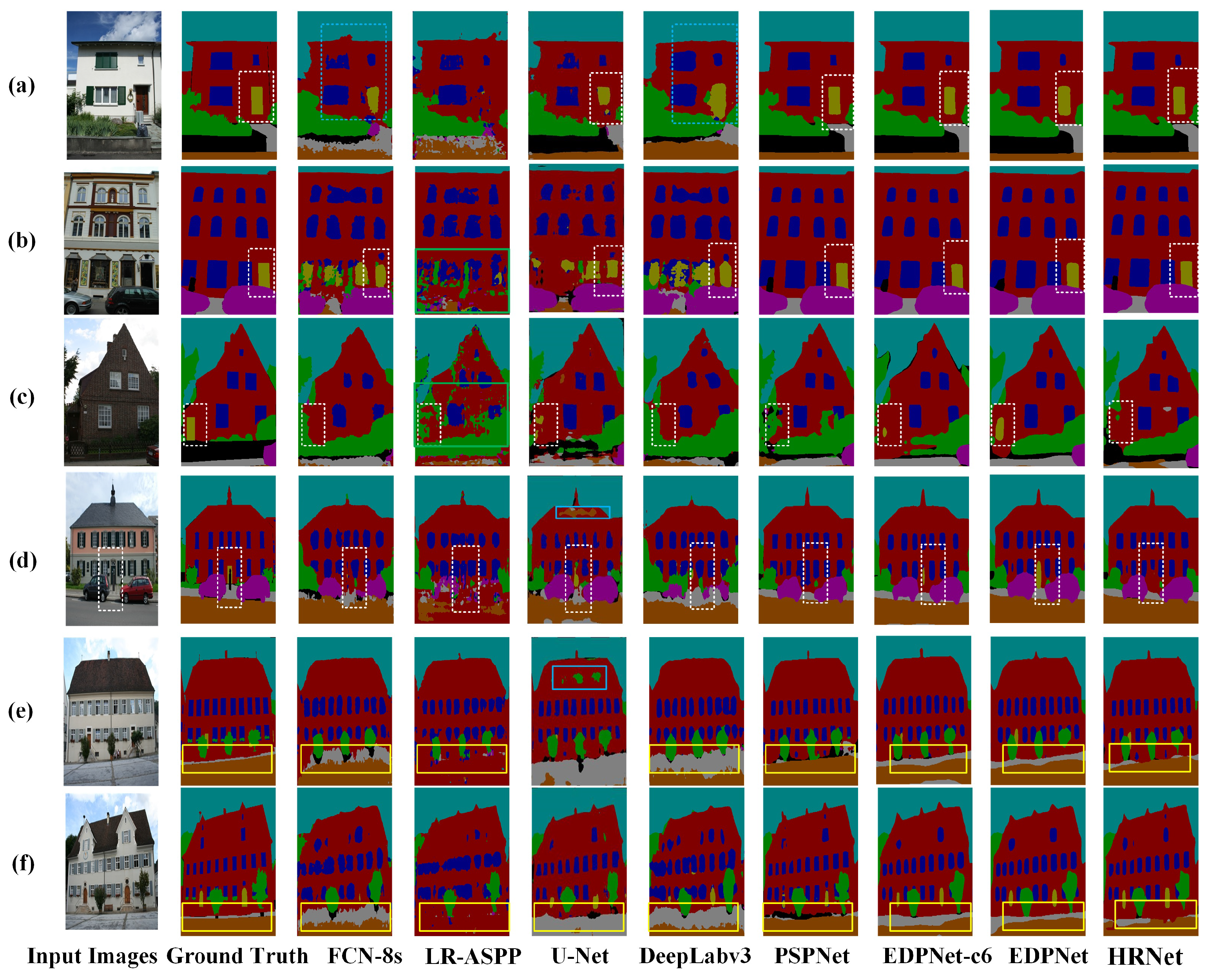
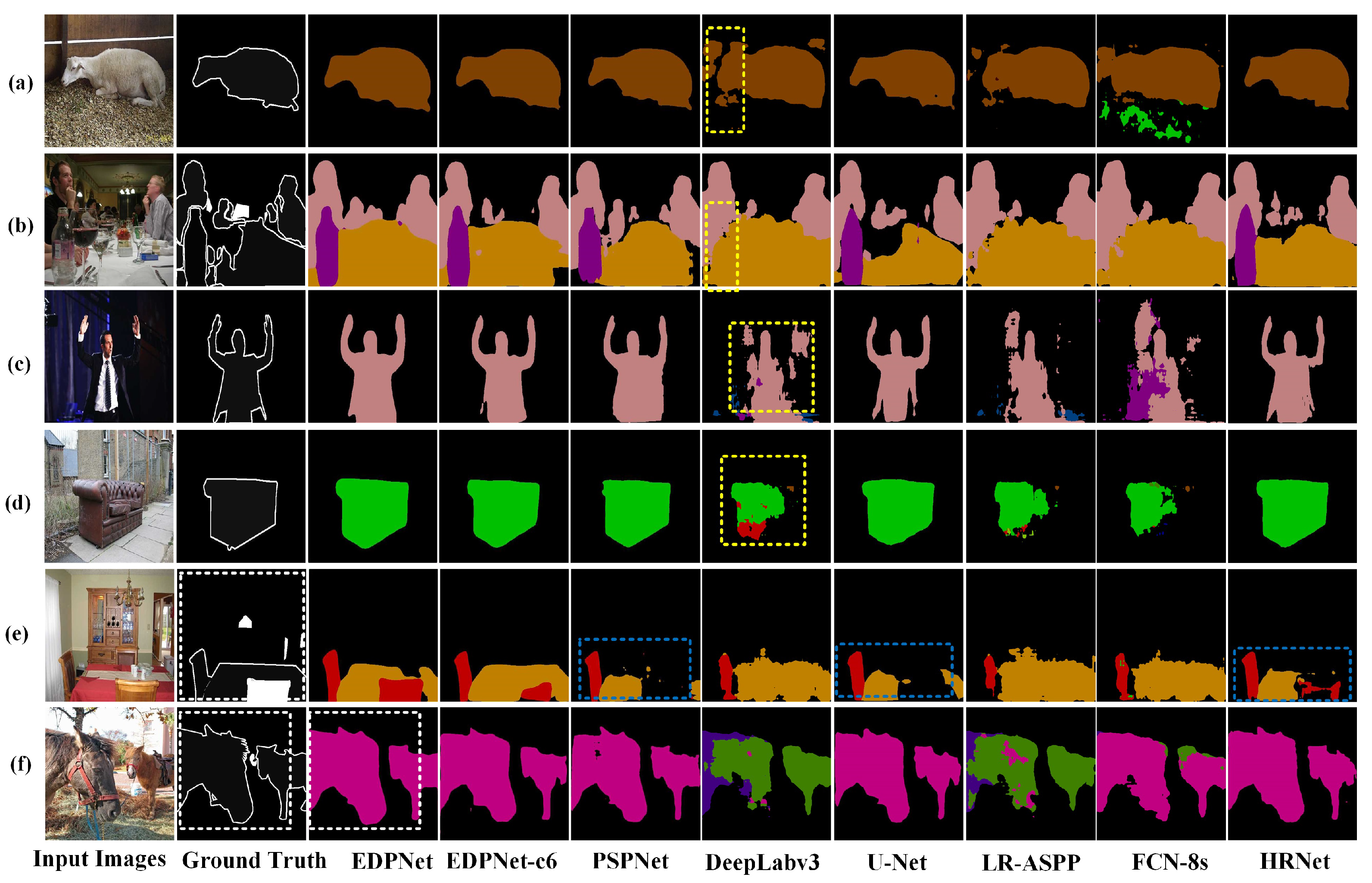
4.6. Prediction Results of Different Networks on the eTRIMS Dataset
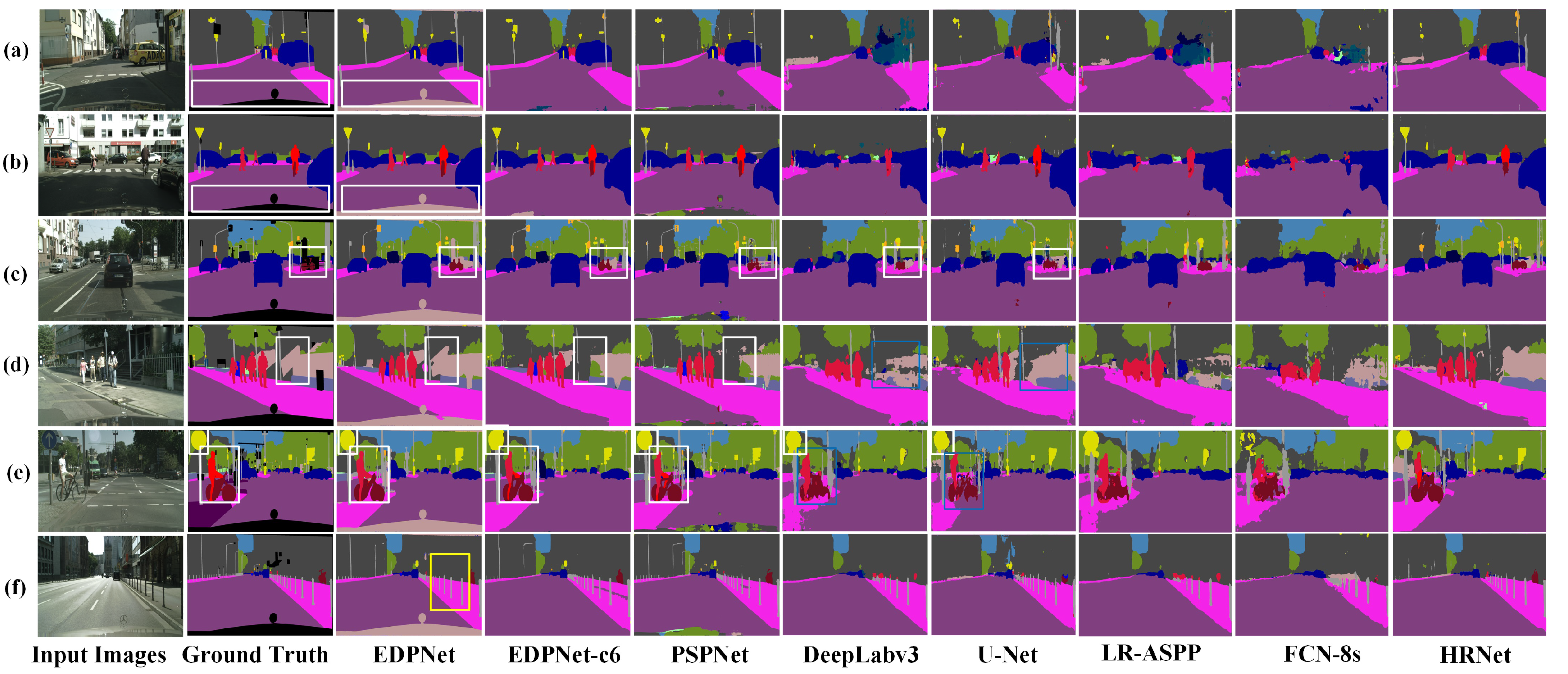
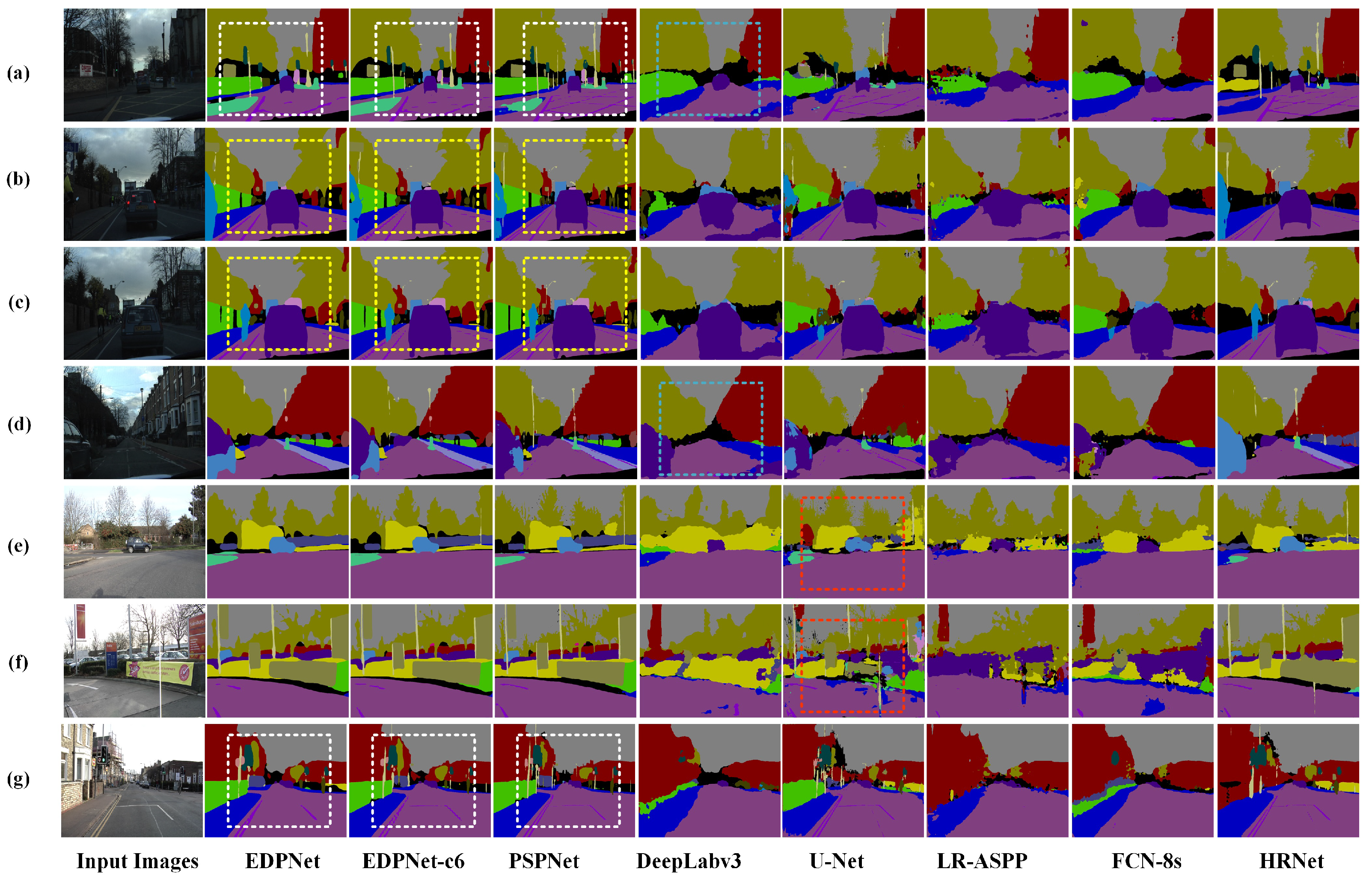
4.7. Evaluation of EDPNet on the Cityscapes Dataset
4.8. Evaluation of EDPNet on the PASCAL VOC 2012 Dataset
4.9. Evaluation of EDPNet on the CamVid Dataset
5. Conclusions and Suggestion for Further Research
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Azad, R.; Aghdam, E.K.; Rauland, A.; Jia, Y.; Avval, A.H.; Bozorgpour, A.; Karimijafarbigloo, S.; Cohen, J.P.; Adeli, E.; Merhof, D. Medical image segmentation review: The success of u-net. arXiv 2022, arXiv:2211.14830. [Google Scholar]
- Sarvamangala, D.; Kulkarni, R.V. Convolutional neural networks in medical image understanding: A survey. Evol. Intell. 2022, 15, 1–22. [Google Scholar] [CrossRef] [PubMed]
- Kamilaris, A.; Prenafeta-Boldú, F.X. A review of the use of convolutional neural networks in agriculture. J. Agric. Sci. 2018, 156, 312–322. [Google Scholar] [CrossRef]
- Meyarian, A.; Yuan, X.; Liang, L.; Wang, W.; Gu, L. Gradient convolutional neural network for classification of agricultural fields with contour levee. Int. J. Remote Sens. 2022, 43, 75–94. [Google Scholar] [CrossRef]
- Lu, R.; Wang, N.; Zhang, Y.; Lin, Y.; Wu, W.; Shi, Z. Extraction of Agricultural Fields via DASFNet with Dual Attention Mechanism and Multi-scale Feature Fusion in South Xinjiang, China. Remote Sens. 2022, 14, 2253. [Google Scholar] [CrossRef]
- Badrloo, S.; Varshosaz, M.; Pirasteh, S.; Li, J. Image-Based Obstacle Detection Methods for the Safe Navigation of Unmanned Vehicles: A Review. Remote Sens. 2022, 14, 3824. [Google Scholar] [CrossRef]
- Wang, H.; Chen, Y.; Cai, Y.; Chen, L.; Li, Y.; Sotelo, M.A.; Li, Z. SFNet-N: An Improved SFNet Algorithm for Semantic Segmentation of Low-Light Autonomous Driving Road Scenes. IEEE Trans. Intell. Transp. Syst. 2022, 23, 21405–21417. [Google Scholar] [CrossRef]
- Wu, Y.; Pan, Z.; Wu, W. Image thresholding based on two-dimensional histogram oblique segmentation and its fast recurring algorithm. J. Commun. 2008, 29, 77–83. [Google Scholar]
- Otsu, N. A threshold selection method from gray-level histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Roberts, L.G. Machine Perception of Three-Dimensional Solids. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 1963. [Google Scholar]
- Prewitt, J.M. Object enhancement and extraction. Pict. Process. Psychopictorics 1970, 10, 15–19. [Google Scholar]
- Kanopoulos, N.; Vasanthavada, N.; Baker, R.L. Design of an image edge detection filter using the Sobel operator. IEEE J. Solid-State Circuits 1988, 23, 358–367. [Google Scholar] [CrossRef]
- Lindeberg, T. Feature detection with automatic scale selection. Int. J. Comput. Vis. 1998, 30, 79–116. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Canny, J. A computational approach to edge detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, PAMI-8, 679–698. [Google Scholar] [CrossRef]
- Yu, Z.; Liu, W.; Zou, Y.; Feng, C.; Ramalingam, S.; Kumar, B.; Kautz, J. Simultaneous edge alignment and learning. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 388–404. [Google Scholar]
- Hojjatoleslami, S.; Kittler, J. Region growing: A new approach. IEEE Trans. Image Process. 1998, 7, 1079–1084. [Google Scholar] [CrossRef]
- Chang, Y.L.; Li, X. Adaptive image region-growing. IEEE Trans. Image Process. 1994, 3, 868–872. [Google Scholar] [CrossRef] [PubMed]
- Seal, A.; Das, A.; Sen, P. Watershed: An image segmentation approach. Int. J. Comput. Sci. Inf. Technol. 2015, 6, 2295–2297. [Google Scholar]
- Shi, Z.; Pun-Cheng, L.S. Spatiotemporal data clustering: A survey of methods. ISPRS Int. J. -Geo-Inf. 2019, 8, 112. [Google Scholar] [CrossRef]
- Koo, H.I.; Kim, D.H. Scene text detection via connected component clustering and nontext filtering. IEEE Trans. Image Process. 2013, 22, 2296–2305. [Google Scholar]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining (KDD-96), Portland, OR, USA, 2–4 August 1996; Volume 96, pp. 226–231. [Google Scholar]
- Hartigan, J.A.; Wong, M.A. Algorithm AS 136: A k-means clustering algorithm. J. R. Stat. Soc. Ser. C 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Bezdek, J.C.; Ehrlich, R.; Full, W. FCM: The fuzzy c-means clustering algorithm. Comput. Geosci. 1984, 10, 191–203. [Google Scholar] [CrossRef]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. B 1977, 39, 1–22. [Google Scholar]
- Duda, R.O.; Hart, P.E. Use of the Hough transformation to detect lines and curves in pictures. Commun. ACM 1972, 15, 11–15. [Google Scholar] [CrossRef]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Schapire, R.E. Explaining adaboost. In Empirical Inference; Springer: Berlin/Heidelberg, Germany, 2013; pp. 37–52. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Ng, P.C.; Henikoff, S. SIFT: Predicting amino acid changes that affect protein function. Nucleic Acids Res. 2003, 31, 3812–3814. [Google Scholar] [CrossRef]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-up robust features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Ghiasi, G.; Lin, T.Y.; Le, Q.V. Nas-fpn: Learning scalable feature pyramid architecture for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7036–7045. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Heidler, K.; Mou, L.; Baumhoer, C.; Dietz, A.; Zhu, X.X. HED-UNet: Combined segmentation and edge detection for monitoring the Antarctic coastline. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–14. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Boston, MA, USA, 7–12 June 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1137–1149. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Mehta, S.; Rastegari, M.; Caspi, A.; Shapiro, L.; Hajishirzi, H. Espnet: Efficient spatial pyramid of dilated convolutions for semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 552–568. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Munich, Germany, 8–14 May 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5693–5703. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1520–1528. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder–decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Strasbourg, France, 27 September–1 October 2021; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Lin, G.; Liu, F.; Milan, A.; Shen, C.; Reid, I. Refinenet: Multi-path refinement networks for dense prediction. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 1228–1242. [Google Scholar] [CrossRef]
- Zhang, H.; Dana, K.; Shi, J.; Zhang, Z.; Wang, X.; Tyagi, A.; Agrawal, A. Context encoding for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7151–7160. [Google Scholar]
- Zhang, Z.; Zhang, X.; Peng, C.; Xue, X.; Sun, J. Exfuse: Enhancing feature fusion for semantic segmentation. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 269–284. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 248–255. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder–decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Korc, F.; Förstner, W. eTRIMS Image Database for Interpreting Images of Man-Made Scenes; Technical report TR-IGG-P-2009-01; Department of Photogrammetry, University of Bonn: Bonn, Germany, 2009. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Brostow, G.J.; Shotton, J.; Fauqueur, J.; Cipolla, R. Segmentation and recognition using structure from motion point clouds. In Proceedings of the European Conference on Computer Vision, Marseille, France, 12–18 October 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 44–57. [Google Scholar]
- Everingham, M.; Eslami, S.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes challenge: A retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Lin, D.; Shen, D.; Ji, Y.; Shen, S.; Xie, M.; Feng, W.; Huang, H. TAGNet: Learning Configurable Context Pathways for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 2475–2491. [Google Scholar] [CrossRef]
- Li, Z.; Sun, Y.; Zhang, L.; Tang, J. CTNet: Context-based tandem network for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 9904–9917. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Recommended Value/Configuration |
|---|---|
| Learning rate (lr) | 0.001 |
| Loss weight factor () | 0∼0.9 |
| Momentum | 0.9 |
| Weight decay | 0.0001 |
| Batchsize | 4 |
| Loss | Cross-entropy Loss |
| Epoch | 1000 |
| lr_scheduler | Poly [63] |
| Models | Configurations | mIoU (%) | Time (min) | Size (MB) | Building | Car | Door | Pavement | Road | Sky | Vegetation | Window |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| EDPNet-c1 | ResNet50+FCN Baseline | 54.7 | 120.0 | 282.9 | 81.2 | 56.0 | 29.4 | 26.0 | 67.9 | 64.9 | 61.6 | 55.4 |
| EDPNet-c2 | ResNet50+P1 +MAX | 80.5 | 169.0 | 393.0 | 89.9 | 87.8 | 72.6 | 71.6 | 93.9 | 97.3 | 72.0 | 79.4 |
| EDPNet-c3 | ‘Xception+’+ P1+ADAVP | 76.3 | 110.0 | 507.7 | 88.3 | 91.2 | 70.5 | 54.7 | 82.6 | 96.8 | 72.0 | 71.7 |
| EDPNet-c4 | ‘Xception+’+P1 +MAX | 77.2 | 113.0 | 507.7 | 88.6 | 91.4 | 72.8 | 58.3 | 85.1 | 97.0 | 71.2 | 71.1 |
| EDPNet-c5 | ‘Xception+’+P1+AVP | 78.4 | 110.0 | 507.7 | 89.1 | 91.4 | 71.1 | 64.4 | 87.4 | 97.0 | 71.3 | 71.9 |
| EDPNet-c6 | ‘Xception+’+P1236 +ADAVP | 77.9 | 107.0 | 507.7 | 87.8 | 90.6 | 68.7 | 65.5 | 88.3 | 96.8 | 71.5 | 70.6 |
| EDPNet-c7 | ‘Xception+’+P1236 +MAX | 78.4 | 107.0 | 507.7 | 88.7 | 91.7 | 70.8 | 62.1 | 87.4 | 97.1 | 74.7 | 71.5 |
| EDPNet-c8 | ‘Xception+’+ P1236+AVP | 77.2 | 107.0 | 507.7 | 88.2 | 91.6 | 70.7 | 60.4 | 85.9 | 97.0 | 72.2 | 70.1 |
| EDPNet-c9 | ‘Xception+’+P1236 +ADAVP+DC | 80.2 | 125.0 | 517.3 | 90.1 | 91.2 | 76.5 | 66.1 | 89.2 | 96.6 | 73.3 | 77.8 |
| EDPNet-c10 | ‘Xception+’+P1236 +MAX+DC | 79.7 | 127.0 | 517.3 | 89.7 | 90.7 | 78.9 | 64.3 | 86.3 | 96.2 | 72.2 | 77.5 |
| EDPNet-c11 | ‘Xception+’+P1236 +AVP+DC | 79.1 | 125.0 | 517.3 | 89.7 | 90.0 | 72.2 | 64.6 | 86.9 | 96.8 | 73.6 | 78.5 |
| Models | mIoU (%) | Time (min) | Background | Building | Car | Door | Pavement | Road | Sky | Vegetation | Window |
|---|---|---|---|---|---|---|---|---|---|---|---|
| PSPNet [41] | 83.0 | 174.0 | 66.8 | 92.4 | 93.0 | 75.6 | 70.5 | 92.6 | 98.0 | 73.7 | 84.2 |
| EDPNet-c6 | 84.7 | 172.0 | 68.5 | 93.4 | 95.6 | 86.6 | 66.4 | 86.1 | 98.2 | 80.3 | 85.9 |
| EDPNet | 85.4 | 180.0 | 69.6 | 93.3 | 95.0 | 85.2 | 73.5 | 90.6 | 97.8 | 78.4 | 85.2 |
| Models | mIoU (%) | Time (min) | Background | Building | Car | Door | Pavement | Road | Sky | Vegetation | Window |
|---|---|---|---|---|---|---|---|---|---|---|---|
| FCN-8s [47] | 56.6 | 120.0 | 21.1 | 81.9 | 61.6 | 34.6 | 27.6 | 67.2 | 93.7 | 64.4 | 56.7 |
| LR-ASPP [64] | 59.3 | 29.0 | 24.1 | 84.4 | 57.9 | 46.3 | 34.3 | 62.2 | 96.7 | 65.0 | 62.7 |
| U-Net [50] | 63.9 | 105.0 | 56.4 | 85.2 | 82.4 | 47.2 | 28.5 | 44.8 | 96.1 | 72.1 | 63.9 |
| DeepLabv3 [63] | 66.4 | 204.0 | 48.9 | 83.3 | 65.0 | 53.0 | 42.6 | 76.7 | 96.3 | 63.0 | 69.2 |
| PSPNet [41] | 83.0 | 174.0 | 66.8 | 92.4 | 93.0 | 75.6 | 70.5 | 92.6 | 98.0 | 73.7 | 84.2 |
| HRNet [46] | 77.7 | 100.0 | 62.4 | 93.4 | 90.7 | 63.6 | 57.6 | 85.9 | 97.4 | 78.2 | 70.2 |
| EDPNet-c6 | 80.5 | 105.0 | 61.2 | 90.7 | 92.7 | 76.5 | 63.9 | 84.5 | 97.8 | 76.7 | 80.3 |
| EDPNet | 83.6 | 125.0 | 66.1 | 91.7 | 93.2 | 80.0 | 72.0 | 91.0 | 96.8 | 76.2 | 82.8 |
| Models | mIoU (%) | Time (h) | Road | Sidewalk | Building | Wall | Fence | Pole | Light | Sign | Vegetation | Terrain | Sky | Person | Rider | Car | Trunk | Bus | Train | Motorcycle | Bicycle |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FCN-8s [47] | 33.3 | 37.0 | 91.5 | 50.9 | 75.6 | 12.2 | 10.8 | 15.2 | / | 19.7 | 77.4 | 36.6 | 84.4 | 35.1 | / | 72.5 | / | 10.1 | / | / | 31.5 |
| LR-ASPP [64] | 36.6 | 16.0 | 92.2 | 53.9 | 78.3 | 22.9 | 13.6 | 18.4 | / | 22.1 | 80.7 | 43.1 | 85.4 | 38.7 | / | 75.8 | / | 16.2 | / | / | 34.3 |
| U-Net [50] | 53.5 | 47.0 | 95.2 | 66.7 | 84.9 | 32.0 | 32.0 | 37.5 | 32.0 | 46.4 | 85.9 | 47.6 | 90.9 | 57.9 | 31.8 | 84.9 | 45.2 | 44.7 | 22.8 | 23.4 | 54.3 |
| DeepLabv3 [63] | 42.0 | 102.0 | 93.8 | 62.0 | 82.0 | 24.6 | 25.5 | 26.9 | 10.5 | 31.8 | 85.2 | 43.0 | 88.4 | 47.1 | / | 80.4 | 10.3 | 27.9 | 12.4 | / | 43.8 |
| PSPNet [41] | 76.0 | 102.0 | 98.1 | 85.4 | 92.7 | 42.2 | 58.4 | 66.4 | 72.7 | 80.4 | 92.5 | 63.6 | 94.7 | 83.7 | 65.1 | 95.2 | 75.3 | 83.2 | 55.0 | 60.2 | 78.6 |
| HRNet [46] | 65.3 | 50.0 | 97.4 | 79.3 | 89.6 | 52.9 | 45.6 | 47.4 | 42.3 | 58.1 | 90.1 | 57.8 | 93.1 | 68.8 | 42.3 | 91.0 | 61.6 | 66.2 | 52.2 | 42.2 | 63.7 |
| EDPNet-c6 | 75.6 | 53.5 | 98.2 | 84.7 | 92.6 | 58.9 | 64.3 | 60.8 | 70.3 | 78.9 | 92.3 | 60.7 | 94.3 | 82.2 | 65.3 | 95.4 | 82.8 | 78.2 | 28.2 | 69.9 | 78.6 |
| EDPNet | 71.2 | 60.0 | 97.6 | 82.4 | 92.3 | 50.1 | 54.6 | 59.0 | 68.5 | 77.1 | 91.7 | 61.0 | 93.8 | 80.3 | 62.3 | 92.9 | 42.8 | 59.5 | 53.1 | 56.5 | 76.5 |
| Models | mIoU (%) | Time (h) | Background | Aero | Bicycle | Bird | Boat | Bottle | Bus | Car | Cat | Chair | Cow | Diningtable | Dog | Horse | Motorbike | Person | Potted Plant | Sheep | Sofa | Train | TV |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FCN-8s [47] | 34.1 | 63.0 | 82.1 | 46.0 | 21.2 | 15.6 | 25.1 | 19.5 | 69.5 | 52.9 | 40.2 | 11.0 | 26.9 | 27.5 | 31.4 | 18.9 | 41.3 | 57.8 | 11.2 | 25.6 | 16.1 | 43.9 | 32.4 |
| LR-ASPP [64] | 36.1 | 15.4 | 82.3 | 52.0 | 22.6 | 27.6 | 31.5 | 23.9 | 58.0 | 55.7 | 38.2 | 11.3 | 30.9 | 29.0 | 33.6 | 18.5 | 46.8 | 55.0 | 11.5 | 30.6 | 18.0 | 47.9 | 33.8 |
| DeepLabv3 [63] | 37.1 | 123.5 | 83.2 | 60.2 | 20.5 | 24.0 | 38.9 | 21.9 | 68.8 | 55.2 | 39.3 | 12.9 | 27.6 | 23.3 | 26.2 | 24.7 | 51.9 | 61.5 | 16.1 | 31.1 | 15.2 | 53.5 | 22.9 |
| U-Net [50] | 55.9 | 131.5 | 90.0 | 70.2 | 33.1 | 66.0 | 51.2 | 49.9 | 71.7 | 69.1 | 72.2 | 22.5 | 51.6 | 33.4 | 61.3 | 52.7 | 62.4 | 73.5 | 40.3 | 55.3 | 28.9 | 64.3 | 54.6 |
| PSPNet [41] | 69.5 | 160.5 | 93.0 | 88.7 | 44.1 | 79.7 | 60.3 | 47.0 | 87.2 | 85.9 | 88.2 | 30.7 | 77.5 | 44.7 | 84.0 | 75.6 | 83.3 | 84.7 | 47.6 | 73.5 | 41.3 | 79.8 | 62.7 |
| HRNet [46] | 73.4 | 125.0 | 93.0 | 89.0 | 43.2 | 87.4 | 61.5 | 80.8 | 92.3 | 84.8 | 87.7 | 38.3 | 79.6 | 42.5 | 80.3 | 78.6 | 87.0 | 84.6 | 60.6 | 83.1. | 43.3 | 81.0 | 62.6 |
| EDPNet-c6 | 68.3 | 70.4 | 92.7 | 83.5 | 41.2 | 76.1 | 50.6 | 59.6 | 86.6 | 84.9 | 87.1 | 30.0 | 64.7 | 51.1 | 73.8 | 76.1 | 83.1 | 82.9 | 46.4 | 75.1 | 44.1 | 77.5 | 67.2 |
| EDPNet | 73.8 | 87.3 | 93.4 | 81.9 | 40.7 | 85.2 | 61.9 | 67.0 | 91.4 | 83.3 | 89.4 | 41.3 | 81.7 | 55.8 | 80.7 | 85.5 | 78.3 | 85.9 | 59.2 | 83.2 | 48.4 | 80.1 | 76.1 |
| Models | mIoU (%) | Time (h) | Bicyclist | Building | Car | Fence | Pedestrian | Road | Sidewalk | Sky | Tree | Truck_bus | Vegetation Misc | Wall |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FCN-8s [47] | 51.1 | 16.0 | 34.1 | 77.6 | 58.8 | 31.8 | 6.8 | 85.6 | 65.7 | 87.9 | 71.3 | 18.9 | 31.2 | 44.0 |
| LR-ASPP [64] | 66.6 | 4.0 | 53.1 | 86.0 | 78.3 | 53,6 | 35.5 | 87.6 | 68.4 | 89.8 | 77.5 | 76.5 | 47.3 | 46.1 |
| U-Net [50] | 74.4 | 21.0 | 75.4 | 88.2 | 79.2 | 71.1 | 48.4 | 93.9 | 84.6 | 92.6 | 81.1 | 79.2 | 61.5 | 66.2 |
| DeepLabv3 [63] | 65.1 | 26.0 | 63.6 | 87.6 | 77.1 | 49.9 | 39.9 | 91.5 | 84.1 | 90.9 | 81.1 | 77.6 | 49.8 | 52.5 |
| PSPNet [41] | 82.6 | 27.5 | 82.6 | 92.5 | 91.0 | 83.3 | 69.0 | 95.0 | 89.1 | 91.6 | 82.2 | 90.5 | 70.2 | 76.8 |
| HRNet [46] | 74.0 | 22.0 | 75.8 | 88.8 | 88.4 | 60.5 | 51.9 | 93.7 | 82.5 | 91.2 | 79.3 | 77.6 | 51.8 | 47.0 |
| EDPNet-c6 | 79.4 | 12.9 | 76.6 | 92.0 | 90.4 | 81.1 | 58.8 | 93.5 | 87.4 | 91.0 | 81.7 | 86.9 | 66.6 | 75.4 |
| EDPNet | 80.8 | 15.2 | 79.5 | 92.2 | 91.0 | 82.3 | 60.8 | 94.1 | 88.8 | 91.1 | 81.8 | 88.9 | 68.1 | 76.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, D.; Li, X.; Hu, F.; Mathiopoulos, P.T.; Di, S.; Sui, M.; Peethambaran, J. EDPNet: An Encoding–Decoding Network with Pyramidal Representation for Semantic Image Segmentation. Sensors 2023, 23, 3205. https://doi.org/10.3390/s23063205
Chen D, Li X, Hu F, Mathiopoulos PT, Di S, Sui M, Peethambaran J. EDPNet: An Encoding–Decoding Network with Pyramidal Representation for Semantic Image Segmentation. Sensors. 2023; 23(6):3205. https://doi.org/10.3390/s23063205
Chicago/Turabian StyleChen, Dong, Xianghong Li, Fan Hu, P. Takis Mathiopoulos, Shaoning Di, Mingming Sui, and Jiju Peethambaran. 2023. "EDPNet: An Encoding–Decoding Network with Pyramidal Representation for Semantic Image Segmentation" Sensors 23, no. 6: 3205. https://doi.org/10.3390/s23063205
APA StyleChen, D., Li, X., Hu, F., Mathiopoulos, P. T., Di, S., Sui, M., & Peethambaran, J. (2023). EDPNet: An Encoding–Decoding Network with Pyramidal Representation for Semantic Image Segmentation. Sensors, 23(6), 3205. https://doi.org/10.3390/s23063205