

Anomaly Detection in Biological Early Warning Systems Using Unsupervised Machine Learning

 , ,
, ,  and
and
Abstract
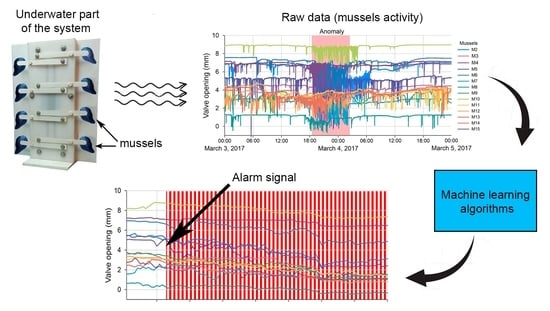
1. Introduction
2. Related Work
3. Materials and Methods
4. Results
4.1. Elliptic Envelope
4.2. Isolation Forest (iForest)
4.3. One-Class SVM
4.4. Local Outlier Factor (LOF)
5. Discussion
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bae, M.-J.; Park, Y.-S. Biological early warning system based on the responses of aquatic organisms to disturbances: A review. Sci. Total Environ. 2013, 466, 635–649. [Google Scholar] [CrossRef]
- Bolognesi, C.; Rabboni, R.; Roggieri, P. Genotoxicity biomarkers in M. Galloprovincialis as indicators of marine pollutants. Comp. Biochem. Physiol. 1996, 113, 319–323. [Google Scholar] [CrossRef]
- Trusevich, V.V.; Gaiskii, P.V.; Kuz’min, K.A. Automated biomonitoring of the aquatic environment using the responses of bivalves. Morsk. Gidrofiz. Zh. 2010, 3, 75–83. [Google Scholar]
- Sluyts, H.; VanHoof, F.; Cornet, A.; Paulussen, J. A dynamic new alarm system for use in biological early warning systems. Environ. Toxicol. Chem. 1996, 15, 1317–1323. [Google Scholar] [CrossRef]
- Diehl, P.; Gerke, T.; Jeuken, A.; Lowis, J.; Steen, R.; van Steenwijk, J.; Stoks, P.; Willemsen, H.-G. Early Warning Strategies and Practices along the River Rhine. In The Rhine; Knepper, T.P., Ed.; The Handbook of Environmental Chemistry; Springer: Berlin/Heidelberg, Germany, 2005; Volume 5L, pp. 1–25. [Google Scholar] [CrossRef]
- Borcherding, J. Ten years of practical experience with the Dreissena-Monitor, a biological early warning system for continuous water quality monitoring. Hydrobiologia 2006, 556, 417–426. [Google Scholar] [CrossRef]
- Liao, C.M.; Jau, S.F.; Lin, C.M.; Jou, L.J.; Liu, C.W.; Liao, V.H.C.; Chang, F.J. Valve movement response of the freshwater clam Corbicula fluminea following exposure to waterborne arsenic. Ecotoxicology 2009, 18, 567–576. [Google Scholar] [CrossRef] [PubMed]
- Sow, M.; Durrieu, G.; Briollais, L.; Ciret, P.; Massabuau, J.C. Water quality assessment by means of HFNI valvometry and high-frequency data modeling. Environ. Monit. Assess. 2011, 182, 155–170. [Google Scholar] [CrossRef] [PubMed]
- Di Giacinto, F.; Berti, M.; Carbone, L.; Caprioli, R.; Colaiuda, V.; Lombardi, A.; Tomassetti, B.; Tuccella, P.; De Iuliis, G.; Pietroleonardo, A.; et al. Biological EarlyWarning Systems: The Experience in the Gran Sasso-Sirente Aquifer. Water 2021, 13, 1529. [Google Scholar] [CrossRef]
- Trusevich, V.V.; Kuz’min, K.A.; Mishurov, V.Z.; Zhuravsky, V.Y.; Vyshkvarkova, E.V. Features of Behavioral Responses of the Mediterranean Mussel in Its Natural Habitat of the Black Sea. Inland Water Biol. 2021, 14, 10–19. [Google Scholar] [CrossRef]
- Omar, S.; Ngadi, A.; Jebur, H.H. Machine learning techniques for anomaly detection: An overview. Int. J. Comput. Appl. 2013, 79, 33–41. [Google Scholar] [CrossRef]
- Russo, S.; Besmer, M.D.; Blumensaat, F.; Bouffard, D.; Disch, A.; Hammes, F.; Hess, A.; Lürig, M.; Matthews, B.; Minaudo, C.; et al. The value of human data annotation for machine learning based anomaly detection in environmental systems. Water Res. 2021, 206, e117695. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Xu, L.; Zeng, S.; Qiao, F.; Jiang, W.; Xu, Z. Rapid detection of mussels contaminated by heavy metals using nearinfrared reflectance spectroscopy and a constrained difference extreme learning machine. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2022, 269, e120776. [Google Scholar] [CrossRef]
- Harley, J.R.; Lanphier, K.; Kennedy, E.; Whitehead, C.; Bidlack, A. Random forest classification to determine environmental drivers and forecast paralytic shellfish toxins in Southeast Alaska with high temporal resolution. Harmful Algae 2020, 99, e101918. [Google Scholar] [CrossRef] [PubMed]
- Almuhtaram, H.; Zamyadi, A.; Hofmann, R. Machine learning for anomaly detection in cyanobacterial fluorescence signals. Water Res. 2021, 197, 117073. [Google Scholar] [CrossRef]
- Cruz, R.C.; Reis Costa, P.; Vinga, S.; Krippahl, L.; Lopes, M.B. A Review of Recent Machine Learning Advances for Forecasting Harmful Algal Blooms and Shellfish Contamination. J. Mar. Sci. Eng. 2021, 9, 283. [Google Scholar] [CrossRef]
- Molares-Ulloa, A.; Fernandez-Blanco, E.; Pazos, A.; Rivero, D. Machine learning in management of precautionary closures caused by lipophilic biotoxins. Comput. Electron. Agric. 2022, 197, e106956. [Google Scholar] [CrossRef]
- Hill, P.R.; Kumar, A.; Temimi, M.; Bull, D.R. Habnet: Machine learning, remote sensing-based detection of harmful algal blooms. IEEE J. Select. Top. Appl. Earth Observ. Remote Sens. 2020, 13, 13. [Google Scholar] [CrossRef]
- Cruz, R.C.; Costa, P.R.; Krippahl, L.; Lopes, M.B. Forecasting biotoxin contamination in mussels across production areas of the Portuguese coast with Artificial Neural Networks. Knowl. Based Syst. 2022, 257, 109895. [Google Scholar] [CrossRef]
- Wang, S.; Li, X.; Li, Y.; Gou, S.; Bi, W.; Jiang, T. Identification of paralytic shellfish poison producing algae based on three-dimensional fluorescence spectra and quaternion principal component analysis. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2021, 261, 120040. [Google Scholar] [CrossRef]
- Grasso, I.; Archer, S.D.; Burnell, C.; Tupper, B.; Rauschenber, C.; Kanwit, K.; Record, N.R. The hunt for red tides: Deep learning algorithm forecasts shellfish toxicity at site scales in coastal Maine. Ecosphere 2019, 10, e02960. [Google Scholar] [CrossRef]
- Kimbrough, K.; Jacob, A.; Regan, S.; Davenport, E.; Edwards, M.; Leight, A.K.; Freitag, A.; Rider, M.; Johnson, W.E. Characterization of polycyclic aromatic hydrocarbons in the Great Lakes Basin using dreissenid mussels. Environ. Monit. Assess. 2021, 193, e833. [Google Scholar] [CrossRef] [PubMed]
- Drake, J.M.; Bossenbroek, J.M. Profiling ecosystem vulnerability to invasion by zebra mussels with support vector machines. Theor. Ecol. 2009, 2, 189–198. [Google Scholar] [CrossRef]
- Kijewski, T.; Zbawicka, M.; Strand, J.; Kautsky, H.; Kotta, J.; Rätsep, M.; Wenne, R. Random forest assessment of correlation between environmental factors and genetic differentiation of populations: Case of marine mussels Mytilus. Oceanologia 2019, 61, 131–142. [Google Scholar] [CrossRef]
- Valletta, J.J.; Torney, C.; Kings, M.; Thornton, A.; Madden, J. Applications of machine learning in animal behavior studies. Anim. Behav. 2017, 124, 203–220. [Google Scholar] [CrossRef]
- Bertolini, C.; Capelle, J.; Royer, E.; Milan, M.; Witbaard, R.; Bouma, T.J.; Pastres, R. Using a clustering algorithm to identify patterns of valve-gaping behavior in mussels reared under different environmental conditions. Ecol. Inform. 2022, 69, e101659. [Google Scholar] [CrossRef]
- Keogh, S.M.; Simons, A.M. Molecules and morphology reveal ‘new’ widespread North American freshwater mussel species (Bivalvia: Unionidae). Mol. Phylogenetics Evol. 2019, 138, 182–192. [Google Scholar] [CrossRef]
- Dogo, E.M.; Nwulu, N.I.; Twala, B.; Aigbavboa, C. A survey of machine learning methods applied to anomaly detection on drinking-water quality data. Urban Water J. 2019, 16, 235–248. [Google Scholar] [CrossRef]
- Jin, T.; Cai, S.; Jiang, D.; Liu, J. A data-driven model for real-time water quality prediction and early warning by an integration method. Environ. Sci. Pollut. Res. 2019, 26, 30374–30385. [Google Scholar] [CrossRef]
- Gao, G.; Xiao, K.; Chen, M. An intelligent IoT-based control and traceability system to forecast and maintain water quality in freshwater fish farms. Comput. Electron. Agric. 2019, 166, 105013. [Google Scholar] [CrossRef]
- Muharemi, F.; Logofătu, D.; Leon, F. Machine learning approaches for anomaly detection of water quality on a real-world data set. J. Inf. Telecommun. 2019, 3, 294–307. [Google Scholar] [CrossRef]
- Shi, B.; Wang, P.; Jiang, J.; Liu, R. Applying high-frequency surrogate measurements and a wavelet-ANN model to provide early warnings of rapid surface water quality anomalies. Sci. Total Environ. 2018, 610–611, 1390–1399. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Wang, P.; Jiang, D.; Nan, J.; Zhu, W. An integrated data-driven framework for surface water quality anomaly detection and early warning. J. Clean. Prod. 2020, 251, 119145. [Google Scholar] [CrossRef]
- Galloway, A.; Brunet, D.; Valipour, R.; McCusker, M.; Biberhofer, J.; Sobol, M.K.; Moussa, M.; Taylor, G.W. Predicting dreissenid mussel abundance in nearshore waters using underwater imagery and deep learning. Limnol. Oceanogr. Methods 2022, 20, 233–248. [Google Scholar] [CrossRef]
- Monsinjon, T.; Andersen, O.K.; Leboulenger, F.; Knigge, T. Data processing and classification analysis of proteomic changes: A case study of oil pollution in the mussel, Mytilus edulis. Proteome Sci. 2006, 4, 1–13. [Google Scholar] [CrossRef]
- Grekov, A.N.; Kuzmin, K.A.; Mishurov, V.Z. Automated early warning system for water environment based on behavioral reactions of bivalves. In 2019 International Russian Automation Conference (RusAutoCon); IEEE: Piscataway, NJ, USA, 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Abou-Moustafa, K.T.; Schuurmans, D. Generalization in unsupervised learning. In Efficient Learning Machines; Apress: Berkeley, CA, USA, 2015; pp. 300–317. [Google Scholar] [CrossRef]
- Raschka, S.; Mirjalili, V. Python Machine Learning, 3rd ed.; Packt Publishing: Mumbai, India, 2019; 772p. [Google Scholar]
- Lipton, Z.C.; Elkan, C.; Narayanaswamy, B. Thresholding classifiers to maximize F1 score. arXiv 2014, arXiv:1402.1892. [Google Scholar]
- Hoyle, B.; Rau, M.M.; Paech, K.; Bonnett, C.; Seitz, S.; Weller, J. Anomaly detection for machine learning redshifts applied to SDSS galaxies. Mon. Not. R. Astron. Soc. 2015, 452, 4183–4194. [Google Scholar] [CrossRef]
- Bella, J.; Fernández, Á.; Dorronsoro, J.R. Supervised Hyperparameter Estimation for Anomaly Detection. In Proceedings of the Hybrid Artificial Intelligent Systems: 15th International Conference, HAIS 2020, Gijón, Spain, 11–13 November 2020; pp. 233–244. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Müller, A.; Nothman, J.; Louppe, G.; et al. Scikit-learn: Machine learning in python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Rousseeuw, P.G.; Driessen, K.V. A FAST algorithm for the minimum covariance determinant estimator. Technometrics 1999, 41, 212–223. [Google Scholar] [CrossRef]
- Witten, I.H.; Eibe, F.; Hall, M.A.; Pal, C.J. Data Mining: Practical Machine Learning Tools and Techniques; Elsevier: Amsterdam, The Netherlands, 2017. [Google Scholar]
- Liu, F.T.; Ting, K.M.; Zhou, Z.-H. Isolation-based anomaly detection. ACM Trans. Knowl. Discov. Data 2012, 6, 1–39. [Google Scholar] [CrossRef]
- Liu, F.T.; Ting, K.M.; Zhou, Z.-H. Isolation forest. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008. [Google Scholar] [CrossRef]
- Scholkopf, B.; Williamson, R.; Smola, A.; Shawe-Taylor, J.; Platt, J. Support Vector Method for Novelty Detection. Adv. Neural Inf. Process. Syst. 1999, 12, 582–586. [Google Scholar]
- Schölkopf, B.; Platt, J.C.; Shawe-Taylor, J.C.; Smola, A.J.; Williamson, R.C. Estimating the support of a high-dimensional distribution. Neural Comput. 2001, 13, 1443–1471. [Google Scholar] [CrossRef]
- Breunig, M.M.; Kriegel, H.-P.; Ng, R.T.; Sander, J. LOF: Identifying density-based local outliers. In Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, Dallas, TX, USA, 16–18 May 2000; ACM Press: New York, NY, USA, 2000; pp. 93–104. [Google Scholar] [CrossRef]
- Basti, L.; Nagai, K.; Shimasaki, Y.; Oshima, Y.; Honjo, T.; Segawa, S. Effects of the toxic dinoflagellate heterocapsa circularisquama on the valve movement behavior of the manila clam ruditapes philippinarum. Aquaculture 2009, 291, 41–47. [Google Scholar] [CrossRef]
- Hartmann, J.T.; Beggel, S.; Auerswald, K.; Stoeckle, B.C.; Geist, J. Establishing mussel behavior as a biomarker in ecotoxicology. Aquat. Toxicol. 2016, 170, 279–288. [Google Scholar] [CrossRef] [PubMed]
- Cichos, F.; Gustavsson, K.; Mehlig, B.; Volpe, G. Machine learning for active matter. Nat. Mach. Intell. 2020, 2, 94–103. [Google Scholar] [CrossRef]
- Guterres, B.V.; Guerreiro, A.; Jun, J.N.; da Botelho Silva, S.C.; Sandrini, J.Z. Mussels as Aquatic Pollution Biosensors using Neural Networks and Control Charts. In IEEE 18th International Conference on Industrial Informatics (INDIN); IEEE: Piscataway, NJ, USA, 2020; Volume 1, pp. 839–844. [Google Scholar] [CrossRef]
- Lürig, M.; Narwani, A.; Penson, H.; Wehrli, B.; Spaak, P.; Matthews, B. Non-additive effects of foundation species determine the response of aquatic ecosystems to nutrient perturbation. Ecology 2021, 102, e03371. [Google Scholar] [CrossRef] [PubMed]
- Figueirêdo, I.; Nani Guarieiro, L.L.; Sperandio Nascimento, E.G. Multivariate real time series data using six unsupervised machine learning algorithms. In Anomaly Detection-Recent Advances, Issues and Challenges; IntechOpen: London, UK, 2022. [Google Scholar] [CrossRef]
- Khan, S.; Liew, C.F.; Yairi, T.; McWilliam, R. Unsupervised anomaly detection in unmanned aerial vehicles. Appl. Soft Comput. 2019, 83, 105650. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Hyperparameters | Anomaly Detection Time | ||
|---|---|---|---|---|
| Anomaly 1 | Anomaly 2 | Anomaly 3 | ||
| Elliptic envelope | Aver. 15 min, cr = 0.0005 | 17:45 | 13:30 | 18:30 |
| Aver. 15 min, cr = 0.00005 | 17:45 | 17:30 | 18:30 | |
| Aver. 5 min, cr = 0.001 | 18:00 | 17:05 | 18:35 | |
| iForest | Aver. 30 min, T = 5, n = 256 | 19:00 | 04:00 | 18:30 |
| Aver. 15 min, T = 5, n = 150 | 18:15 | 03:45 | 18:45 | |
| Aver. 15 min, T = 50, n = 70 | 17:15 | 03:45 | 18:15 | |
| LOF | Aver. 5 min, cr = 0.0001, k = 40 | 19:45 | 05:15 | 18:35 |
| Aver. 5 min, cr = 0.0001, k = 50 | 19:45 | 09:50 | 18:35 | |
| Aver. 5 min, cr = 0.001, k = 50 | 19:25 | 04:20 | 18:35 | |
| Aver. 1 min, cr = 0.0001, k = 100 | 19:51 | 05:12 | 18:34 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Grekov, A.N.; Kabanov, A.A.; Vyshkvarkova, E.V.; Trusevich, V.V. Anomaly Detection in Biological Early Warning Systems Using Unsupervised Machine Learning. Sensors 2023, 23, 2687. https://doi.org/10.3390/s23052687
Grekov AN, Kabanov AA, Vyshkvarkova EV, Trusevich VV. Anomaly Detection in Biological Early Warning Systems Using Unsupervised Machine Learning. Sensors. 2023; 23(5):2687. https://doi.org/10.3390/s23052687
Chicago/Turabian StyleGrekov, Aleksandr N., Aleksey A. Kabanov, Elena V. Vyshkvarkova, and Valeriy V. Trusevich. 2023. "Anomaly Detection in Biological Early Warning Systems Using Unsupervised Machine Learning" Sensors 23, no. 5: 2687. https://doi.org/10.3390/s23052687
APA StyleGrekov, A. N., Kabanov, A. A., Vyshkvarkova, E. V., & Trusevich, V. V. (2023). Anomaly Detection in Biological Early Warning Systems Using Unsupervised Machine Learning. Sensors, 23(5), 2687. https://doi.org/10.3390/s23052687