
Discrimination of Deoxynivalenol Levels of Barley Kernels Using Hyperspectral Imaging in Tandem with Optimized Convolutional Neural Network



Abstract
1. Introduction
2. Materials and Methods
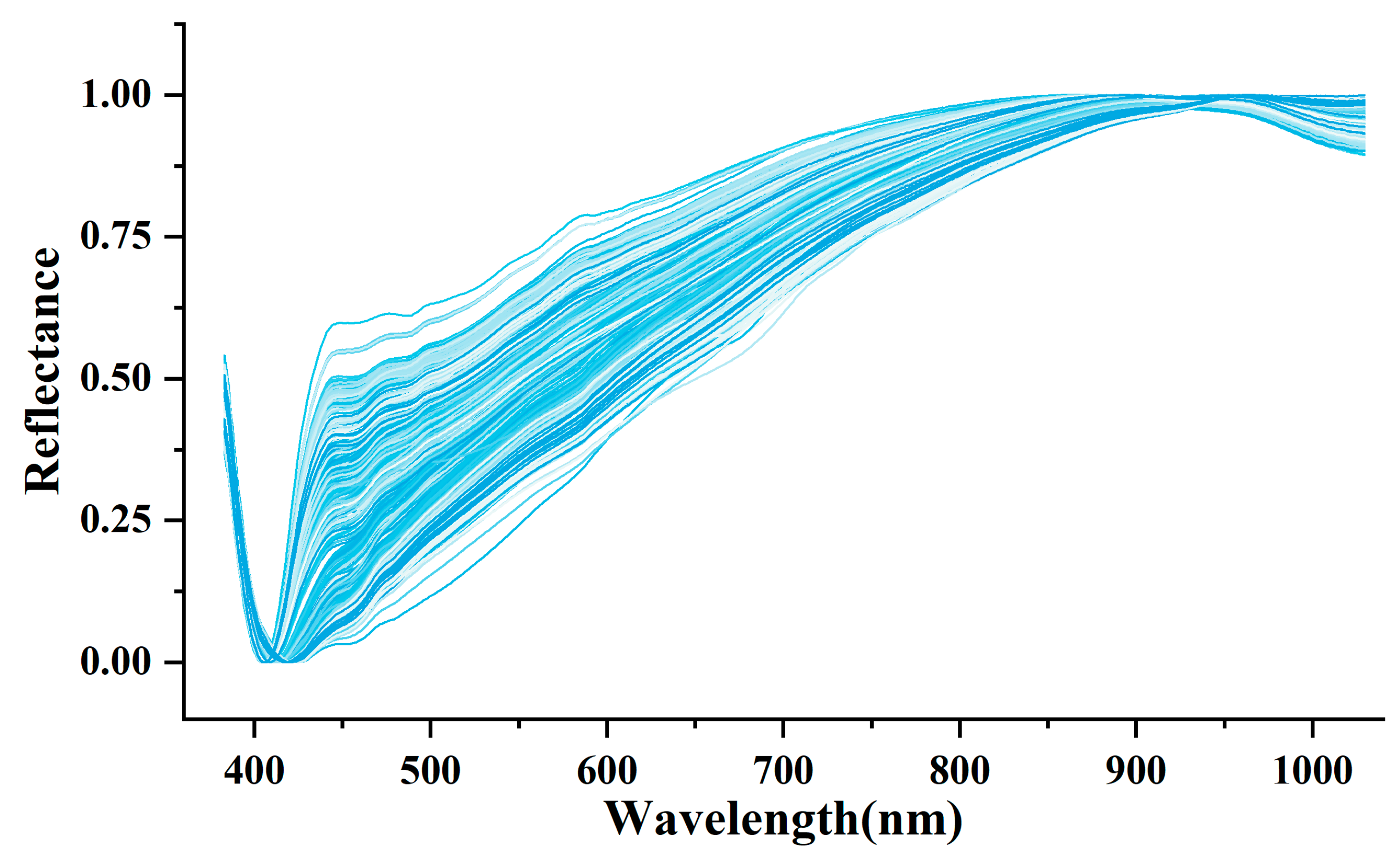
2.1. Data Collection
2.2. Data Pre-Processing Method
2.3. Traditional Machine Learning Methods
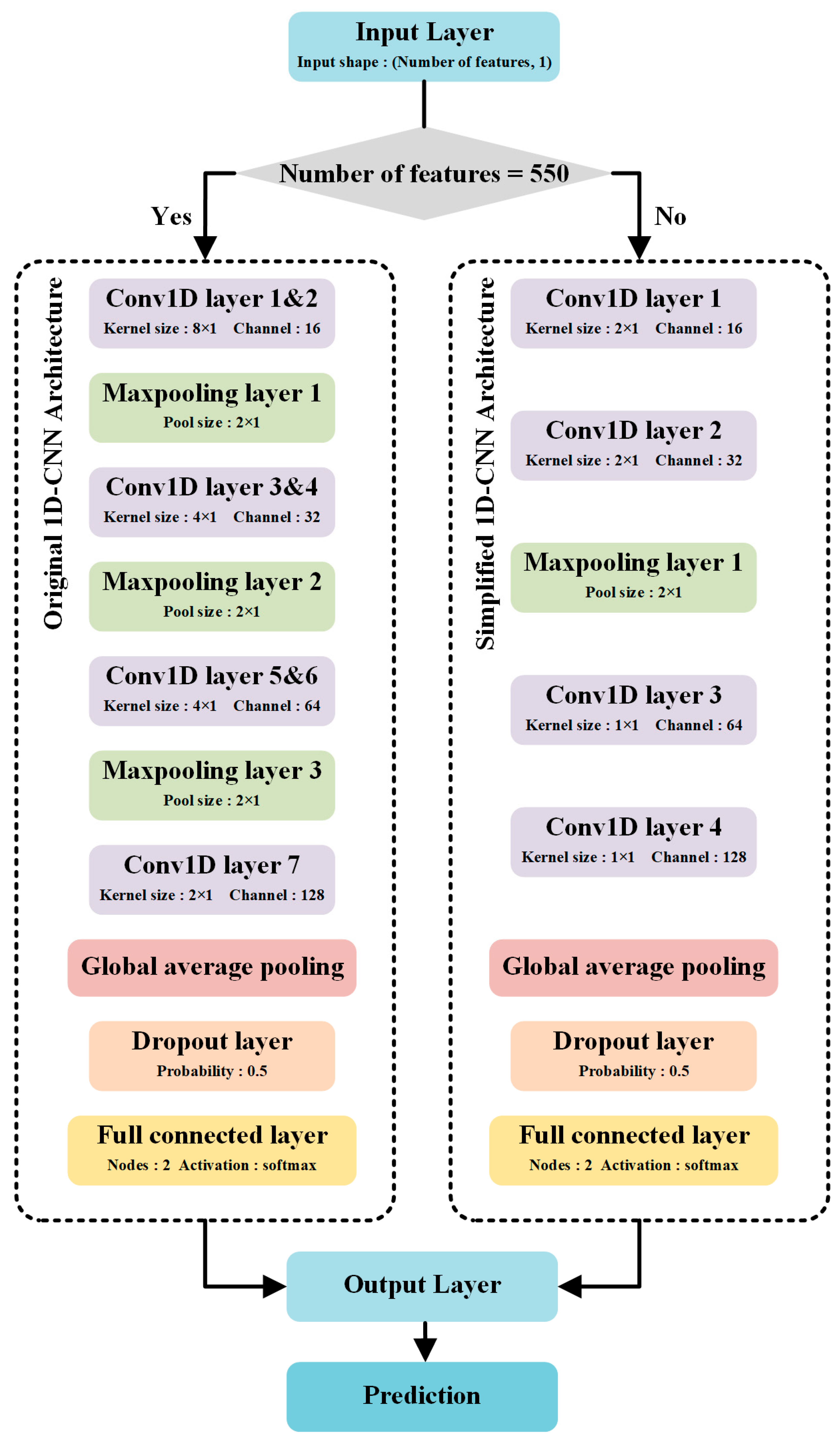
2.4. Convolutional Neural Network (CNN)
2.5. Variable Selection Algorithm
2.6. Model Evaluation
3. Results
3.1. Full Wavelength Models
3.2. Data Pre-Processing
3.3. Feature Wavelength Selection
3.4. Model Optimization
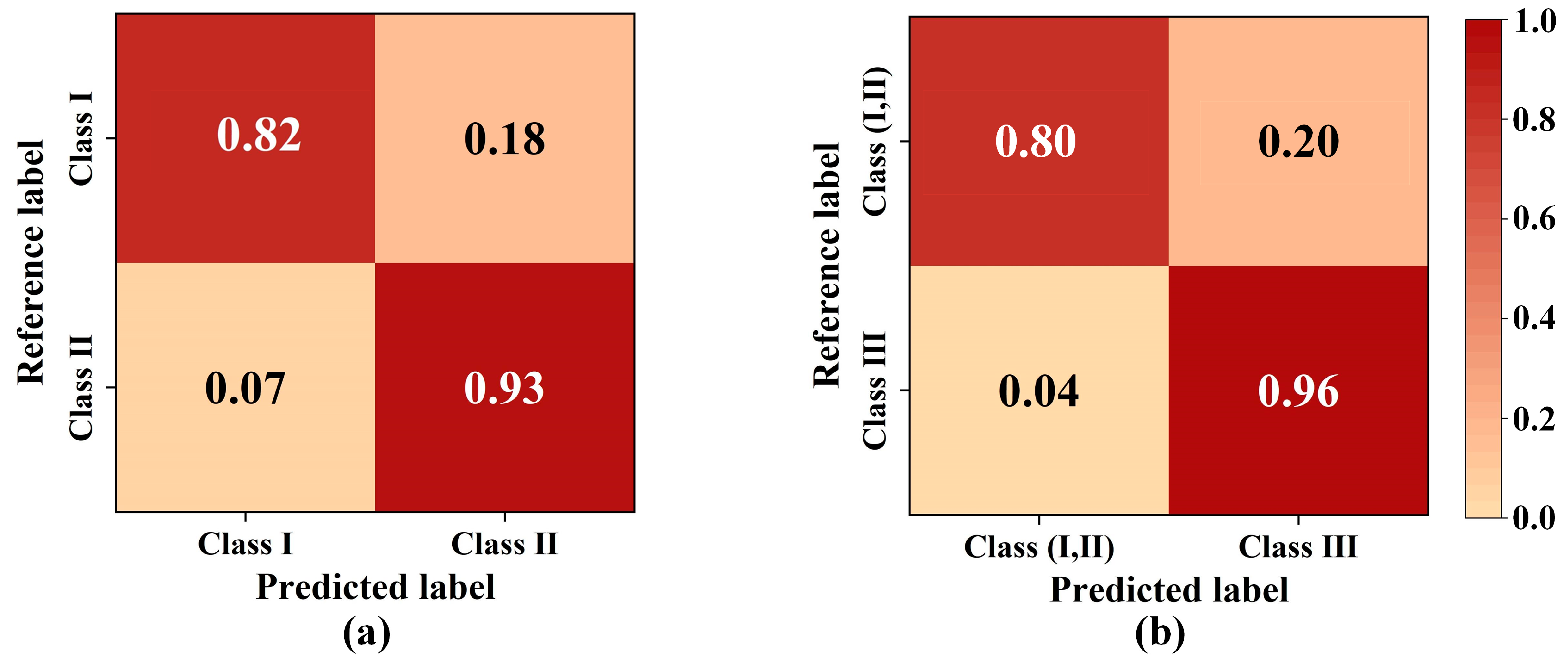
3.5. Comparison of Optimized Models
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ercan, I.; Tombuloglu, H.; Alqahtani, N.; Alotaibi, B.; Bamhrez, M.; Alshumrani, R.; Ozcelik, S.; Kayed, T.S. Magnetic field effects on the magnetic properties, germination, chlorophyll fluorescence, and nutrient content of barley (Hordeum vulgare L.). Plant Physiol. Biochem. 2022, 170, 36–48. [Google Scholar] [CrossRef]
- Baik, B.-K.; Ullrich, S.E. Barley for food: Characteristics, improvement, and renewed interest. J. Cereal Sci. 2008, 48, 233–242. [Google Scholar] [CrossRef]
- Bai, G.; Su, Z.; Cai, J. Wheat resistance to Fusarium head blight. Can. J. Plant Pathol. 2018, 40, 336–346. [Google Scholar] [CrossRef]
- Polišenská, I.; Jirsa, O.; Vaculová, K.; Pospíchalová, M.; Wawroszova, S.; Frydrych, J. Fusarium mycotoxins in two hulless oat and barley cultivars used for food purposes. Foods 2020, 9, 1037. [Google Scholar] [CrossRef]
- Haile, J.K.; N’Diaye, A.; Walkowiak, S.; Nilsen, K.T.; Clarke, J.M.; Kutcher, H.R.; Steiner, B.; Buerstmayr, H.; Pozniak, C.J. Fusarium head blight in durum wheat: Recent status, breeding directions, and future research prospects. Phytopathology 2019, 109, 1664–1675. [Google Scholar] [CrossRef]
- Chilaka, C.A.; De Boevre, M.; Atanda, O.O.; De Saeger, S. The status of Fusarium mycotoxins in sub-Saharan Africa: A review of emerging trends and post-harvest mitigation strategies towards food control. Toxins 2017, 9, 19. [Google Scholar] [CrossRef]
- Audenaert, K.; Van Broeck, R.; Bekaert, B.; De Witte, F.; Heremans, B.; Messens, K.; Höfte, M.; Haesaert, G. Fusarium head blight (FHB) in Flanders: Population diversity, inter-species associations and DON contamination in commercial winter wheat varieties. Eur. J. Plant Pathol. 2009, 125, 445–458. [Google Scholar] [CrossRef]
- Su, W.-H.; Yang, C.; Dong, Y.; Johnson, R.; Page, R.; Szinyei, T.; Hirsch, C.D.; Steffenson, B.J. Hyperspectral imaging and improved feature variable selection for automated determination of deoxynivalenol in various genetic lines of barley kernels for resistance screening. Food Chem. 2021, 343, 128507. [Google Scholar] [CrossRef]
- Schwarz, P.B. Fusarium head blight and deoxynivalenol in malting and brewing: Successes and future challenges. Trop. Plant Pathol. 2017, 42, 153–164. [Google Scholar] [CrossRef]
- US Department of Health; Human Services; Food and Drug Administration. Advisory Levels for Deoxynivalenol (DON) in Finished Wheat Products for Human Consumption and Grains and Grain By-Products Used for Animal Feed; FDA: Rockville, MD, USA, 2010.
- Silva, C.L.; Benin, G.; Rosa, A.C.; Beche, E.; Bornhofen, E.; Capelin, M.A. Monitoring levels of deoxynivalenol in wheat flour of Brazilian varieties. Chil. J. Agric. Res. 2015, 75, 50–56. [Google Scholar] [CrossRef]
- EC. Commission regulation (EC) No. 1881/2006 of 19 December 2006. Setting maximum levels for certain contaminants in foodstuffs (Text with EEA relevance). Off. J. Eur. Comm. 1881, 364, 2006. [Google Scholar]
- Wegulo, S.N.; Baenziger, P.S.; Nopsa, J.H.; Bockus, W.W.; Hallen-Adams, H. Management of Fusarium head blight of wheat and barley. Crop Prot. 2015, 73, 100–107. [Google Scholar] [CrossRef]
- Spanic, V.; Marcek, T.; Abicic, I.; Sarkanj, B. Effects of Fusarium head blight on wheat grain and malt infected by Fusarium culmorum. Toxins 2018, 10, 17. [Google Scholar] [CrossRef]
- Bai, G.; Shaner, G. Management and resistance in wheat and barley to Fusarium head blight. Annu. Rev. Phytopathol. 2004, 42, 135–161. [Google Scholar] [CrossRef]
- De Girolamo, A.; Lippolis, V.; Nordkvist, E.; Visconti, A. Rapid and non-invasive analysis of deoxynivalenol in durum and common wheat by Fourier-Transform Near Infrared (FT-NIR) spectroscopy. Food Addit. Contam. 2009, 26, 907–917. [Google Scholar] [CrossRef]
- Zheng, S.-Y.; Wei, Z.-S.; Li, S.; Zhang, S.-J.; Xie, C.-F.; Yao, D.-S.; Liu, D.-L. Near-infrared reflectance spectroscopy-based fast versicolorin A detection in maize for early aflatoxin warning and safety sorting. Food Chem. 2020, 332, 127419. [Google Scholar] [CrossRef]
- Femenias, A.; Gatius, F.; Ramos, A.J.; Sanchis, V.; Marín, S. Use of hyperspectral imaging as a tool for Fusarium and deoxynivalenol risk management in cereals: A review. Food Control 2020, 108, 106819. [Google Scholar] [CrossRef]
- Hamidisepehr, A.; Sama, M.P. Moisture content classification of soil and stalk residue samples from spectral data using machine learning. Trans. ASABE 2019, 62, 1–8. [Google Scholar] [CrossRef]
- Feng, L.; Wu, B.; Zhu, S.; Wang, J.; Su, Z.; Liu, F.; He, Y.; Zhang, C. Investigation on data fusion of multisource spectral data for rice leaf diseases identification using machine learning methods. Front. Plant Sci. 2020, 11, 577063. [Google Scholar] [CrossRef]
- Zhou, L.; Zhang, C.; Liu, F.; Qiu, Z.; He, Y. Application of deep learning in food: A review. Compr. Rev. Food Sci. Food Saf. 2019, 18, 1793–1811. [Google Scholar] [CrossRef]
- Yu, G.; Ma, B.; Chen, J.; Li, X.; Li, Y.; Li, C. Nondestructive identification of pesticide residues on the Hami melon surface using deep feature fusion by Vis/NIR spectroscopy and 1D-CNN. J. Food Process Eng. 2021, 44, e13602. [Google Scholar] [CrossRef]
- Zhu, J.; Sharma, A.S.; Xu, J.; Xu, Y.; Jiao, T.; Ouyang, Q.; Li, H.; Chen, Q. Rapid on-site identification of pesticide residues in tea by one-dimensional convolutional neural network coupled with surface-enhanced Raman scattering. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2021, 246, 118994. [Google Scholar] [CrossRef]
- Gao, J.; Zhao, L.; Li, J.; Deng, L.; Ni, J.; Han, Z. Aflatoxin rapid detection based on hyperspectral with 1D-convolution neural network in the pixel level. Food Chem. 2021, 360, 129968. [Google Scholar] [CrossRef]
- Li, H.; Zhang, L.; Sun, H.; Rao, Z.; Ji, H. Identification of soybean varieties based on hyperspectral imaging technology and one-dimensional convolutional neural network. J. Food Process Eng. 2021, 44, e13767. [Google Scholar] [CrossRef]
- Su, W.-H.; Sun, D.-W. Comparative assessment of feature-wavelength eligibility for measurement of water binding capacity and specific gravity of tuber using diverse spectral indices stemmed from hyperspectral images. Comput. Electron. Agric. 2016, 130, 69–82. [Google Scholar] [CrossRef]
- Su, W.-H.; Sun, D.-W. Facilitated wavelength selection and model development for rapid determination of the purity of organic spelt (Triticum spelta L.) flour using spectral imaging. Talanta 2016, 155, 347–357. [Google Scholar] [CrossRef]
- Su, W.-H.; Fennimore, S.A.; Slaughter, D.C. Development of a systemic crop signalling system for automated real-time plant care in vegetable crops. Biosyst. Eng. 2020, 193, 62–74. [Google Scholar] [CrossRef]
- Su, W.-H. Systemic crop signaling for automatic recognition of transplanted lettuce and tomato under different levels of sunlight for early season weed control. Challenges 2020, 11, 23. [Google Scholar] [CrossRef]
- Wu, D.; Nie, P.; He, Y.; Bao, Y. Determination of calcium content in powdered milk using near and mid-infrared spectroscopy with variable selection and chemometrics. Food Bioprocess Technol. 2012, 5, 1402–1410. [Google Scholar] [CrossRef]
- Su, W.H.; Sun, D.W. Multispectral Imaging for Plant Food Quality Analysis and Visualization. Compr. Rev. Food Sci. Food Saf. 2018, 17, 220–239. [Google Scholar] [CrossRef]
- Steffenson, B. Fusarium head blight of barley: Impact, epidemics, management, and strategies for identifying and utilizing genetic resistance. In Fusarium Head Blight Wheat Barley; APS Press: St. Pual, MN, USA, 2003; pp. 241–295. [Google Scholar]
- Fuentes, R.; Mickelson, H.; Busch, R.; Dill-Macky, R.; Evans, C.; Thompson, W.; Wiersma, J.; Xie, W.; Dong, Y.; Anderson, J.A. Resource allocation and cultivar stability in breeding for Fusarium head blight resistance in spring wheat. Crop Sci. 2005, 45, 1965–1972. [Google Scholar]
- Tian, S.; Wang, S.; Xu, H. Early detection of freezing damage in oranges by online Vis/NIR transmission coupled with diameter correction method and deep 1D-CNN. Comput. Electron. Agric. 2022, 193, 106638. [Google Scholar]
- Kim, H.-J.; Baek, J.-W.; Chung, K. Associative knowledge graph using fuzzy clustering and Min-Max normalization in video contents. IEEE Access 2021, 9, 74802–74816. [Google Scholar] [CrossRef]
- Leung, A.K.; Chau, F.; Gao, J. A review on applications of wavelet transform techniques in chemical analysis: 1989–1997. Chemom. Intell. Lab. Syst. 1998, 43, 165–184. [Google Scholar] [CrossRef]
- Noble, W.S. What is a support vector machine? Nat. Biotechnol. 2006, 24, 1565–1567. [Google Scholar] [CrossRef]
- Karamizadeh, S.; Abdullah, S.M.; Halimi, M.; Shayan, J.; Rajabi, M.J. Advantage and drawback of support vector machine functionality. In Proceedings of the 2014 IEEE International Conference on Computer, Communications, and Control Technology (I4CT), Langkawi, Malaysia, 2–4 September 2014; pp. 63–65. [Google Scholar]
- Gallant, S.I. Perceptron-based learning algorithms. IEEE Trans. Neural Netw. 1990, 1, 179–191. [Google Scholar] [CrossRef]
- Newton, D.; Yousefian, F.; Pasupathy, R. Stochastic gradient descent: Recent trends. Recent Adv. Optim. Model. Contemp. Probl. 2018, 193–220. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Kramer, O. K-nearest neighbors. In Dimensionality Reduction with Unsupervised Nearest Neighbors; Springer: Berlin/Heidelberg, Germany, 2013; pp. 13–23. [Google Scholar]
- Myles, A.J.; Feudale, R.N.; Liu, Y.; Woody, N.A.; Brown, S.D. An introduction to decision tree modeling. J. Chemom. A J. Chemom. Soc. 2004, 18, 275–285. [Google Scholar] [CrossRef]
- Webb, G.I.; Keogh, E.; Miikkulainen, R. Naïve Bayes. Encycl. Mach. Learn. 2010, 15, 713–714. [Google Scholar]
- Li, H.; Liang, Y.; Xu, Q.; Cao, D. Key wavelengths screening using competitive adaptive reweighted sampling method for multivariate calibration. Anal. Chim. Acta 2009, 648, 77–84. [Google Scholar] [CrossRef]
- Araújo, M.C.U.; Saldanha, T.C.B.; Galvao, R.K.H.; Yoneyama, T.; Chame, H.C.; Visani, V. The successive projections algorithm for variable selection in spectroscopic multicomponent analysis. Chemom. Intell. Lab. Syst. 2001, 57, 65–73. [Google Scholar] [CrossRef]
- Liu, F.; He, Y. Application of successive projections algorithm for variable selection to determine organic acids of plum vinegar. Food Chem. 2009, 115, 1430–1436. [Google Scholar] [CrossRef]
- Seeling, K.; Dänicke, S.; Valenta, H.; Van Egmond, H.; Schothorst, R.; Jekel, A.; Lebzien, P.; Schollenberger, M.; Razzazi-Fazeli, E.; Flachowsky, G. Effects of Fusarium toxin-contaminated wheat and feed intake level on the biotransformation and carry-over of deoxynivalenol in dairy cows. Food Addit. Contam. 2006, 23, 1008–1020. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Class (I, II) and Class III | Class I and Class Ⅱ | ||||
|---|---|---|---|---|---|---|
| Precision (%) | Recall | F1-Score | Precision (%) | Recall | F1-Score | |
| 1D-CNN | 89.41 | 0.8922 | 0.8911 | 90.08 | 0.8947 | 0.8961 |
| SVM | 86.83 | 0.8681 | 0.8674 | 81.68 | 0.7374 | 0.6951 |
| LR | 84.33 | 0.8340 | 0.8299 | 78.92 | 0.6768 | 0.5984 |
| Perceptron | 83.57 | 0.8340 | 0.8322 | 15.52 | 0.3939 | 0.2226 |
| SGD | 81.17 | 0.7489 | 0.7454 | 36.73 | 0.6061 | 0.4574 |
| RF | 81.68 | 0.8170 | 0.8169 | 81.82 | 0.8182 | 0.8149 |
| DT | 77.81 | 0.7787 | 0.7769 | 68.15 | 0.6869 | 0.6824 |
| NB | 59.89 | 0.5277 | 0.4998 | 49.40 | 0.4444 | 0.4388 |
| One-Step Pre-Processing Method * | Class (I, II) and Class III | Class I and Class Ⅱ | ||||
|---|---|---|---|---|---|---|
| Precision (%) | Recall | F1-Score | Precision (%) | Recall | F1-Score | |
| None | 89.41 | 0.8922 | 0.8911 | 90.08 | 0.8947 | 0.8961 |
| FD | 90.20 | 0.9009 | 0.9 | 93.86 | 0.9368 | 0.9373 |
| MMN | 89.72 | 0.8966 | 0.8958 | 93.39 | 0.9263 | 0.9275 |
| MC | 89.41 | 0.8922 | 0.8911 | 88.84 | 0.8842 | 0.8854 |
| MAF | 89.64 | 0.8966 | 0.8962 | 90.62 | 0.9053 | 0.9056 |
| MSC | 90.60 | 0.9052 | 0.9045 | 89.86 | 0.8842 | 0.8865 |
| SNV | 90.13 | 0.9009 | 0.9002 | 86.15 | 0.8632 | 0.8614 |
| Standardlize | 89.67 | 0.8966 | 0.896 | 79.66 | 0.8 | 0.7974 |
| VN | 89.72 | 0.8966 | 0.8958 | 91.97 | 0.9158 | 0.9164 |
| WT | 91.48 | 0.9138 | 0.9132 | 90.62 | 0.9053 | 0.9056 |
| Two-Step Pre-Processing Method | Class (I, II) and Class III | Class I and Class Ⅱ | ||||
|---|---|---|---|---|---|---|
| Precision (%) | Recall | F1-Score | Precision (%) | Recall | F1-Score | |
| MMN-MAF | 90.07 | 0.9009 | 0.9006 | 91.79 | 0.9158 | 0.9164 |
| MMN-WT | 89.20 | 0.8922 | 0.892 | 92.63 | 0.9158 | 0.9173 |
| MAF-MMN | 89.67 | 0.8966 | 0.896 | 90.91 | 0.9053 | 0.9062 |
| MAF-WT | 91.96 | 0.9181 | 0.9174 | 90.47 | 0.9053 | 0.9049 |
| WT-MMN | 90.51 | 0.9052 | 0.9049 | 95.05 | 0.9474 | 0.9479 |
| WT-MAF | 91.48 | 0.9138 | 0.9132 | 92.14 | 0.9158 | 0.9169 |
| Extraction of Feature Bands | Class (I, II) and Class III | Class I and Class Ⅱ | ||||
|---|---|---|---|---|---|---|
| Precision (%) | Recall | F1-Score | Precision (%) | Recall | F1-Score | |
| MAF-WT-CARS(39) | 90.43 | 0.9009 | 0.8995 | 93.95 | 0.9263 | 0.9278 |
| MAF-WT-SPA(31) | 90.38 | 0.9004 | 0.899 | 72.53 | 0.7340 | 0.7275 |
| WT-MAF-CARS(20) | 89.97 | 0.8966 | 0.8971 | 72.13 | 0.7053 | 0.7105 |
| WT-MMN-CARS(28) | 90.95 | 0.9052 | 0.9038 | 92.98 | 0.9263 | 0.9271 |
| WT-MMN-SPA(30) | 91.57 | 0.9138 | 0.9130 | 91.79 | 0.9158 | 0.9164 |
| WT-MMN-CARS-SPA(7) | 88.38 | 0.8836 | 0.8829 | 89.81 | 0.8966 | 0.8955 |
| Models | Class (I, II) and Class III | Class I and Class Ⅱ | ||||
|---|---|---|---|---|---|---|
| Precision (%) | Recall | F1-Score | Precision (%) | Recall | F1-Score | |
| 1D-CNN | 88.38 | 0.8836 | 0.8829 | 89.81 | 0.8966 | 0.8955 |
| SVM | 85.32 | 0.8170 | 0.8090 | 39.22 | 0.6263 | 0.4823 |
| LR | 29.21 | 0.5404 | 0.3792 | 39.22 | 0.6263 | 0.4823 |
| Perceptron | 79.52 | 0.6979 | 0.6592 | 39.22 | 0.6263 | 0.4823 |
| SGD | 83.18 | 0.7702 | 0.7533 | 72.22 | 0.6667 | 0.5798 |
| RF | 84.29 | 0.8340 | 0.8314 | 86.92 | 0.8687 | 0.8665 |
| DT | 79.53 | 0.7914 | 0.7891 | 72.88 | 0.7273 | 0.7279 |
| NB | 65.47 | 0.6553 | 0.6549 | 56.33 | 0.5657 | 0.5644 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fan, K.-J.; Liu, B.-Y.; Su, W.-H. Discrimination of Deoxynivalenol Levels of Barley Kernels Using Hyperspectral Imaging in Tandem with Optimized Convolutional Neural Network. Sensors 2023, 23, 2668. https://doi.org/10.3390/s23052668
Fan K-J, Liu B-Y, Su W-H. Discrimination of Deoxynivalenol Levels of Barley Kernels Using Hyperspectral Imaging in Tandem with Optimized Convolutional Neural Network. Sensors. 2023; 23(5):2668. https://doi.org/10.3390/s23052668
Chicago/Turabian StyleFan, Ke-Jun, Bo-Yuan Liu, and Wen-Hao Su. 2023. "Discrimination of Deoxynivalenol Levels of Barley Kernels Using Hyperspectral Imaging in Tandem with Optimized Convolutional Neural Network" Sensors 23, no. 5: 2668. https://doi.org/10.3390/s23052668
APA StyleFan, K.-J., Liu, B.-Y., & Su, W.-H. (2023). Discrimination of Deoxynivalenol Levels of Barley Kernels Using Hyperspectral Imaging in Tandem with Optimized Convolutional Neural Network. Sensors, 23(5), 2668. https://doi.org/10.3390/s23052668